非侵入式负荷检测与分解:电力数据挖掘新视角
电力数据挖掘
- 概述
- 案例背景
- 分析目标
- 分析过程
- 数据准备
- 数据探索
- 缺失值处理
- 属性构造
- 设备数据
- 周波数据
- 模型训练
- 性能度量
- 推荐阅读

主页传送门:📀 传送
概述
摘要:本案例将根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功率等情况,分析各电力设备的实际用电量,进而为电力公司制定电能能源策略提供一定的参考依据。更多详细内容请参考《Python数据挖掘:入门进阶与实用案例分析》一书。
案例背景
为了更好地监测用电设备的能耗情况,电力分项计量技术随之诞生。电力分项计量对于电力公司准确预测电力负荷、科学制定电网调度方案、提高电力系统稳定性和可靠性有着重要意义。对用户而言,电力分项计量可以帮助用户了解用电设备的使用情况,提高用户的节能意识,促进科学合理用电。
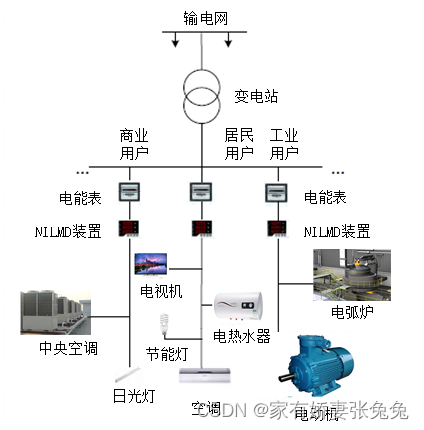
分析目标
本案例根据非侵入式负荷检测与分解的电力数据挖掘的背景和业务需求,需要实现的目标如下:
-
分析每个用电设备的运行属性。
-
构建设备判别属性库。
-
利用K最近邻模型,实现从整条线路中“分解”出每个用电设备的独立用电数据。
分析过程
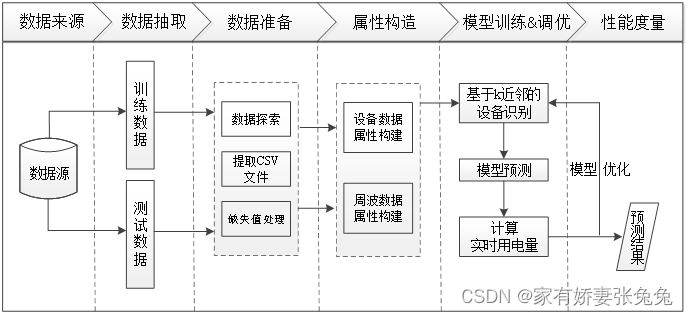
数据准备
数据探索
在本案例的电力数据挖掘分析中,不会涉及操作记录数据。因此,此处主要获取设备数据、周波数据和谐波数据。在获取数据后,由于数据表较多,每个表的属性也较多,所以需要对数据进行数据探索分析。在数据探索过程中主要根据原始数据特点,对每个设备的不同属性对应的数据进行可视化,得到的部分结果如图1~图3所示。
无功功率和总无功功率:
电流轨迹:
电压轨迹:
可视化数据代码示例:
import pandas as pdimport matplotlib.pyplot as pltimport osfilename = os.listdir('../data/附件1') # 得到文件夹下的所有文件名称n_filename = len(filename) # 给各设备的数据添加操作信息,画出各属性轨迹图并保存def fun(a):save_name = ['YD1', 'YD10', 'YD11', 'YD2', 'YD3', 'YD4','YD5', 'YD6', 'YD7', 'YD8', 'YD9']plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号for i in range(a):Sb = pd.read_excel('../data/附件1/' + filename[i], '设备数据', index_col = None)Xb = pd.read_excel('../data/附件1/' + filename[i], '谐波数据', index_col = None)Zb = pd.read_excel('../data/附件1/' + filename[i], '周波数据', index_col = None)# 电流轨迹图plt.plot(Sb['IC'])plt.title(save_name[i] + '-IC')plt.ylabel('电流(0.001A)')plt.show()# 电压轨迹图lt.plot(Sb['UC'])plt.title(save_name[i] + '-UC')plt.ylabel('电压(0.1V)')plt.show()# 有功功率和总有功功率plt.plot(Sb[['PC', 'P']])plt.title(save_name[i] + '-P')plt.ylabel('有功功率(0.0001kW)')plt.show()# 无功功率和总无功功率plt.plot(Sb[['QC', 'Q']])plt.title(save_name[i] + '-Q')plt.ylabel('无功功率(0.0001kVar)')plt.show()# 功率因数和总功率因数plt.plot(Sb[['PFC', 'PF']])plt.title(save_name[i] + '-PF')plt.ylabel('功率因数(%)')plt.show()# 谐波电压plt.plot(Xb.loc[:, 'UC02':].T)plt.title(save_name[i] + '-谐波电压')plt.show()# 周波数据plt.plot(Zb.loc[:, 'IC001':].T)plt.title(save_name[i] + '-周波数据')plt.show()fun(n_filename)
缺失值处理
通过数据探索,发现数据中部分“time”属性存在缺失值,需要对这部分缺失值进行处理。由于每份数据中“time”属性的缺失时间段长不同,所以需要进行不同的处理。对于每个设备数据中具有较大缺失时间段的数据进行删除处理,对于具有较小缺失时间段的数据使用前一个值进行插补。
在进行缺失值处理之前,需要将训练数据中所有设备数据中的设备数据表、周波数据表、谐波数据表和操作记录表,以及测试数据中所有设备数据中的设备数据表、周波数据表和谐波数据表都提取出来,作为独立的数据文件,生成的部分文件如图4所示。
提取数据文件代码示例:
# 将xlsx文件转化为CSV文件import globimport pandas as pdimport mathdef file_transform(xls):print('共发现%s个xlsx文件' % len(glob.glob(xls)))print('正在处理............')for file in glob.glob(xls): # 循环读取同文件夹下的xlsx文件combine1 = pd.read_excel(file, index_col=0, sheet_name=None)for key in combine1:combine1[key].to_csv('../tmp/' + file[8: -5] + key + '.csv', encoding='utf-8')print('处理完成')xls_list = ['../data/附件1/*.xlsx', '../data/附件2/*.xlsx']file_transform(xls_list[0]) # 处理训练数据file_transform(xls_list[1]) # 处理测试数据
提取数据文件完成后,对提取的数据文件进行缺失值处理,处理后生成的部分文件如图5所示。
缺失值处理代码示例:
# 对每个数据文件中较大缺失时间点数据进行删除处理,较小缺失时间点数据进行前值替补def missing_data(evi):print('共发现%s个CSV文件' % len(glob.glob(evi)))for j in glob.glob(evi):fr = pd.read_csv(j, header=0, encoding='gbk')fr['time'] = pd.to_datetime(fr['time'])helper = pd.DataFrame({'time': pd.date_range(fr['time'].min(), fr['time'].max(), freq='S')})fr = pd.merge(fr, helper, on='time', how='outer').sort_values('time')fr = fr.reset_index(drop=True)frame = pd.DataFrame()for g in range(0, len(list(fr['time'])) - 1):if math.isnan(fr.iloc[:, 1][g + 1]) and math.isnan(fr.iloc[:, 1][g]):continueelse:scop = pd.Series(fr.loc[g])frame = pd.concat([frame, scop], axis=1)frame = pd.DataFrame(frame.values.T, index=frame.columns, columns=frame.index)frames = frame.fillna(method='ffill')frames.to_csv(j[:-4] + '1.csv', index=False, encoding='utf-8')print('处理完成')evi_list = ['../tmp/附件1/*数据.csv', '../tmp/附件2/*数据.csv']missing_data(evi_list[0]) # 处理训练数据missing_data(evi_list[1]) # 处理测试数据
属性构造
虽然在数据准备过程中对属性进行了初步处理,但是引入的属性太多,而且这些属性之间存在重复的信息。为了保留重要的属性,建立精确、简单的模型,需要对原始属性进一步筛选与构造。
设备数据
在数据探索过程中发现,不同设备的无功功率、总无功功率、有功功率、总有功功率、功率因数和总功率因数差别很大,具有较高的区分度,故本案例选择无功功率、总无功功率、有功功率、总有功功率、功率因数和总功率因数作为设备数据的属性构建判别属性库。
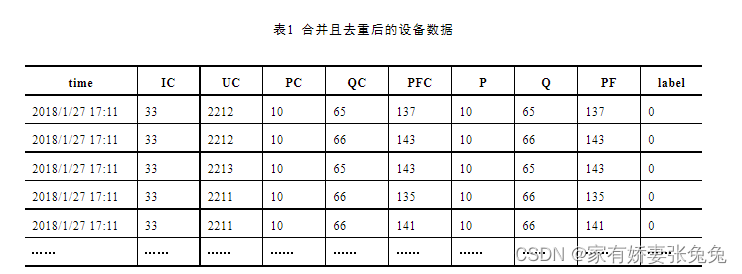
处理好缺失值后,每个设备的数据都由一张表变为了多张表,所以需要将相同类型的数据表合并到一张表中,如将所有设备的设备数据表合并到一张表当中。同时,因为缺失值处理的其中一种方式是使用前一个值进行插补,所以产生了相同的记录,需要对重复出现的记录进行处理,处理后生成的数据表如表1所示。
合并且去重设备数据代码示例:
import globimport pandas as pdimport os# 合并11个设备数据及处理合并中重复的数据def combined_equipment(csv_name):# 合并print('共发现%s个CSV文件' % len(glob.glob(csv_name)))print('正在处理............')for i in glob.glob(csv_name): # 循环读取同文件夹下的CSV文件fr = open(i, 'rb').read()file_path = os.path.split(i)with open(file_path[0] + '/device_combine.csv', 'ab') as f:f.write(fr)print('合并完毕!')# 去重df = pd.read_csv(file_path[0] + '/device_combine.csv', header=None, encoding='utf-8')datalist = df.drop_duplicates()datalist.to_csv(file_path[0] + '/device_combine.csv', index=False, header=0)print('去重完成')csv_list = ['../tmp/附件1/*设备数据1.csv', '../tmp/附件2/*设备数据1.csv']combined_equipment(csv_list[0]) # 处理训练数据combined_equipment(csv_list[1]) # 处理测试数据
周波数据
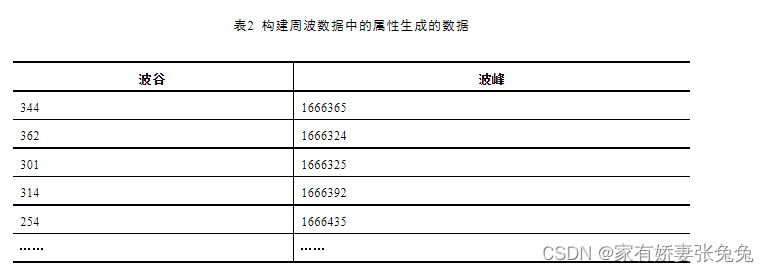
在数据探索过程中发现,周波数据中的电流随着时间的变化有较大的起伏,不同设备的周波数据中的电流绘制出来的折线图的起伏不尽相同,具有明显的差异,故本案例选择波峰和波谷作为周波数据的属性构建判别属性库。
由于原始的周波数据中并未存在电流的波峰和波谷两个属性,所以需要进行属性构建,构建生成的数据表如表2所示。
构建周波数据中的属性代码示例:
# 求取周波数据中电流的波峰和波谷作为属性参数import globimport pandas as pdfrom sklearn.cluster import KMeansimport osdef cycle(cycle_file):for file in glob.glob(cycle_file):cycle_YD = pd.read_csv(file, header=0, encoding='utf-8')cycle_YD1 = cycle_YD.iloc[:, 0:128]models = []for types in range(0, len(cycle_YD1)):model = KMeans(n_clusters=2, random_state=10)model.fit(pd.DataFrame(cycle_YD1.iloc[types, 1:])) # 除时间以外的所有列models.append(model)# 相同状态间平稳求均值mean = pd.DataFrame()for model in models:r = pd.DataFrame(model.cluster_centers_, ) # 找出聚类中心r = r.sort_values(axis=0, ascending=True, by=[0])mean = pd.concat([mean, r.reset_index(drop=True)], axis=1)mean = pd.DataFrame(mean.values.T, index=mean.columns, columns=mean.index)mean.columns = ['波谷', '波峰']mean.index = list(cycle_YD['time'])mean.to_csv(file[:-9] + '波谷波峰.csv', index=False, encoding='gbk ')cycle_file = ['../tmp/附件1/*周波数据1.csv', '../tmp/附件2/*周波数据1.csv']cycle(cycle_file[0]) # 处理训练数据cycle(cycle_file[1]) # 处理测试数据# 合并周波的波峰波谷文件def merge_cycle(cycles_file):means = pd.DataFrame()for files in glob.glob(cycles_file):mean0 = pd.read_csv(files, header=0, encoding='gbk')means = pd.concat([means, mean0])file_path = os.path.split(glob.glob(cycles_file)[0])means.to_csv(file_path[0] + '/zuhe.csv', index=False, encoding='gbk')print('合并完成')cycles_file = ['../tmp/附件1/*波谷波峰.csv', '../tmp/附件2/*波谷波峰.csv']merge_cycle(cycles_file[0]) # 训练数据merge_cycle(cycles_file[1]) # 测试数据
模型训练
在判别设备种类时,选择K最近邻模型进行判别,利用属性构建而成的属性库训练模型,然后利用训练好的模型对设备1和设备2进行判别。构建判别模型并对设备种类进行判别,如代码清单6所示。
建立判别模型并对设备种类进行判别代码示例:
import globimport pandas as pdfrom sklearn import neighborsimport pickleimport os# 模型训练def model(test_files, test_devices):# 训练集zuhe = pd.read_csv('../tmp/附件1/zuhe.csv', header=0, encoding='gbk')device_combine = pd.read_csv('../tmp/附件1/device_combine.csv', header=0, encoding='gbk')train = pd.concat([zuhe, device_combine], axis=1)train.index = train['time'].tolist() # 把“time”列设为索引train = train.drop(['PC', 'QC', 'PFC', 'time'], axis=1)train.to_csv('../tmp/' + 'train.csv', index=False, encoding='gbk')# 测试集for test_file, test_device in zip(test_files, test_devices):test_bofeng = pd.read_csv(test_file, header=0, encoding='gbk')test_devi = pd.read_csv(test_device, header=0, encoding='gbk')test = pd.concat([test_bofeng, test_devi], axis=1)test.index = test['time'].tolist() # 把“time”列设为索引test = test.drop(['PC', 'QC', 'PFC', 'time'], axis=1)# K最近邻clf = neighbors.KNeighborsClassifier(n_neighbors=6, algorithm='auto')clf.fit(train.drop(['label'], axis=1), train['label'])predicted = clf.predict(test.drop(['label'], axis=1))predicted = pd.DataFrame(predicted)file_path = os.path.split(test_file)[1]test.to_csv('../tmp/' + file_path[:3] + 'test.csv', encoding='gbk')predicted.to_csv('../tmp/' + file_path[:3] + 'predicted.csv', index=False, encoding='gbk')with open('../tmp/' + file_path[:3] + 'model.pkl', 'ab') as pickle_file:pickle.dump(clf, pickle_file)print(clf)model(glob.glob('../tmp/附件2/*波谷波峰.csv'),glob.glob('../tmp/附件2/*设备数据1.csv'))
性能度量
根据代码清单6的设备判别结果,对模型进行模型评估,得到的结果如下
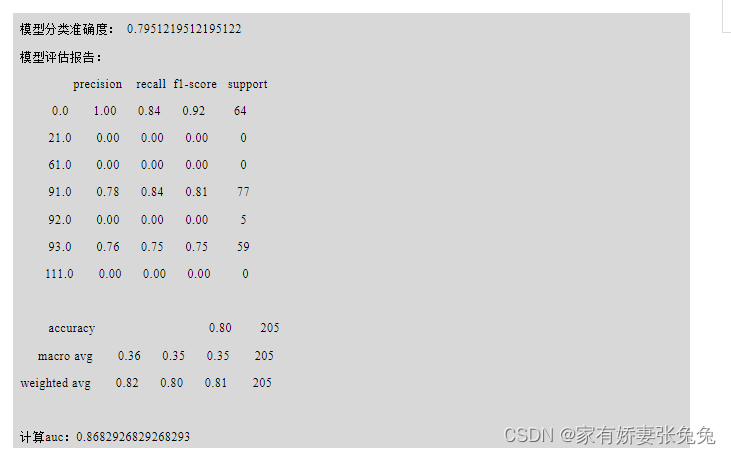
混淆矩阵如图7所示:
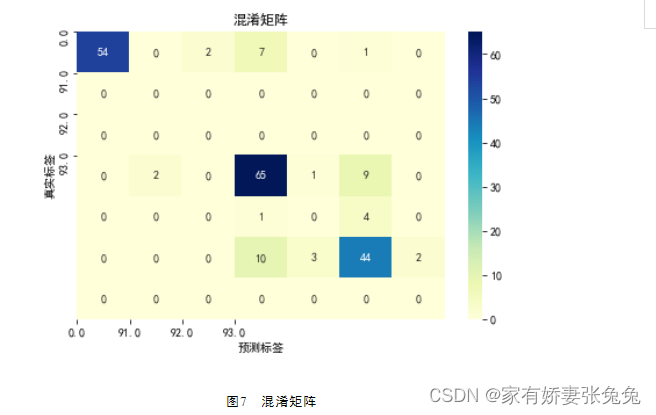
ROC曲线如图8所示 :
模型评估代码示例:
import globimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn import metricsfrom sklearn.preprocessing import label_binarizeimport osimport pickle# 模型评估def model_evaluation(model_file, test_csv, predicted_csv):for clf, test, predicted in zip(model_file, test_csv, predicted_csv):with open(clf, 'rb') as pickle_file:clf = pickle.load(pickle_file)test = pd.read_csv(test, header=0, encoding='gbk')predicted = pd.read_csv(predicted, header=0, encoding='gbk')test.columns = ['time', '波谷', '波峰', 'IC', 'UC', 'P', 'Q', 'PF', 'label']print('模型分类准确度:', clf.score(test.drop(['label', 'time'], axis=1), test['label']))print('模型评估报告:\n', metrics.classification_report(test['label'], predicted))confusion_matrix0 = metrics.confusion_matrix(test['label'], predicted)confusion_matrix = pd.DataFrame(confusion_matrix0)class_names = list(set(test['label']))tick_marks = range(len(class_names))sns.heatmap(confusion_matrix, annot=True, cmap='YlGnBu', fmt='g')plt.xticks(tick_marks, class_names)plt.yticks(tick_marks, class_names)plt.tight_layout()plt.title('混淆矩阵')plt.ylabel('真实标签')plt.xlabel('预测标签')plt.show()y_binarize = label_binarize(test['label'], classes=class_names)predicted = label_binarize(predicted, classes=class_names)fpr, tpr, thresholds = metrics.roc_curve(y_binarize.ravel(), predicted.ravel())auc = metrics.auc(fpr, tpr)print('计算auc:', auc) # 绘图plt.figure(figsize=(8, 4))lw = 2plt.plot(fpr, tpr, label='area = %0.2f' % auc)plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')plt.fill_between(fpr, tpr, alpha=0.2, color='b')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('1-特异性')plt.ylabel('灵敏度')plt.title('ROC曲线')plt.legend(loc='lower right')plt.show()model_evaluation(glob.glob('../tmp/*model.pkl'),glob.glob('../tmp/*test.csv'),glob.glob('../tmp/*predicted.csv'))
根据分析目标,需要计算实时用电量。实时用电量计算的是瞬时的用电器的电流、电压和时间的乘积,公式如下。

其中,为实时用电量,单位是0.001kWh。为功率,单位为W。
实时用电量计算,得到的实时用电量如表3所示。
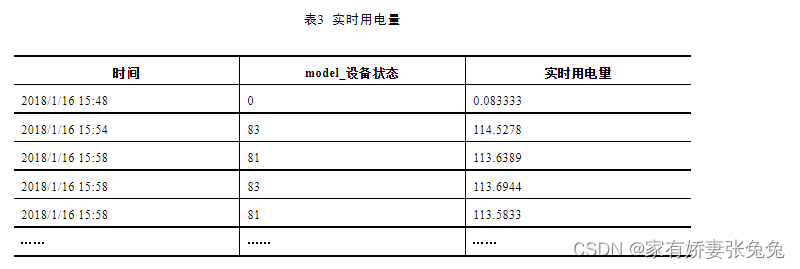
计算实时用电量
# 计算实时用电量并输出状态表def cw(test_csv, predicted_csv, test_devices):for test, predicted, test_device in zip(test_csv, predicted_csv, test_devices):# 划分预测出的时刻表test = pd.read_csv(test, header=0, encoding='gbk')test.columns = ['time', '波谷', '波峰', 'IC', 'UC', 'P', 'Q', 'PF', 'label']test['time'] = pd.to_datetime(test['time'])test.index = test['time']predicteds = pd.read_csv(predicted, header=0, encoding='gbk')predicteds.columns = ['label']indexes = []class_names = list(set(test['label']))for j in class_names:index = list(predicteds.index[predicteds['label'] == j])indexes.append(index)# 取出首位序号及时间点from itertools import groupby # 连续数字dif_indexs = []time_indexes = []info_lists = pd.DataFrame()for y, z in zip(indexes, class_names):dif_index = []fun = lambda x: x[1] - x[0]for k, g in groupby(enumerate(y), fun):dif_list = [j for i, j in g] # 连续数字的列表if len(dif_list) > 1:scop = min(dif_list) # 选取连续数字范围中的第一个else:scop = dif_list[0 ]dif_index.append(scop)time_index = list(test.iloc[dif_index, :].index)time_indexes.append(time_index)info_list = pd.DataFrame({'时间': time_index, 'model_设备状态': [z] * len(time_index)})dif_indexs.append(dif_index)info_lists = pd.concat([info_lists, info_list])# 计算实时用电量并保存状态表test_devi = pd.read_csv(test_device, header=0, encoding='gbk')test_devi['time'] = pd.to_datetime(test_devi['time'])test_devi['实时用电量'] = test_devi['P'] * 100 / 3600info_lists = info_lists.merge(test_devi[['time', '实时用电量']],how='inner', left_on='时间', right_on='time')info_lists = info_lists.sort_values(by=['时间'], ascending=True)info_lists = info_lists.drop(['time'], axis=1)file_path = os.path.split(test_device)[1]info_lists.to_csv('../tmp/' + file_path[:3] + '状态表.csv', index=False, encoding='gbk')print(info_lists)cw(glob.glob('../tmp/*test.csv'),glob.glob('../tmp/*predicted.csv'),glob.glob('../tmp/附件2/*设备数据1.csv'))
推荐阅读

正版链接:https://item.jd.com/13814157.html
《Python数据挖掘:入门、进阶与实用案例分析》是一本以项目实战案例为驱动的数据挖掘著作,它能帮助完全没有Python编程基础和数据挖掘基础的读者快速掌握Python数据挖掘的技术、流程与方法。在写作方式上,与传统的“理论与实践结合”的入门书不同,它以数据挖掘领域的知名赛事“泰迪杯”数据挖掘挑战赛(已举办10届)和“泰迪杯”数据分析技能赛(已举办5届)(累计1500余所高校的10余万师生参赛)为依托,精选了11个经典赛题,将Python编程知识、数据挖掘知识和行业知识三者融合,让读者在实践中快速掌握电商、教育、交通、传媒、电力、旅游、制造等7大行业的数据挖掘方法。
本书不仅适用于零基础的读者自学,还适用于教师教学,为了帮助读者更加高效地掌握本书的内容,本书提供了以下10项附加价值:
(1)建模平台:提供一站式大数据挖掘建模平台,免配置,包含大量案例工程,边练边学,告别纸上谈兵
(2)视频讲解:提供不少于600分钟Python编程和数据挖掘相关教学视频,边看边学,快速收获经验值
(3)精选习题:精心挑选不少于60道数据挖掘练习题,并提供详细解答,边学边练,检查知识盲区
(4)作者答疑:学习过程中有任何问题,通过“树洞”小程序,纸书拍照,一键发给作者,边问边学,事半功倍
(5)数据文件:提供各个案例配套的数据文件,与工程实践结合,开箱即用,增强实操性
(6)程序代码:提供书中代码的电子文件及相关工具的安装包,代码导入平台即可运行,学习效果立竿见影
(7)教学课件:提供配套的PPT课件,使用本书作为教材的老师可以申请,节省备课时间
(8)模型服务:提供不少于10个数据挖掘模型,模型提供完整的案例实现过程,助力提升数据挖掘实践能力
(9)教学平台:泰迪科技为本书提供的附加资源提供一站式数据化教学平台,附有详细操作指南,边看边学边练,节省时间
(10)就业推荐:提供大量就业推荐机会,与1500+企业合作,包含华为、京东、美的等知名企业
通过学习本书,读者可以理解数据挖掘的原理,迅速掌握大数据技术的相关操作,为后续数据分析、数据挖掘、深度学习的实践及竞赛打下良好的技术基础。

相关文章:
非侵入式负荷检测与分解:电力数据挖掘新视角
电力数据挖掘 概述案例背景分析目标分析过程数据准备数据探索缺失值处理 属性构造设备数据周波数据模型训练 性能度量推荐阅读 主页传送门:📀 传送 概述 摘要:本案例将根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功…...
抽丝剥茧,Redis使用事件总线EventBus或AOP优化健康检测
目录 前言 Lettuce 什么是事件总线EventBus? Connected Connection activated Disconnected Connection deactivated Reconnect failed 使用 一种另类方法—AOP 具体实现 前言 在上一篇深入浅出,SpringBoot整合Quartz实现定时任务与Redis健康…...

【Tailwind CSS】当页面内容过少,怎样让footer保持在屏幕底部?
footer通常写版权信息等,显示在页面底部。如果页面内容过少,则footer会出现在屏幕中间位置,很尴尬。在 Tailwind 中,你可以使用flex来实现footer保持在屏幕或页面底部。 代码: <div class"flex flex-col min…...

Docker基础管理
这里写目录标题 Docker基础管理一.Docker 概述1.Docker介绍2.Docker与虚拟机的区别3.容器在内核中支持2种重要技术4.Docker核心概念 二.安装Docker1.安装依赖包2.配置文件及相关 三.Docker操作1.镜像操作2.容器操作 Docker基础管理 一.Docker 概述 1.Docker介绍 Docker是一个…...
基于YOLOv8模型的烟雾目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的烟雾目标检测系统可用于日常生活中检测与定位烟雾目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…...
【代码随想录01】数组总结
抄去吧,保存去吧!...
第二章:Spring创建和使用)
(SpringBoot)第二章:Spring创建和使用
文章目录 一:Sring创建(1)创建一个Maven项目(2)添加Spring框架支持(3)添加启动类二:存储Bean(1)创建Bean(2)将Bean注册到Spring中三:获取并使用Bean(1)创建Spring上下文(2)获取指定Bean(3)使用Bean注意:在Java中对象也叫做Bean,所以后续文章中用Bean代替对…...

力扣刷题 day56:10-26
1.解码异或后的数组 未知 整数数组 arr 由 n 个非负整数组成。 经编码后变为长度为 n - 1 的另一个整数数组 encoded ,其中 encoded[i] arr[i] XOR arr[i 1] 。例如,arr [1,0,2,1] 经编码后得到 encoded [1,2,3] 。 给你编码后的数组 encoded 和原…...

『第四章』一见倾心:初识小雨燕(上)
在本篇博文中,您将学到如下内容: 1. 基本数据类型2. 基本操作符3. 枚举和结构4. 类和 Actor5. 属性、方法与访问控制6. 聚集总结夜月一帘幽梦,春风十里柔情。 无声交谈情意深,一见心曲绕梁成。 1. 基本数据类型 无论是 macOS 还是 iOS 上的开发,Swift 基础类型和功能都内置于…...

elasticsearch-7.9.3 单节点启动配置
一、elasticsearch-7.9.3 单节点启动配置 node.name: node-1 network.host: 192.168.227.128 http.port: 9200 discovery.seed_hosts: ["192.168.227.128"] node.max_local_storage_nodes: 1 discovery.type: single-node二、kibana-7.9.3-linux-x86_64 单节点启动配…...

【2024秋招】2023-10-9 同花顺后端笔试题
1 Hashmap mp new hashmap(50)的大小扩充了几次 初时应该就给了这么多空间,在不考虑添加元素,所以扩容为0次 2 算数表达式的中缀为ab*c-d/e,后缀为abc*de/-,前缀是? 3 50M电信带宽ÿ…...

完美的错误处理:Go 语言最佳实践分享
Go 语言是一门非常流行的编程语言,由于其高效的并发编程和出色的网络编程能力,越来越受到广大开发者的青睐。在任何编程语言中,错误处理都是非常重要的一环,它关系到程序的健壮性和可靠性。Go 语言作为一门现代化的编程语言&#…...

vue首页多模块布局(标题布局)
<template><div class"box"><div class"content"><div class"box1" style"background-color: rgb(245,23,156)">第一个</div><div class"box2" style"background-color: rgb(12,233,…...

嵌入式系统>嵌入式硬件知识
AI芯片的特点包括 :新型计算范式AI芯片的关键特征: 1、新型的计算范式 AI 计算既不脱离传统计算,也具有新的计算特质,如处理的内容往往是非结构化数据(视频、图片等)。处理的过程通常需要很大的计算量&am…...

LeetCode 1402. 做菜顺序【排序,动态规划;贪心,前缀和,递推】1679
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

【多线程】探索Java中的多线程编程
标题:探索Java中的多线程编程 摘要: Java是一种广泛使用的编程语言,具有强大的多线程编程能力。本文将深入探讨Java中的多线程编程,包括线程的创建、同步与互斥、线程池的使用以及常见的多线程编程模式。通过示例代码和详细解释&…...

【算法题】翻转对
题目: 给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。 你需要返回给定数组中的重要翻转对的数量。 示例 1: 输入: [1,3,2,3,1] 输出: 2 示例 2: 输入: [2,4,3,5,1] 输出: 3 注意: 给定数组的长…...
适用于 Mac 或 Windows 的 4 种最佳 JPEG/PNG图片 恢复软件
您的计算机或外部存储驱动器上很可能有大量 JPEG /PNG图片照片,但不知何故,您意识到一些重要的 JPEG /PNG图片文件丢失或被删除,它们对您来说意义重大,您想要找回它们. 4 种最佳 JPEG/PNG图片 恢复软件 要成功执行 JPEG /PNG图片…...

位置信息API
位置信息API 一、获取当前位置:wx.getLocation(object)二、选择位置:wx.chooseLocation(object)三、打开位置:wx.openLocation(object)四、监听位置事件五、地图组件控制API六、收货地址API:wx.chooseAddress(object) 一、获取当前…...
MySQL——九、SQL编程
MySQL 一、触发器1、触发器简介2、创建触发器3、一些常见示例 二、存储过程1、什么是存储过程或者函数2、优点3、存储过程创建与调用 三、存储函数1、存储函数创建和调用2、修改存储函数3、删除存储函数 四、游标1、声明游标2、打开游标3、使用游标4、关闭游标游标案例 一、触发…...
✅)
计算机毕业设计:Python地铁多维度运营分析与数据管理系统 Django框架 数据分析 可视化 大数据 机器学习 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

为什么芯片工程师都在学Chisel?从Verilog到高级硬件设计的跃迁指南
为什么芯片工程师都在学Chisel?从Verilog到高级硬件设计的跃迁指南 在半导体行业,设计效率正成为决定产品成败的关键因素。传统Verilog开发中,工程师们常常需要花费70%的时间调试RTL代码中的低级错误,而非专注于架构创新。这种现状…...

用Unity 2D碰撞体+Effector,5分钟实现《星露谷物语》式的磁铁吸附效果
用Unity 2D碰撞体Effector实现《星露谷物语》式磁铁吸附效果 在《星露谷物语》这类农场模拟游戏中,角色靠近可收集物品时自动吸附的设计极大提升了操作流畅度。这种看似简单的交互背后,其实隐藏着Unity物理系统的巧妙运用。本文将手把手教你如何用2D碰撞…...

春联生成模型-中文-base效果展示:支持‘嵌名联’——将用户姓名自然融入上下联
春联生成模型-中文-base效果展示:支持嵌名联——将用户姓名自然融入上下联 1. 模型效果惊艳展示 春联生成模型-中文-base带来了传统节日文化的智能创新体验。这个基于达摩院AliceMind大模型的专项应用,能够通过简单的两字祝福词,生成符合传…...

LeetCode-001:Python 实现哈希表求两数之和:初识哈希表
一、先说这道题在问什么 “两数之和”是 LeetCode 里非常经典的一道入门题。 题目大意是: 给你一个整数数组 nums 和一个目标值 target,请你在数组中找到 两个数,让它们相加等于 target,并返回这两个数的下标。 比如ÿ…...
Elsevier Tracker:解放科研作者的审稿状态智能追踪方案
Elsevier Tracker:解放科研作者的审稿状态智能追踪方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否曾经历过这样的科研投稿循环:每天早晨第一件事就是登录Elsevier系统,…...

详解PHP中互斥锁库hyperf-wise-locksmith的使用
在分布式系统中,如何确保多台机器之间不会产生竞争条件,是一个常见且重要的问题。hyperf-wise-locksmith 库作为 Hyperf 框架中的一员,提供了一个高效、简洁的互斥锁解决方案。本文将带你了解这个库的安装、特性、基本与高级功能,…...

终极指南:用xbmc-addons-chinese打造完美中文Kodi媒体中心
终极指南:用xbmc-addons-chinese打造完美中文Kodi媒体中心 【免费下载链接】xbmc-addons-chinese Addon scripts, plugins, and skins for XBMC Media Center. Special for chinese laguage. 项目地址: https://gitcode.com/gh_mirrors/xb/xbmc-addons-chinese …...

Janus-Pro-7B计算机网络知识问答:从HTTP协议到网络安全
Janus-Pro-7B计算机网络知识问答:从HTTP协议到网络安全 最近在测试一些大模型在垂直领域的知识深度,Janus-Pro-7B引起了我的注意。它被宣传在编程和技术问答方面有不错的表现,所以我决定把它放到一个硬核的领域里试试水:计算机网…...

颠覆传统下载体验:3步解锁全平台资源获取
颠覆传统下载体验:3步解锁全平台资源获取 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容爆炸的时代&a…...