进程间通信(匿名管道、命名管道、消息队列、共享内存、信号量、信号、Socket)
文章目录
- 一、什么是进程间通信
- 二、管道
- 1.匿名管道(pipe)
- a).创建匿名管道
- b).管道的读写规则
- c).匿名管道的特点
- 2.有名管道(FIFO)
- a).创建命名管道
- b).命名管道的特点
- c).基于命名管道的进程间通信(服务端/客户端)
- 三、消息队列
- 四、共享内存
- 1.什么是共享内存
- 2.为什么要有共享内存
- a).mmap内存共享映射
- b). system V共享内存
- c).POSIX共享内存
- 五、信号量
- 六、信号
- 七、Socket
- 总结
一、什么是进程间通信
进程通信就是指进程之间信息的传播和交换。
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)
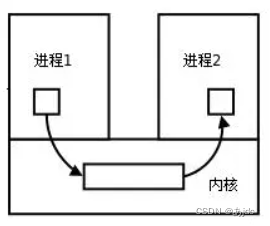
进程间通信的目的:
- 数据传输:一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几兆字节之间。
- 共享数据:多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供锁和同步机制。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
System V IPC和 POSIX IPC的区别:
当我们在 Linux 系统中进行进程间通信时,例如信号量,消息队列,共享内存等方式,会发现有System V以及POSIX两种类型。而它们的区别如下:
- Posix函数有下划线分隔,SystemV函数没有,是连在一起的;
- Posix 每个IPC对象是有名称的,而且名称是一个很重要的概念。mq_open sem_open shm_open三个函数的第一个参数就是这个名称,这个名称不一定是在文件系统中存在的名称。 要使用IPC对象,需要创建或者打开,这与文件操作类似,主要是使用mq_open、sem_open、shm_open 函数操作。在创建或者打开ipc对象时需要指定操作的mode,例如O_RONLY、O_WRONLY、O_RDWR、O_CREAT、O_EXCL 等,IPC对象是有一定权限的,与文件的权限类似。对应的,SystemV每个IPC有一个重要的类型是key_t,在msgget、semget、shmget函数操作中都需要利用这个类型是参数。系统中对每个ipc对象都会有一个结构体来标识
- POSIX 在无竞争条件下,不需要陷入内核,其实现是非常轻量级的; System V 则不同,无论有无竞争都要执行系统调用,因此性能落了下风。
二、管道
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”:
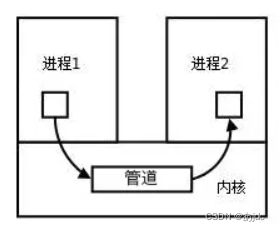
1.匿名管道(pipe)
a).创建匿名管道
如何创建一个匿名管道? 我们通常采用下面的接口:
#include <unistd.h>
int pipe(int fd[2]);功能:创建一无名管道
参数:fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码
这里表示创建一个匿名管道,并返回了两个描述符,一个是管道的读取端描述符 fd[0],另一个是管道的写入端描述符 fd[1]。注意,这个匿名管道是特殊的文件,只存在于内存,不存于文件系统中。
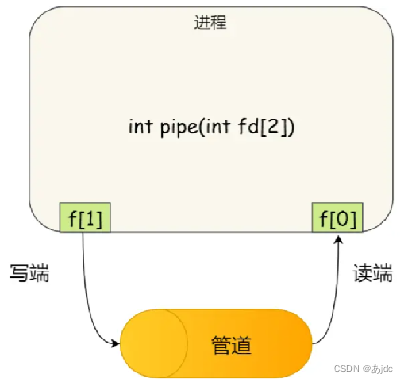
其实,所谓的管道,就是内核里面的一段缓存。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?
我们可以使用 fork 创建子进程,创建的子进程会复制父进程的文件描述符,这样就做到了两个进程各有两个fd[0] 与fd[1],两个进程就可以通过各自的 fd 写入和读取同一个管道文件实现跨进程通信了。
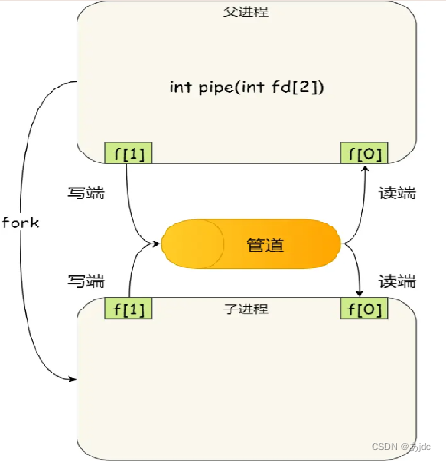
管道只能一端写入,另一端读出,所以上面这种模式容易造成混乱,因为父进程和子进程都可以同时写入,也都可以读出。那么,为了避免这种情况,通常的做法是:
- 父进程关闭读取的 fd[0],只保留写入的 fd[1];
- 子进程关闭写入的 fd[1],只保留读取的 fd[0];
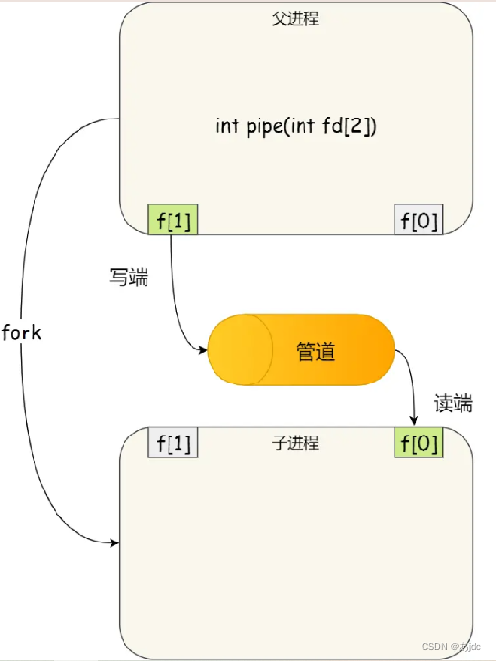
所以说如果需要双向通信,则应该创建两个管道。
到这里,我们仅仅解析了使用管道进行父子进程之间的通信,但是在我们 shell 里面并不是这样的。
在 shell 里面执行 A | B命令的时候,A 进程和 B 进程都是 shell 创建出来的子进程,A 和 B 之间不存在父子关系,它俩的父进程都是 shell。
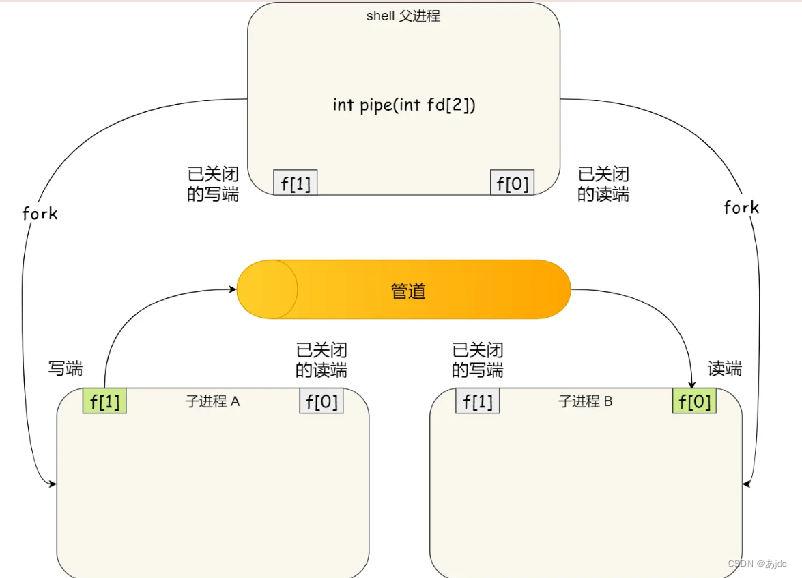
所以说,在 shell 里通过 | 匿名管道将多个命令连接在一起,实际上也就是创建了多个子进程,那么在我们编写 shell 脚本时,能使用一个管道搞定的事情,就不要多用一个管道,这样可以减少创建子进程的系统开销。
b).管道的读写规则
- 当没有数据可读时
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。- 当管道满的时候
O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN- 如果所有管道写端的文件描述符被关闭,则read返回0
- 如果所有管道读端的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
- 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
c).匿名管道的特点
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
- 只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
- 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
- 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
- 一般而言,进程退出,管道释放,所以管道的生命周期随进程
- 一般而言,内核会对管道操作进行同步与互斥
而也可见匿名管道的局限性:
- 只支持单向数据流;
- 只能用于具有亲缘关系的进程之间;
- 没有名字;
- 管道的缓冲区是有限的(管道制存在于内存中,在管道创建时,为缓冲区分配一个页面大小);
- 管道所传送的是无格式字节流,这就要求管道的读出方和写入方必须事先约定好数据的格式,比如多少字节算作一个消息(或命令、或记录)等等;
我们可以用下段代码来测试匿名管道的性质:
#include<stdlib.h>
#include<stdio.h>
#include<iostream>
#include<unistd.h>
#include<assert.h>
#include<sys/wait.h>
#include<sys/types.h>
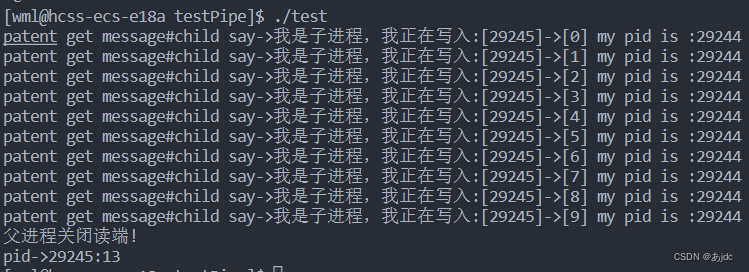
#include<string.h>using namespace std;//子进程进行写入,父进程进行读取
int main()
{int fds[2];int n = pipe(fds);assert(n==0);pid_t id = fork();assert(id>=0);if(id==0)//子进程进行写入{close(fds[0]);//关闭读端const char* s = "我是子进程,我正在写入:";int cnt = 0;while(true){char buffer[1024];snprintf(buffer,sizeof(buffer),"child say->%s[%d]->[%d]",s,getpid(),cnt++);write(fds[1],buffer,strlen(buffer));sleep(1);}//close(fds[1]);//cout<<"子进程关闭写端!\n";exit(0);}//父进程进行读取close(fds[1]);int c = 10;while(c--){char buffer[1024];ssize_t s = read(fds[0],buffer,sizeof(buffer)-1);if(s>0){buffer[s] = 0;cout<<"patent get message#"<<buffer<<" my pid is :"<<getpid()<<endl;}else if(s==0){cout<<"read over!\n";break;}//break;}close(fds[0]);cout<<"父进程关闭读端!\n";int status = 0;n = waitpid(id,&status,0);assert(n==id);cout<<"pid->"<<n<<":"<<(status&0x7f)<<endl;//读端关闭,会向子进程发送SIGPIPE信号,可能导致写端退出!return 0;
}
当父进程关闭读端时,write会产生SIGCHILD信号。
2.有名管道(FIFO)
a).创建命名管道
- 命名管道可以从命令行上创建,命令行方法是使用下面这个命令:
mkfifo filename- 命名管道也可以从程序里创建,相关函数有:
int mkfifo(const char *filename,mode_t mode)
例如我们创建命名管道:
int main(int argc, char *argv[])
{mkfifo("p2", 0644);return 0;
}
b).命名管道的特点
- 命名管道FIFO又叫有名管道,和无名管道的主要区别在于,命名管道有一个名字,命名管道的名字对应于一个磁盘索引节点,但没有数据块,有了这个文件名,任何进程有相应的权限都可以对它进行访问。
- 通过mknode()系统调用或者mkfifo()函数来建立的。一旦建立,任何进程都可以通过文件名将其打开和进行读写,而不局限于父子进程,当然前提是进程对FIFO有适当的访问权。当不再被进程使用时,FIFO在内存中释放,但磁盘节点仍然存在。
- 可以使用open()函数通过文件名可以打开已经创建的命名管道,而无名管道不能由open来打开。当一个命名管道不再被任何进程打开时,它没有消失,还可以再次被打开,就像打开一个磁盘文件一样。
- 可以用删除普通文件的方法将其删除,实际删除的事磁盘上对应的节点信息。
- 命名管道也是半双工的通信方式,命名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
命名管道的打开规则:
- 如果当前打开操作是为读而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
O_NONBLOCK enable:立刻返回成功- 如果当前打开操作是为写而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
O_NONBLOCK enable:立刻返回失败,错误码为ENXIO
c).基于命名管道的进程间通信(服务端/客户端)
当命名管道不再被任何进程打开时,它没有消失,还可以再次被打开,所以它的生命周期不随进程(和匿名管道不同),所以我们使用完后得处理这个命名管道,这些工作我们放在头文件中完成:
#include<iostream>
#include<assert.h>
#include<string>
#include<string.h>
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
#include<fcntl.h>
#include<errno.h>#define NAMED_PIPE "mypipe.tmp"int creatFifo(const std::string &path)
{umask(0);int n = mkfifo(path.c_str(),0600); if(n==0) return 1;else{std::cout<<"error: "<<errno<<" err string "<< strerror(errno)<<std::endl;return -1;}
}void removeFifo(const std::string &path)
{int n = unlink(path.c_str());assert(n==0);(void)n;
}
我们用服务端来读取客户端发送的信息:
#include"comm.hpp"int main()
{int r = creatFifo(NAMED_PIPE);//assert(r==-1);//std::cout<<r<<std::endl;(void)r;std::cout<<"server begin"<<std::endl;int rfd = open(NAMED_PIPE,O_RDONLY);std::cout<<"server end"<<std::endl;if(rfd<0){perror("open");exit(-2);}char buffer[1024];while(true){ssize_t n = read(rfd,buffer,sizeof(buffer)-1);if(n>0){buffer[n] = 0;std::cout<<"get mseeage->"<<buffer<<std::endl; }else if(n==0){std::cout<<"client quit ! me too !"<<std::endl;break;}else{perror("read");break;}}close(rfd);removeFifo(NAMED_PIPE);return 0;
}
我们用客户端来发送信息:
#include"comm.hpp"
int main()
{std::cout<<"client begin"<<std::endl;int wfd = open(NAMED_PIPE,O_WRONLY);std::cout<<"client end"<<std::endl;if(wfd<0){perror("open");exit(-1);}char buffer[1024];while(true){std::cout<<"Please say#";fgets(buffer,sizeof(buffer),stdin);if(strlen(buffer)>0) buffer[strlen(buffer)-1] = 0;ssize_t n = write(wfd,buffer,strlen(buffer));assert(n==strlen(buffer));(void)n;}close(wfd);return 0;
}
而通信的过程如下:
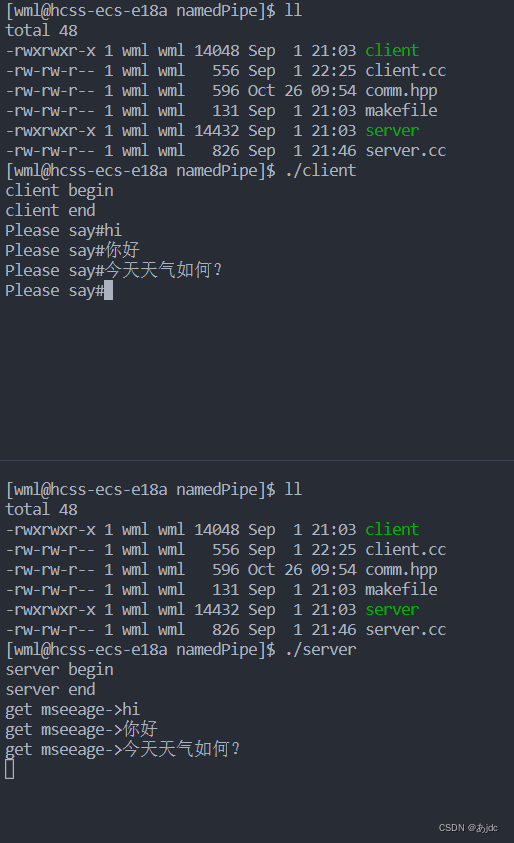
通过上述代码,我们可以更好的理解命名管道,它的操作如同一个磁盘上的文件。
三、消息队列
前面说到管道的通信方式是效率低的,因此管道不适合进程间频繁地交换数据。
对于这个问题,消息队列的通信模式就可以解决。比如,A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。同理,B 进程要给 A 进程发送消息也是如此。
再来,消息队列是保存在内核中的消息链表,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。 如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。
消息队列生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会一直存在,而前面提到的匿名管道的生命周期,是随进程的创建而建立,随进程的结束而销毁。
消息这种模型,两个进程之间的通信就像平时发邮件一样,你来一封,我回一封,可以频繁沟通了。
但邮件的通信方式存在不足的地方有两点,一是通信不及时,二是附件也有大小限制,这同样也是消息队列通信不足的点。
消息队列不适合比较大数据的传输,因为在内核中每个消息体都有一个最大长度的限制,同时所有队列所包含的全部消息体的总长度也是有上限。在 Linux 内核中,会有两个宏定义 MSGMAX 和 MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。
消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷 贝数据到用户态的过程。
四、共享内存
1.什么是共享内存
共享内存区是最快的可用IPC形式。它允许多个不相关的进程去访问同一部分逻辑内存。如果需要在两个运行中的进程之间传输数据,共享内存将是一种效率极高的解决方案。一旦这样的内存区映射到共享它的进程的地址空间,这些进程间数据的传输就不再涉及内核。这样就可以减少系统调用时间,提高程序效率。
共享内存是由IPC为一个进程创建的一个特殊的地址范围,它将出现在进程的地址空间中。其他进程可以把同一段共享内存段“连接到”它们自己的地址空间里去。所有进程都可以访问共享内存中的地址。如果一个进程向这段共享内存写了数据,所做的改动会立刻被有访问同一段共享内存的其他进程看到。
要注意的是共享内存本身没有提供任何同步功能。也就是说,在第一个进程结束对共享内存的写操作之前,并没有什么自动功能能够预防第二个进程开始对它进行读操作。共享内存的访问同步问题必须由程序员负责。可选的同步方式有互斥锁、条件变量、读写锁、纪录锁、信号等。
2.为什么要有共享内存
使用文件或管道进行进程间通信会有很多局限性,比如效率问题以及数据处理使用文件描述符而不如内存地址访问方便,于是多个进程以共享内存的方式进行通信就成了很自然要实现的IPC方案。Linux系统在编程上为我们准备了多种手段的共享内存方案。包括:
- mmap内存共享映射。
- XSI共享内存。
- POSIX共享内存。
a).mmap内存共享映射
mmap用于将文件或设备映射到进程地址空间内 ,使得进程在进程内可以直接访问。基于该特性,Linux系统用它实现多进程的内存共享功能 。其相关调用API原型如下:
#include <sys/mman.h>void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);int munmap(void *addr, size_t length);
由于这个系统调用的特性可以用在很多场合,所以Linux系统用它实现了很多功能,并不仅局限于存储映射。在这主要介绍的就是用mmap进行多进程的内存共享功能。Linux产生子进程的系统调用是fork,根据fork的语义以及其实现,我们知道新产生的进程在内存地址空间上跟父进程是完全一致的。
所以Linux的mmap实现了一种可以在父子进程之间共享内存地址的方式,其使用方法是:
- 父进程将flags参数设置MAP_SHARED方式通过mmap申请一段内存。内存可以映射某个具体文件,也可以不映射具体文件(fd置为-1,flag设置为MAP_ANONYMOUS)。
- 父进程调用fork产生子进程。之后在父子进程内都可以访问到mmap所返回的地址,就可以共享内存了。
b). system V共享内存
考虑到mmap只适用于父子进程间内存共享的这一局限性,为了满足无关进程间共享内存的需求,Linux提供了更具通用性的手段:System V (XSI)共享内存。就是我们常用的shmctl 相关调用:
shmget函数
功能:用来创建共享内存
原型int shmget(key_t key, size_t size, int shmflg);
参数key:这个共享内存段名字size:共享内存大小shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1
对于参数key_t key 的理解
- 一个key是通过ftok函数,使用一个pathname和一个proj_jd产生的。就是说,在一个可能会使用共享内存的项目组中,大家可以约定一个文件名和一个项目的proj_id,来在同一个系统中确定一段共享内存的key。ftok并不会去创建文件,所以必须指定一个存在并且进程可以访问的pathname路径。
- 这里还要指出的一点是,ftok实际上并不是根据文件的文件路径和文件名(pathname)产生key的,在实现上,它使用的是指定文件的inode编号和文件所在设备的设备编号。
- 所以,不要以为你是用了不同的文件名就一定会得到不同的key,因为不同的文件名是可以指向相同inode编号的文件的(硬连接)。
- 也不要认为你是用了相同的文件名就一定可以得到相同的key,在一个系统上,同一个文件名会被删除重建的几率是很大的,这种行为很有可能导致文件的inode变化。所以一个ftok的执行会隐含stat系统调用也就不难理解了。
#include <sys/types.h>
#include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);
proj_id是可以根据自己的约定,随意设置。这个数字,有的称之为project ID;
在UNIX系统上,它的取值是1到255;
shmat函数
功能:将共享内存段连接到进程地址空间
原型void *shmat(int shmid, const void *shmaddr, int shmflg);
参数shmid: 共享内存标识shmaddr:指定连接的地址shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY返回值:成功返回一个指针,指向共享内存第一个字节;失败返回-1
shmdt函数
功能:将共享内存段与当前进程脱离
原型int shmdt(const void *shmaddr);
参数shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1注意:将共享内存段与当前进程脱离不等于删除共享内存段
共享内存由于其特性,与进程中的其他内存段在使用习惯上有些不同。一般进程对栈空间分配可以自动回收,而堆空间通过malloc申请,free回收。这些内存在回收之后就可以认为是不存在了。但是共享内存不同,用shmdt之后,实际上其占用的内存还在,并仍然可以使用shmat映射使用。如果不是用shmctl或ipcrm命令删除的话,那么它将一直保留直到系统被关闭。对于刚接触共享内存的程序员来说这可能需要适应一下。实际上共享内存的生存周期根文件更像:进程对文件描述符执行close并不能删除文件,而只是关闭了本进程对文件的操作接口,这就像shmdt的作用。而真正删除文件要用unlink,活着使用rm命令,这就像是共享内存的shmctl的IPC_RMID和ipcrm命令。当然,文件如果不删除,下次重启依旧还在,因为它放在硬盘上,而共享内存下次重启就没了,因为它毕竟还是内存。
shmctl函数
功能:用于控制共享内存
原型int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数shmid:由shmget返回的共享内存标识码cmd:将要采取的动作(有三个可取值)buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1struct shmid_ds {struct ipc_perm shm_perm; /* Ownership and permissions */size_t shm_segsz; /* Size of segment (bytes) */time_t shm_atime; /* Last attach time */time_t shm_dtime; /* Last detach time */time_t shm_ctime; /* Last change time */pid_t shm_cpid; /* PID of creator */pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */shmatt_t shm_nattch; /* No. of current attaches *//* ... */
};
这些函数的使用如下:
#define MAX_SIZE 4048
#define PROJ_ID 0x66
#define PATHNAME "."
//系统分配共享内存是以4kb为单位的!int main()
{//参数1:共享内存的文件名 参数2:文件的权限//成功返回key,失败返回-1key_t key = ftok(PATHNAME,PROJ_ID);//std::cout<<key<<std::endl;//参数1:key值 参数2:共享内存的最大空间 参数3:IPC_CREAT/IPC_EXCL//成功返回shm的id,失败返回-1,错误码被设置int id = shmget(key,MAX_SIZE,IPC_CREAT);//参数1:shm的id 参数2:const void* shmaddr 参数3:int shmflg //成功返回shm的address 失败返回(void*)-1 错误码被设置以标识错误//参数为NULL,核心自动选择一个地址 char* addr = (char*)shmat(id,NULL,0);//参数:由shmat返回的指针//成功返回0,失败返回-1,错误码被设置int ret = shmdt(addr);//用于控制共享内存//参数2:将要采取的动作 IPC_STAT/IPC_SET/IPC_RMID(删除共享内存段)//int shmctl(int shmid,int cmd,struct shmid_ds *buf);return 0;
}
我们同样可以根据共享内存实现一个客户端和服务端的通信程序,不过不在此赘述了!
c).POSIX共享内存
POSIX共享内存实际上毫无新意,它本质上就是mmap对文件的共享方式映射,只不过映射的是tmpfs文件系统上的文件。
什么是tmpfs?Linux提供一种“临时”文件系统叫做tmpfs,它可以将内存的一部分空间拿来当做文件系统使用,使内存空间可以当做目录文件来用。现在绝大多数Linux系统都有一个叫做/dev/shm的tmpfs目录,就是这样一种存在。
POSIX共享内存使用方法有以下两个步骤:
- 通过shm_open创建或打开一个POSIX共享内存对象
- 调用mmap将它映射到当前进程的地址空间
五、信号量
用了共享内存通信方式,带来新的问题,那就是如果多个进程同时修改同一个共享内存,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。
为了防止多进程竞争共享资源,而造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻只能被一个进程访问。正好,信号量就实现了这一保护机制。
信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据。
信号量表示资源的数量,控制信号量的方式有两种原子操作:
- 一个是 P 操作,这个操作会把信号量减去 1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
- 另一个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
P 操作是用在进入共享资源之前,V 操作是用在离开共享资源之后,这两个操作是必须成对出现的。
接下来,举个例子,如果要使得两个进程互斥访问共享内存,我们可以初始化信号量为 1。
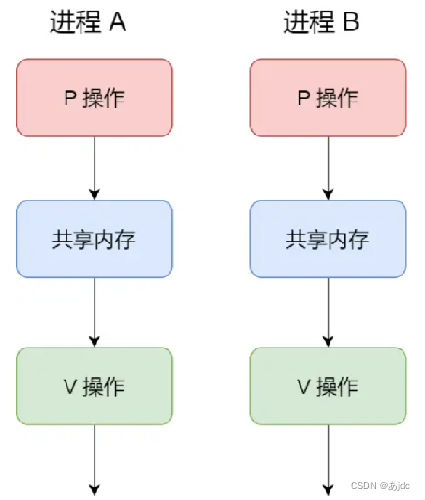
具体的过程如下:
- 进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。
- 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。
- 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
可以发现,信号初始化为 1,就代表着是互斥信号量,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
另外,在多进程里,每个进程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候我们又希望多个进程能密切合作,以实现一个共同的任务。
例如,进程 A 是负责生产数据,而进程 B 是负责读取数据,这两个进程是相互合作、相互依赖的,进程 A 必须先生产了数据,进程 B 才能读取到数据,所以执行是有前后顺序的。
那么这时候,就可以用信号量来实现多进程同步的方式,我们可以初始化信号量为 0。
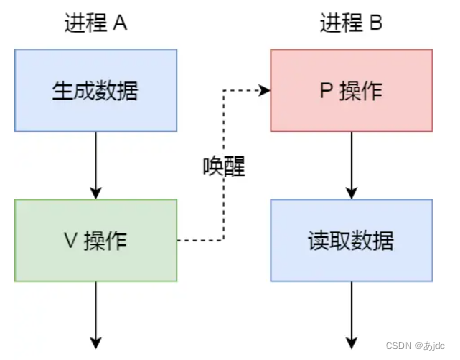
具体过程:
- 如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待;
- 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B;
- 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
可以发现,信号初始化为 0,就代表着是同步信号量,它可以保证进程 A 应在进程 B 之前执行。
对于信号量的更多细节,在后面的文章中会详细介绍!
六、信号
上面说的进程间通信,都是常规状态下的工作模式。对于异常情况下的工作模式,就需要用信号的方式来通知进程。
信号跟信号量虽然名字相似度 66.66%,但两者用途完全不一样,就好像 Java 和 JavaScript 的区别。
在 Linux 操作系统中, 为了响应各种各样的事件,提供了几十种信号,分别代表不同的意义。我们可以通过 kill -l 命令,查看所有的信号:

运行在 shell 终端的进程,我们可以通过键盘输入某些组合键的时候,给进程发送信号。例如
- Ctrl+C 产生 SIGINT 信号,表示终止该进程;
- Ctrl+Z 产生 SIGTSTP 信号,表示停止该进程,但还未结束;
如果进程在后台运行,可以通过 kill 命令的方式给进程发送信号,但前提需要知道运行中的进程 PID 号,例如:
kill -9 1050 ,表示给 PID 为 1050 的进程发送 SIGKILL 信号,用来立即结束该进程;
所以,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令)。
信号是进程间通信机制中唯一的异步通信机制,因为可以在任何时候发送信号给某一进程,一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式。
1.执行默认操作。Linux 对每种信号都规定了默认操作,例如,上面列表中的 SIGTERM 信号,就是终止进程的意思。
2.捕捉信号。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
3.忽略信号。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
对于信号的更多细节,我们会在下一篇文章中介绍!
七、Socket
前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
实际上,Socket 通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信。
我们来看看创建 socket 的系统调用:

三个参数分别代表:
- domain 参数用来指定协议族,比如 AF_INET 用于 IPV4、AF_INET6 用于 IPV6、AF_LOCAL/AF_UNIX 用于本机;
- type 参数用来指定通信特性,比如 SOCK_STREAM 表示的是字节流,对应 TCP、SOCK_DGRAM 表示的是数据报,对应 UDP、SOCK_RAW 表示的是原始套接字;
- protocal 参数原本是用来指定通信协议的,但现在基本废弃。因为协议已经通过前面两个参数指定完成,protocol 目前一般写成 0 即可;
根据创建 socket 类型的不同,通信的方式也就不同:
- 实现 TCP 字节流通信: socket 类型是 AF_INET 和 SOCK_STREAM;
- 实现 UDP 数据报通信:socket 类型是 AF_INET 和 SOCK_DGRAM;
- 实现本地进程间通信: 「本地字节流 socket 」类型是 AF_LOCAL 和 SOCK_STREAM,「本地数据报 socket 」类型是 AF_LOCAL 和 SOCK_DGRAM。另外,AF_UNIX 和 AF_LOCAL 是等价的,所以 AF_UNIX 也属于本地 socket;
而关于socket的更多细节,我们在后面的文章会介绍!
总结
由于每个进程的用户空间都是独立的,不能相互访问,这时就需要借助内核空间来实现进程间通信,原因很简单,每个进程都是共享一个内核空间。
Linux 内核提供了不少进程间通信的方式,其中最简单的方式就是管道,管道分为「匿名管道」和「命名管道」。
匿名管道顾名思义,它没有名字标识,匿名管道是特殊文件只存在于内存,没有存在于文件系统中,shell 命令中的 | 竖线就是匿名管道,通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。
命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号 。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
以上,就是进程间通信的主要机制了。
相关文章:
进程间通信(匿名管道、命名管道、消息队列、共享内存、信号量、信号、Socket)
文章目录 一、什么是进程间通信二、管道1.匿名管道(pipe)a).创建匿名管道b).管道的读写规则c).匿名管道的特点 2.有名管道(FIFO)a).创建命名管道b).命名管道的特点c).基于命名管道的进程间通信(服务端/客户端) 三、消息队列四、共享内存1.什么是共享内存…...
浅谈中国汽车充电桩行业市场状况及充电桩选型的介绍
安科瑞虞佳豪 车桩比降低是完善新能源汽车行业配套的一大重要趋势,目前各国政府都在努力推进政策,通过税收减免、建设补贴等措施提升充电桩建设速度,以满足新能源汽车需求。 近年来,在需求和技术的驱动下,充电桩的平…...

Postgresql在jdbc处理bit字段的解决方案
问题: bit如果长度为1,则会默认为布尔型(1-true 0-false); bit如果长度大于1,则会默认为bit类型,但是代码中以前常用的两种set方式,会报错 第一种方式: ps.setObject(i1,…...

ESMapping字段
在 Elasticsearch 中,字段(field)是指用于表示数据的最小单元。每个文档(document)都由一个或多个字段组成,字段存储了文档的不同属性或数据。 字段可以包含不同的数据类型,如文本、数字、日期…...

基于LDA的隐式标签协同过滤推荐算法_文勇军
, 王全民等人[14]提出了一种交替奇异值分解算法 (ASVD),即结合协同过滤和隐语义分析的混合推荐 算法。唐泽坤等人[15]融合聚类算法和协同过滤推荐 算法,取得了一定效果。高娜等人[16⁃19]将标签因子 和协同过滤推荐算法结合研究缓解了数据稀疏问题,但这…...

在线设计数据库表用Itbuilder,极简易用真香!!!
“如果您想要一个具有快速搜索运行的高性能数据库,那么数据库设计是必不可少的,花时间设计数据库将帮助您避免效率低下和高冗余等问题”。 在线数据库设计软件itbuilder,界面清爽漂亮,功能简洁,没有多余设置很容易上手…...

onclick事件的用法
onclick 事件是一种在网页开发中用来处理用户点击操作的事件。它通常用于 HTML 元素(如按钮、链接、图像等),以便在用户单击该元素时触发 JavaScript 函数或执行一些特定的操作。以下是 onclick 事件的用法: HTML 元素上的 onclic…...
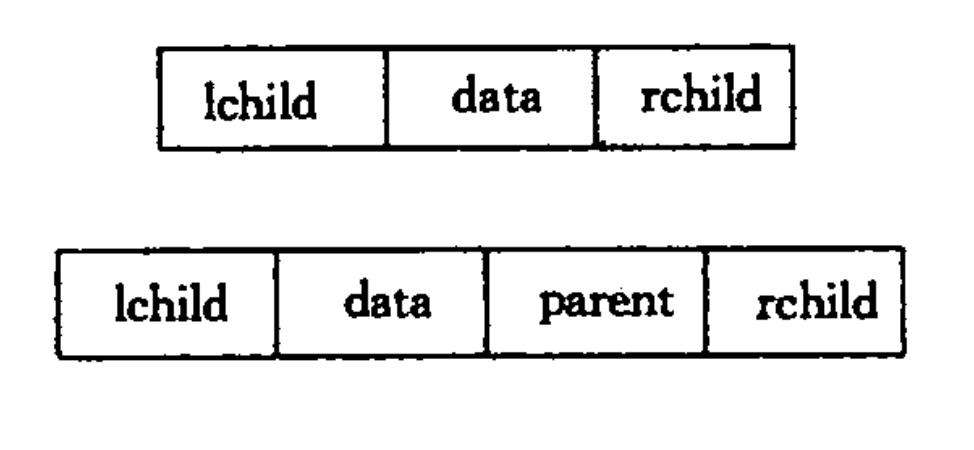
二叉排序树
二叉排序树定义及性质 二叉排序树(Binary Sort Tre)或者是一棵空树,或者是具有如下性质的二叉树: (1) 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; (2) 若它的右子树不空,则右子树上所有结点的值均…...
探秘Spring的设计精髓,深入解析架构原理
序员与平庸的程序员之间的区别,是在于认为自己的代码重要还是数据结构更加重要。平庸的程序员眼里只有代码,优秀的程序员则关注数据结构及之前的关系。” 1、spring的设计理念 spring提供了一个轻量级的开发框架,抽象了实际开发中的很多共…...

Python Wordcloud报错:Only supported for TrueType fonts,多种解决方案
Python Wordcloud报错:Only supported for TrueType fonts,多种解决方案。 报错内容如下: 2023-10-26T09:35:41.190459839Z Traceback (most recent call last): 2023-10-26T09:35:41.190502589Z File “lib/task/compute.py”, line 621, i…...

为虚拟网络提供敏捷负载均衡:Everoute LB 特性解读
为了保证应用系统的可用性,同时避免并发访问导致后端服务器出现性能瓶颈,不少用户都通过负载均衡技术优化流量分发。随着虚拟化平台下用户业务规模的持续扩大,虚拟化网络的数据访问量也不断增加,而传统负载均衡通常通过硬件负载均…...
Jmeter 接口测试,参数值为列表,如何参数化?
最近在我的教学过程中,我的一个学生问了我一个问题,他们公司的一个接口参数值是列表,列表中值的数量有多有少,问我在 jmeter 中如何让这个参数的值进行参数化? 看到这种问题,你的第一反应是什么?…...

DeepinV20实现使用CapsLock键切换输入法
概览 起因参考资料解决问题1. 删除CapsLock键映射关系2. 新建CapsLock键映射关系3. 建立配置文件4. **注销用户或者重启电脑**5. 修改切换输入法快捷键6. 测试输入 起因 看同事的MacBook可以使用CapsLock键切换输入法,而我作为Shift党CapsLock键几乎不使用…...
基于springboot实现校友社交平台管理系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现校友社交平台管理系统演示 摘要 校友社交系统提供给用户一个校友社交信息管理的网站,最新的校友社交信息让用户及时了解校友社交动向,完成校友社交的同时,还能通过论坛中心进行互动更方便。本系统采用了B/S体系的结构,使用了java技…...
WordPress主题模板 大前端D8 5.1版本完整开源版源码简洁大气多功能配置
源码测评:该模板官方已更新至5.2,但是这个5.1也是非常好用的,经测试所有页面均完好,推荐下载使用。 模板简介: 大前端D8 主题是一款非常牛逼的WordPress博客主题,响应式,功能齐全,支持手机,电脑,平板,非常适合做博客站…...

如何在Postman中使用静态HTTP
首先,打开 Postman 软件。在 Postman 的菜单栏中,点击 “Preferences”(偏好设置)。 亲身经验:我自己尝试了这个方法,发现它非常适用于需要使用HTTP的场景。 数据和引证:根据 Postman 官方文档…...

vscode 提升Vue开发效率的必备插件与工具
1,Vetur:提供了Vue语法高亮、智能提示、代码片段、错误检查和格式化等功能,是Vue开发中必不可少的插件。 2,ESLint:用于检查和修复JavaScript和Vue代码中的语法错误和潜在问题,提高代码质量。 3ÿ…...
mysql/java/springboot/javaweb请假系统,分为学生/辅导员/超级管理员
源码下载地址 支持:远程部署/安装/调试、讲解、二次开发/修改/定制 系统分为 学生/辅导员/超级管理员 学生 辅导员 超级管理员...

Android11系统桌面隐藏指定APP图标
做项目时有时会遇到这样的需求,客户要求隐藏Launcher3桌面的某个app图标,但是又不能删除去掉这个app,具体修改如下: diff --git a/src/com/android/launcher3/model/LoaderTask.java b/src/com/android/launcher3/model/LoaderTa…...
WEB使用百度地图展示某地地址
第一步 进入百度地图开发平台 百度地图开放平台 | 百度地图API SDK | 地图开发 第二步注册 获取AK秘钥,点击【创建应用】进入AK申请页面,填写应用名称,务必选择AK类型为“浏览器端”,JS API只支持浏览器端AK进行请求与访问 下面…...

终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹
终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾将macOS应用拖入废纸篓后&…...

NVIDIA Profile Inspector完整指南:200+隐藏设置解锁显卡极致性能
NVIDIA Profile Inspector完整指南:200隐藏设置解锁显卡极致性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼吗?想要彻底掌控NVIDIA…...

Bifrost:轻量高效的实时数据同步平台架构与实战
1. 项目概述:Bifrost,一个被低估的现代数据同步利器如果你正在处理跨数据库、跨数据源的数据同步任务,并且对传统ETL工具的笨重、配置复杂感到头疼,那么maximhq/bifrost这个项目绝对值得你花时间深入了解。我第一次接触Bifrost是在…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...

FinalBurn Neo:终极开源街机模拟器技术深度解析
FinalBurn Neo:终极开源街机模拟器技术深度解析 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo FinalBurn Neo(简称FBNeo)是一款专业级的开源街机模拟器,…...

基于Node.js的Markdown文档自动化转换工具:从原理到CI/CD集成实战
1. 项目概述:一个被低估的文档转换利器如果你和我一样,日常工作中需要处理大量不同格式的文档,比如把Markdown写的技术文档转成Word给产品经理看,或者把项目README转成PDF存档,那你肯定也经历过格式错乱、样式丢失的烦…...

DashClaw:模块化命令行工具的设计哲学与实战应用
1. 项目概述:一个为开发者打造的“瑞士军刀”式命令行工具最近在折腾一个自动化部署脚本时,遇到了一个老生常谈的问题:我需要从一堆杂乱的日志文件里,快速提取出特定时间段的错误信息,同时还要把这些信息按照严重程度分…...

DIY LED眼妆:从电路原理到穿戴制作的完整指南
1. 项目概述:打造你的专属发光眼妆想为下一次Cosplay活动或万圣节派对增添一抹赛博朋克般的未来感吗?厌倦了千篇一律的商店货,渴望一件真正独一无二、能让你在人群中脱颖而出的发光装饰?这个DIY LED眼妆项目,正是为你准…...

量子优化算法在组合优化问题中的应用与性能分析
1. 量子优化算法与组合优化问题概述组合优化问题广泛存在于物流调度、网络设计、芯片布局等工业场景中,其核心挑战在于从离散解空间中高效寻找最优解。传统经典算法在面对NP难问题时往往面临计算复杂度爆炸的困境。量子优化算法通过量子叠加和纠缠等特性,…...

555定时器深度解析:从RC电路到三种工作模式的原理与应用
1. 项目概述在电子设计的工具箱里,有那么几颗芯片,你几乎可以在任何时代的电路板上找到它们的身影。它们可能不是性能最强的,但一定是应用最广、最经久不衰的。今天要聊的555定时器,就是这样一个“活化石”级别的存在。自上世纪70…...