kafka3.X基本概念和使用
kafka基本概念和使用
文章目录
- kafka基本概念和使用
-
-
- kafka的概念
- 基本概念
- Kafka的使用
-
-
- 首先kafka的安装
- kafka的简单实用和理解
- 搭建集群(3个节点)
- windows版本
- 环境搭建
-
-
本文"kafka的概念"部分是在[初谈Kafka][ https://juejin.im/post/5a8e7f296fb9a0635a6573e9]的基础上重新整理而成,看官自行选择阅读…
kafka的概念
kafka是一个分布式的、可区分的、可复制的、基于发布、订阅的**“消息系统”**。
主要应用领域:大数据,当然,在分布式的系统中也有应用。
市面流行的消息队列RocketMQ就是借鉴kafka原理,java开发得到的,可通过文章[RocketMQ原理&最佳实践][https://www.jianshu.com/p/2838890f3284]了解
kafka优势:适合离线、在线的消息消费
- 消息保存位置:磁盘;
- 以Topic为单位,进行消息归纳;
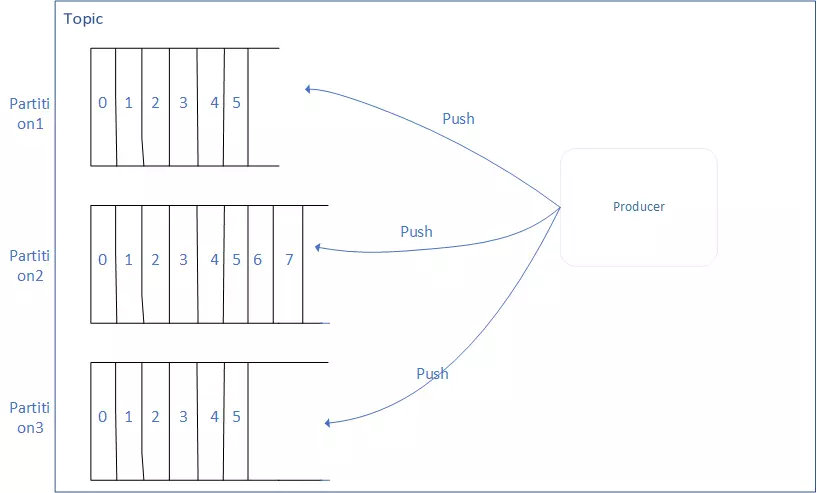
- Producer:向 Topic 发送(Push)消息;
- Cunsumer:消费(Pull)Topic里的消息。
基本概念
基本概念对于理解kafka本身,以及基于kafka原理的消息队列的理解,非常重要,理解基本概念之后,对于kafka的上手,以及使用,以及后续消息队列的使用,会更加得心应手。
- Topic
适用于存储消息的逻辑概念,1个Topic,可以看做是消息的集合。
这个消息的集合(Topic),可以接收多个生产者(Producer)推送(Push)过来的消息,也可以让多个消费者(Consumer)从中消费(Pull)消息。
【这里的消费,是pull之后不保留在集合中,还是pull之后依然保留,待思考或者自行查找资料,目前我的理解是pull之后依然保留,这样多个消费者均可获取到同一条消息,同理,push应该可以push相同的消息,至于是否正确,我们慢慢看看吧】
- 分区(Partition)
分区的概念,可以理解为Topic的子集:1个Topic可能只有1个分区,也可能有多个分区。这里说的多个分区,一个分区就代表磁盘的一块连续的位置,不同的分区也就是磁盘上不同的区域块。
分区存在的意义:
通过不同的区域块,kafka存储在Topic里的消息就可以在多个地方存储,也就是对kafka进行了水平扩展,这样可以增加kafka的并行处理能力。
对于不同区域块存储消息的理解:
同一个Topic下,多个区域块,这些不同的区域块,存储的消息是不同的,也就是说,A、B两个区域块,不会同时存储1类消息。
对于同一个区域内的消息:
在区域块A接收到消息x的时候,该消息x会被接收它的区域块A分配一个offset(代表它在这个区域块中的唯一编号),这个offset使得kafka确定了这条消息x在这个区域块A内的顺序。
要注意的是:这个顺序仅适用于该区域块A,对于另一区域块B内另一条消息y,x和y的顺序是不能确定的。
- Log
分区在逻辑上,对应一个Log,当生产者将消息写入分区的时候,实际上就是写入一个log。
Log:一个逻辑概念,对应着磁盘上的一个文件夹。
Log的组成:由多个Segment组成,每1个Segment对应1个日志文件和一个索引文件。
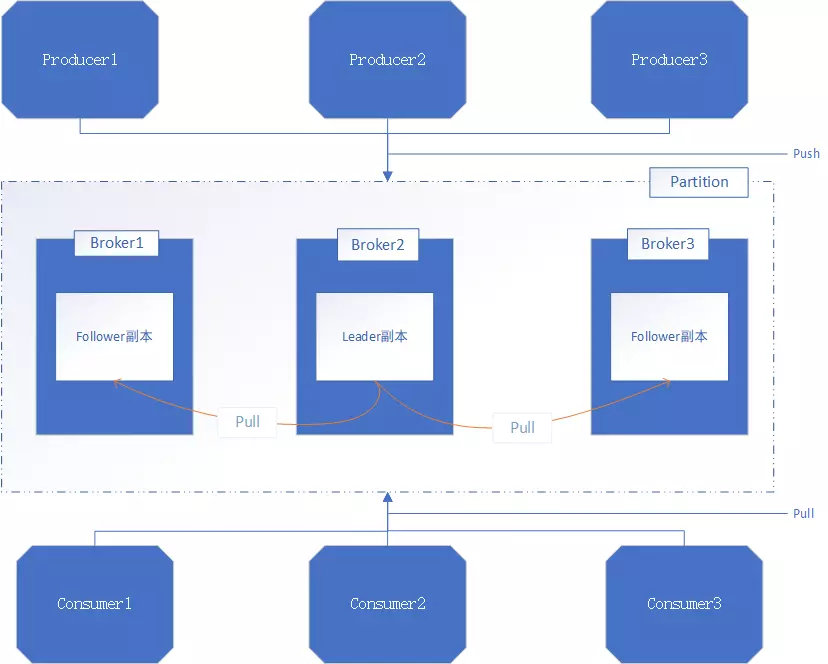
- Broker
说完了Topic,里面提到区域块A会给它接收的消息x分配一个offset,并且x会保存到A所在的磁盘区域上。而这个功能,就是由Broker完成的。
Broker:1个Broker就是一个单独的kafka server。
Broker的主要工作:接收生产者发送来的消息,分配offset,然后将包装过的数据保存到磁盘上。
Broker的其他作用:接收消费者Consumer和其他Broker的请求,根据请求的类型进行相应的处理然后返回响应。
这里引出集群(Cluster)的概念,1个Cluster是由多个Broker构成的,也就是说,1个Broker不会对外提供服务,而是通过Cluster的形式对外提供服务:
因为,一个Cluster里,需要1个Broker担任Controller,这个Broker就是这个集群的指挥中心,负责:
- 管理各个分区(Partition)的状态;
- 管理每个分区(Partition)的副本【这个副本暂时没找到出处】的状态;
- 监听zookeeper的数据变化。
其他的Broker均是通过这个Controller进行指挥的,完成各自相应的功能。
关于Cluster的一主多从实现:
除了担任Controller的Broker会监听其他Broker的状态,其他Broker也会监听Controller的状态,当Controller出翔了故障,就会重新选取新的Broker担任Controller
- 消息
Kafka中最基本的消息单元。有一串字节组成,主要由key和value构成(即key、value都是字节数组)
- key:主要作用是 根据一定策略,将这个消息路由到制定分区中 ==> 这样就保障了,包含同一个key的消息全部写入一个分区A,不会写入另外一个分区。(即实现了Partition分区中提到的“不同分区存储的消息是不一样的”)
- 副本
Kafkah会对消息进行冗余备份,每一个分区Partition,都可以有多个副本(每一个副本包含的消息是相同的,但是不能保证同一时刻下完全相同)。
副本类型:Leader、Follower。
副本选举策略(即选举1个Leader,其余为Follower):
- 当分区只有1个副本,这个副本就是Leader,没有Follower。
- 在其他不同场景,会采取不同的选举策略。
- Leader:处理Kafka中所有的读写请求
- Follower:仅仅把数据从Leader中拉取到本地,同步更新到自己的Log中。
- ISR集合
ISR集合:表示目前可用(alive)、且消息量与Leader相差不多的Follower集合,即ISR是整个副本集合的一个子集。
ISR集合中Follower:
- 所在的节点都和ZooKeeper保持着连接;
- 最后1条消息的offset和Leader中的最后一条消息的offset,差值不能超过指定的阈值
每一个分区Partition上的Leader,都会维护这个Partition的ISR集合。(也就是说,ISR集合内的Follower,都在同一个分区上,归属同一个Leader,那么上面的说法就说得通了)。
根据上面的说法,这个分区上的副本Leader,在进行了消息的写请求之后,副本Follower就会从Leader上拉取Leader写入的消息,同步到自己对应的Log中,这个过程也就说明同一时刻,Follower中的消息数量少于Leader的消息数量,只要这个差值少于指定的阈值(这个就说明了消息量与Leader差不多这一特征),那么这些Follower的集合就是ISR集合。
- 生产者(Producer)**
产生消息的对象,产生消息之后,将消息按照一定的规则推送到Topic的分区中
- 消费者(Consumer)
从Topic中拉取消息,并对消息进行消费。
- Consumer:有一个作用,维护它消费到分区(Partition)上的什么位置(即offset的值)。
- Consumer Group: 在kafka中,多个Consumer可以组成1个Consumer Group,1个Consumer只属于1个Consumer Group.
Consumer Group的作用:保证了这个Consumer Group订阅的Topic(Partition的集合)中的每一个分区(Partition),只被Consumer Group中的一个Consumer处理。
当然,如果要实现消息的广播消费,则将同1条消息放在多个不同的Consumer Group中即可。
就上述这个Consumer和Partition的关系可以理解下面的说法:
通过向Consumer Group中动态添加适量的Consumer, 可以触发kafka的Rebalance操作(重新分配Partition和Consumer的一一对应关系,结合Topic部分的理解,这样就实现了kafka的水平扩展能力)。
Kafka的使用
首先kafka的安装
- Kafka安装需要的环境准备:需要Java环境,centos 7自带java1.6版本,可以安装,如果觉得jdk太旧,可以安装新的jdk,比如1.8版本的https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 安装包下载地址:http://kafka.apache.org/downloads.html
- 下载好kafka安装包之后,解压到/usr/local目录(Linux,windows可自行决定),删除压缩包
- 进入kafka目录进行操作
- 如果想搭建集群,可以参考一下文章[Kafka集群搭建的详细步骤][https://blog.csdn.net/zxy987872674/article/details/72466504],我们在文章后面也有列举到搭建集群的步骤方法
- 注意kafka里的配置文件,应该在kafka文件夹下的config或conf文件夹下,叫server.properties.关于kafka配置的说明,可以参看文章[apache kafka系列之server.properties配置文件参数说明][https://blog.csdn.net/lizhitao/article/details/25667831]
kafka的简单实用和理解
我们抛开kakfa集群搭建什么的,先来简单使用,帮助理解即可。
Linux版本
进入kafka目录下的bin目录
启动zk
nohup ./zookeeper-server-start.sh ../config/zookeeper.properties &
或
nohup ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
nohup(不挂断地运行命令,可以自己百度一下看看,就是nohup 命令 &,让命令在后台执行)
启动kafka
nohup ./kafka-server-start.sh ../config/server.properties &
或
nohup ./bin/kafka-server-start.sh ./config/server.properties &
创建topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
或
./kafka-topics.sh --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test2 --create
列出topic
./kafka-topics.sh --list --zookeeper localhost:2181
或
./kafka-topic --zookeeper localhost:2181 --list
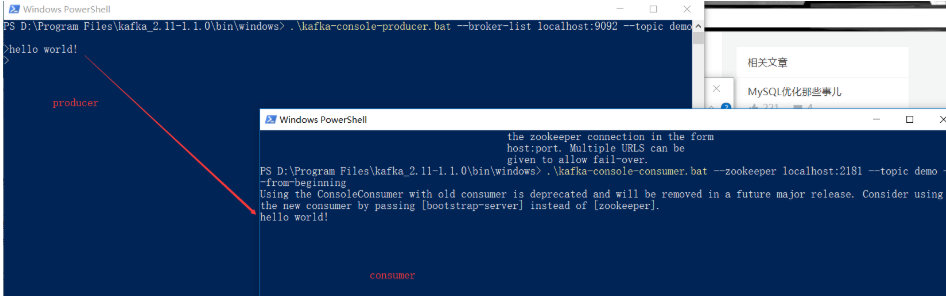
启动生产者并发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic zyl
输入消息:
nihao
china
另外开个终端,启动消费者接受消息
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic zyl --from-beginning
可以接收到:
nihao
china
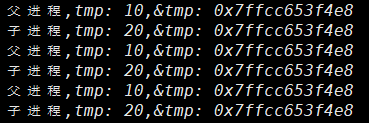
另外开个终端,可以看到有4个进程(分别为zk、kafka、控制台消费者、控制台生产者)
[root[@aa](http://my.oschina.net/test2) bin]# jps | grep -v Jps
9802 QuorumPeerMain
10392 Kafka
10956 ConsoleConsumer
10887 ConsoleProducer
搭建集群(3个节点)
拷贝并修改配置文件
cp server.properties server1.properties
cp server.properties server2.properties
cp server.properties server3.properties
nohup ./kafka-server-start.sh …/config/server1.properties &
nohup ./kafka-server-start.sh …/config/server2.properties &
nohup ./kafka-server-start.sh …/config/server3.properties &
[root@aa bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic(注意,指定的是3)
Created topic “my-replicated-topic”.
[root@aa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
[root@aa bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 4 --partitions 1 --topic my-replicated-topic
Error while executing topic command Topic “my-replicated-topic” already exists.
kafka.common.TopicExistsException: Topic “my-replicated-topic” already exists.
at kafka.admin.AdminUtils . c r e a t e O r U p d a t e T o p i c P a r t i t i o n A s s i g n m e n t P a t h I n Z K ( A d m i n U t i l s . s c a l a : 171 ) a t k a f k a . a d m i n . A d m i n U t i l s .createOrUpdateTopicPartitionAssignmentPathInZK(AdminUtils.scala:171) at kafka.admin.AdminUtils .createOrUpdateTopicPartitionAssignmentPathInZK(AdminUtils.scala:171)atkafka.admin.AdminUtils.createTopic(AdminUtils.scala:156)
at kafka.admin.TopicCommand . c r e a t e T o p i c ( T o p i c C o m m a n d . s c a l a : 86 ) a t k a f k a . a d m i n . T o p i c C o m m a n d .createTopic(TopicCommand.scala:86) at kafka.admin.TopicCommand .createTopic(TopicCommand.scala:86)atkafka.admin.TopicCommand.main(TopicCommand.scala:50)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
[root@aa bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 4 --partitions 1 --topic my-replicated-topic2
Created topic “my-replicated-topic2”.
[root@aa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic2
Topic:my-replicated-topic2 PartitionCount:1 ReplicationFactor:4 Configs:
Topic: my-replicated-topic2 Partition: 0 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
[root@aa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic zyl
Topic:zyl PartitionCount:1 ReplicationFactor:1 Configs:
Topic: zyl Partition: 0 Leader: 0 Replicas: 0 Isr: 0

启动生产者并发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
另外开个终端,启动消费者接受消息
./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
另外开个终端,可以看到有9个进程(分别为1个zk、4个kafka、2个控制台消费者、2个控制台生产者)
[root@aa ~]# jps | grep -v Jps9802 QuorumPeerMain10392 Kafka11547 Kafka12007 ConsoleProducer10956 ConsoleConsumer10887 ConsoleProducer11469 Kafka12054 ConsoleConsumer11710 Kafka
查看单独的进程:
ps -ef | grep server.properties | grep -v grepps -ef | grep "server1.properties" | grep -v grep
测试leader
杀掉进程,然后–describe查看
[root@aaa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topicTopic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0可以看到leader是2.
[root@aa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic2
Topic:my-replicated-topic2 PartitionCount:1 ReplicationFactor:4 Configs:
Topic: my-replicated-topic2 Partition: 0 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
可以看到leader是2.
[root@aa bin]# ps -ef | grep server1.properties | grep -v grep
杀掉某个kafka进程
kill -9 11469
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic2
Topic:my-replicated-topic2 PartitionCount:1 ReplicationFactor:4 Configs:
Topic: my-replicated-topic2 Partition: 0 Leader: 2 Replicas: 1,2,3,0 Isr: 2,3,0
[root@aa bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
可以看到my-replicated-topic2的leader变成了2。
问题:
1.zookeeper-shell.sh如何使用
2.能不能通过kafka-server-stop.sh停止某个kafka呢
Command must include exactly one action: --list, --describe, --create or --alter
| Option | Description |
|---|---|
| –alter | Alter the configuration for the topic. |
| –config <name=value> | A topic configuration override for the topic being created or altered. |
| –create | Create a new topic. |
| –deleteConfig A topic configuration override to be removed for an existing topic | |
| –describe | List details for the given topics. |
| –help | Print usage information. |
| –list | List all available topics. |
| –partitions <Integer: # of partitions> | The number of partitions for the topic being created or altered (WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected |
| –replica-assignment <broker_id_for_part1_replica1 : broker_id_for_part1_replica2 , broker_id_for_part2_replica1 : broker_id_for_part2_replica2 , …> | A list of manual partition-to-broker assignments for the topic being created or altered. |
| –replication-factor <Integer: replication factor> | The replication factor for each partition in the topic being created. |
| –topic | The topic to be create, alter or describe. Can also accept a regular expression except for --create option |
| –topics-with-overrides | if set when describing topics, only show topics that have overridden configs |
| –unavailable-partitions | if set when describing topics, only show partitions whose leader is not available |
| –under-replicated-partitions | if set when describing topics, only show under replicated partitions |
| –zookeeper | REQUIRED: The connection string for the zookeeper connection in the form host:port. Multiple URLS can be given to allow fail-over. |
windows版本
环境搭建
-
jdk环境,上文已经提到过,并配置环境变量,这里不讨论
-
安装zookeeper,这是运行kafka之前需要的环境(但是可以直接去第三步,因为,kafka有自带的zookeeper服务)
2.1. 到http://mirror.bit.edu.cn/apache/zookeeper/下载一个版本的zookeeper即可
2.2. 解压到一个文件夹下,可自己选择
2.3. 将解压后的文件夹里,conf文件夹下zoo_sample.cfg 改名为 zoo.cfg
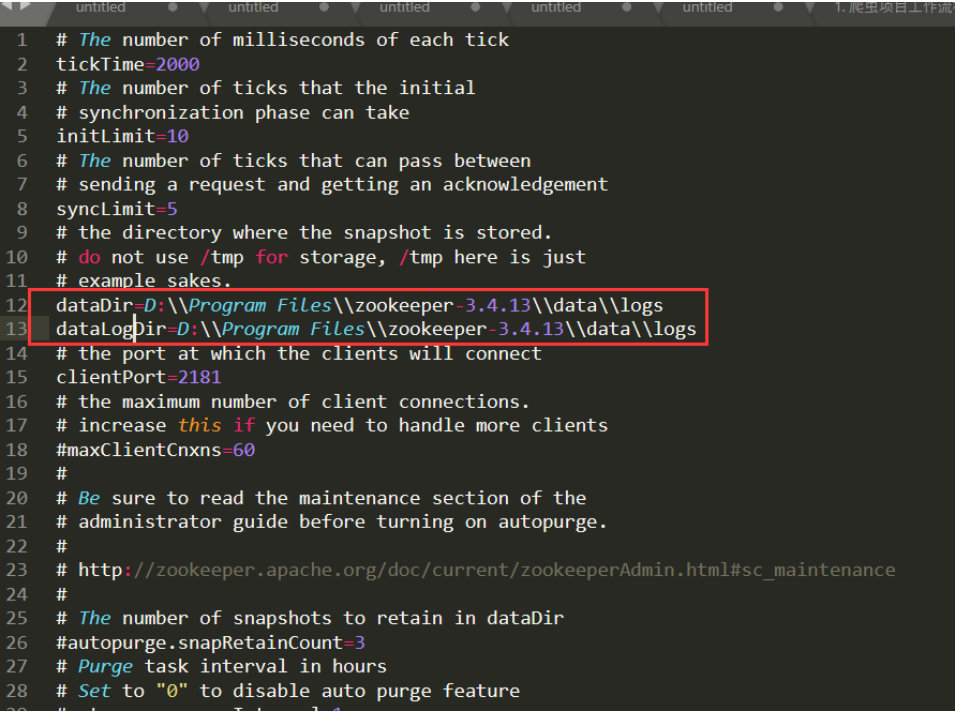
2.4. 修改(如果没有则新增设置)
dataDir和dataLogDir路径dataDir=D:/Program Files/zookeeper-3.4.13/data/logs
dataLogDir=D:/Program Files/zookeeper-3.4.13/data/logs
2.5. 设置环境变量:
新增ZOOKEEPERHOME:D:\Program Files\zookeeper-3.4.13
Path添加:%ZOOKEEPERHOME%\bin;
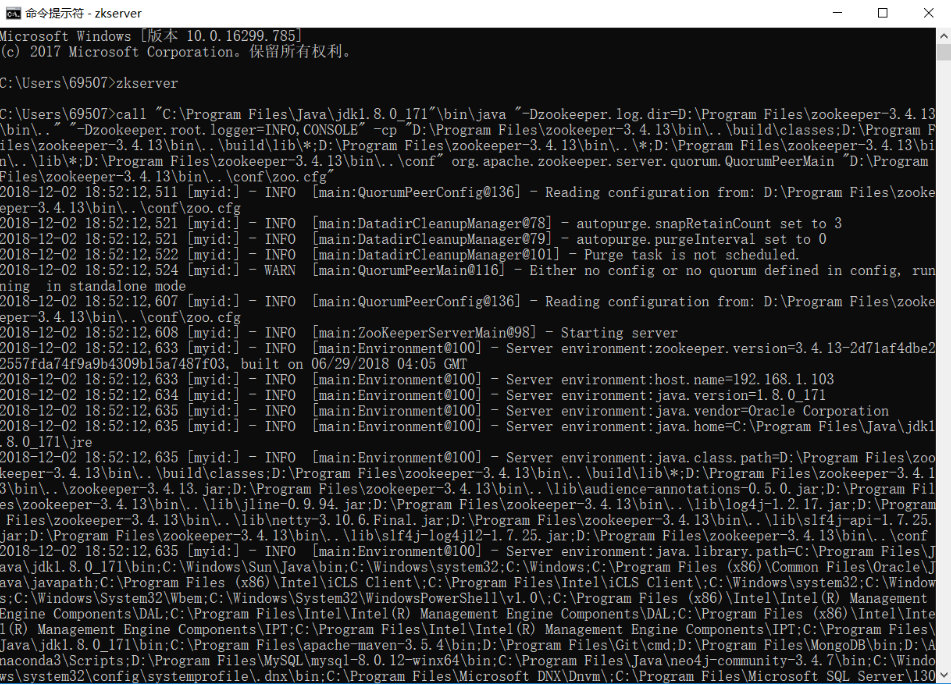
2.6. 检查安装成功与否:打开cmd窗口,输入zkserver,结果应该如下,则安装以及配置环境变量成功:
-
安装kafka
3.1 到http://kafka.apache.org/downloads.html下载
3.2 解压到自己的文件夹路径(如D:\Program Files\kafka_2.11-1.1.0)
3.3.1 修改配置文件在config文件夹下,D:\Program Files\kafka_2.11-1.1.0\server.properties
3.3.2 由于kafka有自带的zookeeper服务,所以如果跳过第2步,可以直接使用自带zk服务,记得配置对应的配置文件/config/zookeeper.properties
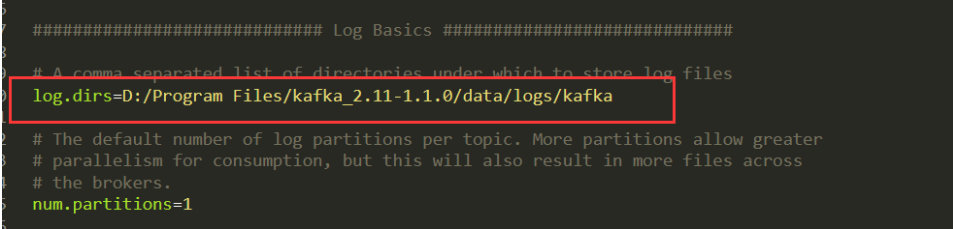
3.4.1 修改server.properties里的log.dirs:
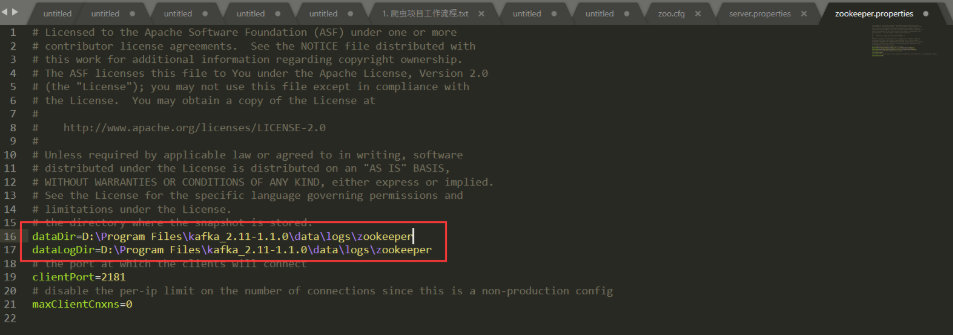
3.4.2 修改zookeeper.properties
3.5 注意观察,bin目录下有一个window文件夹,windows文件夹下的文件内容和bin下的是一样的,只是文件后缀不同,bin目录下的.sh文件需要用shell执行,bat则通过cmd窗口即可执行,当然bat文件通过shell也是可以执行的,至于两者区别,就自行百度了。调出shell窗口的方法:按住shift键+在文件夹空白处单机鼠标右键,就可以看到“在此处打开powershell窗口"的选项。
3.6 在bin目录下启动powerShell,然后入去一下命令,启动kafka:
如果是先装了zookeeper,则可以直接执行: ./windows/kafka-server-start.bat "D:/Program Files/kafka_2.11-1.1.0/config/ser ver.properties"[注意:bat 和 "D:/" 之间有一个空格] (这里,由于路径名Programe Files里包含空格,如果不用双引号引用后面的参数,会报错) 当然,也可以到bin目录的上一层,也就是kafka_2.11-1.1.0目录下执行下面的语句,效果一样: ./bin/windows/kafka-server-start.bat ./config/ser ver.properties"[注意:bat 和 "./config" 之间有一个空格]
如果没有装zookeeper,而是使用自带的,则先执行:
./windows/zookeeper-server-start.bat “D:/Program Files/kafka_2.11-1.1.0/config/zookeeper.properties”
启动自带zookeeper时,可以看到:
然后重新打开一个窗口,开启kafka服务(./windows/kafka-server-start.bat “D:/Program Files/kafka_2.11-1.1.0/config/ser
ver.properties”)时,可以看到:
说明成功了。
-
kafka的简单使用:
4.1 创建一个名字为demo的topic,指定其分区数目为1,副本工厂数目为1:
到bin/window目录下执行:./kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic demo 输出:Created topic "demo". 4.2 查看所有的topics:
./kafka-topics.bat --list --zookeeper localhost:2181如果想删除topics, 可以参考文章:kafka如何彻底删除topic及数据
4.3 向指定topic发送消息,首先打开2个新的powerShell或cmd窗口,一个生产者producer,一个消费者Consumer:
设置生产者,设置端口号,并指定topic: ./kafka-console-producer.bat --broker-list localhost:9092 --topic demo 设置消费者,设置从哪一个端口号(2181)、哪个topic(demo)、什么位置(beginning)开始取出消息: ./kafka-console-consumer.bat --zookeeper localhost:2181 --topic demo --from-beginning在producer窗口里输入消息,就可以在对应的Consumer窗口看到对应的消息
好了,大概就这些,应该可以让各位对kafka的概念和基本使用有了一个不错的理解,哈哈


相关文章:
kafka3.X基本概念和使用
kafka基本概念和使用 文章目录 kafka基本概念和使用 kafka的概念基本概念Kafka的使用 首先kafka的安装kafka的简单实用和理解搭建集群(3个节点)windows版本环境搭建 本文"kafka的概念"部分是在[初谈Kafka][ https://juejin.im/post/5a8e7f…...
用低代码平台代替Excel搭建进销存管理系统
目录 一、用低代码平台搭建系统 1.需求调研 2.基于痛点梳理业务流程 3.低代码实现 (1)基础资料模块 (2)采购管理模块 (3)销售管理模块 (4)库存管理模块 (5&…...

Redis和Memcached网络模型详解
1. Redis单线程单Reactor网络模型 1.1 redis单线程里不能执行十分耗时的流程,不然会客户端响应不及时 解决方法一: beforesleep里删除过期键操作若存在大量过期键时,会耗费大量时间,redis采用的策略之一就是采用timelimit方案超过…...
二叉搜索树的实现(递归方式)
目录 实现思路 插入操作 删除操作 完整代码 测试案例 总结 二叉搜索树(Binary Search Tree,BST)是一种常用的数据结构,它具有以下特点: 左子树上所有节点的值均小于它的根节点的值右子树上所有节点的值均大于它的…...
NetCore IIS Redis JMeter 登录压力测试
近期,由于某项目验收需要,需要登录接口同时满足至少400个账号同时并发登录,于是开始编写测试代码,以满足项目业务需要。首先,安装jdk,由于本机已安装jdk8: 如果你机器上没有安装jdk,…...

进一步了解视频美颜SDK:美颜SDK的技术原理
美颜技术在当今的数字世界中变得越来越流行,尤其是在视频直播、社交媒体和视频通话应用中。用户寻求通过美颜效果增强自己的外观,这种需求催生了众多美颜SDK(软件开发工具包)的出现。这些SDK使开发者能够轻松地将美颜功能集成到他…...

【Qt之QSetting】介绍及使用
概述 QSettings类提供了一种持久的、与平台无关的应用程序设置存储功能。 用户通常期望一个应用能在不同会话中记住其设置(窗口大小和位置,选项等)。在Windows上,这些信息通常存储在系统注册表中;在macOS和iOS上&…...
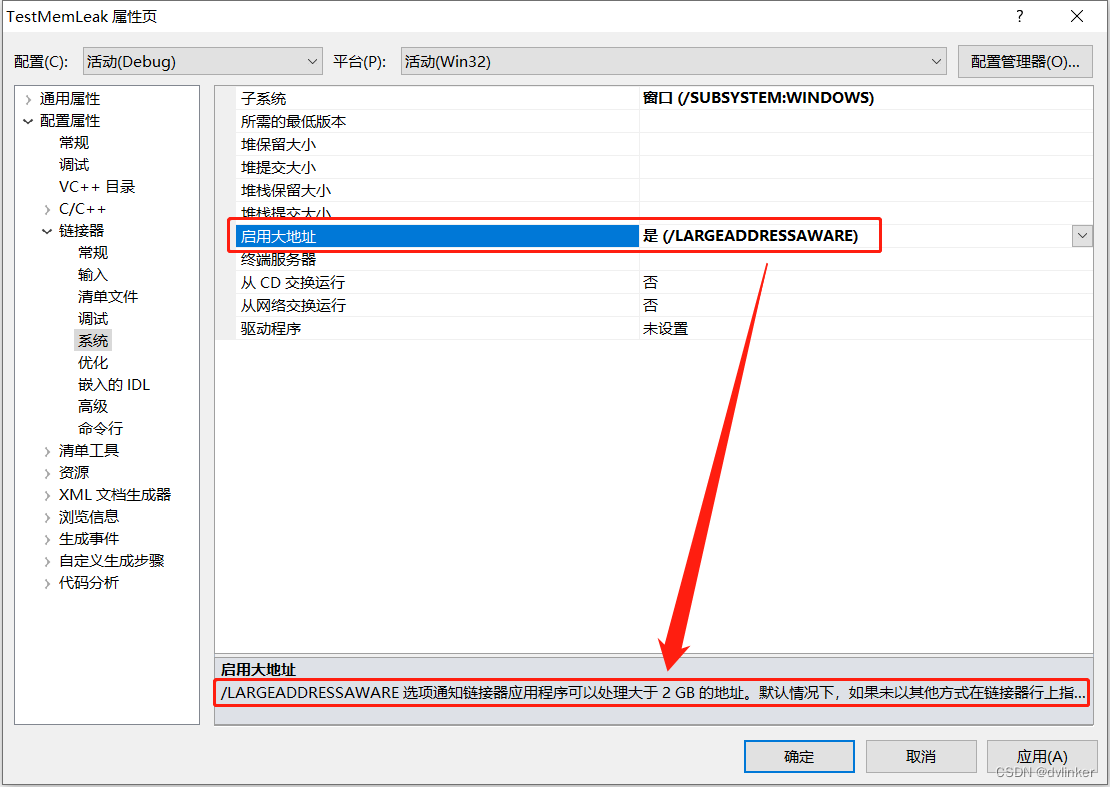
基于WebRTC构建的程序因虚拟内存不足导致闪退问题的排查以及解决办法的探究
目录 1、WebRTC简介 2、问题现象描述 3、将Windbg附加到目标进程上分析 3.1、Windbg没有附加到主程序进程上,没有感知到异常或中断 3.2、Windbg感知到了中断,中断在DebugBreak函数调用上 3.3、32位进程用户态虚拟地址和内核态虚拟地址的划分 …...
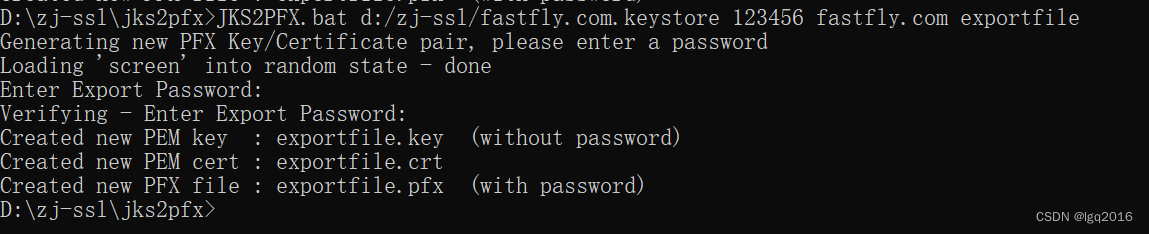
通过jdk自制https证书并配置到nginx并配置http2
生成证书 这里使用自己生成的免费证书。在${JAVA_HOME}/bin 下可以看到keytool.exe,在改目录打开cmd然后输入: keytool -genkey -v -alias lgq.com -keyalg RSA -keystore d:/zj/ssl/fastfly.com.keystore -validity 3650生成证书过程中:【你的名字】对…...

祝贺中国煤科重庆研究院和达索、百世慧PLM项目顺利结项
引言 2023年10月17日,中国煤科重庆研究院与达索系统、百世慧在重庆研究院会议室召开了产品全生命周期管理(PLM)系统结项会。中国煤科重庆研究院科技发展部副主任孙海涛、测控技术研究分院副院长于庆、重庆大学教授鄢萍、达索公司工业装备部南…...

基于springboot实现数码论坛系统设计与实现系统【项目源码+论文说明】
基于springboot实现数码论坛系统设计与实现系统演示 摘要 网络的广泛应用给生活带来了十分的便利。所以把数码论坛与现在网络相结合,利用java技术建设数码论坛系统,实现数码论坛的信息化。则对于进一步提高数码论坛发展,丰富数码论坛经验能起…...

魔域开服需要什么样的配置
魔域是一个非常受玩家喜欢的游戏,是一款大型魔幻题材的网络游戏,关于魔族入侵亚特大陆的故事,玩家在游戏里扮演不同的角色捍卫大陆安全,很多玩家想要更多的体验就会选择开新服,今天就让小编来讲一讲魔域开服要什么配置…...

7个好用的PC端设计软件,设计必看!优漫动游
身为设计师的你是不是还在为到处寻找合适的设计软件而烦恼?是不是在为因为没能用上好的软件而影响自己设计生涯的事情感到焦虑?别担心,你的烦恼可能每个成熟的设计师都遇到过,但他们最终都走了过来。借助以下7个好用的PC端设计软件…...

10-动画animation
动画animation 动画-过渡和动画之间的异同-animation-name 指定要绑定到选择器的关键帧的名称,告诉系统需要执行哪个动画-animation-duration 动画指定需要多少秒或毫秒完成,告诉系统动画持续的时长-animation-timing-function 设置动画将如何完成一个周…...

【带头学C++】----- 1.基础知识 ---- 1.24 逻辑控制语句
1.24 逻辑控制语句 本节主要学习关于C逻辑控制的一些语句的用法,结合实践代码总结一下。 1.24.1 if以及if - else(条件语句) 1.if语句: if(条件){执行语句; }//一旦执行if语句,先判断()里的条件是否满足,…...
微信公众号分销商城源码系统+多元商家+收银台 带完整的搭建教程
给大家推荐一款微信公众号分销商城源码系统,这是一个全新三级分销商城,功能十分丰富。一起来看看你吧。 微信公众号分销商城的功能: 1.商品展示和推广:商家可以在商城中展示商品信息,包括商品名称、价格、库存等&#…...

排序算法:选择排序,分别用c++、java、python实现
选择排序介绍 选择排序(Selection Sort)是一种简单的比较排序算法,它的工作原理如下: 分区: 将待排序的数组分成两个部分,一个部分是已排序的子数组,另一个部分是未排序的子数组。初始时,已排序…...
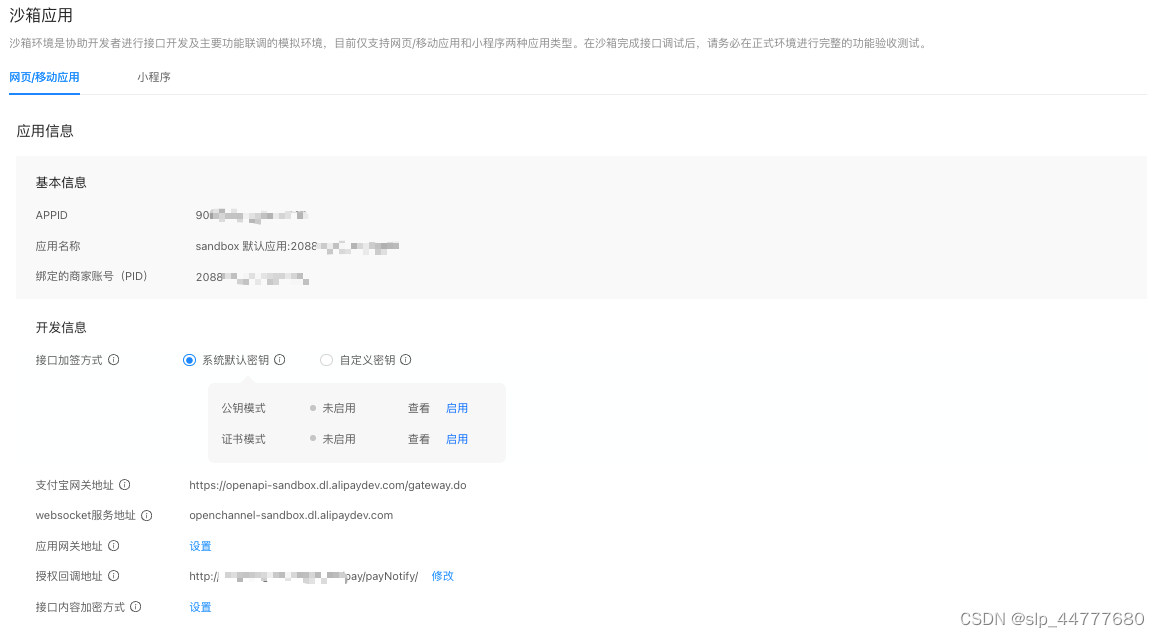
支付宝支付接入流程
一、 接入准备 支付宝支付流程没有微信那么复杂,而且支付宝支持沙箱。登录支付宝开放平台控制台 点击开发工具中的沙箱 接口加密方式,我这里使用的是自定义密钥。生成密钥的方式 使用支付宝官方提供的密钥工具,唯一要注意的是支付宝密钥工具…...
管理员|顾问必看!8个Salesforce权限集的最佳实践
Salesforce中的权限一直始终是热门话题。权限集是简档的附加。它们通常具有相同的设置,用于增加用户的权限,使其超过简档提供的权限。可以将简档视为许多用户共有的基本权限集,而权限集是部分用户需要的额外权限。 本篇文章将介绍Salesforce…...
【linux进程(六)】环境变量再理解程序地址空间初认识
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 程序地址空间 1. 前言2. 在ba…...

s2-pro效果展示:会议纪要转语音+重点语句强调式播报实录
s2-pro效果展示:会议纪要转语音重点语句强调式播报实录 1. 专业语音合成新体验 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,正在重新定义文本转语音的标准。不同于常见的聊天式语音工具,它专注于提供高质量的语音合成服务ÿ…...

终极DBeaver多线程查询优先级控制:基于查询类型的动态调整指南
终极DBeaver多线程查询优先级控制:基于查询类型的动态调整指南 【免费下载链接】dbeaver DBeaver 是一个通用的数据库管理工具,支持跨平台使用。* 支持多种数据库类型,如 MySQL、PostgreSQL、MongoDB 等;提供 SQL 编辑、查询、调试…...

# Kafka 消息队列实战指南
大数据开发核心技能:Kafka 架构原理、生产者消费者配置、Spark/Flink 集成、消息积压处理、数据一致性保障、生产环境案例,从 0 到 1 掌握企业级消息队列📌 前言 真实生产问题 问题场景: 某电商公司数据平台遇到的问题:…...

大数据毕业设计 hadoop+spark+kafka+hive动漫推荐系统 动漫数据分析 可视化 漫画推荐
1、项目介绍 技术栈: Python语言、Django框架、SQLite数据库、Echarts可视化 、HTML、基于物品协同过滤推荐算法 (1)首页------不同类 型的动漫数据 (2)动漫类型饼图 (3)动漫收藏排名和不同国家…...
)
MCP服务器性能翻倍的秘密:基于asyncio+uvloop+Pydantic V2的轻量级模板(压测QPS达12,800+)
第一章:MCP服务器开发模板概述与核心价值MCP(Model-Controller-Protocol)服务器开发模板是一套面向协议驱动、可插拔架构的后端服务构建范式,专为高并发、多协议适配(如HTTP/2、gRPC、WebSocket、MQTT)场景…...
稳定保持在3.4%(2026 - 2032))
全球碳块市场调查:年复合增长率(CAGR)稳定保持在3.4%(2026 - 2032)
市场规模:稳健增长,潜力巨大QYResearch调研数据显示,2025年全球碳块市场规模预计约为17.75亿美元,而到2032年,这一数字将跃升至22.36亿美元。在2026 - 2032年期间,年复合增长率(CAGR)…...

ViGEmBus虚拟手柄驱动:Windows内核级游戏控制器模拟核心技术解析与应用指南
ViGEmBus虚拟手柄驱动:Windows内核级游戏控制器模拟核心技术解析与应用指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus作为Windows…...

本地部署 Ollama + DeepSeek 完整指南:免费跑大模型,数据不出本地
本地部署 Ollama DeepSeek 完整指南:免费跑大模型,数据不出本地不花一分钱,不用科学上网,在自己电脑上跑 DeepSeek 大模型,这篇教程手把手带你搞定一、为什么要本地部署? 很多人用 AI 工具都是调用云端 AP…...

Degrees of Lewdity中文本地化版本完全指南:从安装到精通
Degrees of Lewdity中文本地化版本完全指南:从安装到精通 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Localization …...

从移位相加到硬件实现:FPGA二进制乘法器的设计精髓
1. 从纸笔计算到硬件逻辑:二进制乘法的本质 记得第一次学二进制乘法时,我拿着铅笔在纸上画了半天移位相加的步骤。比如计算11011011,就像小学生列竖式一样,先写下110111101,然后11011左移一位变成11010,接着…...