Redis 集群
文章目录
- 一、集群简介
- 二、Redis集群结构设计
- 🍉2.1 数据存储设计
- 🍉2.2 内部通信设计
- 三、cluster 集群结构搭建
- 🍓3-1 cluster配置 .conf
- 🍓3-2 cluster 节点操作命令
- 🍓3-3 redis-trib 命令
- 🍓3-4 搭建 3主3从结构
- 🍌①开启6个redis服务器
- 🍌②节点连接
- 🍌③读写数据
- 🍌④从节点下线
- 🍌⑤主节点下线 --> 主从切换
提示:以下是本篇文章正文内容,Redis系列学习将会持续更新
一、集群简介
现状问题:业务发展过程中遇到的峰值瓶颈,如
- redis提供的服务OPS可以达到10万/秒,当前业务OPS已经达到10万/秒
- 内存单机容量达到256G,当前业务需求内存容量1T
- 使用集群的方式可以快速解决上述问题
什么是集群?
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果。
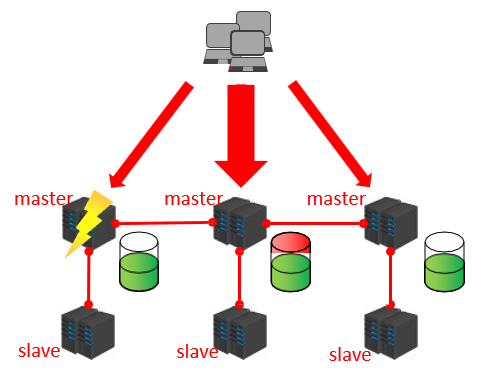
集群作用:
- 分散单台服务器的访问压力,实现负载均衡。
- 分散单台服务器的存储压力,实现可扩展性。
- 降低单台服务器宕机带来的业务灾难。
回到目录…
二、Redis集群结构设计
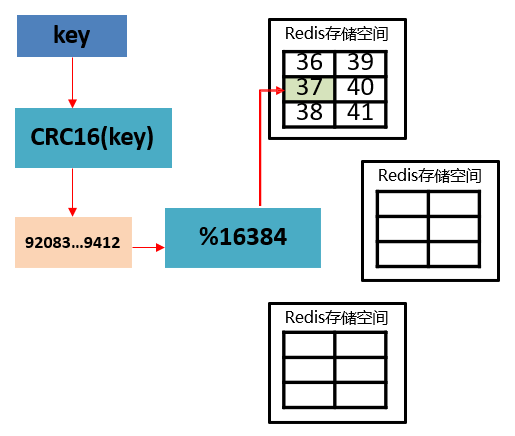
🍉2.1 数据存储设计
- 通过算法设计,计算出 key 应该保存的位置。
- 将所有的存储空间计划切割成16384份,每台主机保存一部分;
每份代表的是一个存储空间,不是一个 key 的保存空间。 - 将 key 按照计算出的结果放到对应的存储空间。
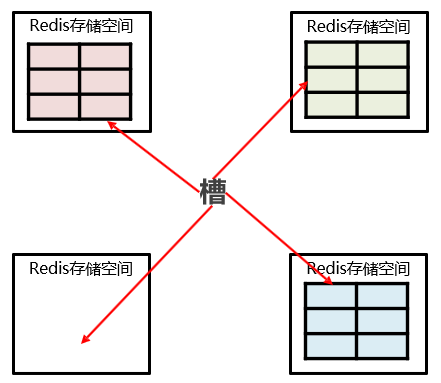
- 增强扩展性。当加入新的master节点时,原本的主节点会各自分出一部分"槽",分给新节点。
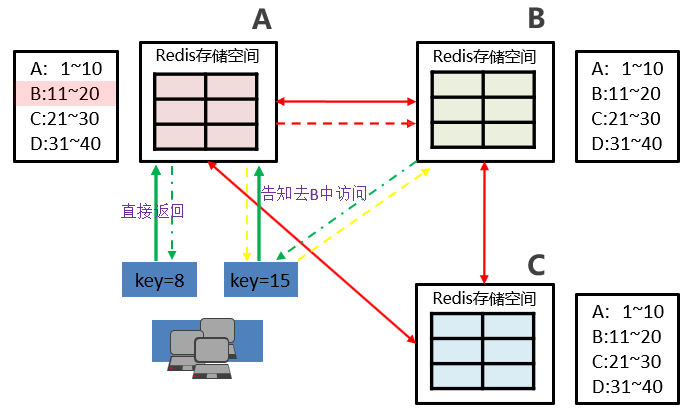
🍉2.2 内部通信设计
- 各个数据库相互通信,保存各个库中槽的编号数据。
- 一次命中,直接返回。
- 一次未命中,告知具体位置。让客户端直接去找编号节点。
回到目录…
三、cluster 集群结构搭建
-
集群采用了多主多从,按照一定的规则进行分片,将数据分别存储,一定程度上解决了哨兵模式下单机存储有限的问题。
-
集群模式一般是3主3从,且需要 ruby 辅助搭建。
🍓3-1 cluster配置 .conf
● 添加节点
cluster-enabled yes|no
● cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file <filename>
● 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout <milliseconds>
● 每个master连接的slave最小数量
cluster-migration-barrier <count>
回到目录…
🍓3-2 cluster 节点操作命令
● 查看集群节点信息
# 在客户端操作,查看节点情况
cluster nodes

● 进入一个从节点 redis,切换其主节点
cluster replicate <master-id>
● 发现一个新节点,新增主节点
cluster meet ip:port
● 忽略一个没有solt的节点
cluster forget <id>
● 手动故障转移
cluster failover
回到目录…
🍓3-3 redis-trib 命令
● 添加节点
redis-trib.rb add-node
● 删除节点
redis-trib.rb del-node
● 重新分片
redis-trib.rb reshard
回到目录…
🍓3-4 搭建 3主3从结构
redis集群需要提前安装脚本和环境,参考文章:Linux 离线安装Ruby和RubyGems环境
🍌①开启6个redis服务器
6个服务器的配置文件(除端口外)都一致,设置了相同的cluster配置。
port 6381
daemonize no
dir /root/redis-4.0.0/data
dbfilename dump-6381.rdb
rdbcompression yes
rdbchecksum yes
save 10 2
appendonly yes
appendfsync always
appendfilename appendonly-6381.aofcluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
全部开启:
redis-server /root/redis-4.0.0/conf/redis-6381.conf
使用 ps -ef | grep redis 查进程:

服务器日志:此时6个基本一致
[root@VM-4-12-centos ~]# redis-server /root/redis-4.0.0/conf/redis-6381.conf
2346399:C 25 Feb 12:09:58.554 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2346399:C 25 Feb 12:09:58.554 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=2346399, just started
2346399:C 25 Feb 12:09:58.554 # Configuration loaded
2346399:M 25 Feb 12:09:58.554 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2346399:M 25 Feb 12:09:58.555 * Node configuration loaded, I'm 0ed68dc297e87f62154aa236e46cb287c22c735a_._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in cluster mode|`-._`-...-` __...-.``-._|'` _.-'| Port: 6381| `-._ `._ / _.-' | PID: 2346399`-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 2346399:M 25 Feb 12:09:58.556 # Server initialized
2346399:M 25 Feb 12:09:58.556 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2346399:M 25 Feb 12:09:58.556 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
2346399:M 25 Feb 12:09:58.556 * DB loaded from disk: 0.000 seconds
2346399:M 25 Feb 12:09:58.556 * Ready to accept connections
回到目录…
🍌②节点连接
# 进入redis的src下
cd /root/redis-4.0.0/src# 执行 redis-trib.rb 程序,该程序需要依赖 ruby 和 rubygem
# replicas 1 表示为集群中的每个主节点创建 1 个从节点
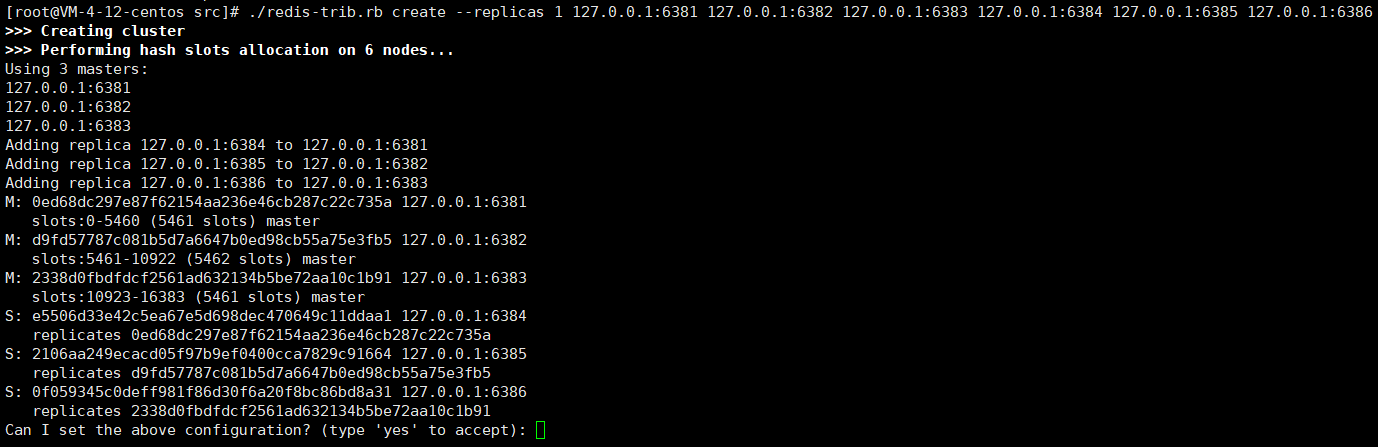
./redis-trib.rb create --replicas 1 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386
例如:构建3主6从,一拖二的结构
./redis-trib.rb create --replicas 2 id:p主 id:p主 id:p主 id:p从 id:p从 id:p从 id:p从 id:p从 id:p从
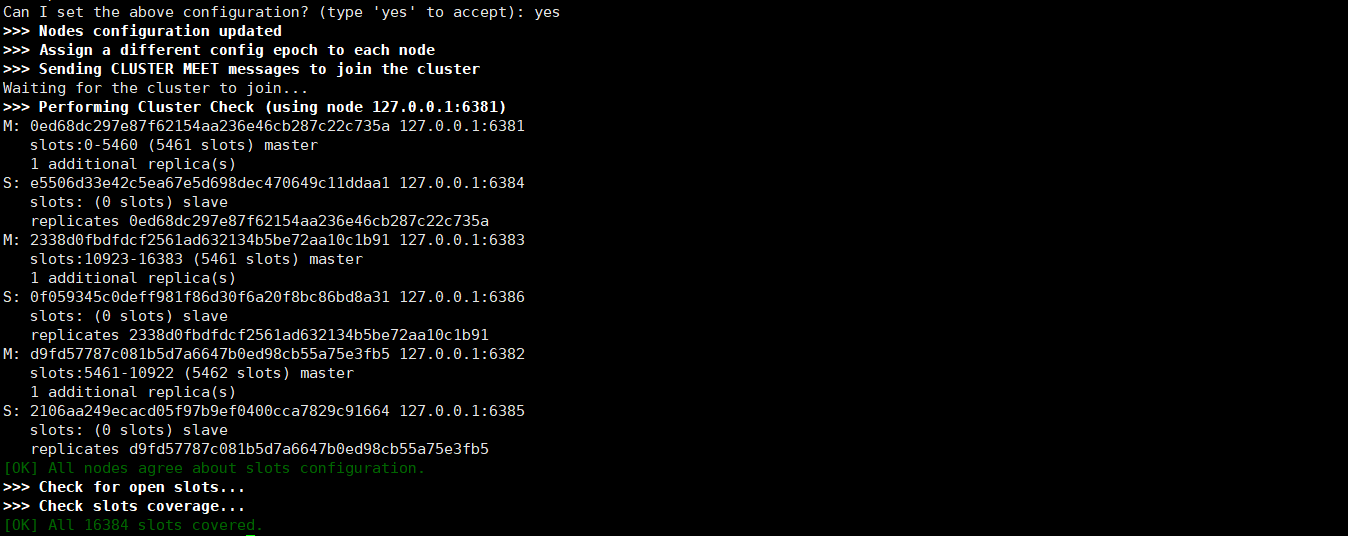
连接成功!
master-6381 日志: 内容和 master-6382、master-6383 差不多
.......
2346399:M 25 Feb 12:09:58.556 * Ready to accept connections
2346399:M 25 Feb 14:22:02.884 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
2346399:M 25 Feb 14:22:02.890 # IP address for this node updated to 127.0.0.1
2346399:M 25 Feb 14:22:06.906 * Slave 127.0.0.1:6384 asks for synchronization
2346399:M 25 Feb 14:22:06.906 * Unable to partial resync with slave 127.0.0.1:6384 for lack of backlog (Slave request was: 1).
2346399:M 25 Feb 14:22:06.906 # Warning: slave 127.0.0.1:6384 tried to PSYNC with an offset that is greater than the master replication offset.
2346399:M 25 Feb 14:22:06.906 * Starting BGSAVE for SYNC with target: disk
2346399:M 25 Feb 14:22:06.907 * Background saving started by pid 2378127
2378127:C 25 Feb 14:22:06.915 * DB saved on disk
2378127:C 25 Feb 14:22:06.916 * RDB: 6 MB of memory used by copy-on-write
2346399:M 25 Feb 14:22:07.002 * Background saving terminated with success
2346399:M 25 Feb 14:22:07.002 * Synchronization with slave 127.0.0.1:6384 succeeded
2346399:M 25 Feb 14:22:07.803 # Cluster state changed: ok
slave-6384 日志: 内容和 slave-6385、slave-6386 差不多
...........
2346637:M 25 Feb 12:10:42.962 * Ready to accept connections
2346637:M 25 Feb 14:22:02.885 # configEpoch set to 4 via CLUSTER SET-CONFIG-EPOCH
2346637:M 25 Feb 14:22:02.992 # IP address for this node updated to 127.0.0.1
2346637:S 25 Feb 14:22:06.897 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2346637:S 25 Feb 14:22:06.897 # Cluster state changed: ok
2346637:S 25 Feb 14:22:06.905 * Connecting to MASTER 127.0.0.1:6381
2346637:S 25 Feb 14:22:06.905 * MASTER <-> SLAVE sync started
2346637:S 25 Feb 14:22:06.905 * Non blocking connect for SYNC fired the event.
2346637:S 25 Feb 14:22:06.905 * Master replied to PING, replication can continue...
2346637:S 25 Feb 14:22:06.905 * Trying a partial resynchronization (request 4037f6d4ae3c949826df258a306140250b64ae2f:1).
2346637:S 25 Feb 14:22:06.907 * Full resync from master: cde4a8dc111330cc81ec5c0d1321b2959741f441:0
2346637:S 25 Feb 14:22:06.907 * Discarding previously cached master state.
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: receiving 175 bytes from master
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Flushing old data
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Loading DB in memory
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Finished with success
回到目录…
🍌③读写数据
常规的连接方式,会出现以下错误:
[root@VM-4-12-centos ~]# redis-cli -p 6381
127.0.0.1:6381> set name zhangsan
(error) MOVED 5798 127.0.0.1:6382
所以应该 redis-cli -c 指令连接。
master客户端添加数据:
[root@VM-4-12-centos ~]# redis-cli -c -p 6381
127.0.0.1:6381> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1:6382
OK
127.0.0.1:6382> set age 21
-> Redirected to slot [741] located at 127.0.0.1:6381
OK
127.0.0.1:6381>
slave客户端获取数据:
[root@VM-4-12-centos ~]# redis-cli -c -p 6384
127.0.0.1:6384> get name
-> Redirected to slot [5798] located at 127.0.0.1:6382
"zhangsan"
127.0.0.1:6382> get age
-> Redirected to slot [741] located at 127.0.0.1:6381
"21"
127.0.0.1:6381>
回到目录…
🍌④从节点下线
slave-6384 下线:

master-6381 日志: 发现它的从节点6384丢失了,并且作了标记
...........
2346399:M 25 Feb 15:22:07.315 # Connection with slave 127.0.0.1:6384 lost.
2346399:M 25 Feb 15:22:12.428 * Marking node e5506d33e42c5ea67e5d698dec470649c11ddaa1 as failing (quorum reached).
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,并记下了这个消息
...........
2346482:M 25 Feb 15:22:12.429 * FAIL message received from 0ed68dc297e87f62154aa236e46cb287c22c735a about e5506d33e42c5ea67e5d698dec470649c11ddaa1
slave-6384 重新上线:

master-6381 日志: 重新作了连接
...........
2346399:M 25 Feb 15:32:33.828 * Clear FAIL state for node e5506d33e42c5ea67e5d698dec470649c11ddaa1: slave is reachable again.
2346399:M 25 Feb 15:32:34.759 * Slave 127.0.0.1:6384 asks for synchronization
2346399:M 25 Feb 15:32:34.759 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for 'bccefbb3fa28bfcb388a9f72af318c28169f4bc1', my replication IDs are 'cde4a8dc111330cc81ec5c0d1321b2959741f441' and '0000000000000000000000000000000000000000')
2346399:M 25 Feb 15:32:34.759 * Starting BGSAVE for SYNC with target: disk
2346399:M 25 Feb 15:32:34.764 * Background saving started by pid 2395173
2395173:C 25 Feb 15:32:34.771 * DB saved on disk
2395173:C 25 Feb 15:32:34.771 * RDB: 6 MB of memory used by copy-on-write
2346399:M 25 Feb 15:32:34.830 * Background saving terminated with success
2346399:M 25 Feb 15:32:34.830 * Synchronization with slave 127.0.0.1:6384 succeeded
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,清除了刚刚的信息
...........
2346482:M 25 Feb 15:32:33.828 * Clear FAIL state for node e5506d33e42c5ea67e5d698dec470649c11ddaa1: slave is reachable again.
回到目录…
🍌⑤主节点下线 --> 主从切换
master-6381 下线:

master-6382、master-6383 日志: 发现主节点6384丢失了,并且作了标记
.......
2346482:M 25 Feb 15:34:59.063 * Marking node 0ed68dc297e87f62154aa236e46cb287c22c735a as failing (quorum reached).
2346482:M 25 Feb 15:34:59.063 # Cluster state changed: fail
2346482:M 25 Feb 15:34:59.939 # Failover auth granted to e5506d33e42c5ea67e5d698dec470649c11ddaa1 for epoch 7
2346482:M 25 Feb 15:34:59.979 # Cluster state changed: ok
slave-6385、slave-6386 日志: 也发现了,并记下了这个消息
.......
2346782:S 25 Feb 15:34:59.063 * FAIL message received from 2338d0fbdfdcf2561ad632134b5be72aa10c1b91 about 0ed68dc297e87f62154aa236e46cb287c22c735a
2346782:S 25 Feb 15:34:59.063 # Cluster state changed: fail
2346782:S 25 Feb 15:34:59.943 # Cluster state changed: ok
slave-6384 -> master-6384 日志: 发现主节点丢失,请求重连,主从切换。
.......
# 发现主节点丢失了
2395168:S 25 Feb 15:34:53.651 # Connection with master lost.
2395168:S 25 Feb 15:34:53.651 * Caching the disconnected master state.
# 在设置的5000ms超时时间内开始重连
2395168:S 25 Feb 15:34:54.015 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:54.015 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:54.015 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:55.018 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:55.018 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:55.018 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:56.020 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:56.020 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:56.020 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:57.024 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:57.024 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:57.024 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:58.027 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:58.027 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:58.028 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:59.031 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:59.031 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:59.031 # Error condition on socket for SYNC: Connection refused
# 确认丢失消息
2395168:S 25 Feb 15:34:59.064 * FAIL message received from 2338d0fbdfdcf2561ad632134b5be72aa10c1b91 about 0ed68dc297e87f62154aa236e46cb287c22c735a
# 开始由 从服务器 切换成 主服务器
2395168:S 25 Feb 15:34:59.064 # Cluster state changed: fail
2395168:S 25 Feb 15:34:59.131 # Start of election delayed for 796 milliseconds (rank #0, offset 5275).
2395168:S 25 Feb 15:34:59.934 # Starting a failover election for epoch 7.
2395168:S 25 Feb 15:34:59.939 # Failover election won: I'm the new master.
2395168:S 25 Feb 15:34:59.939 # configEpoch set to 7 after successful failover
2395168:M 25 Feb 15:34:59.939 # Setting secondary replication ID to cde4a8dc111330cc81ec5c0d1321b2959741f441, valid up to offset: 5276. New replication ID is f9337124051125fde50c606a79678a01de021ce7
2395168:M 25 Feb 15:34:59.939 * Discarding previously cached master state.
2395168:M 25 Feb 15:34:59.939 # Cluster state changed: ok
回到目录…
slave-6381 重新上线: 此时作为 slave 连接到 master-6384上
[root@VM-4-12-centos ~]# redis-server /root/redis-4.0.0/conf/redis-6381.conf
2402821:C 25 Feb 16:03:46.080 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2402821:C 25 Feb 16:03:46.080 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=2402821, just started
2402821:C 25 Feb 16:03:46.080 # Configuration loaded
2402821:M 25 Feb 16:03:46.081 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2402821:M 25 Feb 16:03:46.082 * Node configuration loaded, I'm 0ed68dc297e87f62154aa236e46cb287c22c735a_._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in cluster mode|`-._`-...-` __...-.``-._|'` _.-'| Port: 6381| `-._ `._ / _.-' | PID: 2402821`-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 2402821:M 25 Feb 16:03:46.083 # Server initialized
2402821:M 25 Feb 16:03:46.083 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2402821:M 25 Feb 16:03:46.083 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
2402821:M 25 Feb 16:03:46.083 * DB loaded from disk: 0.000 seconds
2402821:M 25 Feb 16:03:46.083 * Ready to accept connections
2402821:M 25 Feb 16:03:46.083 # Configuration change detected. Reconfiguring myself as a replica of e5506d33e42c5ea67e5d698dec470649c11ddaa1
2402821:S 25 Feb 16:03:46.083 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2402821:S 25 Feb 16:03:46.084 # Cluster state changed: ok
2402821:S 25 Feb 16:03:47.085 * Connecting to MASTER 127.0.0.1:6384
2402821:S 25 Feb 16:03:47.086 * MASTER <-> SLAVE sync started
2402821:S 25 Feb 16:03:47.086 * Non blocking connect for SYNC fired the event.
2402821:S 25 Feb 16:03:47.086 * Master replied to PING, replication can continue...
2402821:S 25 Feb 16:03:47.086 * Trying a partial resynchronization (request cde4a8dc111330cc81ec5c0d1321b2959741f441:5080).
2402821:S 25 Feb 16:03:47.086 * Successful partial resynchronization with master.
2402821:S 25 Feb 16:03:47.086 # Master replication ID changed to f9337124051125fde50c606a79678a01de021ce7
2402821:S 25 Feb 16:03:47.086 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization.
master-6384 日志: 重新作了连接
......
2395168:M 25 Feb 16:03:46.096 * Clear FAIL state for node 0ed68dc297e87f62154aa236e46cb287c22c735a: master without slots is reachable again.
2395168:M 25 Feb 16:03:47.086 * Slave 127.0.0.1:6381 asks for synchronization
2395168:M 25 Feb 16:03:47.086 * Partial resynchronization request from 127.0.0.1:6381 accepted. Sending 196 bytes of backlog starting from offset 5080.
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,清除了刚刚的信息
......
2346482:M 25 Feb 16:03:46.095 * Clear FAIL state for node 0ed68dc297e87f62154aa236e46cb287c22c735a: master without slots is reachable again.
回到目录…
总结:
提示:这里对文章进行总结:
本文是对Redis集群的学习,了解了Redis集群的数据存储设计、内部通信设计,以及 cluster 集群结构搭建的具体方法。之后的学习内容将持续更新!!!
相关文章:
Redis 集群
文章目录一、集群简介二、Redis集群结构设计🍉2.1 数据存储设计🍉2.2 内部通信设计三、cluster 集群结构搭建🍓3-1 cluster配置 .conf🍓3-2 cluster 节点操作命令🍓3-3 redis-trib 命令🍓3-4 搭建 3主3从结…...
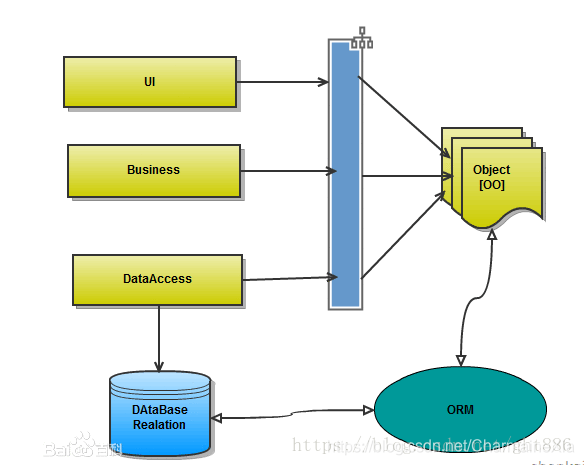
EF 框架的简介、发展历史;ORM框架概念
一、EF 框架简介EF 全称是 EntityFramework 。Entity Framework是ADO.NET 中的一套支持开发面向数据的软件应用程序的技术,是微软的一个ORM框架。ORM框架(Object Relational Mapping) 翻译过来就是对象关系映射。如果不用ORM框架,我们一般这样…...
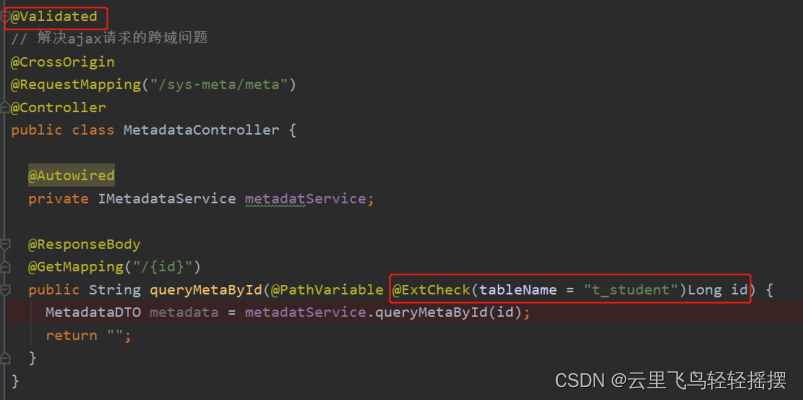
注解原理剖析与实战
一、注解及其原理 1.注解的基本概念 注解,可以看作是对 一个类/方法的一个扩展的模版,每个类/方法按照注解类中的规则,来为类/方法注解不同的参数,在用到的地方可以得到不同的类/方法中注解的各种参数与值。 从JDK5开始ÿ…...

《STL源码剖析》理解之将类成员函数和for_each等算法结合
类成员函数可以通过函数适配器(function adapters)包装成一个仿函数(重载了operator()的类),将其搭配于STL算法一起使用。#include <algorithm> #include <functional> #include <vector> #include <iostream>using namespace std;class In…...

如何构建应用标准化体系
标准化的过程实际上就是对运维对象的识别和建模过程。形成统一的对象模型后,各方在统一的认识下展开有效协作,然后针对不同的运维对象,再抽取出它们所对应的运维场景,接下来才是运维场景的自动化实现。 在标准化的过程中…...

【RabbitMQ笔记03】消息队列RabbitMQ七种模式之WorkQueues工作队列模式
这篇文章,主要介绍消息队列RabbitMQ七种模式之WorkQueues工作队列模式。 目录 一、工作队列模式 1.1、什么是Work Queues模式 1.2、工作队列模式的使用 (1)引入依赖 (2)编写生产者 (3)编写…...

认识html
1.html的特点先看一段简单的html代码<html><head></head><body>hello world</body> </html>如果将这段带有这段代码的.html文件拉进浏览器中,就会出现一个页面,内容就是hello world,如下图:由上面的代码,我们可以了解到一些html代码的特点…...

在外包公司熬了 3 年终于进了字节,竭尽全力....
其实两年前校招的时候就往字节投了一次简历,结果很明显凉了,随后这个理想就被暂时放下了,但是这个种子一直埋在心里这两年除了工作以外,也会坚持写博客,也因此结识了很多优秀的小伙伴,从他们身上学到了特别…...

绝对让你明明白白,脚把脚带你盯着 I2C 时序图将 I2C 程序给扣出来(基于STM32的模拟I2C)
目录前言一、关于STM32 I/O端口位的基本结构讲解二、模拟I2C编写前的需知道的知识1、I2C简介2、根据时序编写模拟I2C程序重要的两点Ⅰ、主机发送数据给从机时的时序控制Ⅱ、主机接收来自从机的数据时的时序控制Ⅲ、完整的I2C时序图(按写程序的思想分割时序ÿ…...

2023年全国最新工会考试精选真题及答案5
百分百题库提供工会考试试题、工会考试预测题、工会考试真题、工会证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题 1.企业工会委员会实行(),重要问题须经(&#x…...

一文2000字手把手教你自动化测试Selenium+pytest+数据驱动
主流自动化框架 selenium :web端自动化框架 ,(行业里面最核心的框架) appium :手机app端框架 requests :接口测试 selenium 工具类封装 selenium提供了很多方法供我们去完成网页元素的操作, …...
windows安装Ubuntu子系统以及图形化界面记录
文章目录1. windows环境设置2. 开始安装3. ubuntu使用3.1 启动和退出 Linux 子系统3.2 安装位置3.3 更换源4. 安装图形化界面4.1 安装VcXsrv4.2 安装桌面环境(1)方法1:VcXsrv Gnome(2)方法2:VcXsrv Xfce4…...

通俗易懂,十分钟读懂DES,详解DES加密算法原理,DES攻击手段以及3DES原理。Python DES实现源码
文章目录1、什么是DES2、DES的基本概念3、DES的加密流程4、DES算法步骤详解4.1 初始置换(Initial Permutation,IP置换)4.2 加密轮次4.3 F轮函数4.3.1 拓展R到48位4.3.2 子密钥K的生成4.3.3 当前轮次的子密钥与拓展的48位R进行异或运算4.3.4 S盒替换(Subs…...

为多态基类声明virtual析构函数
我们知道,有时会让一个基类指针指向用 new 运算符动态生成的派生类对象(类似接口的作用);同时,用 new 运算符动态生成的对象都是通过 delete 指向它的指针来释放的。如果一个基类指针指向用 new 运算符动态生成的派生类…...

啊哈 算法读书笔记 第 2 章 栈、队列、链表
第 2 章 栈、队列、链表 目录 第 2 章 栈、队列、链表 队列: 解密回文——栈 纸牌游戏: 链表 模拟链表 队列: 首先将第 1 个数删除,紧接着将第 2 个数放到这串数的末尾,再将第 3 个数删除并将第 4 个数放到这串…...
Git ---- IDEA 集成 Git
Git ---- IDEA 集成 Git1. 配置 Git 忽略文件2. 定位 Git 程序3. 初始化本地库4. 添加到暂存区5. 提交到本地库6. 切换版本7. 创建分支8. 切换分支9. 合并分支10. 解决冲突1. 配置 Git 忽略文件 1. Eclipse 特定文件 2. IDEA 特定文件 3. Maven 工程的 target 目录 问题1…...

【LeetCode 704】【Go】二分查找
二分查找题解 一、碎碎念 从本周开始,重新更新刷题记录了哈。 基于费曼学习法的原理,最好的输入是输出,所以与大家分享。 鉴于目前这个糟糕的市场环境,还是要练好自己的基本技术,万一那天就被迫 N 1了,你…...

【代码随想录训练营】【Day23】第六章|二叉树|669. 修剪二叉搜索树 |108.将有序数组转换为二叉搜索树|538.把二叉搜索树转换为累加树
修剪二叉搜索树 题目详细:LeetCode.669 做这道题之前建议先看视频讲解,没有想象中那么复杂:代码随想录—修剪二叉搜索树 由题可知,需要删除节点值不在区间内的节点,所以可以得到三种情况: 情况一&#…...
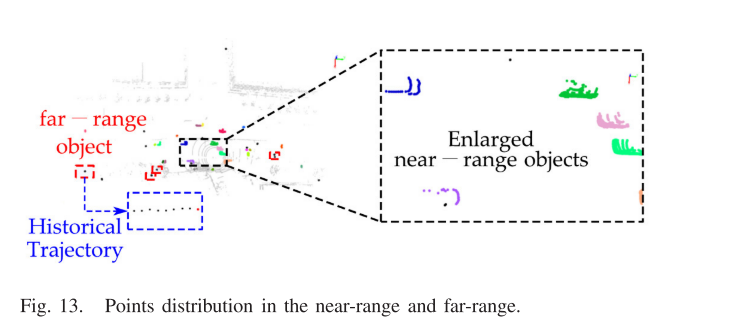
CV——day78 读论文:通过静态背景构建扩展低通道路边雷达的探测距离(目标是规避风险)
Extending the Detection Range for Low-Channel Roadside LiDAR by Static Background Construction 通过静态背景构建扩展低通道路边雷达的探测距离I. INTRODUCTIONII. RELATED WORKA. LiDAR-Based 3-D Vehicle and Road User DetectionB. LiDAR Data Background FilteringC.…...
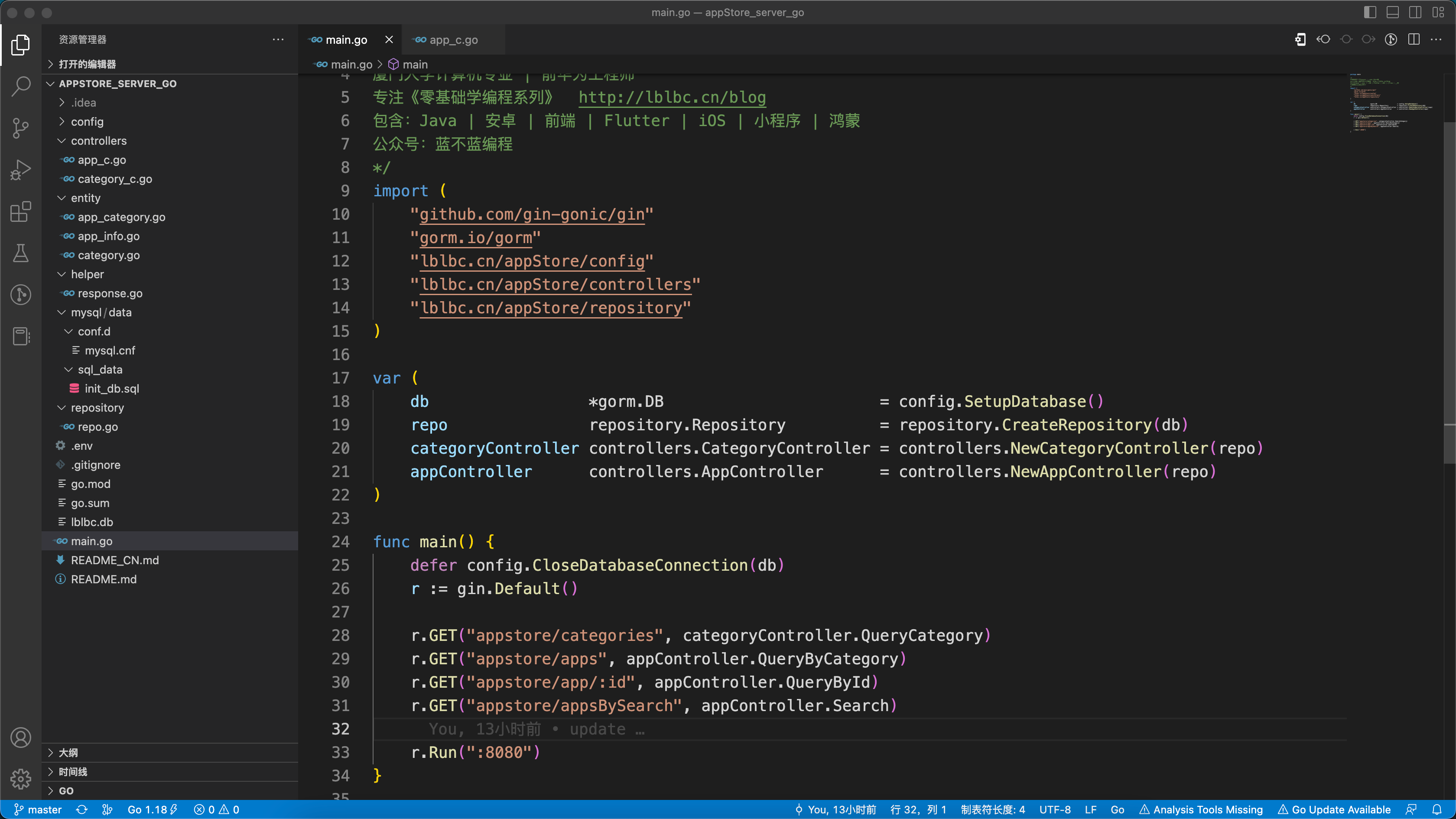
【编程入门】应用市场(go语言版)
背景 前面已输出多个系列: 《十余种编程语言做个计算器》 《十余种编程语言写2048小游戏》 《17种编程语言10种排序算法》 《十余种编程语言写博客系统》 《十余种编程语言写云笔记》 《N种编程语言做个记事本》 目标 为编程初学者打造入门学习项目,使…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...