【Gensim概念】03/3 NLP玩转 word2vec
第三部分 对象函数

八 word2vec对象函数
该对象本质上包含单词和嵌入之间的映射。训练后,可以直接使用它以各种方式查询这些嵌入。有关示例,请参阅模块级别文档字符串。
类型
KeyedVectors
1) add_lifecycle_event(event_name, log_level=20, **event)
将事件附加到该对象的生命周期事件属性中,还可以选择在log_level记录该事件。
事件是对象生命周期中的重要时刻,例如“模型创建”、“模型保存”、“模型加载”等。
Lifecycle_events属性在对象 和操作之间保持不变。它对模型的使用没有影响,但在调试和支持过程中很有用。save()load()
设置self.lifecycle_events = None以禁用此行为。调用add_lifecycle_event() 不会将事件记录到self.lifecycle_events中。
参数:
-
event_name ( str ) – 事件的名称。可以是任何标签,例如“创建”、“存储”等。
-
事件(字典)–
要附加到self.lifecycle_events 的键值映射。应该是 JSON 可序列化的,所以保持简单。可以为空。
此方法会自动将以下键值添加到event,因此您不必指定它们:
-
日期时间:当前日期和时间
-
gensim:当前的 Gensim 版本
-
python : 当前的Python版本
-
平台:当前平台
-
事件:此事件的名称
-
-
log_level ( int ) – 还以指定的日志级别记录完整的事件字典。设置为 False 则根本不记录。
2)add_null_word()
3)build_vocab(
corpus_iterable=None,
corpus_file=None, update=False,
progress_per=10000,
keep_raw_vocab=False,
trim_rule=None,
**kwargs)
从一系列句子构建词汇(可以是一次性生成器流)。
参数
-
corpus_iterable ( iterable of list of str ) – 可以只是标记列表的列表,但对于较大的语料库,请考虑直接从磁盘/网络流式传输句子的迭代。有关此类示例,请参阅BrownCorpus,Text8Corpus 或LineSentencemodule 。
-
corpus_file ( str ,可选) – 格式的语料库文件的路径LineSentence。您可以使用此参数而不是句子来提高性能。仅需要传递句子或 corpus_file参数之一(而不是两者)。
-
update ( bool ) – 如果为 true,句子中的新单词将添加到模型的词汇表中。
-
Progress_per ( int ,可选) – 指示在显示/更新进度之前要处理多少个单词。
-
keep_raw_vocab ( bool ,可选) – 如果为 False,则在缩放完成以释放 RAM 后将删除原始词汇。
-
trim_rule (function, optional) -
词汇表修剪规则,指定某些单词是否应保留在词汇表中、被修剪掉或使用默认值进行处理(如果字数 < min_count 则丢弃)。可以是 None (将使用 min_count,请查看),或者是接受参数(word、count、min_count)并返回、或 的keep_vocab_item()可调用函数 。该规则(如果给定)仅用于在当前方法调用期间修剪词汇,并且不存储为模型的一部分。
gensim.utils.RULE_DISCARDgensim.utils.RULE_KEEPgensim.utils.RULE_DEFAULT输入参数有以下几种类型:
-
word (str) - 我们正在检查的单词
-
count (int) - 语料库中单词的频率计数
-
min_count (int) - 最小计数阈值。
-
-
**kwargs ( object ) – 传播到self.prepare_vocab 的关键字参数。
4)build_vocab_from_freq(
word_freq, keep_raw_vocab=False,
corpus_count=None,
trim_rule=None,
update=False)
从词频词典中构建词汇表。
参数
-
word_freq ( dict of ( str , int ) ) – 从词汇表中的单词到其频率计数的映射。
-
keep_raw_vocab ( bool ,可选) – 如果为 False,则在缩放完成后删除原始词汇以释放 RAM。
-
corpus_count ( int ,可选) – 即使没有提供语料库,此参数也可以显式设置 corpus_count。
-
修剪规则(函数,可选)-
词汇表修剪规则,指定某些单词是否应保留在词汇表中、被修剪掉或使用默认值进行处理(如果字数 < min_count 则丢弃)。可以是 None (将使用 min_count,请查看),或者是接受参数(word、count、min_count)并返回、或 的keep_vocab_item()可调用函数 。该规则(如果给定)仅用于在当前方法调用期间修剪词汇,并且不存储为模型的一部分。
gensim.utils.RULE_DISCARDgensim.utils.RULE_KEEPgensim.utils.RULE_DEFAULT输入参数有以下几种类型:
-
word (str) - 我们正在检查的单词
-
count (int) - 语料库中单词的频率计数
-
min_count (int) - 最小计数阈值。
-
-
update ( bool ,可选) – 如果为 true,则word_freq字典中提供的新单词将被添加到模型的词汇中。
5)create_binary_tree()
创建二叉树( )
使用存储的词汇字数创建二叉霍夫曼树。频繁出现的单词将具有较短的二进制代码。从 内部调用build_vocab()。
估计内存(vocab_size =无,报告=无)
使用当前设置和提供的词汇量估计模型所需的内存。
参数
-
vocab_size ( int ,可选) – 词汇表中唯一标记的数量
-
report ( dict of ( str , int ) ,可选) – 从模型内存消耗成员的字符串表示形式到其大小(以字节为单位)的字典。
返回
从模型内存消耗成员的字符串表示形式到其大小(以字节为单位)的字典。
返回类型
(str, int) 的字典
6)get_latest_training_loss()
获取训练损失的当前值。
返回
当前训练损失。
返回类型
浮点
7)init_sims(replace=False)
预先计算 L2 标准化向量。已过时。
如果您需要某个键的单个单位归一化向量,请 get_vector()改为调用: 。word2vec_model.wv.get_vector(key, norm=True)
要在执行一些非典型带外矢量篡改后刷新规范,请改为调用:meth:`~gensim.models.keyedvectors.KeyedVectors.fill_norms()。
参数
Replace ( bool ) – 如果为 True,则忘记原始训练向量并仅保留标准化向量。如果您这样做,您就会丢失信息。
8)init_weights()
将所有投影权重重置为初始(未训练)状态,但保留现有词汇表。
9)classmethodload(*args, rethrow=False, **kwargs)
加载以前保存的Word2Vec模型。
也可以看看
save()
保存模型。
参数
fname ( str ) – 保存文件的路径。
退货
已加载模型。
返回类型
Word2Vec
10)make_cum_table(domain=2147483647)
使用存储的词汇字数创建累积分布表,以便在负采样训练例程中绘制随机单词。
要绘制单词索引,请选择一个随机整数,直到表中的最大值 (cum_table[-1]),然后找到该整数的排序插入点(就像通过 bisect_left 或 ndarray.searchsorted( )一样)。该插入点是绘制的索引,其按比例等于该槽处的增量。
11)predict_output_word(context_words_list, topn=10)
获取给定上下文单词的中心单词的概率分布。
请注意,即使在 SG 模型中,这也会执行 CBOW 式的传播,并且不会像训练中那样对周围的单词进行加权——因此,这只是使用经过训练的模型作为预测器的一种粗略方法。
参数
-
context_words_list ( list of ( str 和/或 int ) ) – 上下文单词列表,可能是单词本身 (str) 或其在self.wv.vectors (int) 中的索引。
-
topn ( int ,可选) – 返回topn单词及其概率。
return
topn长度的(单词,概率)元组列表。
返回类型
(str, float) 列表
12)prepare_vocab(
update=False,
keep_raw_vocab=False,
trim_rule=None,
min_count=None,
sample=None,
dry_run=False)
对min_count(丢弃频率较低的单词)和样本(控制频率较高的单词的下采样)应用词汇设置。
使用dry_run=True进行调用只会模拟提供的设置并报告保留词汇的大小、有效语料库长度和估计的内存需求。结果均通过日志记录打印并以字典形式返回。
缩放完成后删除原始词汇以释放 RAM,除非设置了keep_raw_vocab 。
13)prepare_weights(update=False)
根据最终词汇设置构建表格和模型权重。
14)reset_from(other_model)
从other_model借用可共享的预构建结构并重置隐藏层权重。
复制的结构是:
-
词汇
-
索引到词映射
-
累积频率表(用于负采样)
-
缓存语料库长度
在同一语料库上并行测试多个模型时非常有用。然而,由于模型共享除向量之外的所有词汇相关结构,因此两个模型都不应该扩展其词汇量(这可能会使另一个模型处于不一致、损坏的状态)。而且,对每个单词“vecattr”的任何更改都会影响这两个模型。
参数
15)other_model ( Word2Vec) – 从中复制内部结构的另一个模型。
16)save(*args, **kwargs)
保存(* args, ** kwargs)
保存模型。可以使用 再次加载保存的模型load(),它支持在线训练和获取词汇向量。
参数
fname ( str ) – 文件的路径。
17)scan_vocab(
corpus_iterable=None,
corpus_file=None,
progress_per=10000,
workers=None,
trim_rule=None)
18)score(
sentences,
total_sentences=1000000,
chunksize=100,
queue_factor=2,
report_delay=1)
对一系列句子的对数概率进行评分。这不会以任何方式改变拟合模型(参见train()参考资料)。
Gensim 目前仅实现了分层 softmax 方案的分数,因此您需要在hs=1和negative=0的情况下运行 word2vec 才能正常工作。
请注意,您应该指定total_sentences;如果你要求得分超过这个数量的句子,你就会遇到问题,但将值设置得太高是低效的。
请参阅Matt Taddy 的文章:“通过分布式语言表示反转进行文档分类”和 gensim 演示,了解如何在文档分类中使用此类分数的示例。
参数
-
Sentences ( iterable of list of str ) – Sentences iterable 可以简单地是 token 列表的列表,但对于较大的语料库,请考虑直接从磁盘/网络流式传输句子的 iterable。请参阅BrownCorpus、Text8Corpus 或模块LineSentence中的word2vec此类示例。
-
Total_sentences ( int ,可选) – 句子计数。
-
chunksize ( int ,可选) – 作业的块大小
-
queue_factor ( int ,可选) – 队列大小的乘数(工作人员数量 * queue_factor)。
-
report_delay ( float ,可选) – 报告进度之前等待的秒数。
19 seeded_vector(seed_string, vector_size)
20)
train(corpus_iterable=None, corpus_file=None, total_examples=None, total_words=None, epochs=None, start_alpha=None, end_alpha=None, word_count=0, queue_factor=2, report_delay=1.0, compute_loss=False, callbacks=(), **kwargs)
根据句子序列更新模型的神经权重。
注意:
为了支持从(初始) alpha到min_alpha的线性学习率衰减以及准确的进度百分比记录,必须提供total_examples(句子计数)或total_words(句子中的原始单词计数) 。如果句子与之前提供的语料库相同,则可以简单地使用total_examples=self.corpus_count。build_vocab()
警告
为了避免模型自身进行多次训练的能力出现常见错误,必须提供明确的epochs参数。在常见且推荐的仅调用一次的情况下,您可以设置epochs=self.epochs。train()
参数
-
corpus_iterable ( str 列表的可迭代) –
它
corpus_iterable可以是简单的标记列表列表,但对于较大的语料库,请考虑直接从磁盘/网络流式传输句子的迭代,以限制 RAM 使用。请参阅BrownCorpus、Text8Corpus 或模块LineSentence中的word2vec此类示例。另请参阅有关 Python 中的数据流的教程。 -
corpus_file ( str ,可选) – 格式的语料库文件的路径LineSentence。您可以使用此参数而不是句子来提高性能。仅需要传递句子或 corpus_file参数之一(而不是两者)。
-
Total_examples ( int ) – 句子计数。
-
Total_words ( int ) – 句子中原始单词的计数。
-
epochs ( int ) – 语料库的迭代次数(epoch)。
-
start_alpha ( float ,可选) – 初始学习率。如果提供,则替换构造函数中的起始alpha,以调用“train()”。仅当您想要自己管理 alpha 学习率时多次调用train()时才使用(不推荐)。
-
end_alpha ( float ,可选) – 最终学习率。从start_alpha线性下降。如果提供的话,这将替换构造函数中的最终min_alpha,对于这一次对train()的调用。仅当您想要自己管理 alpha 学习率时多次调用train()时才使用(不推荐)。
-
word_count ( int ,可选) – 已训练的单词计数。对于对句子中所有单词进行训练的通常情况,将其设置为 0。
-
queue_factor ( int ,可选) – 队列大小的乘数(工作人员数量 * queue_factor)。
-
report_delay ( float ,可选) – 报告进度之前等待的秒数。
-
compute_loss ( bool ,可选) – 如果为 True,则计算并存储可以使用 检索的损失值 get_latest_training_loss()。
-
callback(可迭代CallbackAny2Vec,可选)- 在训练期间的特定阶段执行的回调序列。
例子
>>> from gensim.models import Word2Vec
>>> sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
>>>
>>> model = Word2Vec(min_count=1)
>>> model.build_vocab(sentences) # prepare the model vocabulary
>>> model.train(sentences, total_examples=model.corpus_count, epochs=model.epochs) # train word vectors
(1, 30)
21) update_weights()
复制所有现有权重,并重置新添加词汇的权重。
九、classgensim.models.word2vec.Word2VecTrainables
class gensim.models.word2vec.Word2Vect
基类:SaveLoad
现在保留过时的类作为加载兼容性状态捕获。
1) add_lifecycle_event ( event_name , log_level = 20 , **evnt)
将事件附加到该对象的生命周期事件属性中,还可以选择在log_level记录该事件。
事件是对象生命周期中的重要时刻,例如“模型创建”、“模型保存”、“模型加载”等。
Lifecycle_events属性在对象 和操作之间保持不变。它对模型的使用没有影响,但在调试和支持过程中很有用。save()load()
设置self.lifecycle_events = None以禁用此行为。调用add_lifecycle_event() 不会将事件记录到self.lifecycle_events中。
参数
-
event_name ( str ) – 事件的名称。可以是任何标签,例如“创建”、“存储”等。
-
event(字典)–要附加到self.lifecycle_events 的键值映射。应该是 JSON 可序列化的,所以保持简单。可以为空。
此方法会自动将以下键值添加到event,因此您不必指定它们:
-
日期时间:当前日期和时间
-
gensim:当前的 Gensim 版本
-
python : 当前的Python版本
-
平台:当前平台
-
事件:此事件的名称
-
-
log_level ( int ) – 还以指定的日志级别记录完整的事件字典。设置为 False 则根本不记录。
类方法加载(fname, mmap = None)
save()从文件中加载先前保存的对象。
参数
-
fname ( str ) – 包含所需对象的文件的路径。
-
mmap ( str ,可选) – 内存映射选项。如果对象是用单独存储的大型数组保存的,则可以使用mmap='r' 通过 mmap(共享内存)加载这些数组。如果正在加载的文件是压缩的(“.gz”或“.bz2”),则 必须设置“mmap=None”。
也可以看看
save()
将对象保存到文件。
退货
从fname加载的对象。
返回类型
目的
提高
AttributeError – 当调用对象实例而不是类时(这是一个类方法)。
保存(fname_or_handle,单独= None, sep_limit = 10485760, ignore = freezeset({}), pickle_protocol = 4)
将对象保存到文件中。
参数
-
fname_or_handle ( str或file-like ) – 输出文件或已打开的类文件对象的路径。如果对象是文件句柄,则不会执行特殊的数组处理,所有属性将保存到同一个文件中。
-
单独( str或None列表,可选) –
如果为 None,则自动检测正在存储的对象中的大型 numpy/scipy.sparse 数组,并将它们存储到单独的文件中。这可以防止大对象的内存错误,并且还允许对 大数组进行内存映射,以便在多个进程之间高效加载和共享 RAM 中的大数组。
如果是 str 列表:将这些属性存储到单独的文件中。在这种情况下,不执行自动尺寸检查。
-
sep_limit ( int ,可选) – 不要单独存储小于此值的数组。以字节为单位。
-
ignore ( fredset of str ,可选) – 根本不应该存储的属性。
-
pickle_protocol ( int ,可选) – pickle 的协议号。
也可以看看
load()
从文件加载对象。
class gensim.models.word2vec。Word2VecVocab
基地:SaveLoad
现在保留过时的类作为加载兼容性状态捕获。
add_lifecycle_event ( event_name , log_level = 20 , **事件)
将事件附加到该对象的生命周期事件属性中,还可以选择在log_level记录该事件。
事件是对象生命周期中的重要时刻,例如“模型创建”、“模型保存”、“模型加载”等。
Lifecycle_events属性在对象 和操作之间保持不变。它对模型的使用没有影响,但在调试和支持过程中很有用。save()load()
设置self.lifecycle_events = None以禁用此行为。调用add_lifecycle_event() 不会将事件记录到self.lifecycle_events中。
参数
-
event_name ( str ) – 事件的名称。可以是任何标签,例如“创建”、“存储”等。
-
事件(字典)–
要附加到self.lifecycle_events 的键值映射。应该是 JSON 可序列化的,所以保持简单。可以为空。
此方法会自动将以下键值添加到event,因此您不必指定它们:
-
日期时间:当前日期和时间
-
gensim:当前的 Gensim 版本
-
python : 当前的Python版本
-
平台:当前平台
-
事件:此事件的名称
-
-
log_level ( int ) – 还以指定的日志级别记录完整的事件字典。设置为 False 则根本不记录。
类方法加载(fname, mmap = None)
save()从文件中加载先前保存的对象。
参数
-
fname ( str ) – 包含所需对象的文件的路径。
-
mmap ( str ,可选) – 内存映射选项。如果对象是用单独存储的大型数组保存的,则可以使用mmap='r' 通过 mmap(共享内存)加载这些数组。如果正在加载的文件是压缩的(“.gz”或“.bz2”),则 必须设置“mmap=None”。
也可以看看
save()
将对象保存到文件。
退货
从fname加载的对象。
返回类型
目的
提高
AttributeError – 当调用对象实例而不是类时(这是一个类方法)。
save(fname_or_handle,单独= None, sep_limit = 10485760, ignore = freezeset({}), pickle_protocol = 4)
将对象保存到文件中。
参数
-
fname_or_handle ( str或file-like ) – 输出文件或已打开的类文件对象的路径。如果对象是文件句柄,则不会执行特殊的数组处理,所有属性将保存到同一个文件中。
-
单独( str或None列表,可选) –
如果为 None,则自动检测正在存储的对象中的大型 numpy/scipy.sparse 数组,并将它们存储到单独的文件中。这可以防止大对象的内存错误,并且还允许对 大数组进行内存映射,以便在多个进程之间高效加载和共享 RAM 中的大数组。
如果是 str 列表:将这些属性存储到单独的文件中。在这种情况下,不执行自动尺寸检查。
-
sep_limit ( int ,可选) – 不要单独存储小于此值的数组。以字节为单位。
-
ignore ( fredset of str ,可选) – 根本不应该存储的属性。
-
pickle_protocol ( int ,可选) – pickle 的协议号。
也可以看看
相关文章:
【Gensim概念】03/3 NLP玩转 word2vec
第三部分 对象函数 八 word2vec对象函数 该对象本质上包含单词和嵌入之间的映射。训练后,可以直接使用它以各种方式查询这些嵌入。有关示例,请参阅模块级别文档字符串。 类型 KeyedVectors 1) add_lifecycle_event(event_name, log_level2…...
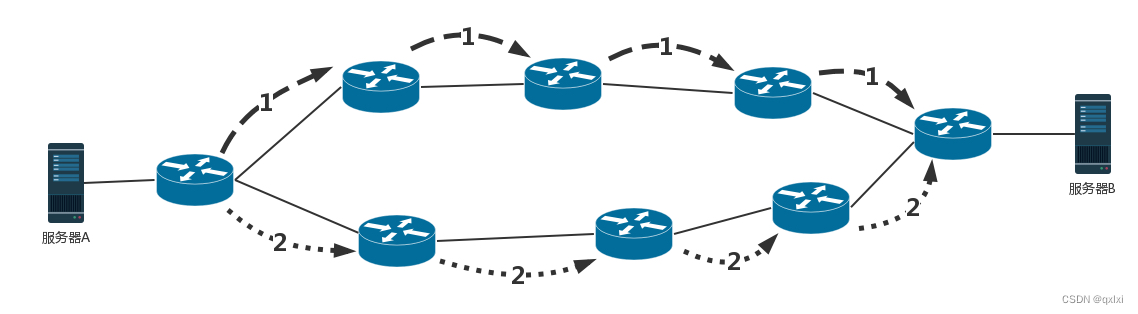
【网络协议】聊聊网络路由相关算法
如何配置路由 路由器是一台网络设备,多张网卡,当一个入口的网络包到达路由器时,会根据本地的信息库决定如何正确的转发流量,通常称为路由表 路由表主要包含如下 核心思想是根据目的 IP 地址来配置路由 目的网络:要去…...

Python 深度学习入门之CNN
CNN 前言一、CNN简介1、简介2、结构 二、CNN简介1、输出层2、卷积层3、池化层4、全连接层5、输出层 前言 1024快乐!1024快乐!今天开新坑,学点深度学习相关的,说下比较火的CNN。 一、CNN简介 1、简介 CNN的全称是Convolutiona…...

国产开发板上打造开源ThingsBoard工业网关--基于米尔芯驰MYD-JD9X开发板
本篇测评由面包板论坛的优秀测评者“JerryZhen”提供。 本文将介绍基于米尔电子MYD-JD9X开发板打造成开源的Thingsboard网关。 Thingsboard网关是一个开源的软件网关,采用python作为开发语言,可以部署在任何支持 python 运行环境的主机上,灵…...

英语——语法——从句——名词性从句——笔记
文章目录 名词性从句一、定义二、分类(一)宾语从句(二)主语从句(三)C同位语从句(四)D表语从句 名词性从句 一、句子成分 简而言之,构成一个句子的成分(或要素…...

PROSTATEx-2 上前列腺癌的 3D CNN 分类
内容 本文介绍了在多参数 MRI 序列上使用 3D CNN 对前列腺癌进行显着性或不显着性分类。内容如下: 数据集描述Dicom 到 Nifti 文件格式的转换不同 MRI 序列的联合配准...

npm ERR! node-sass@6.0.1 postinstall: `node scripts/build.js`
1.遇到的问题 vue npm install提示以下错误 2.首次尝试方法 尝试用下面的方式重新安装弄得-saas,结果不起作用 。 npm config set sass_binary_sitehttps://npm.taobao.org/mirrors/node-sass npm install node-sass 这时考虑降级node版本,node.js从…...

3D学习论文参考-ACCURATE EYE PUPIL LOCALIZATION USING HETEROGENEOUS CNN MODELS
以下是该文档的关键内容: 该论文提出了一种使用异构卷积神经网络(CNN)模型的精确眼睛瞳孔定位算法。这种算法可以抵抗光照、图像分辨率和眼镜佩戴等干扰条件,同时具有高准确性。该算法由两部分组成:一是找到近似眼睛区…...
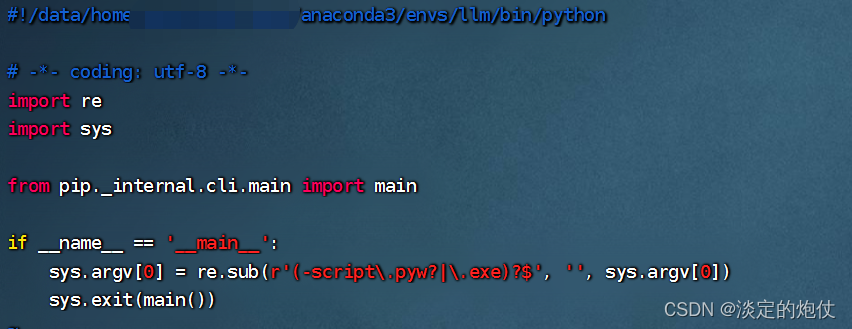
迁移conda环境后,非root用户执行pip命令和jupyter命令报错/bad interpreter: Permission denied
移动conda环境,在移动的环境执行pip和jupyter 报错-bash: /data/home/用户名/anaconda3/envs/llm/bin/pip: /root/anaconda3/envs/llm/bin/python: bad interpreter: Permission denied 报错信息 一、原因 原因是当前的这个data/home/用户名/anaconda3/envs/环境名…...
虚拟机使用linux常用问题(虚拟机操作系统:ubuntu 22.04LTS)
1.虚拟机连接外网 ubuntu解决网络连接的解决方案 CentOS7联网问题解决 明明连接好了但是没有网络的情况 2.虚拟机磁盘扩容 相关博客 利用gparted工具时,直接将unallocated空间的前一个位置的磁盘resize,将unallocated的空间全部覆盖 3.虚拟机与本机共享文件 安装vmtools 设…...
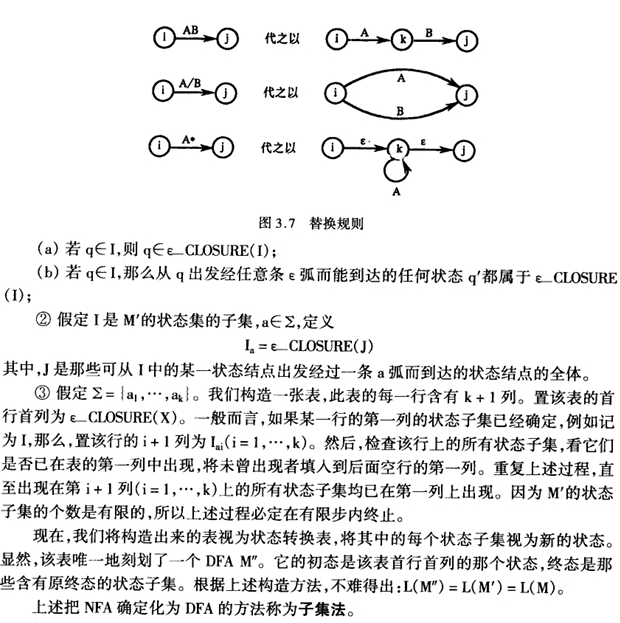
编译原理-词法分析器
文章目录 对于词法分析器的要求概念词法分析器的功能和输出形式 词法分析器的设计词法分析器的结构单词符号的识别:超前搜索状态转换图 正规表达式和有限自动机正规式和正规集确定有限自动机(DFA)非确定有限自动机(NFA)…...
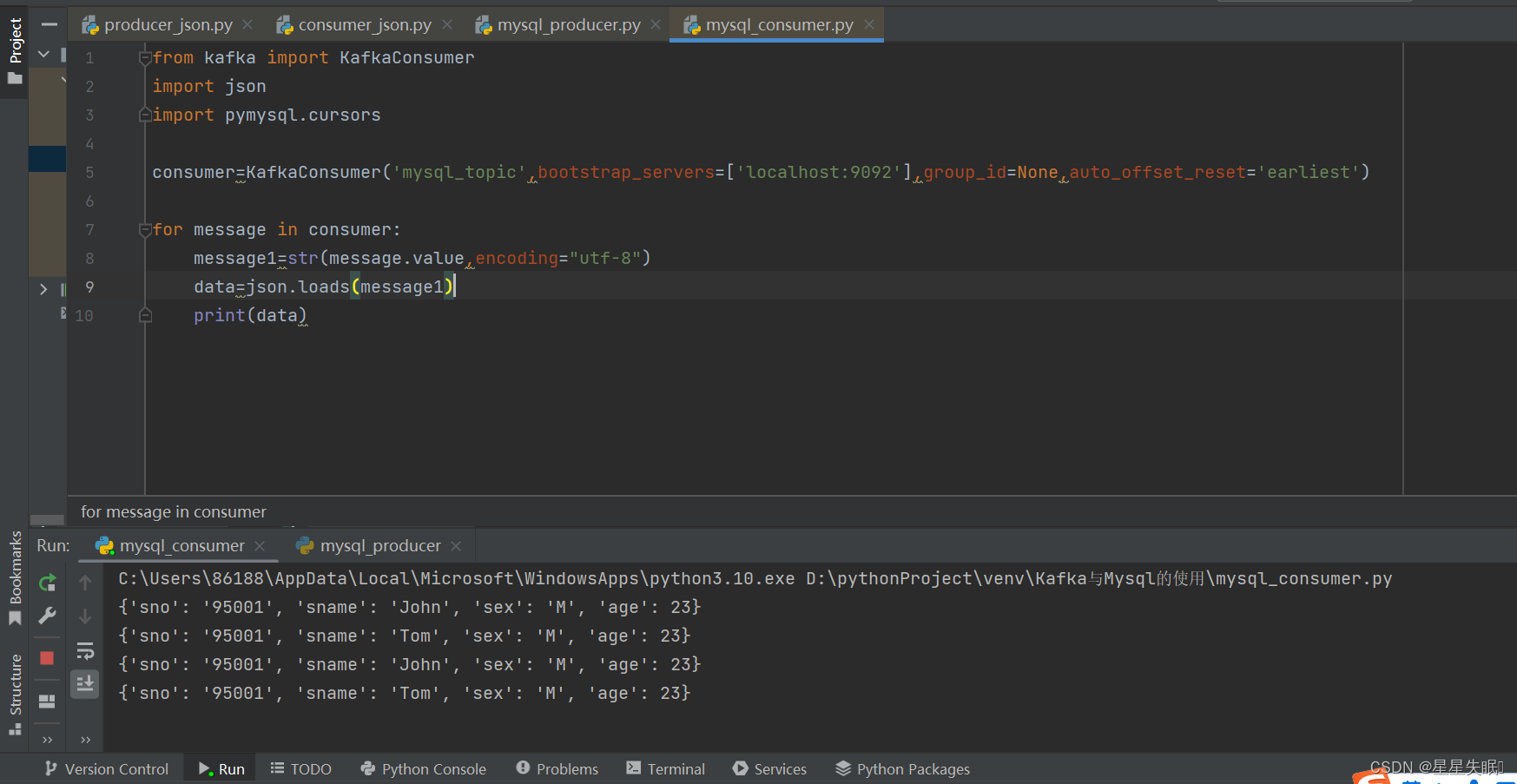
Kafka与MySQL的组合使用
根据上面给出的student表,编写Python程序完成如下操作: (1)读取student表的数据内容,将其转为JSON格式,发送给Kafka; 创建Student表的SQL语句如下: create table student( sno ch…...

2018年亚太杯APMCM数学建模大赛A题老年人平衡能力的实时训练模型求解全过程文档及程序
2018年亚太杯APMCM数学建模大赛 A题 老年人平衡能力的实时训练模型 原题再现 跌倒在老年人中很常见。跌倒可能会导致老年人出现许多并发症,因为他们的康复能力通常较差,因此副作用可能会使人衰弱,从而加速身体衰竭。此外,对跌倒…...
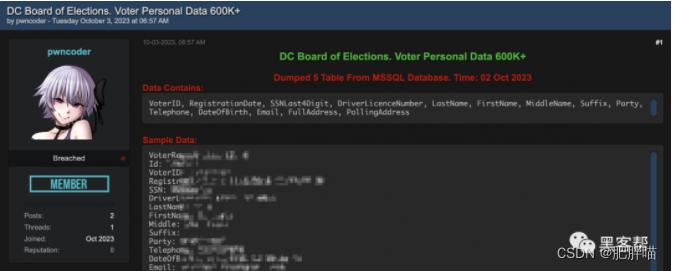
华盛顿特区选举委员会:黑客可能已侵入整个选民名册
导语 近日,华盛顿特区选举委员会(DCBOE)传来了一条令人担忧的消息:黑客可能已经侵入了整个选民名册。这一事件引发了公众的广泛关注和担忧。本文将为大家详细介绍这一事件的经过以及可能带来的后果,并探讨选民数据的保…...
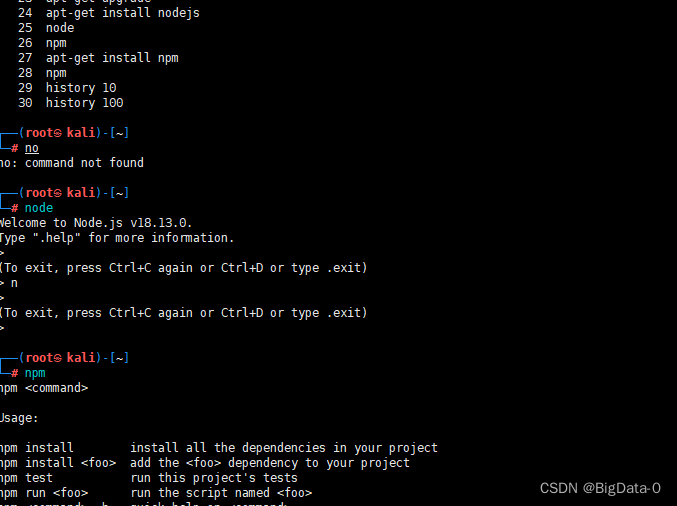
kali安装nodejs、npm失败
更新apt-get再安装,更新时间比较久,看网速,中间有一些确认步骤 22 apt-get update23 apt-get upgrade24 apt-get install nodejs25 node26 npm27 apt-get install npm...
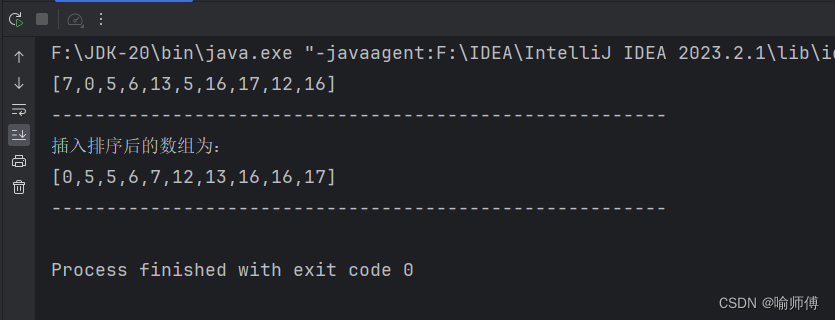
插入排序(学习笔记)
插入排序 每一轮插入排序后的结果与打扑克牌取牌原理相似,将取到的牌插入到合适的位置,但在程序实现方面还是基于交换的算法。 它的基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增1的有序表。 import java.util.…...
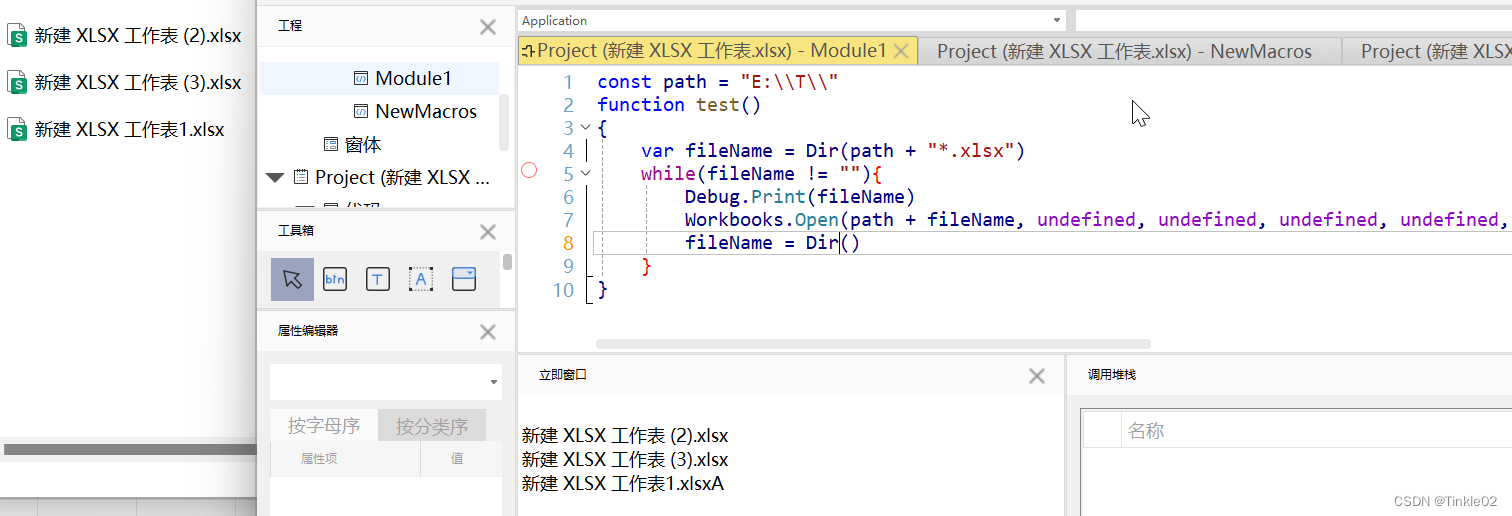
wps excel js编程
定义全局变量 const a "dota" function test() {Debug.Print(a) }获取表格中单元格内容 function test() {Debug.Print("第一行第二列",Cells(1,2).Text)Debug.Print("A1:",Range("A1").Text) }写单元格 Range("C1").Val…...
Python 类继承解释
一、说明 类继承是Python中数据科学家和机器学习工程师需要了解的一个重要概念。在这里,我们的专家解释了它的工作原理。 在Python中,类包含属性和方法。属性是存储数据的变量。类方法是属于类的函数,通常对类属性执行一些逻辑。在本文中&…...

Reactor反应器模式
文章目录 一、单线程Reactor反应器模式二、多线程Reactor反应器模式 在Java的OIO编程中,最初和最原始的网络服务器程序使用一个while循环,不断地监听端口是否有新的连接,如果有就调用一个处理函数来处理。这种方法最大的问题就是如果前一个网…...
 -- JavaBean==》Json字符串、JSONObject、JSONArray)
alibaba.fastjson的使用(六) -- JavaBean==》Json字符串、JSONObject、JSONArray
目录 1. JavaBean转 Json字符串 2. JavaBean转 JSONObject 3. List转JSONArray 在pom文件中引入依赖: <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.14</version></dependency&…...

蓝桥杯19725最优分组
import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);int n scanner.nextInt();double p scanner.nextDouble();double minCost Double.MAX_VAL…...
Android 14 ShellTransitions 实战:手把手教你理解 Transition 如何“抓取”动画参与者(WindowContainer 篇)
Android 14 ShellTransitions 深度解析:WindowContainer 动画参与者捕获机制实战指南 在 Android 14 的动画框架革新中,ShellTransitions 引入了一套精密的"参与者捕获"系统,其运作机制堪比特种部队的精准行动。本文将带您深入这套…...

Flutter Web:混合开发的最佳实践
Flutter Web:混合开发的最佳实践一次编写,多端运行。Flutter Web 让前端开发更加高效。一、Flutter Web 的优势 作为一名追求像素级还原的 UI 匠人,我对跨平台解决方案有着严格的要求。Flutter Web 不仅让我们能够使用相同的代码库构建 Andro…...

MaaYuan自动化辅助工具高效配置避坑指南:零基础入门三步完成环境部署
MaaYuan自动化辅助工具高效配置避坑指南:零基础入门三步完成环境部署 【免费下载链接】MaaYuan 代号鸢 / 如鸢 一键长草小助手 项目地址: https://gitcode.com/gh_mirrors/ma/MaaYuan MaaYuan作为一款基于MaaFramework的自动化辅助工具,专为游戏日…...

res-downloader:全平台网络资源下载工具的高效使用指南
res-downloader:全平台网络资源下载工具的高效使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 当你在微信…...

2026大模型训练全景,从底座到上线,决定AI体验的完整链路
在人工智能飞速发展的2026年,大众对大模型的认知早已不再停留在“参数越大越强”的简单层面。我们日常使用AI助手时感受到的流畅对话、精准指令响应、高效工具调用,甚至稳定可靠的输出风格,背后都不是单一的预训练环节在支撑,而是…...
)
SR-MPLS BE vs TE实战选择:在华三设备上如何根据业务需求规划最优路径(含HCL实验拓扑)
SR-MPLS路径规划实战:华三设备业务驱动型网络设计指南 当企业网络承载的业务类型日益复杂,从普通的办公OA到关键视频会议、实时交易系统并存时,网络工程师面临的核心挑战在于:如何让网络基础设施智能适配不同业务的服务质量需求&a…...

2026最权威的五大降AI率方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在进行 内容创作 时,要降低 AIGC 率,其核心之处在于 削弱 机器生成所…...
)
保姆级教程:用cam_lidar_calibration搞定激光雷达与相机标定(附避坑指南)
从零实现激光雷达与相机高精度标定:cam_lidar_calibration实战全解析 当激光雷达的点云遇上相机的像素,如何让它们"说同一种语言"?传感器标定就像给两个陌生人做翻译,而外参标定决定了翻译的准确性。今天我们要拆解的ca…...

抖音无水印批量下载工具:高效内容采集解决方案
抖音无水印批量下载工具:高效内容采集解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...