BLIP2-图像文本预训练
文章目录
- 摘要
- 解决问题
- 算法
- 模型结构
- 通过frozen图像编码器学习视觉语言表征
- 图像文本对比学习(ITC)
- 基于图像文本生成(ITG)
- 图文匹配(ITM)
- 从大规模语言模型学习视觉到语言生成
- 模型预训练
- 预训练数据
- 预训练图像编码器与LLM
- 预训练设置
- 实验
- 引导零样本图像到文本生成
- 零样本VQA
- 图像描述
- 视觉问答
- 图像文本检索
- 限制
- 结论
论文: 《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models》
github: https://github.com/salesforce/LAVIS/tree/main/projects/blip2
摘要
训练大尺度视觉语言预训练模型成本比较高,BLIP-2,基于现有的图像编码器预训练模型,大规模语言模型进行预训练视觉语言模型;BLIP-2通过轻量级两阶段预训练模型Querying Transformer缩小模态之间gap,第一阶段从冻结图像编码器学习视觉语言表征,第二阶段基于冻结语言模型,进行视觉到语言生成学习;BLIP-2在各种视觉-语言模型达到SOTA。比如在zero-shot VQAv2上超越Flamingo80B 8.7%,也证明该模型可以根据自然语言指引进行zero-shot图像到文本生成。
解决问题
端到端训练视觉语言模型需要大尺度模型及大规模数据,该过程成本大,本文提出方法基于现有高质量视觉模型及语言大模型进行联合训练,为减少计算量及防止遗忘,作者对预训练模型进行frozen,为了将两任务对齐,作者提出Querying Transformer (Q- Former) 预训练,如图1,其将有用视觉特征传递至LLM输出目标文本。

BLIP-2优势如下:
1、高效利用frozen预训练视觉及语言模型;
2、由于大规模语言模型能力,BLIP-2可以根据提示进行zero-shot图像到文本生成;
3、由于使用frozen单模态预训练模型,BLIP-2与现有SOTA方案相比,计算更加高效;
算法
为了对齐视觉特征到LLM文本空间,作者提出Q-Former,进行两阶段预训练:
1、图像编码器frozen进行学习视觉语言表征;
2、使用frozen LLM进行学习视觉到文本生成;
模型结构
如图2,Q-Former包括两个贡共享self-attention层的transformer子模块:图像transformer(Q-Former左半部分)与frozen image encoder相互作用提取视觉特征;文本transformer(Q-Former右半部分)可作为文本编码器,也可作为文本解码器。
可学习query embedding作为图像transformer输入,通过self-attention层相互作用,通过cross-attention层与frozen图像特征相互作用,query同时通过self-attention层与文本相互作用。根据预训练任务,作者使用不同self-attention mask控制query-text之间交互;作者使用BERTbaseBERT_{base}BERTbase初始化Q-Former,cross-attention层进行随机初始化;

通过frozen图像编码器学习视觉语言表征
query通过学习提升与text相关视觉表征,受BLIP启发,作者通过3个目标函数,共享相同输入格式及模型参数,每个目标函数通过不同attention mask策略控制query与text之间相互影响,如图2所示;
图像文本对比学习(ITC)
ITC学习对齐图像表征与文本表征,通过比较成对与非成对的图像-文本相似度实现;计算过程如下:
计算image transformer输出query表征ZZZ(与可学习query长度相同)与text transformer输出文本表征 ttt 中【CLS】token相似性,选取最大值作为图像文本对相似度,为防止信息泄露,作者使用单模态self-attention mask,query与text不能互相可见;由于image encoder进行frozen,显存释放,可以使用batch负样本而不用像BLIP中使用队列。
基于图像文本生成(ITG)
ITG根据输入图像训练Q-Former生成文本,由于Q-Former不允许image encoder与text token直接交互,文本生成所需信息通过query进行提取,通过self-attention进行传递至text token,因此query需要捕获文本相关所有信息,作者使用多模态因果self-attention mask控制query-text交互,query无法获取text token,当前text token 可获取所有query及其之前text token。作者将【CLS】token替换为【DEC】token 作为解码任务标记;
图文匹配(ITM)
ITM为了学习精细化图像文本匹配,作者使用bi-dirention self-atttention mask,所有query与text相互可见,因此输出的query embedding Z捕获多模态信息,Z通过二类线性分类器获取logit,logit均值为匹配得分,作者使用《Align before Fuse》中难例负样本挖掘策略创建负样本对。
难例负样本挖掘策略:
当负样本的图像文本对有相同的语义但在细粒度细节上不同,那么该样本是难样本。作者通过对比相似度寻找batch内的 hard negatives。对于一个batch中的每一幅图像,作者根据对比相似性分布从相同的batch中抽取一个负文本,其中与图像更相似的文本有更高的可能被采样。同样的,作者还为每个文本采样一个hard negative图像。
从大规模语言模型学习视觉到语言生成
作者将Q-Former与LLM相连,后去LLM的语言生成能力。如图3,FC层映射输出的query embedding Z至LLM的text embedding;基于LLM Q-Former提取到的视觉表征作为soft visual prompt,由于Q-Former已经预训练用于提取对文本有用的视觉表征,减轻LLM学习视觉-文本对齐的负担。

作者实验两种LLM,decoder-based LLM以及encoder-decoder-based LLM。
对于decoder-based LLM,作者使用language modeling loss进行预训练,frozen LLM进行文本生成;
对于encoder-decoder-based LLM,使用prefix language modeling loss预训练,将text分为两部分,text前半部分与视觉表征concat输入LLM编码器,后半部分作为LLM解码器的生成目标。
模型预训练
预训练数据
BLIP-2使用与BLIP相同数据,129M图片,包括COCO、Visual Genome、CC3M、CC12M、SBU,其中115M来自 LAION400M,使用CapFilt对网图进行生成caption,具体步骤如下:
1、使用BLIPlargeBLIP_{large}BLIPlarge生成10个caption;
2、生成10个caption+原始web caption通过CLIP ViT-L/14模型与对应图像进行相似度排序;
3、选取top2作为该图的caption,以此作为训练数据;
预训练图像编码器与LLM
两个SOTA视觉transformer预训练模型:
ViT-L/14 from CLIP、ViT-G/14 from EVA-CLIP
移除ViT最后一层,使用倒数第二层特征。
LLM模型:
无监督训练的OPT作为decoder-based LLM
基于指令训练的FlanT5作为encoder-decoder-based LLM
预训练设置
第一阶段训练250k step,第二阶段训练80k step;ViT和LLM 转为FP16,FlanT5转为BFloat16,作者发现相对于32-bit,性能无下降;由于使用frozen模型,作者预训练比现在大规模VLP方法计算量都小,在16个A100(40G)上,对于ViT-G和FlanT5-XXL第一阶段训练耗时6天,第二阶段少于3天。
实验
表1展示BLIP-2在各种零样本视觉语言任务上表现,与之前SOTA方法相比,性能得到改善,而且训练参数大量减少;

引导零样本图像到文本生成
BLIP-2使得LLM具有图像理解能力,同时保留遵循文本提示的能力;作者在视觉promt后增加简单文本promt,图4展示BLIP-2零样本图像文本生成能力,包括:视觉知识推理、视觉共鸣推理、视觉对话、个性化图像到文本生成等。

零样本VQA
表2表明,BLIP-2在VQAv2及GQA数据集达到SOTA。
表2得到一个有希望的发现:一个更好的图像编码器或LLM模型都将使得BLIP-2性能更好;
基于OPT或FlanT5,BLIP-2使用ViT-G性能超越使用VIT-L;
图像编码器固定,BLIP-2使用大LLM模型性能超越使用小模型;
在VQA上,基于指令训练的的FlanT5性能优于无监督训练的OPT;

第一阶段预训练使得Q-Former学习与文本相关视觉表征,图5展示表征学习对生成式学习有效性,不进行表征学习,两种LLM模型在零样本VQA任务上性能大幅下降。

图像描述
表3表明,BLIP-2在NoCaps性能达到SOTA,证明对out-domain图像具有很强生成能力。

视觉问答
Q-Former的输出以及question作为LLM的输入,LLM生成对应answer,为了提取与问题相关图像特征,作者将question输入Q-Former,通过self-attention层与query进行交互,引导Q-Former的cross-attention层更加关注图中有效区域。表4表明BLIP-2在开放式生成模型中达到SOTA。

图像文本检索
图文检索不需要语言模型,作者在COCO数据集将图像编码器与Q-Former一起进行finetune,在COCO及Flickr30K数据集进行图像文本检索以及文本图像检索,作者首先根据图文特征相似度挑选128个样本,而后根据ITM score进行排序。
如表5,BLIP-2在零样本图文检索达到SOTA,相对现有方法,得到显著提升。

表6表明ITG损失对图文检索也有帮助,由于ITG损失版主query提取与文本相关视觉特征。

限制
当LLM模型使用上下文VQA样本时,BLIP-2并未在VQA任务上提升性能,作者归因于预训练数据集为仅有一对图像文本样本,无法学习一个序列中多个图像文本对之间相关性。
BLIP-2在图像文本生成任务仍存在一些不足:LLM不准确知识,不正确推理路径、对于一些新图像缺少相关信息,如图6所示。

结论
BLIP-2是一种通用且计算高效的视觉语言预训练方案,使用frozen 预训练图像编码器及LLM,在多个视觉语言任务达到SOTA,也证明了其在零样本instructed image-to-text生成能力。
相关文章:
BLIP2-图像文本预训练
文章目录摘要解决问题算法模型结构通过frozen图像编码器学习视觉语言表征图像文本对比学习(ITC)基于图像文本生成(ITG)图文匹配(ITM)从大规模语言模型学习视觉到语言生成模型预训练预训练数据预训练图像编码…...
Faster-Rcnn修改转数据集文件
目录 学习python的一些基础知识 argparser assert关键字 让你秒懂Python 类特殊方法__getitem__ lxml.etree.fromstring的使用 统计一下json文件内的种类 正脸红外光 正脸-混合红外光 正脸-交叉偏振光 正脸-平行偏振光 正脸-紫外光 正脸-棕色光 调用mydataset可视化…...
带你沉浸式体验删库跑路
前言:学习的过程比较枯燥,后面会记录一些比较有意思的东西,比如程序员之间流传的删库跑路的梗,当然本次测试是在虚拟机上进行的并进行了快照保护,所以其实没太大问题。首先得要有一个虚拟机要有一个linux iso文件装在虚拟机上以上两点不是本文重点,如果有需要可以私…...
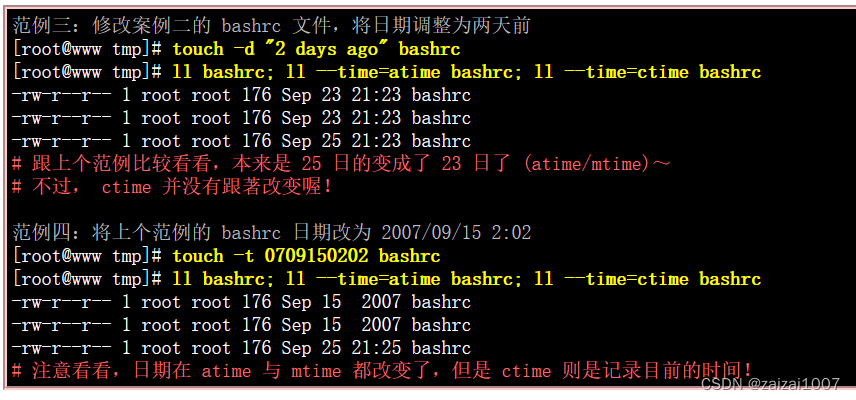
Linux学习(8.5)文件内容查阅
目录 文件内容查阅: 直接检视文件内容 cat (concatenate) tac (反向列示) nl (添加行号列印) 可翻页检视 more (一页一页翻动) less (一页一页翻动) 数据撷取 tail (取出后面几行) 非纯文字档: od 修改文件时间或建置新档: touc…...
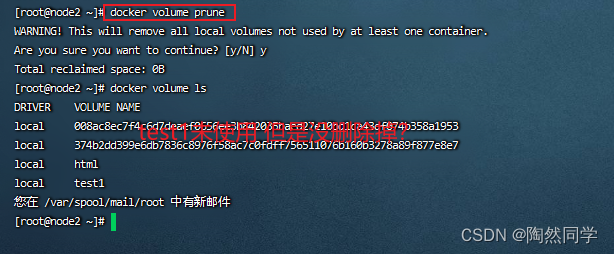
【Docker】命令总结
目录 1.镜像命令 1.1拉取镜像 1.2查看镜像 1.3保存镜像 1.4导入镜像 2.容器命令 2.1创建并运行容器 2.2删除容器 2.3进入容器 2.4查看容器状态 2.5暂停容器 2.6恢复容器 2.7停止容器 2.8启动容器 2.8查看容器日志 3.数据卷命令 3.1创建数据卷 3.2查看所有数据…...
并发编程-学习总结(上)
目录 1、线程基础 1.1、线程实现方法 1.2、如何正确停止线程 1.3、Java线程的六种状态 1.4、wait/notify/notifyAll注意事项 1.4.1、为什么 wait 、notify、notifyAll必须在 synchronized 保护的同步代码中使用? 1.4.2、为什么 wait/notify/notifyAll 被定义…...
QT之OpenGL混合
QT之OpenGL混合1. 概述2. 实现2.1 丢弃片段2.1.1 Demo2.2 混合2.2.1 相关函数2.2.2 排序问题2.2.3 Demo1. 概述 OpenGL中,混合(Blending)通常是实现物体透明度(Transparency)的一种技术。 2. 实现 2.1 丢弃片段 在某些情况下,有些片段是只需要设置显…...

【1255. 得分最高的单词集合】
来源:力扣(LeetCode) 描述: 你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。 请你帮忙计算玩家在单词拼写游戏中所能获…...

nginx模块介绍
新编译前,在对应的nginx原编译文件夹 如:nginx-1.23.0 下,要 make clean 清空以前编译的objs文件夹,实际上就是执行了rm objs文件夹。 很多要用到git,先yum install git -y echo-nginx-module 让nginx直接使用echo的…...
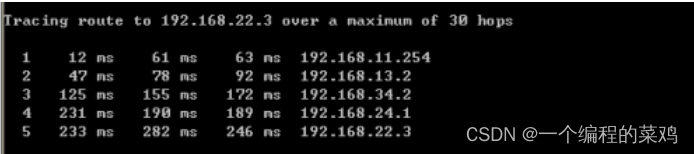
排错工具ping和trace(电子科技大学TCP/IP实验四)
一.实验目的 1、了解网络连通性测试的方法和工作原理 2、了解网络路径跟踪的方法和工作原理 3、掌握 MTU 的概念和 IP 分片操作 4、掌握 IP 分组生存时间(TTL)的含义和作用 5、掌握路由表的作用和路由查找算法 二.预备知识 …...

node.js中ws模块创建服务端和客户端
一、WebSocket出现的原因 1、Http协议发布REST API 的不足: 每次请求响应完成之后,服务器与客户端之间的连接就断开了,如果客户端想要继续获取服务器的消息,必须再次向服务器发起请 求。这显然无法适应对实时通信有高要求的场景…...

kubernates-1.26.1 kubeadm containerd 单机部署
k8s1.26 kubeadm containerd 安装 kubeadm init 时提示 containerd 错误 failed to pull image “k8s.gcr.io/pause:3.6” 报错日志显示containerd pull时找不到对应的pause版本,而不是registry.k8s.io/pause:3.9 [rootk8s-master containerd]# kubeadm init --k…...
如何在 iPhone 上恢复已删除的通话记录/通话记录
您的通话记录/通话记录可能很重要,尤其是当您想要拨打之前联系过但未保存的号码时。如果您碰巧删除了通话记录(有意或无意),本指南将帮助您了解如何检索它们并找回您需要使用的所有记录。我们将根据您的情况和您拥有的工具讨论不同…...
Canonical为所有支持的Ubuntu LTS系统发布了新的Linux内核更新
导读Canonical近日为所有支持的Ubuntu LTS系统发布了新的Linux内核更新,以解决总共19个安全漏洞。新的Ubuntu内核更新仅适用于长期支持的Ubuntu系统,包括Ubuntu 22.04 LTS(Jammy Jellyfish)、Ubuntu 20.04 LTS(Focal F…...
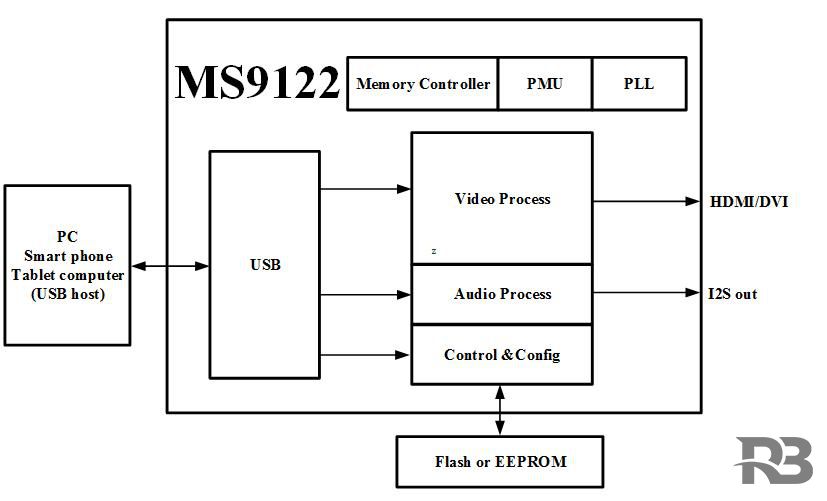
MS9122是一款USB单芯片投屏器,内部集成了USB2 0 控制器和数据收发模块、HDMI 数据接口和音视频处理模块。MS9122可以通过USB接口显示
MS9122是一款USB单芯片投屏器,内部集成了USB2.0 控制器和数据收发模块、HDMI 数据接口和音视频处理模块。MS9122可以通过USB接口显示或者扩展PC、智能手机、平板电脑的显示信息到更大尺寸的显示设备,支持HDMI视频接口。 主要功能特征 HDMI v1.4兼容 最大…...

C++学习笔记-数据抽象
简单的说,数据抽象是用来描述数据结构的。数据抽象就是 ADT。一个 ADT 主要表现为它支持的一些操作,比方说 stack.push、stack.pop,这些操作应该具有明确的时间和空间复杂度。另外,一个 ADT 可以隐藏其实现细节,比方说…...

【Android】Android开发笔记(一)
【Android】Android开发笔记(一) 在Android Studio中import module和delete moduleimport moduledelete moduleAndroid Studio中App(Module)无法正常运行在实机上测试App一些基本概念App的工程结构结语在Android Studio中import m…...

C语言数据结构(二)—— 受限线性表 【栈(Stack)、队列(Queue)】
在数据结构逻辑层次上细分,线性表可分为一般线性表和受限线性表。一般线性表也就是我们通常所说的“线性表”,可以自由的删除或添加结点。受限线性表主要包括栈和队列,受限表示对结点的操作受限制。一般线性表详解,请参考文章&…...
线程安全之synchronized和volatile
目录 1.线程不安全的原因 2.synchronized和volatile 2.1 synchronized 2.1.1 synchornized的特性 2.1.2 synchronized使用示例 2.2 volatile 我们先来看一段代码: 分析以上代码,t1和t2这两个线程的任务都是分别将count这个变量自增5000次ÿ…...

量子计算对网络安全的影响
量子计算的快速发展,例如 IBM 的 Quantum Condor 处理器具有 1000 个量子比特的容量,促使专家们宣称第四次工业革命即将实现“量子飞跃”。 量子计算机的指数处理能力已经受到政府和企业的欢迎。 由于从学术和物理原理到商业可用解决方案的不断转变&am…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
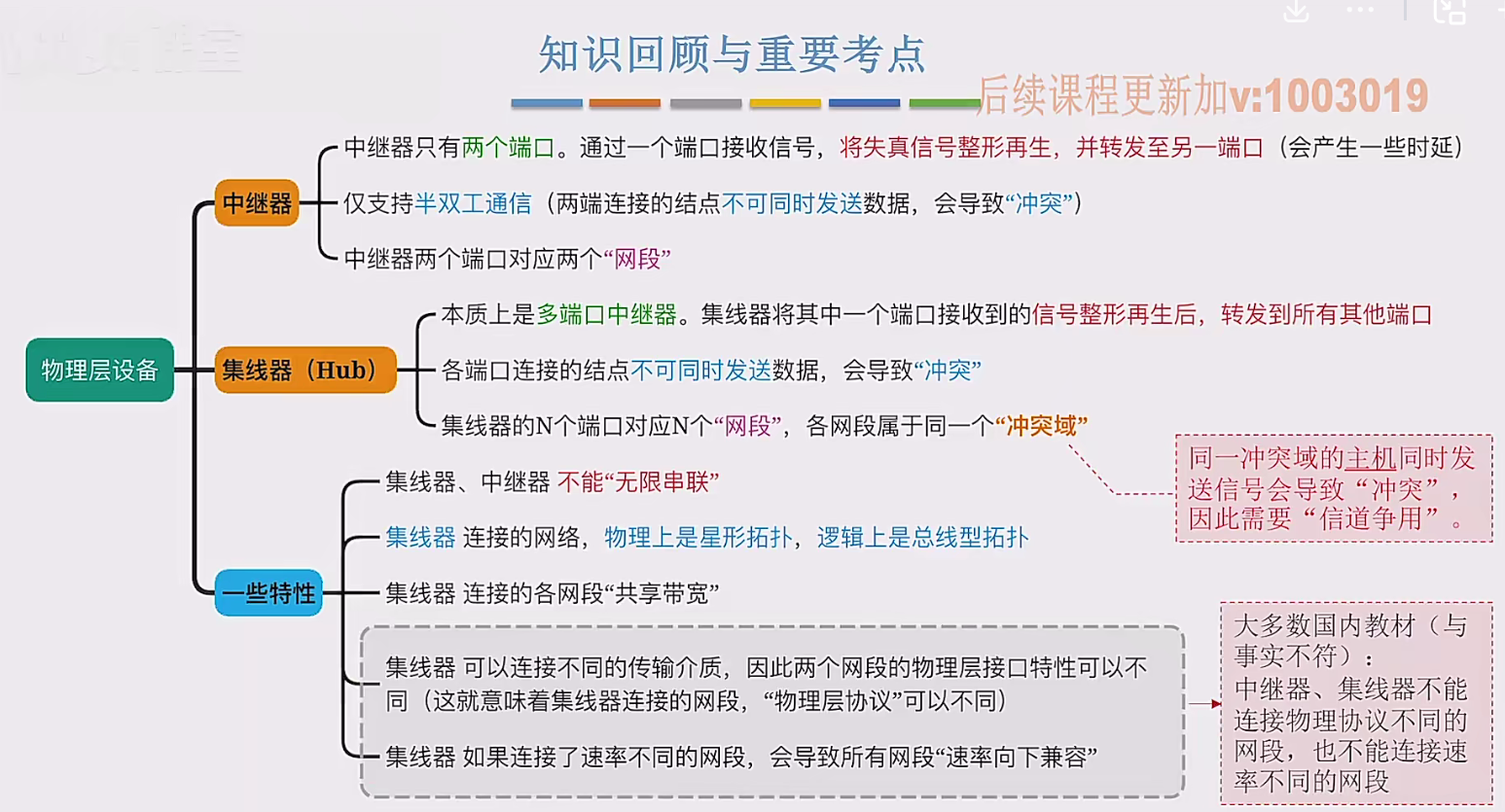
2.3 物理层设备
在这个视频中,我们要学习工作在物理层的两种网络设备,分别是中继器和集线器。首先来看中继器。在计算机网络中两个节点之间,需要通过物理传输媒体或者说物理传输介质进行连接。像同轴电缆、双绞线就是典型的传输介质,假设A节点要给…...
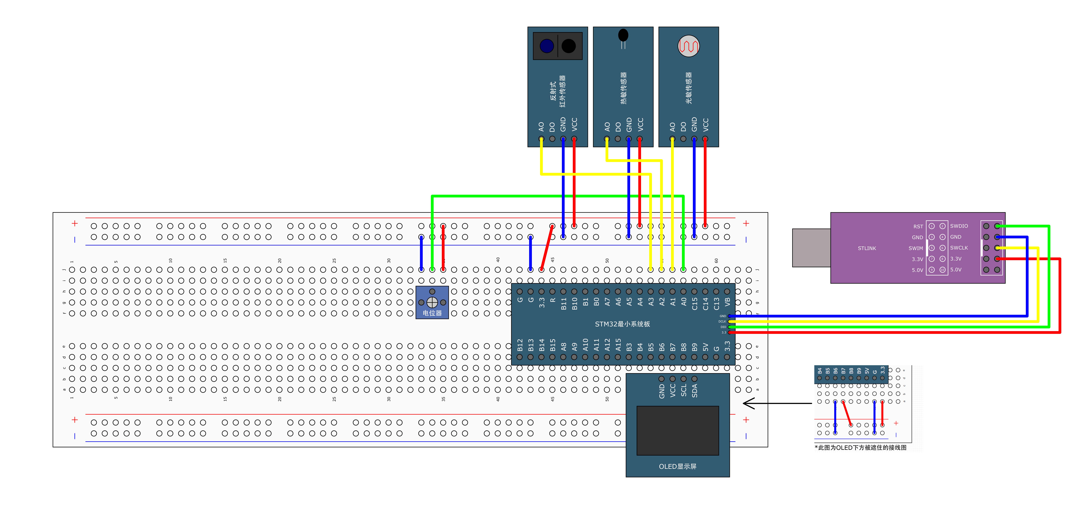
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...