SQL性能优化的47个小技巧,果断收藏!
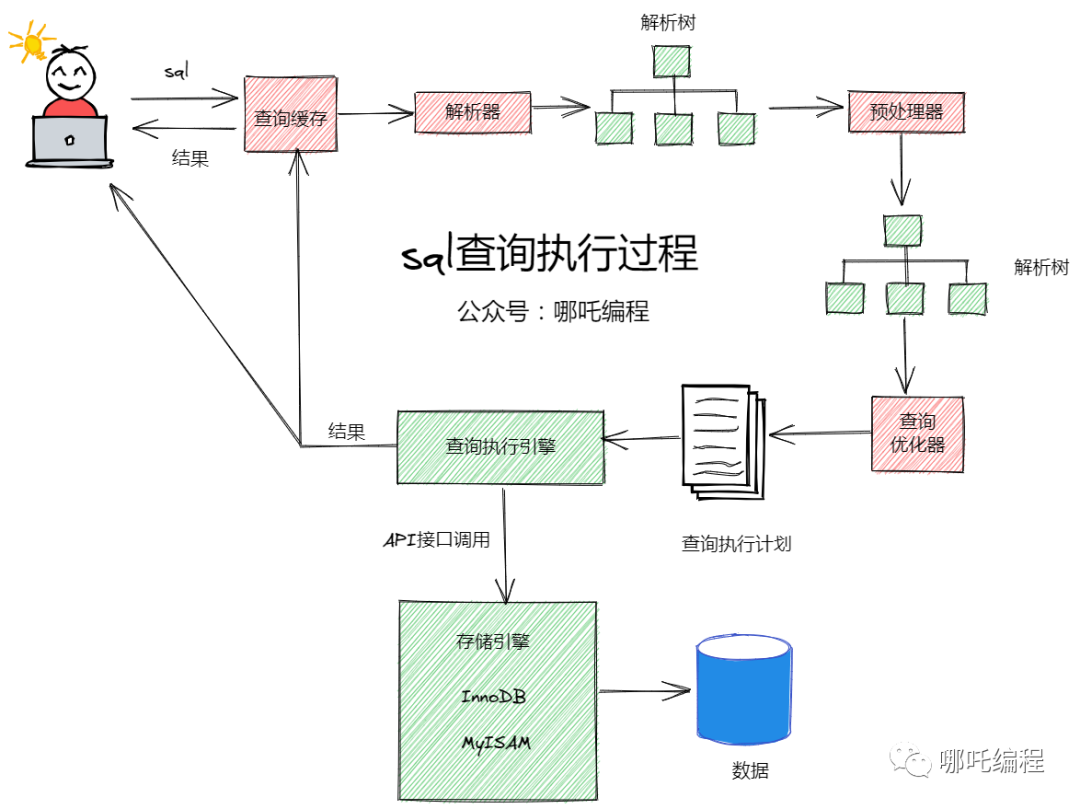
1、先了解MySQL的执行过程
了解了MySQL的执行过程,我们才知道如何进行sql优化。
-
客户端发送一条查询语句到服务器;
-
服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据;
-
未命中缓存后,MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树,MySQL解析器将使用MySQL语法进行验证和解析。例如,验证是否使用了错误的关键字,或者关键字的使用是否正确;
-
预处理是根据一些MySQL规则检查解析树是否合理,比如检查表和列是否存在,还会解析名字和别名,然后预处理器会验证权限;
-
根据执行计划查询执行引擎,调用API接口调用存储引擎来查询数据;
-
将结果返回客户端,并进行缓存;
2、数据库常见规范
-
所有数据库对象名称必须使用小写字母并用下划线分割;
-
所有数据库对象名称禁止使用mysql保留关键字;
-
数据库对象的命名要能做到见名识意,并且最后不要超过32个字符;
-
临时库表必须以tmp_为前缀并以日期为后缀,备份表必须以bak_为前缀并以日期(时间戳)为后缀;
-
所有存储相同数据的列名和列类型必须一致;
3、所有表必须使用Innodb存储引擎
没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎(mysql5.5之前默认使用Myisam,5.6以后默认的为Innodb)。
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
4、每个Innodb表必须有个主键
Innodb是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
Innodb是按照主键索引的顺序来组织表的
-
不要使用更新频繁的列作为主键,不适用多列主键;
-
不要使用UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长);
-
主键建议使用自增ID值;
5、数据库和表的字符集统一使用UTF8
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储emoji表情的需要,字符集需要采用utf8mb4字符集。
6、查询SQL尽量不要使用select *,而是具体字段
select *的弊端:
-
增加很多不必要的消耗,比如CPU、IO、内存、网络带宽;
-
增加了使用覆盖索引的可能性;
-
增加了回表的可能性;
-
当表结构发生变化时,前端也需要更改;
-
查询效率低;
7、避免在where子句中使用 or 来连接条件
-
使用
or可能会使索引失效,从而全表扫描; -
对于
or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描; -
也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定;
-
虽然
mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的;
8、尽量使用数值替代字符串类型
-
因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
-
而对于数字型而言只需要比较一次就够了;
-
字符会降低查询和连接的性能,并会增加存储开销;
9、使用varchar代替char
-
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间; -
char按声明大小存储,不足补空格; -
其次对于查询来说,在一个相对较小的字段内搜索,效率更高;
10、财务、银行相关的金额字段必须使用decimal类型
-
非精准浮点:float,double
-
精准浮点:decimal
-
Decimal类型为精准浮点数,在计算时不会丢失精度;
-
占用空间由定义的宽度决定,每4个字节可以存储9位数字,并且小数点要占用一个字节;
-
可用于存储比bigint更大的整型数据;
11、避免使用ENUM类型
-
修改ENUM值需要使用ALTER语句;
-
ENUM类型的ORDER BY操作效率低,需要额外操作;
-
禁止使用数值作为ENUM的枚举值;
12、去重distinct过滤字段要少
-
带distinct的语句占用
cpu时间高于不带distinct的语句 -
当查询很多字段时,如果使用
distinct,数据库引擎就会对数据进行比较,过滤掉重复数据 -
然而这个比较、过滤的过程会占用系统资源,如
cpu时间
13、where中使用默认值代替null
-
并不是说使用了
is null或者is not null就会不走索引了,这个跟mysql版本以及查询成本都有关; -
如果
mysql优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件!=,<>,is null,is not null经常被认为让索引失效; -
其实是因为一般情况下,查询的成本高,优化器自动放弃索引的;
-
如果把
null值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点;
14、避免在where子句中使用!=或<>操作符
-
使用
!=和<>很可能会让索引失效 -
应尽量避免在
where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描 -
实现业务优先,实在没办法,就只能使用,并不是不能使用
15、inner join 、left join、right join,优先使用inner join
三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小。
-
inner join 内连接,只保留两张表中完全匹配的结果集;
-
left join会返回左表所有的行,即使在右表中没有匹配的记录;
-
right join会返回右表所有的行,即使在左表中没有匹配的记录;
为什么?
-
如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点;
-
使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少;
-
这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优;
16、提高group by语句的效率
1、反例
先分组,再过滤
select job, avg(salary) from employee
group by job
having job ='develop' or job = 'test';
2、正例
先过滤,后分组
select job,avg(salary) from employee
where job ='develop' or job = 'test'
group by job;
3、理由
可以在执行到该语句前,把不需要的记录过滤掉
17、清空表时优先使用truncate
truncate table在功能上与不带 where子句的 delete语句相同:二者均删除表中的全部行。但 truncate table比 delete速度快,且使用的系统和事务日志资源少。
delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。truncate table通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
truncate table删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 drop table语句。
对于由 foreign key约束引用的表,不能使用 truncate table,而应使用不带 where子句的 DELETE 语句。由于 truncate table不记录在日志中,所以它不能激活触发器。
truncate table不能用于参与了索引视图的表。
18、操作delete或者update语句,加个limit或者循环分批次删除
(1)降低写错SQL的代价
清空表数据可不是小事情,一个手抖全没了,删库跑路?如果加limit,删错也只是丢失部分数据,可以通过binlog日志快速恢复的。
(2)SQL效率很可能更高
SQL中加了limit 1,如果第一条就命中目标return, 没有limit的话,还会继续执行扫描表。
(3)避免长事务
delete执行时,如果age加了索引,MySQL会将所有相关的行加写锁和间隙锁,所有执行相关行会被锁住,如果删除数量大,会直接影响相关业务无法使用。
(4)数据量大的话,容易把CPU打满
如果你删除数据量很大时,不加 limit限制一下记录数,容易把cpu打满,导致越删越慢。
(5)锁表
一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误,所以建议分批操作。
19、UNION操作符
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select username,tel from user
union
select departmentname from department
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。推荐方案:采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
20、SQL语句中IN包含的字段不宜过多
MySQL的IN中的常量全部存储在一个数组中,这个数组是排序的。如果值过多,产生的消耗也是比较大的。如果是连续的数字,可以使用between代替,或者使用连接查询替换。
21、批量插入性能提升
(1)多条提交
INSERT INTO user (id,username) VALUES(1,'哪吒编程');INSERT INTO user (id,username) VALUES(2,'妲己');
(2)批量提交
INSERT INTO user (id,username) VALUES(1,'哪吒编程'),(2,'妲己');
默认新增SQL有事务控制,导致每条都需要事务开启和事务提交,而批量处理是一次事务开启和提交,效率提升明显,达到一定量级,效果显著,平时看不出来。
22、表连接不宜太多,索引不宜太多,一般5个以内
(1)表连接不宜太多,一般5个以内
-
关联的表个数越多,编译的时间和开销也就越大
-
每次关联内存中都生成一个临时表
-
应该把连接表拆开成较小的几个执行,可读性更高
-
如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了
-
阿里规范中,建议多表联查三张表以下
(2)索引不宜太多,一般5个以内
-
索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率;
-
索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间;
-
索引表的数据是排序的,排序也是要花时间的;
-
insert或update时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定; -
一个表的索引数最好不要超过5个,若太多需要考虑一些索引是否有存在的必要;
23、禁止给表中的每一列都建立单独的索引
真有这么干的,我也是醉了。
2万字带你精通MySQL索引
24、如何选择索引列的顺序
建立索引的目的是:希望通过索引进行数据查找,减少随机IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)。
尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好)。
使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)。
25、对于频繁的查询优先考虑使用覆盖索引
覆盖索引:就是包含了所有查询字段(where,select,ordery by,group by包含的字段)的索引。
覆盖索引的好处:
(1)避免Innodb表进行索引的二次查询
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。
而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了IO操作,提升了查询效率。
(2)可以把随机IO变成顺序IO加快查询效率
由于覆盖索引是按键值的顺序存储的,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO。
26、建议使用预编译语句进行数据库操作
预编译语句可以重复使用这些计划,减少SQL编译所需要的时间,还可以解决动态SQL所带来的SQL注入的问题。
只传参数,比传递SQL语句更高效。
相同语句可以一次解析,多次使用,提高处理效率。
27、避免产生大事务操作
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对MySQL的性能产生非常大的影响。
特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
28、避免在索引列上使用内置函数
使用索引列上内置函数,索引失效。
29、组合索引
排序时应按照组合索引中各列的顺序进行排序,即使索引中只有一个列是要排序的,否则排序性能会比较差。
create index IDX_USERNAME_TEL on user(deptid,position,createtime);
select username,tel from user where deptid= 1 and position = 'java开发' order by deptid,position,createtime desc;
实际上只是查询出符合 deptid= 1 and position = 'java开发'条件的记录并按createtime降序排序,但写成order by createtime desc性能较差。
30、复合索引最左特性
(1)创建复合索引
ALTER TABLE employee ADD INDEX idx_name_salary (name,salary)
(2)满足复合索引的最左特性,哪怕只是部分,复合索引生效
SELECT * FROM employee WHERE NAME='哪吒编程'
(3)没有出现左边的字段,则不满足最左特性,索引失效
SELECT * FROM employee WHERE salary=5000
(4)复合索引全使用,按左侧顺序出现 name,salary,索引生效
SELECT * FROM employee WHERE NAME='哪吒编程' AND salary=5000
(5)虽然违背了最左特性,但MySQL执行SQL时会进行优化,底层进行颠倒优化
SELECT * FROM employee WHERE salary=5000 AND NAME='哪吒编程'
(6)理由
复合索引也称为联合索引,当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
联合索引不满足最左原则,索引一般会失效。
31、必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用forceindex来强制优化器使用我们制定的索引。
32、优化like语句
模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效。
-
首先尽量避免模糊查询,如果必须使用,不采用全模糊查询,也应尽量采用右模糊查询, 即
like ‘…%’,是会使用索引的; -
左模糊
like ‘%...’无法直接使用索引,但可以利用reverse + function index的形式,变化成like ‘…%’; -
全模糊查询是无法优化的,一定要使用的话建议使用搜索引擎。
33、统一SQL语句的写法
对于以下两句SQL语句, 程序员认为是相同的,数据库查询优化器认为是不同的。
select * from user;
select * From USER;
这都是很常见的写法,也很少有人会注意,就是表名大小写不一样而已。然而,查询解析器认为这是两个不同的SQL语句,要解析两次,生成两个不同的执行计划,作为一名严谨的Java开发工程师,应该保证两个一样的SQL语句,不管在任何地方都是一样的。
34、不要把SQL语句写得太复杂
经常听到有人吹牛逼,我写了一个800行的SQL语句,逻辑感超强,我们还开会进行了SQL讲解,大家都投来了崇拜的目光。。。
一般来说,嵌套子查询、或者是3张表关联查询还是比较常见的,但是,如果超过3层嵌套的话,查询优化器很容易给出错误的执行计划,影响SQL效率。SQL执行计划是可以被重用的,SQL越简单,被重用的概率越大,生成执行计划也是很耗时的。
35、将大的DELETE,UPDATE、INSERT 查询变成多个小查询
能写一个几十行、几百行的SQL语句是不是显得逼格很高?然而,为了达到更好的性能以及更好的数据控制,你可以将他们变成多个小查询。
36、关于临时表
-
避免频繁创建和删除临时表,以减少系统表资源的消耗;
-
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log;
-
如果数据量不大,为了缓和系统表的资源,应先create table,然后insert;
-
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除。先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
37、使用explain分析你SQL执行计划
(1)type
-
system:表仅有一行,基本用不到;
-
const:表最多一行数据配合,主键查询时触发较多;
-
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型;
-
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
-
range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range;
-
index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小;
-
all:全表扫描;
-
性能排名:system > const > eq_ref > ref > range > index > all。
-
实际sql优化中,最后达到ref或range级别。
(2)Extra常用关键字
-
Using index:只从索引树中获取信息,而不需要回表查询;
-
Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
-
Using temporary:mysql常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的
GROUP BY和ORDER BY子句时;
38、读写分离与分库分表
当数据量达到一定的数量之后,限制数据库存储性能的就不再是数据库层面的优化就能够解决的;这个时候往往采用的是读写分离与分库分表同时也会结合缓存一起使用,而这个时候数据库层面的优化只是基础。
读写分离适用于较小一些的数据量;分表适用于中等数据量;而分库与分表一般是结合着用,这就适用于大数据量的存储了,这也是现在大型互联网公司解决数据存储的方法之一。
39、使用合理的分页方式以提高分页的效率
select id,name from user limit 100000, 20
使用上述SQL语句做分页的时候,随着表数据量的增加,直接使用limit语句会越来越慢。
此时,可以通过取前一页的最大ID,以此为起点,再进行limit操作,效率提升显著。
select id,name from user where id> 100000 limit 20
40、尽量控制单表数据量的大小,建议控制在500万以内。
500万并不是MySQL数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
41、谨慎使用Mysql分区表
-
分区表在物理上表现为多个文件,在逻辑上表现为一个表;
-
谨慎选择分区键,跨分区查询效率可能更低;
-
建议采用物理分表的方式管理大数据。
42、尽量做到冷热数据分离,减小表的宽度
Mysql限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节。
减少磁盘IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO);
更有效的利用缓存,避免读入无用的冷数据;
经常一起使用的列放到一个表中(避免更多的关联操作)。
43、禁止在表中建立预留字段
-
预留字段的命名很难做到见名识义;
-
预留字段无法确认存储的数据类型,所以无法选择合适的类型;
-
对预留字段类型的修改,会对表进行锁定;
44、禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机IO操作,文件很大时,IO操作很耗时。
通常存储于文件服务器,数据库只存储文件地址信息。
45、建议把BLOB或是TEXT列分离到单独的扩展表中
Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,Mysql还是要进行二次查询,会使sql性能变得很差,但是不是说一定不能使用这样的数据类型。
如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select * 而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。
46、TEXT或BLOB类型只能使用前缀索引
因为MySQL对索引字段长度是有限制的,所以TEXT类型只能使用前缀索引,并且TEXT列上是不能有默认值的。
MySql基础知识总结(SQL优化篇)
47、一些其它优化方式
(1)当只需要一条数据的时候,使用limit 1
limit 1可以避免全表扫描,找到对应结果就不会再继续扫描了。
(2)如果排序字段没有用到索引,就尽量少排序
(3)所有表和字段都需要添加注释
使用comment从句添加表和列的备注,从一开始就进行数据字典的维护。
(4)SQL书写格式,关键字大小保持一致,使用缩进。
(5)修改或删除重要数据前,要先备份。
(6)很多时候用 exists 代替 in 是一个好的选择
(7)where后面的字段,留意其数据类型的隐式转换。
(8)尽量把所有列定义为NOT NULL
NOT NULL列更节省空间,NULL列需要一个额外字节作为判断是否为 NULL的标志位。NULL列需要注意空指针问题,NULL列在计算和比较的时候,需要注意空指针问题。
(9)伪删除设计
(10)索引不适合建在有大量重复数据的字段上,比如性别,排序字段应创建索引
(11)尽量避免使用游标
因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
相关文章:
SQL性能优化的47个小技巧,果断收藏!
1、先了解MySQL的执行过程 了解了MySQL的执行过程,我们才知道如何进行sql优化。 客户端发送一条查询语句到服务器; 服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据; 未命中缓存后,MySQL通…...

SE | 哇哦!让人不断感叹真香的数据格式!~
1写在前面 最近在用的包经常涉及到SummarizedExperiment格式的文件,不知道大家有没有遇到过。🤒 一开始觉得这种格式真麻烦,后面搞懂了之后发现真是香啊,爱不释手!~😜 2什么是SummarizedExperiment 这种cla…...

运行Qt后出现无法显示字库问题的解决方案
问题描述:运行后字体出现问题QFontDatabase: Cannot find font directory解决前提: 其实就是移植后字体库中是空的,字没办法进行显示本质就是我们只需要通过某种手段将QT界面中的字母所调用的库进行填充即可此处需要注意的是,必须…...
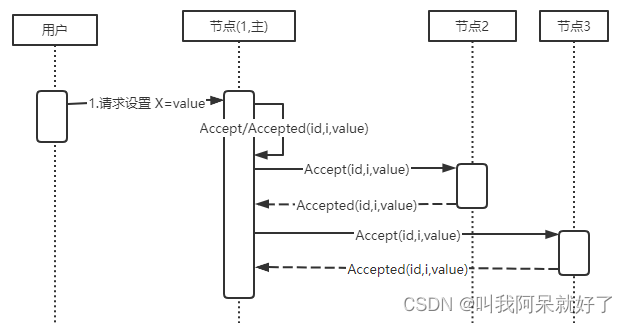
数据库浅谈之共识算法
数据库浅谈之共识算法 HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是数据库浅谈系列,收录在专栏 DATABASE 中 😜😜😜 本系列阿呆将记录一些数据库领域相关的知识 …...

代码随想录算法训练营 || 贪心算法 455 376 53
Day27贪心算法基础贪心的本质是选择每一阶段的局部最优,从而达到全局最优。刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心。做题的时候,只要想清楚 局部最优 是什么&…...

PMP考前冲刺2.25 | 2023新征程,一举拿证
题目1-2:1.项目经理正在进行挣值分析,计算出了当前的成本偏差和进度偏差。发起人想要知道基于当前的绩效水平,完成所有工作所需的成本。项目经理应该提供以下哪一项数据?A.完工预算(BAC)B.完工估算(EAC)C.完工尚需估算(ETC)D.完工偏差(VAC)2…...

【自然语言处理】Topic Coherence You Need to Know(主题连贯度详解)
Topic Coherence You Need to Know皮皮,京哥皮皮,京哥皮皮,京哥CommunicationUniversityofChinaCommunication\ University\ of\ ChinaCommunication University of China 在大多数关于主题建模的文章中,常用主题连贯度ÿ…...

C++入门:模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。每个容器都有一个单一的定义,…...
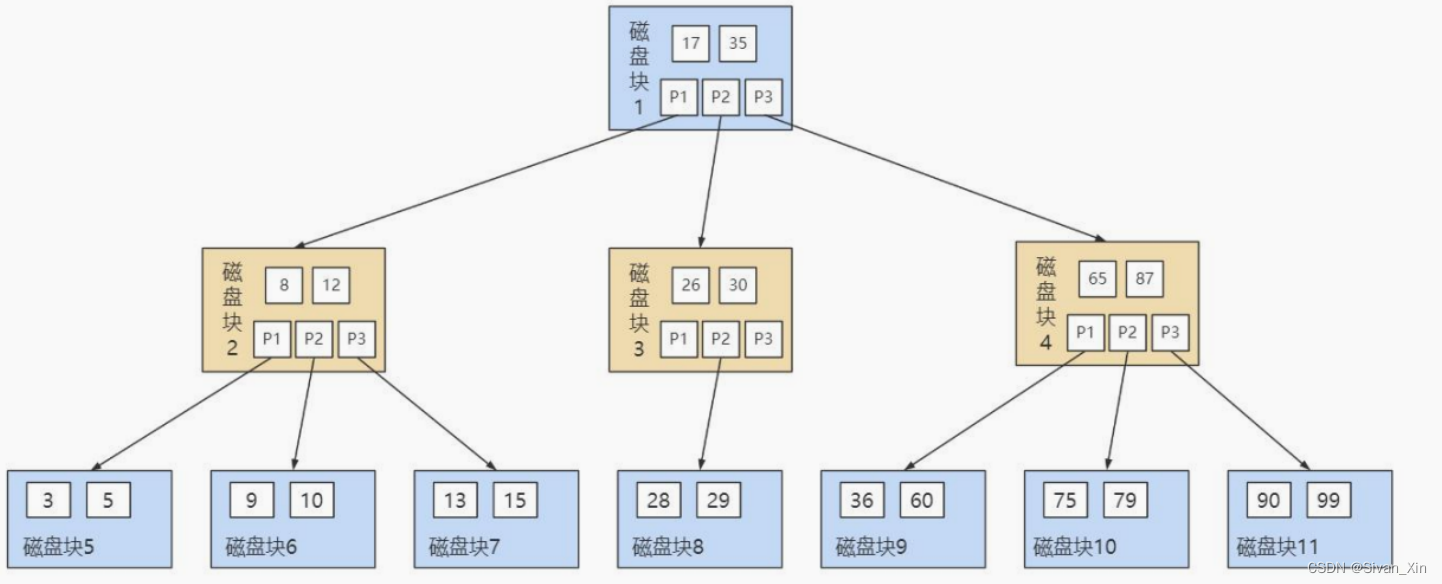
【MySQL】索引常见面试题
文章目录索引常见面试题什么是索引索引的分类什么时候需要 / 不需要创建索引?有什么优化索引的方法?从数据页的角度看B 树InnoDB是如何存储数据的?B 树是如何进行查询的?为什么MySQL采用B 树作为索引?怎样的索引的数…...

【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf
【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf声明一、了解protobuf协议:二、前期准备:二、目标网站:三、开始分析:我们一句句分析:先for循环部分:后…...

Amazon S3 服务15岁生日快乐!
2021年3月14日,作为第一个发布的服务,Amazon S3 服务15周岁啦!在中国文化里,15岁是个临界点,是从“舞勺之年”到“舞象之年”的过渡。相信对于 Amazon S3 和其他的云服务15周岁也将是其迎接更加美好未来的全新起点。亚…...

【python】函数详解
注:最后有面试挑战,看看自己掌握了吗 文章目录基本函数-function模块的引用模块搜索路径不定长参数参数传递传递元组传递字典缺陷,容易改了原始数据,可以用copy()方法避免变量作用域全局变量闭包closurenonlocal 用了这个声明闭包…...

AoP-@Aspect注解处理源码解析
对主类使用EnableAspectJAutoProxy注解后会导入组件, Import(AspectJAutoProxyRegistrar.class) public interface EnableAspectJAutoProxy {AspectJAutoProxyRegistrar类实现了ImportBeanDefinitionRegistrar接口中的registerBeanDefinitions()方法,此…...
宝塔搭建实战php悟空CRM前后端分离源码-vue前端篇(二)
大家好啊,我是测评君,欢迎来到web测评。 上一期给大家分享了悟空CRM server端在宝塔部署的方式,但是由于前端是用vue开发的,如果要额外开发新的功能,就需要在本地运行、修改、打包重新发布到宝塔才能实现功能更新&…...
FastASR+FFmpeg(音视频开发+语音识别)
想要更好的做一件事情,不仅仅需要知道如何使用,还应该知道一些基础的概念。 一、音视频处理基本梳理 1.多媒体文件的理解 1.1 结构分析 多媒体文件本质上可以理解为一个容器 容器里有很多流 每种流是由不同编码器编码的 在众多包中包含着多个帧(帧在音视…...

二分查找的实现代码JAVA
二分查找一、思路二、实现代码(普通版)三、整数溢出问题四、改进代码一、思路 1.前提: 有已排序数组A (假设已经做好) 2.定义左边界L、 右边界R,确定搜索范围,循环执行二分查找(3、4两步) 3.获取中间索引 M Floor((LR) 1/2) 4.中间素索引的值…...

cesium: 设置skybox透明并添加背景图 ( 003 )
第003个 点击查看专栏目录 本示例的目的是介绍如何在vue+cesium中设置skybox透明并添加背景图。 我们不想要黑乎乎的背景,想自定义一个背景图,然后前面显示地球。 直接复制下面的 vue+cesium源代码,操作2分钟即可运行实现效果. 文章目录 示例效果配置方式示例源代码(共70…...
【python】类的详解
注:最后有面试挑战,看看自己掌握了吗 文章目录PO verses OOPOOO当一个类很复杂的时候,考虑多弄一个类的改造私有类的模块化静态类verses动态类动态类查看模块源代码对象机制的基石 PyObjectPO verses OO PO PO耦合性高,很多过程…...

西安银行就业总结
引 进银行性价比最高的时刻是本科,研究生的话可以去需要研究生较多的银行,比如邮储或者证券类的中信建投。中信建投很香,要求本硕西电。研究生学历的话,一般情况下银行不会卡本科,只看最高学历,部分银行需…...

JavaScript Window
文章目录JavaScript Window浏览器对象模型 (BOM)Window 对象Window 尺寸其他 Window 方法JavaScript Window 浏览器对象模型 (BOM) 使 JavaScript 有能力与浏览器"对话"。 浏览器对象模型 (BOM) 浏览器对象模型(Browser Object Model (BOM))…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...