自然语言处理---Transformer模型
Transformer概述
相比LSTM和GRU模型,Transformer模型有两个显著的优势:
- Transformer能够利用分布式GPU进行并行训练,提升模型训练效率。
- 在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好。
Transformer模型的作用
-
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务,如机器翻译,文本生成等。同时又可以构建预训练语言模型,用于不同任务的迁移学习。
-
假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作,因此很多命名方式遵循NLP中的规则。比如:Embeddding层将称作文本嵌入层,Embedding层产生的张量称为词嵌入张量,它的最后一维将称作词向量等。
Transformer总体架构图
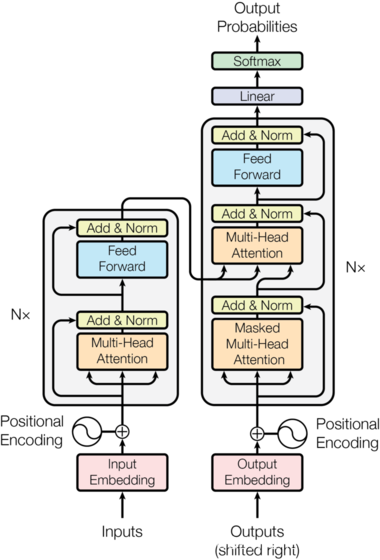
输入部分实现
输入部分包含
源文本嵌入层及其位置编码器;目标文本嵌入层及其位置编码器。
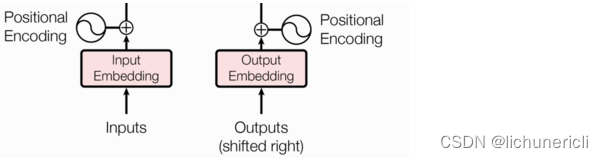
文本嵌入层的作用
无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示,希望在这样的高维空间捕捉词汇间的关系。
位置编码器的作用
在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
词汇向量中特征的分布曲线
- 保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化。
- 正弦波和余弦波的值域范围都是1到-1,这很好的控制了嵌入数值的大小,有助于梯度的快速计算。
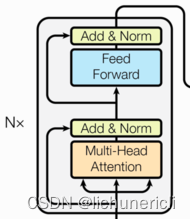
编码器部分实现
编码器介绍
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量
掩代表遮掩,码就是张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,它的表现形式是一个张量。
掩码张量的作用
在transformer中,掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知量未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用。所以会进行遮掩。
注意力机制
注意力的计算规则
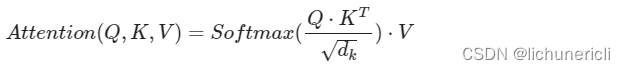
多头注意力机制
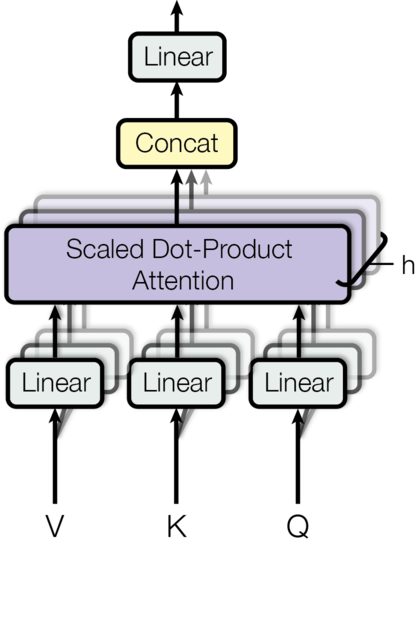
- 所谓的多个头就是指多组线性变换层,其实并不是,只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q,K,V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分,也就是只分割了最后一维的词嵌入向量。这就是所谓的多头,将每个头的获得的输入送到注意力机制中, 就形成多头注意力机制。
- 这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果。
前馈全连接层
- 在Transformer中前馈全连接层就是具有两层线性层的全连接网络。
- 前馈全连接层的作用:考虑注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力。
规范化层
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢。因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内。
子层连接结构
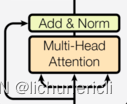
输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构。
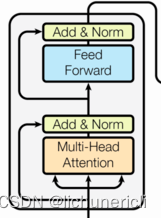
编码器层
- 作为编码器的组成单元,每个编码器层完成一次对输入的特征提取过程,即编码过程。
- 编码器层的构成图:
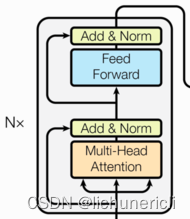
编码器
-
编码器用于对输入进行指定的特征提取过程,也称为编码,由N个编码器层堆叠而成。
-
编码器的结构图:
解码器部分实现
解码器介绍
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
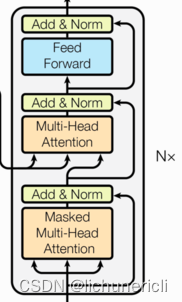
- 解码器层中的各个部分,如,多头注意力机制,规范化层,前馈全连接网络,子层连接结构都与编码器中的实现相同。因此这里可以直接拿来构建解码器层。
解码器层
作为解码器的组成单元,每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程。
解码器
根据编码器的结果以及上一次预测的结果,对下一次可能出现的'值'进行特征表示。
输出部分实现
输出部分介绍
输出部分包含:线性层、softmax层。
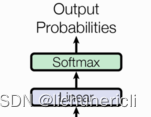
线性层的作用
通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用。
softmax层的作用
使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1。
模型构建
Transformer总体架构图
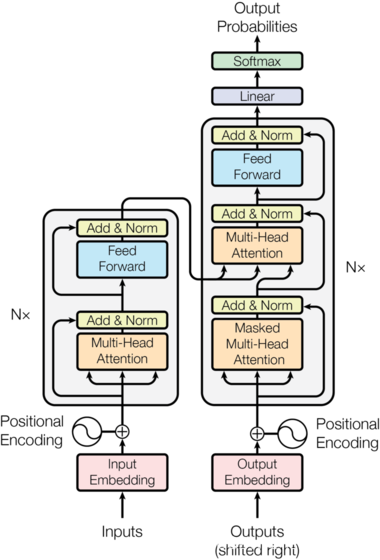
- Transformer模型架构,大范围内包括两部分分别是encoder(编码器)和decoder(解码器),编码器和解码器的内部实现都使用了注意力机制实现。
- 这里完成的是德文到英文的翻译: Willkommen in peking → welcome to BeiJing。
- 编码器首先处理中文输入"Willkommen in peking",通过Transformer内部的注意力机制提取信息之后的输出张量,就是一个中间语义张量c,接着解码器将使用这个中间语义张量c以及每一个时间步的目标语言的语义张量,逐个生成对应的翻译语言。
案例Transformer机器翻译模型
数据集:使用的是torchtext中自带的数据集Multi30k,直接可以使用内置的API函数即可下载
# 默认下载的路径为: /root/.torchtext/cache/Multi30k
└── Multi30k├── mmt16_task1_test.tar.gz├── test.de├── test.en├── train.de├── train.en├── training.tar.gz├── val.de├── val.en└── validation.tar.gz
1 导入必备的工具包
import torch
import torch.nn as nn
import mathfrom torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torchtext.datasets import Multi30k
from typing import Iterable, List
from torch import Tensor
from torch.nn import Transformer
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
from timeit import default_timer as timerDEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
2 导入Multi30k数据集并做基本处理
2.1 加载对应的tokenizer
# 源语言是德语
SRC_LANGUAGE = 'de'
# 目标语言是英语
TGT_LANGUAGE = 'en'# 定义token的字典, 定义vocab字典
token_transform = {}
vocab_transform = {}# 创建源语言和目标语言的kokenizer, 确保依赖关系已经安装
# pip install -U spacy
# python -m spacy download en_core_web_sm
# python -m spacy download de_core_news_sm
# get_tokenizer是分词函数, 如果没有特殊的则按照英语的空格分割, 如果有这按照对应的分词库返回. 比如spacy, 返回对应的分词库
token_transform[SRC_LANGUAGE] = get_tokenizer('spacy', language='de_core_news_sm')
token_transform[TGT_LANGUAGE] = get_tokenizer('spacy', language='en_core_web_sm')
2.2 构建生成分词的迭代器
def yield_tokens(data_iter: Iterable, language: str) -> List[str]:# data_iter: 对象的迭代对象 Multi30k对象# language: 对应的翻译语言 {'de': 0, 'en': 1}language_index = {SRC_LANGUAGE: 0, TGT_LANGUAGE: 1}# 返回对应的数据迭代器对象for data_sample in data_iter:# data_sample:(德文, 英文)# data_sample:('Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche.\n', 'Two young, White males are outside near many bushes.\n')# token_transform['de']()=['Zwei', 'junge', 'weiße', 'Männer', 'sind', 'im', 'Freien', 'in', 'der', 'Nähe', 'vieler', 'Büsche', '.', '\n']# or token_transform['en']分别进行构造对应的字典yield token_transform[language](data_sample[language_index[language]])
2.3 定义特殊字符并下载数据设置默认索引
# 定义特殊字符及其对应的索引值
UNK_IDX, PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2, 3
# 确保标记按其索引的顺序正确插入到词汇表中
special_symbols = ['<unk>', '<pad>', '<bos>', '<eos>']for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:# 训练数据集的迭代器,# 数据集是用英文描述图像的英文语句, 然后人工将其翻译为德文的语句,有两个文件, 一个是train.de 一个是train.en文件,# 然后将其构建为(德文, 英文)的形式train_iter = Multi30k(split='train', language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))# 创建torchtext的vocab对象, 即词汇表vocab_transform[ln] = build_vocab_from_iterator(yield_tokens(train_iter, ln), # 用于构建 Vocab 的迭代器。必须产生令牌列表或迭代器min_freq=1,#在词汇表中包含一个标记所需的最低频率specials=special_symbols, # 用于添加的特殊字符special_first=True) # 指示是在开头还是结尾插入符号# 将 UNK_IDX 设置为默认索引。未找到令牌时返回此索引
# 如果未设置,则在 Vocabulary 中找不到查询的标记时抛出 RuntimeError
for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:vocab_transform[ln].set_default_index(UNK_IDX)
3 构建Transformer模型
3.1 定义位置编码器类
class PositionalEncoding(nn.Module):def __init__(self,emb_size: int,dropout: float, maxlen: int = 5000):'''emb_size: 词嵌入的维度大小dropout: 正则化的大小maxlen: 句子的最大长度'''super(PositionalEncoding, self).__init__()# 将1000的2i/d_model变型为e的指数形式den = torch.exp(- torch.arange(0, emb_size, 2)* math.log(10000) / emb_size)# 效果等价与torch.arange(0, maxlen).unsqueeze(1)pos = torch.arange(0, maxlen).reshape(maxlen, 1)# 构建一个(maxlen, emb_size)大小的全零矩阵pos_embedding = torch.zeros((maxlen, emb_size))# 偶数列是正弦函数填充pos_embedding[:, 0::2] = torch.sin(pos * den)# 奇数列是余弦函数填充pos_embedding[:, 1::2] = torch.cos(pos * den)# 将其维度变成三维, 为了后期方便计算pos_embedding = pos_embedding.unsqueeze(-2)# 添加dropout层, 防止过拟合self.dropout = nn.Dropout(dropout)'''向模块添加持久缓冲区。这通常用于注册不应被视为模型参数的缓冲区。例如,pos_embedding不是一个参数,而是持久状态的一部分。缓冲区可以使用给定的名称作为属性访问。说明:应该就是在内存中定义一个常量,同时,模型保存和加载的时候可以写入和读出'''self.register_buffer('pos_embedding', pos_embedding)def forward(self, token_embedding: Tensor):# 将token_embedding和位置编码相融合return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])
3.2 定义词嵌入层类
class TokenEmbedding(nn.Module):def __init__(self, vocab_size: int, emb_size):'''vocab_size:词表的大小emb_size:词嵌入的维度'''super(TokenEmbedding, self).__init__()# 调用nn中的预定义层Embedding, 获取一个词嵌入对象self.embeddingself.embedding = nn.Embedding(vocab_size, emb_size)# 将emb_size传入类内, 变成类内的变量self.emb_size = emb_sizedef forward(self, tokens: Tensor):# 让 embeddings vector 在增加 之后的 postion encoing 之前相对大一些的操作,# 主要是为了让position encoding 相对的小,这样会让原来的 embedding vector 中的信息在和 position encoding 的信息相加时不至于丢失掉# 让 embeddings vector 相对大一些return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
3.3 构建Seq2SeqTransformer模型
class Seq2SeqTransformer(nn.Module):def __init__(self,num_encoder_layers, num_decoder_layers,emb_size,nhead,src_vocab_size,tgt_vocab_size,dim_feedforward = 512,dropout = 0.1):'''num_encoder_layers: 编码器的层数num_decoder_layers: 解码器的层数emb_size: 词嵌入的维度nhead: 头数src_vocab_size: 源语言的词表大小tgt_vocab_size: 目标语言的词表大小dim_feedforward: 前馈全连接层的维度dropout: 正则化的大小'''# 继承nn.Module类, 一般继承习惯行的写法super(Seq2SeqTransformer, self).__init__()# 创建Transformer对象self.transformer = Transformer(d_model=emb_size,nhead=nhead,num_encoder_layers=num_encoder_layers,num_decoder_layers=num_decoder_layers,dim_feedforward=dim_feedforward,dropout=dropout)# 创建全连接线性层self.generator = nn.Linear(emb_size, tgt_vocab_size)# 创建源语言的embedding层self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)# 创建目标语言的embedding层self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)# 创建位置编码器层对象self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)def forward(self,src, trg, src_mask, tgt_mask, src_padding_mask, tgt_padding_mask, memory_key_padding_mask):'''src: 源语言trg: 目标语言src_mask: 源语言掩码tgt_mask: 目标语言掩码src_padding_mask: 源语言的padding_masktgt_padding_mask: 目标语言的padding_maskmemory_key_padding_mask: 中间语义张量的padding_mask'''# 获取源语言的embedding张量融合了位置编码src_emb = self.positional_encoding(self.src_tok_emb(src))# 获取目标语言的embedding张量融合了位置编码tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))# 经过Transformer进行编解码之后输出out值outs = self.transformer(src_emb, tgt_emb, src_mask, tgt_mask, None, src_padding_mask, tgt_padding_mask, memory_key_padding_mask)# outs值经过输出层得到最后的输出分布值return self.generator(outs)# 定义Transformer的编码器def encode(self, src, src_mask):'''src:源语言src_mask:源语言掩码'''return self.transformer.encoder(self.positional_encoding(self.src_tok_emb(src)), src_mask)# 定义Transformer的解码器def decode(self, tgt, memory, tgt_mask):'''tgt:目标语言memory:中间语言张量输出tgt_mask: 目标语言的掩码'''return self.transformer.decoder(self.positional_encoding(self.tgt_tok_emb(tgt)), memory, tgt_mask)
4 定义mask的函数, 创建对应的不同的mask
4.1 定义掩码
作用是防止模型在进行预测的过程中查看到未来的单词. 同时需要掩码来隐藏源语言和目标语言的padding tokens
def generate_square_subsequent_mask(sz):# sz: 句子的长度# triu生成的是上三角, 经过transpose之后变成了下三角矩阵mask = (torch.triu(torch.ones((sz, sz), device=DEVICE)) == 1).transpose(0, 1)# 将0的位置填充负无穷小, 将1的位置填充为0mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))return maskdef create_mask(src, tgt):'''src: 源语言张量形状为: [seq_length , batch_size]tgt: 目标语言张量形状为: [seq_length , batch_size]'''# 获取源语言的句子长度src_seq_len = src.shape[0]# 获取目标语言的句子长度tgt_seq_len = tgt.shape[0]# 产生目标语言的掩码张量tgt_mask = generate_square_subsequent_mask(tgt_seq_len)# 产生源语言的掩码张量src_mask = torch.zeros((src_seq_len, src_seq_len),device=DEVICE).type(torch.bool)# 构建源语言的padding_mask src_padding_mask==> [batch_size, seq_len]src_padding_mask = (src == PAD_IDX).transpose(0, 1)# 构建目标语言的padding_mask tgt_paddig_mask ==> [batch_size, seq_len-1]tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
5 定义批次数据处理的回调函数
5.1 将字符串转化为整数的tensor张量
# 将句子字符转化为对应的tensor张量
def sequential_transforms(*transforms):'''Transformers中会传入三个迭代器: 第一个是Tokenization的, 第二个是Numericalization, 第三个是Add BOS/EOS and create tensor'''def func(txt_input):# 循环三个迭代器, 第一个进行语句的分割, 第二个将对应的词语映射为对应的张量表示, 第三个是在整个句子的首尾部分添加起始和结束标志.for transform in transforms:txt_input = transform(txt_input)return txt_inputreturn func
5.2 在句子首尾添加起始和结束符号
# 辅助函数, 完成句子首尾BOS/EOS的添加过程
def tensor_transform(token_ids: List[int]):# 添加的是列表形式的数据, 将BOS和EOS添加到句子的首尾部分return torch.cat((torch.tensor([BOS_IDX]),torch.tensor(token_ids),torch.tensor([EOS_IDX])))text_transform = {}
# 循环添加源语言和目标语言
for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:text_transform[ln] = sequential_transforms(token_transform[ln], #Tokenizationvocab_transform[ln], #Numericalizationtensor_transform) # Add BOS/EOS and create tensor
5.3 数据进行批次化处理
# 按照批次进行源语言和目标语言的组装
def collate_fn(batch):# 定义源语言和目标语言的批次列表src_batch, tgt_batch = [], []# 循环批次样本for src_sample, tgt_sample in batch:# 添加源语言句子到列表中src_batch.append(text_transform[SRC_LANGUAGE](src_sample.rstrip("\n")))# 添加目标语言句子到列表中tgt_batch.append(text_transform[TGT_LANGUAGE](tgt_sample.rstrip("\n")))# 将源语言和目标语言进行截断补齐 PAD_IDX=1# src_batch的形状为: [seq_length, batch] seq_length是最长的句子长度src_batch = pad_sequence(src_batch, padding_value=PAD_IDX)# tgt_batch的形状为: [seq_length, batch] seq_length是最长的句子长度tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_IDX)return src_batch, tgt_batch
6 构建训练函数和评估函数
6.1 实例化模型并定义损失函数和优化器
# 设置种子用于生成随机数,以使得结果是确定的
torch.manual_seed(0)# 设置调用时候使用的参数
SRC_VOCAB_SIZE = len(vocab_transform[SRC_LANGUAGE])
TGT_VOCAB_SIZE = len(vocab_transform[TGT_LANGUAGE])
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3# 实例化Transformer对象
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS, EMB_SIZE,NHEAD, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, FFN_HID_DIM)
# 为了保证每层的输入和输出的方差相同, 防止梯度消失问题
for p in transformer.parameters():if p.dim() > 1:# 此处使用的是xavier的均匀分布nn.init.xavier_uniform_(p)
# 如果有GPU则将模型移动到GPU上
transformer = transformer.to(DEVICE)
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
# 定义优化器 betas: 用于计算梯度及其平方的运行平均值的系数 eps:添加到分母以提高数值稳定性
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
6.2 定义批次训练函数
def train_epoch(model, optimizer):# 开启训练模式model.train()# 定义其实的损失值为0losses = 0# 获取训练数据集的迭代器, 语言对为(de, en)train_iter = Multi30k(split='train', language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))# 加载数据, 按照一个批次一个批次进行加载, 返回一个迭代器train_dataloader = DataLoader(train_iter, batch_size=BATCH_SIZE, collate_fn=collate_fn)# 循环数据迭代器for src, tgt in train_dataloader:# 将源语言数据移动到对应的设备上去src = src.to(DEVICE)# 将目标语言数据移动到对应设备上去tgt = tgt.to(DEVICE)# 获取输入真实的张量 第一个单词到倒数第二个单词tgt_input = tgt[:-1, :]# 调用mask函数, 生成对应的四个masksrc_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)# 调用模型进行训练, 得到最后的张量分布logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)# 梯度清零optimizer.zero_grad()# 获取输出真实的标签数据 第二个单词到最后一个单词tgt_out = tgt[1:, :]# 计算损失loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))# 反向传播loss.backward()# 梯度更新optimizer.step()# 损失值累加求和losses += loss.item()# 返回平均损失值return losses / len(train_dataloader)
6.3 定义批次评估函数
def evaluate(model):# 开启模型评估模式model.eval()# 定义起始损失值losses = 0# 加载验证数据集, 语言对为(de, en)val_iter = Multi30k(split='valid', language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))# 返回验证集的数据加载器val_dataloader = DataLoader(val_iter, batch_size=BATCH_SIZE, collate_fn=collate_fn)# 循环验证集for src, tgt in val_dataloader:# 源语言数据移动到对应的设备上src = src.to(DEVICE)# 目标语言数据移动到对应的设备上tgt = tgt.to(DEVICE)# 获取输入的真实的张量tgt_input = tgt[:-1, :]# 调用mask函数, 产生对应的四个mask值src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)# 调用模型, 得到对应的输出分布值logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)# 获取输出的真实张量tgt_out = tgt[1:, :]# 计算损失值loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))# 损失值累加, 求和losses += loss.item()# 求得对应的平均损失return losses / len(val_dataloader)
7 训练Transformer模型
7.1 利用循环训练Transformer模型
# 定义epoch的次数
NUM_EPOCHS = 18# 循环整个数据集num_epochs次
for epoch in range(1, NUM_EPOCHS+1):# 获取开始时间start_time = timer()# 将整个训练数据集进行训练train_loss = train_epoch(transformer, optimizer)# 获取结束时间end_time = timer()# 将整个验证集进行评估val_loss = evaluate(transformer)# 打印每个epoch的训练损失, 验证损失, 和训练时间.print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Val loss: {val_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s"))
8 进行解码生成目标语言语句
8.1 使用贪心算法构建生成序列函数
def greedy_decode(model, src, src_mask, max_len, start_symbol):# 将对应的源语言数据移动的对应的设备上src = src.to(DEVICE)# 将对应的源语言的mask移动到对应的设备上src_mask = src_mask.to(DEVICE)# 将源语言使用模型的编码器, 得到中间语义张量 memory的形状为: [seq_len, batch_size, dim]memory = model.encode(src, src_mask)# 构建一个起始的二维矩阵, 然后准备开始句子的解码过程. ys形状为[1, 1]二维的ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(DEVICE)for i in range(max_len-1):# 将中间语义张量的数据一定到对应的设备上memory = memory.to(DEVICE)# 生成目标语言的mask值tgt_mask = (generate_square_subsequent_mask(ys.size(0)).type(torch.bool)).to(DEVICE)# 调用模型的解码器进行解码 out形状为:[seq_len, 1, 512]==> [seq_len, batch_size, emb_size]out = model.decode(ys, memory, tgt_mask)# 输出张量进行形状的转换out = out.transpose(0, 1)# 经过最后输出层, 获取最后的输出概率分布 out[:, -1]形状为: [1, 512] --> [seq_len, emb_size]# prob的形状为: [1, tgt_vocab_size]prob = model.generator(out[:, -1])# 在1维度上, 获取概率最大的那个就是最后预测的那个值 max返回两个值, 第一个是返回的最大值的概率, 第二个是返回最大概率的下标值._, next_word = torch.max(prob, dim=1)# 获取对应的那个下标值next_word = next_word.item()# 拼接上一步和这一步产生的单词, 作为下一步使用的ys fill_()表示用括号中的数字去填充整个矩阵ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)if next_word == EOS_IDX:breakreturn ys
8.2 定义最终的翻译转化函数
def translate(model: torch.nn.Module, src_sentence: str):'''model: 输入整个Transformer模型src_sentence:要翻译的语句'''# 开启模型的评估模式model.eval()# 将源语句转化为对应的张量表示 起初是一维的(seq_len, ), 后经过view(-1, 1)转化为[seq_len, 1]二维的形状.src = text_transform[SRC_LANGUAGE](src_sentence).view(-1, 1)# src.shape==> [seq_len, 1]num_tokens = src.shape[0]# 创建一个全零的矩阵作为src_mask的起始矩阵src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)# 使用贪心算法进行解码tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()# 现将数据从GPU上迁移到CPU上, 然后进行tensor类型转化为numpy.ndarray类型的整数值# 使用lookup_tokens进行索引到对应字符的查找, 反转为对应的字符, 然后将句子的首尾的bos和eos替换掉, 即为解码之后的语句.return " ".join(vocab_transform[TGT_LANGUAGE].lookup_tokens(list(tgt_tokens.cpu().numpy()))).replace("<bos>", "").replace("<eos>", "")
9 模型的保存和重加载
9.1 模型的保存
path = './model/transformer_translation_18.pth'
torch.save(transformer.state_dict(), path)
9.2 模型的重加载
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS, EMB_SIZE,NHEAD, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, FFN_HID_DIM)
transformer.load_state_dict(torch.load(path))
相关文章:
自然语言处理---Transformer模型
Transformer概述 相比LSTM和GRU模型,Transformer模型有两个显著的优势: Transformer能够利用分布式GPU进行并行训练,提升模型训练效率。 在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好。 Transformer模型的作用 基于seq…...
动画系统的前世今生(一)
掐指一算,五年没更新过我的CSDN账号啦,方向也从人工智能变成了计算机图形学,当然也依旧会关注AI的发展,之前在知乎上写了一些文章[传送门],后续也会逐渐同步到CSDN上~ 这个系列将包含五篇文章,内…...

11 结构型模式- 代理模式
结构性模式一共包括七种: 代理模式、桥接模式、装饰者模式、适配器模式、门面(外观)模式、组合模式、和享元模式。 1 代理模式介绍 软件开发中的代理: 代理模式中引入了一个新的代理对象,代理对象在客户端对象和目标对象之间起到了中介的作用,它去掉客…...
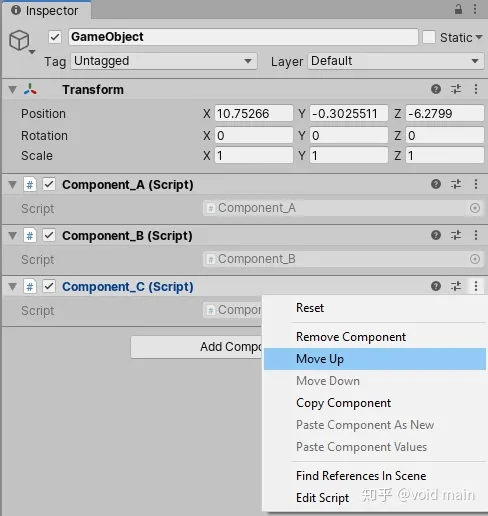
Unity--用户界面
目录 “使用工具栏”: “层次结构”窗口: 层次结构窗口 制作子GameObject “游戏”视图: “场景视图“: ”项目窗口“: 项目窗口工具栏: "Inspector" 窗口: Inspector 游戏…...

BUUCTF 乌镇峰会种图 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 乌镇互联网大会召开了,各国巨头汇聚一堂,他们的照片里隐藏着什么信息呢?(答案格式:flag{答案},只需提交答案࿰…...

Runner GoUI自动化测试发布
构建自动化测试体系是当下每个项目团队愿意去做的,自动化测试减少重复操作节省人力成本。 RunnerGo UI自动化平台 RunnerGo提供从API管理到API性能再到可视化的API自动化、UI自动化测试功能模块,覆盖了整个产品测试周期。 RunnerGo UI自动化基于Selen…...

【Gensim概念】03/3 NLP玩转 word2vec
第三部分 对象函数 八 word2vec对象函数 该对象本质上包含单词和嵌入之间的映射。训练后,可以直接使用它以各种方式查询这些嵌入。有关示例,请参阅模块级别文档字符串。 类型 KeyedVectors 1) add_lifecycle_event(event_name, log_level2…...
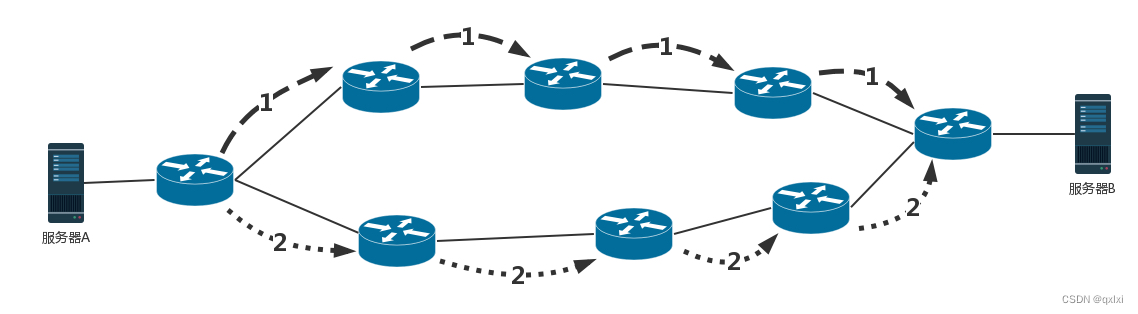
【网络协议】聊聊网络路由相关算法
如何配置路由 路由器是一台网络设备,多张网卡,当一个入口的网络包到达路由器时,会根据本地的信息库决定如何正确的转发流量,通常称为路由表 路由表主要包含如下 核心思想是根据目的 IP 地址来配置路由 目的网络:要去…...

Python 深度学习入门之CNN
CNN 前言一、CNN简介1、简介2、结构 二、CNN简介1、输出层2、卷积层3、池化层4、全连接层5、输出层 前言 1024快乐!1024快乐!今天开新坑,学点深度学习相关的,说下比较火的CNN。 一、CNN简介 1、简介 CNN的全称是Convolutiona…...

国产开发板上打造开源ThingsBoard工业网关--基于米尔芯驰MYD-JD9X开发板
本篇测评由面包板论坛的优秀测评者“JerryZhen”提供。 本文将介绍基于米尔电子MYD-JD9X开发板打造成开源的Thingsboard网关。 Thingsboard网关是一个开源的软件网关,采用python作为开发语言,可以部署在任何支持 python 运行环境的主机上,灵…...

英语——语法——从句——名词性从句——笔记
文章目录 名词性从句一、定义二、分类(一)宾语从句(二)主语从句(三)C同位语从句(四)D表语从句 名词性从句 一、句子成分 简而言之,构成一个句子的成分(或要素…...

PROSTATEx-2 上前列腺癌的 3D CNN 分类
内容 本文介绍了在多参数 MRI 序列上使用 3D CNN 对前列腺癌进行显着性或不显着性分类。内容如下: 数据集描述Dicom 到 Nifti 文件格式的转换不同 MRI 序列的联合配准...

npm ERR! node-sass@6.0.1 postinstall: `node scripts/build.js`
1.遇到的问题 vue npm install提示以下错误 2.首次尝试方法 尝试用下面的方式重新安装弄得-saas,结果不起作用 。 npm config set sass_binary_sitehttps://npm.taobao.org/mirrors/node-sass npm install node-sass 这时考虑降级node版本,node.js从…...

3D学习论文参考-ACCURATE EYE PUPIL LOCALIZATION USING HETEROGENEOUS CNN MODELS
以下是该文档的关键内容: 该论文提出了一种使用异构卷积神经网络(CNN)模型的精确眼睛瞳孔定位算法。这种算法可以抵抗光照、图像分辨率和眼镜佩戴等干扰条件,同时具有高准确性。该算法由两部分组成:一是找到近似眼睛区…...
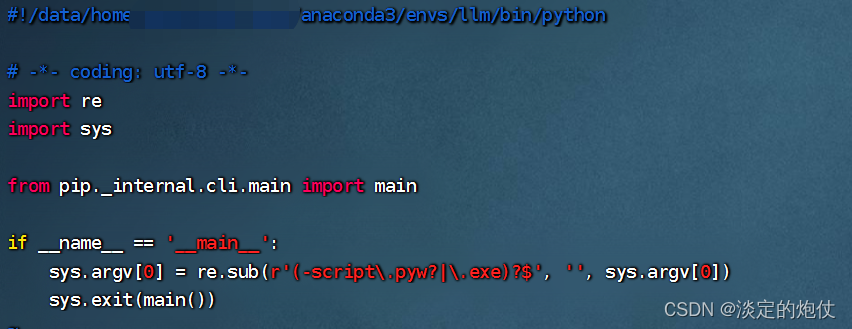
迁移conda环境后,非root用户执行pip命令和jupyter命令报错/bad interpreter: Permission denied
移动conda环境,在移动的环境执行pip和jupyter 报错-bash: /data/home/用户名/anaconda3/envs/llm/bin/pip: /root/anaconda3/envs/llm/bin/python: bad interpreter: Permission denied 报错信息 一、原因 原因是当前的这个data/home/用户名/anaconda3/envs/环境名…...
虚拟机使用linux常用问题(虚拟机操作系统:ubuntu 22.04LTS)
1.虚拟机连接外网 ubuntu解决网络连接的解决方案 CentOS7联网问题解决 明明连接好了但是没有网络的情况 2.虚拟机磁盘扩容 相关博客 利用gparted工具时,直接将unallocated空间的前一个位置的磁盘resize,将unallocated的空间全部覆盖 3.虚拟机与本机共享文件 安装vmtools 设…...
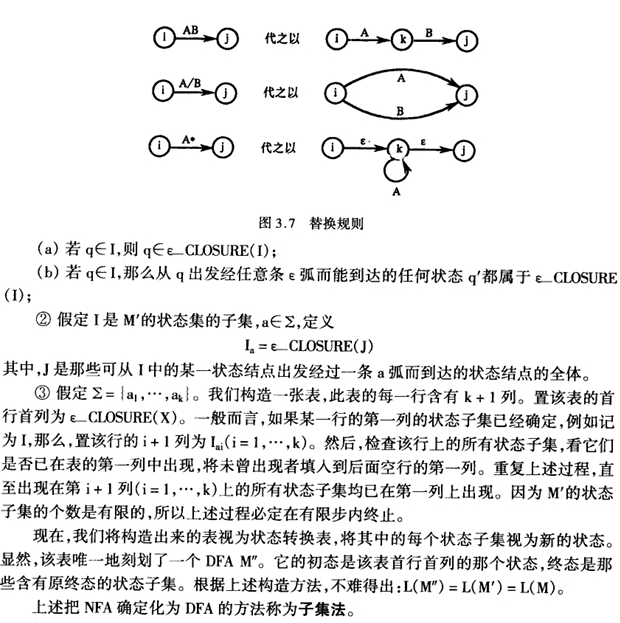
编译原理-词法分析器
文章目录 对于词法分析器的要求概念词法分析器的功能和输出形式 词法分析器的设计词法分析器的结构单词符号的识别:超前搜索状态转换图 正规表达式和有限自动机正规式和正规集确定有限自动机(DFA)非确定有限自动机(NFA)…...
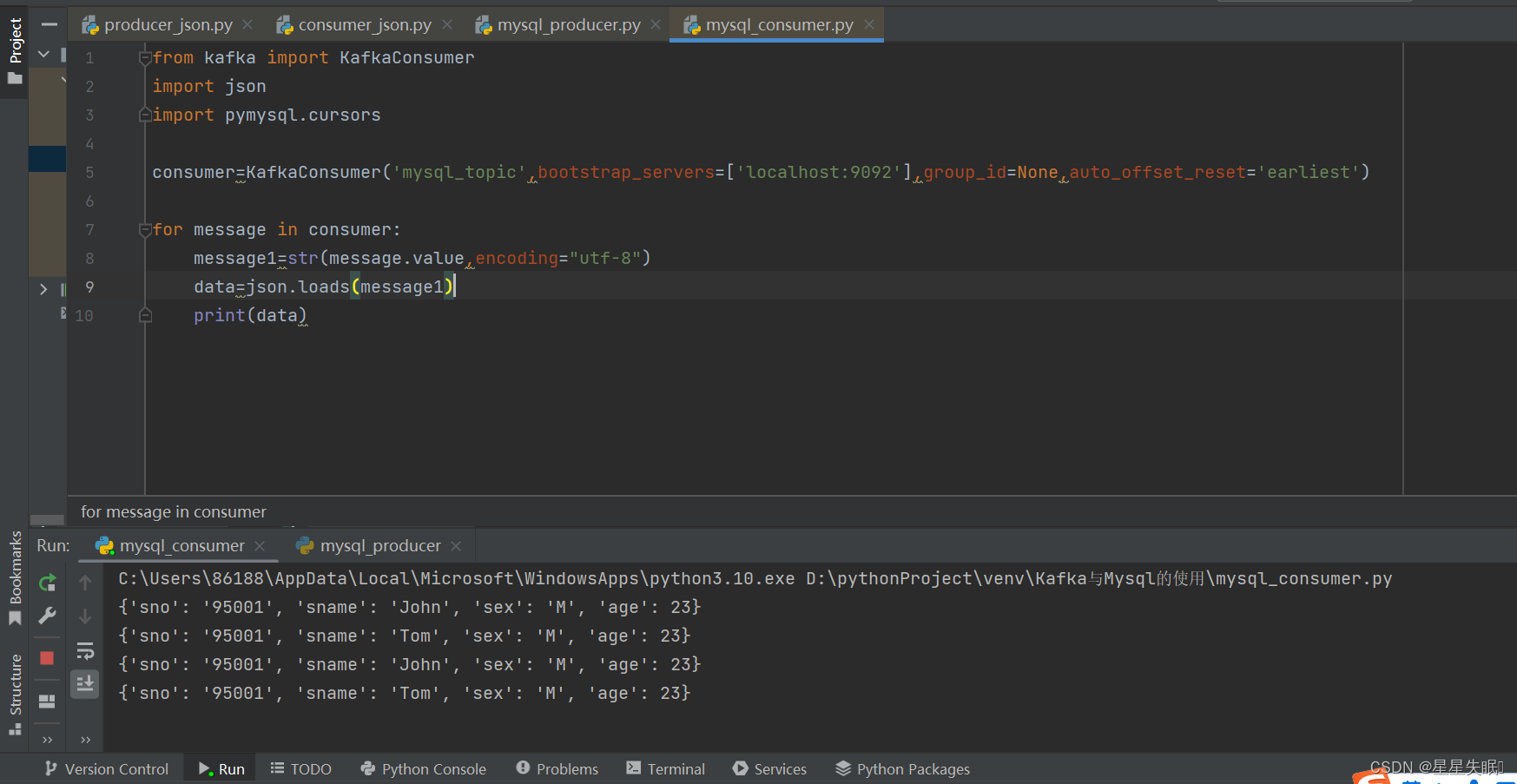
Kafka与MySQL的组合使用
根据上面给出的student表,编写Python程序完成如下操作: (1)读取student表的数据内容,将其转为JSON格式,发送给Kafka; 创建Student表的SQL语句如下: create table student( sno ch…...

2018年亚太杯APMCM数学建模大赛A题老年人平衡能力的实时训练模型求解全过程文档及程序
2018年亚太杯APMCM数学建模大赛 A题 老年人平衡能力的实时训练模型 原题再现 跌倒在老年人中很常见。跌倒可能会导致老年人出现许多并发症,因为他们的康复能力通常较差,因此副作用可能会使人衰弱,从而加速身体衰竭。此外,对跌倒…...
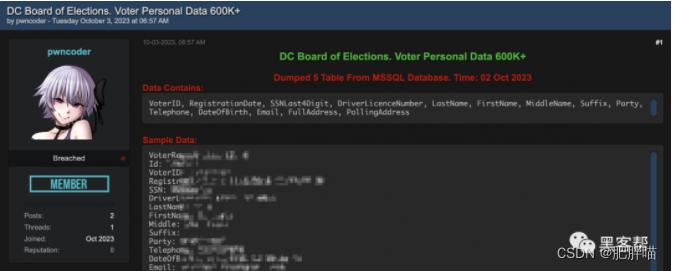
华盛顿特区选举委员会:黑客可能已侵入整个选民名册
导语 近日,华盛顿特区选举委员会(DCBOE)传来了一条令人担忧的消息:黑客可能已经侵入了整个选民名册。这一事件引发了公众的广泛关注和担忧。本文将为大家详细介绍这一事件的经过以及可能带来的后果,并探讨选民数据的保…...

2025届学术党必备的六大AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为人工智能写作工具,于学术论文撰写里能够起到辅助方面的作用…...

无效加班多,工资一般的软件开发公司有必要留在公司吗?你的代码可以重构,但你的人生不能重来。及时止损才是最理性的选择。
你的代码可以重构,但你的人生不能重来。在一家既给不了钱、又给不了成长、还在消耗你健康的公司,及时止损才是最理性的选择。 无效加班多,工资一般的软件开发公司有必要留在公司吗? 面对“无效加班多”且“工资一般”的现状&#…...

2025届学术党必备的六大AI科研工具推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 减小AIGC印记的关键之处在于模仿人类创作的非直线特性。其一,改变句式架构&#…...

ngx_sort
1 定义 ngx_sort 函数 定义在 ./nginx-1.24.0/src/core/ngx_string.cvoid ngx_sort(void *base, size_t n, size_t size,ngx_int_t (*cmp)(const void *, const void *)) {u_char *p1, *p2, *p;p ngx_alloc(size, ngx_cycle->log);if (p NULL) {return;}for (p1 (u_char…...

论文AI率80%+的紧急处理方案,答辩前用得上
距离答辩3天,AI率检出80%——这是最糟糕的时间点碰到最糟糕的问题。 不要慌,这个情况有成熟的处理方案,我见过很多人在这个时间节点成功降下来的。下面是紧急情况下的处理方法,按照时间紧迫程度分了几个场景。 先做一个判断&…...

综合能源系统中的经济-碳协调:最优调度和灵敏度分析【IEEE33节点】附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…...

Flutter Web:混合开发的最佳实践
Flutter Web:混合开发的最佳实践一次编写,多端运行。Flutter Web 让前端开发更加高效。一、Flutter Web 的优势 作为一名追求像素级还原的 UI 匠人,我对跨平台解决方案有着严格的要求。Flutter Web 不仅让我们能够使用相同的代码库构建 Andro…...
)
olonCode v0.0.20 发布 - 编程智能体(新增子代理和浏览器能力)
关于 SolonCode(编程智能体)SolonCode 是由杭州无耳科技有限公司,基于 Java 8 Solon AI 开发的 “Claude Code” 国产开源实现版本。它不仅是一个 AI 终端智能助手(帮你查资料、写报告、发邮件,生成图片、视频&#x…...

跨平台电子书阅读器 | Readest最新版 安卓版+PC版全平台
软件简介: Readest 是一款现代化、功能丰富的电子书阅读器,专为狂热读者设计,提供无缝的跨平台访问、强大的工具和直观的界面,以提升你的阅读体验。 功能特点: 多格式支持 – 支持 EPUB、MOBI、KF8(AZW3…...

如何运用AI技术有效破解企业视觉检测难题
「本文已用流量券推广,欢迎收藏 关注」AI智能体视觉检测系统(TVA)的核心突破,在于实现了从“被动识别”到“主动决策”的历史性跨越。以汽车零部件制造车间的经典场景为例,螺母焊接点的质检曾是长期困扰各个企业多年的…...