Spring是怎么解决循环依赖的
1.什么是循环依赖:
这里给大家举个简单的例子,相信看了上一篇文章大家都知道了解了spring的生命周期创建流程。那么在Spring在生命周期的哪一步会出现循环依赖呢?
第一阶段:实例化阶段 Instantiation
第二阶段:属性赋值 Populate
第三阶段:初始化阶段 Initialization
第四阶段:销毁阶段 Destruction
首先在第一阶段实例化阶段,会出现循环依赖。
@Component
public class TestService {private OrderService orderService;public void TestService(OrderService orderService){this.orderService=orderService;}
}-----------------------------------
@Component
public class OrderService {private TestService testService;public void OrderService (TestService testService){this.testService=testService;}
}
Spring在实例化阶段创建我们对象的时候,是通过反射调用我们的构造方法进行创建。如果你没有写无参构造方法,写了有参构造方法。那么spring就会调用你的有参构造方法进行创建对象。那么这个时候问题就来了,
1.首先TestService 它的有参对象是OrderService,这个时候spring就会对我的有参对象进行属性注入,它就会去创建我们的OrderService 。
2.在创建OrderService 的时候发现orderService的构造方法有参是TestService ,它又会去创建我们的TestService 。这个时候就会出现循环依赖,TestService 依赖OrderService , OrderService 依赖TestService 。
其次在第二阶属性赋值阶段,也会出现循环依赖。
@Component
public class TestService {@Autowiredprivate OrderService orderService;}
-----------------------------------@Component
public class OrderService {@Autowiredprivate TestService testService;
}Spring在调用我们构造方法进行创建对象后,就会进行属性赋值。
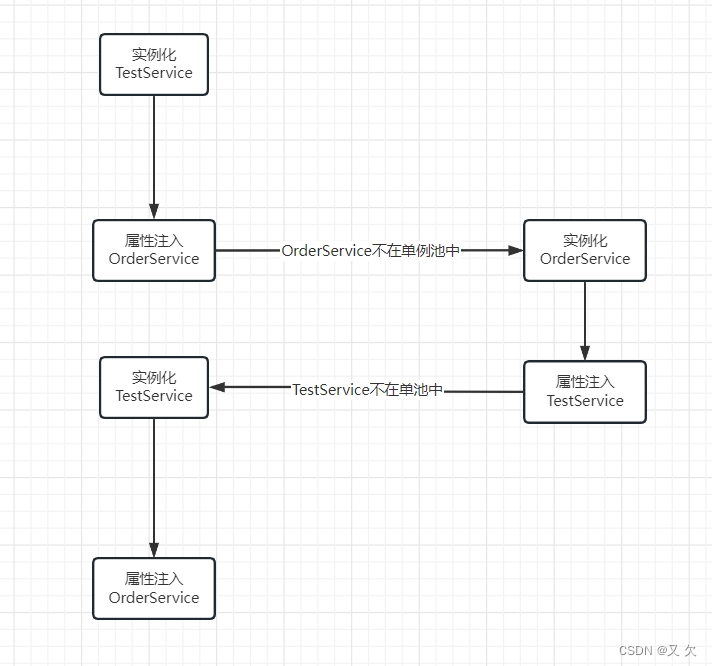
- 当我们注入TestService 时,发现OrderService属性不在单例池中,就会去创建OrderService。
- 创建OrderService时,发现OrderService也有属性需要注入,就会去注入TestService 。这个时候也会出现魂环依赖问题。那么对于Spring来说,它是怎么去解决这些循环依赖问题的呢?
2.解决思路:
下路就是循环依赖我画的简单流程图,如果要解决循环依赖。我们怎么去解决呢?
思路一: 既然每次都要查看单例池存不存在,那我实例化的时候就放入单例池中吗。这样不就可以解决循环依赖了吗。
假如你现在有两个线程,在实例化阶段完成后你就把TestService放入单例池中,这个时候线程二去单例池中获取TestService对象。线程二获取的是完整的spring对象吗?并不是,这个时候我们的TestService他没有走完我们的生命周期,线程二它获取的会是TestService的普通对象,如果在后面阶段TestService需要AOP呢,Spring给它生成了代理对象。这个时候线程二就拿不到TestService的代理对象了。
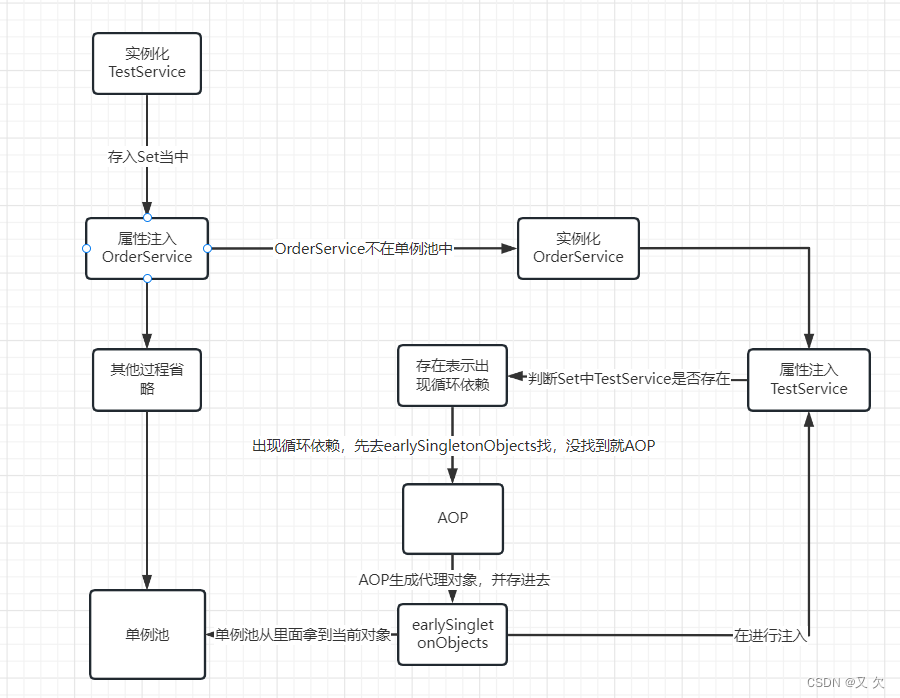
思路二:不能直接放入单例池中,那么我就搞一个Set 集合,每次实例化对象的时候就把BeanName存入集合当中,表示这个对象正在创建中。为了解决代理对象问题,我在生成一个map我们叫他earlySingletonObjects 。它用来存储我们的代理对象。
其实这样就可以解决循环依赖的问题了,但是Spring在这方面没有这样实现。而是采用了另一种方法。因为这样违背了Spring设计原则。
Spring结合AOP跟Bean的生命周期,是在Bean创建完全之后通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
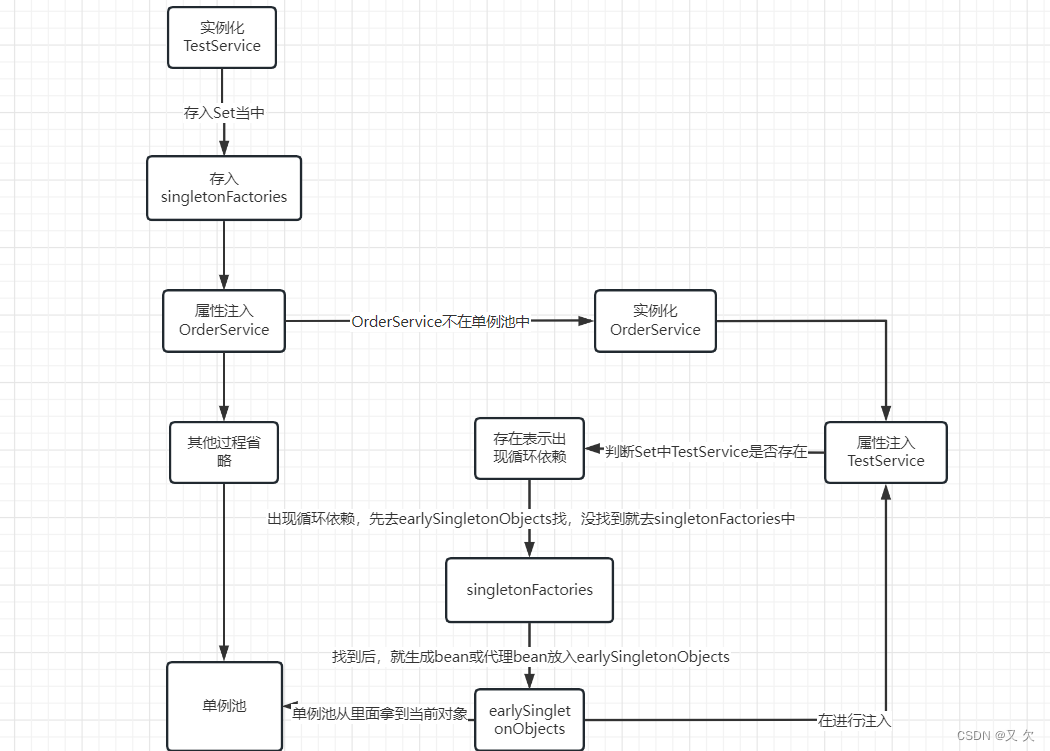
思路三:在实例化后,我在加入一个Map<String, ObjectFactory<?>> singletonFactories 的map,每次实例化之后就把当前类存入map中,等后面产生循环依赖时,我先从earlySingletonObjects 中去找,没有找到的话。我在去singletonFactories 中去找。
3.源码分析:
首先在我们spring中有三级缓存
// 从上至下 分表代表这“三级缓存”//一级缓存 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); //二级缓存 提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); // 三级缓存 单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); 1. 在构造Bean对象之后,将对象提前曝光到三级缓存中,这时候曝光的对象仅仅是构造完成,还没注入属性和初始化。
public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactoryimplements AutowireCapableBeanFactory {protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)''''''throws BeanCreationException { // 这里就是调用你的构造方法,进行创建对象if (instanceWrapper == null) {instanceWrapper = createBeanInstance(beanName, mbd, args);}Object bean = instanceWrapper.getWrappedInstance();'''''''// mbd.isSingleton() 判断对象是否是单例的// 当前对象是否允许循环依赖 this.allowCircularReferences 默认是true// isSingletonCurrentlyInCreation(beanName) 当前对象是否在创建中boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}// 循环依赖-添加到三级缓存中。value是lambda表达式,这个时候并未执行addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}……}
}
2. 提前曝光的对象被放入Map<String, ObjectFactory<?>> singletonFactories缓存中,这里并不是直接将Bean放入缓存,而是包装成ObjectFactory对象再放入。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {// 一级缓存if (!this.singletonObjects.containsKey(beanName)) {// 添加到三级缓存中this.singletonFactories.put(beanName, singletonFactory);// 从二级缓存中移除,因为在spring中bean是单例的,防止后面出现bug导致不是单例this.earlySingletonObjects.remove(beanName);// 将当前bean加入到set当中this.registeredSingletons.add(beanName);}}}
3. 为什么要包装一层ObjectFactory对象?
这里也就是Spring为什么采用第三级缓存的主要原因。
如果创建的Bean有对应的代理,那其他对象注入时,注入的应该是对应的代理对象;但是Spring无法提前知道这个对象是不是有循环依赖的情况,而正常情况下(没有循环依赖情况),Spring都是在创建好完成品Bean之后才创建对应的代理。这时候Spring有两个选择:
1.不管有没有循环依赖,都提前创建好代理对象,并将代理对象放入缓存,出现循环依赖时,其他对象直接就可以取到代理对象并注入。
2.不提前创建好代理对象,在出现循环依赖被其他对象注入时,才实时生成代理对象。这样在没有循环依赖的情况下,Bean就可以按着Spring设计原则的步骤来创建。
Spring选择了第二种方式,那怎么做到提前曝光对象而又不生成代理呢?
Spring就是在对象外面包一层ObjectFactory,提前曝光的是ObjectFactory对象,在被注入时才在ObjectFactory.getObject方式内实时生成代理对象,并将生成好的代理对象放入到第二级缓存Map<String, Object> earlySingletonObjects。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);}}return exposedObject;}
为了防止对象在后面的初始化(init)时重复代理,在创建代理时,earlyProxyReferences缓存会记录已代理的对象。
@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);this.earlyProxyReferences.put(cacheKey, bean);return wrapIfNecessary(bean, beanName, cacheKey);}在这里spring会创建对象,判断你是否需要代理,是否创建代理对象。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {return bean;}if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {return bean;}if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}// Create proxy if we have advice.Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);if (specificInterceptors != DO_NOT_PROXY) {this.advisedBeans.put(cacheKey, Boolean.TRUE);Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));this.proxyTypes.put(cacheKey, proxy.getClass());return proxy;}this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}
也可以理解为三级缓存的ObjectFactory其实在做的是一种缓存机制,当我们后面初始化需要代理时,Spring就会先从这个缓存中去拿代理对象,拿得到就不创建代理对象,而是使用这个代理对象。
4. 注入属性和初始化
Spring会调用populateBean()进行属性注入,然后该对象在单例池中,就直接从单例池拿,不在就进行对象的创建并注入。
public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactoryimplements AutowireCapableBeanFactory {protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)throws BeanCreationException {……// Initialize the bean instance.Object exposedObject = bean;try {// 注入属性populateBean(beanName, mbd, instanceWrapper);exposedObject = initializeBean(beanName, exposedObject, mbd);}catch (Throwable ex) {if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {throw (BeanCreationException) ex;}else {throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);}}……}
}
在进行对象创建过程中会调用getSingleton方法从缓存中获取注入对象
// 获取要注入的对象protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 先从单例池一级缓存中拿,看能不能获取beanObject singletonObject = this.singletonObjects.get(beanName);// 如果单例池拿的是空,并且正在创建中if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {// 那么就在从二级缓存中去拿singletonObject = this.earlySingletonObjects.get(beanName);// 如果二级缓存中没有,就加锁在进行判断if (singletonObject == null && allowEarlyReference) {synchronized (this.singletonObjects) {// 如果一级缓存还是没有singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {// 就找二级缓存 singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {// 二级缓存还是没有就找三级缓存ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 三级缓存获取到了,(这时三级缓存会执行lambad表达式并创建普通对象或者代理对象)singletonObject = singletonFactory.getObject();// 把获取到的对象放入二级缓存中this.earlySingletonObjects.put(beanName, singletonObject);// 从三级缓存删除该对象,防止lambad表达式重复执行,防止出现bug让spring不能保证单例this.singletonFactories.remove(beanName);}}}}}}return singletonObject;}
5.放入已完成创建的单例缓存中
最终Spring会通过addSingleton方法将最终生成的可用的Bean放入到单例缓存里。
/*** Add the given singleton object to the singleton cache of this factory.* <p>To be called for eager registration of singletons.* @param beanName the name of the bean* @param singletonObject the singleton object*/protected void addSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {// 将创建好的bean放入一级缓存,单例池中this.singletonObjects.put(beanName, singletonObject);// 删除三级缓存this.singletonFactories.remove(beanName);// 删除二级缓存this.earlySingletonObjects.remove(beanName);// 放入已注册实例的Set集合当中this.registeredSingletons.add(beanName);}}
总结:
1.Spring有哪三级缓存
// 从上至下 分表代表这“三级缓存”//一级缓存 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); //二级缓存 提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); // 三级缓存 单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); 2.只要二级缓存,不要三级缓存可不可以。
其实我试验过,用二级缓存也可以达到和三级缓存同样的效果。只不过为了不违背Spring设计原则,Spring采用了三级缓存。
Spring结合AOP跟Bean的生命周期,是在Bean创建完全之后通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
3. Spring三级缓存完整流程思路
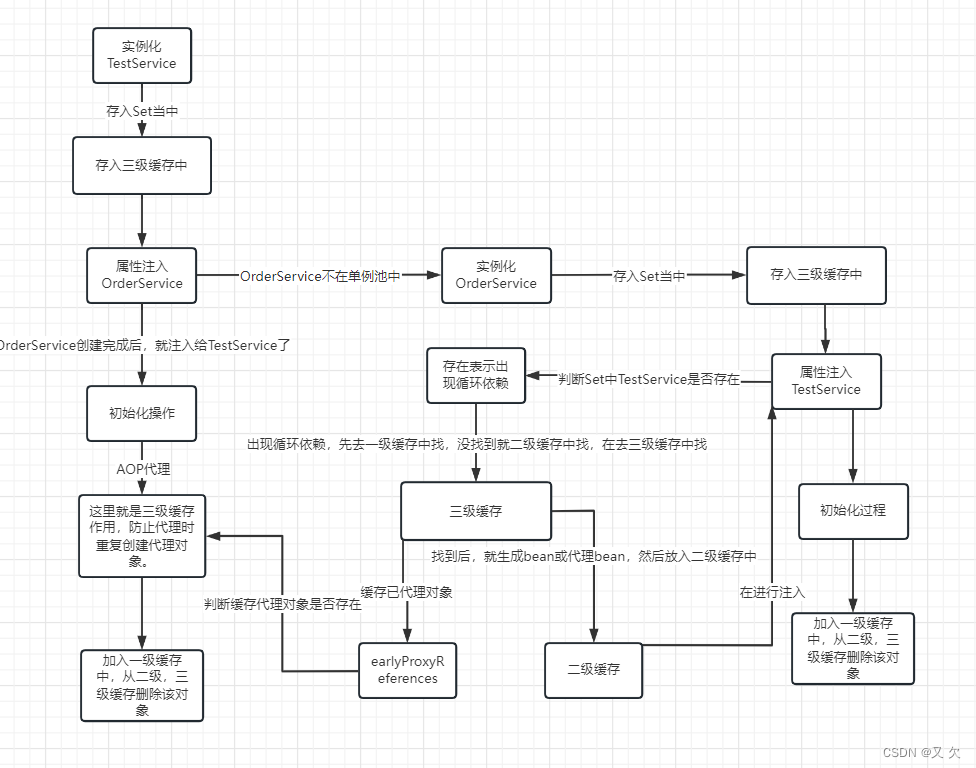
-
实例化普通对象UserService (对象U),将普通对象U加入Set集合(判断是不是在创建中),将对象U加入三级缓存
-
U注入属性OrderService(对象O),发现O不在创建中,实例化普通对象OrderService (对象O))将对象O加入Set集合(用于判断是不是在创建中),将对象O加入三级缓存。
-
O注入属性U,发现对象U在创建中(循环依赖),在一级缓存中找(没找到),在二级缓存中找(没找到),在三级缓存中(找到了),创建对象U的代理对象。将代理对象加入二级缓存,并在三级缓存中进行remove,将U的代理对象注入给O
-
注入完属性后,就进行初始化等操作,完成对象的创建。将O注入到一级缓存中,从二级,三级缓存删除O对象。
-
O对象创建完成后,U对象就注入属性O的代理对象,U在完成初始化等操作,最后将U注入到一级缓存中,从二级,三级缓存删除O对象。
相关文章:
Spring是怎么解决循环依赖的
1.什么是循环依赖: 这里给大家举个简单的例子,相信看了上一篇文章大家都知道了解了spring的生命周期创建流程。那么在Spring在生命周期的哪一步会出现循环依赖呢? 第一阶段:实例化阶段 Instantiation 第二阶段:属性赋…...
HTML创意动画代码
目录1、动态气泡背景2、创意文字3、旋转立方体1、动态气泡背景 <!DOCTYPE html> <html> <head><title>Bubble Background</title><style>body {margin: 0;padding: 0;height: 100vh;background: #222;display: flex;flex-direction: colum…...

软工第一次个人作业——阅读和提问
软工第一次个人作业——阅读和提问 项目内容这个作业属于哪个课程2023北航敏捷软件工程这个作业的要求在哪里个人作业-阅读和提问我在这个课程的目标是体验敏捷开发过程,掌握一些开发技能,为进一步发展作铺垫这个作业在哪个具体方面帮助我实现目标对本课…...

urho3d的自定义文件格式
Urho3D尽可能使用现有文件格式,仅在绝对必要时才定义自定义文件格式。当前使用的自定义文件格式有: 二进制模型格式(.mdl) Model geometry and vertex morph data byte[4] Identifier "UMDL" or "UMD2" …...
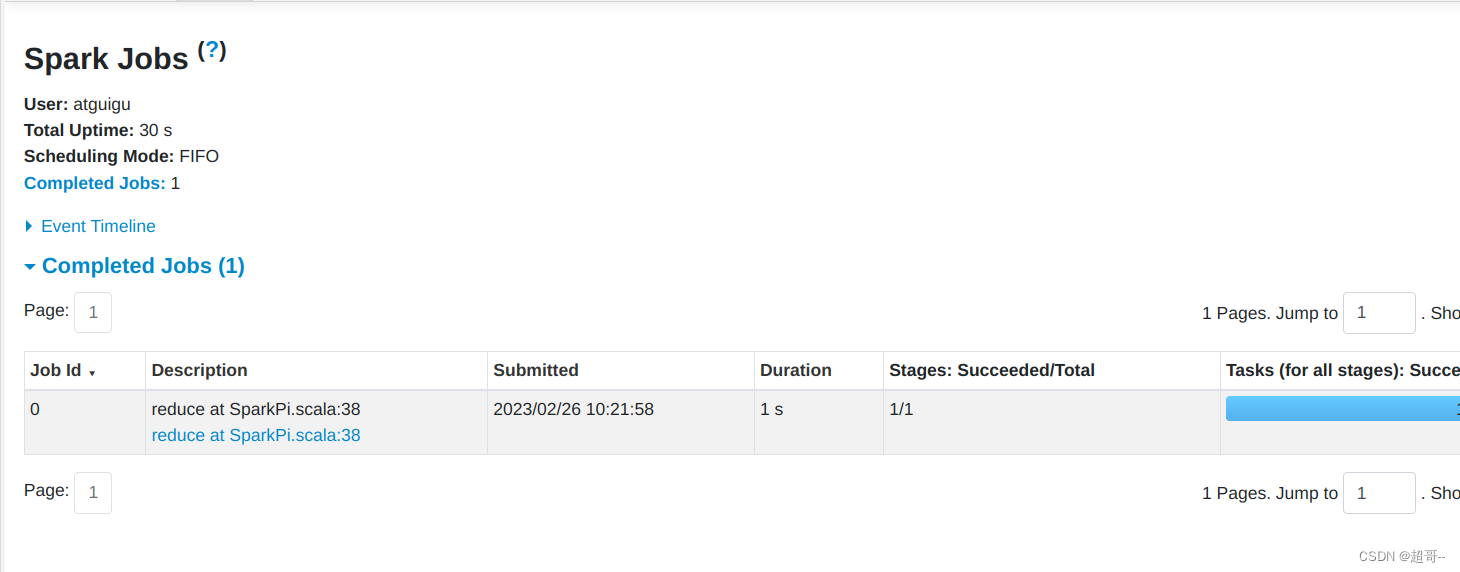
spark第一章:环境安装
系列文章目录 spark第一章:环境安装 文章目录系列文章目录前言一、文件准备1.文件上传2.文件解压3.修改配置4.启动环境二、历史服务器1.修改配置2.启动历史服务器总结前言 spark在大数据环境的重要程度就不必细说了,直接开始吧。 一、文件准备 1.文件…...

MySQL---存储过程与存储函数的相关概念
MySQL—存储过程与存储函数的相关概念 存储函数和存储过程的主要区别: 存储函数一定会有返回值的存储过程不一定有返回值 存储过程和函数能后将复杂的SQL逻辑封装在一起,应用程序无需关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调…...

PMP值得考吗?
第一,PMP的价值体现 1、PMP是管理岗位必考证书。 多数企业会选择优先录用持PMP证书的管理人才,PMP成为管理岗位的必考证书。PMP在很多外企和国内中大型企业非常受重视,中石油、中海油、华为等等都会给内部员工做培训。 这些机构对项目管理…...
)
Quartus 报错汇总(持续更新...)
1、Error (10663): Verilog HDL Port Connection error at top_rom.v(70): output or inout port "stcp" must be connected to a structural net expression输出变量stcp在原设计文件中已经定义为reg型,在实例化时不能再定义为reg型,而应该是…...
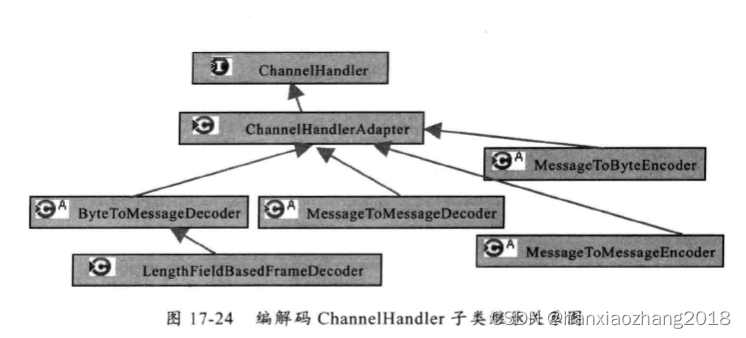
Netty权威指南总结(一)
一、为什么选择Netty:API使用简单,开发门槛低,屏蔽了NIO通信的底层细节。功能强大,预制了很多种编解码功能,支持主流协议。定制能力强,可以通过ChannelHandler对通信框架进行灵活地拓展。性能高、成熟、稳定…...

Elasticsearch:如何轻松安全地对实时 Elasticsearch 索引重新索引你的数据
在很多的时候,由于一些需求,我们不得不修改索引的映射,也即 mapping,这个时候我们需要重新索引(reindex)来把之前的数据索引到新的索引中。槽糕的是,我们的这个索引还在不断地收集实时数据&…...

【算法笔记】前缀和与差分
第一课前缀和与差分 算法是解决问题的方法与步骤。 在看一个算法是否优秀时,我们一般都要考虑一个算法的时间复杂度和空间复杂度。 现在随着空间越来越大,时间复杂度成为了一个算法的重要指标,那么如何估计一个算法的时间复杂度呢…...
)
python实战应用讲解-【实战应用篇】函数式编程-八皇后问题(附示例代码)
目录 知识储备-迭代器相关模块 itertools 模块 创建新的迭代器 根据最短输入序列长度停止的迭代器...
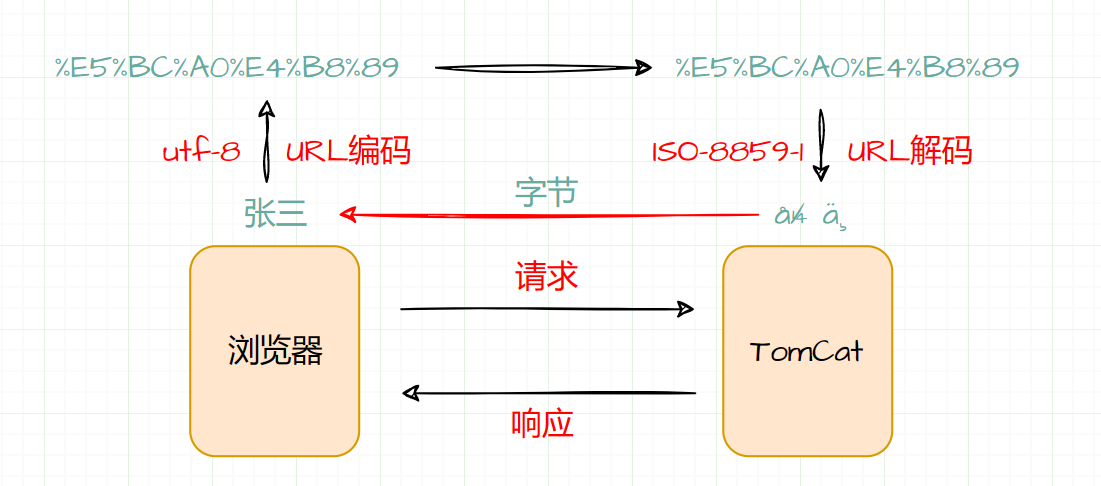
【Servlet篇】如何解决Request请求中文乱码的问题?
前言 前面一篇文章我们探讨了 Servlet 中的 Request 对象,Request 请求对象中封装了请求数据,使用相应的 API 就可以获取请求参数。 【Servlet篇】一文带你读懂 Request 对象 也许有小伙伴已经发现了前面的方式获取请求参数时,会出现中文乱…...

SpringBoot:SpringBoot简介与快速入门(1)
SpringBoot快速入门1. SpringBoot简介2. SpringBoot快速入门2.1 创建SpringBoot项目(必须联网,要不然创建失败,在模块3会讲到原因)2.2 编写对应的Controller类2.3 启动测试3. Spring官网构建工程4. SpringBoot工程快速启动4.1 为什…...
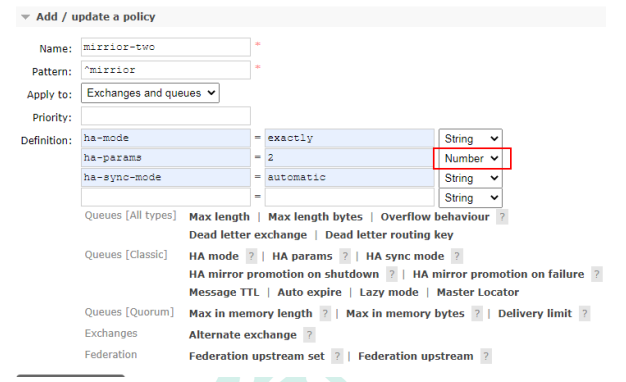
RabbitMQ学习(十一):RabbitMQ 集群
一、集群1.1 为什么要使用集群前面我们介绍了如何安装及运行 RabbitMQ 服务,不过这些是单机版的,无法满足目前真实应用的 要求。如果 RabbitMQ 服务器遇到内存崩溃、机器掉电或者主板故障等情况,该怎么办?单台 RabbitMQ 服务器可以…...
学渣适用版——Transformer理论和代码以及注意力机制attention的学习
参考一篇玩具级别不错的代码和案例 自注意力机制 注意力机制是为了transform打基础。 参考这个自注意力机制的讲解流程很详细, 但是学渣一般不知道 key,query,value是啥。 结合B站和GPT理解 注意力机制是一种常见的神经网络结构࿰…...

网上这么多IT的培训机构,我们该怎么选?
说实话,千万不要把这个答案放在网上来找,因为你只能得到别人觉得合适的或者机构的广告;当然个人的培训经历可以听一听的,毕竟不靠谱的机构也有,比如让你交一两万去上线上课程或者一百号来人坐一起看视频,这…...
)
数据结构与算法—跳表(skiplist)
目录 前言 跳表 查询时间分析 1、时间复杂度 o(logn) 2、空间复杂度O(n) 动态插入和删除 跳表动态更新 跳表与红黑树比较 跳表实现 前言 二分查找用的数组 链表可不可以实现二分查找呢? 跳表 各方面性能比较优秀的动态数据结构,可以支持快速…...

【C++】5.C/C++内存管理
1.C/C内存管理 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";char* pChar3 "abcd";int* ptr1 (int*)malloc(sizeof (int)*4);int* ptr2 …...
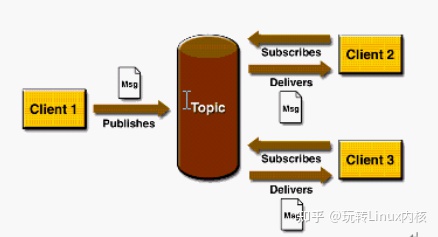
一文让你彻底理解关于消息队列的使用
一、消息队列概述 消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。目前使用较多的消息队列有ActiveMQ,Rabbit…...

3步搞定黑苹果:OpCore-Simplify自动化配置工具深度体验
3步搞定黑苹果:OpCore-Simplify自动化配置工具深度体验 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而头痛不已…...

HDF5文件可视化指南:用HDFView检查你的Python数据存储结果
HDF5文件可视化指南:用HDFView检查你的Python数据存储结果 当你用Python处理完一批数据并存入HDF5文件后,最让人忐忑的莫过于——数据真的按预期存储了吗?结构是否正确?数值有无异常?本文将带你用HDFView这款专业工具&…...

3大核心突破!MAT图像修复技术全解析:从环境部署到实战应用
3大核心突破!MAT图像修复技术全解析:从环境部署到实战应用 【免费下载链接】MAT MAT: Mask-Aware Transformer for Large Hole Image Inpainting 项目地址: https://gitcode.com/gh_mirrors/ma/MAT MAT(Mask-Aware Transformer for La…...

逆向分析实战:从IDA反编译看bjdctf_2020_babystack的栈溢出漏洞成因与利用
逆向工程实战:bjdctf_2020_babystack栈溢出漏洞的深度解析 在二进制安全领域,栈溢出漏洞始终是攻防对抗的经典课题。今天我们将以bjdctf_2020_babystack这道CTF题目为案例,通过IDA Pro的静态分析视角,完整还原从漏洞发现到利用的…...

解锁智能监控:提升网页变化追踪效率的完整指南
解锁智能监控:提升网页变化追踪效率的完整指南 【免费下载链接】changedetection.io The best and simplest free open source website change detection, website watcher, restock monitor and notification service. Restock Monitor, change detection. Designe…...

保姆级教程:在MounRiver Studio上为CH32V307配置FreeRTOS与LwIP网络栈
从零构建CH32V307物联网网关:FreeRTOS与LwIP全流程实战指南 当一块搭载RISC-V内核的CH32V307开发板遇上实时操作系统与轻量级TCP/IP协议栈,会碰撞出怎样的火花?本文将带你完整经历从开发环境搭建到网络功能验证的全过程。不同于简单的代码移植…...

PT 助手 Plus:全方位提升 PT 站点种子下载体验
PT 助手 Plus:全方位提升 PT 站点种子下载体验 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项目地址: h…...

3分钟彻底解决Windows安装错误2502/2503:AtlasOS一键修复方案揭秘 [特殊字符]
3分钟彻底解决Windows安装错误2502/2503:AtlasOS一键修复方案揭秘 🚀 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.…...

有关数组的学习
数组的概念简介数组是编程中最基础也最常用的数据结构之一,理解它能帮你高效管理一组同类型的数据。1. 什么是数组?核心概念同类型:数组里的所有元素必须是相同的数据类型(如全是 int 或全是 float)。连续内存…...
)
Vant4移动端电商实战:用Card和Cell组件打造订单详情页(附完整代码)
Vant4移动端电商实战:用Card和Cell组件打造订单详情页(附完整代码) 在移动电商应用开发中,订单详情页是用户查看购买信息的重要界面。Vant4作为轻量、可靠的移动端组件库,其Card和Cell组件能够快速构建清晰、美观的订单…...