kafka丢数据的原因
目录
- 背景
- kafkaClient代码
- 消息丢失的可能原因
- `broker is down`
- `RD_KAFKA_MSG_SIZE_TOO_LARGE`
- 分区问题
- Kafka Broker的处理能力无法跟上,可能会出现以下情况
- Some基础知识补充
背景
采用的client是librdkafka,在producerClient Send的数据时候发现会有数据丢失,并没有到达kafka对应topic的xxx.log中。
写ut测试
kafka_config为:
{"kafka_config": {"is_async_sending": true,"kafka_consume_batch": 5000,"kafka_consume_millsec": 1000,"kafka_ip_list": ["kafka-0.kafka-headless.middlewares.svc.cluster.local"],"kafka_port": 9092,"kafka_type": "librdkafka"},"operation_logger_thread_num": 16
}UT测试,当is_async_sending设置为false的时候,测试推送1、10、100均无问题,当推送1k-1w时,发现这一次插入的数据均丢失,也就是说send前后kafka的offset没有变化
#include "xxx/common/kafka/kafka_log_producer.h"
#include "xxx/common/kafka/kafka_log_consumer.h"
#include <glog/logging.h>
#include <gflags/gflags.h>
#include <gtest/gtest.h>
#include "common/storage/log/log_factory.h"
#include "common/config/rapidjson_helper.h"
#include "common/config/json_config_helper.h"
#include "common/error_code.h"
#include "common/config/jsonizable.h"
#include <boost/shared_ptr.hpp>
#include <gtest/gtest.h>
#include <glog/logging.h>
#include <gmock/gmock.h>using namespace std;
using namespace xxx;DEFINE_int32(total_num, 100, "导入的数据总量");
DEFINE_string(kfk_topic, "track_surveillance", "需要检查的topic");
int main(int argc, char **argv)
{int rtn;google::ParseCommandLineFlags(&argc, &argv, false);JsonConfigHelper mConfig;mConfig.Load("kfk_config.json");xxx::common::storage::kafka::KafkaClientConfig kafkaConfig;rtn = xxx::product::face_platform::fig_app_worker_helper::GetKafkaConfig(mConfig, kafkaConfig);if (rtn < 0){CHECK_RTN_LOGE_DESC(XXX_INVALID_ARGUMENT_ERROR, "GetKafkaConfig ERROR config = " + mConfig.ToString());}boost::shared_ptr<common::storage::log::ILogProducer> producer(new common::storage::kafka::KafkaLogProducer(kafkaConfig));boost::shared_ptr<common::storage::log::ILogConsumer> consumer(new common::storage::kafka::KafkaLogConsumer(kafkaConfig));// JsonConfigHelper config;// config.Load("op_log_sample.json");std::cout << "FLAGS_total_num: " << FLAGS_total_num;std::cout << "FLAGS_kfk_topic: " << FLAGS_kfk_topic;// SAMPLE dataJsonConfigHelper config;config.Load("kfk_sample_data.json");std::string data = config.ToString();std::cout << "data=" << data.c_str() << std::endl;int64_t currentOffset = 0;currentOffset = consumer->GetCurrentOffset(FLAGS_kfk_topic, 0);// 循环插入for (int i = 0; i < FLAGS_total_num; i++){xxx::common::storage::log::LogEnvelope logEnv(FLAGS_kfk_topic, 0, data);int rtn = producer->SendMessage(logEnv);std::cout << "第" << i << "轮" << std::endl;}boost::this_thread::sleep(boost::posix_time::seconds(5));int64_t tmpOffset = consumer->GetCurrentOffset(FLAGS_kfk_topic, 0);if (tmpOffset > 0 && (tmpOffset - currentOffset) == FLAGS_total_num){std::cout << "UT PASS"<< std::endl;}else{std::cout << "DIFF OFFSET = " << (tmpOffset - currentOffset) << std::endl;}return 0;当改成同步的时候,每次推送耗时稳定在100ms,观察librdkafka的发送代码可以看出异步的话发送流程会多一个ProducerFlush流程
kafkaClient代码
// For Producer
int RdKafkaClient::Send(const std::string &topic, int partition,const std::vector<KafkaMessage> &messages)
{if (!mInitSucc){LOG(ERROR) << "Fail to Initialize";return XXX_KAFKA_FAILED_TO_SENDING_MESSAGES_ERROR;}RdkafkaTopicPtr pTopicPtr;CHECK_RTN_LOGE_OF_FUNC(GetTopic(topic, "producer", pTopicPtr));VLOG(1) << "finished getting topic for producer, topic name: " << topic;// Produce Messagefor (int i = 0; i < messages.size(); ++i){RdKafka::ErrorCode resp = mpProducer->produce(pTopicPtr.get(), partition,RdKafka::Producer::RK_MSG_COPY,const_cast<char *>(messages[i].mValue.c_str()),messages[i].mValue.size(), &messages[i].mKey, nullptr);if (resp != RdKafka::ERR_NO_ERROR){if (resp == RdKafka::ERR__QUEUE_FULL){// retry for queue fullint reservedEventsNum = mpProducer->poll(mConfigParam.produceTimeout);LOG(WARNING) << "Fail to Produce, error: " << RdKafka::err2str(resp)<< "\nWaiting for queue space, reservedEventsNum: " << reservedEventsNum;i--;continue;}LOG(ERROR) << "Fail to produce, error: " << RdKafka::err2str(resp);if (resp == RdKafka::ERR_MSG_SIZE_TOO_LARGE){LOG(ERROR) << "Message is too large, message len: " << messages[i].mValue.size();}return XXX_KAFKA_FAILED_TO_SENDING_MESSAGES_ERROR;}else{// Serve the queued callbacks waiting to be calledmpProducer->poll(0);}}if (!mConfigParam.isAsyncSending){CHECK_RTN_LOGE_OF_FUNC(ProducerFlush());}return XXX_SUCC;
}int RdKafkaClient::ProducerFlush()
{int reservedEventsNum = 0, sumWaitTime = 0;if (mpProducer.get() == nullptr){// 现在的代码计算是用作consumer也会创建producer实例LOG(WARNING) << "This is not a producer, no need to flush producer";}elsewhile (mpProducer->outq_len() > 0){reservedEventsNum = mpProducer->poll(mConfigParam.pollTimeout);LOG_EVERY_N(INFO, 100) << "ReservedEventsNum: " << reservedEventsNum<< ", Waiting for: " << mpProducer->outq_len();sumWaitTime += mConfigParam.pollTimeout;if (sumWaitTime > mConfigParam.flushTimeout){CHECK_RTN_LOGE_DESC(XXX_UNEXPECTED_ERROR,"fail to wait all messages be sent, timeout: " << mConfigParam.flushTimeout);}}return XXX_SUCC;
}
mpProducer->outq_len():当前等待发送的消息数量
poll()方法的返回值reservedEventsNum表示处理的事件数量。
该函数通过循环调用poll()方法等待所有消息被发送和确认,以确保消息成功提交到Kafka服务器。如果在规定的等待时间内无法完成发送操作,将输出错误日志并返回错误码
消息丢失的可能原因
消息丢失可能由以下原因导致,需要从客户端到Kafka内部的各个组件进行分析:
- 客户端配置:首先,您应该检查客户端的配置是否正确。确保您设置了适当的参数,例如
bootstrap.servers、acks和retries等。这些参数控制着消息发送的行为,错误的配置可能导致消息丢失。bootstrap.servers:这个参数指定了 Kafka 服务的地址列表,用于在 Producer 初始化时建立与 Kafka 集群的连接。如果配置错误,Producer 将无法连接到正确的 Kafka 集群,导致消息无法发送。acks:该参数指定了 Producer 在发送消息后需要收到多少个副本的确认才视为成功。可选的值包括"all"(所有副本都确认)、"0"(不需要任何确认)和大于等于 1 的整数值(表示需要指定数量的副本确认)。如果设置得太低,可能会导致消息发送后因为网络延迟或节点故障而丢失;如果设置得太高,可能会影响性能和吞吐量。retries:该参数指定了在发生可重试的发送错误时,Producer 进行重试的次数。如果设置得太低,可能会导致消息发送失败后未经过足够多次的重试;如果设置得太高,可能会增加延迟和网络负载。
- 网络故障:网络问题可能导致消息丢失。当客户端无法连接到Kafka集群或与其中的某个节点断开连接时,消息可能会丢失。您可以检查网络连接并确认没有防火墙或其他网络设备阻止了消息的传输。
- Kafka集群状态:确认Kafka集群是否正常工作。如果集群中的某个Broker发生故障或宕机,那么在该Broker上分布的分区可能无法接收到消息。使用Kafka命令行工具或Kafka管理界面来监控集群状态,并确保所有Broker都处于正常运行状态。
- 分区分配策略:Kafka使用分区来存储和分发消息。如果未正确配置分区分配策略,消息可能会被发送到错误的分区中,或者分区可能无法分配给任何可用的Broker,导致消息丢失。
- 消息过大:如果您发送的消息超出了Kafka Broker的
message.max.bytes配置值,那么消息将被拒绝并丢失。 - 发送速率过快:在连续发送大量消息的情况下,如果消息发送速率过快,可能会超出Kafka Broker的处理能力。这可能导致消息被丢弃或拒绝。您可以尝试控制消息发送速率,例如通过增加延迟或减少发送频率来避免过载。
- 异常处理:在使用librdkafka时,您应该适当处理异常情况。例如,检查消息发送结果的返回值、重试失败的消息等。没有正确处理异常可能导致消息丢失。
下面是遇到的问题:
broker is down
Kafka 打印 “broker is down” 的日志消息通常表示某个 Kafka 代理(broker)在集群中不可用或无法连接。
这种情况可能有几个原因:
- 代理故障:如果一个或多个 Kafka 代理发生故障,例如宕机、崩溃或网络故障,那么其他代理就可能无法与它建立连接。此时,其他代理将打印 “broker is down” 的日志消息来指示该故障代理的状态。
- 网络问题:Kafka 集群中的代理之间通过网络进行通信。如果代理之间的网络出现问题,如网络分区、延迟过高或丢包等,那么可能会导致某个代理被标记为不可用。这时其他代理可能会记录 “broker is down” 的日志消息。
- 配置错误:如果配置文件中的代理信息设置不正确,比如指定了错误的主机名或端口号,那么连接到该代理时会失败,并导致 “broker is down” 的日志消息出现。
- 资源不足:如果代理所在的机器资源不足,例如 CPU、内存或磁盘空间等,可能会影响代理的正常运行,并导致其他代理报告 “broker is down” 错误。
要解决 “broker is down” 的问题,可以考虑以下步骤:
- 检查故障的代理是否真正不可用,可以尝试连接到该代理并检查其状态。
- 检查网络是否正常,确保所有代理之间能够正常通信。
- 确保代理的配置信息正确,并且主机名、端口号等参数与实际情况匹配。
- 检查代理所在的机器资源是否充足,例如 CPU、内存和磁盘空间等。
RD_KAFKA_MSG_SIZE_TOO_LARGE
默认情况下,当消息大小超过message.max.bytes时,client 会返回一个RD_KAFKA_MSG_SIZE_TOO_LARGE错误码。这个错误表示消息大小超出了Broker设置的限制,并且不允许将该消息写入主题中。
message.max.bytes是Kafka Broker的一个配置参数,它用于限制单个消息的最大大小。该参数的默认值是1000000字节(1MB)
应用程序可以通过捕获此异常并采取适当的处理措施,例如拆分消息、压缩消息或增加message.max.bytes的值来适应更大的消息。
如果修改了这个值,还需要记得同步修改这几个参数:
包括replica.fetch.max.bytes和fetch.message.max.bytes
replica.fetch.max.bytes:该参数用于控制副本同步时从主题分区获取数据的最大字节大小。当副本需要从主题分区中拉取数据进行同步时,如果单个消息的大小超过该参数设置的值,则副本不会拉取该消息。默认情况下,该参数的值与message.max.bytes相同。fetch.message.max.bytes:该参数用于控制消费者从Broker获取消息的最大字节大小。当消费者从主题分区中获取消息时,如果单个消息的大小超过该参数设置的值,则对应的消息将被截断,并且仅返回截断后的部分。默认情况下,该参数的值也与message.max.bytes相同。
这些参数的存在是为了限制单个消息的大小,以防止网络传输和存储负载过大,同时也可以保护系统免受恶意或异常情况下的过大消息影响。在调整这些参数时,需要综合考虑生产者、消费者和副本同步等方面的需求。
分区问题
如果未正确配置分区分配策略,可能会导致消息被发送到错误的分区中或者分区无法分配给可用的Broker,从而导致消息丢失。
librdkafka会返回一个错误码来指示问题。以下是一些常见的错误码及其含义:
RD_KAFKA_RESP_ERR__UNKNOWN_PARTITION:表示未知分区错误。这个错误码通常表示Producer尝试将消息发送到不存在的分区,或者未正确配置分区分配策略,导致无法确定应该将消息发送到哪个分区。RD_KAFKA_RESP_ERR__UNKNOWN_TOPIC:表示未知主题错误。这个错误码通常表示Producer尝试将消息发送到不存在的主题,或者未正确配置主题和分区的元数据信息。RD_KAFKA_RESP_ERR__PARTITION_EOF:表示分区已达到末尾错误。这个错误码通常表示Consumer尝试从分区中读取消息,但该分区已经没有更多消息可供消费。RD_KAFKA_RESP_ERR__UNKNOWN_TOPIC_OR_PART:表示未知主题或分区错误。这个错误码通常表示Producer或Consumer尝试操作一个不存在的主题或分区。
注意分区数的设置依赖于创建主题时指定的num_partitions参数,一旦主题创建后,分区数通常是固定的,无法更改。
Kafka Broker的处理能力无法跟上,可能会出现以下情况
RequestTimedOut(请求超时):当消息发送请求无法及时得到Broker的响应时,例如由于Broker过载导致无法及时处理请求,librdkafka会返回请求超时的错误。这通常意味着消息被丢弃,因为没有及时得到Broker的确认。NotEnoughReplicas(副本不足):在某些情况下,如果消息发送请求无法满足复制因子(replication factor)要求,例如由于可用的副本数量不足,Broker会拒绝接收消息并返回此错误。这表明消息可能会被丢弃或者在复制因子满足后重新发送。LeaderNotAvailable(无可用Leader):如果消息发送请求的分区的Leader不可用,例如由于Leader选举正在进行或Leader所在的Broker发生故障,那么Broker会拒绝接收消息并返回此错误。这可能会导致消息被丢弃或在Leader重新恢复后重新发送。
消息发送请求为什么需要满足复制因子的要求呢?
在Kafka中,每个分区都有若干个副本(Replica),其中一个被称为Leader副本(Leader),其他副本被称为追随者副本(Follower)。Leader负责处理消息的写入和读取请求,而追随者副本则用于实现数据的冗余备份。
当消息发送请求到达Kafka Broker时,Broker会将消息写入Leader副本,并通过一定的机制将消息复制到追随者副本。只有当消息被成功写入所有指定的副本(即满足复制因子)后,Kafka才会向Producer确认消息写入成功。
复制因子可以在创建主题时进行配置,指定了要为每个分区使用多少个副本。通常,常见的复制因子值为大于1的整数,例如3或2。这意味着每个分区将在多个Broker上维护多个副本,以提供数据冗余和容错能力。
- 容错性:如果某个Broker或副本发生故障,仍然可以从其他副本中获取数据,保证数据的可用性和服务的连续性。
- 可靠性:只有当消息被成功写入所有指定的副本后,Kafka才会向Producer确认消息写入成功。这样可以确保数据在多个副本之间得到复制,防止消息丢失。
- 可扩展性:通过在多个Broker上维护多个副本,Kafka能够提供更高的吞吐量和并行处理能力。
需要注意的是,复制因子也会对消息发送请求的性能产生一定的影响。增加复制因子将增加消息复制和同步的开销,可能导致稍微延迟较高的写入操作。tips:设置一个奇数的复制因子可以更容易进行Leader选举
Some基础知识补充
在Kafka中,分区(Partition)、Broker和Topic是三个核心概念,并且它们之间存在着密切的关系。
- 分区(Partition):分区是Kafka中数据存储和分发的基本单元。每个主题(Topic)可以被分成多个分区,每个分区是一个有序、持久化的日志流。分区允许主题的数据水平扩展和并行处理。每个分区都有一个唯一的标识符(partition ID),从0开始递增。
- Broker:Broker是Kafka集群中的一个节点或服务器实例。每个Broker负责管理若干个分区,并且可以接收来自Producers的消息和为Consumers提供消息数据。一个Kafka集群由多个Broker组成,它们协同工作来提供高可用性和扩展性。
- 主题(Topic):主题是Kafka中数据记录的逻辑分类单元。生产者(Producers)将消息发布到特定的主题,消费者(Consumers)则从主题中读取消息进行处理。每个主题可以拥有一个或多个分区,这些分区可以分布在不同的Broker上,以实现数据的分散存储和负载均衡。
一个主题(Topic)可以由多个分区(Partition)组成,每个分区属于某个Broker,而一个Kafka集群由多个Broker组成。
在Kafka中,同一个主题的多个分区不会被强制地分布在同一个Broker上。相反,Kafka通过将不同分区均匀地分布在不同的Broker上实现负载均衡和容错性。
当创建一个新的主题并指定分区数时,Kafka会根据集群中可用的Broker数量,自动将分区分配到不同的Broker上。这样做可以确保消息在整个集群中的分散存储,并允许并行处理。
具体的分区分配策略是由Kafka的partitioner配置参数决定的。默认情况下,Kafka使用一种称为"consistent_random"的分区分配策略,它会根据Producer发送的消息键(如果有)进行计算,以确保具有相同键的消息被分配到同一个分区,而没有键的消息则随机分配到各个分区,当然也可以直接指定消息的分区id。
在分布式环境中,Kafka通过在Broker之间共享分区元数据信息来维护分区的分布情况。这样,当消费者(Consumer)需要读取消息时,它们可以根据分区元数据信息直接找到存储该分区的Broker,从而实现高效的消息传递和消费。
当创建一个新的主题并指定分区数时,Kafka会根据集群中可用的Broker数量自动将分区分配到不同的Broker上。如果主题的分区数大于可用的Broker数量,Kafka会对一些Broker进行多个分区的分配。
这种情况下,Kafka使用的是一种称为"partition reassignment"的机制。它会尽量将分区均匀地分配给可用的Broker,并确保每个Broker上承载的分区数量尽可能接近。这样可以实现负载均衡和高吞吐量。
然而,如果可用的Broker数量远远少于主题所需的分区数,那么可能无法保证每个分区都能被分配到不同的Broker上。在这种情况下,某些Broker可能需要承载多个相同主题的分区。
需要注意的是,虽然这种情况下会在一个Broker上存在多个同一主题的分区,但Kafka仍然能够正确处理消息的存储和传递。每个分区都是独立存储和维护的,Kafka可以根据分区元数据信息准确地将消息发送到目标分区,并由消费者进行消费。
Broker是以进程为单位的。在Kafka中,每个Broker都是一个独立的Kafka服务器实例,运行在单独的进程中。
一个机器上可以运行多个Broker实例,这样就可以创建一个Kafka集群。每个Broker都有一个唯一的标识符(Broker ID),用于在集群中进行识别和通信。在集群中,每个Broker负责管理若干个分区,并处理来自Producers的消息和为Consumers提供消息数据。
通过在不同的机器上运行多个Broker实例,可以实现高可用性和容错性。如果一个Broker因故障或其他原因不可用,仍然可以通过其他可用的Broker继续提供服务。此外,通过多个Broker,Kafka还能够将负载分布在不同的机器上,提供更好的吞吐量和性能。
每个Broker实例需要配置独立的端口、日志存储路径和其他相关参数,以确保它们之间的互相独立性和协作。同时,Broker之间会建立网络连接和通信,以便进行消息复制和集群管理操作,例如分区分配和Leader选举等。
总结起来,Broker是以进程为单位的,每个Broker是一个独立的Kafka服务器实例。在一个机器上可以运行多个Broker实例,形成一个Kafka集群,提供高可用性、容错性和负载均衡。
相关文章:

kafka丢数据的原因
目录 背景kafkaClient代码消息丢失的可能原因broker is downRD_KAFKA_MSG_SIZE_TOO_LARGE分区问题Kafka Broker的处理能力无法跟上,可能会出现以下情况 Some基础知识补充 背景 采用的client是librdkafka,在producerClient Send的数据时候发现会有数据丢…...

音视频编解码技术学习笔记
音视频编解码技术是音视频处理领域的重要部分,涉及到对原始音视频数据的压缩、编码和解码。以下是音视频编解码技术的一些要点和难点: 要点: 压缩技术 音视频编解码的核心是对原始音视频数据进行压缩,以减小文件大小和传输带宽…...

[C#基础训练]FoodRobot食品管理部分代码-1
代码参考: using System;namespace FoodRobotDemo { public class FoodRobot{private int[] foodCountArr;private string[] foodNameArr;public FoodRobot(){foodCountArr new int[3];foodNameArr new string[3] {"航天","航空","宇航" };}…...

YModem协议总结
《YModem协议总结》 目录 第1章 YModem协议简介 4 1.1 基本介绍 4 1.2 YModem基本介绍 4 第2章 YModem传输协议 5 2.1 起始帧的数据格式 5 2.2 数据帧的数据格式 5 2.3 结束帧数据结构 6 2.4 文件传输过程 6 2.5 CRC的计算 7 附录A 附录 8 A.1 附录 8 第1章 YModem协议简…...
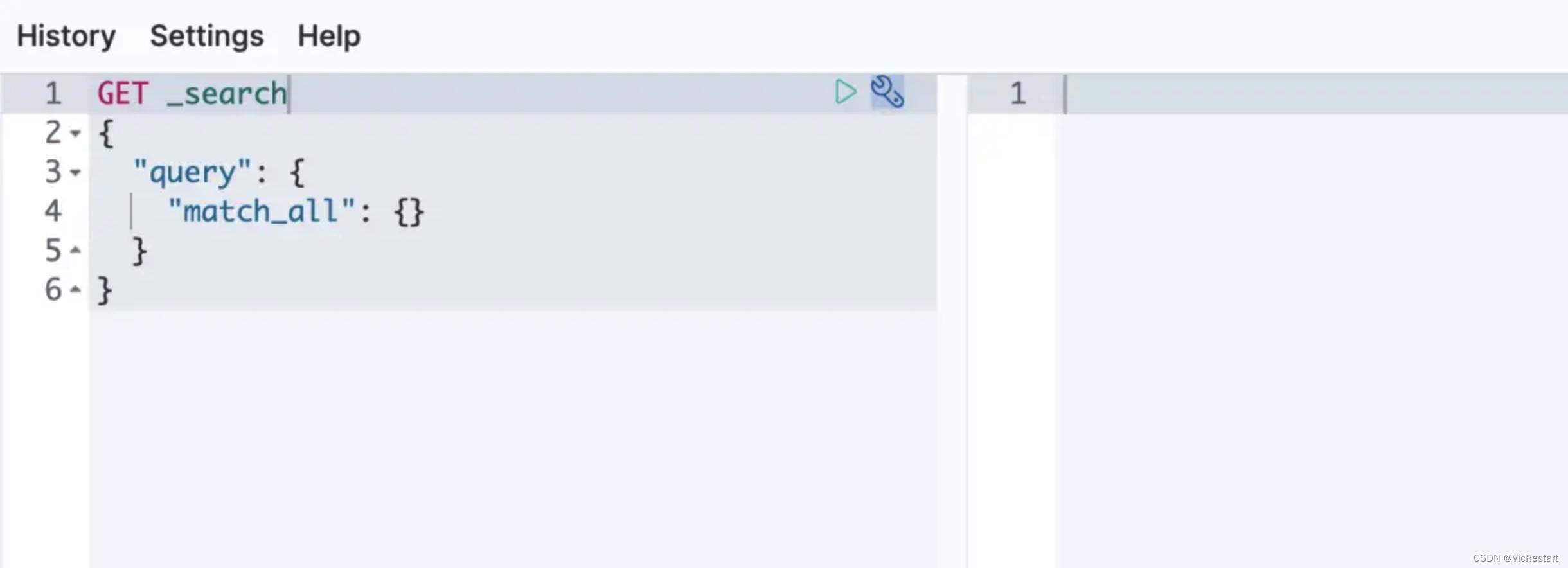
ElasticSearch(ES)8.1及Kibana在docker环境下如何安装
ES基本信息介绍 Elasticsearch(简称ES)是一个开源的分布式搜索和分析引擎,最初由Elastic公司创建。它属于Elastic Stack(ELK Stack)的核心组件之一,用于实时地存储、检索和分析大量数据。 以下是Elastics…...
常用Win32 API的简单介绍
目录 前言: 控制控制台程序窗口的指令: system函数: COORD函数: GetStdHandle函数: GetConsoleCursorInfo函数: CONSOLE_CURSOR_INFO函数: SetConsoleCursorInfo函数: SetC…...
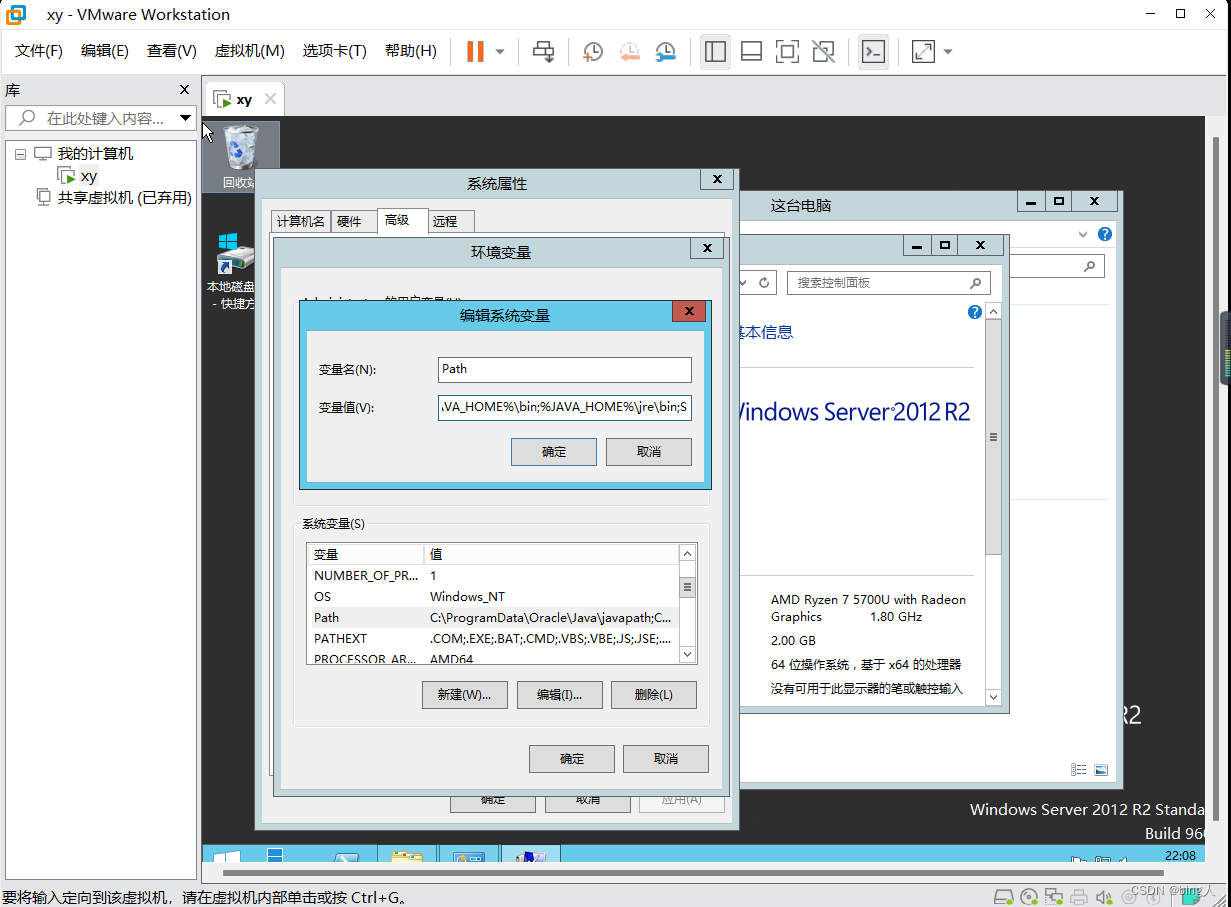
VM及WindowsServer安装
目录 一.操作系统的简介及常用的操作系统 二.windows的安装 安装VMWare虚拟机 注意点一 编辑 注意点二 三.安装配置Windows Server 2012 R2 四、虚拟机的环境配置及连接 1. 主机连接虚拟机 2. 虚拟机环境配置及共享 3. 环境配置 一.操作系统的简介及常用的操作系…...

操作系统【OS】调度算法对比图
FCFS SJF 高响应比 时间片轮转 多级反馈队列 可抢占? √ √ √ 队列内算法不一定 不可抢占? √ √ √ 队列内算法不一定 特点&优点 公平实现简单有利于长作业不利于短作业有利于CPU繁忙作业不利于IO繁忙作业 因为CPU繁忙型进程即…...
:视频黑屏)
音视频开发常见问题(五):视频黑屏
摘要 本文介绍了视频黑屏的可能原因和解决方案。主要原因包括用户主动关闭视频、网络问题和渲染问题。解决方案包括优化网络稳定性、确保视频渲染视图设置正确、提供清晰的提示、实时监测网络质量、使用详细的日志系统、开启视频预览功能、使用视频流回调、处理编解码问题、处…...

力扣 第 368 场周赛
2908. 元素和最小的山形三元组 I 给你一个下标从 0 开始的整数数组 nums 。 如果下标三元组 (i, j, k) 满足下述全部条件,则认为它是一个 山形三元组 : i < j < k nums[i] < nums[j] 且 nums[k] < nums[j] 请你找出 nums 中 元素和最小 的…...
)
文件的常用操作(读取压缩文件、解压、删除)
背景:最近做一个腾讯 cos 桶 文件的读写与本地数据库查询等操作 Retrofit 中文件下载的可以添加 Streaming StreamingGETObservable<ResponseBody> downloadCosFile(Url String downloadUrl);Streaming 的作用: 注解通常用于指示Retrofit或其他HTT…...

Simulation Studio - TRNSYS
简单记录一下最近学习 Simulation Studio的一些经历。 在学习之初,参考了一些大佬们的文章: Fortran学习笔记——1.基本内容 - 知乎 但是我主要的目的是使用Simulation Studio(下文用SS代替)编译自己的组件,看到Sim…...

python实现串口通信
python实现串口通信是一件简单的事情,只要通过pyserial模块就可以实现。 一、串口通信 1、什么是串口通信? 串口通信是一种通过串行接口(Serial Port)进行数据传输的通信方式。在串口通信中,数据位按顺序一位一位地传…...
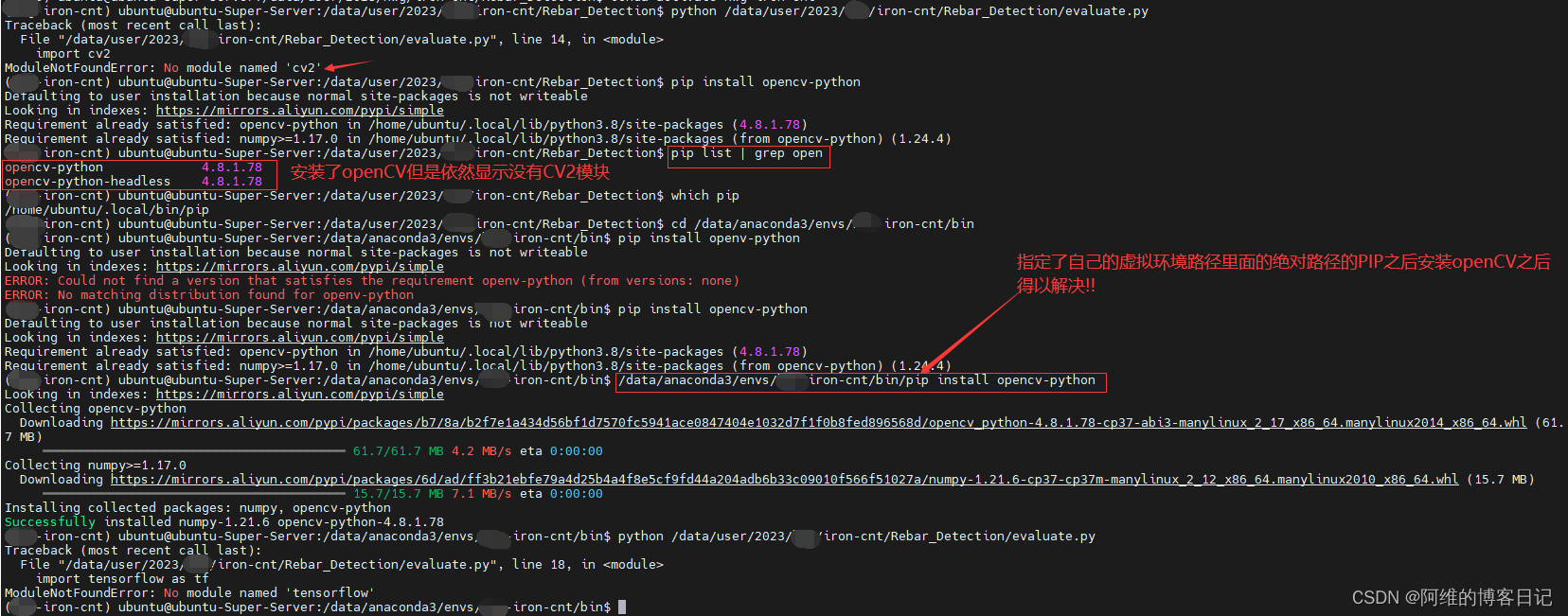
No module named ‘cv2’ 解决方法
目录 解决方案1解决方案2 解决方案1 一般情况下的解决方案 在自己的虚拟环境里面安装就行 pip install opencv-python解决方案2 但是我遇到的情况没有这么简单,我使用了pip list | grep open 搜索含有open字样的opencv的包,结果显示已经安装了 我直接进入我的自定义的虚拟…...
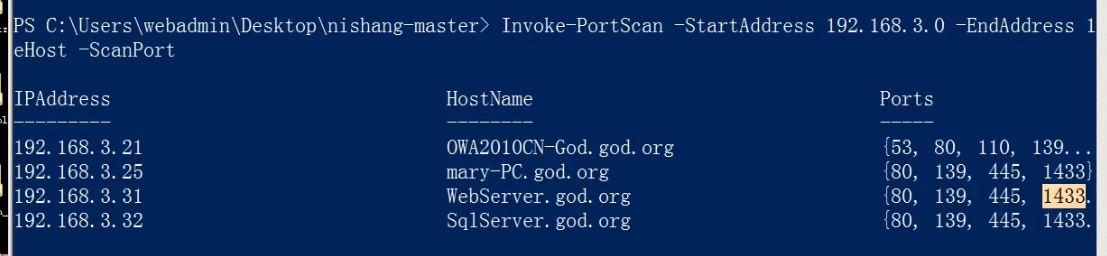
65、内网安全-域环境工作组局域网探针方案
目录 案例1-基本信息收集操作演示案例2-网络信息收集操作演示案例3-用户信息收集操作演示案例4-凭据信息收集操作演示案例5-探针主机域控架构服务操作演示涉及资源 我们攻击内网一般是借助web攻击,直接进去,然后再去攻击内网,那么攻击的对象一…...

C#:EXCEL列名、列序号之间互相转换
EXCEL的列名与列序号 之前的关系如下 A1B2C3D4E5F6G7H8I9J10K11L12M13N14O15P16Q17R18S19T20U21V22W23X24Y25Z26AA27AB28 /// <summary>/// 根据给的EXCEL列序号,得出列名字母/// </summary>/// <param name"iColNum">序号</param&…...
云原生微服务实战 Spring Cloud Alibaba 之 Nacos
系列文章目录 第一章 Java线程池技术应用 第二章 CountDownLatch和Semaphone的应用 第三章 Spring Cloud 简介 第四章 Spring Cloud Netflix 之 Eureka 第五章 Spring Cloud Netflix 之 Ribbon 第六章 Spring Cloud 之 OpenFeign 第七章 Spring Cloud 之 GateWay 第八章 Sprin…...

ubuntu gcc版本降级 Reset gcc version from 11.3 to 11.2 on Ubuntu 22.04
aptitude 需要自己安装 sudo apt-get install aptitude # 安装# aptitude的一些常用的操作: sudo aptitude update # 更新软件源 sudo aptitude search 软件名称 # 查看软件 sudo aptitude install 软件名称 …...

基于机器视觉的二维码识别检测 - opencv 二维码 识别检测 机器视觉 计算机竞赛
文章目录 0 简介1 二维码检测2 算法实现流程3 特征提取4 特征分类5 后处理6 代码实现5 最后 0 简介 🔥 优质竞赛项目系列,今天要分享的是 基于机器学习的二维码识别检测 - opencv 二维码 识别检测 机器视觉 该项目较为新颖,适合作为竞赛课…...

Windows客户端下pycharm配置跳板机连接内网服务器
问题:实验室服务器仅限内网访问,无法在宿舍(外网)访问实验室的所有内部服务器,但同时实验室又提供了一个外网可以访问的跳板机,虽然可以先ssh到跳板机再从跳板机ssh到内网服务器,但这种方式不方…...

AI-Youtube-Shorts-Generator完全指南:从安装到批量处理
AI-Youtube-Shorts-Generator完全指南:从安装到批量处理 【免费下载链接】AI-Youtube-Shorts-Generator A python tool that uses GPT-4, FFmpeg, and OpenCV to automatically analyze videos, extract the most interesting sections, and crop them for an impro…...

为什么极限不是总存在的?
并不总是存在,是因为“趋近”的过程必须满足非常严苛的条件:唯一性和确定性。如果函数在趋近某个点时的表现变得“混乱”或“不一致”,极限就会失效。如果函数在趋近某个点时的表现变得“混乱”或“不一致”,极限就会失效。以下是…...

OFA图像语义蕴含模型实战:基于Python的英文图文关系判断
OFA图像语义蕴含模型实战:基于Python的英文图文关系判断 用AI看懂图片和文字之间的关系,原来这么简单 你有没有遇到过这样的情况:看到一张图片和一段英文描述,想要快速判断它们是否匹配?比如电商平台需要自动审核商品图…...

OpenClaw自动化效率对比:Qwen3.5-9B-AWQ-4bit与GPT-4V多模态任务实测
OpenClaw自动化效率对比:Qwen3.5-9B-AWQ-4bit与GPT-4V多模态任务实测 1. 测试背景与实验设计 去年冬天,我在整理家庭相册时萌生了一个想法:能否用AI自动识别照片内容并生成描述?这促使我开始探索OpenClaw与多模态模型的结合。经…...

3个强力技巧,用WaveTools彻底提升鸣潮游戏体验
3个强力技巧,用WaveTools彻底提升鸣潮游戏体验 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 鸣潮工具箱WaveTools是一款专为《鸣潮》PC玩家设计的开源辅助工具,通过三大核心功能解…...

如何用GetQzonehistory高效备份QQ空间历史说说实现青春记忆永久保存
如何用GetQzonehistory高效备份QQ空间历史说说实现青春记忆永久保存 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 解决数字记忆流失的痛点方案 在这个信息快速迭代的时代,…...

下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式
下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET COMET(A Neural Framework for MT Evaluation)…...
避坑指南:从‘能用’到‘好用’,我踩过的那些Glue Logic和变量延时坑)
SystemVerilog断言(SVA)避坑指南:从‘能用’到‘好用’,我踩过的那些Glue Logic和变量延时坑
SystemVerilog断言进阶实战:破解Glue Logic与动态延时的工程困局 当你的SVA断言从实验室demo走向真实芯片验证时,总会遇到这样的时刻:精心编写的断言在仿真中突然失效,或是让仿真速度下降了30%,又或是变成团队里没人敢…...

wan2.1-vae高性能部署:TensorRT优化+FP16量化提速与显存占用实测
wan2.1-vae高性能部署:TensorRT优化FP16量化提速与显存占用实测 1. 项目背景与价值 wan2.1-vae是基于Qwen-Image-2512模型构建的高性能图像生成平台,在实际应用中面临两个核心挑战: 生成高分辨率图像时推理速度慢(单张2048x204…...

Qwen-Image-2512-ComfyUI入门指南:从安装到生成第一张海报
Qwen-Image-2512-ComfyUI入门指南:从安装到生成第一张海报 1. 快速部署与启动 1.1 硬件准备与环境搭建 Qwen-Image-2512-ComfyUI作为阿里开源的图片生成模型最新版本,对硬件要求相对友好。以下是部署前的准备工作: 显卡要求:N…...