Kafka磁盘写满日志清理操作
最近项目组的kafka集群,老是由于应用端写入kafka topic的消息太多,导致所在的broker节点占满,导致其他的组件接连宕机。
这里和应用端沟通可以删除1天之前的消息来清理磁盘,并且可以调整topic的消息存活时间。
一、调整Topic的消息存活时长删除消息
kafka-configs --zookeeper localhost:2181 --entity-type topics --entity-name topicName --alter --add-config retention.ms=86400000如上调整topic的消息存活时长为为1天,当执行完之后执行查询topic详细信息,可以看到已经发生了修改,并且过一会过期的消息会被删除。
kafka-topics --bootstrap-server localhost:9092 --describe --topic topicName二、不修改Topic消息存活时长删除消息
1.登录到相应的机器上。
2.找到写满的磁盘,删除掉不需要的业务数据。数据清理原则:
- 不可直接删除Kafka的数据目录,避免造成不必要的数据丢失。
- 找到占用空间较多或者明确不需要的Topic,选择其中某些Partition,从最早的日志数据开始删除。删除segment及相应地index和timeindex文件。不要清理内置的Topic,例如__consumer_offsets和_schema等。
3.重启磁盘被写满的相应的Broker节点,使日志目录online。
参考:Kafka磁盘写满时如何运维操作_开源大数据平台E-MapReduce-阿里云帮助中心 (aliyun.com)
怎么删除kafka中的数据-火山引擎 (volcengine.com)
三、Kafka消息清理策略
在Kafka中,存在数据过期的机制,称为data expire。如何处理过期数据是根据指定的policy(策略)决定的,而处理过期数据的行为,即为log cleanup。
在Kafka中有以下几种处理过期数据的策略:
log.cleanup.policy=delete(Kafka中所有用户创建的topics,默认均为此策略)
- 根据数据已保存的时间,进行删除(默认为1周)
- 根据log的max size,进行删除(默认为-1,也就是无限制)
log.cleanup.policy=compact(topic __consumer_offsets 默认为此策略)
- 根据messages中的key,进行删除操作
- 在active segment 被commit 后,会删除掉old duplicate keys
- 无限制的时间与空间的日志保留
自动清理Kafka中的数据可以控制磁盘上数据的大小、删除不需要的数据,同时也减少了对Kafka集群的维护成本。
那Log cleanup 在什么时候发生呢?
- 首先值得注意的是:log cleanup 在partition segment 上发生
- 更小/更多的segment,也就意味着log cleanup 发生的频率会上升
- Log cleanup 不应该频繁发生=> 因为它会消耗CPU与内存资源
- Cleaner的检查会在每15秒进行一次,由log.cleaner.backoff.ms 控制
log.cleanup.policy=delete
log.cleanup.policy=delete 的策略,根据数据保留的时间、以及log的max size,对数据进行cleanup。控制数据保留时间以及log max size的参数分别为:
log.retention.hours:指定数据保留的时常(默认为一周,168)
- 将参数调整到更高的值,也就意味着会占据更多的磁盘空间
- 更小值意味着保存的数据量会更少(假如consumer 宕机超过一周,则数据便会再未处理前即丢失)
log.retention.bytes:每个partition中保存的最大数据量大小(默认为-1,也就是无限大)
- 再控制log的大小不超过一个阈值时,会比较有用
在到达log cleanup 的条件后,cleaner会自动根据时间或是空间的规则进行删除,新数据仍写入active segment:

针对于这个参数,一般有以下两种使用场景,分别为:
log保留周期为一周,根据log保留期进行log cleanup:
- log.retention.hours=168 以及 log.retention.bytes=-1
log保留期为无限制,根据log大小进行进行log cleanup:
- log.retention.hours=17520以及 log.retention.bytes=524288000
其中第一个场景会更常见。
Log Compaction
Log compaction用于确保:在一个partition中,对任意一个key,它所对应的value都是最新的。
这里举个例子:我们有个topic名为employee-salary,我们希望维护每个employee当前最新的工资情况。
左边的是compaction前,segments中的数据,右边为compaction 后,segments中的数据,其中有部分key对应的value有更新:
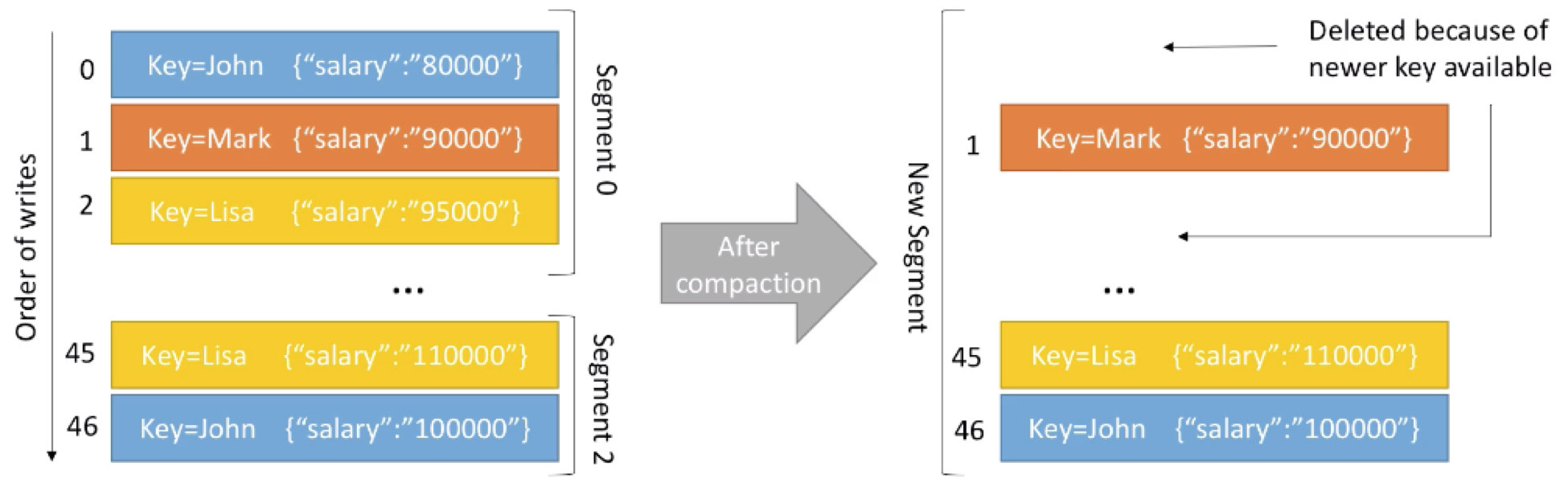
可以看到在log compaction后,相对于更新后的key-value message,旧的message被删除。
Log Compaction 有如下特点:
- messages的顺序仍然是保留的,log compaction 仅移除一些messages,但不会重新对它们进行排序
- 一条message的offset是无法改变的(immutable),如果一条message缺失,则offset会直接被跳过
- 被删除的records在一段时间内仍然可以被consumers访问到,这段时间由参数delete.retention.ms(默认为24小时)控制
需要注意的是:Kafka 本身是不会组织用户发送duplicate data的。这些重复数据也仅会在一个segment在被commit 的时候做重复数据删除,所以consumer仍会读取到这部分重复数据(如果客户端有发的话)。
Log Compaction也会有时失败,compaction thread 可能会crash,所以需要确保给Kafka server 足够的内存用于做这些操作。如果log compaction异常,则需要重启Kafka(此为一个已知的bug)。
Log Compaction也无法通过API手动触发(至少到现在为止是这样),只能server端自动触发。
下面是一个 Log Compaction过程的示意图:

正在写入的records仍会被写入Active Segment,已经committed segments会自动做compaction。此过程会遍历所有segments中的records,并移除掉所有需要被移除的messages。
Log compaction由上文提到的log.cleanup.policy=compact进行配置,其中:
- Segment.ms(默认为7天):在关闭一个active segment前,所需等待的最长时间
- Segment.bytes(默认为1G):一个segment的最大大小
- Min.compaction .lag.ms(默认为0):在一个message可以被compact前,所需等待的时间
- Delete.retention.ms(默认为24小时):在一条message被加上删除标记后,在实际删除前等待的时间
- Min.Cleanable.dirty.ratio(默认为0.5):若是设置的更高,则会有更高效的清理,但是更少的清理操作触发。若是设置的更低,则清理的效率稍低,但是会有更多的清理操作被触发
相关文章:
Kafka磁盘写满日志清理操作
最近项目组的kafka集群,老是由于应用端写入kafka topic的消息太多,导致所在的broker节点占满,导致其他的组件接连宕机。 这里和应用端沟通可以删除1天之前的消息来清理磁盘,并且可以调整topic的消息存活时间。 一、调整Topic的消…...

SSL证书:网络通信安全的基石
随着互联网的深入发展和电子商务的普及,网络安全问题变得越来越重要。SSL证书作为保障网络通信安全的重要组成部分,扮演着至关重要的角色。本文将深入剖析SSL证书的底层原理、作用、应用场景以及优缺点,帮助您更好地理解网络通信安全。 一、…...

Python第三方库 - Flash(python web框架)
1 Flask 1.1 认识Flask Web Application Framework( Web 应用程序框架)或简单的 Web Framework( Web 框架)表示一个库和模块的集合,使 Web 应用程序开发人员能够编写应用程序,而不必担心协议,线…...

基于C#使用winform技术的游戏平台的实现【C#课程设计】
基于C#使用winform技术的游戏平台的实现【C#课程设计】 说明项目结构项目运行截图及实现的功能 部分代码一些说明(个人觉得一些难点的说明)一、ListView ,ImageList 的综合使用二、图片上传以及picturebox 图片的动态替换三、图表插件的使用四、SQL工具类封装五、高…...

springboot缓存篇之内置缓存
前言 前面我们讲了mybatis的一级缓存和二级缓存,这种缓存是基于持久层的缓存,存在很大的局限性。这篇文章主要分享一下另外的一种缓存方式,springboot的内置缓存,看看内置缓存的用法和它的优劣。 开启缓存 在使用springboot的内…...
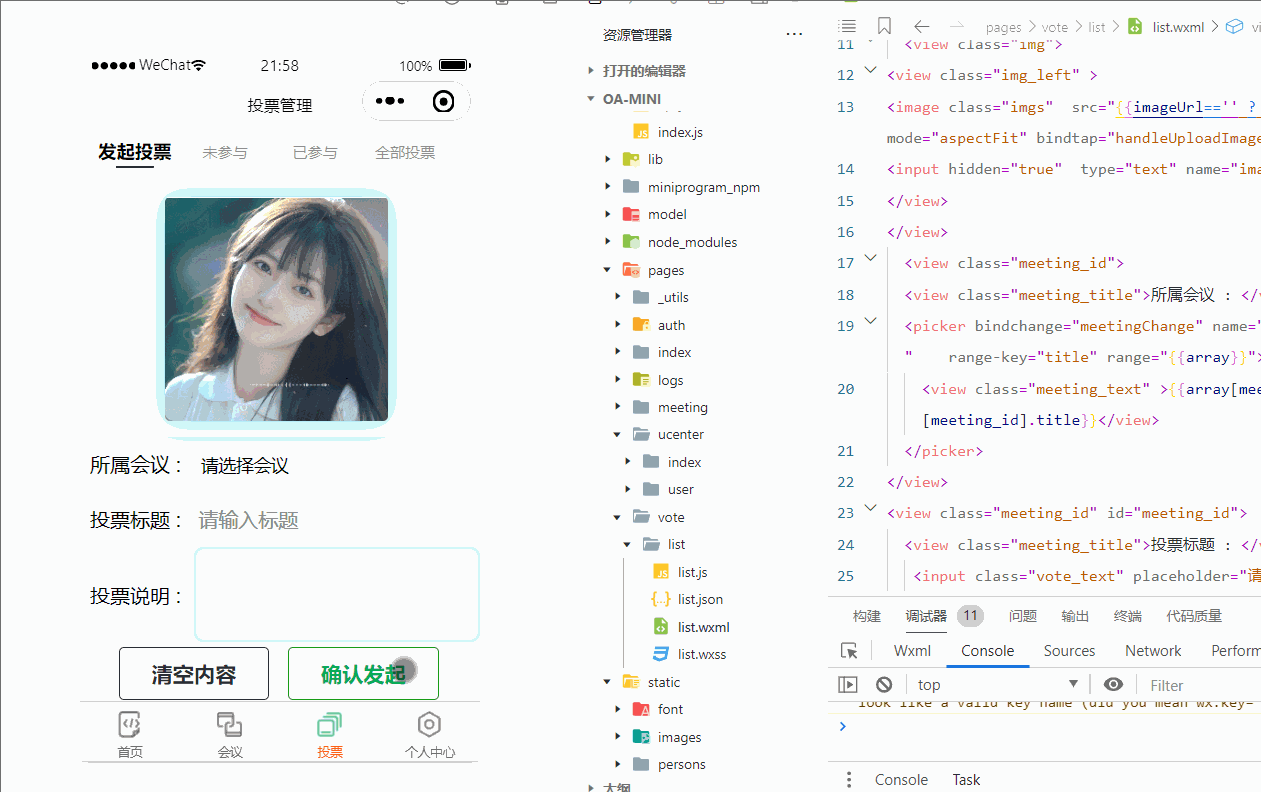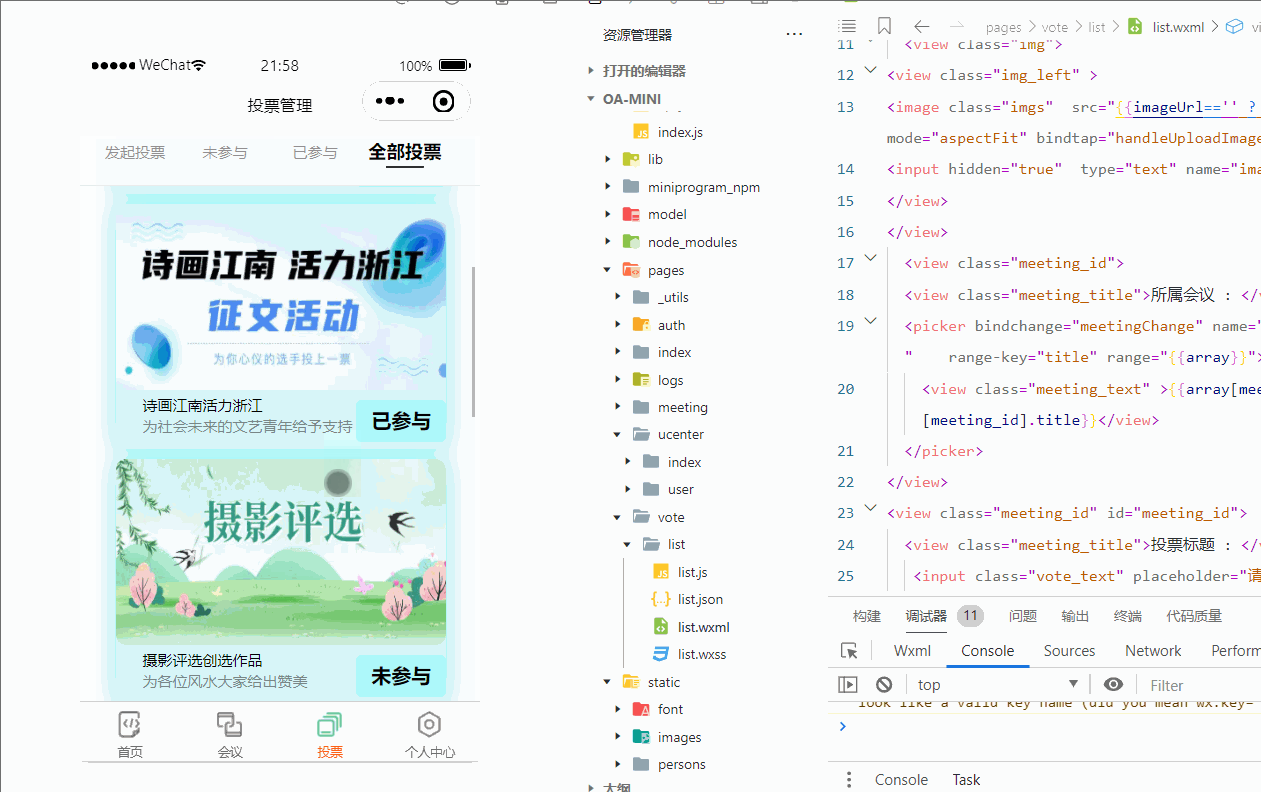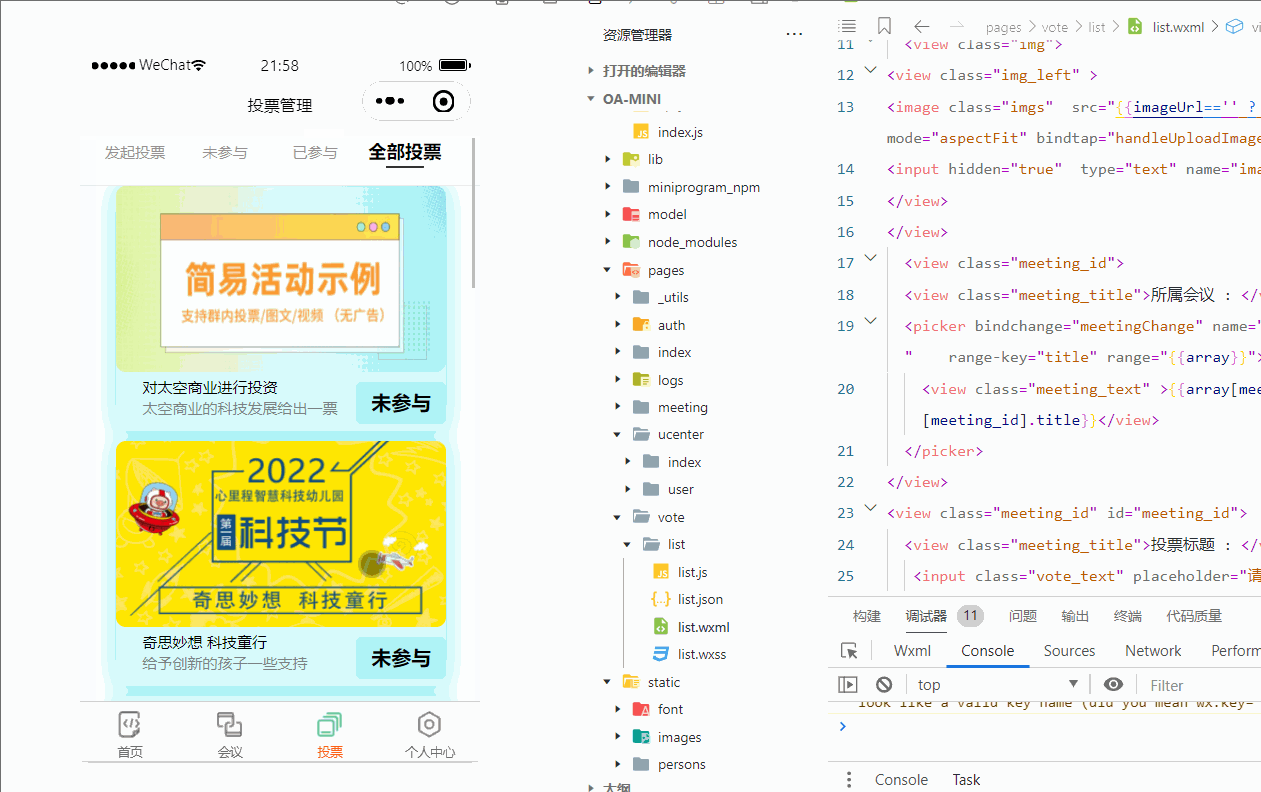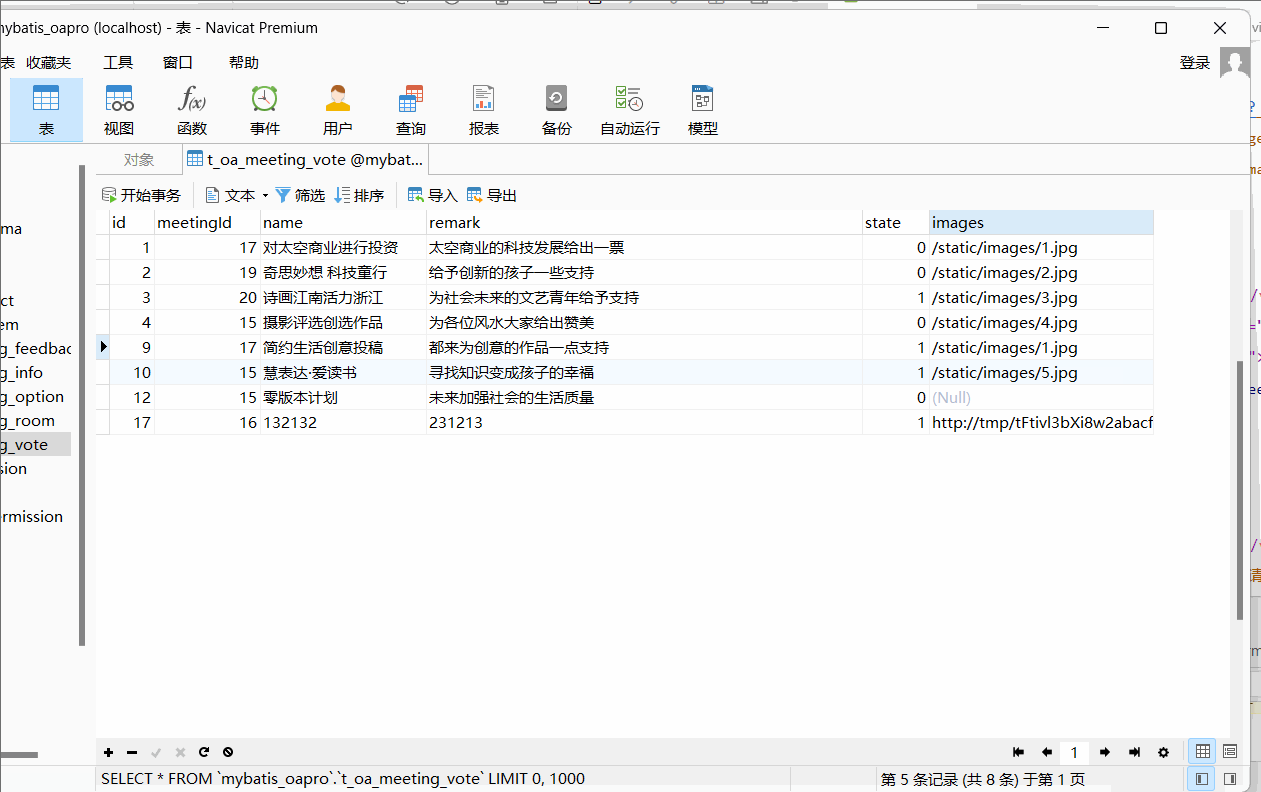
微信小程序开发之投票管理及小程序UI的使用
目录 一、小程序UI 1.讲述 2. 介绍vantWeapp 3. 使用vantWeapp 安装 构建 依赖 引用 二、后端 1. 后端实体对象 2. 后端接口 3. 实现类 4. 请求处理类 三、前端 1. 定义路径 2. 页面引用 3. 页面 4. 页面美化 5. 数据 6. 效果展示 一、小程序UI 1.讲述 小…...

EPB功能开发与测试(基于ModelBase实现)
ModelBase是经纬恒润开发的车辆仿真软件,包含两个大版本:动力学版本、智能驾驶版本。动力学版包含高精度动力学模型,能很好地复现车辆在实际道路中运行的各种状态变化,可用于乘用车、商用车动力底盘系统算法开发、控制器仿真测试&…...

微信小程序:点击按钮出现右侧弹窗
效果 代码 wxml <!-- 弹窗信息 --> <view class"popup-container" wx:if"{{showPopup}}"><view class"popup-content"><!-- 弹窗内容 --><text>这是一个右侧弹窗</text></view> </view> <…...

EEG脑电信号的具体采集过程
脑电图(EEG)是一种记录大脑活动的非侵入性方法。下面是EEG脑电信号的典型采集过程: 准备:在进行EEG采集之前,需要准备好以下设备和材料: EEG采集设备:包括EEG电极、放大器和记录设备。电极帽或电…...
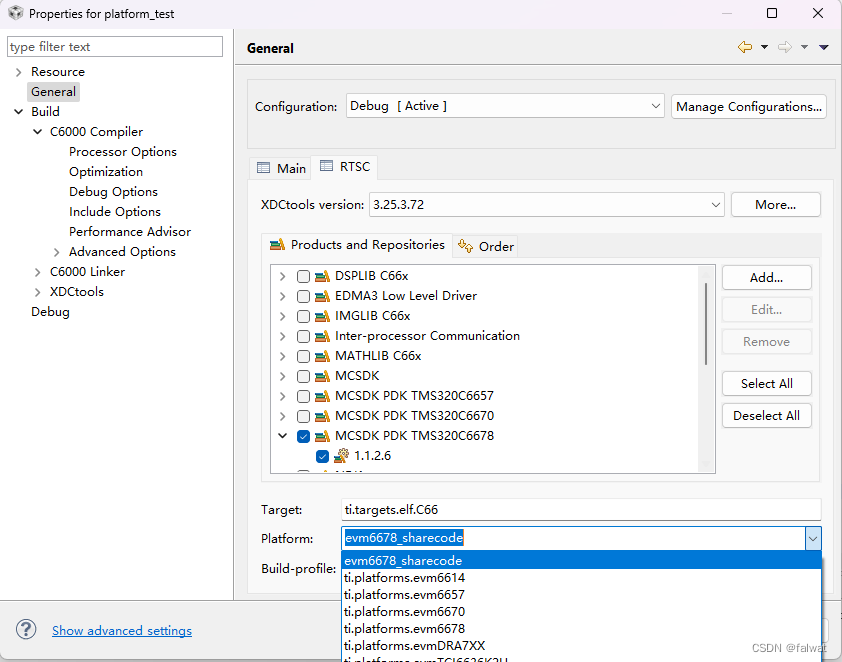
SYS/BIOS 开发教程: 创建自定义平台
目录 SYS/BIOS 开发教程: 创建自定义平台创建自定义平台新建工程并指定自定义平台修改现有工程使用自定义平台 参考: TI SYS/BIOS v6.35 Real-time Operating System User’s Guide 6.2节 本示例基于 EVMC6678L 开发板, 创建自定义平台, 并将代码段的位置指定到C6678器件内部的…...
【Qt样式(qss)-5】qss局部渲染混乱,错乱,不生效的一种原因
前言: 之前写过一些关于qss的文章: 【Qt样式(qss)-1】手册小结(附例:软件深色模式)_深蓝色主题qss表-CSDN博客 【Qt样式(qss)-2】使用小结(软件换肤&#…...
最新基于机器学习模型单图换脸离线版软件包及使用方法,本地离线版本模型一键运行(免费下载)
最新基于机器学习模型单图换脸离线版软件包及使用方法,本地离线版本模型一键运行(免费下载)。 “单图换脸”离线一键运行版来了。Roop发布几十个小时后,马不停蹄地搞了Colab在线版。其实这东西都挺好的,又快又方便,几乎没有任何硬件要求,点一点就可以搞定了。但是它有…...
通过VScode连接远程 Linux 服务器修改vue代码
1先在Linux环境安装node,官网下载的node安装包放在自己新建文件夹 2解压 tar -zxvf node-v18.18.0-linux-x64.tar.xz 3新建代码路径, 下载代码 4安装 OpenSSH OpenSSH 可以让你在终端使用 ssh 命令,Windows10 一般自带。 可以通过以下方式…...
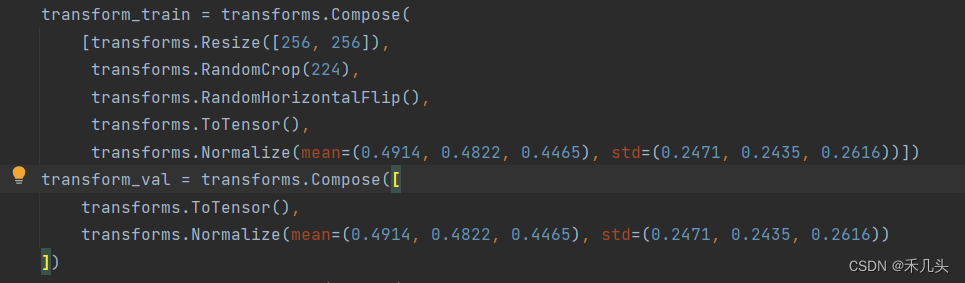
Pytorch实现深度学习常见问题
RuntimeError: stack expects each tensor to be equal size, but got [3, 300, 300] at entry 0 and [3, 301, 301] at entry 24 这里的问题出现的原因肯定是在数据预处理处,如下图,当数据使用不同的transforms处理方式时,会导致数据的尺寸大…...

ICMP权限许可和访问控制漏洞处理(CVE-1999-0524)
一、问题描述 某次例行安全扫描,发现:ICMP权限许可和访问控制漏洞,编号:CVE-1999-0524,危险级别:低风险。利用该漏洞,远程主机会回复ICMP_TIMESTAMP查询并返回它们系统的当前时间,I…...

Java生成优惠券兑换码并确保唯一性最终添加到数据库
1.使用随机数生成器或其他生成唯一标识符的算法来生成兑换码。 2.创建一个 HashSet 或其他适合存储兑换码的数据结构来确保唯一性。每次生成一个兑换码时,先检查它是否已经存在于 HashSet 中,如果存在则重新生成直到生成一个新的唯一兑换码。 3.循环调…...

【Linux/脚本/芯片学习】Perl学习
Title:Perl学习 个人学习策略 主用python. 看懂perl 和 tcl 即可。 之前的存货 开始搬砖后,整理 ”网络发布版笔记“ 的心思寡淡了好多,可能就是被工作榨干的原因8… 但今天至少得赶个1024节日… ( ̄▽ ̄)"~ 1 介…...
)
嵌入式实时操作系统的设计与开发(信号量学习)
信号量 除了临界点机制、互斥量机制可实现临界资源的互斥访问外,信号量(Semaphore)是另一选择。 信号量与互斥量的区别 对于互斥量来说,主要应用于临界资源的互斥访问,并且能够有效地避免优先级反转问题。对于信号量…...

python环境安装教程
Python是一种流行的高级编程语言,它简单易学、功能强大,适用于各种应用领域,从Web开发到数据科学和人工智能。在本教程中,我将向您介绍如何安装Python并设置您的开发环境。请注意,以下步骤适用于Windows操作系统。 步…...

【学习笔记】CF1784F Minimums or Medians
首先让 n n n乘上 2 2 2。 考虑枚举最终被删除的位置有哪些。 a i 0 a_i0 ai0表示这个位置被删除, a i 1 a_i1 ai1表示这个位置被保留,设满足 a i 0 a_i0 ai0的前缀长度为 l l l( l l l是偶数), p r e i pre…...

剪流AI事业大使是不是割韭菜?深度解析其真实运作细节与收益模型
近年来,“AI事业大使”成为一个热门话题,尤其是剪流AI推出的相关计划,引发了广泛讨论。其中,“AI事业大使是不是割韭菜”是许多观望者心中的核心疑问。本文将基于其公开的运作细节与权益体系,进行客观、深度的解析&…...

开始举报功能测试
这说明记录添加成功,举报功能测试正常...

AI Agent的推理能力边界:大模型之外的关键技术突破
AI Agent的推理能力边界:大模型之外的关键技术突破 关键词:AI Agent、推理能力边界、工具增强推理、神经符号推理、自主规划、多Agent协同、幻觉抑制 摘要:本文针对当前行业普遍存在的「大模型参数堆得越高,AI Agent推理能力就越强」的认知误区,系统拆解了大模型原生推理能…...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...
的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”))
面向对象分析(OOA)的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”)
面向对象分析(OOA)的第一个步骤是识别问题域中的对象和类(也称为“识别对象与类”或“确定问题域中的概念类”)。 这一步要求分析师深入理解用户需求和现实世界的问题背景,通过用例分析、领域建模、名词提取等方法&…...

WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案
WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的种种限制而烦恼吗…...

终极免费方案:如何用Wand-Enhancer解锁WeMod高级功能完整指南
终极免费方案:如何用Wand-Enhancer解锁WeMod高级功能完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否厌倦了WeMod免费版的种种…...

Claude Code质量崩了?Anthropic认错;3人+100个AI月烧130万美元,炸了
每天更新,带你读懂科技圈。 今日看点: Anthropic正式发布Claude Code质量事故复盘;OpenClaw之父晒出130万美元月账单——3人100个AI agent震撼业界;Hermes团队砍掉预训练六成成本;GitHub Copilot推桌面应用狙击AI编程对…...

Windows Subsystem for Android终极指南:5大核心优势与完整开发实战
Windows Subsystem for Android终极指南:5大核心优势与完整开发实战 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Andr…...

使用 Elcomsoft System Recovery 恢复 Windows 凭据
在传统的取证工作流程中,获取 Windows 系统的访问权限曾是一件比较直接的事情:从本地数据库中提取 NT 哈希,然后运行一次快速的离线攻击。如今,Windows 身份验证正从那些本质上不安全的 NTLM 哈希向更具弹性的机制迁移。微软正积极…...