【 OpenGauss源码学习 —— 列存储(update_pages_and_tuples_pgclass)】
列存储(update_pages_and_tuples_pgclass)
- 概述
- update_pages_and_tuples_pgclass 函数
- ReceivePageAndTuple 函数
- estimate_cstore_blocks 函数
- get_attavgwidth 函数
- get_typavgwidth 函数
- vac_update_relstats 函数
- 测试案例
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档和一些学习资料
概述
本文所学习的重点依旧围绕列存储展开。
update_pages_and_tuples_pgclass 函数
update_pages_and_tuples_pgclass 函数的主要功能是在 PostgreSQL 数据库中更新表和索引的统计信息,特别是更新 pg_class 中的关系页面数、总行数和总死行数等统计数据。它还计算并更新一个表扩展因子,用于查询优化。此函数还负责对表的索引进行统计信息的更新,以帮助查询优化器做出更准确的决策。
update_pages_and_tuples_pgclass 函数源码如下所示:(路径:src/gausskernel/optimizer/commands/analyze.cpp)
/** update_pages_and_tuples_pgclass: 更新用于分析到pg_class的关系页面和元组。** 参数:* @in onerel: 用于分析或清理的关系* @in vacstmt: 用于分析或清理命令的语句* @in attr_cnt: 用于分析的属性计数* @in vacattrstats: 所有属性的统计结构,或通过分析命令索引的统计结构,用于计算并更新pg_statistic。* @in hasindex: 是否存在索引用于分析* @in nindexes: 分析的索引数量* @in indexdata: 用于分析的每个索引的数据* @in Irel: 为分析malloc的新索引关系* @in relpages: 关系页面数* @in totalrows: 关系的总行数* @in totaldeadrows: 关系的总死行数* @in numrows: 样本行数* @in inh: 是否为继承表进行分析** 返回: 无*/
static void update_pages_and_tuples_pgclass(Relation onerel, VacuumStmt* vacstmt, int attr_cnt,VacAttrStats** vacattrstats, bool hasindex, int nindexes, AnlIndexData* indexdata, Relation* Irel,BlockNumber relpages, double totalrows, double totaldeadrows, int64 numrows, bool inh)
{BlockNumber updrelpages = relpages;/** 当我们从dn1接收pg_class时,我们已在ReceivePageAndTuple函数中更新了pg_class,* 因此,此处仅在数据节点上更新pg_class。*/if (IS_PGXC_DATANODE) {BlockNumber mapCont = 0;/* 更新列存储表的relpages */if (RelationIsColStore(onerel)) {/** 对于CU格式和PAX格式,由于RelationGetNumberOfBlocks返回0,因此我们必须从totalrows生成relpages** 最佳方法是使用所有行(活动和死行),但为了确保向前兼容性,我们只能处理所有行都为死行的情况。*/double allrows = totalrows > 0 ? totalrows : totaldeadrows;/* 如果关系是DFS表,则从HDFS文件获取relpage。 */if (RelationIsPAXFormat(onerel)) {updrelpages = estimate_cstore_blocks(onerel, vacattrstats, attr_cnt, numrows, allrows, true);} else {updrelpages = estimate_cstore_blocks(onerel, vacattrstats, attr_cnt, numrows, allrows, false);}}
#ifdef ENABLE_MULTIPLE_NODESelse if (RelationIsTsStore(onerel)) {updrelpages = estimate_tsstore_blocks(onerel, attr_cnt, totalrows);}
#endif /* ENABLE_MULTIPLE_NODES */if (RelationIsPartitioned(onerel)) {Relation partRel = NULL;ListCell* partCell = NULL;Partition part = NULL;foreach (partCell, vacstmt->partList) {part = (Partition)lfirst(partCell);partRel = partitionGetRelation(onerel, part);mapCont += visibilitymap_count(onerel, part);releaseDummyRelation(&partRel);}} else {mapCont = visibilitymap_count(onerel, NULL);}Relation classRel = heap_open(RelationRelationId, RowExclusiveLock);vac_update_relstats(onerel, classRel, updrelpages, totalrows, mapCont, hasindex, InvalidTransactionId);heap_close(classRel, RowExclusiveLock);}/* 估算表扩展因子 */double table_factor = 1.0;/* 使用GUC参数PARAM_PATH_OPTIMIZATION计算table_factor */if (ENABLE_SQL_BETA_FEATURE(PARAM_PATH_OPT) && onerel && onerel->rd_rel) {BlockNumber pages = onerel->rd_rel->relpages;/* 在此处重用索引估算(基于相同类型的估算更好) */double estimated_relpages = (double)estimate_index_blocks(onerel, totalrows, table_factor);table_factor = (double)pages / estimated_relpages;/* 如果表因子太小,则使用1.0 */table_factor = table_factor > 1.0 ? table_factor : 1.0;}/** 对于索引,情况类似。清理总是扫描所有索引,因此如果我们在VACUUM的一部分,* 则不要覆盖VACUUM已插入的准确计数。*/if (!((unsigned int)vacstmt->options & VACOPT_VACUUM) || ((unsigned int)vacstmt->options & VACOPT_ANALYZE)) {for (int ind = 0; ind < nindexes; ind++) {AnlIndexData* thisdata = &indexdata[ind];double totalindexrows;BlockNumber nblocks = 0;totalindexrows = ceil(thisdata->tupleFract * totalrows);/** @global stats* 更新CN中发出分析的地方的索引的全局relpages和全局reltuples的pg_class。*/if (IS_PGXC_COORDINATOR && ((unsigned int)vacstmt->options & VACOPT_ANALYZE) &&(0 != vacstmt->pstGlobalStatEx[vacstmt->tableidx].totalRowCnts)) {nblocks = estimate_index_blocks(Irel[ind], totalindexrows, table_factor);Relation classRel = heap_open(RelationRelationId, RowExclusiveLock);vac_update_relstats(Irel[ind], classRel, nblocks, totalindexrows, 0, false, BootstrapTransactionId);heap_close(classRel, RowExclusiveLock);continue;}/* 不要为VACUUM更新pg_class。 */if ((unsigned int)vacstmt->options & VACOPT_VACUUM)break;nblocks = GetOneRelNBlocks(onerel, Irel[ind], vacstmt, totalindexrows);Relation classRel = heap_open(RelationRelationId, RowExclusiveLock);vac_update_relstats(Irel[ind], classRel, nblocks, totalindexrows, 0, false, InvalidTransactionId);heap_close(classRel, RowExclusiveLock);}}
}
这个函数的执行过程如下:
- 函数开始,它接受多个参数,包括一个表示要分析或清理的关系(onerel)以及与该操作相关的其他信息和统计数据。
- 首先,函数初始化一个名为 updrelpages 的变量,将其设置为与 relpages 相等,relpages 表示关系中的页面数。
- 然后,函数检查当前会话是否在 PostgreSQL 数据节点上运行(IS_PGXC_DATANODE)。如果是在数据节点上执行,它会继续执行更新 pg_class 目录表中的统计信息的操作。这包括计算和更新与关系有关的各种统计数据,如 relpages、totalrows 和 totaldeadrows 等,这些统计数据对于查询优化非常重要。
- 如果关系是列存储表(RelationIsColStore(onerel)),则会根据特定的算法估算 relpages 的值。这个值是为了帮助数据库系统更好地了解表的物理存储结构。
- 接着,它计算一个叫做 table_factor 的表扩展因子,用于查询优化。这个因子根据关系的页面数和一些估算值计算而来。
- 然后,函数会对关系的索引进行循环迭代,为每个索引计算统计信息,包括块数(nblocks)和总索引行数。如果这是在协调器节点上执行 ANALYZE 操作,它会更新每个索引的 pg_class 中的统计信息。
- 最后,如果这不是一个 VACUUM 操作,函数还会更新每个索引的 pg_class 统计信息,并考虑之前计算的表扩展因子(table_factor)。
ReceivePageAndTuple 函数
在函数 update_pages_and_tuples_pgclass 中提到:
/*
* we have updated pg_class in function ReceivePageAndTuple when we receive pg_class from dn1,
* so, we only update pg_class on datanodes this place.
*/
这里所表达的含义如下:
ReceivePageAndTuple 函数和 update_pages_and_tuples_pgclass 函数之间的关系是,ReceivePageAndTuple 函数用于接收从远程节点传来的统计信息,并将这些信息用于更新 pg_class 中的页面、元组等统计数据。这是分布式数据库系统中的一种机制,用于从远程节点获取统计信息并将其同步到中央数据库。一般情况下,ReceivePageAndTuple 函数在远程节点执行,而 update_pages_and_tuples_pgclass 函数在中央数据库执行。
具体来说,ReceivePageAndTuple 函数用于接收来自远程节点的统计信息并将其传递给中央数据库,然后中央数据库中的 update_pages_and_tuples_pgclass 函数会使用这些统计信息来更新 pg_class 中的相关数据,以维护关系的统计信息。这种机制允许分布式数据库系统在多个节点上分布式地维护和更新统计信息,以支持查询优化和性能调优。
ReceivePageAndTuple 函数源码如下所示:(路径:src/common/backend/pgxc_single/pool/execRemote.cpp)
/** update pages, tuples, etc in pg_class* 更新pg_class中的页面、元组等信息*/
static void ReceivePageAndTuple(Oid relid, TupleTableSlot* slot, VacuumStmt* stmt)
{Relation rel;Relation classRel;RelPageType relpages;double reltuples;BlockNumber relallvisible;bool hasindex = false;// 从TupleTableSlot中获取并初始化关系的统计信息relpages = (RelPageType)DatumGetFloat8(slot->tts_values[0]);reltuples = (double)DatumGetFloat8(slot->tts_values[1]);relallvisible = (BlockNumber)DatumGetInt32(slot->tts_values[2]);hasindex = DatumGetBool(slot->tts_values[3]);// 打开关系和pg_class表rel = relation_open(relid, ShareUpdateExclusiveLock);classRel = heap_open(RelationRelationId, RowExclusiveLock);// 调用vac_update_relstats函数来更新pg_class中的统计信息vac_update_relstats(rel, classRel, relpages, reltuples, relallvisible, hasindex, BootstrapTransactionId);/* 保存标识是否有脏数据的标志到stmt中 */if (stmt != NULL) {stmt->pstGlobalStatEx[stmt->tableidx].totalRowCnts = reltuples;}/** 从远程DN/CN不获取已删除元组的信息,仅将deadtuples设置为0。* 这不会有影响,因为我们应该从所有数据节点获取已删除元组的信息来计算用户定义表的已删除元组信息。*/if (!IS_PGXC_COORDINATOR || IsConnFromCoord())pgstat_report_analyze(rel, (PgStat_Counter)reltuples, (PgStat_Counter)0);// 关闭pg_class表和关系heap_close(classRel, NoLock);relation_close(rel, NoLock);
}
estimate_cstore_blocks 函数
函数 estimate_cstore_blocks 用于估算列存储表所需的页数,以便进行资源分配和存储优化。它考虑了元组的宽度、总元组数以及存储格式(DFS或非DFS),并根据这些因素计算出所需的总页数。这对于数据库的存储和查询性能优化非常重要。
update_pages_and_tuples_pgclass 函数源码如下所示:(路径:src/gausskernel/optimizer/commands/analyze.cpp)
static BlockNumber estimate_cstore_blocks(Relation rel, VacAttrStats** vacAttrStats, int attrCnt, double sampleTuples, double totalTuples, bool dfsStore)
{int tuple_width = 0; // 初始化元组宽度为0BlockNumber total_pages = 0; // 初始化总页数为0int i;bool isPartition = RelationIsPartition(rel); // 检查关系是否为分区表if (totalTuples <= 0) {return 0; // 如果总元组数小于等于0,返回0页}/* 计算元组宽度,循环遍历关系的属性 */for (i = 1; i <= RelationGetNumberOfAttributes(rel); i++) {Form_pg_attribute att = rel->rd_att->attrs[i - 1]; // 获取属性信息int32 item_width = -1; // 初始化属性宽度为-1if (att->attisdropped)continue; // 如果属性被删除,跳过item_width = get_typlen(att->atttypid); // 获取属性的类型宽度if (item_width > 0) {/* 对于定长数据类型,累加宽度 */tuple_width += item_width;continue;}if (sampleTuples > 0) {/* 从当前正在执行的统计信息中获取 stawidth */bool found = false;for (int attIdx = 0; attIdx < attrCnt; ++attIdx) {VacAttrStats* stats = vacAttrStats[attIdx];if (att->attnum == stats->tupattnum) {item_width = stats->stawidth;found = true;break;}}if (found) {tuple_width += item_width;continue;}}if (item_width <= 0) /* 从现有的统计信息中获取 stawidth */item_width = get_attavgwidth(RelationGetRelid(rel), i, isPartition);if (item_width <= 0) /* 获取属性类型值的平均宽度 */item_width = get_typavgwidth(att->atttypid, att->atttypmod);Assert(item_width > 0);tuple_width += item_width; // 累加属性宽度到元组宽度}if (dfsStore)total_pages = ceil((totalTuples * tuple_width * ESTIMATE_BLOCK_FACTOR) / BLCKSZ);elsetotal_pages = ceil(totalTuples / RelDefaultFullCuSize) * (RelDefaultFullCuSize * tuple_width / BLCKSZ);if (totalTuples > 0 && totalTuples < total_pages)total_pages = totalTuples; // 如果总元组数小于总页数,将总页数设为总元组数if (totalTuples > 0 && total_pages <= 0)total_pages = 1; // 如果总元组数大于0且总页数小于等于0,将总页数设为1return total_pages; // 返回估算的总页数
}
注:stawidth 表示统计信息中的一个字段,它用于存储某一属性的估算宽度(width)。这个宽度是指在关系中存储该属性的平均字节数。在数据库统计信息中,为了更好地进行查询优化和成本估算,通常会估算每个属性的宽度,这有助于数据库系统决定如何在磁盘上存储数据以及如何执行查询计划。
具体来说,stawidth 存储了该属性的平均宽度,它是根据对表的样本数据进行统计估算得出的。这个估算值可以用于计算数据存储和传输成本,以便数据库系统可以更好地规划查询执行计划和资源分配。
在数据库中,属性的宽度是指该属性的数据在磁盘上占用的字节数。不同的数据类型(例如整数、文本、日期等)具有不同的宽度。因此,估算每个属性的宽度对于数据库系统来说是非常重要的,它有助于优化查询性能和资源利用。
stawidth 通常在数据库的统计信息中使用,以帮助查询优化器做出更好的决策。在上面的代码示例中,estimate_cstore_blocks 函数使用 stawidth 来估算列存储表的页数,以帮助数据库管理和查询优化。
get_attavgwidth 函数
在 estimate_cstore_blocks 函数中使用 get_attavgwidth 函数来查询表的属性的平均宽度,以帮助数据库系统进行查询优化和成本估算。它首先检查表是否处于升级模式,如果是,则直接返回0。然后,它根据表的持久性和属性号来决定是获取全局临时表的属性统计信息还是表的属性统计信息。最后,它返回属性的平均宽度,如果没有可用的统计信息,则返回0。其函数源码如下:(路径:src/common/backend/utils/cache/lsyscache.cpp)
/** get_attavgwidth* 给定表和属性号,获取该列中条目的平均宽度。如果没有可用数据,则返回零。** 当前只用于单个表,不用于继承树,因此不需要 "inh" 参数。* 在这一点上调用挂接看起来有些奇怪,但是因为优化器调用这个函数而没有其他方式让插件控制结果,所以需要挂接。*/
int32 get_attavgwidth(Oid relid, AttrNumber attnum, bool ispartition)
{HeapTuple tp;int32 stawidth;char stakind = ispartition ? STARELKIND_PARTITION : STARELKIND_CLASS;// 如果处于升级模式,返回0if (u_sess->attr.attr_common.upgrade_mode != 0)return 0;// 如果不是分区表并且表的持久性是全局临时表,则获取全局临时表的属性统计信息if (!ispartition && get_rel_persistence(relid) == RELPERSISTENCE_GLOBAL_TEMP) {tp = get_gtt_att_statistic(relid, attnum);if (!HeapTupleIsValid(tp)) {return 0;}stawidth = ((Form_pg_statistic)GETSTRUCT(tp))->stawidth;if (stawidth > 0) {return stawidth;} else {return 0;}}// 否则,获取表的属性统计信息tp = SearchSysCache4(STATRELKINDATTINH, ObjectIdGetDatum(relid), CharGetDatum(stakind), Int16GetDatum(attnum), BoolGetDatum(false));if (HeapTupleIsValid(tp)) {stawidth = ((Form_pg_statistic)GETSTRUCT(tp))->stawidth;ReleaseSysCache(tp);if (stawidth > 0)return stawidth;}// 如果没有有效的统计信息,返回0return 0;
}
get_typavgwidth 函数
get_typavgwidth 函数用于估算指定数据类型的平均宽度,以帮助规划器进行查询计划和成本估算。如果数据类型是固定宽度的(typlen > 0),则直接返回该类型的长度。如果数据类型不是固定宽度的,根据最大宽度(maxwidth)和数据类型来猜测典型数据宽度。如果不知道最大宽度,函数采用一个默认的猜测值。这有助于规划器在不知道确切宽度的情况下做出估算,以便更好地选择查询执行计划。
/** get_typavgwidth* 给定类型 OID 和类型修饰(typmod)值(如果不知道 typmod,则传递 -1),* 估算该类型值的平均宽度。这用于规划器(planner),* 不需要绝对正确的结果;如果我们不确定,猜测也可以。*/
int32 get_typavgwidth(Oid typid, int32 typmod)
{int typlen = get_typlen(typid); // 获取类型的长度(字节数)int32 maxwidth;/** 如果是固定宽度类型,直接返回类型的长度*/if (typlen > 0) {return typlen;}/** type_maximum_size 知道某些数据类型的 typmod 的编码;* 不要在这里重复这个知识。*/maxwidth = type_maximum_size(typid, typmod);if (maxwidth > 0) {/** 对于 BPCHAR(定长字符类型),最大宽度也是唯一的宽度。* 否则,我们需要根据最大宽度来猜测典型数据宽度。* 对于最大宽度,假设有一个百分比的典型数据宽度是合理的。*/if (typid == BPCHAROID) {return maxwidth;}if (maxwidth <= 32) {return maxwidth; /* 假设是全宽度 */}if (maxwidth < 1000) {return 32 + (maxwidth - 32) / 2; /* 假设是 50% */}/** 超过1000后,假设我们正在处理类似 "varchar(10000)" 这样的类型,* 其限制并不经常达到,因此使用一个固定的估计值。*/return 32 + (1000 - 32) / 2;}/** 如果不知道最大宽度,采用猜测。*/return 32;
}
vac_update_relstats 函数
函数 vac_update_relstats 用于在执行 VACUUM 和 ANALYZE 操作时,更新一个关系(表或索引)的统计信息,以确保查询优化和成本估算的准确性。函数的核心功能是通过修改 pg_class 表中的相应条目,更新关系的各种统计信息,包括页数、元组数量、可见页数、是否有索引等。这些统计信息对于数据库系统的性能优化和查询计划非常重要。其函数源码如下所示:(路径:src/gausskernel/optimizer/commands/vacuum.cpp)
/** vac_update_relstats() -- 更新一个关系的统计信息** 更新保存在 `pg_class` 表中的关系的整体统计信息,这些统计信息会被用于查询优化和成本估算。* 如果进行 ANALYZE,还会更新其他统计信息,但总是要更新这些统计信息。* 此函数适用于 `pg_class` 表中的索引和堆关系条目。** 我们违反了事务语义,通过使用新值覆盖了关系的现有 `pg_class` 元组。这是合理的,因为不管这个事务是否提交,新值都是正确的。* 这样做的原因是,如果我们按常规方式更新这些元组,那么对 `pg_class` 自身的 VACUUM 将无法很好地工作 --- 在 VACUUM 周期结束时,* `pg_class` 中的大多数元组都将变得过时。当然,这仅适用于固定大小且非 NULL 的列,而这些列确实是如此。** 注意另一个假设:不会有两个表的 VACUUM/ANALYZE 同时运行,也不会有 VACUUM/ANALYZE 与添加索引、规则或触发器等模式更改并行运行。* 否则,我们对 relhasindex 等的更新可能会覆盖未提交的更新。** 另一个采用这种方式的原因是,当我们处于延迟 VACUUM 并且设置了 PROC_IN_VACUUM 时,我们不能进行任何更新 ---* `pg_class` 中的某些元组可能会认为它们可以删除 xid = 我们的 xid 的元组。* isdirty - 用于标识关系的数据是否发生了更改。** 此函数由 VACUUM 和 ANALYZE 共享。*/
void vac_update_relstats(Relation relation, Relation classRel, RelPageType num_pages, double num_tuples,BlockNumber num_all_visible_pages, bool hasindex, TransactionId frozenxid)
{Oid relid = RelationGetRelid(relation);HeapTuple ctup;HeapTuple nctup = NULL;Form_pg_class pgcform;bool dirty = false;bool isNull = false;TransactionId relfrozenxid;Datum xid64datum;bool isGtt = false;/* 对于全局临时表,将 relstats 保存到 localhash 和 rel->rd_rel,而不是 catalog 中 */if (RELATION_IS_GLOBAL_TEMP(relation)) {isGtt = true;up_gtt_relstats(relation,static_cast<unsigned int>(num_pages), num_tuples,num_all_visible_pages,frozenxid);}/* 获取要修改的元组的副本 */ctup = SearchSysCacheCopy1(RELOID, ObjectIdGetDatum(relid));if (!HeapTupleIsValid(ctup))ereport(ERROR,(errcode(ERRCODE_NO_DATA_FOUND), errmsg("在进行 VACUUM 期间,relid %u 的 pg_class 条目已经消失", relid)));pgcform = (Form_pg_class)GETSTRUCT(ctup);/* 对复制的元组应用必需的更新,如果有的话 */dirty = false;
#ifdef PGXC// frozenxid == BootstrapTransactionId 表示是由 execRemote.cpp:ReceivePageAndTuple() 调用if (IS_PGXC_DATANODE || (frozenxid == BootstrapTransactionId) || IsSystemRelation(relation)) {
#endifif (isGtt) {relation->rd_rel->relpages = (int32) num_pages;relation->rd_rel->reltuples = (float4) num_tuples;relation->rd_rel->relallvisible = (int32) num_all_visible_pages;} else {if (pgcform->relpages - num_pages != 0) {pgcform->relpages = num_pages;dirty = true;}if (pgcform->reltuples - num_tuples != 0) {pgcform->reltuples = num_tuples;dirty = true;}if (pgcform->relallvisible != (int32)num_all_visible_pages) {pgcform->relallvisible = (int32)num_all_visible_pages;dirty = true;}}
#ifdef PGXC}
#endifif (pgcform->relhasindex != hasindex) {pgcform->relhasindex = hasindex;dirty = true;}/** 如果我们发现没有索引,那么也没有主键。这可能需要更加彻底的处理...*/if (pgcform->relhaspkey && !hasindex) {pgcform->relhaspkey = false;dirty = true;}/* 如果需要,我们还会清除 relhasrules 和 relhastriggers */if (pgcform->relhasrules && relation->rd_rules == NULL) {pgcform->relhasrules = false;dirty = true;}if (pgcform->relhastriggers && relation->trigdesc == NULL) {pgcform->relhastriggers = false;dirty = true;}/** relfrozenxid 不应该回退,除非在 PGXC 中,当 xid 与 gxid 不同步且我们希望使用独立后台进程来纠正时。* 调用方可以传递 InvalidTransactionId,如果没有新数据。*/xid64datum = tableam_tops_tuple_getattr(ctup, Anum_pg_class_relfrozenxid64, RelationGetDescr(classRel), &isNull);if (isNull) {relfrozenxid = pgcform->relfrozenxid;if (TransactionIdPrecedes(t_thrd.xact_cxt.ShmemVariableCache->nextXid, relfrozenxid) ||!TransactionIdIsNormal(relfrozenxid))relfrozenxid = FirstNormalTransactionId;} else {relfrozenxid = DatumGetTransactionId(xid64datum);}if (TransactionIdIsNormal(frozenxid) && (TransactionIdPrecedes(relfrozenxid, frozenxid)
#ifdef PGXC|| !IsPostmasterEnvironment)
#endif) {Datum values[Natts_pg_class];bool nulls[Natts_pg_class];bool replaces[Natts_pg_class];errno_t rc;pgcform->relfrozenxid = (ShortTransactionId)InvalidTransactionId;rc = memset_s(values, sizeof(values), 0, sizeof(values));securec_check(rc, "", "");rc = memset_s(nulls, sizeof(nulls), false, sizeof(nulls));securec_check(rc, "", "");rc = memset_s(replaces, sizeof(replaces), false, sizeof(replaces));securec_check(rc, "", "");replaces[Anum_pg_class_relfrozenxid64 - 1] = true;values[Anum_pg_class_relfrozenxid64 - 1] = TransactionIdGetDatum(frozenxid);nctup = (HeapTuple) tableam_tops_modify_tuple(ctup, RelationGetDescr(classRel), values, nulls, replaces);ctup = nctup;dirty = true;}/* 如果有任何更改,将元组写入 */if (dirty) {if (isNull && nctup) {simple_heap_update(classRel, &ctup->t_self, ctup);CatalogUpdateIndexes(classRel, ctup);} elseheap_inplace_update(classRel, ctup);if (nctup)heap_freetuple(nctup);}
}
测试案例
1. 创建列存储表,执行以下 SQL:
postgres=# create table t2 (id int) with (orientation=column);
CREATE TABLE
postgres=# insert into t2 values (generate_series(1,10));
INSERT 0 10
postgres=# analyze t2;
2. 步入 estimate_cstore_blocks 函数:
调试信息如下:
- 首先检查是否为分区表,gdb调试信息如下:
bool isPartition = RelationIsPartition(rel);
---------------------------------------------
(gdb) p isPartition
$1 = false
- 检查属性是否被删除,gdb调试信息如下:
if (att->attisdropped)continue;
---------------------------------------------
(gdb) p isPartition
(gdb) p att->attisdropped
$2 = false
- 获取属性类型宽度:
item_width = get_typlen(att->atttypid);
---------------------------------------------
(gdb) p item_width
$3 = 4
- 根据判断是否为 DFS 表来计算总页数 total_pages :
if (dfsStore)total_pages = ceil((totalTuples * tuple_width * ESTIMATE_BLOCK_FACTOR) / BLCKSZ);
elsetotal_pages = ceil(totalTuples / RelDefaultFullCuSize) * (RelDefaultFullCuSize * tuple_width / BLCKSZ);
---------------------------------------------
(gdb) p total_pages
$4 = 29
- 根据判断 totalTuples 和 total_pages 的大小来为总页数赋值:
if (totalTuples > 0 && totalTuples < total_pages)total_pages = totalTuples;if (totalTuples > 0 && total_pages <= 0)total_pages = 1;
---------------------------------------------
(gdb) p total_pages
$4 = 10
注:以上两段代码含义如下:
- 如果 totalTuples(实际数据记录数)小于 total_pages(计算出的页数),这可能会导致问题,因为没有足够的数据来填充所有这些页,这会浪费存储空间。这样做可以确保不会浪费额外的页用于存储数据,因为页的数量应该与数据的数量相匹配。
- 是为了处理可能的特殊情况,当总元组数大于0但计算出的总页数小于等于0时,将总页数设置为1。这可以确保总页数至少为1,以便能够存储数据。当总元组数非零但由于某些原因总页数计算为非正数时,将其设置为1是一个常见的做法,以确保有一个最小的页来存储数据。
以上有关列存更新 pages 的数据已经得到了。
相关文章:
】)
【 OpenGauss源码学习 —— 列存储(update_pages_and_tuples_pgclass)】
列存储(update_pages_and_tuples_pgclass) 概述update_pages_and_tuples_pgclass 函数ReceivePageAndTuple 函数estimate_cstore_blocks 函数get_attavgwidth 函数get_typavgwidth 函数 vac_update_relstats 函数 测试案例 声明:本文的部分内…...
爬虫进阶-反爬破解7(逆向破解被加密数据:全方位了解字体渲染的全过程+字体文件的检查和数据查看+字体文件转换并实现网页内容还原+完美还原上百页的数据内容)
目录 一、全方位了解字体渲染的全过程 1.加载顺序 2.实践操作:浏览器中调试字体渲染 3.总结: 二、字体文件的检查和数据查看 1.字体文件的操作软件 2.映射关系的建立 3.实践操作:翻找样式和真实内容 4.总结: 三、字体文…...

系统架构设计师之RUP软件开发生命周期
系统架构设计师之RUP软件开发生命周期...
VM虚拟机 13.5 for Mac
VMware Fusion Pro for Mac是一款强大的虚拟机软件,可以在Mac操作系统中创建、运行和管理多个虚拟机,使用户可以在一台Mac电脑上同时运行多个操作系统和应用程序。 以下是VMware Fusion Pro for Mac的主要特点: 1. 支持多种操作系统ÿ…...

一篇教你学会Ansible
前言 Ansible首次发布于2012年,是一款基于Python开发的自动化运维工具,核心是通过ssh将命令发送执行,它可以帮助管理员在多服务器上进行配置管理和部署。它的工作形式依托模块实现,自己没有批量部署的能力。真正具备批量部署的是…...
Mysql第四篇---数据库索引优化与查询优化
文章目录 数据库索引优化与查询优化索引失效案例数据准备1. 全值匹配2 最佳左前缀法则(联合索引)主键插入顺序4 计算、函数导致索引失效5 类型转换(自动或手动)导致索引失效6 范围条件右边的列索引失效7 不等于(!或者<>)索引失效8 is null可以使用索引, is not null无法使…...

SpringBoot手动获取实例
1.首先创建一个接口里面是关于建库建表的方法 public interface MetaMapper {//三个核心建表方法void createExchangeTable();void createQueueTable();void createBingdingTable(); } 2.启动类中定义一个ConfigurableApplicationContext 类型的变量context接收SpringApplica…...

栈(Stack)的概念+MyStack的实现+栈的应用
文章目录 栈(Stack)一、 栈的概念1.栈的方法2.源码分析 二、MyStack的实现1.MyStack的成员变量2.push方法3.isEmpty方法和pop方法4.peek方法 三、栈的应用1.将递归转化为循环1.调用递归打印2.通过栈逆序打印链表 栈(Stack) 一、 栈…...

C语言进阶第九课 --------动态内存管理
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...
嵌入式 Tomcat 调校
SpringBoot 嵌入了 Web 容器如 Tomcat/Jetty/Undertow,——这是怎么做到的?我们以 Tomcat 为例子,尝试调用嵌入式 Tomcat。 调用嵌入式 Tomcat,如果按照默认去启动,一个 main 函数就可以了。 简单的例子 下面是启动…...

初始化固定长度的数组
完全解析Array.apply(null,「length: 1000」) 创建固定长度数组,并且初始化值。直接可以使用map、forEach、reduce等有遍历性质的方法。 如果直接使用Array(81),map里面的循环不会执行。 //方法一 Array.apply(null, { length: 20 })//方法二 Array(81)…...
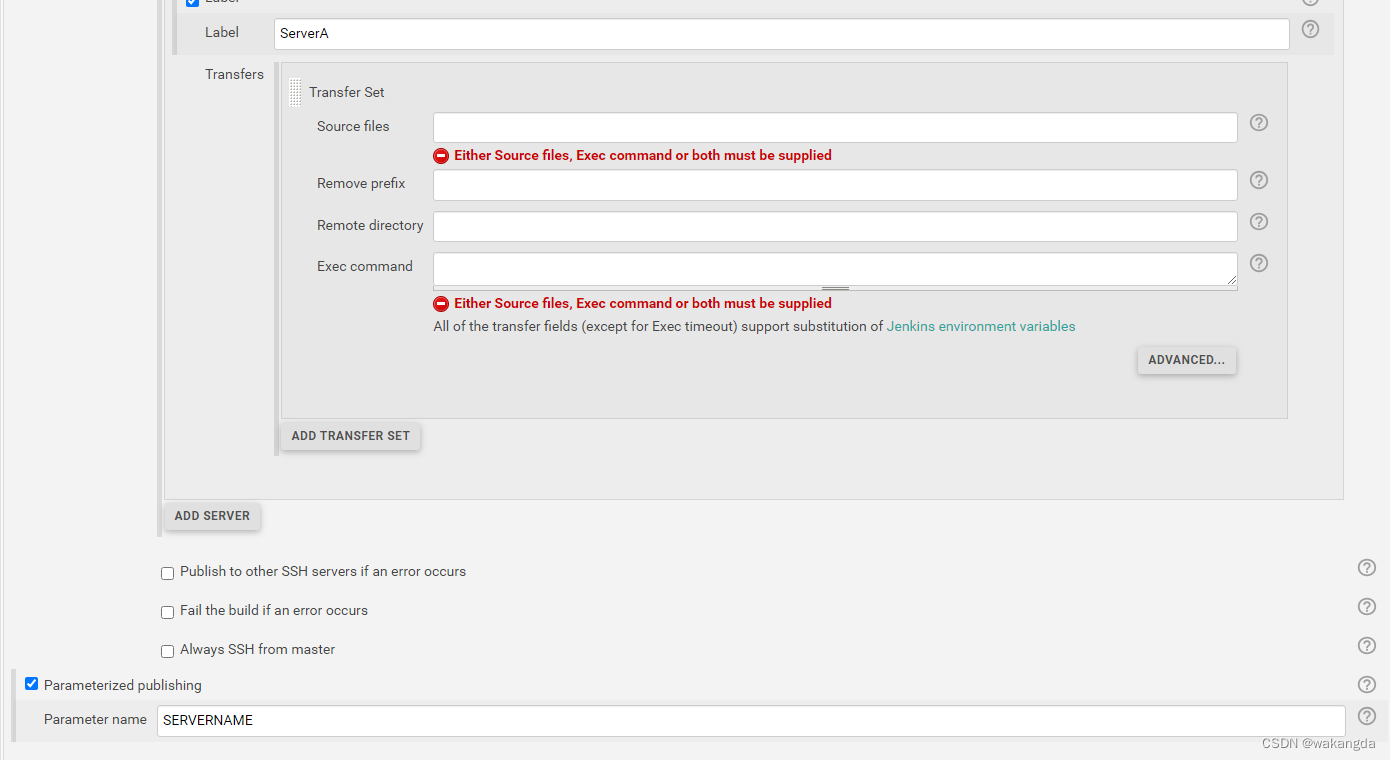
实现基于 Jenkins 的多服务器打包方案
实现基于 Jenkins 的多服务器打包方案 在实际项目中,我们经常会遇到需要将一个应用程序或服务部署到不同的服务器上的需求。而使用 Jenkins 可以很方便地自动化这个过程。 设置参数 首先,我们需要设置一些参数,以便在构建过程中指定要部署…...

探索现代IT岗位:职业机遇的海洋
目录 1 引言2 传统软件开发3 数据分析与人工智能4 网络与系统管理5 信息安全6 新兴技术领域 1 引言 随着现代科技的迅猛发展,信息技术(IT)行业已经成为了全球经济的关键引擎,改变了我们的生活方式、商业模式和社会互动方式。IT行…...

np.linspace精确度
前言 今天发现一个大坑,如果是序列是小数的话,不要用np.linspace,而要用np.arrange指定等差序列。比如入下图中a和b是一样的意思,但是b是有较大误差的。 anp.arange(0,4,0.4) bnp.linspace(0,4,10) print("a",a) prin…...

GD32_定时器输入捕获波形频率
GD32_定时器输入捕获波形频率(多通道轮询) 之前项目上用到一个使用定时器捕获输入采集风扇波形频率得到风扇转速的模块,作为笔记简单记录以下当时的逻辑结构和遇到的问题,有需要参考源码、有疑问或需要提供帮助的可以留言告知 。…...

单窗口单IP适合炉石传说游戏么?
游戏道具制作在炉石传说中是一个很有挑战的任务,但与此同时,它也是一个充满机遇的领域。在这篇文章中,我们将向您展示如何在炉石传说游戏中使用动态包机、多窗口IP工具和动态IP进行游戏道具制作。 作者与主题的关系:作为一名热爱炉…...
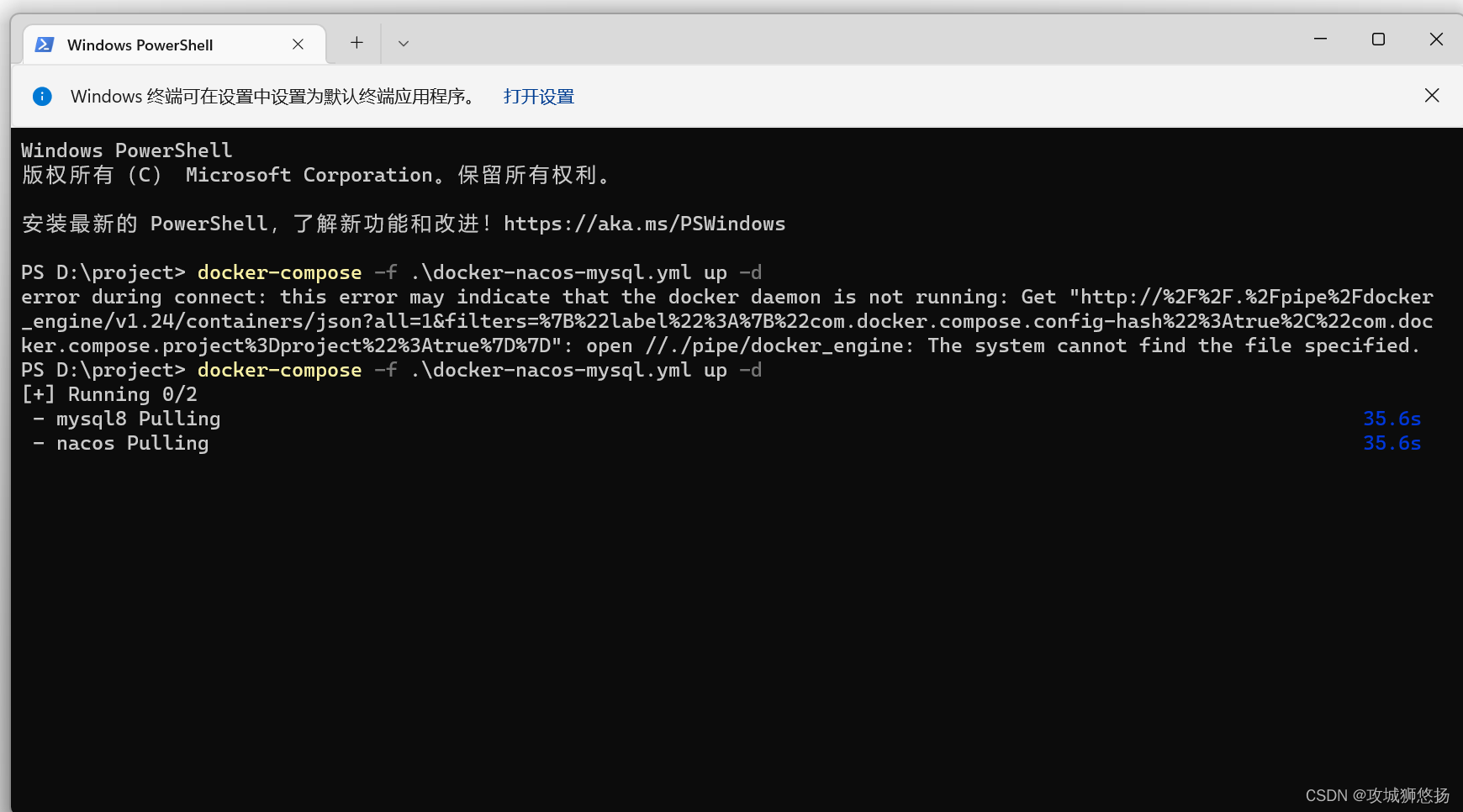
win11安装docekr、docker-compose
1.docker安装 下载地址:Install Docker Desktop on Windows | Docker Docs 出问题别慌,看清楚提示信息,cmd更新wsl,什么是wsl,百度好好理解一下哦 2.docker-compose安装 还是去官方看看怎么说的,然后跟着处…...
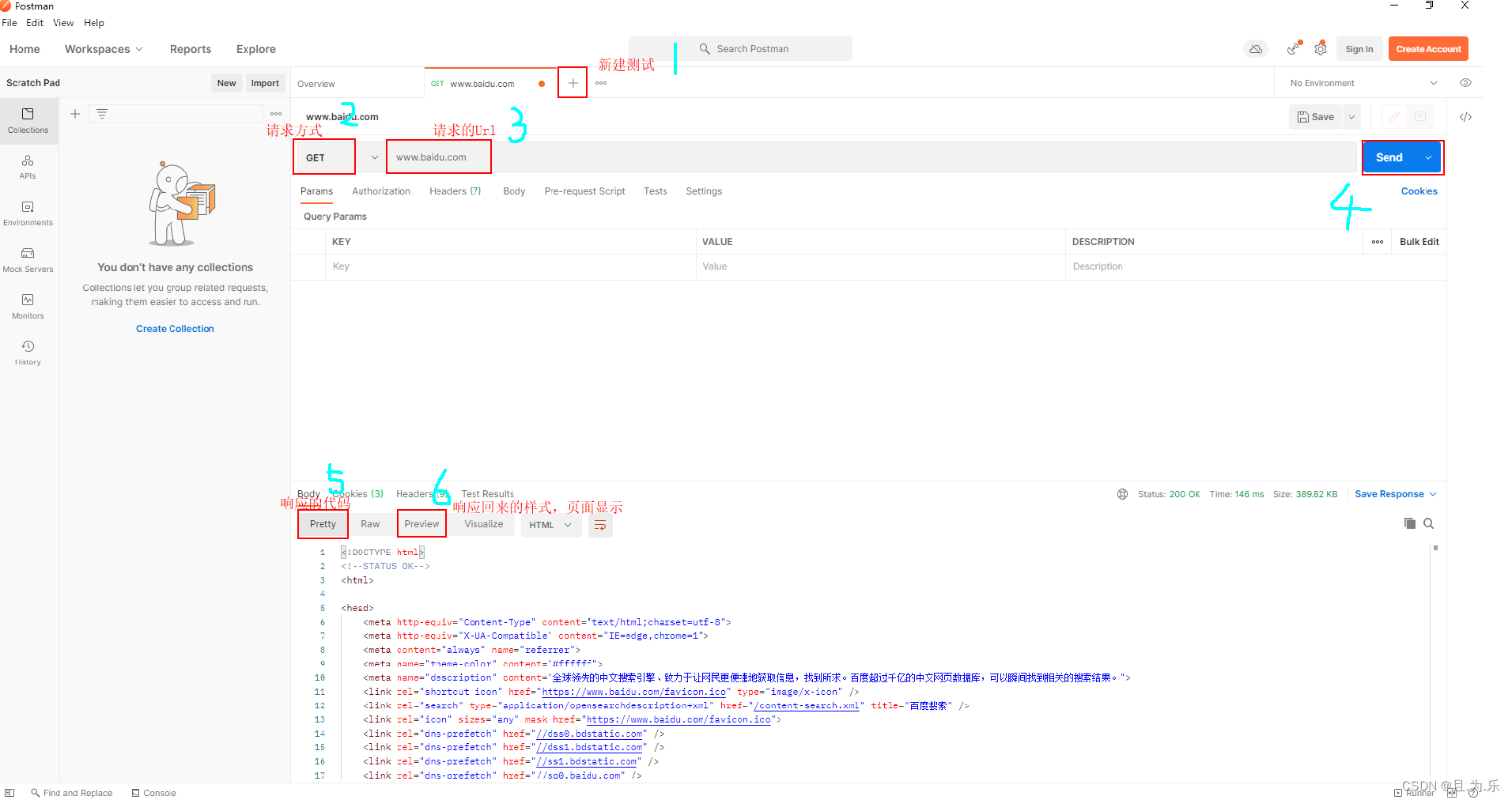
Postman的简单使用
Postman简介 官网 Postman是Google公司开发的一款功能强大的网页调试与发送HTTP请求,并能运行测试用例的Chrome插件 使用Postman进行简单接口测试 新建测试 → 选择请求方式 → 请求URL,下面用百度作为例子: 参考文档 [1] Postman使用教程…...
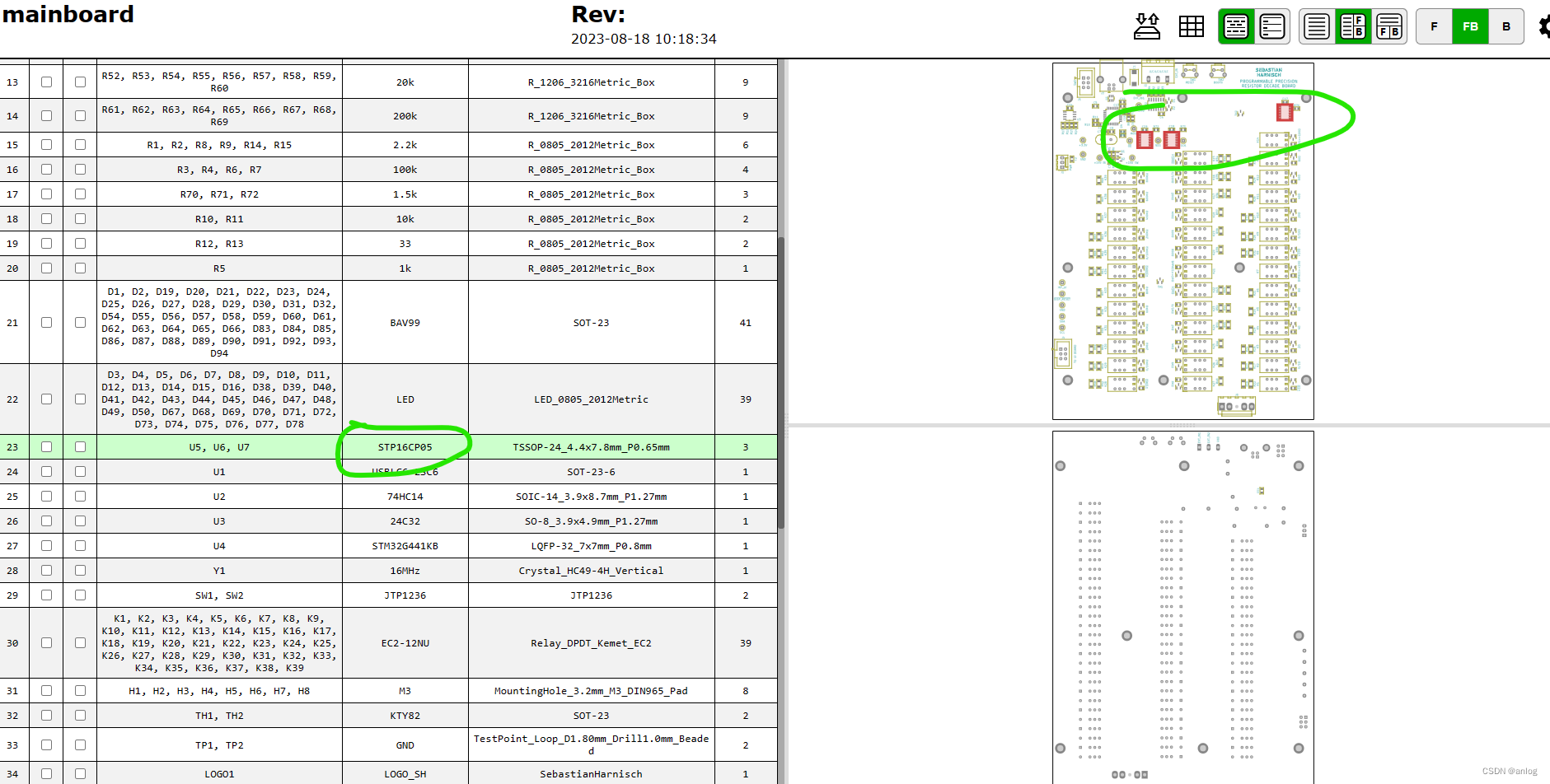
信号继电器驱动芯片(led驱动芯片)
驱动继电器需要配合BAV99(防止反向脉冲)使用 具体应用参考开源项目 电阻箱 sbstnh/programmable_precision_resistor: A SCPI programmable precision resistor (github.com) 这个是芯片的输出电流设置 对应到上面的实际开源项目其设置电阻为1.5K&…...
IDEA配置HTML和Thymeleaf热部署开发
IDEA配置HTML和Thymeleaf热部署开发 1.项目配置2. IDEA配置3. 使用 需求:现在我们在开发不分离项目的时候(SpringBootThmeleaf)经常会改动了类或者静态html文件就需要重启一下服务器, 这样不仅时间开销很大,而且经常重…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

gwadd:轻量级Git仓库组管理工具,提升多项目开发效率
1. 项目概述:一个被低估的Git仓库管理利器如果你和我一样,日常工作中需要频繁地在多个Git仓库之间穿梭,处理各种依赖、子模块,或者仅仅是同步一堆相关的项目代码,那么你一定对那种重复、繁琐的切换和操作感到头疼。今天…...

5分钟学会创建专业交通网络可视化地图
5分钟学会创建专业交通网络可视化地图 【免费下载链接】transit-map The server and client used in transit map simulations like swisstrains.ch 项目地址: https://gitcode.com/gh_mirrors/tr/transit-map 你想在网页上展示动态的公共交通网络吗?Transit…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...

保姆级教程:用STM8S207R6和FD6288T自制BLDC驱动板,从原理图到代码框架搭建
从零构建BLDC驱动板:STM8S207R6与FD6288T实战指南 在创客和嵌入式开发领域,无刷直流电机(BLDC)控制一直是兼具挑战性和实用性的热门方向。与有刷电机相比,BLDC电机具有高效率、长寿命和低噪音等优势,但驱动电路和控制系统也更为复…...

深度学习训练理论:初始化与梯度消失
深度学习训练理论:初始化与梯度消失 1. 技术分析 1.1 训练挑战概述 深度学习训练面临多种挑战: 训练挑战梯度消失: 梯度趋近于0梯度爆炸: 梯度过大参数初始化: 权重初始化影响激活函数选择: 影响梯度流动1.2 梯度消失原因 原因机制影响激活函数sigmoid/t…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...