CUDA学习笔记(九)Dynamic Parallelism
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。
Dynamic Parallelism
到目前为止,所有kernel都是在host端调用,CUDA Dynamic Parallelism允许GPU kernel在device端创建调用。Dynamic Parallelism使递归更容易实现和理解,由于启动的配置可以由device上的thread在运行时决定,这也减少了host和device之间传递数据和执行控制。我们接下来会分析理解使用Dynamic Parallelism。
Nested Execution
在host调用kernel和在device调用kernel的语法完全一样。kernel的执行则被分为两种类型:parent和child。一个parent thread,parent block或者parent grid可以启动一个新的grid,即child grid。child grid必须在parent 之前完成,也就是说,parent必须等待所有child完成。
当parent启动一个child grid时,在parent显式调用synchronize之前,child不保证会开始执行。parent和child共享同一个global和constant memory,但是有不同的shared 和local memory。不难理解的是,只有两个时刻可以保证child和parent见到的global memory完全一致:child刚开始和child完成。所有parent对global memory的操作对child都是可见的,而child对global memory的操作只有在parent进行synchronize操作后对parent才是可见的。

Nested Hello World on the GPU
为了更清晰的讲解Dynamic Parallelism,我们改编最开始写的hello world程序。下图显示了使用Dynamic Parallelism的执行过程,host调用parent grid(每个block八个thread)。thread 0调用一个child grid(每个block四个thread),thread 0 的第一个thread又调用一个child grid(每个block两个thread),依次类推。
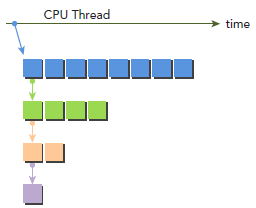
下面是具体的代码,每个thread会先打印出Hello World;然后,每个thread再检查自己是否该停止。
__global__ void nestedHelloWorld(int const iSize,int iDepth) {int tid = threadIdx.x;printf("Recursion=%d: Hello World from thread %d block %d\n",iDepth,tid,blockIdx.x);// condition to stop recursive executionif (iSize == 1) return;// reduce block size to halfint nthreads = iSize>>1;// thread 0 launches child grid recursivelyif(tid == 0 && nthreads > 0) {nestedHelloWorld<<<1, nthreads>>>(nthreads,++iDepth);printf("-------> nested execution depth: %d\n",iDepth);}
}
编译:
$ nvcc -arch=sm_35 -rdc=true nestedHelloWorld.cu -o nestedHelloWorld -lcudadevrt
-lcudadevrt是用来连接runtime库的,跟gcc连接库一样。-rdc=true使device代码可重入,这是DynamicParallelism所必须的,至于原因则将是一个比较大的话题,以后探讨。
代码的输出为:
./nestedHelloWorld Execution Configuration: grid 1 block 8 Recursion=0: Hello World from thread 0 block 0 Recursion=0: Hello World from thread 1 block 0 Recursion=0: Hello World from thread 2 block 0 Recursion=0: Hello World from thread 3 block 0 Recursion=0: Hello World from thread 4 block 0 Recursion=0: Hello World from thread 5 block 0 Recursion=0: Hello World from thread 6 block 0 Recursion=0: Hello World from thread 7 block 0 -------> nested execution depth: 1 Recursion=1: Hello World from thread 0 block 0 Recursion=1: Hello World from thread 1 block 0 Recursion=1: Hello World from thread 2 block 0 Recursion=1: Hello World from thread 3 block 0 -------> nested execution depth: 2 Recursion=2: Hello World from thread 0 block 0 Recursion=2: Hello World from thread 1 block 0 -------> nested execution depth: 3 Recursion=3: Hello World from thread 0 block 0
这里的01234….输出顺序挺诡异的,太规整了,我们暂且认为CUDA对printf做过修改吧。还有就是,按照CPU递归程序的经验,这里的输出顺序就更怪了,当然,肯定不是编译器错误或者CUDA的bug,大家可以在调用kernel后边加上cudaDeviceSynchronize,就可以看到“正常”的顺序了,原因也就清楚了。
使用nvvp可以查看执行情况,空白说明parent在等待child执行结束:
$nvvp ./nesttedHelloWorld
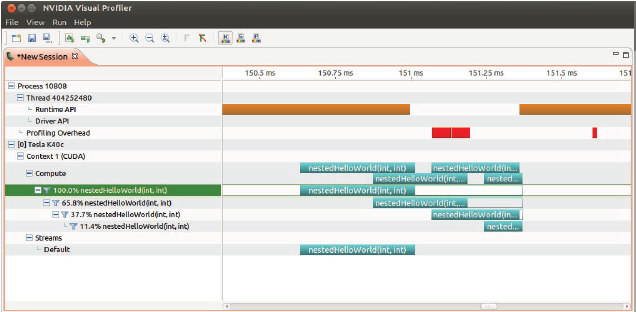
接着,我们尝试使用两个block而不是一个:
$ ./nestedHelloWorld 2
输出是:
./nestedHelloWorld 2Execution Configuration: grid 2 block 8 Recursion=0: Hello World from thread 0 block 1 Recursion=0: Hello World from thread 1 block 1 Recursion=0: Hello World from thread 2 block 1 Recursion=0: Hello World from thread 3 block 1 Recursion=0: Hello World from thread 4 block 1 Recursion=0: Hello World from thread 5 block 1 Recursion=0: Hello World from thread 6 block 1 Recursion=0: Hello World from thread 7 block 1 Recursion=0: Hello World from thread 0 block 0 Recursion=0: Hello World from thread 1 block 0 Recursion=0: Hello World from thread 2 block 0 Recursion=0: Hello World from thread 3 block 0 Recursion=0: Hello World from thread 4 block 0 Recursion=0: Hello World from thread 5 block 0 Recursion=0: Hello World from thread 6 block 0 Recursion=0: Hello World from thread 7 block 0 -------> nested execution depth: 1 -------> nested execution depth: 1 Recursion=1: Hello World from thread 0 block 0 Recursion=1: Hello World from thread 1 block 0 Recursion=1: Hello World from thread 2 block 0 Recursion=1: Hello World from thread 3 block 0 Recursion=1: Hello World from thread 0 block 0 Recursion=1: Hello World from thread 1 block 0 Recursion=1: Hello World from thread 2 block 0 Recursion=1: Hello World from thread 3 block 0 -------> nested execution depth: 2 -------> nested execution depth: 2 Recursion=2: Hello World from thread 0 block 0 Recursion=2: Hello World from thread 1 block 0 Recursion=2: Hello World from thread 0 block 0 Recursion=2: Hello World from thread 1 block 0 -------> nested execution depth: 3 -------> nested execution depth: 3 Recursion=3: Hello World from thread 0 block 0 Recursion=3: Hello World from thread 0 block 0
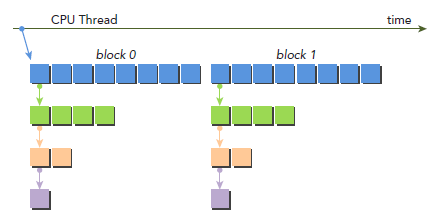
从上面结果来看,首先应该注意到,所有child的block的id都是0。下图是调用过程,parent有两个block了,但是所有child都只有一个blcok:
nestedHelloWorld<<<1, nthreads>>>(nthreads, ++iDepth);
注意:Dynamic Parallelism只有在CC3.5以上才被支持。通过Dynamic Parallelism调用的kernel不能执行于不同的device(物理上实际存在的)上。调用的最大深度是24,但实际情况是,kernel要受限于memory资源,其中包括为了同步parent和child而需要的额外的memory资源。
Nested Reduction
学过算法导论之类的算法书应该知道,因为递归比较消耗资源的,所以如果可以的话最好是展开,而这里要讲的恰恰相反,我们要实现递归,这部分主要就是再次证明DynamicParallelism的好处,有了它就可以实现像C那样写递归代码了。
下面的代码就是一份实现,和之前一样,每个child的有一个block,block中第一个thread调用kernel,不同的是,parent的grid有很多的block。第一步还是讲global memory的地址g_idata转化为每个block本地地址。然后,if判断是否该退出,退出的话,就将结果拷贝回global memory。如果不该退出,就进行本地reduction,一般的线程执行in-place(就地)reduction,然后,同步block来保证所有部分和的计算。thread0再次产生一个只有一个block和当前一半数量thread的child grid。
__global__ void gpuRecursiveReduce (int *g_idata, int *g_odata,
unsigned int isize) {
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0]+idata[1];
return;
}
// nested invocation
int istride = isize>>1;
if(istride > 1 && tid < istride) {
// in place reduction
idata[tid] += idata[tid + istride];
}
// sync at block level
__syncthreads();
// nested invocation to generate child grids
if(tid==0) {
gpuRecursiveReduce <<<1, istride>>>(idata,odata,istride);
// sync all child grids launched in this block
cudaDeviceSynchronize();
}
// sync at block level again
__syncthreads();
}
编译运行,下面结果是运行在Kepler K40上面:
$ nvcc -arch=sm_35 -rdc=true nestedReduce.cu -o nestedReduce -lcudadevrt ./nestedReduce starting reduction at device 0: Tesla K40c array 1048576 grid 2048 block 512 cpu reduce elapsed 0.000689 sec cpu_sum: 1048576 gpu Neighbored elapsed 0.000532 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nested elapsed 0.172036 sec gpu_sum: 1048576<<<grid 2048 block 512>>>
相较于neighbored,nested的结果是非常差的。
从上面结果看,2048个block被初始化了。每个block执行了8个recursion,16384个child block被创建,__syncthreads也被调用了16384次。这都是导致效率很低的原因。
当一个child grid被调用后,他看到的memory是和parent完全一样的,因为child只需要parent的一部分数据,block在每个child grid的启动前的同步操作是不必要的,修改后:
__global__ void gpuRecursiveReduceNosync (int *g_idata, int *g_odata,unsigned int isize) {
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// nested invoke
int istride = isize>>1;
if(istride > 1 && tid < istride) {
idata[tid] += idata[tid + istride];
if(tid==0) {
gpuRecursiveReduceNosync<<<1, istride>>>(idata,odata,istride);
}
}
}
运行输出,时间减少到原来的三分之一:
./nestedReduceNoSync starting reduction at device 0: Tesla K40c array 1048576 grid 2048 block 512 cpu reduce elapsed 0.000689 sec cpu_sum: 1048576 gpu Neighbored elapsed 0.000532 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nested elapsed 0.172036 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nestedNosyn elapsed 0.059125 sec gpu_sum: 1048576<<<grid 2048 block 512>>>
不过,性能还是比neighbour-paired要慢。接下来在做点改动,主要想法如下图所示,kernel的调用增加了一个参数iDim,这是因为每次递归调用,child block的大小就减半,parent 的blockDim必须传递给child grid,从而使每个thread都能计算正确的global memory偏移地址。注意,所有空闲的thread都被移除了。相较于之前的实现,每次都会有一半的thread空闲下来而被移除,也就释放了一半的计算资源。
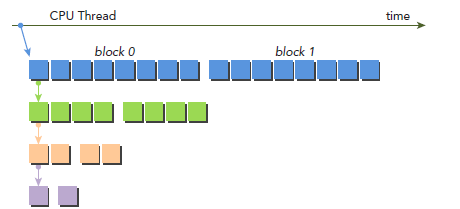
__global__ void gpuRecursiveReduce2(int *g_idata, int *g_odata, int iStride,int const iDim) {
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x*iDim;
// stop condition
if (iStride == 1 && threadIdx.x == 0) {
g_odata[blockIdx.x] = idata[0]+idata[1];
return;
}
// in place reduction
idata[threadIdx.x] += idata[threadIdx.x + iStride];
// nested invocation to generate child grids
if(threadIdx.x == 0 && blockIdx.x == 0) {
gpuRecursiveReduce2 <<<gridDim.x,iStride/2>>>(
g_idata,g_odata,iStride/2,iDim);
}
}
编译运行:
./nestedReduce2 starting reduction at device 0: Tesla K40c array 1048576 grid 2048 block 512 cpu reduce elapsed 0.000689 sec cpu_sum: 1048576 gpu Neighbored elapsed 0.000532 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nested elapsed 0.172036 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nestedNosyn elapsed 0.059125 sec gpu_sum: 1048576<<<grid 2048 block 512>>> gpu nested2 elapsed 0.000797 sec gpu_sum: 1048576<<<grid 2048 block 512>>>
从这个结果看,数据又好看了不少,可以猜测,大约是由于调用了较少的child grid,我们可以用nvprof来验证下:
$ nvprof ./nestedReduce2
部分输出结果如下,第二列上显示了dievice kernel 的调用次数,第一个和第二个创建了16384个child grid。gpuRecursiveReduce2八层nested Parallelism只创建了8个child。
Calls (host) Calls (device) Avg Min Max Name 1 16384 441.48us 2.3360us 171.34ms gpuRecursiveReduce 1 16384 51.140us 2.2080us 57.906ms gpuRecursiveReduceNosync 1 8 56.195us 22.048us 100.74us gpuRecursiveReduce2 1 0 352.67us 352.67us 352.67us reduceNeighbored
对于一个给定的算法,我们可以有很多种实现方式,避免大量的nested 调用可以提升很多性能。同步对算法的正确性至关重要,但也是一个消耗比较大的操作,block内部的同步操作倒是可以去掉。因为在device上运行nested程序需要额外的资源,nested调用是有限的。
相关文章:
CUDA学习笔记(九)Dynamic Parallelism
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。 Dynamic Parallelism 到目前为止,所有kernel都是在host端调用,CUDA Dynamic Parallelism允许GPU kernel在device端创建调用。Dynamic Parallelism使递归更容易实现…...

周记之马上要答辩了
“ 要变得温柔和强大,就算哪天突然孤身一人,也能平静地活下去,不至于崩溃。” 10.16 今天提前写完了一篇六级阅读,积累了一些词组: speak out against 公然反对,印象最深刻的就这个; 先了解…...

git简介和指令
git是一个开源的的分布式版本控制系统,用于高效的管理各种大小项目和文件 用途:防止代码丢失,做备份 项目的版本管理和控制,可以通过设置节点进行跳转 建立各自的开发环境分支,互不影响,方便合并 在多终端开…...
-- Json数组字符串 ==》 JSONArray)
alibaba.fastjson的使用(五)-- Json数组字符串 ==》 JSONArray
目录 1. 使用到的方法 2. 实例演示 1. 使用到的方法 static JSONArray parseArray(String text) 2. 实例演示 /*** 将Json数组字符串转JsonArray*/@Testpublic void test5() {String jsonArrStr = "[{\"name\":\"郭靖\",\"age\":35},{\…...

ts json的中boolean布尔值或者int数字都是字符串,转成对象对应类型
没啥好写的再水一篇 json中都是字符串,转换一下就好,简单来说就是转换一次不行,再转换换一次,整体转换不够,细分的再转换一次 这是vue中 ts写法 ,我这里是拿对象做对比,不好字符和对象做对比,…...

【OpenGL】七、混合
混合 文章目录 混合混合公式glBlendFunc(混合函数)glBlendFuncSeparate渲染半透明纹理 参考链接 混合(Blending)通常是实现物体透明度(Transparency)的一种技术 简而言之:混合就是如何将输出颜色和目标缓冲区颜色结合起来。 混合公式 C_fina…...

JVM——堆内存调优(Jprofiler使用)Jprofile下载和安装很容易,故没有记录,如有需要,在评论区留言)
堆内存调优 当遇到OOM时,可以进行调参 1、尝试扩大堆内存看结果 2、分析内存,看哪个地方出现了问题(专业工具) 调整初始分配内存为1024M,调整最大分配内存为1024M,打印GC细节(如何添加JVM操…...

Android cmdline-tools 版本与其最小JDK关系
关键词:Android cmdline-tools 历史版本、Android cmdline-tools 最小JDK版本、JDK 对应 major version、JDK LTS 信息 由于 JDK8 是一个常用的、较低的版本,因此只需要关注 JDK8 及以上版本的运行情况。 cmdline-tools 版本和最低 JDK 最终结论&…...

基于ARM+FPGA+AD的多通道精密数据采集仪方案
XM 系列具备了数据采集仪应具备的“操作简单、便于携带、满足各种测量需求”等功能的产品。具有超小、超轻量的手掌大小尺寸,支持8 种测量模块,还可进行最多576 Ch的多通道测量。另外,支持省配线系统,可大幅削减配线工时。使用时不…...
【JAVA学习笔记】43 - 枚举类
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter11/src/com/yinhai/enum_ 〇、创建时自动填入版权 作者等信息 如何在每个文件创建的时候打入自己的信息以及版权呢 菜单栏-File-setting-Editor-File and Code Templaters -Includes-输入信…...

Springcloud介绍
1.基本介绍 Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring …...
)
LK光流法和LK金字塔光流法(含python和c++代码示例)
0 引言 本文主要记录LK光流算法及LK金字塔光流算法的详细原理,最后还调用OpenCV中的cv2.calcOpticalFlowPyrLK()函数实现LK金字塔光流算法,其中第3部分是python语言实现版本,第4部分是c++语言实现版本。 1 LK光流算法 1.1 简述 LK光流法是一种计算图像序列中物体运动的光…...

数据库索引是什么?创建索引的注意事项
数据库索引: 索引(index)是帮助MySQL高效获取数据的数据结构(有效),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向&#x…...

java中的异常,以及出现异常后的处理【try,catch,finally】
一、异常概念 异常 :指的是程序在执行过程中,出现的非正常的情况,最终会导致JVM的非正常停止。 注意: 在Java等面向对象的编程语言中,异常本身是一个类,产生异常就是创建异常对象并抛出了一个异常对象。Java处理异常的…...

前端构建但没有更新
使用jenkins构建vue前端代码时,构建完成后,jenkins提示构建成功, 但前端刷新提示还是原来的效果,此时需要查看下jenkins构建日志,如果出现下面的文字,说明缺少依赖,最新的代码并没有构建到项目中…...
【Opencv】OpenCV使用CMake和MinGW的编译安装出错解决
编译时出现的错误: mingw32-make[1]: *** [modules/core/CMakeFiles/opencv_core.dir/all] Error 2 Makefile:161: recipe for target ‘all’ failed mingw32-make: *** [all] Error 2解决方法: 根据贴吧老哥的解答,发现是mingw版本有问题导…...

#Day Day Plan# 《NCB_PCI_Express_Base 5.0.1.0》pdf 译文笔记 模版
目录 一 本章节主讲知识点 1.1 xxx 1.2 sss 1.3 ddd 二 本章节原文翻译 2.1 ddd 三 本章节关联知识点 2.1 ddd 四 本章节存疑问题 2.1 222 五 总结 一 本章节主讲知识点 1.1 xxx 1.2 sss 1.3 ddd 二 本章节原文翻译 2.1 ddd 三 本章节关联知识点 2.1 ddd 四…...
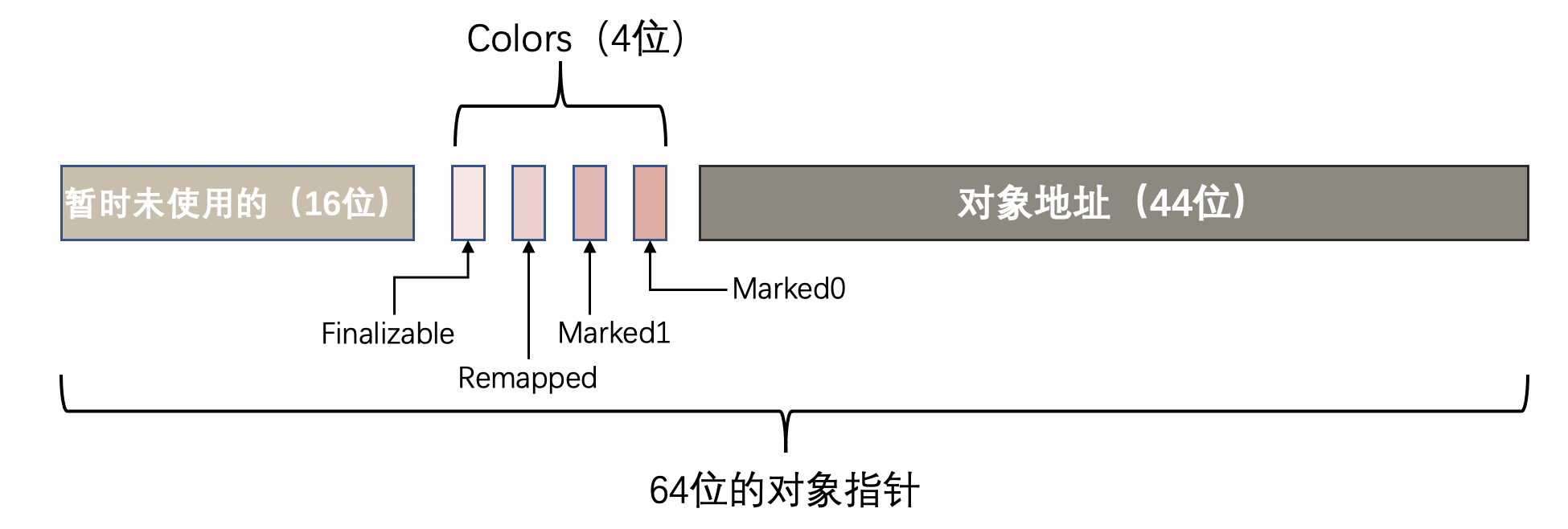
分代ZGC详解
ZGC(Z Garbage Collector)是Java平台上的一种垃圾收集器,它是由Oracle开发的,旨在解决大堆的低延迟垃圾收集问题。ZGC是一种并发的分代垃圾收集器,它主要针对具有大内存需求和低停顿时间要求的应用程序 分代ZGC收集器…...

vue图片懒加载
Vue图片懒加载是一种优化页面性能的技术,它可以延迟加载页面上的图片,直到它们进入可见区域。这可以减少页面的加载时间,提高用户体验。 在Vue中实现图片懒加载可以使用第三方库vue-lazyload。首先需要安装该库: npm install vu…...

【c++】运算符重载实例
重载自增自减运算符 Intger num(2); num; num;对自增运算符的重载要区分前置和后置。在重载之前需要思考一个问题,num是返回一个临时变量还是num对象的本体。 为了解决这个问题可以考虑实现一个Inc_()函数和_Inc()函数分别模仿后置和前置的行为 Integer Inc_(){i…...

Picocli错误处理终极指南:7个技巧构建健壮命令行应用
Picocli错误处理终极指南:7个技巧构建健壮命令行应用 【免费下载链接】picocli Picocli is a modern framework for building powerful, user-friendly, GraalVM-enabled command line apps with ease. It supports colors, autocompletion, subcommands, and more.…...

OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性
OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性 1. 为什么需要AI辅助代码测试? 作为长期与Python打交道的开发者,我经常面临一个经典困境:在快速迭代功能时,测试用例的编写往往成为瓶颈。传统方案要…...

重新安装微信新版本后才发现历史记录文件夹名称不匹配!解决方法
重新 安装/恢复 电脑,安装微信最新版本 记录文件夹变更为:xwechat_files 旧的格式:WeChat Files 找很多方法,以及腾讯官方的说明,无效、费解,来点干货,成功解决经验: (1&…...

OpenClaw自动化写作对比:千问3.5-35B-A3B-FP8与纯文本模型的产出差异
OpenClaw自动化写作对比:千问3.5-35B-A3B-FP8与纯文本模型的产出差异 1. 为什么需要对比不同模型的写作表现 上周我在用OpenClaw自动生成技术文档时,发现一个有趣的现象:同样的任务指令,交给不同的大模型处理,产出的…...

OpenClaw+千问3.5-9B自动化写作:技术博客大纲与初稿生成
OpenClaw千问3.5-9B自动化写作:技术博客大纲与初稿生成 1. 为什么需要自动化写作助手 作为一个技术博主,我经常面临这样的困境:明明对某个技术点有深刻理解,却卡在如何组织文章结构上。有时候花在列大纲上的时间比实际写作还长&…...

从晶体管到ALU:计算机运算基础全解析
1. 从晶体管到二进制:计算机运算的物理基础现代计算机的核心运算能力源于晶体管这一基础电子元件的巧妙运用。晶体管本质上是一个由半导体材料制成的三端器件,通过控制其中一个电极(基极或栅极)的电压,可以精确控制另外…...
研究(Matlab代码实现))
【DBO三维路径规划】基于多策略改进的蜣螂算法MSDBO多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

电子工程师眼中的城市电路板:无人机航拍引发的职业思考
1. 电子工程师的强迫症与无人机视角的冲突作为一名从业十年的电子工程师,我完全理解小舒所说的那种"焊盘上的电阻、电容不能歪"的强迫症。这种职业习惯已经深深烙印在我们的工作方式中 - 从PCB布局到元件焊接,从线缆走线到机箱布线,…...

Lansium-Arduino:面向物联网终端的轻量级MQTT通信库
1. 项目概述 Lansium-Arduino 是一个面向嵌入式物联网终端的轻量级通信库,专为 Arduino 生态(含 ESP32、ESP8266、Arduino Uno Ethernet/WiFi 扩展板等平台)设计,用于实现设备与 Lansium Server 的可靠双向连接。其核心通信协议…...

2009 Text 1
2009 Text 1...