数据结构笔记——树和图(王道408)(持续更新)
文章目录
- 传送门
- 前言
- 树(重点)
- 树的数据结构
- 定义
- 性质
- 二叉树的数据结构
- 定义
- 性质
- 储存结构
- 二叉树算法
- 先中后序遍历
- 层次展开法
- 递归模拟法
- 层次遍历
- 遍历序列逆向构造二叉树
- 线索二叉树(难点)
- 定义
- 线索化的本质
- 二叉树线索化
- 线索二叉树中找前驱后继
- 中序
- 先序
- 后序
- 树算法
- 储存结构
- 树和森林的遍历
- 树遍历
- 森林遍历
- 树应用
- 哈夫曼树
- 并查集
- 数据结构
- 优化
- 并集:控制高度
- 查集:压缩路径
传送门
思维导图+精炼的个人思考
前言
数据结构的笔记相比于其他3门,笔记的重要性要低很多,毕竟对于选择408的同学来说,大二时候应该有足够的时间学习,所以基础是比较好的,再加上csdn上一大堆数据结构和算法的帖子,我再重复造轮子也没啥意思了。
所以我这篇文章不打算写的很细节,就是单纯地把思路提纯出来,并附上自己深入的理解,再搭配思维导图就行了,而不去记录过于细节的知识。
树(重点)
树的数据结构
定义
除了根节点,任何节点有且仅有1前驱:
- 根节点:0前驱,n后继
- 分支节点:1前驱,n后继
- 叶节点:1前驱,0后继
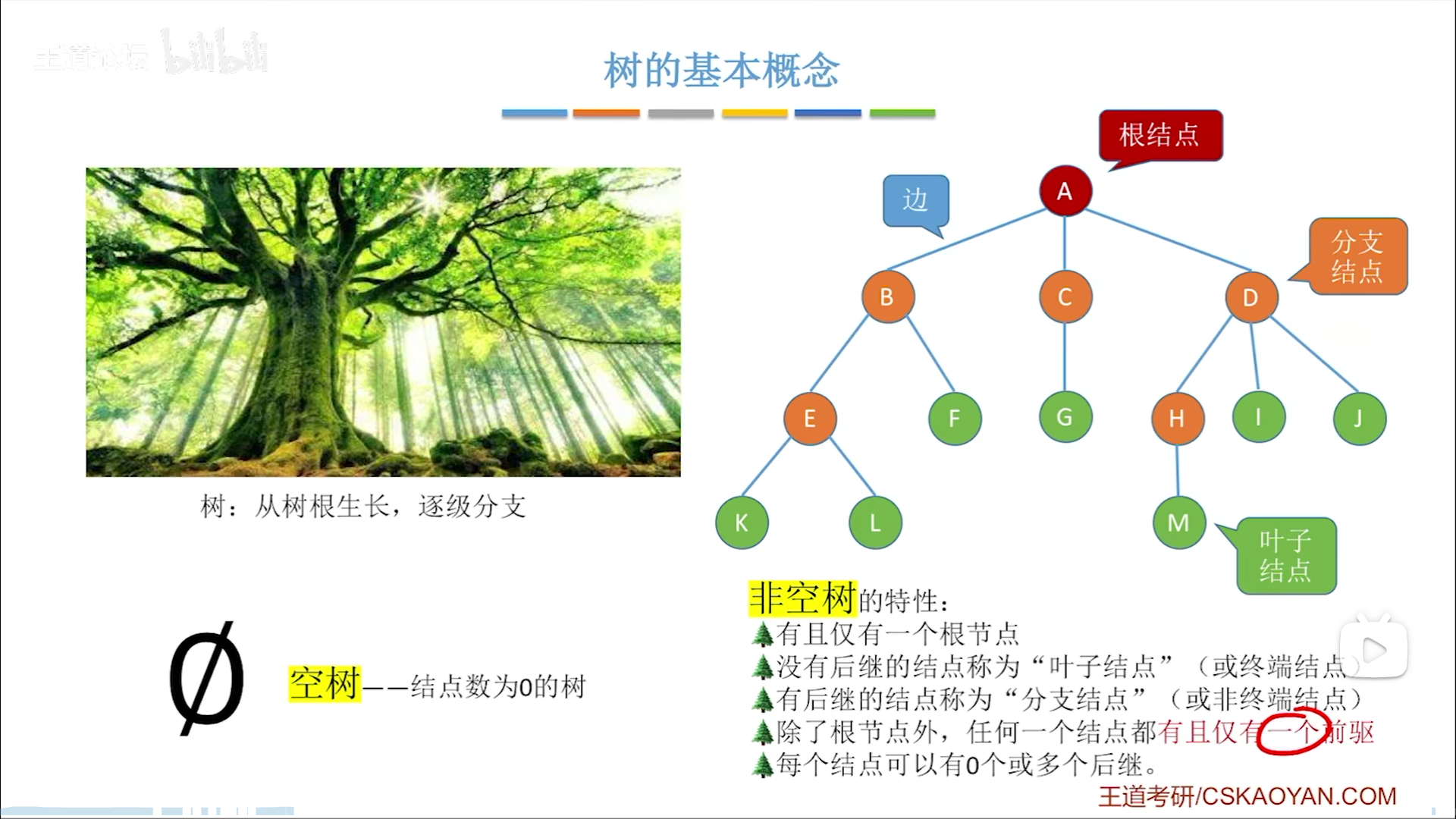
节点之间的关系:
- 祖先/子孙:所有有血缘关系的前辈/子孙。注:你叔和你没血缘关系,所以不算祖先
- 父亲/孩子:直接血缘关系的上下层节点
- 兄弟/堂兄弟: 在树的同一层,区分点在于是否是同一个爹生的
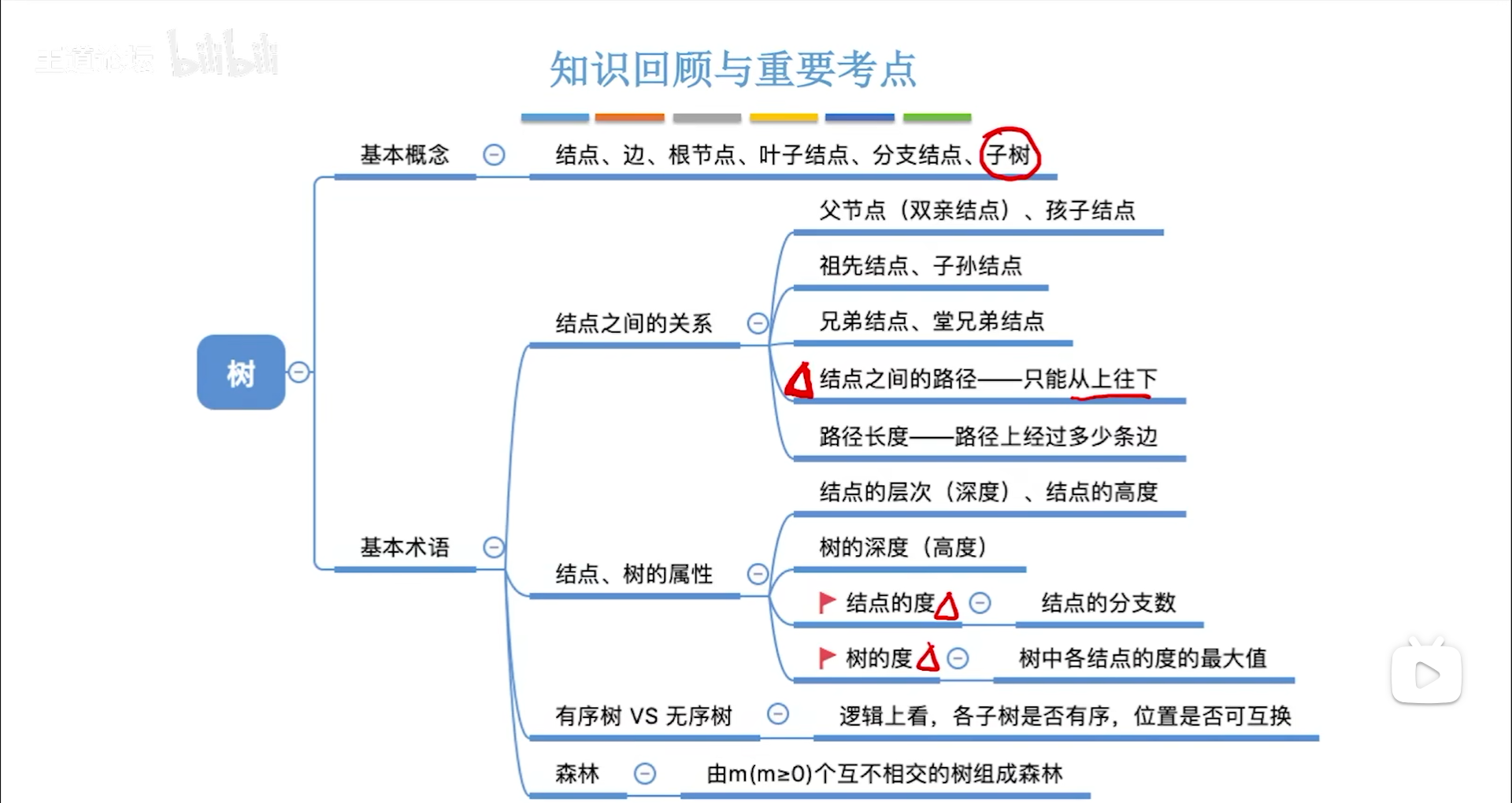
术语:
- 高度:从下往上数,叶节点是1
- 深度:从上往下算,根节点默认是1
- 节点的度:分支数
- 在图里要分入度出度,树的入度确定,所以不讨论
- 叶节点度=0,非叶节点度≠0
- 树的度:最大的节点度
性质
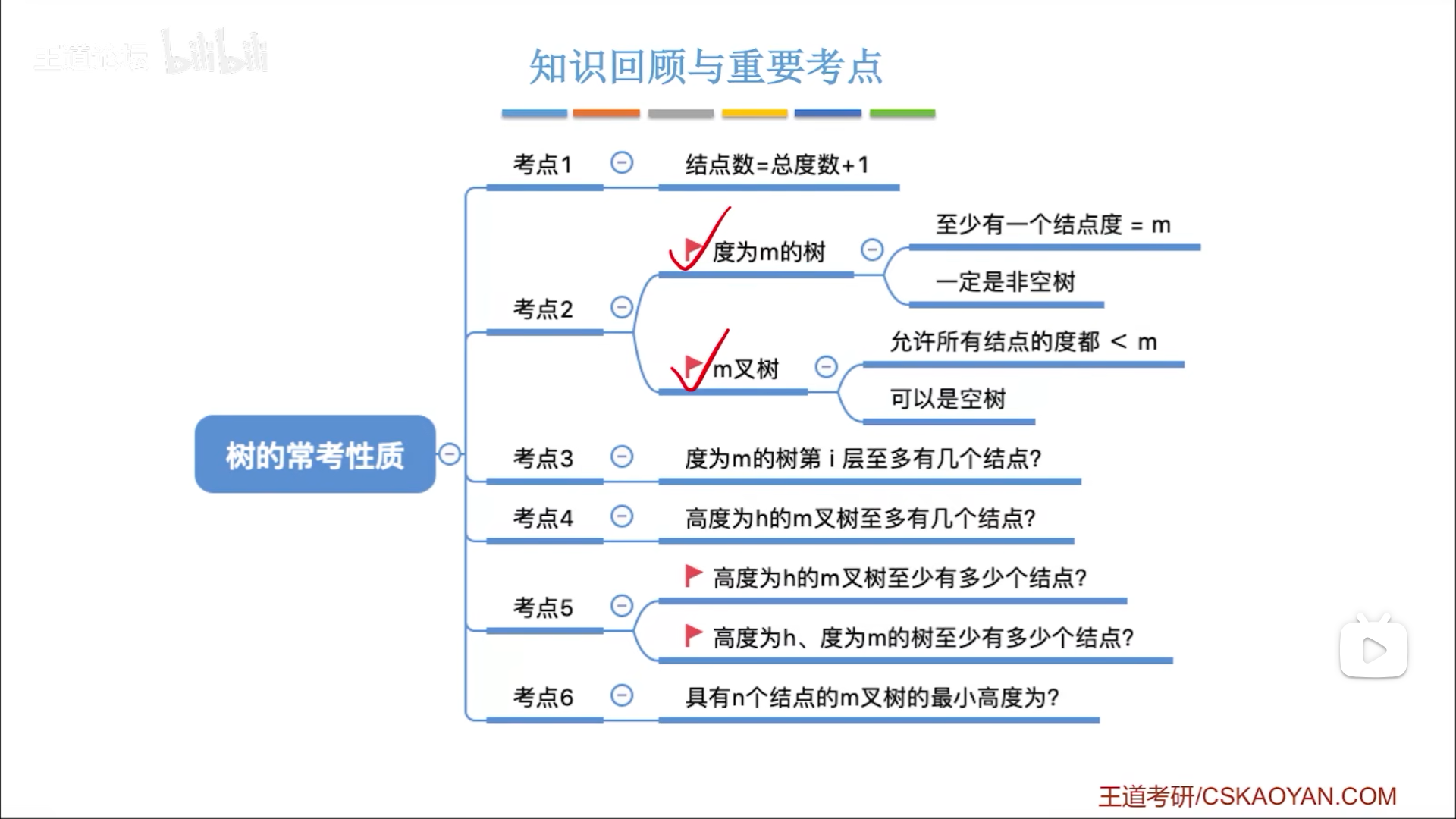
- 每个度代表分出一个节点,所以n个度即分出n节点,考虑到1个根节点,即n+1个节点。
- 不需要考虑重复,因为每次分支都是实实在在的,后面再分支也不会影响现在已经分出去的节点
- 度为m的树是m叉树(树度≤m)的特例
- 树度=m,至少有一个为m度节点,因此至少有m+1个节点
- 给定深度/高度后的最多节点数。满度:m叉树,满度情况下,每层节点数是以1开头,m为比的等比数列,总和用等比数列求和
- 给定深度/高度后的最少节点数
- m叉树,度没有下限,为了满足高度,极限情况需要有一条线,即h个节点
- 度为m的数,在满足高度的一条线前提下,还要找一个节点额外分(m-1)个节点,所以h+m-1

- 给定节点数,求最小高度。列不等式,下界<n≤上界,变形后可以得到h的范围。
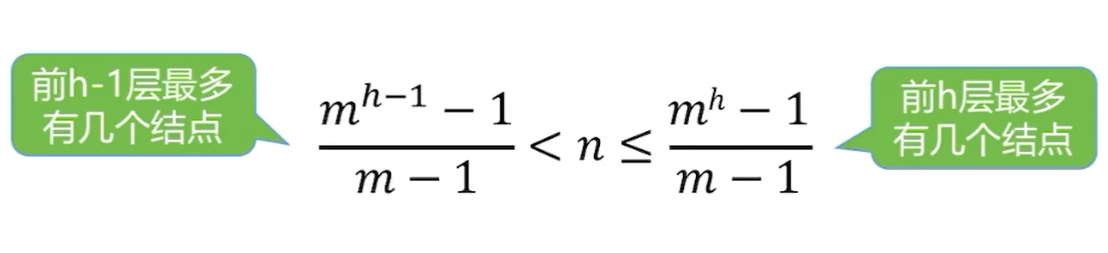
二叉树的数据结构
定义
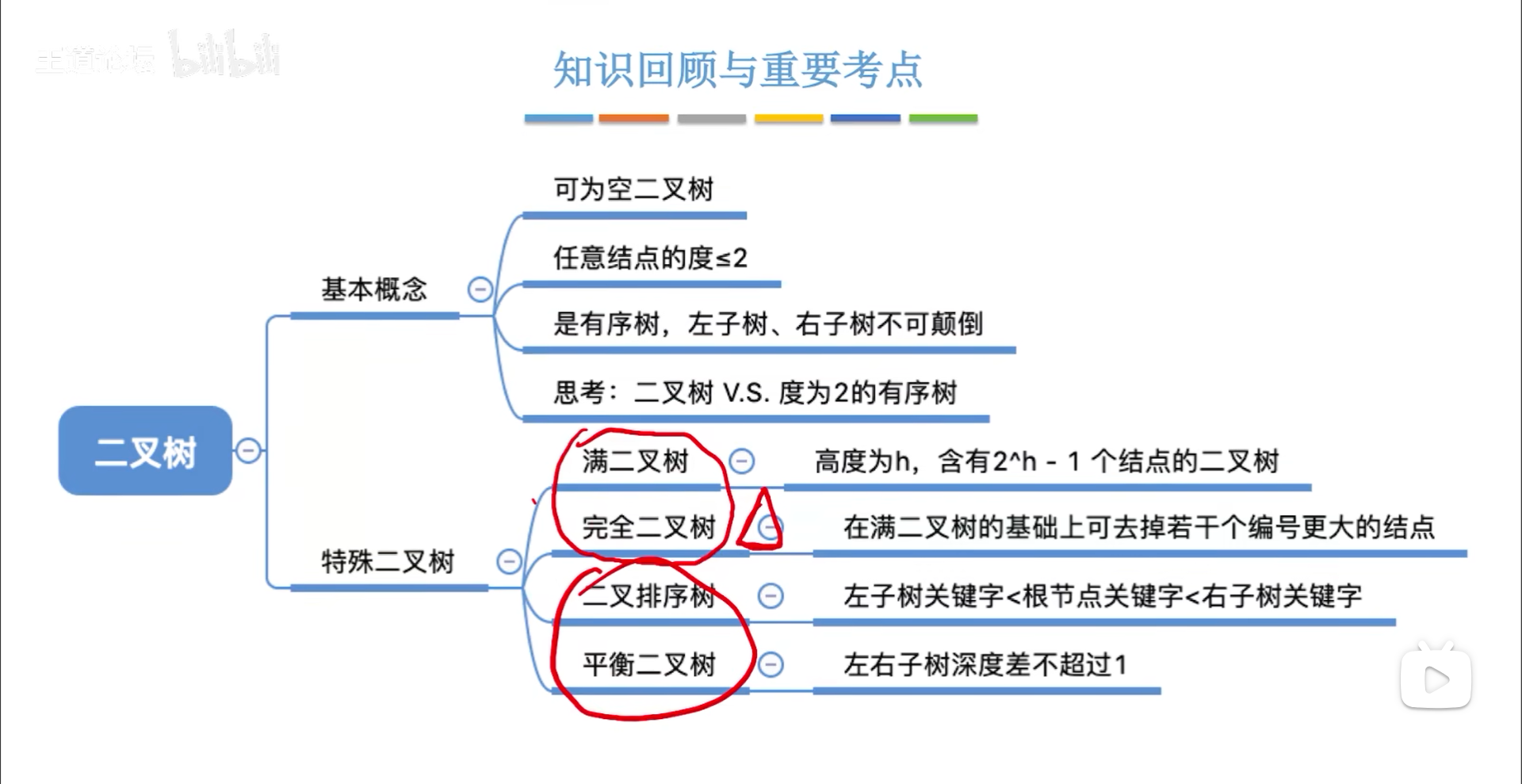
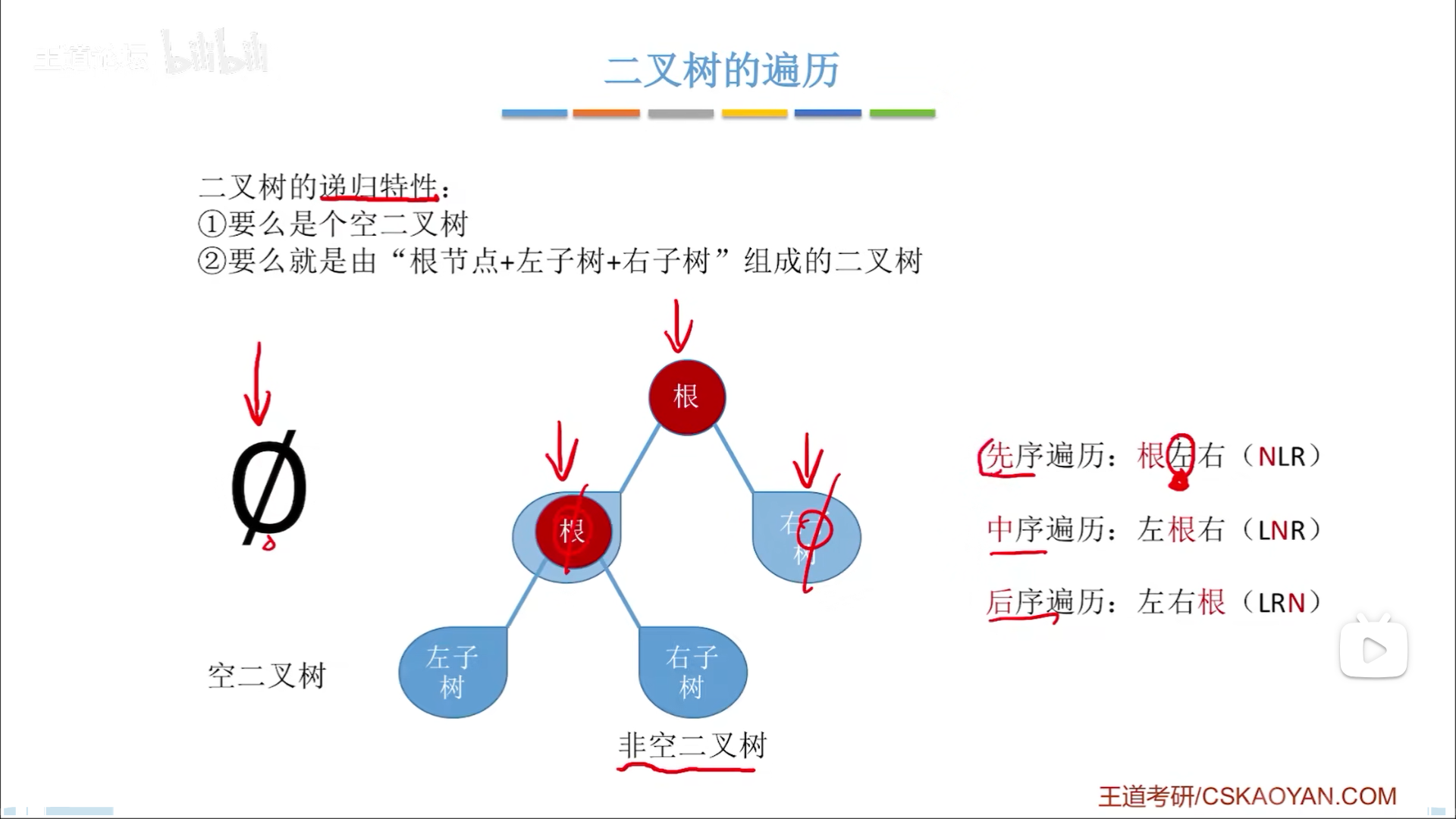
二叉树是一个纯粹的递归定义,二叉树只有两种状态:
- 空树
- 非空:根节点+左右子树
- 左右子树也可以是空树或者非空
- 左右之分,代表有序
具体来讲,有5种细分状态:
- 空
- 叶节点:度=0
- 单个孩子的节点:度=1
- 两个孩子的节点:度=2
通过度就可以区分节点的状态,后面说的所谓度为几,其实就是说xx状态的节点。
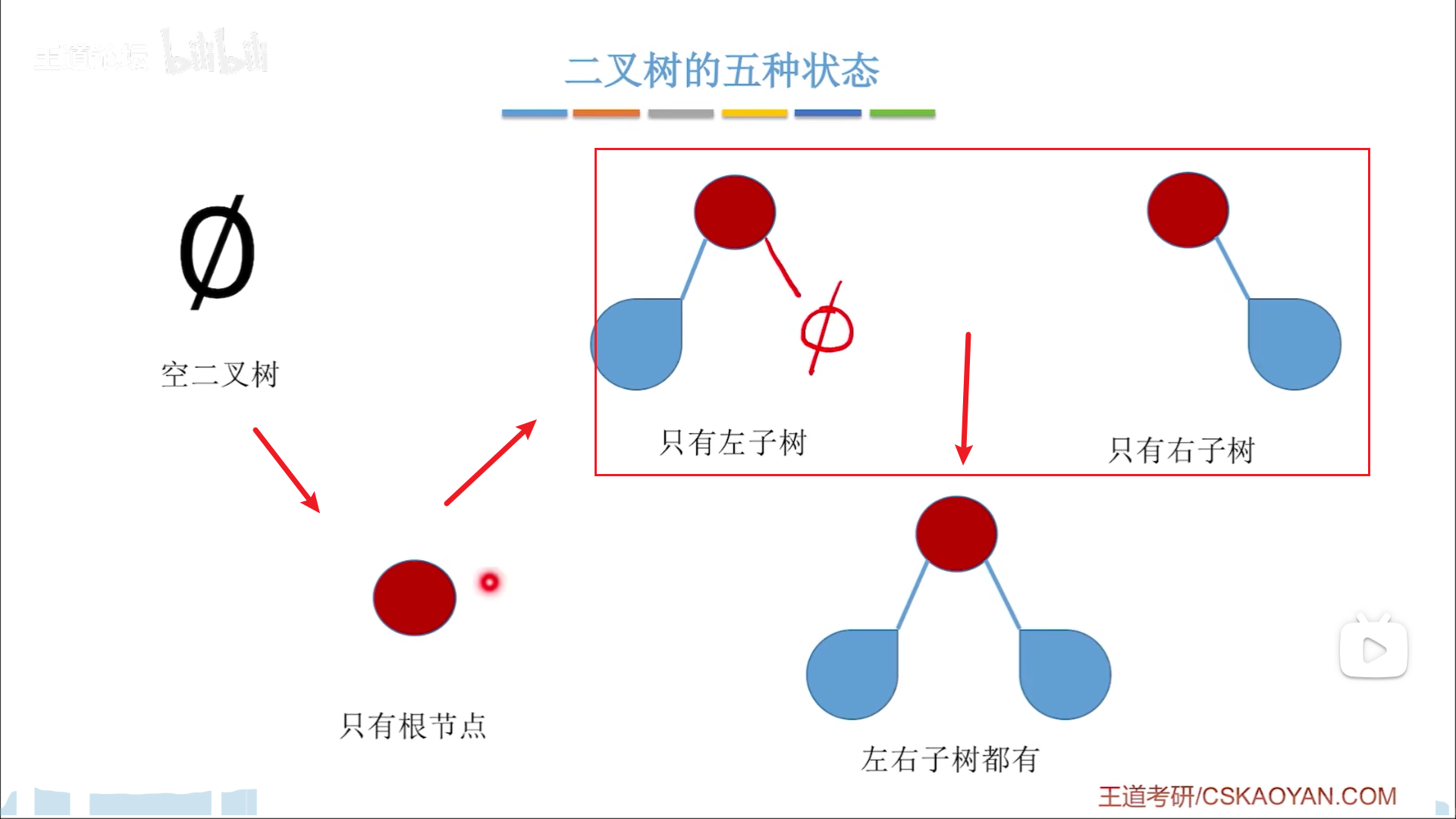
完全二叉树:节点是从上到下,从左到右连续排列的,没有空隙
满二叉树:最后一层是满的完全二叉树
直接特性就是,如果n层有节点,代表n-1层一定是排满的,且n层这个节点左边也是排满的
接下来解读二者差别:
- 度分析
- n+1层无节点,因此n层所有节点度=0
- 完全二叉树
- n-2层开始往上都满度。n层有节点,说明n-1层满,从n-2层开始往上都是满度(2)的
- n-1层可能有0,1,2三种度,从左到右,先是一排2度,然后
仅有一个1度,然后全是0度。如果有两个1度,就会打破完全二叉树连续排列的定义。 - 总结,n-2层往上全满,n-1层可能有任何类型节点,n层全是叶子
- 满二叉树,n层满,因此n-1层往上都是满度
- 父子关系。
- 左孩子2i,右孩子2i+1
- 父亲是孩子除以2,
向下取整
- 结合1,2来定位完全二叉树的1度节点。
- 1度节点肯定是最后一个孩子的父亲,直接除二向下取整,1度和2度节点都是分支节点,0度节点是叶节点。
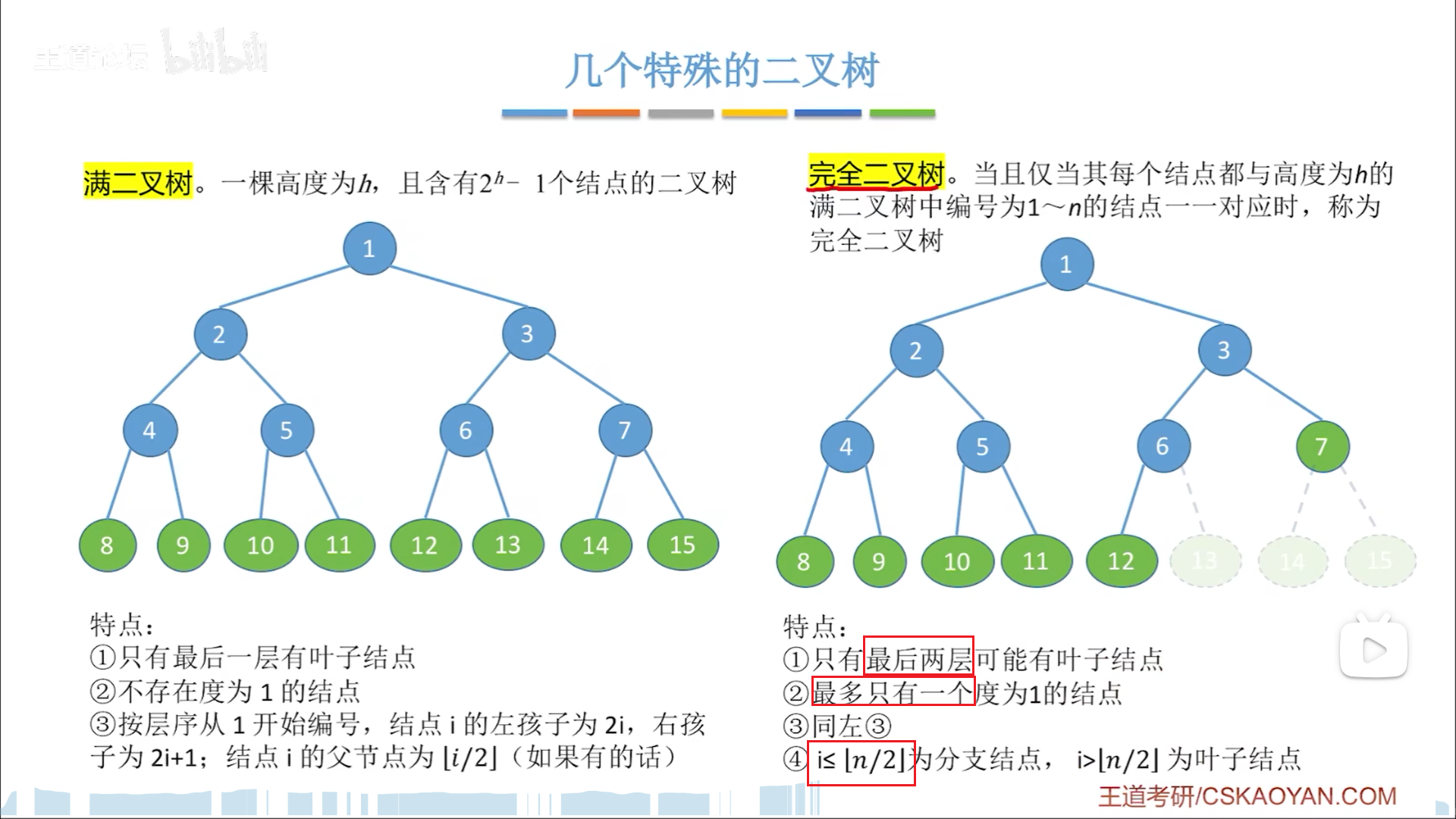
性质
二叉树推导:
- n0=n2+1
- 推导:n=n0+n1+n2(节点总数),且n=n1+2n2+1(节点总数=总度数+1),减一下可得结果
- 直观理解:度=1的节点不影响叶子结点数量。度=2的节点,每分叉一次,都是浪费一个叶子结点,同时生成两个叶子结点
- 即,最开始有1个叶节点(根),每分叉一次(2度节点),就会多一个叶节点,因此最后n0=n2(分叉次数)+1(根)
- 2,3都是等比数列性质
完全二叉树推导:
- 推导公式,要从≤或者≥哪里去推导。因为上下界有两种理解方式,所以就会有两种结果:
- 2 h − 1 − 1 < n ≤ 2 h − 1 2^{h-1}-1<n≤2^h-1 2h−1−1<n≤2h−1,用右边的小于等于就可以推导出一个公式
- 2 h − 1 ≤ n < 2 h 2^{h-1}≤n<2^h 2h−1≤n<2h,用左边的大于等于也可以推导一个h公式
- 给定完全二叉树的n,可以彻底确定其形状,节点的数量,类型,分布,下面有三个方程,联立就可以算出结果:
- n=n0+n1+n2
- n0=n2+1
- n1只可能是0或者1,只需要看n奇偶就可以。n如果是偶数,最后这个节点是独生子,即其父为1度节点,n1=1;如果n是奇数,说明这个节点有亲兄弟,场上就不存在1度节点了。
纵观这些公式,关键在于几点:
- 完全二叉树对等比数列的认知
- 对完全二叉树结构的认识,第n-1层的度数排列,左2,中1,右0,分支带来的节点变化(对应公式)

储存结构
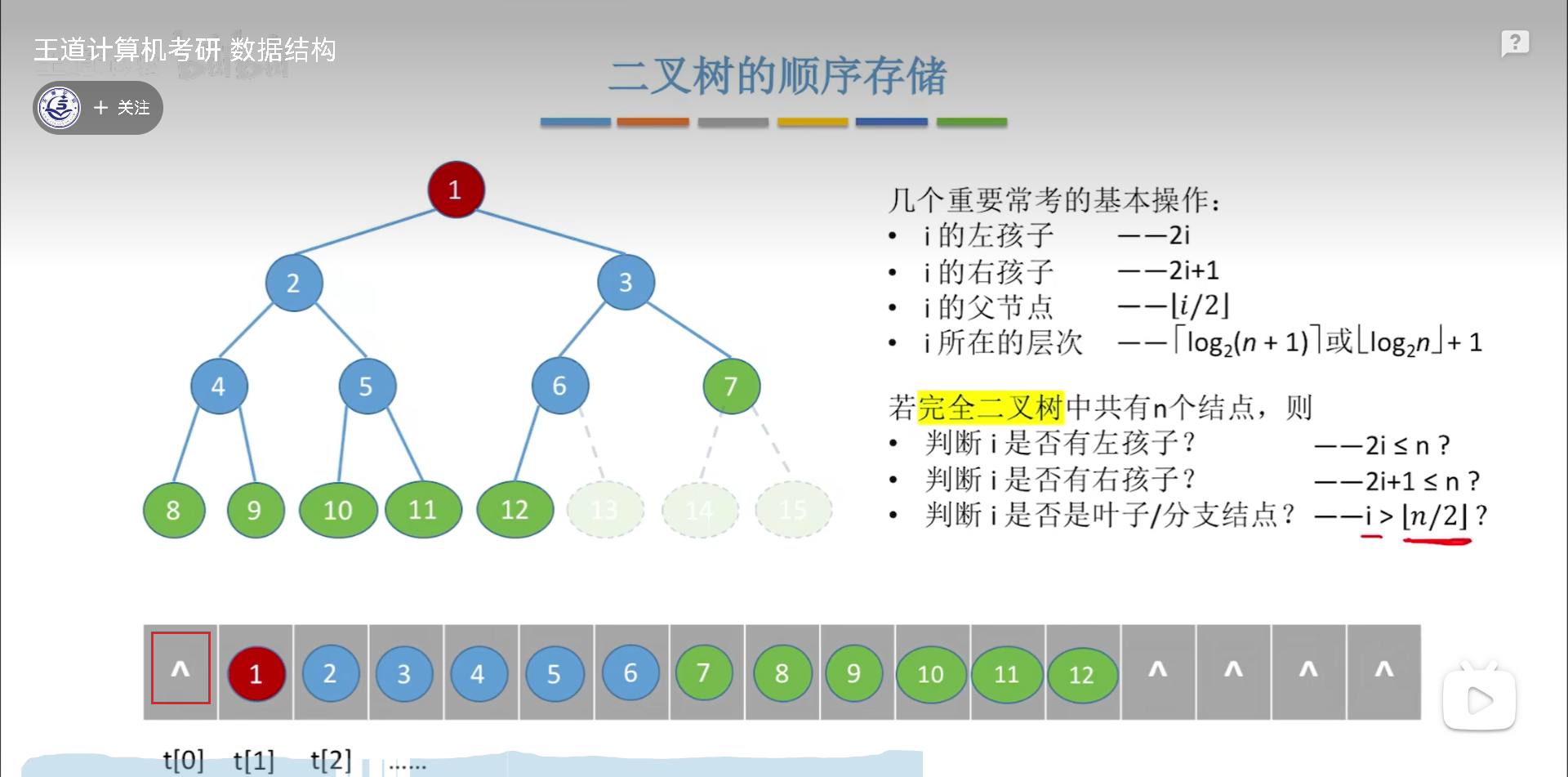
顺序存储,先说完全二叉树:
- 首先是,第一个元素不储存,这样就可以把位序和下标对应,简化代码和逻辑。
- 其次就是找父子,判断层次,这些都是数量关系
- 然后就是判断节点状态,是0度还是1,2度?
- 12度的区分这就需要结合n来判断,看看其左孩子,右孩子的位序是否越界n
- 0度判断要先找到0度2度的分界点,即n/2向下取整,左边是2,右边是0。至于这个节点本身,就要区分12度了。
一般的二叉树,如果在数组中连续存储,就会破坏位序关系
如果按位序存储,仍然有很多不便。一来节点状态无法通过n来判断了,只能新增bool变量,二来还会浪费空间,因此二叉树其实一般是用链式结构储存的。
链式储存:
假设有n个节点,那么总共就有2n个链域,除根节点外每有一个节点就会有一条边,每条边都会占用一个链域,总共n-1条边
因此就会剩下2n-(n-1)=n+1个空链域
这些链域可以用来逆向构建线索二叉树
在只有两个链域的情况下,找父节点要从根节点遍历,比较麻烦,因此要频繁查找父节点的话,还应该加入parent链域。

二叉树算法
先中后序遍历
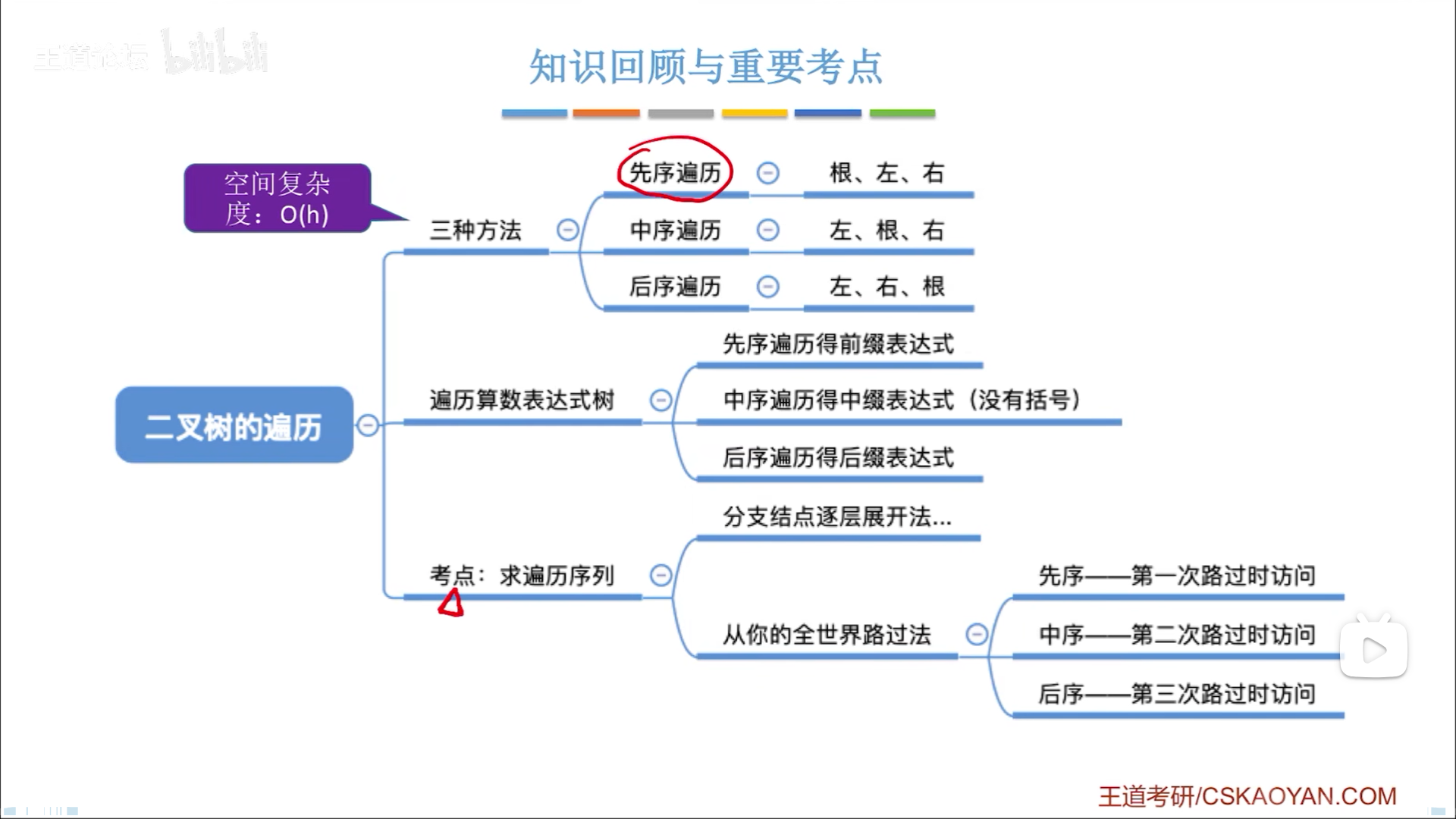
所谓的先序,其实是先根序
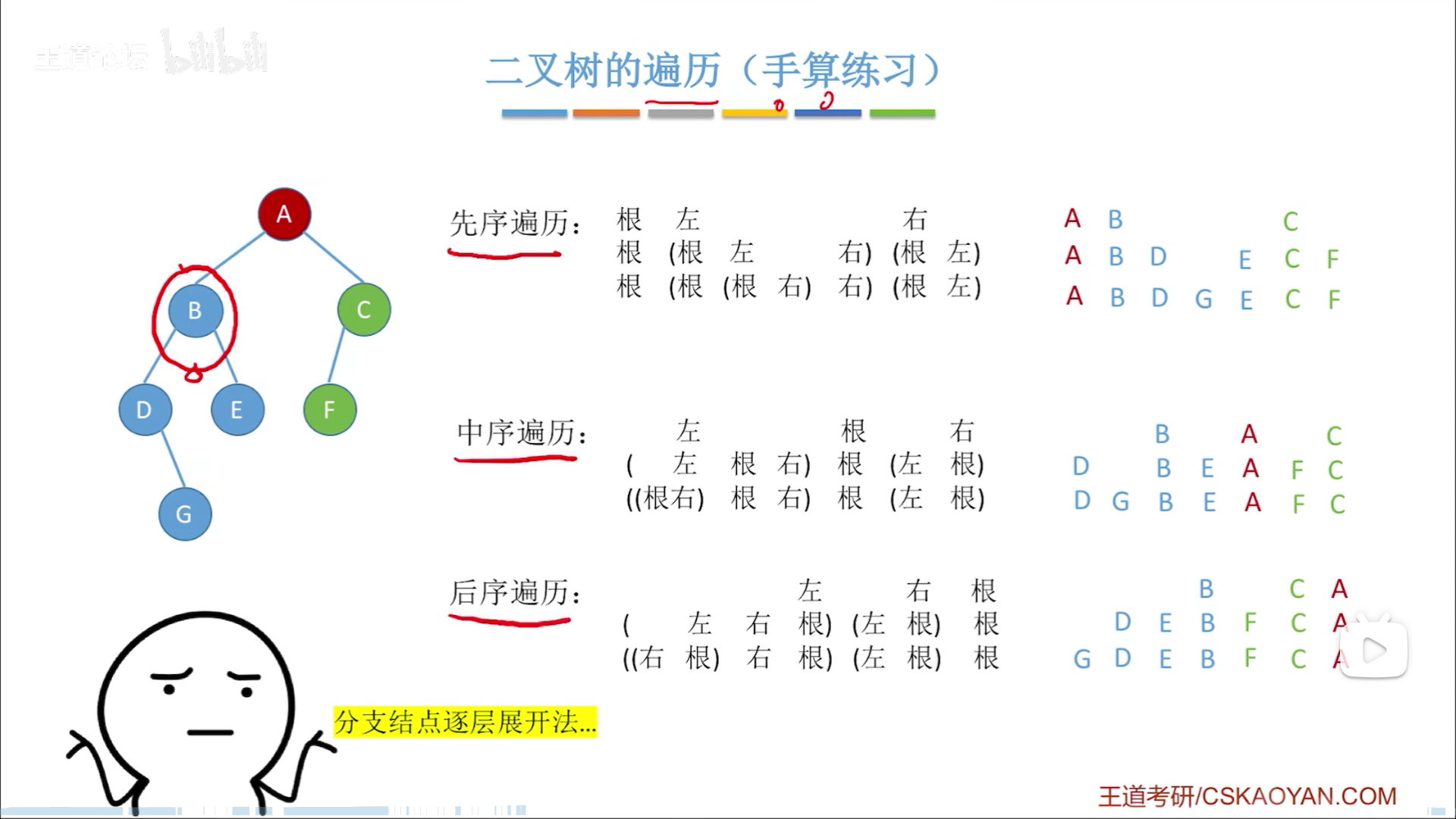
层次展开法
我此前是直接在脑子里去遍历,就是在脑子里模拟递归调用栈,虽然也能做,但是费脑子,不如下面的省劲:
逐层去展开,就像是前面从中缀转前缀/后缀的时候
先留出括号,然后将未处理部分在下一层继续展开
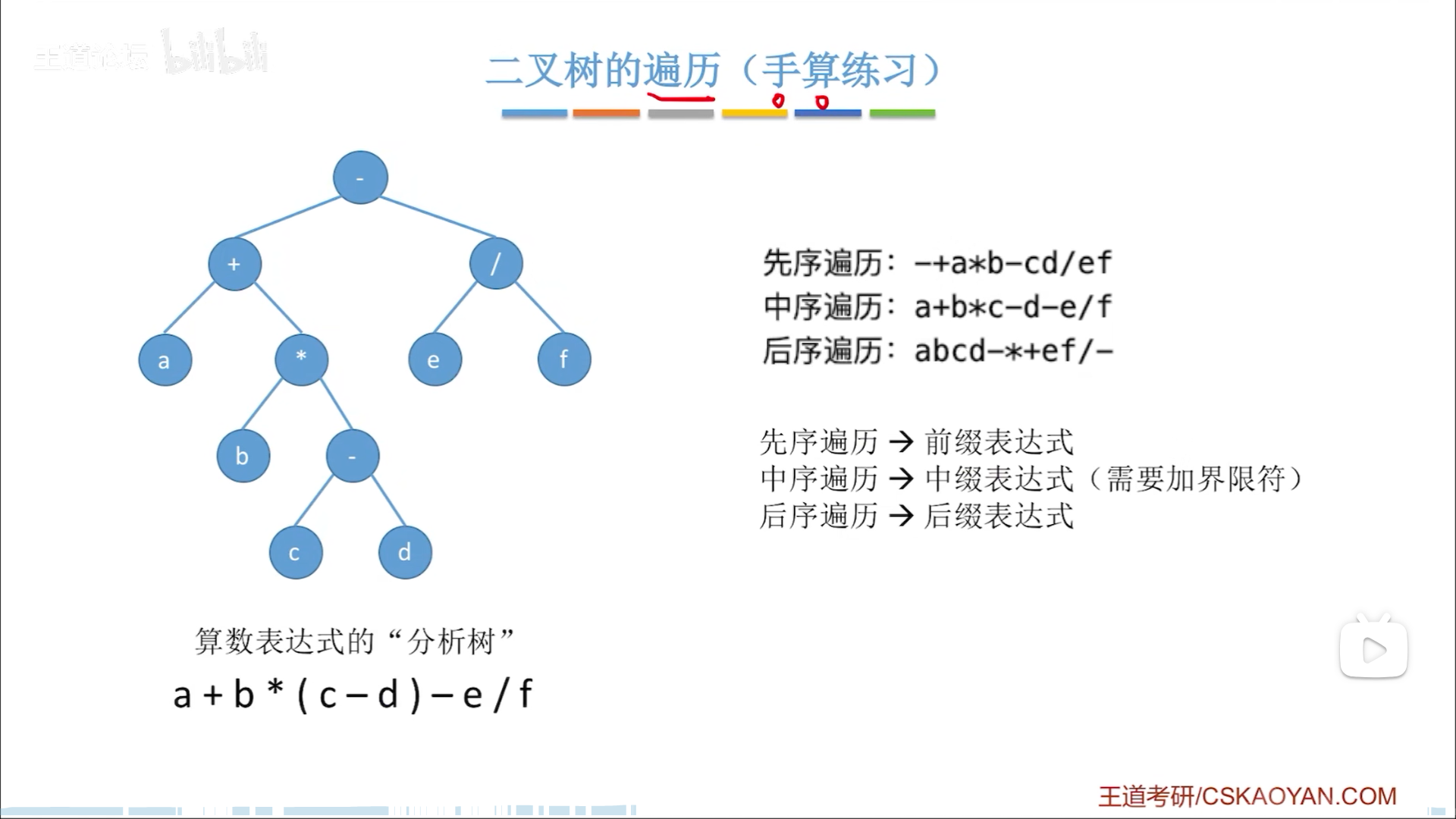
二叉树,可以理解为一个代表中缀表达式的结构,分支节点上是运算符,叶节点是操作数,树结构代表了运算先后顺序
对其进行先序遍历,就是把符号放在前面,也就是前缀表达式,后序就是后缀表达式。注意,中缀的时候,需要加括号,之前我也写过一道这个算法题,我记得大致是从层次里提取括号。
递归模拟法
至于递归代码,就很简单了:
T!=NULL是判断条件,如果空就不操作,非空就进行遍历。
visit代表对根结点的访问
根据前中后序遍历,可以在对左右孩子的递归调用之间找到一个合适的位置。
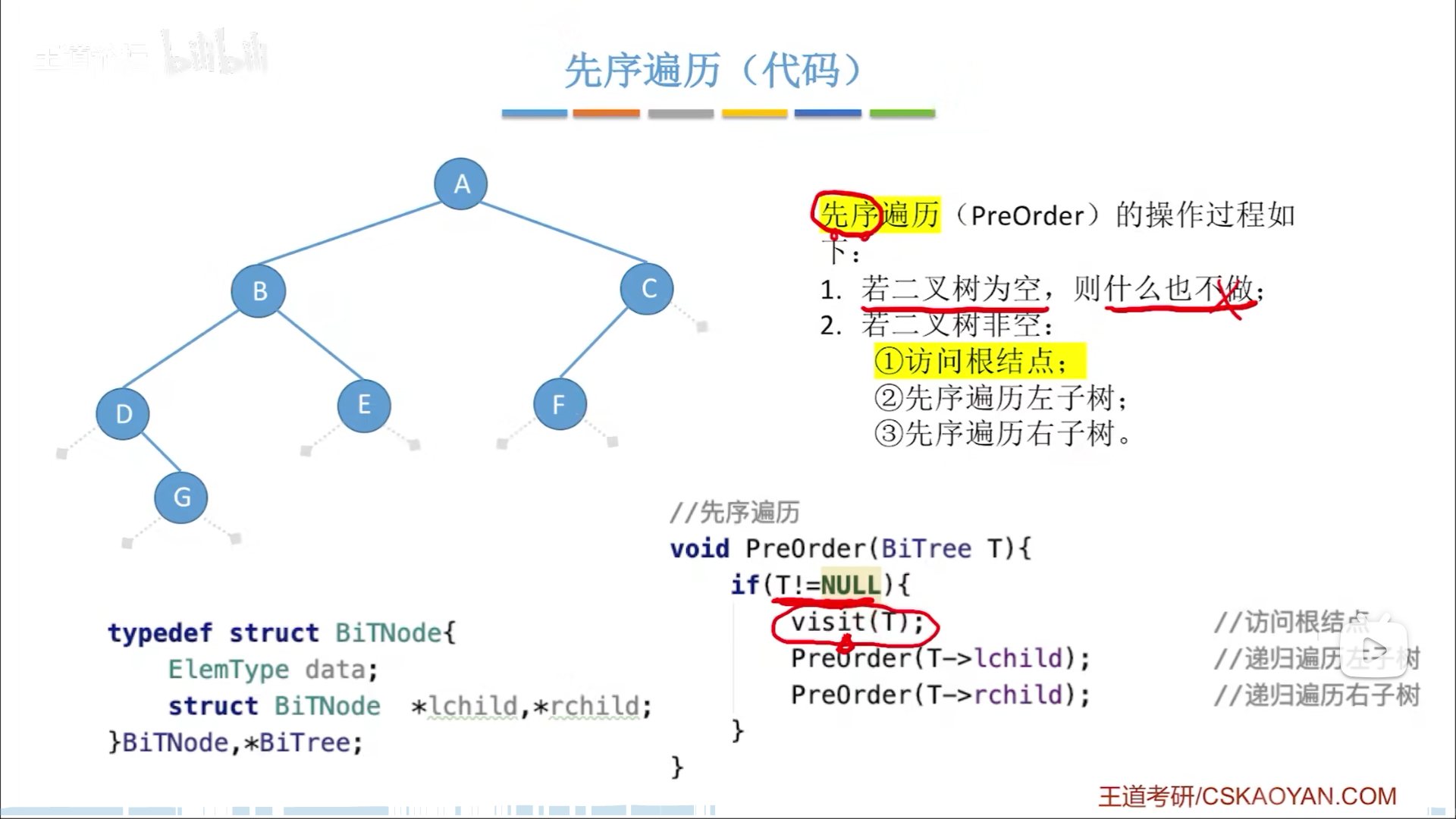
有的考题会让你分析递归过程,前进回退,其实无论是哪种遍历,路径都是一模一样的,每个节点都被经过三次(算上左右孩子为空的情况):
- 刚到这个节点
- 从左边返回
- 从右边返回
前中后序遍历的区别就在于,是在哪一次经过的时候访问节点,先序就是在1,中序就是在2,后序就是3,到时候画一条路,然后脑补在该访问的时候写出节点就好。
需要注意,NULL孩子也算孩子,即使孩子为空,也要象征性地访问一下,一来是程序逻辑,二来是为了你好写顺序。
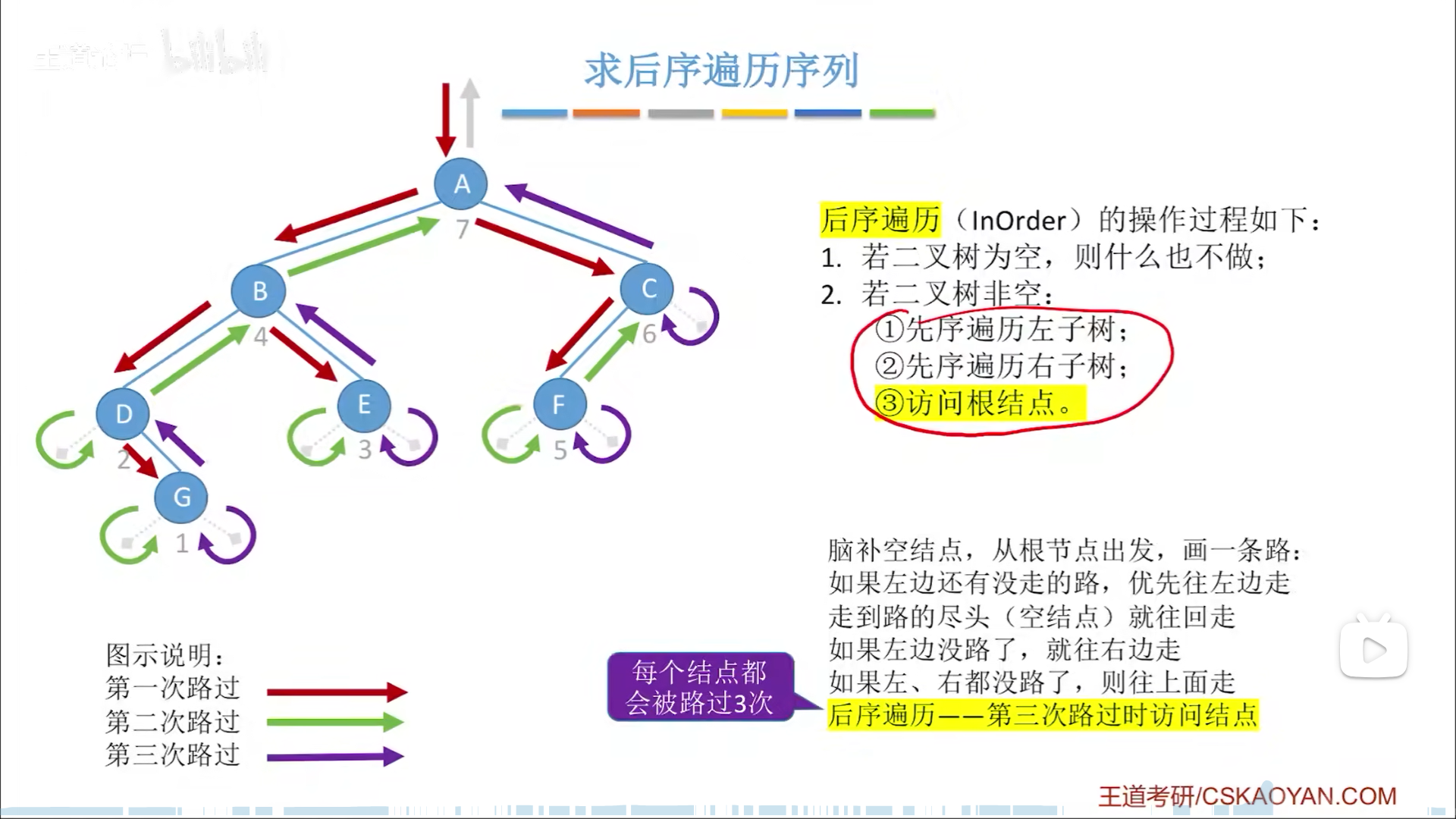
层次遍历

思路很简单,就是用队列。
访问当前一层的时候,把下一层可以加的孩子都按序加进来。
直到最后队列为空

遍历序列逆向构造二叉树
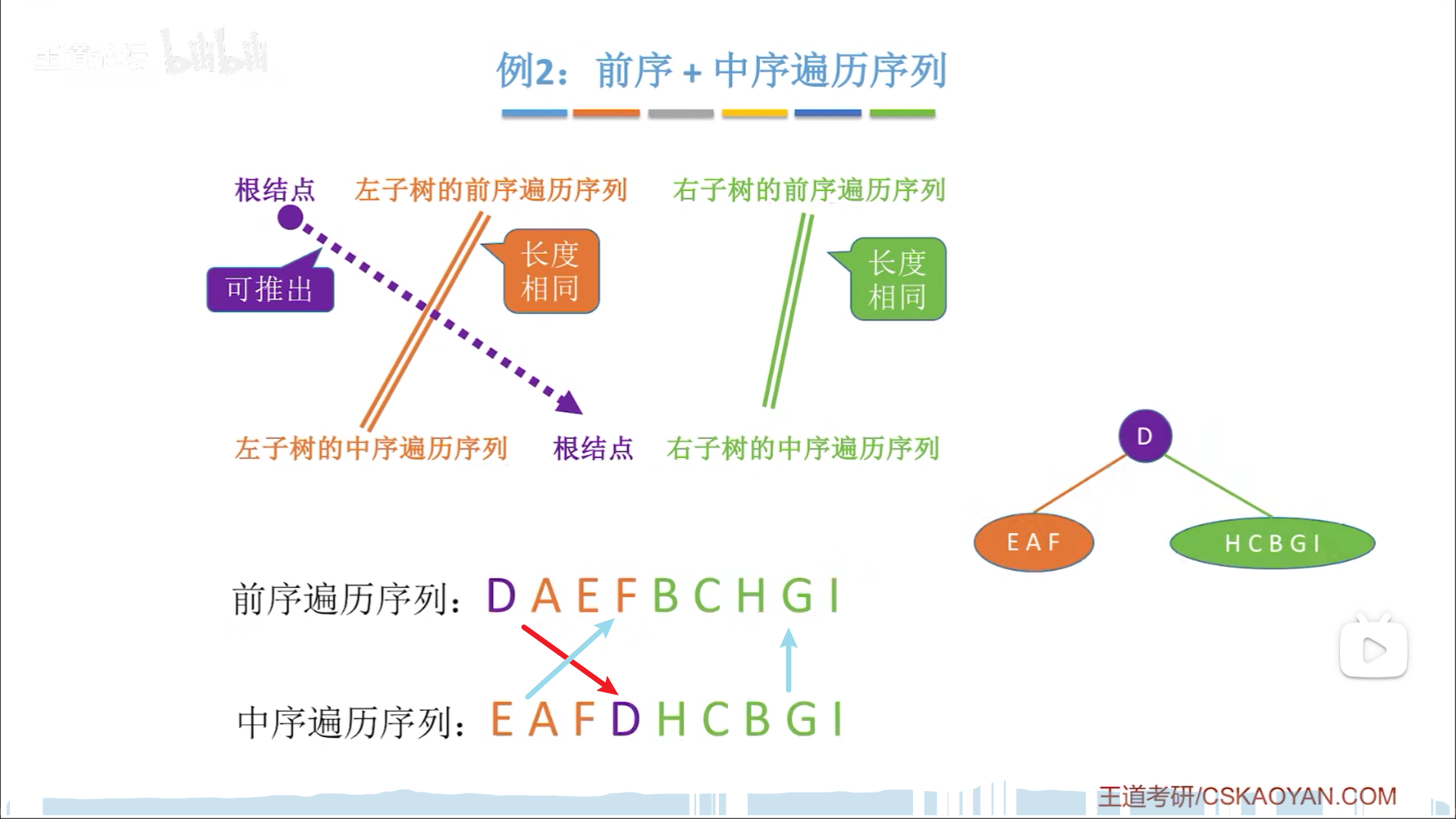
前/后序+中序的逻辑一样,都是先找到根节点
然后去中序里面切分,对应回去将前/后序序列分割
如此就完成了一段的切分,然后递归地去切分剩下两段,类似于快排的感觉。
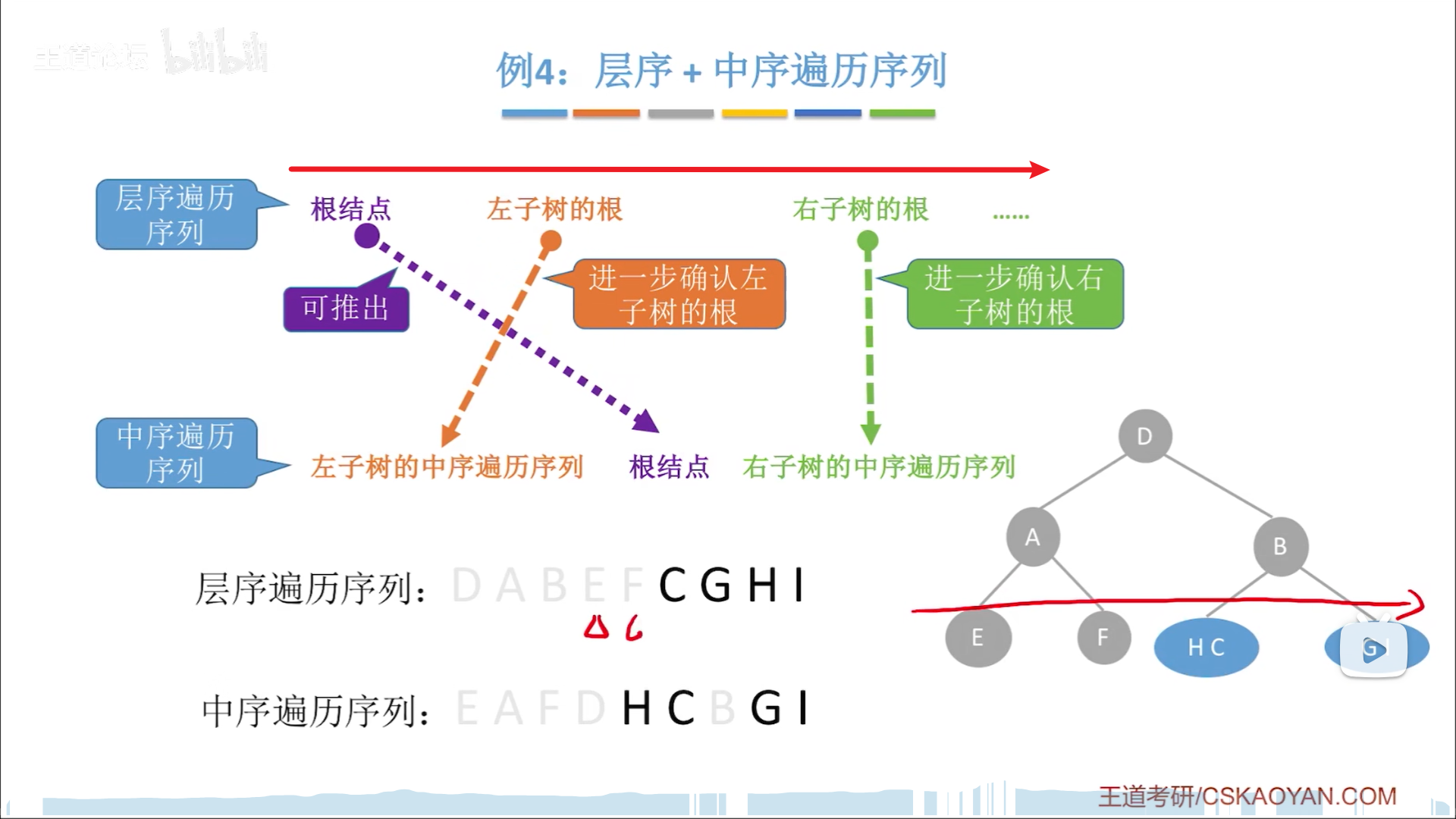
层序的话,仍然是利用层序找根节点,然后用中序切割。
层序找根节点,是从前往后,以层为单位去找的,那么每层要考虑几个根节点呢?这就得看中序的切分情况了
中序切分后,该层所有根节点,只要有孩子就+1,最终数量就是下次要考虑的根节点数目比如下图:
- D
- AB(D中序切分后,左右非空,因此一个节点分2个)
- EFCG(AB中序切分后,AB节点左右都非空,因此是2+2)
- HI(EFCG中序切分后,只有CG有子节点,C和G各有一个,因此是1+1)
又以下图为例:
- A
- B(A因为中序左边没有,因此是1)
- CD(B中序左右都有,因此是2)
- E

线索二叉树(难点)
这一部分是难点,需要深入理解先中后序的逻辑,灵活利用展开的方法去分析,并且还要熟悉在树上遍历的过程。
定义
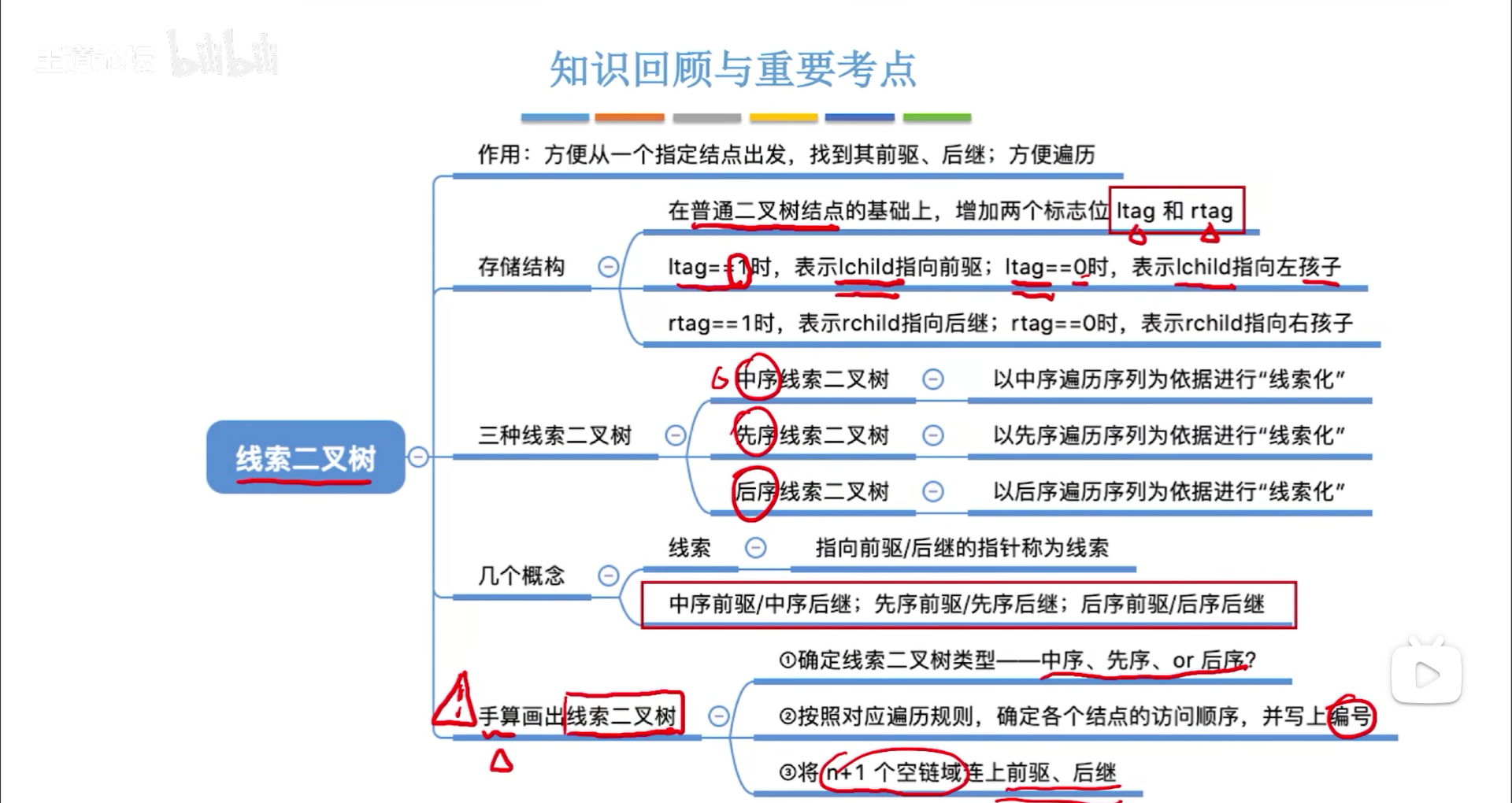
线索化的本质
首先这里区分一下,这里说的前驱和后继,都是特指在中序遍历序列中的前驱后继,而不是二叉树上的前驱后继
一般情况下,我们遍历一颗二叉树,一定要从根节点开始,否则后面会有一些节点漏掉。比如下图,要想找到p的(中序)前驱和(中序)后继,要用q和pre指针进行一前一后的移动,从根节点开始把整个树遍历一次。
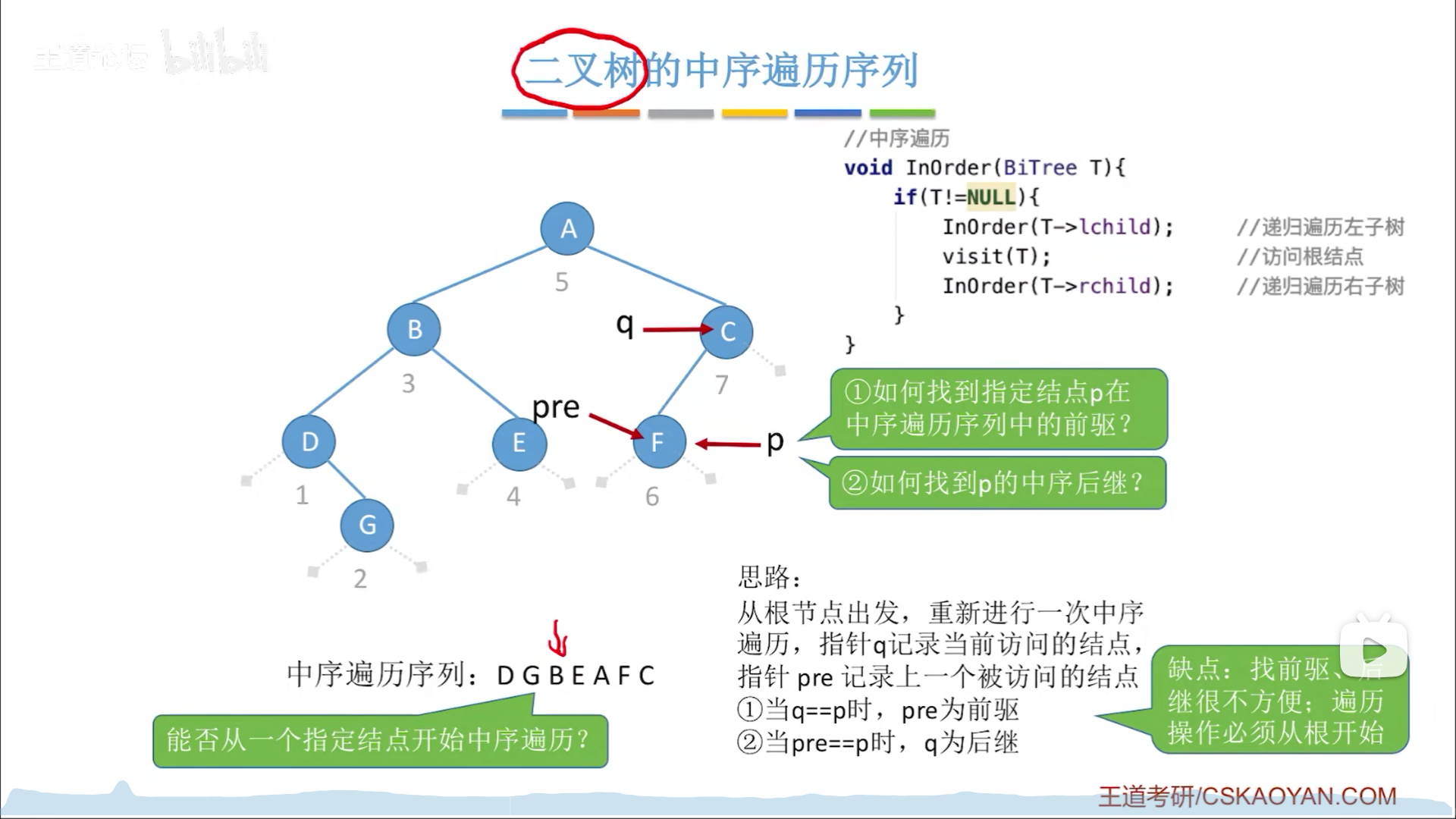
假如有一种情况,需要反复利用中序遍历序列,那么每次都从根节点获取中序遍历序列就很麻烦,于是有人直接利用线索二叉树,把中序遍历序列的信息储存到空链域里,这就是线索化的本质。姑且不论线索如何生效,你只知道利用线索就可以从中序遍历序列中的一个节点开始遍历出后面完整的中序遍历序列。
在上图中,完全可以从B开始,就可以依次遍历BEAFC,不用担心丢了某个节点。
按这个思路,按照线索可以直接遍历中序,加速遍历,甚至线索里本身就存着p在中序序列的前驱后继,你直接输出就行。
这就是线索化的意义,下图为线索化的过程,先遍历出一个中序序列,然后把中序序列前驱后继的信息填充到线索里,左对应前驱,右是后继,有n+1个空链域,因此有n+1个线索。为了区分链域储存的到底是线索还是孩子,需要用两个tag区分。
此处疑惑的点是,有的节点有后继但是没有链域存放后继,这个后面有解决办法。你姑且知道,有线索,就可以从中提取中序的前驱后继
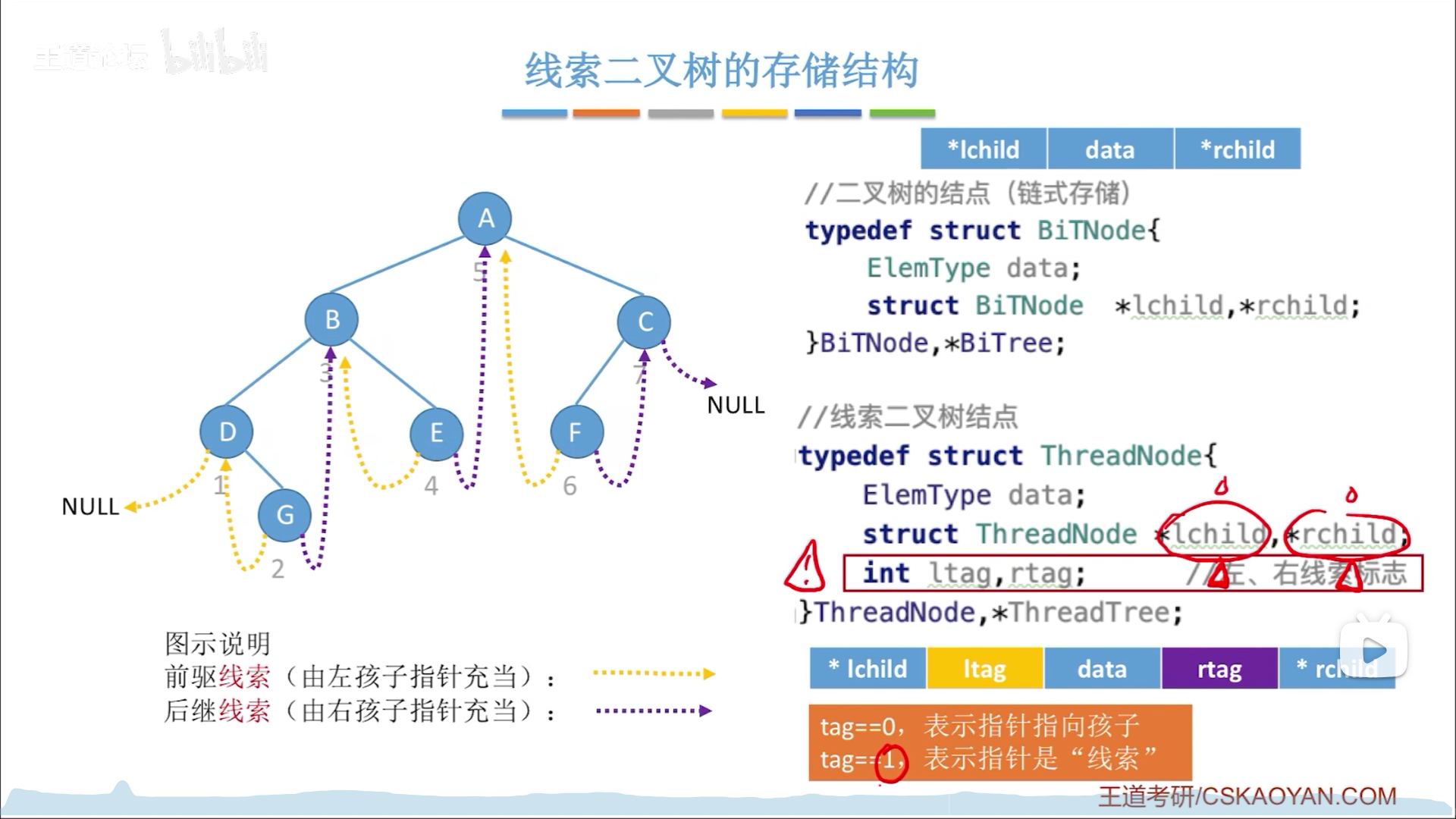
下图为标准的储存结构图像,先序和后序的思路同中序。
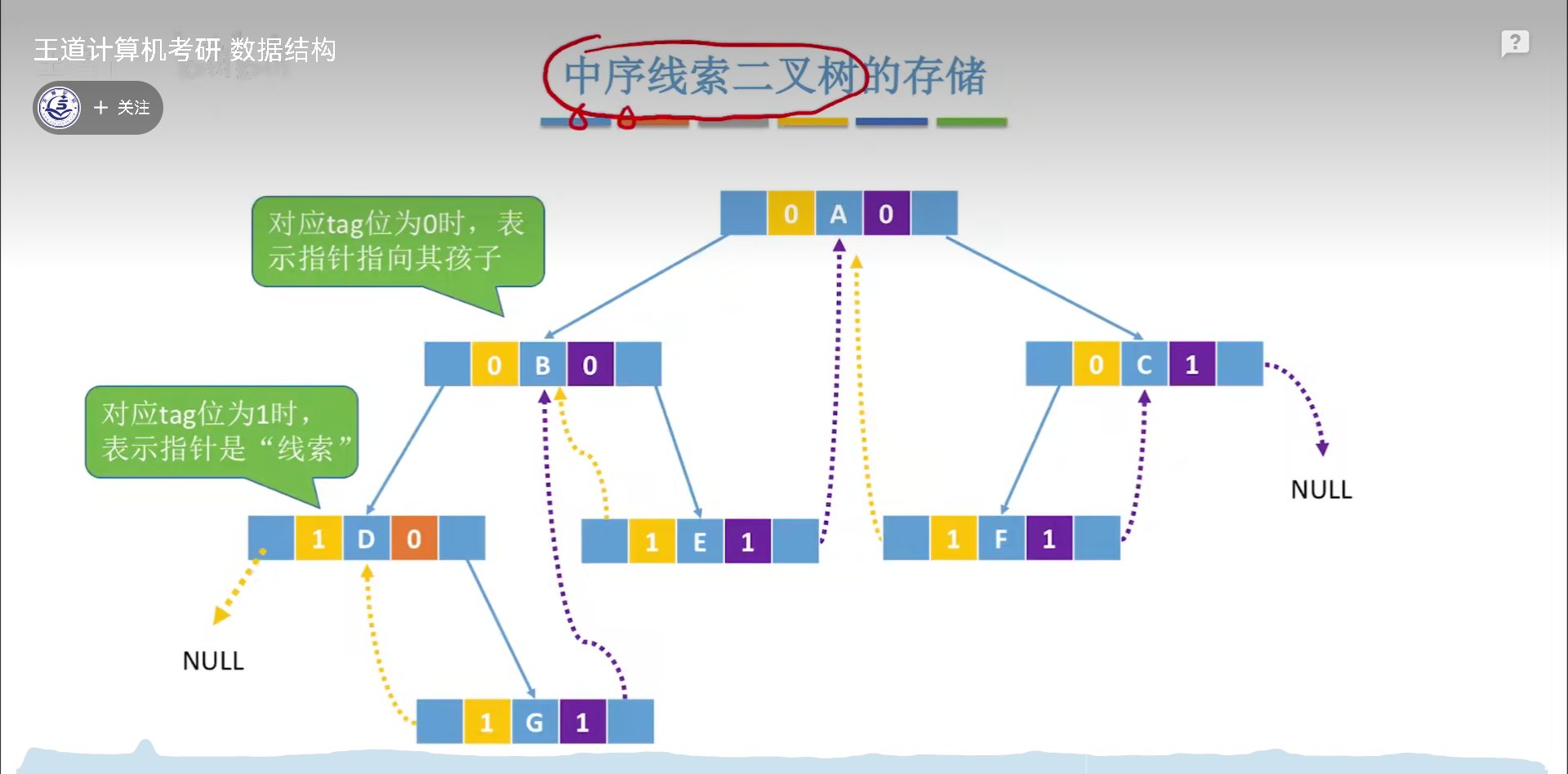
二叉树线索化
二叉树线索化,本质就是把这个节点的左孩子链接到中序前驱,右孩子连到中序后继。
因此当务之急是在中序遍历的过程中,维护前驱和后继信息,其实在最开始已经说了,就是用一个pre指针(全局变量),pre是q的前驱,而q是pre的后继,此乃相对性
已经有信息了,那么在visit过程中就直接修改链域就好
- 判断条件
- q一定非空,所以只需要判断左链域
- 而pre可能空,所以还要都一个非空判断。
- 添加线索
- 如果链域为空,就修改为对应的线索
- 记得把tag同步修改。
- 最后修补
- 注意到,最后一次visit,q指向尾部,而pre指向倒数第二,也就是说,q的后继是没有考虑的
- 因此在程序执行完毕后,还要额外判断pre的右链域,全局变量的好处在此处体现。
- 有些写法是直接让pre右链域=NULL,pre->rtag=1的,这种也没错,因为在中序遍历里,如果这个节点有右孩子,那这个节点就不是最后一个节点了。但是在后序遍历里面,最后一个visit的节点有可能有右孩子,所以就不能这么个判断。
总的来说加判断可以涵盖一切情况,因此就统一加判断,只有前序和中序情况下,才可以不判断。
下图为具体的代码,左上角为主函数:
- 初始化pre=NULL,
- 然后线索化,q就是从T开始
- 最后再善后pre右链域

先序线索化基本照搬,就是在先序遍历的过程中,去添加线索。
但是这里有一个bug,对于没有左孩子的节点(比如D),按道理说,添加完线索以后就没他什么事情了,而且访问过以后,也没有机会再访问第二次了。
但是在先序线索化过程中,会先visit,添加前驱线索,之后左孩子的链域就非空了,此时如果还按照原有逻辑,就又会跳回到前驱,开始进行遍历,这就是一个死循环。
破解办法很简单,本来左孩子的链域应该是空的,此时有了指针,可以用tag来判断原来是否为空,只有tag=0(原来非空,真正的有左子树),这才能跳转到左孩子的节点。

线索二叉树中找前驱后继
总评:这一章是线索二叉树的核心难点,尤其是三叉链表情况下的别扭题。
我的建议是,一切的一切,要抓准先序中序后续的本质特性,比如先序就是“根左右”,你到时候现场推导判断条件,灵活且不容易出错。

中序
之所以用中序为例子,是因为中序线索化是完美的,“左根右”,有根节点,找前驱就去左孩子里面找,找后继就去右孩子里找,而先序只能找后继,后序只能找前驱。
先说后继,判断rtag,两种情况:
- rtag=1,证明右链域是线索,那么直接用线索
- rtag=0,证明右链域有右子树,那么就需要找到右子树中序遍历序列中最左边的节点
- 其实就是右子树左下角的节点
- 具体就是下面FirstNode函数,一直找左孩子,直到没有左子树
- 因为此时已经线索化了,终止条件所以不再用NULL,而是用ltag判断
既然能找到中序后继,一次快速的中序遍历就很简单了:
- 先通过FirstNode,找到第一个节点
- 然后从第一个节点开始,不停找后继,直到遍历完毕
这种方法的特色在于,找后继过程中,可以通过线索大大加速遍历速度,复杂度为O(1)
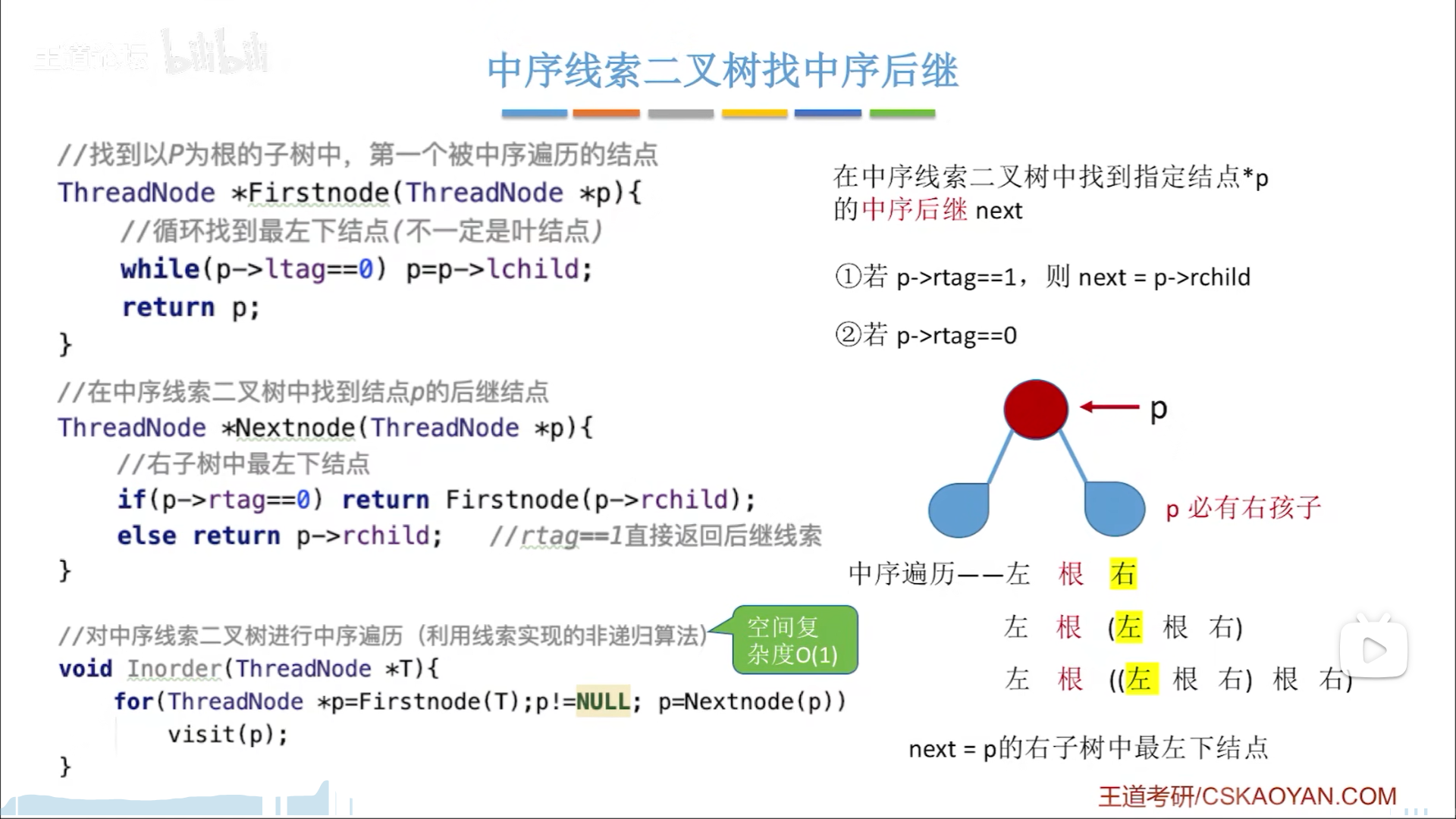
中序线索的前驱思路和后继一样,整体是镜像的感觉,左变右,有前驱线索就用线索,没有就找左子树右下角节点。
LastNode函数,就是一直去找右孩子,直到rtag=1
因此也衍生出逆向遍历中序线索的方式。

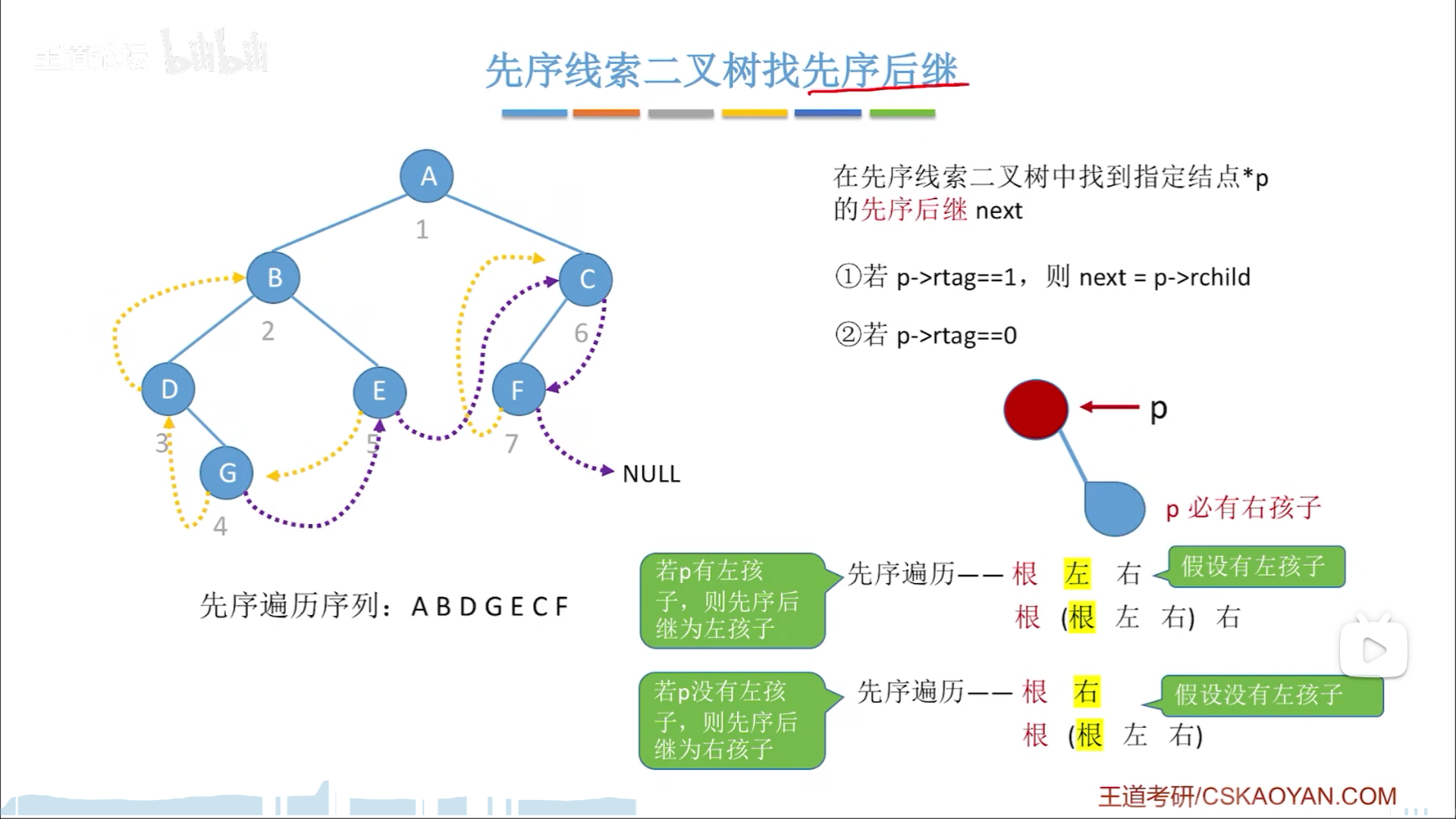
先序
中序最为规整,符合直观,先序后序就比较别扭,容易混乱,本质上是先序会浪费链域,比如本来就有左孩子,然后你右链域如果为空,还要再指向左孩子,这就是浪费,这也就是其前驱后继只能二选一的原因,浪费了信息,自然就无法实现全部的功能。
回归正题,先序找后继,后序找前驱,反之则不一定,容易记混,而且实际生产也没用,要我说还不如深入理解,临场画图,更加保险
先序找后继,本质思路就是“根左右”:
- rtag=1,有线索,用线索
- rtag=0,无线索,即有右孩子,此时用“根左右”思考
- 有左孩子,则左孩子为后继
- 无左孩子,则右孩子为后继
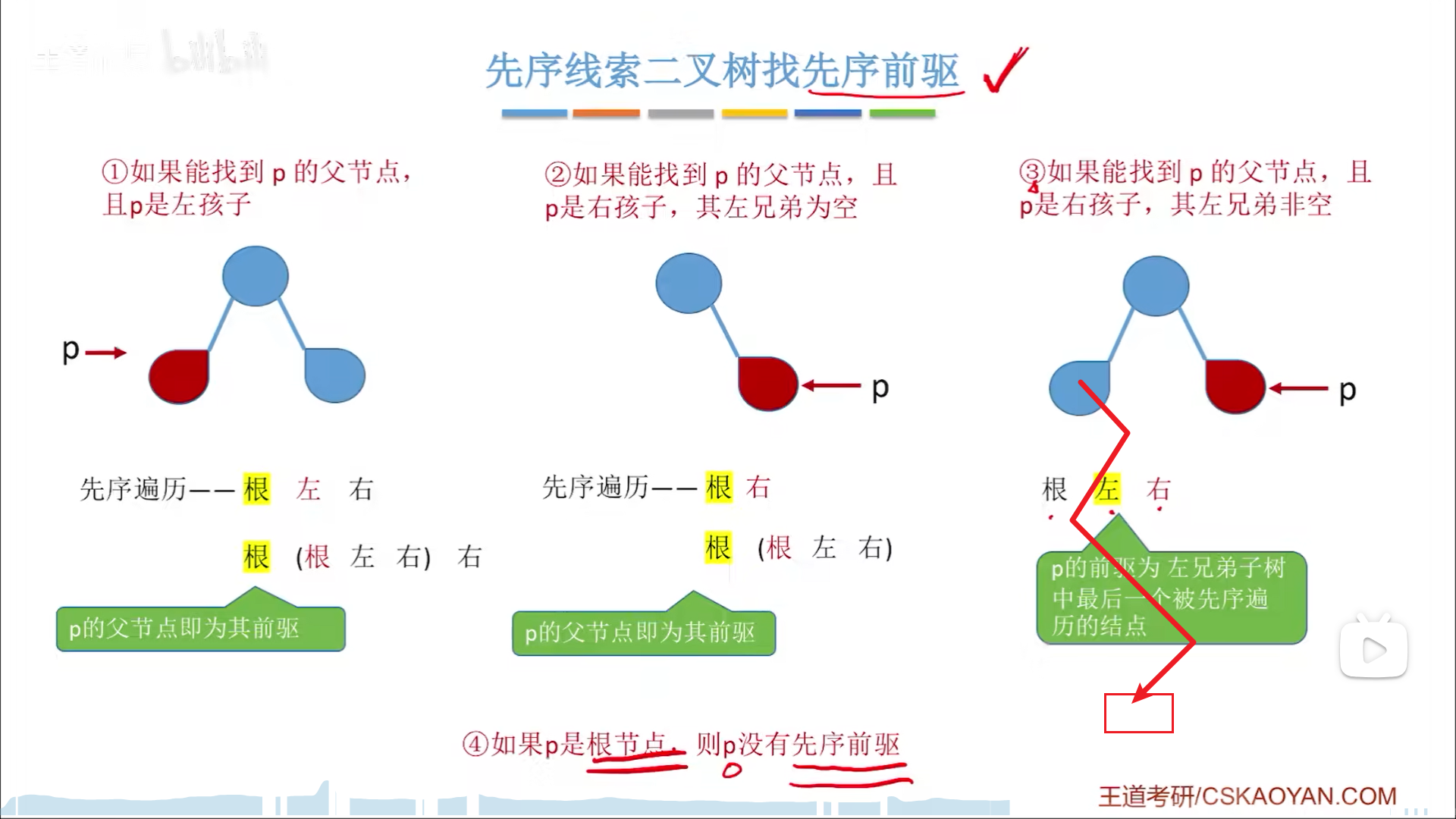
前驱不一定有,逻辑如下:
- ltag=1,有线索,用线索
- ltag=0,有左孩子
- 问题在于,遍历序列是“根左右”,以根开始,无论你找左孩子还是右孩子,先序情况下只要你找的是孩子,你顶天了只能是后继
- 因此ltag=0的时候只能从根开始遍历,用不了线索
但是很明显,这里可以加考点,如果用三叉链表,允许找到父节点,那么事情会有转机,当然也特别麻烦(为考而考),一切的关键是理解先序遍历的根左右思想
- ltag=1,用线索
- lgat=0,先找父节点
- 情况1:p无父节点,则无前驱
- p有父节点,有前驱,然后进行判断。先看上层结构:“根左右”
- 情况2:p是左孩子,则为“根(
根左右)右”,则父(根)节点为前驱 - p是右孩子,p处在序列中“右”的位置,则要判断“左这一部分的情况”
- 情况3:“左”为空,即“根()(
根左右)”,那么父节点当前驱 - 情况4:“左”非空,即“根(左子树)(
根左右)”,那么就要在父节点左子树里,走一遍先序遍历,用其最后一个节点当前驱。这一步要求你对先序遍历极其熟悉(可以简化,有右找右,没右找左,右左都没,就是最后一个)
- 情况3:“左”为空,即“根()(
- 情况2:p是左孩子,则为“根(
说实话真的有点大冰,建议直接画图思考,把这几种情况都画出来,这么多背不会的。
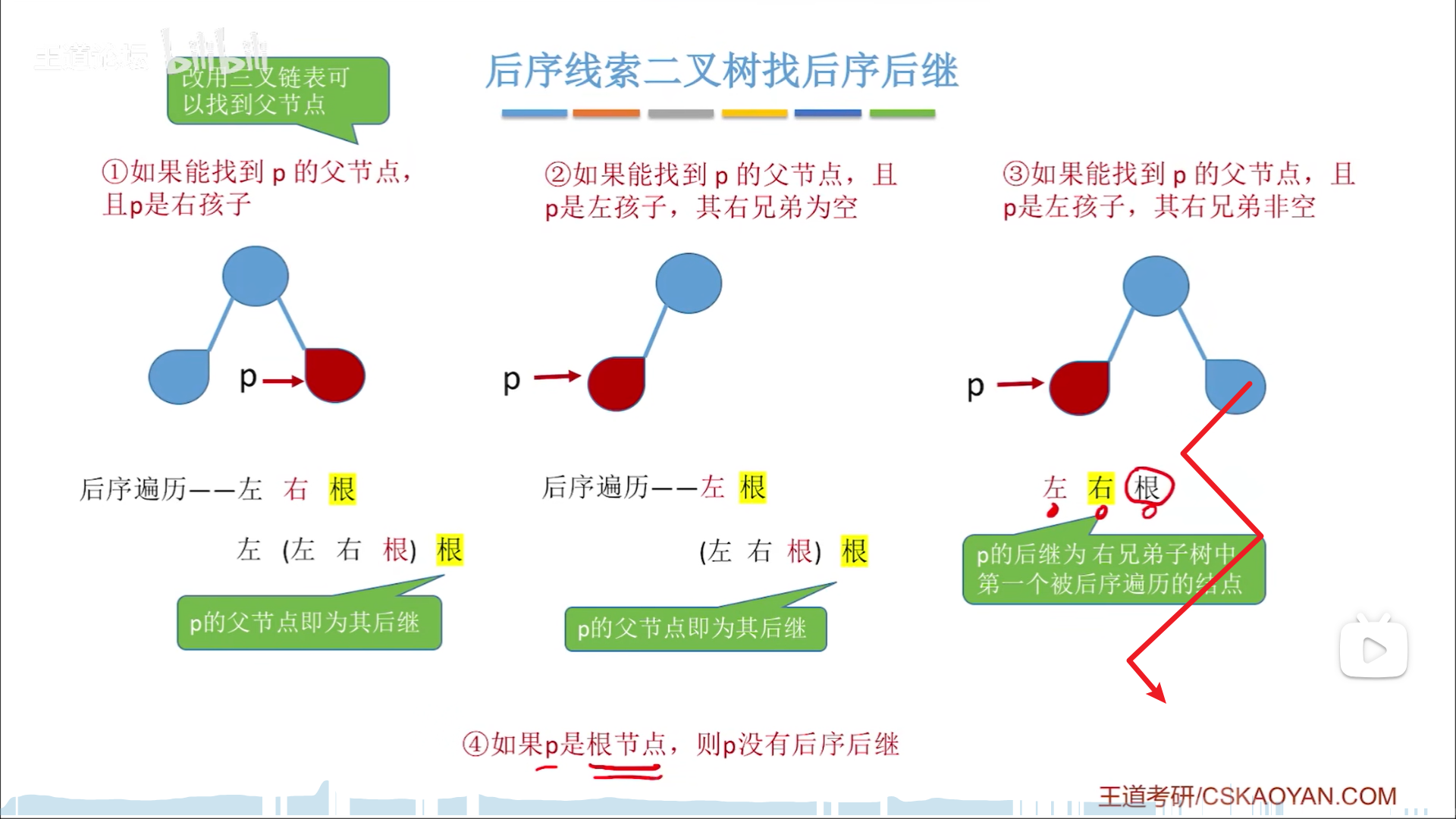
后序
后序线索,只能找前驱,如果要找后继,同样麻烦。
后序前驱:
- ltag=1,用线索
- ltag=0,则有左孩子,利用“左右根”寻找前驱
- 有右孩子,则为“左(左右根)根”,因此右孩子就是前驱
- 无右孩子,则为“(左右根)()根”,因此左孩子就是前驱
后续后继,因为是“左右根”,无法通过左右子树找根的后继,同样需要三叉链表配合:
- rtag=1,用线索
- rtag=0,先找父节点
- 情况1:p无父节点,则无后继
- p有父节点,此时上一层为**“左右根”**,我们这一层仍然需要先定位
- 情况2:p为右孩子,则为左(左右根)根,因此p的后继就是父节点
- p为左孩子,因此要判断“右”这一部分是否存在
- 情况3:父节点无右孩子,则为“(左右
根)()根”,p的后继是父节点 - 情况4:父节点有右孩子,则为“(左右
根)(左右根)根”,p的后继是父节点右子树后序遍历序列中第一个输出的节点(简化逻辑就是,有左就左,没左找右,没左没右,就是后继)
- 情况3:父节点无右孩子,则为“(左右
再次吐槽,真的是有大冰,建议推导两三次,就不用记了,直接临场速推。
树算法
储存结构
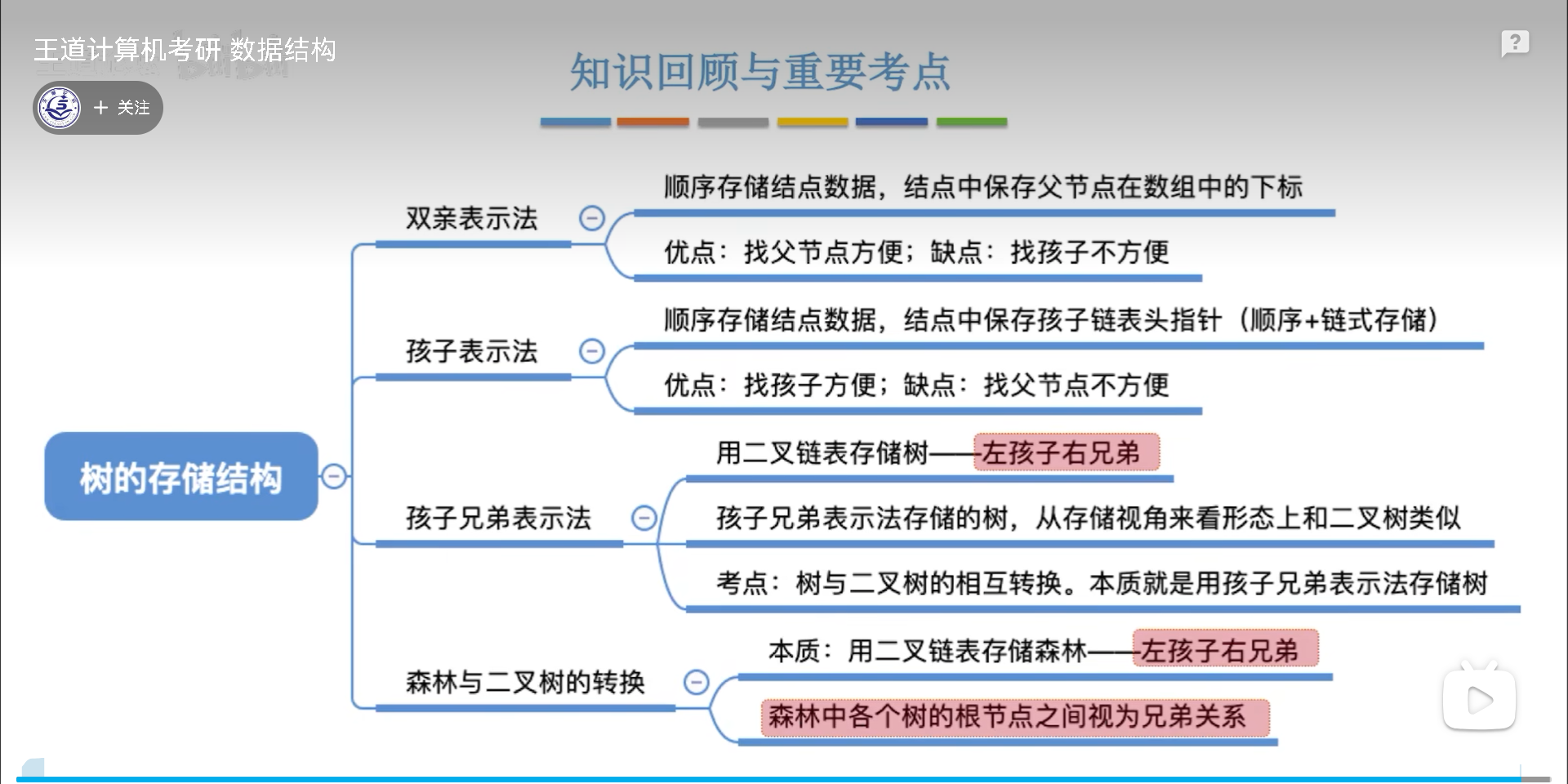
树的难点在于,因为度是没限制的,所以链域给几个是不确定的,树的所有结构都是为了解决这个核心问题而创造的。
最开始双亲表示法的思路:
- 出度不确定,入度确定啊
- 因此采用逆向指针,链域=1,非根节点就可以保证有且只有1个前驱
因为结构比较简陋,因此一般用数组存,也只能用数组存,因为找孩子节点只能用遍历实现(查)
增删如何实现呢?增,在最后增加元素就行,删就是直接把链域抹-1就行,但是更好的方法是把最后一个元素挪到这个位置覆盖,因为这样可以缩减数组长度,提高遍历速度。
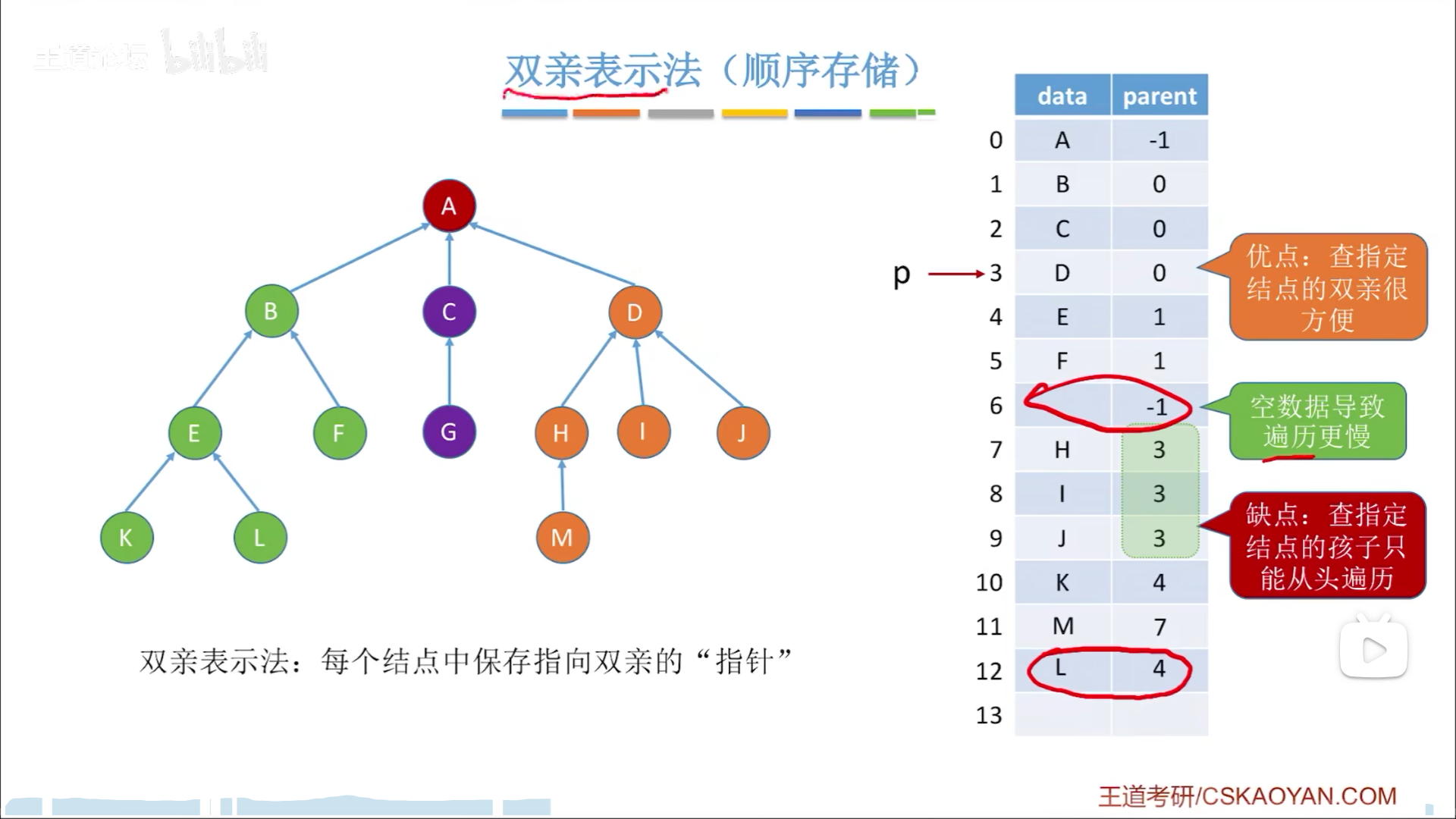
双亲表示是纯数组表示,而孩子表示法是数组+链表的混合存储结构(其实就是图的邻接表结构用在了树上)
延续链域不确定的思路,解决不确定的数量自然会想到链表,因此用一串链表表示一个节点的所有孩子:
- 数组元素储存节点本身
- 链表元素储存孩子的位置信息。
- 链表元素可以看做是两类指针的结合体,孩子下标算一个指针,指向具体元素,而链表next也是指针,指向下一个链表元素。
这个结构其实是图的结构,优劣势这里就不讲了,简单来说就是找孩子简单找双亲难。
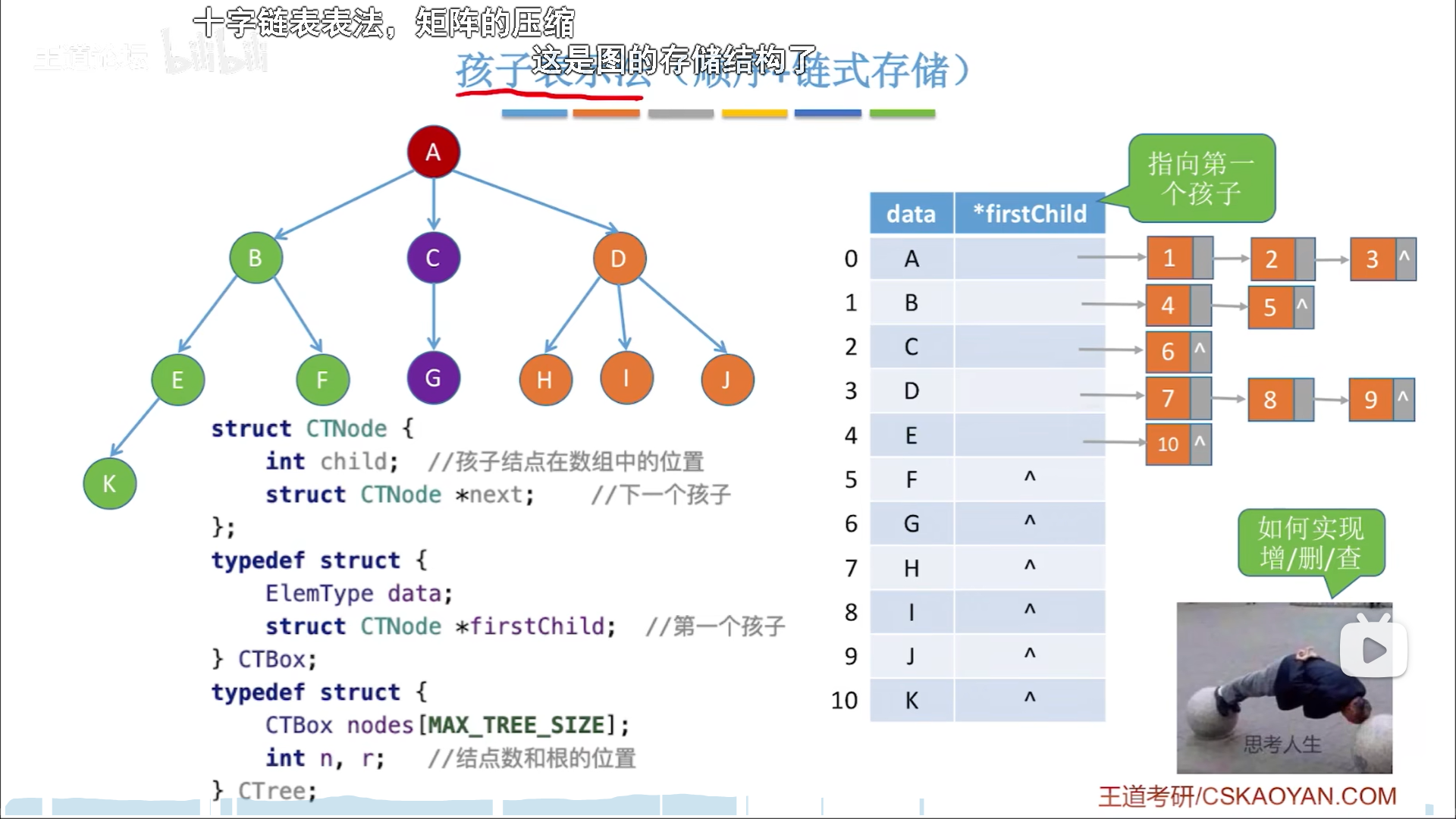
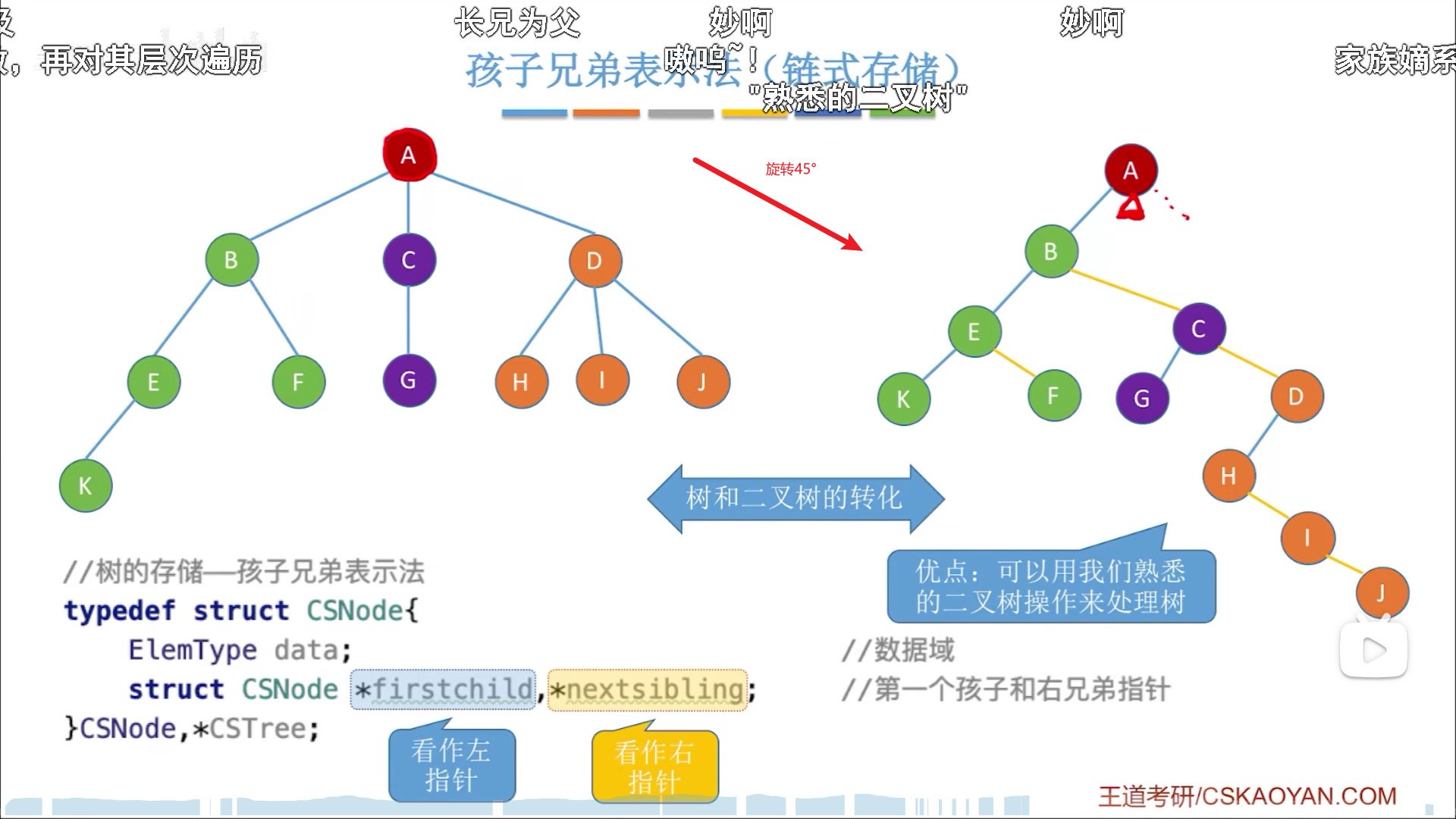
最后就是孩子兄弟表示法,纯链式存储。
纯链式存储怎么能解决链域不定的问题呢?换个思路,链域里不储存所有孩子的指针,而是储存一个孩子+右兄弟,这样链域就固定为两个了,可以用二叉树储存了。
从视图来看,新的二叉树就是就是原有的树顺时针旋转45°,然后用孩子兄弟法重新连线后的结果。
逆过来转换就是左转,然后重新连线。
为了防止出错,可以用两种颜色的笔区分孩子链域和兄弟链域,又或者你直接记住左分叉是孩子链域,右分叉是兄弟链域就好。
森林和二叉树,只需要补兄弟边就好,每一颗树的根,合起来在同一层,互为兄弟。
之后就是经典的旋转转化了,还原的时候,几何上应该从右边开始画线,一层一层往左边推。
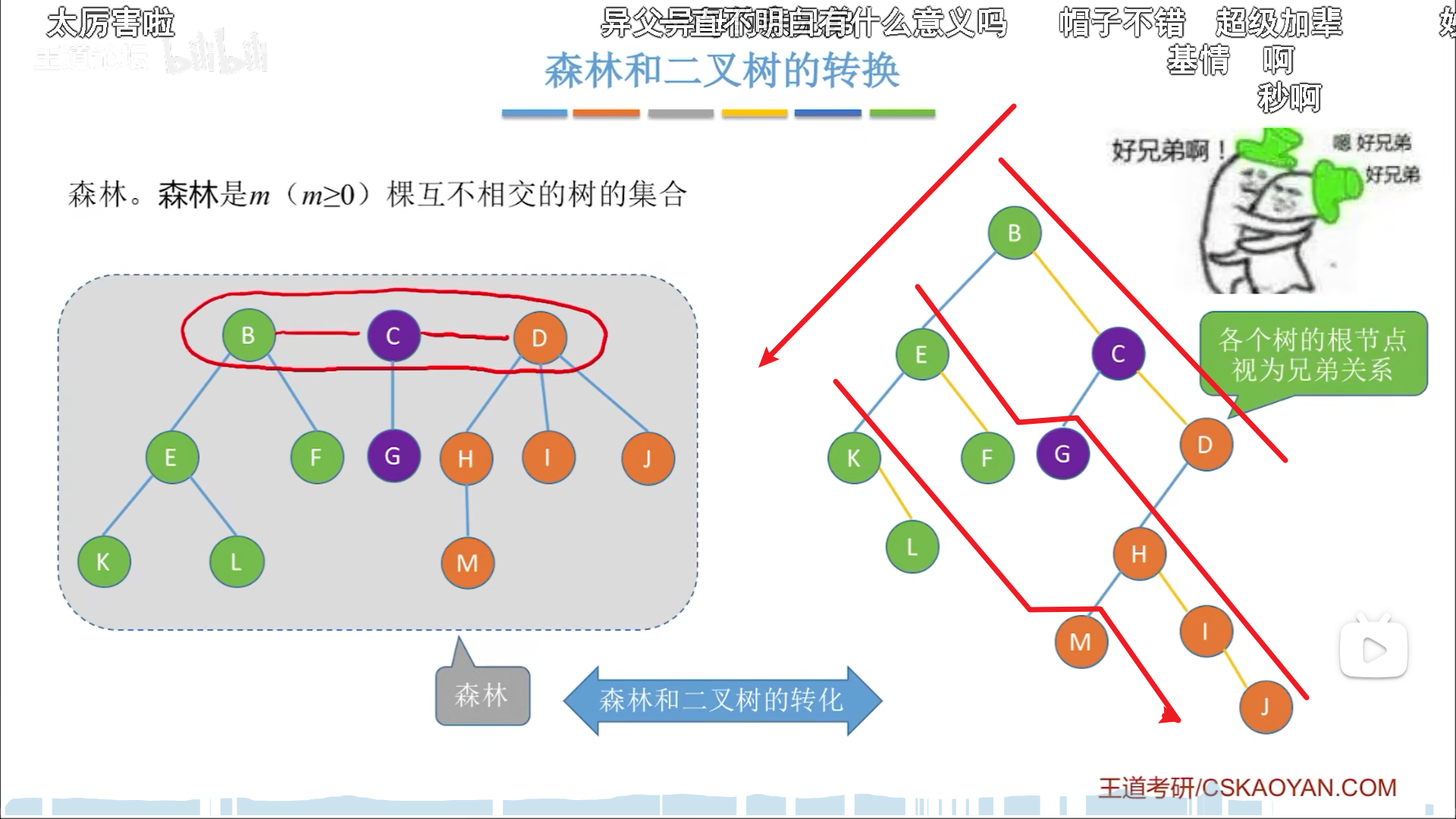
树和森林的遍历
对应关系,森林->树->二叉树,二叉树是宇宙万法的尽头,硬要你写代码的话,一切代码都可以用二叉树实现。

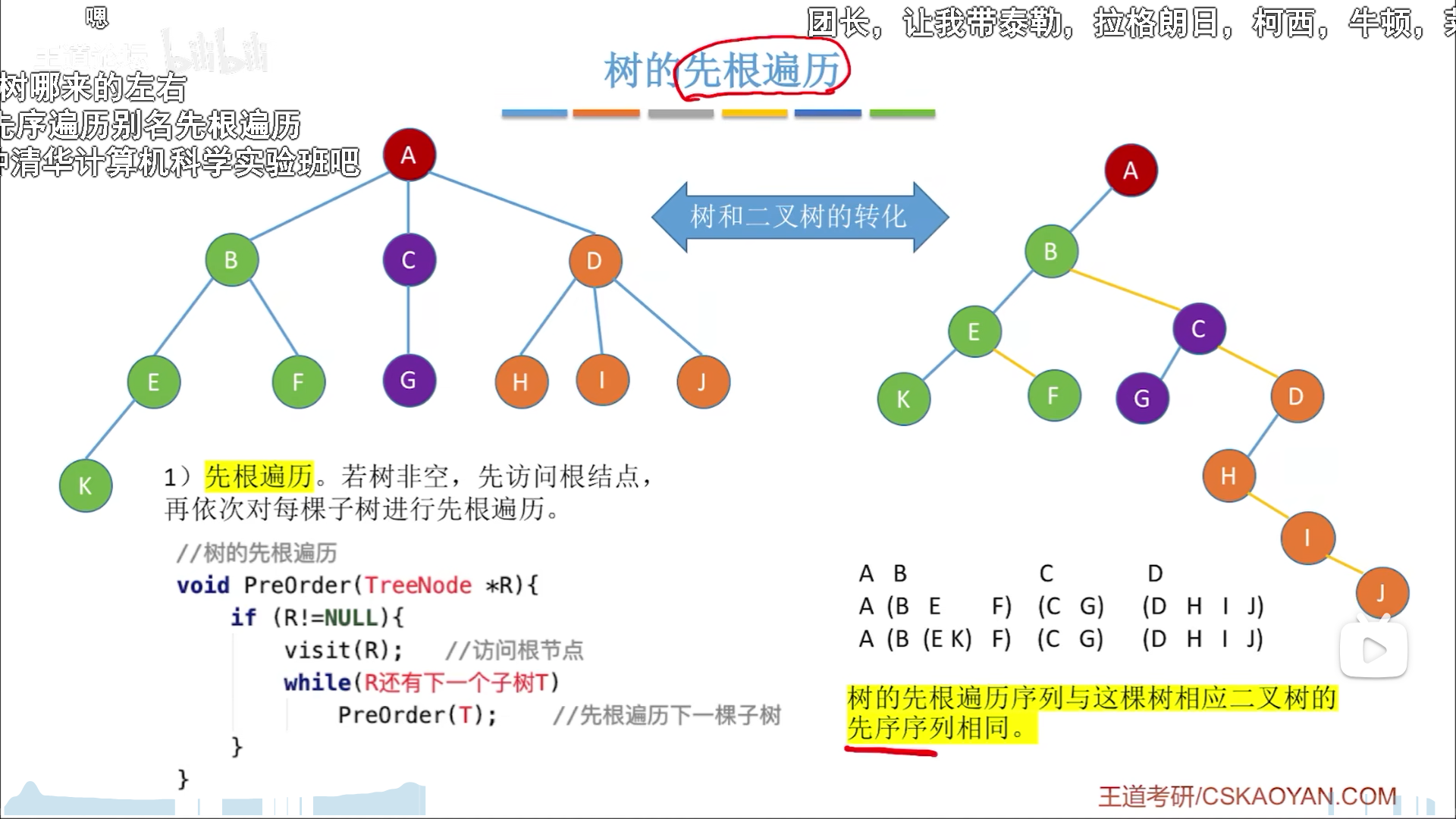
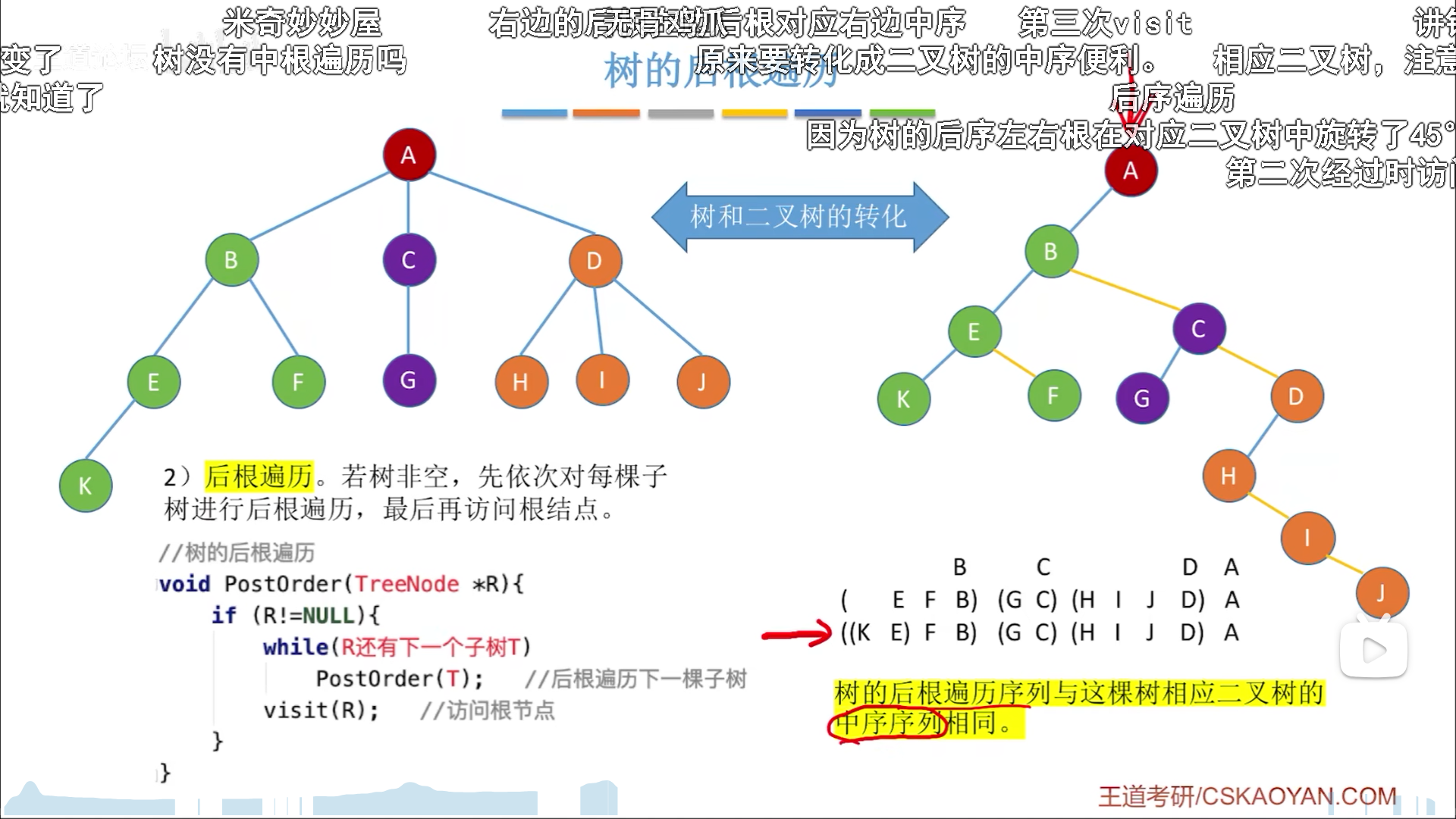
树遍历
树只有先序和后序,不存在中序的说法,因为无法确定孩子数量,所以干脆就不往中间排,要么先访问再依次递归孩子,要么先递归完孩子再访问。
数的初始逻辑结构和其二叉树形态有所不同,因此遍历序列也不相同,对应关系:
- 树先序=二叉树
先序 - 树后序=二叉树
中序
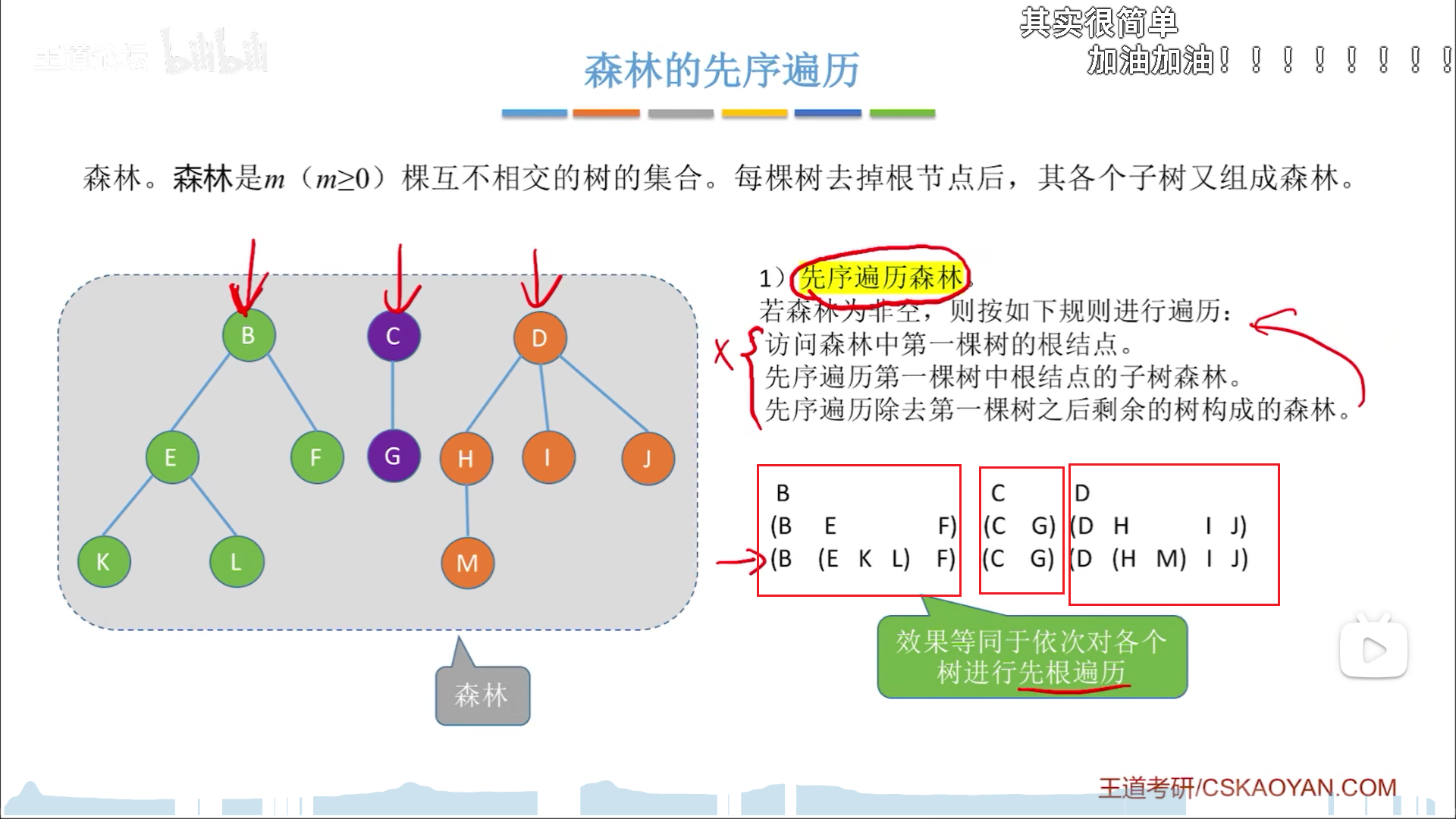
森林遍历
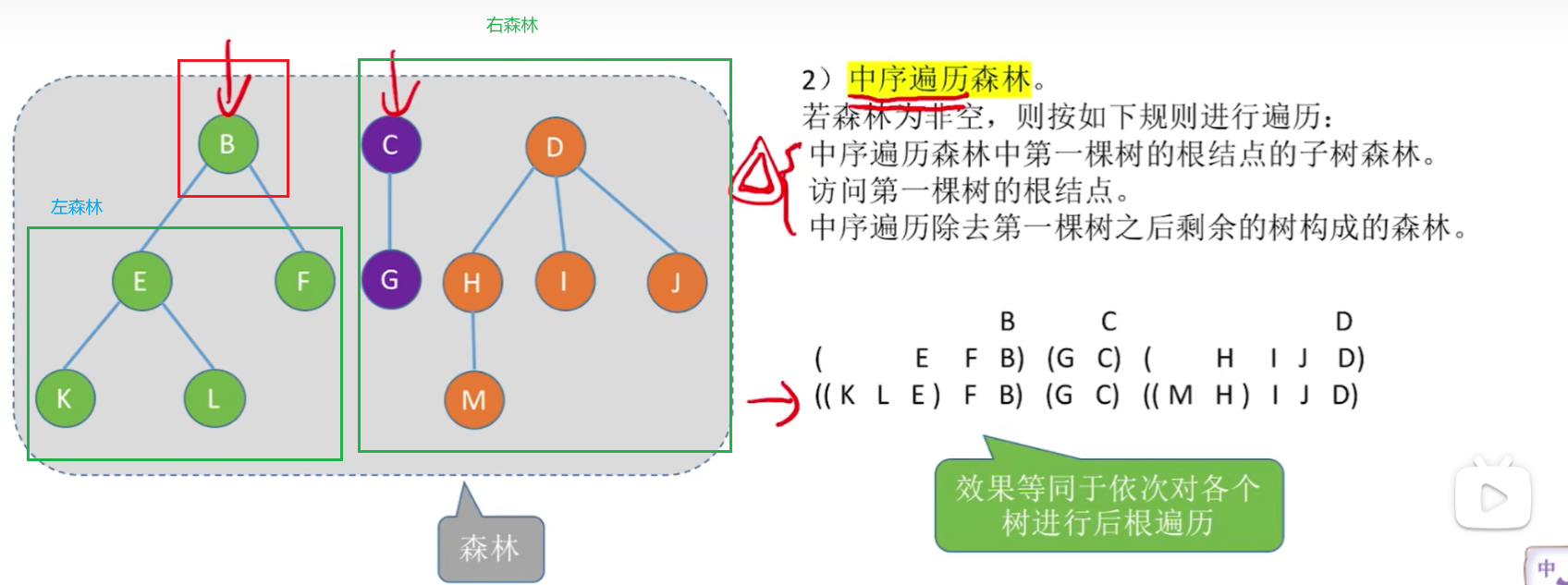
森林遍历涉及二层递归,这里先简单理解下。先序还好,主要是中序,为什么树没有中序,森林这里就是中序了呢?因为可以以一个节点,切分出两片森林,这才可以把根节点放在中间,即中序。理论上森林还有后序,但是过于阴间,就没有放出来。
写代码的话,比较复杂,直接换个思路,用效果等价:
- 森林先序=每棵树先序遍历
- 森林中序=每棵树后序遍历
实在考出来写代码,也可以取巧,先把森林转化为二叉树储存结构,然后把森林的遍历等效到树的遍历,再对标到二叉树的遍历,比如森林中=树后=二叉树中,这样也可以写代码。
树应用
哈夫曼树
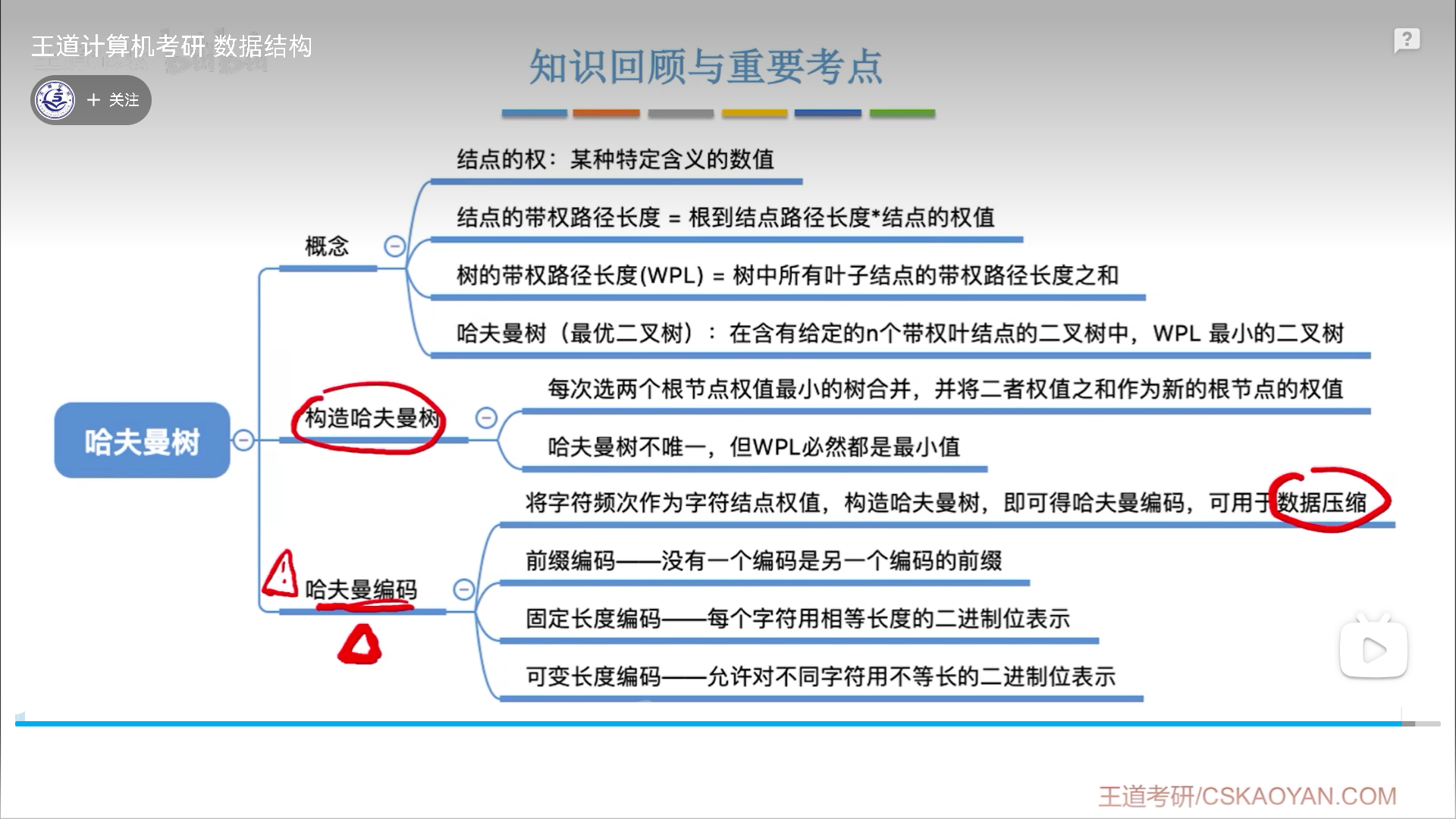
首先说带权路径长度(WPL,Weighted Path Length)
一条路径的WPL=经过的边数×终点权值
一棵树的WPL=所有叶节点的WPL
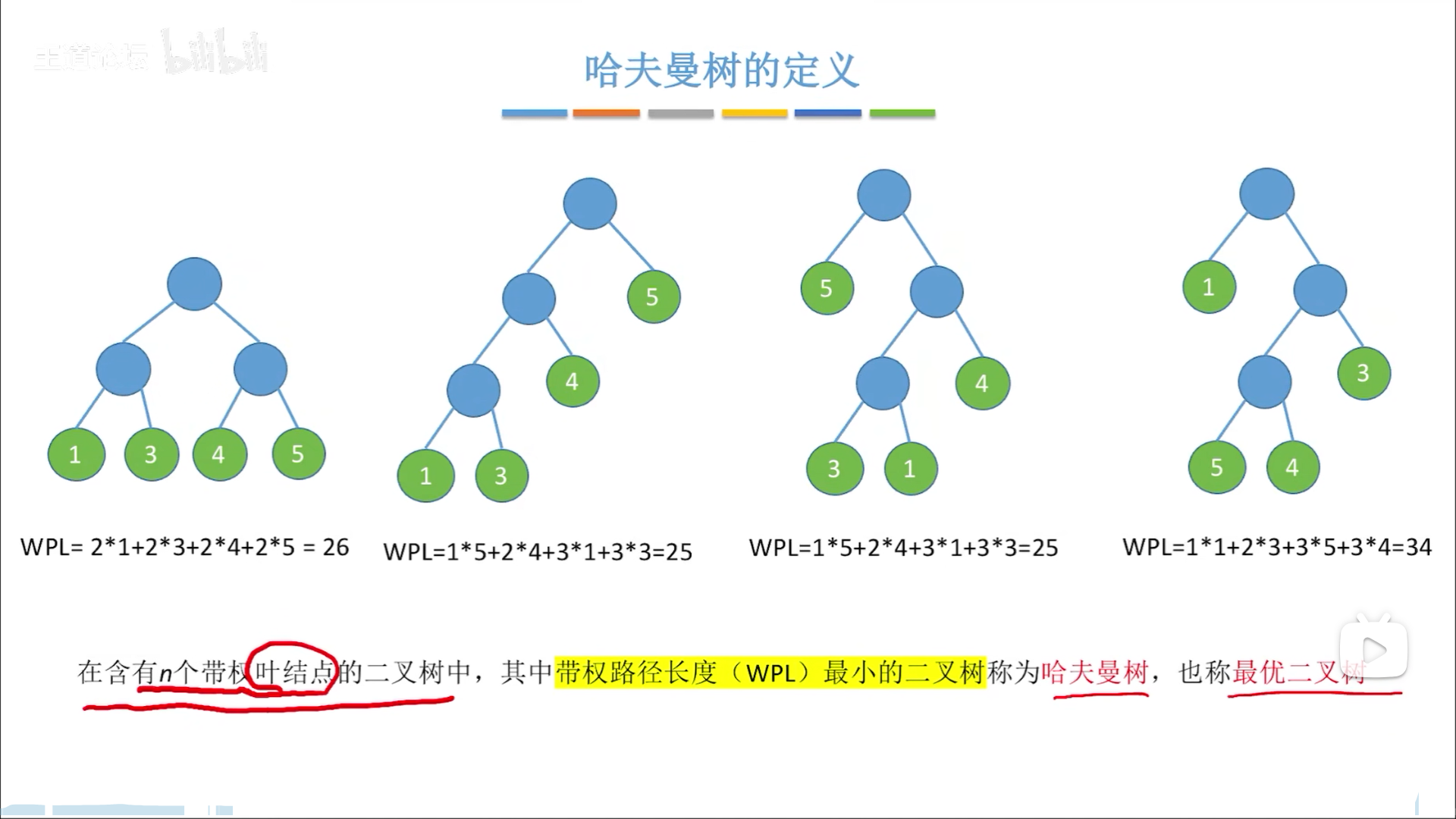
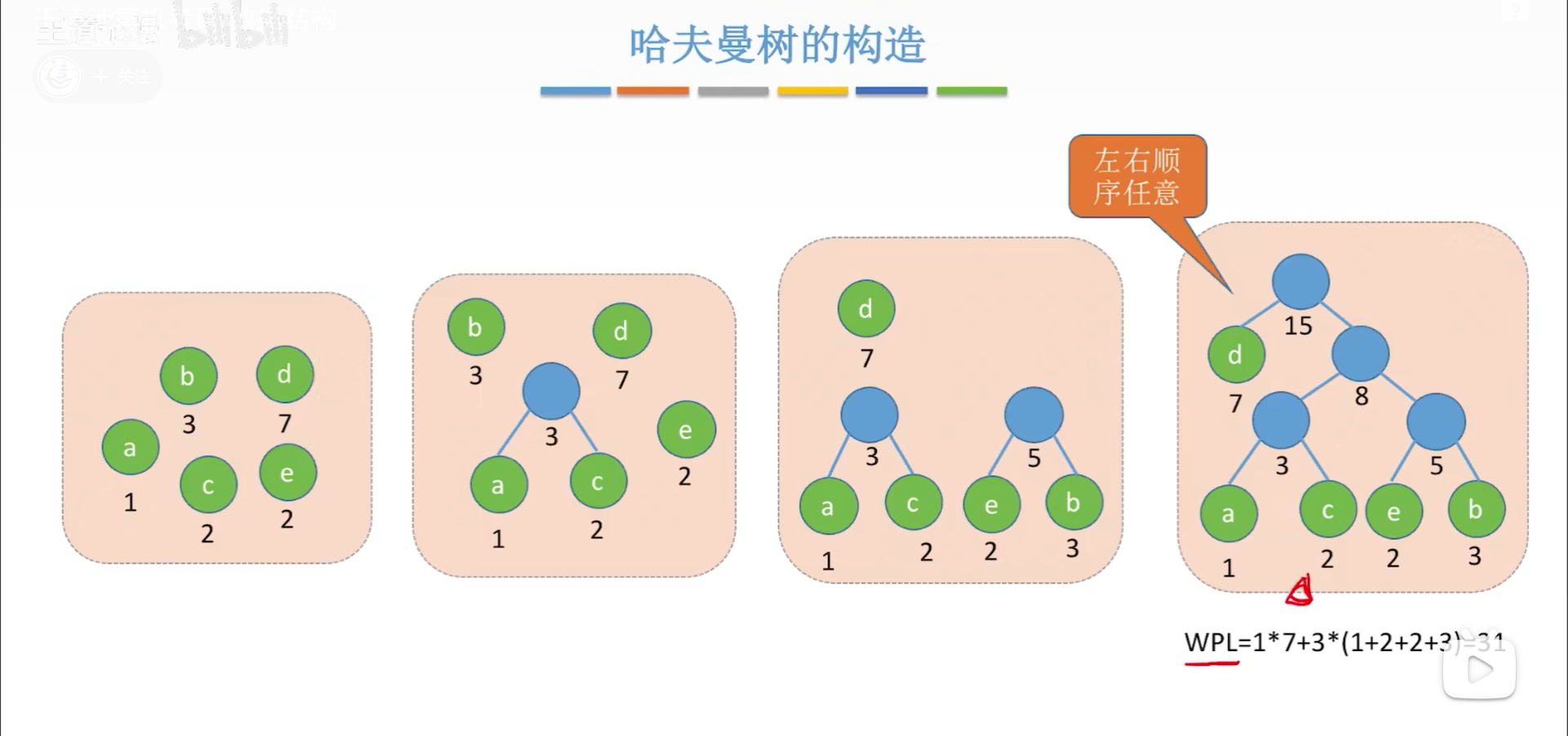
哈夫曼树就是WPL最小的二叉树,给定一些带权叶节点,这里首先定义一下树的总权值=叶节点权值和,构造一颗哈夫曼树过程如下:
- 所有叶节点构成一个集合
- 合并
- 找场上总权值最小的两棵树
- 二合一,并将树的总权值记录在根节点上
- 循环2步骤,直到集合中只剩一个元素
哈夫曼树的特点如下:
- WPL最小。权值小的,路径长,权值大的,路径短,那么总共的WPL就被平衡下来,达到最小。
- 无歧义。初始节点最后只能成为叶节点,中间结点无意义。
- 哈夫曼树不唯一
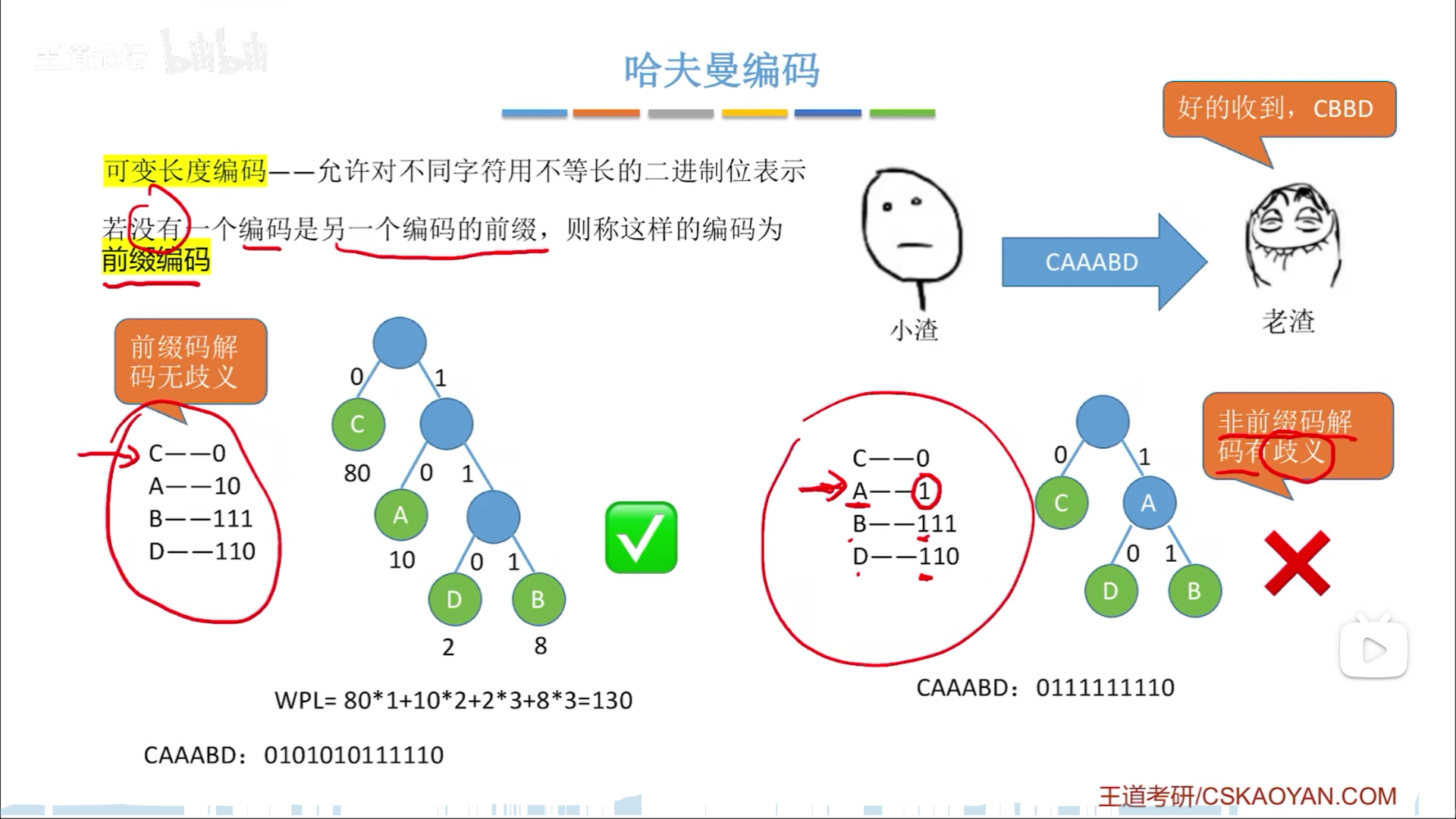
哈夫曼树的应用是可变长度编码
权值可以理解为使用频率,或者重要程度。重要的,就应该放在上面,以更少的消耗编码:
- 先按照权值构造哈夫曼树
- 哈夫曼树获得编码
如下图,C最重要,因此只用1个bit,ABD长度依次增加。
这种不定长编码的问题在于,可能会有歧义,因为无法定长分节解析,但是恰巧哈弗曼编码无歧义,为前缀编码,因此可以使用异步方式解析。如何解码呢?其实就是把这一串序列送到哈夫曼树里面,走到叶节点就解析一个字符,然后下一个序列继续从根开始。这个过程其实就是一个FDA,和编译原理有共同之处
如此,从概率来看最后编码和解码的总消耗都是最少的(实际上不见得最少)
并查集
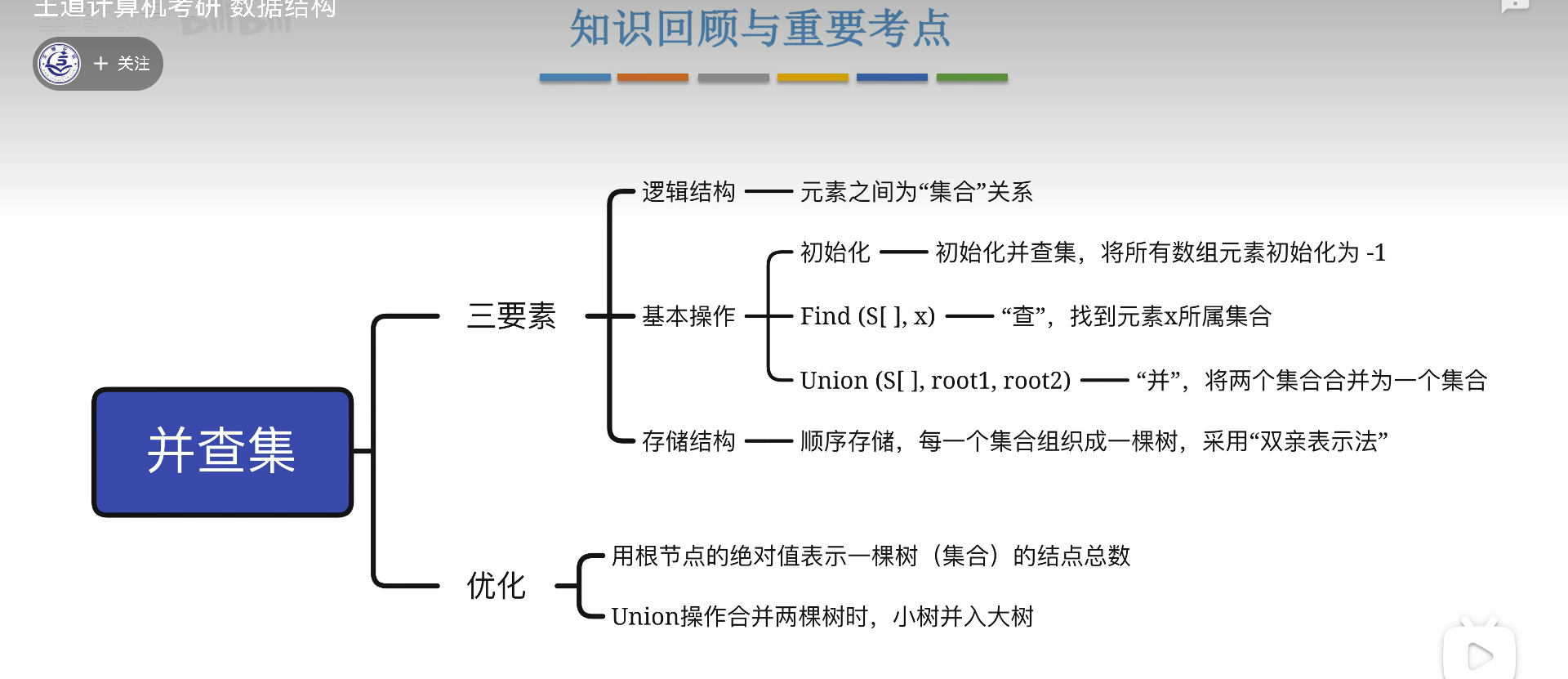
数据结构
并查集就是集合,集合之间互不相交,我们此处要用数据结构描述这种互不相交的关系。
基于这个关系,还应该实现两个基本功能:
- 查:给定元素,判断所属的集合
- 这个操作说白了就是找根节点
- 并:合并两个集合
- 直接让一颗树的根节点成为另一棵树的子节点就好
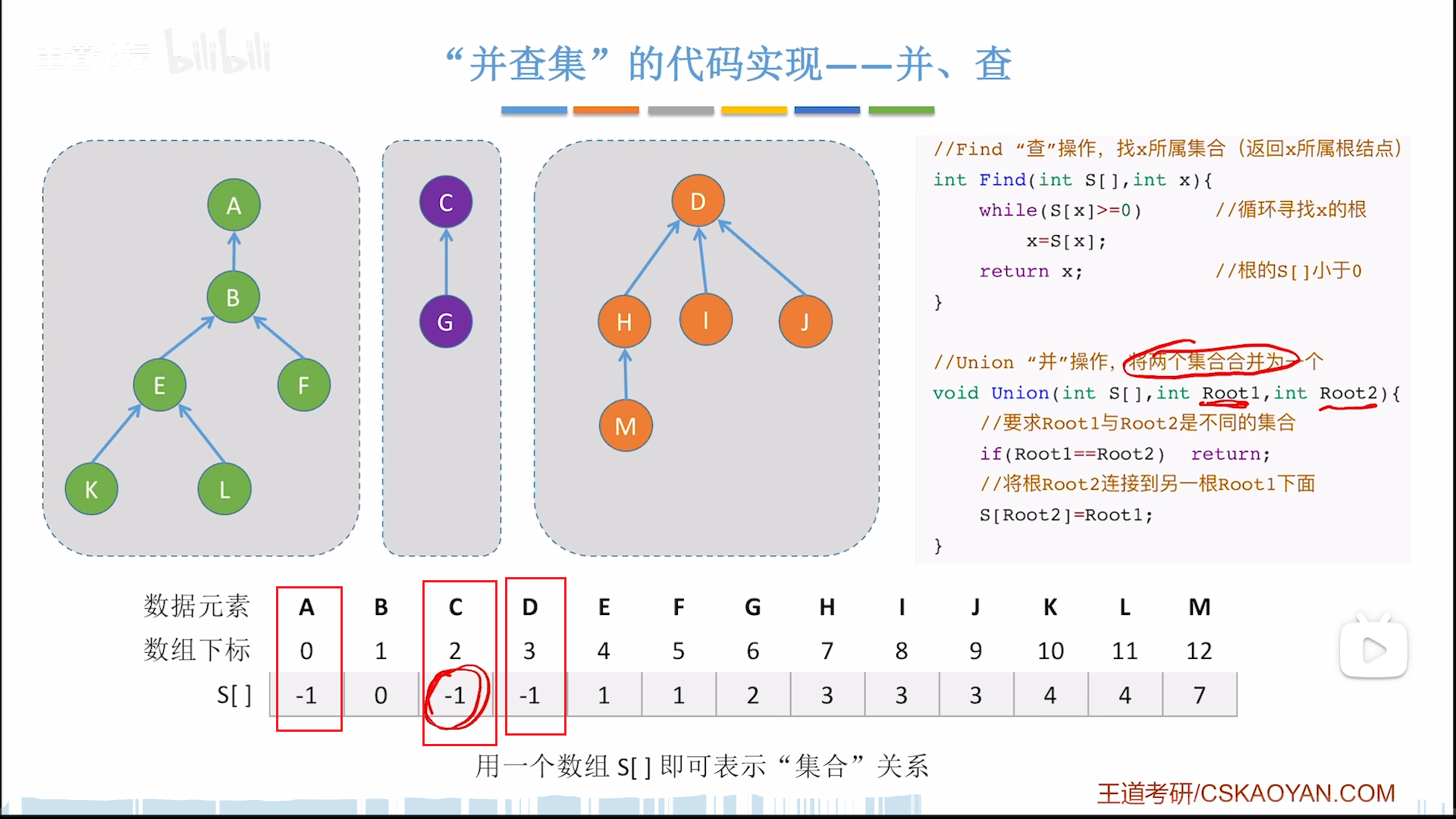
这两种方法,用双亲表示法都是最有效率的,实现也很容易。
其实也可以用链表,我也做过链表的题,但是因为链表找到头比较慢,要O(n),而树结构分叉,高度大概只有O(logN),查一次要的迭代次数更少,因此时间效率上,双亲表示法完胜
现在唯一的技术难点其实就是如何用一个数组储存一个森林呢?本质就在于要同时维持多个根节点,但是这个问题其实不是问题,因为不同的根节点可以通过下标来区分,反正我们只有并查操作,只需要找双亲,所以这样储存完全没问题,就这么简单粗暴。
说白了,把操作限制在并查,就可以针对性的使用高效率的结构实现,操作越复杂,耗时越多,还需要用更精巧复杂的结构来降低操作的损耗,这是不变的道理
优化
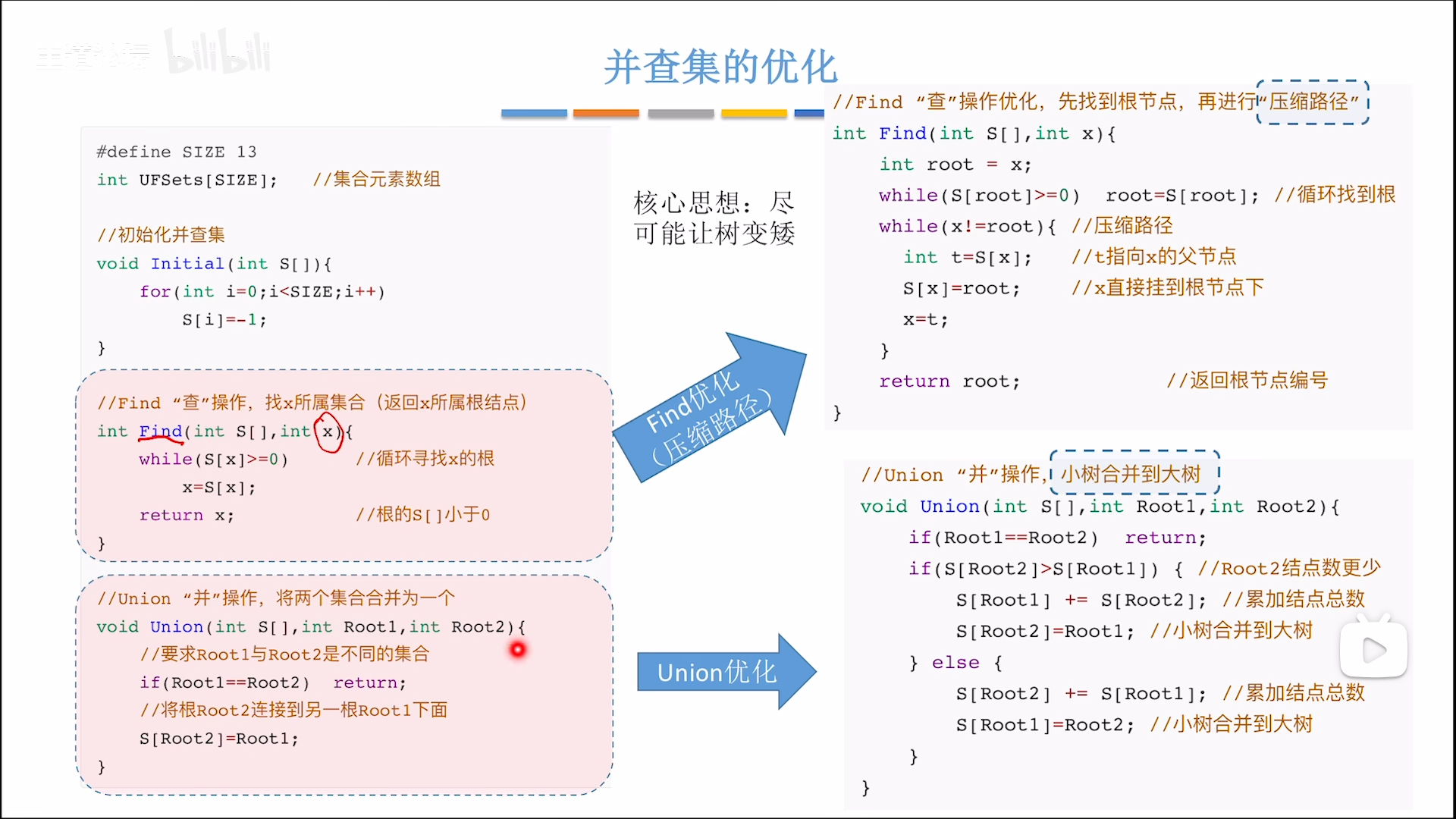
并集:控制高度
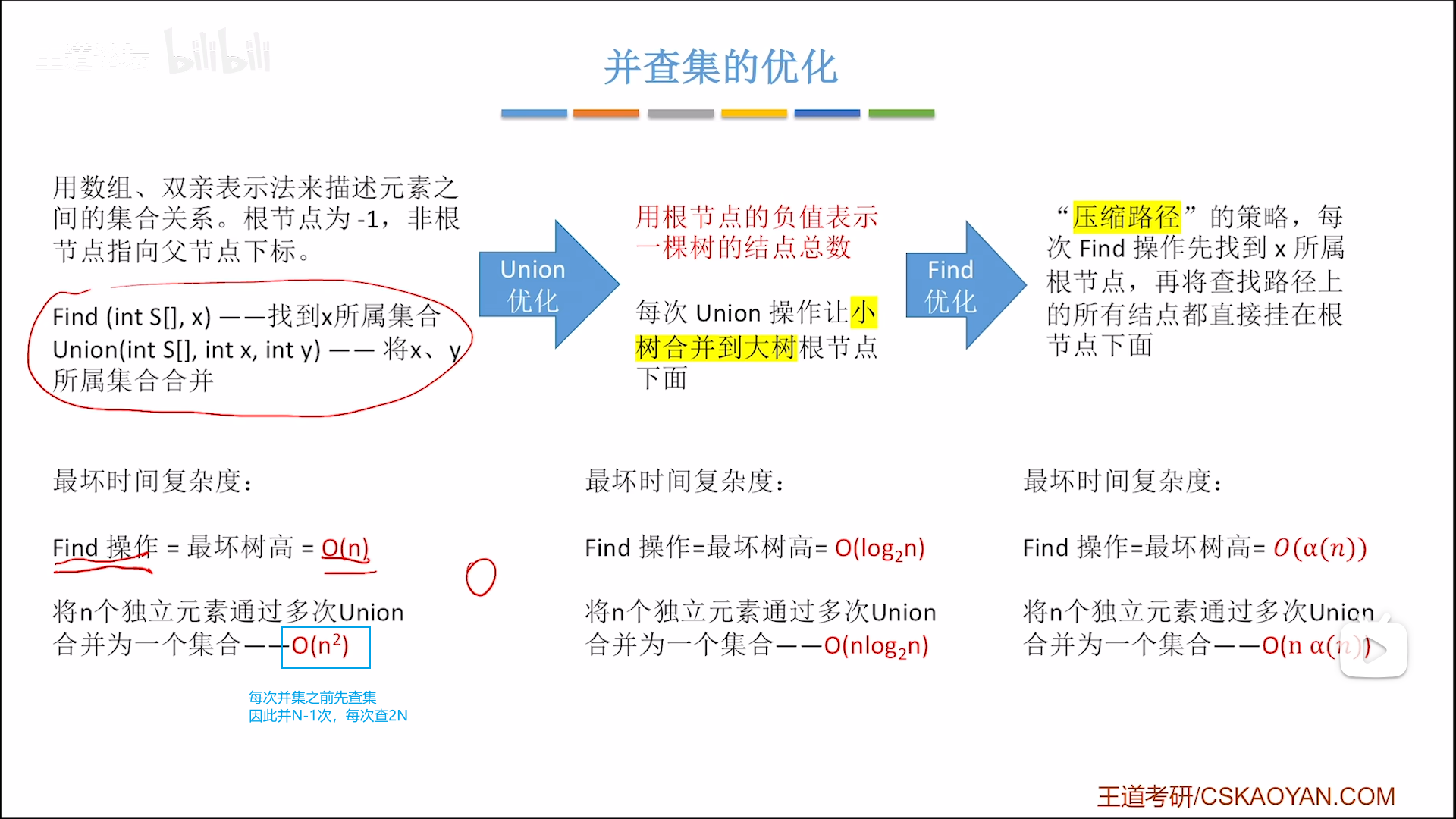
优化效率,就要分析复杂度。
并集为O(1),改下指针就行,查需要逆向迭代,如果所有元素串成一条线,那么最坏就是O(n),反之,如果平铺开来,尽可能降低高度,就可以提高效率。
注意,双亲法是树,不限制孩子个数,所以每次并集都是直接并到根节点上,现在我们要优化这个过程:
仔细分析Union过程,在把一颗高度为n的树插到另一颗树上时,这颗子树算上根节点,总高度其实是变成了n+1。
假如有三个节点ABC,把C插到B上,再把B插到A上,总高度就是3
换个思路,如果把C插到B,然后把A插到B,总高度只有2,在第二次插入过程中,总高度并没有变化。
具体逻辑如下:
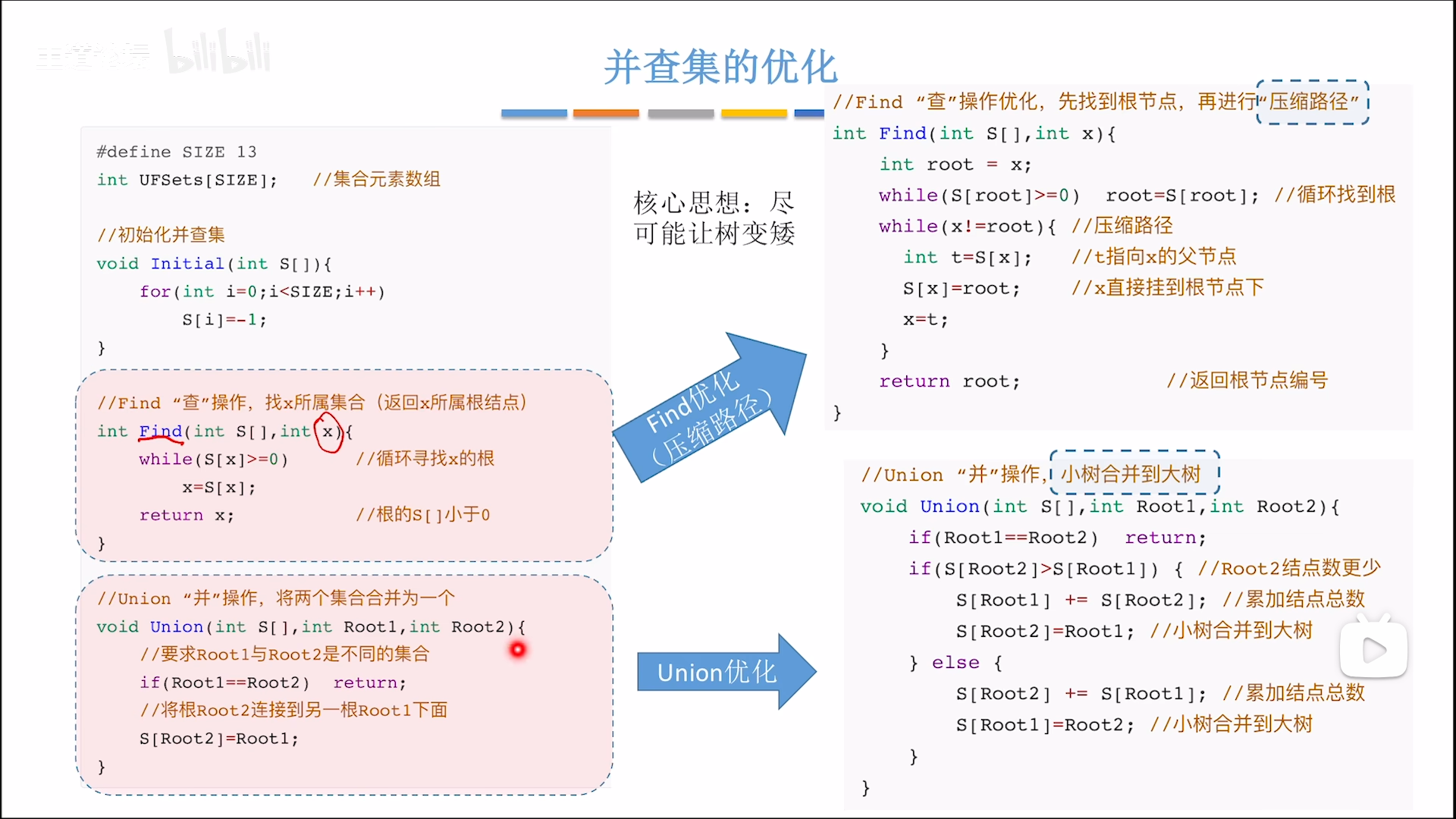
- 把矮树并到高树上,就不会增加总高度
- 若两树高度相同,则并集会令高度+1
但是呢,我们对高度其实并没有一个衡量,所以只能用挂载节点的数量(元素数量)来近似高度,既然无法判断高矮,判断大小也是可以的,具体操作如下:
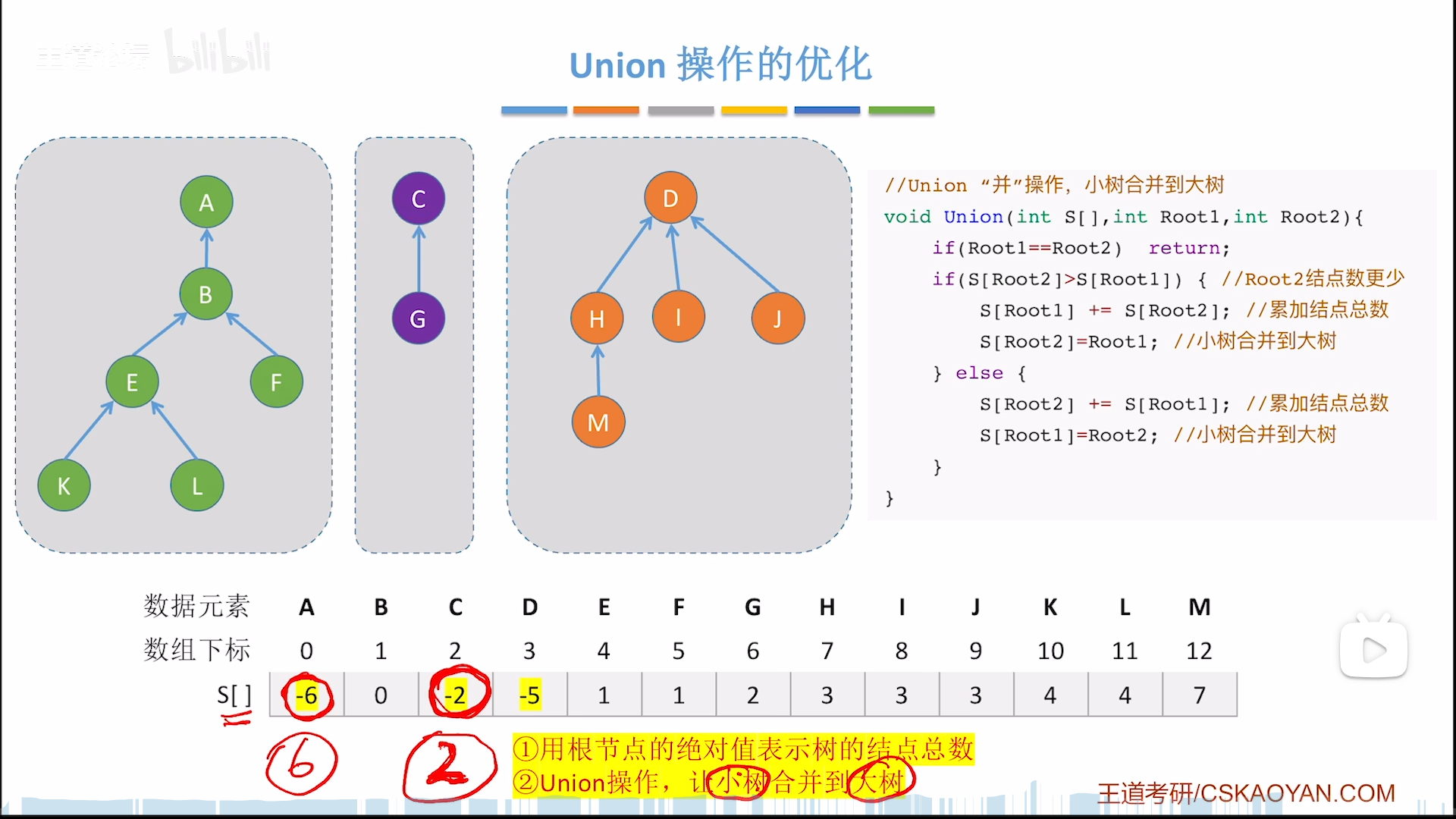
但是你以为这就完了吗?如果你从离散的叶节点开始合并,你会发现最后的长度无论如何都不会超过这个数,即时间复杂度最好O(1),最坏都是O(logN)

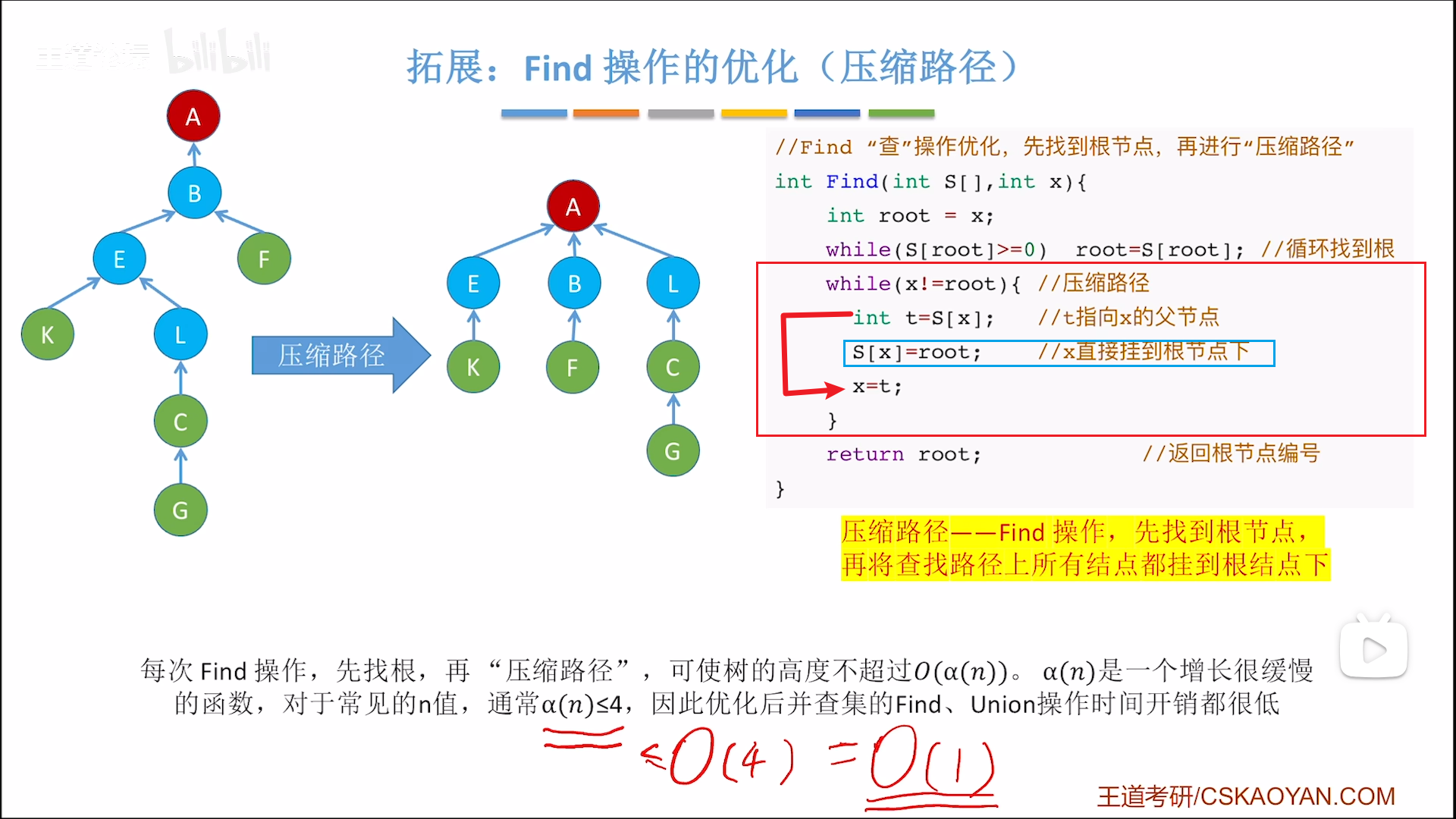
查集:压缩路径
前面说的是在并集过程中对于高度的优化
现在进一步,在查集的过程中进一步优化,属实是脑洞大开,令人拍案:
- 首先找到根节点,保存根节点位置
- 然后进行二轮回溯压缩路径,从路径终点开始
- 先保存父节点备用
- 拆桥,把当前节点挂载到根节点
- 保存的父节点派上用场,当做下一轮循环要调整位置的节点
如此,每次查询,都可以进行一次压缩,越查越快,可以对抗并集导致的高度增加,配合并集优化,可以使得一般情况下高度维持在4以内,牛逼。
相关文章:
数据结构笔记——树和图(王道408)(持续更新)
文章目录 传送门前言树(重点)树的数据结构定义性质 二叉树的数据结构定义性质储存结构 二叉树算法先中后序遍历层次展开法递归模拟法 层次遍历遍历序列逆向构造二叉树 线索二叉树(难点)定义线索化的本质 二叉树线索化线索二叉树中…...
Redis 主从
目录 编辑一、构建主从架构 1、集群结构 2、准备实例和配置 (1)创建目录 (2)修改原始配置 (3)拷贝配置文件到每个实例目录 (4)修改每个实例的端口,工作目录 &a…...

嵌入式学习笔记(63)位操作实战
(1)给定一个整型数a,设置a的bit3,保证其他位不变。 a | (1<<3) (2)给定一个整形数a,设置a的bit3~bit7,保持其他位不变 a | (0x1f<<3) (3)给定一个整型数a,清除a的bit15,保证其他位不变。 a …...

8位机adc采样正弦波频率
相位/峰峰值高电平? 检 测峰值电压? y 开始计数 检测零电压 y 计数器值16ms/20ms 斩波开x关x延时 tt 频率 1/2t 电路 增减常数 aT...

react中使用监听
在 React 中,您可以使用 addEventListener 函数来监听事件。以下是一个示例: import React, { useRef, useEffect } from react;function App() {const inputRef useRef(null);useEffect(() > {inputRef.current.addEventListener(input, handleInp…...
Java基础总结
0、Java语言 1.java和c 2.编译和解释 3.jre和jdk,jvm 简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。 Java 语言既具…...
基于SSM的OA办公系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

【第25例】IPD体系进阶:需求分析团队RAT
目录 简介 RAT CSDN学院相关内容推荐 作者简介 简介 RAT是英文Requirement Analysis Team英文首字母的简称,也即需求分析团队,每个产品线都需要设定对应的一个RAT的组织。 RAT主要负责产品领域内需求的分析活动,是RMT的支撑团队: 这个时候可以将RAT细化为PL-RAT团队,…...

5G与无人驾驶:引领未来交通的新潮流
5G与无人驾驶:引领未来交通的新潮流 随着5G技术的快速发展和普及,无人驾驶技术也日益受到人们的关注。5G技术为无人驾驶提供了更高效、更准确、更及时的通信方式,从而改变了我们对交通出行的认知和使用方式。本文将探讨5G技术在无人驾驶领域的…...

FreeRTOS学习2018.6.27
《FreeRTOS学习》 1.freeRTOS基本功能函数: 定义任务:ATaskFunction(); 创建任务:xTaskCreate(); 改优先级:vTaskPrioritySet(); 系统延时:vTaskDelay(); 精确延时:vTaskDelayUntil(); 空闲任务钩子函数&…...

【异常】理解Java中的异常处理机制
标题:理解Java中的异常处理机制 摘要: 异常处理是Java编程中的重要概念之一,它可以帮助开发者识别和处理程序运行过程中的错误和异常情况。本文将深入探讨Java中的异常处理机制,包括异常的分类、异常处理的语法和最佳实践。通过示…...

很久没写JAVA程序了,原来用GMAIL发送邮件这么简单
写完代码,配置了GMAIL,死活发布出去,碰到了错误535-5.7.8 Username and Password not accepted. 首先先写代码,然后配置GMAIL. 第一写代码: 当你需要在 Spring Boot 中实现邮件通知时,你可以使用 Spring 的 JavaMailSender 来发送电子邮件。首先,确保你的 Spring Boo…...
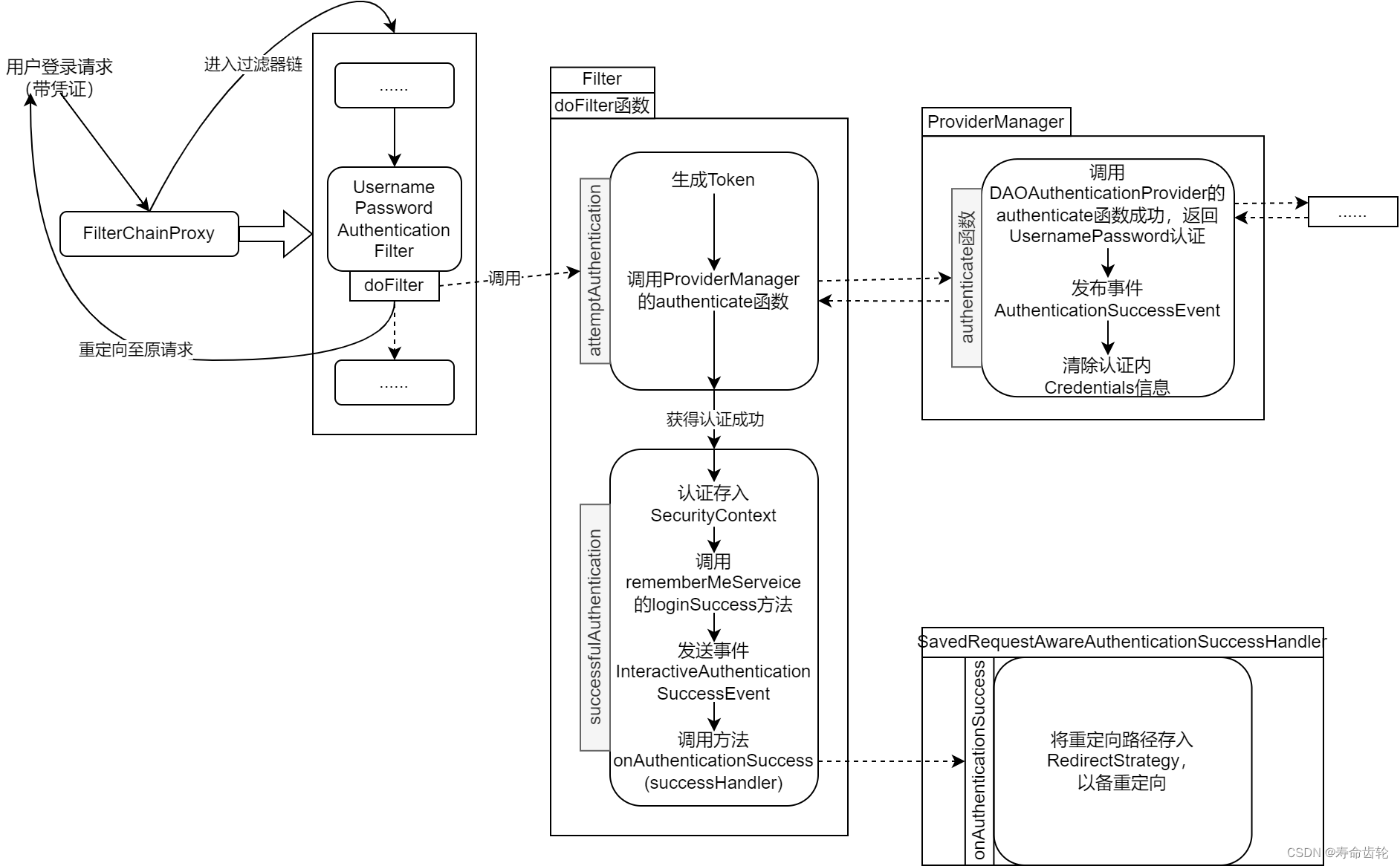
Spring Security获得认证流程解析(示意图)
建议先看完Spring Security总体架构介绍和Spring Security认证架构介绍,然后从FilterChainProxy的doFilterInternal函数开始,配合文章进行debug以理解Spring Security认证源码的执行流程。 在之前的Spring Security认证架构介绍中,我们已经知…...
 got an unexpected keyword argument ‘eq‘)
scrapy typeerror: attrs() got an unexpected keyword argument ‘eq‘
问题: scrapy 爬虫程序报错 scrapy typeerror: attrs() got an unexpected keyword argument eq原因: Twisted 版本过高 解决方法: # 安装指定版本 pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ Twisted21.7.0# 几个可…...

非侵入式负荷检测与分解:电力数据挖掘新视角
电力数据挖掘 概述案例背景分析目标分析过程数据准备数据探索缺失值处理 属性构造设备数据周波数据模型训练 性能度量推荐阅读 主页传送门:📀 传送 概述 摘要:本案例将根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功…...
抽丝剥茧,Redis使用事件总线EventBus或AOP优化健康检测
目录 前言 Lettuce 什么是事件总线EventBus? Connected Connection activated Disconnected Connection deactivated Reconnect failed 使用 一种另类方法—AOP 具体实现 前言 在上一篇深入浅出,SpringBoot整合Quartz实现定时任务与Redis健康…...

【Tailwind CSS】当页面内容过少,怎样让footer保持在屏幕底部?
footer通常写版权信息等,显示在页面底部。如果页面内容过少,则footer会出现在屏幕中间位置,很尴尬。在 Tailwind 中,你可以使用flex来实现footer保持在屏幕或页面底部。 代码: <div class"flex flex-col min…...

Docker基础管理
这里写目录标题 Docker基础管理一.Docker 概述1.Docker介绍2.Docker与虚拟机的区别3.容器在内核中支持2种重要技术4.Docker核心概念 二.安装Docker1.安装依赖包2.配置文件及相关 三.Docker操作1.镜像操作2.容器操作 Docker基础管理 一.Docker 概述 1.Docker介绍 Docker是一个…...
基于YOLOv8模型的烟雾目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的烟雾目标检测系统可用于日常生活中检测与定位烟雾目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…...
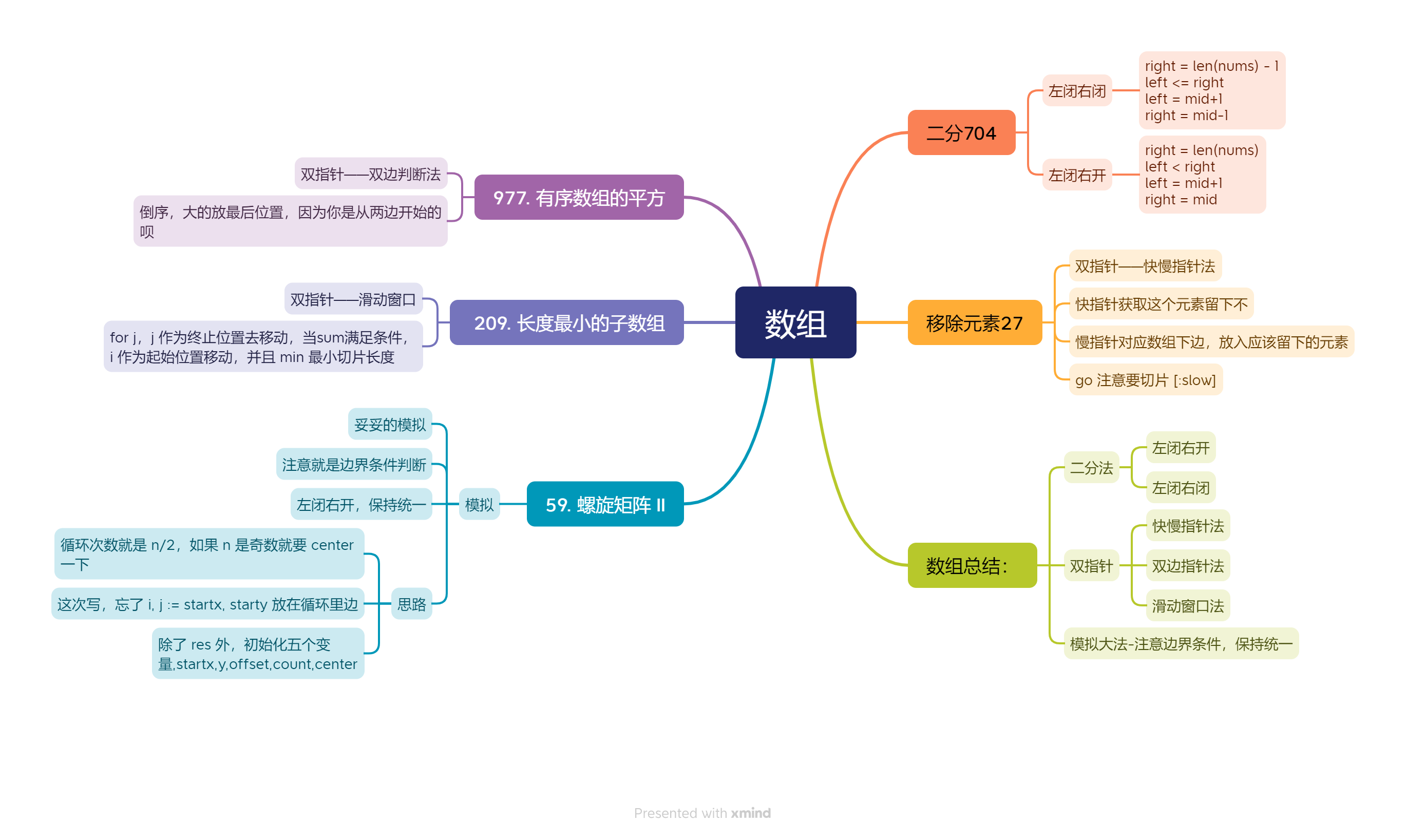
【代码随想录01】数组总结
抄去吧,保存去吧!...

AI率85%的论文,这款工具降完后我直接去答辩了
答辩前5天,知网AIGC检测报告出来了:AI率85%。 我是那种遇到问题喜欢先搜索再行动的人,所以花了两个小时看了很多经验帖。最终决策:不手改,直接上比话降AI。 结果:11%,答辩前3天处理完…...

【FastAPI】 + SQLAlchemy 异步 ORM 实现完整 CRUD 操作
🚀从零实战:FastAPI SQLAlchemy 异步 ORM 实现完整 CRUD 操作(附完整代码) 一、为什么要学「FastAPI SQLAlchemy 异步 ORM」? 在现代 Web 服务中,数据库是核心组件。然而,传统同步操作&#x…...
了!Python字典setdefault()的3个进阶技巧(含性能对比))
别再乱用get()了!Python字典setdefault()的3个进阶技巧(含性能对比)
别再乱用get()了!Python字典setdefault()的3个进阶技巧(含性能对比) 字典操作是Python开发中最频繁的基础动作之一,但很多中高级开发者依然停留在get()方法的舒适区。本文将带你突破常规用法,探索setdefault()在真实项…...
✅)
计算机毕业设计:Python城市地铁客流与票务可视化分析平台 Django框架 数据分析 可视化 大数据 机器学习 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

镜像是什么?怎么用?解决下载慢的终极指南
作为计算机小白,最头疼的事莫过于下载软件——明明点击了下载,速度却慢得像蜗牛,动辄几KB/s,下一个几百MB的软件要等大半天,甚至中途断开重新来;偶尔听大佬说“用国内镜像啊”,却一脸懵…...

避开带宽陷阱:用低成本示波器搞定MIPI CSI-2信号的眼图与时序分析
避开带宽陷阱:用低成本示波器搞定MIPI CSI-2信号的眼图与时序分析 当你手头只有一台几百MHz带宽的示波器,却要分析动辄上Gbps的MIPI CSI-2高速信号时,是否感到无从下手?别担心,这篇文章将带你突破硬件限制,…...

基于光伏出力利用率的电动汽车充电站能量调度策略:动态评估充放电灵活性,优化准入规则与电价制定...
考虑光伏出力利用率的电动汽车充电站能量调度策略。 程序注释非常非常详细 针对间歇性能源利用的问题,构建电动汽车的充放电灵活度指标,用以评估电动汽车参与光伏充电站能量调度的能力; 令充电站在饥饿模式或饱和模式下运行,并根据…...

免费游戏串流平台Sunshine:5步搭建你的专属云端游戏服务器
免费游戏串流平台Sunshine:5步搭建你的专属云端游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏大作,却受限于硬件配…...

python tarfile
# Python tarfile模块:不止是打包与解包 在Python的标准库中,tarfile模块常常被开发者们忽视,或者仅仅被当作一个简单的压缩工具来使用。实际上,这个模块的功能远比表面看起来要丰富得多,它处理的是tar格式的归档文件…...

MAA助手跨平台部署与自动化实践指南
MAA助手跨平台部署与自动化实践指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.com/GitHub_Trending/ma/…...