华为OD机考算法题:寻找最大价值的矿堆
题目部分
| 题目 | 寻找最大价值的矿堆 |
| 难度 | 难 |
| 题目说明 | 给你一个由 '0'(空地)、'1'(银矿)、'2'(金矿)组成的的地图,矿堆只能由上下左右相邻的金矿或银矿连接形成。超出地图范围可以认为是空地。 假设银矿价值 1 ,金矿价值 2 ,请你找出地图中最大价值的矿堆并输出该矿堆的价值。 |
| 输入描述 | 地图元素信息如: 4 表示输入数据为 4 行, 5 表示输入数据为 5 列; |
| 输出描述 | 矿堆的最大价值。 |
| 补充说明 | 无 |
| ------------------------------------------------------ | |
| 示例 | |
| 示例1 | |
| 输入 | 4 5 22220 00000 00000 01111 |
| 输出 | 8 |
| 说明 | 无 |
| 示例2 | |
| 输入 | 4 5 22220 00020 00010 01111 |
| 输出 | 15 |
| 说明 | 无 |
| 示例2 | |
| 输入 | 4 5 20000 00020 00000 00111 |
| 输出 | 3 |
| 说明 | 无 |
解读与分析
题目解读:
如果两个格子的的关系为上、下、左、右中的一种情况,且两个格子的数据不为 0,那么认为这两个格子是相邻。如果三个格子 A、B、C 中 A 与 B 相邻,B 与 C 相邻,那么 A、B、C 放到一个集合中。这样的集合可能有多个,计算这些集合中所有格子的数据之和,并输出数据之和最大的一个。
分析与思路:
分析与思路此题和《华为OD机考算法题:机器人活动区域》类似。
遍历所有的格子:
1. 在遍历过程中,新建一个集合setGrid1,把这个格子放到 setGrid1 中,求出当前格子的所有相邻格子,并依据相邻格子求出更多的相邻格子,直到所有的相邻格子求出。将得到的相邻格子放到集合 setGrid1 中,计算集合中所有格子的数据之和,设为 sum1;
2. 继续遍历下个格子,如果下一个格子不在任何一个集合中,则表示这个格子尚未使用过。如果已经使用,则继续遍历下一个搁置;如果未使用,新建一个集合setGridn,把它放到 setGridn 中,并继续步骤 1 的操作。
3. 最后,比较所有集合的数据之和大小,sum1、sum2 …… sumn,输出最大的值。
代码实现
Java代码
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.Set;
import java.util.HashSet;/*** 寻找最大价值的矿堆* * @since 2023.10.25* @version 0.1* @author Frank**/
public class MaxMineValue {public static void main(String[] args) {Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String input = sc.nextLine();String[] inputStr = input.split(" ");int row = Integer.parseInt(inputStr[0]);int column = Integer.parseInt(inputStr[1]);int[][] mineMap = new int[row][column];for (int i = 0; i < row; i++) {input = sc.nextLine();// inputStr.length == columnint[] eachColumn = new int[column];for (int j = 0; j < input.length(); j++) {eachColumn[j] = Integer.parseInt(input.substring(j, j + 1));}mineMap[i] = eachColumn;}processMaxMineValue(mineMap);}}private static void processMaxMineValue(int[][] mineMap) {List minSetList = new ArrayList<Set<String>>();Set<String> usedPoint = new HashSet<String>();int maxSum = 0;for (int i = 0; i < mineMap.length; i++) {for (int j = 0; j < mineMap[0].length; j++) {String pos = i + " " + j;if (usedPoint.contains(pos)) {continue;}Set<String> newSet = new HashSet<String>();usedPoint.add(pos);newSet.add(pos);int sum = mineMap[i][j];sum += getAdjacentGridsSum(i, j, usedPoint, newSet, mineMap);if (sum > maxSum) {maxSum = sum;}minSetList.add(newSet);}}System.out.println(maxSum);}private static int getAdjacentGridsSum(int i, int j, Set<String> usedPoint, Set<String> newSet, int[][] mineMap) {int[][] possiblePoint = { { i, j - 1 }, { i, j + 1 }, { i + 1, j }, { i - 1, j } };int sum = 0;for (int k = 0; k < possiblePoint.length; k++) {int[] currentPoint = possiblePoint[k];if (currentPoint[0] < 0 || currentPoint[1] < 0 || currentPoint[0] >= mineMap.length|| currentPoint[1] >= mineMap[0].length) {continue;}String pos = currentPoint[0] + " " + currentPoint[1];if (usedPoint.contains(pos)) {continue;}if (mineMap[currentPoint[0]][currentPoint[1]] == 0) {continue;}usedPoint.add(pos);newSet.add(pos);sum += mineMap[currentPoint[0]][currentPoint[1]];sum += getAdjacentGridsSum(currentPoint[0], currentPoint[1], usedPoint, newSet, mineMap);}return sum;}}在以上算法中,使用了 minSetList 记录每个矿堆的坐标集合,在实际计算时,不要求输出矿堆坐标,所以 minSetList 是可以省掉的。
JavaScript代码
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void async function() {while (line = await readline()) {var inputArr = line.split(" ");var row = parseInt(inputArr[0]);var column = parseInt(inputArr[1]);var mineMap = new Array();for (var i = 0; i < row; i++) {line = await readline();var eachContent = new Array();for (var j = 0; j < column; j++) {eachContent[j] = line.substring(j, j + 1);}mineMap[i] = eachContent;}processMaxMineValue(mineMap);}
}();function processMaxMineValue(mineMap) {var minSetList = new Array();var usedPoint = new Set();var maxSum = 0;for (var i = 0; i < mineMap.length; i++) {for (var j = 0; j < mineMap[0].length; j++) {var pos = i + " " + j;if (usedPoint.has(pos)) {continue;}var newSet = new Set();usedPoint.add(pos);newSet.add(pos);var sum = parseInt( mineMap[i][j] );sum += getAdjacentGridsSum(i, j, usedPoint, newSet, mineMap);if (sum > maxSum) {maxSum = sum;}minSetList.push(newSet);}}console.log( maxSum );
}function getAdjacentGridsSum(i, j, usedPoint, newSet, mineMap) {var possiblePoint = [[i, j - 1],[i, j + 1],[i + 1, j],[i - 1, j]];var sum = 0;for (var k = 0; k < possiblePoint.length; k++) {var currentPoint = possiblePoint[k];if (currentPoint[0] < 0 || currentPoint[1] < 0 || currentPoint[0] >= mineMap.length ||currentPoint[1] >= mineMap[0].length) {continue;}var pos = currentPoint[0] + " " + currentPoint[1];if (usedPoint.has(pos)) {continue;}var curValue = parseInt( mineMap[currentPoint[0]][currentPoint[1]] );if ( curValue == 0) {continue;}usedPoint.add(pos);newSet.add(pos);sum += curValue;sum += getAdjacentGridsSum(currentPoint[0], currentPoint[1], usedPoint, newSet, mineMap);}return sum;
}(完)
相关文章:

华为OD机考算法题:寻找最大价值的矿堆
题目部分 题目寻找最大价值的矿堆难度难题目说明给你一个由 0(空地)、1(银矿)、2(金矿)组成的的地图,矿堆只能由上下左右相邻的金矿或银矿连接形成。超出地图范围可以认为是空地。 假设银矿价值…...

wf-docker集群搭建(未完结)
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、redis集群二、mysql集群三、nacos集群1. 环境要求2. 拉取镜像2.1. 拉取镜像方式配置集群2.2. 自定义nacos镜像配置集群 3 自定义…...

uni-app 在 APP 端的版本强制更新与热更新
整包更新与热更新的区别 ① 整包更新是指下载完整 apk 文件进行覆盖安装 ② 热更新是指把 app 有改动的地方打包进 wgt 文件,只更新 wgt 文件中的内容,不进行整包安装,在用户视角也叫做省流量更新 版本号规则约束 建议严格遵循 Semantic …...

实在智能受邀参加第14届珠中江数字化应用大会,AI赋能智能制造,共话“湾区经验”
制造业是实体经济的主体,是技术创新的主战场,是供给侧结构性改革的重要领域。抢占新一轮产业竞争制高点,制造业的数字化转型已成为行业升级的必由之路。 10月21日,第14届“珠中江”(珠海、中山、江门)数字…...

Qt 窗口的尺寸
默认尺寸 对于一个Qt的窗口(继承于QWidget),获取其窗体尺寸的方法size(); 以一个Qt创建Qt Widgets Application项目的默认生成代码为基础,做如下测试 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent…...

游戏数据分析对于运营游戏平台的重要性
游戏数据分析对于运营游戏平台具有至关重要的意义,它可以提供深入的见解,帮助了解玩家行为、偏好和互动,从而优化游戏体验,提高玩家参与度和留存率。 首先,通过游戏数据分析,运营者可以了解玩家在游戏中的表…...
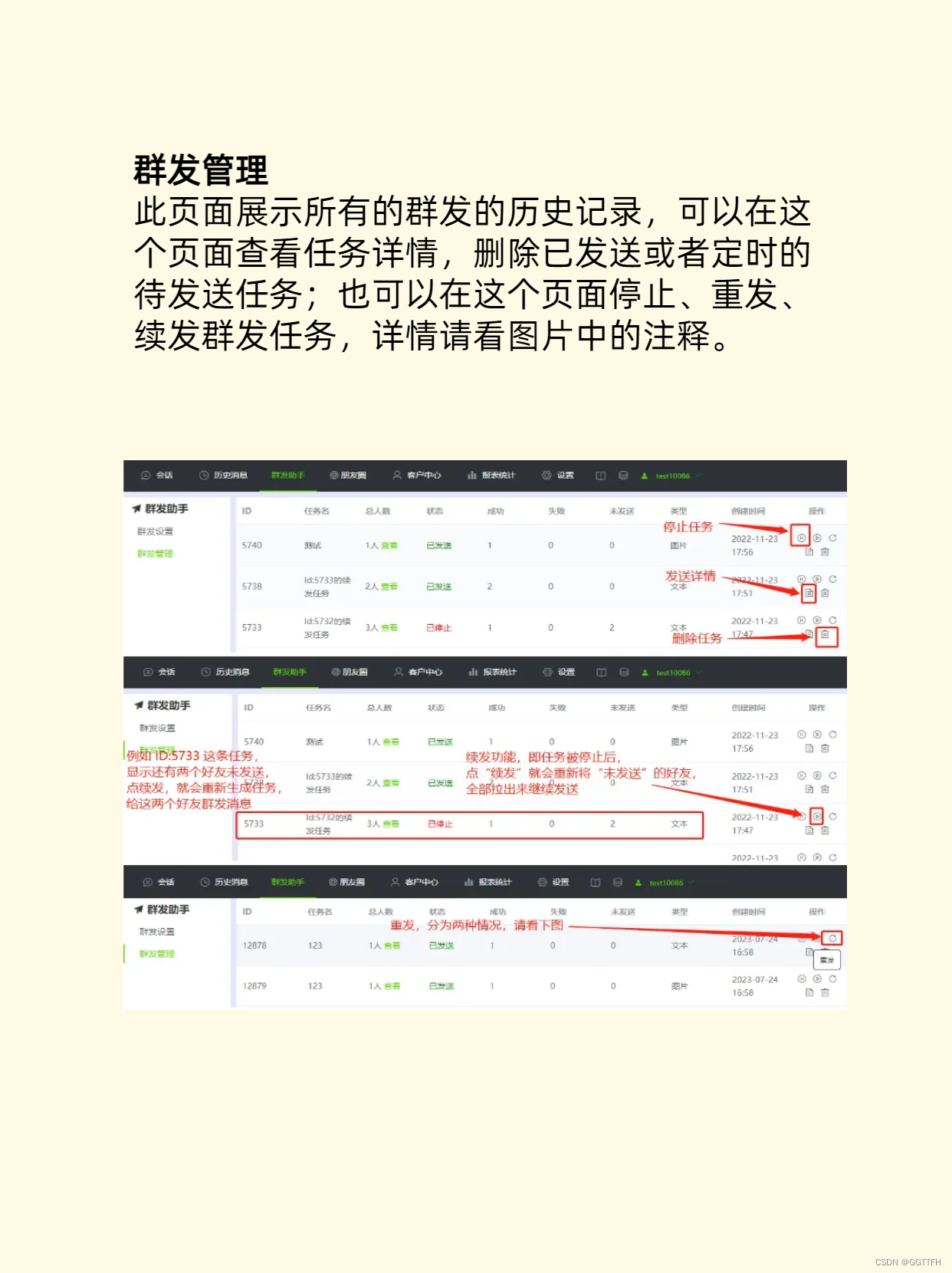
微信群发消息的正确打开方式,让你的社交更高效!
在当今的社交媒体时代,微信已经成为了我们生活中必不可少的一部分。而微信的群发消息功能,让我们可以方便地将信息一次性发送给多个联系人。然而,微信的群发消息功能有一个限制,即每次只能群发200个联系人。这对于需要发送消息给大…...

HTML5语义化标签 header 的详解
🌟🌟🌟 专栏详解 🎉 🎉 🎉 欢迎来到前端开发之旅专栏! 不管你是完全小白,还是有一点经验的开发者,在这里你会了解到最简单易懂的语言,与你分享有关前端技术和…...

SpringCloud复习:(2)@LoadBalanced注解的工作原理
LoadBalanced注解标记了一个RestTemplate或WebClient bean使用LoadBalancerClient来进行负载均衡。 LoadBalancerAutoConfiguration类给带注解的RestTemplate添加了拦截器:LoadBalancerInterceptor. 具体流程如下: 首先定义一个LoadBalancerInterceptor…...

vue钩子函数以及例子
Vue.js 是一个基于组件化的前端框架,它提供了一些钩子函数,用于控制组件在不同阶段的行为和处理。以下是 Vue.js 常用的钩子函数以及它们的作用和示例: beforeCreate:在实例被创建之前调用。此时组件的数据、方法等还没有被初始化…...
redis场用命令及其Java操作
目录 1. Redis入门 1.1 Redis简介 1.2 Redis下载与安装 1.2.1 Redis下载 1.2.2 Redis安装 1.3 Redis服务启动与停止 1.3.1 服务启动命令 1.3.2 客户端连接命令 1.3.3 修改Redis配置文件 1.3.4 Redis客户端图形工具 2. Redis数据类型 2.1 五种常用数据类型介绍 2.2 …...
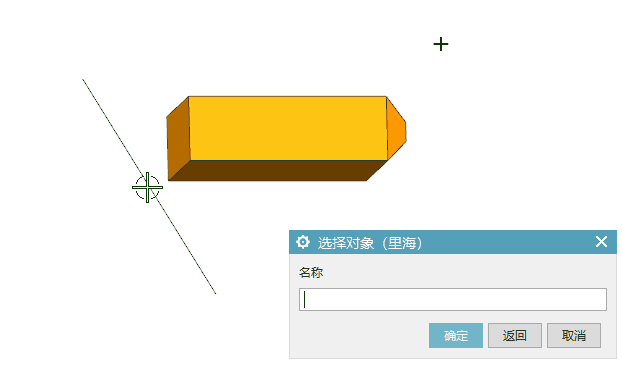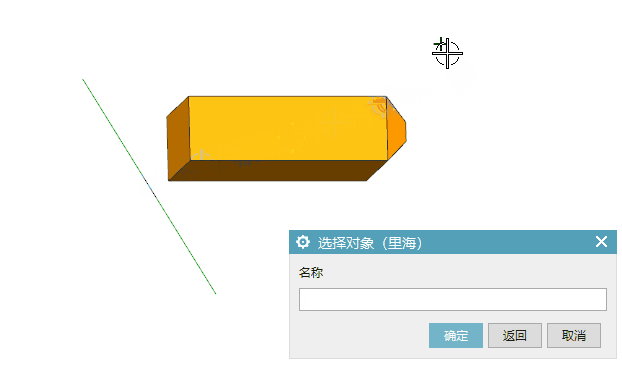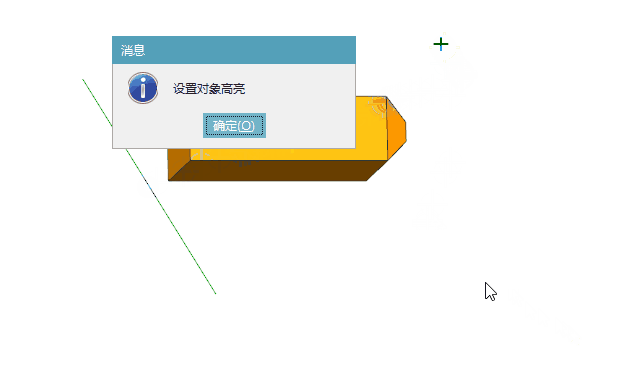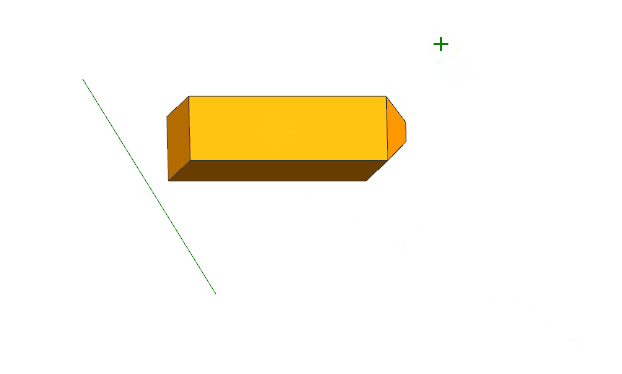
UG\NX二次开发 同时设置多个对象的高亮状态 UF_DISP_set_highlights
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,里海BlockUI专栏,C\C++-CSDN博客 感谢粉丝订阅 感谢 captainliubang 订阅本专栏,非常感谢。 简介 UG\NX二次开发 同时设置多个对象的高亮状态 UF_DISP_set_highlights 效果 代码(在for循环中逐个设置多个对象…...

Qt+树莓派4B 手动设置系统日期和时间
文章目录 前言一、设置日期二、设置时间 前言 某些设备需要在无网络环境下工作,系统时间和日期无法通过网络实时同步,此时就需要人为设置. 一、设置日期 QString m_date,m_time;QDateEdit *dateEdit new QDateEdit(this); dateEdit->setFixedSize(250,60); connect(date…...

用大顶堆和小顶堆实现优先队列
大顶堆小顶堆(或大根堆小根堆) 利用大顶堆实现优先队列,所谓大顶堆,容器内部元素是有序的,而且是按从大到小排序的(小顶堆刚好相反,从小到大)。容器只有一个出口一个入口࿰…...
PDCA项目开发环境搭建说明
PDCA项目开发环境搭建说明 环境准备 JDK 15.0 ; IDEA Community Edition 2021.3 版本要对应,不然会报错 Jdk 安装步骤:https://blog.csdn.net/qq_34913677/article/details/108894727 IDea 安装说明:https://blog.csdn.net/dream…...
Git简明教程
1.Git的定位 在我们自己开发项目的过程中,经常会遇到这样的情况,为了防止代码丢失,或者新变更的代码影响到原有的代码功能,为了在失误后能恢复到原来的版本,不得不复制出一个副本,比如:“坦克大战1.0”“坦…...
)
数据结构顺序表(C语言版)
目录 1.实现的接口及其功能2.代码块 1.实现的接口及其功能 //初始化顺序表void initSL(SL* p); //销毁顺序表 void DestorySL(SL* p); //头插 void PushFont(SL* p, SeqListType x); //尾插 void PushBack(SL* p, SeqListType x); //头删 void PopFont(SL* p); //尾删 void Pop…...
新手如何备考学习PMP?
一、PMP学习7步走攻略 1、熟悉考试大纲: PMP考试大纲是备考的基础,考生需要详细熟悉考试大纲,了解各个知识领域的重点和难点。 2、制定学习计划: 根据考试大纲和个人情况,制定学习计划,合理分配学习时间…...
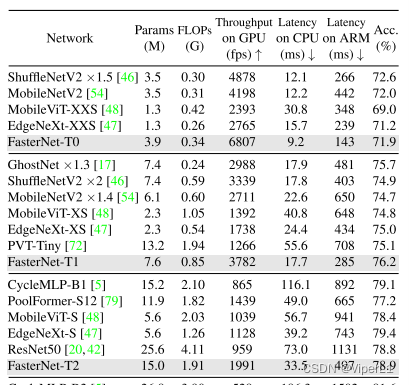
[卷积神经网络]FasterNet论文解析
一、概述 FasterNet是CVPR2023的文章,通过使用全新的部分卷积PConv,更高效的提取空间信息,同时削减冗余计算和内存访问,效果非常明显。相较于DWConv,PConv的速度更快且精度也非常高,识别精度基本等同于大型…...

知识图谱+推荐系统 文献阅读
文献阅读及整理 知识图谱推荐系统 知识图谱 1 基于知识图谱的电商领域智能问答系统研究与实现 [1]蒲海坤. 基于知识图谱的电商领域智能问答系统研究与实现[D].西京学院,2022.DOI:10.27831/d.cnki.gxjxy.2021.000079. 知识点 BIO标记策略进行人工标记,构建了电商领域商品…...

大语言模型驱动SVG代码生成:原理、实践与应用前景
1. 项目概述:当大语言模型遇上SVG图形生成最近在开源社区里,一个名为“ximinng/LLM4SVG”的项目引起了我的注意。这个项目名字直译过来就是“用于SVG的大语言模型”,它瞄准了一个非常具体且有趣的交叉领域:利用大语言模型来生成或…...

开源轻量CRM系统skill-twenty-crm技术解析与全栈部署指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫devchaudhary24k/skill-twenty-crm。光看这个名字,你可能会有点懵,这“Skill Twenty CRM”到底是个啥?作为一个在软件开发和团队协作领域摸爬滚打多年的老手&#x…...

高校图书馆未公开的Perplexity学术协议:解锁DOI深度解析、跨库引文追踪与灰色文献捕获权限
更多请点击: https://codechina.net 第一章:高校图书馆未公开的Perplexity学术协议全景解析 Perplexity学术协议并非官方发布的标准规范,而是国内部分高校图书馆在采购或对接Perplexity Pro教育版API服务时,经谈判形成的定制化协…...

cargo-whero:极致轻量·满血性能!Rust 原生 HTTP 压测神器正式开源
一、前言:告别臃肿低效,重塑 HTTP 压测体验 在后端开发、接口性能优化、服务容量压测的日常工作中,我们总会被传统压测工具的各种短板困扰: Apache AB:功能极简,不支持复杂请求、限流、精细化统计…...

DIY改造:为Hakko FX-901烙铁打造USB-C充电电池包
1. 项目概述:打造你的专属USB充电无线烙铁 如果你和我一样,经常需要带着烙铁跑现场——无论是调试RC模型、在Maker Faire上修复作品,还是在户外临时搭建一个电子装置——那你一定对传统无线烙铁的痛点深有体会。四节AA电池,用不了…...

NotebookLM讨论模块写作:为什么87%的用户输出缺乏论证纵深?3个可立即部署的认知框架
更多请点击: https://intelliparadigm.com 第一章:NotebookLM讨论模块写作的认知断层诊断 NotebookLM 的讨论模块(Discussion Panel)旨在基于用户上传的文档生成上下文感知的对话,但实践中常出现“理解正确却表达失焦…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

3大创新突破:APK Installer如何重新定义Windows上的Android应用体验
3大创新突破:APK Installer如何重新定义Windows上的Android应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在当今跨平台应用需求日益增长的背景下…...

Consul-K8s实战:Kubernetes与Consul服务网格的无缝集成指南
1. 项目概述:当Consul遇见Kubernetes如果你正在Kubernetes集群里管理微服务,并且已经听说过或者正在使用HashiCorp Consul来做服务发现和配置管理,那么hashicorp/consul-k8s这个项目绝对是你绕不开的工具。简单来说,它不是一个独立…...

DDrawCompat:如何在现代Windows上为经典DirectX游戏注入新生命?
DDrawCompat:如何在现代Windows上为经典DirectX游戏注入新生命? 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/…...