扩散模型学习——代码学习
文章目录
- 引言
- 正文
- UNet网络结构
- 训练方法
- DDPM采样方法讲解
- Context上下文信息添加
- DDIM的方法详解
- 总结
- 参考
引言
- 这是第一次接触扩散模型,为了学习,这里好好分析一下他的代码
正文
UNet网络结构
- 这部分主要是定义一下网络结构,以及相关的网络超参数
- 具体网络结构的图片如下

下述为网络结构各个层的定义
- 结合定义和模型的具体输出,会更加理解
class ContextUnet(nn.Module):def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context featuressuper(ContextUnet, self).__init__()# number of input channels, number of intermediate feature maps and number of classes# 输入通道数self.in_channels = in_channels# 映射特征数量self.n_feat = n_feat# 生成类别数self.n_cfeat = n_cfeat# 生成的是方形图,并且输入必须能够被4整除self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...# Initialize the initial convolutional layerself.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)# 初始化下采样层self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())# 仅仅进行平均池化,并没有改变他的通道数self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())# Embed the timestep and context labels with a one-layer fully connected neural network# 定义两个嵌入层,将时间戳信息和上下文消息都转为对应的embedding向量# 这里仅仅是改变通道数,并没有改变上下文信息的特征self.timeembed1 = EmbedFC(1, 2*n_feat)self.timeembed2 = EmbedFC(1, 1*n_feat)self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)# Initialize the up-sampling path of the U-Net with three levels# 并不改变通道数,仅仅是进行上采样self.up0 = nn.Sequential(nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample nn.GroupNorm(8, 2 * n_feat), # normalize nn.ReLU(),)# 降低通道数,并进行上采样,同下self.up1 = UnetUp(4 * n_feat, n_feat)# 降低通道数,并进行上采样,这里输入通道和up1的输出通道不同,是因为还有上下文信息和之前下采样的输出self.up2 = UnetUp(2 * n_feat, n_feat)# 初始化最终的卷积层,将最终的输出映射为和输入相同大小self.out = nn.Sequential(nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0nn.GroupNorm(8, n_feat), # normalizenn.ReLU(),nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input)
网络结构的每一层参数如下
# 初始化卷积层
init_conv.conv1.0.weight torch.Size([256, 3, 3, 3])
init_conv.conv1.0.bias torch.Size([256])
init_conv.conv1.1.weight torch.Size([256])
init_conv.conv1.1.bias torch.Size([256])
init_conv.conv2.0.weight torch.Size([256, 256, 3, 3])
init_conv.conv2.0.bias torch.Size([256])
init_conv.conv2.1.weight torch.Size([256])
init_conv.conv2.1.bias torch.Size([256])# 下采样层一
down1.model.0.conv1.0.weight torch.Size([256, 256, 3, 3])
down1.model.0.conv1.0.bias torch.Size([256])
down1.model.0.conv1.1.weight torch.Size([256])
down1.model.0.conv1.1.bias torch.Size([256])
down1.model.0.conv2.0.weight torch.Size([256, 256, 3, 3])
down1.model.0.conv2.0.bias torch.Size([256])
down1.model.0.conv2.1.weight torch.Size([256])
down1.model.0.conv2.1.bias torch.Size([256])
down1.model.1.conv1.0.weight torch.Size([256, 256, 3, 3])
down1.model.1.conv1.0.bias torch.Size([256])
down1.model.1.conv1.1.weight torch.Size([256])
down1.model.1.conv1.1.bias torch.Size([256])
down1.model.1.conv2.0.weight torch.Size([256, 256, 3, 3])
down1.model.1.conv2.0.bias torch.Size([256])
down1.model.1.conv2.1.weight torch.Size([256])
down1.model.1.conv2.1.bias torch.Size([256])# 下采样层二
down2.model.0.conv1.0.weight torch.Size([512, 256, 3, 3])
down2.model.0.conv1.0.bias torch.Size([512])
down2.model.0.conv1.1.weight torch.Size([512])
down2.model.0.conv1.1.bias torch.Size([512])
down2.model.0.conv2.0.weight torch.Size([512, 512, 3, 3])
down2.model.0.conv2.0.bias torch.Size([512])
down2.model.0.conv2.1.weight torch.Size([512])
down2.model.0.conv2.1.bias torch.Size([512])
down2.model.1.conv1.0.weight torch.Size([512, 512, 3, 3])
down2.model.1.conv1.0.bias torch.Size([512])
down2.model.1.conv1.1.weight torch.Size([512])
down2.model.1.conv1.1.bias torch.Size([512])
down2.model.1.conv2.0.weight torch.Size([512, 512, 3, 3])
down2.model.1.conv2.0.bias torch.Size([512])
down2.model.1.conv2.1.weight torch.Size([512])
down2.model.1.conv2.1.bias torch.Size([512])# 时间上下文信息embedding
timeembed1.model.0.weight torch.Size([512, 1])
timeembed1.model.0.bias torch.Size([512])
timeembed1.model.2.weight torch.Size([512, 512])
timeembed1.model.2.bias torch.Size([512])
timeembed2.model.0.weight torch.Size([256, 1])
timeembed2.model.0.bias torch.Size([256])
timeembed2.model.2.weight torch.Size([256, 256])
timeembed2.model.2.bias torch.Size([256])# 上下文信息的embedding
contextembed1.model.0.weight torch.Size([512, 10])
contextembed1.model.0.bias torch.Size([512])
contextembed1.model.2.weight torch.Size([512, 512])
contextembed1.model.2.bias torch.Size([512])
contextembed2.model.0.weight torch.Size([256, 10])
contextembed2.model.0.bias torch.Size([256])
contextembed2.model.2.weight torch.Size([256, 256])
contextembed2.model.2.bias torch.Size([256])# 上采样零层,如果不用加上上下文信息,这层完全没有必要,现在是加上了。
up0.0.weight torch.Size([512, 512, 7, 7])
up0.0.bias torch.Size([512])
up0.1.weight torch.Size([512])
up0.1.bias torch.Size([512])
up1.model.0.weight torch.Size([1024, 256, 2, 2])
up1.model.0.bias torch.Size([256])# 上采样一层
up1.model.1.conv1.0.weight torch.Size([256, 256, 3, 3])
up1.model.1.conv1.0.bias torch.Size([256])
up1.model.1.conv1.1.weight torch.Size([256])
up1.model.1.conv1.1.bias torch.Size([256])
up1.model.1.conv2.0.weight torch.Size([256, 256, 3, 3])
up1.model.1.conv2.0.bias torch.Size([256])
up1.model.1.conv2.1.weight torch.Size([256])
up1.model.1.conv2.1.bias torch.Size([256])
up1.model.2.conv1.0.weight torch.Size([256, 256, 3, 3])
up1.model.2.conv1.0.bias torch.Size([256])
up1.model.2.conv1.1.weight torch.Size([256])
up1.model.2.conv1.1.bias torch.Size([256])
up1.model.2.conv2.0.weight torch.Size([256, 256, 3, 3])
up1.model.2.conv2.0.bias torch.Size([256])
up1.model.2.conv2.1.weight torch.Size([256])
up1.model.2.conv2.1.bias torch.Size([256])# 上采样二层
up2.model.0.weight torch.Size([512, 256, 2, 2])
up2.model.0.bias torch.Size([256])
up2.model.1.conv1.0.weight torch.Size([256, 256, 3, 3])
up2.model.1.conv1.0.bias torch.Size([256])
up2.model.1.conv1.1.weight torch.Size([256])
up2.model.1.conv1.1.bias torch.Size([256])
up2.model.1.conv2.0.weight torch.Size([256, 256, 3, 3])
up2.model.1.conv2.0.bias torch.Size([256])
up2.model.1.conv2.1.weight torch.Size([256])
up2.model.1.conv2.1.bias torch.Size([256])
up2.model.2.conv1.0.weight torch.Size([256, 256, 3, 3])
up2.model.2.conv1.0.bias torch.Size([256])
up2.model.2.conv1.1.weight torch.Size([256])
up2.model.2.conv1.1.bias torch.Size([256])
up2.model.2.conv2.0.weight torch.Size([256, 256, 3, 3])
up2.model.2.conv2.0.bias torch.Size([256])
up2.model.2.conv2.1.weight torch.Size([256])
up2.model.2.conv2.1.bias torch.Size([256])# 最终的输出层,将输出的通道进行调整为3
out.0.weight torch.Size([256, 512, 3, 3])
out.0.bias torch.Size([256])
out.1.weight torch.Size([256])
out.1.bias torch.Size([256])
out.3.weight torch.Size([3, 256, 3, 3])
out.3.bias torch.Size([3])
当前网络每一层输出的张量情况
# 输入的图片为[32,3,28,28]=[batch_size,channel,height,width]
# 提取特征,扩充通道数
Layer: ResidualConvBlock
Input shape: torch.Size([32, 3, 28, 28])
Output shape: torch.Size([32, 64, 28, 28])
==============================
# 下采样层一:尺寸减半,通道数不变
Layer: UnetDown
Input shape: torch.Size([32, 64, 28, 28])
Output shape: torch.Size([32, 64, 14, 14])
==============================
# 下采样层二:尺寸减半,通道数翻倍
Layer: UnetDown
Input shape: torch.Size([32, 64, 14, 14])
Output shape: torch.Size([32, 128, 7, 7])
==============================
# 还是对输入的特征图进行下采样,是4*4的方格进行下采样
Layer: Sequential
Input shape: torch.Size([32, 128, 7, 7])
Output shape: torch.Size([32, 128, 1, 1])
==============================# 下述四层为上下文信息处理层,分别处理上下文类别信息和时间序列信息,分层加入到模型中
# 下述为特征上下文信息,每一个样本都有自己的特征上下文
Layer: EmbedFC
Input shape: torch.Size([32, 5])
Output shape: torch.Size([32, 128])
==============================
# 下述为时间序列上下文,所有样本的时间序列是统一的
Layer: EmbedFC
Input shape: torch.Size([1, 1, 1, 1])
Output shape: torch.Size([1, 128])
==============================
# 下述为经过扩展的样本上下文,用于加到第二个上采样层
Layer: EmbedFC
Input shape: torch.Size([32, 5])
Output shape: torch.Size([32, 64])
==============================
# 下述为经过扩展的时间序列信息,用于加到第二个上采样层
Layer: EmbedFC
Input shape: torch.Size([1, 1, 1, 1])
Output shape: torch.Size([1, 64])
==============================# 上采样层零:扩展维度,对应两个下采样层下的第一个卷积层
Layer: Sequential
Input shape: torch.Size([32, 128, 1, 1])
Output shape: torch.Size([32, 128, 7, 7])
==============================
# 上采样层一
Layer: UnetUp
Input shape: torch.Size([32, 128, 7, 7])
Output shape: torch.Size([32, 64, 14, 14])
==============================
# 上采样层二
Layer: UnetUp
Input shape: torch.Size([32, 64, 14, 14])
Output shape: torch.Size([32, 64, 28, 28])
==============================
# 输出调整层,将输出的信道调整为原始图层
Layer: Sequential
Input shape: torch.Size([32, 128, 28, 28])
Output shape: torch.Size([32, 3, 28, 28])
==============================
网络各层的连接方式
- 这里最好对照着图片看,会更加清晰,知道他这个网络模型的各个层级之间如何记性沟通。
- 整体来说,下采样比较简单,上采样比较复杂,因为涉及到添加对应下采样层的输出还有上下文信息、时间序列信息等,所以需要好好看看。
- 不过可以学到,如何添加额外信息的
def forward(self, x, t, c=None):"""x : (batch, n_feat, h, w) : input imaget : (batch, n_cfeat) : time stepc : (batch, n_classes) : context label"""# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on'''下采样过程'''# 将输入的图片传入初始化卷积层中x = self.init_conv(x)# 将结果传入下采样层down1 = self.down1(x) #[10, 256, 8, 8]down2 = self.down2(down1) #[10, 256, 4, 4]# 将特征映射为向量hiddenvec = self.to_vec(down2)'''上采样过程'''# mask out context if context_mask == 1# 判定是否有上下文信息if c is None:c = torch.zeros(x.shape[0], self.n_cfeat).to(x)# 将上下文信息context information还有timestep转为embeddingcemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")# 上采样过程,分别和对应下采样对应层和对应上下文信息加入到每一个上采样层中up1 = self.up0(hiddenvec)up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddingsup3 = self.up2(cemb2*up2 + temb2, down1)out = self.out(torch.cat((up3, x), 1))return out
训练方法
- 这里需要明白训练公式,通过公式推导,书写代码,需要明确如下参数
- α ‾ \overline{\alpha} α 表示若干个 α t \alpha_t αt的连乘
- ξ θ \xi_\theta ξθ 表示预测的噪声,另外一个表示实际生成的噪声

下述为定义增加噪声的过程
# helper function: perturbs an image to a specified noise level
def perturb_input(x, t, noise):# 前向传播公示return ab_t.sqrt()[t, None, None, None] * x + (1 - ab_t[t, None, None, None]) * noise
下述为具体的训练代码
# training without context code# set into train mode
nn_model.train()for ep in range(n_epoch):print(f'epoch {ep}')# linearly decay learning rate# 定义学习率进行线性衰减optim.param_groups[0]['lr'] = lrate*(1-ep/n_epoch)# 加载进度条pbar = tqdm(dataloader, mininterval=2 )for x, _ in pbar: # x: imagesoptim.zero_grad()x = x.to(device)# perturb data# 给当前的图片增加噪声noise = torch.randn_like(x) # 随机生成噪声t = torch.randint(1, timesteps + 1, (x.shape[0],)).to(device) # 随机生成timestepx_pert = perturb_input(x, t, noise) # 增加噪声扰动# use network to recover noise# 使用网络去预测噪声pred_noise = nn_model(x_pert, t / timesteps)# loss is mean squared error between the predicted and true noise# 使用MSE计算损失loss = F.mse_loss(pred_noise, noise)loss.backward()optim.step()# save model periodically# 按照周期保存模型if ep%4==0 or ep == int(n_epoch-1):if not os.path.exists(save_dir):os.mkdir(save_dir)torch.save(nn_model.state_dict(), save_dir + f"model_{ep}.pth")print('saved model at ' + save_dir + f"model_{ep}.pth")
DDPM采样方法讲解
- 在这个基础的扩散模型中,最为重要的是denoise_add_noise方法,该方法主要是先如下功能
- 生成model预测的噪声,从原来数据中减去模型预测的噪声
- 添加新的额外的噪声,防止训练崩溃
- 这里的采样方法完全是按照公式进行展开的,重要的是几个参数的构建方法
- 下属方法中的a_t是公式中的 α t \sqrt\alpha_t αt,

# construct DDPM noise schedule
# 构建DDPM的计算模式
# 定义 \beta_t ,表示从零到一的若干均匀分布的小数,有几个时间步骤,就有几个
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1# 计算\alpha_t 得值
a_t = 1 - b_t
# 这里是通过取对数,然后再去指数,来避免小数连乘的溢出。
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
# 确保x_0的连续性
ab_t[0] = 1# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
# 祛除模型预测的噪声,并且添加一些额外的噪声,避免过拟合
def denoise_add_noise(x, t, pred_noise, z=None):# 重参数化,实现对特定复杂分布的采样,z是从高斯分布进行的正常采样if z is None:z = torch.randn_like(x)noise = b_t.sqrt()[t] * z# 公式的前半项,x是当前timestep的情况,这里完全是按照公式进行推倒的mean = ((x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) # 减去预测噪声/ a_t[t].sqrt())# 增加额外的噪声,防止过拟合return mean + noise
-
上述方法完全是按照对应的公示进行展开的,看过了推导之后,发现对于整个公式的理解更加明确。
-
下述为整体的采样过程
- 对于每一张图片,都是多次迭代,并且逐步减去噪声
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):# x_T ~ N(0, 1), sample initial noisesamples = torch.randn(n_sample, 3, height, height).to(device) # array to keep track of generated steps for plottingintermediate = [] for i in range(timesteps, 0, -1):print(f'sampling timestep {i:3d}', end='\r')# reshape time tensort = torch.tensor([i / timesteps])[:, None, None, None].to(device)# sample some random noise to inject back in. For i = 1, don't add back in noisez = torch.randn_like(samples) if i > 1 else 0eps = nn_model(samples, t) # predict noise e_(x_t,t)samples = denoise_add_noise(samples, i, eps, z)if i % save_rate ==0 or i==timesteps or i<8:intermediate.append(samples.detach().cpu().numpy())intermediate = np.stack(intermediate)return samples, intermediate
Context上下文信息添加
- 关于上下文的添加,在之前的模型定义中ContextUNet是说明了上下文添加具体网络结构,这里就专门讲讲如何在采样过程中,增加对应的上下文信息
- 就是在之前定义model的forward参数中增加了一个参数c
# sample with context using standard algorithm
@torch.no_grad()
def sample_ddpm_context(n_sample, context, save_rate=20):# x_T ~ N(0, 1), sample initial noisesamples = torch.randn(n_sample, 3, height, height).to(device) # array to keep track of generated steps for plottingintermediate = [] for i in range(timesteps, 0, -1):print(f'sampling timestep {i:3d}', end='\r')# reshape time tensort = torch.tensor([i / timesteps])[:, None, None, None].to(device)# sample some random noise to inject back in. For i = 1, don't add back in noisez = torch.randn_like(samples) if i > 1 else 0# 和之前一样,就是增加了对应的上下文信息eps = nn_model(samples, t, c=context) # predict noise e_(x_t,t, ctx)samples = denoise_add_noise(samples, i, eps, z)if i % save_rate==0 or i==timesteps or i<8:intermediate.append(samples.detach().cpu().numpy())intermediate = np.stack(intermediate)return samples, intermediate
DDIM的方法详解
- DDIM和DDPM二者在前向传播的过程中,是完全相同的,所以他们的模型定义是相同的,完全可以共用的。
- 但是他们的采样过程是不同,DDIM能够实现跨步采样,速度更快,他是基于任意分布假设,并不是基于马卡洛夫链,所以不用逐步推理。具体算法描述如下

具体代码如下,下述要结合对应的采样公式,来实现对应的代码
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1# 下述为根据采样公式写出的采样函数
# t是当前的状态数量
# t-prev是根据当前状态t,需要预测prev向前的内容
def denoise_ddim(x, t, t_prev, pred_noise):ab = ab_t[t]ab_prev = ab_t[t_prev]x0_pred = ab_prev.sqrt() / ab.sqrt() * (x - (1 - ab).sqrt() * pred_noise)dir_xt = (1 - ab_prev).sqrt() * pred_noisereturn x0_pred + dir_xt# 具体调用采样过程
# sample quickly using DDIM
@torch.no_grad()
def sample_ddim(n_sample, n=20):# x_T ~ N(0, 1), sample initial noisesamples = torch.randn(n_sample, 3, height, height).to(device) # array to keep track of generated steps for plottingintermediate = [] step_size = timesteps // nfor i in range(timesteps, 0, -step_size):print(f'sampling timestep {i:3d}', end='\r')# reshape time tensort = torch.tensor([i / timesteps])[:, None, None, None].to(device)eps = nn_model(samples, t) # predict noise e_(x_t,t)samples = denoise_ddim(samples, i, i - step_size, eps)intermediate.append(samples.detach().cpu().numpy())intermediate = np.stack(intermediate)return samples, intermediate
总结
- 之前的学习方式有点问题,在扩散模型这里就卡了差不多一周,看公式推导,看相关的代码,学习相关的数学推理,还没有将当前模块嵌入到对应的模型进行测试,效率被大大降低了,所以对于DDIM的学习就简单很多。
参考
- AIGC爆火的背后——扩散模型DDPM浅析
- 扩散模型探索:DDIM 笔记与思考
相关文章:
扩散模型学习——代码学习
文章目录 引言正文UNet网络结构训练方法DDPM采样方法讲解Context上下文信息添加DDIM的方法详解 总结参考 引言 这是第一次接触扩散模型,为了学习,这里好好分析一下他的代码 正文 UNet网络结构 这部分主要是定义一下网络结构,以及相关的网…...
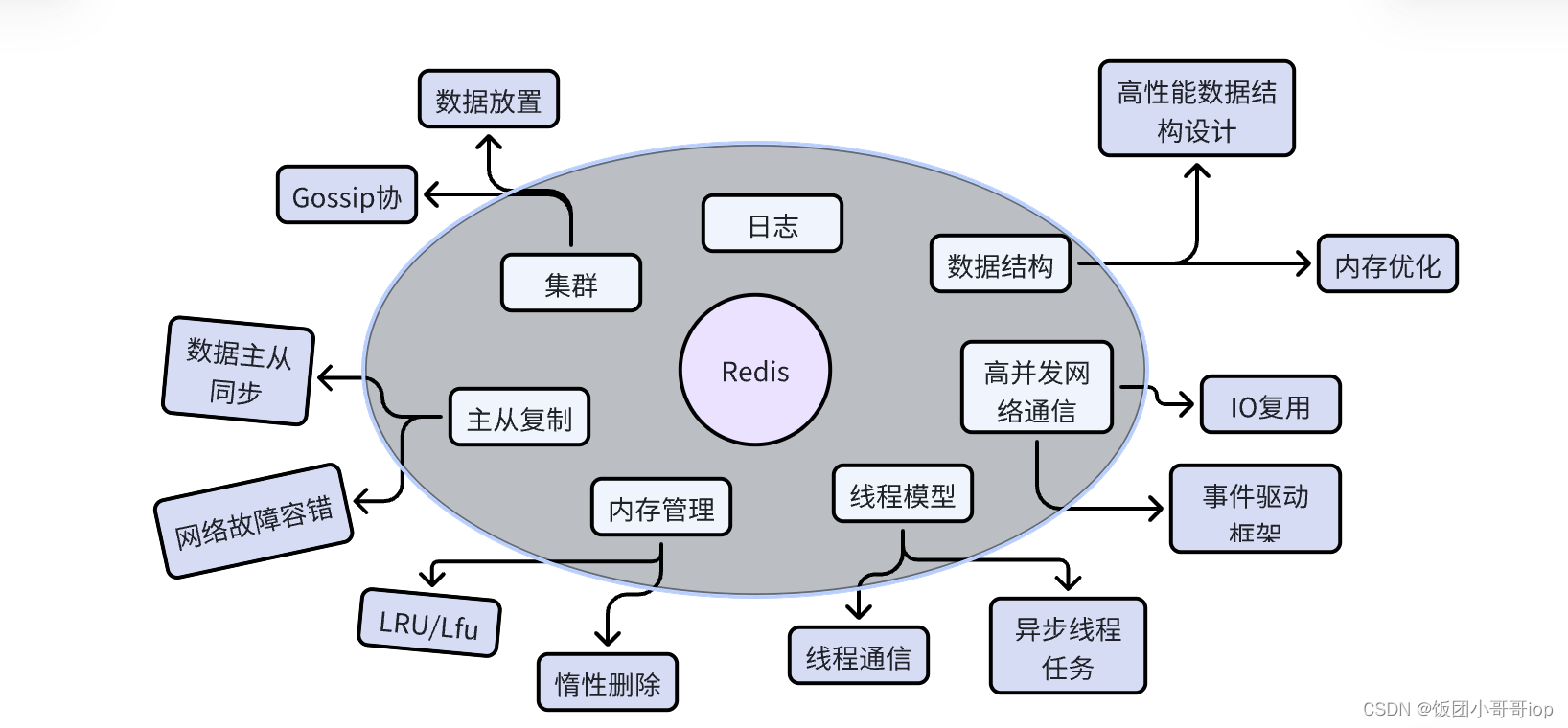
redis 数据结构
一、为什么要扒一下底层技术 首先我是一个解决方案工程师,为什么要看redis底层的设计呢?总结下来分几点: 1. 让系统跑起来更放心 2. 面试中可以对跟对面的牛马侃大山、吹🐮 3. 虚一点,举一反三,学习一下…...

node.js中express框架cookie-parser包设置cookie的问题
后端使用node.js express cookie-parser技术栈设置cookie的时候出现了无法成功设置的问题 前端发送axios请求部分代码: axios({method: "post",data: {content: remark,relatedArticles: relatedArticleId,userId: userId,userEmail: userEmail,topRema…...
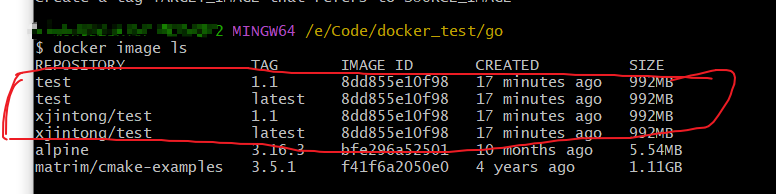
Docker命令手册
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 记录平时用的比较多的Docker命令。 docker学习地址 1、docker停止并删除运行的容器 首先查看…...
Selenium+Pytest自动化测试框架详解
前言 selenium自动化 pytest测试框架 本章你需要 一定的python基础——至少明白类与对象,封装继承;一定的selenium基础——本篇不讲selenium,不会的可以自己去看selenium中文翻译网 一、测试框架简介 测试框架有什么优点 代码复用率高&…...

CentOS7安装部署CDH6.2.1
文章目录 CentOS7安装部署CDH6.2.1一、前言1.简介2.架构3.环境 二、环境准备1.部署服务器2.安装包准备3.修改机器名4.关闭防火墙5.关闭 SELinux6.Hosts文件7.limits文件8.设置swap空间9.关闭透明巨页内存10.免密登录 三、安装CM管理端1.安装第三方依赖包2.安装Oracle的JDK3.安装…...
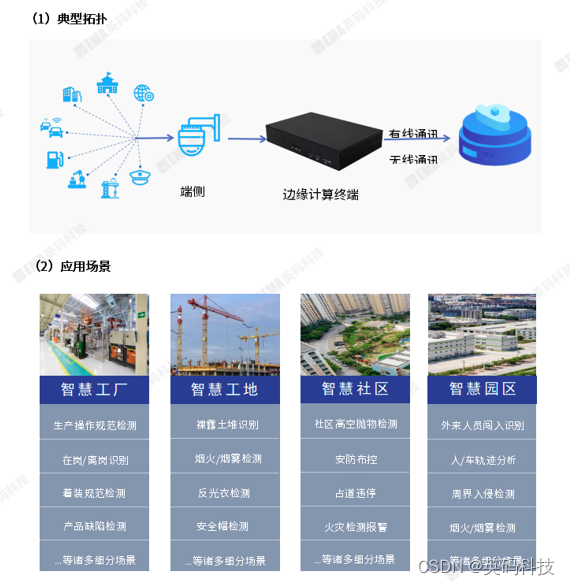
海思Hi3519DV500边缘计算盒子-英码IVP09A,双核A55 64位处理器
产品简介 IVP09A是英码科技推出的边缘计算智能工作站,搭载双核 Cortex-A55 架构AI 处理器;内置高效的神经网络推理引擎,提供2.5TopsNPU算力;支持多路视频图像识别硬件加速。IVP09A,高效能低成本、稳定易开发、多点布线、联网管控…...

理解数据库
文章目录 一、了解什么是信息1.1 信息和数据1.1.1 信息 (information)1.1.2 数据 (Data) 1.2 数据处理 二、如何描述数据具备的信息2.1 数据库的一些术语: 三、数据模型3.1 概念模型 E-R,是对信息世界的建模…...
RHCE---Shell基础 2
文章目录 目录 文章目录 前言 一.变量 概述 定义 自定义变量 环境变量 概述: 定义环境变量: 位置变量 "$*"会把所有位置参数当成一个整体(或者说当成一个单词 变量的赋值和作用域 read 命令 变量和引号 变量的作用域 变…...

Git报错解决
本篇主要汇总在使用 Git 进行提交和拉取文件时,遇到的问题的解决方案,以便下次查找。 1 关于使用Git出现“git Failed to connect to 127.0.0.1 port xxxx: Connection refused”的问题解决方案 1. 问题描述 在使用 git 拉取、提交代码的时候ÿ…...
TechSmith Camtasia 2023 for Mac 屏幕录像视频录制编辑软件
TechSmith Camtasia for Mac 2023中文破解版 是一款专业的屏幕录像视频录制编辑软件,非常容易就可以获得精彩的截屏视频。创建引人注目的培训,演示和演示视频。Camtasia 屏幕录制软件简化,直观,让您看起来像专业人士。利用Camt…...
高效MMdetection(3.1.0)环境安装和训练自己数据集教程(实现于Linux(ubuntu),可在windows尝试)
一、前言 很久没用mmdetection了,作为目标检测常见的几个深度学习框架,mmdetection用的人还是很多的,其中比较吸引人的一点就是mmdetection集成了非常多的算法,对于想做实验对比和算法学习的人来说,基于这个框架可以事…...

软考-入侵检测技术原理与应用
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 by 2023年10月 入侵检测技术概念 入侵检测技术是指一种计算机安全技术,旨在监测计算机系统、…...
openGaussDatakit让运维如丝般顺滑!
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

整理MongoDB文档:身份验证
整理MongoDB文档:身份验证 个人博客,求关注。 文章概叙 本文主要讲MongoDB在单机状态下的账户配置。理解了MongoDB的语法,对于如何配置用户权限会知道怎么配置,但是请注意给谁配置什么权限才是最重要的。 最小权限原则 系统的每个程序或者…...
逐字稿 | 视频理解论文串讲(下)【论文精读】
1 为什么研究者这么想把这个双流网络替换掉,想用3D 卷积神经网络来做? 大家好,上次我们讲完了上半部分,就是 2D 网络和一些双流网络以及。它们的。变体。今天我们就来讲一下下半部分,就是 3D 网络和 video Transformer…...

【C++入门:C++世界的奇幻之旅】
1. 什么是C 2. C发展史 3. C的重要性 4. C关键字 5. 命名空间 6. C输入&输出 7. 缺省参数 8. 函数重载 9. 引用 10. 内联函数 11. auto关键字(C11) 12. 基于范围的for循环(C11) 13. 指针空值---nullptr(C11)05. 1. 什么是C C语言是结构化和模块化的语言&…...
rancher2.6.4配置管理k8s,docker安装
docker快速安装rancher并管理当前k8s集群。 1、拉镜像 docker pull rancher/rancher:v2.6.4 2、启动rancher 启动很慢 --privileged必须拥有root权限,并挂载卷 docker run --privileged -d --restartunless-stopped -p 80:80 -p 443:443 -v /usr/local/docker_vo…...

Python---练习:使用while嵌套循环打印 9 x 9乘法表
案例 使用while嵌套循环打印 9 x 9乘法表 思考 之前做过打印出三角形,那个三角形是5行的,这次打印9行的三角形。可以先使用while嵌套循环打印9行的直角三角形 相关链接Python---练习:打印直角三角形(利用wihle循环嵌套…...

仅手机大小!极空间T2随身数据魔盒发布:既是NAS 又是U盘
今天极空间召开新品发布会,带来了极空间T2随身数据魔盒,售价1999元起。 极空间T2随身数据魔盒体积仅手机大小,充电宝可供电。既是个NAS,又是个U盘。 其具备双M.2插槽,可安装两块固态硬盘。4G内存支持docker,…...

嵌入式系统中联合体的高效数据管理实践
1. 联合体在嵌入式系统中的高效数据管理实践在嵌入式系统开发中,如何高效地管理和传输数据一直是个值得深入探讨的话题。最近我在一个智能家居控制项目中遇到了一个典型场景:需要同时管理7个用电器的开关状态和4组电源线参数(电压、电流、有功…...

如何监控和分析自己网站的顶级SEO效果
如何监控和分析自己网站的顶级SEO效果 在当今数字化时代,网站的顶级SEO效果直接关系到网站的流量和用户参与度。了解如何有效监控和分析自己网站的SEO效果,对于提升网站的搜索排名和用户体验至关重要。本文将详细介绍如何监控和分析自己网站的顶级SEO效…...

ROS2多线程调试避坑指南:用gdb同时监控3个关键线程的交互问题
ROS2多线程调试避坑指南:用gdb同时监控3个关键线程的交互问题 调试ROS2节点时,多线程问题往往是最棘手的挑战之一。上周在调试一个图像处理节点时,我遇到了三个线程相互竞争导致的数据不一致问题——主线程发布消息、回调线程处理数据、定时器…...

STM32F407实战指南:基于74HC595的4位数码管驱动与动态扫描详解
1. 从零认识数码管:你的第一个嵌入式显示方案 第一次接触数码管时,我完全被它简单粗暴的显示方式吸引了。这种由7个LED灯组成的显示器件,通过不同段的组合就能展示0-9的数字,成本不到2块钱却能在各种家电上看到它的身影。我们这次…...
)
手把手教你用RK3588的NPU跑通第一个YOLOv5模型(附环境配置避坑点)
从零部署YOLOv5到RK3588 NPU:完整环境配置与模型转换实战 拿到RK3588开发板的第一时间,许多开发者最迫不及待想验证的就是其NPU的AI推理性能。作为瑞芯微第四代RKNPU架构的旗舰芯片,RK3588的6TOPS算力在边缘计算领域确实令人期待。但在实际部…...

从零搭建PX4无人机仿真环境:Gazebo场景构建与Offboard模式初探
1. 环境准备:从零搭建PX4开发基础 第一次接触PX4无人机开发的朋友,往往会被复杂的工具链吓到。其实只要跟着正确的步骤走,半小时内就能搭建好完整的仿真环境。我用的是一台装好Ubuntu 20.04的笔记本,建议至少预留30GB磁盘空间。 关…...

海康工业相机——Python二次开发实战:构建实时条形码识别系统
1. 环境准备与硬件选型 第一次接触海康工业相机时,我被它金属外壳下的精密光学元件震撼到了。这种工业级设备和我们平时用的消费级摄像头完全不同,它的稳定性、帧率和图像质量完全是为生产线环境设计的。如果你手头正好有台海康相机,跟着我的…...

MVP.css代码块和引用样式终极指南:提升内容可读性的完整秘诀
MVP.css代码块和引用样式终极指南:提升内容可读性的完整秘诀 【免费下载链接】mvp MVP.css — Minimalist classless CSS stylesheet for HTML elements 项目地址: https://gitcode.com/gh_mirrors/mv/mvp MVP.css是一个极简主义的无类CSS样式表,…...

突破3D资产生产瓶颈:Hunyuan3D-2赋能企业级内容创作的实战案例
突破3D资产生产瓶颈:Hunyuan3D-2赋能企业级内容创作的实战案例 【免费下载链接】Hunyuan3D-2 High-Resolution 3D Assets Generation with Large Scale Hunyuan3D Diffusion Models. 项目地址: https://gitcode.com/GitHub_Trending/hu/Hunyuan3D-2 Hunyuan3…...
,大模型检索从入门到精通,收藏这一篇就够了!)
RAG 不需要向量库?无向量检索新范式全攻略(非常硬核),大模型检索从入门到精通,收藏这一篇就够了!
基于推理的检索如何击败结构化文档上的相似性搜索,以及如何使用 PageIndex 构建它 你向 AI 智能体询问一份 200 页合同的问题。它自信地回答。答案是错误的。它从正确的主题中提取了文本,但却是错误的条款,而模型从未注意到。 这不是模型问…...