Python 类继承解释
一、说明
二、PYTHON 中的类继承
继承允许您定义一个新类,该新类可以访问已定义的另一个类的方法和属性。具有将被另一个类继承的方法和属性的类称为父类。能够访问父类的属性和方法的类称为子类。
萨德拉赫·皮埃尔的更多作品Python 中的函数包装器:模型运行时和调试
2.1 什么是类继承?
继承允许您定义一个新类,该新类可以访问已定义的另一个类的方法和属性。具有将被另一个类继承的方法和属性的类称为父类。您可能遇到的父类的其他名称是基类和超类。能够访问父类的属性和方法的类称为子类。子类也称为子类。除了定义从现有类继承的类之外,还可以定义从多个父类继承的子类。
2.2 如何创建子类
子类继承父类的方法和属性。子类的其他名称是子类和派生类。子类可用于通过添加新方法和属性来扩展父类的功能。它还可用于覆盖或自定义父类。
子类是通过将父类作为参数传递给子类来定义的:
Class ChildClass(ParentClass):
def __init__(self):super().__iniit__(attribute)
def print_attribute(self):print(“attribute inherited from Parent Class:”, self.attribute)
2.3 如何创建父类
父类具有由新子类继承的方法和属性。父类具有可以由子类覆盖或自定义的方法和属性。在Python中定义父类的方法很简单,就是定义一个带有方法和属性的类,就像通常定义一个普通的类一样。
下面,我们定义一个简单的父类示例。该init方法是存在的,就像我们对普通类一样。在该init方法中,我们定义一个类属性并在该类属性中存储一些值。然后我们定义一个名为的类方法,print_attribute该方法打印该方法中定义的属性init:
Class ParentClass:
def __init__(self, attribute):self.attribute = attribute
def print_attribute(self):print(Self.attribute)
2.4 继承的好处
继承非常强大,因为它允许开发人员限制代码重复。通过设计类的层次结构,您可以防止执行相同任务的重复代码行。这不仅使代码易于阅读,而且还显着提高了可维护性。例如,如果代码中有很多地方要计算模型预测的错误率,则可以将其重构为由子类继承的父类方法。
当层次类设计(继承)做得好时,它也使测试和调试变得更加容易。这是因为明确定义的任务将被本地化到代码库中的单个位置,因此当需要更改任务的完成方式时,找到需要更改的必要代码应该很简单。此外,一旦对父类中的方法进行更改,该更改就会传播到所有无关的子类。
三、Python 中类继承的示例
我们用于机器学习的许多包(例如Scikit-learn和Keras)都包含从父类继承的类。例如,线性回归、支持向量机和随机森林等类都是从称为 BaseEstimator 的父类继承的子类。基本估计器类包含大多数数据科学家应该熟悉的预测和拟合等方法。
一个更有趣的应用是通过使用多个包来定义从 Python 中的父类继承的自定义子类。例如,您可以编写一个自定义 DataFrame 类作为继承自Pandas中的 DataFrame 类的子类。同样,您可以定义一个继承自父类RandomForestClassifier的自定义分类类。
您还可以定义自定义父类和子类。例如,您可以定义指定特定类型分类模型的自定义父类和分析模型输出的子类。例如,您还可以编写父类和子类来进行模型预测数据可视化。父类可以指定分类模型的类型及其输入和输出的属性。然后,子类可以生成可视化效果(例如混淆矩阵)来分析模型输出。
对于我们的分类模型,我们将使用虚构的 Telco 流失数据集,该数据集在 Kaggle 上公开提供。该数据集在Apache 2.0 License下可以免费使用、修改和共享 。
3.1 扩展 PYTHON 包中的现有类
我们首先将流失数据读入 Pandas 数据框:
import pandas as pd
df = pd.read_csv('telco_churn.csv')接下来,让我们定义输入和输出。我们将使用 MonthlyCharges、Gender、Tenure、InternetService 和 OnlineSecurity 字段来预测流失率。让我们将分类列转换为机器可读的值:
df['gender'] = df['gender'].astype('category')
df['gender_cat'] = df['gender'].cat.codesdf['InternetService'] = df['InternetService'].astype('category')
df['InternetService_cat'] = df['InternetService'].cat.codesdf['OnlineSecurity'] = df['OnlineSecurity'].astype('category')
df['OnlineSecurity_cat'] = df['OnlineSecurity'].cat.codesdf['Churn'] = np.where(df['Churn']=='Yes', 1, 0)
cols = ['MonthlyCharges', 'tenure', 'gender_cat', 'InternetService_cat', 'OnlineSecurity_cat']接下来,让我们定义输入和输出:
from sklearn.model_selection import train_test_split
X = df[cols]
y = df['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)现在我们可以定义我们的自定义子类。让我们从 Scikit-learn 导入随机森林分类器并定义一个名为 CustomClassifier 的空类。CustomClassifier 将采用 RandomForestClassifier 类作为参数:
from sklearn.ensemble import RandomForestClassifierclass CustomClassifier(RandomForestClassifier):pass test_size我们将在我们的方法中指定一个init,使我们能够指定测试和训练样本的大小。我们还将使用 super 方法来允许我们的自定义类继承随机森林类的方法和属性。这将使用任何其他自定义方法扩展父随机森林类。
from sklearn.ensemble import RandomForestClassifierclass CustomClassifier(RandomForestClassifier):def __init__(self, test_size=0.2, **kwargs):super().__init__(**kwargs)self.test_size = test_size现在我们将定义一种方法来分割数据以进行训练和测试:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_splitclass CustomClassifier(RandomForestClassifier):def __init__(self, test_size=0.2, **kwargs):super().__init__(**kwargs)self.test_size = test_sizedef split_data(self):self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=self.custom_param, random_state=42) 接下来,我们可以定义类的实例。我们将为我们的 传递一个值 0.2 test_size。这意味着测试集将由 20% 的数据组成,训练集将由其余 80% 的数据组成:
rf_model = CustomClassifier(0.2)
rf_model.split_data()我们可以通过打印子类的属性和方法来了解我们的子类:
print(dir(rf_model))我们将看到,通过子类,我们拥有父随机森林对象可访问的所有方法和属性:
['__abstractmethods__', '__annotations__', '__class__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__',
'__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__',
'_abc_impl', '_check_feature_names', '_check_n_features',
'_compute_oob_predictions', '_estimator_type', '_get_oob_predictions',
'_get_param_names', '_get_tags', '_make_estimator', '_more_tags',
'_repr_html_', '_repr_html_inner', '_repr_mimebundle_',
'_required_parameters', '_set_oob_score_and_attributes',
'_validate_X_predict', '_validate_data', '_validate_estimator',
'_validate_y_class_weight', 'apply', 'base_estimator', 'bootstrap',
'ccp_alpha', 'class_weight', 'criterion', 'decision_path',
'estimator_params', 'feature_importances_', 'fit', 'get_params',
'max_depth', 'max_features', 'max_leaf_nodes', 'max_samples',
'min_impurity_decrease', 'min_samples_leaf', 'min_samples_split',
'min_weight_fraction_leaf', 'n_estimators', 'n_features_', 'n_jobs',
'oob_score', 'predict', 'predict_log_proba', 'predict_proba',
'random_state', 'score', 'set_params', 'split_data', 'test_size',
'verbose', 'warm_start']为了表明我们的自定义子类实例可以访问父随机森林类的方法和属性,让我们尝试通过自定义类实例将随机森林模型拟合到我们的训练数据:
rf_model = CustomClassifier(0.2)
rf_model.split_data()
rf_model.fit(rf_model.X_train, rf_model.y_train)尽管我们正在调用属于外部类的方法,但该代码执行时没有错误。这就是Python继承的美妙之处!它允许您轻松扩展现有类的功能,无论它们是包的一部分还是自定义的。
除了方法之外,我们还可以访问随机森林分类器类属性。例如,特征重要性是随机森林分类器类的属性。让我们使用类实例访问并显示随机森林特征的重要性:
importances = dict(zip(rf_model.feature_names_in_,
rf_model.feature_importances_))
print("Feature Importances: ", importances)
这给出了以下结果:
Feature Importances: {'MonthlyCharges': 0.5192056776242303,'tenure': 0.3435083140171441,'gender_cat': 0.015069195786109523,'InternetService_cat': 0.0457071535620191,'OnlineSecurity_cat': 0.07650965901049701}软件工程的更多内容如何使用GDB
3.2 扩展自定义父类
Python 继承的另一个机器学习用例是使用子类扩展自定义父类功能。例如,我们可以定义一个训练随机森林模型的父类。然后,我们可以定义一个子类,它使用继承的测试集和预测属性生成混淆矩阵。
让我们首先定义将用于构建模型的类。对于此示例,我们将使用Seaborn库和度量模块中的混淆度量方法。我们还将训练集和测试集存储为父级的属性:
from sklearn.metrics import confusion_matrix
import seaborn as snsclass Model:def __init__(self):self.n_estimators = 10self.max_depth = 10self.y_test = y_testself.y_train = y_trainself.X_train = X_trainself.X_test = X_test接下来,我们可以定义一个拟合方法,将随机森林分类器适合我们的训练数据:
from sklearn.metrics import confusion_matrix
import seaborn as snsclass Model:...def fit(self):self.model = RandomForestClassifier(n_estimators = self.n_estimators, max_depth = self.max_depth, random_state=42)self.model.fit(self.X_train, self.y_train)最后,我们可以定义一个返回模型预测的预测方法:
from sklearn.metrics import confusion_matrix
import seaborn as snsclass Model:...def predict(self):self.y_pred = self.model.predict(X_test)return self.y_pred现在我们可以定义我们的子类了。我们将我们的子类命名为“ModelVisulaization”。这个类将继承我们的Model类的方法和属性:
class ModelVisualization(Model):def __init__(self):super().__init__()我们将通过添加生成混淆矩阵的方法来扩展我们的模型类:
class ModelVisualization(Model):def __init__(self):super().__init__()def generate_confusion_matrix(self):cm = confusion_matrix(self.y_test, self.y_pred)cm = cm / cm.astype(np.float).sum(axis=1)sns.heatmap(cm, annot=True, cmap='Blues')现在我们可以定义子类的实例并绘制混淆矩阵:
results = ModelVisualization()
results.fit()
results.predict()
results.generate_confusion_matrix()这会生成以下内容:
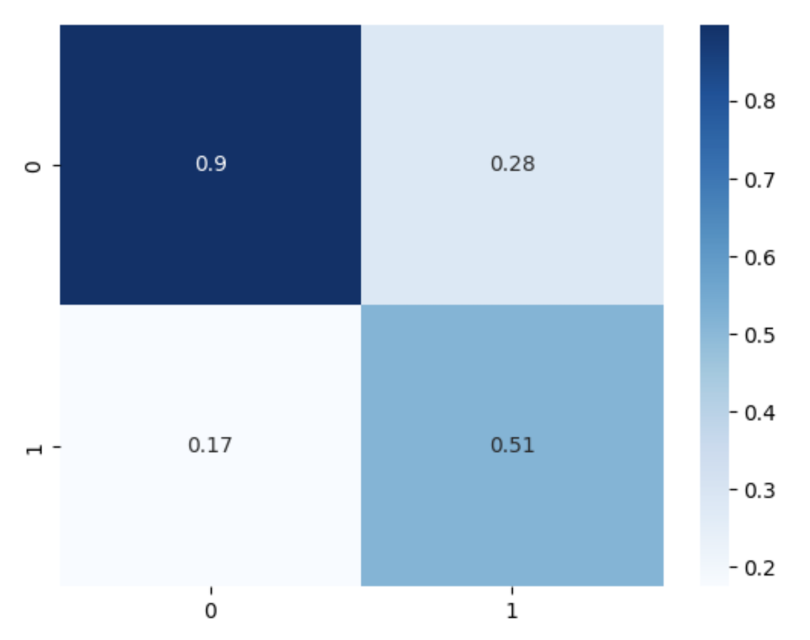
图片:屏幕截图。
显然,如何设计自定义类有一定的自由度,无论它们是现有包中的类的子类还是其他自定义父类的子类。根据您的用例,一条路线可能比另一条路线更有意义。例如,如果您只想添加少量附加属性和方法,则扩展现有类可能更合适。如果需要定制大量任务,构建定制的父类和子类会更合适。
Python 类继承对于数据科学和机器学习任务非常有用。扩展现有机器学习包中的类的功能是一个常见的用例。虽然我们在这里介绍了扩展随机森林分类器类,但您还可以扩展 Pandas 数据帧类和数据转换类的功能,例如标准缩放器和最小最大缩放器。对于数据科学家和机器学习工程师来说,大致了解如何使用 Python 继承来扩展现有类非常有价值。
此外,在某些情况下,属于不同工作流程的许多任务需要自定义。我们考虑了扩展自定义类的示例,我们使用该类来构建具有可视化功能的分类模型。这允许我们继承建模类的方法和属性,并在子类中生成可视化。
这篇文章中的代码可以在 GitHub上找到。
相关文章:
Python 类继承解释
一、说明 类继承是Python中数据科学家和机器学习工程师需要了解的一个重要概念。在这里,我们的专家解释了它的工作原理。 在Python中,类包含属性和方法。属性是存储数据的变量。类方法是属于类的函数,通常对类属性执行一些逻辑。在本文中&…...

Reactor反应器模式
文章目录 一、单线程Reactor反应器模式二、多线程Reactor反应器模式 在Java的OIO编程中,最初和最原始的网络服务器程序使用一个while循环,不断地监听端口是否有新的连接,如果有就调用一个处理函数来处理。这种方法最大的问题就是如果前一个网…...
 -- JavaBean==》Json字符串、JSONObject、JSONArray)
alibaba.fastjson的使用(六) -- JavaBean==》Json字符串、JSONObject、JSONArray
目录 1. JavaBean转 Json字符串 2. JavaBean转 JSONObject 3. List转JSONArray 在pom文件中引入依赖: <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.14</version></dependency&…...
uniapp 自定义导航栏
自定义导航栏 修改 pages.json 在 pages.json 中将 navigateionStyle 设为 custom 新建 systemInfo.js systemInfo.js 用来获取当前设备的机型系统信息,放在 common 目录下 /*** 此 js 文件管理关于当前设备的机型系统信息*/ const systemInfo function() {/***…...

查分小程序:一键查询成绩,班主任和家长的得力助手
作为一名老师,是否曾经为了让学生能够方便地查询成绩而烦恼?担心学生忘记密码?还是手动输入成绩太繁琐?今天,给大家分享一个超级实用的查分小程序,让成绩查询变得更轻松! 什么是成绩查询系统&am…...

Linux内核驱动开发的步骤
Linux操作系统的内核是一个强大的、开源的操作系统内核,它为各种硬件设备提供支持。为了让硬件设备能够与Linux系统无缝协作,需要编写相应的内核驱动程序。本文将介绍Linux内核驱动开发的一般步骤,以帮助开发者了解如何创建自己的内核驱动。 …...

【Java 进阶篇】HTML DOM 事件详解
当用户在网页上点击按钮、输入文本、鼠标移动到某个区域或执行其他互动操作时,这些动作都可以触发事件。HTML DOM(文档对象模型)允许我们使用JavaScript来捕获、处理和响应这些事件,以实现网页的交互和动态性。本篇博客将围绕HTML…...
redis 从小白到大师系列
字符串 Redis 字符串数据类型 set 字符串 /*** 设置字符串*/ $t $redis->set(o1,o1); //返回true or false var_dump($t);get字符串 /*** 获取字符串*/ $t $redis->get(o1); //返回true or false var_dump($t);结果: string(2) “o1” 返回 key 中字符串…...

vue使用.filter方法检索数组中指定时间段内的数据
假设你有一个名为dataArray的数组,其中包含了你要筛选的数据。那么,你可以按照以下步骤进行筛选: 创建一个名为filteredArray的新数组,用于存储筛选后的结果。使用数组的filter方法遍历dataArray,并对每个元素应用筛选…...

Ubuntu 安装 npm 和 node
前言 最近学习VUE,在ubuntu 2204 上配置开发环境,涉及到npm node nodejs vue-Cli脚手架等内容,做以记录。 一、node nodejs npm nvm 区别 ? node 是框架,类似python的解释器。nodejs 是编程语言,是js语言的…...
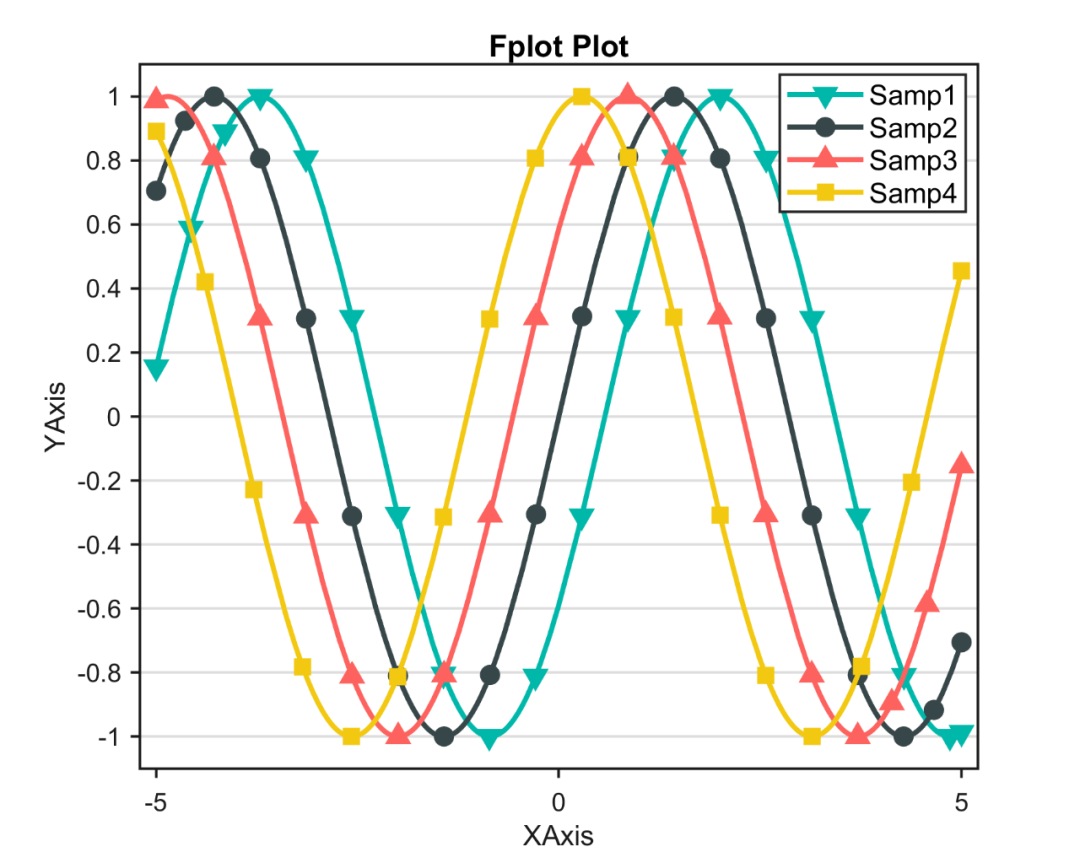
Matlab论文插图绘制模板第122期—函数折线图(fplot)
本期分享的是函数折线图的绘制模板。 所谓函数折线图,就是将自定义线函数进行可视化表达。 先来看一下成品效果: 特别提示:本期内容『数据代码』已上传资源群中,加群的朋友请自行下载。有需要的朋友可以关注同名公号【阿昆的…...
IK分词器如何修改支持跨版本ES
一、问题描述:IK分词器版本和ES版本不一致,无法找到和自己ES版本匹配的分词器。 IK分词器,提供的插件版本,远赶不上ES的更新版本,在使用过程中,不一定能顺利的找到与自己使用的ES版本相对应。在ES集群中使用…...
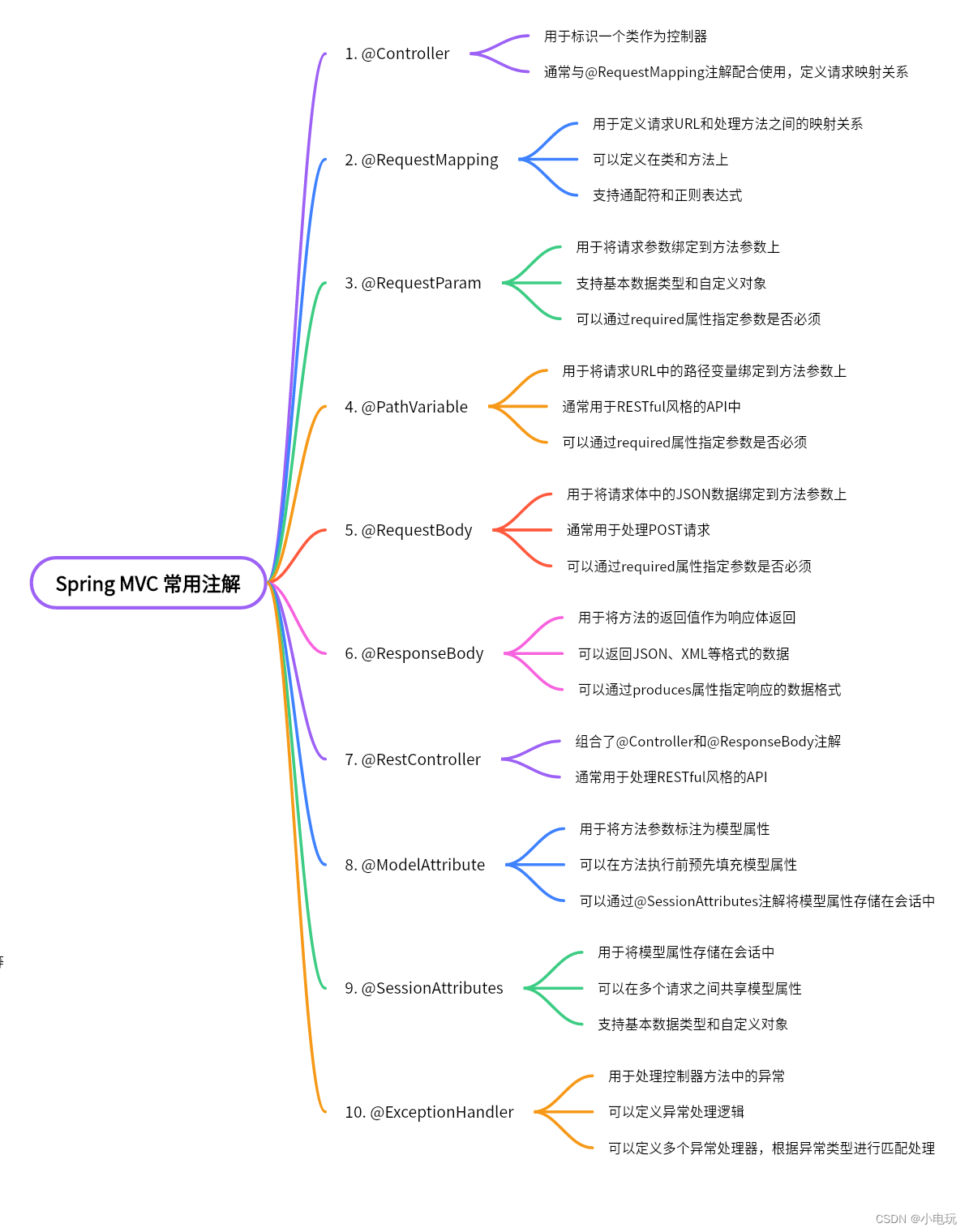
Spring MVC常用十大注解
Spring MVC常用十大注解 一,什么要使用注解 使用注解可以简化配置,提高代码的可读性和可维护性。通过注解可以实现依赖注入,减少手动管理对象的代码量。注解还支持面向切面编程,实现切面、切入点和通知等。此外,注解提…...

二、【MyBatis】 MyBatis入门与简单使用
二、【MyBatis】 MyBatis入门与简单使用 二、【MyBatis】 MyBatis入门与简单使用一、什么是ORM二、为什么mybatis是半自动的ORM框架2.1 Hibernate优点2.2 Hibernate缺点2.3 MyBatis与Hibernate区别三、Mybatis快速入门3.1 项目引入Maven相关依赖3.2 创建测试数据库3.3 编写数据…...

基于DF模式的协作通信技术matlab性能仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、DF概述 4.2、DF基本原理 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2013b 3.部分核心程序 clc; clear; close all; warning off; addpath(genpath(pwd))…...

Angular-01:基本架构
各种学习后的知识点整理归纳,非原创! ① 概述 angular是一个使用HTML、CSS、TypeScript构建的客户端应用的框架,用来构建单页面应用程序。是一个重量级的框架,内部集成了大量开箱即用的功能模块。是为大型应用开发而设计…...

字符串划分
题目描述 给定一个小写字母组成的字符串s,请找出字符串中两个不同位置的字符作为分割点,使得字符串分成的三个连续子串且子串权重相等,注意子串不包含分割点。 若能找到满足条件的两个分割点,请输出这两个分割点在字符串中的位置…...

ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9‘ not found的解决方法
导致该错误的原因:gcc动态库版本太老了 解决方法: 1、编辑~/.bash_profile vim ~/.bash_profile 2、将anaconda3/lib的路径加入库文件的路径 LD_LIBRARY_PATH/your_path/anaconda3/lib:$LD_LIBRARY_PATH export LD_LIBRARY_PATH 3、重载~/.bash_pr…...

华为云全新上线Serverless应用中心,支持一键构建文生图应用
近日,华为云全新上线Serverless应用中心,提供了大量应用模板,让用户能够一键部署函数和周边依赖资源,节省部署时间,快速上手将应用部署到华为云函数计算FunctionGraph,并一键开通周边依赖资源。 本次Serve…...
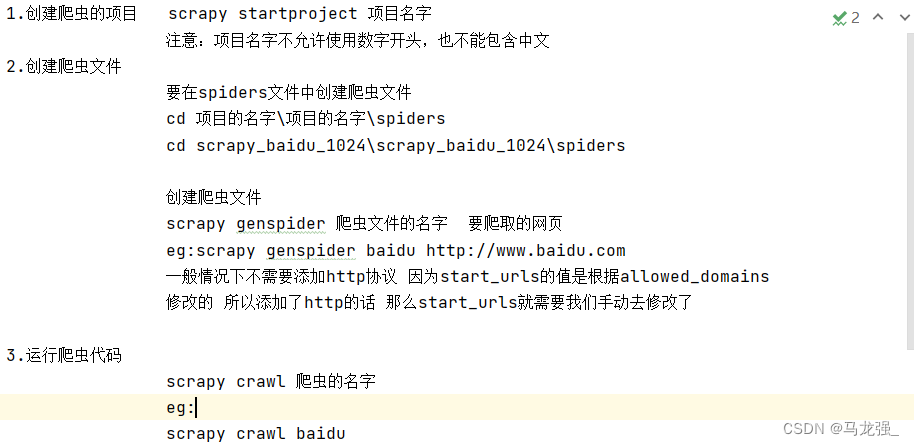
scrapy的安装和使用
一、scrapy是什么:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序 二、scrapy的安装:pip install scrapy -i https://pypi.douban.com/…...

18.children 这个 props 的意义何在?该怎样正确使用?
在 React 里,children 是一个非常特殊、非常常用的 prop, 它专门用来接收:写在组件标签中间的那一部分内容。你可以把它理解为:组件外层负责搭“外壳”,children 负责装进这个壳里的“内容物”。一、children 到底是什…...

电子电路设计中7种关键接口技术解析与应用
1. 电路接口概述:信号传输的关键桥梁在嵌入式系统和电子电路设计中,接口技术就像城市之间的高速公路系统。当CPU需要与传感器"对话",当存储器要与处理器"交换情报",这些不同模块之间的信号传输总会面临三大挑…...

从“中式英语”到地道表达:我用Notion搭建了一个动态写作原则库
从“中式英语”到地道表达:我用Notion搭建了一个动态写作原则库 第一次参加国际学术会议时,我站在海报前手足无措——不是研究内容不够扎实,而是当外国学者用"Your findings are intriguing but the methodology section lacks clarity&…...

实战指南:基于快马平台生成企业级cc switch管理系统,助力游戏项目开发
今天想和大家分享一个在游戏开发中特别实用的技术——CC Switch系统。这个系统在商业游戏项目中经常被用来做调试和功能开关控制,最近我在InsCode(快马)平台上快速实现了一个完整的企业级解决方案,整个过程特别顺畅。 先说说什么是CC Switch。简单理解就…...

从零搭建WebRTC SFU服务器:基于Mediasoup的1080P视频会议部署教程
从零搭建WebRTC SFU服务器:基于Mediasoup的1080P视频会议部署教程 视频会议已成为现代远程协作的核心工具,而WebRTC技术让浏览器间的实时音视频通信变得触手可及。但当你需要支持10人以上的高清会议时,单纯的P2P连接就会暴露出带宽和性能瓶颈…...

2026届最火的AI论文助手推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要想切实有效地把文本的AIGC检测概率给降低下去,就得从词汇多样性、句式结构以及…...

当英文游戏遇上中文玩家:Degrees of Lewdity本地化之旅
当英文游戏遇上中文玩家:Degrees of Lewdity本地化之旅 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Localization …...

告别subfloat!LaTeX中minipage+subfigure排版多图的最佳实践
LaTeX多图排版进阶指南:minipage与subfigure的黄金组合 在学术论文和技术文档写作中,图片排版往往是让人头疼的问题。特别是当需要处理多张图片并为其添加子标题时,传统的subfloat方法常常会遇到标题溢出、无法自动换行等令人沮丧的情况。本文…...

抖音无水印视频批量下载全攻略:从痛点解决到高效管理
抖音无水印视频批量下载全攻略:从痛点解决到高效管理 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

基于粒子群算法的含分布式电源配电网动态无功优化程序——IEEE33节点配电网应用与性能分析
电力系统动态无功优化含分布式电源MATLAB程序IEEE33配电网 1)该程序为基于粒子群算法的含分布式电源配电网动态无功优化程序,期刊论文源程序,配有该论文。(2)该程序为动态无功优化,并且考虑了分布式电源的接…...