【分布式】大模型分布式训练入门与实践 - 04
大模型分布式训练
- 数据并行-Distributed Data Parallel
- 1.1 背景
- 1.2 PyTorch DDP
- 1) DDP训练流程
- 2)DistributedSampler
- 3)DataLoader: Parallelizing data loading
- 4)Data-parallel(DP)
- 5)DDP原理解析
- 2 模型并行Model Parallel
- 1)tensor parallel
- 2) Pipeline parallel
- 参考
数据并行-Distributed Data Parallel
1.1 背景
数据并行(Distributed Data Parallel)是一种用于加快深度学习模型训练速度的技术。在过去,训练大型模型往往受限于单卡训练的瓶颈,尤其是当处理大规模数据集时。数据并行通过在多个处理单元上同时训练模型,并通过增加BatchSize来提高并行度,有效地减少了训练时间。这种技术在加快深度学习模型训练速度的同时,还提高了模型处理大规模数据集的能力,为解决现实世界中的复杂问题提供了强有力的支持。
1.2 PyTorch DDP
1) DDP训练流程
这里我们通过一段代码过一下DDP的训练流
import torch
import torchvision
import argparse# Step 1: import distributed
import torch.distributed as dist
parser = argparse.ArgumentParser()# Step 2: torch.distributed.launchlocal_rank
parser.add_argument("--local_rank", default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
torch.cuda.set_device(local_rank)# Step 3: DDP backend
dist.init_process_group(backend='nccl') # ncclgloompi
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True)# Step 4: DistributedSamplerDataLoaderbatch_sizebatch_sizebatch_sizebatch_size)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(my_trainset, batch_size=batch_size, sampler=train_sampler)
device = torch.device("cuda", local_rank)
model = nn.Linear(batch_size*32*32, 10).to(device)# Step 5: DDP wrapper model
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)for epoch in range(num_epochs):# Step 6: sampler epoch and shuffletrain_loader.sampler.set_epoch(epoch)for step, (input, label) in enumerate(train_loader):optimizer.zero_grad()input, label = input.to(device), label.to(device)output = model(input) loss = loss_fn(output, label)loss.backward()optimizer.step()
运行测试一下
## Bash
# 5torch.distributed.launchDDP
# main.pylocal_rank":local_rank"
python -m torch.distributed.launch --nproc_per_node 4 main.py
2)DistributedSampler

Worldsize: num Hosts x num GPUs per host (= 2x3 = 6)
每个进程都知道本端的进程序号(local rank)和节点序号(host number),可以根据这一点计算全局序号(global rank)
global rank = local rank + num GPUs per host x host number

在distributed.py的源码中:
# DistributedSampler
def __iter__(self):# deterministically shuffle based on epochg = torch.Generator()g.manual_seed(self.epoch)indices = torch.randperm(len(self.dataset), generator=g).tolist()# add extra samples to make it evenly divisibleindices += indices[: self.total_size - len(indices))]assert len(indices) == self.total_size# subsampleindices = indices(self.rank:self.total_size:self.num_replicas]assert len(indeices) == self.num_samplesprint("len_indices {0}".format(len(indices)))return iter(indices)
由于每次epoch我们都会随机shuffle数据集,
- 不同进程之间要怎么保持shuffle后数据集的一致性?
- 每次epoch怎么保证取到的数据集顺序不一样呢?
原理很简单,就是给不同进程分配数据集的不重叠、不交叉部分。
DistributedSampler使用set_epoch方法当前epoch作为随机数种子,保证每个epoch的随机数种子不一样,从而使得不同epoch下有不同的shuffle结果。
3)DataLoader: Parallelizing data loading

Dataloader在每个batch的加载过程如下:
- 从磁盘加载数据到主机(host)。
- 将数据从可页内存(pageable memory)转移到主机上的固定内存(pinnedmemory)
- 将数据从固定内存传输到GPU。
- 在GPU上运行前向(forward)和反向(backward)传递过程。
当设置多个num_workers时,多个进程同时加载数据,通过预取(prefetch)减少了IO带来的影响。
4)Data-parallel(DP)
model = torch.nn.DataParallel(model)

在旧版pytorch1.0之前使用DP实现数据并行。整个过程如图,没有主GPU。
- 从硬盘加载数据到host端页锁定内存(Page-locked Memory)。用多个工作进程实现数据并行加载。
- 把minibatch数据从页锁定内存(Page-locked Memory)并行转移到每个GPU上。不需要广播数据。每个GPU都拥有一个独立的模型拷贝,所以也不需要广播模型。
- 每个GPU进行前向计算,输出结果(Output)
- 计算loss,计算反向梯度。并利用allreduce并行计算梯度
- 更新模型参数。因为每个GPU在一开始就有独立的模型拷贝,而且梯度已经全部完成更新,也不需要模型同步。
在DP模式中,总共只有一个进程,所以存在很多缺点:
- 冗余的数据拷贝:master GPU拿到数据后需要分发给其他GPU
- 在forward之前其他GPU需要做一次模型拷贝:这是由于模型参数是在master GPU上更新的,所以要每次forward将更新好的参数同步给其他GPU
- 存在不必需要的output gather
- 不均衡的GPU利用率:master GPU占用率很高,CPU要完成数据分发,gather output,loss计算,梯度聚合以及参数更新等。
与DP相比,DDP流程明显就少了很多:
- 每个GPU基于DistributedSampler load自己的那份数据,而不像DP那样由master GPU load,然后分发给其他GPU
- master GPU不需要在做额外的那些冗余工作,GPU利用率是均衡的。通过allreduce完成梯度更新后,获得所有GPU的梯度,然后由同步后的梯度更新参数,保证参数一致性。不像DP那样master GPU完成梯度计算和参数更新,然后再同步给其他GPU
5)DDP原理解析
在使用分布式数据并行(DDP)时,我们需要处理的是模型的参数以及梯度。
DDP的核心在于同步各进程间的参数变化量,而不是直接同步参数本身。因此,确保各进程的模型状态一致性变得至关重要。模型的状态主要由模型的权重参数以及梯度组成。
也就是要关注模型的状态一致性,同时需要一个简单的逻辑构成。
Parameter和buffer
在PyTorch中,所有的模型都会继承module类。可以说,一个模型就是由一系列module组合而成的。要了解模型,就必须从module下手。
module的基本要素分为两种:1. 状态 2. 钩子(hooks)
当一个模型的网络结构被定义后,其状态就是由parameter和buffer的迭代组合表示的。当我们保存模型,调用model.state_dict()的时候,我们同时会得到模型的parameter和buffer
也就是说,在DDP中,如果我们要在不同进程中维持相同的状态,我们不光要传递parameter的梯度,也要传递buffer。事实上,DDP就是这么做的。当每次网络传播开始前,其都会把master节点上的buffer广播给其他节点,维持状态的统一。
同时再利用钩子(hooks),提供插入接口。
主程序提供的这样的钩子定义,用户实现钩子函数,而这个函数会在实际运行中插入执行。
这个在tf和早期的mxnet中经常见到,就不做赘述。
通过这一系列定义和工具,我们可以完成对模型状态的统一,也可以利用钩子函数来实现整个逻辑结构。
具体实现
第一步初始化:
| 操作 | 具体实现 |
|---|---|
| 准备环境 init_process_group | 如果进程数量不足(小于worldsize),进程会一直等待。 |
| DDP初始化model=DDP(model) | parameter和buffer从master节点传到其他节点,使得所有进程状态一致 (这一步过后不可修改模型的任何参数)。 |
| 然后根据指定的size进行分组,每一组称为一个bucket(默认25M为一组)。 | |
| 最后创建reducer管理器,给每个parameter注册平均的hook |
正式训练:
| 操作 | 具体实现 |
|---|---|
| 1. 采样数据 | 从dataloader得到一个batch的数据,用于当前计算(for input, lable in dataloader); DistributedSampler会使各个进程之间的数据不重复。 |
| 2.forward | 同步各进程状态(即各进程之间的buffer和parameters。 |
| 执行forward过程 | |
| (可选)当DDP参数find_unused_parameter为true时,其会在forward结束时,启动一个回溯,标记出所有没被用到的parameter,提前把这些设定为ready。但这个配置默认是关闭的,会影响速度 | |
| 3.backward | reducer外面:各个进程各自开始从后往前反向计算梯度,即最后面的参数反而是最先得到梯度的。 |
| reducer外面:当某个parameter的梯度计算好了的时候,其之前注册的grad hook就会被触发,在bucket里把这个parameter的状态标记为ready。 | |
| reducer里面:当某个bucket的所有parameter都是ready状态时,reducer会开始对这个bucket的所有parameter都开始一个异步的allreduce梯度平均操作。 | |
| 4.优化器optimizer应用gradient,更新参数 | 这一部分为了保证各个进程参数一直,需要确保optimizer的初始状态和每次step()时的梯度相同。这个在model初始化时就会做,因此optimeizer的初始化必须放在DDP模型创建后。如果是自己实现的optimizer,则需要自己利用接口来保证更新时的一致性。 |
2 模型并行Model Parallel
背景:数据并行下分布式训练的显存占用
早在AlexNet诞生之时就有模型并行了。
已知训练时占用显存的只有4个部分,parameters,gradients,activation和optimizer states
parameter、gradients和optimizer_states所占的显存训练全程都会存在,activation则只占用前向阶段。
由于大模型的parameters和buffer动则上百G,所以现在的模型并行,是为了保证有限显存情况下,Transformer结构大模型的训练和推理。
1)tensor parallel
tensor parallel是把层的权重(即tensor)切分到不同的 tensor parallel process group所在的rank上。
以Megatron FFN为例:
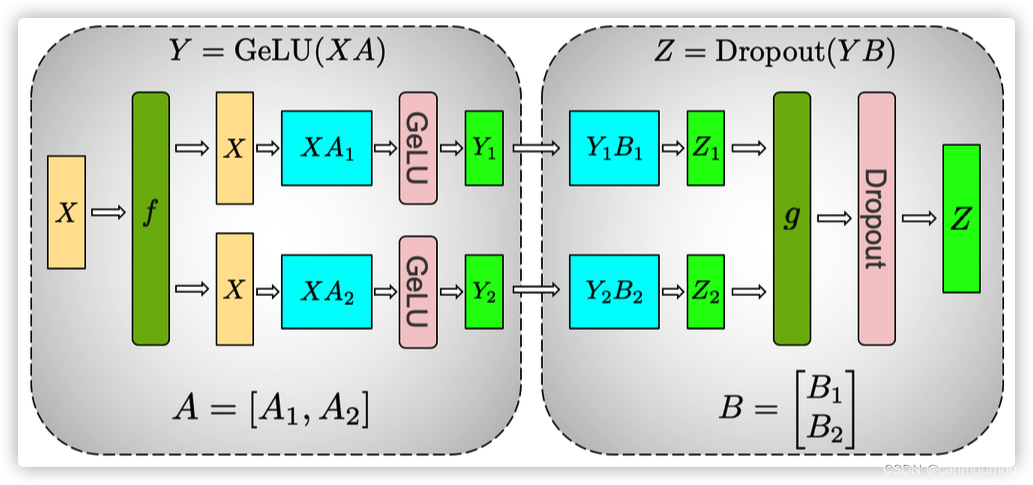
def forward(self, hidden_states):# [b,s, h]->[b, s, 4h/tp]intermediate_parallel = self.dense_h_to_4h(hidden_states) # ColumnParallelintermediate_parallel = F.Gelu(intermediate_parallel + bias_parallel)#[b, s, 4h/tp]->[b, s, h]output = self.dense_4h_to_h(intermediate_parallel) # RowParallelLinearreturn output
column parallel(纵向切分)
在这里插入图片描述
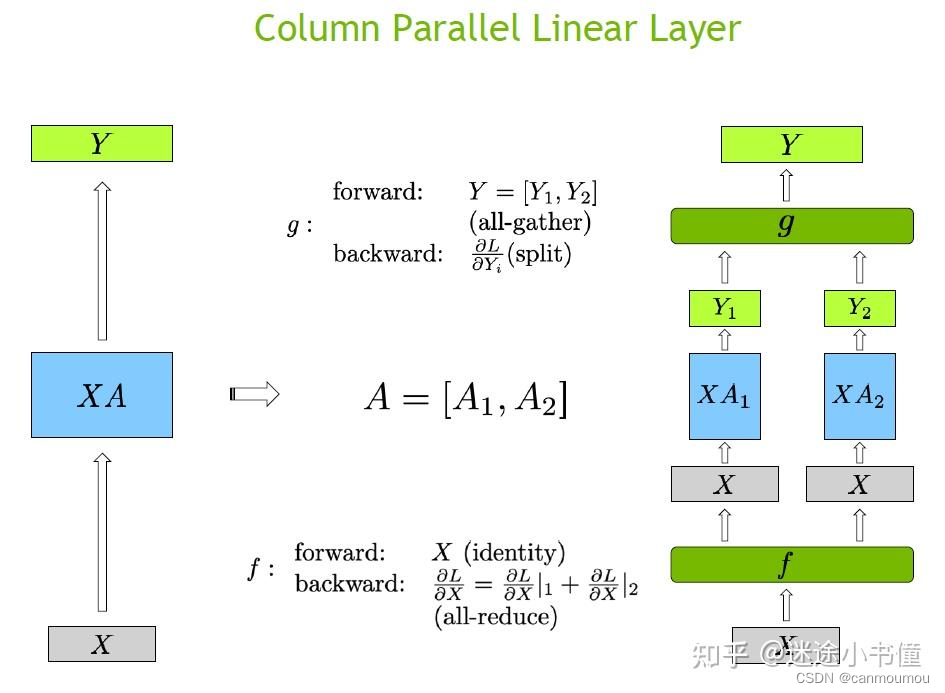
def forward(self, input_):# Set up backprop all-reduce. h4h/pgpuidentityall-reducefinput_parallel = copy_to_tensor_model_parallel_region(input_) bias = self.bias if not self.skip_bias_add else None # X * A_i^T = (b, s, h) * (h, 4h/tp) = (b, s, 4h/tp)output_parallel = F.linear(input_parallel, self.weight, bias) return output_parallel
row parallel(横向)
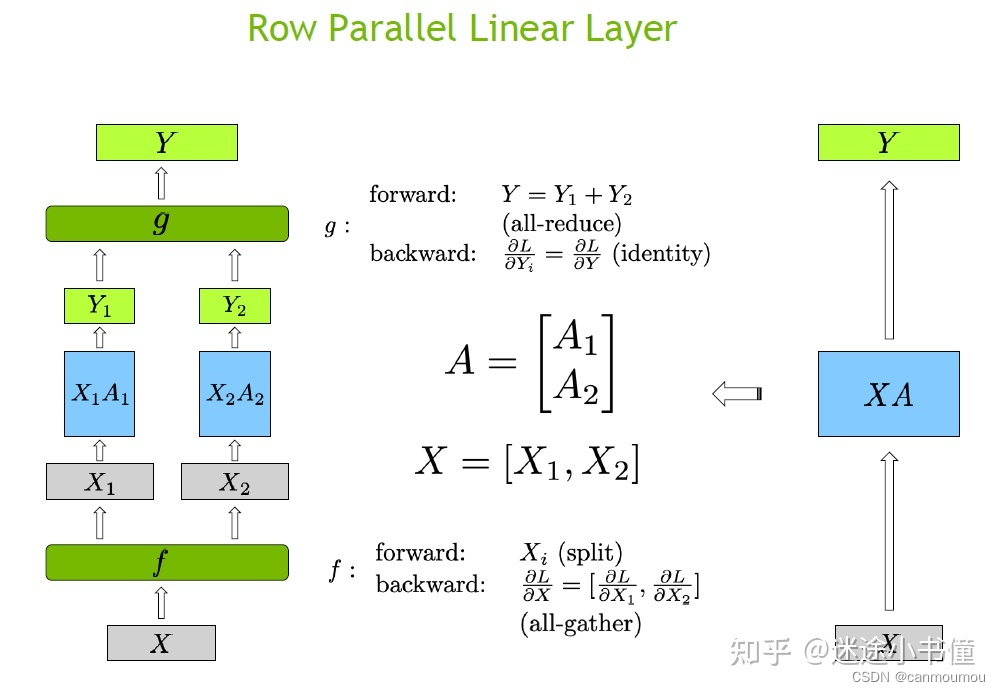
def forward(self, input_):# Matrix multiply. X_i=(b, s, 4h/tp) * A_i^T=(4h/tp, h) -> (b, s, h)output_parallel = F.linear(input_, self.weight) # All-reduce across all the partitionsg.output_ = reduce_from_tensor_model_parallel_region(output_parallel) if not self.skip_bias_add:output = output_ + self.bias if self.bias is not None else output_ else:output = output_return output
疑问:为什么第1个linear层是列切而不是行切?
如果第一个linear层使用行切,relu或者bert中的gelu都是非线性函数,那么我们无法先执行这个非线性函数,然后再相加,即gelu(X1A1)+gelu(X2A2) != gelu(X1A1+X2A2)。所以满足等价性,需要在gelu之前加一个allreduce同步一下,这种做法性能不是最优的。
2) Pipeline parallel
pipeline parallel是把整个模型的层数切分到不同的 pipeline parallel process group所在的rank上,每个pipeline stage拿到的层是不同的,如下图:

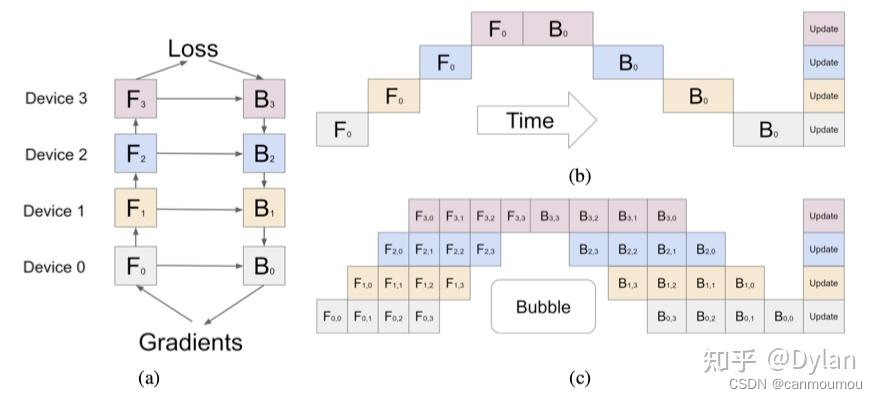
这样做的话,大部分GPU都处在一个等待状态,所以利用率并不高。
假设有K个GPU,每个mini-batch切分成M个micro-batches,Bubble率为
K − 1 / M + K − 1 K-1/M+K-1 K−1/M+K−1
GPipe的论文中提到当M大于四倍K的时候,基本上Bubble就可以忽略不计了(还有一部分原因是在计算梯度的时候,作者在前面的层提前计算了activation,而不用等到后面层的梯度计算完,这样能一定程度上实现并行)。
G-pipe
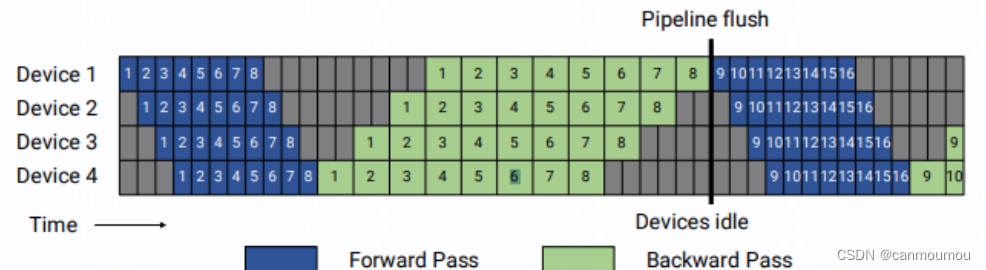
可以看到,G-pipe将1个mini-batch切分成多个micro-batch(上图是8),前向时每个micro-batch从device1流向device4,反向时在device4上算出梯度后并更新device4对应层的参数,然后将梯度send给device3,device3做梯度计算和参数更新后传给device2,以此类推直至device1参数更新完后,第一个mini-batch就结束了。
在G-pipe里,micro-batch切的数量越多,pipeline bubble就越少,但会带来很高的显存占用,因为每份micro-batch都要存储activation为反向计算梯度使用。
为了缓解显存问题,NV提出了1F1B(one forward one backward)方法。

与G-pipe不同,1F1B在每算完一个micro-batch的前向后就会立即算反向,反向完成后就可以释放该micro-batch对应的activation。
在step中间稳定阶段,形成1前向1反向的形式,该阶段每个device上只需要保存1份micro-batch的激活。相比于G-pipe要保存micro-batch数量的激活值,无论是显存占用还是pipeline bubble率均减少了很多。
Interleaved 1F1B
为了进一步降低Bubble率,Megatron-LM的第二篇论文里面在PipeDream的基础上做了进一步改进。
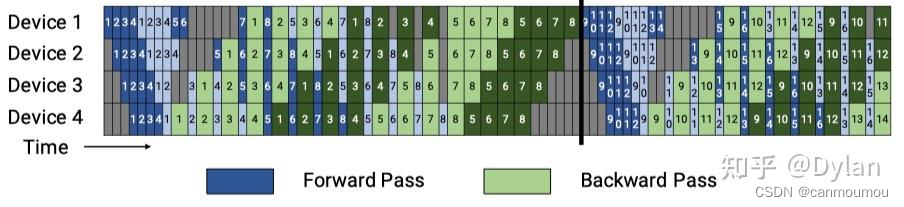
interleaved-1F1B在 device 数量不变的情况下,对micro-batch进一步切分,分出了更多的 pipeline stage(称为virtual pipeline stage),以更多的通信量,换取pipeline bubble比率降低。
那么它是怎么解决计算负载不均衡呢?假设网络共16层(编号 0-15),4个Device,前述 G-pipe 和 1F1B是分成 4 个stage, 按编号 0-3 层放 Device1,4-7层放 Device2 以此类推。
interleaved-1F1B则是按virtual_pipeline_stage 概念减小切分粒度,以 virtual_pipeline_stage=2 为例,将 0-1 层放 Device1、2-3 层放在 Device2,…,6-7 层放到 Device4,8-9 层继续放在 Device1,
10-11 层放在 Device2,…,14-15 层放在 Device4。
不过如果本身在PipeDream里面每个设备就只执行一层网络的话,就没有办法进一步通过Interleaved 1F1B进行优化了。
Megatron-LM 1F1B核心代码
def forward_backward_pipelining_without_interleaving(...):for i in range(num_microbatches_remaining):output_tensor = forward_step(...)if forward_only:p2p_communication.send_forward(output_tensor, timers)else:output_tensor_grad = p2p_communication.send_forward_recv_backward(output_tensor, timers)# Add input_tensor and output_tensor to end of list, then pop from the# start of the list for backward pass.input_tensors.append(input_tensor)output_tensors.append(output_tensor)if forward_only:if not last_iteration:input_tensor = p2p_communication.recv_forward(timers)else:input_tensor, output_tensor = input_tensors.pop(0), output_tensors.pop(0)input_tensor_grad = backward_step(...)if last_iteration:input_tensor = Nonep2p_communication.send_backward(input_tensor_grad, timers)else:input_tensor = p2p_communication.send_backward_recv_forward(input_tensor_grad, timers)
参考
- How PyTorch implements DataParallel?
- PyTorch2 doc:DATAPARALLEL
- PyTorch distributed: experiences on accelerating data parallel training
- GPU-内存拷贝
- https://arxiv.org/pdf/2001.08361.pdf
- https://www.usenix.org/conference/osdi20/presentation/jiang
相关文章:
【分布式】大模型分布式训练入门与实践 - 04
大模型分布式训练 数据并行-Distributed Data Parallel1.1 背景1.2 PyTorch DDP1) DDP训练流程2)DistributedSampler3)DataLoader: Parallelizing data loading4)Data-parallel(DP)5)DDP原理解析…...

欧拉图相关的生成与计数问题探究
最近学了一波国家集训队2018论文的最后一个专题。顺便带上了一些我的注解。 先放一波这个论文 1.基本概念 欧拉图问题是图论中的一类特殊的问题。在本文的介绍过程中,我们将会使用一些图 论术语。为了使本文叙述准确,本节将给出一些术语的定义。 定义…...
CSS3属性详解(一)文本 盒模型中的 box-ssize 属性 处理兼容性问题:私有前缀 边框 背景属性 渐变 前端开发入门笔记(七)
CSS3是用于为HTML文档添加样式和布局的最新版本的层叠样式表(Cascading Style Sheets)。下面是一些常用的CSS3属性及其详细解释: border-radius:设置元素的边框圆角的半径。可以使用四个值设置四个不同的圆角半径,也可…...

小程序:如何合理规划分包使主包不超过2M
背景 做过小程序项目的同学应该都有这样的经历,项目做着做着,突然发现代码包的大小超过了 2M,小程序无法提审,然后痛苦的删文件改代码来减少包大小。 虽然我们也知道小程序给我们提供了分包的功能可以减少主包的大小,…...

迭代器的封装与反向迭代器
一、反向迭代器 在list模拟实现的过程中,第一次接触了迭代器的封装,将list的指针封装成了一个新的类型,并且以迭代器的基本功能对其进行了运算符重载 反向迭代器是对正向迭代器的封装,并且体现了泛型编程的思想,任意…...

PHP项目学习笔记-萤火商城https://www.yiovo.com/doc
萤火商城学习笔记 注意事项关于建表增加页面流程前台页面的数据列表数据下拉列表的数据 关于时间的处理前台界面数据处理 多年没有碰过php代码了,这个项目不错,想好好学习下,持续更新 注意事项 打开APP_DEBUG有些时候改了前台页面后&#x…...

我国有多少个港口?
港口是什么? 港口是海洋运输中不可或缺的重要设施之一,是连接陆路和水路运输的重要节点。港口通常是指位于沿海地区的水陆交通枢纽,是船舶停靠、装卸货物、储存物资和维修船只的场所。港口一般由码头、泊位、仓库、货场、客运站等设施组成&a…...
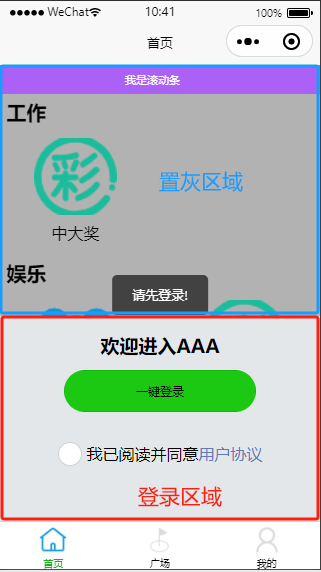
uniapp实现登录组件之外区域置灰并引导登录
实现需求 每个页面需要根据用户是否登录决定是否显示登陆组件,登录组件半屏底部显示,登录组件之外区域置灰,功能按钮点击之后引导提示登录.页面效果如下: 实现思路说明 设置登录组件背景颜色为灰色,将页面分成登录区域(底部)和非登陆区域(上面灰色显示部分), 置灰区域添加…...
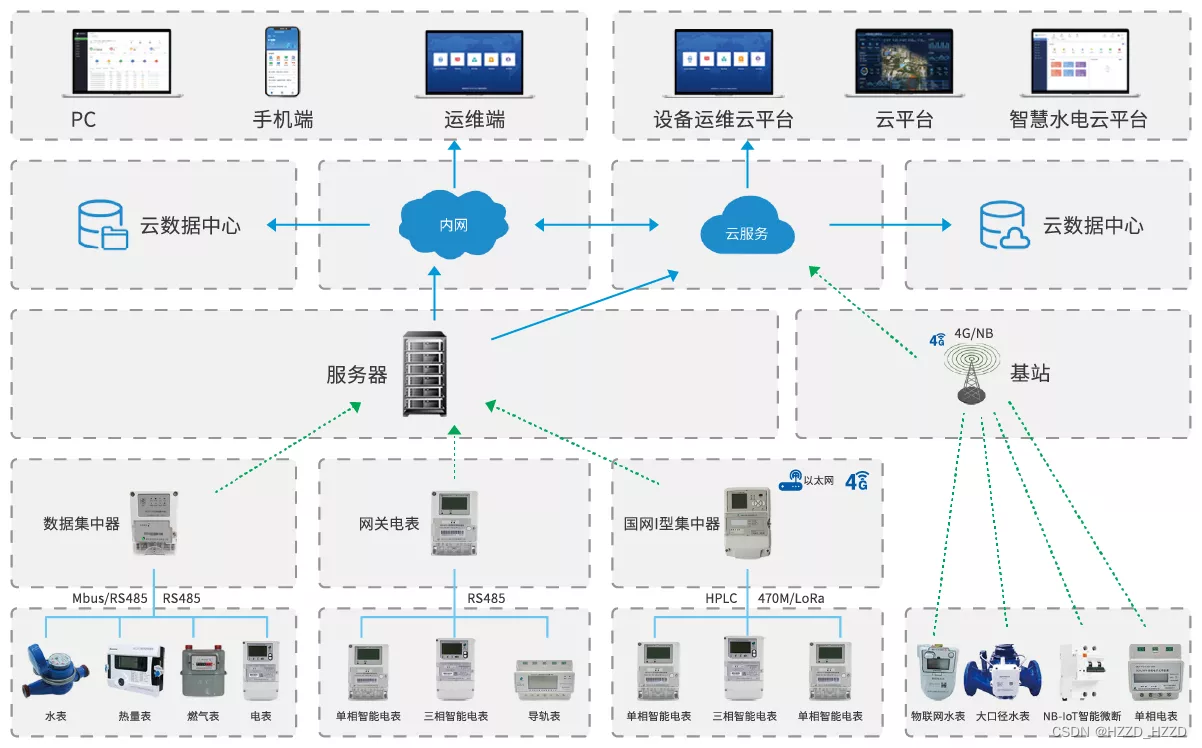
抄表系统是如何抄到电表水表的数据的?
抄表系统是一种利用无线通信技术,实现远程读取电表水表数据的系统。抄表系统主要由三部分组成:电表水表、集中器和后台管理平台。接下来,小编来为大家详细的介绍下抄表系统是如何抄到电表水表的数据的,一起来看下吧! 电表水表是抄…...
Qt之自定义事件QEvent
在Qt中,自定义事件的步骤大概如下: 1.创建自定义事件,自定义事件需要继承QEvent 2.使用QEvent::registerEventType()注册自定义事件类型,事件的类型需要在 QEvent::User 和 QEvent::MaxUser 范围之间,在QEvent::User之前是预留给系统的事件 3.使用sendEvent() 和 postEv…...

项目管理week5——交个作业
...

5.5G移动通信技术
5.5G即5G-Advanced,是一种移动通信技术。 5.5G 是 5G 和 6G 之间的过渡阶段,将在速率、时延、连接规模和能耗方面全面超越现有 5G,有望实现下行万兆和上行千兆的峰值速率、毫秒级时延和低成本千亿物联。按照国际标准组织 3GPP 定义ÿ…...

chrony时间服务
目录 1.1.重要性 1.2. Linux的两个时钟 1.3. NTP 1.4. Chrony介绍 2.安装与配置 2.1.安装: 2.2. Chrony配置文件分析 3.实验 3.1实验1 3.2实验2 3.常见时区 1.1.重要性 ●由于IT系统中,准确的计时非常重要,有很多种原因需要准确计时: 。在网络…...
音乐制作软件 Studio One 6 mac中文版软件特点
Studio One mac是一款专业的音乐制作软件,该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One mac软件特点 1. 直观易用的界面&…...

SpringBoot整合redis集群和redis单节点
// 连接redis单节点配置类Configuration public class RedisConfig {Value("${spring.redis.host}")private String host;Value("${spring.redis.port}")private Integer port;Value("${spring.redis.password}")private String password;/*** d…...

【ARM Coresight 系列文章19.1 -- Cortex-A720 PMU 详细介绍】
文章目录 概述Cortex-A720 PMU Features1.1 PMU 使用介绍1.2 Performance monitors events1.3 Performance Monitors Extension registers1.3.1 Performance monitors program1.4 Performance monitors interrupts1.5 Interaction with the Performance Monitoring Unit and De…...
FoneDog iOS Unlocker(ios解锁工具) 适用macos电脑
FoneDog iOS Unlocker是一款专业的iOS设备解锁工具,旨在帮助用户解决iOS设备上的解锁问题。该软件支持解锁各种锁定类型,如数字密码锁、手势密码锁、Touch ID和Face ID等,可以解除iPhone、iPad和iPod Touch等设备的锁定状态。FoneDog iOS Unl…...
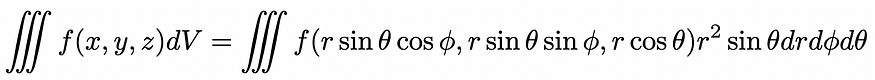
雅可比矩阵和雅可比坐标
雅可比行列式的简要介绍 一、说明 在本教程中,您将回顾一下雅可比行列式的简单介绍。完成本教程后,您将了解: 雅可比矩阵收集了可用于反向传播的多元函数的所有一阶偏导数。雅可比行列式在变量之间变化时非常有用,它充当一个坐标空…...
macOS鼠标管理操作增强BetterMouse简体中文
BetterMouse是一款专为Mac用户设计的鼠标增强工具,旨在帮助用户更好地掌握和管理鼠标操作。它提供了全局鼠标手势、高度可定制的鼠标设置选项以及一些有用的鼠标增强功能,如鼠标放大镜、鼠标轨迹和应用程序切换功能。这些功能可以大大提高用户的工作效率…...

塔式服务器介绍
大家都知道服务器分为机架式服务器、刀片式服务器、塔式服务器三类,今天小编就分别讲一讲这三种服务器,第三篇先来讲一讲塔式服务器的介绍。 塔式服务器定义:塔式服务器的外观和普通电脑差不多,直立放置。机箱比较大,服…...

基于STM32的物联网健康监测平台:硬件设计、驱动开发与系统整合
1. 项目概述:一个面向物联网健康监测的STM32开发平台最近在整理手头的项目资料,翻出来一块几年前自己设计并打样的STM32开发板。这块板子当初的定位很明确,就是做一个功能集成度高的“物联网健康监测终端”原型平台。它不是那种追求极致性能的…...

AI智能体评估框架AgentEval:模块化设计与自动化评测实践
1. 项目概述:AgentEval,一个为AI智能体“打分”的裁判最近在折腾AI智能体(Agent)的开发,从简单的自动化脚本到复杂的多步推理系统,我前前后后也做了不少。但每次做完一个Agent,最头疼的问题就来…...

SAP ECC6 2027年停服倒计时:中小企业主必看的4条务实出路与成本分析
SAP ECC6 2027年停服倒计时:中小企业主必看的4条务实出路与成本分析 当2027年的钟声敲响时,全球数十万家企业将面临一个关键抉择:是继续坚守已有二十年历史的SAP ECC6系统,还是踏上数字化转型的新征程?对于资源有限的中…...

ESP32 Arduino IDE 看门狗实战:从硬件看门狗到Task Watchdog Timer的配置与避坑指南
1. ESP32看门狗机制入门:为什么你的程序总在重启? 刚接触ESP32的开发者经常会遇到一个诡异现象:程序运行得好好的,突然就重启了。这很可能就是看门狗(Watchdog Timer)在作祟。我第一次用ESP32做物联网传感器…...

如何构建基于UNet的眼底血管图像分割系统
如何构建基于UNet的眼底血管图像分割系统 文章目录1. 数据预处理2. 定义UNet模型3. 训练过程4. 测试过程5. 日志记录1构建一个基于UNet的眼底血管图像分割系统涉及多个步骤,包括数据预处理、模型定义、训练过程、测试过程以及日志记录。下面是一个完整的指南&#x…...

TortoiseGit重置与还原功能详解:除了‘后悔药’,还能当‘时光机’和‘后悔药解药’?
TortoiseGit重置与还原功能深度解析:从版本控制到历史重构的艺术 在代码开发的漫长旅途中,每个开发者都曾有过"如果当时..."的瞬间。与大多数版本控制系统不同,Git提供的不仅是一个简单的"撤销"按钮,而是一套…...

别再写一堆CASE WHEN了!PostgreSQL里COALESCE和NULLIF这两个函数,帮你把SQL写得又短又稳
告别冗长SQL:用PostgreSQL的COALESCE和NULLIF重构条件逻辑 在数据处理的世界里,SQL就像是我们与数据库对话的语言。但你是否经常遇到这样的情况:为了处理各种空值和边界条件,你的SQL查询变成了一个由无数CASE WHEN语句组成的庞然大…...

代码语义可视化架构的突破性实现:MultiHighlight如何将代码理解效率提升300%
代码语义可视化架构的突破性实现:MultiHighlight如何将代码理解效率提升300% 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiH…...

AWS实战|从零搭建高可用Web应用网络架构
1. 为什么需要高可用Web应用架构? 最近帮朋友公司迁移电商平台到AWS时,他们最担心的就是大促期间服务器挂掉。这让我想起三年前自己踩过的坑——当时用单可用区部署的官网,因为一次区域级故障直接宕机8小时。现在回头看,其实只要在…...

如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南
如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老旧Mac无法升级到…...