【spark客户端】Spark SQL CLI详解:怎么执行sql文件、注释怎么写,支持的文件路径协议、交互式模式使用细节
文章目录
- 一. Spark SQL Command Line Options(命令行参数)
- 二. The hiverc File
- 1. without the -i
- 2. .hiverc 介绍
- 三. 支持的路径协议
- 四. 支持的注释类型
- 五. Spark SQL CLI交互式命令
- 六. Examples
- 1. running a query from the command line
- 2. setting Hive configuration variables
- 3. setting Hive configuration variables and using it in the SQL query
- 4. setting Hive variables substitution
- 5. dumping data out from a query into a file using silent mode
- 6. running a script non-interactively:
- 7. running an initialization script before entering interactive mode
- 8. entering interactive mode
- 9. entering interactive mode with escape ; in comment:
- 七. 非交互模式用法小结
The Spark SQL CLI is a convenient interactive command tool to run the Hive metastore service and execute SQL queries input from the command line. Note that the Spark SQL CLI cannot talk to the Thrift JDBC server.
spark SQL Cli 用于运行hive metastore服务和通过命令行执行sql查询。注意,Spark SQL CLI不能和Thrift JDBC server进行通讯。
一. Spark SQL Command Line Options(命令行参数)
执行./bin/spark-sql --help 获取所有的执行参数
CLI options:-d,--define <key=value> 用于HIVE命令的变量替换 比如 -d A=B 或者 --define A=B--database <databasename> 指定使用哪个数据库-e <quoted-query-string> 执行sql语句,可以以;号分割的多个sql,比如:spark-sql -e "show databases; select 1,'a'" -f <filename> 执行sql文件,文件中可以存在以;号分割的多个sql,比如:spark-sql -f spark-test.sql -H,--help Print help information--hiveconf <property=value> Use value for given property--hivevar <key=value> Variable substitution to apply to Hive commands. e.g. --hivevar A=B-i <filename> Initialization SQL file:初始化sql文件-S,--silent Silent mode in interactive shell-v,--verbose Verbose mode (echo executed SQL to the console)
二. The hiverc File
1. without the -i
When invoked without the -i, the Spark SQL CLI will attempt to load $HIVE_HOME/bin/.hiverc and $HOME/.hiverc as initialization files.
在没有使用 -i 选项的情况下调用 Spark SQL CLI 时,它将尝试加载 $HIVE_HOME/bin/.hiverc 和 $HOME/.hiverc 作为初始化文件。
这里介绍下.hiverc
2. .hiverc 介绍
在Apache Hive中,.hiverc 文件是一个用于配置Hive客户端的启动脚本。它允许你在启动Hive命令行客户端(hive)时执行一些自定义操作,如设置环境变量、加载自定义函数、定义别名等。
.hiverc 文件通常位于Hive的安装目录下的 bin 子目录。它是一个可执行的脚本文件,当你启动Hive客户端时,会自动执行其中的命令。
以下是一些你可以在 .hiverc 文件中执行的操作:
- 设置环境变量:你可以在 .hiverc 文件中设置环境变量,以便在Hive会话期间使用。例如,你可以设置 HADOOP_HOME 或其他环境变量。
- 加载自定义函数:如果你有自定义的Hive函数,你可以在 .hiverc 文件中使用 ADD JAR 命令加载这些函数。
- 定义别名:你可以定义Hive命令的别名,以简化常用命令的输入。例如,你可以定义一个别名来运行一组复杂的查询。
- 其他初始化操作:你还可以执行其他自定义的初始化操作,以适应特定的需求和工作流程。
如下示例:
#!/bin/bash# 设置环境变量
export HADOOP_HOME=/path/to/hadoop
export HIVE_HOME=/path/to/hive# 加载自定义函数
ADD JAR /path/to/custom_functions.jar;# 定义别名
CREATE ALIAS myquery AS 'SELECT * FROM mytable WHERE condition';注意,.hiverc 文件中的命令将在每次启动Hive客户端时执行,因此你可以将其中的常用操作自动化,以提高工作效率。
三. 支持的路径协议
Spark SQL CLI supports running SQL from initialization script file(-i) or normal SQL file(-f), If path url don’t have a scheme component, the path will be handled as local file. For example: /path/to/spark-sql-cli.sql equals to file:///path/to/spark-sql-cli.sql.
User also can use Hadoop supported filesystems such as s3://[mys3bucket]/path/to/spark-sql-cli.sql or hdfs://[namenode]:[port]/path/to/spark-sql-cli.sql.
Spark SQL CLI 支持通过
- (-i)初始化脚本
- (-f)普通SQL文件
两种方式执行sql,如果路径没有协议,则被处理为本地文件。
用户也可以使用hadoop支持的s3和hdfs协议的路径,比如说:s3://<mys3bucket>/path/to/spark-sql-cli.sql、 hdfs://<namenode>:<port>/path/to/spark-sql-cli.sql.
四. 支持的注释类型

五. Spark SQL CLI交互式命令
当spark-sql没有使用-e 或 -f (sql字符和sql文件)时,命令将进入交互模式,使用;号终止命令。
注意:
- 该CLI仅在分号 ; 出现在行尾且没有被反斜杠 \; 转义时,才将其用于终止命令。
- 分号 ; 是唯一用于终止命令的方式。如果用户输入 SELECT 1 并按回车键,控制台将等待进一步输入。
- 如果用户在同一行中输入多个命令,例如 SELECT 1; SELECT 2;,则命令 SELECT 1 和 SELECT 2 将分别被执行。
- 如果分号 ; 出现在SQL语句中(而不是行尾),则它没有特殊含义:继续解释 SQL 语句的执行
再看一个例子:
/* This is a comment contains ;
*/ SELECT 1;
如果分号 ; 出现在行尾,它将终止SQL语句。上面的例子将被切分为:/* This is a comment contains 和*/ SELECT 1 两个sql执行,此时执行就会报错。
相关交互命令

六. Examples
1. running a query from the command line
./bin/spark-sql -e 'SELECT COL FROM TBL'
2. setting Hive configuration variables
./bin/spark-sql -e 'SELECT COL FROM TBL' --hiveconf hive.exec.scratchdir=/home/my/hive_scratch
3. setting Hive configuration variables and using it in the SQL query
./bin/spark-sql -e 'SELECT ${hiveconf:aaa}' --hiveconf aaa=bbb --hiveconf hive.exec.scratchdir=/home/my/hive_scratch
spark-sql> SELECT ${aaa};
bbb
4. setting Hive variables substitution
./bin/spark-sql --hivevar aaa=bbb --define ccc=ddd
spark-sql> SELECT ${aaa}, ${ccc};
bbb ddd
5. dumping data out from a query into a file using silent mode
./bin/spark-sql -S -e 'SELECT COL FROM TBL' > result.txt
6. running a script non-interactively:
[user_excute@poc11v ~/clients]$ spark-sql -f spark-test.sqlJava HotSpot(TM) 64-Bit Server VM warning: Using the ParNew young collector with the Serial old collector is deprecated and will likely be removed in a future release
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
23/10/26 15:02:23 WARN SparkConf: The configuration key 'spark.scheduler.executorTaskBlacklistTime' has been deprecated as of Spark 2.1.0 and may be removed in the future. Please use the new blacklisting options, spark.blacklist.*
23/10/26 15:02:23 WARN SparkConf: The configuration key 'spark.akka.frameSize' has been deprecated as of Spark 1.6 and may be removed in the future. Please use the new key 'spark.rpc.message.maxSize' instead.
23/10/26 15:02:24 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/10/26 15:02:30 INFO Client: Requesting a new application from cluster with 1 NodeManagers
23/10/26 15:02:30 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
23/10/26 15:02:30 INFO Client: Will allocate AM container, with 2432 MB memory including 384 MB overhead
23/10/26 15:02:30 INFO Client: Setting up container launch context for our AM
23/10/26 15:02:30 INFO Client: Setting up the launch environment for our AM container
23/10/26 15:02:30 INFO Client: Preparing resources for our AM container
23/10/26 15:02:31 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
23/10/26 15:02:35 INFO Client: Uploading resource file:/tmp/spark-abdc8f1b-5f01-42c5-820e-9213f4895e69/__spark_libs__927845140246214662.zip -> hdfs://xmanhdfs3/home/user_excute/spark/cache/.sparkStaging/application_1698291202798_0002/__spark_libs__927845140246214662.zip
23/10/26 15:02:38 INFO Client: Uploading resource file:/tmp/spark-abdc8f1b-5f01-42c5-820e-9213f4895e69/__spark_conf__3928501941049491781.zip -> hdfs://xmanhdfs3/home/user_excute/spark/cache/.sparkStaging/application_1698291202798_0002/__spark_conf__.zip
23/10/26 15:02:40 INFO Client: Submitting application application_1698291202798_0002 to ResourceManager
23/10/26 15:02:41 INFO Client: Application report for application_1698291202798_0002 (state: ACCEPTED)
23/10/26 15:02:41 INFO Client:client token: N/Adiagnostics: AM container is launched, waiting for AM container to Register with RMApplicationMaster host: N/AApplicationMaster RPC port: -1queue: root.user_excutestart time: 1698303760575final status: UNDEFINEDtracking URL: http://xxx:8888/proxy/application_1698291202798_0002/user: user_excute
23/10/26 15:02:42 INFO Client: Application report for application_1698291202798_0002 (state: ACCEPTED)
23/10/26 15:02:43 INFO Client: Application report for application_1698291202798_0002 (state: ACCEPTED)
23/10/26 15:02:44 INFO Client: Application report for application_1698291202798_0002 (state: ACCEPTED)
23/10/26 15:02:45 INFO Client: Application report for application_1698291202798_0002 (state: ACCEPTED)
23/10/26 15:02:46 INFO Client: Application report for application_1698291202798_0002 (state: RUNNING)
23/10/26 15:02:46 INFO Client:client token: N/Adiagnostics: N/AApplicationMaster host: xxx.xxx.xxx.xxxApplicationMaster RPC port: -1queue: root.user_excutestart time: 1698303760575final status: UNDEFINEDtracking URL: http://xxx:8888/proxy/application_1698291202798_0002/user: user_excute
default
Time taken: 1.274 seconds, Fetched 1 row(s)
1
Time taken: 9.996 seconds, Fetched 1 row(s)
7. running an initialization script before entering interactive mode
./bin/spark-sql -i /path/to/spark-sql-init.sql8. entering interactive mode
./bin/spark-sql
spark-sql> SELECT 1;
1
spark-sql> -- This is a simple comment.
spark-sql> SELECT 1;
1
9. entering interactive mode with escape ; in comment:
./bin/spark-sql
spark-sql>/* This is a comment contains \\;> It won't be terminated by \\; */> SELECT 1;
1
七. 非交互模式用法小结
命令语法:
spark-sql -f file_path
- -f:指定文件参数
- file_path:支持本地路径,也支持hdfs路径,例如:hdfs://[namenode]:[port]/path/to/spark-sql-cli.sql.
sql文件内容的书写格式:
- 各个sql以;号分割;
- 注释的语法:见上
参考:
https://spark.apache.org/docs/latest/sql-distributed-sql-engine-spark-sql-cli.html
相关文章:
【spark客户端】Spark SQL CLI详解:怎么执行sql文件、注释怎么写,支持的文件路径协议、交互式模式使用细节
文章目录 一. Spark SQL Command Line Options(命令行参数)二. The hiverc File1. without the -i2. .hiverc 介绍 三. 支持的路径协议四. 支持的注释类型五. Spark SQL CLI交互式命令六. Examples1. running a query from the command line2. setting Hive configuration vari…...
虹科干货 | HK-TrueNAS版本大揭秘!一文教您如何选择合适的TrueNAS软件
文章来源:虹科网络基础设施 阅读原文:https://mp.weixin.qq.com/s/Iv0zDDmiDgE9vEGlAZs-sg 1.导语 TrueNAS是虹科iXsystems 设计和开发的NAS 操作系统,提供许多功能,例如文件存储、虚拟机 (VM) 和媒体服务器。它基于…...

前端html+css+js实现的2048小游戏,很完善。
源码下载地址 支持:远程部署/安装/调试、讲解、二次开发/修改/定制 逻辑用的是JavaScript,界面用canvas实现,暂时还没有添加动画。 视频浏览地址...

学习通签到
要在Vue中使用H5lock.js,首先需要将H5lock.js引入到项目中。可以通过以下步骤来使用: 1. 将H5lock.js文件保存到项目中的某个目录下,例如src/assets文件夹。 2. 在需要使用H5lock.js的组件中,通过import语句将H5lock.js引入进来…...
target采退、测评养号购物下单操作教程
1.点击右上角的Create account注册账号 2.填写账号信息 3. 进入自己需要购买的商品页面 点击pick it up购买 4. 进入购物车页面选择快递方式和地址后点击 check out按钮 5. 之后会提示绑定XYK,这里我是用虚拟XYK开卡平台进行支付的. 6. 确认订单无误后点击Place you…...

SEACALL海外呼叫中心系统的优势包括
SEACALL海外呼叫中心系统的优势包括 封卡封号问题解决 海外呼叫中心系统通过API开放平台能力,定制电话营销系统,提供多项功能如自动拨打、智能应答、真人语音交互等,帮助企业克服员工离职率高、客户资源流失严重等挑战。 - 高级管理者操控 …...

Painter:使用视觉提示来引导网络推理
文章目录 1. 论文2. 示意图3. 主要贡献4. 代码简化 1. 论文 paper:Images Speak in Images: A Generalist Painter for In-Context Visual Learning github:https://github.com/baaivision/Painter 2. 示意图 3. 主要贡献 在 In-context Learning 中,作为自然语言…...

Fedora Linux 38 安装数学动画制作工具manimgl工具包
manimgl可以制作数学动画,它使用的是Python编程语言。 这里介绍他在Fedora Linux 38下的安装过程。 1. sudo dnf update 2. sudo dnf install python3-devel python3-pip python3-tools -y 3. sudo dnf install python3-numpy python3-scipy python3-sympy -y …...
行业追踪,2023-10-26
自动复盘 2023-10-26 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
Android 和 iOS APP 测试的那些区别
目前市面上主流的移动操作系统就是 Android 和 iOS 两种,移动端测试本身就跟 Web 应用测试有自己的专项测试,比如安装、卸载、升级、消息推送、网络类型测试、弱网测试、中断测试、兼容性测试等都是区别于 Web 应用需要关注的测试领域。 那么࿰…...
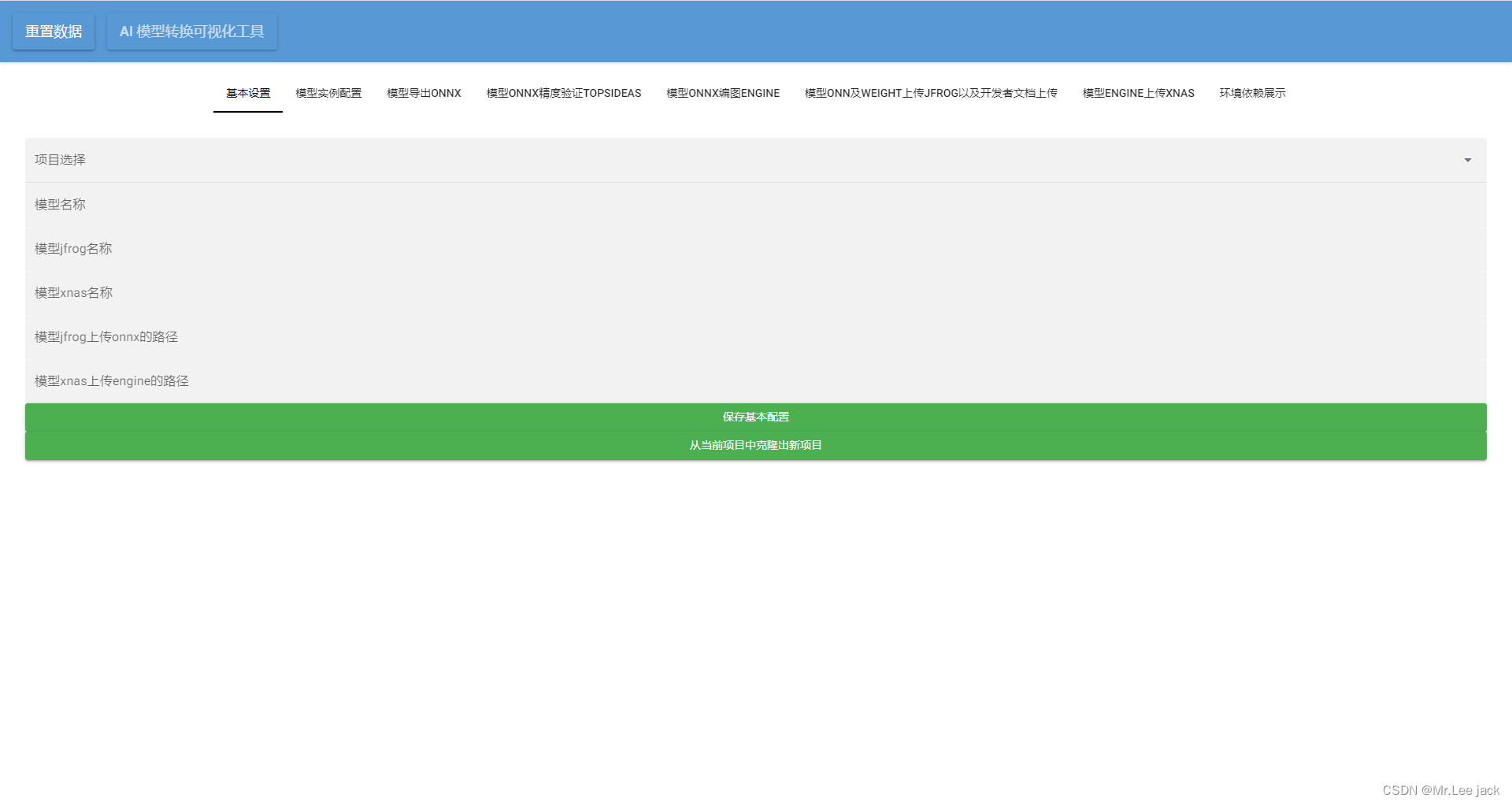
利用nicegui开发ai工具示例
from fastapi import FastAPI import uvicorn from nicegui import uiclass PipRequirement:def __init__(self):ui.label("依赖安装与依赖展示")class BasicSettings:def __init__(self):self.project_select ui.select(["test"], label"项目选择&q…...

HarmonyOS鸿蒙原生应用开发设计- 流转图标
HarmonyOS设计文档中,为大家提供了独特的流转图标,开发者可以根据需要直接引用。 开发者直接使用官方提供的流转图标内容,既可以符合HarmonyOS原生应用的开发上架运营规范,又可以防止使用别人的图标侵权意外情况等,减…...
postgresql14管理(六)-备份恢复
定义 备份(backup):通过物理复制或逻辑导出的方式,将数据库的文件或结构和数据拷贝到其他位置进行存储; 还原(restore):是一种不完全的恢复。使用备份文件将数据库恢复到备份时的状…...
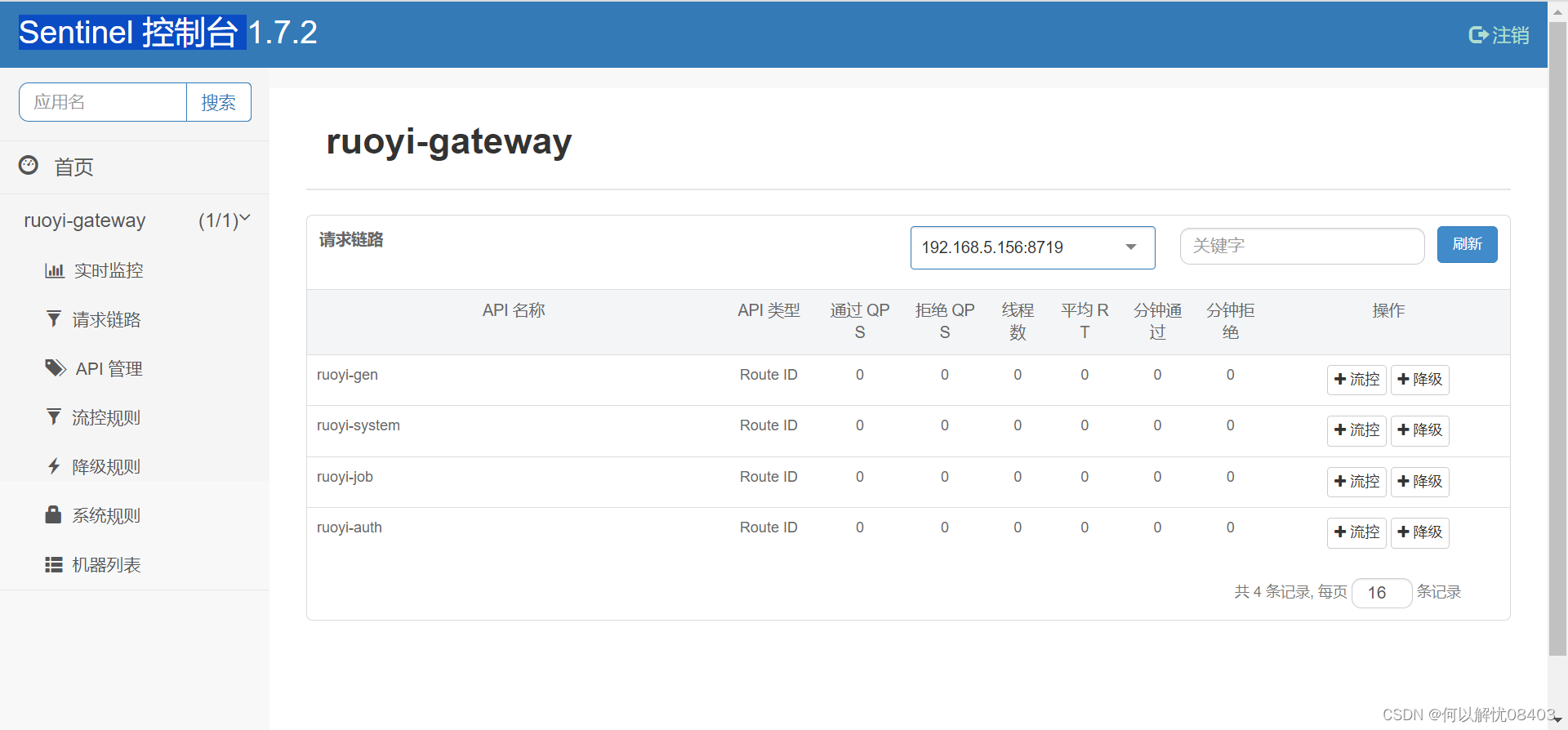
配置Sentinel 控制台
1.遇到的问题 服务网关 | RuoYi 最近调试若依的微服务版本需要用到Sentinel这个组件,若依内部继承了这个组件连上即用。 Sentinel是阿里巴巴开源的限流器熔断器,并且带有可视化操作界面。 在日常开发中,限流功能时常被使用,用…...
【漏洞复现】酒店宽带运营系统RCE
漏洞描述 安美数字 酒店宽带运营系统 server_ping.php 远程命令执行漏洞 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益ÿ…...

Autojs 利用OpenCV识别棋子之天天象棋你马没了
本例子通过代码像你介绍利用OpenCV实现霍尔找圆的方法定位棋子位置 通过autojs脚本实现自动点击棋子 开源地址 https://github.com/Liberations/TtxqYourHorseIsGone/blob/master/main.js AutoXJs https://github.com/kkevsekk1/AutoX/releasesauto() //安卓版本高于Android 9…...

好数组——尺取法
好数组 给定一个长度为 n 的数组 a,计算数组 a 中所有子数组中好数组的数目。 好数组定义如下: 对于数组 al ,al1, ⋯ ,ar ,若数组中所有数的质因数种类数不超过 k,则称为好数组。 Input 输入的第一行包含两个正整数 n,k (1≤…...

【Linux】Ubuntu升级nodejs版本
在下载nvm对nodejs版本进行管理时,由于网络因素一直下载失败,于是采用了新的方法对nodejs版本进行升级。 首先我们先查询一下现存的nodejs版本号,发现是12 我们下载一个名为n的软件包,n 是一个非常方便的 Node.js 版本管理工具&am…...

二维码智慧门牌管理系统升级解决方案:一级属性 二级属性
文章目录 前言一、什么是智慧门牌管理系统?二、一级属性 vs. 二级属性三、升级中的实践意义 前言 在本文中,我们将深入探讨二维码智慧门牌管理系统的升级解决方案,特别聚焦于一级属性和二级属性的关键概念。我们将详细解释这些概念ÿ…...
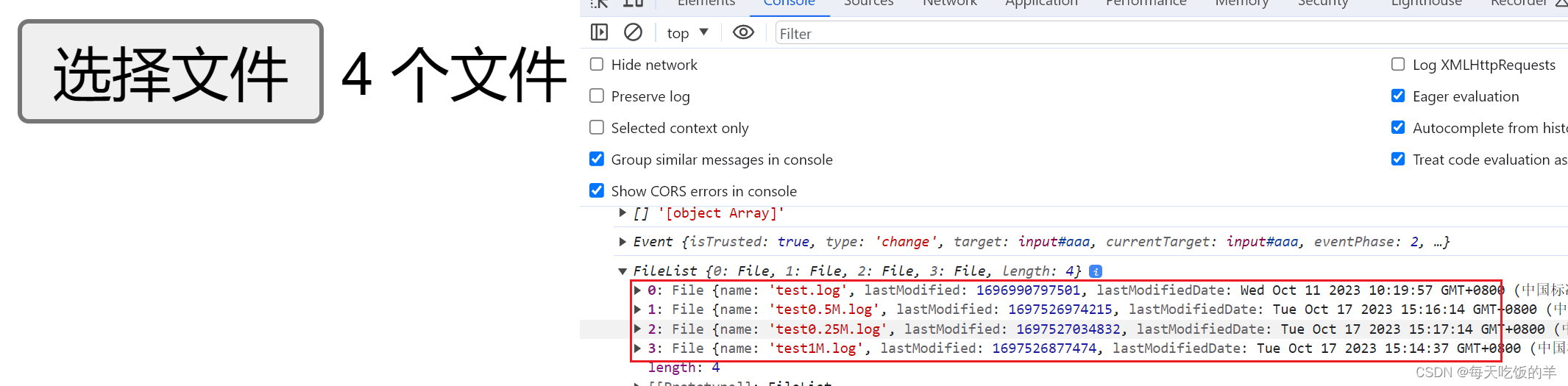
input改造文件上传,el-table的改造,点击上传,拖拽上传,多选上传
第一个input标签效果 第二个input标签的效果 el-table的改造效果 <template><div class"outerBox"><div class"analyze" v-if"status"><div class"unFile"><div class"mainBox"><img clas…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...
、连读规则注入与敬语语调开关(内测白名单已开放))
仅限菲律宾本地团队使用的ElevenLabs隐藏功能:Tagalog重音标记语法(`[ˈba.ka]`)、连读规则注入与敬语语调开关(内测白名单已开放)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾文语音能力的本地化演进背景 菲律宾语(Filipino)作为以他加禄语(Tagalog)为基础的国家官方语言,拥有约1.05亿母语及第二语言…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

Git安全增强实战:使用Ante实现策略即代码的版本控制防护
1. 项目概述:一个为开发者打造的“代码保险箱”如果你和我一样,在职业生涯中经历过几次“代码灾难”——比如不小心git push -f覆盖了同事的提交,或者手滑rm -rf删除了一个正在开发中的功能分支——那你一定会对“代码安全”这四个字有切肤之…...