【C++入门:C++世界的奇幻之旅】
1. 什么是C++
2. C++发展史
3. C++的重要性
4. C++关键字
5. 命名空间
6. C++输入&输出
7. 缺省参数
8. 函数重载
9. 引用
10. 内联函数
11. auto关键字(C++11)
12. 基于范围的for循环(C++11)
13. 指针空值---nullptr(C++11)05.
1. 什么是C++
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的 程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机 界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一 种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而 产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的 程序设计,还可以进行面向对象的程序设计。
C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式 等。熟悉C语言之后,对C++学习有一定的帮助,
本章节主要目标:
- 1. 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用 域方面、IO方面、函数方面、指针方面、宏方面等。
- 2. 为后续类和对象学习打基础。
2. C++的发展史
1979年,贝尔实验室的本贾尼等人试图分析unix内核的时候,试图将内核模块化,于是在C 语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序,称之为C with classes。
语言的发展就像是练功打怪升级一样,也是逐步递进,由浅入深的过程。我们先来看下C++的历史版本。
| 阶段 | 内容 |
| C with classes | 类及派生类、公有和私有成员、类的构造和析构、友元、内联函数、赋值运算符 重载等 |
| C++1.0 | 类及派生类、公有和私有成员、类的构造和析构、友元、内联函数、赋值运算符 重载等 |
| C++2.0 | 更加完善支持面向对象,新增保护成员、多重继承、对象的初始化、抽象类、静 态成员以及const成员函数 |
| C++3.0 | 进一步完善,引入模板,解决多重继承产生的二义性问题和相应构造和析构的处 理 |
| C++98 | C++标准第一个版本,绝大多数编译器都支持,得到了国际标准化组织(ISO)和美 国标准化协会认可,以模板方式重写C++标准库,引入了STL(标准模板库) |
| C++03 | C++标准第二个版本,语言特性无大改变,主要:修订错误、减少多异性 |
| C++05 | C++标准委员会发布了一份计数报告(Technical Report,TR1),正式更名 C++0x,即:计划在本世纪第一个10年的某个时间发布 |
| C++11 | 增加了许多特性,使得C++更像一种新语言,比如:正则表达式、基于范围for循 环、auto关键字、新容器、列表初始化、标准线程库等 |
| C++14 | 对C++11的扩展,主要是修复C++11中漏洞以及改进,比如:泛型的lambda表 达式,auto的返回值类型推导,二进制字面常量等 |
| C++17 | 在C++11上做了一些小幅改进,增加了19个新特性,比如:static_assert()的文 本信息可选,Fold表达式用于可变的模板,if和switch语句中的初始化器等 |
| C++20 | 自C++11以来最大的发行版,引入了许多新的特性,比如:模块(Modules)、协 程(Coroutines)、范围(Ranges)、概念(Constraints)等重大特性,还有对已有 特性的更新:比如Lambda支持模板、范围for支持初始化等 |
| C++23 | 制定ing |
C++还在不断的向后发展。但是:现在公司主流使用还是C++98和C++11,所有大家不用追求最 新,重点将C++98和C++11掌握好,等工作后,随着对C++理解不断加深,有时间可以去琢磨下更 新的特性。
关于C++2X最新特性的讨论:链接
3. C++的重要性
3.1 语言的使用广泛度
下图数据来自TIOBE编程语言社区2023年最新的排行榜,在30多年的发展中,C/C++几乎一 致稳居前5。

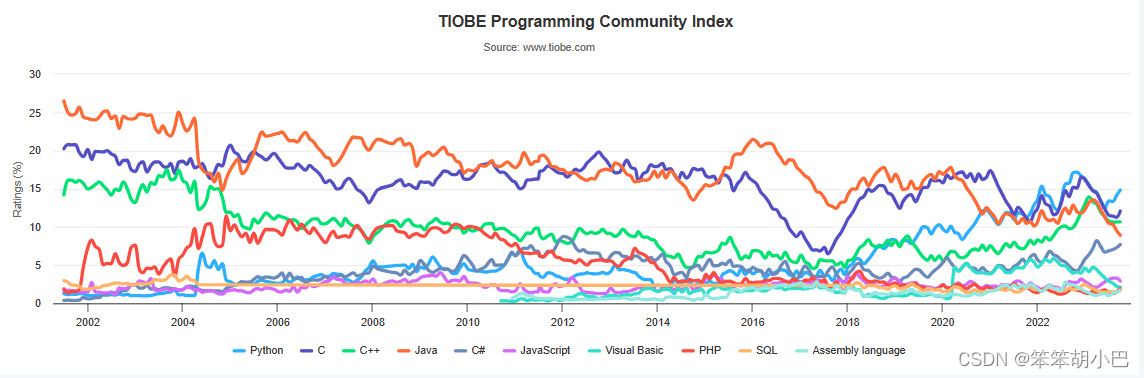
TIOBE 编程语言社区排行榜是编程语言流行趋势的一个指标,每月更新,这份排行榜排名基于互 联网上有经验的程序员、 课程和第三方厂商的数量。排名使用著名的搜索引擎(诸如 Google、 MSN、Yahoo!、Wikipedia、YouTube 以及 Baidu 等)进行计算。 注意:排名不能说明那个语言好,那个不好,每门编程语言都有适应自己的应用场景。
3.2 在工作领域
1. 操作系统以及大型系统软件开发
所有操作系统几乎都是C/C++写的,许多大型软件背后几乎都是C++写的,比如: Photoshop、Office、JVM(Java虚拟机)等,究其原因还是性能高,可以直接操控硬件。
2. 服务器端开发
后台开发:主要侧重于业务逻辑的处理,即对于前端请求后端给出对应的响应,现在主流采 用java,但内卷化比较严重,大厂可能会有C++后台开发,主要做一些基础组件,中间件、 缓存、分布式存储等。服务器端开发比后台开发跟广泛,包含后台开发,一般对实时性要求 比较高的,比如游戏服务器、流媒体服务器、网络通讯等都采用C++开发的。
3. 游戏开发
PC平台几乎所有的游戏都是C++写的,比如:魔兽世界、传奇、CS、跑跑卡丁车等,市面上 相当多的游戏引擎都是基于C++开发的,比如:Cocos2d、虚幻4、DirectX等。三维游戏领 域计算量非常庞大,底层的数学全都是矩阵变换,想要画面精美、内容丰富、游戏实时性 搞,这些高难度需求无疑只能选C++语言。比较知名厂商:腾讯、网易、完美世界、巨人网 络等。
4. 嵌入式和物联网领域
嵌入式:就是把具有计算能力的主控板嵌入到机器装置或者电子装置的内部,能够控制这些 装置。比如:智能手环、摄像头、扫地机器人、智能音响等。
谈到嵌入式开发,大家最能想到的就是单片机开发(即在8位、16位或者32位单片机产品或者 裸机上进行的开发),嵌入式开发除了单片机开发以外,还包含在soc片上、系统层面、驱动 层面以及应用、中间件层面的开发。
常见的岗位有:嵌入式开发工程师、驱动开发工程师、系统开发工程师、Linux开发工程 师、固件开发工程师等。
知名的一些厂商,比如:以华为、vivo、oppo、小米为代表的手机厂;以紫光展锐、乐鑫为 代表的芯片厂;以大疆、海康威视、大华、CVTE等具有自己终端业务厂商;以及海尔、海 信、格力等传统家电行业。
随着5G的普及,物联网(即万物互联,)也成为了一种新兴势力,比如:阿里lot、腾讯lot、京 东、百度、美团等都有硬件相关的事业部。
5. 数字图像处理
数字图像处理中涉及到大量数学矩阵方面的运算,对CPU算力要求比较高,主要的图像处理 算法库和开源库等都是C/C++写的,比如:OpenCV、OpenGL等,大名鼎鼎的Photoshop 就是C++写的。
6. 人工智能
一提到人工智能,大家首先想到的就是python,认为学习人工智能就要学习python,这个 是误区,python中库比较丰富,使用python可以快速搭建神经网络、填入参数导入数据就 可以开始训练模型了。但人工智能背后深度学习算法等核心还是用C++写的。
7. 分布式应用
近年来移动互联网的兴起,各应用数据量业务量不断攀升;后端架构要不断提高性能和并发 能力才能应对大信息时代的来临。在分布式领域,好些分布式框架、文件系统、中间组件等 都是C++开发的。对分布式计算影响极大的Hadoop生态的几个重量级组件:HDFS、 zookeeper、HBase等,也都是基于Google用C++实现的GFS、Chubby、BigTable。包括分 布式计算框架MapReduce也是Google先用C++实现了一套,之后才有开源的java版本。
除了上述领域外,在:科学计算、浏览器、流媒体开发、网络软件等都是C++比较适合的场景, 作为一名老牌语言的常青树,C++一直霸占编程语言前5名,肯定有其存在的价值。
4. C++关键字(C++98)
C++总计63个关键字,C语言32个关键字

5. 命名空间
我们首先来看一下一个C++程序的样子。
#include<iostream>//头文件
using namespace std;//命名空间stdint main()
{cout << "hello world" << endl;//输出并换行return 0;
}5.1 命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。现在我们来介绍一下命名空间,注意:C++是兼容90%的C语言。
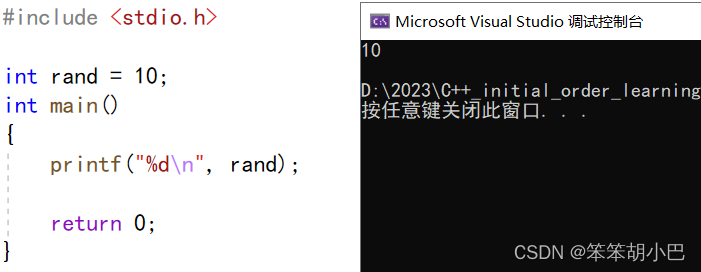
当我们加入头文件<stdlib.h>时程序就报错了,因为该文件下有一个rand函数,和我们当前的全局变量rand出现了命名冲突的问题。
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
// C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
int main()
{printf("%d\n", rand);return 0;
}
// 编译后后报错:error C2365: “rand”: 重定义;以前的定义rand是“函数”在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
命名冲突解决方法如下:不指定命名空间的名字不能访问该全局变量。
#include <stdio.h>
#include <stdlib.h>namespace yu //是命名空间的名字,一般开发中是用项目名字做命名空间名。
{int rand = 10;
}//这里没有分号int main()
{printf("%p\n", rand);//这里rand是函数,需要%p打印// :: 域作用限定符printf("%d\n", yu::rand);//这里rand是变量,需要%d打印return 0;
}命名空间中可以定义变量 / 函数 / 类型:
namespace yu //是命名空间的名字,一般开发中是用项目名字做命名空间名。
{int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}//这里没有分号//命名空间变量
yu::rand;
yu:Add(1,2);
struct yu::Node node;命名空间可以嵌套:
namespace yu
{namespace yu1{int rand = 10;}namespace yu2{int rand = 10;}
}printf("%d\n", yu::yu1::rand);//输出
printf("%d\n", yu::yu2::rand);//输出同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
// ps:一个工程中的test.h和上面test.cpp中两个yu会被合并成一个
// test.h
namespace yu
{int Add(int left, int right){return left + right;}
}5.2 命名空间使用
命名空间中成员该如何使用呢?比如:
#include <stdio.h>
#include <stdlib.h>
namespace yu
{// 命名空间中可以定义变量/函数/类型int a = 0;int b = 1;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}
int main()
{// 编译报错:error C2065: “a”: 未声明的标识符printf("%d\n", a);return 0;
}命名空间的使用有三种方式:
- 加命名空间名称及作用域限定符
int main()
{printf("%d\n", yu::a);return 0;
}
- 使用using将命名空间中某个成员引入
using yu::b;
int main()
{printf("%d\n", N::a);printf("%d\n", b);return 0;
}
- 使用using namespace 命名空间名称 引入
using namespce yu;
int main()
{printf("%d\n", yu::a);printf("%d\n", b);Add(10, 20);return 0;
}
总结:
std是C++标准库的命名空间,如何展开std使用更合理呢?
- 1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
- 2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std::cout展开常用的库对象/类型等方式。
6. C++输入&输出
新生婴儿会以自己独特的方式向这个崭新的世界打招呼,C++刚出来后,也算是一个新事物,那C++是否也应该向这个美好的世界来声问候呢?我们来看下C++是如何来实现问候的。
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{cout << "Hello world!!!" << endl;return 0;
}说明:
- 1. 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件 以及按命名空间使用方法使用std。
- 2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
- 3. <<是流插入运算符,>>是流提取运算符。
- 4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。 C++的输入输出可以自动识别变量类型。
- 5. 实际上cout和cin分别是ostream和istream类型的对象,>>和<<也涉及运算符重载等知识, 这些知识我们我们后续才会学习,所以我们这里只是简单学习他们的使用。后面我们还有有 一个章节更深入的学习IO流用法及原理。
注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间, 规定C++头文件不带.h;旧编译器(vc 6.0)中还支持格式,后续编译器已不支持,因 此推荐使用+std的方式。
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{int a = 1;double d = 1.1;// 可以自动识别变量的类型cout << a << endl;cout << d << endl;// 可以多种类型拼接cout << a << "+" << d << "=" << a + d << endl;return 0;
}运行结果:

// ps:关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。因为C++兼容C语言的用法,这些又用得不是很多,我们这里就不展开学习了。后续如果有需要,我们再配合文档学习。如果需要,可以使用C语言的printf去控制精度。
7. 缺省参数
7.1缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
#include<iostream>using std::cout;
using std::endl;void Func(int a = 0 ,int b = 1)
{cout << a << endl;cout << b << endl << endl;
}
int main()
{Func(); // 没有传参时,使用参数的默认值Func(10); // 传参时,使用指定的实参 -> 传参顺序:10->aFunc(10, 20); // 传参时,使用指定的实参 -> 传参顺序:10->a,20->breturn 0;
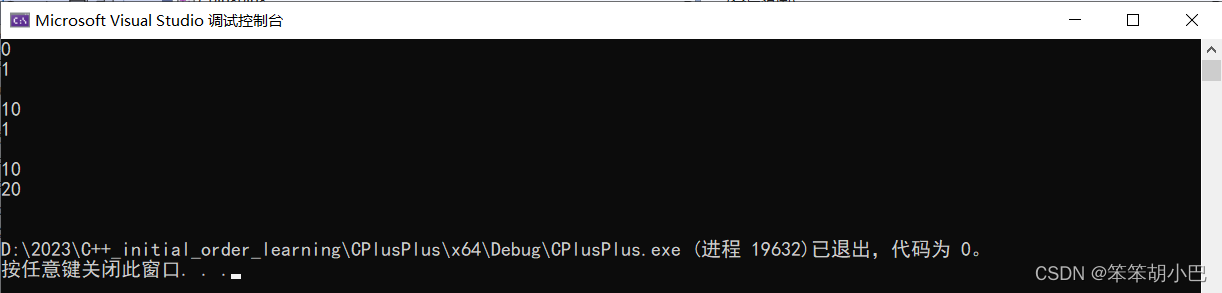
}运行结果:
7.2 缺省参数分类
-
全缺省参数
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}- 半缺省参数
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}注意:
- 1. 半缺省参数必须从右往左依次来给出,不能间隔着给
- 2. 缺省参数不能在函数声明和定义中同时出现
//a.h void Func(int a = 10);// a.cpp void Func(int a = 20) {}//如果声明与定义位置同时出现,恰巧两个位置提供的值不同,\ 那编译器就无法确定到底该用那个缺省值。//规定:在声明的地方写缺省参数 //a.h void Func(int a = 10);// a.cpp void Func(int a) {}
- 3. 缺省值必须是常量或者全局变量
- 4. C语言不支持(编译器不支持)
8. 函数重载
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。 比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是“谁也赢不了!”,后者是“谁也赢不了!”
8.1 函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型 不同的问题。
#include<iostream>
using namespace std;//重载:函数名相同,参数不同(类型不同,个数不同,类型顺序不同)返回值可同可不同// 1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}// 2、参数个数不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}// 3、参数类型顺序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}问:下面这个能构成重载吗? --- 构成(参数不同构成重载),但是实际上不会写这样的代码,不传参的时候调用存在二义性。
#include<iostream>
using namespace std;
void f()
{cout << "f()" << endl;
}
void f(int a = 0)
{cout << "f(int a = 0)" << endl;
}8.2 C++支持函数重载的原理--名字修饰(name Mangling)
为什么C++支持函数重载,而C语言不支持函数重载呢?
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。

1. 实际项目通常是由多个头文件和多个源文件构成,而通过C语言阶段学习的编译链接,我们可以知道,【当前a.cpp中调用了b.cpp中定义的Add函数时】,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢?
2. 所以链接阶段就是专门处理这种问题,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。
3. 那么链接时,面对Add函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的 函数名修饰规则。
4. 由于Windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们使 用了g++演示了这个修饰后的名字。
5. 通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度 +函数名+类型首字母】。
- 采用C语言编译器编译后结果
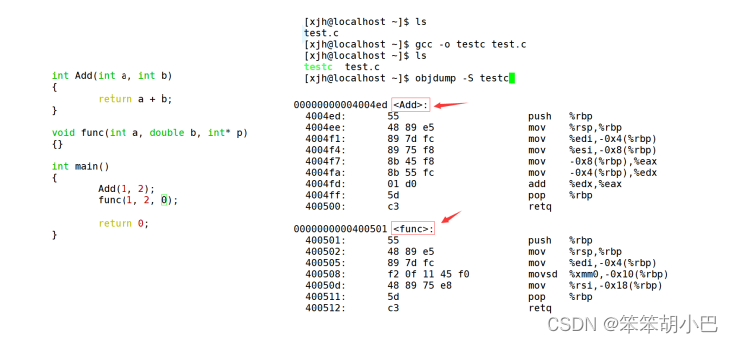
结论:在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。
- 采用C++编译器编译后结果
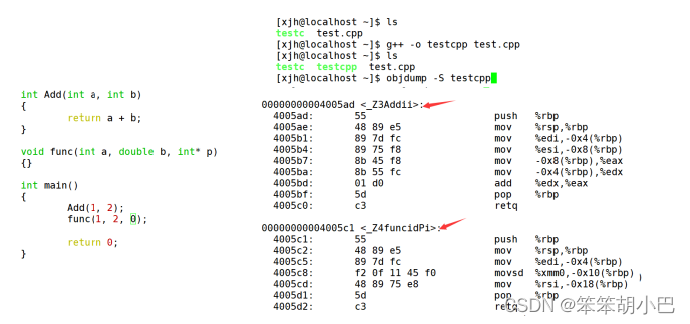
结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参 数类型信息添加到修改后的名字中。
- Windows下名字修饰规则

结论:对比一下发现修饰后的格式为:? + 函数名 + @@YA + 返回值 + 参数1 + 参数2 + @Z,int类型对应的是字母H,void类型对应的是字母X,double类型对应的是字母N。扩展:float类型对应的是字母M
对比Linux会发现,windows下vs编译器对函数名字修饰规则相对复杂难懂,但道理都是类似的,我们就不做细致的研究了。【扩展学习:C/C++函数调用约定和名字修饰规则--有兴趣好奇的同学可以看看,里面 有对vs下函数名修饰规则讲解】
C/C++的调用约定
6. 通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
7. 如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
9. 引用
9.1 引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。
类型& 引用变量名(对象名) = 引用实体;
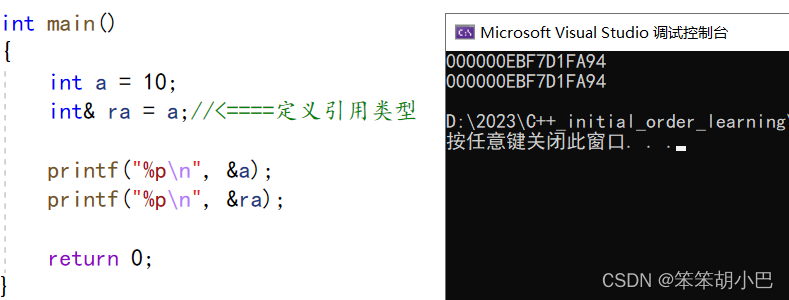
注意:引用类型必须和引用实体是同种类型的。
9.2 引用特性
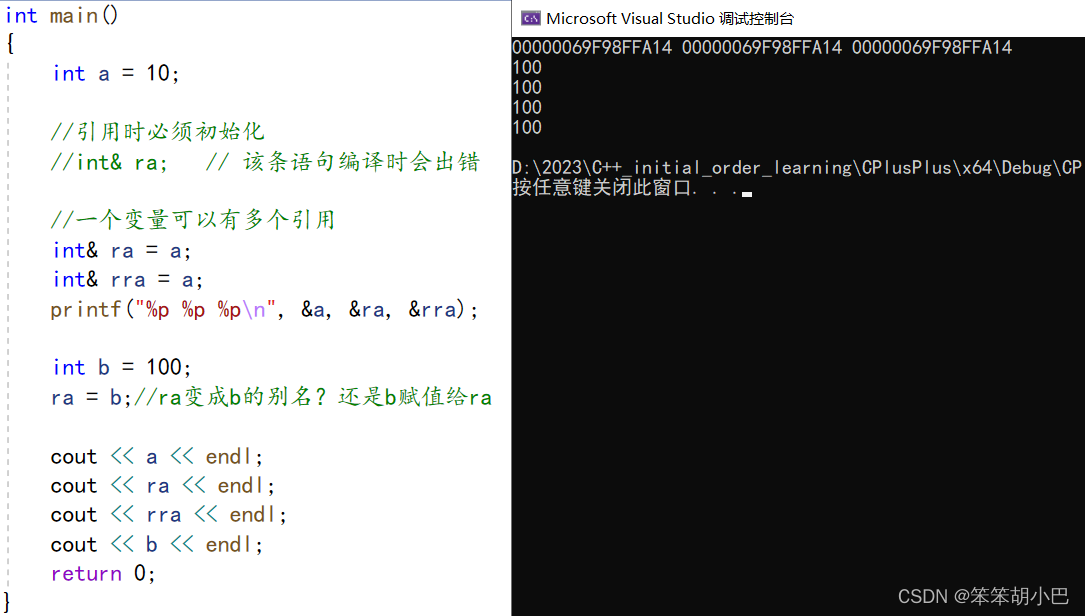
- 1. 引用在定义时必须初始化
- 2. 一个变量可以有多个引用,可以给别名起别名
- 3. 引用一旦引用一个实体,再不能引用其他实体,此时引用只是赋值,不改变指向
9.3 常引用
void TestConstRef()
{// 权限不能放大const int a = 10;int& ra = a; // 该语句编译时会出错,a为常量const int& ra = a;int& b = 10; // 该语句编译时会出错,b为常量const int& b = 10;int c = 10;const int& rc = c;//权限可以缩小double d = 12.34;int& rd = d; // 该语句编译时会出错,类型不同const int& rd = d;//产生了临时变量12,此时是给临时变量取别名
}9.4 使用场景
1. 做参数
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
2. 做返回值
int Count()
{int n = 0;n++;return n;
}int main()
{int ret = Count();cout << ret << endl;return 0;
}上面这个程序ret接收的是n还是n的拷贝???这里接收的是n的拷贝,当Count函数调用完后,局部变量就销毁了,所以我们这里是传值返回。如果我们引用返回呢???
int &Count()
{int n = 0;n++;return n;
}int main()
{int ret = Count();cout << ret << endl;return 0;
}这里的ret值是不确定的,它返回的是n的别名然后赋值给ret,但是这要取决于编译器在释放了函数栈帧后有没有将n这个变量的值清理掉。vs编译器下,函数栈帧释放后不会将值清理掉。
运行结果:

下面代码输出什么结果?为什么?
ret是上面c的别名,但是局部变量c出了函数作用域,返回对象就销毁了,不能用引用返回,否则结果是不确定滴。
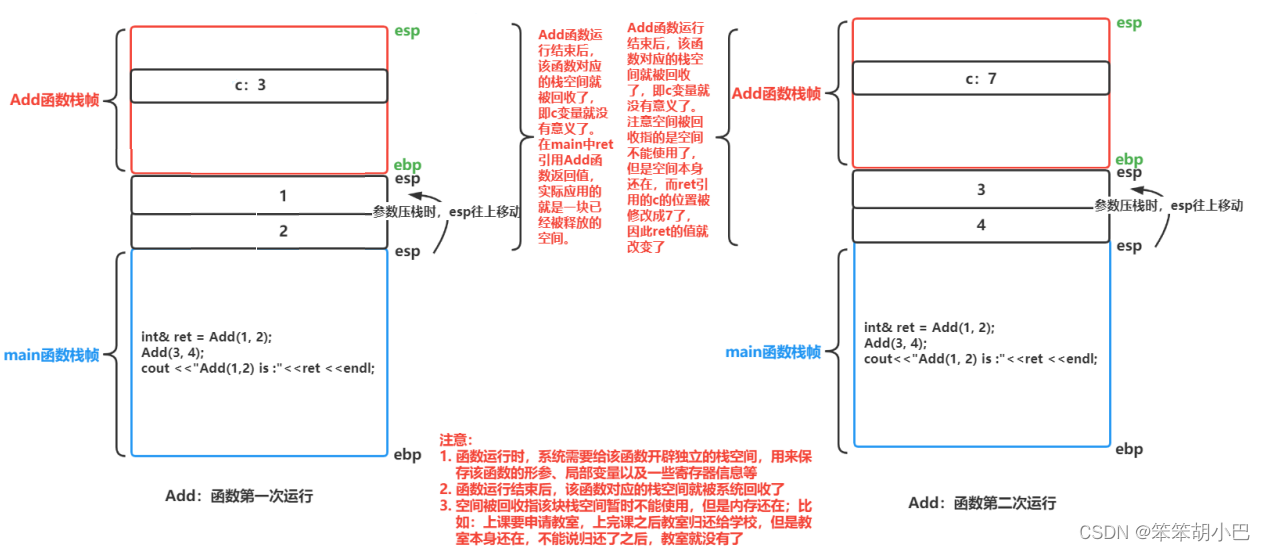
注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用 引用返回,如果已经还给系统了,则必须使用传值返回。
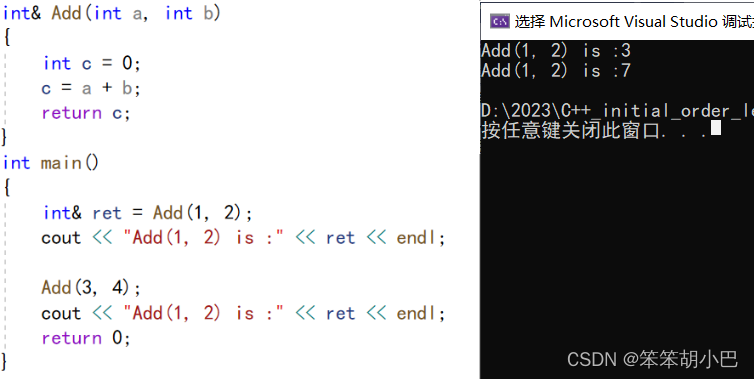
那引用作返回值我们该如何使用呢?我们可以给变量增加static修饰。
int& Add(int a, int b)
{static int c = a + b;return c;
}
int main()
{int& ret = Add(1, 2);cout << "Add(1, 2) is :" << ret << endl;Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;return 0;
}运行结果:

这里输出这样的结果是因为静态局部变量只会初始化一次,后面再调用就不会执行。
9.5 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效 率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
#include <iostream>
using namespace std;#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}运行结果:

值和引用的作为返回值类型的性能比较
#include <time.h>
struct A { int a[10000]; };
A a; //全局变量
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestReturnByRefOrValue();return 0;
}
通过上述代码的比较,发现传值和引用在作为传参以及返回值类型上效率相差很大。
9.6 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
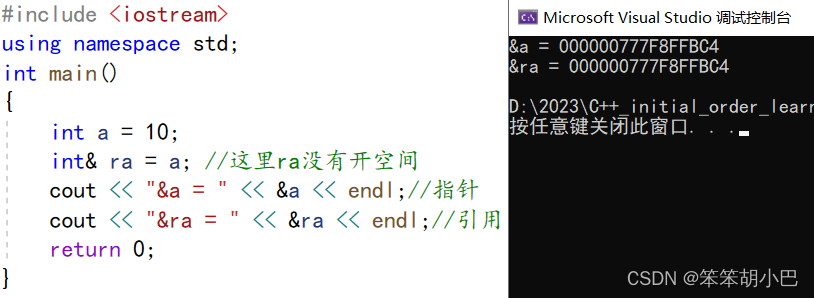
int main()
{int a = 10;// 语法,ra没有开空间int& ra = a;ra = 20;// 语法,pa开了空间int* pa = &a;*pa = 20;return 0;
}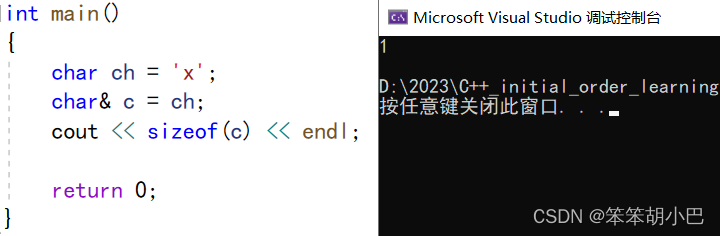
这里可以验证引用就是变量的别名,没有开空间,语法上这里引用只占一个字节。我们来看下引用和指针的汇编代码对比:

现象:底层上引用和指针的汇编代码一样,引用是按照指针方式来实现的。
引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
10. 内联函数
10.1 概念
稍微介绍一下宏:
优点:
- 1.增强代码的复用性。
- 2.提高性能。
缺点:
- 1.不方便调试宏。(因为预编译阶段进行了替换)
- 2.导致代码可读性差,可维护性差,容易误用。
- 3.没有类型安全的检查 。
C++有哪些技术替代宏?
- 1. 常量定义换用const enum
- 2. 短小函数定义换用内联函数
所以C++出现内联函数,以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调 用建立栈帧的开销,内联函数提升程序运行的效率。

如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的 调用。
查看方式:
- 1. 在release模式下,查看编译器生成的汇编代码中是否存在call Add
- 2. 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不 会对代码进行优化,以下给出vs2013的设置方式)

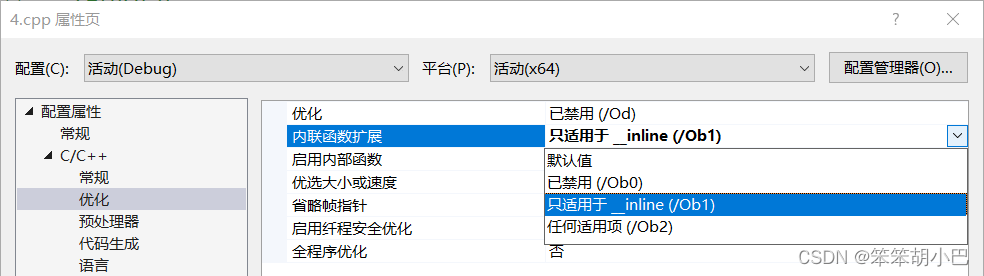

这里就直接展开了,没有call去函数内部。
10.2 特性
1. inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为 《C++prime》第五版关于inline的建议:

3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。?
// F.h
#include <iostream>
using namespace std;
inline void f(int i);// F.cpp
#include "F.h"
void f(int i)
{cout << i << endl;
}// main.cpp
#include "F.h"
int main()
{f(10);return 0;
}// 链接错误:main.obj : error LNK2019: 无法解析的外部符号 "void __cdecl \
f(int)" (?f@@YAXH@Z),该符号在函数 _main 中被引用
11. auto关键字(C++11)
11.1 auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的 是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
int TestAuto()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();//typeid ->输出变量的类型cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
}运行结果:

【注意】:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto 的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
11.2 类型别名思考
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
- 1. 类型难于拼写
- 2. 含义不明确导致容易出错
#include <string>
#include <map>
int main()
{std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange","橙子" },{"pear","梨"} };std::map<std::string, std::string>::iterator it = m.begin();while (it != m.end()){//....}return 0;
}std::map::iterator 是一个类型,但是该类型太长了,特别容 易写错。聪明的同学可能已经想到:可以通过typedef给类型取别名,比如:
#include <string>
#include <map>
typedef std::map<std::string, std::string> Map;
int main()
{Map m{ { "apple", "苹果" },{ "orange", "橙子" }, {"pear","梨"} };Map::iterator it = m.begin();while (it != m.end()){//....}return 0;
}使用typedef给类型取别名确实可以简化代码,但是typedef有会遇到新的难题:
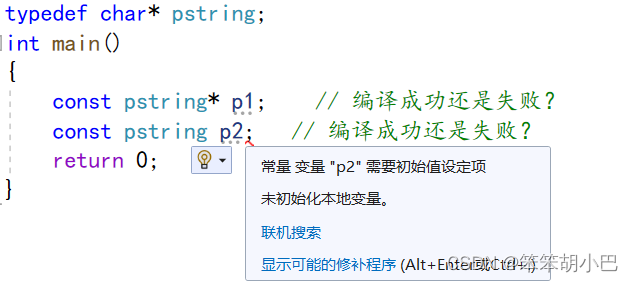
在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的 类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义。
11.3 auto的使用细则
1. auto与指针和引用结合起来使用
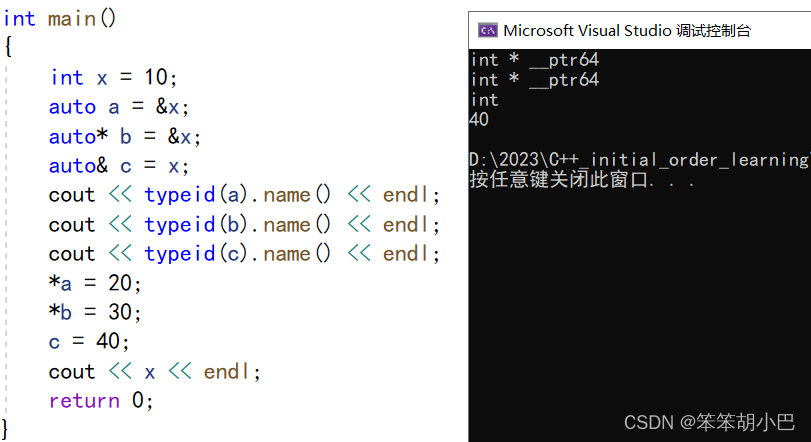
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
2. 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译 器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。

11.4 auto不能推导的场景
1. auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
2. auto不能直接用来声明数组

3. 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
4. auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有 lambda表达式等进行配合使用。
12. 基于范围的for循环(C++11)
12.1 范围for的语法
在C++98中如果要遍历一个数组,可以按照以下方式进行:
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)cout << *p << endl;
}对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因 此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };// 依次取数组中的数赋给e// 自动判断结束,自动++往后走for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";
}注意:与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
12.2 范围for的使用条件
1. for循环迭代的范围必须是确定的
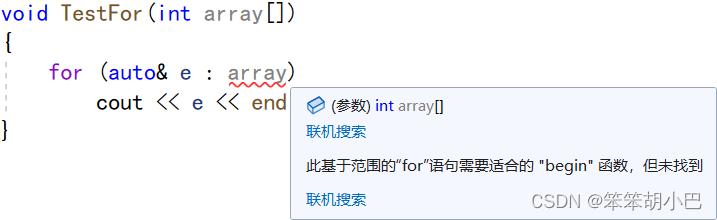
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供 begin和end的方法,begin和end就是for循环迭代的范围。 注意:以下代码就有问题,因为for的范围不确定。
2. 迭代的对象要实现++和==的操作。(关于迭代器这个问题,以后会讲,现在提一下,没办法 讲清楚,现在大家了解一下就可以了)
13. 指针空值nullptr(C++11)
13.1 C++98中的指针空值
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现 不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下 方式对其进行初始化:
void TestPtr()
{int* p1 = NULL;int* p2 = 0;// ……
}NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
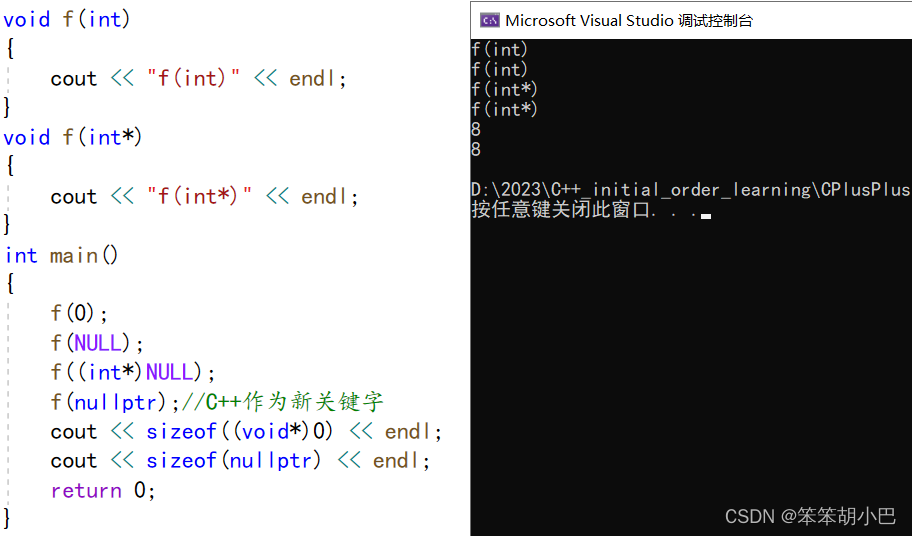
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何 种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{cout << "f(int)" << endl;
}
void f(int*)
{cout << "f(int*)" << endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}运行结果:

程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的 初衷相悖。 在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器 默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。
注意:
- 1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入 的。
- 2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。

相关文章:
【C++入门:C++世界的奇幻之旅】
1. 什么是C 2. C发展史 3. C的重要性 4. C关键字 5. 命名空间 6. C输入&输出 7. 缺省参数 8. 函数重载 9. 引用 10. 内联函数 11. auto关键字(C11) 12. 基于范围的for循环(C11) 13. 指针空值---nullptr(C11)05. 1. 什么是C C语言是结构化和模块化的语言&…...
rancher2.6.4配置管理k8s,docker安装
docker快速安装rancher并管理当前k8s集群。 1、拉镜像 docker pull rancher/rancher:v2.6.4 2、启动rancher 启动很慢 --privileged必须拥有root权限,并挂载卷 docker run --privileged -d --restartunless-stopped -p 80:80 -p 443:443 -v /usr/local/docker_vo…...

Python---练习:使用while嵌套循环打印 9 x 9乘法表
案例 使用while嵌套循环打印 9 x 9乘法表 思考 之前做过打印出三角形,那个三角形是5行的,这次打印9行的三角形。可以先使用while嵌套循环打印9行的直角三角形 相关链接Python---练习:打印直角三角形(利用wihle循环嵌套…...

仅手机大小!极空间T2随身数据魔盒发布:既是NAS 又是U盘
今天极空间召开新品发布会,带来了极空间T2随身数据魔盒,售价1999元起。 极空间T2随身数据魔盒体积仅手机大小,充电宝可供电。既是个NAS,又是个U盘。 其具备双M.2插槽,可安装两块固态硬盘。4G内存支持docker,…...

设计院图纸加密防泄密方案——天锐绿盾加密软件@德人合科技
天锐绿盾是一款专业的企业信息化防泄密软件,主要针对文档全生命周期进行加密保护,包括创建、修改、传输、归档、分发、销毁等全过程。它可以加强外发数据及终端离线的管理,对正常授权外带范围内的数据流程进行规范。设计图纸、文档等成果数据…...
AD9371 官方例程HDL详解之JESD204B TX侧时钟生成 (二)
AD9371 系列快速入口 AD9371ZCU102 移植到 ZCU106 : AD9371 官方例程构建及单音信号收发 ad9371_tx_jesd -->util_ad9371_xcvr接口映射: AD9371 官方例程之 tx_jesd 与 xcvr接口映射 AD9371 官方例程 时钟间的关系与生成 : AD9371 官方…...

实用新型和发明的区别
实用新型专利:是指对产品的形状、构造或者其结合所提出的适于实用的新的技术方案,指对有具体产品结构提出的改进或创造。与发明相比,实用新型专利申请对于技术的要求更低一点,在审查的时候不会进行详细的检索和对比,授…...
Oracle通过透明网关查询SQL Server 报错ORA-00904
Oracle通过透明网关查询SQL Server 报错ORA-00904 问题描述: 只有全表扫描SELECT * 时SQL语句可以正常执行 添加WHERE条件或指定列名查询,查询语句就报错 问题原因: 字段大小写和SQLSERVER中定义的不一致导致查询异常 解决办法: 给…...
MySQL表操作—存储
建表: mysql> create table sch( -> id int primary key, -> name varchar(50) not null, -> glass varchar(50) not null -> ); Query OK, 0 rows affected (0.01 sec) 插入数据: mysql> insert into sch (id,name,…...
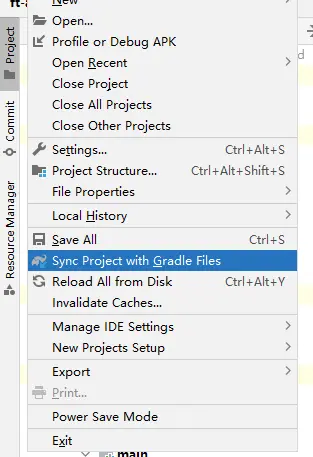
Android Studio Gradle中没有Task任务,没有Assemble任务,不能方便导出aar包
Gradle中,没有Assemble任务 1. 在编译aar包或者编译module的时候,没有release包,我们一般都是通过assemble进行编译。 如果在Gradle中找不到task。 可以通过设置File->setting -->Experimental→取消勾选“Do not build Gradle task …...

重复性管理--从泛值到泛型以及泛函(中)--泛函是什么及为什么
在前面, 我们探讨了泛型范式在解决重复性问题上的应用, 在这里, 将继续探讨泛函范式在解决重复性问题上的作用. 注: 关于"泛函(functional)“这一名称, 前面说了, 泛型的本质是"参数化类型”, 那么, 按照这一思路, 泛函的意思也可以理解为"函数的参数化"或…...

Arm推出Total Design生态系统,优化基于Neoverse CSS的SoC开发流程
目录 构建生态系统 将Arm架构小芯片带给大众 关于Arm Total Design的结语 我们最近报道了Arm的Neoverse CSS Genesis N2平台的发布,这是一个近乎现成的计算子系统设计,旨在加快尖端基础设施中定制加速器的上市时间。我们当时评论说,我们可…...

30天精通Nodejs--目录与说明
说明 本系列博客主要针对nodejs零基础的小伙伴,涵盖了Node.js从基础到高级的各个方面。 前置条件,有js的基础,了解css和html。 nodejs版本20.8.1。 目录 基础知识 第1天:基础介绍 第2天:模块系统与npm 第3天&#…...

如何创建前端绘图和图表?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
Python基础入门例程3-NP3 读入字符串
描述 小白正在学习Python,从变量输出开始。请使用input函数读入一个字符串,然后将其输出。 输入描述: 输入一行字符串。 输出描述: 将读入的变量输出。 示例1 输入: Nowcoder 复制输出: Nowcoder…...

每日一练 | 网络工程师软考真题Day44
1、在IEEE 802.11标准中使用了扩频通信技术,下面选项中有关扩频通信技术说法正确的选项是 。 A.扩频技术是一种带宽很宽的红外通信技术 B.扩频技术就是用伪随机序列对代表数据的模拟信号进行调制 C.扩频通信系统的带宽随着数据…...

Python11-正则表达式
Python11-正则表达式 1.正则表达式简介2.正则表达式常见用法和符号3.正则查找4.re.Match对象与group5.re.compile6.正则表达式修饰符7.正则匹配规则8.正则表达式匹配练习9.正则替换10.贪婪模式和非贪婪模式 1.正则表达式简介 正则表达式(Regular Expression&#x…...
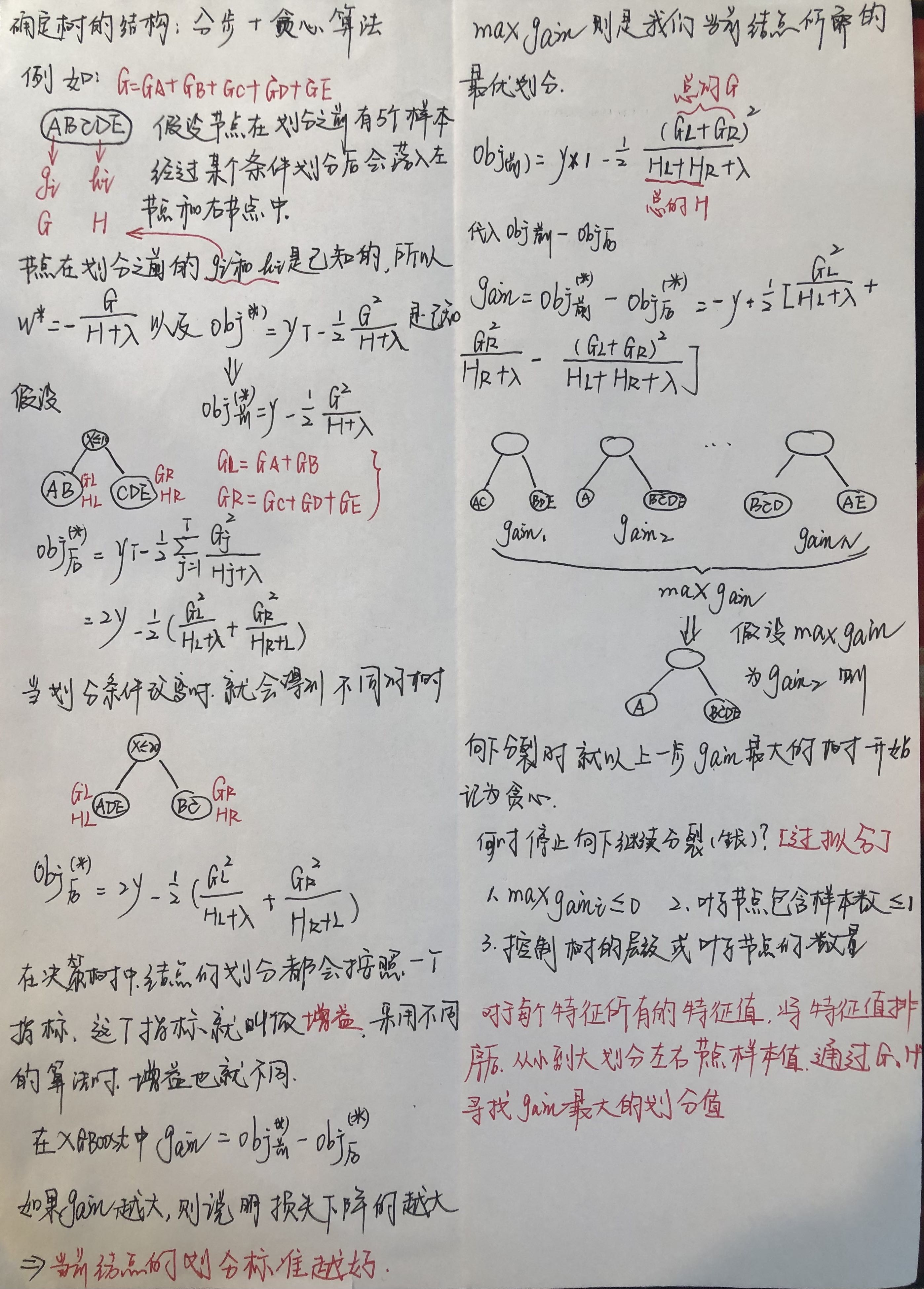
【机器学习】XGBoost
1.什么是XGBoost XGBoost(eXtreme Gradient Boosting)极度梯度提升树,属于集成学习中的boosting框架算法。对于提升树,简单说就是一个模型表现不好,继续按照原来模型表现不好的那部分训练第二个模型,依次类推。本质思想与GBDT一致…...
如何复制禁止复制的内容
今天找到一段代码,但是复制时页面提示“这个是VIP会员才有的权限”。我该怎么复制呢。 现在的平台大都是用钱说话,以便响应知识付费的主张。对错我就不说了,我认为既然我有权利看到代码,当然也有权把他复制下来。这并不涉及侵权。…...
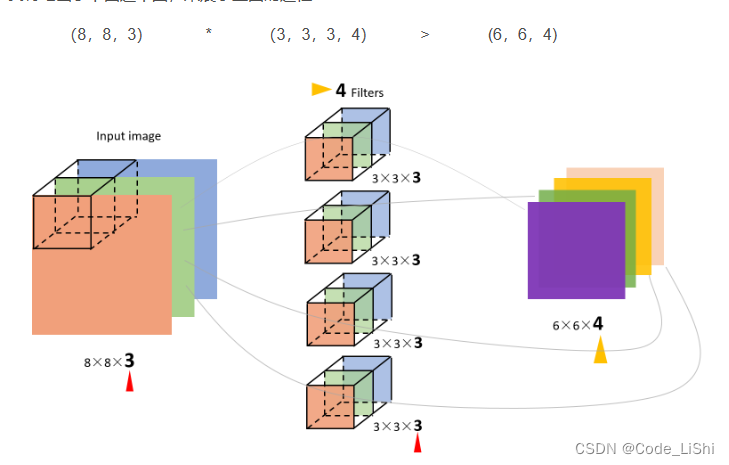
多通道图片的卷积过程
多通道(channels)图片的卷积 如果输入图片是三维的(三个channel),例如(8,8,3),那么每一个filter的维度就是(3,3,3&#x…...

静态图分布式训练总失败?PyTorch 3.0官方未公开的3类隐式依赖、4个环境校验checklist,立即自查!
第一章:静态图分布式训练失败的典型现象与归因框架静态图分布式训练(如 TensorFlow 1.x Graph 模式或 MindSpore Graph 模式)在大规模模型训练中常因图构建期与执行期分离的特性,导致错误暴露滞后、定位困难。典型失败现象包括&am…...

Qwen3-TTS开源镜像部署:RabbitMQ消息队列解耦高并发语音合成任务
Qwen3-TTS开源镜像部署:RabbitMQ消息队列解耦高并发语音合成任务 1. 项目概述与核心价值 Qwen3-TTS-12Hz-1.7B-VoiceDesign是一个功能强大的语音合成模型,支持10种主要语言(中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文和…...

Step3-VL-10B与Keil5开发环境:嵌入式视觉系统实战
Step3-VL-10B与Keil5开发环境:嵌入式视觉系统实战 用最简单的方式,带你从零搭建一个能"看懂世界"的嵌入式视觉系统 1. 开篇:为什么需要嵌入式视觉? 你有没有想过,让一个小小的单片机也能像人一样"看见…...

一键生成九宫格:用yz-bijini-cosplay快速制作社交媒体宣传素材
一键生成九宫格:用yz-bijini-cosplay快速制作社交媒体宣传素材 1. 项目简介:Cosplay内容创作新范式 在社交媒体运营中,视觉内容的重要性不言而喻。对于动漫展会、Cosplay摄影棚等内容创作者而言,如何快速产出高质量的九宫格宣传…...

应对“中年危机”的前置策略:留学生入职第一天就该考虑的事情——如何建立你的“被动求职”网络?
在 2026 年的北美科技职场,拿到全职 Offer 签下字的那一刻,许多留学生会如释重负地认为自己终于进入了“保险箱”。然而,在残酷的宏观经济周期和快速迭代的 AI 浪潮面前,传统的“绝对稳定”早已不复存在。 无论是硅谷巨头…...

Unity | HDRP高清渲染管线实战:优化Lightmapping性能的10个关键技巧
1. 理解HDRP中的Lightmapping核心机制 在HDRP高清渲染管线中,光照烘焙(Lightmapping)是将复杂光照计算转化为纹理贴图的关键技术。与实时渲染不同,烘焙过程会预先计算场景中静态物体的间接光照、阴影和环境光遮蔽效果,…...

星图GPU云体验OpenClaw:免安装调试Phi-3-mini-128k-instruct镜像
星图GPU云体验OpenClaw:免安装调试Phi-3-mini-128k-instruct镜像 1. 为什么选择云端体验OpenClaw 上周我尝试在本地笔记本上部署OpenClaw时,被各种环境依赖和权限问题折磨得够呛。正当我准备放弃时,偶然发现星图平台提供了预装OpenClaw的GP…...

OpenClaw技能市场探秘:Phi-3-vision支持的十大实用插件
OpenClaw技能市场探秘:Phi-3-vision支持的十大实用插件 1. 为什么需要关注OpenClaw技能市场? 作为一个长期在自动化工具领域折腾的技术爱好者,我最初接触OpenClaw时,最吸引我的不是它的基础框架,而是它那个充满可能性…...

OpenClaw+千问3.5-9B会议纪要:语音转文字自动生成重点
OpenClaw千问3.5-9B会议纪要:语音转文字自动生成重点 1. 为什么需要自动化会议纪要 每次开完会最头疼的就是整理会议纪要。作为团队里经常负责记录的人,我经历过太多这样的场景:会议中疯狂打字记录,结果漏掉关键讨论点ÿ…...

OpenAI 把 Codex 接进 Claude Code,这件事比你想的更“工程化”
目录这次到底发生了什么为什么说这是一次“反常识”的动作插件能力拆解:三个命令背后的工程价值Claude Code Codex 的真实工作流长什么样技术实现拆解:它到底怎么接进去的对开发者意味着什么变化一些容易被忽略的坑一、这次到底发生了什么最近一个比较有…...