java实现hbase数据导出
1. HBase-client方式实现
1.1 依赖
<!--HBase依赖坐标--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.2.6</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>1.2.6</version><exclusions><!--排除依赖:不加入这句会报错--><exclusion><groupId>*</groupId><artifactId>*</artifactId></exclusion></exclusions></dependency>1.2 配置及代码
1.2.1 get方式
public class HBaseService {private static final Logger logger = LoggerFactory.getLogger(HBaseService.class);/*** 配置文件读取的配置信息*/static Configuration configuration = HBaseConfiguration.create();/*** 链接信息*/private static Connection conn = null;static {try {conn = ConnectionFactory.createConnection(configuration);} catch (IOException e) {e.printStackTrace();}}/*** 进行数据的查询以及写入到文件中(通过get方式查询获得数据并写入文件)* @param rowKey rowKey信息* @param tableName 表名* @param dirName 文件目录* @param fileExist 文件是否存在的标志*/public static void addInfoToFile(String rowKey, String tableName, String dirName, boolean fileExist){Table table = null;ResultScanner result = null;try {Connection connection = ConnectionFactory.createConnection(configuration);table = connection.getTable(TableName.valueOf(tableName));List<Get> gets = new ArrayList<>();Get get = new Get(Bytes.toBytes(rowKey));gets.add(get);// result的集合Result[] resultArr = table.get(gets);Map<String, Map<String,String>> dataMap = new HashMap<>();for (Result r : resultArr) {String rowKey1 = Bytes.toString(r.getRow());Map<String, String> columnDataMap;if (dataMap.containsKey(rowKey1)){columnDataMap = dataMap.get(rowKey1);}else {columnDataMap = new HashMap<>();}for (Cell kv : r.rawCells()) {String qualifire = Bytes.toString(CellUtil.cloneQualifier(kv));String value = Base64Encoder.encode(CellUtil.cloneValue(kv));columnDataMap.put(qualifire, value);dataMap.put(rowKey1, columnDataMap);}}if (MapUtil.isNotEmpty(dataMap)){for (String r : dataMap.keySet()) {Map<String, String> columnMap = dataMap.get(r);StrBuilder lineStr = new StrBuilder();lineStr.append(r + "||");for (String s : columnMap.keySet()) {lineStr.append(s + ":" + columnMap.get(s) + "\t");}String fileName = dirName + File.separator + "data.txt";File f = new File(fileName);if (!f.exists()){try {f.createNewFile();}catch (IOException e){logger.error("创建文件失败,异常信息:{}", e.getMessage());}}BufferedWriter writer = new BufferedWriter(new FileWriter(fileName, true));writer.write(lineStr.toString() + "\n");logger.info("写入rowkey:{}的波形数据到:{}", r, fileName);writer.close();}}}catch (Exception e){logger.error("写入rowkey:{}的波形数据到:{}失败,错误的信息:{}", rowKey, dirName, e.getMessage());}}
}
1.3.1 Scan方式
/*** 通过scan的方式进行数据获取* @param rowKey rowkey* @param startKey 开始的rowKey* @param stopKey 结束的rowKey* @param regexStr rowKey的正则匹配表达式*/public static void findRowKey(String rowKey, String startKey, String stopKey, String regexStr){Table table = null;ResultScanner result = null;try {TableName[] tbs = conn.getAdmin().listTableNames();FilterList filters = new FilterList();table = conn.getTable(TableName.valueOf("Vibration_WaveData"));Scan scan = new Scan();// 通过正则匹配的方式+rowkey进行数据过滤RegexStringComparator regexComparator = new RegexStringComparator(regexStr);RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, regexComparator);// 设置start和stop Rowkey 可以提供检索效率scan.setStartRow(startKey.getBytes());scan.setStopRow(stopKey.getBytes());scan.setFilter(rowFilter);// 每次从服务器端获取的行数scan.setCaching(100000);ResultScanner result1 = table.getScanner(scan);for (Result r : result1) {for (KeyValue kv : r.raw()) {System.out.println(String.format("row:%s, family:%s, qualifier:%s, qualifiervalue:%s, timestamp:%s.",Bytes.toString(kv.getRow()),Bytes.toString(kv.getFamily()),Bytes.toString(kv.getQualifier()),Bytes.toString(kv.getValue()),kv.getTimestamp()));}}result1.close();conn.close();}catch (Exception e){System.out.println(e.getMessage());}}
2. mapReduce实现
2.1 依赖
<!--hadoop依赖坐标--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.6</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>2.7.6</version></dependency><dependency><groupId>commons-cli</groupId><artifactId>commons-cli</artifactId><version>1.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.6</version></dependency>
2.2 配置文件
hbase-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><!-- 指定 hbase 是分布式的 --><name>hbase.cluster.distributed</name><value>true</value></property><property><!-- 指定 zk 的地址,多个用“,”分割 --><name>hbase.zookeeper.quorum</name><value>192.168.1.100:2181,192.168.1.102:2181</value></property><!-- 开启 uber 模式,默认关闭 --><property><name>mapreduce.job.ubertask.enable</name><value>true</value></property><!-- uber 模式中最大的 mapTask 数量,可向下修改 --><property><name>mapreduce.job.ubertask.maxmaps</name><value>9</value></property><!-- uber 模式中最大的 reduce 数量,可向下修改 --><property><name>mapreduce.job.ubertask.maxreduces</name><value>1</value></property><!-- uber 模式中最大的输入数据量,默认使用 dfs.blocksize 的值,可向下修改 --><property><name>mapreduce.job.ubertask.maxbytes</name><value></value></property>
</configuration>
2.3 导出的代码
public class ReadHbaseDataByMRToHDFS {
static Configuration configuration = HBaseConfiguration.create();/*** 进行hbase数据导出的操作* @param tableName 表名* @param dirName 文件夹名称* @param startRow 开始的row key* @param stopRow 结束的row key* @param regexStr 进行匹配的字符*/public void exportHbaseData(String tableName, String dirName, String startRow, String stopRow, String regexStr) {logger.info("开始进行HBase数据导出,tableName:{}, dirName:{}, startRow:{}, stopRow:{}, regexStr:{}", tableName, dirName, startRow, stopRow, regexStr);System.setProperty("HADOOP_USER_NAME", "root");// 一次rpc请求的超时时间,如果某次RPC请求超过该值,客户端就会主动管理Socketconfiguration.set("hbase.rpc.timeout", "600000");// ,该参数是表示HBase客户端发起一次scan操作的rpc调用至得到响应之间总的超时时间configuration.set("hbase.client.scanner.timeout.period", "600000");configuration.set("mapreduce.job.ubertask.maxmaps", "10");configuration.set("mapreduce.job.ubertask.maxreduces", "1");configuration.set("mapreduce.task.io.sort.mb", "1024");configuration.set("mapred.map.tasks", "10");try {Job job = Job.getInstance(configuration);job.setJarByClass(ReadHbaseDataByMRToHDFS.class);//设置reduce个数job.setNumReduceTasks(0);//设置mapScan scan = new Scan();
// 设置start和stop rowkey以及regex提高检索效率RegexStringComparator regexComparator = new RegexStringComparator(regexStr);scan.setStartRow(startRow.getBytes()).setStopRow(stopRow.getBytes());RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, regexComparator);scan.setFilter(rowFilter);// 每次从服务器端获取的行数scan.setCaching(900000);//参数false,关于添加依赖jarTableMapReduceUtil.initTableMapperJob(tableName,scan,ReadHBaseDataByMRToHDFSMapper.class,Text.class,NullWritable.class,job,false);//输出目录FileOutputFormat.setOutputPath(job, new Path(dirName));//提交boolean isDone = job.waitForCompletion(true);if (isDone){Thread.sleep(3000);logger.info("进行HBase数据导出成功,tableName:{}, dirName:{}, startRow:{}, stopRow:{}, regexStr:{},状态:{}", tableName, dirName, startRow, stopRow, regexStr, isDone);}} catch (Exception e) {logger.error("进行HBase数据导出时出现异常,tableName:{}, dirName:{}, startRow:{}, stopRow:{}, regexStr:{},异常信息:{}",tableName, dirName, startRow, stopRow, regexStr, e.getMessage());}}/*** 参数* ImmutableBytesWritable* Result :HBase中的数据每次取出来是一个Result:就是一个rowkey做一个result* <p>* keyOut:* valueOut:*/static class ReadHBaseDataByMRToHDFSMapper extends TableMapper<Text, NullWritable> {Text outKey = new Text();@Overrideprotected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {List<Cell> cells = value.listCells();Map<String, Map<String, String>> cellMap = new HashMap<>();//一个cell一条数据 包含一个columnfor (Cell cell : cells) {String rowkey = Bytes.toString(CellUtil.cloneRow(cell));Map<String, String> columnMap = new HashMap<>();if (cellMap.containsKey(rowkey)){columnMap = cellMap.get(rowkey);}// String family = Bytes.toString(CellUtil.cloneFamily(cell));String column = Bytes.toString(CellUtil.cloneQualifier(cell));String columnValue = Base64Encoder.encode(CellUtil.cloneValue(cell));columnMap.put(column, columnValue);cellMap.put(rowkey, columnMap);// long timeStamp = cell.getTimestamp();// outKey.set(rowkey + "\t\t" + column + "\t\t" + columnValue + "\n");}if (CollUtil.isNotEmpty(cellMap)){String lineStr = "";for (String s : cellMap.keySet()) {Map<String, String> columnMap = cellMap.get(s);lineStr = s + "||";for (String c : columnMap.keySet()) {lineStr += c + ":" + columnMap.get(c) + "\t";}}outKey.set(lineStr);context.write(outKey, NullWritable.get());outKey.clear();}}}
}
相关文章:

java实现hbase数据导出
1. HBase-client方式实现 1.1 依赖 <!--HBase依赖坐标--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.2.6</version></dependency><dependency><group…...

Unity之ShaderGraph如何实现旋涡效果
前言 今天我们来通过ShaderGraph来实现一个旋涡的效果 如下图所示: 主要节点 Distance:返回输入 A 和输入 B 的值之间的欧几里德距离。除了其他方面的用途,这对于计算空间中两点之间的距离很有用,通常用于计算有符号距离函数 (…...
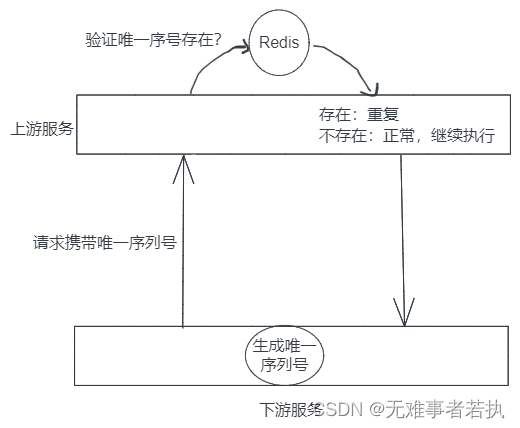
【分布式】: 幂等性和实现方式
【分布式】: 幂等性和实现方式 幂等(idempotent、idempotence)是一个数学与计算机学概念, 常见于抽象代数中。在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是…...
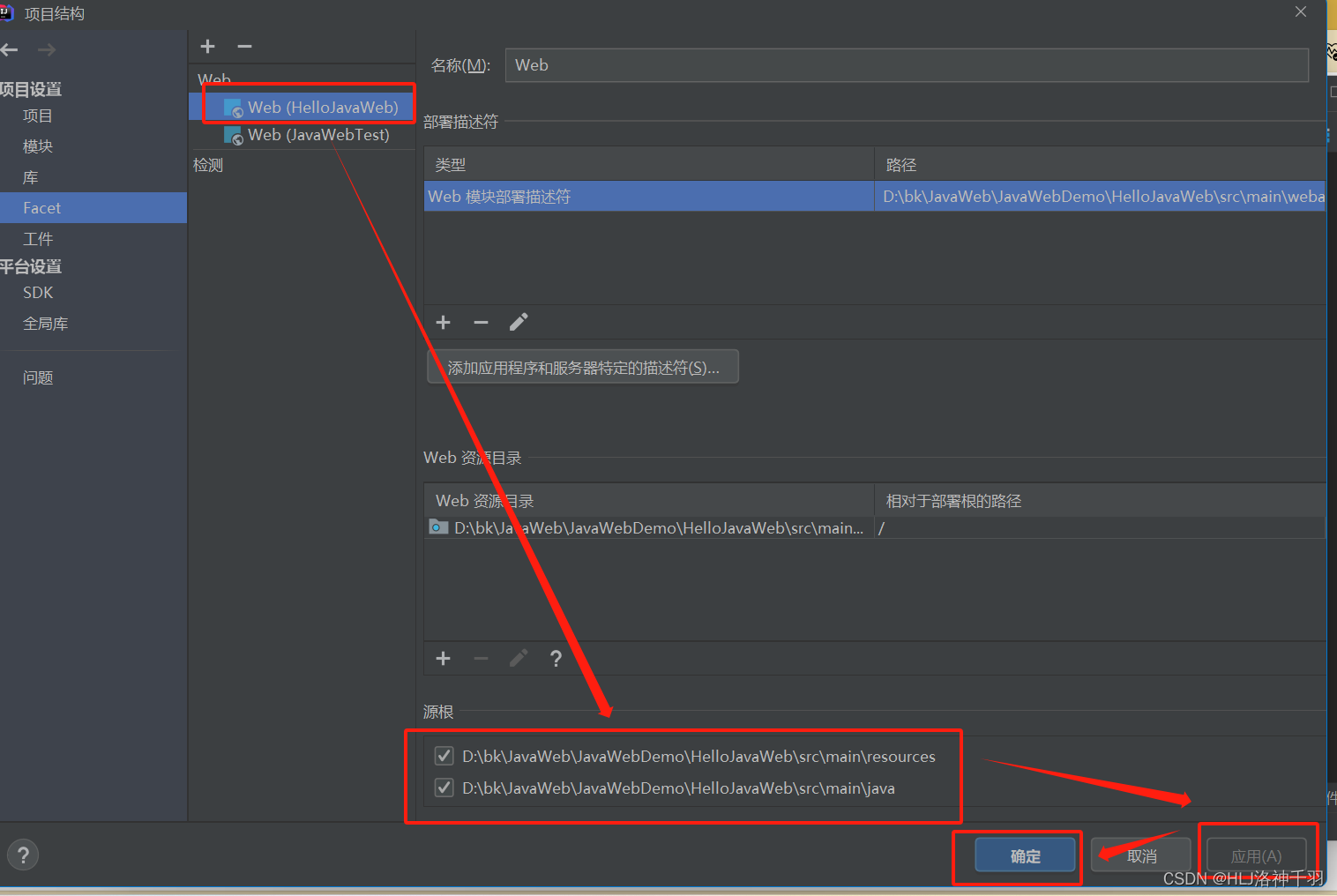
idea 设置serlvet 类模板(快捷生成servlet类)
我的版本是idea2020.3.4,博客中有相应安装教程,其他版本设置类似: 1.选择文件-->设置 2.选择编辑器-->文件和代码模板-->其他 3.选择Web-->Servlet Annotated Class.java-->复制相应模板,下面顺便设置了注释模板 …...
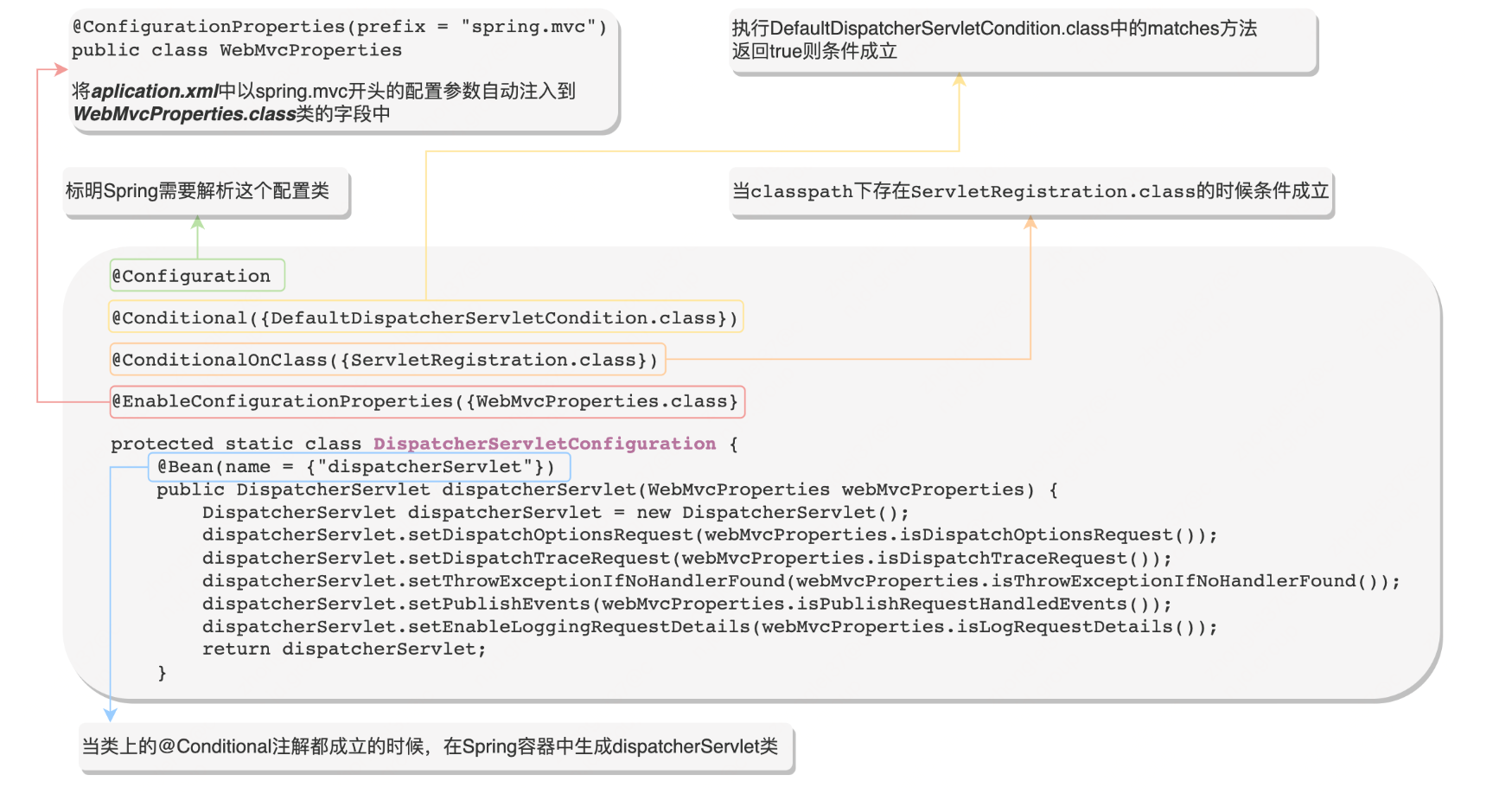
SpringBoot自动配置原理解析 | 京东物流技术团队
1: 什么是SpringBoot自动配置 首先介绍一下什么是SpringBoot,SpringBoost是基于Spring框架开发出来的功能更强大的Java程序开发框架,其最主要的特点是:能使程序开发者快速搭建一套开发环境。SpringBoot能将主流的开发框架(例如Sp…...

AOP 笔记
AOP【面向切面编程】 作用:在不惊动原始设计的基础上进行功能增强。 无侵入式编程 连接点:程序执行的任意位置,SpringAOP中,理解为方法的执行。 切入点:匹配连接点的式子,要追加功能的方法 通知(写在通…...
)
微信小程序导航退回及跳转 传参(navigateBack,navigateTo)
一、uniapp navigateBack 退回上一级 当前页面-传递参数 uni.$emit(update, params)uni.navigateBack({delta: 1});退回的页面-接收参数 可以写在 onLoad 和 onShow 里面 onLoad(o) {uni.$on(update, function(e) {//参数e}}onShow() {}返回前两级 uni.navigateBack({delta: 2}…...

python实例代码介绍python基础知识
TODO: 知识点仍有待整理 import 使用 import 关键字可以让你选择性地导入所需的模块,而不必导入整个模块库。这样可以减少内存占用和加载时间,尤其是当你只需要使用模块中的某些功能时。 同时,使用 import 可以提高代码的可读性和可维护性&…...

【每日一题】掷骰子等于目标和的方法数
文章目录 Tag题目来源题目解读解题思路方法一:动态规划 写在最后 Tag 【动态规划】【数组】 题目来源 1155. 掷骰子等于目标和的方法数 题目解读 你手里有 n 个一样的骰子,每个骰子都有 k 个面,分别标号 1 到 n。给定三个整数 n࿰…...

霸王条款惹品牌争议,京东双11站在商家对立面?
作者 | 江北 来源 | 洞见新研社 双11活动第一天,京东就站上了风口浪尖。 与烘焙烤箱品牌海氏的话题接连登上微博热搜,海氏控诉京东滥用市场竞争地位,破坏市场竞争秩序。在海氏的声明中,京东的行为让吃瓜群众大开眼界:…...

深度神经网络为何成功?其中的过程、思想和关键主张选择
LeNet(1989)在小数据集上取得了很好的效果,但是在更大、更真实地数据集上训练卷积神经网络地性能和可行性还有待研究。 与神经网络竞争的是传统机器学习方法,比如SVM(支持向量机)。这个阶段性能比神经网络方…...

什么是服务器节点?
一.服务器节点的概念: 服务器节点是一种服务器装置,节点服务器是针对服务器集群来说的。主要应用在WEB、FTP等等的服务上。所以节点服务器并不是单指某一种服务器。它由多个节点和管理装置整体的管理单元构成,其特征在于:各节点具…...

水电站与数据可视化:洞察未来能源趋势的窗口
在信息时代的浪潮中,数据可视化正成为推动能源领域发展的重要工具。今天,我们将带您一起探索水电站与数据可视化的结合,如何成为洞察未来能源趋势的窗口。水电站作为传统能源领域的重要组成部分,它的运行与管理涉及大量的数据。然…...
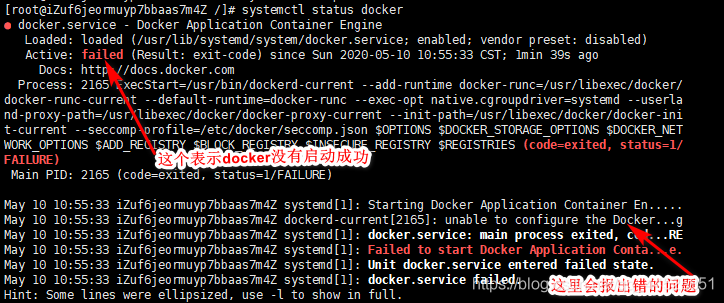
Mac运行Docker报错
Mac运行Docker报错 📔 千寻简笔记介绍 千寻简笔记已开源,Gitee与GitHub搜索chihiro-notes,包含笔记源文件.md,以及PDF版本方便阅读,且是用了精美主题,阅读体验更佳,如果文章对你有帮助请帮我点…...
.click(function(){ 和代码 $(document).ready(function() 有啥区别?)
代码 $(“.btn“).click(function(){ 和代码 $(document).ready(function() 有啥区别?
看下面的内容前可以先看下博文:https://blog.csdn.net/wenhao_ir/article/details/134029389 $(".btn").click(function(){...}) 和 $(document).ready(function(){...}) 是两种不同的 jQuery 事件处理方式,它们有不同的用途和时机࿱…...

【nodejs脚本】为文件夹中的所有node项目执行命令 npm install 并收集error日志
目录 im 下有很多的node项目,我需要批量为这些项目执行 npm install,另外npm的error信息需要单独收集至log文件中 var fs require(fs); var util require(util); var exec util.promisify(require(child_process).exec);var projectsDirectory .; v…...

非父子组件通信-发布订阅模式
发布订阅模式其实与vue无关,完全是ES6的代码,但是它可以通过这种模式实现非父子组件的通信 store.js文件 首先创建一个store.js文件,用于提供发布与订阅方法 export default {datalist: [], //存放带一个参数的函数集合//订阅subscribe(fu…...

iPhone手机分辨率整理
手机机型(iPhone)屏幕尺寸 (inch)逻辑分辨率(pt)设备分辨率(px)缩放因子(Scale Factor)竖屏安全区域(safeAreaInsets)纵横比(Aspect ratio)像素密度(ppi)2G/3G/3GS3.5320*480320*4801xtop:20 bottom:03:21654/4(s)3.5320*480640*9602xtop:20 bottom:016:…...
【linux】SourceForge 开源软件开发平台和仓库
在linux上面安装服务和工具。我们经常会下载安装包。今天推荐一个网站。 SourceForge 开源软件开发平台和仓库 全球最大开源软件开发平台和仓库 SourceForge.net,又称SF.net,是开源软件开发者进行开发管理的集中式场所。 SourceForge.net由VA Softwa…...
LabVIEW应用开发——控件的使用(四)
接上文,这篇介绍时间控件。 LabVIEW应用开发——控件的使用(三) 1、时间控件Time Stamp control 在日常软件开发场景中,时间也是一种常用的控件,用于表达当前时间的显示、对下设置时间、时间同步等等场景。LabVIEW专门…...

Pearcleaner:macOS应用彻底清理的终极免费解决方案
Pearcleaner:macOS应用彻底清理的终极免费解决方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的烦恼:在Ma…...

别再只用CyclicBarrier了!聊聊Java并发库里那个小众但好用的Exchanger
解锁Java并发编程中的隐藏利器:Exchanger深度实战指南 在Java并发编程的世界里,开发者们往往对CyclicBarrier、CountDownLatch这些同步工具如数家珍,却很少有人注意到并发库中那个低调但强大的Exchanger。这个专为线程间数据交换设计的同步点…...

独立开发者如何借助Taotoken多模型能力优化个人项目成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力优化个人项目成本 对于独立开发者和小型项目而言,在探索大模型应用时࿰…...

ceshi1
进入2026年,企业数字化转型已从“流程数字化”全面转向“认知自动化”。 据最新行业数据显示,企业内部超过85%的数据以PDF、图片、音视频、扫描件等非结构化形式存在。 这些数据曾被视为“沉默的资产”,因为传统OCR或规则引擎难以处理其复杂的…...

51c自动驾驶~合集57
我自己的原文哦~ https://blog.51cto.com/whaosoft/13960249 #端到端自动驾驶算法实现原理 1从传感器数据到控制策略的端到端方法 端到端自动驾驶基本流程: (1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型; (2)…...

WordPress Playground部署实战:从开发到生产的完整流程指南
WordPress Playground部署实战:从开发到生产的完整流程指南 【免费下载链接】wordpress-playground Run WordPress in the browser via WebAssembly PHP 项目地址: https://gitcode.com/gh_mirrors/wo/wordpress-playground WordPress Playground 是一个革命…...

Linux应用回滚流程排查方法
Linux应用回滚流程排查方法本文面向具备一定 Linux 基础的技术人员,围绕应用回滚流程展开,重点讨论版本切换、配置恢复和数据兼容。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

Linux巡检报告生成实战指南
Linux巡检报告生成实战指南本文面向具备一定 Linux 基础的技术人员,围绕巡检报告生成展开,重点讨论检查汇总、异常标记和结果归档。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...
)
NotebookLM信息冗余顽疾破解指南(92%用户忽略的3层语义去重机制)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM信息去重的核心挑战与认知重构 NotebookLM 作为 Google 推出的基于用户文档构建的 AI 助手,其核心能力依赖于对上传资料的语义理解与上下文关联。然而,当用户批量导入…...
GitGitHub实操图文详解教程(06)—git status命令)
(最新版)GitGitHub实操图文详解教程(06)—git status命令
版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl 1. 应用场景 git status 是 Git 中最常用的命令之一,用于查看当前仓库的状态。它能够告诉你: 当前所在分支 哪些文件被修改但未暂存 哪些文件已暂存但尚未提交 哪些文件未被 Git 跟踪 对于初学…...