正则表达式[总结]
文章目录
- 1. 为什么要学习正则表达式
- 2. 再提出几个问题?
- 3. 解决之道-正则表达式
- 4. 正则表达式基本介绍
- 5. 正则表达式底层实现(重要)
- 6. 正则表达式语法
- 6.1 基本介绍
- 6.2 元字符(Metacharacter)-转义号 \\\
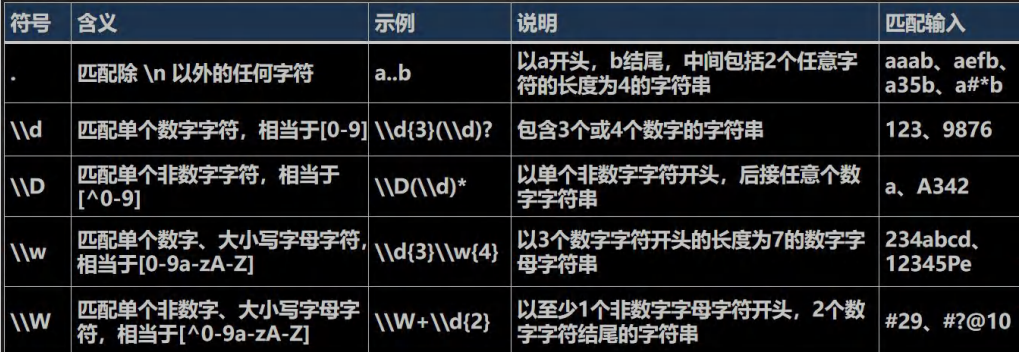
- 6.3 元字符-字符匹配符
- 6.4 元字符-选择匹配符
- 6.5 元字符-限定符
- 6.6 元字符-定位符
- 6.7 分组
- 6.8 非贪婪匹配
- 7. 应用实例
- 8. 正则表达式三个常用类
- 9. 分组、捕获、反向引用
- 9.1 提出需求
- 9.2 介绍
- 9.3 看几个小案例
- 9.4 经典的结巴程序
- 10. String 类中使用正则表达式
- 10.1 替换功能
- 10.2 判断功能
- 10.3 分割功能
1. 为什么要学习正则表达式
- 极速体验正则表达式威力

//1. 先创建一个 Pattern 对象 , 模式对象, 可以理解成就是一个正则表达式对象
//Pattern pattern = Pattern.compile("[a-zA-Z]+");
//Pattern pattern = Pattern.compile("[0-9]+");
//Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");
//Pattern pattern = Pattern.compile("<a target=\"_blank\" title=\"(\\S*)\"");
2. 再提出几个问题?


3. 解决之道-正则表达式

4. 正则表达式基本介绍

5. 正则表达式底层实现(重要)
为让大家对正则表达式底层实现有一个直观的映象,给大家举个实例
给你一段字符串(文本),请找出所有四个数字连在一起的子串, 比如:
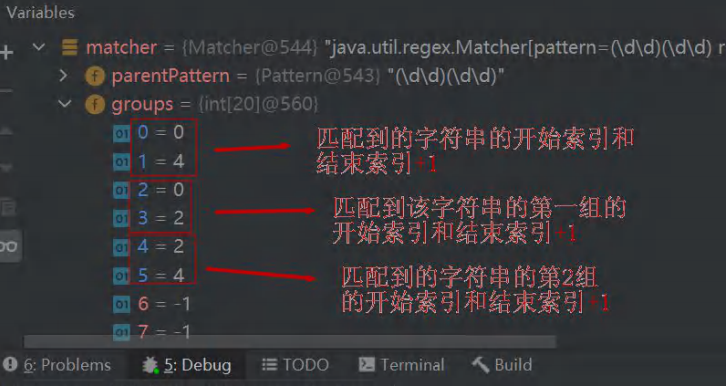
应该找到 1998 1999 3443 9889 ===> 分析底层实现 RegTheory.java
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 分析 java 的正则表达式的底层实现(重要)*/
public class RegTheory {public static void main(String[] args) {String content = "1998 年 12 月 8 日,第二代 Java 平台的企业版 J2EE 发布。1999 年 6 月,Sun 公司发布了" +"第二代 Java 平台(简称为 Java2)的 3 个版本:J2ME(Java2 Micro Edition,Java2 平台的微型" +"版),应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2 平台的" +"标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2 平台的企业版),应" +"用 3443 于基于 Java 的应用服务器。Java 2 平台的发布,是 Java 发展过程中最重要的一个" +"里程碑,标志着 Java 的应用开始普及 9889 ";//目标:匹配所有的四个数字//说明//1. \\d 表示一个任意的数字String regStr = "(\\d\\d)(\\d\\d)";//2. 创建模式对象[即正则表达式对象]Pattern pattern = Pattern.compile(regStr);//3. 创建匹配器//说明:创建匹配器 matcher,按照 正则表达式的规则 去匹配 content 字符串Matcher matcher = pattern.matcher(content);//4. 开始匹配/**** matcher.find() 完成的任务 (考虑分组)* 什么是分组,比如 (\d\d)(\d\d),正则表达式中有() 表示分组,第一个()表示第 1组,第2个()表示第 2组..* 1. 根据指定的规则,定位满足规则的子字符串(比如(19)(98))* 2. 找到后,将 子字符串的开始的索引记录到 matcher 对象的属性 int[] groups;* 2.1 groups[0] = 0,把该子字符串的结束的索引+1 的值记录到 groups[1] = 4* 2.2 记录 1组()匹配到的字符串 groups[2] = 0 groups[3] = 2* 2.3 记录 2组()匹配到的字符串 groups[4] = 2 groups[5] = 4* 2.4 如果有更多的分组..* 3. 同时记录 oldLast 的值为 子字符串的结束的 索引 +1 的值 即 35,即下次执行 find时,就从 35 开始匹配** matcher.group(0) 分析* 源码:* public String group(int group) {* if (first < 0)* throw new IllegalStateException("No match found");* if (group < 0 || group > groupCount())* throw new IndexOutOfBoundsException("No group " + group);* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))* return null;* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();* }* 1. 根据 groups[0]=31 和 groups[1]=35 的记录的位置,从 content 开始截取子字符串返回* 就是 [31,35) 包含 31但是不包含索引为 35 的位置** 如果再次指向 find 方法,仍然按上面分析来执行*/while (matcher.find()){//小结//1. 如果正则表达式有() 即分组//2. 取出匹配的字符串规则如下//3. group(0) 表示匹配到的子字符串//4. group(1) 表示匹配到的子字符串的第一组子串//5. group(2) 表示匹配到的子字符串的第二组子串//6. ... 但是分组的数不能越界.System.out.println("找到" + matcher.group(0));System.out.println("第 1 组()匹配到的值=" + matcher.group(1));System.out.println("第 2 组()匹配到的值=" + matcher.group(2));}}
}
6. 正则表达式语法
6.1 基本介绍

6.2 元字符(Metacharacter)-转义号 \\

package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/**
* @author xjz_2002
* @version 1.0
* 演示转义字符的使用
*/
public class RegExp02 {public static void main(String[] args) {String content = "abc$(a.bc(123()";//匹配( --> \\(//匹配. --> \\.//String regStr = "\\(";//String regStr = "\\.";//String regStr = "\\d\\d\\d";String regStr = "\\d{3}"; // \\d\\d\\d == \\d{3}Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到 " + matcher.group(0));}}
}

6.3 元字符-字符匹配符
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示字符匹配符 的使用*/
public class RegExp03 {public static void main(String[] args) {String content = "a11c8abc _ABCy @";//String regStr = "[a-z]";//匹配 a-z 之间任意一个字符//String regStr = "[A-Z]";//匹配 A-Z 之间任意一个字符//String regStr = "abc";//匹配 abc 字符串[默认区分大小写]//String regStr = "(?i)abc";//匹配 abc 字符串[不区分大小写]//String regStr = "[0-9]";//匹配 0-9 之间任意一个字符//String regStr = "[^a-z]";//匹配 不在 a-z 之间任意一个字符//String regStr = "[^0-9]";//匹配 不在 0-9 之间任意一个字符//String regStr = "[abcd]";//匹配 在 abcd中任意一个字符//String regStr = "\\D";//匹配 不在 0-9 的任意一个字符//String regStr = "\\w";//匹配 大小写英文字法、数字、下划线//String regStr = "\\W";//匹配 等价于[^a-zA-Z0-9_]// \\s 匹配任何空白字符(空格、制表符等)//String regStr = "\\s";// \\S 匹配任何非空白字符串,和\\s刚好相反//String regStr = "\\S";//. 匹配出 \n 之外的所有字符,如果要匹配 .本身则需要使用 \\.String regStr = ".";//说明//1. 当创建 Pattern 对象时,指定 Pattern CASE_INSENSITIVE,表示匹配是不区分字符大小写Pattern pattern = Pattern.compile(regStr/*,Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
6.4 元字符-选择匹配符

package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 选择匹配符 |*/
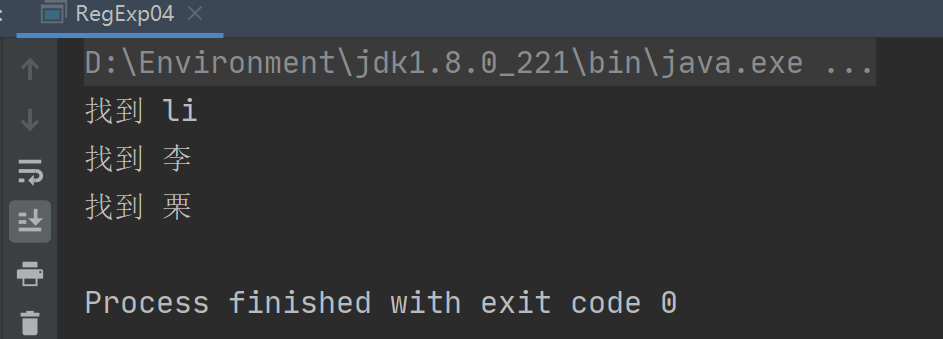
public class RegExp04 {public static void main(String[] args) {String content = "liyunlong 李 栗子";String regStr = "li|李|栗";Pattern pattern = Pattern.compile(regStr/*,Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到 " + matcher.group(0));}}
}
- 运行结果
6.5 元字符-限定符
用于指定其前面的字符和组合项连续出现多少次


应用案例
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示限定符的作用*/
public class RegExp05 {public static void main(String[] args) {String content = "a211111aaaaaahello";//a{3}, 1{4}, \\d{2}//String regStr = "a{3}";// 表示匹配 aaa//String regStr = "1{4}";// 表示匹配 1111//String regStr = "\\d{2}";// 表示匹配 两位的任意数字字符//a{3,4}, 1{4,5}, \\d{2,5}//细节:java 匹配默认贪婪匹配,即 尽可能匹配多的//String regStr = "a{3,4}";//表示匹配 aaa 或者 aaaa//String regStr = "a{4,5}";//表示匹配 1111 或者 11111//String regStr = "\\d{2,5}";//表示匹配 2位数或者 3,4,5位的数字0-9//1+//String regStr = "1+";//匹配一个 1 或者多个 1//String regStr = "\\d+";//匹配一个数字或者多个数字//1*//String regStr = "1*";//匹配 0个1 或者多个1//演示 ? 的使用,遵守贪婪匹配String regStr = "a1?";//匹配 a 或者 a1Pattern pattern = Pattern.compile(regStr/*,Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到 " + matcher.group(0));}}
}
6.6 元字符-定位符
定位符, 规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,这个也是相当有用的,必须掌握
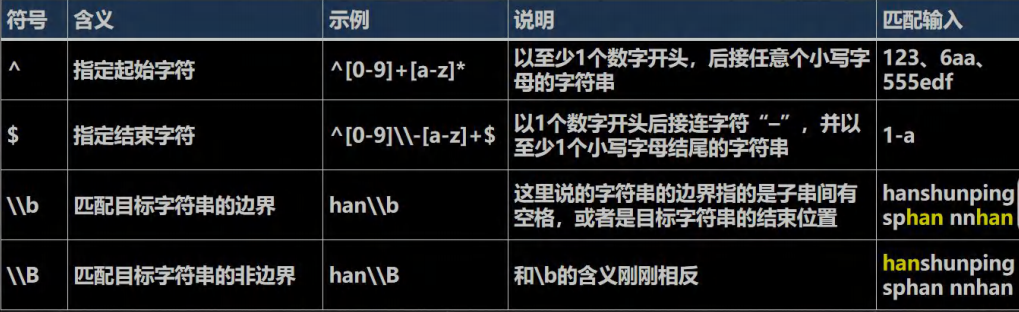
RegExp06.java
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示定位符的使用*/
public class RegExp06 {public static void main(String[] args) {String content = "xujinzhuo xuspxu nnxu";//String content = "123-abc";//以至少 1个数字开头,后接任意个小写字母的字符串//String regStr = "^[0-9]+[a-z]*";//以至少 1个数字开头,必须以至少一个小写字符结束//String regStr = "^[0-9]+\\-[a-z]+$";//表示匹配边界的 xu[这里的边界是指:被匹配的字符串最后,// 也可以是空格字符串的前面]//String regStr = "xu\\b";//和\\b的含义刚刚相反[被匹配的字符串最前面,也可以是空掉的字符串的后面]String regStr = "xu\\B";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到=" + matcher.group(0));}}
}
6.7 分组


RegExp07.java
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 分组:*/
public class RegExp07 {public static void main(String[] args) {String content = "xujinzhuo s7789 nn1189xu";//下面就是非命名分组//说明// 1. matcher.group(0) 得到匹配到的字符串// 2. matcher.group(1) 得到匹配到的字符串的第 1 个分组内容// 3. matcher.group(2) 得到匹配到的字符串的第 2 个分组内容//String regStr = "(\\d\\d)(\\d\\d)";//匹配 4 个数字的字符串//命名分组:即可以给分组取名String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配 4 个数字的字符串Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到=" + matcher.group(0));System.out.println("第 1 个分组内容=" +matcher.group(1));System.out.println("第 1 个分组内容[通过组名]=" +matcher.group("g1"));System.out.println("第 2 个分组内容=" +matcher.group(2));System.out.println("第 2 个分组内容[通过组名]=" +matcher.group("g2"));}}
}
RegExp08.java
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示非捕获分组,语法比较奇怪*/
public class RegExp08 {public static void main(String[] args) {String content = "hello 李云龙团长 jack 李云龙营长 李云龙同志 hello";// 找到 李云龙团长、李云龙营长、李云龙同志 子字符串//String regStr = "李云龙团长|李云龙营长|李云龙同志";//上面的写法可以等价非捕获分组,注意:不能 matcher group(1)//String regStr = "李云龙(?:团长|营长|同志)";//找到 韩顺平 这个关键字,但是要求只是查找李云龙团长和 李云龙营长 中包含有的李云龙//下面也是非捕获分组,不能使用 matcher.group(1)String regStr = "李云龙(?=团长|营长)";//找到 李云龙 这个关键字,但是要求只是查找 不是 (李云龙团长 和 李云龙营长) 中包含有的李云龙//下面也是非捕获分组,不能使用 matcher.group(1)//String regStr = "李云龙(?!团长|营长)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()){System.out.println("找到:" + matcher.group(0));}}
}
6.8 非贪婪匹配
?
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 非贪婪匹配 ?*/
public class RegExp09 {public static void main(String[] args) {String content = "tom111111jack";//String regStr = "\\d+";//默认贪婪匹配String regStr = "\\d+?";// 非 贪婪匹配Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到=" + matcher.group(0));}}}
运行结果
7. 应用实例

package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 正则表达式的应用实例*/
public class RegExp10 {public static void main(String[] args) {String content = "13588889999";// 汉字//String regStr = "^[\u0391-\uffe5]+$";// 邮政编码// 要求:是 1-9 开头的一个六位数. 比如:123890//String regStr = "^[1-9]\\d{5}$";// QQ 号码// 要求: 是 1-9 开头的一个(5 位数-10 位数) 比如: 12389 , 1345687 , 187698765//String regStr = "^[1-9]\\d{4,9}$";// 手机号码// 要求: 必须以 13,14,15,18 开头的 11 位数 , 比如 13588889999String regStr = "^1[3|4|5|8]\\d{9}$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if (matcher.find()) {System.out.println("满足格式");} else {System.out.println("不满足格式");}}
}
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示正则表达式的使用*/
public class RegExp11 {public static void main(String[] args) {String content = "https://www.bilibili.com/video/BV1eu4y1W7PL/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=c5907cbcddead65ce568e72fc5ad5385";/*** 思路* 1. 先确定 url 的开始部分 https://* 2. 然后通过 ([\w-]+\.)+[\w-] 匹配 www.bilibili.com**///多写多练,多总结String regStr = "^((http|https)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=/.&]*)?$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if(matcher.find()) {System.out.println("满足格式");} else {System.out.println("不满足格式");}//这里如果使用 Pattern 的 matches 整体匹配 比较简洁System.out.println(Pattern.matches(regStr, content));//}
}
8. 正则表达式三个常用类

package com.xjz.regexp;import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* 演示 matches 方法,用于 整体匹配,在验证输入的字符串是否满足条件使用*/
public class PatternMethod {public static void main(String[] args) {String content = "hello world 雪豹";
// String regStr = "hello";String regStr = "hello.*";boolean matches = Pattern.matches(regStr, content);System.out.println("整体匹配=" + matches);}
}
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0* Matcher 类的常用方法*/
public class MatcherMethod {public static void main(String[] args) {String content = "hello edu jack xjz2002 hello smith hello xjz2002 xjz2002";String regStr = "hello";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("==========================");System.out.println(matcher.start());System.out.println(matcher.end());System.out.println("找到:"+content.substring(matcher.start(), matcher.end()));}//整体匹配方法,常用于,去校验某个字符串是否满足某个规则System.out.println("整体匹配=" + matcher.matches());//完成如果 content 有 xjz2002 替换成 老鼠爱大米regStr = "xjz2002";pattern = Pattern.compile(regStr);matcher = pattern.matcher(content);//注意: 返回的字符串才是替换后的字符串 原来的 content 不变化String newContent = matcher.replaceAll("老鼠爱大米");System.out.println("newContent=" + newContent);System.out.println("content=" + content);}
}
9. 分组、捕获、反向引用
9.1 提出需求

9.2 介绍

9.3 看几个小案例

9.4 经典的结巴程序
package com.xjz.regexp;import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @author xjz_2002* @version 1.0*/
public class RegExp13 {public static void main(String[] args) {String content = "我...我要....学学学学..编程java!";//1. 去掉所有的.Pattern pattern = Pattern.compile("\\.");Matcher matcher = pattern.matcher(content);content = matcher.replaceAll("");// System.out.println("content=" + content);//2. 去掉重复的字 我我要学学学学编程java!// 思路//(1) 使用 (.)\\1+//(2) 使用 反向引用 $1 来替换匹配到的内容// 注意:因为正则表达式变化,所以需要重置 matcher
// pattern = Pattern.compile("(.)\\1+");
// matcher = pattern.matcher(content);
// while (matcher.find()){
// System.out.println("找到=" + matcher.group(0));
// }
//
// //使用 反向引用$1 来替换匹配到的内容
// content = matcher.replaceAll("$1");
// System.out.println("content=" + content);//3. 使用一条语句 去掉重复的字 我我要学学学学编程java!content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");System.out.println("content=" + content);}}
10. String 类中使用正则表达式
10.1 替换功能
String 类 public String replaceAll(String regex,String replacement)
10.2 判断功能
String 类 public boolean matches(String regex){} **//**使用 Pattern 和 Matcher 类
10.3 分割功能
String 类 public String[] split(String regex)
StringReg.java 代码如下:
package com.xjz.regexp;/*** @author xjz_2002* @version 1.0*/
public class StringReg {public static void main(String[] args) {String content = "2000 年 5 月,JDK1.3、JDK1.4 和 J2SE1.3 相继发布,几周后其" +"获得了 Apple 公司 Mac OS X 的工业标准的支持。2001 年 9 月 24 日,J2EE1.3 发" +"布。" +"2002 年 2 月 26 日,J2SE1.4 发布。自此 Java 的计算能力有了大幅提升";//使用正则表达式方式,将 JDK1.3 和 JDK1.4 替换成 JDKcontent = content.replaceAll("JDK1.3|JDK1.4","JDK");System.out.println(content);//要求:验证一个手机号,要求必须是以 138 139 开头的content = "13888899999";if (content.matches("1(38|39)\\d{8}")) {System.out.println("验证成功");} else {System.out.println("验证失败");}//要求 按照 # 或者 - 或者 ~ 或者 数字来分割System.out.println("======================================");content = "hello#abc-jack12smith~北京";String[] split = content.split("#|-|~|\\d+");for (String s : split) {System.out.println(s);}}
}
相关文章:
正则表达式[总结]
文章目录 1. 为什么要学习正则表达式2. 再提出几个问题?3. 解决之道-正则表达式4. 正则表达式基本介绍5. 正则表达式底层实现(重要)6. 正则表达式语法6.1 基本介绍6.2 元字符(Metacharacter)-转义号 \\\6.3 元字符-字符匹配符6.4 元字符-选择匹配符6.5 元字符-限定符…...

【docker】搭建xxl-job
首先创建数据库,例如我已经有了mysql 在 192.168.20.17上 #首先要有对应的数据库,创建xxl-job所需表CREATE database if NOT EXISTS xxl_job default character set utf8mb4 collate utf8mb4_unicode_ci; use xxl_job;SET NAMES utf8mb4;CREATE TABLE xx…...
)
k8s-----3、kubernetes集群部署(kubeadm部署)
集群部署 1、kubeadm流程(重新配置)1.1 安装要求1.2 准备环境 1.3. 所有节点安装Docker/kubeadm/kubelet1.3.1 安装Docker1.3.2 添加阿里云YUM软件源1.3.3 安装kubeadm,kubelet和kubectl 1.4 部署Kubernetes Master1.5. 加入Kubernetes Node1…...

党建展馆vr仿真解说员具有高质量的表现力和互动性
随着虚拟数字人应用渐成趋势,以虚拟数字人为核心的营销远比其他更能加速品牌年轻化进程和认识,助力企业在激烈的市场竞争中脱颖而出,那么企业虚拟IP代言人解决了哪些痛点? 解决品牌与代言人之间的风险问题 传统代言人在代言品牌时࿰…...

Webpack 基础以及常用插件使用方法
目录 一、前言二、修改打包入/出口配置步骤 三、常用插件使用html-webpack-plugin打包 CSS 代码提取 CSS 代码优化压缩过程打包 less 代码打包图片文件 一、前言 本质上,Webpack 是一个用于现代 JavaScript 应用程序的 静态模块打包工具。当 webpack 处理应用程序时…...
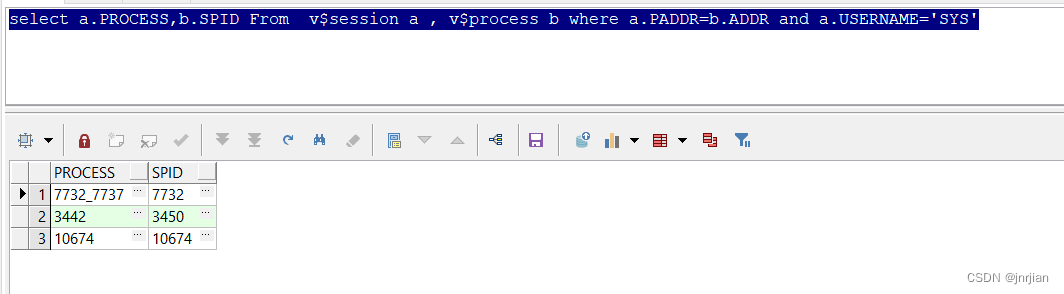
ROCESS SPID 代表什么进程
ROCESS 发出sql命令 所在主机的进程 可以不在数据库主机上发出 SPID 对应数据库的服务进程id select a.PROCESS,b.SPID From v$session a , v$process b where a.PADDRb.ADDR and a.USERNAMESYS SQL> !ps -ef|grep sqlplus oracle 385 2792 0 21:01 pts/…...

oracle rac了解
Oracle RAC 是一种高可用性和高性能的数据库解决方案,它允许多台服务器共享同一个数据库。简而言之,Oracle RAC 允许你将多个计算节点连接到一个共享的数据库实例中,从而提供了以下优势: 高可用性:Oracle RAC 提供了故…...
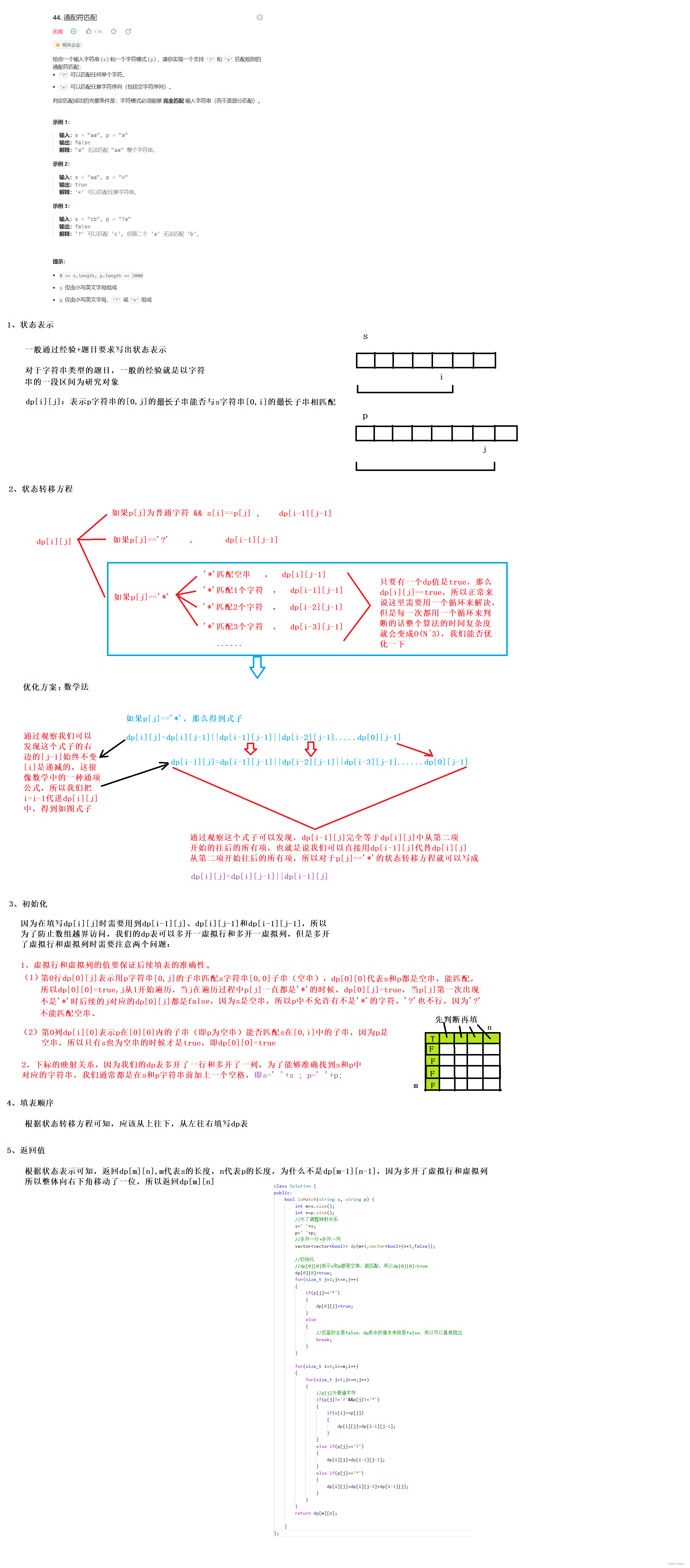
力扣 -- 44. 通配符匹配
解题步骤: 参考代码: class Solution { public:bool isMatch(string s, string p) {int ms.size();int np.size();//为了调整映射关系s s;p p;//多开一行多开一列vector<vector<bool>> dp(m1,vector<bool>(n1,false));//初始化//dp[0…...

电脑msvcp100.dll丢失的解决办法,靠谱的五个解决方法分享
在计算机使用过程中,我们经常会遇到一些错误提示,其中最常见的就是“缺少xxx.dll文件”。而msvcp100.dll就是其中之一。那么,msvcp100.dll到底是什么呢?它对我们的计算机有什么作用?本文将从多个方面对msvcp100.dll进行…...
HTML+CSS+JS+Django 实现前后端分离的科学计算器、利率计算器(附全部代码在gitcode链接)
🧮前后端分离计算器 📚git仓库链接和代码规范链接💼PSP表格🎇成品展示🏆🏆科学计算器:1. 默认界面与页面切换2. 四则运算、取余、括号3. 清零Clear 回退Back4. 错误提示 Error5. 读取历史记录Hi…...
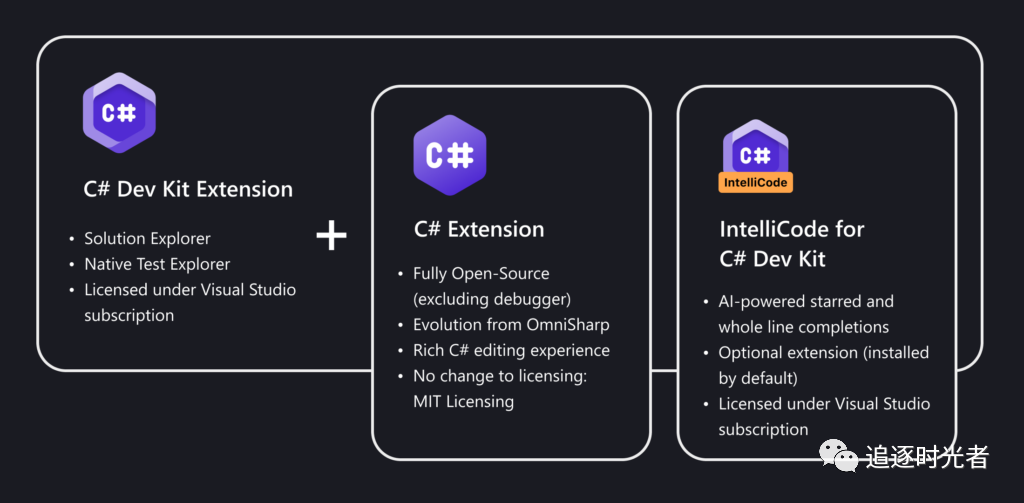
VS Code C# 开发工具包正式发布
前言 微软于本月正式发布Visual Studio Code C#开发工具包,此前该开发套件已经以预览版的形式在6月份问世。经过4个月的测试和调整,微软修复了350多个问题,其中大部分是用户反馈导致的问题。此外,微软还对产品进行了300多项有针对…...

【计算机网络】HTTPS 的加密流程
HTTPS (Hypertext Transfer Protocol Secure) 是一种安全的 HTTP 协议,采用了加密通信技术,可以保护客户端与服务器之间的数据传输安全,从而防止中间人攻击、窃听、篡改等恶意操纵。HTTPS 的加密流程包括以下几个步骤: 客户端发送…...
若依和芋道
国外卷技术,国内卷业务,做管理业务通常使用开源框架就可以快速满足,若依和芋道都是开源二开工具较为流行的框架,芋道是基于若依的,基本上是开发人员自己写业务开发框架的天花板,两者的前端都是基于vue-element-admin的,使用Gitee上两者的SpringBoot的最轻量化版本进行对…...
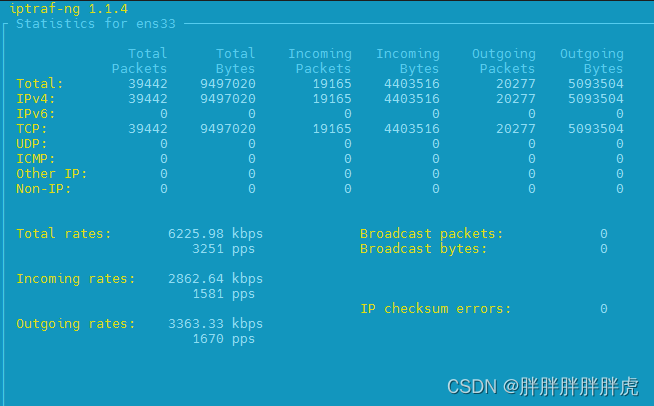
Linux流量监控
yum install -y iptrafiptraf-ng -d ens33...

高流量大并发Linux TCP性能调优
最近在使用jmeter做压测,当jmeter的并发量高的时候发现jmeter服务器一直报错Cannot assign requested address, 查看了一下发现系统中存在大量处于TIME_WAIT状态的tcp端口 netstat -n | awk ‘/^tcp/ {S[$NF]} END {for(a in S) print a, S[a]}’ TIME_W…...

ATT 格式汇编语言语法
GNU 汇编器是 GNU 二进制实用程序 (binutils) 的一部分,也是 GNU 编译器集合的后端。尽管 as 不是编写相当大的汇编程序的首选汇编程序,但它是当代类 Unix 系统的重要组成部分,特别是对于内核级黑客攻击。 经常因其神秘的 AT&T 风格语法而…...

Linux系统编程学习 NO.8 ——make和Makefile、进度条程序
前言 今天是1024程序员节,不知不觉离第一次写博客已经过去了一年了。在此祝各位程序员不写bug,不再秃头。 make和Makefile 什么是make和Makefile? make和Makefile是软件开发时所用到的工具和文件。make是一个指令工具。Makefile是一个当前…...
elementUI 中 date-picker 的使用的坑(vue3)
目录 1. 英文显示2. format 与 value-format 无效3. date-picker 时间范围4. 小结 1. 英文显示 <el-date-pickerv-model"dateValue"type"date"placeholder"选择日期"></el-date-picker>解决方案: 引用 zhCn <script&g…...
1-07 React配置postcss-px-to-viewport
React配置postcss-px-to-viewport 移动端适配 安装依赖:在项目根目录下运行以下命令安装所需的依赖包: npm install postcss-px-to-viewport --save-dev配置代码 const path require(path);module.exports {webpack: {alias: {: path.resolve(__di…...

ITSource 分享 第3期【在线个人网盘】
项目介绍 本期给大家介绍一个在线个人网盘 系统. 可以上传,下载,分享文件。 一 业务介绍 本系统分为以下几个模块: 1.登录注册 除了账号密码登录,如果配置了qq邮箱配置的话,还支持qq一键授权登录。 2.首页大盘 首页是个人网盘…...

G-Helper终极指南:如何让你的华硕笔记本性能翻倍,告别臃肿控制软件
G-Helper终极指南:如何让你的华硕笔记本性能翻倍,告别臃肿控制软件 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyru…...

终极Ventoy指南:从RAID阵列轻松启动多系统的完整解决方案
终极Ventoy指南:从RAID阵列轻松启动多系统的完整解决方案 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 你是否曾为从复杂的RAID存储阵列启动系统而烦恼?传统方法需要繁琐的BI…...

Appstore 上架问题汇总--持续更新
一、Guideline 3.2.1(viii) - Business - Other Business Model Issues - Acceptable 问题: We still found the app provides loan services but the domains listed on the apps Product Pages are not clearly under your control or ownership. Since users m…...

Anthropic 新政策与功能更新:AI 市场竞争下的博弈与挑战
Claude 新收费政策:第三方代理使用需额外付费上周末,Anthropic 告知订阅用户,若大量使用 Claude AI 模型驱动 OpenClaw 等第三方代理,需额外付费。月度订阅用户虽仍可通过第三方代理使用 Claude 模型,但需通过 Anthrop…...

单片机自动脱模剂喷雾控制系统
/***实现功能:检测报警信号,脱模剂开模数计数信号***/ /***参数:1:脱模剂开模数 2:喷雾时间 3:延时时间 ***/ /***串口接收触摸屏参数设置字符串,接收并保存******/ /***端子输入口读开模数,比较设定值后输出到电磁阀**/ /***端子输入口读报警信号,到设定值关闭电机及加热**/#i…...
 15 SU4a - 统一通信与协作)
Cisco Unified Communications Manager (CallManager) 15 SU4a - 统一通信与协作
Cisco Unified Communications Manager (CallManager) 15 SU4a - 统一通信与协作 思科统一通信管理器 (CallManager) 请访问原文链接:https://sysin.org/blog/cisco-ucm-15/ 查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org 思…...

Qwen3-TTS-Tokenizer-12Hz优化技巧:如何提升语音压缩与重建速度?
Qwen3-TTS-Tokenizer-12Hz优化技巧:如何提升语音压缩与重建速度? 1. 理解Qwen3-TTS-Tokenizer-12Hz的核心优势 1.1 超低采样率带来的效率革命 Qwen3-TTS-Tokenizer-12Hz最显著的特点是12Hz的超低采样率。这意味着: 传统音频处理通常使用1…...

避开这3个坑,你的LVGL界面动画才能流畅不卡顿:定时器使用避坑指南
避开这3个坑,你的LVGL界面动画才能流畅不卡顿:定时器使用避坑指南 在嵌入式GUI开发中,流畅的动画效果往往能大幅提升用户体验。但很多开发者在使用LVGL定时器实现动画时,常会遇到界面卡顿、响应迟缓的问题。这通常不是LVGL本身的问…...

端到端性能对比:NLP-StructBERT与其他开源相似度模型效果横评
端到端性能对比:NLP-StructBERT与其他开源相似度模型效果横评 最近在做一个智能客服的项目,需要判断用户问题和知识库答案的相似度。选型的时候,我对着好几个开源的中文相似度模型犯了难:都说自己效果好,到底哪个最适…...

忍者像素绘卷:天界画坊卷积神经网络原理与应用:解析像素风格生成内核
忍者像素绘卷:天界画坊卷积神经网络原理与应用 1. 卷积神经网络基础入门 在开始探索忍者像素绘卷的神奇世界之前,我们需要先了解支撑它的核心技术——卷积神经网络(CNN)。CNN就像一位精通像素艺术的数字画家,能够从原始图像中提取特征&…...