docker 部署tig监控服务
前言
- tig对应的服务是influxdb grafana telegraf
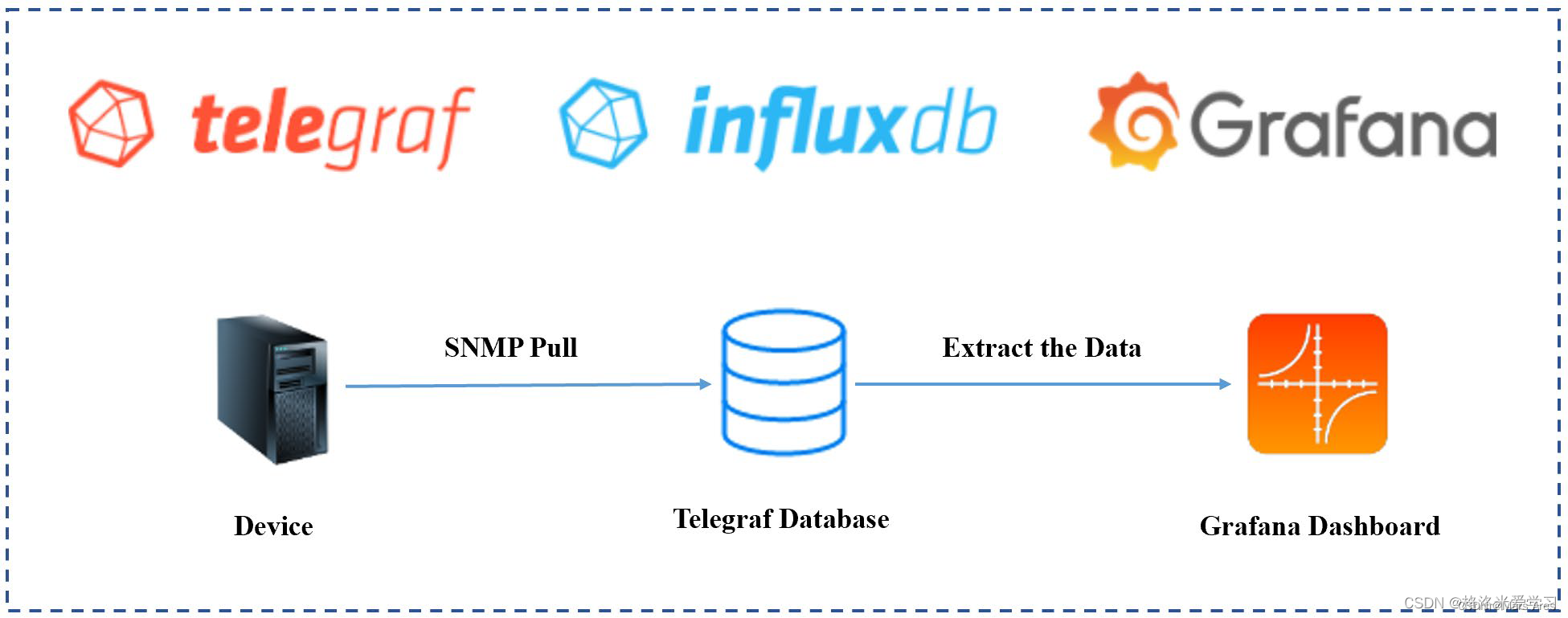
- 此架构比传统的promethus架构更为简洁,虽然influxdb开源方案没有集群部署,但是对于中小型服务监控需求该方案简单高效
- 本文以docker-compose来演示这套监控体系的快速搭建和效果。
部署
docker-compose.yaml
version: '3'
networks:monitor:driver: bridge
#配置应用
services:#grafana 报警推送 #账号密码 prometheusalert prometheusalertprometheusalert:image: feiyu563/prometheus-alertcontainer_name: prometheusalerthostname: prometheusalertrestart: alwaysports:- 8087:8080networks:- monitorvolumes:- ./docker/prometheusalert/conf:/app/conf- ./docker/prometheusalert/db:/app/dbenvironment:- PA_LOGIN_USER=prometheusalert- PA_LOGIN_PASSWORD=prometheusalert- PA_TITLE=PrometheusAlert- PA_OPEN_FEISHU=1#界面展示 默认账号密码 admin admingrafana:image: grafana/grafanacontainer_name: grafanahostname: grafanarestart: alwaysvolumes:- ./docker/grafana/data/grafana:/var/lib/grafanaports:- "3000:3000"networks:- monitor#influxdb数据库v2自带管理端#账号密码 root rootinfluxdb:image: influxdbcontainer_name: influxdbenvironment:INFLUX_DB: test # 可能无效INFLUXDB_USER: root # 可能无效INFLUXDB_USER_PASSWORD: root # 可能无效ports:- "8086:8086"restart: alwaysvolumes:- ./docker/influxdb/:/var/lib/influxdbnetworks:- monitor#indluxdb数据库v1#influxdb1x: # image: influxdb:1.8# container_name: influxdb1.8# environment:# INFLUXDB_DB: test# INFLUXDB_ADMIN_ENABLED: true# INFLUXDB_ADMIN_USER: root# INFLUXDB_ADMIN_PASSWORD: root# ports:# - "8098:8086"# restart: always# volumes:# - ./docker/influxdb1x/influxdb1x.conf:/etc/influxdb/influxdb.conf# - ./docker/influxdb1x/:/var/lib/influxdb# networks:# - monitortelegraf 安装 官方文档
# telegraf是采集端,部署于监控数据的源头,详细的部署教程可以通过官网,下面以linux服务器为例子
# 编写源
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key
EOF# 安装
sudo yum install telegraf# 校验
telegraf --help
使用
- 登陆influxdb http://localhost:8086.
- 首次登陆会创建账号
- org是分区意思
- buk是库的概念


- 配置telegraf采集etl流程 官方telegraf采集插件介绍
- 配置influxdb数据的访问的token
- 配置telegraf采集的配置文件
- 采集端启动telegraf采集etl
a. 配置token b. 可以通过平台生成配置文件,也可以自己保存配置文件。平台生成配置则提供http接口远程提供配置下载
b. 可以通过平台生成配置文件,也可以自己保存配置文件。平台生成配置则提供http接口远程提供配置下载
以nginx文件为例提供配置
telegraf.conf
# Configuration for telegraf agent
# telegraf 采集端配置都是默认配置
[agent]## Default data collection interval for all inputsinterval = "10s"## Rounds collection interval to 'interval'## ie, if interval="10s" then always collect on :00, :10, :20, etc.round_interval = true## Telegraf will send metrics to outputs in batches of at most## metric_batch_size metrics.## This controls the size of writes that Telegraf sends to output plugins.metric_batch_size = 1000## Maximum number of unwritten metrics per output. Increasing this value## allows for longer periods of output downtime without dropping metrics at the## cost of higher maximum memory usage.metric_buffer_limit = 10000## Collection jitter is used to jitter the collection by a random amount.## Each plugin will sleep for a random time within jitter before collecting.## This can be used to avoid many plugins querying things like sysfs at the## same time, which can have a measurable effect on the system.collection_jitter = "0s"## Default flushing interval for all outputs. Maximum flush_interval will be## flush_interval + flush_jitterflush_interval = "10s"## Jitter the flush interval by a random amount. This is primarily to avoid## large write spikes for users running a large number of telegraf instances.## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15sflush_jitter = "0s"## By default or when set to "0s", precision will be set to the same## timestamp order as the collection interval, with the maximum being 1s.## ie, when interval = "10s", precision will be "1s"## when interval = "250ms", precision will be "1ms"## Precision will NOT be used for service inputs. It is up to each individual## service input to set the timestamp at the appropriate precision.## Valid time units are "ns", "us" (or "µs"), "ms", "s".precision = ""## Log at debug level.# debug = false## Log only error level messages.# quiet = false## Log target controls the destination for logs and can be one of "file",## "stderr" or, on Windows, "eventlog". When set to "file", the output file## is determined by the "logfile" setting.# logtarget = "file"## Name of the file to be logged to when using the "file" logtarget. If set to## the empty string then logs are written to stderr.# logfile = ""## The logfile will be rotated after the time interval specified. When set## to 0 no time based rotation is performed. Logs are rotated only when## written to, if there is no log activity rotation may be delayed.# logfile_rotation_interval = "0d"## The logfile will be rotated when it becomes larger than the specified## size. When set to 0 no size based rotation is performed.# logfile_rotation_max_size = "0MB"## Maximum number of rotated archives to keep, any older logs are deleted.## If set to -1, no archives are removed.# logfile_rotation_max_archives = 5## Pick a timezone to use when logging or type 'local' for local time.## Example: America/Chicago# log_with_timezone = ""## Override default hostname, if empty use os.Hostname()hostname = ""## If set to true, do no set the "host" tag in the telegraf agent.omit_hostname = false# influxdb_v2 输出插件配置 这里需要配置的
# 数据库地址:urls 分区:organization 库:bucket 授权token:token
[[outputs.influxdb_v2]]## The URLs of the InfluxDB cluster nodes.#### Multiple URLs can be specified for a single cluster, only ONE of the## urls will be written to each interval.## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"]urls = ["http://localhost:8086"] ## Token for authentication.token = "上一步创建的token"## Organization is the name of the organization you wish to write to; must exist.organization = "创建的分区 这里是test"## Destination bucket to write into.bucket = "创建的表 这里是test"## The value of this tag will be used to determine the bucket. If this## tag is not set the 'bucket' option is used as the default.# bucket_tag = ""## If true, the bucket tag will not be added to the metric.# exclude_bucket_tag = false## Timeout for HTTP messages.# timeout = "5s"## Additional HTTP headers# http_headers = {"X-Special-Header" = "Special-Value"}## HTTP Proxy override, if unset values the standard proxy environment## variables are consulted to determine which proxy, if any, should be used.# http_proxy = "http://corporate.proxy:3128"## HTTP User-Agent# user_agent = "telegraf"## Content-Encoding for write request body, can be set to "gzip" to## compress body or "identity" to apply no encoding.# content_encoding = "gzip"## Enable or disable uint support for writing uints influxdb 2.0.# influx_uint_support = false## Optional TLS Config for use on HTTP connections.# tls_ca = "/etc/telegraf/ca.pem"# tls_cert = "/etc/telegraf/cert.pem"# tls_key = "/etc/telegraf/key.pem"## Use TLS but skip chain & host verification# insecure_skip_verify = false# Parse the new lines appended to a file
# tail 输入插件配置,以监听nginx日志为例 需要配置
# 监听文件位置 files
# nginx行数据解析表达式 grok_patterns 提取监控字段,gork表达式不单独说明了
# nginx监控数据存储表名 name_override
[[inputs.tail]]## File names or a pattern to tail.## These accept standard unix glob matching rules, but with the addition of## ** as a "super asterisk". ie:## "/var/log/**.log" -> recursively find all .log files in /var/log## "/var/log/*/*.log" -> find all .log files with a parent dir in /var/log## "/var/log/apache.log" -> just tail the apache log file## "/var/log/log[!1-2]* -> tail files without 1-2## "/var/log/log[^1-2]* -> identical behavior as above## See https://github.com/gobwas/glob for more examples##files = ["/logs/nginx/access_main.log"]## Read file from beginning.#from_beginning = false## Whether file is a named pipe# pipe = false## Method used to watch for file updates. Can be either "inotify" or "poll".# watch_method = "inotify"## Maximum lines of the file to process that have not yet be written by the## output. For best throughput set based on the number of metrics on each## line and the size of the output's metric_batch_size.# max_undelivered_lines = 1000## Character encoding to use when interpreting the file contents. Invalid## characters are replaced using the unicode replacement character. When set## to the empty string the data is not decoded to text.## ex: character_encoding = "utf-8"## character_encoding = "utf-16le"## character_encoding = "utf-16be"## character_encoding = ""# character_encoding = ""## Data format to consume.## Each data format has its own unique set of configuration options, read## more about them here:## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.mdgrok_patterns = ["%{NGINX_ACCESS_LOG}"]name_override = "nginx_access_log"#grok_custom_pattern_files = []#grok_custom_patterns = '''#NGINX_ACCESS_LOG %{IP:remote_addr} - (-|%{WORD:remote_user}) [%{HTTPDATE:time_local}] %{BASE10NUM:request_time:float} (-|%{BASE10NUM:upstream_response_time:float}) %{IPORHOST:host} %{QS:request} %{NUMBER:status:int} %{NUMBER:body_bytes_sent:int} %{QS:referrer} %{QS:agent} %{IPORHOST:xforwardedfor}#'''grok_custom_patterns = '''NGINX_ACCESS_LOG %{IP:remote_addr} - (-|%{WORD:remote_user:drop}) \[%{HTTPDATE:ts:ts}\] %{BASE10NUM:request_time:float} %{BASE10NUM:upstream_response_time:float} %{IPORHOST:host:tag} "(?:%{WORD:verb:drop} %{NOTSPACE:request:tag}(?: HTTP/%{NUMBER:http_version:drop})?|%{DATA:rawrequest})" %{NUMBER:status:tag} (?:%{NUMBER:resp_bytes}|-) %{QS:referrer:drop} %{QS:agent:drop} %{QS:xforwardedfor:drop}'''grok_timezone = "Local"data_format = "grok"## Set the tag that will contain the path of the tailed file. If you don't want this tag, set it to an empty string.# path_tag = "path"## multiline parser/codec## https://www.elastic.co/guide/en/logstash/2.4/plugins-filters-multiline.html#[inputs.tail.multiline]## The pattern should be a regexp which matches what you believe to be an## indicator that the field is part of an event consisting of multiple lines of log data.#pattern = "^\s"## This field must be either "previous" or "next".## If a line matches the pattern, "previous" indicates that it belongs to the previous line,## whereas "next" indicates that the line belongs to the next one.#match_which_line = "previous"## The invert_match field can be true or false (defaults to false).## If true, a message not matching the pattern will constitute a match of the multiline## filter and the what will be applied. (vice-versa is also true)#invert_match = false## After the specified timeout, this plugin sends a multiline event even if no new pattern## is found to start a new event. The default timeout is 5s.#timeout = 5s
gork表达式举例
# nginx 日志格式
'$remote_addr - $remote_user [$time_local] $request_time $upstream_response_time $host "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"'# grok 解析格式 NGINX_ACCESS_LOG %{IP:remote_addr} - (-|%{WORD:remote_user:drop}) \[%{HTTPDATE:ts:ts}\] %{BASE10NUM:request_time:float} %{BASE10NUM:upstream_response_time:float} %{IPORHOST:host:tag} "(?:%{WORD:verb:drop} %{NOTSPACE:request:tag}(?: HTTP/%{NUMBER:http_version:drop})?|%{DATA:rawrequest})" %{NUMBER:status:tag} (?:%{NUMBER:resp_bytes}|-) %{QS:referrer:drop} %{QS:agent:drop} %{QS:xforwardedfor:drop}# nginx 日志举例
1.1.1.2 - - [30/Jan/2023:02:27:24 +0000] 0.075 0.075 xxx.xxx.xxx "POST /api/xxx/xxx/xxx HTTP/1.1" 200 69 "https://xxx.xxx.xxx/" "Mozilla/5.0 (iPhone; CPU iPhone OS 16_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148" "1.1.1.1"# grok 解析变量如下再取变量生成influxdb行协议
{"NGINX_ACCESS_LOG": [["1.1.1.2 - - [30/Jan/2023:02:27:24 +0000] 0.075 0.075 prod.webcomicsapp.com "POST /api/xxx/xxx/xxx HTTP/1.1" 200 69 "https://xxx.xxx.xxx/" "Mozilla/5.0 (iPhone; CPU iPhone OS 16_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148" "1.46.138.190""]],"remote_addr": [["1.1.1.2"]],"IPV6": [[null,null]],"IPV4": [["1.1.1.2",null]],"remote_user": [[null]],"ts": [["30/Jan/2023:02:27:24 +0000"]],"MONTHDAY": [["30"]],"MONTH": [["Jan"]],"YEAR": [["2023"]],"TIME": [["02:27:24"]],"HOUR": [["02"]],"MINUTE": [["27"]],"SECOND": [["24"]],"INT": [["+0000"]],"request_time": [["0.075"]],"upstream_response_time": [["0.075"]],"host": [["xxx.xxx.xxx"]],"HOSTNAME": [["xxx.xxx.xxx"]],"IP": [[null]],"verb": [["POST"]],"request": [["/api/xxx/xxx/xxx"]],"http_version": [["1.1"]],"BASE10NUM": [["1.1","200","69"]],"rawrequest": [[null]],"status": [["200"]],"resp_bytes": [["69"]],"referrer": [[""https://xxx.xxx.xxx/""]],"QUOTEDSTRING": [[""https://xxx.xxx.xxx/"",""Mozilla/5.0 (iPhone; CPU iPhone OS 16_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148"",""1.1.1.1""]],"agent": [[""Mozilla/5.0 (iPhone; CPU iPhone OS 16_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148""]],"xforwardedfor": [[""1.1.1.1""]]
}
启动telegraf
# 测试启动
nohup telegraf --config telegraf.conf --debug
# 退出测试
ctl+c
# 后台进程开启
nohup telegraf --config telegraf.conf >/dev/null 2>&1 &
# 关闭后台进程
ps -aux | grep telegraf
kill -9 '对应pid'
3.配置granfa
a. 登陆granfa http://localhost:3000/login admin admin。首次登陆需要改密码


b.添加数据源



至此tig流转全部完成
相关文章:
docker 部署tig监控服务
前言 tig对应的服务是influxdb grafana telegraf 此架构比传统的promethus架构更为简洁,虽然influxdb开源方案没有集群部署,但是对于中小型服务监控需求该方案简单高效 本文以docker-compose来演示这套监控体系的快速搭建和效果。 部署 docker-compos…...

ETL工具与数据处理的关系
ETL工具与数据处理之间存在密切的关系。数据处理是指对原始数据进行清洗、整理、加工和分析等操作,以便生成有用的信息和洞察力。而ETL工具则提供了一种自动化和可视化的方式来执行这些数据处理任务。通过ETL工具,用户可以定义数据抽取、转换和加载的规则…...

Flink几个性能调优
1 配置内存 操作场景 Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。 监控节点进程的…...

后端工程进阶| 青训营笔记
这是我参与「第五届青训营 」伴学笔记创作活动的第 2 天 并发编程 协程Goroutine通道Channel锁Lock 并发基础 串行程序与并发程序:串行程序特指只能被顺序执行的指令列表,并发程序则是可以被并发执行的两个及以上的串行程序的综合体。并发程序与并行程序…...
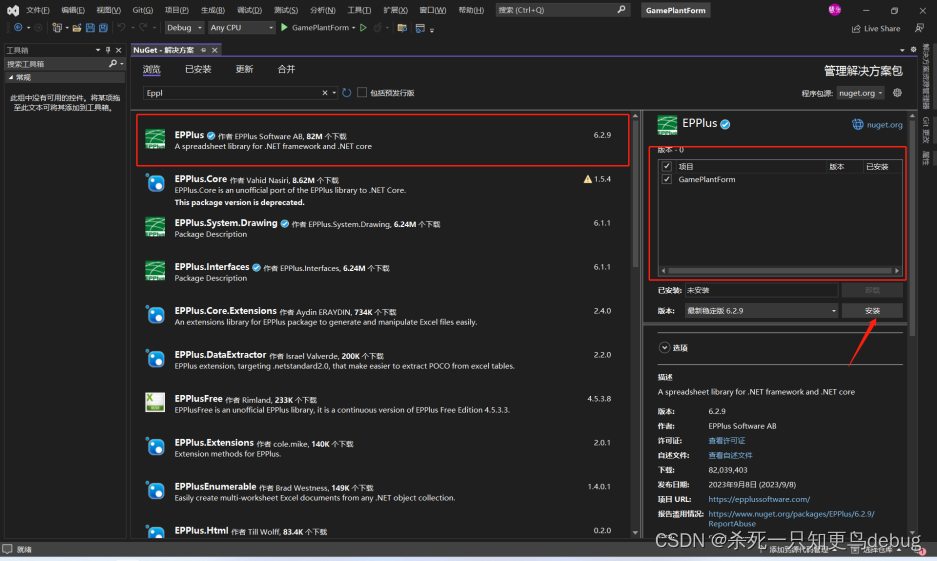
EPPlus库的安装和使用 C# 中 Excel的导入和导出
安装 工具栏->NuGet 包管理器->管理解决方案的NuGet程序包 安装到当前项目中 使用 将 DataGridView 数据导出为Excel 首先,需要将数据DataGridView对象转换为DataTable private void btnExport_Click(object sender, EventArgs e) {// 1.将当前页面的data…...
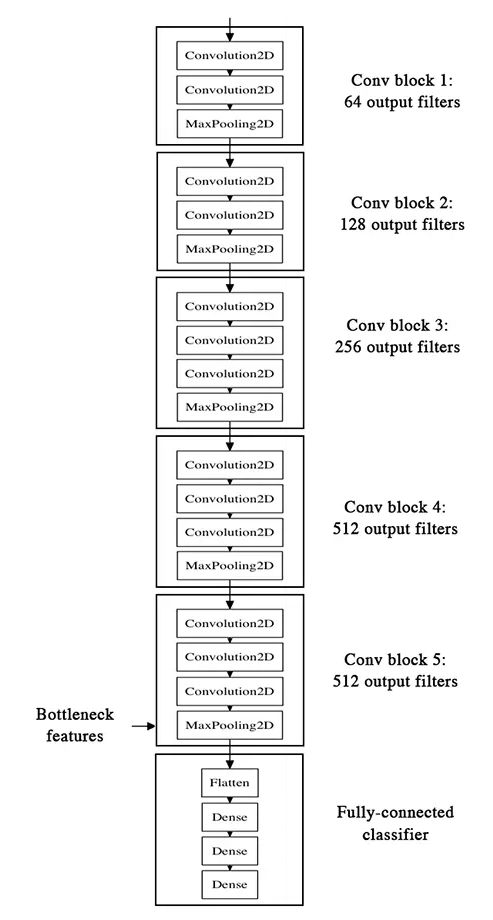
深度学习使用Keras进行迁移学习提升网络性能
上一篇文章我们用自己定义的模型来解决了二分类问题,在20个回合的训练之后得到了大约74%的准确率,一方面是我们的epoch太小的原因,另外一方面也是由于模型太简单,结构简单,故而不能做太复杂的事情,那么怎么提升预测的准确率了?一个有效的方法就是迁移学习。 迁移学习其…...
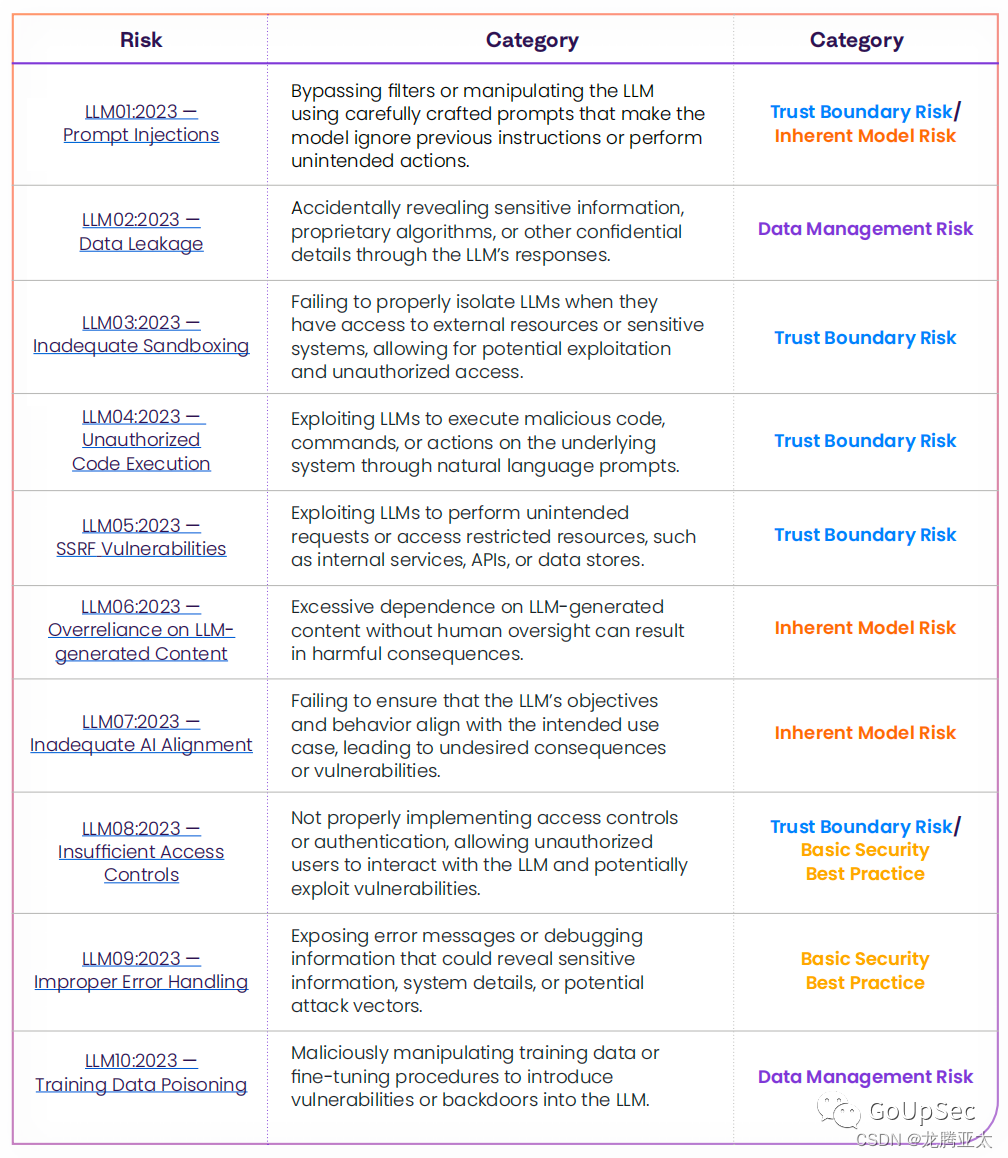
越流行的大语言模型越不安全
源自:GoUpSec “人工智能技术与咨询” 发布 安全研究人员用OpenSSF记分卡对GitHub上50个最流行的生成式AI大语言模型项目的安全性进行了评估,结果发现越流行的大语言模型越危险。 近日,安全研究人员用OpenSSF记分卡对GitHub上50个最流…...

搜维尔科技:伦敦艺术家利用Varjo头显捕捉盲人隐藏的梦想
在伦敦举行的弗里泽艺术博览会上,与专业级虚拟现实/XR硬件和软件领域的全球领先者Varjo合作,展示一个突破性的混合现实艺术装置, 皇家国家盲人学会 (rnib),英国领先的视力丧失慈善机构。 这个名为"公共交通的私人生活"的装置是一个互动的声音和图像雕塑,旨在让有眼光…...

如何将html转化为pdf
html转换为pdf html2pdf.js库, 基于html2canvas和jspdf,只能打印2-3页pdf,比较慢,分页会截断html2canvas 只能打印2-3页pdf,比较慢,分页会截断 // canvasDom-to-image 不支持某些css属性Pdfmake html-to-p…...

ES6初步了解生成器
生成器函数是ES6提供的一种异步编程解决方案,语法行为与传统函数完全不同 语法: function * fun(){ } function * gen(){console.log("hello generator");}let iterator gen()console.log(iterator)打印: 我们发现没有打印”hello…...
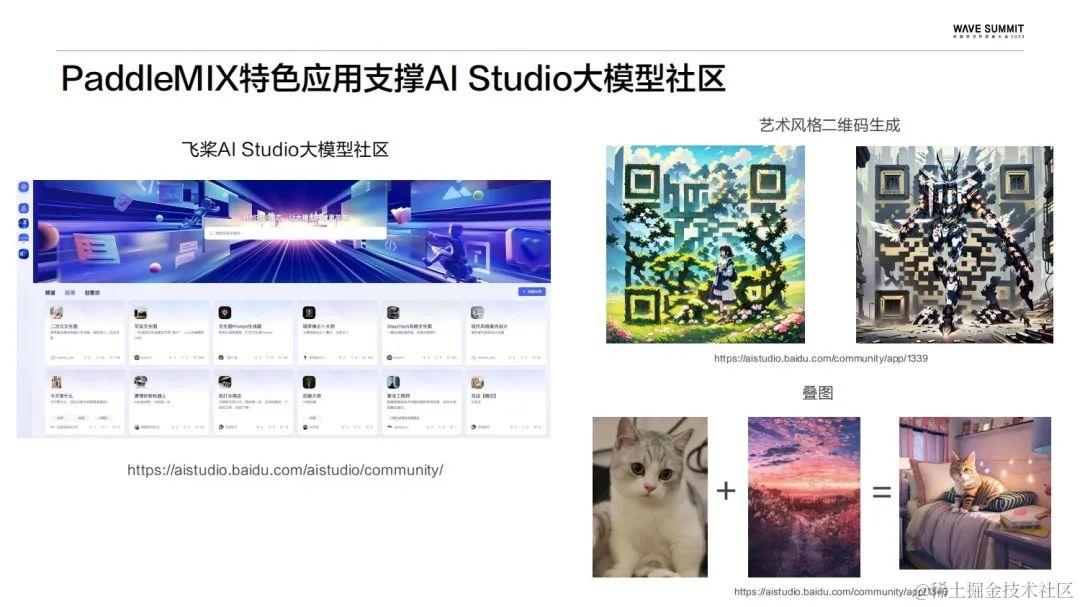
飞桨大模型套件:一站式体验,性能极致,生态兼容
在Wave Summit 2023深度学习开发者大会上,来自百度的资深研发工程师贺思俊和王冠中带来的分享主题是:飞桨大模型套件,一站式体验,性能极致,生态兼容。 大语言模型套件PaddleNLP 众所周知PaddleNLP并不是一个全新的模型…...

【C++入门到精通】哈希 (STL) _ unordered_map _ unordered_set [ C++入门 ]
阅读导航 前言一、unordered系列容器二、unordered_map1. unordered_map简介⭕函数特点 2. unordered_map接口- 构造函数- unordered_map的容量- unordered_map的迭代器- unordered_map的元素访问- unordered_map的修改操作- unordered_map的桶操作 三、unordered_set1. unorde…...
创建 Edge 浏览器扩展教程(上)
创建 Edge 浏览器扩展教程(上) 介绍开始之前后续步骤开始之前1:创建清单 .json 文件2 :添加图标3:打开默认弹出对话框 介绍 在如今日益数字化的时代,浏览器插件在提升用户体验、增加功能以及改善工作流程方…...

container_of解析及应用
container_of是一个C语言中比较少见,但实际经常用到的宏,在Linux kernel中也有大范围的应用。...

搜维尔科技:Varjo-最自然和最直观的互动
创建真实生活虚拟设计 Varjo让你沉浸在最自然的混合和虚拟现实环境中。 世界各地的设计团队可以聚集在一个摄影现实的虚拟空间中,以真实的准确性展示新的概念-实时的讨论和迭代。这是一个充满无限创造潜力的新时代,加速了人类前所未有的想象力。 虚拟现实、自动反应和XR设计的…...
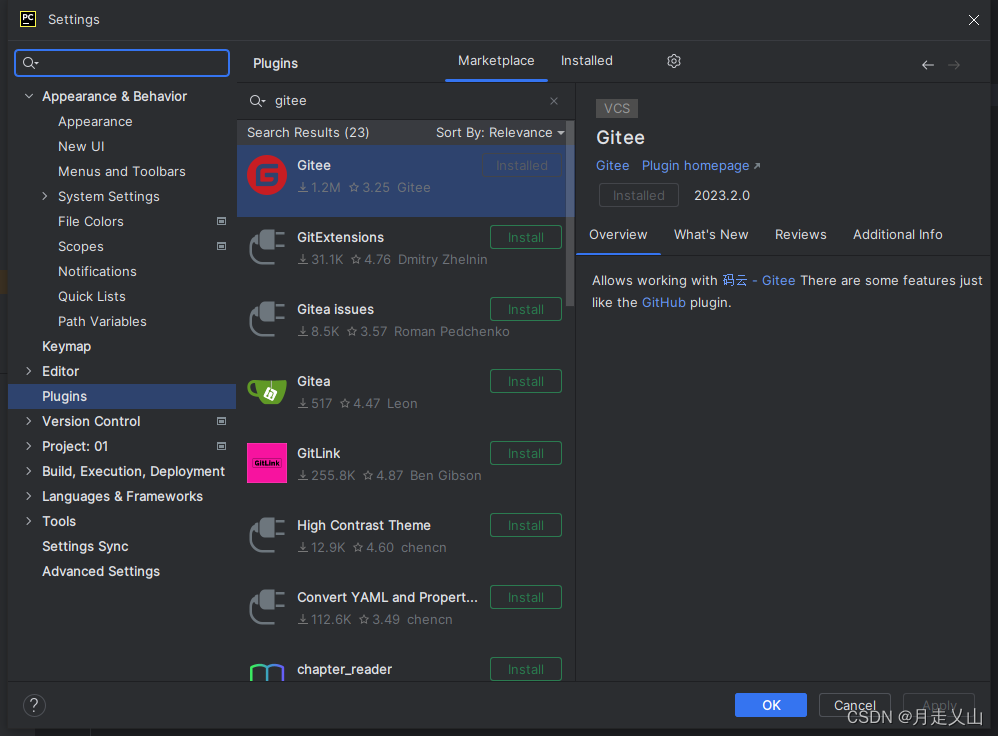
Postman环境配置
Postman环境配置 安装Postman安装node.js安装newman安装htmlextra安装git注册163邮箱用163邮箱注册gitee在pycharm中安装gitee详细文档 安装Postman 网址:https://www.postman.com/downloads/ 注册一个账号即可 安装node.js 安装newman npm install -g newman …...
Windows下Eclipse C/C++开发环境配置教程
1.下载安装Eclipse 官网下载eclipse-installer(eclipse下载器),或者官方下载对应版本zip。 本文示例: Eclipse IDE for C/C Developers Eclipse Packages | The Eclipse Foundation - home to a global community, the Eclipse ID…...

深入 Maven:构建杰出的软件项目的完美工具
掌握 Meven:构建更强大、更智能的应用程序的秘诀 Maven1.1 初识Maven1.1.1 什么是Maven1.1.2 Maven的作用 02. Maven概述2.1 Maven介绍2.2 Maven模型2.3 Maven仓库2.4 Maven安装2.4.1 下载2.4.2 安装步骤 03. IDEA集成Maven3.1 配置Maven环境3.1.1 当前工程设置3.1.…...

一文了解企业云盘和大文件传输哪个更适合企业传输
文件传输是企业工作中必不可少的环节,无论是内部协作还是外部沟通,都需要高效、安全、稳定地传输各种类型和大小的文件。然而,市面上的文件传输工具众多,如何选择合适的工具呢?本文将从两种常见的文件传输工具——企业…...
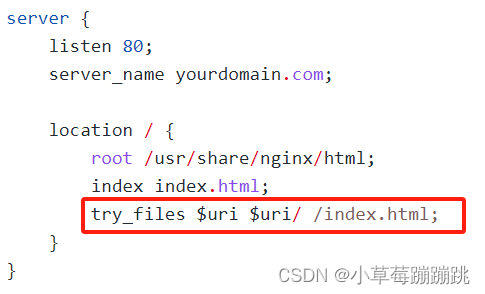
在 history 模式下,为什么刷新页面会出现404?
1、原因 因为浏览器在刷新页面时,它会向服务器发送 GET 请求,但此时服务器并没有配置相应的资源来匹配这个请求,因此返回 404 错误。 2、解决方案 为了解决这个问题,我们需要在服务器端进行相关配置,让所有的路由都指…...

C++中如何调用C语言的代码实现
为什么要是用 extern "C"在进行C开发的时候,由于C、C编译规则是不同的。C编译函数方法是 使用mangle的技术 。123456789101112void func(int age) {}void func(int age, int height) {}/*如果有这两个函数要被调用,在C语言中函数重载是不允许的…...

手把手拆解FD-SOI工艺流程:从SOI衬底到应变硅外延的保姆级图解
从SOI衬底到应变硅外延:FD-SOI工艺全流程拆解指南 想象一下建造一座微型城市,每一栋建筑只有头发丝直径的万分之一大小。这就是FD-SOI工艺工程师的日常工作——在硅片上用原子级精度"建造"晶体管。与传统的体硅工艺不同,FD-SOI&…...

北京房山区浇筑阁楼测评:天顺诚达工艺佳但价格略高,适合这类
为了避免违反规则,以下内容去除了联系方式等违规信息。随着对居住空间利用需求的增加,在北京房山区浇筑阁楼成为不少人的选择。本次测评旨在为对北京房山区浇筑阁楼服务感兴趣的人群,客观呈现相关服务的情况。参与本次测评的是北京天顺诚达建…...

CLI-Anything与MCP服务器:打造强大后端的实战教程
CLI-Anything与MCP服务器:打造强大后端的实战教程 【免费下载链接】CLI-Anything "CLI-Anything: Making ALL Software Agent-Native" -- CLI-Hub: https://clianything.cc/ 项目地址: https://gitcode.com/GitHub_Trending/cl/CLI-Anything CLI-A…...

3步掌握B站视频转文字神器:为什么你需要这个效率提升10倍的工具
3步掌握B站视频转文字神器:为什么你需要这个效率提升10倍的工具 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理一个精彩的B站…...

基于ESP8266与TFT屏的桌面智能天气站DIY全攻略
1. 项目概述:打造一个桌面级的智能天气信息中心 几年前,当我第一次把玩ESP8266这块小芯片时,就被它“麻雀虽小,五脏俱全”的特性震撼了——一个比硬币大不了多少的模块,竟然内置了完整的Wi-Fi协议栈和可编程的微控制器…...

视觉优先无人机避障系统ViSafe:高速场景下的安全解决方案
1. ViSafe系统概述:视觉优先的高速无人机避障方案 在无人机技术快速发展的今天,空域安全已成为行业面临的核心挑战。传统避障系统依赖雷达、ADS-B等主动传感器,但这些方案对小型无人机(sUAS)存在明显的适用性瓶颈——尺…...

vibe coding效率高:一个新mcp server已经试运行尚可
下面是文档: judicial-doc-quality-mcp v0.1.0 司法裁判文书质量评估 MCP 服务器 — 桥接架构,零 LLM 调用 English | 中文 概述 judicial-doc-quality-mcp 是一个基于 Model Context Protocol (MCP) 的裁判文书质量评估服务器,采用**桥接…...

Magisk:重新定义Android系统定制边界的技术框架
Magisk:重新定义Android系统定制边界的技术框架 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统定制领域的革命性框架,以其独特的"无系统"&#…...

车载ETH数据链路层
以太网帧协议是数据链路层的核心封装格式,遵循IEEE 802.3标准。 标准以太网帧结构(IEEE 802.3): 前导码(7B)| 帧起始符(1B)| 目标 MAC (6B) | 源 MAC (6B) | EtherType (2B) | Payload (46-1500B) | FCS (4B) | 1. 前导码 (Preamble) 长度…...