代码解读-自然语言处理
目录
- demo3文本转为向量
- 代码
- 解读
- 给出每一步的输出
demo3文本转为向量
代码
from tensorflow.keras.preprocessing.text import Tokenizer # 标记器(每一个词,以我们的数值做映射,)words = ['LaoWang has a Wechat account.', 'He is not a nice person.', 'Be careful.'] # 把这句话中每一个单词,映射成我们的数值
tokenizer = Tokenizer(num_words=15) # 上面三句话中,词的总数不超过 15 个(估算的值), num_words 设置单词的数量
tokenizer.fit_on_texts(words)
word_index = tokenizer.word_index
print(word_index, len(word_index))
# 把文本转化为序列编码
sequences = tokenizer.texts_to_sequences(words)
print(sequences)
# 文本转化为矩阵
one_hot_matrix = tokenizer.texts_to_matrix(words, mode='binary')
# 向量化是构建神经网络的第一步
print(tokenizer.word_index.keys())
print(one_hot_matrix, one_hot_matrix.shape)
解读
这段代码使用tensorflow的keras库中的Tokenizer类对文本数据进行预处理。让我们逐步解读这段代码:
- 导入必要的库
from tensorflow.keras.preprocessing.text import Tokenizer
这行代码导入了Tokenizer类,这是一个用于文本标记化的工具,可以将每个词映射到一个数值。
- 定义文本数据
words = ['LaoWang has a Wechat account.', 'He is not a nice person.', 'Be careful.']
这里定义了一个包含三个句子的列表。
- 初始化标记器
tokenizer = Tokenizer(num_words=15)
这里创建了一个Tokenizer对象,设置了最大的单词数为15。这意味着它只会考虑频率最高的15个单词。
- 适应数据
tokenizer.fit_on_texts(words)
这行代码会将定义的句子列表传给标记器,使其学习句子中的单词及其频率。
- 获取词到索引的映射
word_index = tokenizer.word_index
print(word_index, len(word_index))
这里获取了每个词及其对应的索引,并打印它们。len(word_index)将显示总共有多少个唯一单词。
- 将文本转化为序列编码
sequences = tokenizer.texts_to_sequences(words)
print(sequences)
此行代码将原始句子转化为整数序列,每个整数对应句子中的一个单词。例如,如果“LaoWang”对应的索引是1,则“LaoWang”在序列中将被替换为1。
- 文本转化为矩阵
one_hot_matrix = tokenizer.texts_to_matrix(words, mode='binary')
这行代码将句子转换为二进制矩阵。如果一个词在句子中,那么它的位置为1,否则为0。
- 显示单词和矩阵
print(tokenizer.word_index.keys())
print(one_hot_matrix, one_hot_matrix.shape)
这两行代码首先打印出所有的单词,然后打印出转化后的二进制矩阵以及它的形状。
综上所述,这段代码的主要目的是展示如何使用Tokenizer进行文本的预处理,从而为后续的神经网络模型做准备。
给出每一步的输出
在每行代码的末尾添加注释,以描述其执行后的结果。
from tensorflow.keras.preprocessing.text import Tokenizerwords = ['LaoWang has a Wechat account.', 'He is not a nice person.', 'Be careful.'] # words = ['LaoWang has a Wechat account.', 'He is not a nice person.', 'Be careful.']tokenizer = Tokenizer(num_words=15) # 初始化了一个 Tokenizer 对象tokenizer.fit_on_texts(words) # 这里没有直接的输出,它只是让 tokenizer 学习 words 的内容word_index = tokenizer.word_index
print(word_index, len(word_index)) # 输出 word_index 的内容和它的长度, 例如: {'laowang': 1, 'has': 2,...} 12sequences = tokenizer.texts_to_sequences(words)
print(sequences) # 输出 sequences, 例如: [[1, 2, 3, 4, 5], [6, 7, 8, 3, 9, 10], [11, 12]]one_hot_matrix = tokenizer.texts_to_matrix(words, mode='binary')
# 没有直接的输出,但 one_hot_matrix 会变成一个二进制矩阵print(tokenizer.word_index.keys()) # 输出 word_index 的所有键,例如: dict_keys(['laowang', 'has',...])
print(one_hot_matrix, one_hot_matrix.shape) # 输出 one_hot_matrix 的内容和形状, 例如: [[0., 1., 1., ...], ...] (3, 15)
注意:以上的输出值示例(例如:'laowang': 1, 'has': 2,...)是基于输入数据而给出的假设。实际的输出可能会根据具体的输入数据和Tokenizer的实现方式而有所不同。
相关文章:

代码解读-自然语言处理
目录 demo3文本转为向量代码解读给出每一步的输出 demo3文本转为向量 代码 from tensorflow.keras.preprocessing.text import Tokenizer # 标记器(每一个词,以我们的数值做映射,)words [LaoWang has a Wechat account., He is not a nice person., …...

docker指令
镜像操作: # 搜索镜像 docker search image_name # 搜索结果过滤:是否是官方 docker search --filter --filter is-official image_name # 搜索结果过滤:是否是自动化构建 docker search --filter --filter is-automated image_name # 搜索结…...
【MySql】9- 实践篇(七)
文章目录 1. 一主多从的主备切换1.1 基于位点的主备切换1.2 GTID1.3 基于 GTID 的主备切换1.4 GTID 和在线 DDL 2. 读写分离问题2.1 强制走主库方案2.2 Sleep 方案2.3 判断主备无延迟方案2.4 配合 semi-sync方案2.5 等主库位点方案2.6 GTID 方案 3. 如何判断数据库是否出问题了…...

Maven compile时报错 系统资源不足,出现OOM:GC overhead limit exceeded
今天在对项目进行Maven clean compile的时候,报出了如下的错误, 系统资源不足。 有关详细信息,请参阅一下堆栈跟踪。 java.lang.OutOfMemoryError: GC overhead limit exceededat java.util.EnumSet.noneOf(EnumSet.java:115)at com.sun.too…...

启动内核ip转发和其他优化
1.临时修改 echo 1 > /proc/sys/net/ipv4/ip_forward echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse 2.配置文件修改 vim /etc/sysctl.conf net.ipv4.ip_forward 1 net.ipv4.tcp_tw_reuse 1 vm.swappiness 0 kernel.sysrq 1 net.ipv4.neigh.default.gc_stale_t…...
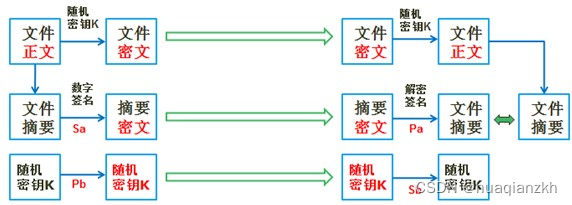
信息安全技术
1.与区块链相关的技术 区块链技术的核心是一系列的信息安全技术,其体系结构为: 区块链技术核心相关技术:A..非对称加密 B.时间戳 C.哈希函数 D.智能合约 E.POS 2.哈希函数 哈希算法 MD5SHA 哈希算法作用 用于保障信息完…...

SQL 选择数据库 USE语句
SQL 选择数据库 USE语句 当SQL Schema中有多个数据库时,在开始操作之前,需要选择一个执行所有操作的数据库。 SQL USE语句用于选择SQL架构中的任何现有数据库。 句法 USE语句的基本语法如下所示 : USE DatabaseName;数据库名称在RDBMS中必须是唯一的。…...
FL Studio21版无限破解版下载 软件内置破解补丁
FL Studio是一款非常好用方便的音频媒体制作工具,它的功能是非常的强大全面的,想必那些喜欢音乐创作的朋友们应该都知道这款软件是多么的好用吧,它还能够给用户们带来更多的创作灵感,进一步加强提升我们的音乐制作能力。该软件还有…...
【代码随想录】算法训练计划02
1、977. 有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 思路: 这题思路在于——双指针…...

hive针对带有特殊字符非法json数据解析
一、背景 有的时候前端或者后端进行埋点日志,会把json里面的数据再加上双引号,或者特殊字符,在落日志的时候,组装的格式就不是正常的json数据了,我们就需要将带有特殊字符的json数据解析成正常的json数据。 二、正则…...

【C++进阶之路】第三篇:二叉搜索树 kv模型
文章目录 一、二叉搜索树1.二叉搜索树概念2.二叉搜索树操作3.二叉搜索树的实现 二、二叉搜索树的应用1.kv模型2.kv模型的实现 三、 二叉搜索树的性能分析 一、二叉搜索树 1.二叉搜索树概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性…...
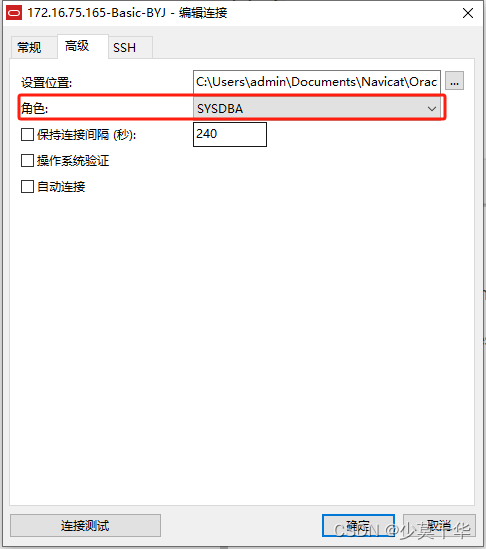
【Oracle】Navicat Premium 连接 Oracle的两种方式
Navicat Premium 使用版本说明 Navicat Premium 版本 11.2.16 (64-bit) 一、配置OCI 1.1 配置OCI环境变量 1.1.2 设置\高级系统设置 1.1.2 系统属性\高级\环境变量(N) 1.1.3 修改/添加系统变量 ORACLE_HOME ORACLE_HOME D:\app\root\product\12.1.0\dbhome_11.1.4 添加系…...

在python里如何实现switch函数的功能
在许多编程语言中,包括Python,都提供了switch语句或类似的功能来根据不同的条件执行不同的代码块。然而,Python本身并没有内置的switch语句,但是您可以使用其他方式来实现类似的功能。下面是一种常见的方法: 使用if-e…...

Python 继承和子类示例:从 Person 到 Student 的演示
继承允许我们定义一个类,该类继承另一个类的所有方法和属性。父类是被继承的类,也叫做基类。子类是从另一个类继承的类,也叫做派生类。 创建一个父类 任何类都可以成为父类,因此语法与创建任何其他类相同: 示例&…...
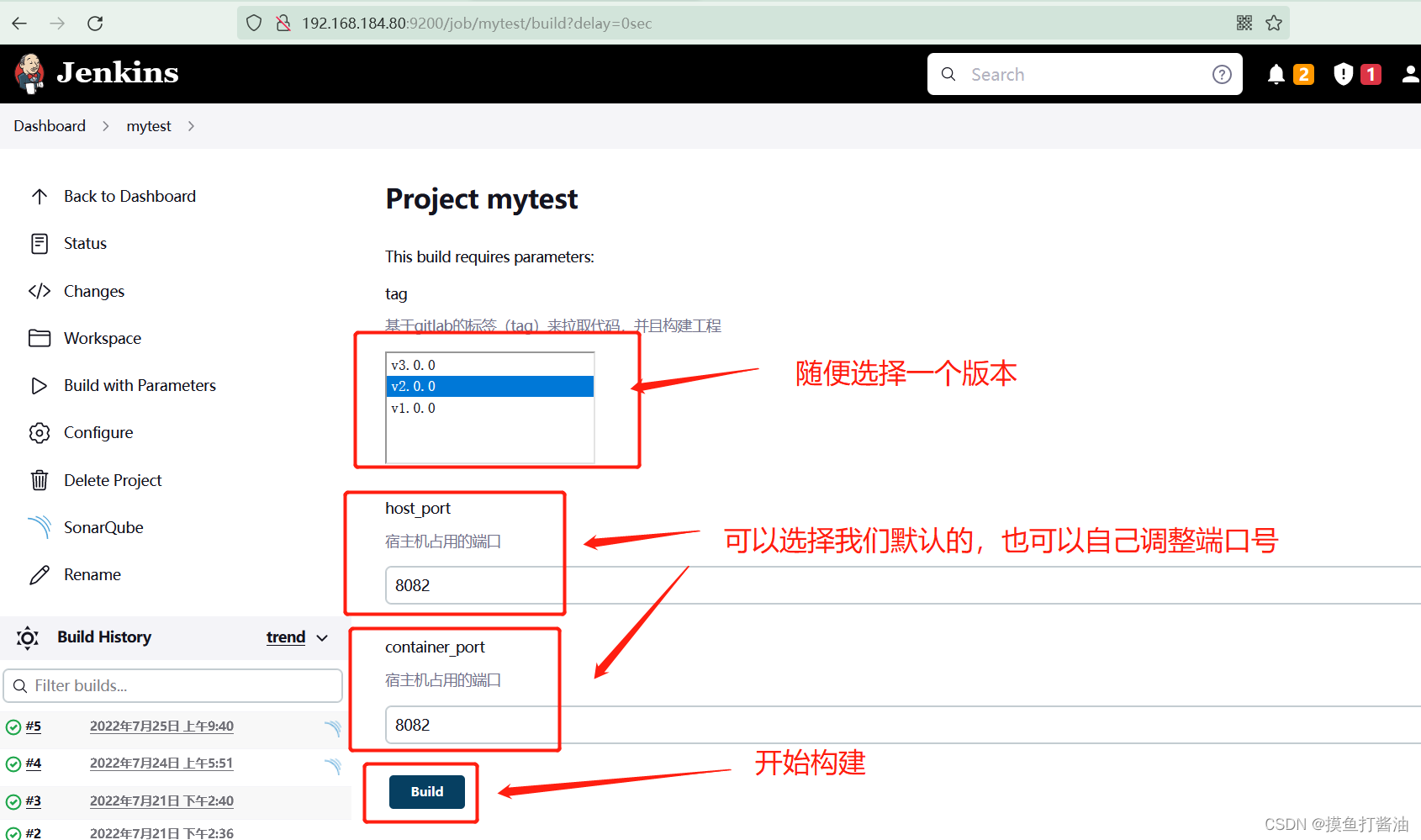
DevOps持续集成-Jenkins(3)
文章目录 DevOpsDevOps概述Jenkins实战3:实战1和实战2的加强版(新增SonarQube和Harbor)⭐环境准备⭐项目架构图对比Jenkins实战1和实战2,新增内容有哪些?SonarQube教程采用Docker安装SonarQube (在Jenkins所…...
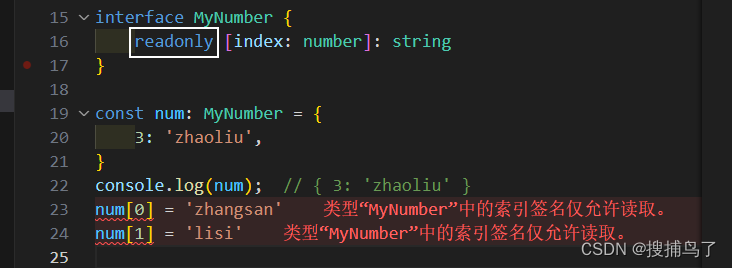
TypeScript之索引签名
1. 索引签名 在 TypeScript 中,索引签名是一种定义对象类型的方式,它允许我们使用字符串或数字作为索引来访问对象的属性。 索引签名最主要的作用就是允许我们动态地添加或访问对象的属性,通过使用索引签名,我们可以在编译时无法…...
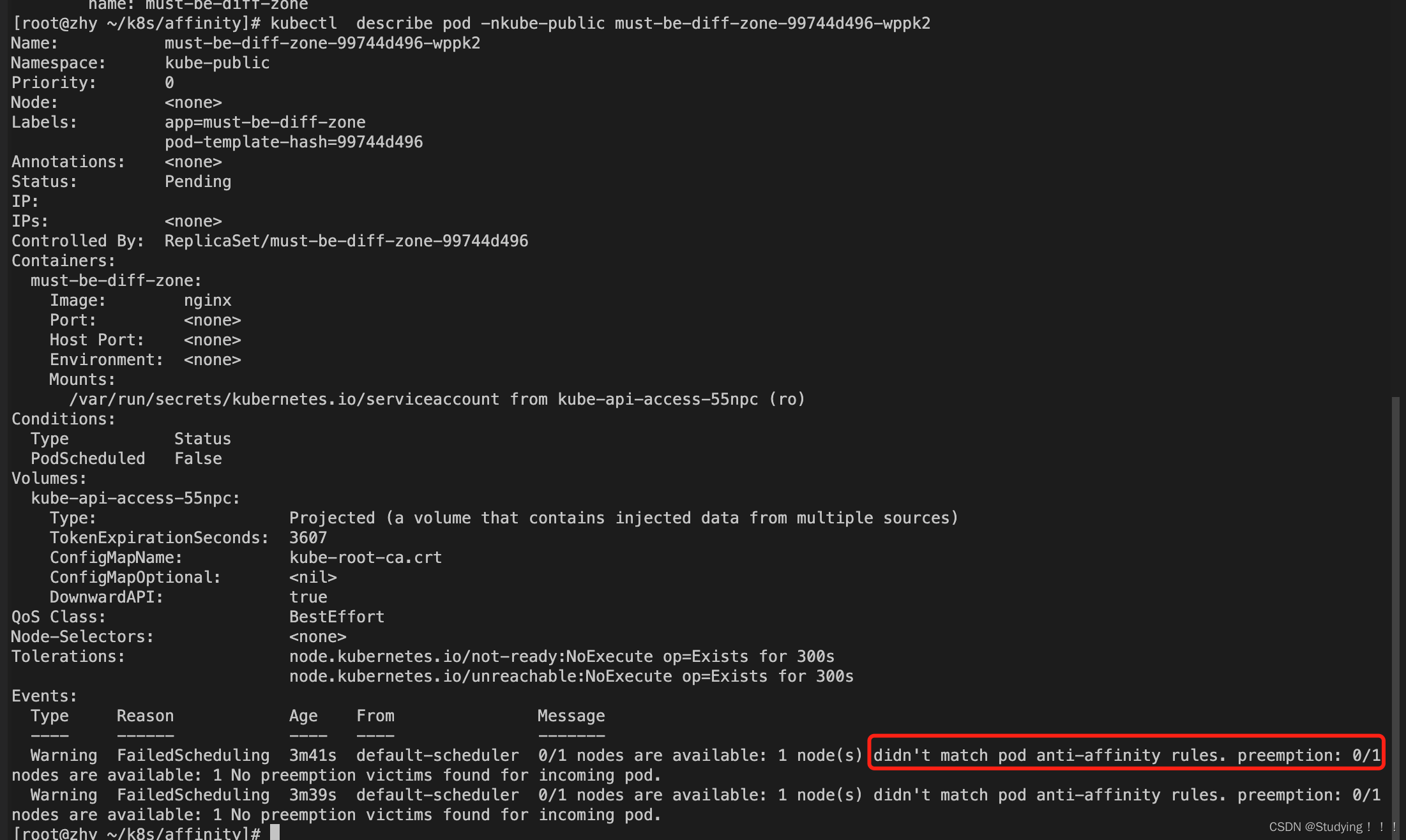
k8s-----24、亲和力Affinity
1、应用场景 pod和节点间的关系: 某些Pod优先选择有ssdtrue标签的节点,如果没有在考虑部署到其它节点;某些Pod需要部署在ssdtrue和typephysical的节点上,但是优先部署在ssdtrue的节点上; pod和pod间的关系: 同一个应用的Pod不…...

860. 柠檬水找零
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,…...
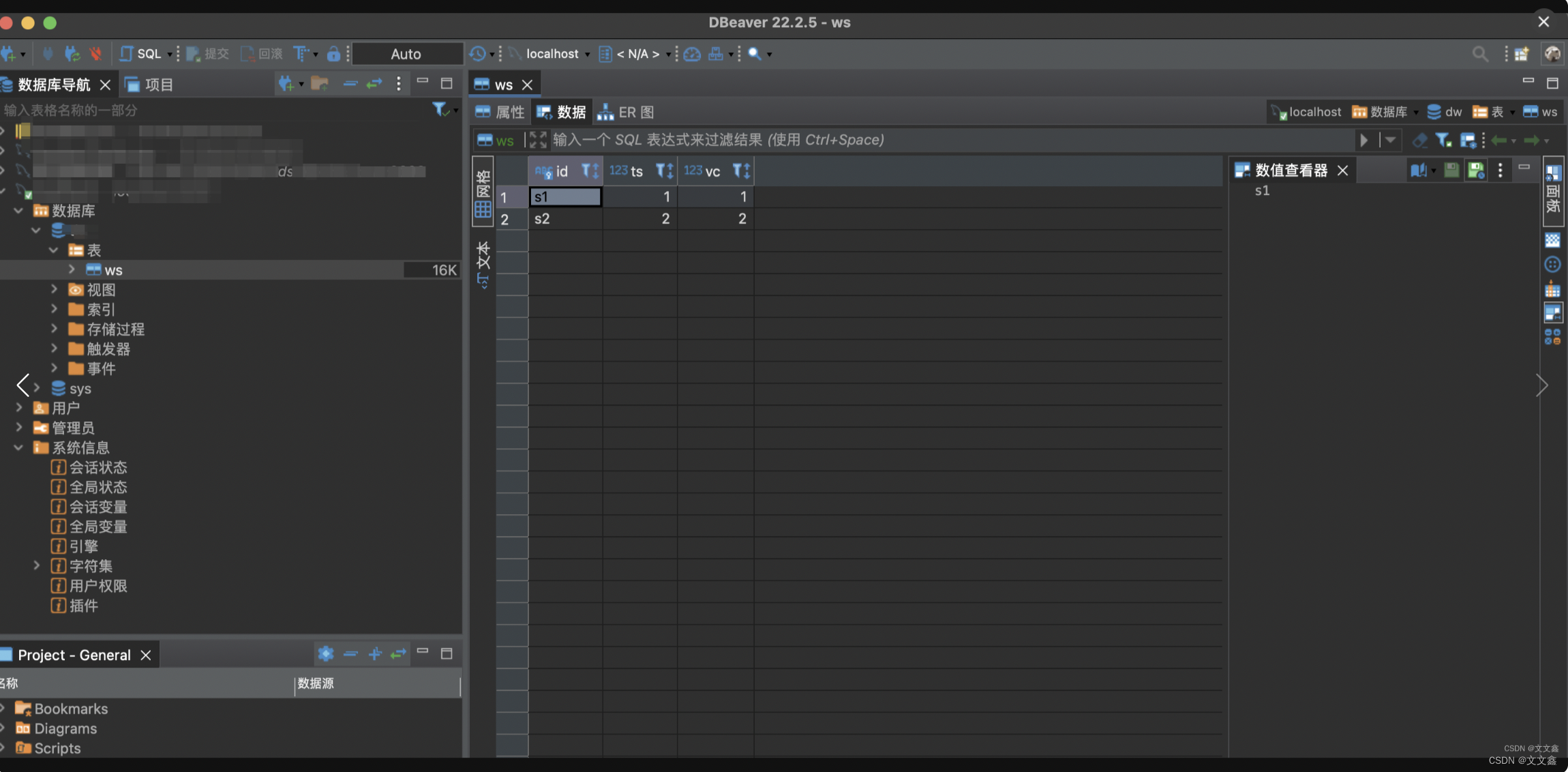
Flink将数据写入MySQL(JDBC)
一、写在前面 在实际的生产环境中,我们经常会把Flink处理的数据写入MySQL、Doris等数据库中,下面以MySQL为例,使用JDBC的方式将Flink的数据实时数据写入MySQL。 二、代码示例 2.1 版本说明 <flink.version>1.14.6</flink.version…...
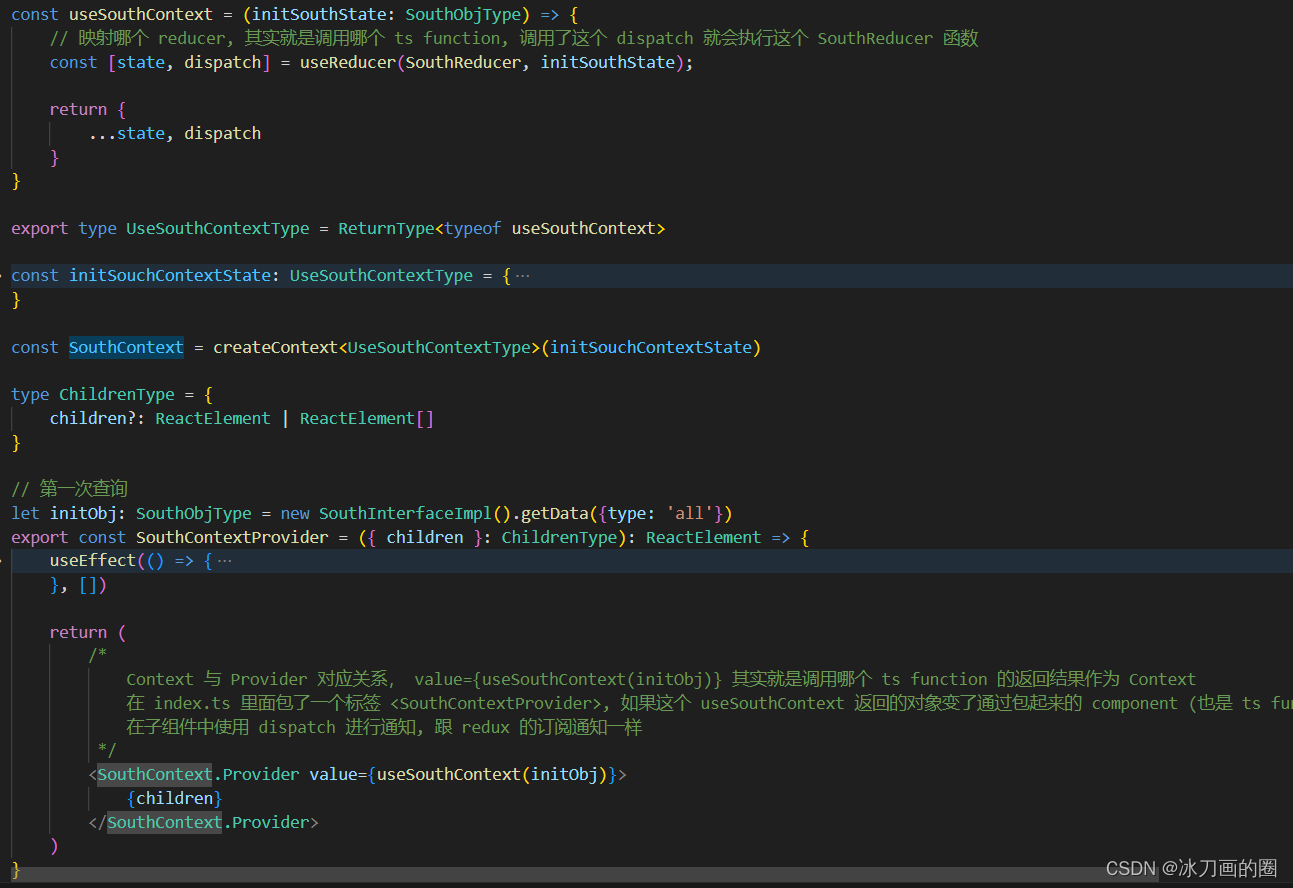
react-typescript-demo
1.使用 Context 来存储数据...

两步修复Win11下conda无法激活问题
Anaconda安装在了D盘,也添加了环境变量,但虚拟环境一直无法激活1.执行策略设置为 RemoteSigned以管理员身份打开WindowsPowershell,然后输入如下代码将当前用户的执行策略设置为 RemoteSigned。Set-ExecutionPolicy -Scope CurrentUser Remot…...

ZoteroDuplicatesMerger:文献库智能去重解决方案的技术深度解析
ZoteroDuplicatesMerger:文献库智能去重解决方案的技术深度解析 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 文献管理工具Zoter…...

claude加持快马平台:三步生成你的第一个博客网站原型
最近想快速搭建一个个人博客网站的原型,用来验证一些内容创作的想法。作为一个前端开发新手,我尝试了在InsCode(快马)平台上使用Claude模型来生成代码,整个过程出乎意料地顺畅。下面记录下我的实践过程,或许对同样想快速实现原型的…...

SEO_详解SEO优化中站内与站外优化的区别
SEO优化中站内与站外优化的区别详解 在当今的网络世界,SEO(搜索引擎优化)是每一个网站主人都必须掌握的技能。SEO优化主要分为站内优化和站外优化,两者在策略和目标上有着显著的区别。本文将详细解析这两者的区别,并为…...

B站硬核会员智能答题:AI驱动的高效通关解决方案
B站硬核会员智能答题:AI驱动的高效通关解决方案 【免费下载链接】bili-hardcore bilibili 硬核会员 AI 自动答题脚本,直接调用 B 站 API,非 OCR 实现 项目地址: https://gitcode.com/gh_mirrors/bi/bili-hardcore B站硬核会员身份象征…...

跨设备移动计算的挑战与突破:Portable-VirtualBox实现系统随身化方案
跨设备移动计算的挑战与突破:Portable-VirtualBox实现系统随身化方案 【免费下载链接】Portable-VirtualBox Portable-VirtualBox is a free and open source software tool that lets you run any operating system from a usb stick without separate installatio…...

飞书机器人接入OpenClaw:千问3.5-35B-A3B-FP8实现群聊问答自动化
飞书机器人接入OpenClaw:千问3.5-35B-A3B-FP8实现群聊问答自动化 1. 为什么选择OpenClaw飞书千问3.5组合? 去年我在团队内部尝试用各种工具搭建智能问答系统时,发现三个核心痛点:一是公有云API调用成本高且数据要出域࿰…...
)
告别EEPROM!用FRAM FM25W256给你的GD32F303项目做个不掉电的‘记事本’(附SPI配置避坑指南)
告别EEPROM!用FRAM FM25W256给你的GD32F303项目做个不掉电的‘记事本’(附SPI配置避坑指南) 在嵌入式系统开发中,数据存储一直是个让人头疼的问题。想象一下,你花了几个月调试的工业控制器,因为一次意外断电…...

AI辅助开发:探索快马AI生成智能命令提示与分析的下一代终端工具
今天想和大家分享一个有趣的开发实践:如何用前端技术模拟实现一个具备AI辅助功能的智能命令行终端Web应用。这个项目的灵感来源于日常开发中频繁使用终端工具时遇到的痛点,比如记不住复杂命令、报错信息难以理解等问题。 基础终端界面搭建 首先需要创建一…...

AI for Science:当语言学遇见人工智能,一场研究范式的革命
AI for Science:当语言学遇见人工智能,一场研究范式的革命 引言 语言学,这门探索人类语言本质的古老学科,正与人工智能发生前所未有的深度碰撞。从濒危语言的数字化抢救,到古籍文献的自动化解析,再到语言…...