Elasticsearch跨集群检索配置
跨集群检索字面意思,同一个检索语句,可以检索到多个ES集群中的数据,ES集群默认是支持跨集群检索的,只需要动态的增加入节点即可,下面跟我一起来体验下ES的跨集群检索的魅力。
Elasticsearch 跨集群检索推荐的是不同集群版本是相同的。
对于 Elasticsearch 的 8.1.3 版本,跨集群检索对应的 Elasticsearch 的版本信息如下,通过看图可以知道,Elasticsearch 的 8.1 版本最多支持到 7.17 版本。
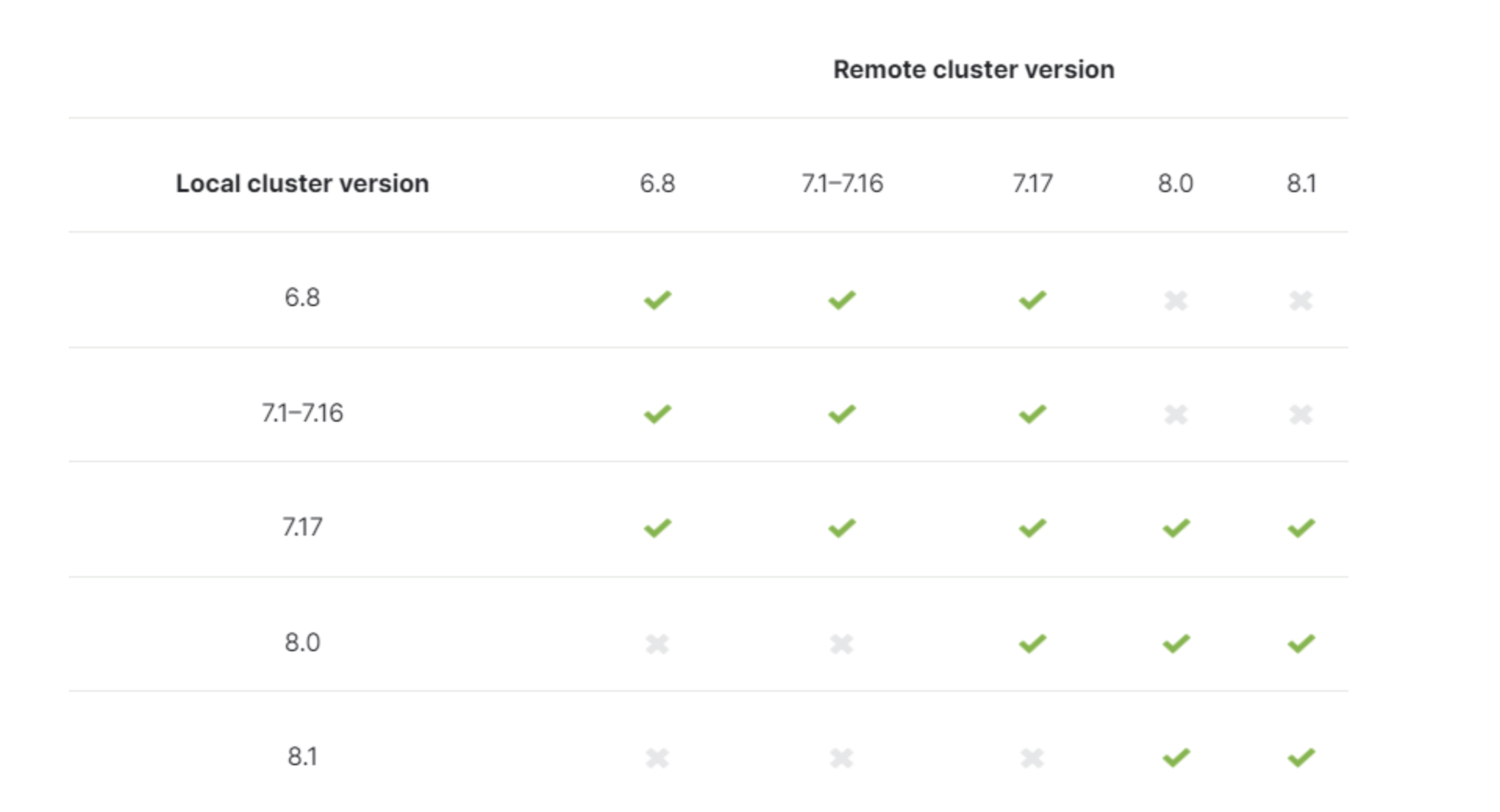
图片来源:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
跨集群检索语句等实际操作跳过环境这一节,直接跳转文章底部查看。
环境
集群一:es-docker-cluster
集群一为IP:192.168.160.245这台机器上面以docker形式部署的ES 8.1.3集群,集群名为es-docker-cluster
version: '3.8'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://eshot:9200
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:8.1.3
container_name: kibana
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
- ELASTICSEARCH_HOSTS=http://eshot:9200
- server.publicBaseUrl=http://192.168.160.245:5601
ports:
- "5601:5601"
networks:
- elastic
eshot:
image: elasticsearch:8.1.3
container_name: eshot
environment:
- node.name=eshot
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=hot
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\eshot\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\eshot\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
- 9300:9300
networks:
- elastic
eswarm:
image: elasticsearch:8.1.3
container_name: eswarm
environment:
- node.name=eswarm
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=warm
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\eswarm\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\eswarm\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
networks:
- elastic
escold:
image: elasticsearch:8.1.3
container_name: escold
environment:
- node.name=escold
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\escold\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\escold\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
networks:
- elastic
# volumes:
# eshotdata:
# driver: local
# eswarmdata:
# driver: local
# escolddata:
# driver: local
networks:
elastic:
driver: bridge
集群二:zuiyu-application
集群二为IP:192.168.160.31机器上面部署的ES8.1.3集群,集群名称为zuiyu-application他们三个的配置分别如下
node1
cluster.name: zuiyu-application
node.name: node-1
path.data: D:\elasticsearch-8.1.3-windows-x86_64\elasticsearch-8.1.3/813/data
path.logs: D:\elasticsearch-8.1.3-windows-x86_64\elasticsearch-8.1.3/813/logs
network.host: 192.168.160.31
http.port: 9200
transport.port: 9300
cluster.initial_master_nodes: ["node-1"]
discovery.seed_hosts: ["192.168.160.31:9300", "192.168.160.31:9302","192.168.160.31:9303"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: falseverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
node2
cluster.name: zuiyu-application
node.name: node-2
path.data: D:\elasticsearch-8.1.3-windows-x86_64\node2/813/data
path.logs: D:\elasticsearch-8.1.3-windows-x86_64\node2/813/logs
network.host: 192.168.160.31
http.port: 9202
transport.port: 9302
cluster.initial_master_nodes: [node-2"]
discovery.seed_hosts: ["192.168.160.31:9300", "192.168.160.31:9302","192.168.160.31:9303"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: falseverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
node3
cluster.name: zuiyu-application
node.name: node-3
path.data: D:\elasticsearch-8.1.3-windows-x86_64\node3/813/data
path.logs: D:\elasticsearch-8.1.3-windows-x86_64\node3/813/logs
network.host: 192.168.160.31
http.port: 9203
transport.port: 9303
cluster.initial_master_nodes: ["node-3"]
discovery.seed_hosts: ["192.168.160.31:9300", "192.168.160.31:9302","192.168.160.31:9303"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: falseverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
现在环境已经搭建好了,下面 进入实验环节,首先打开集群es-docker-cluster所对应的kibana
Kibana 自行安装
跨集群检索
-
先对集群
es-docker-cluster设置跨集群检索的集群信息PUT _cluster/settings {"persistent": {"cluster": {"remote": {"zuiyu-application": {"seeds": ["192.168.160.31:9300"]}}}} }其中
zuiyu-application为自定义的跨集群检索的名称 -
在当前集群
es-docker-cluster中插入一条数据POST zfc-doc-000011/_doc/1 {"name":"zuiyu","content":"test cluster doc 1" } -
打开集群
zuiyu-application对应的Kibana,同样进行增加一条数据,使他们的name的值都是zuiyu# 集群 zuiyu-application 中插入 POST zfc-doc-000011/_doc/1 {"name":"zuiyu","content":"test cluster doc 2,this doc in cluster zuiyu-application" }到这,基础的测试数据已经完成,开始跨集群检索
-
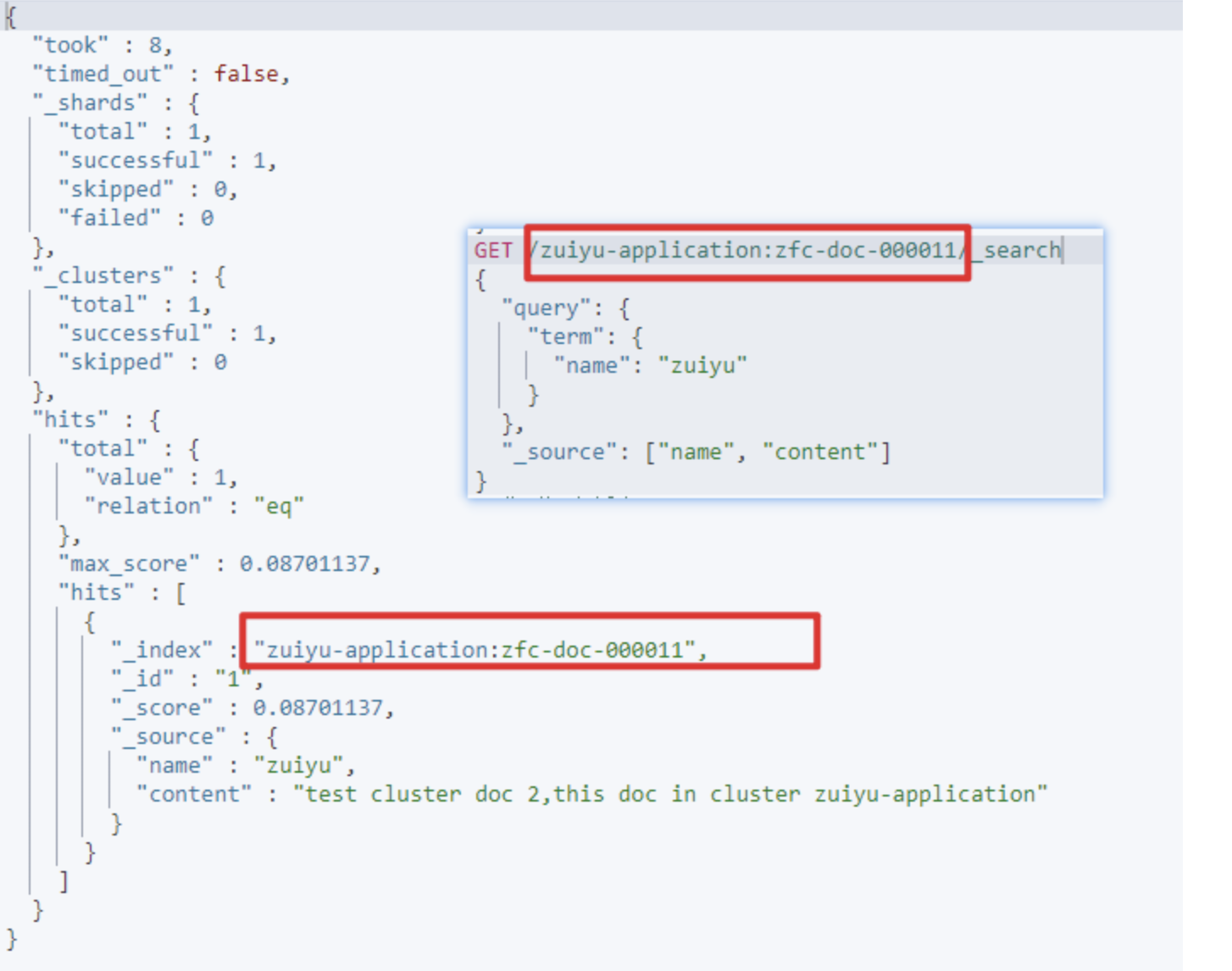
指定集群进行检索
GET /集群名:索引名/_search
GET /zuiyu-application:zfc-doc-000011/_search {"query": {"term": {"name": "zuiyu"}},"_source": ["name", "content"] }响应结果如下,可以看到已经在集群
zuiyu-application中查询出来数据了
-
跨集群检索
同时检索
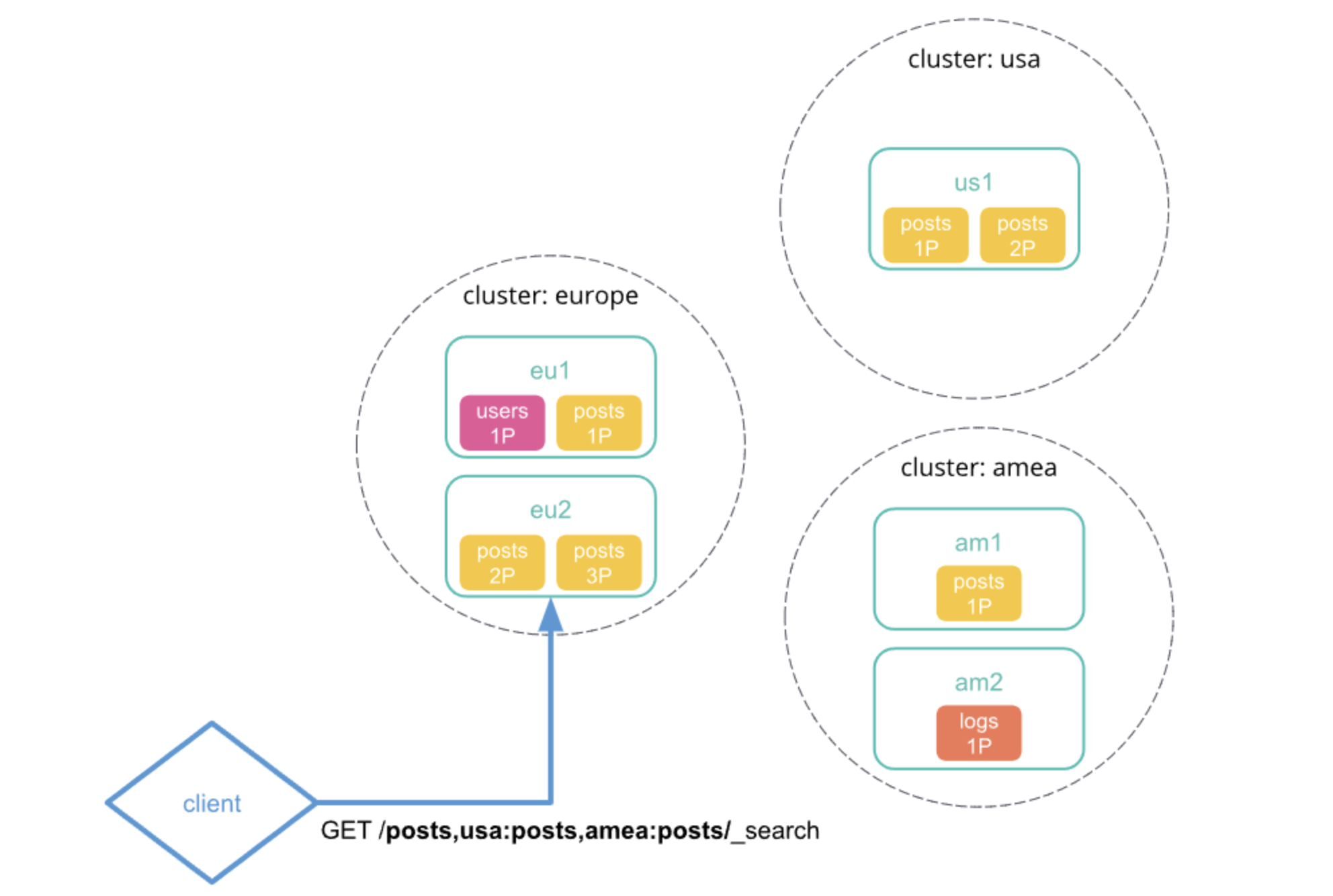
es-docker-cluster与zuiyu-application两个集群中索引为zfc-doc-000011中的内容GET zfc-doc-000011,zuiyu-application:zfc-doc-000011/_search {"query": {"term": {"name": "zuiyu"}},"_source": ["name", "content"] }响应结果如下
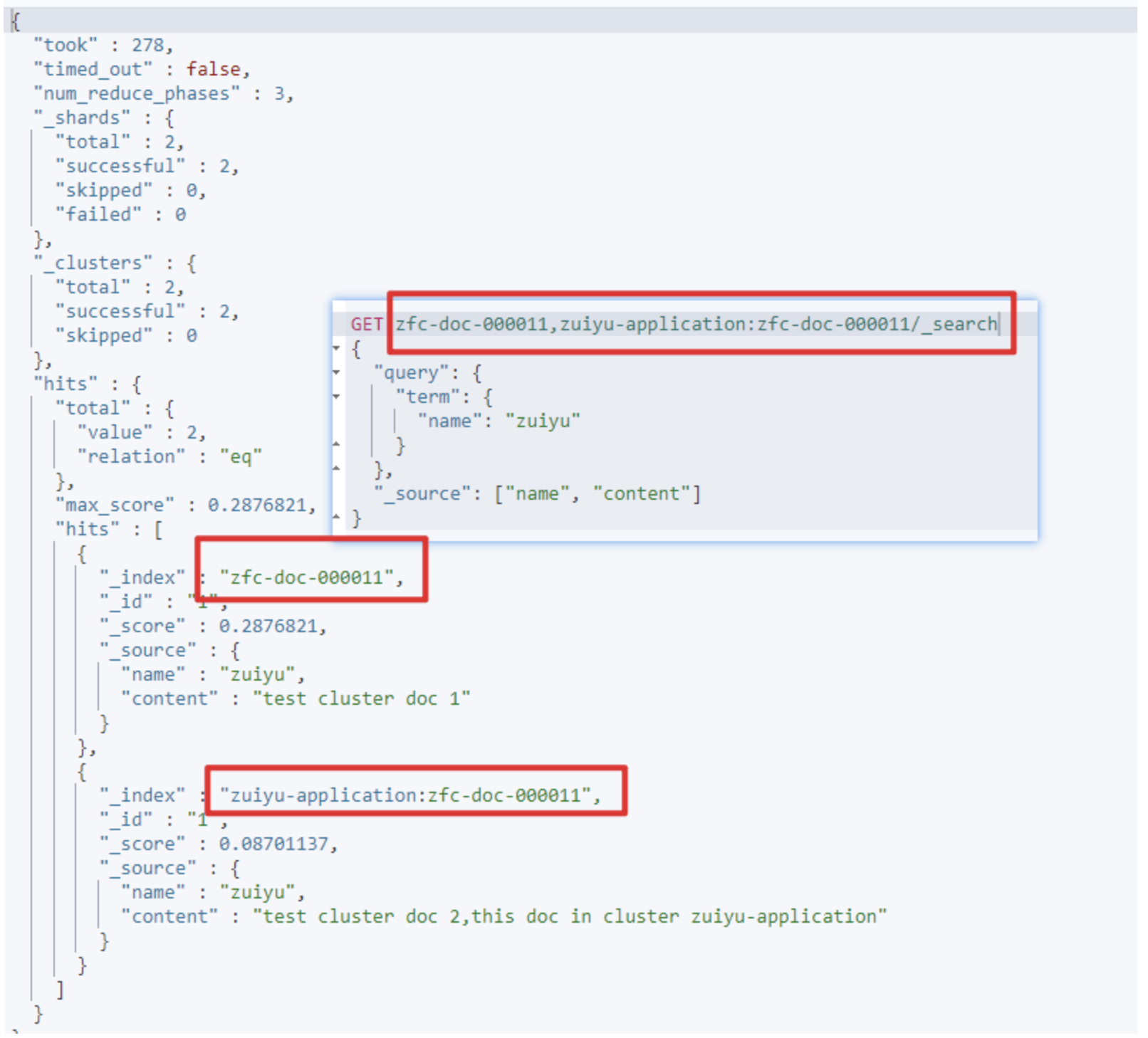
因为我们是在 es-docker-cluster集群对应的Kibana中执行的,所以本集群的名称可以不用指定。如果想查询多个索引,只需要追加集群名:索引名即可。
基础的跨集群配置与检索就到此, 实际的使用中查询语句的条件等各个方法都会有限制,这个需要根据实际使用场景来进行修改了,反正现在怎么操作你会了,比着葫芦画瓢还不简单吗。
集群不可用时的处理
默认情况下,如果请求的远程集群返回错误或者不可用,跨集群检索将失败。此时我们可以使用 skip_unavailable ,设置该参数为 true,可以在远程集群不可用时跳过该集群。
修改语句如下,该语句设置将在集群 zuiyu-application 不可用时跳过该集群。
PUT _cluster/settings
{"persistent": {"cluster.remote.zuiyu-application.skip_unavailable": false}
}
处理网络延迟的方式
-
最小化网络往返次数
默认情况下,Elasticsearch 会减少与远程集群之间的网络往返次数。这就减少了网络延迟对搜索速度的影响。但是Elasticsearch 无法减少大型检索请求的网络往返次数,例如包含
scroll或者inner_hits的请求。ccs_minimize_roundtrips的值为true时来使用此选项。 -
不要最小化网络往返次数
对于
scroll或者inner_hits的请求,Elasticsearch 会向每个远程集群发送多个传入传出请求。我们可以通过修改ccs_minimize_roundtrips的值为false来使用此选项。虽然说速度会较慢,但是对于低延迟网络还是很适用的。对于该参数
ccs_minimize_roundtrips不了解的可以参考这篇文章枯燥无味的Elasticsearch检索参数字典
打不开的复制链接地址到浏览器打开即可: https://mp.weixin.qq.com/s/DC_2sv5icjR63wZ6XmK6MA
最小化网络往返次数
图片来自官网,可点击左下角原文链接
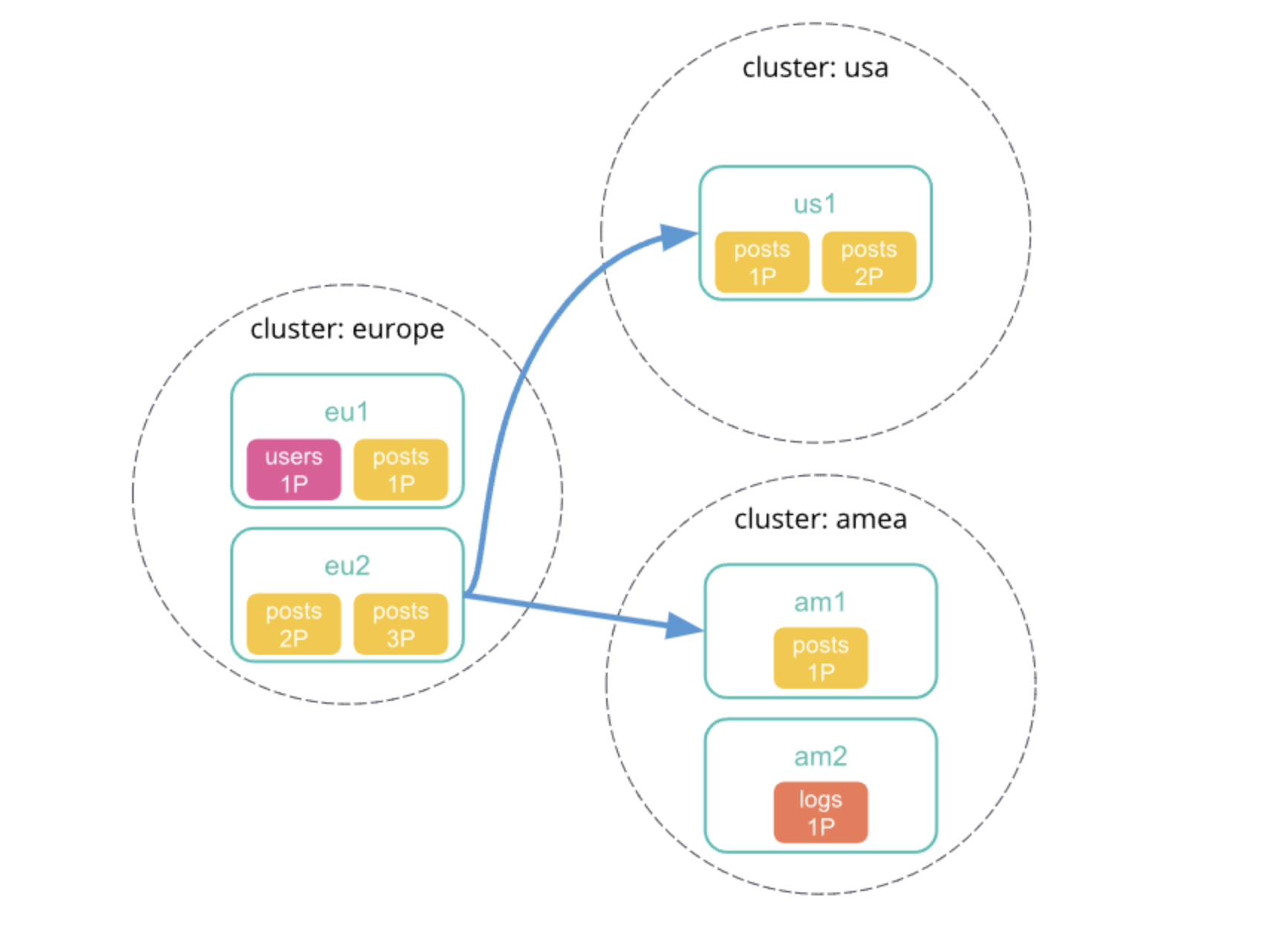
1、向本地集群中发送跨集群检索请求,该集群中的协调节点接收并解析请求。
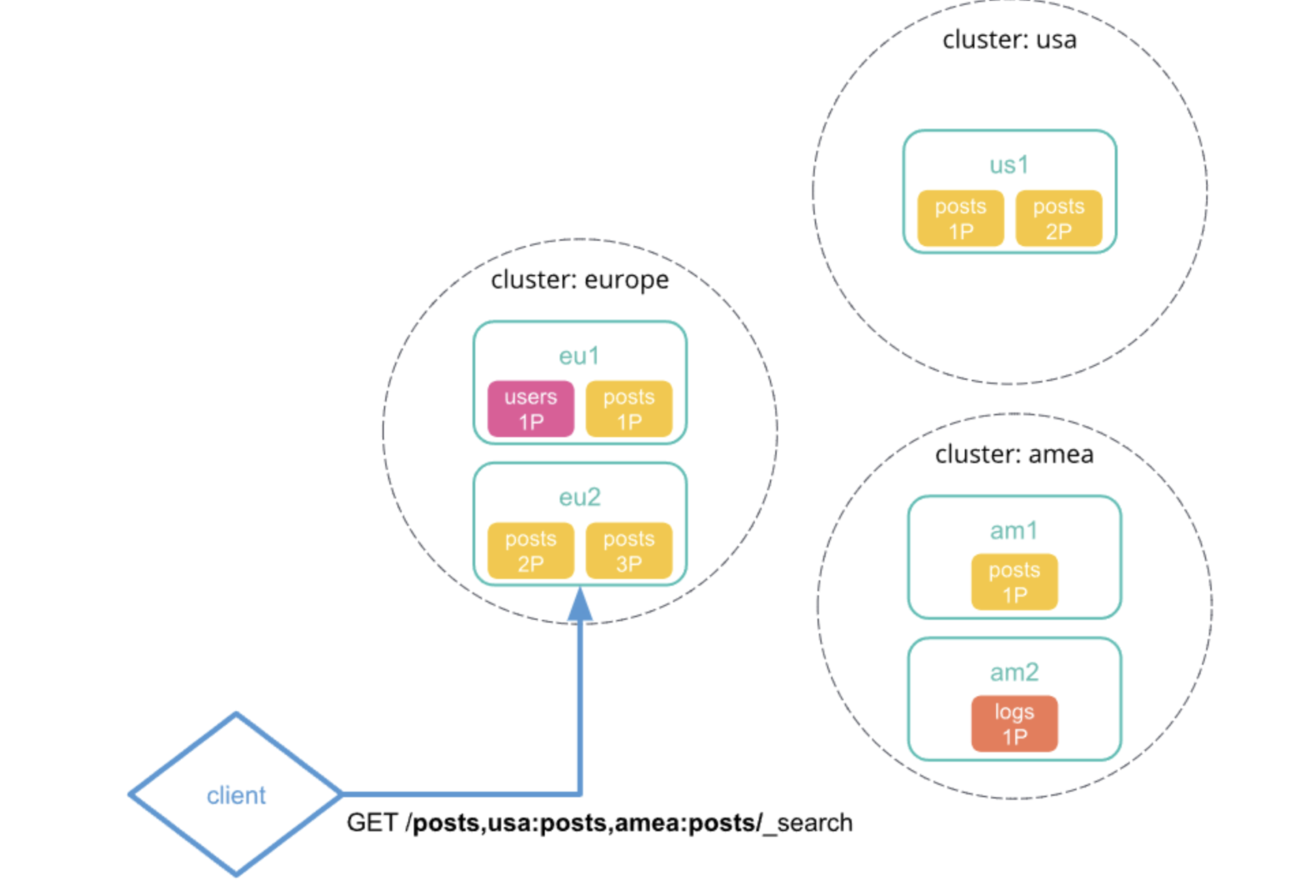
2、协调节点向每个集群包括本地集群发送单个搜索请求。每个集群独立执行搜索请求。
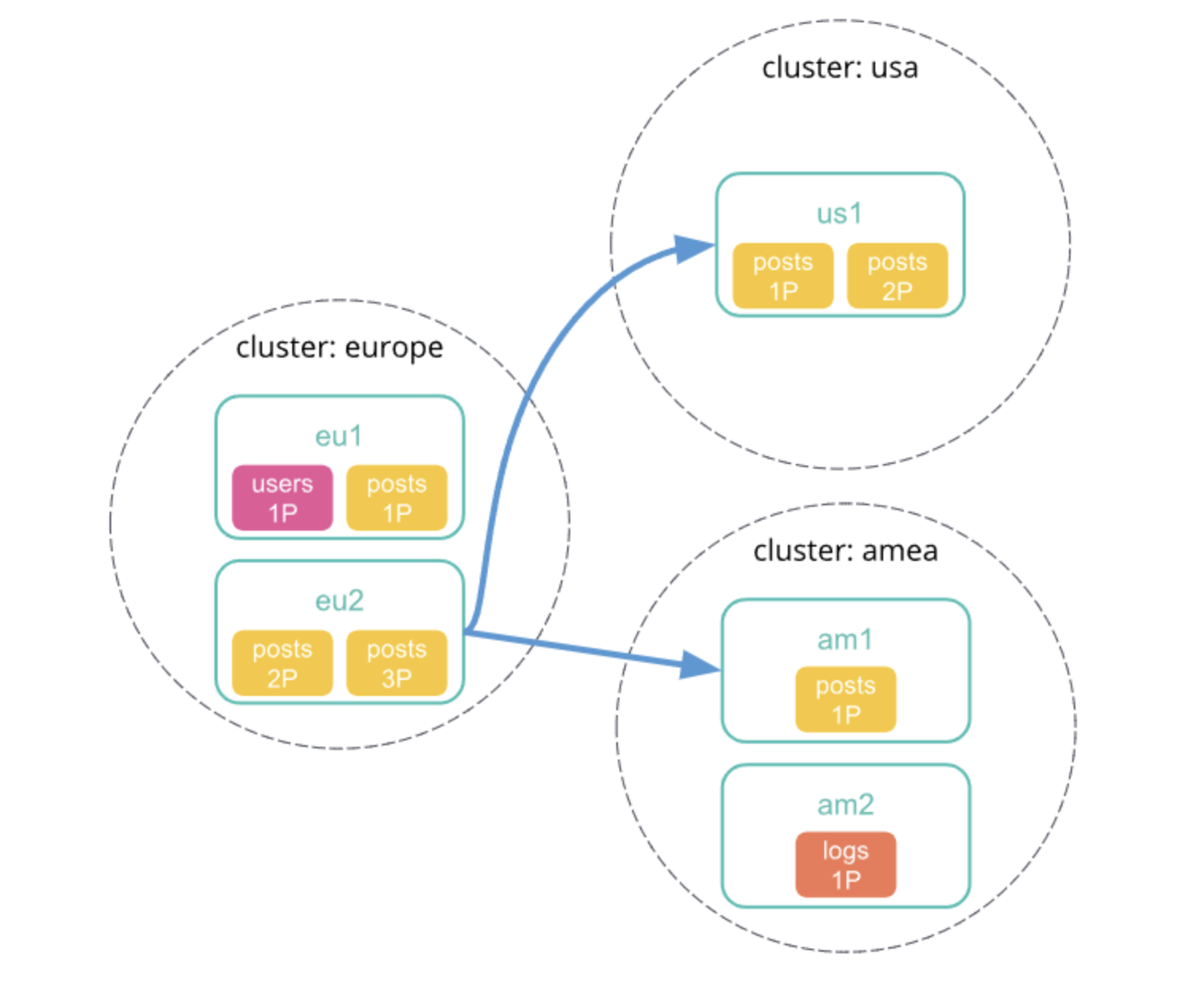
3、每个远程集群响应检索结果给协调节点。
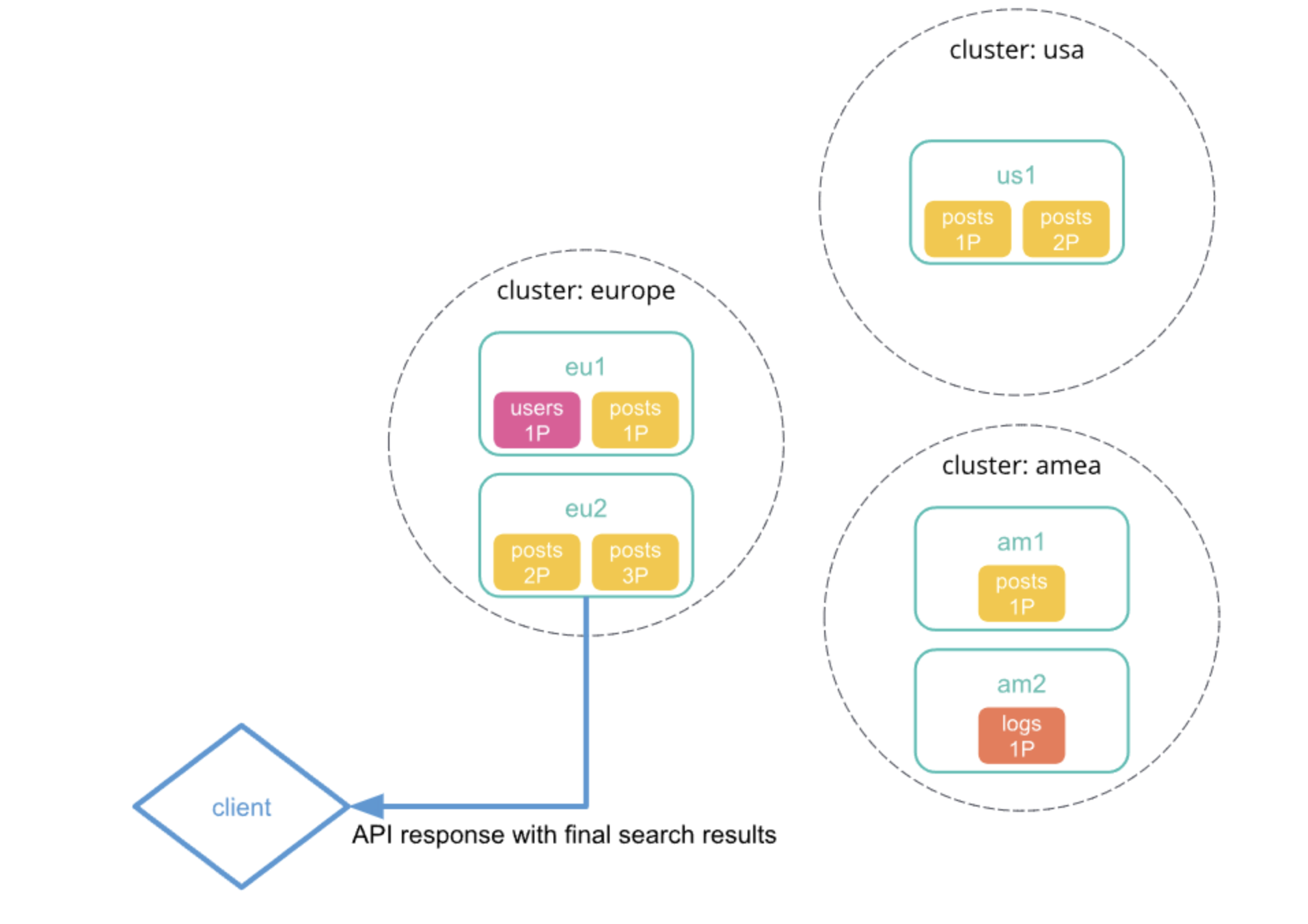
4、从每个集群收集结果之后,协调节点在跨集群检索请求响应中返回最终的结果。
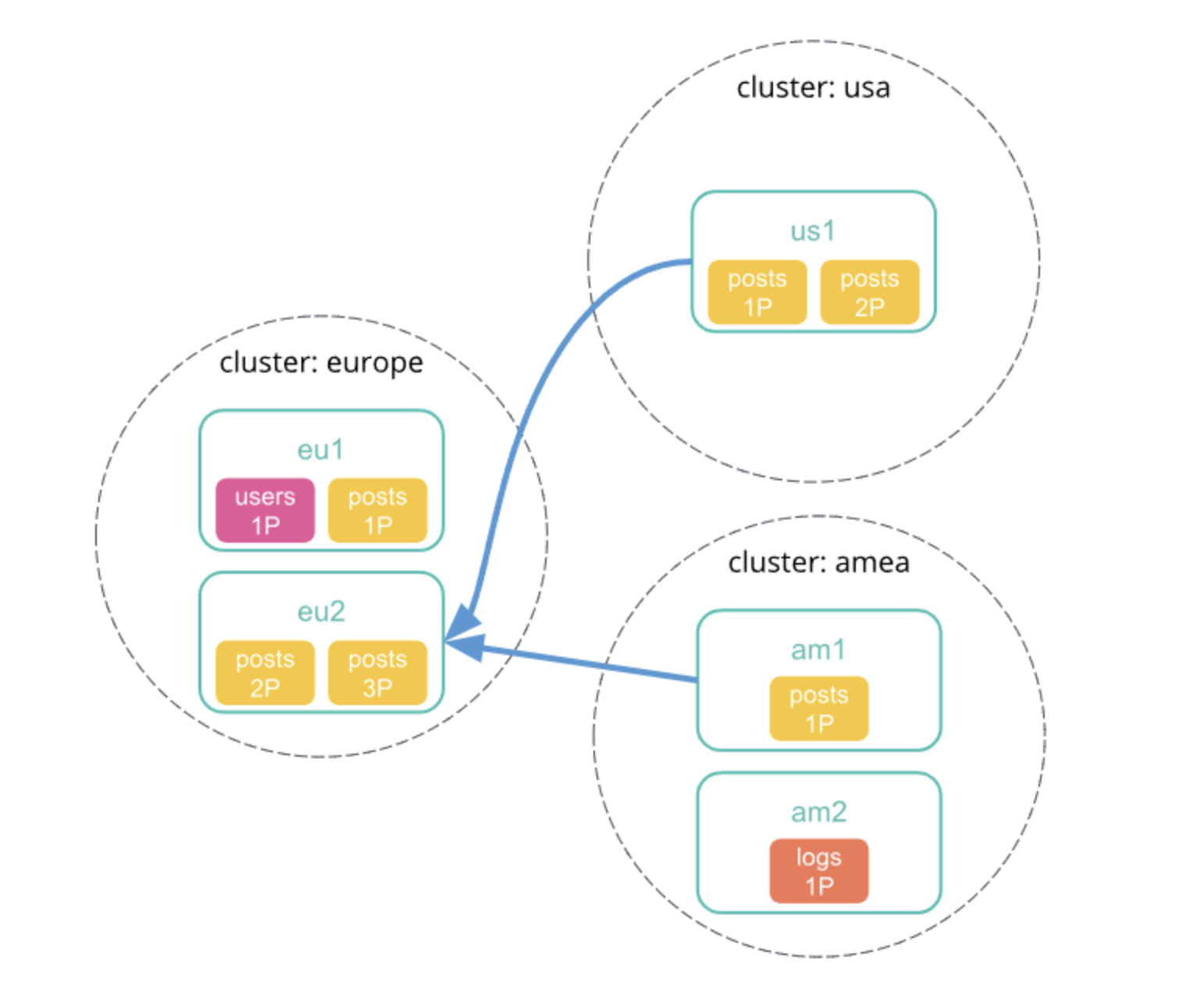
不使用最小化网络往返次数
图片来自官网,可点击左下角原文链接
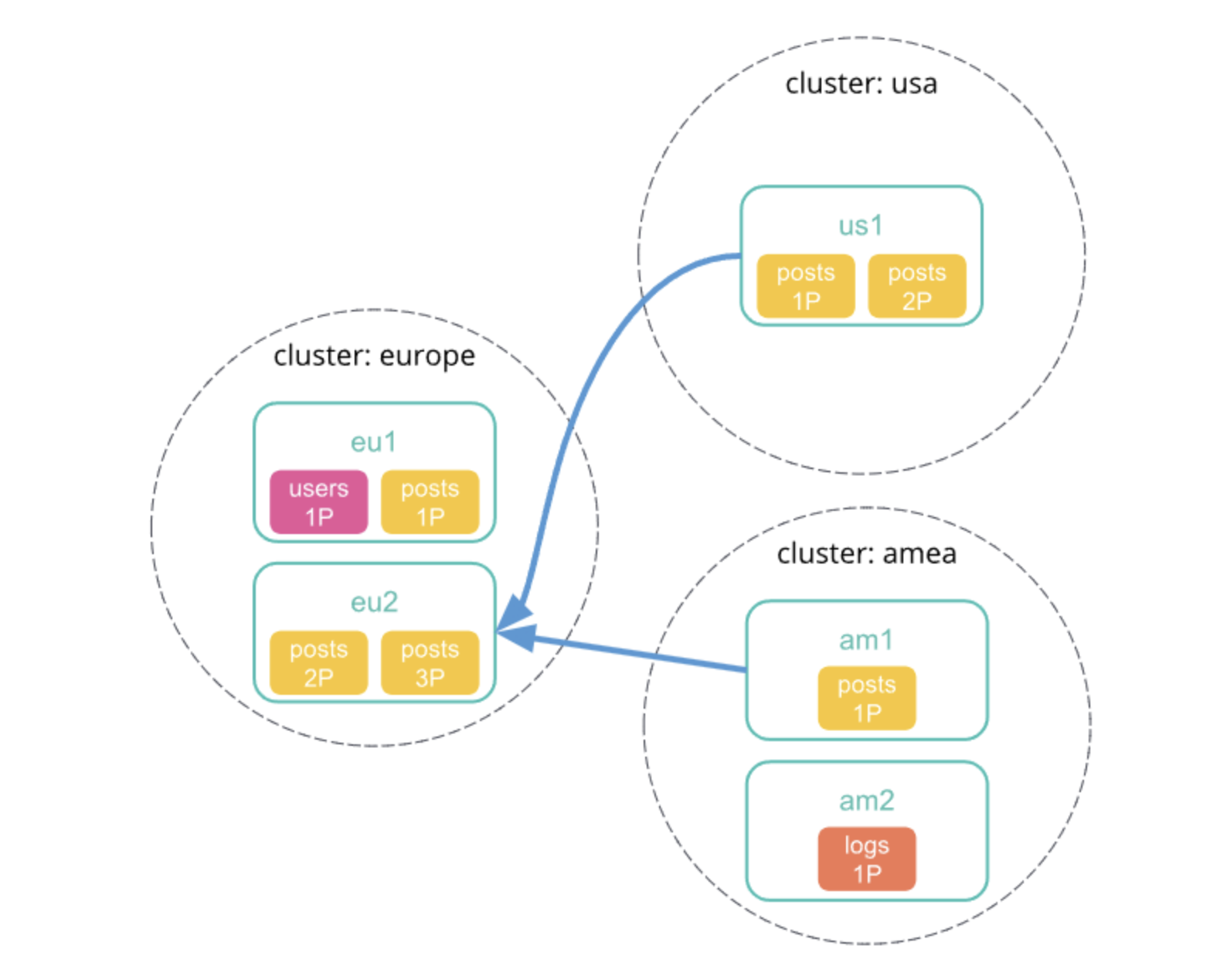
1、向本地集群中发送跨集群检索请求,该集群中的协调节点接收并解析请求。
2、协调节点向每个集群发送分片检索请求。
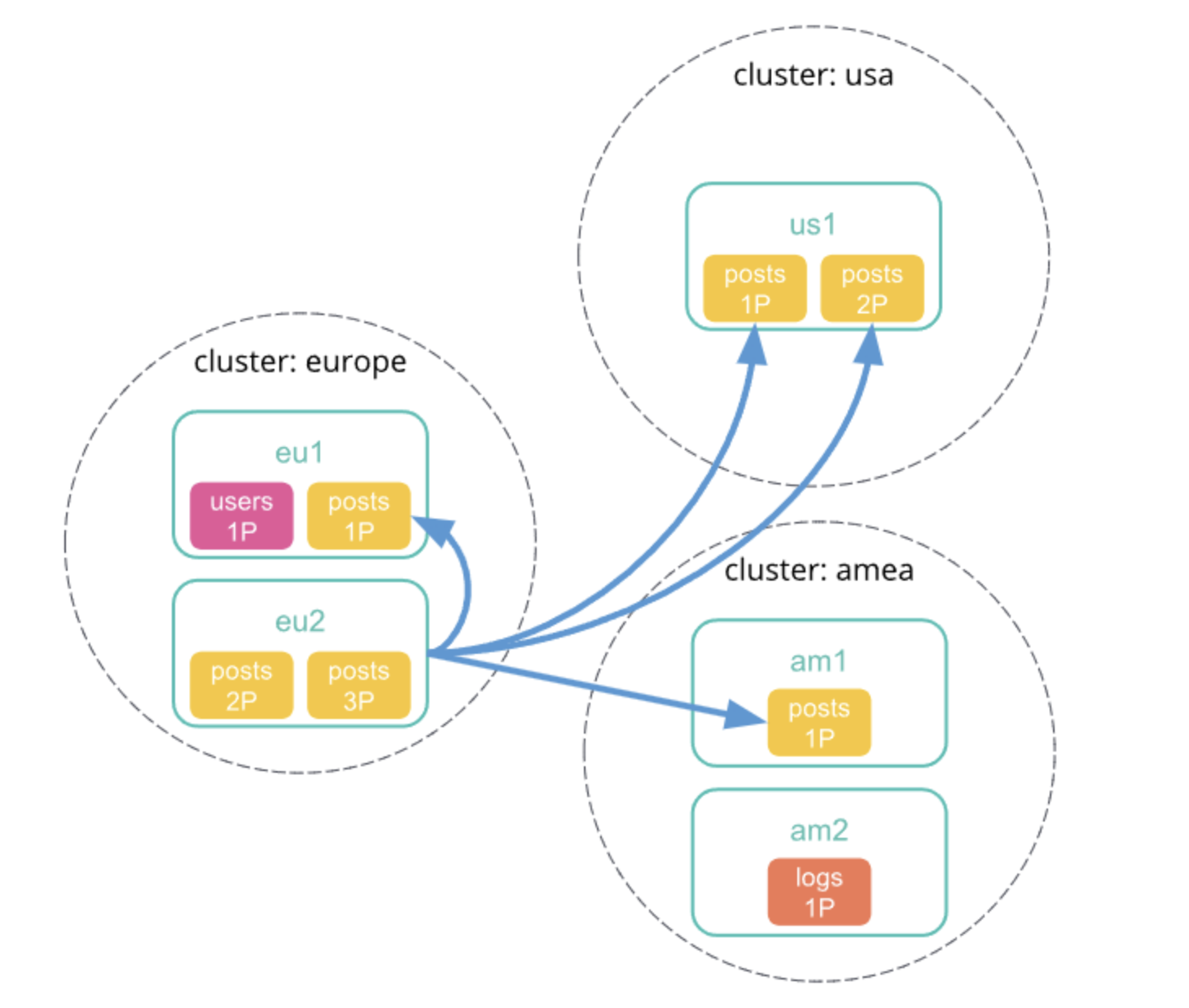
3、每个远程集群将其响应发送回协调节点。此响应包含跨集群检索请求将在其集群上执行的索引和分片的信息。
4、协调节点向每个分片发送检索请求,包括自己本身集群的分片。每个分片独立执行检索请求。
当网络的往返没有最小化时,因为会发送所有的分片进行检索,所以搜索的结果就好比全在协调节点中保存中一样。所以我们可以修改集群的检索设置,比如
action.search.shard_count.limit,pre_filter_shard_size,max_concurrent_shard_requests,如果这些限制太低的话,检索请求可能会被直接拒绝。
对于该参数不了解的可以参考这篇文章
枯燥无味的Elasticsearch检索参数字典
打不开的复制链接地址到浏览器打开即可: https://mp.weixin.qq.com/s/DC_2sv5icjR63wZ6XmK6MA
5、每个分片将检索结果返回给协调节点。
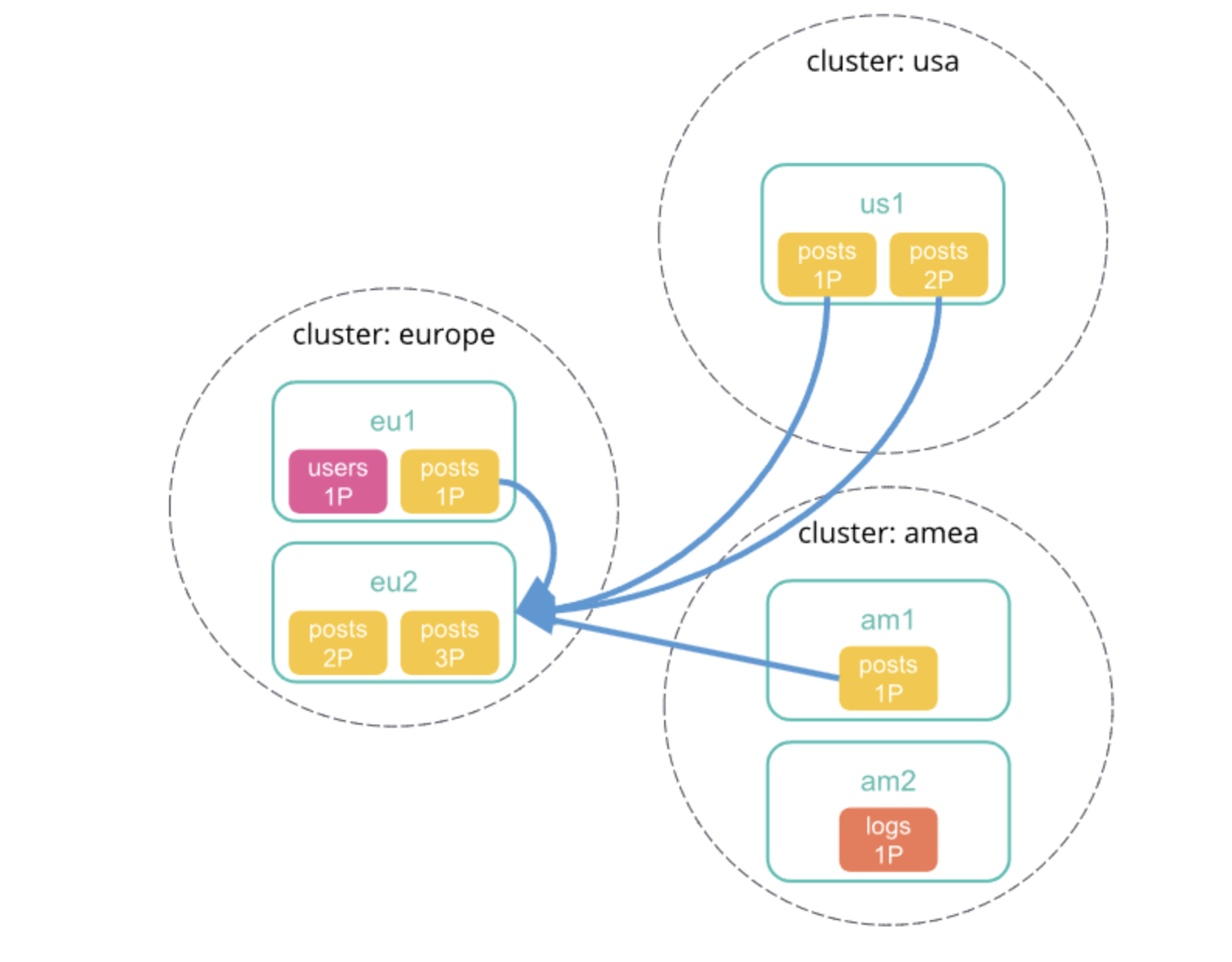
6、协调节点收集所有的结果后,在跨集群检索请求响应中返回最终的响应结果。
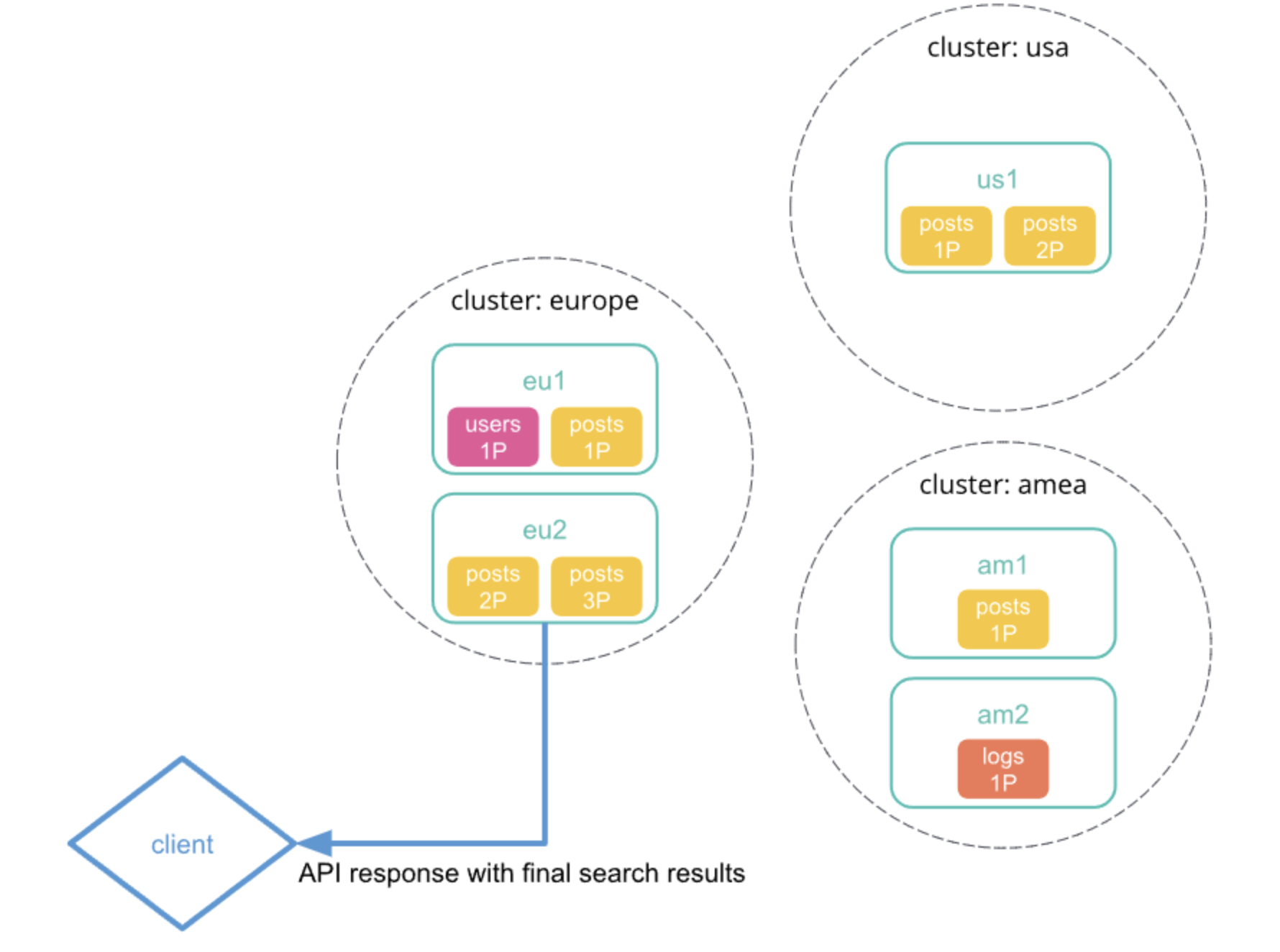
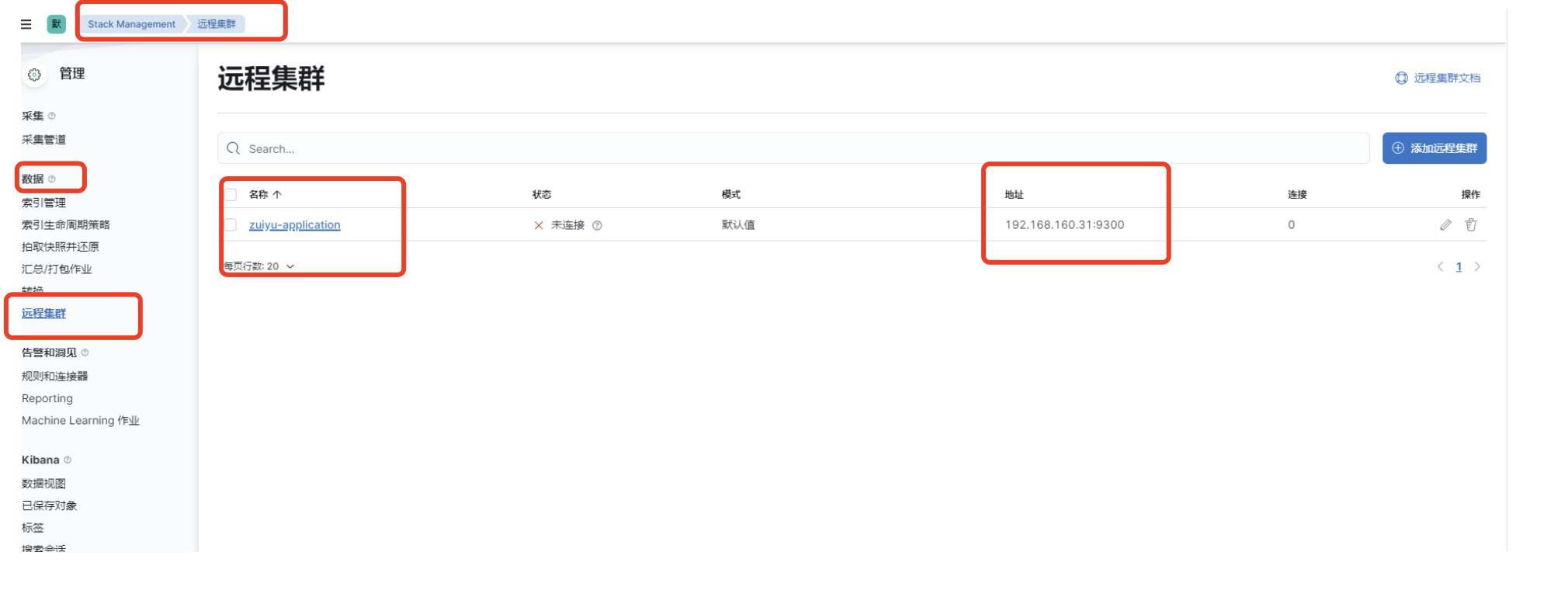
Kibana 中远程集群查看
创建完成之后的远程集群可以在Kibana中查看
本文由 mdnice 多平台发布
相关文章:
Elasticsearch跨集群检索配置
跨集群检索字面意思,同一个检索语句,可以检索到多个ES集群中的数据,ES集群默认是支持跨集群检索的,只需要动态的增加入节点即可,下面跟我一起来体验下ES的跨集群检索的魅力。 Elasticsearch 跨集群检索推荐的是不同集群…...

第九章 软件BUG和管理
一、学习目的与要求 软件测试的目的就是为了发现软件BUG。通过本章的学习,应了解软件BUG的产生和影响,掌握软件开发过程中产生的BUG种类,掌握使BUG重现的技术,了解软件BUG报告单应该包括的主要内容及软件BUG的管理流程。 二、考核…...
大厂面试题-Java并发编程基础篇(二)
目录 一、wait和notify这个为什么要在synchronized代码块中? 二、ThreadLocal是什么?它的实现原理呢? 三、基于数组的阻塞队列ArrayBlockingQueue原理 四、怎么理解线程安全? 五、请简述一下伪共享的概念以及如何避免 六、什…...

测绘屠夫报表系统V1.0.0-beta
1. 简介 测绘屠夫报表系统,能够根据变形监测数据:水准、平面、轴力、倾斜等数据,生成对应的报表,生成报表如下图。如需进一步了解,可以加QQ:3339745885。视频教程可以在bilibili观看。 2. 软件主界面 3. …...
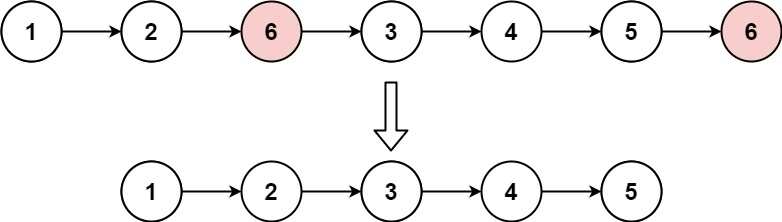
『力扣刷题本』:移除链表元素
一、题目 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head [1,2,6,3,4,5,6], val 6 输出:[1,2,3,4,5]示例 2: 输入&a…...
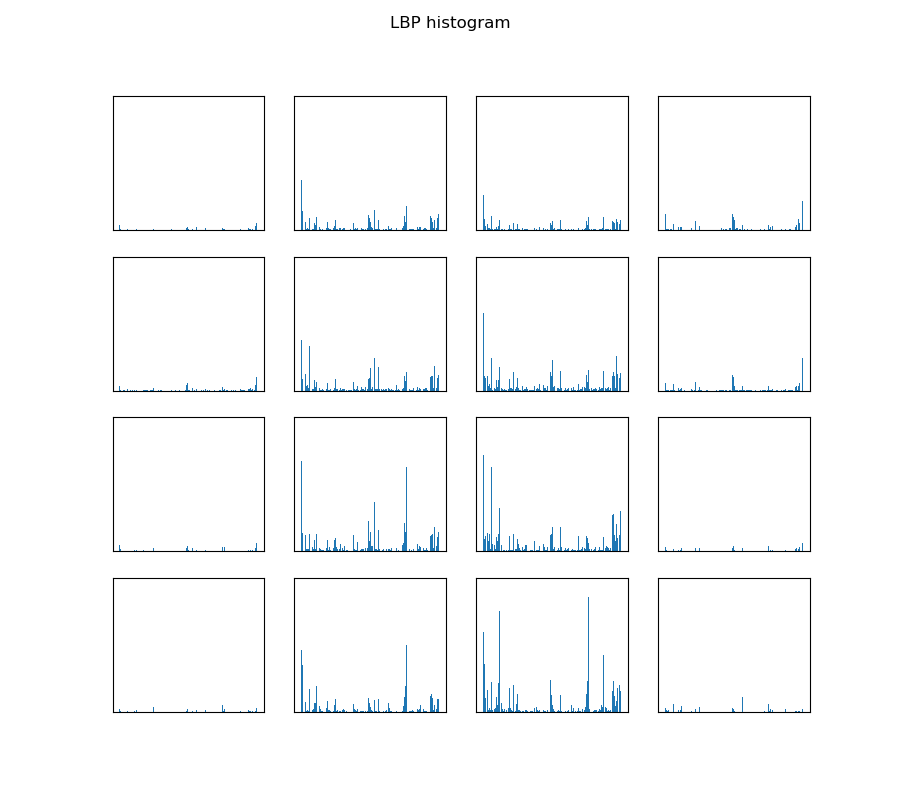
图像特征Vol.1:计算机视觉特征度量|第一弹:【纹理区域特征】
目录 一、前言二、纹理区域度量2.1:边缘特征度量2.2:互相关和自相关特征2.3:频谱方法—傅里叶谱2.4:灰度共生矩阵(GLCM)2.5:Laws纹理特征2.6:局部二值模式(LBP) 一、前言 …...
day01:数据库DDL
一:基础概念 数据库:存储数据的仓库,数据是有组织的进行存储 数据库管理系统:操纵和管理数据库的大型软件 SQL:操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准 关系图 二:数据模型 关系型数据库:建…...
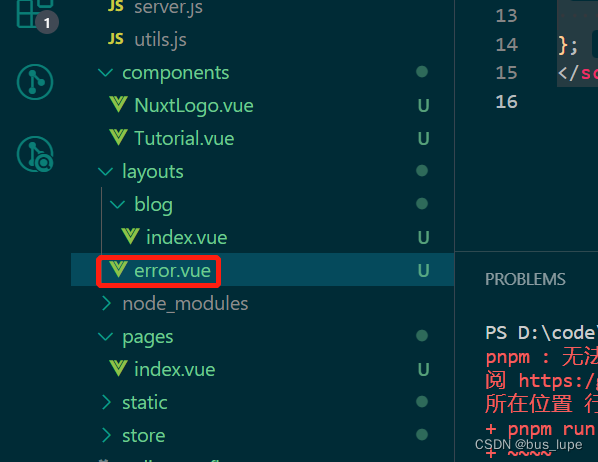
9、定义错误页
在layouts目录下新建error.vue,可以通过layout函数使用布局文件,通过props: [“error”]能拿到错误信息对象。 <template><div>{{ error.statusCode }}: {{ error.message }}</div> </template><script> export default {…...

有关多线程环境下的Volatile、lock、Interlocked和Synchronized们
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:新的征程,我们面对的不仅…...

spring boot利用redis作为缓存
一、缓存介绍 在 Spring Boot 中,可以使用 Spring Cache abstraction 来实现缓存功能。Spring Cache abstraction 是 Spring 框架提供的一个抽象层,它对底层缓存实现(如 Redis、Ehcache、Caffeine 等)进行了封装,使得在…...
Android Studio 查看Framework源码
1、背景 安卓系统源码量很庞大,选择好的开发工具和方式去开发可以提升开发效率,常用的开发工具有Source Insight 、Visual Studio Code、Android Studio,vscode适合C和C代码开发,java层代码无法跳转和提示,因此&#…...
FileInputStream文件字节输入流
一.概念 以内存为基准,把磁盘文件中的数据以字节形式读入内存中 二.构造器 public FileInputStream(File file) public FileInputStream(String pathname) 这两个都是创建字节输入流管道与源文件接通 三.方法 public int read() :每次读取一个字节返回,如…...

【Qt】窗口和对话框区别、主窗口和二级窗口区别、QMainWindow和QDialog区别
窗口和对话框(Window and Dialog Widgets) 未嵌入在父界面中的界面称为窗口。(通常,窗口具有边框和标题栏,尽管也可以使用合适的窗口标志创建没有此类标志的窗口)。 在Qt中,QMainWindow和QDial…...

Python参数种类介绍
Python参数种类介绍 相比于一些其他编程语言,Python提供了更多的参数种类选项。这是Python的一大特点,使用不同的参数类型,可以提高函数的可读性和可维护性。例如,使用关键字参数可以使函数调用更加清晰,不需要记住参数…...

react事件机制
React 事件机制 React的事件机制是React框架中非常重要的一部分,用于处理用户交互和用户界面上的事件。React的事件机制在底层使用了虚拟DOM以及合成事件来提高性能和跨浏览器兼容性。以下是关于React事件机制的详细信息: 合成事件(Syntheti…...

JAVA删除excel指定列
首先POI没有提供删除列的API,所以就需要用其他的方式实现。 在 java - Apache POI xls column Remove - Stack Overflow 这里找到了实现方式: 先将该列所有值都清空,然后将该列之后的所有列往前移动。 下面的工具类中 deleteColumns(Inpu…...

Netty编码器和解码器
文章目录 一、Decoder原理与实践1、ByteToMessageDecoder解码器2、自定义整数解码器1)常规方式2)ReplayingDecoder解码器 3、分包解码器3、MessageToMessageDecoder解码器 二、Netty内置的Decoder1、LineBasedFrameDecoder解码器2、DelimiterBasedFrameD…...
大语言模型(LLM)综述(三):大语言模型预训练的进展
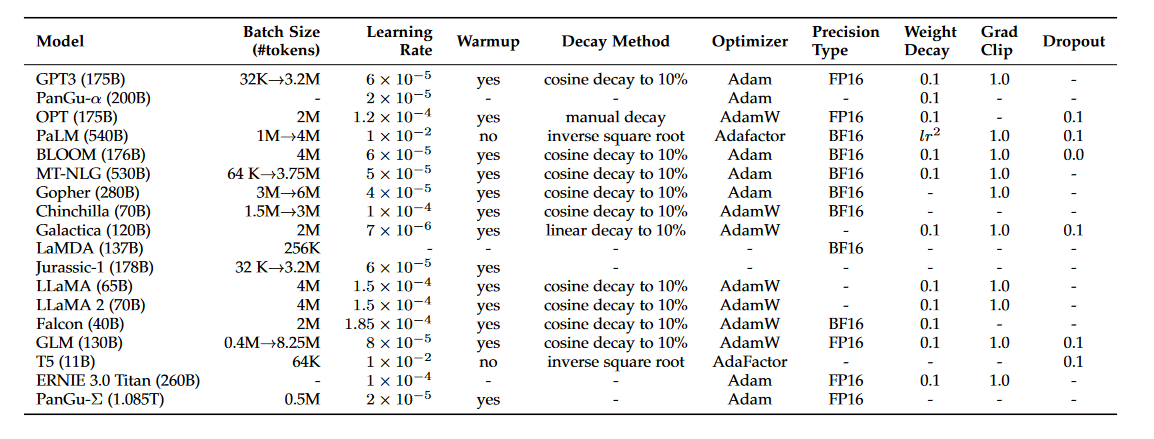
A Survey of Large Language Models 前言4. PRE-TRAINING4.1数据收集4.1.1 数据源4.1.2 数据预处理4.1.3 预训练数据对LLM的影响 4.2 模型架构4.2.1 典型架构4.2.2 详细配置4.2.3 预训练任务4.2.4 解码策略4.2.5 总结和讨论 4.3 模型训练4.3.1 优化设置4.3.2 可扩展的训练技术 …...

如何在Node.js中使用环境变量或命令行参数来设置HTTP爬虫ip?
首先,定义问题:在 Node.js 应用程序中,我们可以通过环境变量或命令行参数来设置HTTP爬虫ip,以便在发送请求时使用这些HTTP爬虫ip。 亲身经验:我曾经需要为一个项目设置HTTP爬虫ip,以便在发送请求时使用这些…...
VMware打开共享虚拟机后找不到/mnt/hgfs/文件夹,以及不能拖拽/复制粘贴等操作,ubuntu不能安装VMware tools
问题原因 我的问题出现原因是,安装ubuntn虚拟机的时候VMware tools没有安装好,需要重新安装,但安装选项是暗的,不能操作。 类似这种情况,虚拟机开启时也是,因为我虚拟机已经装好了,开启时是亮…...

Trae+Playwright MCP:企业级浏览器自动化测试底座构建指南
1. 这不是又一个“安装教程”,而是一套能跑通、能维护、能交付的浏览器自动化测试底座你有没有遇到过这样的情况:项目刚立项,测试同学信心满满说“用Playwright写自动化脚本”,结果三天过去,环境还卡在npm install pla…...

无Root安卓隐私检测:Frida+Camille实战指南
1. 为什么“不Root也能做隐私检测”这件事值得大书特书 去年在给一家金融类App做第三方合规评估时,客户明确提了一条硬性要求:“所有检测必须在未Root的量产机上完成,测试环境要完全模拟真实用户场景。”当时我第一反应是皱眉——毕竟市面上…...

Playwright安装本质:四层架构与跨平台部署详解
1. 为什么Playwright的安装过程比你想象中更值得深挖 “零基础入门:Playwright安装图解教程”——这个标题乍看平平无奇,像极了网上随手一搜就出十几页的“保姆级教程”。但我在带新人做自动化测试的三年里,亲手帮67位完全没写过Python、连终…...

收藏!小白程序员必看:如何用RAG让大模型秒变“知识达人”
大模型虽强但知识易过时且难接入私有信息。RAG通过检索增强生成,为模型加装“搜索引擎”和“知识库”,解决时效性、私有数据接入和答案追溯问题。RAG分为朴素、高级、模块化及智能体阶段,对AI初学者而言,它是让大模型落地企业场景…...

Drupal YAML反序列化RCE漏洞CVE-2017-6920深度解析
1. 这不是“又一个RCE”,而是一次对Drupal架构信任边界的彻底重写2017年3月,Drupal官方发布安全通告,编号CVE-2017-6920,定级为Critical(严重),CVSS评分高达9.8。当时我正在给一家省级政务平台做…...

用PyTorch和TD3教AI玩赛车:从像素输入到稳定驾驶的保姆级调参指南
用PyTorch和TD3构建赛车AI:视觉输入下的强化学习调参实战当游戏画面从单纯的娱乐载体转变为强化学习的训练场时,每一个像素都承载着决策信息。CarRacing-v2环境将这种挑战具象化——96x96的彩色图像输入需要转化为精确的转向、油门和刹车控制。不同于传统…...

棋牌类网站渗透测试五大高危漏洞实战解析
1. 为什么棋牌类网站总在渗透测试中“反复栽跟头”做渗透测试这十多年,我经手过上百个在线游戏类系统,其中棋牌类网站的漏洞复现率之高、利用链之典型、业务逻辑之“反直觉”,在所有垂直领域里排得上前三。不是它们代码写得最差,而…...

Linux系统启动卡住了?手把手教你用systemd-analyze和dmesg诊断UEFI启动各阶段耗时
Linux系统启动卡住了?手把手教你用systemd-analyze和dmesg诊断UEFI启动各阶段耗时当你的Linux服务器在凌晨三点突然启动失败,或是开发工作站卡在GRUB界面无法继续时,那种焦虑感每个运维工程师都深有体会。启动过程就像多米诺骨牌——任何一个…...

饲料颗粒机生产厂家
行业痛点分析:一场关于“磨损”与“成本”的持久战在饲料加工领域,颗粒机设备的稳定性与耐用性,直接决定了生产线的整体效率与运营成本。然而,长期困扰行业的核心痛点之一,是磨盘与压辊的耐磨性问题。根据行业调研数据…...

用Python和Pandas搞定泰坦尼克号数据集:从数据清洗到特征工程的完整实战
用Python和Pandas征服泰坦尼克号数据集:从数据清洗到特征工程的实战指南当第一次打开泰坦尼克号数据集时,那些密密麻麻的乘客信息就像一艘沉船上的碎片——杂乱无章却又充满故事。作为数据科学领域最经典的入门数据集,它包含了891名乘客的12个…...