Spring Cloud Nacos源码讲解(九)- Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移
在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0tebMgFe-1677029918442)(image-20211027191504884.png)]](https://img-blog.csdnimg.cn/ac3a04d883f042bea053952bde342171.png)
本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当中,也就是通过Map的形式承载,这样查询操作都方便。第二方面便是通过磁盘文件的形式定时缓存起来,以备不时之需。
故障转移也分两方面,第一方面是故障转移的开关是通过文件来标记的;第二方面是当开启故障转移之后,当发生故障时,可以从故障转移备份的文件中来获得服务实例信息。
ServiceInfoHolder功能概述
ServiceInfoHolder类,顾名思义,服务信息的持有者。每次客户端从注册中心获取新的服务信息时都会调用该类,其中processServiceInfo方法来进行本地化处理,包括更新缓存服务、发布事件、更新本地文件等。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cuBsv384-1677029918446)(image-20211027152442627.png)]](https://img-blog.csdnimg.cn/a66da43488ce4370bfae175034e3ada3.png)
除了这些核心功能以外,该类在实例化的时候,还做了本地缓存目录初始化、故障转移初始化等操作,下面我们来分析。
ServiceInfo的本地内存缓存
ServiceInfo,注册服务的信息,其中包含了服务名称、分组名称、集群信息、实例列表信息,上次更新时间等,所以我们由此得出客户端从服务端注册中心获得到的信息在本地都以ServiceInfo作为承载者。
而ServiceInfoHolder类又持有了ServiceInfo,通过一个ConcurrentMap来储存
// ServiceInfoHolder
private final ConcurrentMap<String, ServiceInfo> serviceInfoMap;
这就是Nacos客户端对服务端获取到的注册信息的第一层缓存,并且之前的课程中我们分析processServiceInfo方法时,我们已经看到,当服务信息变更时会第一时间更新ServiceInfoMap中的信息
public ServiceInfo processServiceInfo(ServiceInfo serviceInfo) {....//缓存服务信息serviceInfoMap.put(serviceInfo.getKey(), serviceInfo);// 判断注册的实例信息是否更改boolean changed = isChangedServiceInfo(oldService, serviceInfo);if (StringUtils.isBlank(serviceInfo.getJsonFromServer())) {serviceInfo.setJsonFromServer(JacksonUtils.toJson(serviceInfo));}....return serviceInfo;
}
serviceInfoMap的使用就是这样,当变动实例向其中put最新数据即可。当使用实例时,根据key进行get操作即可。
serviceInfoMap在ServiceInfoHolder的构造方法中进行初始化,默认创建一个空的ConcurrentMap。但当配置了启动时从缓存文件读取信息时,则会从本地缓存进行加载。
public ServiceInfoHolder(String namespace, Properties properties) {initCacheDir(namespace, properties);// 启动时是否从缓存目录读取信息,默认false。if (isLoadCacheAtStart(properties)) {this.serviceInfoMap = new ConcurrentHashMap<String, ServiceInfo>(DiskCache.read(this.cacheDir));} else {this.serviceInfoMap = new ConcurrentHashMap<String, ServiceInfo>(16);}this.failoverReactor = new FailoverReactor(this, cacheDir);this.pushEmptyProtection = isPushEmptyProtect(properties);
}
这里我们要注意一下,涉及到了本地缓存目录,在我们上节课的学习中我们知道,processServiceInfo方法中,当服务实例变更时,会看到通过DiskCache#write方法向该目录写入ServiceInfo信息。
public ServiceInfo processServiceInfo(ServiceInfo serviceInfo) {.....// 服务实例已变更if (changed) {NAMING_LOGGER.info("current ips:({}) service: {} -> {}", serviceInfo.ipCount(), serviceInfo.getKey(),JacksonUtils.toJson(serviceInfo.getHosts()));// 添加实例变更事件InstancesChangeEvent,订阅者NotifyCenter.publishEvent(new InstancesChangeEvent(serviceInfo.getName(), serviceInfo.getGroupName(),serviceInfo.getClusters(), serviceInfo.getHosts()));// 记录Service本地文件DiskCache.write(serviceInfo, cacheDir);}return serviceInfo;
}
本地缓存目录
本地缓存目录cacheDir是ServiceInfoHolder的一个属性,用于指定本地缓存的根目录和故障转移的根目录。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iNCn2sip-1677029918448)(image-20211027163722859.png)]](https://img-blog.csdnimg.cn/77f6b58a85374da4988a35d3f0c2dbf1.png)
在ServiceInfoHolder的构造方法中,初始化并且生成缓存目录
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RJQq3COb-1677029918449)(image-20211027163940247.png)]](https://img-blog.csdnimg.cn/f487b3e85fb5429699cee58f89b9c615.png)
这个initCacheDir就不用了细看了,就是生成缓存目录的操作,默认路径:${user.home}/nacos/naming/public,也可以自定义,通过System.setProperty(“JM.SNAPSHOT.PATH”)自定义
这里初始化完目录之后,故障转移信息也存储在该目录下。
private void initCacheDir(String namespace, Properties properties) {String jmSnapshotPath = System.getProperty(JM_SNAPSHOT_PATH_PROPERTY);String namingCacheRegistryDir = "";if (properties.getProperty(PropertyKeyConst.NAMING_CACHE_REGISTRY_DIR) != null) {namingCacheRegistryDir = File.separator + properties.getProperty(PropertyKeyConst.NAMING_CACHE_REGISTRY_DIR);}if (!StringUtils.isBlank(jmSnapshotPath)) {cacheDir = jmSnapshotPath + File.separator + FILE_PATH_NACOS + namingCacheRegistryDir+ File.separator + FILE_PATH_NAMING + File.separator + namespace;} else {cacheDir = System.getProperty(USER_HOME_PROPERTY) + File.separator + FILE_PATH_NACOS + namingCacheRegistryDir+ File.separator + FILE_PATH_NAMING + File.separator + namespace;}
}
故障转移
在ServiceInfoHolder的构造方法中,还会初始化一个FailoverReactor类,同样是ServiceInfoHolder的成员变量。FailoverReactor的作用便是用来处理故障转移的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mmQqhDeE-1677029918451)(image-20211027170511242.png)]](https://img-blog.csdnimg.cn/065882385126457183bd7cc72ec2fc77.png)
public ServiceInfoHolder(String namespace, Properties properties) {....// this为ServiceHolder当前对象,这里可以立即为两者相互持有对方的引用this.failoverReactor = new FailoverReactor(this, cacheDir);.....
}
我们来看一下FailoverReactor的构造方法,FailoverReactor的构造方法基本上把它的功能都展示出来了:
1. 持有ServiceInfoHolder的引用
2. 拼接故障目录:${user.home}/nacos/naming/public/failover,其中public也有可能是其他的自定义命名空间
3. 初始化executorService(执行者服务)
4. init方法:通过executorService开启多个定时任务执行
public FailoverReactor(ServiceInfoHolder serviceInfoHolder, String cacheDir) {// 持有ServiceInfoHolder的引用this.serviceInfoHolder = serviceInfoHolder;// 拼接故障目录:${user.home}/nacos/naming/public/failoverthis.failoverDir = cacheDir + FAILOVER_DIR;// 初始化executorServicethis.executorService = new ScheduledThreadPoolExecutor(1, new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);// 守护线程模式运行thread.setDaemon(true);thread.setName("com.alibaba.nacos.naming.failover");return thread;}});// 其他初始化操作,通过executorService开启多个定时任务执行this.init();
}
init方法执行
在这个方法中开启了三个定时任务,这三个任务其实都是FailoverReactor的内部类:
1. 初始化立即执行,执行间隔5秒,执行任务SwitchRefresher
2. 初始化延迟30分钟执行,执行间隔24小时,执行任务DiskFileWriter
3. 初始化立即执行,执行间隔10秒,执行核心操作为DiskFileWriter
public void init() {// 初始化立即执行,执行间隔5秒,执行任务SwitchRefresherexecutorService.scheduleWithFixedDelay(new SwitchRefresher(), 0L, 5000L, TimeUnit.MILLISECONDS);// 初始化延迟30分钟执行,执行间隔24小时,执行任务DiskFileWriterexecutorService.scheduleWithFixedDelay(new DiskFileWriter(), 30, DAY_PERIOD_MINUTES, TimeUnit.MINUTES);// backup file on startup if failover directory is empty.// 如果故障目录为空,启动时立即执行,立即备份文件// 初始化立即执行,执行间隔10秒,执行核心操作为DiskFileWriterexecutorService.schedule(new Runnable() {@Overridepublic void run() {try {File cacheDir = new File(failoverDir);if (!cacheDir.exists() && !cacheDir.mkdirs()) {throw new IllegalStateException("failed to create cache dir: " + failoverDir);}File[] files = cacheDir.listFiles();if (files == null || files.length <= 0) {new DiskFileWriter().run();}} catch (Throwable e) {NAMING_LOGGER.error("[NA] failed to backup file on startup.", e);}}}, 10000L, TimeUnit.MILLISECONDS);
}
这里我们先看DiskFileWriter,这里的逻辑不难,就是获取ServiceInfo中缓存的ServiceInfo,判断是否满足写入磁盘,如果条件满足,就将其写入拼接的故障目录,因为后两个定时任务执行的都是DiskFileWriter,但是第三个定时任务是有前置判断的,只要文件不存在就会立即执行把文件写入到本地磁盘中。
class DiskFileWriter extends TimerTask {@Overridepublic void run() {Map<String, ServiceInfo> map = serviceInfoHolder.getServiceInfoMap();for (Map.Entry<String, ServiceInfo> entry : map.entrySet()) {ServiceInfo serviceInfo = entry.getValue();if (StringUtils.equals(serviceInfo.getKey(), UtilAndComs.ALL_IPS) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ENV_LIST_KEY) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ENV_CONFIGS) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.VIP_CLIENT_FILE) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ALL_HOSTS)) {continue;}// 将缓存写入磁盘DiskCache.write(serviceInfo, failoverDir);}}
}
接下来,我们再来看第一个定时任务SwitchRefresher的核心实现,具体逻辑如下:
1. 如果故障转移文件不存在,则直接返回(文件开关)
2. 比较文件修改时间,如果已经修改,则获取故障转移文件中的内容。
3. 故障转移文件中存储了0和1标识。0表示关闭,1表示开启。
4. 当为开启状态时,执行线程FailoverFileReader。
class SwitchRefresher implements Runnable {long lastModifiedMillis = 0L;@Overridepublic void run() {try {File switchFile = new File(failoverDir + UtilAndComs.FAILOVER_SWITCH);// 文件不存在则退出if (!switchFile.exists()) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());NAMING_LOGGER.debug("failover switch is not found, {}", switchFile.getName());return;}long modified = switchFile.lastModified();if (lastModifiedMillis < modified) {lastModifiedMillis = modified;// 获取故障转移文件内容String failover = ConcurrentDiskUtil.getFileContent(failoverDir + UtilAndComs.FAILOVER_SWITCH,Charset.defaultCharset().toString());if (!StringUtils.isEmpty(failover)) {String[] lines = failover.split(DiskCache.getLineSeparator());for (String line : lines) {String line1 = line.trim();// 1 表示开启故障转移模式if (IS_FAILOVER_MODE.equals(line1)) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.TRUE.toString());NAMING_LOGGER.info("failover-mode is on");new FailoverFileReader().run();// 0 表示关闭故障转移模式} else if (NO_FAILOVER_MODE.equals(line1)) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());NAMING_LOGGER.info("failover-mode is off");}}} else {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());}}} catch (Throwable e) {NAMING_LOGGER.error("[NA] failed to read failover switch.", e);}}
}
FailoverFileReader
顾名思义,故障转移文件读取,基本操作就是读取failover目录存储的备份服务信息文件内容,然后转换成ServiceInfo,并且将所有的ServiceInfo储存在FailoverReactor的ServiceMap属性中。
流程如下:
1. 读取failover目录下的所有文件,进行遍历处理
2. 如果文件不存在跳过
3. 如果文件是故障转移开关标志文件跳过
4. 读取文件中的备份内容,转换为ServiceInfo对象
5. 将ServiceInfo对象放入到domMap中
6. 最后判断domMap不为空,赋值给serviceMap
class FailoverFileReader implements Runnable {@Overridepublic void run() {Map<String, ServiceInfo> domMap = new HashMap<String, ServiceInfo>(16);BufferedReader reader = null;try {File cacheDir = new File(failoverDir);if (!cacheDir.exists() && !cacheDir.mkdirs()) {throw new IllegalStateException("failed to create cache dir: " + failoverDir);}File[] files = cacheDir.listFiles();if (files == null) {return;}for (File file : files) {if (!file.isFile()) {continue;}// 如果是故障转移标志文件,则跳过if (file.getName().equals(UtilAndComs.FAILOVER_SWITCH)) {continue;}ServiceInfo dom = new ServiceInfo(file.getName());try {String dataString = ConcurrentDiskUtil.getFileContent(file, Charset.defaultCharset().toString());reader = new BufferedReader(new StringReader(dataString));String json;if ((json = reader.readLine()) != null) {try {dom = JacksonUtils.toObj(json, ServiceInfo.class);} catch (Exception e) {NAMING_LOGGER.error("[NA] error while parsing cached dom : {}", json, e);}}} catch (Exception e) {NAMING_LOGGER.error("[NA] failed to read cache for dom: {}", file.getName(), e);} finally {try {if (reader != null) {reader.close();}} catch (Exception e) {//ignore}}if (!CollectionUtils.isEmpty(dom.getHosts())) {domMap.put(dom.getKey(), dom);}}} catch (Exception e) {NAMING_LOGGER.error("[NA] failed to read cache file", e);}// 读入缓存if (domMap.size() > 0) {serviceMap = domMap;}}
}
但是这里还有一个问题就是serviceMap是哪里用到的,这个其实是我们之前读取实例时候用到的getServiceInfo方法
其实这里就是一旦开启故障转移就会先调用failoverReactor.getService方法,此方法便是从serviceMap中获取ServiceInfo
public ServiceInfo getService(String key) {ServiceInfo serviceInfo = serviceMap.get(key);if (serviceInfo == null) {serviceInfo = new ServiceInfo();serviceInfo.setName(key);}return serviceInfo;
}
调用serviceMap方法getServiceInfo方法就在ServiceInfoHolder中
// ServiceInfoHolder
public ServiceInfo getServiceInfo(final String serviceName, final String groupName, final String clusters) {NAMING_LOGGER.debug("failover-mode: {}", failoverReactor.isFailoverSwitch());String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);String key = ServiceInfo.getKey(groupedServiceName, clusters);if (failoverReactor.isFailoverSwitch()) {return failoverReactor.getService(key);}return serviceInfoMap.get(key);
}
相关文章:
Spring Cloud Nacos源码讲解(九)- Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移 在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。 本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当…...

MySQL知识点小结
事务 进行数据库提交操作时使用事务就是为了保证四大特性,原子性,一致性,隔离性,持久性Durability. 持久性:事务一旦提交,对数据库的改变是永久的. 事务的日志用于保存对数据的更新操作. 这个操作T1事务操作的会发生丢失,因为最后是T2提交的修改,而且T2先进行一次查询,按照A…...
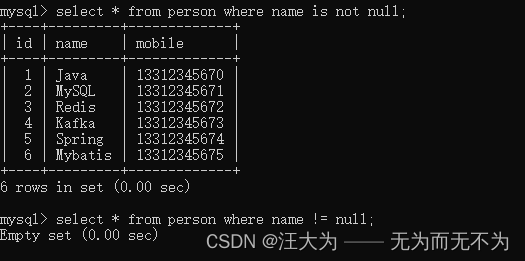
MySQL关于NULL值,常见的几个坑
数据库版本MySQL8。 1.count 函数 觉得 NULL值 不算数 ,所以开发中要避免count的时候丢失数据。 如图所示,以下有7条记录,但是count(name)却只有6条。 为什么丢失数据?因为MySQL的count函数觉得 Null值不算数,就是说…...

OllyDbgqaqazazzAcxsaZ
本文通过吾爱破解论坛上提供的OllyDbg版本为例,讲解该软件的使用方法 F2对鼠标所处的位置打下断点,一般表现为鼠标所属地址位置背景变红F3加载一个可执行程序,进行调试分析,表现为弹出打开文件框F4执行程序到光标处F5缩小还原当前…...

Elasticsearch7.8.0版本进阶——自定义分析器
目录一、自定义分析器的概述二、自定义的分析器的测试示例一、自定义分析器的概述 Elasticsearch 带有一些现成的分析器,然而在分析器上 Elasticsearch 真正的强大之 处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单 …...

spring事务-创建代理对象
用来开启事务的注解EnableTransactionManagement上通过Import导入了TransactionManagementConfigurationSelector组件,TransactionManagementConfigurationSelector类的父类AdviceModeImportSelector实现了ImportSelector接口,因此会调用public final St…...

Linux 配置NFS与autofs自动挂载
目录 配置NFS服务器 安装nfs软件包 配置共享目录 防火墙放行相关服务 配置NFS客户端 autofs自动挂载 配置autofs 配置NFS服务器 nfs主配置文件参数(/etc/exports) 共享目录 允许地址1访问(选项1,选项2) 循序地…...
【编程入门】应用市场(Python版)
背景 前面已输出多个系列: 《十余种编程语言做个计算器》 《十余种编程语言写2048小游戏》 《17种编程语言10种排序算法》 《十余种编程语言写博客系统》 《十余种编程语言写云笔记》 《N种编程语言做个记事本》 目标 为编程初学者打造入门学习项目,使…...

异常信息记录入库
方案介绍 将异常信息放在日志里面,如果磁盘定期清理,会导致很久之前的日志丢失,因此考虑将日志中的异常信息存在表里,方便后期查看定位问题。 由于项目是基于SpringBoot构架的,所以采用AdviceControllerExceptionHand…...

Spring Batch 高级篇-分区步骤
目录 引言 概念 分区器 分区处理器 案例 转视频版 引言 接着上篇:Spring Batch 高级篇-并行步骤了解Spring Batch并行步骤后,接下来一起学习一下Spring Batch 高级功能-分区步骤 概念 分区:有划分,区分意思,在…...
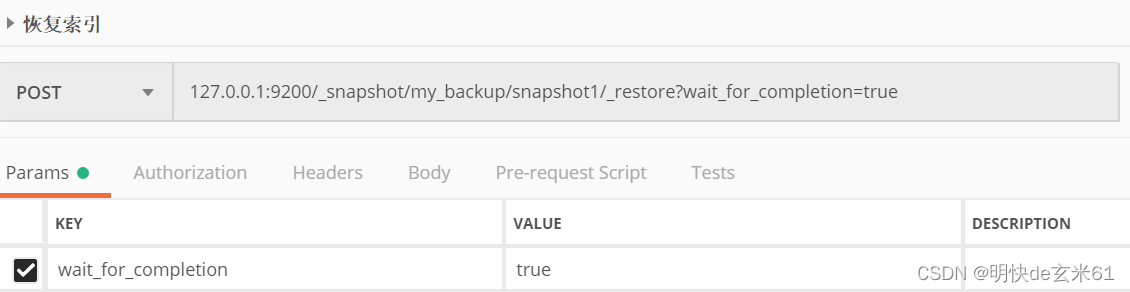
ES数据迁移_snapshot(不需要安装其他软件)
参考文章: 三种常用的 Elasticsearch 数据迁移方案ES基于Snapshot(快照)的数据备份和还原CDH修改ElasticSearch配置文件不生效问题 目录1、更改老ES和新ES的config/elasticsearch.yml2、重启老ES,在老ES执行Postman中创建备份目录…...

【Vue3 第二十章】异步组件 代码分包 Suspense内置组件 顶层 await
异步组件 & 代码分包 & Suspense内置组件 & 顶层 await 一、概述 在大型项目中,我们可能需要拆分应用为更小的块,以减少主包的体积,并仅在需要时再从服务器加载相关组件。这时候就可以使用异步组件。 Vue 提供了 defineAsyncC…...

「媒体邀约」四川有哪些媒体,成都活动媒体邀约
传媒如春雨,润物细无声,四川省位于中国西南地区,是中国的一个省份。成都市是四川省的省会,成都市是中国西部地区的政治、经济、文化和交通中心,也是著名的旅游胜地。每年的文化交流活动很多,也有许多的大企…...

@Autowired和@Resource的区别
文章目录1. Autowired和Resource的区别2. 一个接口多个实现类的处理2.1 注入时候报错情况2.2 使用Primary注解处理2.3 使用Qualifer注解处理2.4 根据业务情况动态的决定注入哪个serviceImpl1. Autowired和Resource的区别 Aurowired是根据type来匹配;Resource可以根…...

Linux系列:glibc程序设计规范与内存管理思想
文章目录前言命名规范说明版式风格内存管理与智能指针关于UML前言 这是一个基于lightdm、glibc、gobject、gtk、qt、glibc、x11、wayland等多个高质量开源项目总结而来的规范。 glibc处于内核态与用户态的边界,承上启下,对用户的体验影响非常大。其在系…...

Redis 集群
文章目录一、集群简介二、Redis集群结构设计🍉2.1 数据存储设计🍉2.2 内部通信设计三、cluster 集群结构搭建🍓3-1 cluster配置 .conf🍓3-2 cluster 节点操作命令🍓3-3 redis-trib 命令🍓3-4 搭建 3主3从结…...
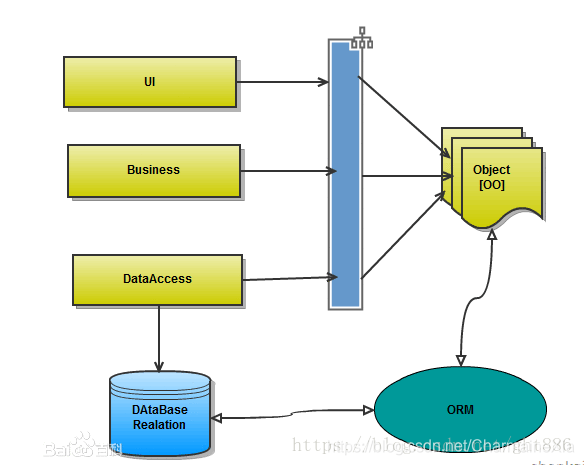
EF 框架的简介、发展历史;ORM框架概念
一、EF 框架简介EF 全称是 EntityFramework 。Entity Framework是ADO.NET 中的一套支持开发面向数据的软件应用程序的技术,是微软的一个ORM框架。ORM框架(Object Relational Mapping) 翻译过来就是对象关系映射。如果不用ORM框架,我们一般这样…...
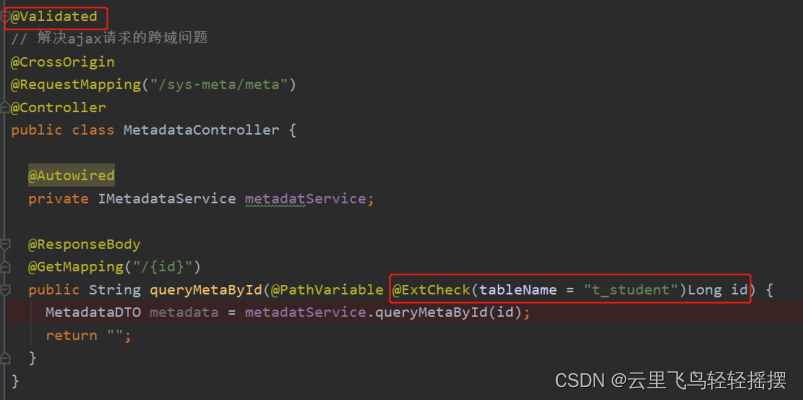
注解原理剖析与实战
一、注解及其原理 1.注解的基本概念 注解,可以看作是对 一个类/方法的一个扩展的模版,每个类/方法按照注解类中的规则,来为类/方法注解不同的参数,在用到的地方可以得到不同的类/方法中注解的各种参数与值。 从JDK5开始ÿ…...

《STL源码剖析》理解之将类成员函数和for_each等算法结合
类成员函数可以通过函数适配器(function adapters)包装成一个仿函数(重载了operator()的类),将其搭配于STL算法一起使用。#include <algorithm> #include <functional> #include <vector> #include <iostream>using namespace std;class In…...

如何构建应用标准化体系
标准化的过程实际上就是对运维对象的识别和建模过程。形成统一的对象模型后,各方在统一的认识下展开有效协作,然后针对不同的运维对象,再抽取出它们所对应的运维场景,接下来才是运维场景的自动化实现。 在标准化的过程中…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...