28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、DROP
- 1、DROP CATALOG
- 2、DROP DATABASE
- 3、DROP TABLE
- 4、DROP VIEW
- 5、DROP FUNCTION
- 6、drop table示例
- 二、alter
- 1、ALTER DATABASE
- 2、ALTER TABLE
- 1)、建表
- 2)、ADD
- 1、增加单列示例
- 2、增加watermark列
- 3)、MODIFY
- 1、修改列
- 2、修改水印
- 4)、DROP
- 5)、RENAME
- 6)、SET
- 7)、RESET
- 3、ALTER VIEW
- 4、ALTER FUNCTION
- 三、insert
- 1、将 SELECT 查询数据插入表中
- 1)、语法
- 2)、示例
- 2、将值插入表中
- 1)、语法
- 2)、示例
- 3、插入数据到多张表
- 1)、语法
- 2)、示例
- 四、analyze
- 1、语法
- 2、Flink SQL示例
- 1)、非分区表示例
- 2)、分区表
- 五、Flink SQL常见的操作示例
本文简单介绍了DROP、alter、insert和analyze的语法及示例 ,并且将FLink sql常用的sql以java 方法整理成一个类,可以直接在java中使用,或在Flink sql cli中直接使用。
本文依赖flink集群能正常使用。
本文示例java api的实现是通过Flink 1.13.5版本做的示例,SQL是在Flink 1.17版本的环境中运行的。
本文分为5个部分,即drop、alter、insert 和analyze、Flink SQL常见的操作示例。
一、DROP
DROP 语句可用于删除指定的 catalog,也可用于从当前或指定的 Catalog 中删除一个已经注册的表、视图或函数。
Flink SQL 截至版本Flink 1.17支持以下 DROP 语句:
DROP CATALOG
DROP TABLE
DROP DATABASE
DROP VIEW
DROP FUNCTION
1、DROP CATALOG
DROP CATALOG [IF EXISTS] catalog_name
删除给定名字的 catalog。
- IF EXISTS
如果目标 catalog 不存在,则不会执行任何操作。
2、DROP DATABASE
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
根据给定的表名删除数据库。若需要删除的数据库不存在会抛出异常 。
- IF EXISTS
若数据库不存在,不执行任何操作。
- RESTRICT
当删除一个非空数据库时,会触发异常。(默认为开)
- CASCADE
删除一个非空数据库时,把相关联的表与函数一并删除。
3、DROP TABLE
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
根据给定的表名删除某个表。若需要删除的表不存在,则抛出异常。
- IF EXISTS
表不存在时不会进行任何操作。
4、DROP VIEW
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
删除一个有 catalog 和数据库命名空间的视图。若需要删除的视图不存在,则会产生异常。
- TEMPORARY
删除一个有 catalog 和数据库命名空间的临时视图。
- IF EXISTS
若视图不存在,则不会进行任何操作。
依赖管理
Flink 没有使用 CASCADE / RESTRICT 关键字来维护视图的依赖关系,当前的方案是在用户使用视图时再提示错误信息,比如在视图的底层表已经被删除等场景。
5、DROP FUNCTION
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
删除一个有 catalog 和数据库命名空间的 catalog function。若需要删除的函数不存在,则会产生异常。
- TEMPORARY
删除一个有 catalog 和数据库命名空间的临时 catalog function。
- TEMPORARY SYSTEM
删除一个没有数据库命名空间的临时系统函数。
- IF EXISTS
若函数不存在,则不会进行任何操作。
6、drop table示例
具体的、完整的实现可以参考文章:24、Flink 的table api与sql之Catalogs(java api操作分区与函数、表)-4
- java-sql
/*** @author alanchan**/
public class TestCreateHiveTableBySQLDemo {static String databaseName = "viewtest_db";public static final String tableName = "alan_hivecatalog_hivedb_testTable";public static final String hive_create_table_sql = "CREATE TABLE " + tableName + " (\n" + " id INT,\n" + " name STRING,\n" + " age INT" + ") " + "TBLPROPERTIES (\n" + " 'sink.partition-commit.delay'='5 s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + " 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {// 0、运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 1、创建数据库HiveCatalog hiveCatalog = init(tenv);// 2、创建表tenv.getConfig().setSqlDialect(SqlDialect.HIVE);tenv.executeSql(hive_create_table_sql);// 3、插入数据String insertSQL = "insert into " + tableName + " values (1,'alan',18)";tenv.executeSql(insertSQL);// 4、查询数据List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + tableName).collect());for (Row row : results) {System.out.println(tableName + ": " + row.toString());}// 5、删除数据库tenv.executeSql("drop database " + databaseName + " cascade");}private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {String moduleName = "myhive";String hiveVersion = "3.1.2";tenv.loadModule(moduleName, new HiveModule(hiveVersion));String name = "alan_hive";String defaultDatabase = "default";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog(name, hiveCatalog);tenv.useCatalog(name);tenv.listDatabases();hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {}, true);tenv.useDatabase(databaseName);return hiveCatalog;}
}
-
java-api
-
sql
Flink SQL> CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...);
[INFO] Table has been created.Flink SQL> SHOW TABLES;
OrdersFlink SQL> DROP TABLE Orders;
[INFO] Table has been removed.Flink SQL> SHOW TABLES;
[INFO] Result was empty.
二、alter
ALTER 语句用于修改一个已经在 Catalog 中注册的表、视图或函数定义。
Flink SQL 截至Flink 1.17支持以下 ALTER 语句:
ALTER TABLE
ALTER VIEW
ALTER DATABASE
ALTER FUNCTION
1、ALTER DATABASE
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
在数据库中设置一个或多个属性。若个别属性已经在数据库中设定,将会使用新值覆盖旧值。
- 示例
Flink SQL> SHOW CURRENT CATALOG;
+----------------------+
| current catalog name |
+----------------------+
| default_catalog |
+----------------------+
1 row in setFlink SQL> create database IF NOT EXISTS default_catalog.alan_test COMMENT 'this is a create database comment' with ('author'='alanchan','createdate'='2023-10-20');
[INFO] Execute statement succeed.Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default_database |
| alan_test |
+------------------+
2 rows in setFlink SQL> ALTER database default_catalog.alan_test set('createdate'='2023-11-20');
[INFO] Execute statement succeed.Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default_database |
| alan_test |
+------------------+
2 rows in set2、ALTER TABLE
截至Flink 1.17支持的 ALTER TABLE 语法如下
ALTER TABLE [IF EXISTS] table_name {ADD { <schema_component> | (<schema_component> [, ...]) }| MODIFY { <schema_component> | (<schema_component> [, ...]) }| DROP {column_name | (column_name, column_name, ....) | PRIMARY KEY | CONSTRAINT constraint_name | WATERMARK}| RENAME old_column_name TO new_column_name| RENAME TO new_table_name| SET (key1=val1, ...)| RESET (key1, ...)
}<schema_component>:{ <column_component> | <constraint_component> | <watermark_component> }<column_component>:column_name <column_definition> [FIRST | AFTER column_name]<constraint_component>:[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED<watermark_component>:WATERMARK FOR rowtime_column_name AS watermark_strategy_expression<column_definition>:{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> } [COMMENT column_comment]<physical_column_definition>:column_type<metadata_column_definition>:column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]<computed_column_definition>:AS computed_column_expression
- IF EXISTS
若表不存在,则不进行任何操作。
1)、建表
以下示例使用的表均采用本表。
-- 创建表
Flink SQL> CREATE TABLE t_user (
> t_id BIGINT,
> t_name STRING,
> t_balance DOUBLE,
> t_age INT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://HadoopHAcluster/flinktest/sql1/',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.Flink SQL> show tables;
+------------+
| table name |
+------------+
| t_user |
+------------+
1 row in set
2)、ADD
使用 ADD 语句向已有表中增加 columns, constraints,watermark。
向表新增列时可通过 FIRST or AFTER col_name 指定位置,不指定位置时默认追加在最后。
ADD 语句示例如下。
-- add a new column
ALTER TABLE MyTable ADD category_id STRING COMMENT 'identifier of the category';-- add columns, constraint, and watermark
ALTER TABLE MyTable ADD (log_ts STRING COMMENT 'log timestamp string' FIRST,ts AS TO_TIMESTAMP(log_ts) AFTER log_ts,PRIMARY KEY (id) NOT ENFORCED,WATERMARK FOR ts AS ts - INTERVAL '3' SECOND
);
注意 指定列为主键列时会隐式修改该列的 nullability 为 false。
1、增加单列示例
增加多列类似,带“()”即可
-- 增加not null列
Flink SQL> ALTER TABLE t_user ADD `sex` INTEGER NOT NULL;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------+--------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+-----------+--------+-------+-----+--------+-----------+
| t_id | BIGINT | TRUE | | | |
| t_name | STRING | TRUE | | | |
| t_balance | DOUBLE | TRUE | | | |
| t_age | INT | TRUE | | | |
| sex | INT | FALSE | | | |
+-----------+--------+-------+-----+--------+-----------+-- 增加 带备注的列
Flink SQL> ALTER TABLE t_user ADD `address` STRING COMMENT 'address docs' ;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------+--------+-------+-----+--------+-----------+--------------+
| name | type | null | key | extras | watermark | comment |
+-----------+--------+-------+-----+--------+-----------+--------------+
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
+-----------+--------+-------+-----+--------+-----------+--------------+-- 增加 带顺序的列(放在表的第一个位置)
Flink SQL> ALTER TABLE t_user ADD `country` STRING COMMENT 'country docs' FIRST;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------+--------+-------+-----+--------+-----------+--------------+
| name | type | null | key | extras | watermark | comment |
+-----------+--------+-------+-----+--------+-----------+--------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
+-----------+--------+-------+-----+--------+-----------+--------------+-- 增加 带顺序的列(放在表的某一列位置后面)
Flink SQL> ALTER TABLE t_user ADD telphone STRING COMMENT 'telphone docs' AFTER `t_name`;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------+--------+-------+-----+--------+-----------+---------------+
| name | type | null | key | extras | watermark | comment |
+-----------+--------+-------+-----+--------+-----------+---------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
+-----------+--------+-------+-----+--------+-----------+---------------+-- 增加 计算的列(`t_balance` / `t_age` * 10)
Flink SQL> ALTER TABLE t_user ADD age_balance_avg AS (t_balance/t_age*10) AFTER t_age;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+--------+-------+-----+-------------------------------+-----------+---------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+--------+-------+-----+-------------------------------+-----------+---------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
+-----------------+--------+-------+-----+-------------------------------+-----------+---------------+2、增加watermark列
-- 增加时间列
Flink SQL> ALTER TABLE t_user ADD ts TIMESTAMP(3);
[INFO] Execute statement succeed.
-- 对时间列增加水印
Flink SQL> alter table t_user add watermark for ts as ts;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` | |
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+
-- 删除时间列水印
Flink SQL> alter table t_user drop watermark;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+--------------+-------+-----+-------------------------------+-----------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+--------------+-------+-----+-------------------------------+-----------+-------------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
| ts | TIMESTAMP(3) | TRUE | | | | |
+-----------------+--------------+-------+-----+-------------------------------+-----------+-------------------+
11 rows in set
-- 对时间列增加水印
Flink SQL> alter table t_user add watermark for ts as ts - interval '1' second;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address docs |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+3)、MODIFY
使用 MODIFY 语句修改列的位置 、类型 、注释 、nullability,主键或 watermark。
可使用 FIRST 或 AFTER col_name 将已有列移动至指定位置,不指定时默认保持位置不变。
MODIFY 语句示例如下。
-- modify a column type, comment and position
ALTER TABLE MyTable MODIFY measurement double COMMENT 'unit is bytes per second' AFTER `id`;-- modify definition of column log_ts and ts, primary key, watermark. They must exist in table schema
ALTER TABLE MyTable MODIFY (log_ts STRING COMMENT 'log timestamp string' AFTER `id`, -- reorder columnsts AS TO_TIMESTAMP(log_ts) AFTER log_ts,PRIMARY KEY (id) NOT ENFORCED,WATERMARK FOR ts AS ts -- modify watermark strategy
);
注意 指定列为主键列时会隐式修改该列的 nullability 为 false。
1、修改列
差不多和增加,具体示例如下
Flink SQL> alter table t_user modify address string comment 'address comment';
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| address | STRING | TRUE | | | | address comment |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
11 rows in setFlink SQL> alter table t_user modify address string comment 'address comment' first
> ;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| address | STRING | TRUE | | | | address comment |
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | INT | FALSE | | | | |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| address | STRING | TRUE | | | | address comment |
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 10 | | |
| sex | ARRAY<STRING NOT NULL> | FALSE | | | | |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
11 rows in setFlink SQL> alter table t_user modify age_balance_avg AS (t_balance/t_age*20);
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| address | STRING | TRUE | | | | address comment |
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 20 | | |
| sex | ARRAY<STRING NOT NULL> | FALSE | | | | |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+2、修改水印
差不多和增加,具体语句如下,未执行,不会有语法错误
alter table t_user modify watermark for ts as ts
alter table t_user modify watermark for ts as ts - interval '1' second
alter table alan_test.t_user modify watermark for ts as ts - interval '1' second
alter table default_catalog.alan_test.t_user modify watermark for ts as ts - interval '1' second
4)、DROP
使用 DROP 语句删除列 、主键或 watermark。
DROP 语句示例如下。
-- drop a column
ALTER TABLE MyTable DROP measurement;-- drop columns
ALTER TABLE MyTable DROP (col1, col2, col3);-- drop primary key
ALTER TABLE MyTable DROP PRIMARY KEY;-- drop a watermark
ALTER TABLE MyTable DROP WATERMARK;
- 示例
删除上面演示的列和水印
Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
| address | STRING | TRUE | | | | address comment |
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 20 | | |
| sex | ARRAY<STRING NOT NULL> | FALSE | | | | |
| ts | TIMESTAMP(3) *ROWTIME* | TRUE | | | `ts` - INTERVAL '1' SECOND | |
+-----------------+------------------------+-------+-----+-------------------------------+----------------------------+-------------------+
11 rows in setFlink SQL> ALTER TABLE t_user DROP WATERMARK;
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+
| name | type | null | key | extras | watermark | comment |
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+
| address | STRING | TRUE | | | | address comment |
| country | STRING | TRUE | | | | country docs |
| t_id | BIGINT | TRUE | | | | |
| t_name | STRING | TRUE | | | | |
| telphone | STRING | TRUE | | | | telphone docs |
| t_balance | DOUBLE | TRUE | | | | |
| t_age | INT | TRUE | | | | |
| t_email | STRING | TRUE | | | | add t_email filed |
| age_balance_avg | DOUBLE | TRUE | | AS `t_balance` / `t_age` * 20 | | |
| sex | ARRAY<STRING NOT NULL> | FALSE | | | | |
| ts | TIMESTAMP(3) | TRUE | | | | |
+-----------------+------------------------+-------+-----+-------------------------------+-----------+-------------------+Flink SQL> ALTER TABLE t_user DROP (address, country, telphone,t_email,age_balance_avg,sex,ts);
[INFO] Execute statement succeed.Flink SQL> desc t_user;
+-----------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+-----------+--------+------+-----+--------+-----------+
| t_id | BIGINT | TRUE | | | |
| t_name | STRING | TRUE | | | |
| t_balance | DOUBLE | TRUE | | | |
| t_age | INT | TRUE | | | |
+-----------+--------+------+-----+--------+-----------+5)、RENAME
使用 RENAME 语句修改列名或表名。
RENAME 语句示例如下。
-- rename column
ALTER TABLE MyTable RENAME request_body TO payload;-- rename table
ALTER TABLE MyTable RENAME TO MyTable2;
6)、SET
为指定的表设置一个或多个属性。若个别属性已经存在于表中,则使用新值覆盖旧值。
SET 语句示例如下。
-- set 'rows-per-second'
ALTER TABLE DataGenSource SET ('rows-per-second' = '10');
7)、RESET
为指定的表重置一个或多个属性。
RESET 语句示例如下。
-- reset 'rows-per-second' to the default value
ALTER TABLE DataGenSource RESET ('rows-per-second');
3、ALTER VIEW
修改视图名称,简单,不再示例
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
修改视图,改成不同的查询结果,好像也很简单,不再示例
ALTER VIEW [catalog_name.][db_name.]view_name AS new_query_expression
4、ALTER FUNCTION
ALTER [TEMPORARY|TEMPORARY SYSTEM] FUNCTION[IF EXISTS] [catalog_name.][db_name.]function_nameAS identifier [LANGUAGE JAVA|SCALA|PYTHON]
修改一个有 catalog 和数据库命名空间的 catalog function ,需要指定一个新的 identifier ,可指定 language tag 。若函数不存在,删除会抛出异常。
如果 language tag 是 JAVA 或者 SCALA ,则 identifier 是 UDF 实现类的全限定名。关于 JAVA/SCALA UDF 的实现,请参考 19、Flink 的Table API 和 SQL 中的自定义函数(2)。
- TEMPORARY
修改一个有 catalog 和数据库命名空间的临时 catalog function ,并覆盖原有的 catalog function 。
- TEMPORARY SYSTEM
修改一个没有数据库命名空间的临时系统 catalog function ,并覆盖系统内置的函数。
- IF EXISTS
若函数不存在,则不进行任何操作。
- LANGUAGE JAVA|SCALA|PYTHON
Language tag 用于指定 Flink runtime 如何执行这个函数。截至版本Flink 1.17,只支持 JAVA,SCALA 和 PYTHON,且函数的默认语言为 JAVA。
三、insert
1、将 SELECT 查询数据插入表中
通过 INSERT 语句,可以将查询的结果插入到表中,
1)、语法
[EXECUTE] INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name [PARTITION part_spec] select_statementpart_spec:(part_col_name1=val1 [, part_col_name2=val2, ...])
- OVERWRITE
INSERT OVERWRITE 将会覆盖表中或分区中的任何已存在的数据。否则,新数据会追加到表中或分区中。
- PARTITION
PARTITION 语句应该包含需要插入的静态分区列与值。
2)、示例
更多的示例请参考:
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
5、hive的load、insert、事务表使用详解及示例
24、Flink 的table api与sql之Catalogs(java api操作分区与函数、表)-4
-- 创建一个分区表
CREATE TABLE country_page_view (user STRING, cnt INT, date STRING, country STRING)
PARTITIONED BY (date, country)
WITH (...)-- 追加行到该静态分区中 (date='2023-9-30', country='China')
INSERT INTO country_page_view PARTITION (date='2023-9-30', country='China')SELECT user, cnt FROM page_view_source;-- Insert语句的开头可以额外增加EXECUTE关键字,带EXECUTE关键字和不带是等价的
EXECUTE INSERT INTO country_page_view PARTITION (date='2023-9-30', country='China')SELECT user, cnt FROM page_view_source;-- 追加行到分区 (date, country) 中,其中 date 是静态分区 '2023-9-30';country 是动态分区,其值由每一行动态决定
INSERT INTO country_page_view PARTITION (date='2023-9-30')SELECT user, cnt, country FROM page_view_source;-- 覆盖行到静态分区 (date='2023-9-30', country='China')
INSERT OVERWRITE country_page_view PARTITION (date='2023-9-30', country='China')SELECT user, cnt FROM page_view_source;-- 覆盖行到分区 (date, country) 中,其中 date 是静态分区 '2023-9-30';country 是动态分区,其值由每一行动态决定
INSERT OVERWRITE country_page_view PARTITION (date='2023-9-30')SELECT user, cnt, country FROM page_view_source;
2、将值插入表中
通过 INSERT 语句,也可以直接将值插入到表中,
1)、语法
[EXECUTE] INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name VALUES values_row [, values_row ...]values_row:: (val1 [, val2, ...])
OVERWRITE
INSERT OVERWRITE 将会覆盖表中的任何已存在的数据。否则,新数据会追加到表中。
2)、示例
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);EXECUTE INSERT INTO studentsVALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
3、插入数据到多张表
STATEMENT SET 可以实现通过一个语句插入数据到多个表。
1)、语法
EXECUTE STATEMENT SET
BEGIN
insert_statement;
...
insert_statement;
END;insert_statement:<insert_from_select>|<insert_from_values>
2)、示例
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);EXECUTE STATEMENT SET
BEGIN
INSERT INTO studentsVALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
INSERT INTO studentsVALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
END;
四、analyze
ANALYZE 语句被用于为存在的表收集统计信息,并将统计信息写入该表的 catalog 中。截至Flink 1.17版本中,ANALYZE 语句只支持 ANALYZE TABLE, 且只能由用户手动触发。
现在, ANALYZE TABLE 只支持批模式(Batch Mode),且只能用于已存在的表,如果表不存在或者是视图(View)则会报错。
1、语法
ANALYZE TABLE [catalog_name.][db_name.]table_name PARTITION(partcol1[=val1] [, partcol2[=val2], ...]) COMPUTE STATISTICS [FOR COLUMNS col1 [, col2, ...] | FOR ALL COLUMNS]
- 对于分区表, 语法中 PARTITION(partcol1[=val1] [, partcol2[=val2], …]) 是必须指定的
如果没有指定某分区,则会收集所有分区的统计信息
如果指定了某分区,则只会收集该分区的统计信息
如果该表为非分区表,但语句中指定了分区,则会报异常
如果指定了某个分区,但是该分区不存在,则会报异常
- 语法中,FOR COLUMNS col1 [, col2, …] 或者 FOR ALL COLUMNS 也是可选的
如果没有指定某一列,则只会收集表级别的统计信息
如果指定的列不存在,或者该列不是物理列,则会报异常
如果指定了某一列或者某几列,则会收集列的统计信息
列级别的统计信息包括:
ndv: 该列中列值不同的数量
nullCount: 该列中空值的数量
avgLen: 列值的平均长度
maxLen: 列值的最大长度
minValue: 列值的最小值
maxValue: 列值的最大值
valueCount: 该值只应用于 boolean 类型
对于列统计信息,支持类型和对应的列统计信息值如下表所示(“Y” 代表支持,“N” 代表不支持):
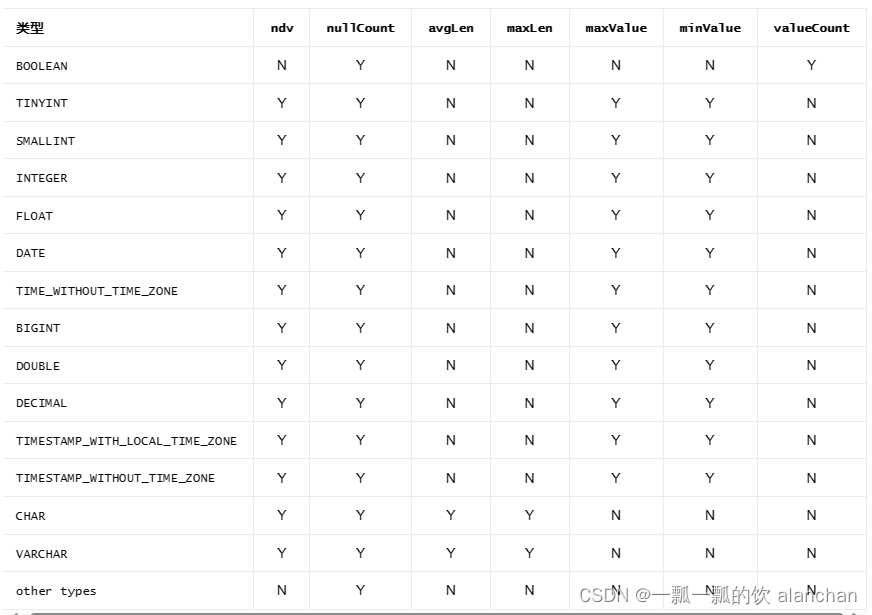
对于数据值定长的类型(例如:BOOLEAN, INTEGER, DOUBLE 等), Flink 不会去收集 avgLen 和 maxLen 值。
2、Flink SQL示例
1)、非分区表示例
Flink SQL> CREATE TABLE t_user (
> t_id BIGINT,
> t_name STRING,
> t_balance DOUBLE,
> t_age INT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'file:///usr/local/bigdata/testdata/flink_test/',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user COMPUTE STATISTICS;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: ANALYZE TABLE is not supported for streaming mode nowFlink SQL> SET execution.runtime-mode = batch;
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user COMPUTE STATISTICS;
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user COMPUTE STATISTICS FOR ALL COLUMNS;
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user COMPUTE STATISTICS FOR COLUMNS t_balance;
[INFO] Execute statement succeed.2)、分区表
关于分区表,如果不涉及具体的分区,则可以正常分析,如果涉及到具体分区,则提示不支持操作异常。
目前不确定是Flink不支持还是环境不正常,待有空闲了再仔细的查找具体的原因。
Flink SQL> CREATE TABLE t_user_p (
> t_id BIGINT,
> t_name STRING,
> t_balance INT,
> t_age INT
> ) PARTITIONED BY (t_age, t_balance) WITH (
> 'connector'='filesystem',
> 'path' = 'file:///usr/local/bigdata/testdata/flink_test_p/',
> 'format'='csv'
> );
[INFO] Execute statement succeed.Flink SQL> select * from t_user_p;
+----+----------------------+--------------------------------+--------------------------------+-------------+
| op | t_id | t_name | t_balance | t_age |
+----+----------------------+--------------------------------+--------------------------------+-------------+
| +I | 1 | 8fb | 10 | 25 |
| +I | 2 | e61 | 10 | 25 |
| +I | 5 | 6da | 25 | 35 |
| +I | 6 | bd6 | 25 | 35 |
| +I | 3 | 622 | 20 | 30 |
| +I | 4 | eac | 20 | 30 |
+----+----------------------+--------------------------------+--------------------------------+-------------+Flink SQL> SET execution.runtime-mode = batch;
[INFO] Execute statement succeed.Flink SQL> select * from t_user_p3 where t_age=35 and t_balance = 25;
+------+--------+-----------+-------+
| t_id | t_name | t_balance | t_age |
+------+--------+-----------+-------+
| 5 | 9bb | 25 | 35 |
| 6 | 8f6 | 25 | 35 |
+------+--------+-----------+-------+Flink SQL> ANALYZE TABLE t_user_p PARTITION(t_age, t_balance) COMPUTE STATISTICS;
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user_p PARTITION(t_age, t_balance) COMPUTE STATISTICS FOR COLUMNS t_age, t_balance;
[INFO] Execute statement succeed.Flink SQL> ANALYZE TABLE t_user_p PARTITION(t_age='35', t_balance='25') COMPUTE STATISTICS;
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationExceptionFlink SQL> ANALYZE TABLE t_user_p PARTITION(t_age='35', t_balance='25') COMPUTE STATISTICS FOR ALL COLUMNS;
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationExceptionFlink SQL> ANALYZE TABLE t_user_p PARTITION(t_age='35', t_balance) COMPUTE STATISTICS FOR ALL COLUMNS;
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationExceptionFlink SQL> ANALYZE TABLE t_user_p PARTITION(t_age='35', t_balance='25') COMPUTE STATISTICS FOR COLUMNS t_age;
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationExceptionFlink SQL> ANALYZE TABLE t_user_p PARTITION (t_age='35', t_balance='25') COMPUTE STATISTICS FOR COLUMNS t_age, t_balance;
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationException五、Flink SQL常见的操作示例
下面的示例是常见的操作,比如create、update、alter、insert 、执行计划、分析等SQL。
使用的Flink SQL版本是Flink1.17版本。
注释掉的是当前Flink版本不支持的功能。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestFlinkSQLParserDemo {/*** @param args*/public static void main(String[] args) {// 0、运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);}static void testShowCatalogs(StreamTableEnvironment tenv) {tenv.executeSql("show catalogs");}static void testShowCurrentCatalog(StreamTableEnvironment tenv) {tenv.executeSql("show current catalog");}static void testDescribeCatalog(StreamTableEnvironment tenv) {tenv.executeSql("describe catalog a");tenv.executeSql("desc catalog a");}static void testUseCatalog(StreamTableEnvironment tenv) {tenv.executeSql("use catalog a");}static void testCreateCatalog(StreamTableEnvironment tenv) {tenv.executeSql("create catalog c1 WITH ('key1'='value1','key2'='value2')");}static void testDropCatalog(StreamTableEnvironment tenv) {tenv.executeSql("drop catalog c1");}static void testShowDataBases(StreamTableEnvironment tenv) {tenv.executeSql("show databases");}static void testShowCurrentDatabase(StreamTableEnvironment tenv) {tenv.executeSql("show current database");}static void testUseDataBase(StreamTableEnvironment tenv) {tenv.executeSql("use default_db");tenv.executeSql("use defaultCatalog.default_db");}static void testCreateDatabase(StreamTableEnvironment tenv) {tenv.executeSql("create database db1");tenv.executeSql("create database if not exists db1");tenv.executeSql("create database catalog1.db1");final String sql = "create database db1 comment 'test create database'";tenv.executeSql(sql);final String sql1 = "create database db1 comment 'test create database' with ( 'key1' = 'value1', 'key2.a' = 'value2.a')";tenv.executeSql(sql1);}static void testDropDatabase(StreamTableEnvironment tenv) {tenv.executeSql("drop database db1");tenv.executeSql("drop database catalog1.db1");tenv.executeSql("drop database db1 RESTRICT");tenv.executeSql("drop database db1 CASCADE");}static void testAlterDatabase(StreamTableEnvironment tenv) {final String sql = "alter database db1 set ('key1' = 'value1','key2.a' = 'value2.a')";tenv.executeSql(sql);}static void testDescribeDatabase(StreamTableEnvironment tenv) {tenv.executeSql("describe database db1");tenv.executeSql("describe database catalog1.db1");tenv.executeSql("describe database extended db1");tenv.executeSql("desc database db1");tenv.executeSql("desc database catalog1.db1");tenv.executeSql("desc database extended db1");}static void testAlterFunction(StreamTableEnvironment tenv) {tenv.executeSql("alter function function1 as 'org.apache.flink.function.function1'");tenv.executeSql("alter temporary function function1 as 'org.apache.flink.function.function1'");tenv.executeSql("alter temporary function function1 as 'org.apache.flink.function.function1' language scala");tenv.executeSql("alter temporary system function function1 as 'org.apache.flink.function.function1'");tenv.executeSql("alter temporary system function function1 as 'org.apache.flink.function.function1' language java");}static void testShowFunctions(StreamTableEnvironment tenv) {tenv.executeSql("show functions");tenv.executeSql("show user functions");tenv.executeSql("show functions like '%'");tenv.executeSql("show functions not like '%'");tenv.executeSql("show user functions like '%'");tenv.executeSql("show user functions not like '%'");tenv.executeSql("show functions from db1");tenv.executeSql("show user functions from db1");tenv.executeSql("show functions in db1");tenv.executeSql("show user functions in db1");tenv.executeSql("show functions from catalog1.db1");tenv.executeSql("show user functions from catalog1.db1");tenv.executeSql("show functions in catalog1.db1");tenv.executeSql("show user functions in catalog1.db1");tenv.executeSql("show functions from db1 like '%'");tenv.executeSql("show user functions from db1 like '%'");tenv.executeSql("show functions in db1 ilike '%'");tenv.executeSql("show user functions in db1 ilike '%'");tenv.executeSql("show functions from catalog1.db1 ilike '%'");tenv.executeSql("show user functions from catalog1.db1 ilike '%'");tenv.executeSql("show functions in catalog1.db1 like '%'");tenv.executeSql("show user functions in catalog1.db1 like '%'");tenv.executeSql("show functions from db1 not like '%'");tenv.executeSql("show user functions from db1 not like '%'");tenv.executeSql("show functions in db1 not ilike '%'");tenv.executeSql("show user functions in db1 not ilike '%'");tenv.executeSql("show functions from catalog1.db1 not like '%'");tenv.executeSql("show user functions from catalog1.db1 not like '%'");tenv.executeSql("show functions in catalog1.db1 not ilike '%'");tenv.executeSql("show user functions in catalog1.db1 not ilike '%'");// tenv.executeSql("show functions ^likes^");
// tenv.executeSql("show functions not ^likes^");
// tenv.executeSql("show functions ^ilikes^");
// tenv.executeSql("show functions not ^ilikes^");}static void testShowProcedures(StreamTableEnvironment tenv) {tenv.executeSql("show procedures");tenv.executeSql("show procedures not like '%'");tenv.executeSql("show procedures from db1");tenv.executeSql("show procedures in db1");tenv.executeSql("show procedures from catalog1.db1");tenv.executeSql("show procedures in catalog1.db1");tenv.executeSql("show procedures from db1 like '%'");tenv.executeSql("show procedures in db1 ilike '%'");tenv.executeSql("show procedures from catalog1.db1 Ilike '%'");tenv.executeSql("show procedures in catalog1.db1 like '%'");tenv.executeSql("show procedures from db1 not like '%'");tenv.executeSql("show procedures in db1 not ilike '%'");tenv.executeSql("show procedures from catalog1.db1 not like '%'");tenv.executeSql("show procedures in catalog1.db1 not ilike '%'");// tenv.executeSql("show procedures ^db1^");
// tenv.executeSql("show procedures ^catalog1^.db1");
// tenv.executeSql("show procedures ^search^ db1");
// tenv.executeSql("show procedures from db1 ^likes^ '%t'");}static void testShowTables(StreamTableEnvironment tenv) {tenv.executeSql("show tables");tenv.executeSql("show tables not like '%'");tenv.executeSql("show tables from db1");tenv.executeSql("show tables in db1");tenv.executeSql("show tables from catalog1.db1");tenv.executeSql("show tables in catalog1.db1");tenv.executeSql("show tables from db1 like '%'");tenv.executeSql("show tables in db1 like '%'");tenv.executeSql("show tables from catalog1.db1 like '%'");tenv.executeSql("show tables in catalog1.db1 like '%'");tenv.executeSql("show tables from db1 not like '%'");tenv.executeSql("show tables in db1 not like '%'");tenv.executeSql("show tables from catalog1.db1 not like '%'");tenv.executeSql("show tables in catalog1.db1 not like '%'");// tenv.executeSql("show tables ^db1^");
// tenv.executeSql("show tables ^catalog1^.db1");
// tenv.executeSql("show tables ^search^ db1");
// tenv.executeSql("show tables from db1 ^likes^ '%t'");}static void testShowCreateTable(StreamTableEnvironment tenv) {tenv.executeSql("show create table tbl");tenv.executeSql("show create table catalog1.db1.tbl");}static void testShowCreateView(StreamTableEnvironment tenv) {tenv.executeSql("show create view v1");tenv.executeSql("show create view db1.v1");tenv.executeSql("show create view catalog1.db1.v1");}static void testDescribeTable(StreamTableEnvironment tenv) {tenv.executeSql("describe tbl");tenv.executeSql("describe catalog1.db1.tbl");tenv.executeSql("describe extended db1");tenv.executeSql("desc tbl");tenv.executeSql("desc catalog1.db1.tbl");tenv.executeSql("desc extended db1");}static void testShowColumns(StreamTableEnvironment tenv) {tenv.executeSql("show columns from tbl");tenv.executeSql("show columns in tbl");tenv.executeSql("show columns from db1.tbl");tenv.executeSql("show columns in db1.tbl");tenv.executeSql("show columns from catalog1.db1.tbl");tenv.executeSql("show columns in catalog1.db1.tbl");tenv.executeSql("show columns from tbl like '%'");tenv.executeSql("show columns in tbl like '%'");tenv.executeSql("show columns from db1.tbl like '%'");tenv.executeSql("show columns in db1.tbl like '%'");tenv.executeSql("show columns from catalog1.db1.tbl like '%'");tenv.executeSql("show columns in catalog1.db1.tbl like '%'");tenv.executeSql("show columns from tbl not like '%'");tenv.executeSql("show columns in tbl not like '%'");tenv.executeSql("show columns from db1.tbl not like '%'");tenv.executeSql("show columns in db1.tbl not like '%'");tenv.executeSql("show columns from catalog1.db1.tbl not like '%'");tenv.executeSql("show columns in catalog1.db1.tbl not like '%'");}static void testAlterTable(StreamTableEnvironment tenv) {tenv.executeSql("alter table t1 rename to t2");tenv.executeSql("alter table if exists t1 rename to t2");tenv.executeSql("alter table c1.d1.t1 rename to t2");tenv.executeSql("alter table if exists c1.d1.t1 rename to t2");tenv.executeSql("alter table t1 set ('key1'='value1')");tenv.executeSql("alter table if exists t1 set ('key1'='value1')");tenv.executeSql("alter table t1 add constraint ct1 primary key(a, b) not enforced");tenv.executeSql("alter table if exists t1 add constraint ct1 primary key(a, b) not enforced");tenv.executeSql("alter table if exists t1 " + "add unique(a, b)");tenv.executeSql("alter table t1 drop constraint ct1");tenv.executeSql("alter table if exists t1 drop constraint ct1");tenv.executeSql("alter table t1 rename a to b");tenv.executeSql("alter table if exists t1 rename a to b");tenv.executeSql("alter table if exists t1 rename a.x to a.y");}static void testAlterTableAddNestedColumn(StreamTableEnvironment tenv) {// add a row columntenv.executeSql("alter table t1 add new_column array<row(f0 int, f1 bigint)> comment 'new_column docs'");tenv.executeSql("alter table t1 add (new_row row(f0 int, f1 bigint) comment 'new_column docs', f2 as new_row.f0 + 1)");// add a field to the rowtenv.executeSql("alter table t1 add (new_row.f2 array<int>)");// add a field to the row with aftertenv.executeSql("alter table t1 add (new_row.f2 array<int> after new_row.f0)");}static void testAlterTableAddSingleColumn(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 add new_column int not null");tenv.executeSql("alter table t1 add new_column string comment 'new_column docs'");tenv.executeSql("alter table t1 add new_column string comment 'new_column docs' first");tenv.executeSql("alter table t1 add new_column string comment 'new_column docs' after id");// add compute columntenv.executeSql("alter table t1 add col_int as col_a - col_b after col_b");// add metadata columntenv.executeSql("alter table t1 add col_int int metadata from 'mk1' virtual comment 'comment_metadata' after col_b");}static void testAlterTableAddWatermark(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 add watermark for ts as ts");tenv.executeSql("alter table t1 add watermark for ts as ts - interval '1' second");tenv.executeSql("alter table default_database.t1 add watermark for ts as ts - interval '1' second");tenv.executeSql("alter table default_catalog.default_database.t1 add watermark for ts as ts - interval '1' second");}static void testAlterTableAddMultipleColumn(StreamTableEnvironment tenv) {final String sql1 = "alter table t1 add ( col_int int, log_ts string comment 'log timestamp string' first, ts AS to_timestamp(log_ts) after log_ts, "+ "col_meta int metadata from 'mk1' virtual comment 'comment_str' after col_b, primary key (id) not enforced, unique(a, b),\n"+ "watermark for ts as ts - interval '3' second )";tenv.executeSql(sql1);}public static void testAlterTableModifySingleColumn(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 modify new_column string comment 'new_column docs'");tenv.executeSql("alter table t1 modify new_column string comment 'new_column docs'");tenv.executeSql("alter table t1 modify new_column string comment 'new_column docs' first");tenv.executeSql("alter table t1 modify new_column string comment 'new_column docs' after id");// modify column typetenv.executeSql("alter table t1 modify new_column array<string not null> not null");// modify compute columntenv.executeSql("alter table t1 modify col_int as col_a - col_b after col_b");// modify metadata columntenv.executeSql("alter table t1 modify col_int int metadata from 'mk1' virtual comment 'comment_metadata' after col_b");// modify nested columntenv.executeSql("alter table t1 modify row_column.f0 int not null comment 'change nullability'");// modify nested column, shift positiontenv.executeSql("alter table t1 modify row_column.f0 int after row_column.f2");}static void testAlterTableModifyWatermark(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 modify watermark for ts as ts");tenv.executeSql("alter table t1 modify watermark for ts as ts - interval '1' second");tenv.executeSql("alter table default_database.t1 modify watermark for ts as ts - interval '1' second");tenv.executeSql("alter table default_catalog.default_database.t1 modify watermark for ts as ts - interval '1' second");}static void testAlterTableModifyConstraint(StreamTableEnvironment tenv) {tenv.executeSql("alter table t1 modify constraint ct1 primary key(a, b) not enforced");tenv.executeSql("alter table t1 modify unique(a, b)");}public static void testAlterTableModifyMultipleColumn(StreamTableEnvironment tenv) {final String sql1 = "alter table t1 modify (\n" + "col_int int,\n" + "log_ts string comment 'log timestamp string' first,\n" + "ts AS to_timestamp(log_ts) after log_ts,\n"+ "col_meta int metadata from 'mk1' virtual comment 'comment_str' after col_b,\n" + "primary key (id) not enforced,\n" + "unique(a, b),\n"+ "watermark for ts as ts - interval '3' second\n" + ")";tenv.executeSql(sql1);}public static void testAlterTableDropSingleColumn(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 drop id");tenv.executeSql("alter table t1 drop id");tenv.executeSql("alter table t1 drop (id)");tenv.executeSql("alter table t1 drop tuple.id");}public static void testAlterTableDropMultipleColumn(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 drop (id, ts, tuple.f0, tuple.f1)");tenv.executeSql("alter table t1 drop (id, ts, tuple.f0, tuple.f1)");}public static void testAlterTableDropPrimaryKey(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 drop primary key");tenv.executeSql("alter table t1 drop primary key");}public static void testAlterTableDropConstraint(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 drop constraint ct");tenv.executeSql("alter table t1 drop constraint ct");// tenv.executeSql("alter table t1 drop constrain^t^");}public static void testAlterTableDropWatermark(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 drop watermark");tenv.executeSql("alter table t1 drop watermark");}static void testAlterTableReset(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 reset ('key1')");tenv.executeSql("alter table t1 reset ('key1')");tenv.executeSql("alter table t1 reset ('key1', 'key2')");tenv.executeSql("alter table t1 reset(StreamTableEnvironment tenv)");}static void testAlterTableCompact(StreamTableEnvironment tenv) {tenv.executeSql("alter table if exists t1 compact");tenv.executeSql("alter table t1 compact");tenv.executeSql("alter table db1.t1 compact");tenv.executeSql("alter table cat1.db1.t1 compact");tenv.executeSql("alter table t1 partition(x='y',m='n') compact");// tenv.executeSql("alter table t1 partition(^)^ compact");}public static void testAddPartition(StreamTableEnvironment tenv) {tenv.executeSql("alter table c1.d1.tbl add partition (p1=1,p2='a')");tenv.executeSql("alter table tbl add partition (p1=1,p2='a') with ('k1'='v1')");tenv.executeSql("alter table tbl add if not exists partition (p=1) partition (p=2) with ('k1' = 'v1')");}public static void testDropPartition(StreamTableEnvironment tenv) {tenv.executeSql("alter table c1.d1.tbl drop if exists partition (p=1)");tenv.executeSql("alter table tbl drop partition (p1='a',p2=1), partition(p1='b',p2=2)");tenv.executeSql("alter table tbl drop partition (p1='a',p2=1), " + "partition(p1='b',p2=2), partition(p1='c',p2=3)");}static void testCreateTable(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a bigint,\n" + " h varchar, \n" + " g as 2 * (a + 1), \n" + " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'), \n"+ " b varchar,\n" + " proc as PROCTIME(StreamTableEnvironment tenv), \n" + " meta STRING METADATA, \n" + " my_meta STRING METADATA FROM 'meta', \n"+ " my_meta STRING METADATA FROM 'meta' VIRTUAL, \n" + " meta STRING METADATA VIRTUAL, \n" + " PRIMARY KEY (a, b)\n" + ")\n" + "PARTITIONED BY (a, h)\n"+ " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableIfNotExists(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE IF NOT EXISTS tbl1 (\n" + " a bigint,\n" + " h varchar, \n" + " g as 2 * (a + 1), \n"+ " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'), \n" + " b varchar,\n" + " proc as PROCTIME(StreamTableEnvironment tenv), \n" + " PRIMARY KEY (a, b)\n" + ")\n"+ "PARTITIONED BY (a, h)\n" + " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithComment(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a bigint comment 'test column comment AAA.',\n" + " h varchar, \n" + " g as 2 * (a + 1), \n"+ " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'), \n" + " b varchar,\n" + " proc as PROCTIME(StreamTableEnvironment tenv), \n"+ " meta STRING METADATA COMMENT 'c1', \n" + " my_meta STRING METADATA FROM 'meta' COMMENT 'c2', \n"+ " my_meta STRING METADATA FROM 'meta' VIRTUAL COMMENT 'c3', \n" + " meta STRING METADATA VIRTUAL COMMENT 'c4', \n" + " PRIMARY KEY (a, b)\n" + ")\n"+ "comment 'test table comment ABC.'\n" + "PARTITIONED BY (a, h)\n" + " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithCommentOnComputedColumn(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a bigint comment 'test column comment AAA.',\n" + " h varchar, \n"+ " g as 2 * (a + 1) comment 'test computed column.', \n" + " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'), \n" + " b varchar,\n"+ " proc as PROCTIME(StreamTableEnvironment tenv), \n" + " PRIMARY KEY (a, b)\n" + ")\n" + "comment 'test table comment ABC.'\n" + "PARTITIONED BY (a, h)\n"+ " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testColumnConstraints(StreamTableEnvironment tenv) {final String sql3 = "CREATE TABLE tbl1 (\n" + " a bigint primary key not enforced,\n" + " h varchar,\n" + " g as 2 * (a + 1),\n"+ " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'),\n" + " b varchar,\n" + " proc as PROCTIME(StreamTableEnvironment tenv)\n" + ") with (\n"+ " 'connector' = 'kafka',\n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql3);}static void testTableConstraintsWithEnforcement(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a bigint primary key enforced comment 'test column comment AAA.',\n" + " h varchar constraint ct1 unique not enforced,\n"+ " g as 2 * (a + 1), \n" + " ts as toTimestamp(b, 'yyyy-MM-dd HH:mm:ss'),\n" + " b varchar constraint ct2 unique,\n"+ " proc as PROCTIME(StreamTableEnvironment tenv),\n" + " unique (g, ts) not enforced" + ") with (\n" + " 'connector' = 'kafka',\n"+ " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithWatermark(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " ts timestamp(3),\n" + " id varchar, \n" + " watermark FOR ts AS ts - interval '3' second\n" + ")\n" + " with (\n"+ " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithWatermarkOnComputedColumn(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " log_ts varchar,\n" + " ts as to_timestamp(log_ts), \n" + " WATERMARK FOR ts AS ts + interval '1' second\n" + ")\n"+ " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithWatermarkOnNestedField(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " f1 row<q1 bigint, q2 row<t1 timestamp, t2 varchar>, q3 boolean>,\n"+ " WATERMARK FOR f1.q2.t1 AS NOW(StreamTableEnvironment tenv)\n" + ")\n" + " with (\n" + " 'connector' = 'kafka', \n" + " 'kafka.topic' = 'log.test'\n"+ ")\n";tenv.executeSql(sql);}static void testCreateTableWithComplexType(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a ARRAY<bigint>, \n" + " b MAP<int, varchar>,\n" + " c ROW<cc0 int, cc1 float, cc2 varchar>,\n"+ " d MULTISET<varchar>,\n" + " PRIMARY KEY (a, b) \n" + ") with (\n" + " 'x' = 'y', \n" + " 'asd' = 'data'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithNestedComplexType(StreamTableEnvironment tenv) {final String sql = "CREATE TABLE tbl1 (\n" + " a ARRAY<ARRAY<bigint>>, \n" + " b MAP<MAP<int, varchar>, ARRAY<varchar>>,\n"+ " c ROW<cc0 ARRAY<int>, cc1 float, cc2 varchar>,\n" + " d MULTISET<ARRAY<int>>,\n" + " PRIMARY KEY (a, b) \n" + ") with (\n" + " 'x' = 'y', \n"+ " 'asd' = 'data'\n" + ")\n";tenv.executeSql(sql);}static void testCreateTableWithUserDefinedType(StreamTableEnvironment tenv) {final String sql = "create table t(\n" + " a catalog1.db1.MyType1,\n" + " b db2.MyType2\n" + ") with (\n" + " 'k1' = 'v1',\n" + " 'k2' = 'v2'\n" + ")";tenv.executeSql(sql);}static void testCreateTableWithMinusInOptionKey(StreamTableEnvironment tenv) {final String sql = "create table source_table(\n" + " a int,\n" + " b bigint,\n" + " c string\n" + ") with (\n" + " 'a-b-c-d124' = 'ab',\n" + " 'a.b.1.c' = 'aabb',\n"+ " 'a.b-c-connector.e-f.g' = 'ada',\n" + " 'a.b-c-d.e-1231.g' = 'ada',\n" + " 'a.b-c-d.*' = 'adad')\n";tenv.executeSql(sql);}static void testCreateTableLikeWithoutOption(StreamTableEnvironment tenv) {final String sql = "create table source_table(\n" + " a int,\n" + " b bigint,\n" + " c string\n" + ")\n" + "LIKE parent_table";tenv.executeSql(sql);}static void testCreateTableWithLikeClause(StreamTableEnvironment tenv) {final String sql = "create table source_table(\n" + " a int,\n" + " b bigint,\n" + " c string\n" + ")\n" + "LIKE parent_table (\n" + " INCLUDING ALL\n"+ " OVERWRITING OPTIONS\n" + " EXCLUDING PARTITIONS\n" + " INCLUDING GENERATED\n" + " INCLUDING METADATA\n" + ")";tenv.executeSql(sql);}static void testCreateTableWithLikeClauseWithoutColumns(StreamTableEnvironment tenv) {final String sql = "" + "create TEMPORARY table source_table (\n" + " WATERMARK FOR ts AS ts - INTERVAL '5' SECOND\n" + ") with (\n"+ " 'scan.startup.mode' = 'specific-offsets',\n" + " 'scan.startup.specific-offsets' = 'partition:0,offset:1169129'\n" + ") like t_order_course (\n"+ " OVERWRITING WATERMARKS\n" + " OVERWRITING OPTIONS\n" + " EXCLUDING CONSTRAINTS\n" + ")";tenv.executeSql(sql);}static void testCreateTemporaryTable(StreamTableEnvironment tenv) {final String sql = "create temporary table source_table(\n" + " a int,\n" + " b bigint,\n" + " c string\n" + ") with (\n" + " 'x' = 'y',\n" + " 'abc' = 'def'\n" + ")";tenv.executeSql(sql);}static void testCreateTableWithNoColumns(StreamTableEnvironment tenv) {final String sql = "create table source_table with (\n" + " 'x' = 'y',\n" + " 'abc' = 'def'\n" + ")";tenv.executeSql(sql);}static void testCreateTableWithOnlyWaterMark(StreamTableEnvironment tenv) {final String sql = "create table source_table (\n" + " watermark FOR ts AS ts - interval '3' second\n" + ") with (\n" + " 'x' = 'y',\n" + " 'abc' = 'def'\n" + ")";tenv.executeSql(sql);}static void testDropTable(StreamTableEnvironment tenv) {final String sql = "DROP table catalog1.db1.tbl1";tenv.executeSql(sql);}static void testDropIfExists(StreamTableEnvironment tenv) {final String sql = "DROP table IF EXISTS catalog1.db1.tbl1";tenv.executeSql(sql);}static void testTemporaryDropTable(StreamTableEnvironment tenv) {final String sql = "DROP temporary table catalog1.db1.tbl1";tenv.executeSql(sql);}static void testDropTemporaryIfExists(StreamTableEnvironment tenv) {final String sql = "DROP temporary table IF EXISTS catalog1.db1.tbl1";tenv.executeSql(sql);}static void testInsertPartitionSpecs(StreamTableEnvironment tenv) {final String sql1 = "insert into emps partition (x='ab', y='bc') (x,y) select * from emps";tenv.executeSql(sql1);final String sql2 = "insert into emp\n" + "partition(empno='1', job='job')\n" + "(empno, ename, job, mgr, hiredate,\n" + " sal, comm, deptno, slacker)\n"+ "select 'nom', 0, timestamp '1970-01-01 00:00:00',\n" + " 1, 1, 1, false\n" + "from (values 'a')";tenv.executeSql(sql2);final String sql3 = "insert into empnullables\n" + "partition(ename='b')\n" + "(empno, ename)\n" + "select 1 from (values 'a')";tenv.executeSql(sql3);}static void testInsertCaseSensitivePartitionSpecs(StreamTableEnvironment tenv) {tenv.executeSql("insert into \"emps\" " + "partition (\"x\"='ab', \"y\"='bc')(\"x\",\"y\") select * from emps");}static void testInsertExtendedColumnAsStaticPartition1(StreamTableEnvironment tenv) {tenv.executeSql("insert into emps(z boolean) partition (z='ab') (x,y) select * from emps");}static void testInsertOverwrite(StreamTableEnvironment tenv) {// non-partitionedfinal String sql = "INSERT OVERWRITE myDB.myTbl SELECT * FROM src";tenv.executeSql(sql);// partitionedfinal String sql1 = "INSERT OVERWRITE myTbl PARTITION (p1='v1',p2='v2') SELECT * FROM src";tenv.executeSql(sql1);}static void testCreateView(StreamTableEnvironment tenv) {final String sql = "create view v as select col1 from tbl";tenv.executeSql(sql);}static void testCreateViewWithComment(StreamTableEnvironment tenv) {final String sql = "create view v COMMENT 'this is a view' as select col1 from tbl";tenv.executeSql(sql);}static void testCreateViewWithFieldNames(StreamTableEnvironment tenv) {final String sql = "create view v(col1, col2) as select col3, col4 from tbl";tenv.executeSql(sql);}static void testCreateTemporaryView(StreamTableEnvironment tenv) {final String sql = "create temporary view v as select col1 from tbl";tenv.executeSql(sql);}static void testCreateTemporaryViewIfNotExists(StreamTableEnvironment tenv) {final String sql = "create temporary view if not exists v as select col1 from tbl";tenv.executeSql(sql);}static void testCreateViewIfNotExists(StreamTableEnvironment tenv) {final String sql = "create view if not exists v as select col1 from tbl";tenv.executeSql(sql);}static void testDropView(StreamTableEnvironment tenv) {final String sql = "DROP VIEW IF EXISTS view_name";tenv.executeSql(sql);}static void testDropTemporaryView(StreamTableEnvironment tenv) {final String sql = "DROP TEMPORARY VIEW IF EXISTS view_name";tenv.executeSql(sql);}static void testAlterView(StreamTableEnvironment tenv) {tenv.executeSql("ALTER VIEW v1 RENAME TO v2");tenv.executeSql("ALTER VIEW v1 AS SELECT c1, c2 FROM tbl");}static void testShowViews(StreamTableEnvironment tenv) {tenv.executeSql("show views");}static void testShowPartitions(StreamTableEnvironment tenv) {tenv.executeSql("show partitions c1.d1.tbl");tenv.executeSql("show partitions tbl partition (p=1)");}static void testCreateViewWithEmptyFields(StreamTableEnvironment tenv) {String sql = "CREATE VIEW v1 AS SELECT 1";tenv.executeSql(sql);}static void testCreateFunction(StreamTableEnvironment tenv) {tenv.executeSql("create function catalog1.db1.function1 as 'org.apache.flink.function.function1'");tenv.executeSql("create temporary function catalog1.db1.function1 as 'org.apache.flink.function.function1'");tenv.executeSql("create temporary function db1.function1 as 'org.apache.flink.function.function1'");tenv.executeSql("create temporary function function1 as 'org.apache.flink.function.function1'");tenv.executeSql("create temporary function if not exists catalog1.db1.function1 as 'org.apache.flink.function.function1'");tenv.executeSql("create temporary function function1 as 'org.apache.flink.function.function1' language java");tenv.executeSql("create temporary system function function1 as 'org.apache.flink.function.function1' language scala");// test create function using jartenv.executeSql("create temporary function function1 as 'org.apache.flink.function.function1' language java using jar 'file:///path/to/test.jar'");tenv.executeSql("create temporary function function1 as 'org.apache.flink.function.function1' language scala using jar '/path/to/test.jar'");tenv.executeSql("create temporary system function function1 as 'org.apache.flink.function.function1' language scala using jar '/path/to/test.jar'");tenv.executeSql("create function function1 as 'org.apache.flink.function.function1' language java using jar 'file:///path/to/test.jar', jar 'hdfs:///path/to/test2.jar'");}static void testDropTemporaryFunction(StreamTableEnvironment tenv) {tenv.executeSql("drop temporary function catalog1.db1.function1");tenv.executeSql("drop temporary system function catalog1.db1.function1");tenv.executeSql("drop temporary function if exists catalog1.db1.function1");tenv.executeSql("drop temporary system function if exists catalog1.db1.function1");}static void testLoadModule(StreamTableEnvironment tenv) {tenv.executeSql("load module core");tenv.executeSql("load module dummy with ('k1' = 'v1', 'k2' = 'v2')");}static void testUnloadModule(StreamTableEnvironment tenv) {tenv.executeSql("unload module core");}static void testUseModules(StreamTableEnvironment tenv) {tenv.executeSql("use modules core");tenv.executeSql("use modules x, y, z");}static void testShowModules(StreamTableEnvironment tenv) {tenv.executeSql("show modules");tenv.executeSql("show full modules");}static void testBeginStatementSet(StreamTableEnvironment tenv) {tenv.executeSql("begin statement set");}static void testEnd(StreamTableEnvironment tenv) {tenv.executeSql("end");}static void testExecuteStatementSet(StreamTableEnvironment tenv) {tenv.executeSql("execute statement set begin insert into t1 select * from t2; insert into t2 select * from t3; end");}static void testExplainStatementSet(StreamTableEnvironment tenv) {tenv.executeSql("explain statement set begin insert into t1 select * from t2; insert into t2 select * from t3; end");}static void testExplain(StreamTableEnvironment tenv) {String sql = "explain select * from emps";tenv.executeSql(sql);}static void testExecuteSelect(StreamTableEnvironment tenv) {String sql = "execute select * from emps";tenv.executeSql(sql);}static void testExplainPlanFor(StreamTableEnvironment tenv) {String sql = "explain plan for select * from emps";tenv.executeSql(sql);}static void testExplainChangelogMode(StreamTableEnvironment tenv) {String sql = "explain changelog_mode select * from emps";tenv.executeSql(sql);}static void testExplainEstimatedCost(StreamTableEnvironment tenv) {String sql = "explain estimated_cost select * from emps";tenv.executeSql(sql);}static void testExplainUnion(StreamTableEnvironment tenv) {String sql = "explain estimated_cost select * from emps union all select * from emps";tenv.executeSql(sql);}static void testExplainAsJson(StreamTableEnvironment tenv) {String sql = "explain json_execution_plan select * from emps";tenv.executeSql(sql);}static void testExplainPlanAdvice(StreamTableEnvironment tenv) {String sql = "explain plan_advice select * from emps";tenv.executeSql(sql);}static void testExplainAllDetails(StreamTableEnvironment tenv) {String sql = "explain changelog_mode,json_execution_plan,estimated_cost,plan_advice select * from emps";tenv.executeSql(sql);}static void testExplainInsert(StreamTableEnvironment tenv) {tenv.executeSql("explain plan for insert into emps1 select * from emps2");}static void testExecuteInsert(StreamTableEnvironment tenv) {tenv.executeSql("execute insert into emps1 select * from emps2");}static void testExecutePlan(StreamTableEnvironment tenv) {tenv.executeSql("execute plan './test.json'");tenv.executeSql("execute plan '/some/absolute/dir/plan.json'");tenv.executeSql("execute plan 'file:///foo/bar/test.json'");}static void testCompilePlan(StreamTableEnvironment tenv) {tenv.executeSql("compile plan './test.json' for insert into t1 select * from t2");tenv.executeSql("compile plan './test.json' if not exists for insert into t1 select * from t2");tenv.executeSql("compile plan 'file:///foo/bar/test.json' if not exists for insert into t1 select * from t2");tenv.executeSql("compile plan './test.json' for statement set " + "begin insert into t1 select * from t2; insert into t2 select * from t3; end");tenv.executeSql("compile plan './test.json' if not exists for statement set " + "begin insert into t1 select * from t2; insert into t2 select * from t3; end");tenv.executeSql("compile plan 'file:///foo/bar/test.json' if not exists for statement set " + "begin insert into t1 select * from t2; insert into t2 select * from t3; end");}static void testCompileAndExecutePlan(StreamTableEnvironment tenv) {tenv.executeSql("compile and execute plan './test.json' for insert into t1 select * from t2");tenv.executeSql("compile and execute plan './test.json' for statement set " + "begin insert into t1 select * from t2; insert into t2 select * from t3; end");tenv.executeSql("compile and execute plan 'file:///foo/bar/test.json' for insert into t1 select * from t2");}static void testExplainUpsert(StreamTableEnvironment tenv) {String sql = "explain plan for upsert into emps1 values (1, 2)";tenv.executeSql(sql);}static void testAddJar(StreamTableEnvironment tenv) {tenv.executeSql("add Jar './test.sql'");tenv.executeSql("add JAR 'file:///path/to/\nwhatever'");tenv.executeSql("add JAR 'oss://path/helloworld.go'");}static void testRemoveJar(StreamTableEnvironment tenv) {tenv.executeSql("remove Jar './test.sql'");tenv.executeSql("remove JAR 'file:///path/to/\nwhatever'");tenv.executeSql("remove JAR 'oss://path/helloworld.go'");}static void testShowJars(StreamTableEnvironment tenv) {tenv.executeSql("show jars");}static void testSetReset(StreamTableEnvironment tenv) {tenv.executeSql("SET");tenv.executeSql("SET 'test-key' = 'test-value'");tenv.executeSql("RESET");tenv.executeSql("RESET 'test-key'");}static void testAnalyzeTable(StreamTableEnvironment tenv) {tenv.executeSql("analyze table emps compute statistics");tenv.executeSql("analyze table emps partition(x='ab') compute statistics");tenv.executeSql("analyze table emps partition(x='ab', y='bc') compute statistics");tenv.executeSql("analyze table emps compute statistics for columns a");tenv.executeSql("analyze table emps compute statistics for columns a, b");tenv.executeSql("analyze table emps compute statistics for all columns");tenv.executeSql("analyze table emps partition(x, y) compute statistics for all columns");tenv.executeSql("analyze table emps partition(x='ab', y) compute statistics for all columns");tenv.executeSql("analyze table emps partition(x, y='cd') compute statistics for all columns");}static void testCreateTableAsSelectWithoutOptions(StreamTableEnvironment tenv) {tenv.executeSql("CREATE TABLE t AS SELECT * FROM b");}static void testCreateTableAsSelectWithOptions(StreamTableEnvironment tenv) {tenv.executeSql("CREATE TABLE t WITH ('test' = 'zm') AS SELECT * FROM b");}static void testReplaceTableAsSelect(StreamTableEnvironment tenv) {// test replace table as select without optionstenv.executeSql("REPLACE TABLE t AS SELECT * FROM b");// test replace table as select with optionstenv.executeSql("REPLACE TABLE t WITH ('test' = 'zm') AS SELECT * FROM b");}static void testCreateOrReplaceTableAsSelect(StreamTableEnvironment tenv) {// test create or replace table as select without optionstenv.executeSql("CREATE OR REPLACE TABLE t AS SELECT * FROM b");// test create or replace table as select with optionstenv.executeSql("CREATE OR REPLACE TABLE t WITH ('test' = 'zm') AS SELECT * FROM b");}static void testShowJobs(StreamTableEnvironment tenv) {tenv.executeSql("show jobs");}static void testStopJob(StreamTableEnvironment tenv) {tenv.executeSql("STOP JOB 'myjob'");tenv.executeSql("STOP JOB 'myjob' WITH SAVEPOINT");tenv.executeSql("STOP JOB 'myjob' WITH SAVEPOINT WITH DRAIN");}static void testTruncateTable(StreamTableEnvironment tenv) {tenv.executeSql("truncate table t1");}}
以上,本文简单介绍了DROP、alter、insert和analyze的语法及示例 ,并且将FLink sql常用的sql以java 方法整理成一个类,可以直接在java中使用,或在Flink sql cli中直接使用。
相关文章:
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

正则表达式[总结]
文章目录 1. 为什么要学习正则表达式2. 再提出几个问题?3. 解决之道-正则表达式4. 正则表达式基本介绍5. 正则表达式底层实现(重要)6. 正则表达式语法6.1 基本介绍6.2 元字符(Metacharacter)-转义号 \\\6.3 元字符-字符匹配符6.4 元字符-选择匹配符6.5 元字符-限定符…...

【docker】搭建xxl-job
首先创建数据库,例如我已经有了mysql 在 192.168.20.17上 #首先要有对应的数据库,创建xxl-job所需表CREATE database if NOT EXISTS xxl_job default character set utf8mb4 collate utf8mb4_unicode_ci; use xxl_job;SET NAMES utf8mb4;CREATE TABLE xx…...
)
k8s-----3、kubernetes集群部署(kubeadm部署)
集群部署 1、kubeadm流程(重新配置)1.1 安装要求1.2 准备环境 1.3. 所有节点安装Docker/kubeadm/kubelet1.3.1 安装Docker1.3.2 添加阿里云YUM软件源1.3.3 安装kubeadm,kubelet和kubectl 1.4 部署Kubernetes Master1.5. 加入Kubernetes Node1…...

党建展馆vr仿真解说员具有高质量的表现力和互动性
随着虚拟数字人应用渐成趋势,以虚拟数字人为核心的营销远比其他更能加速品牌年轻化进程和认识,助力企业在激烈的市场竞争中脱颖而出,那么企业虚拟IP代言人解决了哪些痛点? 解决品牌与代言人之间的风险问题 传统代言人在代言品牌时࿰…...

Webpack 基础以及常用插件使用方法
目录 一、前言二、修改打包入/出口配置步骤 三、常用插件使用html-webpack-plugin打包 CSS 代码提取 CSS 代码优化压缩过程打包 less 代码打包图片文件 一、前言 本质上,Webpack 是一个用于现代 JavaScript 应用程序的 静态模块打包工具。当 webpack 处理应用程序时…...
ROCESS SPID 代表什么进程
ROCESS 发出sql命令 所在主机的进程 可以不在数据库主机上发出 SPID 对应数据库的服务进程id select a.PROCESS,b.SPID From v$session a , v$process b where a.PADDRb.ADDR and a.USERNAMESYS SQL> !ps -ef|grep sqlplus oracle 385 2792 0 21:01 pts/…...

oracle rac了解
Oracle RAC 是一种高可用性和高性能的数据库解决方案,它允许多台服务器共享同一个数据库。简而言之,Oracle RAC 允许你将多个计算节点连接到一个共享的数据库实例中,从而提供了以下优势: 高可用性:Oracle RAC 提供了故…...
力扣 -- 44. 通配符匹配
解题步骤: 参考代码: class Solution { public:bool isMatch(string s, string p) {int ms.size();int np.size();//为了调整映射关系s s;p p;//多开一行多开一列vector<vector<bool>> dp(m1,vector<bool>(n1,false));//初始化//dp[0…...

电脑msvcp100.dll丢失的解决办法,靠谱的五个解决方法分享
在计算机使用过程中,我们经常会遇到一些错误提示,其中最常见的就是“缺少xxx.dll文件”。而msvcp100.dll就是其中之一。那么,msvcp100.dll到底是什么呢?它对我们的计算机有什么作用?本文将从多个方面对msvcp100.dll进行…...
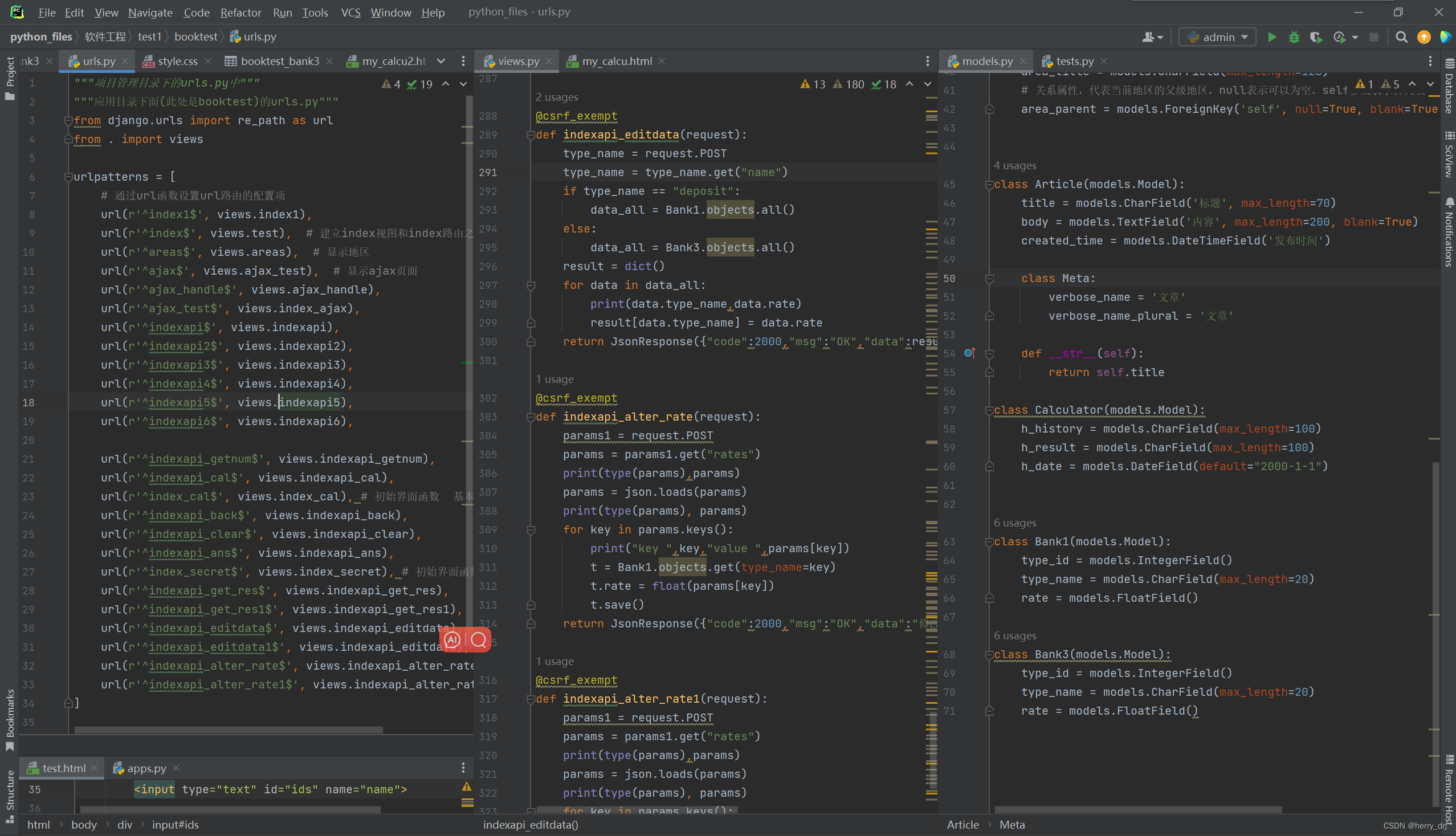
HTML+CSS+JS+Django 实现前后端分离的科学计算器、利率计算器(附全部代码在gitcode链接)
🧮前后端分离计算器 📚git仓库链接和代码规范链接💼PSP表格🎇成品展示🏆🏆科学计算器:1. 默认界面与页面切换2. 四则运算、取余、括号3. 清零Clear 回退Back4. 错误提示 Error5. 读取历史记录Hi…...
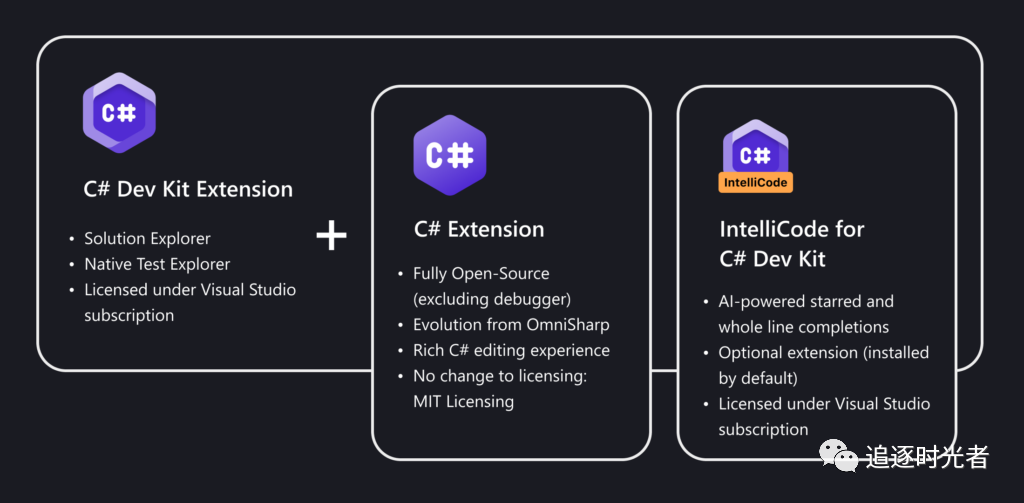
VS Code C# 开发工具包正式发布
前言 微软于本月正式发布Visual Studio Code C#开发工具包,此前该开发套件已经以预览版的形式在6月份问世。经过4个月的测试和调整,微软修复了350多个问题,其中大部分是用户反馈导致的问题。此外,微软还对产品进行了300多项有针对…...

【计算机网络】HTTPS 的加密流程
HTTPS (Hypertext Transfer Protocol Secure) 是一种安全的 HTTP 协议,采用了加密通信技术,可以保护客户端与服务器之间的数据传输安全,从而防止中间人攻击、窃听、篡改等恶意操纵。HTTPS 的加密流程包括以下几个步骤: 客户端发送…...
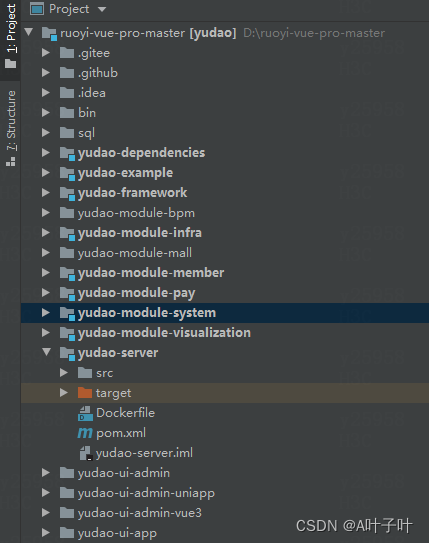
若依和芋道
国外卷技术,国内卷业务,做管理业务通常使用开源框架就可以快速满足,若依和芋道都是开源二开工具较为流行的框架,芋道是基于若依的,基本上是开发人员自己写业务开发框架的天花板,两者的前端都是基于vue-element-admin的,使用Gitee上两者的SpringBoot的最轻量化版本进行对…...
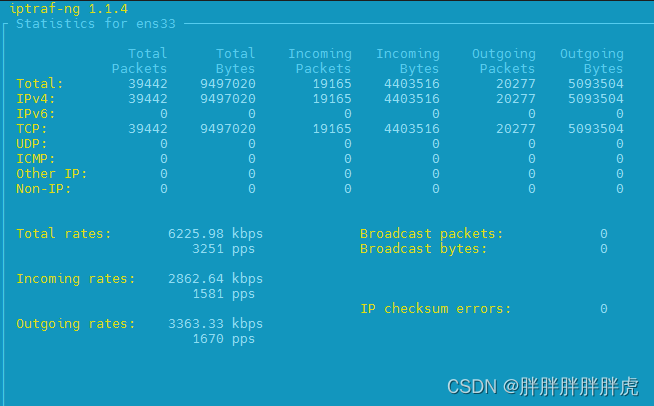
Linux流量监控
yum install -y iptrafiptraf-ng -d ens33...

高流量大并发Linux TCP性能调优
最近在使用jmeter做压测,当jmeter的并发量高的时候发现jmeter服务器一直报错Cannot assign requested address, 查看了一下发现系统中存在大量处于TIME_WAIT状态的tcp端口 netstat -n | awk ‘/^tcp/ {S[$NF]} END {for(a in S) print a, S[a]}’ TIME_W…...

ATT 格式汇编语言语法
GNU 汇编器是 GNU 二进制实用程序 (binutils) 的一部分,也是 GNU 编译器集合的后端。尽管 as 不是编写相当大的汇编程序的首选汇编程序,但它是当代类 Unix 系统的重要组成部分,特别是对于内核级黑客攻击。 经常因其神秘的 AT&T 风格语法而…...

Linux系统编程学习 NO.8 ——make和Makefile、进度条程序
前言 今天是1024程序员节,不知不觉离第一次写博客已经过去了一年了。在此祝各位程序员不写bug,不再秃头。 make和Makefile 什么是make和Makefile? make和Makefile是软件开发时所用到的工具和文件。make是一个指令工具。Makefile是一个当前…...
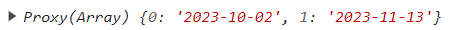
elementUI 中 date-picker 的使用的坑(vue3)
目录 1. 英文显示2. format 与 value-format 无效3. date-picker 时间范围4. 小结 1. 英文显示 <el-date-pickerv-model"dateValue"type"date"placeholder"选择日期"></el-date-picker>解决方案: 引用 zhCn <script&g…...
1-07 React配置postcss-px-to-viewport
React配置postcss-px-to-viewport 移动端适配 安装依赖:在项目根目录下运行以下命令安装所需的依赖包: npm install postcss-px-to-viewport --save-dev配置代码 const path require(path);module.exports {webpack: {alias: {: path.resolve(__di…...

如何实现重组抗体的精准定制?
一、重组抗体定制与传统抗体制备有何本质区别?重组抗体定制是通过基因工程技术在体外构建并表达目标抗体的创新方法。与传统杂交瘤技术相比,重组抗体技术具有多方面的显著优势。首先,其生产完全不依赖于动物免疫系统,而是通过人工…...
)
C++编译产物为何在边缘端频繁触发OOM?深度解析.lto、.eh_frame、.comment段的隐藏开销(含Bloaty对比报告)
第一章:C编译产物在边缘端触发OOM的根本动因边缘设备普遍受限于物理内存(如 512MB–2GB RAM)、无 Swap 分区、缺乏内存过载保护机制,而现代 C 编译器(如 GCC 11/Clang 14)默认启用的优化策略与运行时特性&a…...

Spring Security框架从入门到精通!
安全管理是Java应用开发中无法避免的问题,随着Spring Boot和微服务的流行,Spring Security受到越来越多Java开发者的重视,究其原因,还是沾了微服务的光。作为Spring家族中的一员,其在和Spring家族中的其他产品如SpringBoot、Spring Cloud等进…...

深入Anomalib:如何用Padim、PatchCore等算法为你的自定义数据集做异常定位?
深入Anomalib:如何用Padim、PatchCore等算法为你的自定义数据集做异常定位? 在工业质检和医疗影像领域,异常检测正从"有没有问题"的定性判断,升级到"问题在哪里"的精准定位。当你的数据集充满特殊纹理的PCB板…...

感官伪造风暴:AI用触觉反馈实施千万美元诈骗
一场静默的技术入侵当公众的注意力还停留在AI换脸与拟声诈骗的警示时,一条更隐蔽、更具欺骗性的技术路径已在黑暗中悄然铺就。如果说视觉与听觉的伪造尚可通过“多看两眼”、“多问一句”来警觉,那么当触觉——这一人类最原始、最信赖的感官——也被人工…...

AI模型输出流被中间人篡改?FastAPI 2.0异步响应完整性保障方案:TLS 1.3+Chunked-Hash-Signature+WebTransport双通道校验
第一章:AI模型输出流被中间人篡改?FastAPI 2.0异步响应完整性保障方案:TLS 1.3Chunked-Hash-SignatureWebTransport双通道校验在高敏感AI服务场景中,LLM流式响应(如 Server-Sent Events 或 chunked transfer encoding&…...

小米平板4/4Plus驱动板安装与调试全攻略:从HDMI连接到触摸校准
1. 小米平板4驱动板安装前的准备工作 第一次接触驱动板安装的朋友可能会觉得有点复杂,但其实只要做好准备工作,整个过程就会顺利很多。我去年帮朋友改装过三台小米平板4,总结出几个关键点。首先,你需要确认手头的驱动板型号是否匹…...

Redis如何断开主从同步关系_使用REPLICAOF NO ONE命令将从节点提升为独立主节点
执行REPLICAOF NO ONE后从节点未真正独立,因状态切换有延迟、需确认同步完成、配置文件残留、版本兼容性(4.x用SLAVEOF)、集群模式不支持、提升后写入风险及原主无感知。执行 REPLICAOF NO ONE 后从节点没真正“独立”?命令本身没…...
Pixel Script Temple参数详解:LoRA秩(Rank)对剧本专业度与风格稳定性的权衡
Pixel Script Temple参数详解:LoRA秩(Rank)对剧本专业度与风格稳定性的权衡 1. 理解LoRA秩(Rank)的基本概念 1.1 什么是LoRA秩 LoRA(Low-Rank Adaptation)是一种高效的大模型微调技术&#x…...

到 2030 年的能力-AI
近年来,人工智能进步的关键投入(算力、算法改进和数据)呈指数级增长,新的推理时扩展(inferencetime scaling)方法正进一步提高模型的能力,甚至在模型完成训练之后。如果这些趋势继续下去&#x…...