LLVM高级架构介绍
LLVM
为什么要开一个LLVM的新坑呢? 我从智能穿戴转行到芯片软件行业,从事编译器开发,不过是AI编译器。不过基本的传统编译器还是绕不过去啊,所以开始学习LLVM,后面开始学习TVM,MLIR。
LLVM GitHub地址
L LVM官网
-
LLVM 项目是模块化和可重用的编译器和工具链技术的集合。
-
LLVM 项目中的代码根据“Apache 2.0 License with LLVM exceptions”获得许可
LLVM高级架构
- Intro to LLVM
the main thing that sets LLVM apart from other compilers is its internal architecture.
1. 经典编译器快速介绍
传统静态编译器

- 前端解析源代码,检查错误,并构建特定语言的抽象语法树 (AST) 来表示输入代码。 AST 可选地转换为新的表示进行优化,优化器和后端在代码上运行。
- 优化器负责进行各种转换以尝试提高代码的运行时间,例如消除冗余计算,并且通常或多或少独立于语言和目标。
- 后端(也称为代码生成器)然后将代码映射到目标指令集。除了编写正确的代码外,它还负责生成利用所支持架构的不寻常特性的良好代码。编译器后端的常见部分包括指令选择、寄存器分配和指令调度。
经典编译器的优点:
当编译器决定支持多种源语言或目标架构时,这种经典设计最重要的优点就出现了。如果编译器在其优化器中使用通用代码表示,则可以为任何可以编译到它的语言编写前端,并且可以为任何可以从它编译的目标编写后端,
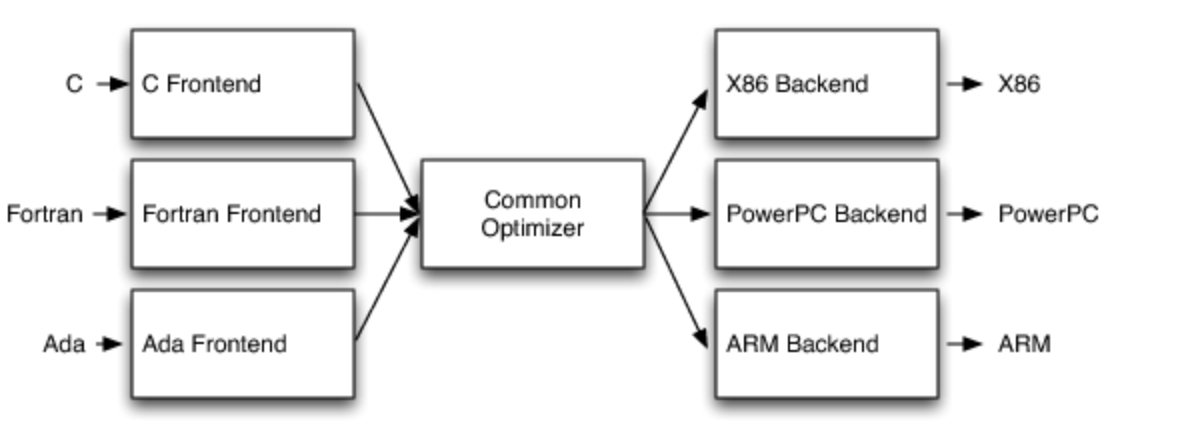
- 多种语言可以共用优化器和后段,每加入一种新语言,只需要加入一个新的解析前段即可。
- 前中后工作分离,逻辑分离,更好的协作。
2. 现在存在的编译器实现方式
虽然三阶段设计的好处令人信服,并且在编译器教科书中有详细记录,**但实际上它几乎从未完全实现。**纵观开源语言实现(回到 LLVM 启动时),您会发现 Perl、Python、Ruby 和 Java 的实现不共享任何代码。此外,像 Glasgow Haskell Compiler (GHC) 和 FreeBASIC 这样的项目可以重定向到多个不同的 CPU,但它们的实现非常特定于它们支持的一种源语言。还部署了多种专用编译器技术来实现 JIT 编译器,用于图像处理、正则表达式、显卡驱动程序和其他需要 CPU 密集型工作的子域。
也就是说,这个模型有三个主要的成功案例,第一个是 Java 和 .NET 虚拟机。这些系统提供 JIT 编译器、运行时支持和定义良好的字节码格式。这意味着任何可以编译为字节码格式的语言(有几十种)都可以利用优化器和 JIT 以及运行时所付出的努力。权衡是这些实现在选择运行时方面提供的灵活性很小:它们都有效地强制 JIT 编译、垃圾收集和使用非常特殊的对象模型。这会导致在编译与此模型不紧密匹配的语言(例如 C 语言(例如,使用 LLJVM 项目))时性能欠佳。
第二个成功案例可能是最不幸的,但也是最流行的重用编译器技术的方法:将输入源转换为 C 代码(或其他语言)并通过现有的 C 编译器发送。这允许重用优化器和代码生成器,提供良好的灵活性、对运行时的控制,并且前端实现者非常容易理解、实现和维护。不幸的是,这样做会妨碍异常处理的有效实现,提供糟糕的调试体验,减慢编译速度,并且对于需要保证尾调用(或 C 不支持的其他功能)的语言可能会出现问题
该模型的最终成功实现是 GCC4。 GCC 支持许多前端和后端,并拥有一个活跃而广泛的贡献者社区。 GCC 作为一个 C 编译器有着悠久的历史,它支持多个目标,并为其他一些语言提供了 hacky 支持。随着岁月的流逝,GCC 社区正在慢慢演变出更清洁的设计。从 GCC 4.4 开始,它有一个新的优化器表示(称为“GIMPLE Tuples”),它比以前更接近于与前端表示分离。此外,它的 Fortran 和 Ada 前端使用干净的 AST。
这三种方法虽然非常成功,但对它们的用途有很大的限制,因为它们被设计为单片应用程序。例如,实际上不可能将 GCC 嵌入到其他应用程序中,将 GCC 用作运行时/JIT 编译器,或者在不引入大部分编译器的情况下提取和重用 GCC 片段。想要使用 GCC 的 C++ 前端进行文档生成、代码索引、重构和静态分析工具的人们不得不将 GCC 用作以 XML 形式发出有趣信息的单体应用程序,或者编写插件以将外部代码注入 GCC 进程.
GCC 的各个部分不能作为库重用的原因有很多,包括大量使用全局变量、强制执行不变量、设计不良的数据结构、庞大的代码库以及使用宏阻止代码库被编译以支持更多一次超过一个前端/目标对。然而,最难解决的问题是源于其早期设计和时代的固有架构问题。具体来说,GCC 存在分层问题和泄漏抽象:后端走前端 AST 生成调试信息,前端生成后端数据结构,整个编译器依赖于命令行接口设置的全局数据结构.
3. LLVM 的代码表示:LLVM IR
抛开历史背景和背景,让我们深入了解 LLVM:其设计中最重要的方面是 LLVM 中间表示 (IR),这是它用于在编译器中表示代码的形式。 LLVM IR 旨在托管您在编译器的优化器部分中找到的中级分析和转换。它的设计考虑了许多特定目标,包括支持轻量级运行时优化、跨功能/跨过程优化、整个程序分析和积极的重组转换等。不过,它最重要的方面是它本身被定义为具有明确语义的一流语言。为了具体说明,这里有一个 .ll 文件的简单示例:
define i32 @add1(i32 %a, i32 %b) {
entry:%tmp1 = add i32 %a, %bret i32 %tmp1
}define i32 @add2(i32 %a, i32 %b) {
entry:%tmp1 = icmp eq i32 %a, 0br i1 %tmp1, label %done, label %recurserecurse:%tmp2 = sub i32 %a, 1%tmp3 = add i32 %b, 1%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)ret i32 %tmp4done:ret i32 %b
}
这个 LLVM IR 对应于这个 C 代码,它提供了两种不同的整数相加方式:
unsigned add1(unsigned a, unsigned b) {return a+b;
}// Perhaps not the most efficient way to add two numbers.
unsigned add2(unsigned a, unsigned b) {if (a == 0) return b;return add2(a-1, b+1);
}
从这个例子可以看出,LLVM IR 是一个低级的类似 RISC 的虚拟指令集。像真正的 RISC 指令集一样,它支持简单指令的线性序列,如加法、减法、比较和分支。这些指令采用三地址形式,这意味着它们接受一定数量的输入并在不同的寄存器中产生结果。5 LLVM IR 支持标签,通常看起来像是一种奇怪的汇编语言形式。
与大多数 RISC 指令集不同,LLVM 使用简单的类型系统进行强类型化(例如,i32 是 32 位整数,i32** 是指向 32 位整数的指针)并且机器的一些细节被抽象掉了。例如,调用约定是通过 call 和 ret 指令以及显式参数抽象出来的。与机器代码的另一个显着区别是 LLVM IR 不使用一组固定的命名寄存器,它使用一组无限的以 % 字符命名的临时寄存器。
除了作为一种语言实现之外,LLVM IR 实际上以三种同构形式定义:
- 上面的文本格式、
- 通过优化本身检查和修改的内存数据结构
- 以及高效且密集的磁盘二进制“位码”格式。
- LLVM 项目还提供了将磁盘格式从文本转换为二进制的工具:-
llvm-as将文本.ll文件组装成包含位码goop的.bc文件,llvm-dis将.bc文件转换成.ll文件.
- LLVM 项目还提供了将磁盘格式从文本转换为二进制的工具:-
编译器的中间表示很有趣,因为它可以是编译器优化器的“完美世界”:与编译器的前端和后端不同,优化器不受特定源语言或特定目标机器的约束.另一方面,它必须很好地服务于两者:它必须被设计成易于前端生成并且具有足够的表现力以允许对实际目标执行重要的优化。
3.1 编写 LLVM IR 优化
为了直观地了解优化的工作原理,浏览一些示例很有用。有许多不同种类的编译器优化,因此很难提供解决任意问题的方法。也就是说,大多数优化都遵循简单的三部分结构:
- 寻找要转换的模式。
- 验证匹配实例的转换是否安全/正确。
- 进行转换,更新代码。
最简单的优化是对算术恒等式的模式匹配,例如:对于任何整数 X,X-X is 0, X-0 is X, (X*2)-X is X. 他的第一个问题是这些在 LLVM IR 中是什么样子的。一些例子是:
⋮ ⋮ ⋮
%example1 = sub i32 %a, %a
⋮ ⋮ ⋮
%example2 = sub i32 %b, 0
⋮ ⋮ ⋮%tmp = mul i32 %c, 2
%example3 = sub i32 %tmp, %c
对于这些类型的“窥孔”转换,LLVM 提供了一个指令简化接口,该接口被各种其他更高级别的转换用作实用程序。这些特定的转换位于 SimplifySubInst 函数中,如下所示:
// X - 0 -> X
if (match(Op1, m_Zero()))return Op0;// X - X -> 0
if (Op0 == Op1)return Constant::getNullValue(Op0->getType());// (X*2) - X -> X
if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>())))return Op1;…return 0; // Nothing matched, return null to indicate no transformation.
如果发现:SimplifyInstruction是可以进行替换的,则进行替换操作。
for (BasicBlock::iterator I = BB->begin(), E = BB->end(); I != E; ++I)if (Value *V = SimplifyInstruction(I))I->replaceAllUsesWith(V);
4. LLVM 的三阶段设计实现
在基于 LLVM 的编译器中,前端负责解析、验证和诊断输入代码中的错误,然后将解析的代码转换为 LLVM IR(通常但不总是,通过构建 AST,然后将 AST 转换为 LLVM)。该 IR 可选地通过一系列分析和优化传递来改进代码,然后发送到代码生成器以生成本机机器代码,如图 所示。这是三阶段设计的一个非常简单的实现,但是这个简单的描述掩盖了 LLVM 架构从 LLVM IR 派生的一些功能和灵活性
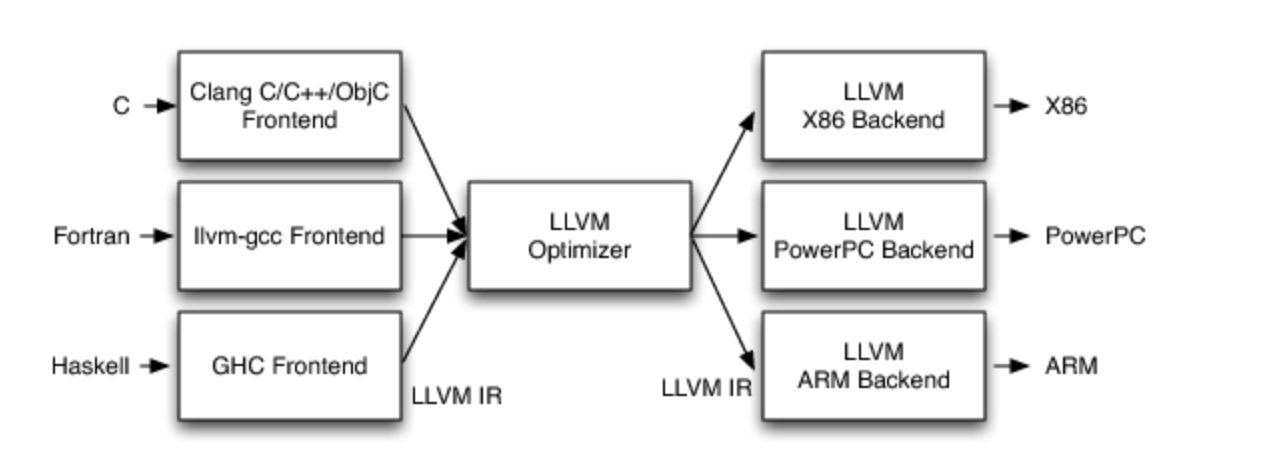
1. LLVM IR 是一个完整的代码表示
特别是,LLVM IR既被明确规定,又是优化器的唯一接口。这一特性意味着你为LLVM写一个前端所需要知道的就是LLVM IR是什么,它是如何工作的,以及它所期望的不变量。由于LLVM IR具有一流的文本形式,因此建立一个将LLVM IR输出为文本的前端是可能的,也是合理的,然后使用Unix管道将其发送到你选择的优化器序列和代码生成器中。
这可能令人惊讶,但这实际上是LLVM的一个相当新颖的特性,也是它在广泛的不同应用中取得成功的主要原因之一。即使是广泛成功且架构相对完善的GCC编译器也不具备这种属性:它的GIMPLE中级表示法不是一个自足的表示法。GCC没有办法倾倒出 “代表我的代码的一切”,也没有办法以文本形式读写GIMPLE(以及构成代码代表的相关数据结构)。其结果是,用GCC做实验相对困难,因此它的前端也相对较少。
2. LLVM 是库的集合
在设计 LLVM IR 之后,LLVM 的下一个最重要的方面是它被设计为一组库,而不是像 GCC 那样的单片命令行编译器或像 JVM 或 .NET 虚拟机这样的不透明虚拟机。 LLVM 是一种基础架构,是一组有用的编译器技术,可以用于解决特定问题(例如构建 C 编译器,或特殊效果管道中的优化器)。虽然是其最强大的功能之一,但它也是其最不为人知的设计点之一。
让我们以优化器的设计为例:它读入 LLVM IR,稍加咀嚼,然后发出 LLVM IR,希望它执行得更快。在 LLVM(与许多其他编译器一样)中,优化器被组织为不同优化通道的管道,每个优化通道都在输入上运行并有机会做某事。通行证的常见示例是内联(将函数体替换为调用站点)、表达式重新关联、循环不变的代码运动等。根据优化级别,运行不同的通行证:例如在 -O0(无优化) Clang 编译器不运行任何通道,在 -O3 它在其优化器中运行一系列 67 通道(从 LLVM 2.8 开始)。
每个 LLVM pass 都写成一个 C++ 类,它(间接)从 Pass 类派生。大多数通行证都编写在单个 .cpp 文件中,并且它们的 Pass 类的子类定义在匿名命名空间中(这使其对定义文件完全私有)。为了使 pass 有用,文件外部的代码必须能够获取它,因此从文件中导出了一个函数(用于创建 pass)。这是一个稍微简化的例子,让事情变得具体。
namespace {class Hello : public FunctionPass {public:// Print out the names of functions in the LLVM IR being optimized.virtual bool runOnFunction(Function &F) {cerr << "Hello: " << F.getName() << "\n";return false;}};
}FunctionPass *createHelloPass() { return new Hello(); }
如前所述,LLVM 优化器提供了数十种不同的传递,每一种都以相似的风格编写。这些通道被编译成一个或多个 .o 文件,然后被构建到一系列存档库(Unix 系统上的 .a 文件)中。这些库提供了各种分析和转换功能,并且通道尽可能松散耦合:它们应该独立存在,或者如果它们依赖于其他分析来完成工作,则在其他通道中显式声明它们的依赖关系。当给定一系列传递运行时,LLVM PassManager 使用显式依赖信息来满足这些依赖关系并优化传递的执行。
库和抽象功能很棒,但它们实际上并不能解决问题。当有人想要构建一个可以从编译器技术中受益的新工具时,有趣的一点就出现了,也许是用于图像处理语言的 JIT 编译器。这个 JIT 编译器的实现者考虑到了一组约束:例如,也许图像处理语言对编译时延迟高度敏感,并且具有一些惯用的语言属性,这些属性对于出于性能原因进行优化很重要。
LLVM 优化器的基于库的设计允许我们的实现者挑选并选择传递执行的顺序,以及哪些对图像处理领域有意义:如果所有内容都定义为单个大函数,它不会感觉浪费时间在内联上。如果指针很少,别名分析和内存优化就不值得费心了。然而,尽管我们尽了最大的努力,LLVM 并没有神奇地解决所有的优化问题!由于 pass 子系统是模块化的,并且 PassManager 本身对 pass 的内部情况一无所知,因此实现者可以自由地实现他们自己的特定于语言的传递,以弥补 LLVM 优化器中的缺陷或明确的特定于语言的优化机会.图 11.4 显示了我们假设的 XYZ 图像处理系统的一个简单示例:
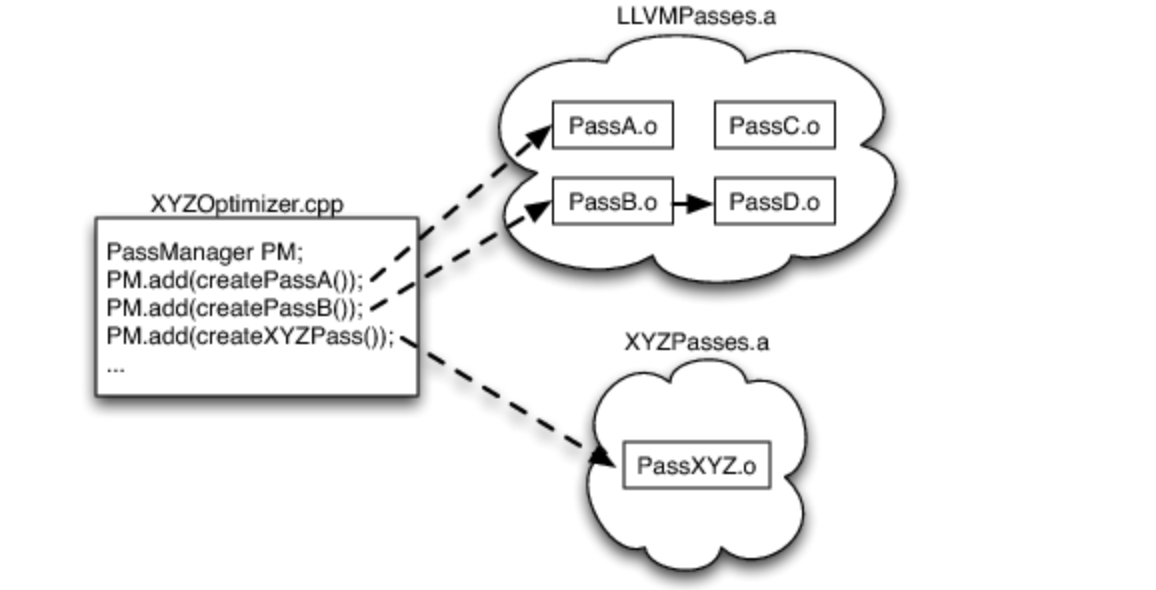
一旦选择了一组优化(并且为代码生成器做出了类似的决定),图像处理编译器就会被构建到可执行或动态库中。由于对 LLVM 优化通道的唯一引用是每个 .o 文件中定义的简单创建函数,并且由于优化器存在于 .a 存档库中,因此只有实际使用的优化通道链接到最终应用程序,而不是整个LLVM 优化器。在我们上面的示例中,由于引用了 PassA 和 PassB,它们将被链接。由于 PassB 使用 PassD 进行一些分析,因此 PassD 被链接。但是,由于没有使用 PassC(和许多其他优化) ,其代码未链接到图像处理应用程序。
这就是 LLVM 基于库的设计的力量发挥作用的地方。这种直接的设计方法允许 LLVM 提供大量的功能,其中一些可能只对特定的受众有用,而不会惩罚只想做简单事情的库的客户。相比之下,传统的编译器优化器构建为紧密互连的大量代码,这更难于子集化、推理和加速。使用 LLVM,您可以了解各个优化器,而无需了解整个系统如何组合在一起。
这种基于库的设计也是很多人误解 LLVM 是什么的原因:LLVM 库有很多功能,但它们实际上并没有自己做任何事情。由库客户端(例如,Clang C 编译器)的设计者决定如何充分利用这些部分。这种仔细的分层、分解和对子集能力的关注也是 LLVM 优化器可用于不同上下文中如此广泛的不同应用程序的原因。另外,仅仅因为 LLVM 提供了 JIT 编译能力,并不意味着每个客户端都使用它。
5. 可重定向 LLVM 代码生成器的设计
LLVM 代码生成器负责将 LLVM IR 转换为目标特定的机器代码。一方面,代码生成器的工作是为任何给定目标生成尽可能好的机器代码。理想情况下,每个代码生成器都应该是目标的完全自定义代码,但另一方面,每个目标的代码生成器都需要解决非常相似的问题。例如,每个目标都需要为寄存器分配值,尽管每个目标都有不同的寄存器文件,但应该尽可能共享所使用的算法。
与优化器中的方法类似,LLVM 的代码生成器将代码生成问题拆分为单独的通道——指令选择、寄存器分配、调度、代码布局优化和程序集发射——并提供许多默认运行的内置通道。然后,目标作者有机会在默认传递中进行选择,覆盖默认值并根据需要实现完全自定义的特定于目标的传递。例如,x86 后端使用减少寄存器压力的调度程序,因为它的寄存器很少,但 PowerPC 后端使用延迟优化调度程序,因为它有很多。 x86 后端使用自定义传递来处理 x87 浮点堆栈,而 ARM 后端使用自定义传递将常量池岛放置在需要的函数内。这种灵活性允许目标作者生成出色的代码,而无需为他们的目标从头开始编写整个代码生成器。
LLVM 目标描述文件
“混合和匹配”方法允许目标作者选择对他们的架构有意义的内容,并允许跨不同目标进行大量代码重用。这带来了另一个挑战:每个共享组件都需要能够以通用方式推理目标特定属性。例如,共享寄存器分配器需要知道每个目标的寄存器文件以及指令与其寄存器操作数之间存在的约束。 LLVM 对此的解决方案是让每个目标以由 tblgen 工具处理的声明性域特定语言(一组 .td 文件)提供目标描述。 x86 目标的(简化)构建过程如图 11.5 所示。
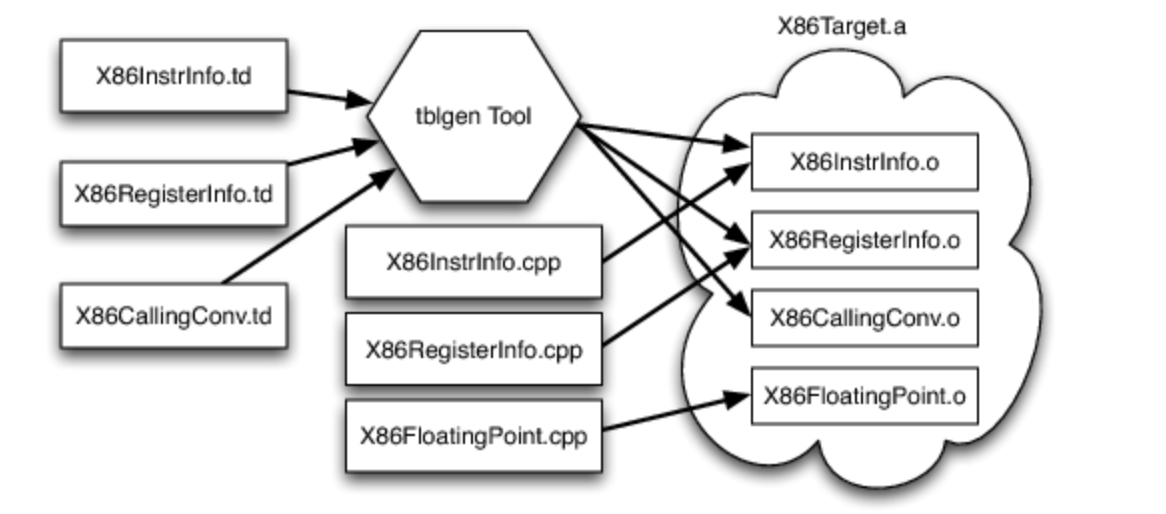
.td 文件支持的不同子系统允许目标作者构建他们目标的不同部分。例如,x86 后端定义了一个寄存器类,该类包含其所有名为“GR32”的 32 位寄存器(在 .td 文件中,特定于目标的定义都是大写的),如下所示:
def GR32 : RegisterClass<[i32], 32,[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { … }
该定义表明,此类中的寄存器可以保存 32 位整数值(“i32”),更倾向于 32 位对齐,具有指定的 16 个寄存器(在 .td 文件的其他位置定义)并具有更多信息指定首选分配顺序和其他内容。给定这个定义,具体的指令可以引用它,将它用作操作数。例如,“对 32 位寄存器进行补码”指令定义为
let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,(outs GR32:$dst), (ins GR32:$src),"not{l}\t$dst",[(set GR32:$dst, (not GR32:$src))]>;
这个定义说 NOT32r 是一条指令(它使用 I tblgen 类),指定编码信息(0xF7,MRM2r),指定它定义了一个“输出”32 位寄存器 $dst 并具有一个 32 位寄存器“输入”命名为 $src(上面定义的 GR32 寄存器类定义了哪些寄存器对操作数有效),指定指令的汇编语法(使用 {} 语法来处理 AT&T 和 Intel 语法),指定指令的效果并提供它应该在最后一行匹配的模式。第一行的“let”约束告诉寄存器分配器输入和输出寄存器必须分配给同一个物理寄存器。
这个定义是对指令的非常密集的描述,普通的 LLVM 代码可以利用从它(通过 tblgen 工具)派生的信息做很多事情。这一定义足以让指令选择通过对编译器的输入 IR 代码进行模式匹配来形成该指令。它还告诉寄存器分配器如何处理它,足以将指令编码和解码为机器代码字节,并足以以文本形式解析和打印指令。这些功能允许 x86 目标支持从目标描述生成独立的 x86 汇编器(它是“gas”GNU 汇编器的直接替代品)和反汇编器,以及处理 JIT 指令的编码。
除了提供有用的功能之外,从同一个“真相”中生成多条信息还有其他好处。这种方法使得汇编程序和反汇编程序几乎不可能在汇编语法或二进制编码中相互不一致。它还使目标描述易于测试:指令编码可以进行单元测试,而无需涉及整个代码生成器。
虽然我们的目标是以良好的声明形式将尽可能多的目标信息放入 .td 文件中,但我们仍然没有一切。相反,我们要求目标作者为各种支持例程编写一些 C++ 代码,并实现他们可能需要的任何特定于目标的传递(如处理 x87 浮点堆栈的 X86FloatingPoint.cpp)。随着 LLVM 不断增长新的目标,增加可以在 .td 文件中表达的目标的数量变得越来越重要,我们继续增加 .td 文件的表达能力来处理这个问题。一个很大的好处是,随着时间的推移,在 LLVM 中编写目标变得越来越容易。
6. 模块化设计提供的有趣功能
除了作为一个普遍优雅的设计之外,模块化还为 LLVM 库的客户端提供了一些有趣的功能。这些功能源于 LLVM 提供功能这一事实,但让客户端决定如何使用它的大部分策略。
1. 选择每个阶段运行的时间和地点
如前所述,LLVM IR 可以有效地(反)序列化为/从称为 LLVM 位码的二进制格式。由于 LLVM IR 是自包含的,并且序列化是一个无损过程,我们可以进行部分编译,将我们的进度保存到磁盘,然后在将来的某个时间点继续工作。此功能提供了许多有趣的功能,包括对链接时和安装时优化的支持,这两者都延迟了“编译时”的代码生成。
链接时优化 (LTO) 解决了编译器传统上一次只能看到一个翻译单元(例如,带有所有标头的 .c 文件)的问题,因此无法跨文件边界进行优化(如内联)。像 Clang 这样的 LLVM 编译器通过 -flto 或 -O4 命令行选项支持这一点。此选项指示编译器将 LLVM 位代码发送到 .ofile,而不是写出本机目标文件,并将代码生成延迟到链接时间,如图 11.6 所示。

详细信息取决于您使用的操作系统,但重要的是链接器检测到它在 .o 文件而不是本机目标文件中具有 LLVM 位码。当它看到这一点时,它将所有位码文件读入内存,将它们链接在一起,然后在聚合上运行 LLVM 优化器。由于优化器现在可以查看更大部分的代码,它可以内联、传播常量、进行更积极的死代码消除,以及更多跨文件边界。虽然许多现代编译器支持 LTO,但它们中的大多数(例如 GCC、Open64、英特尔编译器等)都是通过昂贵且缓慢的序列化过程来实现的。在 LLVM 中,LTO 自然地脱离了系统的设计,并且可以跨不同的源语言工作(与许多其他编译器不同),因为 IR 是真正的源语言中立的。
安装时间优化是延迟代码生成甚至比链接时间更晚的想法,一直到安装时间,如图 11.7 所示。安装时间是一个非常有趣的时间(在软件装箱、下载、上传到移动设备等情况下),因为这是您了解您所针对的设备的具体情况的时间。例如,在 x86 系列中,有各种各样的芯片和特性。通过延迟指令选择、调度和代码生成的其他方面,您可以为应用程序最终运行的特定硬件选择最佳答案。
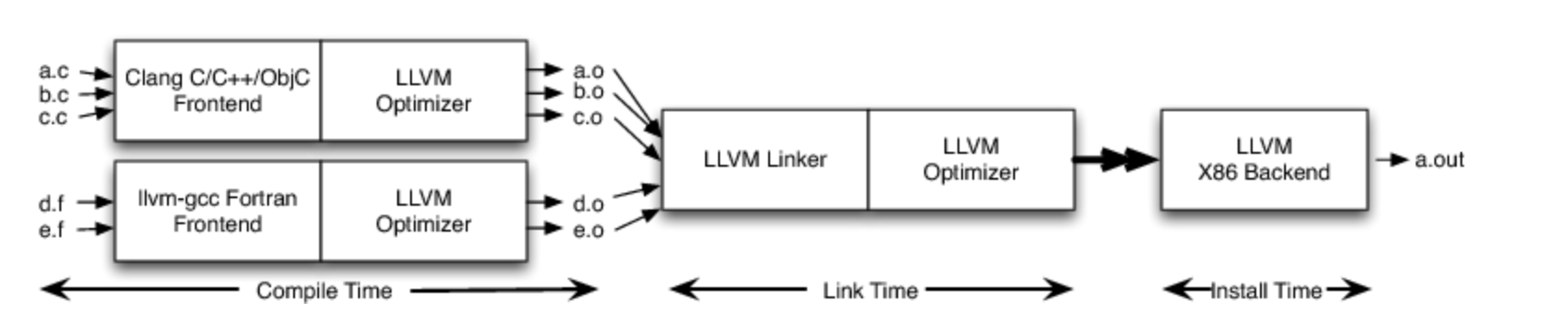
2. 单元测试优化器
编译器非常复杂,质量很重要,因此测试至关重要。例如,在修复了导致优化器崩溃的错误之后,应该添加回归测试以确保它不会再次发生。对此进行测试的传统方法是编写一个通过编译器运行的 .c 文件(例如),并拥有一个测试工具来验证编译器不会崩溃。例如,这是 GCC 测试套件使用的方法。
这种方法的问题在于编译器由许多不同的子系统组成,甚至在优化器中包含许多不同的通道,所有这些都有机会在输入代码到达之前有问题的代码时改变它的样子。如果前端或早期的优化器发生变化,测试用例很容易无法测试它应该测试的内容。
通过使用带有模块化优化器的 LLVM IR 的文本形式,LLVM 测试套件具有高度集中的回归测试,可以从磁盘加载 LLVM IR,运行它恰好通过一个优化通道,并验证预期的行为。除了崩溃之外,更复杂的行为测试想要验证优化是否实际执行。这是一个简单的测试用例,用于检查常量传播传递是否与添加指令一起使用:
; RUN: opt < %s -constprop -S | FileCheck %s
define i32 @test() {%A = add i32 4, 5ret i32 %A; CHECK: @test(); CHECK: ret i32 9
}
RUN 行指定要执行的命令:在本例中,是 opt 和 FileCheck 命令行工具。 opt 程序是 LLVM 通道管理器的简单包装器,它链接所有标准通道(并且可以动态加载包含其他通道的插件)并将它们公开到命令行。 FileCheck 工具验证其标准输入是否与一系列 CHECK 指令匹配。在这种情况下,这个简单的测试是验证 constprop pass 是否将 4 和 5 的加法折叠成 9。
虽然这看起来像是一个非常微不足道的例子,但很难通过编写 .c 文件来进行测试:前端在解析时经常会进行常量折叠,因此编写将下游转换为常量的代码非常困难和脆弱折叠优化通道。因为我们可以将 LLVM IR 作为文本加载并通过我们感兴趣的特定优化通道发送它,然后将结果作为另一个文本文件转储出来,所以无论是回归测试还是特征测试,都可以直接准确地测试我们想要的内容。
7. 回顾和未来方向
LLVM 的模块化最初并不是为了直接实现这里描述的任何目标而设计的。这是一种自卫机制:很明显,我们不会在第一次尝试时就做好一切。例如,模块化传递管道的存在是为了更容易隔离传递,以便在被更好的实现替换后可以丢弃它们8。
LLVM 保持灵活的另一个主要方面(以及与库客户有争议的话题)是我们愿意重新考虑以前的决定并对 API 进行广泛的更改,而不用担心向后兼容性。例如,对 **LLVM IR 本身的侵入性更改需要更新所有优化通道,并导致 C++ API 大量流失。我们已经多次这样做了,虽然这给客户带来了痛苦,**但保持快速前进的进步是正确的做法。为了使外部客户的生活更轻松(并支持其他语言的绑定),我们为许多流行的 API(旨在极其稳定)提供 C 包装器,新版本的 LLVM 旨在继续阅读旧的 .ll 和 .bc 文件.
展望未来,我们希望继续使 LLVM 更加模块化并且更易于子集化。例如,代码生成器仍然过于单一:目前无法根据特性对 LLVM 进行子集化。例如,如果您想使用 JIT,但不需要内联汇编、异常处理或调试信息生成,则应该可以构建代码生成器而无需链接以支持这些功能。我们还在不断提高优化器和代码生成器生成的代码质量,添加 IR 功能以更好地支持新语言和目标结构,并为在 LLVM 中执行高级语言特定优化添加更好的支持。
LLVM 项目以多种方式继续发展和改进。看到 LLVM 在其他项目中使用的不同方式的数量以及它如何不断出现在其设计者从未想过的令人惊讶的新环境中,真是令人兴奋。新的 LLDB 调试器就是一个很好的例子:它使用 Clang 中的 C/C++/Objective-C 解析器来解析表达式,使用 LLVM JIT 将它们转换为目标代码,使用 LLVM 反汇编器,并使用 LLVM 目标来处理调用约定等等。能够重用这些现有代码使开发调试器的人可以专注于编写调试器逻辑,而不是重新实现另一个(勉强正确的)C++ 解析器。
尽管迄今为止取得了成功,但仍有很多工作要做,而且随着年龄的增长,LLVM 将变得不那么灵活和更加钙化的风险始终存在。虽然这个问题没有神奇的答案,但我希望继续接触新的问题领域、重新评估以前的决定以及重新设计和丢弃代码的意愿会有所帮助。毕竟,目标不是完美,而是随着时间的推移不断变得更好。
相关文章:
LLVM高级架构介绍
LLVM 为什么要开一个LLVM的新坑呢? 我从智能穿戴转行到芯片软件行业,从事编译器开发,不过是AI编译器。不过基本的传统编译器还是绕不过去啊,所以开始学习LLVM,后面开始学习TVM,MLIR。 LLVM GitHub地址 L…...

全网最经典函数题型【详解】——C语言
文章目录1. 写一个函数可以判断一个数是不是素数。2. 写一个函数判断一年是不是闰年。3. 写一个函数,实现一个整形有序数组的二分查找。4. 写一个函数,每调用一次这个函数,就会将 num 的值增加1。5. 写一个函数,打印乘法口诀表。6…...
emqx桥接配置+常见问题解决+jmeter压测emqx
一,桥接资源配置及规则配置 Emqx桥接配置流程 1,配置资源并测试连接通过 规则引擎——>资源——>新建——>选择MQTT Bridge——>填写参数测试连接 参数描述详见3.1资源配置 2,配置规则 2.1根据实际业务选择合适sql 规则引擎…...
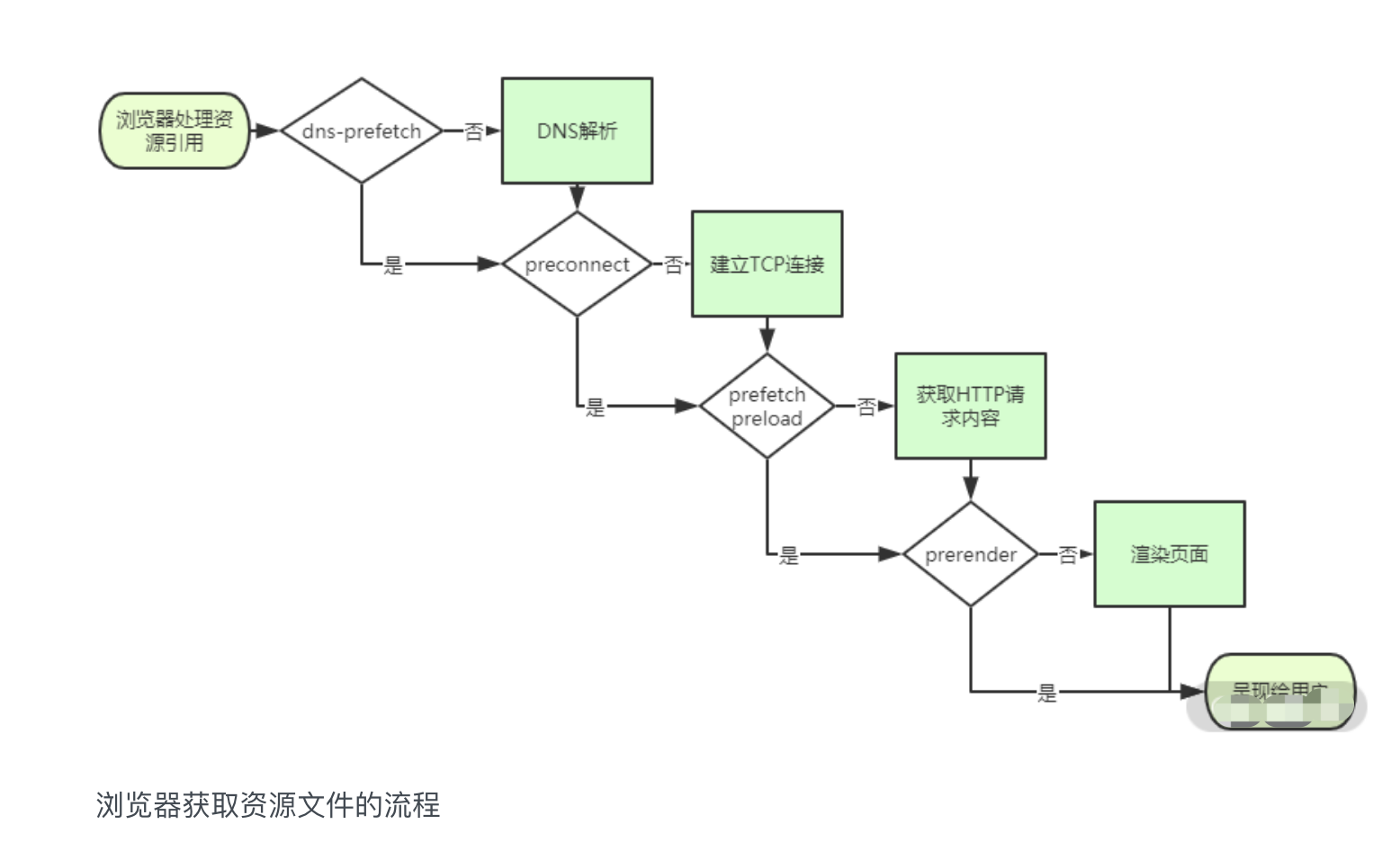
improve-1
类型及检测方式 1. JS内置类型 JavaScript 的数据类型有下图所示 其中,前 7 种类型为基础类型,最后 1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要…...

华为OD机试用Python实现 -【云短信平台优惠活动】(2023-Q1 新题)
华为OD机试题 华为OD机试300题大纲云短信平台优惠活动题目描述输入描述输出描述示例一输入输出说明示例二输入输出说明Python 代码实现代码编写思路华为OD机试300题大纲 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单查看…...

Facebook广告投放运营中的关键成功因素是什么?
在当今数字化的时代,广告投放已经成为了各种企业获取市场份额和增加品牌曝光的重要手段之一。Facebook作为全球最大的社交媒体平台之一,其广告投放运营的成功,将直接影响企业的品牌推广和市场营销效果。本文将探讨Facebook广告投放运营中的关…...
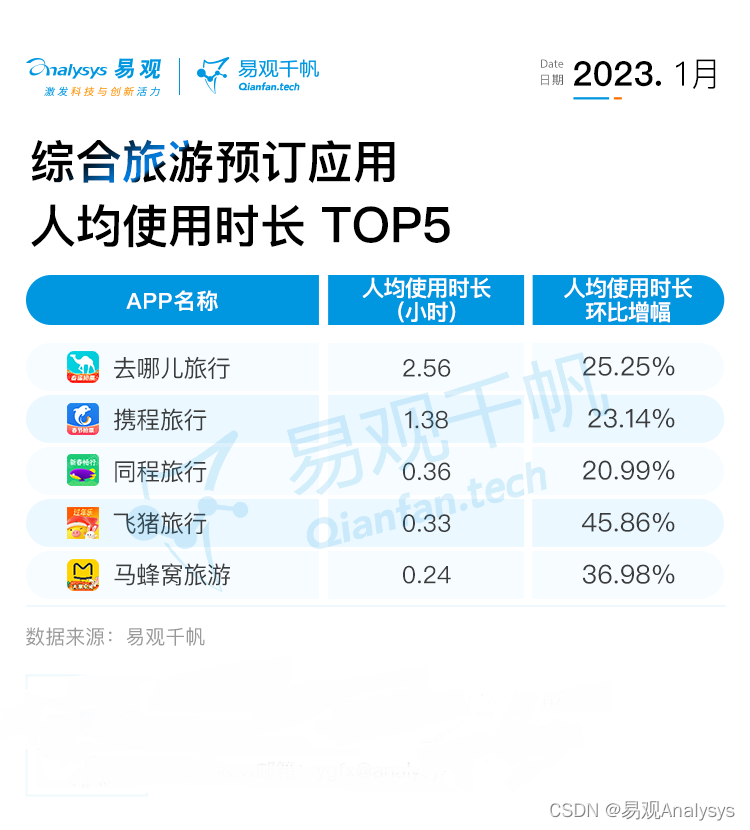
2023年1月综合预订类APP用户洞察——旅游市场复苏明显,三年需求春节集中释放
2023年1月,随着国家对新型冠状病毒感染实施“乙类乙管”,不再对入境人员和货物等采取检疫传染病管理措施,并且取消入境后全员核酸检测和集中隔离,横亘在旅游者与旅游目的地之间的隔阂从此彻底消失。2023年1月恰逢春节假期…...

基于stm32计算器设计
这里写目录标题 完整de代码可q我获取1 系统功能设计2 系统硬件系统分析设计2.1 STM32单片机核心电路设计2.2 LCD1602液晶显示模块电路设计2.3 4X4矩阵键盘模块设计3 STM32单片机系统软件设计3.1 编程语言选择3.2 Keil程序开发环境3.3 FlyMcu程序烧录软件介绍3.4 CH340串口程序烧…...
)
基于SpringCloud的可靠消息最终一致性02:项目骨架代码(上)
在上一节中咱们已经把分布式事务问题交代了一遍,包括两大定理、五大解决方案和一个成熟的开源框架,而咱们最终的目标是用Spring Cloud实现一个实际创业项目的可靠消息最终一致性的分布式事务方案。 先交代一下项目背景。 前几年,社会上慢慢兴起一种称为C2C同城快递的业务,也…...

RockerMQ集群部署
目录一、Broker集群模式1、单Master:2、多Master多Slave模式异步复制3、多Master多Slave模式同步双写二、集群搭建实践1、集群架构2、克隆生成rocketmqos13、修改rocketmqos1配置文件4、克隆生成rocketmqOS25、修改rocketmqOS2配置文件6、启动服务器7、测试一、Brok…...

unicloud的aggregate聚合查询时间戳转日期
我特么不知道看了这个帖子几百遍才看明白到-----》unicloud数据库中,聚合操作如何操作时间戳? - DCloud问答 自己淋过雨老想着为别人撑伞,可怜我这35岁的老人家,给我去点关注!!!!&a…...

Vue2.0开发之——使用ref引用组件实例(41)
一 概述 在本组件内部修改count的值在父组件内修改子组件的count值 二 在本组件内部修改count的值 2.1 Left.vue 布局代码 <template><div class"left-container"><h3 >Left 组件---{{count}}</h3><button click"count 1"&…...

极狐GitLab仓库瘦身
参考文章: [分享] 极狐GitLab仓库瘦身 - 官方技术分享 - 极狐GitLab 论坛 一、瘦身概述 Git仓库随着时间推移会变得越来越大,比如很多比较大的文件加入Git仓库时,可能引起以下问题: 下载仓库越来越慢,因为每个人都…...

2288hv5超融合服务器 数码管报888
【问题现象】 2288hv5超融合服务器,前面板数码管报888,电源灯黄灯闪烁,开不了机,ibmc网络是通的,但是web网页打不开 【问题原因】 iBMC的版本过低,iBMC在智能诊断数据库保护机制存在异常,导…...

【Zabbix实战之部署篇】Zabbix监控windows系统配置方法
【Zabbix实战之部署篇】Zabbix监控windows系统配置方法 一、检查Zabbix监控平台状态1.检查Zabbix各组件状态2.检查Zabbix的首页二、下载windows代理1.访问Zabbix官网下载界面2.查看下载安装包三、安装windows agent2代理1.安装windows agent2代理2.代理基本配置信息3.开始进行安…...

在Windows上编译Nginx
《在Windows上编译Nginx》视频教程官方编译说明 Building nginx on the Win32 platform with Visual C 环境准备 1. Microsoft Visual Studio(Microsoft Visual C 编译器),下载地址:https://visualstudio.microsoft.com/zh-hans/。 2. Git(备用)&…...

语音识别与Python编程实践
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...
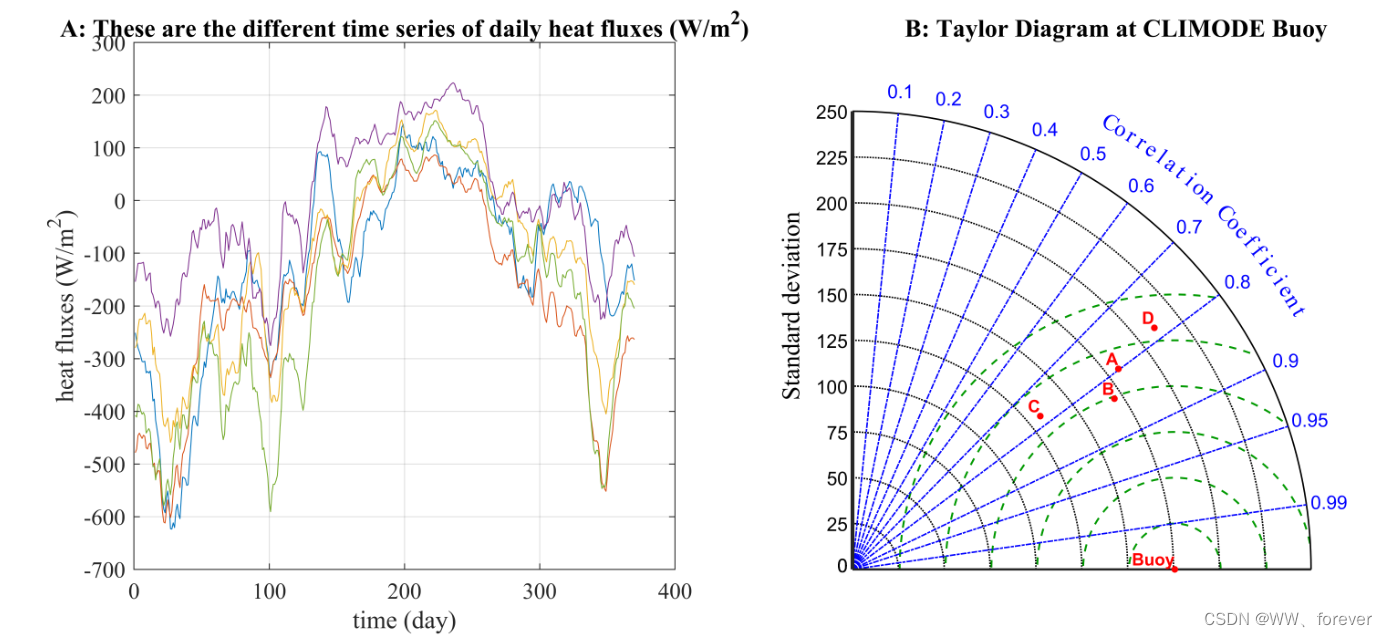
MATLAB绘制泰勒图(Taylor diagram)
泰勒图(Taylor diagram) 泰勒图是Karl E. Taylor于2001年首先提出,主要用来比较几个气象模式模拟的能力,因此该表示方法在气象领域使用最多,但是在其他自然科学领域也有一定的应用。 泰勒图常用于评价模型的精度&…...
ClickHouse高可用集群分片-副本实操(四)
目录 一、ClickHouse高可用之ReplicatedMergeTree引擎 二、 ClickHouse高可用架构准备-环境说明和ZK搭建 三、高可用集群架构-ClickHouse副本配置实操 四、ClickHouse高可用集群架构分片 4.1 ClickHouse高可用架构之两分片实操 4.2 ClickHouse高可用架构之两分片建表实操 一…...

2022年中国工业机器人行业市场回顾及2023年发展前景预测分析
工业机器人是一种能自动定位控制、可重复编程的、多功能的、多自由度的操作机,广泛应用于码垛、冲压、分拣、焊接、切割、喷涂、上下料等工业场景中,极大提高了生产效率、安全性以及智能化水平。工业机器人作为我国高端制造业的典型代表,近年…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...