竞赛 深度学习图像分类算法研究与实现 - 卷积神经网络图像分类
文章目录
- 0 前言
- 1 常用的分类网络介绍
- 1.1 CNN
- 1.2 VGG
- 1.3 GoogleNet
- 2 图像分类部分代码实现
- 2.1 环境依赖
- 2.2 需要导入的包
- 2.3 参数设置(路径,图像尺寸,数据集分割比例)
- 2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
- 2.5 数据预处理
- 2.6 训练分类模型
- 2.7 模型训练效果
- 2.8 模型性能评估
- 3 1000种图像分类
- 4 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习图像分类算法研究与实现 - 卷积神经网络图像分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 常用的分类网络介绍
1.1 CNN
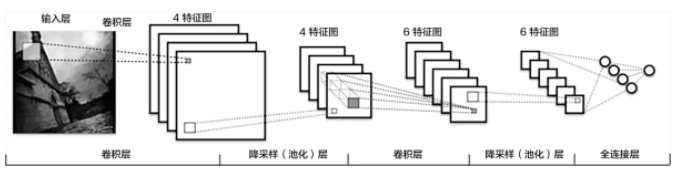
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。如下图:
-
卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
-
池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
-
全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
-
非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
-
Dropout : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合
在CNN的训练过程总,由于每一层的参数都是不断更新的,会导致下一次输入分布发生变化,这样就需要在训练过程中花费时间去设计参数。在后续提出的BN算法中,由于每一层都做了归一化处理,使得每一层的分布相对稳定,而且实验证明该算法加速了模型的收敛过程,所以被广泛应用到较深的模型
1.2 VGG
VGG 模型是由牛津大学提出的(19层网络),该模型的特点是加宽加深了网络结构,核心是五组卷积操作,每两组之间做Max-
Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。该模型由于每组内卷积层的不同主要分为
11、13、16、19 这几种模型

增加网络深度和宽度,也就意味着巨量的参数,而巨量参数容易产生过拟合,也会大大增加计算量。
1.3 GoogleNet
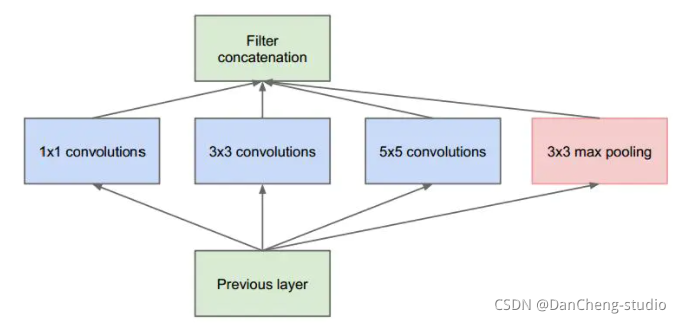
GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想.
NIN模型特点:
-
1. 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。 - 2)设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
2 图像分类部分代码实现
2.1 环境依赖
python 3.7
jupyter-notebook : 6.0.3
cudatoolkit 10.0.130
cudnn 7.6.5
tensorflow-gpu 2.0.0
scikit-learn 0.22.1
numpy
cv2
matplotlib
2.2 需要导入的包
import osimport cv2import numpy as npimport pandas as pdimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers,modelsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.callbacks import Callbackfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.applications import VGG19from tensorflow.keras.models import load_modelimport matplotlib.pyplot as pltfrom sklearn.preprocessing import label_binarizetf.compat.v1.disable_eager_execution()os.environ['CUDA_VISIBLE_DEVICES'] = '0' #使用GPU
2.3 参数设置(路径,图像尺寸,数据集分割比例)
preprocessedFolder = '.\\ClassificationData\\' #预处理文件夹outModelFileName=".\\outModelFileName\\" ImageWidth = 512ImageHeight = 320ImageNumChannels = 3TrainingPercent = 70 #训练集比例ValidationPercent = 15 #验证集比例
2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
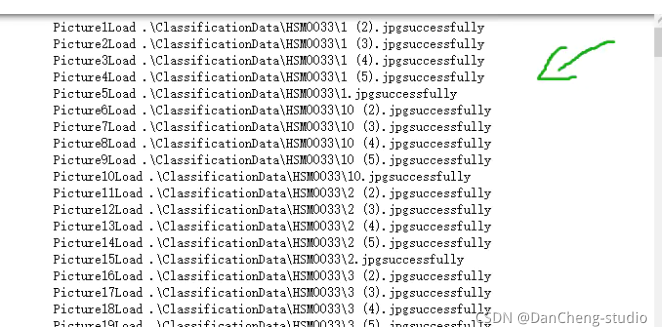
def read_dl_classifier_data_set(preprocessedFolder):num = 0 # 图片的总数量cnt_class = 0 #图片所属的类别label_list = [] # 存放每个图像的label,图像的类别img_list = [] #存放图片数据for directory in os.listdir(preprocessedFolder):tmp_dir = preprocessedFolder + directorycnt_class += 1for image in os.listdir(tmp_dir):num += 1tmp_img_filepath = tmp_dir + '\\' + imageim = cv2.imread(tmp_img_filepath) # numpy.ndarrayim = cv2.resize(im, (ImageWidth, ImageHeight)) # 重新设置图片的大小img_list.append(im)label_list.append(cnt_class) # 在标签中添加类别print("Picture " + str(num) + "Load "+tmp_img_filepath+"successfully")
print("共有" + str(num) + "张图片")
print("all"+str(num)+"picturs belong to "+str(cnt_class)+"classes")
return np.array(img_list),np.array(label_list)all_data,all_label=read_dl_classifier_data_set(preprocessedFolder)
2.5 数据预处理
图像数据压缩, 标签数据进行独立热编码one-hot
def preprocess_dl_Image(all_data,all_label):all_data = all_data.astype("float32")/255 #把图像灰度值压缩到0--1.0便于神经网络训练all_label = to_categorical(all_label) #对标签数据进行独立热编码return all_data,all_labelall_data,all_label = preprocess_dl_Image(all_data,all_label) #处理后的数据
对数据及进行划分(训练集:验证集:测试集 = 0.7:0.15:0.15)
def split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent):s = np.arange(all_data.shape[0])np.random.shuffle(s) #随机打乱顺序all_data = all_data[s] #打乱后的图像数据all_label = all_label[s] #打乱后的标签数据all_len = all_data.shape[0]train_len = int(all_len*TrainingPercent/100) #训练集长度valadation_len = int(all_len*ValidationPercent/100)#验证集长度temp_len=train_len+valadation_lentrain_data,train_label = all_data[0:train_len,:,:,:],all_label[0:train_len,:] #训练集valadation_data,valadation_label = all_data[train_len:temp_len, : , : , : ],all_label[train_len:temp_len, : ] #验证集test_data,test_label = all_data[temp_len:, : , : , : ],all_label[temp_len:, : ] #测试集return train_data,train_label,valadation_data,valadation_label,test_data,test_labeltrain_data,train_label,valadation_data,valadation_label,test_data,test_label=split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent)
2.6 训练分类模型
-
使用迁移学习(基于VGG19)
-
epochs = 30
-
batch_size = 16
-
使用 keras.callbacks.EarlyStopping 提前结束训练
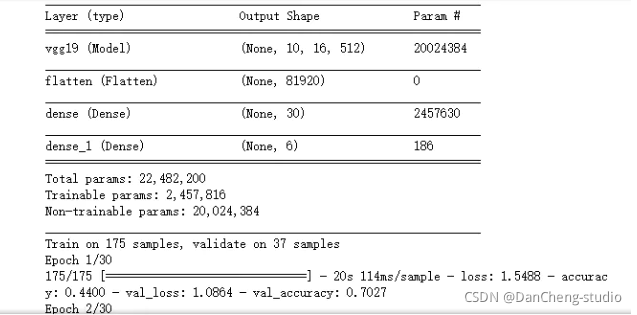
def train_classifier(train_data,train_label,valadation_data,valadation_label,lr=1e-4):conv_base = VGG19(weights='imagenet',include_top=False,input_shape=(ImageHeight, ImageWidth, 3) ) model = models.Sequential()model.add(conv_base)model.add(layers.Flatten())model.add(layers.Dense(30, activation='relu')) model.add(layers.Dense(6, activation='softmax')) #Dense: 全连接层。activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层conv_base.trainable=Falsemodel.compile(loss='categorical_crossentropy',#loss: 拟合损失方法,这里用到了多分类损失函数交叉熵 optimizer=Adam(lr=lr),#optimizer: 优化器,梯度下降的优化方法 #rmspropmetrics=['accuracy'])model.summary() #每个层中的输出形状和参数。early_stoping =tf.keras.callbacks.EarlyStopping(monitor="val_loss",min_delta=0,patience=5,verbose=0,baseline=None,restore_best_weights=True)history = model.fit(train_data, train_label,batch_size=16, #更新梯度的批数据的大小 iteration = epochs / batch_size,epochs=30, # 迭代次数validation_data=(valadation_data, valadation_label), # 验证集callbacks=[early_stoping])return model,history model,history = train_classifier(train_data,train_label,valadation_data,valadation_label,)
2.7 模型训练效果
def plot_history(history):history_df = pd.DataFrame(history.history)history_df[['loss', 'val_loss']].plot()plt.title('Train and valadation loss')history_df = pd.DataFrame(history.history)history_df[['accuracy', 'val_accuracy']].plot()plt.title('Train and valadation accuracy')plot_history(history)
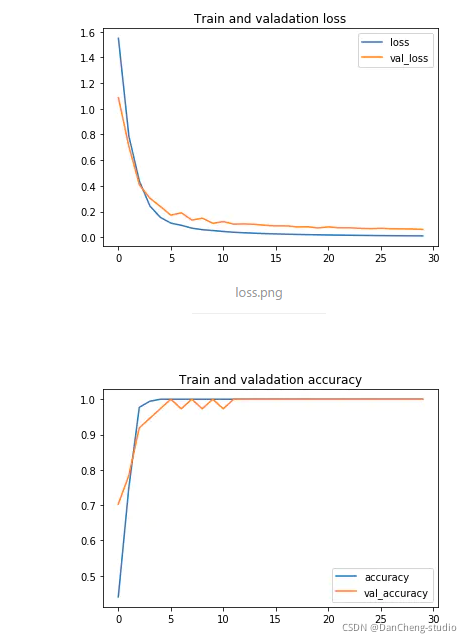
2.8 模型性能评估
-
使用测试集进行评估
-
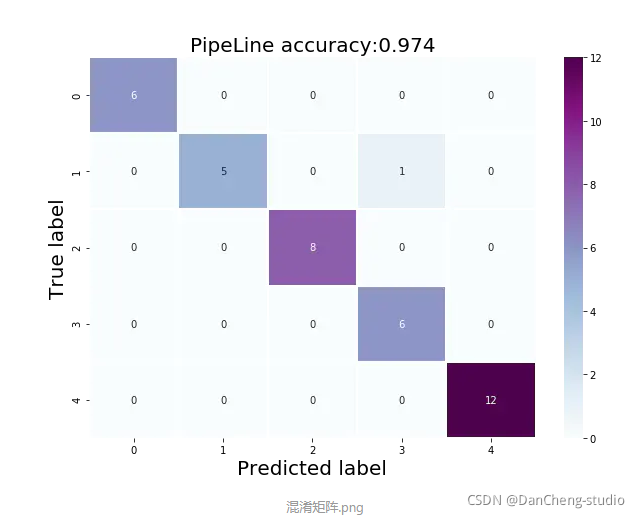
输出分类报告和混淆矩阵
-
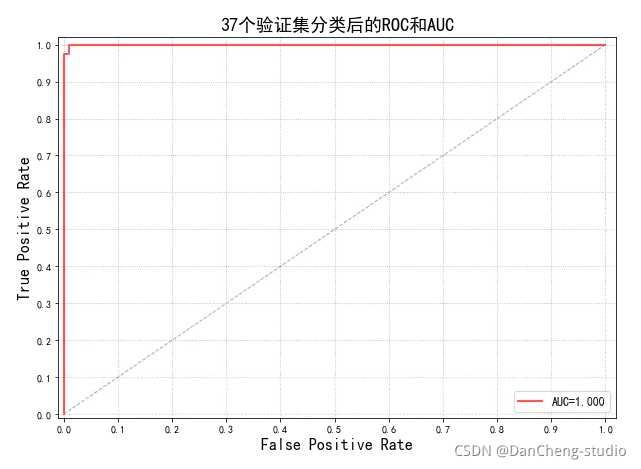
绘制ROC和AUC曲线
from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score import seaborn as sns Y_pred_tta=model.predict_classes(test_data) #模型对测试集数据进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 Y_pred_tta=model.predict_classes(test_data) #模型对测试集进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 print('验证集分类报告:\n',classification_report(Y_test,Y_pred_tta)) confusion_mc = confusion_matrix(Y_test,Y_pred_tta)#混淆矩阵 df_cm = pd.DataFrame(confusion_mc) plt.figure(figsize = (10,7)) sns.heatmap(df_cm, annot=True, cmap="BuPu",linewidths=1.0,fmt="d") plt.title('PipeLine accuracy:{0:.3f}'.format(accuracy_score(Y_test,Y_pred_tta)),fontsize=20) plt.ylabel('True label',fontsize=20) plt.xlabel('Predicted label',fontsize=20)

from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.metrics import roc_curve
from sklearn import metrics
import matplotlib as mpl# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(test_data)
# 1、调用函数计算验证集的AUC
print ('调用函数auc:', metrics.roc_auc_score(test_label, y_score, average='micro'))
# 2、手动计算验证集的AUC
#首先将矩阵test_label和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(test_label.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.figure(figsize = (10,7))
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title('37个验证集分类后的ROC和AUC', fontsize=18)
plt.show()
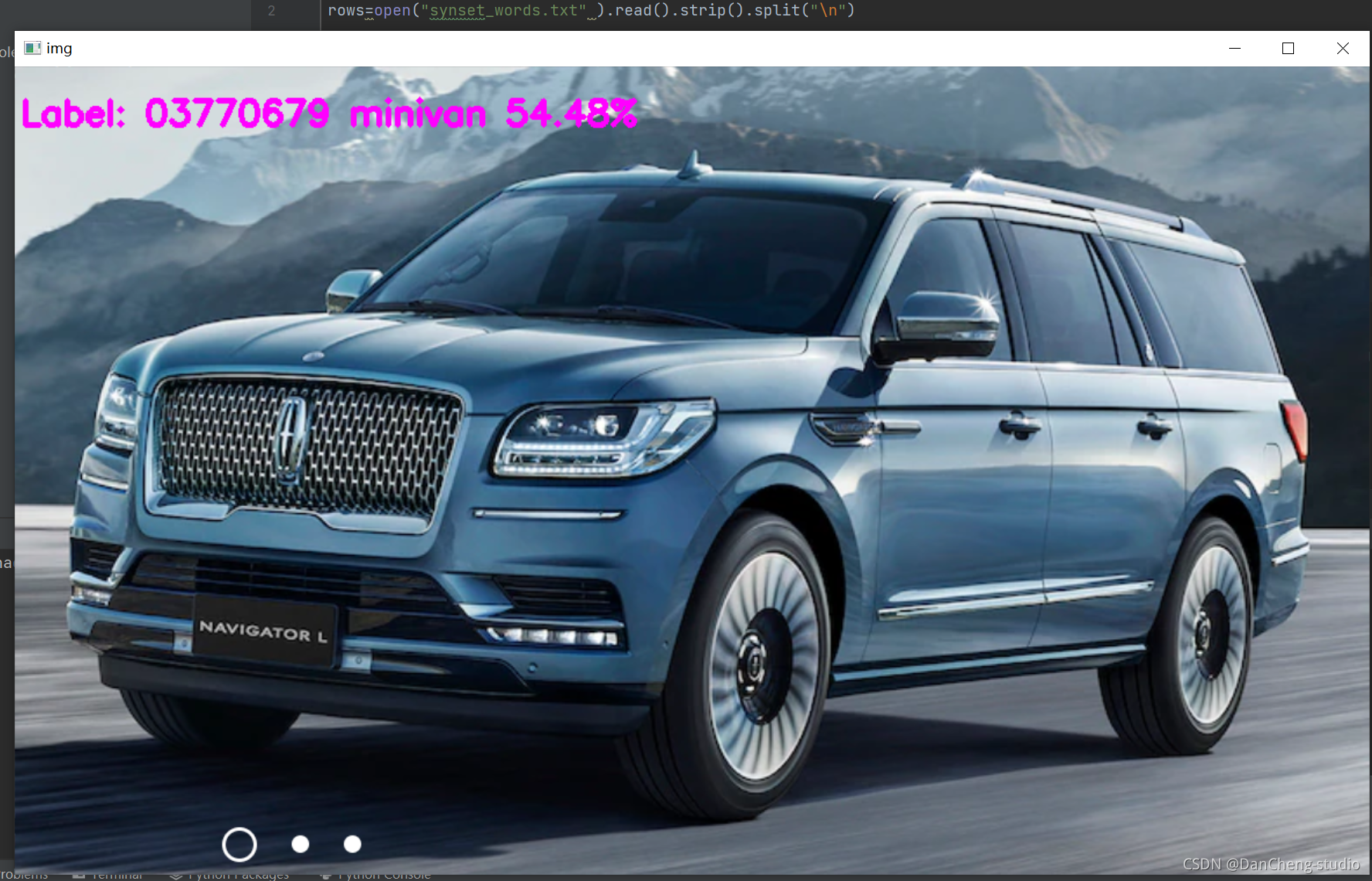
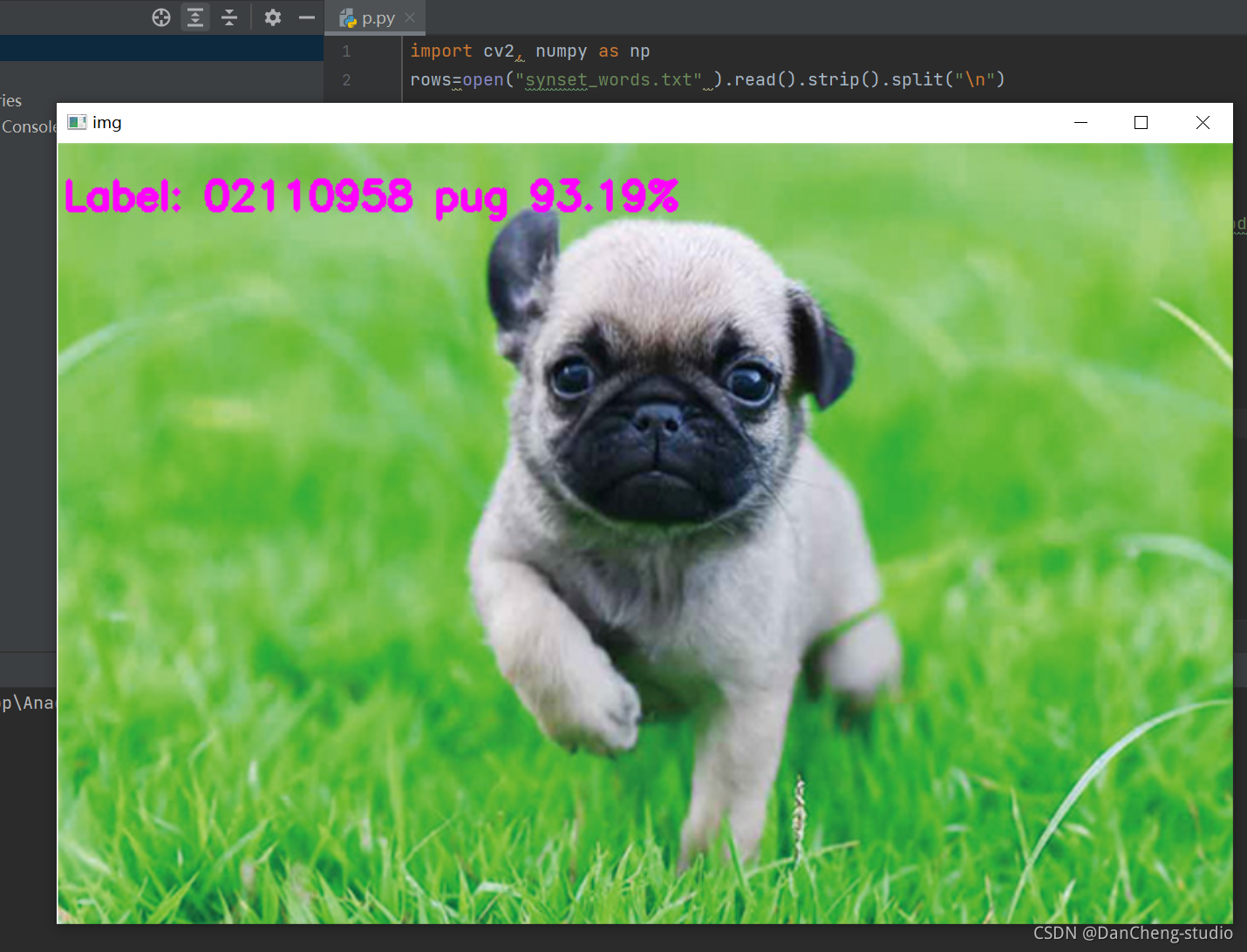
3 1000种图像分类
这是学长训练的能识别1000种类目标的图像分类模型,演示效果如下

4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 深度学习图像分类算法研究与实现 - 卷积神经网络图像分类
文章目录 0 前言1 常用的分类网络介绍1.1 CNN1.2 VGG1.3 GoogleNet 2 图像分类部分代码实现2.1 环境依赖2.2 需要导入的包2.3 参数设置(路径,图像尺寸,数据集分割比例)2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)2.5 数据预…...
jvm摘要
第 2 章 Java 内存区域与内存溢出异常 2.2 运行时数据区域 程序计数器-线程私有:是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。 程序计数器是唯一一个没有规定任何OutOfMemoryError 情况的区域。 Java 虚拟机栈-线程私有:用于执行Java …...

GZ035 5G组网与运维赛题第1套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第1套 赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) 子任务2:5G室内与室外站点建设(20分) 竞赛模块2--5G公共网络运维与优化(3…...

MySQL数据xtrabackup物理备份方法
目录 一、物理备份的方式二、xtrabackup物理备份1.安装xtrabackup2.完整备份/恢复流程3.增量备份流程4.差异备份流程5.物理备份总结 一、物理备份的方式 1.完整备份 每次对数据进行完整的备份,即对整个数据库的备份、数据库结构和文件结构的备份,保存的…...
vue3 使用 elementUi: ./lib/theme-chalk/index.css is not exported from package
目录 1. 在 vue3 中使用 element-ui2. 如果启动报错:Module not found: Error: Package path ./lib/theme-chalk/index.css is not exported from package 1. 在 vue3 中使用 element-ui 在 vue3 中使用 element-ui,我们的流程一般是这样的:…...
[ROS系列]ORB_SLAM3错误版本(仅记录)
背景: 1、设备:pc;旭日派x3(后续会加上,目前只有pc) 2、环境:Ubuntu20.04;ROS2(Foxy) ros2机器人foxy版用笔记本摄像头跑单目orb_slam3-CSD…...

APP盾的防御机制及应用场景
移动应用(APP)在我们日常生活中扮演着越来越重要的角色,但随之而来的是各种网络安全威胁的增加。为了保障APP的安全性,APP盾作为一种专门设计用于防御移动应用威胁的工具得以广泛应用。本文将深入探讨APP盾的防御机制以及在不同应…...
Unity性能优化一本通
文章目录 关于Unity性能优化一、资源部分:1、图片1.1、 图片尺寸越小越好1.2、使用2N次幂大小1.3、取消勾选Read/Write Enabled1.4、图片压缩1.5、禁用多余的Mip Map1.6、合并图集 2、模型2.1.限制模型面数2.2.限制贴图的大小2.3.禁用Read/Write Enables2.4.不勾选其…...
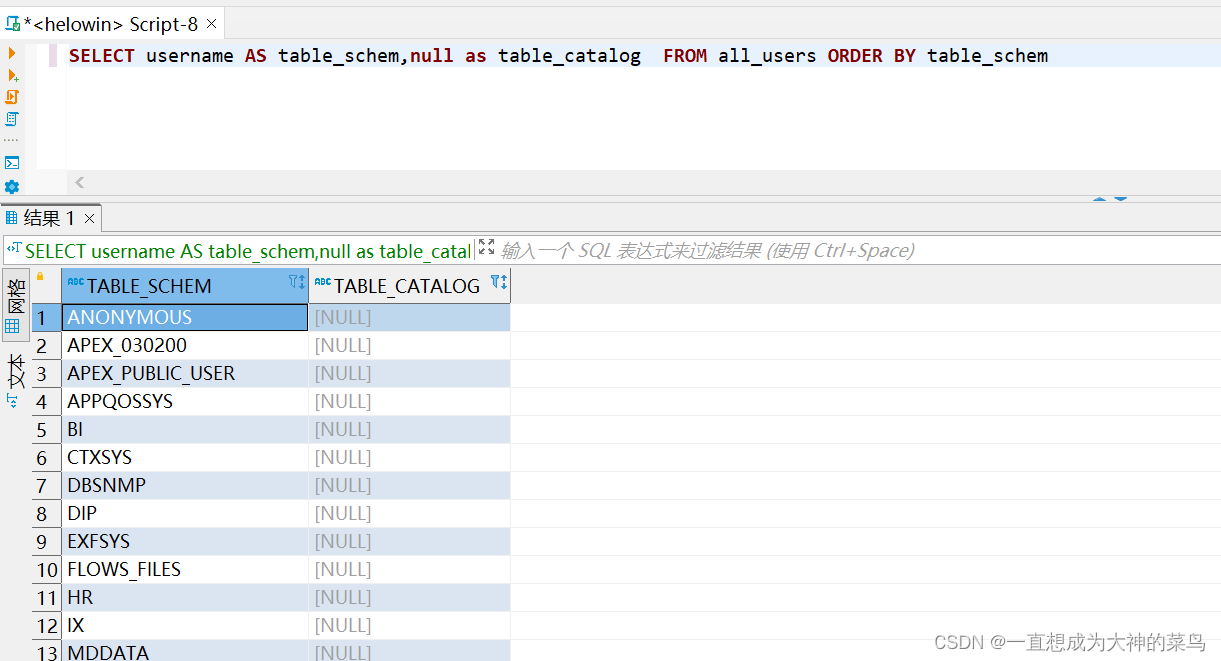
Mysql,SqlServer,Oracle获取库名 表名 列名
先看下需求背景: 获取某个数据源连接下所有库名,库下所有表名,表中所有字段 1.MySql 先说MySql吧,最简单 1.1获得所有数据库库名 这是一个mysql和sqlserver公用的方法,这里url不用担心数据库问题,他其实…...

errno变量和显示错误信息
一、errno Linux很多函数发生错误,只会返回-1。因此,我们只知道函数发生了错误,却不知道具体发生了什么错误。 因此Linux 系统下对常见的错误做了一个编号,每一个编号都代表着每一种不同的错误类型。 发生错误时,对…...

Centos 7 安装 Docker Enginee
文章目录 Centos 安装 Docker Enginee系统要求卸载旧版本使用 RPM 仓库设置 Docker 仓库安装 Docker Enginee升级 Docker Enginee 卸载 Docker Centos 安装 Docker Enginee 要在 Centos 安装 Docker Enginee,需要满足以下要求: 系统要求 CentOS 7Cent…...

通过js来实现用身份证号来判断性别和出生年月
html: <input type"text" id"shenfenzhenghao" oninput"hao()" placeholder"证件号"><input type"text" id"xingbie" disabled"disabled" placeholder"性别"><input type&qu…...

华为数通方向HCIP-DataCom H12-831题库(多选题:61-80)
第61题 在MPLS VPN中,为了区分使用相同地址空间的IPV4前缀,将IPV4的地址增加了RD值,下列选项描述正确的是: A、在PE设备上,每一个VPN实例都对应一个RD值,同一PE设备上,必须保证RD值唯一 B、RD可用于来控制VPN路由信息的发布 C、RD在传递过程中作为BGP的扩展团体性封装在…...

【T】03
A 【模板】快速幂 板子,略 #include<bits/stdc.h> #define ll long long using namespace std; ll a,p,k; int main() {scanf("%lld%lld%lld",&a,&p,&k);printf("%lld^%lld mod %lld",a,p,k);ll ans1,wa;a%k;while(p){if(p…...

VBA技术资料MF73:将Logo添加到页眉侧
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...
)
听GPT 讲Rust源代码--library/std(1)
std git:(master) ✗ tree.├── Cargo.toml├── benches│ ├── hash│ │ ├── map.rs│ │ ├── mod.rs│ │ └── set_ops.rs│ └── lib.rs├── build.rs├── src│ ├── alloc.rs│ ├── ascii.rs│ ├── backtrace│ │…...

Vue源码总结
1,根据vue工程package.json配置文件查看scripts命令,找到build命令执行的js文件 2,根据构建执行的js文件继续跟进,找到主入口文件 3,从主入口文件直接分析主干代码,追踪export的Vue对象 4,跟…...

记一次调试微信订阅消息的坑
微信发送订阅消息文档 发送订阅消息 | 微信开放文档 按照文档说明的,一直报data param错误,编码47001,从程序中把请求参数扣出来,放到微信提供的工具里面调试 微信调试工具 然后报data参数要用string,转化为string…...

ASP.NET Core3.1 API 创建(Swagger配置、数据库连接Sql Server)、开发、部署
文章目录 创建项目点击Nuget安装包删除原有controllers编辑新建controll、添加注释Startup 注册Swagger服务使用swagger中间件配置XML注释更改启动端口 launchsettings.json在startup.cs跨域处理运行 数据库设计与连接安装库新建类继承框架根据数据库表设计对应设计类在DataCon…...
)
大数据之LibrA数据库常见术语(八)
SCTP Stream Control Transmission Protocol,流控制传输协议。是IETF于2000年新定义的一个传输层协议。是提供基于不可靠传输业务的协议之上的可靠的数据报传输协议。SCTP的设计用于通过IP网传输SCN窄带信令消息。 Session 数据库系统在接收到应用程序的连接请求时…...

JPEXS Free Flash Decompiler与Web3.0存储:去中心化SWF文件管理的终极指南
JPEXS Free Flash Decompiler与Web3.0存储:去中心化SWF文件管理的终极指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的开源…...

本地部署 Ollama + DeepSeek 完整指南:免费跑大模型,数据不出本地
本地部署 Ollama DeepSeek 完整指南:免费跑大模型,数据不出本地不花一分钱,不用科学上网,在自己电脑上跑 DeepSeek 大模型,这篇教程手把手带你搞定一、为什么要本地部署? 很多人用 AI 工具都是调用云端 AP…...

ETH-01模块避坑指南:为什么HTTP协议不行而TCP直接监听成功?
ETH-01模块协议选择实战:从HTTP困境到TCP高效监听 第一次拿到ETH-01这个串口转以太网模块时,我和大多数开发者一样,本能地选择了HTTP协议进行通信测试。毕竟在Web开发领域,HTTP就像空气一样无处不在。但当我花了整整两天时间调试…...
)
Echarts实战:如何用散点图+面积图模拟Power BI丝带图效果(附完整代码)
Echarts实战:用散点图与面积图组合实现Power BI丝带图效果 1. 理解丝带图的核心价值与实现难点 丝带图(Ribbon Chart)作为Power BI的特色可视化组件,其独特之处在于能够直观展示数据在不同时间维度上的变化趋势和相对排名。这种图…...
)
Debian 12上彻底卸载TigerVNC的5个隐藏步骤(附残留文件清理技巧)
Debian 12上彻底卸载TigerVNC的5个隐藏步骤(附残留文件清理技巧) 作为Linux系统管理员,你是否遇到过TigerVNC卸载后仍然出现端口占用或配置冲突的情况?常规的apt remove往往无法彻底清除所有痕迹。本文将揭示那些鲜为人知的清理技…...

跨境服务数字化转型 JAVA 国际版打手俱乐部陪玩系统完整开发教程
以下是基于JAVA开发国际版打手俱乐部陪玩系统的完整开发教程,涵盖技术选型、核心功能实现、安全合规及部署方案:一、技术选型与架构设计后端框架:Spring Boot 3.2 Spring Cloud Alibaba:提供微服务拆分能力,支持Nacos…...

用Mermaid Live Editor 5分钟搞定技术图表:从零开始的完整实战指南
用Mermaid Live Editor 5分钟搞定技术图表:从零开始的完整实战指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid…...

IT 流程越来越完整,但管理反而变得更难了
在很多企业的 IT 管理过程中,一个非常明显的趋势是:流程在不断增加。 从最初的简单问题处理,到后来的事件管理、问题管理、变更管理,再到审批流程、发布流程,各类流程逐渐被建立起来。从管理角度看,这是一种…...
)
STM32F103C8T6与HC05蓝牙模块实战:手机APP控制OLED显示(附完整代码)
STM32F103C8T6与HC05蓝牙模块实战:手机APP控制OLED显示(附完整代码) 1. 项目概述与硬件准备 在物联网终端设备交互场景中,蓝牙通信因其低功耗、低成本的特点成为短距离无线传输的理想选择。本项目基于STM32F103C8T6微控制器与HC05…...

BilibiliDown:你的专属B站视频管家,轻松下载与管理海量内容
BilibiliDown:你的专属B站视频管家,轻松下载与管理海量内容 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.…...