华为开源自研AI框架昇思MindSpore数据变换:Transforms
目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、数据变换 Transforms
- Common Transforms
- Compose
- Vision Transforms
- Rescale
- Normalize
- HWC2CWH
- Text Transforms
- BasicTokenizer
- Lookup
- Lambda Transforms
通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
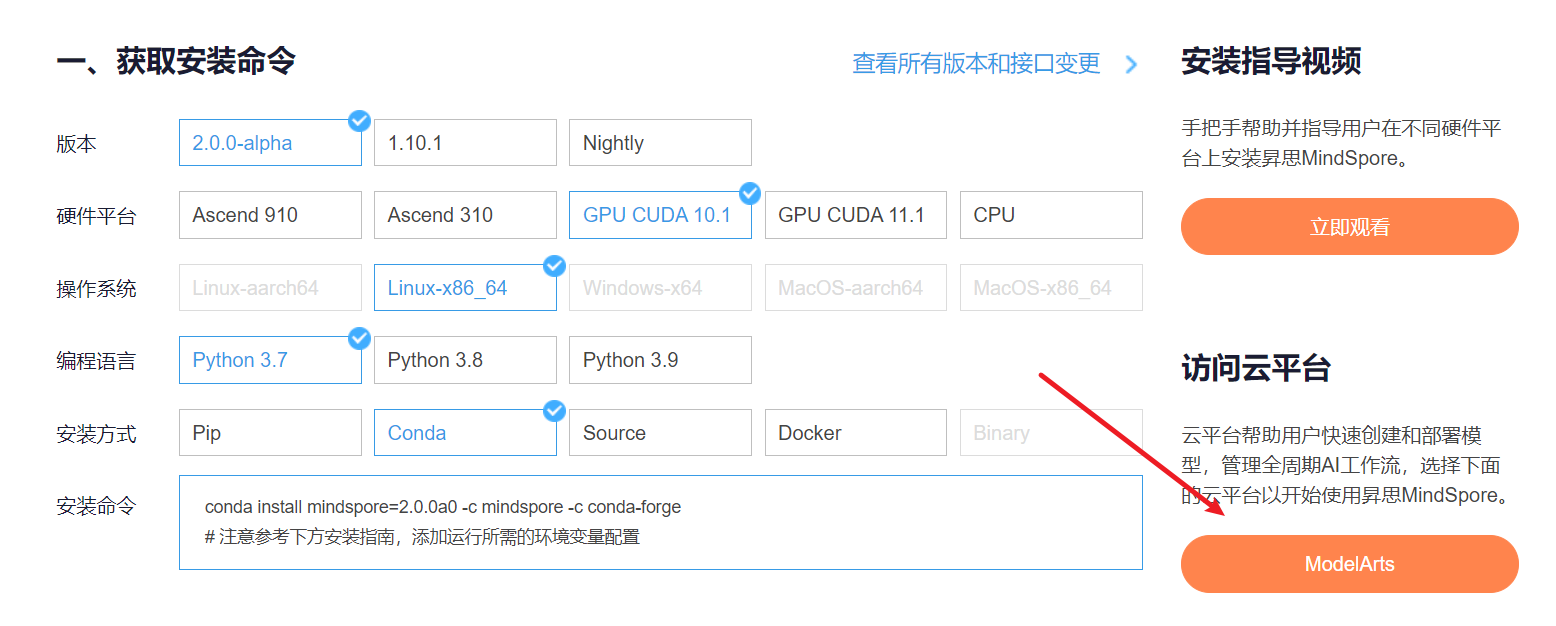
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
选择下方CodeLab立即体验
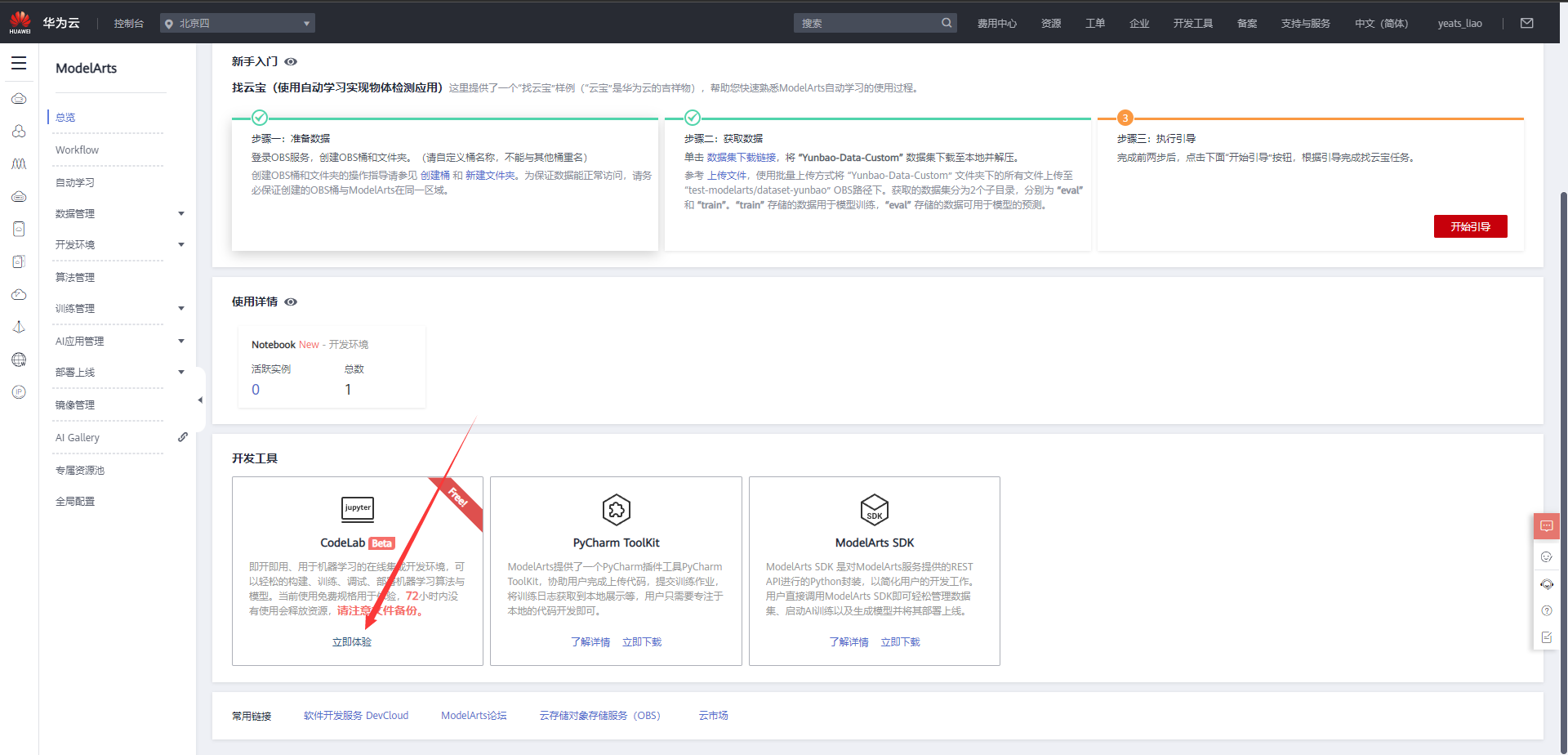
等待环境搭建完成
2.使用CodeLab体验Notebook实例
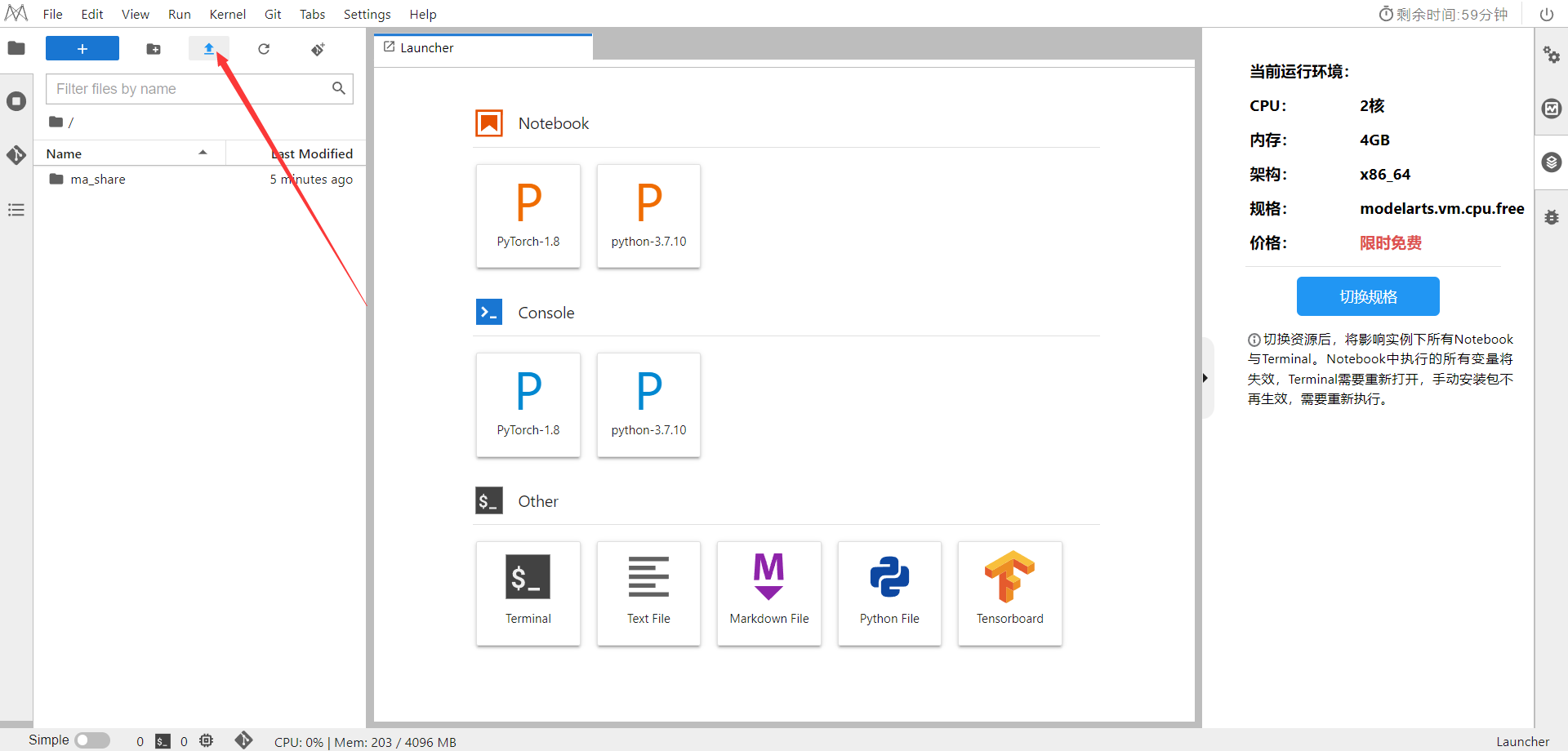
下载NoteBook样例代码,.ipynb为样例代码
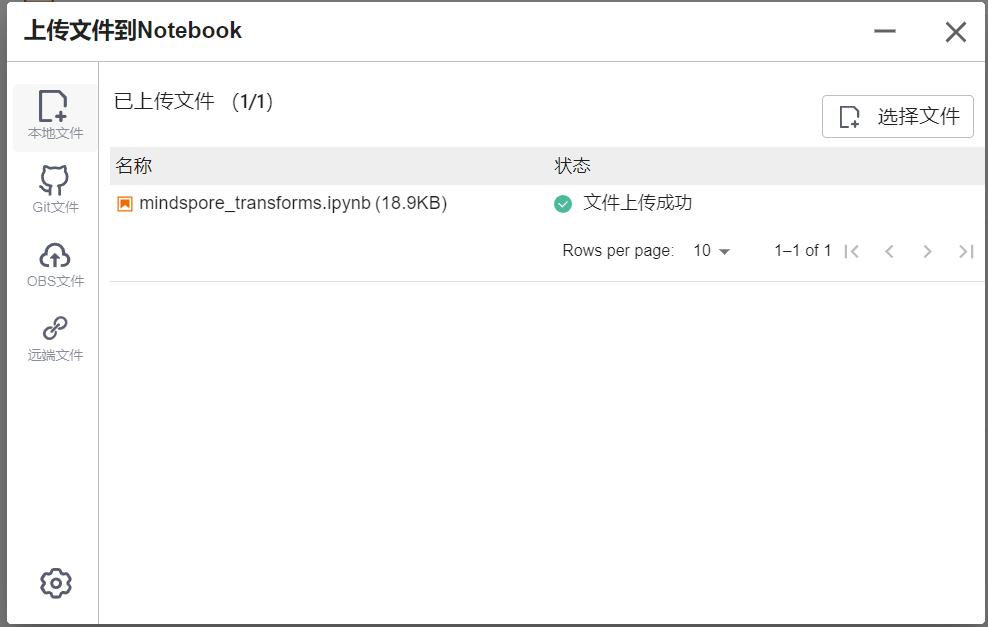
选择ModelArts Upload Files上传.ipynb文件
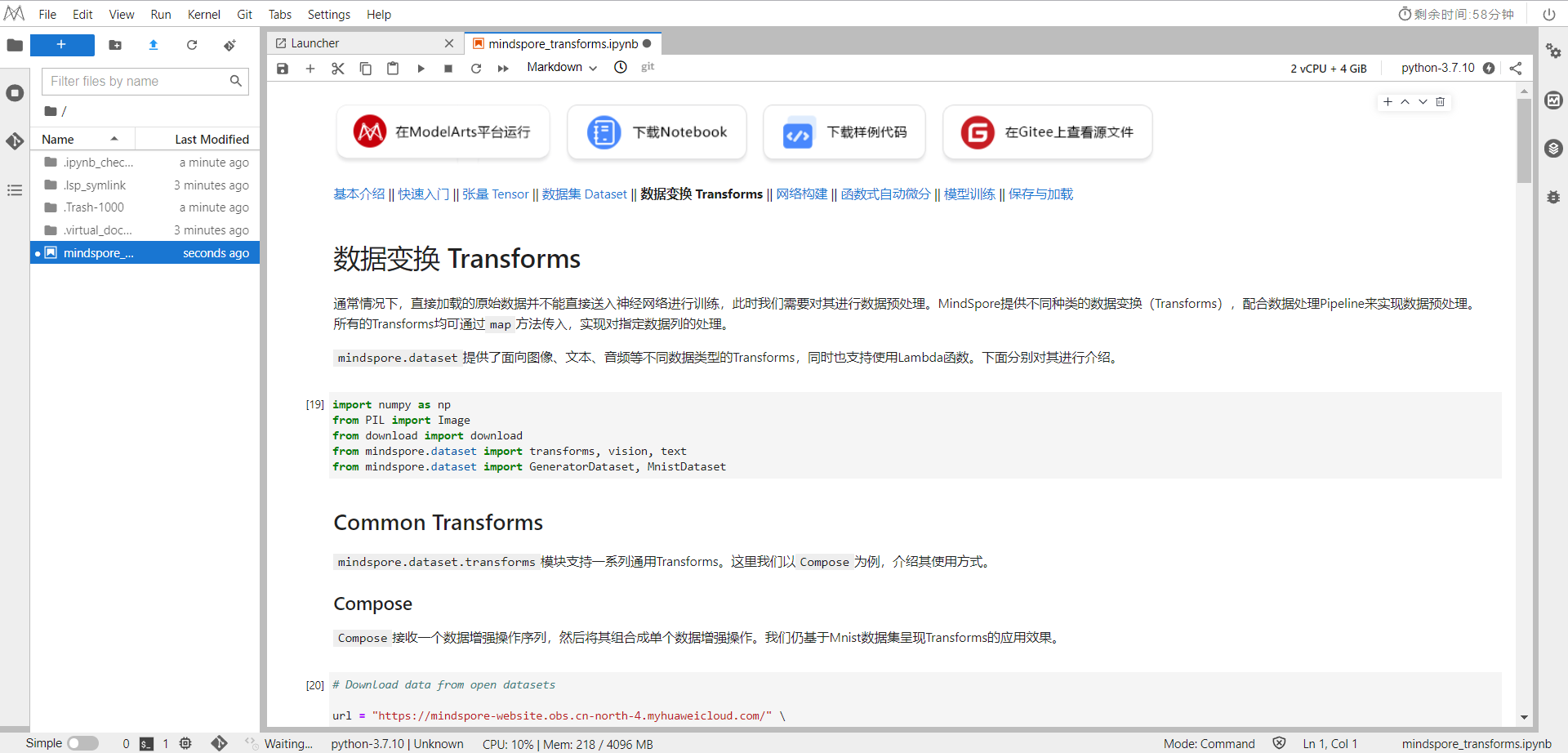
选择Kernel环境
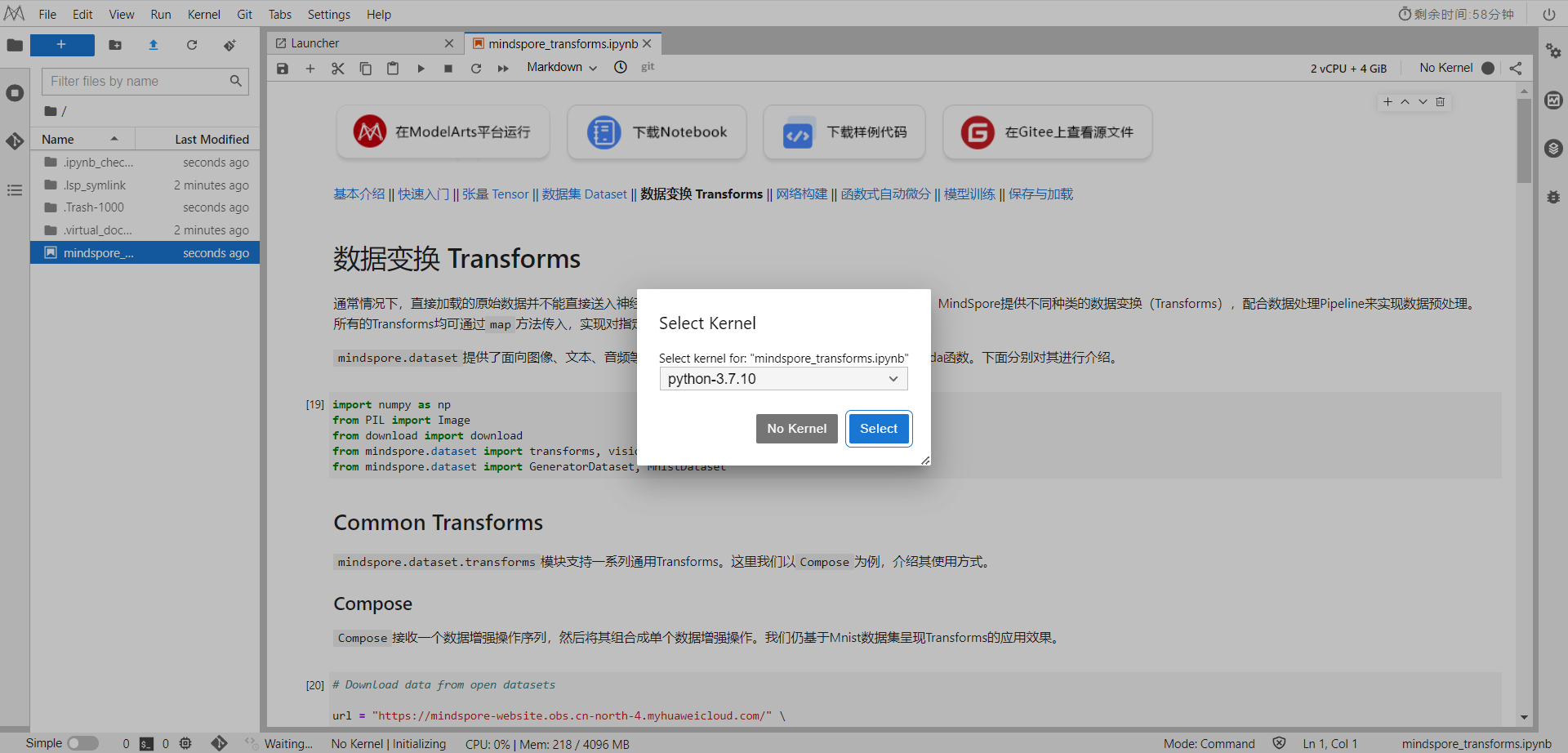
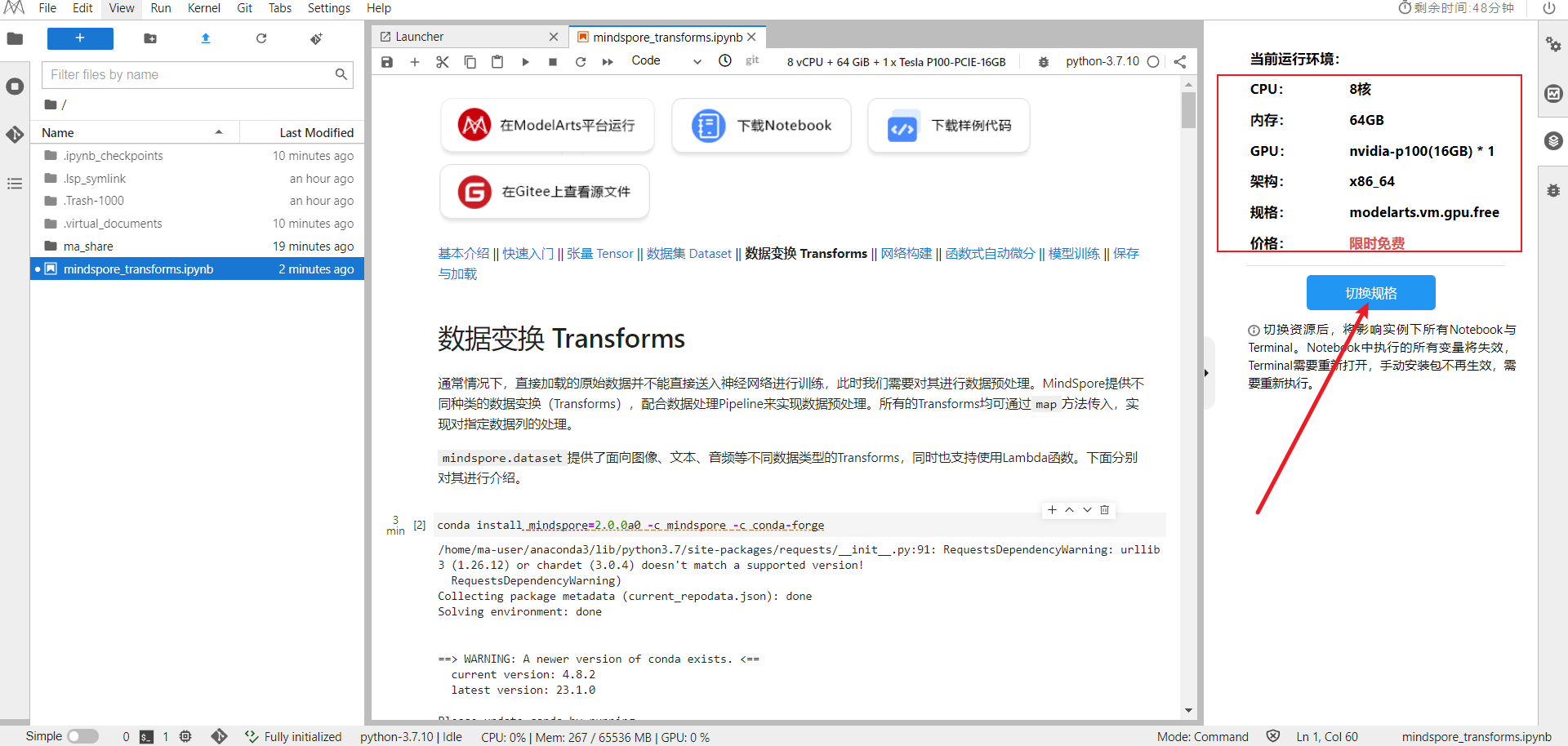
切换至GPU环境
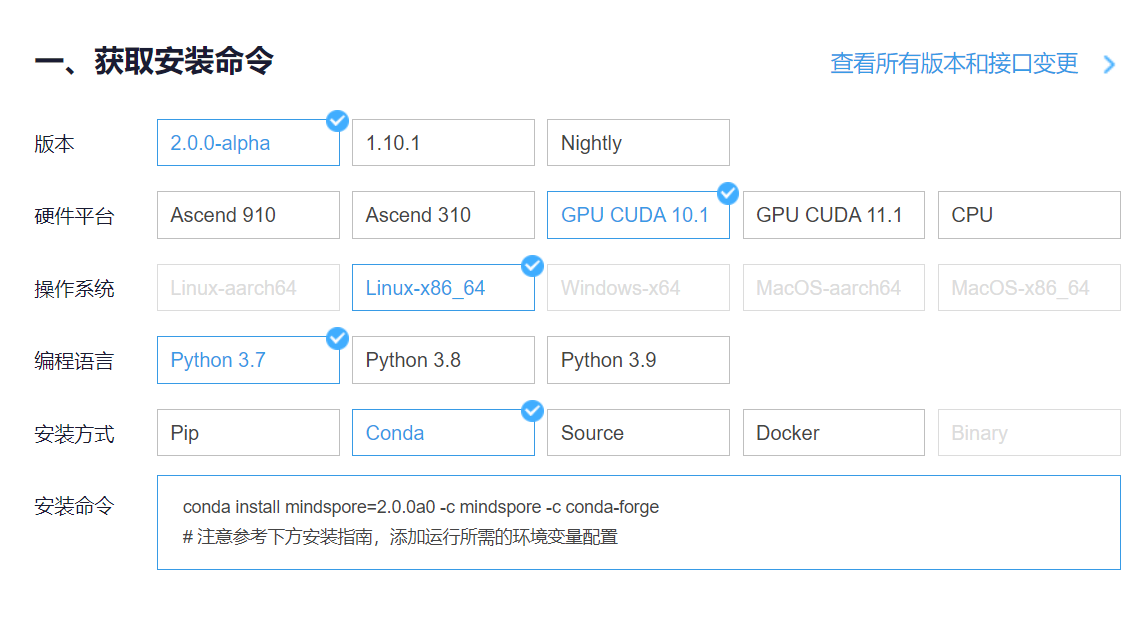
进入昇思MindSpore官网,点击上方的安装

获取安装命令
回到Notebook中,在第一块代码前加入命令
pip install --upgrade pip
本章节中的示例代码依赖download,可使用命令pip install download安装
pip install download
安装MindSpore2.0.0-alpha版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
导入mindspore
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset

二、数据变换 Transforms
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。下面分别对其进行介绍。
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset

Common Transforms
mindspore.dataset.transforms模块支持一系列通用Transforms。这里我们以Compose为例,介绍其使用方式。
Compose
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们仍基于Mnist数据集呈现Transforms的应用效果。
# Download data from open datasetsurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
composed = transforms.Compose([vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]
)train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
Vision Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换。下面对其进行详述。
Rescale
Rescale变换用于调整图像像素值的大小,包括两个参数:
- rescale:缩放因子。
- shift:平移因子。
图像的每个像素将根据这两个参数进行调整,输出的像素值为 𝑜𝑢𝑡𝑝𝑢𝑡𝑖=𝑖𝑛𝑝𝑢𝑡𝑖∗𝑟𝑒𝑠𝑐𝑎𝑙𝑒+𝑠ℎ𝑖𝑓𝑡
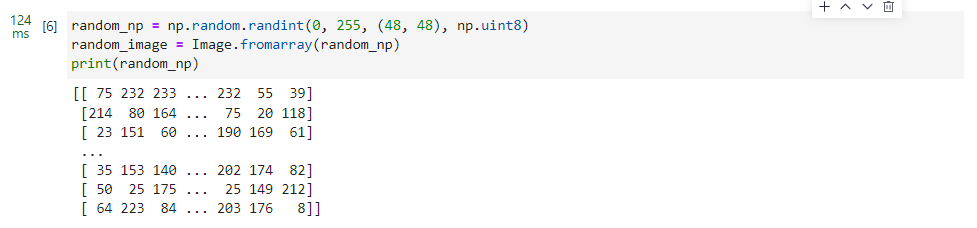
这里我们先使用numpy随机生成一个像素值在[0, 255]的图像,将其像素值进行缩放。
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
为了更直观地呈现Transform前后的数据对比,我们使用Transforms的Eager模式进行演示。首先实例化Transform对象,然后调用对象进行数据处理。
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
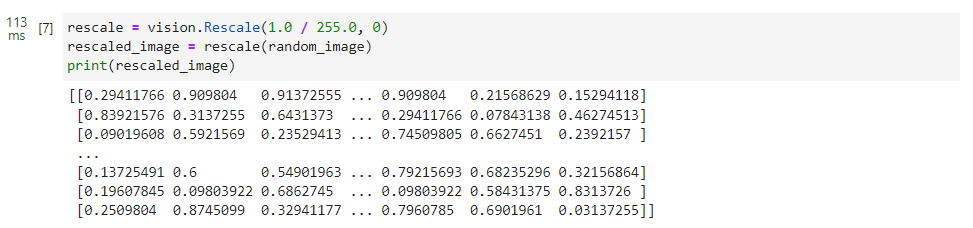
可以看到,使用Rescale后的每个像素值都进行了缩放。
Normalize
Normalize变换用于对输入图像的归一化,包括三个参数:
- mean:图像每个通道的均值。
- std:图像每个通道的标准差。
- is_hwc:输入图像格式为(height, width, channel)还是(channel, height, width)。

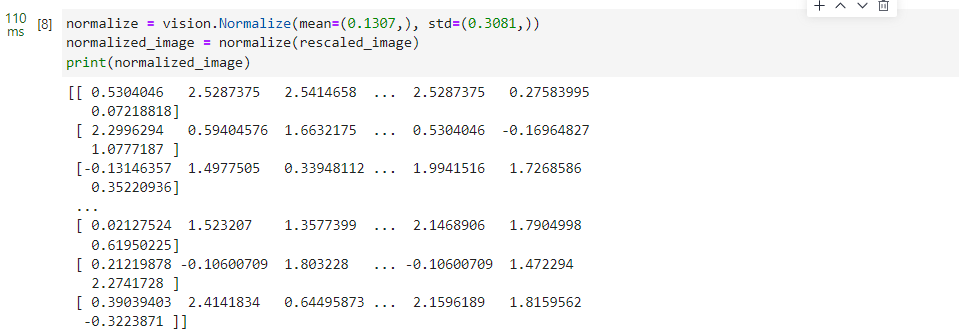
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
HWC2CWH
HWC2CWH变换用于转换图像格式。在不同的硬件设备中可能会对(height, width, channel)或(channel, height, width)两种不同格式有针对性优化。MindSpore设置HWC为默认图像格式,在有CWH格式需求时,可使用该变换进行处理。
这里我们先将前文中normalized_image处理为HWC格式,然后进行转换。可以看到转换前后的shape发生了变化。
hwc_image = np.expand_dims(normalized_image, -1)
hwc2cwh = vision.HWC2CHW()
chw_image = hwc2cwh(hwc_image)
print(hwc_image.shape, chw_image.shape)

Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
texts = ['Welcome to Beijing','北京欢迎您!','我喜欢China!',
]
test_dataset = GeneratorDataset(texts, 'text')

BasicTokenizer
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的BasicTokenizer举例。配合map,将三段文本进行分词,可以看到处理后的数据成功分词。
test_dataset = test_dataset.map(text.BasicTokenizer())
print(next(test_dataset.create_tuple_iterator()))

Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
vocab = text.Vocab.from_dataset(test_dataset)

获得词表后我们可以使用vocab方法查看词表。
print(vocab.vocab())

生成词表后,可以配合map方法进行词表映射变换,将Token转为Index。
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))

Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2:
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))

[[Tensor(shape=[], dtype=Int64, value= 2)], [Tensor(shape=[], dtype=Int64, value= 4)], [Tensor(shape=[], dtype=Int64, value= 6)]]
可以看到map传入Lambda函数后,迭代获得数据进行了乘2操作。
我们也可以定义较复杂的函数,配合Lambda函数实现复杂数据处理:
def func(x):return x * x + 2test_dataset = test_dataset.map(lambda x: func(x))
print(list(test_dataset.create_tuple_iterator()))

相关文章:
华为开源自研AI框架昇思MindSpore数据变换:Transforms
目录一、环境准备1.进入ModelArts官网2.使用CodeLab体验Notebook实例二、数据变换 TransformsCommon TransformsComposeVision TransformsRescaleNormalizeHWC2CWHText TransformsBasicTokenizerLookupLambda Transforms通常情况下,直接加载的原始数据并不能直接送入…...

软件测试之边界值测试法
边界值测试法 1. 介绍 边界值分析法就是对输入或输出边界值进行测试的,也是一种黑盒测试. 边界值分析法通常作为等价类划分法的补充,其测试用例来自等价类的边界;长期的经验得知,大量的错误是发现在输入或输出范围的边界上,而不是发生再输入输出范围的内部&#…...

【华为OD机试模拟题】用 C++ 实现 - 最近的点(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 获得完美走位(2023.Q1) 文章目录 最近更新的博客使用说明最近的点题目输入输出示例一输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单查看地址…...
Qt windeployqt.exe 打包qml
Qt系列文章目录 文章目录Qt系列文章目录前言一、遇到的坑二、参考前言 我们在QtCreator下面开发程序,一般都会遇到工程发布给客户使用的情况。我们通常会使用Qt自带的打包工具:windeployqt.exe。 windeployqt.exe是Qt自带的工具,用于创建应用…...
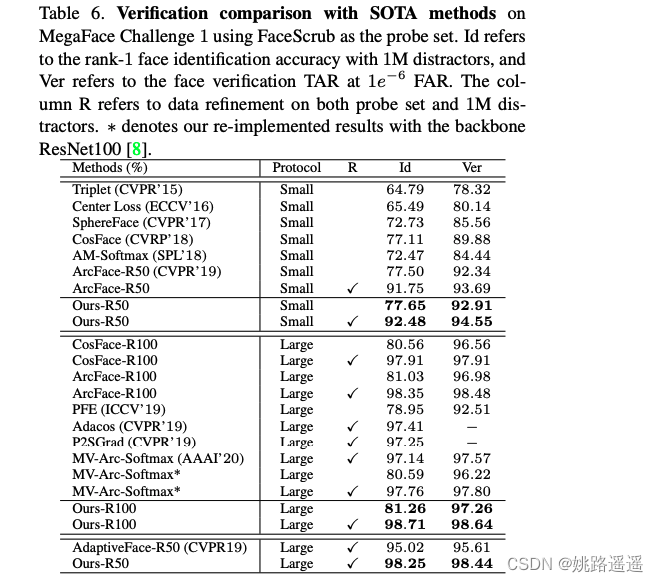
【人脸识别】CurricularFace:自适应课程学习人脸识别损失函数
论文题目:《CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition》 论文地址:https://arxiv.org/pdf/2004.00288v1.pdf 代码地址:https://github.com/HuangYG123/CurricularFace 建议先了解下这篇文章:…...
)
springmvc之rest风格(RESTFUL)
目录 一、介绍 1.什么是REST? 2.REST的实质 3.REST风格的优点 4.REST风格的缺点 3.什么是RESTful? 二、代码理解 一、介绍 1.什么是REST? 答:REST(Representational State Transfer) ,表现形式转…...
django项目实战十四(django+bootstrap实现增删改查)进阶混合数据使用modelform上传
目录 一、启用media 1、URL设置 2、settings.py配置 二、url 三、upload.py 新增upload_modelform方法 四、form.py新增UpModelForm 五、创建city表 六、创建city_list.html 接上一篇《django项目实战十三(djangobootstrap实现增删改查)进阶混合数据f…...
)
2023年CDGA考试模拟题库(1-100)
2023年CDGA考试模拟题库(1-100) 1.以下哪种活动中 ,混淆是不足以保护数据 的?[1分] A.数据共享 B.数据转换 C.数据脱敏 D.以上都正确 答案C 2.关于受控词表描述不正确的是?[1分] A.系统地组织文件档案和内容离不开受控词表 B.受控词表的一个例子是用于出版物分类的都…...
HTML常用基础内容总结
文章目录一、对HTML的感性认知前置知识什么是web前端,什么是web后端前端技术栈、后端技术栈开发与运行的区别浏览器的功能是什么简介写一个简单可运行的的html代码前端开发方式二、VSCode的简单使用三、常用的HTML标签最最基本的HTML结构HTML代码特点注释标签标题标…...
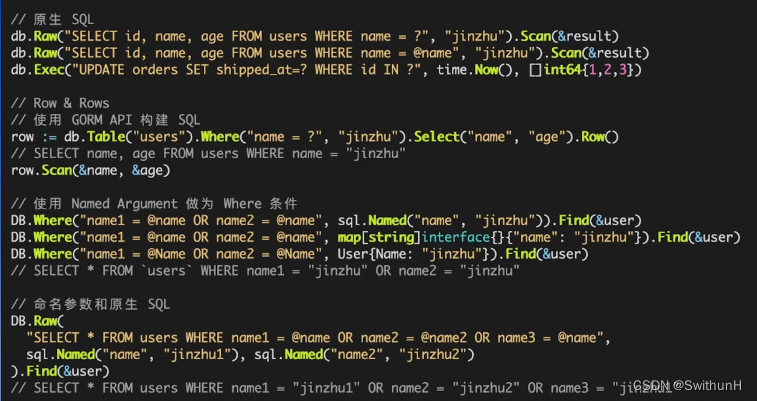
Gorm-学习笔记
1 基本使用 2 创建数据 2.1 如何使用Upsert 使用clause.OnConflict处理数据冲突 2.2 如何使用默认值 通过使用default标签为字段定义默认值 3 查询数据 3.1 First与Find 使用First时,需要注意查询不到数据会返回ErrRecordNotFound。 使用Find查询多条数据&#x…...
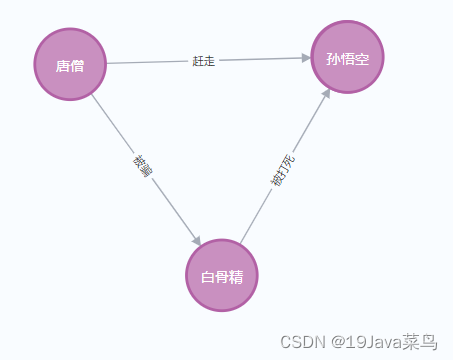
【Neo4j】图数据库CypherQueryLanguage随笔
CQL语言随笔 一、Cyther关系描述 如图:唐僧,孙悟空,白骨精三者的关系图: Cypher语言描述他们的关系: (孙悟空)<-[:赶走]-(唐僧)-[:被骗]->(白骨精)-[:被打死]->(孙悟空) 二、CQL语言的使用案例 创建结点…...
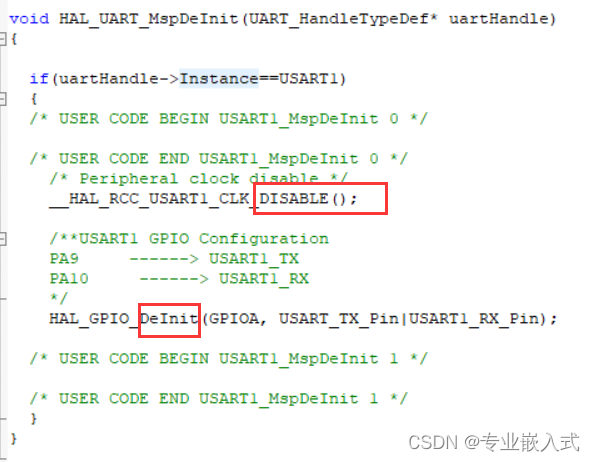
STM32Cube串口USART发送接收数据
本文代码使用 HAL 库。 文章目录前言一、USART 同步/异步串行接收/发送器二、USART 原理图三、CubeMX 创建工程四、usart.c 文件解析五,设计实验:在 串口输入字符点亮led实验现象:总结前言 这篇文章介绍 实现 USART 异步模式下 通过 串口助手…...

OpenFeign详解
OpenFeign是什么? OpenFeign: OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如RequesMapping等等。OpenFeign的FeignClient可以解析SpringMVC的RequestMapping注解下的接口,并通过动态代理的方式产生实现类&am…...
python多线程网络编程
背景 使用过flask框架后,我对request这个全局实例非常感兴趣。它在客户端发起请求后会保存着所有的客户端数据,例如用户上传的表单或者文件等。那么在很多客户端发起请求时,服务器是怎么去区分不同的request对象呢?当查看了大量的…...

BFS-走迷宫
题目描述 给定一个 NM 的网格迷宫 G。G 的每个格子要么是道路,要么是障碍物(道路用 1 表示,障碍物用 0 表示)。 已知迷宫的入口位置为 (x1,y1),出口位置为 (x2...

【蓝牙mesh】Lower协议层介绍
【蓝牙mesh】Lower协议层介绍 Lower层简介 Lower协议层用于处理网络层以下的功能,包括节点的广播、重传、路由和网络拓扑等,是实现蓝牙mesh网络的关键协议之一。其中Lower协议层中最主要的一部分工作就是mesh数据的分片和组包。 Lower层是将Upper层发过…...
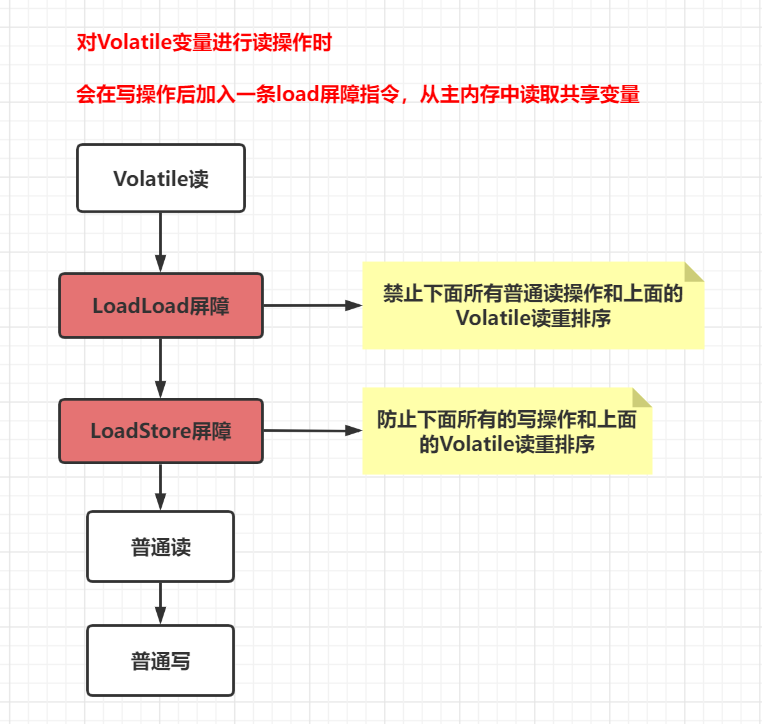
Java-重排序,happens-before 和 as-if-serial 语义
目录1. 如何解决重排序带来的问题2. happens-before1. 如何解决重排序带来的问题 对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序。对于处理器重排序,JMM 的处理器重排序规则会要求编译器在生成指令序列时,插入特定类型的内…...
Nginx安装及介绍
前言:传统结构上(如下图所示)我们只会部署一台服务器用来跑服务,在并发量小,用户访问少的情况下基本够用但随着用户访问的越来越多,并发量慢慢增多了,这时候一台服务器已经不能满足我们了,需要我们增加服务…...
【华为OD机试模拟题】用 C++ 实现 - 寻找路径 or 数组二叉树(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 获得完美走位(2023.Q1) 文章目录 最近更新的博客使用说明寻找路径 or 数组二叉树题目输入输出描述示例一输入输出示例二输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过…...

LINUX学习记录
回顾系列:两天的时间(2023.2.24-2023.2.25)重新学了遍Linux基础课,收获非常多,以前只会一些简单的Linux命令,对shell,git,管道,复杂Linux命令都不熟悉,学完之…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...