JavaSE学习笔记day15
零、 复习昨日
HashSet 不允许重复元素,无序
HashSet去重原理:
- 先比较hashcode,如果hashcode不一致,直接存储
- 如果hashcode值一样,再比较equals
- 如果equals值为true,则认为完全一样,不存储即去重
- 否则存储
如果使用的是空参构造创建出的TreeSet集合,那么它底层使用的就是自然排序,即放入TreeSet的元素都必须实现Comparable接口,重写方法compareTo
一、作业
public static void main(String[] args) {String[] arr = {"a","b","c","a","b","c"};String[] strArr = setArray(arr);System.out.println(Arrays.toString(strArr ) );}// 第一题// 设计方法,将传入的数组去重后返回// 例如: 字符串数组:[“aa”,”bb”,”cc”,”aa”,”cc”,”bb”],将其去重变为[“aa”,”bb”,”cc”]public static String[] setArray(String[] arr) {// 遍历数组,取出一个,向set集合放一个,最后再变回数组HashSet<String> set = new HashSet<>( );for (String s : arr) {set.add(s);}String[] strArr = new String[set.size()];// 集合转数组String[] result = set.toArray(strArr);return result;}
注意: T[] toArray(T[] arr)
4 创建一个Teacher类 属性age name salary 创建10个Teacher对象 装入TreeSet中通过设置Teacher类 保证age大的在Treeset前面 age相同 salary小的在Treeset前面salary相同 name长度小的在Treeset前面
package com.qf.homework;/*** --- 天道酬勤 ---** @author QiuShiju* @desc*/
public class Teacher implements Comparable<Teacher>{private int age;private String name;private double salary;// 省略部分代码...@Overridepublic int compareTo(Teacher o) {// 如果年龄相同,则继续判断if(o.getAge() - this.age == 0){// 再判断工资,如果工资相同,则继续判断if (this.salary - o.getSalary() == 0) {// 判断名字长度,如果名字长度一致,要保留该人名,所以不能返回0,随意返回一个1或者-1// 如果名字长度不一致,名字短的在前return this.name.length() - o.getName().length() == 0 ? 1 : this.name.length() - o.getName().length();} else {// 如果工资不同,工资低的在前return this.salary - o.getSalary() > 0 ? 1 : -1;}} else {// 如果年龄不同,年龄大在前return o.getAge() - this.age;}}
}
public static void main(String[] args) {TreeSet<Teacher> treeSet = new TreeSet<>( );treeSet.add(new Teacher(18,"老邢",50000));treeSet.add(new Teacher(21,"老邢",50000));treeSet.add(new Teacher(19,"小老邢",40000));treeSet.add(new Teacher(19,"老邢",40000));for (Teacher teacher : treeSet) {System.out.println(teacher );}}
二、比较器排序
TreeSet是会对元素进行排序去重,有两种实现方案
- 使用空参构造方法创建出的TreeSet,底层使用自然排序,即元素要实现Comparable接口才能实现排序
- 第二种方案: 可以使用有参构造,在创建TreeSet集合时,传入一个
Comparator比较器,这样存入的元素就会按照该比较器指定的排序方案排序( 不再使用默认的自然排序)
TreeSet(Comparator comparator)构造一个新的空 TreeSet,它根据指定比较器进行排序。
使用步骤
- 自定义类实现Comparator 接口
- 重写compar(T o1,T o2)方法
- o1 就是之前compareTo方法中的this,即正在存储的元素
- o2 就是之前compareTo方法中的o,即以前存储过的元素
- 方法返回值与之前compareTo方法的返回值一样
- 返回0 去重
- 返回负数放左边
- 返回正数放右边
- 在创建TreeSet时,创建该比较器对象,传入TreeSet的构造方法
练习: 把昨天的排序练习使用比较器排序再写一遍
学生语数外总成绩排序题目改写
// 学生成绩类
public class StudentScore{private String name;private int chinese;private int math;private int english;// set get...// 有参 无参构造
}
// 自定义成绩比较器
public class MyScoreComparator implements Comparator<StudentScore> {@Overridepublic int compare(StudentScore o1, StudentScore o2) {return o2.getTotal() - o1.getTotal() == 0 ? 1 : o2.getTotal() - o1.getTotal();}
}
public static void main(String[] args) {// 创建集合时指定成绩比较器TreeSet<StudentScore> set2 = new TreeSet<>(new MyScoreComparator() );set2.add(new StudentScore("zhang3",70,70,70 ));set2.add(new StudentScore("wang5",100,100,100 ));set2.add(new StudentScore("li4",80,80,80 ));set2.add(new StudentScore("zhao6",60,60,60 ));set2.add(new StudentScore("zhou7",90,90,90 ));for (StudentScore score : set2) {System.out.println(score );}}
三、Collections
类似于与Arrays,Collections是集合的工具类,方法都是静态的
- Collections.reverse(List<?> list) 反转
- Collections.shuffle(List<?> list) 混洗
- Collections.sort(List<?> list) 排序
public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>( );list.add(3);list.add(2);list.add(5);list.add(4);list.add(1);System.out.println(list );// 反转// Collections.reverse(list);//System.out.println(list );// 混洗//Collections.shuffle(list);// 排序,升序Collections.sort(list);System.out.println(list );}
四、Map<K,V>
Map代表
双列集合,一次存储一对键值对(K,V)
Map是接口,代表是键映射到值的对象,一个Map不能包含重复的键,值允许重复.每个键最多只能映射到一个值,即可以通过键找到值,但是不能通过值找键.
方法都是非常常见的方法,但是Map是接口无法演示
Map有两个常用实现类
- HashMap
- TreeMap
五、HashMap
HashMap是Map的实现类,现在JDK8及以后底层是由数组+链表+红黑树实现
并允许使用null值和null键HashMap存储的元素是
不保证迭代顺序,存储的键不允许重复,值允许重复
除了非同步和允许使用 null 之外,
HashMap类与Hashtable大致相同
补充: Hashtable是线程安全的map集合,效率低 ; HashMap是线程不安全的,效率高
ConcurrentHashMap 即安全又高效的Map集合
HashMap的容量和扩容: 初始容量16,加载因子0.75 阈值是 16 * 0.75,达到阈值扩容至原来的2倍
ps: 昨天学习的HashSet所有特性,其实就是HashMap的特性,包括去重原理
5.1 方法演示
构造方法
HashMap()
构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity)
构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor)
构造一个带指定初始容量和加载因子的空 HashMap。
HashMap(Map<? extends K,? extends V> m)
构造一个映射关系与指定 Map 相同的新 HashMap。
方法
每个都很重要!!!
public static void main(String[] args) {// 创建空的HashMap;HashMap<String,Integer> map = new HashMap<>();System.out.println(map );// 添加元素,一次添加一对,键值// put方法的返回值,如果该键之前没有映射值,返回null// 如果该键之前映射的有值,则将值覆盖,返回上次的旧值Integer v1 = map.put("a",1);System.out.println(v1 );Integer v2 = map.put("a", 2);System.out.println(v2 );Integer v3 = map.put("d", 4);System.out.println(v3 );map.put("b",2);System.out.println(map );// 取出元素// 通过键返回值Integer v = map.get("a");System.out.println(v );// 集合大小(元素个数)System.out.println(map.size() );// 集合是否为空System.out.println(map.isEmpty() );// 清空集合//map.clear();// 集合大小(元素个数)//System.out.println(map.size() );// 集合是否为空//System.out.println(map.isEmpty() );// 移除元素,根据键移除整个键值对,返回值Integer a = map.remove("a");System.out.println(a );System.out.println(map );/*** boolean containsKey(Object key)* 判断集合中是否包含指定键,有则返回 true。* boolean containsValue(Object value)* 判断集合中是否包含指定值,有则返回 true。*/System.out.println(map.containsKey("A"));System.out.println(map.containsValue(11));}
5.2 迭代/遍历
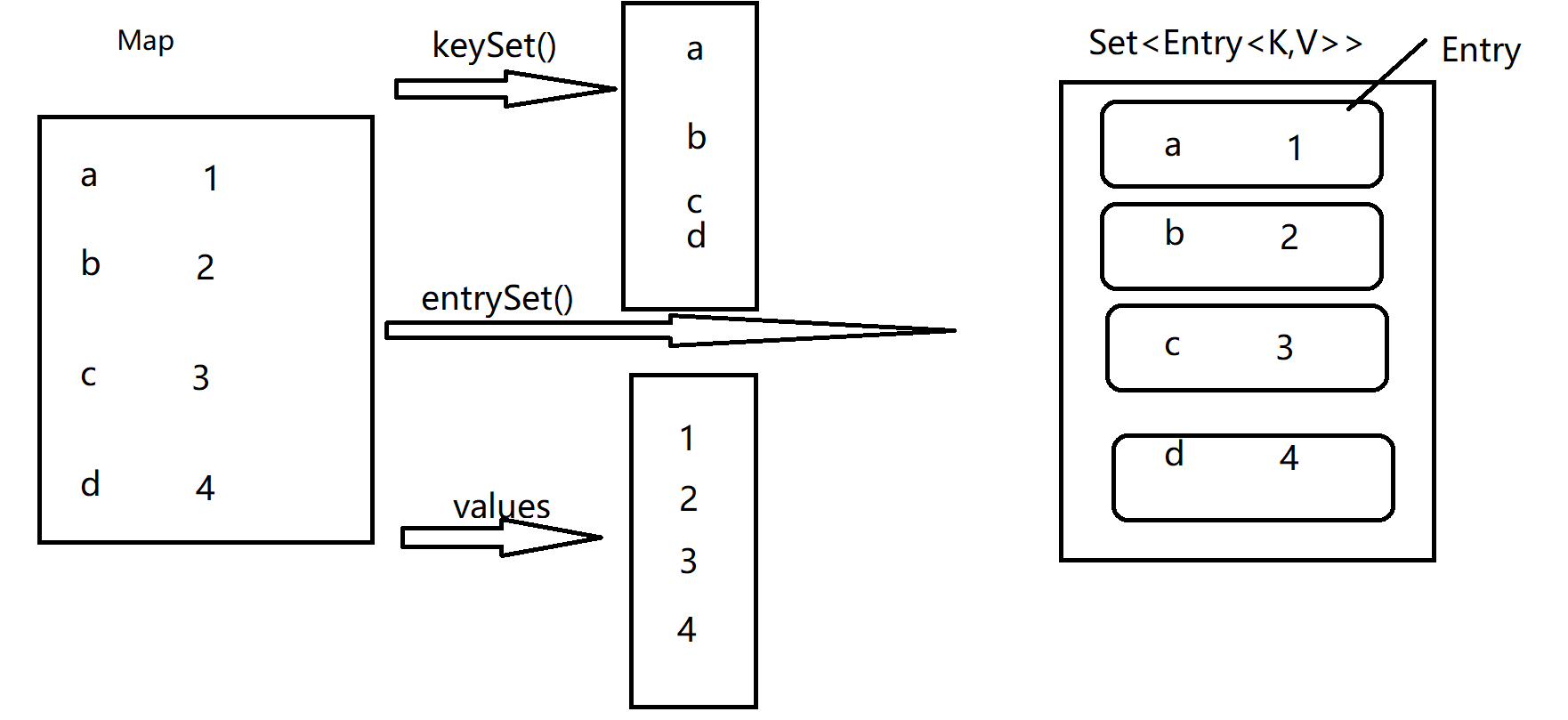
Map接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容
- Set keySet() 键集,返回一个Set集合,其中只有键
- Collection values() 值集,返回一个Collection集合,其中只有值
- Set<Map.Entry<K,V>> entrySet() 键值映射集,返回一个Set集合,其中放着key-value对象
5.2.1 键集
public static void main(String[] args) {HashMap<String,Integer> map = new HashMap<>();map.put("a",1);map.put("b",2);map.put("c",3);map.put("d",4);// 键集遍历Set<String> keySet = map.keySet();// 获得迭代器Iterator<String> iterator = keySet.iterator( );while (iterator.hasNext()) {System.out.println(iterator.next());}System.out.println("-----------" );for(String key : keySet) {System.out.println(key );}}
5.2.2 值集
// 值集Collection<Integer> values = map.values();Iterator<Integer> iterator1 = values.iterator( );while (iterator1.hasNext( )) {System.out.println(iterator1.next());}System.out.println("-----------" );for (Integer value : values) {System.out.println(value );}
5.2.3 键值映射集 [非常重要]
Entry是Map接口中的内部接口,代表是一个键值对,即包含键和值.
且该Entry接口中提供了关于操作单个键,值的方法
- K getKey()
- V getValue()
// 获得键值映射集合Set,其中放着EntrySet<Entry<String,Integer>> entrySet = map.entrySet();Iterator<Entry<String,Integer>> iterator2 = entrySet.iterator();while (iterator2.hasNext( )) {// 从迭代器取出的是EntryMap.Entry<String,Integer> entry = iterator2.next();// 通过entry可以单独获得键,值String key = entry.getKey( );Integer value = entry.getValue( );System.out.println(key +"-->" + value );}// for循环for(Map.Entry<String,Integer> entry : entrySet) {System.out.println(entry.getKey() +"--->" +entry.getValue() );}
5.3 去重原理
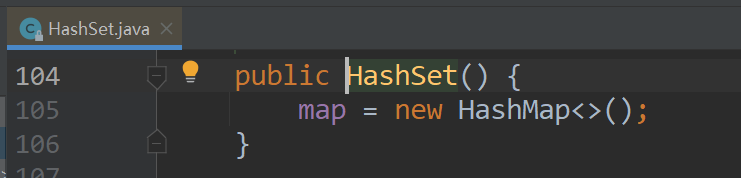
HashMap的去重其实就是昨天讲的HashSet的去重,因为HashSet底层就是HashMap
在创建HashSet时,其实在底层创建了HashMap
在向set中添加元素时,其实是向map的key上添加
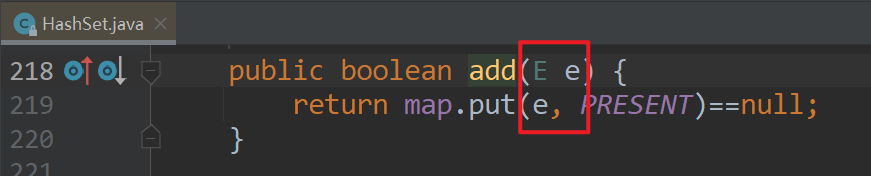
所以HashMap的
键的去重原理就是
- 向键存储数据时,先调用键的hashcode()方法
- 如果hashcode值不一样则直接存储
- 如果hashcode值一样,再调用元素的equals()方法
- 如果equals方法返回false,则存储
- 如果equals方法返回true,则不存储
5.4 HashMap的应用
场景一: 适合有关联映射的场景
设计方法,传入字符串,输出该字符串中每个字符出现的次数,使用HashMap实现
例如: “abcHelloabcWorld”,输出 a出现2次,b出现2次,l出现3次,H出现1次
/*** 倒推: a --> 3 b --> 2* @param str*/public static void cishu(String str) {String[] strArr = str.split("");System.out.println(Arrays.toString( strArr) );HashMap<String, Integer> map = new HashMap<>( );for (int i = 0; i < strArr.length; i++) {String s = strArr[i];if (!map.containsKey(s)) {map.put(s,1);} else {Integer count = map.get(s);count++;map.put(s,count);}}// System.out.println(map );Set<Map.Entry<String, Integer>> entrySet = map.entrySet( );for (Map.Entry<String,Integer> entry :entrySet) {String s = entry.getKey( );Integer count = entry.getValue( );System.out.println("字符"+s+",出现"+count+"次" );}}
场景二: Map可以当实体类对象
public class Student{private int age;private String name;// ...}
Student s1 = new Student(18,"zs");
s1.getAge();
s1.getName();
使用Map模拟对象
HashMap<String, Object> stu = new HashMap<>( );
stu.put("age",18);
stu.put("name","zs");
stu.put("sex","男");
LinkedHashMap: …
六、TreeMap
TreeMap底层是红黑树(平衡二叉树的一种)
同样式存储键值对,键不允许重复且还会排序
默认是根据键元素的自然顺序排序或者,根据创建TreeMap时指定的Comparator比较器来排序
6.1 方法演示
方法详见api
public static void main(String[] args) {TreeMap<String, Integer> map = new TreeMap<>( );map.put("b",2);map.put("e",5);map.put("a",1);map.put("a",2);map.put("d",4);map.put("c",3);// 其他正常的map方法...// 三个遍历方法...// 特殊的,有关于头尾操作的方法// 获得排序后的第一个String key = map.firstKey( );// 获得排序后的第一个EntryMap.Entry<String, Integer> entry = map.firstEntry( );System.out.println(entry );}
6.2 TreeMap排序去重原理
昨天学习的TreeSet的底层其实就是TreeMap
创建TreeSet时,创建TreeMap

向set集合添加元素时,其实是向TreeMap的键添加元素

即TreeMap的排序去重原理是什么?其实如果自然排序就是compareTo(),如果是比较器排序就是compar()方法
- 方法返回0 去重
- 方法返回负数 放在树左侧
- 方法返回正数 放在树的右侧
七、总结
集合体系中最重要最常见的两个集合是ArrayList,HashMap
其他的,
- 记住常用的API(crud和遍历)
- 记住List和Set区别
- 记住ArrayList和LinkedList区别
- 记住HashMap扩容,去重原理
- 记住TreeMap的排序去重原理
相关文章:
JavaSE学习笔记day15
零、 复习昨日 HashSet 不允许重复元素,无序 HashSet去重原理: 先比较hashcode,如果hashcode不一致,直接存储如果hashcode值一样,再比较equals如果equals值为true,则认为完全一样,不存储即去重否则存储 如果使用的是空参构造创建出的TreeSet集合,那么它底层使用的就是自然排序,…...
Spring Security认证研究
1.项目中认证的三种方式: 1.统一认证 认证通过由认证服务向给用户颁发令牌,相当于访问系统的通行证,用户拿着令牌去访问系统的资源。 2.单点登录,对于微服务项目,因为包含多个模块,所以单点登录就是使得用户…...

BigKey、布隆过滤器、分布式锁、红锁
文章目录 BigKey发现 BigKey如何删除BigKeyunlinkdelBigKey配置优化布隆过滤器布隆过滤器构建、使用、减少误判布隆过滤器二进制数组,如何处理删除?实现白名单 whitelistCustomer解决缓存穿透分布式锁依赖Redis 分布式锁代码使用红锁POM依赖yaml使用其他redis分布式锁容错率公…...
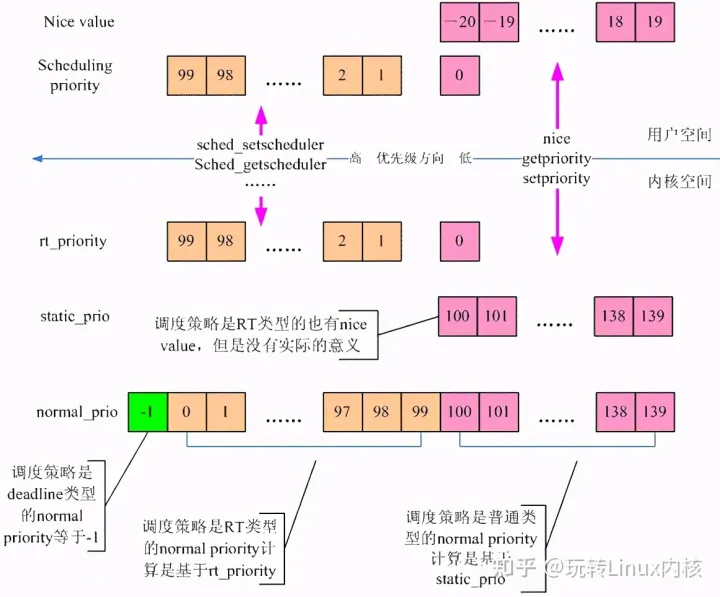
一文让你彻底理解Linux内核调度器进程优先级
一、前言 本文主要描述的是进程优先级这个概念。从用户空间来看,进程优先级就是nice value和scheduling priority,对应到内核,有静态优先级、realtime优先级、归一化优先级和动态优先级等概念。我们希望能在第二章将这些相关的概念描述清楚。…...

Java 抽象类和接口
文章目录一、抽象类1. 抽象类定义2. 抽象类成员特点二、接口1. 接口概述2. 接口成员特点3. 类和接口的关系4. 抽象类和接口的区别5. 接口案例三、形参和返回值一、抽象类 1. 抽象类定义 在 Java 中,一个没有方法体的方法应该定义为抽象方法,而类中如果…...
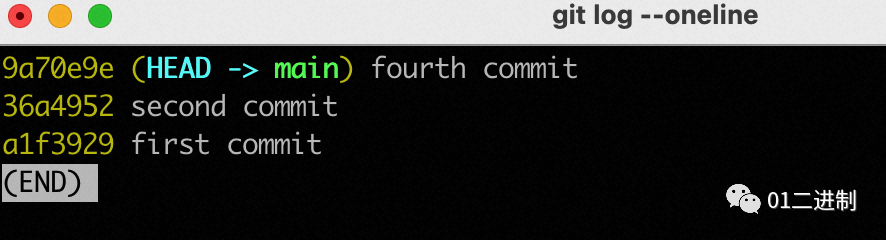
三行代码让你的git记录保持整洁
前言笔者最近在主导一个项目的架构迁移工作,由于迁移项目的历史包袱较重,人员合作较多,在迁移过程中免不了进行多分支、多次commit的情况,时间一长,git的提交记录便混乱不堪,随便截一个图形化的git提交历史…...

阿里巴巴内网 Java 面试 2000 题解析(2023 最新版)
前言 这份面试清单是今年 1 月份之后开始收集的,一方面是给公司招聘用,另一方面是想用它来挖掘在 Java 技术栈中,还有一些知识点是我还在探索的,我想找到这些技术盲点,然后修复它,以此来提高自己的技术水平…...
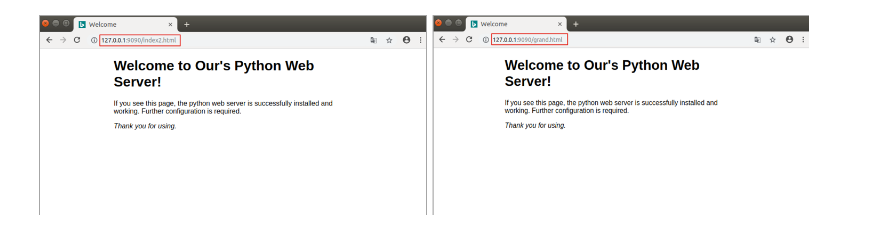
网络应用之静态Web服务器
静态Web服务器-返回固定页面数据学习目标能够写出组装固定页面数据的响应报文1. 开发自己的静态Web服务器实现步骤:编写一个TCP服务端程序获取浏览器发送的http请求报文数据读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器。HTTP响应报文数据发送完…...

IndexDB 浏览器服务器
IndexDB 浏览器服务器 文章部分内容引用: https://www.ruanyifeng.com/blog/2018/07/indexeddb.html https://juejin.cn/post/7026900352968425486#heading-15 基本概念 数据库:IDBDatabase 对象对象仓库:IDBObjectStore 对象索引࿱…...
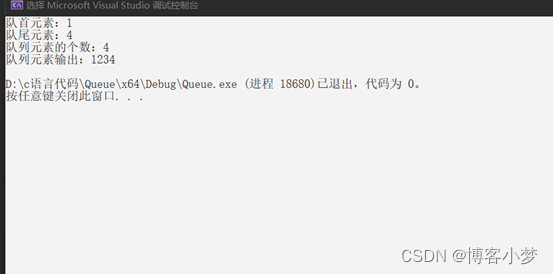
追梦之旅【数据结构篇】——详解C语言实现链队列
详解C语言实现链队列~😎前言🙌整体实现内容分析💞预备小知识🙌1.链队列头文件编写🙌2.链队列功能文件(Queue.c )编写:🙌1)初始化函数实现2)销毁函…...
SpringMVC - 13 - SpringMVC执行流程
文章目录1、SpringMVC常用组件2、DispatcherServlet初始化过程a>初始化WebApplicationContextb>创建WebApplicationContextc>DispatcherServlet初始化策略3、DispatcherServlet调用组件处理请求a>processRequest()b>doService()c>doDispatch()d>processDi…...

6091: 斐波那契数列
描述一个斐波那契序列,F(0) 0, F(1) 1, F(n) F(n-1) F(n-2) (n>2),根据n的值,计算斐波那契数F(n)。输入输入数据的第一行为测试用例的个数t,接下来为t行,每行为一个整数n(2≤n≤40)。输出…...
任何人均可上手的数据库与API搭建平台
编写API可能对于很多后端开发人员来说,并不是什么难事儿,但如果您主要从事前端功能,那么可能还是有一些门槛。 那么有没有工具可以帮助我们降低编写API的学习门槛和复杂度呢? 今天就来给大家推荐一个不错的开源工具:…...

Ubuntu(虚拟机)的Anaconda 及使用
安装Anaconda 使用firefox打开Ananconda网址Anaconda | The Worlds Most Popular Data Science Platform 下载后有.sh文件: Anaconda3-2022.10-Linux-x86_64.sh 进入所在目录打开终端并输入 $ bash Anaconda3-2022.10-Linux-x86_64.sh 然后开始安装。 对于给…...
Git ---- IDEA集成 GitHub
Git ---- IDEA集成 GitHub1. 设置 GitHub 账号2. 分享工程到 GitHub3. push 推送本地库到远程库4. pull 拉取远程库到本地库5. clone 克隆远程库到本地1. 设置 GitHub 账号 新版的 IDEA 选择之后会自动登录,就不需要设置 token 了。 如果是老版的 IDEA 的话&…...

opencv提取结构化文本总结
扫描文件表格识别 1.识别结构 situation1 有明确表格结构 1.纠正表格偏移角度(获取最大轮廓,计算最小的矩形,变换坐标截取矩形) 获取面积最大轮廓 _, contours, HIERARCHY cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2…...
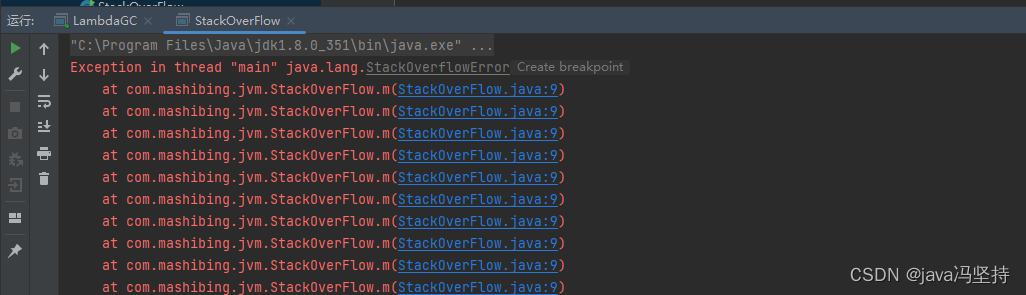
JVM知识体系学习八:OOM的案例(承接上篇博文,可以作为面试中的案例)
文章目录前言一、概述二、案例二三、案例:方法区内存溢出1、代码:LambdaGC.java2、元空间内存溢出日志3、分析4、疑问*****四、案例:直接内存溢出问题(少见)(尽量不说)五、案例:栈内存溢出问题1…...
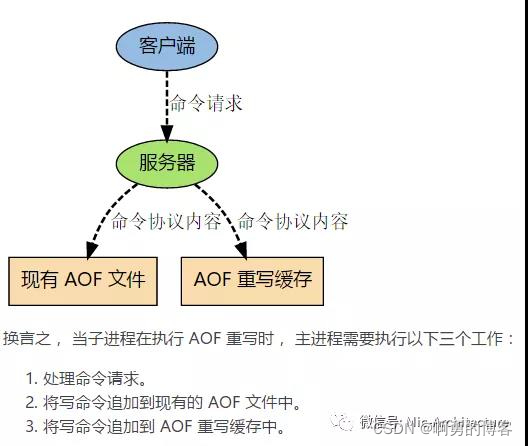
Redis的持久化方式
Redis支持两种方式的持久化,一种是RDB方式、另一种是AOF(append-only-file)方式,两种持久化方式可以单独使用其中一种,也可以将这两种方式结合使用。 •RDB:根据指定的规则“定时”将内存中的数据存储在硬…...

【unity游戏制作-mango的冒险】-4.场景二的镜头和法球特效跟随
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity游戏制作 ⭐mango的冒险场景二——镜头和法球特效跟随⭐ 文章目录⭐mango的冒险场景二——镜…...
handwrite-1
-------------------- 实现防抖函数(debounce) 防抖函数原理:把触发非常频繁的事件合并成一次去执行 在指定时间内只执行一次回调函数,如果在指定的时间内又触发了该事件,则回调函数的执行时间会基于此刻重新开始计算…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧
终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

如何永久保存微信聊天记录?WeChatMsg终极数据导出指南
如何永久保存微信聊天记录?WeChatMsg终极数据导出指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...