《动手学深度学习 Pytorch版》 9.5 机器翻译与数据集
机器翻译(machine translation)指的是将序列从一种语言自动翻译成另一种语言,基于神经网络的方法通常被称为神经机器翻译(neural machine translation)。
import os
import torch
from d2l import torch as d2l
9.5.1 下载和预处理数据集
“Tab-delimited Bilingual Sentence Pairs”数据集是由双语句子对组成的“英-法”数据集,数据集中的每一行都是制表符分隔的文本序列对,序列对由英文文本序列和翻译后的法语文本序列组成。请注意,每个文本序列可以是一个句子,也可以是包含多个句子的一个段落。在这个将英语翻译成法语的机器翻译问题中,英语是源语言(source language), 法语是目标语言(target language)。
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""载入“英语-法语”数据集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
print(raw_text[:75])
Downloading ..\data\fra-eng.zip from http://d2l-data.s3-accelerate.amazonaws.com/fra-eng.zip...
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
原始文本数据需要经过几个预处理步骤,例如:
-
用空格代替不间断空格(non-breaking space)
-
使用小写字母替换大写字母
-
在单词和标点符号之间插入空格。
#@save
def preprocess_nmt(text):"""预处理“英语-法语”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格# 使用小写字母替换大写字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
print(text[:80])
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
9.5.2 词元化
在机器翻译中更喜欢单词级词元化(最先进的模型可能使用更高级的词元化技术)。
#@save
def tokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""source, target = [], [] # source 是源语言 target 是目标语言for i, line in enumerate(text.split('\n')): # 按行遍历if num_examples and i > num_examples: # 限制句子数breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' ')) # 分割成词元列表target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
source[:6], target[:6]
([['go', '.'],['hi', '.'],['run', '!'],['run', '!'],['who', '?'],['wow', '!']],[['va', '!'],['salut', '!'],['cours', '!'],['courez', '!'],['qui', '?'],['ça', 'alors', '!']])
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target);

9.5.3 词表
使用单词级词元化时,词表大小将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,将出现次数少于2次的低频率词元视为相同的未知(“<unk>”)词元。 除此之外还指定了额外的特定词元,例如在小批量时用于将序列填充到相同长度的填充词元(“<pad>”),以及序列的开始词元(“<bos>”)和结束词元(“<eos>”)。这些特殊词元在自然语言处理任务中比较常用。
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab)
10012
9.5.4 加载数据集
在机器翻译中,每个样本都是由源和目标组成的文本序列对,其中的每个文本序列可能具有不同的长度,因此需要通过截断(truncation)和填充(padding)方式实现一次只处理一个小批量的文本序列。简言之就是多了截断,短了补齐。
#@save
def truncate_pad(line, num_steps, padding_token):"""截断或填充文本序列"""if len(line) > num_steps:return line[:num_steps] # 长了截断return line + [padding_token] * (num_steps - len(line)) # 短了填充truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
定义 build_array_nmt 函数将文本序列转换成小批量数据集用于训练。将特定的“<eos>”词元添加到所有序列的末尾,用于表示序列的结束。
此外,还记录了每个文本序列的长度,统计长度时排除了填充词元。
#@save
def build_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines] # 将句子中的各词元转换为下标lines = [l + [vocab['<eos>']] for l in lines] # 添加结束符array = torch.tensor([truncate_pad( # 分成小批量l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1) # 计算长度return array, valid_len
9.5.5 整合
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""text = preprocess_nmt(read_data_nmt()) # 预处理source, target = tokenize_nmt(text, num_examples) # 词元化src_vocab = d2l.Vocab(source, min_freq=2, # 源语言词表reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2, # 目标语言词表reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps) # 源语言小批量化tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps) # 目标语言小批量化data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效长度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效长度:', Y_valid_len)break
X: tensor([[ 39, 91, 4, 3, 1, 1, 1, 1],[139, 12, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效长度: tensor([4, 4])
Y: tensor([[ 92, 12, 5, 3, 1, 1, 1, 1],[111, 0, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
Y的有效长度: tensor([4, 4])
练习
(1)在 load_data_nmt 函数中尝试不同的 num_examples 参数值。这对源语言和目标语言的词表大小有何影响?
for num_examples in range(100, 1201, 100):train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8, num_examples=num_examples)print(f"num_examples = {'%4d'%num_examples} len(src_vocab) = {len(src_vocab)} len(tgt_vocab) = {len(tgt_vocab)}")
num_examples = 100 len(src_vocab) = 40 len(tgt_vocab) = 40
num_examples = 200 len(src_vocab) = 69 len(tgt_vocab) = 67
num_examples = 300 len(src_vocab) = 102 len(tgt_vocab) = 107
num_examples = 400 len(src_vocab) = 130 len(tgt_vocab) = 125
num_examples = 500 len(src_vocab) = 159 len(tgt_vocab) = 163
num_examples = 600 len(src_vocab) = 184 len(tgt_vocab) = 201
num_examples = 700 len(src_vocab) = 208 len(tgt_vocab) = 224
num_examples = 800 len(src_vocab) = 229 len(tgt_vocab) = 250
num_examples = 900 len(src_vocab) = 249 len(tgt_vocab) = 286
num_examples = 1000 len(src_vocab) = 266 len(tgt_vocab) = 321
num_examples = 1100 len(src_vocab) = 293 len(tgt_vocab) = 359
num_examples = 1200 len(src_vocab) = 314 len(tgt_vocab) = 384
(2)某些语言(例如中文和日语)的文本没有单词边界指示符(例如空格)。对于这种情况,单词级词元化仍然是个好主意吗?为什么?
没有边界指示符不意味着没有单词,仍然是需要分词的,只是麻烦些。
相关文章:
《动手学深度学习 Pytorch版》 9.5 机器翻译与数据集
机器翻译(machine translation)指的是将序列从一种语言自动翻译成另一种语言,基于神经网络的方法通常被称为神经机器翻译(neural machine translation)。 import os import torch from d2l import torch as d2l9.5.1 …...
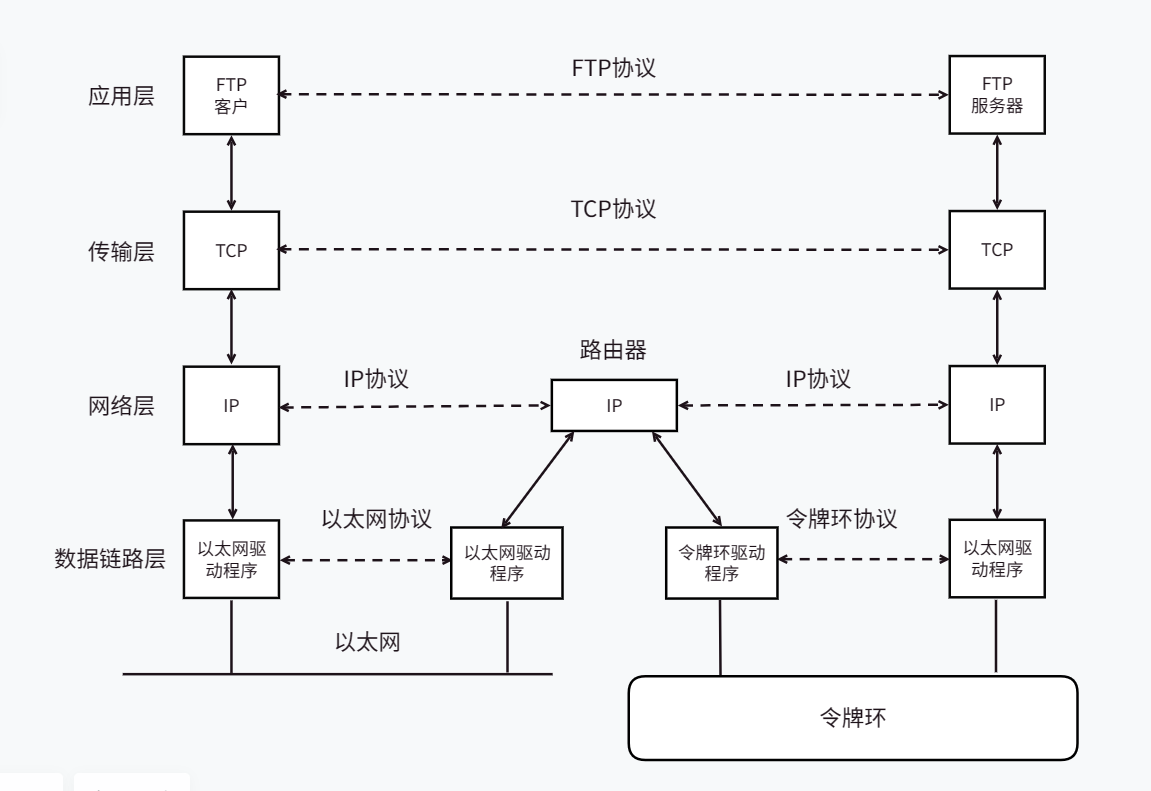
网络入门基础
网络入门基础 文章目录 网络入门基础网络的发展协议的概念网络协议初识协议分层层状结构OSI七层模型TCP/IP五层(或四层)模型TCP/IP模型和计算机软硬体系结构的关系 网络传输基本流程同局域网的两台主机通信不同局域网的两台主机通信 网络中的地址管理认识IP地址认识MAC地址 网络…...

Towards a Rigorous Evaluation of Time-series Anomaly Detection(论文翻译)
1 Introduction 随着工业4.0加速系统自动化,系统故障的后果可能会产生重大的社会影响(Baheti和Gill 2011; Lee 2008; Lee,Bagheri和Kao 2015)。为了防止这种故障,检测系统的异常状态比以往任何时候都更加重要ÿ…...

理解Python装饰器
本文将从多个方面对Python装饰器进行详细的阐述,并给出完整的代码示例。 一、装饰器的概念 装饰器是Python中非常重要的概念,它可以在不修改函数本身的情况下对函数的功能进行扩展或修改。装饰器本质上是一个函数,它接收一个函数作为参数&a…...

VR智慧景区,为游客开启智慧旅游新时代
近年来,文旅部加强了5G、VR虚拟技术等在文旅产业行业的运用,随着科技的不断发展,VR技术的运用越来越广泛,VR智慧景区作为一种全新的旅游方式,也渐渐的受到了人们广泛的关注,它可以让人们足不出户就欣赏到各…...

蓝桥杯 Java 青蛙过河
import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改/**二分法从大(n)到小找足够小的步长前缀和记录每个位置的前面有的总石头数(一个石头表示可以容纳一个青蛙,一位置有多少个石头hi就是多少)&…...

雷达图应该如何去绘制?
雷达图(又称为蜘蛛网图、星形图)是一种用来显示多变量数据的图表,它可以直观地展示出数据在多个维度上的表现。雷达图中,每个轴代表一个维度,所有的轴都从中心点射出并均匀分布在圆周上,形成一个星形。每个…...

1024 蓝屏漏洞攻防战(第十九课)
1024 蓝屏漏洞攻防战(第十九课) 思维导图 一 永恒之蓝的介绍 漏洞为外界所知源于勒索病毒的爆发,该病毒利用NSA(美国国家安全局)泄露的网络攻击工具 永恒之蓝( EternalBlue )改造而成,漏洞通过TCP的445和139端口,利用SMB远程代码执行漏洞,攻击者可以在目标系统上执行…...

短视频矩阵系统软件源码
短视频矩阵系统软件源码 视频成为获得免费流量最便宜的渠道,平台给所有视频最基础的保底流量。如果按照一个视频最低500流量计算,5个账户就是2500的流量,200个视频就是50W流量,如果从其他渠道获得50W流量是个很困难的事情。短视频…...
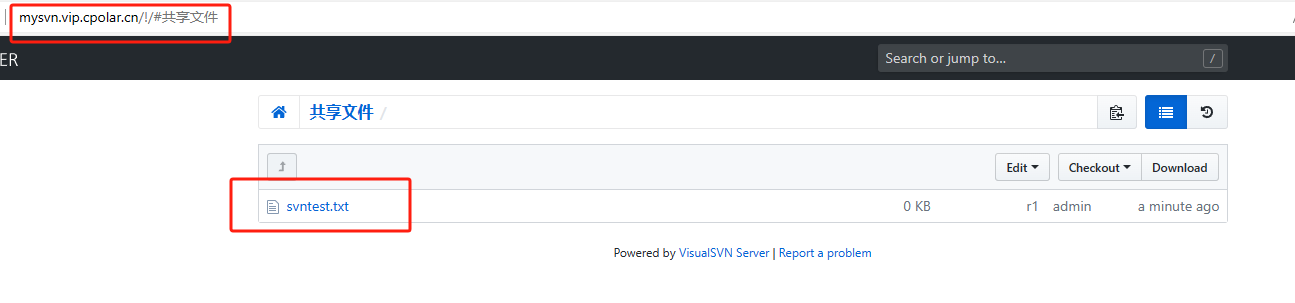
内网穿透的应用-如何通过TortoiseSVN+内网穿透,实现公网提交文件到内网SVN服务器?
文章目录 前言1. TortoiseSVN 客户端下载安装2. 创建检出文件夹3. 创建与提交文件4. 公网访问测试 前言 TortoiseSVN是一个开源的版本控制系统,它与Apache Subversion(SVN)集成在一起,提供了一个用户友好的界面,方便用…...
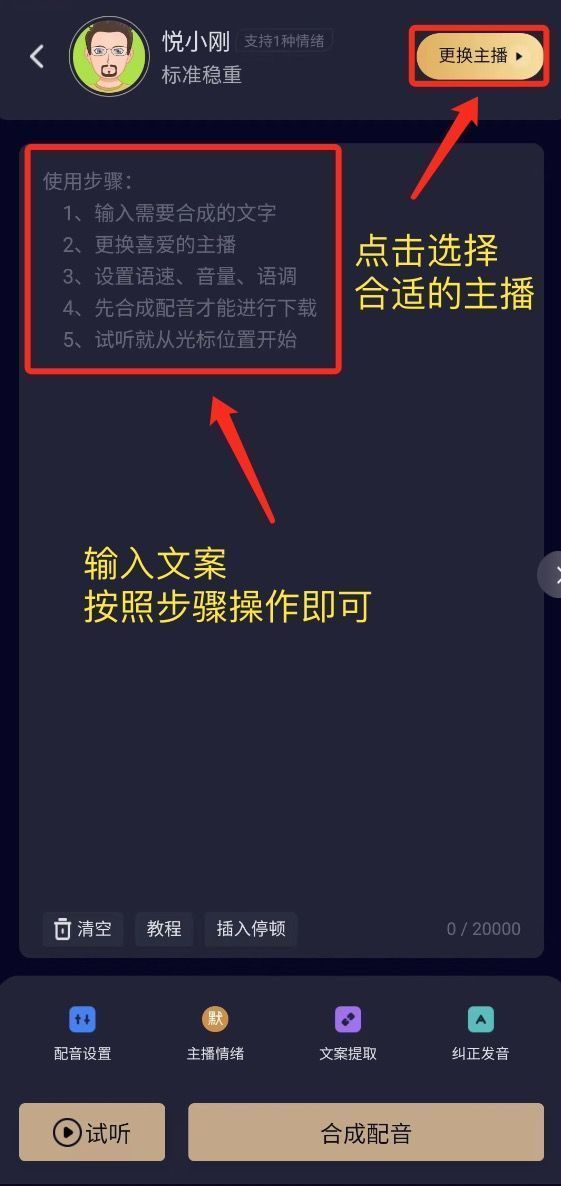
有没有PC端的配音软件推荐?(免下载)
配音软件还是电脑上使用最方便,而且电脑上可以使用的配音软件也非常多。只是你平时使用的不多,所有想用的时候才会找不到,对于经常使用配音软件的人来说,那真的太多了。今天给大家推荐一个免下载的配音网站,微信扫码即…...

clickhouse
官方链接 <insert id"insertTable" parameterType"com.ioc.orm.ck.model.TableModel">insert into table_name<trim prefix"(" suffix")" suffixOverrides","><if test"ts ! null">ts,</if…...

linux下创建文件夹软链接
软链接: 软链接是Linux下常用的一种共享文件方式、目录的方式,这种方式类似于Windows下的快捷方式。一般一个文件或者目录在不同的路径都需要的时候,可以通过创建软链接的方式来共享,这样系统下面只有一份源文件、目录。另外&…...

常用的工具网站
1.免费的在线pdf解密网站:https://smallpdf.com/unlock-pdf 2.常用的梯子登录页面:https://3.akkcloud1.com/auth/login 3.chatgpt登录页面:https://chat.openai.com/auth/login 4.国外短信收发平台:https://sms-activate.org/cn/…...
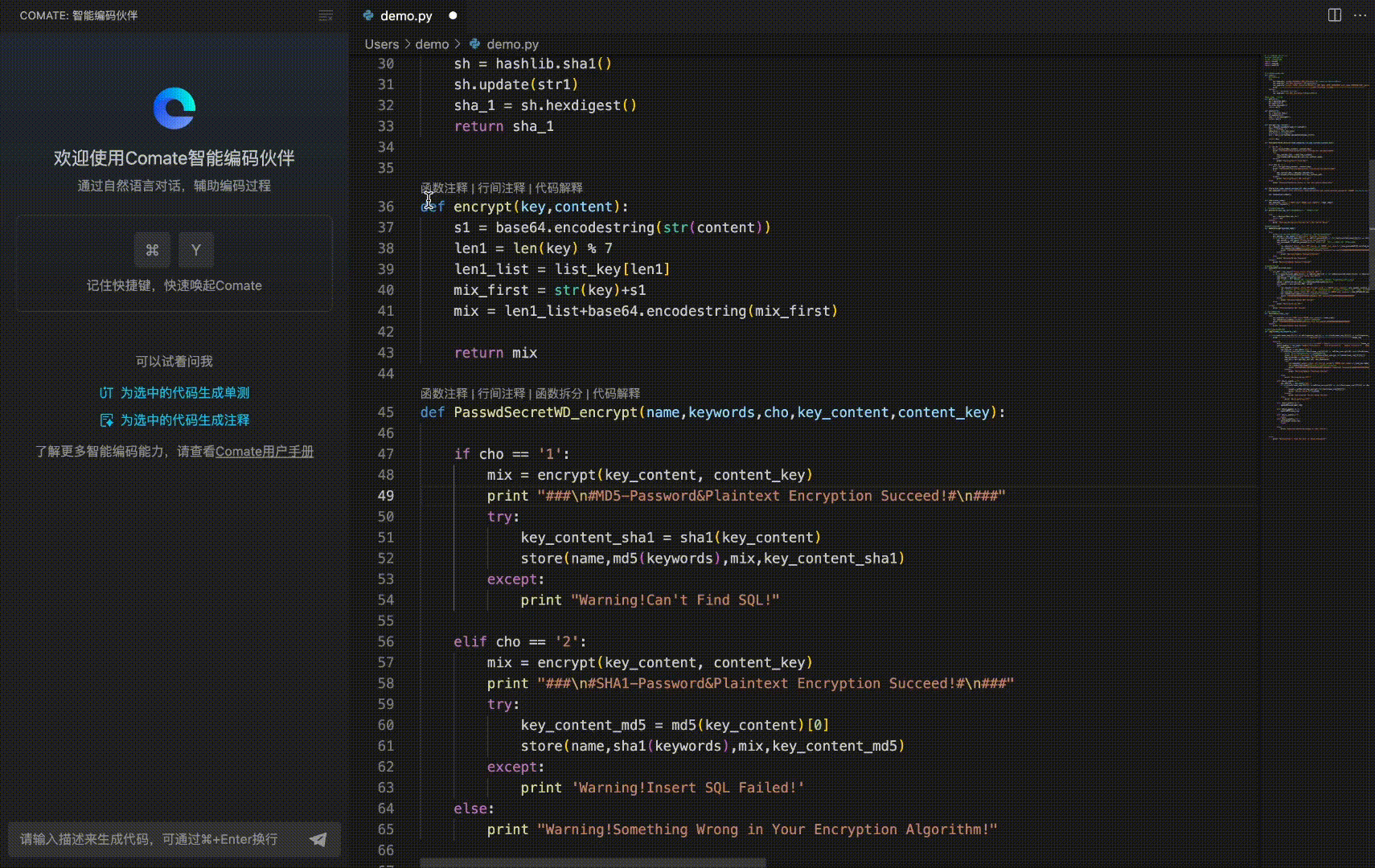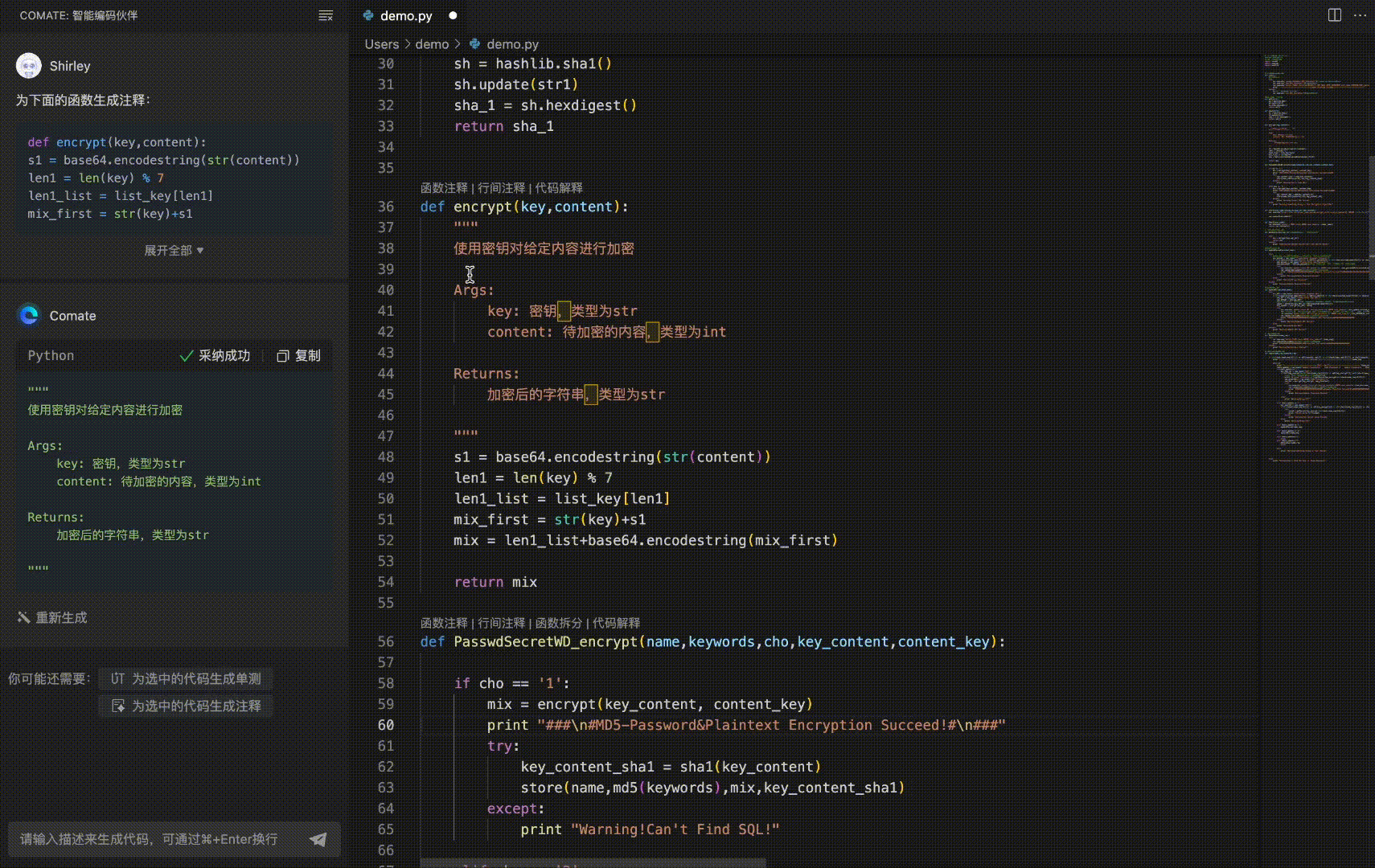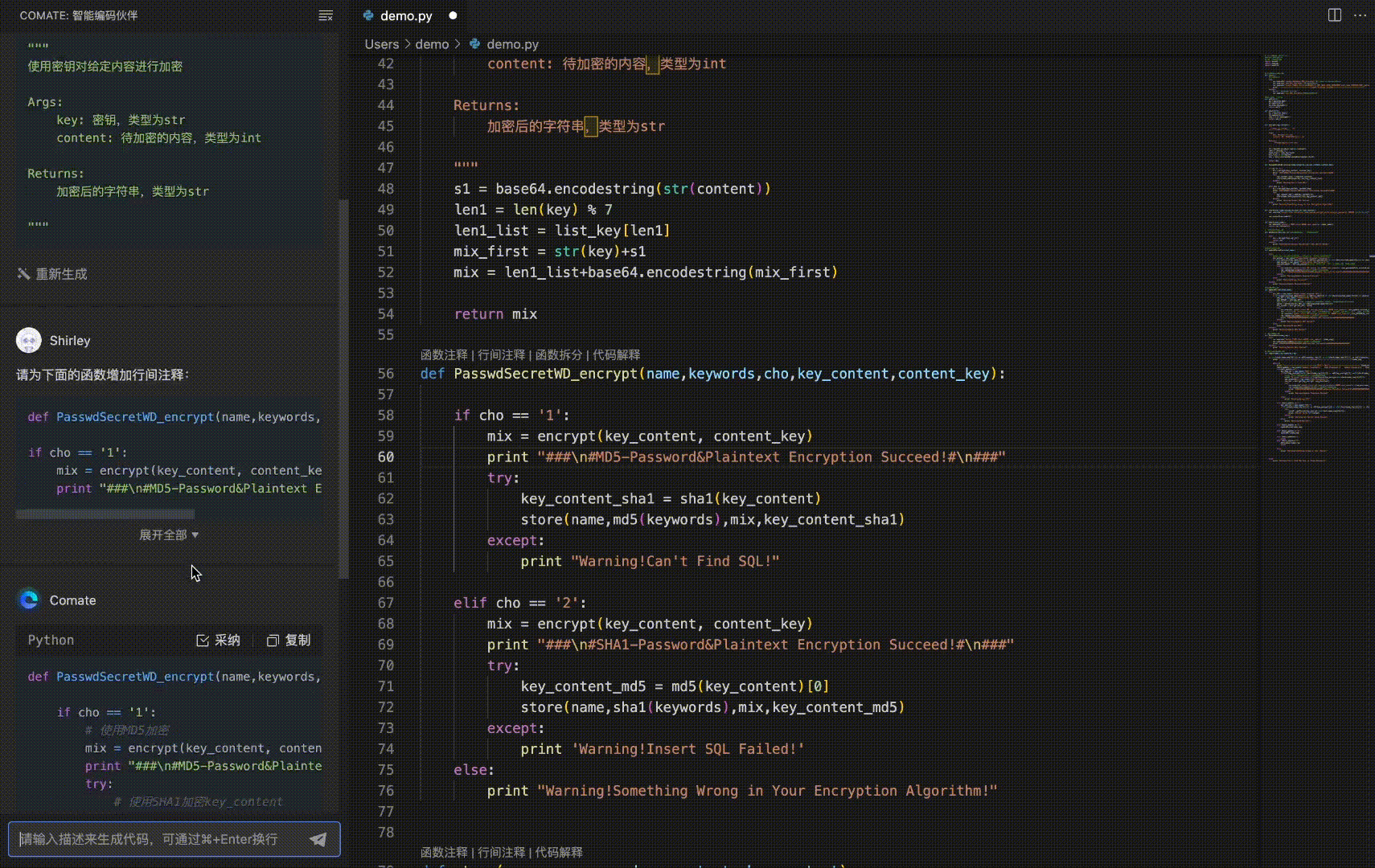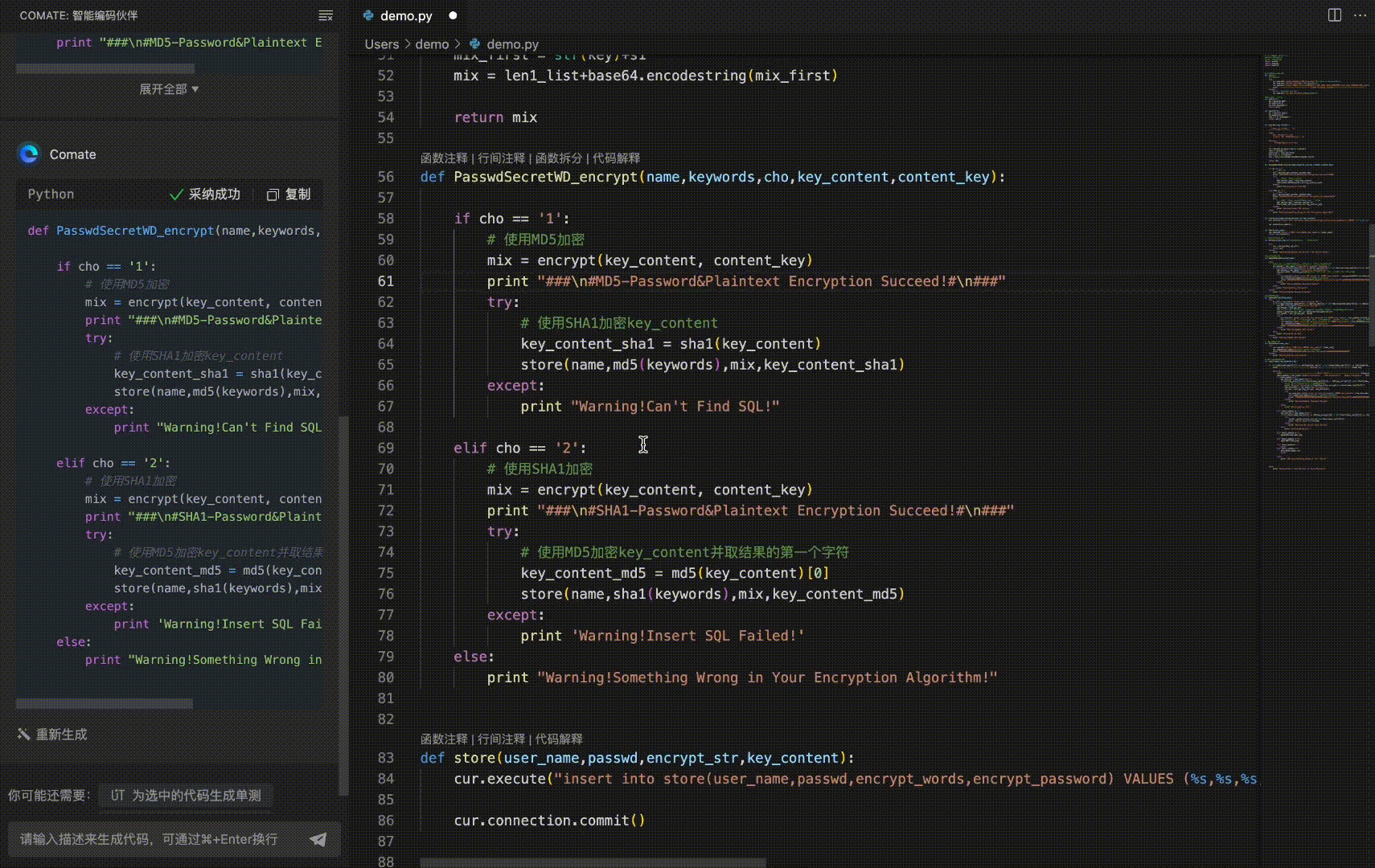
号外!百度Comate代码助手全新上线SaaS服务 - 免费申请试用+深入教程解读!
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
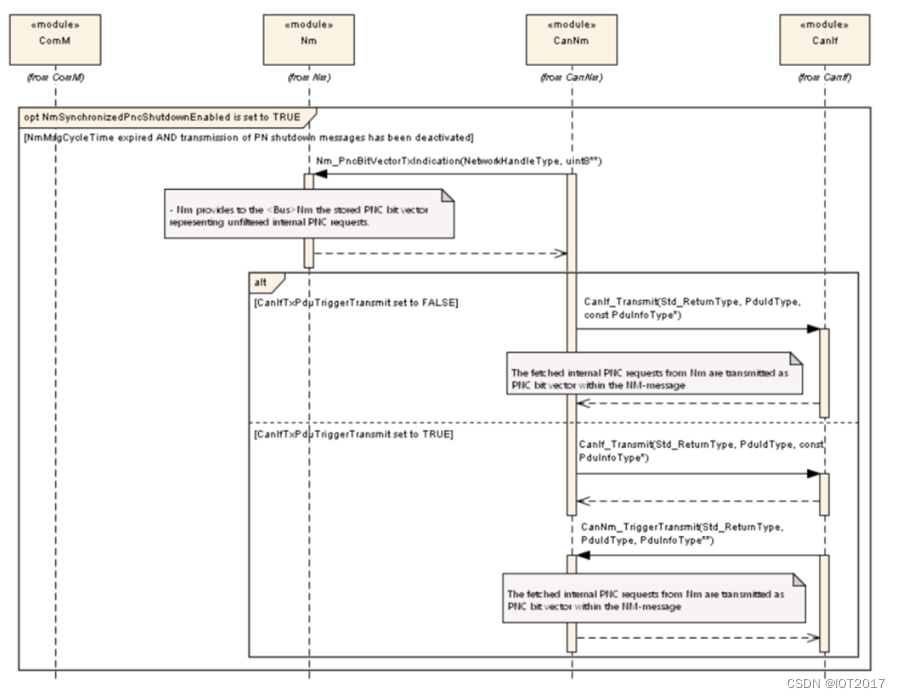
AUTOSAR通信篇 - CAN网络通信(七:Nm)
文章目录 基础功能NM协调器功能NM协调器功能的适用性保持协调总线活动总线关闭的协调嵌套子总线的协调关闭定时器的计算同步用例1 – 同步指令同步用例2-同步启动同步用例3 -同步网络睡眠示例 唤醒和中止协调关闭外部的网络唤醒协调唤醒协调关闭的中止 部分网络功能PNC位向量过…...

CentOS 7 中安装Kafka
文章目录 安装JDK解压环境变量验证 安装ZooKeeper下载解压环境变量配置启动开放端口 安装Kafka下载解压配置启动 CentOS 7.6 JDK 1.8 ZooKeeper 3.5.7 Kafka 2.11-2.4.0 安装JDK 解压 # 解压 tar -xzvf jdk-8u181-linux-x64.tar.gz mv jdk1.8.0_181 /usr/local/jdk1.8环境变量…...

Centos 7 部署Docker CE和docker-compose教程
一、Docker CE 1、Docker CE 安装 ①、安装依赖包 yum install -y yum-utils device-mapper-persistent-data lvm2②、设置yum源 # 官方源(二选一) yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # 阿里源…...

【数据结构】模拟实现无头单向非循环链表
链表的概念 学过ArrayList后我们知道它的底层是用数组来存储元素的,是连续的存储空间,当我们要从ArrayList任意位置删除或插入元素时,我们要把后续整体向前或后移动,时间复杂度为O(n),效率比较低,因此Arra…...

linux驱动开发学习001:概述
linux的内核源码编译后,会生成一个总的镜像。镜像加载到内存中运行他,就会启动内核。驱动属于内核代码的一部分,对驱动修改要重编整个内核,麻烦但驱动可以独立于内核镜像外,并能动态加载和卸载字符设备驱动,…...

基于深度学习的手把手学习 YOLOv8-Pose 关键点检测实战:杂草根茎关键点标注与训练全流程指南
YOLOv8-Pose 关键点检测实战:杂草根茎关键点标注与训练全流程指南 作者:张教授(计算机视觉与农业AI实验室主任) 引言在精准农业和智能除草领域,杂草根茎关键点检测技术具有重要意义。传统YOLO系列主要关注目标检测&…...

uosc性能优化实战:解决UI卡顿与渲染延迟问题终极指南
uosc性能优化实战:解决UI卡顿与渲染延迟问题终极指南 【免费下载链接】uosc Feature-rich minimalist proximity-based UI for MPV player. 项目地址: https://gitcode.com/gh_mirrors/uo/uosc uosc是一款功能丰富的极简主义基于接近度的MPV播放器用户界面&a…...
引发的UE6.5符号丢失问题全解析,微软/EPIC联合补丁已验证)
C++27模块二进制接口(MBI)引发的UE6.5符号丢失问题全解析,微软/EPIC联合补丁已验证
第一章:C27模块二进制接口(MBI)与UE6.5符号丢失问题的本质溯源C27标准草案中正式引入的模块二进制接口(Module Binary Interface, MBI)旨在终结传统头文件包含机制带来的ODR违规、编译冗余与符号污染问题。MBI通过标准…...

基于Matlab Simulink的单相PWM整流器仿真模型:全桥整流,电压电流PI双闭环控制...
单相PWM整流器仿真模型 单相全桥整流 电压电流PI双闭环 输出电压可调 输入交流220V/50Hz,输出直流电压可调 Maltab/simulink玩过电力电子的老铁们肯定对PWM整流器不陌生。今天咱们来撸一个单相全桥PWM整流器的Simulink仿真,支持输出电压连续可调的那种。先上张主电…...
)
NAS不只是存文件!极空间Docker部署汉化游戏全攻略(含避坑技巧)
极空间NAS变身游戏主机:Docker部署汉化游戏的完整实践指南 你是否曾想过,那台安静躺在角落里的NAS设备,除了存储照片和电影外,还能摇身一变成为你的私人游戏服务器?极空间NAS凭借其出色的硬件性能和友好的操作界面&…...

CAPL诊断脚本避坑指南:diagSetPrimitiveData和diagSetPrimitiveByte到底怎么选?
CAPL诊断脚本避坑指南:diagSetPrimitiveData和diagSetPrimitiveByte到底怎么选? 在汽车电子诊断测试领域,CAPL脚本的高效编写直接关系到测试覆盖率和执行效率。许多中级开发者在处理大数据块传输或多帧诊断请求时,常常陷入diagSet…...

OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能
OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能 1. 为什么选择为gemma-3-12b-it开发技能 去年冬天第一次接触OpenClaw时,我就被它的设计理念吸引了——一个真正能在本地运行的AI智能体框架。当时我正为重复性的数据清洗工作头疼,而…...

QT——计算器核心算法
1.中缀表达式转后缀表达式(1)分离算法(数字和符号分离)中缀表达式中包含:数字和小数点、符号位(或-)、运算符(-*/)、括号思想:以符号作为标志对表达式中的字符逐个访问当前字符exp[i…...

突破限制的AI开发助手:Cursor Free VIP开源工具全攻略
突破限制的AI开发助手:Cursor Free VIP开源工具全攻略 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

别再只用协同过滤了!聊聊Spark电商推荐系统中的‘冷启动’与实时推荐那些事儿
突破传统推荐瓶颈:Spark电商系统中的冷启动与实时推荐实战解析 1. 电商推荐系统的演进与挑战 在数字化消费时代,推荐系统已成为电商平台的核心竞争力。从早期的简单规则推荐到如今的深度学习模型,推荐技术经历了三次重要迭代: 第一…...