Kafka与Spark案例实践
1.概述
Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接。例如,实时计算引擎Spark。接下来通过一个完整案例,运用Kafka和Spark来合理完成。
2.内容
2.1 初始Spark
在大数据应用场景中,面对实时计算、处理流数据、降低计算耗时等问题时,Apache Spark提供的计算引擎能很好的满足这些需求。
Spark是一种基于内存的分布式计算引擎,其核心为弹性分布式数据集(Resilient Distributed Datasets简称,RDD),它支持多种数据来源,拥有容错机制,数据集可以被缓存,并且支持并行操作,能够很好的地用于数据挖掘和机器学习。
Spark是专门为海量数据处理而设计的快速且通用的计算引擎,支持多种编程语言(如Java、Scala、Python等),并且拥有更快的计算速度。
提示: 据Spark官方数据统计,通过利用内存进行数据计算,Spark的计算速度比Hadoop中的MapReduce的计算速度快100倍左右。
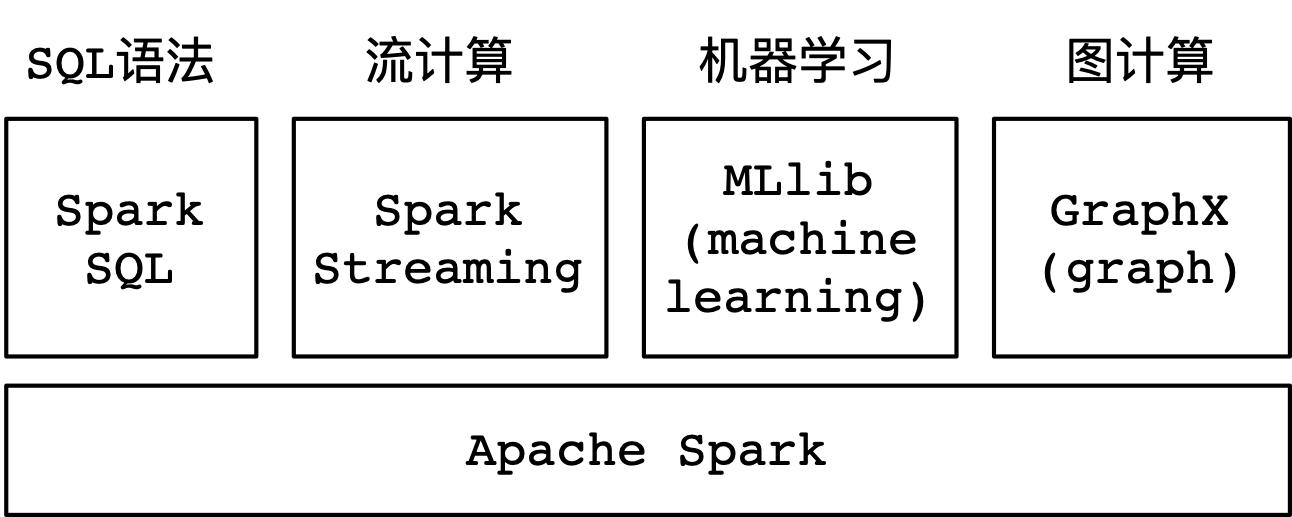
另外,Spark提供了大量的库,其中包含Spark SQL、Spark Streaming、MLlib、GraphX等。在项目开发的过程当中,可以在同一个应用程序中轻松地组合使用这些类库,如下图所示:
2.2 Spark SQL
Spark SQL是Spark处理结构化数据的一个模块,。与Spark的RDD应用接口不同,Spark SQL提供的接口更加偏向于处理结构化的数据。在使用相同的执行引擎时,不同的应用接口或者编程语言在做计算时都是相互独立的,。这意味着,用户在使用时,可以很方便的地在不同的应用接口或编程语言之间进行切换。
Spark SQL很重要的一个优势就是,可以通过SQL语句来实现业务功能,。Spark SQL可以读取不同的存储介质,例如Kafka、Hive、HDFS等。
在使用编程语言执行一个Spark SQL语句时,执行后的结果会返回一个数据集,用户可以通过使用命令行、JDBC、ODBC的方式与Spark SQL进行数据交互。
提示: JDBC是一个面向对象的应用程序接口,通过它可以访问各类关系型数据库。 ODBC是微软公司开放服务结构中有关数据库的一个组成部分,它制定并提供了一套访问数据库的应用接口。
2.3 Spark Streaming
Spark Streaming是Spark核心应用接口的一种扩展,它可以用于进行大规模数据处理、高吞吐量处理、容错处理等场景。同时,Spark Streaming支持从不同的数据源中读取数据,并且能够使用聚合函数、窗口函数等这类复杂算法来处理数据。
处理后的数据结果可以保存到本地文件系统(如文本)、分布式文件系统(如HDFS)、关系型数据库(如MySQL)、非关系型数据库(如HBase)等存储介质中。
2.4 MLlib
MLlib是Spark的机器学习(Machine Learning)类库,目的在于简化机器学习的可操作性和易扩展性。
MLlib由一些通用的学习算法和工具组成,其内容包含分类、回归、聚类、协同过滤等。
2.5 GraphX
GraphX是构建在Spark之上的图计算框架,它使用RDD来存储图数据,并提供了实用的图操作方法。
由于RDD的特性,GraphX高效的地实现了图的分布式存储和处理,可以应用于社交网络这类大规模的图计算场景。
3.操作Spark命令
在$SPARK_HOME/bin目录中,提供了一系列的脚本,例如spark-shell、spark-submit等。
进入到Hadoop集群,准备好数据源并将数据源上传Hadoop分布式文件系统(HDFS)中。然后使用Spark Shell的方式读取HDFS上的数据,并统计单词出现的频率,具体操作步骤如下。
1.准备数据源
(1)在本地创建一个文本文件,并在该文本文件中添加待统计的数据,具体操作命令如下。
# 新建文本文件 [hadoop@dn1 tmp]$ vi wordcount.txt
(2)然后,在wordcount.txt文件中添加待统计的单词,内容如下。
kafka spark hadoop spark kafka hadoop kafka hbase
2.上传数据源到HDFS
(1)将本地准备好的wordcount.txt文件上传到HDFS中,具体操作命令如下。
# 在HDFS上创建一个目录 [hadoop@dn1 tmp]$ hdfs dfs -mkdir -p /data/spark # 上传wordcount.txt到HDFS指定目录 [hadoop@dn1 tmp]$ hdfs dfs -put wordcount.txt /data/spark
(2)然后,执行HDFS查看命令,验证本地文件是否上传成功,具体操作命令如下。
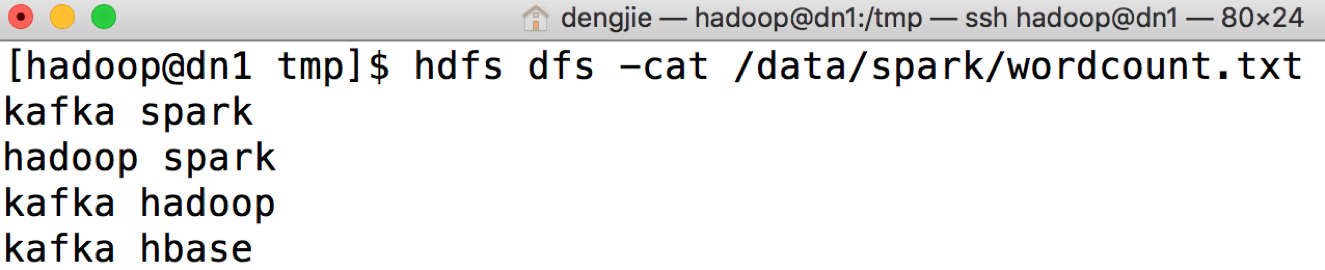
# 查看上传的文件是否成功 [hadoop@dn1 tmp]$ hdfs dfs -cat /data/spark/wordcount.txt
若查看命令执行成功,输出结果如图所示:
3.使用Spark Shell统计单词出现频
(1)进入到$SPARK_HOME/bin目录,然后运行./spark-shell脚本进入到Spark Shell控制台。
提示: 如果直接执行该脚本,则表示以本地模式单线程方式启动。 如果执行./spark-shell local[n]命令,则表示以多线程方式启动,其中变量n代表线程数。
(2)通过本地模式运行,等待Spark加载配置文件,加载完成后,输出结果
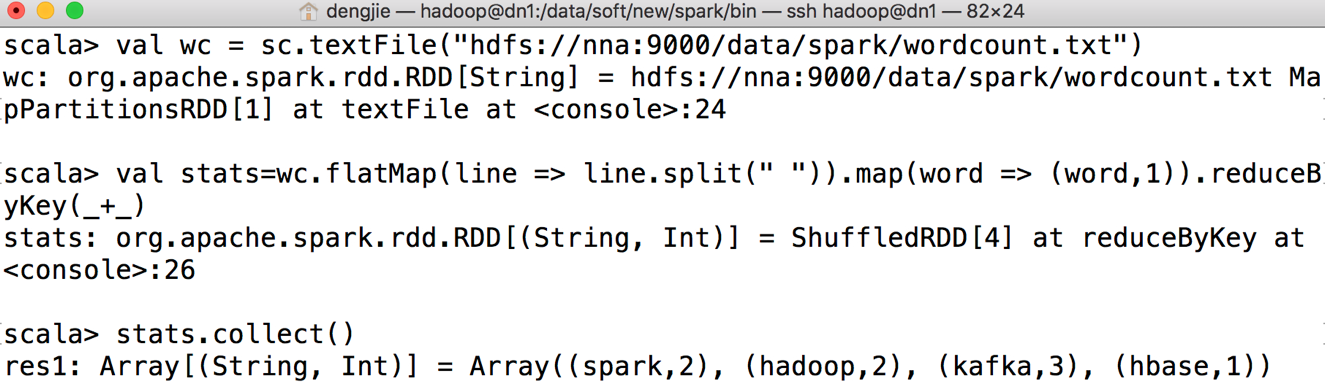
(3)统计单词出现的频率,具体实现如下:
![]()
val wc = sc.textFile("hdfs://nna:9000/data/spark/wordcount.txt")
val stats=wc.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
stats.collect()
提示:
第一行代码表示,读取HDFS上待统计单词的原始数据;
第二行代码表示,实现统计单词出现频率的具体业务逻辑;
第三行代码表示,从弹性分布式数据集(RDD)中获取数据,并以数组的形式展示统计结果。
![]()
(4)执行上述代码后,Spark Shell控制台输出结果如图所示:
4.案例实践
Kafka是一种实时消息队列技术,通过Kafka中间件,可以构建实时消息处理平台来满足企业的实时类需求。
本案例以Kafka为核心中间件,以Spark作为实时计算引擎,来完成对游戏明细数据的实时统计。
以本项目为例,需要实时描绘当天游戏用户的行为轨迹,例如用户订单、用户分布、新增用户等指标数据。针对这类需求,可以将游戏用户实时产生的业务数据上报到Kafka消息队列系统进行存储,然后通过Spark流计算的方式来统计应用指标。最后,将统计后的业务结果形成报表或者趋势图进行展示,为制作数据方案者提供数据支持。
4.1 背景和价值
1. 背景
在实时应用场景中,与离线统计任务有所不同。它对时延的要求比较高,需要缩短业务数据计算的时间。对于离线任务来说,通常是计算前一天或者更早的业务数据。
现实业务场景中,很多业务场景需要实时查看统计结果。流计算能够很好的弥补这一不足之处,对于当天变化的流数据可以通过流计算(比如Flink、Spark Streaming、Storm等)后,及时呈现报表数据或趋势图。
2. 价值
这样一个实时计算项目能够实时掌握游戏用户的行为轨迹、活跃度。具体涉及的内容如下:
- 通过对游戏用户实时产生的业务数据进行实时统计,可以分析出游戏用户在各个业务模块下的活跃度、停留时间等。将这些结果形成报表或者趋势图,让以便能够实时地准确的掌握游戏用户的行为轨迹;
- 按小时维度将当天的实时业务数据进行统计,那么可以知道游戏用户在哪个时间段具有最高的访问量。利用这些数据可以针对这个时间段做一些推广活动,例如道具“秒杀”活动、打折优惠等,从而刺激游戏用户去充值消费。
- 将实时计算产生的结果,去发挥它应有的价值。在高峰时间段推广一些优惠活动后,通过实时统计的数据结果分析活动的效果,例如促销的“秒杀”活动、道具打折等这些活动是否受到游戏用户的喜爱。针对这些反馈效果,可以做出快速合理的反应。
4.2 实现流程
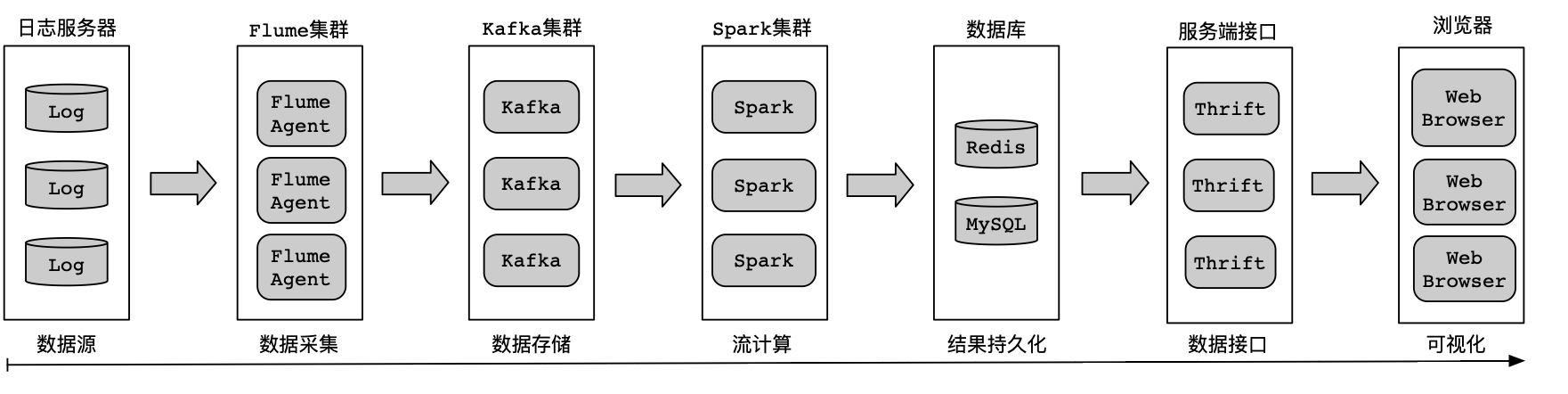
架构体系可以分为数据源、数据采集、数据存储、流计算、结果持久化、服务接口、数据可视化等,实现流程图如图所示:
1. 数据源
游戏用户通过移动设备或者浏览器操作游戏产生的记录,会实时上报到日志服务器进行存储,数据格式会封装成JSON对象进行上报,便于后续消费解析。
2. 数据采集
在日志服务器中部署Flume Agent来实时监控上报的业务日志数据,。当业务日志数据有更新(可通过文件MD5值、文件日期等来判断文件的变动)时,由Flume Agent启动采集任务,通过Flume Sink组件配置Kafka集群连接地址进行数据传输。
3. 数据存储
利用Kafka的消息队列特性来存储消息记录。将接收的数据按照业务进行区分,以不同的Topic来存储各种类型的业务数据。
4. 流计算
Spark拥有实时计算的能力,使用Spark Streaming将Spark和Kafka关联起来。
通过消费Kafka集群中指定的Topic来获取业务数据,并将获取的业务数据利用Spark集群来做实时计算。
5. 结果持久化
通过Spark计算引擎,将统计后的结果存储到数据库,方便可视化系统查询展示。
选用Redis和MySQL来作为持久化的存储介质,在Spark代码逻辑中使用对应的编程接口(如Java Redis API或Java MySQL API)将计算后的结果存储到数据库。
6. 数据接口
数据库中存储的统计结果需要对外共享,可以通过统一的接口服务对外提供访问。
可以选择Thrift框架来实现数据接口,编写RPC服务供外界访问。
提示: Apache Thrift是一个软件框架,用来进行可扩展且跨编程语言服务的开发工作。 Apache Thrift结合了功能强大的软件堆栈和代码生成引擎,可以与Java、Go、Python、Ruby等编程语言进行无缝连接。
7. 可视化
从RPC服务中获取数据库中存储的统计结果。然后,在浏览器中将这些结果进行渲染,以报表和趋势图表的形式进行呈现。
5.核心逻辑实现
通过读取Kafka系统Topic中的流数据,对平台号进行分组统计。每隔10秒钟,将相同平台号下用户金额进行累加计算,并将统计后的结果写入到MySQL数据库。
5.1 MySQL工具类实现
![]()
/*** 实现一个MySQL工具类.* * @author smartloli.** Created by Jul 15, 2022*/
public class MySQLPool {private static LinkedList<Connection> queues; // 声明一个连接队列static {try {Class.forName("com.mysql.jdbc.Driver"); // 加载MySQL驱动} catch (ClassNotFoundException e) {e.printStackTrace(); // 打印异常信息}}/** 初始化MySQL连接对象. */public synchronized static Connection getConnection() {try {if (queues == null) { // 判断连接队列是否为空queues = new LinkedList<Connection>(); // 实例化连接队列for (int i = 0; i < 5; i++) {Connection conn = DriverManager.getConnection("jdbc:mysql://nna:3306/game", "root", "123456");queues.push(conn); // 初始化连接队列}}} catch (Exception e) {e.printStackTrace(); // 打印异常信息}return queues.poll(); // 返回最新的连接对象}/** 释放MySQL连接对象到连接队列. */public static void release(Connection conn) {queues.push(conn); // 将连接对象放回到连接队列}
}
![]()
5.2 Spark逻辑实现
实现按平台号分组统计用户金额,具体实现见代码:
![]()
/*** 使用Spark引擎来统计用户订单主题中的金额.* * @author smartloli.** Created by Jul 14, 2022*/
public class UserOrderStats {public static void main(String[] args) throws Exception {// 设置数据源输入参数if (args.length < 1) { System.err.println("Usage: GroupId <file>"); // 打印提示信息System.exit(1); // 退出进程}String bootStrapServers = "dn1:9092,dn2:9092,dn3:9092"; // 指定Kafka连接地址String topic = "user_order_stream"; // 指定Kafka主题名String groupId = args[0]; // 动态获取消费者组名SparkConf sparkConf = new SparkConf().setMaster("yarn-client").setAppName("UserOrder"); // 实例化Spark配置对象// 实例化一个SparkContext对象, 用来打印日志信息到控制台, 便于调试JavaSparkContext sc = new JavaSparkContext(sparkConf);sc.setLogLevel("WARN");// 创建一个流对象, 设置窗口时间为10秒JavaStreamingContext jssc = new JavaStreamingContext(sc, Durations.seconds(10));JavaInputDStream<ConsumerRecord<Object, Object>> streams =KafkaUtils.createDirectStream(jssc,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(Arrays.asList(topic),configure(groupId, bootStrapServers))); // 获取流数据集// 将Kafka主题(user_order_stream)中的消息转化成键值对(key/value)形式JavaPairDStream<Integer, Long> moneys =streams.mapToPair(new PairFunction<ConsumerRecord<Object, Object>,Integer, Long>() {/** 序列号ID. */private static final long serialVersionUID = 1L;/** 执行回调函数来处理业务逻辑. */@Overridepublic Tuple2<Integer, Long> call(ConsumerRecord<Object, Object> t)throws Exception {JSONObject object = JSON.parseObject(t.value().toString());return new Tuple2<Integer, Long>(object.getInteger("plat"),object.getLong("money"));}}).reduceByKey(new Function2<Long, Long, Long>() {/** 序列号ID. */private static final long serialVersionUID = 1L;@Overridepublic Long call(Long v1, Long v2) throws Exception {return v1 + v2; // 通过平台号(plat)进行分组聚合}});// 将统计结果存储到MySQL数据库moneys.foreachRDD(rdd -> {Connection connection = MySQLPool.getConnection(); // 实例化MySQL连接对象Statement stmt = connection.createStatement(); // 创建一个操作MySQL的实例rdd.collect().forEach(line -> {int plat = line._1.intValue(); // 获取平台号long total = line._2.longValue(); // 获取用户总金额// 将写入到MySQL的数据,封装成SQL语句String sql = String.format("insert into `user_order` (`plat`, `total`)values (%s, %s)", plat, total);try {// 调用MySQL工具类, 将统计结果组装成SQL语句写入到MySQL数据库stmt.executeUpdate(sql); } catch (SQLException e) {e.printStackTrace(); // 打印异常信息}});MySQLPool.release(connection); // 是否MySQL连接对象到连接队列});jssc.start(); // 开始计算try {jssc.awaitTermination(); // 等待计算结束} catch (Exception ex) {ex.printStackTrace(); // 打印异常信息} finally {jssc.close(); // 发生异常, 关闭流操作对象}}/** 初始化Kafka集群信息. */private static Map<String, Object> configure(String group, String brokers) {Map<String, Object> props = new HashMap<>(); // 实例化一个配置对象props.put("bootstrap.servers", brokers); // 指定Kafka集群地址props.put("group.id", group); // 指定消费者组props.put("enable.auto.commit", "true"); // 开启自动提交props.put("auto.commit.interval.ms", "1000"); // 自动提交的时间间隔// 反序列化消息主键props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");// 反序列化消费记录props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");return props; // 返回配置对象}}
![]()
5.3 执行提交
将打包好的应用程序上传到Spark集群的其中一个节点,然后通过spark-submit脚本来调度应用程序,具体操作命令如下。
# 执行应用程序 [hadoop@dn1 bin]$ ./spark-submit --master yarn-client --class org.smartloli.kafka.game.x.book_11.jubas.UserOrderStats --executor-memory 512MB --total-executor-cores 2 /data/soft/new/UserOrder.jar ke6
5.4 结果预览
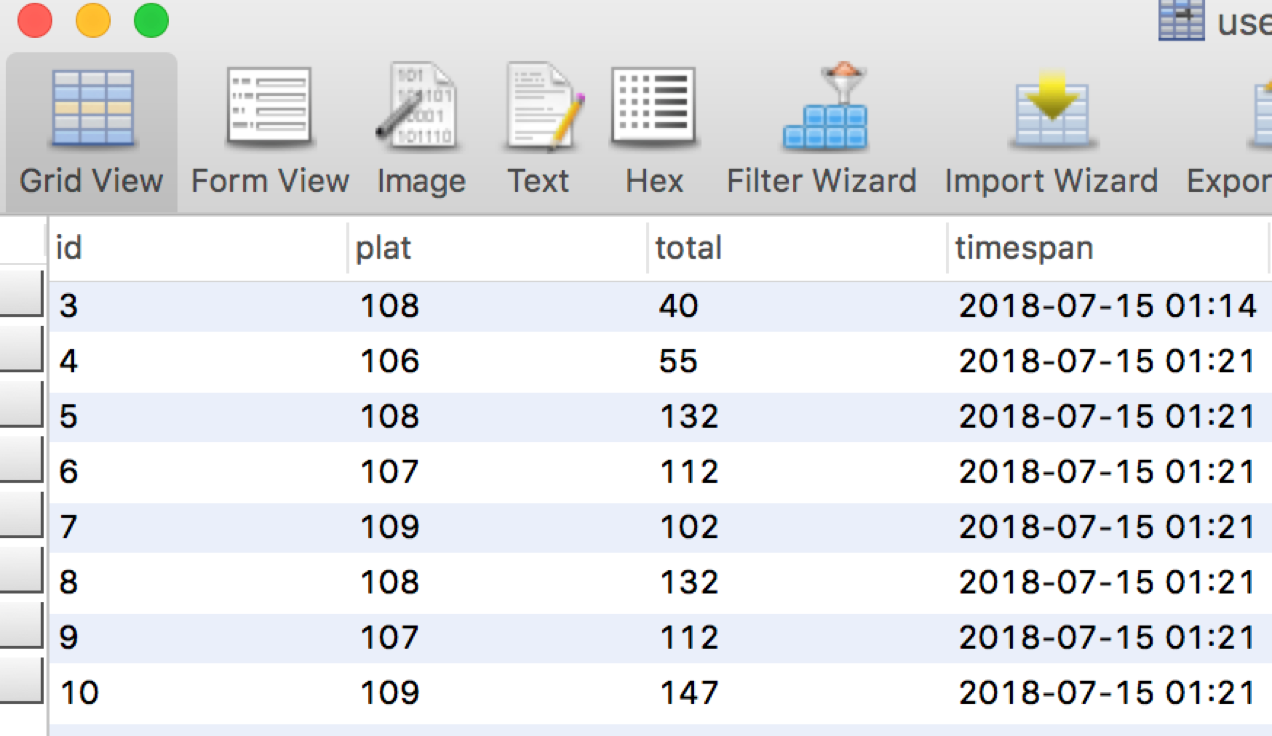
相关文章:
Kafka与Spark案例实践
1.概述 Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接。例如,实时计算引擎Spark。接下来通过一个完整案例,运用Kafka和Spark来合理完成。 2.内容 2.1 初始Spark 在大数据应用场景中,面对…...

山西电力市场日前价格预测【2023-10-27】
日前价格预测 预测说明: 如上图所示,预测明日(2023-10-27)山西电力市场全天平均日前电价为347.06元/MWh。其中,最高日前电价为618.09元/MWh,预计出现在18: 15。最低日前电价为163.49元/MWh,预计…...
)
centos7安装redis(包含各种报错)
本文主要介绍如果在Centos7下安装Redis。 1.安装依赖 redis是由C语言开发,因此安装之前必须要确保服务器已经安装了gcc,可以通过如下命令查看机器是否安装: gcc -v如果没有安装则通过以下命令安装: yum install -y gcc2.下载r…...

使用GoQuery实现头条新闻采集
概述 在本文中,我们将介绍如何使用Go语言和GoQuery库实现一个简单的爬虫程序,用于抓取头条新闻的网页内容。我们还将使用爬虫代理服务,提高爬虫程序的性能和安全性。我们将使用多线程技术,提高采集效率。最后,我们将展…...

“一带一路”十周年:用英语讲好中华传统故事
图为周明霏小选手 2023年是“一带一路”倡议提出十周年。十年来,中国的“友谊圈”已经扩展到亚洲、非洲、欧洲、大洋洲和拉丁美洲,这一倡议已经成为提升我国文化软实力、传播中华传统文化的重要策略和途径之一。在这个广阔的交流平台上,使用…...

机器视觉兄弟们还有几个月就拿到年终奖了,但我想跑路了
大聪明的我一般会把年终奖拿了,再走。听说有人还没有年终奖,太伤心了,赶紧跑吧。注意,机器视觉小白不要轻举妄动。 今年太难了,真的是让人很难过,很不爽,很不舒服。 公司难,机器视…...
base_lcoal_planner的LocalPlannerUtil类中getLocalPlan函数详解
本文主要介绍base_lcoal_planner功能包中LocalPlannerUtil类的getLocalPlan函数,以及其调用的transformGlobalPlan函数、prunePlan函数的相关内容 一、getLocalPlan函数 getLocalPlan函数的源码如下: bool LocalPlannerUtil::getLocalPlan(const geomet…...
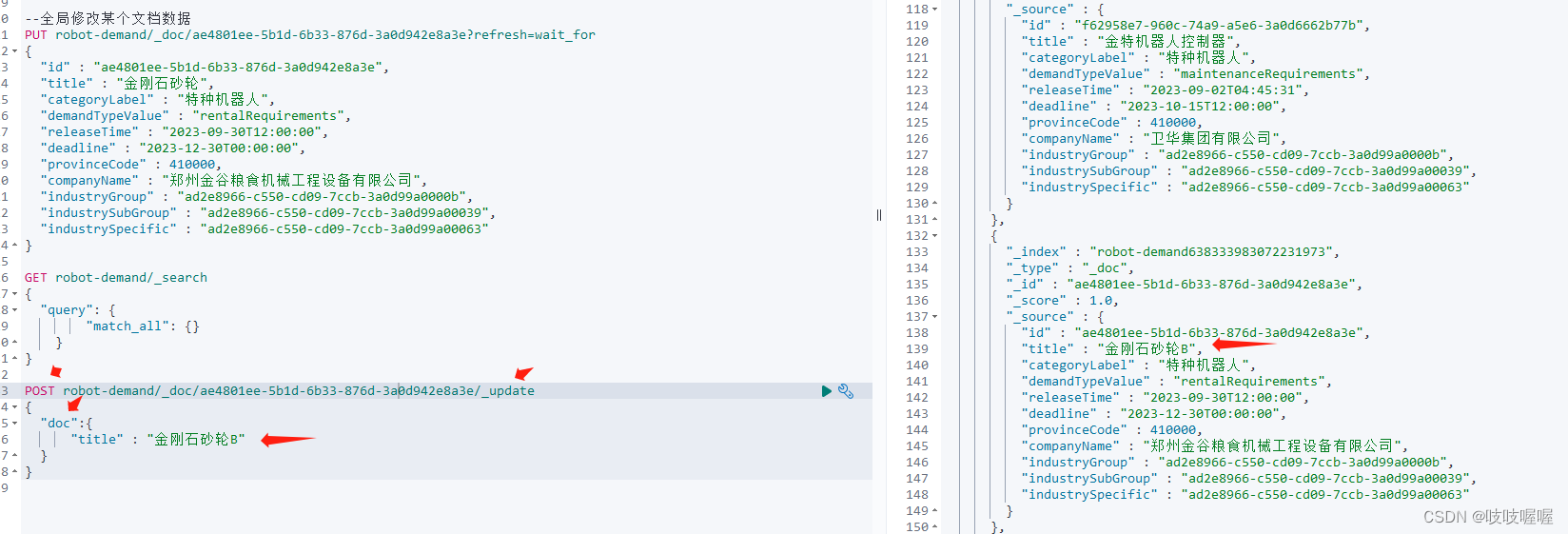
elasticSearch put全局更新和单个字段更新语法
1、如下:更新改类型未doc(文档)的全局字段数据 注意:如果你使用的是上面的语句,但是只写了id和title并赋值,图片上其他字段没有填写,执行命令后,则会把原文档中的其他字段都给删除了,你会发现查…...
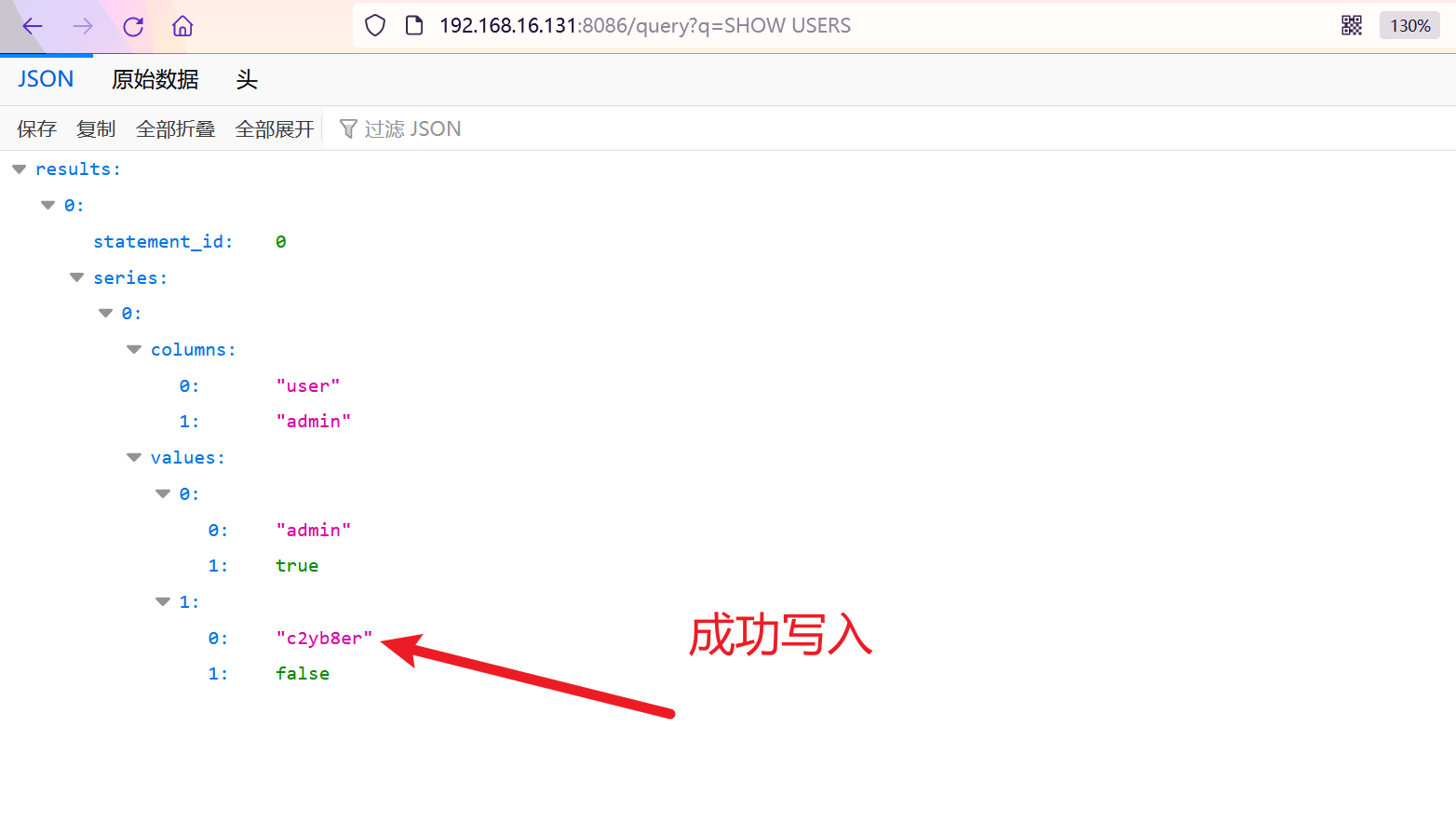
记录一次时序数据库的实战测试
0x1.前言 本文章仅用于信息安全防御技术分享,因用于其他用途而产生不良后果,作者不承担任何法律责任,请严格遵循中华人民共和国相关法律法规,禁止做一切违法犯罪行为。文中涉及漏洞均以提交至教育漏洞平台。 0x2.背景 在某…...
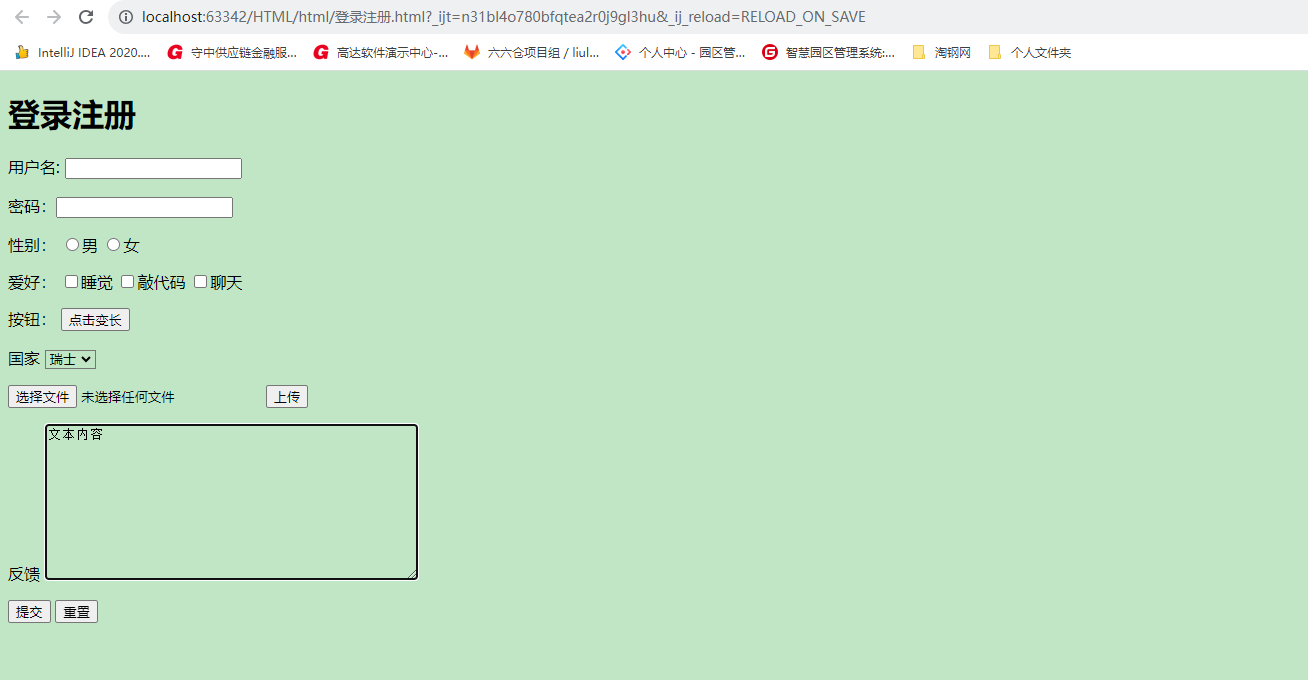
HTML中文本框\单选框\按钮\多选框
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body> <h1>登录注册</h1> <form action"第一个网页.html" method"post&quo…...
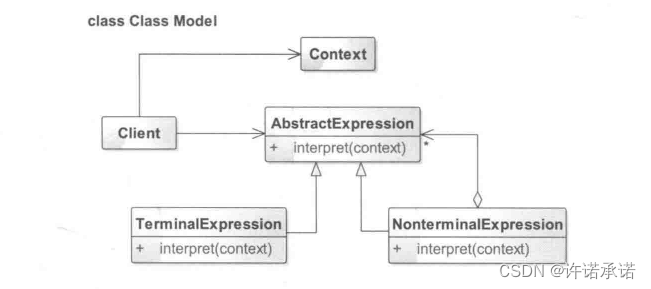
解释器模式——化繁为简的翻译机
● 解释器模式介绍 解释器模式(Interpreter Pattern)是一种用的比较少的行为型模式,其提供了一种解释语言的语法或表达的方式,该模式定义了一个表达式接口,通过该接口解释一个特定的上下文。在这么多的设计模式中&…...

【凡人修仙传】定档,四女神出场,韩立遭极阴岛陷阱,蛮胡子亮相
【侵权联系删除】【文/郑尔巴金】 距离凡人修仙传动画星海飞驰序章完结,已经过去了两个月的时间,相信大家等待的心情相当难熬,而且也愈发期待韩立结丹后在乱星海发生的故事。按照官方当初立下的FLAG,新年番动画即将在金秋十一月上…...
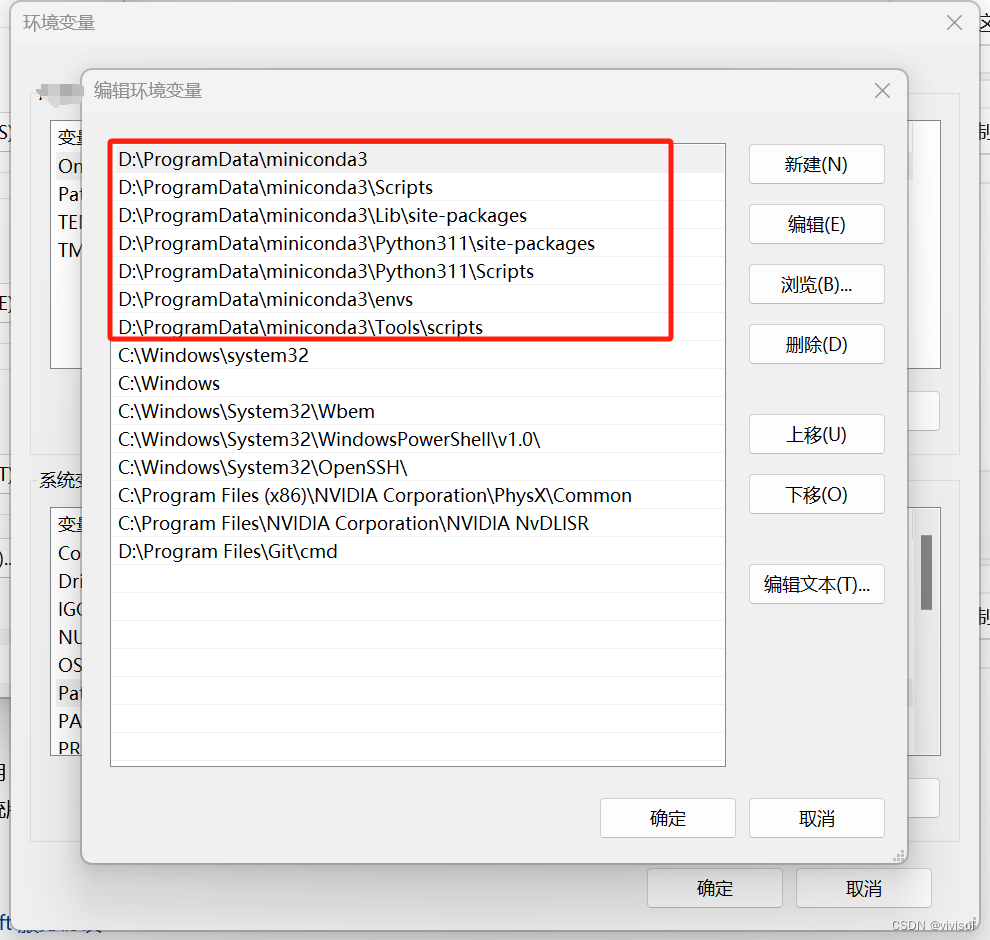
【解决】设置pip安装依赖包路径默认路径在conda路径下,而不是C盘路径下
【解决】设置pip安装依赖包路径默认路径在conda路径下,而不是C盘路径下 问题描述 在win11下安装miniconda,在conda环境里使用pip安装,依赖包总是安装到C盘路径,如 C:\Users\Jimmy\AppData\Local\Programs\Python\Python311\Lib\…...

JoySSL-新兴国产品牌数字证书
随着我国对数据安全重视程度的不断提升,国产SSL证书越来越受到广大政府机关和企业的青睐,成为提升网站数据安全能力的重要技术手段。那么什么是国产SSL证书?国产SSL证书和普通SSL证书又有什么区别呢? 什么是国产SSL证书ÿ…...
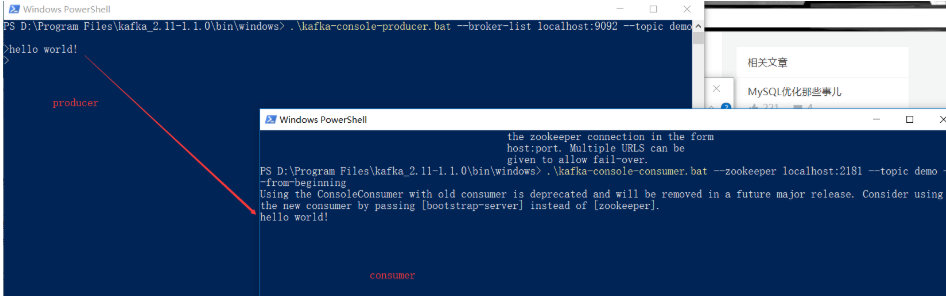
kafka3.X基本概念和使用
kafka基本概念和使用 文章目录 kafka基本概念和使用 kafka的概念基本概念Kafka的使用 首先kafka的安装kafka的简单实用和理解搭建集群(3个节点)windows版本环境搭建 本文"kafka的概念"部分是在[初谈Kafka][ https://juejin.im/post/5a8e7f…...
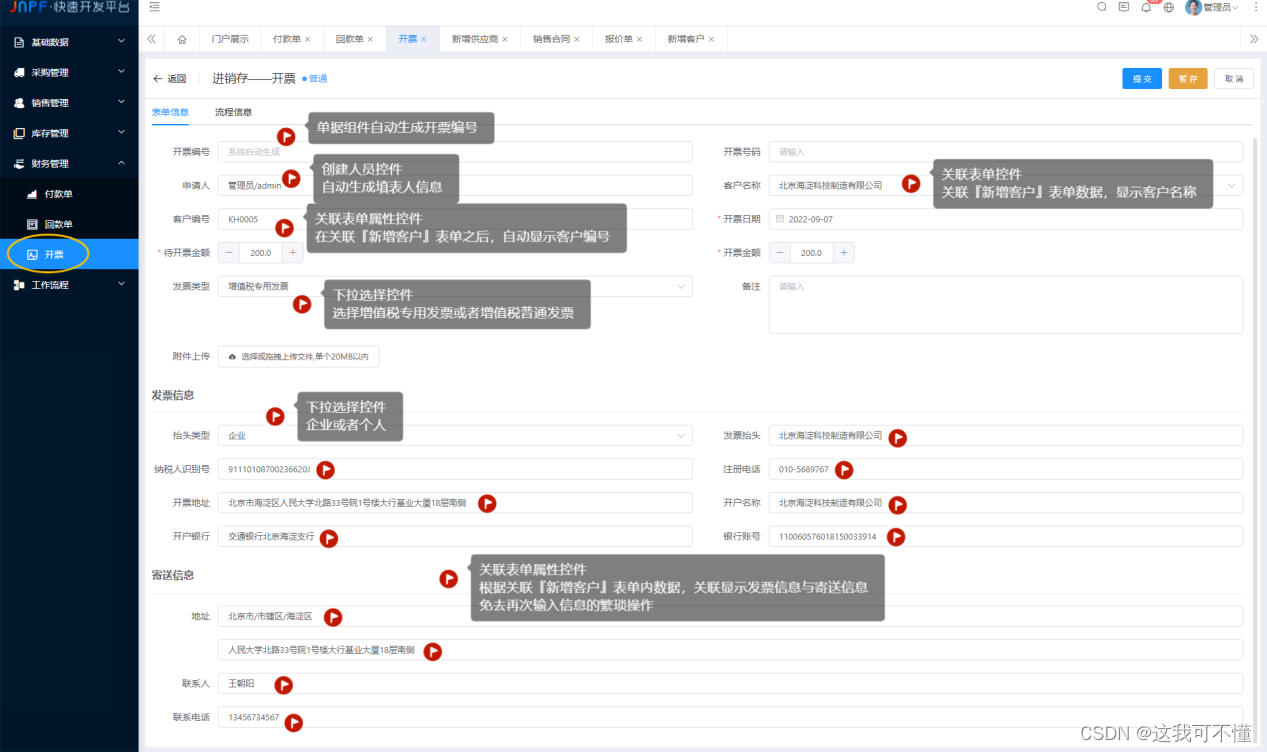
用低代码平台代替Excel搭建进销存管理系统
目录 一、用低代码平台搭建系统 1.需求调研 2.基于痛点梳理业务流程 3.低代码实现 (1)基础资料模块 (2)采购管理模块 (3)销售管理模块 (4)库存管理模块 (5&…...

Redis和Memcached网络模型详解
1. Redis单线程单Reactor网络模型 1.1 redis单线程里不能执行十分耗时的流程,不然会客户端响应不及时 解决方法一: beforesleep里删除过期键操作若存在大量过期键时,会耗费大量时间,redis采用的策略之一就是采用timelimit方案超过…...
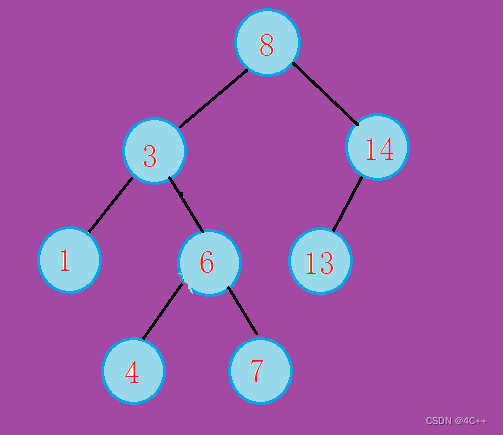
二叉搜索树的实现(递归方式)
目录 实现思路 插入操作 删除操作 完整代码 测试案例 总结 二叉搜索树(Binary Search Tree,BST)是一种常用的数据结构,它具有以下特点: 左子树上所有节点的值均小于它的根节点的值右子树上所有节点的值均大于它的…...
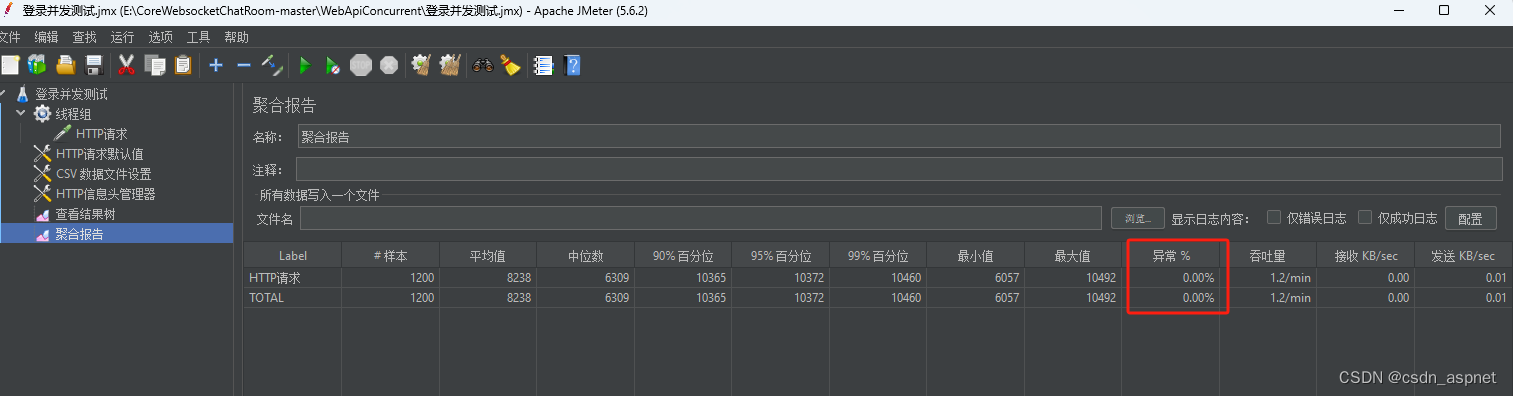
NetCore IIS Redis JMeter 登录压力测试
近期,由于某项目验收需要,需要登录接口同时满足至少400个账号同时并发登录,于是开始编写测试代码,以满足项目业务需要。首先,安装jdk,由于本机已安装jdk8: 如果你机器上没有安装jdk,…...

进一步了解视频美颜SDK:美颜SDK的技术原理
美颜技术在当今的数字世界中变得越来越流行,尤其是在视频直播、社交媒体和视频通话应用中。用户寻求通过美颜效果增强自己的外观,这种需求催生了众多美颜SDK(软件开发工具包)的出现。这些SDK使开发者能够轻松地将美颜功能集成到他…...

手指划过屏幕放大模型界面,环氧树脂层和纤维基体在激光路径下呈现出清晰的物理场分布。突然发现这个双层材料烧蚀模型跑得格外顺畅——看来前几天通宵调参没白费
comsol激光清洗、烧蚀双层材料 表面一层50μm厚度的环氧树脂(可更换成其他材料),基体材料为纤维材料。 添加功率为13W的激光进行清洗或烧蚀 模型非常成功、角度选择很奈斯在COMSOL里建模时有个小细节特别关键:把环氧树脂层的厚度参数设为全局变量。别小看…...

nli-distilroberta-base实际项目:高校招生简章关键条款与考生疑问逻辑关系库构建
nli-distilroberta-base实际项目:高校招生简章关键条款与考生疑问逻辑关系库构建 1. 项目背景与需求 高校招生简章通常包含大量专业条款和政策说明,每年都会收到大量考生关于条款理解的咨询。传统的人工解答方式存在几个痛点: 效率低下&am…...
)
从4G到RedCap:手把手教你升级老旧工业设备的无线通信模块(附功耗测试数据)
从4G到RedCap:工业设备无线通信模块升级实战指南 在工业物联网快速发展的今天,老旧设备的通信模块升级成为许多工厂面临的现实挑战。传统4G模块虽然稳定可靠,但面对5G时代RedCap技术带来的低功耗、低成本优势,升级改造已成为提升设…...

Vue项目中el-tabs标签栏的5个高级用法与避坑指南
Vue项目中el-tabs标签栏的5个高级用法与避坑指南 在Vue生态中,Element UI的el-tabs组件是构建标签式界面的首选方案。但很多开发者仅停留在基础使用层面,未能充分发挥其潜力。本文将揭示五个高阶技巧,助你打造更灵活、高效的标签系统。 1. 标…...

SDMatte惊艳抠图效果展示:10组高难度玻璃/纱布/叶片实测对比图
SDMatte惊艳抠图效果展示:10组高难度玻璃/纱布/叶片实测对比图 1. 开篇:当AI遇见高难度抠图 在图像处理领域,抠图一直是个技术活。特别是遇到玻璃杯、薄纱窗帘、树叶这些半透明或边缘复杂的物体时,传统工具往往力不从心。今天我…...

Qwen3-ASR-0.6B惊艳效果:藏语、维吾尔语等少数民族语言识别案例
Qwen3-ASR-0.6B惊艳效果:藏语、维吾尔语等少数民族语言识别案例 1. 引言:多语言语音识别的突破 语音识别技术正在改变我们与设备交互的方式,但有一个领域一直存在巨大挑战——少数民族语言的识别。传统的语音识别模型往往只支持主流语言&am…...

从安装到跑通第一个旋转立方体:Ubuntu 22.04 + OpenGL完整开发环境搭建实录
从零到旋转立方体:Ubuntu 22.04下OpenGL开发环境实战指南 刚接触图形编程时,最令人兴奋的莫过于看到自己编写的代码在屏幕上"活"起来。本文将带你从零开始,在Ubuntu 22.04系统上搭建完整的OpenGL开发环境,并最终实现一个…...

02.Linux常用文件操作命令
1.mkdir 目录名:创建目录 mkdir 目录名 mkdir -p a/b/c 创建多级目录 2.touch 创建空文件 touch 文件名 touch 文件名 文件名 创建多个文件 3.文件写入内容 echo写入 覆盖写入 echo 文件内容 >文件名 追加写入(日志必用) echo 文件内容 >…...

DFPlayer Mini串口协议与嵌入式驱动开发实战
1. DFPlayer Mini 驱动库技术解析:面向嵌入式工程师的底层控制实践DFPlayer Mini 是 DFRobot 推出的一款高度集成、低成本、低功耗的串口控制 MP3 播放模块,广泛应用于智能语音播报、工业人机交互、教育机器人、IoT 音频终端等场景。其核心价值在于&…...

2025终极指南:如何快速解锁雀魂全角色皮肤?Mod工具使用全攻略
2025终极指南:如何快速解锁雀魂全角色皮肤?Mod工具使用全攻略 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法体验雀魂…...