分布式日志和链路追踪
分布式日志
实现思路
分布式日志框架服务的实现思路基本是一致的,如下:
- 日志收集器:微服务中引入日志客户端,将记录的日志发送到日志服务端的收集器,然后以某种方式存储
- 数据存储:一般使用ElasticSearch分布式存储,把收集器收集到的日志格式化,然后存储到分布式存储中
- web服务:利用ElasticSearch的统计搜索功能,实现日志查询和报表输出
比较知名的分布式日志服务包括:
- ELK:elasticsearch、Logstash、Kibana
- GrayLog
ELK存在的问题
- 不能处理多行日志,比如Mysql慢查询,Tomcat/Jetty应用的Java异常打印
- 不能保留原始日志,只能把原始日志分字段保存,这样搜索日志结果是一堆Json格式文本,无法阅读。
- 不符合正则表达式匹配的日志行,被全部丢弃。
Graylog的优点
- 一体化方案,安装方便,不像ELK有3个独立系统间的集成问题。
- 采集原始日志,并可以事后再添加字段,比如http_status_code,response_time等等。
- 自己开发采集日志的脚本,并用curl/nc发送到Graylog Server,发送格式是自定义的GELF,Flunted和Logstash都有相应的输出GELF消息的插件。自己开发带来很大的自由度。实际上只需要用inotifywait监控日志的modify事件,并把日志的新增行用curl/netcat发送到Graylog Server就可。
- 搜索结果高亮显示,就像google一样。
- 搜索语法简单,比如:
source:mongo AND reponse_time_ms:>5000,避免直接输入elasticsearch搜索json语法 - 搜索条件可以导出为elasticsearch的搜索json文本,方便直接开发调用elasticsearch rest api的搜索脚本。
GrayLog的使用
GrayLog的流程框架图

流程如下:
- 微服务中的GrayLog客户端发送日志到GrayLog服务端
- GrayLog把日志信息格式化,存储到Elasticsearch
- 客户端通过浏览器访问GrayLog,GrayLog访问Elasticsearch
这里MongoDB是用来存储GrayLog的配置信息的,这样搭建集群时,GrayLog的各节点可以共享配置。
GrayLog的安装
此时我们需要在docker中安装Mongodb, elasticSearch,GrayLog。
#部署Elasticsearch
docker run -d \--name elasticsearch \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.17.5#部署MongoDB(
docker run -d \
--name mongodb \
-p 27017:27017 \
--restart=always \
-v mongodb:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=sl \
-e MONGO_INITDB_ROOT_PASSWORD=123321 \
mongo:4.4#部署 ,分别设置es和mongo的地址
docker run \
--name graylog \
-p 9000:9000 \
-p 12201:12201/udp \
-e GRAYLOG_HTTP_EXTERNAL_URI=http://192.168.150.101:9000/ \
-e GRAYLOG_ELASTICSEARCH_HOSTS=http://192.168.150.101:9200/ \
-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai" \
-e GRAYLOG_WEB_ENDPOINT_URI="http://192.168.150.101:9000/:9000/api" \
-e GRAYLOG_PASSWORD_SECRET="somepasswordpepper" \
-e GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 \
-e GRAYLOG_MONGODB_URI=mongodb://sl:123321@192.168.150.101:27017/admin \
-d \
graylog/graylog:4.3命令解读:
- 端口信息:
-
-p 9000:9000:GrayLog的http服务端口,9000-p 12201:12201/udp:GrayLog的GELF UDP协议端口,用于接收从微服务发来的日志信息
- 环境变量
-
-e GRAYLOG_HTTP_EXTERNAL_URI:对外开放的ip和端口信息,这里用9000端口-e GRAYLOG_ELASTICSEARCH_HOSTS:GrayLog依赖于ES,这里指定ES的地址-e GRAYLOG_WEB_ENDPOINT_URI:对外开放的API地址-e GRAYLOG_PASSWORD_SECRET:密码加密的秘钥-e GRAYLOG_ROOT_PASSWORD_SHA2:密码加密后的密文。明文是admin,账户也是admin-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai":GrayLog容器内时区-e GRAYLOG_MONGODB_URI:指定MongoDB的链接信息
graylog/graylog:4.3:使用的镜像名称,版本为4.3
进行测试
访问对应的9000端口。
 集成微服务进行测试
集成微服务进行测试
导入依赖
<dependency><groupId>biz.paluch.logging</groupId><artifactId>logstash-gelf</artifactId><version>1.15.0</version>
</dependency>修改Logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。-->
<!--scanPeriod: 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。-->
<!--debug: 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。-->
<configuration debug="false" scan="false" scanPeriod="60 seconds"><springProperty scope="context" name="appName" source="spring.application.name"/><!--文件名--><property name="logback.appname" value="${appName}"/><!--文件位置--><property name="logback.logdir" value="/data/logs"/><!-- 定义控制台输出 --><appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"><layout class="ch.qos.logback.classic.PatternLayout"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} - [%thread] - %-5level - %logger{50} - %msg%n</pattern></layout></appender><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>DEBUG</level></filter><File>${logback.logdir}/${logback.appname}/${logback.appname}.log</File><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><FileNamePattern>${logback.logdir}/${logback.appname}/${logback.appname}.%d{yyyy-MM-dd}.log.zip</FileNamePattern><maxHistory>90</maxHistory></rollingPolicy><encoder><charset>UTF-8</charset><pattern>%d [%thread] %-5level %logger{36} %line - %msg%n</pattern></encoder></appender><appender name="GELF" class="biz.paluch.logging.gelf.logback.GelfLogbackAppender"><!--GrayLog服务地址--><host>udp:192.168.150.101</host><!--GrayLog服务端口--><port>12201</port><version>1.1</version><!--当前服务名称--><facility>${appName}</facility><extractStackTrace>true</extractStackTrace><filterStackTrace>true</filterStackTrace><mdcProfiling>true</mdcProfiling><timestampPattern>yyyy-MM-dd HH:mm:ss,SSS</timestampPattern><maximumMessageSize>8192</maximumMessageSize></appender><!--evel:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,--><!--不能设置为INHERITED或者同义词NULL。默认是DEBUG。--><root level="INFO"><appender-ref ref="stdout"/><appender-ref ref="GELF"/></root>
</configuration>这样就实现了微服务的分布式日志。
调用work服务的查询方法,日志就会出现在控制面板上。
日志回收策略
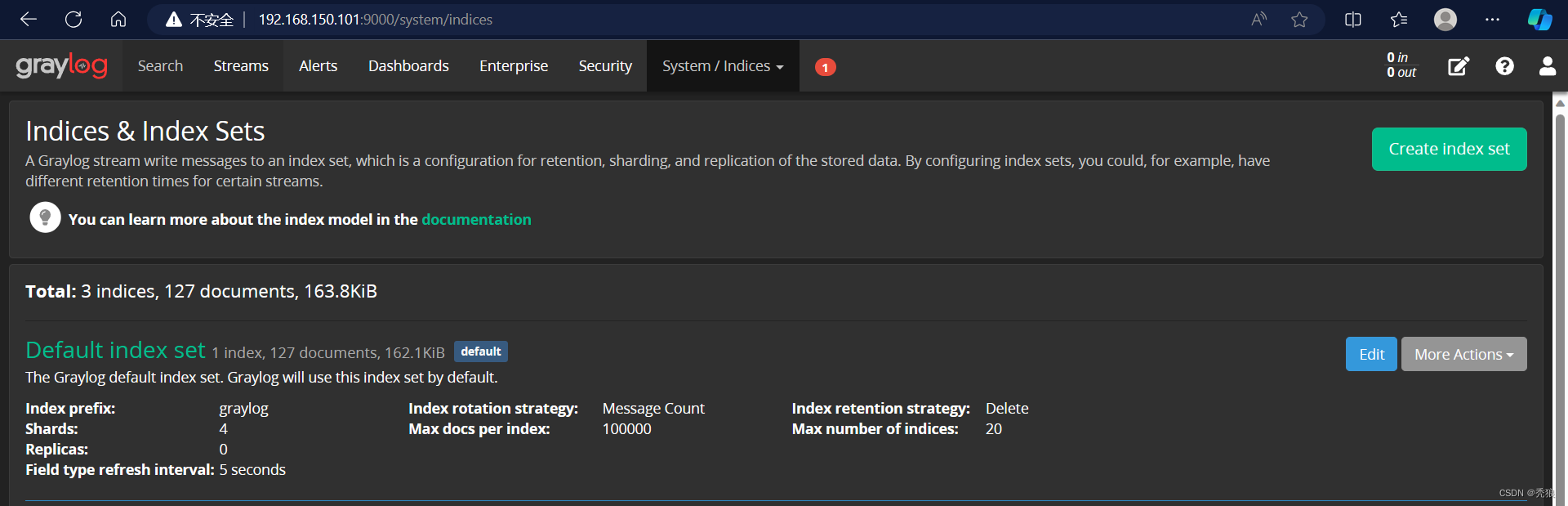 点击Default index set的Edit进行设置日志的回收策略。
点击Default index set的Edit进行设置日志的回收策略。
日志的回策略有三种。
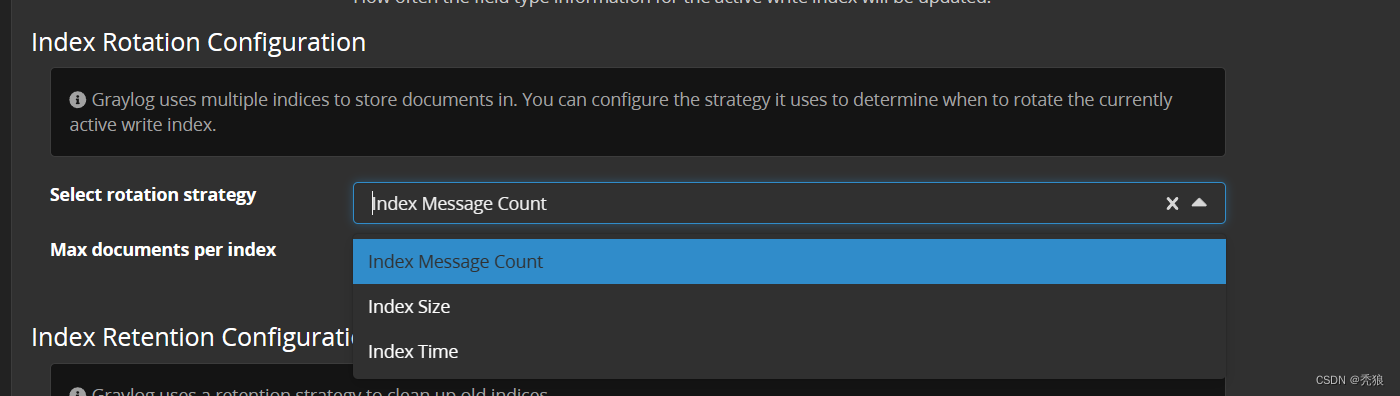
分别是:
Index Message Count:按照日志数量统计,默认超过20000000条日志开始清理Index Size:按照日志大小统计,默认超过1GB开始清理Index Time:按照日志日期清理,默认日志存储1天
搜索语法
搜索语法的格式
#不指定字段,默认从message字段查询
输入:undo#输入两个关键字,关系为or
undo 统计#加引号是需要完整匹配
"undo 统计"#指定字段查询,level表示日志级别,ERROR(3)、WARNING(4)、NOTICE(5)、INFO(6)、DEBUG(7)
level: 6#或条件
level:(6 OR 7)自定义展示字段
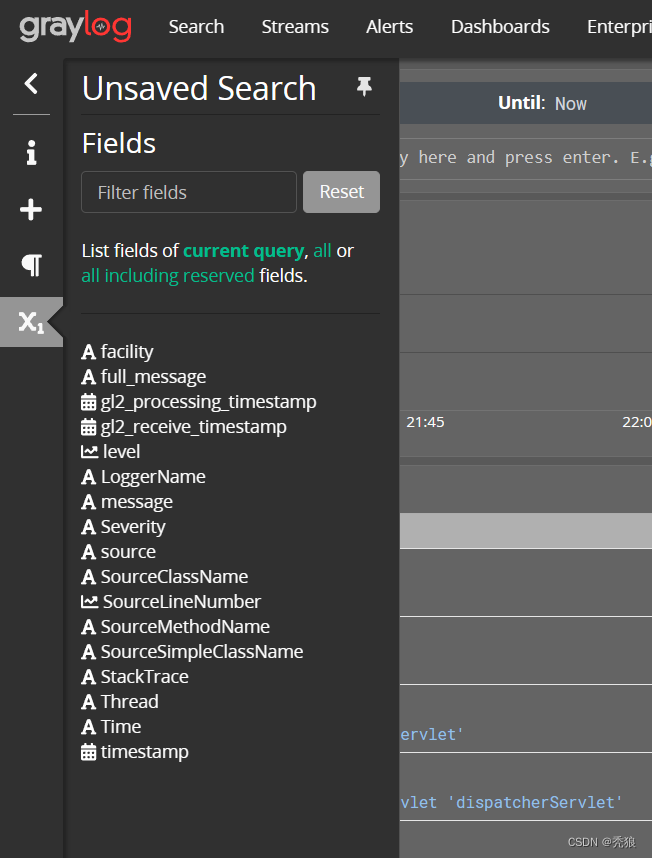
可以在allMessage中显示字段。
 这里添加了level字段。
这里添加了level字段。
日志统计仪表
创建仪表
点击Create new dashboard,创建一个新的仪表。
 在该仪表中我们可以进行DIY。
在该仪表中我们可以进行DIY。
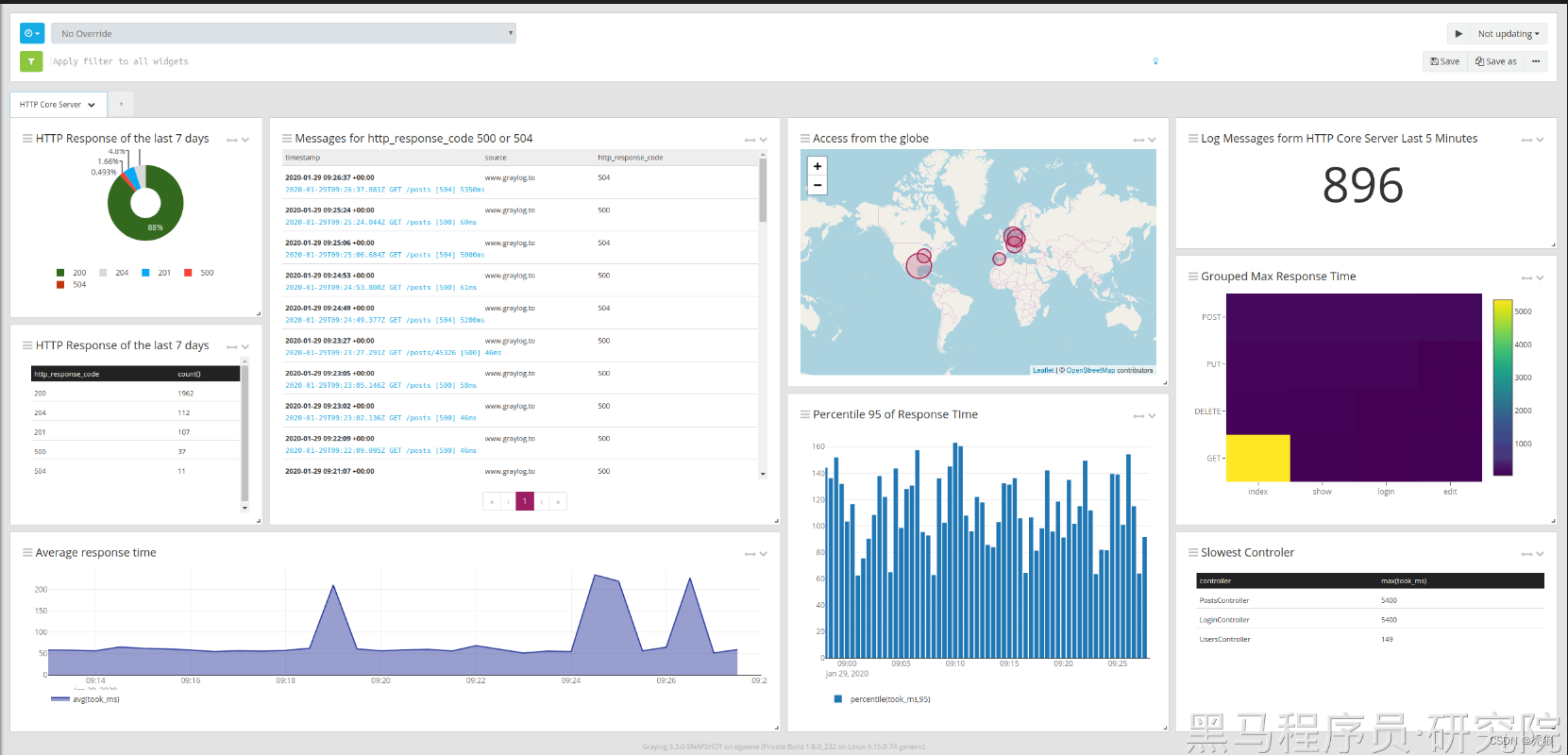
可以DIY成这种效果。
分布式日志面试题
问: 在服务中你们通常会进入哪些信息呢?
答: 会记录: 服务的名称,日志的级别,日志的详细信息,时间,对应的类,调用的方法。
问: 那会在什么时候进行记录日志?
答: 在有异常信息和调用重要方法时的参数传入时会记录日志。
链路追踪
APM
什么是APM?
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现
- 服务有可能布在了几千台服务器,横跨多个不同的数据中心
因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统,全称是(Application Performance Monitor,当然也有叫 Application Performance Management tools)
APM最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统,自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
原理
- 包括:前端(A),两个中间层(B和C),以及两个后端(D和E)
- 当用户发起一个请求时,首先到达前端A服务,然后分别对B服务和C服务进行RPC调用;
- B服务处理完给A做出响应,但是C服务还需要和后端的D服务和E服务交互之后再返还给A服务,最后由A服务来响应用户的请求;
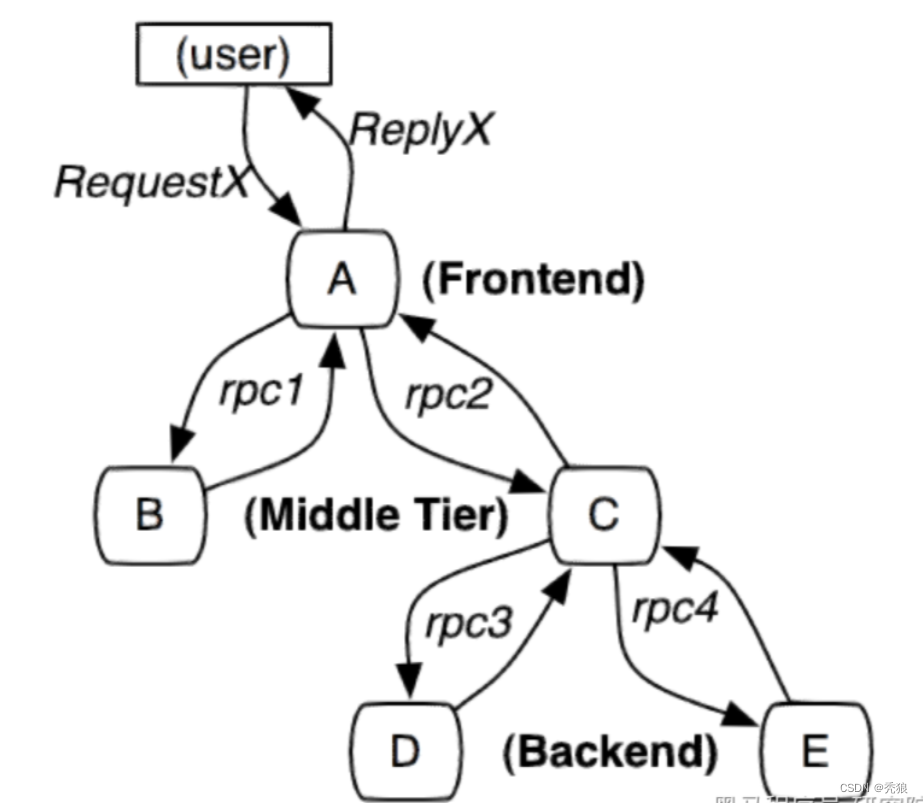
如何才能实现跟踪呢?需要明白下面几个概念:
- 探针:负责在客户端程序运行时收集服务调用链路信息,发送给收集器
- 收集器:负责将数据格式化,保存到存储器
- 存储器:保存数据
- UI界面:统计并展示
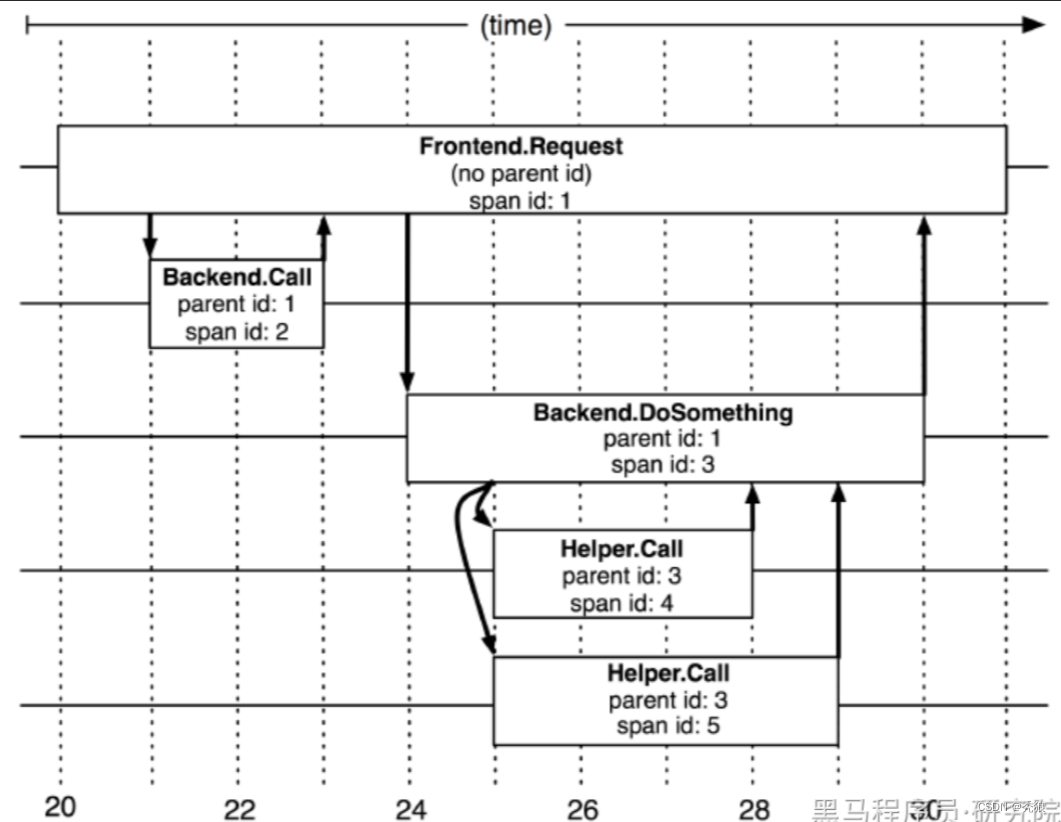
探针会在链路追踪时记录每次调用的信息,Span是基本单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它;同时附加(Annotation)作为payload负载信息,用于记录性能等数据。
span的基本结构
type Span struct {TraceID int64 // 用于标示一次完整的请求idName string //名称ID int64 // 当前这次调用span_idParentID int64 // 上层服务的调用span_id 最上层服务parent_id为null,代表根服务rootAnnotation []Annotation // 记录性能等数据Debug bool
}
Skywalking的使用
主要的特征:
- 多语言探针或类库
-
- Java自动探针,追踪和监控程序时,不需要修改源码。
- 社区提供的其他多语言探针
-
-
- .NET Core
- Node.js
-
- 多种后端存储: ElasticSearch, H2
- 支持OpenTracing
-
- Java自动探针支持和OpenTracing API协同工作
- 轻量级、完善功能的后端聚合和分析
- 现代化Web UI
- 日志集成
- 应用、实例和服务的告警
部署安装
#在此之前需要部署es#oap服务,需要指定Elasticsearch以及链接信息
docker run -d \
-e TZ=Asia/Shanghai \
--name oap \
-p 12800:12800 \
-p 11800:11800 \
-e SW_STORAGE=elasticsearch \
-e SW_STORAGE_ES_CLUSTER_NODES=192.168.150.101:9200 \
apache/skywalking-oap-server:9.1.0#部署ui,需要指定oap服务
docker run -d \
--name oap-ui \
-p 48080:8080 \
-e TZ=Asia/Shanghai \
-e SW_OAP_ADDRESS=http://192.168.150.101:12800 \
apache/skywalking-ui:9.1.0访问对应的端口48080。
微服务探针
我们需要在对应的微服务中添加探针。
需要准备Keywalking-gent文件(在资源中获取)
打开Idea在对应的微服务上添加VM的配置
#在探针处添加skywalking-agent.jar在电脑的对应位置
#设置服务的名称
#设置skywalking的面板地址
-javaagent:D:\skywalking-agent\skywalking-agent.jar
-Dskywalking.agent.service_name=ms::sl-express-ms-work
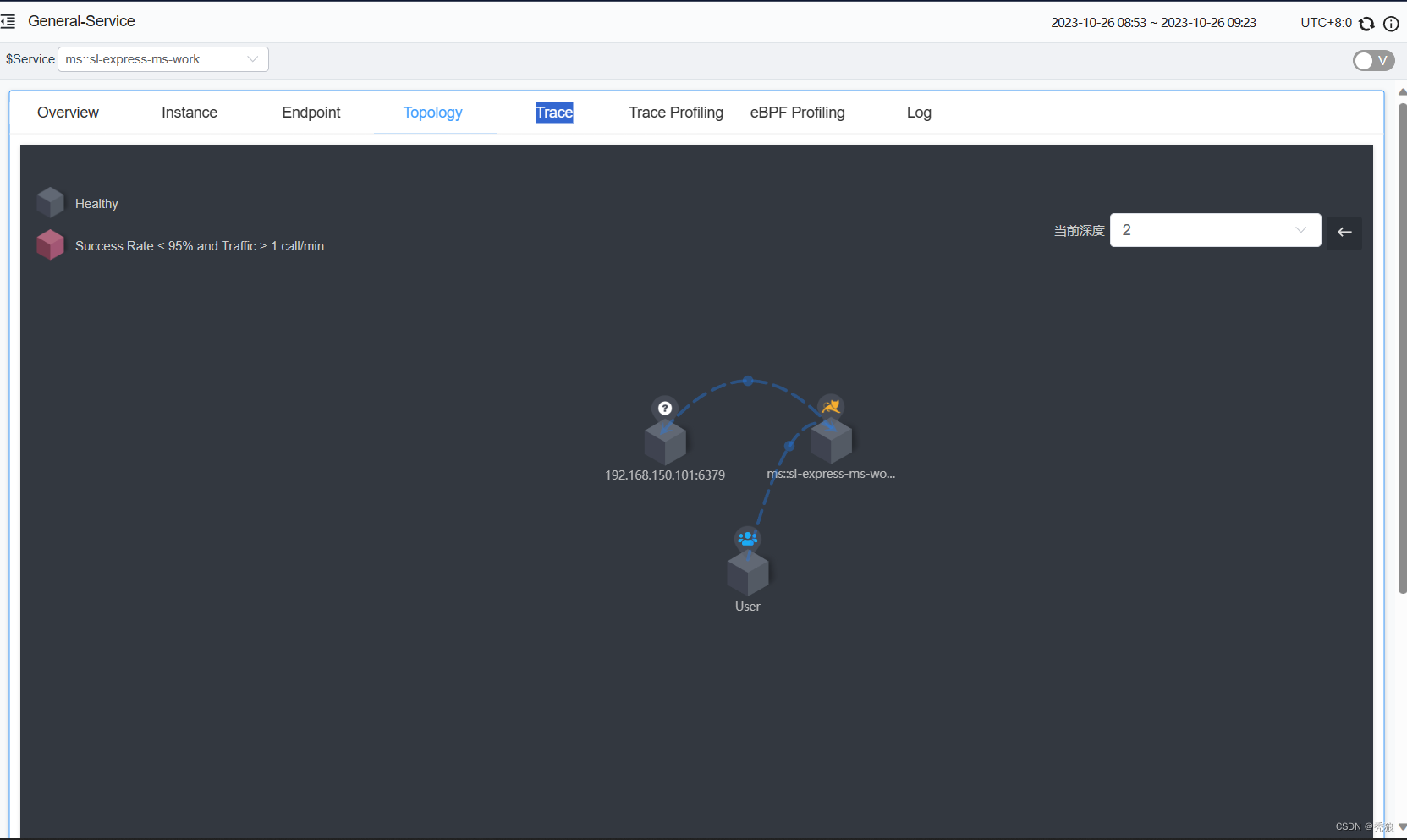
-Dskywalking.collector.backend_service=192.168.150.101:11800进行配置,效果为下:
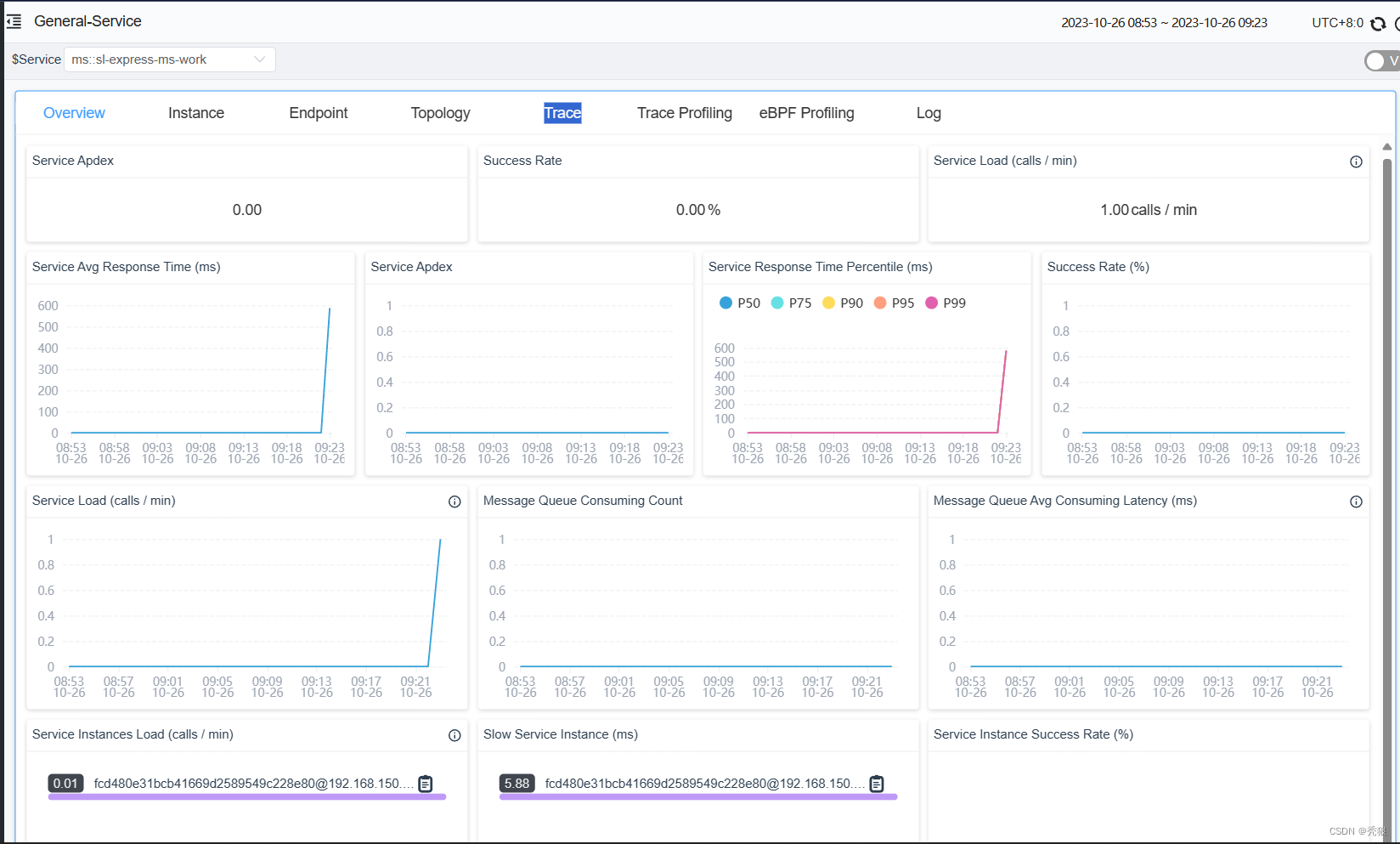
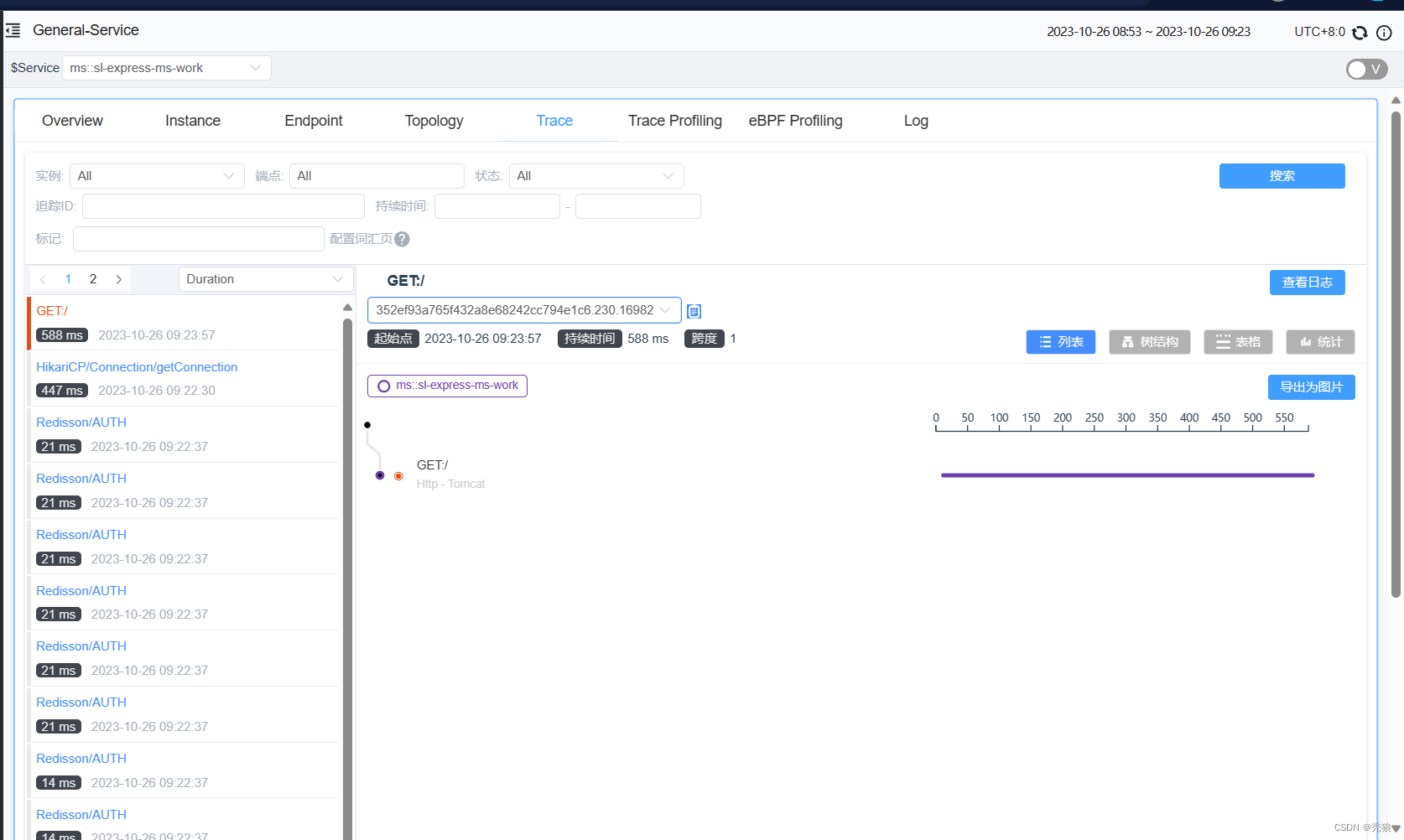
访问接口进行测试
相关文章:
分布式日志和链路追踪
分布式日志 实现思路 分布式日志框架服务的实现思路基本是一致的,如下: 日志收集器:微服务中引入日志客户端,将记录的日志发送到日志服务端的收集器,然后以某种方式存储数据存储:一般使用ElasticSearch分…...

el-select multiple表单校验问题
el-select multiple表单校验问题 <el-form refform :modelform><el-form-item propvulTypes label漏洞类型><el-select v-modelform.vulTypes changevulTypeChange><el-option v-foritem in vulList :keyitem :labelitem :valueitem></el-option&g…...

论文阅读——BART
Arxiv: https://arxiv.org/abs/1910.13461 一个去噪自编码器的预训练序列到序列的模型。是一个结合了双向和自回归transformers的模型。 预训练分为两个阶段:任意噪声函数破坏文本和序列模型重建原始文本 一、模型 input:被破坏的文本-->bidirecti…...
InstructionGPT
之前是写在[Instruction-tuning(指令微调)]里的,抽出来单独讲一下。 基本原理 在做下游的任务时,我们发现GPT-3有很强大的能力,但是只要人类说的话不属于GPT-3的范式,他几乎无法理解。例如,我们…...

电脑视频怎么转音频mp3
如果你在电脑上观看视频时喜欢上某个片段的背景音乐,且想将喜欢的背景音乐制作为手机铃声。我是建议你将此视频转换为 MP3 格式,因为 MP3 几乎与所有设备相兼容,让你可以在不同设备上不受限制地去聆听它。那该如何转换呢?无需担心…...

java 读取pdf文件内容
一、引入maven <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.25</version> </dependency>二、代码工具类 package com.jiayou.peis.utils;//import com.itextpdf.text.pd…...

【linux】安装rpmrebuild
rpmrebuild是一种从已经安装的包中构建RPM文件的工具。它可以用于轻松构建修改后的包,并适用于任何使用RPM的Linux发行版。 访问地址 rpm rebuild download | SourceForge.net 选择版本 版本地址:版本地址 下载安装包 安装 rpm -ivh rpmrebuild-2.15…...
+ Spring相关源码)
设计模式——访问者模式(Visitor Pattern)+ Spring相关源码
文章目录 一、访问者模式(Visitor Pattern)二、文字描述三、例子例子一:菜鸟教程对象定义访问者定义使用总结 例子二:Spring的BeanDefinitionVisitor 一、访问者模式(Visitor Pattern) 行为型模式。 目的&…...

SQL Delete 语句(删除表中的记录)
SQL DELETE 语句 DELETE语句用于删除表中现有记录。 SQL DELETE 语法 DELETE FROM table_name WHERE condition; 请注意删除表格中的记录时要小心!注意SQL DELETE 语句中的 WHERE 子句! WHERE子句指定需要删除哪些记录。如果省略了WHERE子句ÿ…...

在 Android 上测试 Kotlin 数据流
文章目录 一 创建虚构数据提供方二 在测试中断言数据流发出测试期间持续收集 三 测试 StateFlow使用 stateIn 创建的 StateFlow 转自: https://developer.android.google.cn/kotlin/flow/test?hlzh-cn#producer 与数据流进行通信的单元或模块的测试方式取决于受测对…...

day43
今日内容 python操作MySQL(重要) SQL注入问题(安全相关的xss,csrf) 视图(了解) 触发器(了解) 事务(重要) 存储过程(了解) 内置函数(了解,很多) 流程控制(了解) 索引(重点) python操作MySQL MySQL本身就是一款c/s架构,有服务端、有客户端&…...

终端管理制度
1、总则 1.1、目的 为规范XXXXX单位员工在使用计算机终端过程中的行为,提高计算机终端的安全性,确保员工安全使用计算机终端,特制定本制度。 1.2、范围 本规定适用于在XXXXX单位使用计算机终端的所有员工,包括内部终端和外部终…...
视频相关学习笔记
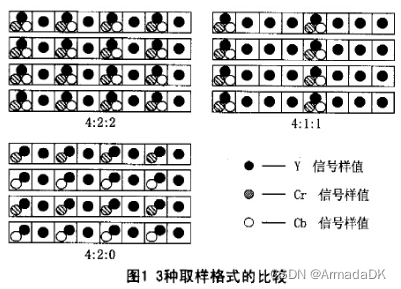
YUV 和rgb一样是一种表示色彩的格式,Y表示亮度,UV表示色度(U是蓝色投影,V是红色投影),只有Y就是黑白的,所以这个格式的视频图片可以兼容黑白电视,所以彩色电视使用的都是YUV 存储方…...

神经网络中epoch、batch、batchsize区别
目录 1 epoch 2 batch 3 batchsize 4 区别 1 epoch 当数据集中的全部数据样本通过神经网络一次并且返回一次的过程即完成一次训练称为一个epoch。 当我们分批学习时,每次使用过全部训练数据完成一次Forword运算以及一次BP运算,称为完成了一次epoch。 epoch时期 = 所有训练…...
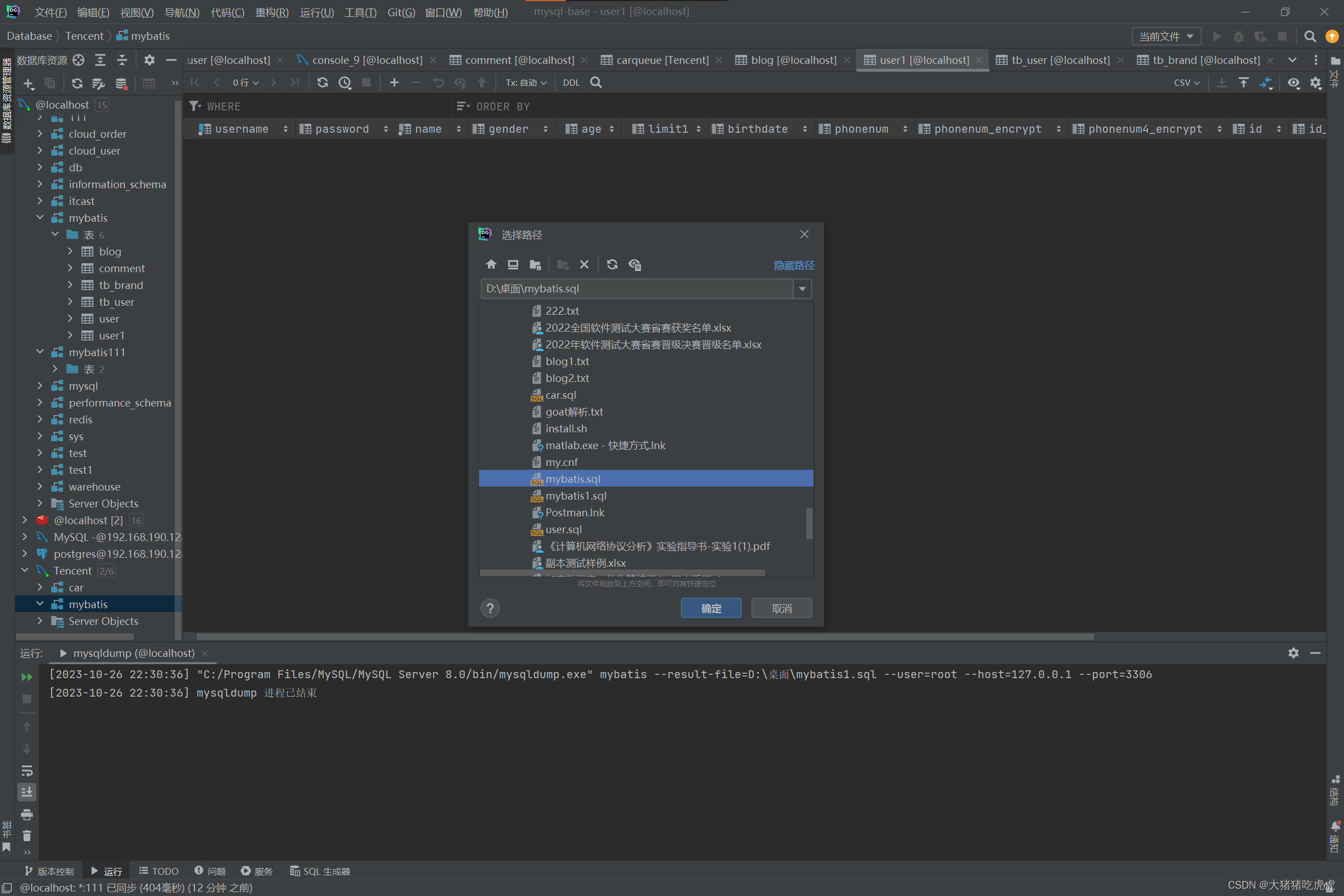
如何将Mysql数据库的表导出并导入到另外的架构
如何将Mysql数据库的表导出并导入到另外的架构 准备一、解决方法1.右键->导出->用mysqldump导出2.注意路径一般为:C:/Program Files/MySQL/MySQL Server 8.0/bin/mysqldump.exe和导出的sql文件位置3.右键->SQL脚本->运行SQL脚本4.找到SQL脚本并点击确定…...
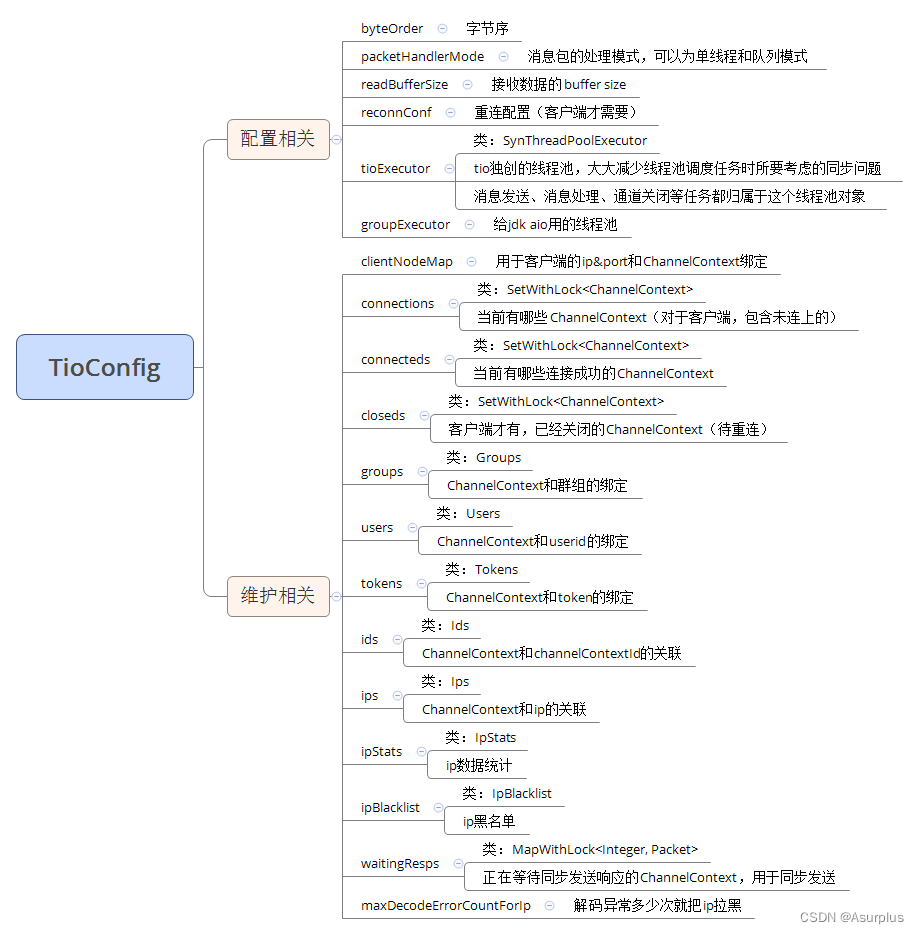
【tio-websocket】9、服务配置与维护—TioConfig
场景 我们在写 TCP Server 时,都会先选好一个端口以监听客户端连接,再创建N组线程池来执行相关的任务,譬如发送消息、解码数据包、处理数据包等任务,还要维护客户端连接的各种数据,为了和业务互动,还要把这些客户端连接和各种业务数据绑定起来,譬如把某个客户端绑定到一…...

数据结构—线性表(下)
文章目录 6.线性表(下)(4).栈与队列的定义和ADT#1.ADT#2.栈的基本实现#3.队列的形式#4.队列的几种实现 (5).栈与队列的应用#1.栈的应用i.后缀表达式求值ii.中缀表达式转后缀表达式 #2.队列的应用 (6).线性表的其他存储方式#1.索引存储#2.哈希存储i.什么是哈希存储ii.碰撞了怎么…...

apisix之插件开发,包含java和lua两种方式
https://download.csdn.net/download/tiantangpw/88475630 有ppt和springboot程序包,可以运行...
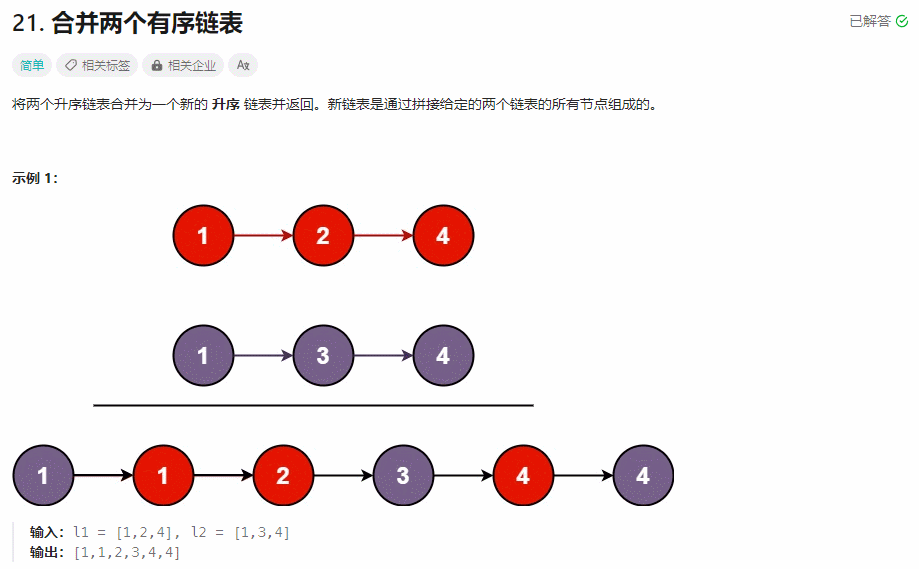
【面试经典150 | 链表】合并两个有序链表
文章目录 Tag题目来源题目解读解题思路方法一:递归方法二:迭代 写在最后 Tag 【递归】【迭代】【链表】 题目来源 21. 合并两个有序链表 题目解读 合并两个有序链表。 解题思路 一种朴素的想法是将两个链表中的值存入到数组中,然后对数组…...

【linux】麒麟v10安装Redis主从集群(ARM架构)
安装redis单示例的请看:麒麟v10安装Redis(ARM架构) 安装环境 HostnameIP addressmaster192.168.0.1slave1192.168.0.2slave2192.168.0.3 下载安装包 (三台都操作) wget https://repo.huaweicloud.com/kunpeng/…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南
如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导
如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址…...
)
从图片到摄像头:用YOLOv8n.pt模型在Win10上实现实时目标检测(代码+命令详解)
从图片到摄像头:用YOLOv8n.pt模型在Win10上实现实时目标检测(代码命令详解) 当计算机视觉遇上边缘计算,目标检测技术正在重塑人机交互的边界。YOLOv8作为当前最先进的实时检测框架之一,其轻量级版本yolov8n.pt在普通消…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...
)
Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包)
更多请点击: https://intelliparadigm.com 第一章:Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包) Tea印相(TeaYinXiang)在 v…...

本地可控 AI 助手搭建|Windows 一键安装 OpenClaw 操作指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建专属数字员工 前言 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),在 GitHub 收获大量关注,凭借本地运行、零代码操作、自动…...

为什么92%的设计师调不出正宗铂金印相?3个被忽略的色彩科学陷阱与CIE LAB空间修正公式
更多请点击: https://intelliparadigm.com 第一章:铂金印相的视觉本质与历史语境 铂金印相(Platinum Print)并非一种数字图像处理技术,而是一种19世纪末诞生于摄影化学工艺巅峰的物理显影体系。其视觉本质在于——铂金…...

5.11-5.17周报
牛客周赛 Round 143:A B C D E...