Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第五章 高效的多线程日志
“日志(logging)”有两个意思:
1.诊断日志(diagnostic log)。即log4j、logback、slf4j、glog、g2log、log4cxx、log4cpp、log4cplus、Pantheios、ezlogger等常用日志库提供的日志功能。
2.交易日志(trasaction log)。即数据库的write-ahead log、文件系统的journaling等,用于记录状态变更,通过回放日志可以逐步恢复每一次修改之后的状态。
本章的“日志”是前一个意思,即文本的、供人阅读的日志,通常用于故障诊断和追踪(trace),也可用于性能分析。日志通常是分布式系统中事故调查的唯一线索,用来追寻蛛丝马迹,查出元凶。
在服务端编程中,日志是必不可少的,在生产环境中应该做到“Log Evenrything All The Time”。对于关键进程,日志通常要记录:
1.收到的每条内部消息的id(还可以包括关键字段、长度、hash等)。
2.收到的每条外部消息的全文。
3.发出的每条消息的全文,每条消息都有全局唯一的id。
4.关键内部状态的变更,等等。
每条日志都有时间戳,这样就能完整追踪分布式系统中一个事件的来龙去脉。也只有这样才能查清楚发生故障时究竟发生了什么,比如业务处理流程卡在了哪一步。
诊断日志不光是给程序员看的,更多的时候是给运维人员看的,因此日志的内容应避免造成误解,不要误导调查故障的主攻方向,拖延故障解决的时间。
一个日志库大体可分为前端(frontend)和后端(backend)两部分。前端是供应用程序使用的接口(API),并生成日志消息(log message);后端则负责把日志消息写到目的地(destination)。这两部分的接口有可能简单到只有一个回调函数:
void output(const char *message, int len);
其中的message字符串是一条完整的日志消息,包含日志级别、时间戳、源文件位置、线程id等基本字段,以及程序出书的具体消息内容。
在多线程程序中,前端和后端都与单线程程序无甚区别,无非是每个线程有自己的前端,整个程序共用一个后端。但难点在于将日志数据从多个前端高效地传输到后端。这是一个典型的多生产者-单消费者问题,对生产者(前端)而言,要尽量做到低延迟、低CPU开销、无阻塞;对消费者(后端)而言,要做到足够大的吞吐量,并占用较少资源。
对C++程序而言,最好整个程序(包括主程序和程序库)都使用相同的日志库,程序有一个整体的日志输出,而不要各个组件有各自的日志输出。从这个意义上讲,日志库是个Singleton。
C++日志库的前端大体上有两种API风格:
1.C/Java的printf(fmt, …)风格,例如:
log_info("Received %d bytes from %s", len, getClientName().c_str());
2.C++的stream <<风格,例如:
LOG_INFO << "Received " << len << " bytes from " << getClientName();
muduo的日志库是C++ stream风格,这样用起来更自然,不必费心保持格式字符串与参数类型的一致性,可以随用随写,而且是类型安全(编译时或运行时没有不兼容或不合法的数据类型操作)的。
stream风格的另一个好处是当输出的日志级别高于语句的日志级别时,打印日志是个空操作,运行时开销接近零。比方说当日志级别为WARNING时,LOG_INFO<<是个空操作,这个语句根本不会调用std::string getClientName()函数,减小了开销。而printf风格不易做到这一点。
muduo没有用标准库中的iostream,而是自己写的LogStream class,这主要是出于性能原因(第十一章)。
常规的通用日志库如log4j/logback通常会提供丰富的功能,但这些功能不一定全都是必需的。
1.日志消息有多种级别(level),如TRACE、DEBUG、INFO、WARN、ERROR、FATAL等。
2.日志消息可能有多个目的地(appender),如文件、socket、SMTP等。
3.日志消息的格式可配置(layout),例如org.apache.log4j.PatternLayout(它是Apache Log4j 1.x中的一种日志输出布局,用于定义日志输出的格式,允许你指定日志消息中各种信息(例如日期、日志级别、日志消息内容等)的显示方式)。
4.可以设置运行时过滤器(filter),控制不同组件的日志消息的级别和目的地。
在上面几项中,作者认为除了第一项之外,其余三项都是非必需的功能。
日志的输出级别在运行时可调,这样同一个可执行文件可以分别在QA测试环境的时候输出DEBUG级别的日志,在生产环境输出INFO级别的日志(muduo默认输出INFO级别的日志,可通过环境变量控制输出DEBUG或TRACE级别的日志)。在必要的时候也可以临时在线调整日志的输出级别。例如某台机器的消息量过大、日志文件太多、磁盘空间紧张,那么可以临时调整为WARNING级别输出,减少日志数目。又比如某个新上线的进程的行为略显古怪,则可以临时调整为DEBUG级别输出,打印更细节的日志消息以便分析查错。调整日志的输出级别不需要重新编译,也不需要重启进程,只要调用muduo::Logger::setLogLevel()就能即时生效。
对于分布式系统中的服务进程而言,日志的目的地(destination)只有一个:本地文件。往网络写日志消息是不靠谱的,因为诊断日志的功能之一正是诊断网络故障,比如连接断开(网卡或交换机故障)、网络暂时不通(若干秒内没有收到心跳消息)、网络拥塞(消息延迟明显加大)等等。如果日志消息也是通过网络发到另一台机器上的,那岂不是一损俱损?如果接收网络日志消息的服务器(日志服务器)发生故障或者出现进程死锁(阻塞),通常会导致发送日志的多个服务进程阻塞,或者内存暴涨(用户态和内核态的TCP缓存),这无异于放大了单机故障。往网络写日志消息的另一个坏处是增加网络带宽消耗。试想收到一条业务消息、发出一条业务消息时都会写日志,如果写到网络上岂不是让网络带宽消耗翻倍,加剧trashing?同理,应该避免往网络文件系统(如NFS)上写日志,这等于掩耳盗铃。
以本地文件为日志的destination,那么日志文件的滚动(rolling)是必需的,这样可以简化日志归档(archive)的实现。rolling的条件通常有两个:文件大小(例如每写满1GB就换下一个文件)和时间(例如每天零点新建一个日志文件,不论前一个文件有没有写满)。muduo日志库的LogFile会自动根据文件大小和时间来主动滚动日志。既然能主动rolling,自然也就不必支持SIGUSR1了,毕竟多线程程序处理signal很麻烦(第四章)。
一个典型的日志文件的文件名如下:
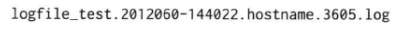
这个文件名由以下几部分组成:
1.第1部分logfile_test是进程的名字。通常是main()参数中argv[0]的basename(3),这样容易区分究竟是哪个服务器程序的日志。必要时还可以把程序版本加进去。
2.第2部分是文件的创建时间(GMT时区,格林威治标准时间(Greenwich Mean Time)对应的本地时区)。这样很容易通过文件名来选择某一时间范围内的日志,例如用通配符*.20120603-14*表示2012年6月3日下午2点(GMT)左右的日志文件。
3.第3部分是机器名称。这样即使把日志文件拷贝到别的机器上也能追溯其来源。
4.第4部分是进程id。如果一个程序一秒内反复重启,那么每次都会生成不同的日志文件(第九章)。
5.第5部分是统一的后缀名.log。同样是为了便于周边配套脚本的编写。
muduo的日志文件滚动没有采用文件改名的办法,即dmesg.log是最新日志,dmesg.log.1是前一个日志,dmesg.log.2.gz是更早的日志等。这种做法的一个好处是dmesg.log始终是最新日志,便于编写某些及时解析日志的脚本。将来可以增加一个功能,每次滚动日志文件之后立刻创建(更新)一个symlink(符号链接,软链接),logfile_test.log始终指向当前最新的日志文件,这样达到相同的效果。
日志文件压缩与归档(archive,例如在非繁忙时段把压缩后的日志文件拷贝到某个NFS位置,以便集中保存和分析)不是日志库应有的功能,而应该交给专门的脚本去做,这样C++和Java的服务程序可以共享这一基础设施。如果想更换日志压缩算法或归档策略也不必动业务程序,改改周边配套脚本就行了。磁盘空间监控也不是日志库的必备功能。有人或许曾经遇到日志文件把磁盘占满的情况,因此希望日志库能限制空间使用,例如只分配10GB磁盘空间,用满之后就冲掉旧日志,重复利用空间,就像循环磁带一样。殊不知如果出现程序死循环拼命写日志的异常情况,那么往往是开头的几条日志最关键,它往往反映了引发异常(busy-loop)的原因(例如收到某条非法消息),后面都是无用的垃圾日志。如果日志库具备重复利用空间的“功能”,只会帮倒忙。磁盘写入的带宽按100MB/s计算,写满一个100GB的磁盘分组需要16分钟,这足够监控系统报警并人工干预了(第九章)。
往文件写日志的一个常见问题是,万一程序崩溃,那么最后若干条日志往往就丢失了,因为日志库不能每条消息都flush硬盘,更不能每条日志都open/close文件,这样性能开销太大。muduo日志库用两个办法来应对这一点,其一是定期(默认3秒)将缓冲区内的日志消息flush到硬盘;其二是每条内存中的日志消息都带有cookie(或者叫哨兵值/sentry),其值为某个函数的地址,这样通过在core dump文件中查找cookie就能找到尚未来得及写入磁盘的消息。
日志消息的格式是固定的,不需要运行时配置,这样可节省每条日志解析格式字符串的开销。作者认为日志的格式在项目的整个生命周期几乎不会改变,因为我们经常会为不同目的编写parse日志的脚本,既要解析最近几天的日志文件,也要和几个月之前,甚至一年之前的日志文件的同类数据做对比。如果在此期间日志格式变了,势必会增加很多无谓的工作量。如果真的需要调整消息格式,直接修改代码并重新编译即可。以下是muduo日志库的默认消息格式(图5-100):

日志消息格式有几个要点:
1.尽量每条日志占一行。这样很容易用awk、sed、grep等命令行工具来快速联机分析日志,比方说要查看“2012-06-03 08:02:00”至“2012-06-03 08:02:59”这一分钟内每秒打印日志的条数(直方图),可以运行:
grep -o '^20120603 08:02:..' | sort | uniq -c
2.时间戳精确到微秒。每条消息都通过gettimeofday(2)(可获得timeval时间结构)获得当前时间,这么做不会有什么性能损失。因为在x86-64 Linux上,gettimeofday(2)不是系统调用,不会陷入内核(可用strace(1)命令验证)。
3.始终使用GMT时区。对于跨州的分布式系统而言,可省去本地时区转换的麻烦(主要西方国家大多实行夏令时),更易于追查事件的顺序。
4.打印线程id。便于分析多线程程序的时序,也可以检测死锁。这里的线程id是指用调用LOG_INFO <<的线程,线程id的获取见第四章。
5.打印日志级别。在线查错的时候先看看有无ERROR日志,通常可加速定位问题。
6.打印源文件名和行号。修复bug的时候不至于搞错对象。
每行日志的前4个字段的宽度是固定的,以空格分隔,便于用脚本解析。另外,应该避免在日志格式(特别是消息id)中出现正则表达式的元字符(meta character),例如’[‘和’]'等等,这样在用less(1)命令查看日志文件的时候查找字符串更加便捷。
运行时的日志过滤器(filter)或许是有用的,例如控制不同部件(程序库)的输出日志级别,但作者认为这应该放到编译器去做,整个程序有一个整体的输出级别就足够好了。同时作者认为一个程序同时写多个日志文件(例如不同的日志级别或不同的组件写到不同的文件)是非常罕见的需求,这可以事后留给log archiver来分流,不必做到日志库中。不实现filter自然也能减小生成每条日志的运行时开销,可以提高日志库的性能。
编写Linux服务端程序的时候,我们需要一个高效的日志库。只有日志库足够高效,程序员才敢在代码中输出足够多的诊断信息,减小运维难度,提升效率。高性能体现在几方面:
1.每秒写几千上万条日志的时候没有明显的性能损失。
2.能应对一个进程产生大量日志数据的场景,例如1GB/min。
3.不阻塞正常的执行流程。
4.在多线程程序中,不造成争用(contention)。
这里列举一些具体的性能指标,考虑往普通7400 rpm SATA硬盘写日志文件的情况:
1.磁盘带宽约是110MB/s,日志库应该能瞬时写满这个带宽(不必持续太久)。
2.假如每条日志消息的平均长度是110字节,这意味着一秒要写100万条日志。
以上是“高性能”日志库的最低指标。如果磁盘带宽更高,那么日志库的预期性能指标也会相应提高。反过来说,在磁盘带宽确定的情况下,日志库的性能只要“足够好”就行了。假如某个神奇的日志库能往/dev/null写1000MB数据,那么到哪里去找这么快的磁盘来让程序写诊断日志呢?
这些指标初看起来有些异想天开,什么程序需要1秒写100万条日志消息呢?换一个角度其实很容易想明白,如果一个程序耗尽全部CPU资源和磁盘带宽可以做到1秒写100万条日志消息,那么当只需要1秒写10万条时候(比方说一秒处理两三万条消息,每条消息写三条日志:从哪里收到、计算结果如何、发到哪里),立刻就能腾出90%的资源来干正事(处理业务)。相反,如果一个日志库在满负荷的情况下只能1秒写10万条日志,真正用到生产环境,恐怕就只能1秒写1万条日志才不会影响正常业务处理,这其实钳制了服务器的吞吐量。
以下是muduo日志库在两台机器上的实测性能数据:
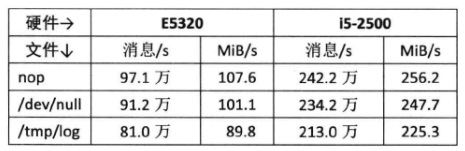
可见muduo日志库在现在的PC上能写到每秒200万条消息,带宽足够撑满两个千兆网连接或4个SATA组成的RAID10(也被称为RAID 1+0,是一种磁盘阵列级别,它将RAID 1(镜像)和RAID 0(条带化)两种技术结合在一起,最少需要4块硬盘,它提供了可靠的数据保护,同时在读写操作方面表现出色),性能是达标的(日志文件是顺序写入的,是对磁盘最友好的一种负载,对IOPS要求不高)。
为了实现这样的性能指标,muduo日志库的实现有几点优化措施值得一提:
1.时间戳字符串中的日期和时间两部分是缓存的,一秒之内的多条日志只需重新格式化微秒部分。图5-100中的3条日志消息中,“20120603 08:02:46”是复用的,每条日志只需要格式化微秒部分(“.125770Z”)。
2.日志消息的前4个字段是定长的,因此可以避免在运行期求字符串长度(不会反复调用strlen)。因为编译器认识memcpy(),对于定长的内存复制,会在编译期把它inline展开为高效的目标代码。
3.线程id是预先格式化为字符串,在输出日志消息时只需简单拷贝几个字节。见CurrentThread::tidString()。
4.每行日志消息的源文件名部分采用了编译期计算来获得basename,避免运行期strrchr(2)函数开销。见SourceFile class,这里利用了gcc的内置函数。
多线程程序对日志库提出了新的需求:线程安全,即多个线程可以并发写日志,两个线程的日志消息不会出现交织。线程安全不难办到,简单的办法是用一个全局mutex保护IO,或者每个线程单独写一个日志文件(Google C++日志库的默认多线程实现即如此),但这两种做法的高效性就堪忧了。前者会造成全部线程抢一个锁,后者有可能让业务线程阻塞在写磁盘操作上。
作者认为一个多线程程序的每个进程最好只写一个日志文件,这样分析日志更容易,不必在多个文件中跳来跳去。再说多线程写多个文件也不一定能提速(操作同一磁盘时,有磁盘读写队列)。解决办法不难想到,用一个背景线程负责收集日志消息,并写入日志文件,其他业务线程只管往这个“日志线程”发送日志消息,这称为“异步日志”。
在多线程服务程序中,异步日志(叫“非阻塞日志”似乎更准确)是必需的,因为如果在网络IO线程或业务线程中直接往磁盘写数据的话,写操作偶尔可能阻塞长达数秒之久(原因很复杂,可能是磁盘或磁盘控制器复位)。这可能导致请求方超时,或者耽误发送心跳消息,在分布式系统中更可能造成多米诺骨牌效应,例如误报死锁引发自动failover等。因此,在正常的实时业务处理流程中应该彻底避免磁盘IO,这在使用one loop per thread模型的非阻塞服务端程序中尤为重要,因为线程是复用的,阻塞线程意味着影响多个客户连接。
我们需要一个“队列”来将前端日志的数据发送到后端(日志线程),但这个“队列”不必是现成的BlockingQueue<std::string>,因为不用每次产生一条日志消息都通知(notify())接收方。
muduo日志库采用的是双缓冲(double buffering)技术,基本思路是准备两块buffer:A和B,前段负责往buffer A填数据(日志消息),后端负责将buffer B的数据写入文件。当buffer A写满后,交换A和B,让后端将buffer A的数据写入文件,而前端则往buffer B填入新的日志消息,如此往复。用两个buffer的好处是在新建日志消息的时候不必等待磁盘文件操作,也避免每条新日志消息都触发(唤醒)后端日志线程。换言之,前端不是将一条条日志分别传送到后端,而是将多条日志消息拼成一个大的buffer传送给后端,相当于批处理,减少了线程唤醒的频度,降低开销。另外,为了及时将日志消息写入文件,即使buffer A未满,日志库也会每3秒执行一次上述交换写入操作。
muduo异步日志的性能开销大约是前端每写一条日志消息耗时1.0us~1.6us。
muduo实际采用了四个缓冲区,这样可以进一步减少或避免日志前端的等待。数据结构如下(muduo/base/AsyncLogging.h):

boost::ptr_vector是Boost C++ 库中的一个容器类,用于管理指针的动态数组。它提供了一种在运行时创建和销毁对象的方式,这些对象以指针的形式存储在容器中。boost::ptr_vector已经过时,并不再推荐在新代码中使用。C++11和以后的标准库提供了更好的智能指针和容器,如std::vector与std::shared_ptr或std::unique_ptr结合使用,以实现更安全和高效的动态内存管理。
boost::ptr_vector::auto_type是boost::ptr_vector类中的一个成员类型,它用于表示boost::ptr_vector中存储的指针类型。
其中,LargeBuffer类型是FixedBuffer class template的一份具体实现(instantiation),其大小为4MB,可以存至少1000条日志消息。boost::ptr_vector<T>::auto_type类型类似C++11中的std::unique_ptr,具备移动语义(move semantics),而且能自动管理对象生命期。mutex_用户保护后面的4个数据成员。buffers_存放的是供后端写入的buffer。
先来看发送方代码:
void AsyncLogging::append(const char *logline, int len)
{muduo::MutexLockGuard lock(mutex_);// most common case: buffer is not full, copy data hereif (currentBuffer_->avail() > len){currentBuffer_->append(logline, len);}// buffer is full, push it, and find next spare bufferelse {// 将currentBuffer移入buffers_buffers_.push_back(currentBuffer_.release());// is there is one already, use itif (nextBuffer_){// 移动,而非复制// 在Boost C++库的boost::ptr_container中,move是一个成员函数// 用于将元素从一个ptr_container移动到另一个// 这个函数对于在不同容器之间转移拥有的指针对象非常有用,而不是复制它们。currentBuffer_ = boost::ptr_container::move(nextBuffer_);}// allocate a new oneelse{// Rarely happenscurrentBuffer_.reset(new LargeBuffer);}currentBuffer_->append(logline, len);cond_.notify();}
}
前端在生成一条日志消息的时候会调用AsyncLogging::append()。在这个函数中,如果当前缓冲(currentBuffer_)剩余的空间足够大,则会直接把日志消息拷贝(追加)到当前缓冲中,这是最常见的情况。这里拷贝一条日志消息并不会带来多大开销。前后端代码的其余部分都没有拷贝日志,而是简单的指针交换。
否则说明当前缓冲已经写满,就把它送入(移入)buffers_( buffers_.push_back(currentBuffer_.release());),然后试图把预备好的另一块缓冲(next_Buffer_)移用(move)为当前缓冲,然后追加消息日志并通知(唤醒)后端开始写入日志数据。以上两种操作在临界区之内都没有耗时的操作,运行时间为常数。
如果前端写入速度太快,一下子把两块缓冲都用完了,那么只好分配一块新的buffer,作为当前缓冲,这是极少发生的情况。
再来看接收方(后端)实现,这里只给出了最关键的临界区内代码:
void AsyncLogging::threadFunc()
{BufferPtr newBuffer1(new LargeBuffer);BufferPtr newBuffer2(new LargeBuffer);// reserve()从略BufferVector buffersToWrite;while (running_){// swap out what need to be written, keep CS short{muduo::MutexLockGuard lock(mutex_);// unusual usage!if (buffers_.empty()){cond_.waitForSeconds(flushInterval_);}// 移动,而非复制buffers_.push_back(currentBuffer_.release());// 移动,而非复制currentBuffer_ = boost::ptr_container::move(newBuffer1);// 内部指针交换,而非复制buffersToWrite.swap(buffers_);// 如果没有nextBuffer_,说明在append的时候第currentBuffer_已被写满,因此// currentBuffer_已经被移到了buffers_中,nextBuffer_的内容已被move到了currentBuffer_里if (!nextBuffer_){// 移动,而非复制nextBuffer_ = boost::ptr_container::move(newBuffer2);}}// output buffersToWrite to file// re-fill newBuffer1 and newBuffer2}// flush output
}
首先准备好两块空闲的buffer,以备在临界区内交换。在临界区内,等待条件触发,这里的条件有两个:其一是超时,其二是前端写满了一个或多个buffer。这里是非常规的condition variable用法,它没有使用while循环,而且等待时间有上限。
当“条件”满足时,先将当前缓冲(currentBuffer_)移入buffers_,并立刻将空闲的newBuffer1移为当前缓冲。注意这整段代码位于临界区之内,因此不会有任何race condition。接下来将buffers_与buffersToWrite交换,后面的代码可以在临界区之外安全地访问buffersToWrite,将其中的日志数据写入文件。临界区里最后干的一件事情是用newBuffer2替换nextBuffer_,这样前端始终有一个预备buffer可供调配。nextBuffer_可以减少前端临界区分配内存的概率,缩短前端临界区长度。注意到后端临界区内也没有耗时操作,运行时间为常数。
// re-fill newBuffer1 and newBuffer2会将buffersToWrite内的buffer重新填充到newBuffer1和newBuffer2(newBuffer1和newBuffer2在临界区中被move了,指向空,此处重新将buffersToWrite里的缓冲区赋予newBuffer1和newBuffer2),这样下次执行的时候还有两个空闲buffer可用于替换前端的当前缓冲和预备缓冲。最后,这四个缓冲在程序启动的时候会全部填充为0,这样可以避免程序热身时page fault(页错误,缺页中断)引发性能不稳定(在程序启动时,将缓冲区填充为0可以让程序访问那些未加载到物理内存中的页面,从而将其加载到物理内存中,这样在程序的热身阶段,即程序刚开始运行时,不会因为打印日志时的缓冲区缺页而引起性能降低)。
以下用图表展示前端和后端的具体交互情况。一开始分配好四个缓冲区A、B、C、D,前端和后端各持有其中两个。前端和后端各有一个缓冲区数组,初始时都是空的。
第一种情况是前端写日志的频度不高,后端3秒超时后将“当前缓冲currentBuffer_”写入文件:

在第2.9秒的时候,currentBuffer_使用了80%,在第3秒的时候后端线程醒过来,先把currentBuffer_送入buffers_,再把newBuffer1移用为currentBuffer_。随后第3+秒,交换buffers_和buffersToWrite,离开临界区,后端开始将buffer A写入文件。写完(write done)之后再把newBuffer1重新填上,等待下一次cond_.waitForSeconds()返回。
后面在画图时将有所简化,不再画出buffers_和buffersToWrite交换的步骤。
第二种情况,在3秒超时之前已经写满了当前缓冲,于是唤醒后端线程开始写入文件:
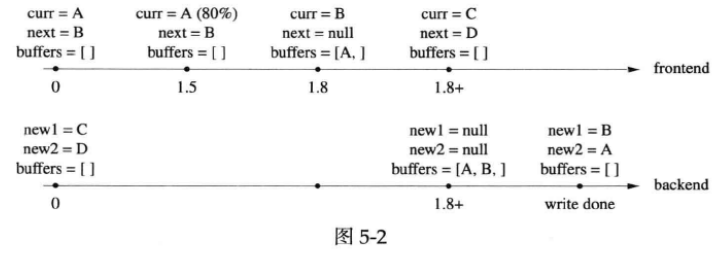
在第1.5秒的时候,currentBuffer_使用了80%;第1.8秒,currentBuffer_写满,于是将当前缓冲送入buffers_,并将nextBuffer_移用为当前缓冲,然后唤醒后端线程开始写入。当后端线程唤醒之后(第1.8+秒),先将currentBuffer_送入buffers_,再把newBuffer1移用为currentBuffer_,然后交换buffers_和buffersToWrite,最后用newBuffer2替换nextBuffer_,即保证前端有两个空缓冲可用。离开临界区之后,将buffersToWrite中的缓冲区A和B写入文件,写完之后重新填充newBuffer1和newBuffer2,完成一次循环。
上面这两种情况都是最常见的,再来看一看前端需要分配新buffer的两种情况。
第三种情况,前端在短时间内密集写入日志消息,用完了两个缓冲,并重新分配了一块新的缓存:
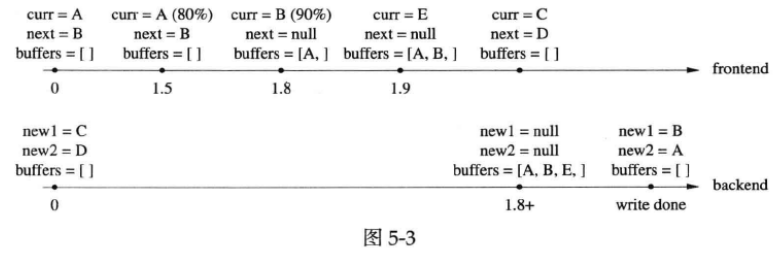
在第1.8秒的时候,缓冲A已经写满,缓冲B也接近写满,并且已经notify()了后端线程,但是出于种种原因,后端线程并没有立刻开始工作。到了第1.9秒,缓冲区B也已经写满,前端线程新分配了缓冲E。到了第1.8+秒,后端线程终于获得控制权,将C、D两块缓冲交给前端,并开始将A、B、E依次写入文件。一段时间之后,完成写入操作,用A、B重新填充那两块空闲缓冲。注意这里有意用A和B来填充newBuffer1/2,而释放了缓冲E,这是因为使用A和B不会造成page fault。
第四种情况,文件写入速度较慢,导致前端耗尽了两个缓冲,并分配了新缓冲:

前1.8+秒的场景和前面“第二种情况”相同,前端写满了一个缓冲,唤醒后端线程开始写入文件。之后,后端花了较长时间(大半秒)才将数据写完。这期间前端又用完了两个缓冲,并分配了一个新的缓冲,这期间前端的notify()已经丢失。当后端写完(write done)后,发现buffers_不为空,立刻进入下一循环。即替换前端的两个缓冲,并开始一次写入C、D、E。假定前端在此期间产生的日志较少,后端会将C、D分别填充到new1、new2,然后释放E,之后进入下一次循环。
前面我们一共准备了四块缓冲,应该足以应付日常需求,如果需要进一步增加buffer数目,可以改用下面的数据结构:

初始化时在emptyBuffers_中放入足够多空闲buffer,这样前端几乎不会遇到需要在临界区内新分配buffer的情况,这是一种空间换时间的做法。为了避免短时突发写大量日志造成新分配的buffer占用过多内存,后端代码应该保证emptyBuffers_和fullBuffers_的长度之和不超过某个定值。buffer在前端和后端之间流动,形成一个循环:

万一前端陷入死循环,拼命发送日志消息,超过后端的处理(输出)能力,会导致什么后果?对于同步日志来说,这不是问题,因为阻塞IO自然就限制了前端的写入速度,起到了节流阀(throttling)的作用。但是对于异步日志来说,这就是典型的生产速度高于消费速度问题,会造成数据在内存中堆积,严重时引发性能问题(可用内存不足)或程序崩溃(分配内存失败)。
muduo日志库处理日志堆积的方法很简单:直接丢掉多余的日志buffer,以腾出内存,见muduo/base/AsyncLogging.cc第87~96行代码。这样可以防止日志库本身引起程序故障,是一种自我保护措施。将来或许可以加上网络报警功能,通知人工介入,以尽快修复故障。
当然在前端和后端之间高效传递日志消息的办法不止这一种,比方说使用常规的muduo::BlockingQueue<std::string>或muduo::BoundedBlockingQueue<std::string>在前后端之间传递日志消息,其中每个std::string是一条消息。这种做法每条日志消息都要分配内存,特别是在前端线程分配的内存要由后端线程释放,因此对malloc的实现要求较高,需要针对多线程特别优化。另外,如果用这种方案,那么需要修改LogStream的Buffer,使之直接将日志写到std::string中,可节省一次内存拷贝。
相比前面展示的直接拷贝日志消息的做法,这个传递指针的方案(前文说的是传递string,这里的意思是改为传递string的指针?)似乎会更高效,但据作者测试,直接拷贝日志数据的做法比传递指针快3倍(在每条日志消息不大于4kB的时候),估计是内存分配的开销所致。因此muduo日志库只提供了C风格字符串、双缓冲区的异步日志机制。这再次说明性能不能凭感觉说了算,一定要有典型场景的测试数据作为支撑。
muduo现在的异步日志实现用了一个全局锁。尽管临界区很小,但是如果线程数目较多,锁争用(lock contention)也可能影响性能。一种解决办法是像Java的ConcurrentHashMap那样用多个桶子(bucket),前端写日志的时候再按线程id哈希到不同的bucket中,以减少contention。这种方案的后端实现较为复杂。
为了简化实现,目前muduo日志库只允许指定日志文件的名字,不允许指定其路径。日志库会把日志文件写到当前路径,因此可以在启动脚本(shell脚本)里改变当前路径,以达到相同的目的。
Linux默认会把core dump写到当前目录,而且文件名是固定的core。为了不让新的core dump文件冲掉旧的,我们可以通过sysctl命令设置kernel.core_pattern参数(也可以修改/proc/sys/kernel/core_pattern),让每次core dump都产生不同的文件。例如设为%e.%t.%p.%u.core,其中各个参数的含义见man 5 core。另外也可以使用Apport来收集有用的诊断信息,见https://wiki.ubuntu.com/Apport。
相关文章:
Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第五章 高效的多线程日志
“日志(logging)”有两个意思: 1.诊断日志(diagnostic log)。即log4j、logback、slf4j、glog、g2log、log4cxx、log4cpp、log4cplus、Pantheios、ezlogger等常用日志库提供的日志功能。 2.交易日志(trasac…...

利用Pholcus框架提取小红书数据的案例分析
前言 在当今互联网时代,数据的获取和分析变得越来越重要。爬虫技术作为一种数据采集的方法,被广泛涉及各个领域。在本文中,我们将介绍如何使用Python Spark语言和Pholcus框架来实现一本小红书数据爬虫的案例分析。 开发简述 Go语言作为一种…...
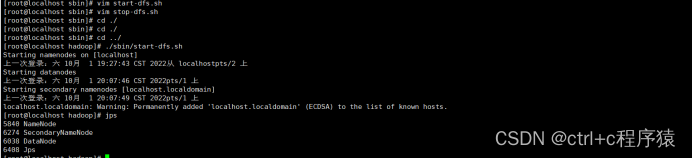
超详细Hadoop安装教程(单机版、伪分布式)
超详细Hadoop安装教程(单机版、伪分布式) 1.Hadoop分布式系统基础架构介绍1.1.Hadoop核心 2.Hadoop安装教程2.1.环境准备2.2.配置用户ssh 免密登录2.3.JAVA环境的安装和配置2.4.Hadoop安装2.5.单机版Hadoop配置2.6.伪分布式Hadoop配置2.7Hadoop初始化 1.…...

持续集成部署-k8s-服务发现-Ingress
持续集成部署-k8s-服务发现-Ingress 1. Ingress 是什么2. Ingress 控制器3. 安装 Ingress-Nginx3.1 添加 Helm 仓库3.2 更新 Helm 仓库3.3 下载 Ingress-Nginx 安装包3.4 配置 Ingress-Nginx 配置文件参数3.5 安装 Ingress-Nginx1. Ingress 是什么 Ingress是 Kubernetes 中的一…...

从零开始搭建Prometheus+grafana服务器组件监控系统
服务器及相关组件监控 本文档主要记录了常用企业级服务器及各种组件的监控手段和监控部署方案,使企业可以实时感知服务器组件的健康状态,并在服务器或组件出现异常时及时做出反应。 本方案采用的Prometheusgrafana的方式实现对服务器及各种组件的监控&am…...

智能水厂运行与调控3D模拟仿真在线展示提高整个系统的协同效应
水厂在生活中的重要性不可忽视。它们提供清洁、安全的水源,满足人们饮用、洗浴、烹饪等基本需求,保障公共卫生,预防疾病传播;同时,水厂也促进经济发展,为工业生产和农业灌溉提供保障,吸引和支持企业的投资和…...
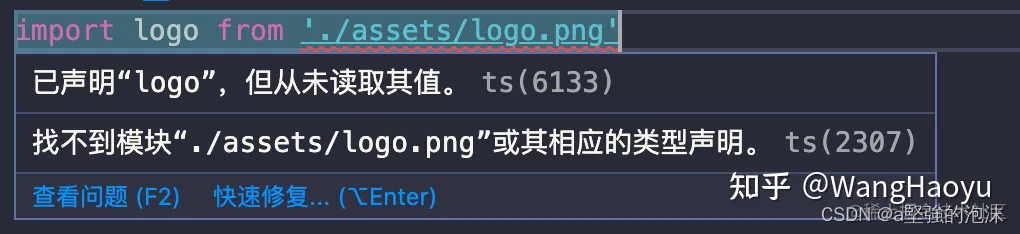
ts声明文件
1 背景 对于为第三方模块/库写声明文件之前,我们需要知道第三方模块/库,是否需要声明文件,或者是否已有声明文件。 若第三方模块/库,是ts编写且无声明文件, 可以使用--declaration配置选项来生成;可以在命…...

JPA联合主键使用
在实际工作中,我们会经常遇到联合主键的情况,所以我用简单例子列举JPA两种实现联合主键的方式。 1、如何通过IdClass 实现联合主键 第一步:新建一个UserInfoID类,里面是联合主键 Data Builder NoArgsConstructor AllArgsConstructor publi…...
【计算机毕设经典案例】基于微信小程序的图书管理系统
前言:我是IT源码社,从事计算机开发行业数年,专注Java领域,专业提供程序设计开发、源码分享、技术指导讲解、定制和毕业设计服务 👉IT源码社-SpringBoot优质案例推荐👈 👉IT源码社-小程序优质案例…...

如何制作rpm离线安装包
如何制作rpm离线安装包 在内网环境中使用rpm安装zabbix-agent-6.4.6时,发现rpm无法下载依赖 1.准备一个可以连接外网的纯净centos7环境 防止本地已有的依赖不会被重复下载 docker pull centos:7docker stop mycentos7 docker rm mycentos72.启动centos7并挂载一…...

golang中快速用melody搭建轻量的websocket服务
在Go中,可以使用gin和melody库来搭建一个轻量级的WebSocket服务。gin是一个流行的Web框架,而melody是一个用于处理WebSocket的库。以下是一个简单的示例代码,演示了如何使用gin和melody搭建WebSocket服务: package mainimport (&…...

Profinet转EtherNET/IP从站连接欧姆龙plc与西门子200smart通讯的配置方法
本案例是200smart plc与欧姆龙plc进行通讯的方法,远创智控YC-PNM-EIP网关可以读写全系列西门子 PLC 数据。一般不需要 PLC 里做特殊的设置。只需要把 PLC 的变量地址配置到网关中,网关就可以读取指定地址的数据或者写数据到指定的地址。 PLC 通过网线连接…...

elementUI el-table实现鼠标悬浮某一行,在鼠标右侧展示提示信息
背景 el-table组件中,可以通过勾选某条数据来创建单据,但是有些数据没有权限使用,就需要禁用掉勾选的功能,然后当鼠标悬浮在这一行的时候,展示类似于toolTip的提示框。 除了当鼠标悬浮在某一行,展示类似于…...
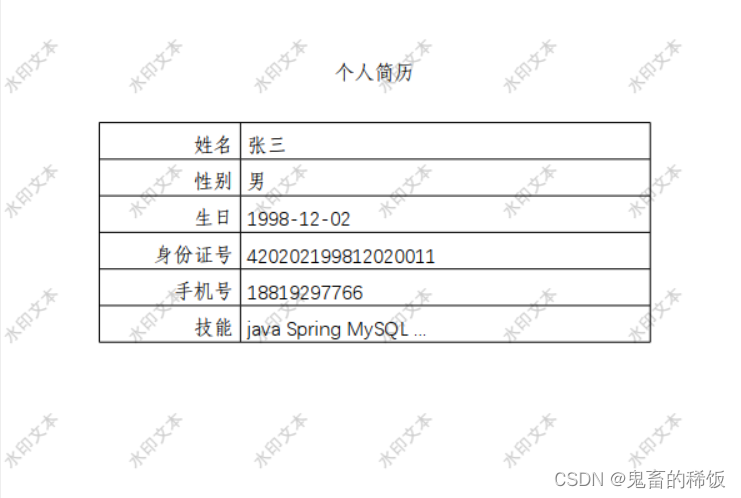
Java 使用 poi 和 aspose 实现 word 模板数据写入并转换 pdf 增加水印
本项目所有源码和依赖资源都在文章顶部链接,有需要可以下载使用 1. 需求描述 从指定位置读取一个 word 模板获取业务数据并写入该 word 模板,生成新的 word 文档将新生成的 word 文档转换为 pdf 格式对 pdf 文档添加水印 2. 效果预览 word 模板 带水印的…...

Spring Boot进阶(93):体验式教程:手把手教你整合Spring Boot和Zipkin
📣前言 分布式系统开发中,服务治理是一个比较重要的问题。为了更好地实现服务治理,需要解决服务跟踪问题,即如何对分布式系统中的服务进行监控和追踪。本文将介绍如何使用Zipkin进行服务跟踪,并结合Spring Boot进行整合…...
Lvs +keepalivede : 高可用集群
keepalived为Ivs应运而生的高可用服务。Ivs的调度器无法做高可用,于是keepalived这个软件。 实现的是调度器的高可用。 但是: keepalived不是专为Ivs集群服务的,也可以做其他代理服务器的高可用。 lvs的高可用集群:主调度器和备调度器&…...
得物 Redis 设计与实践yu
一、前言 自建 Redis 系统是得物 DBA 团队自研高性能分布式 KV 缓存系统,目前管理的 ECS 内存总容量超过数十TB,数百多个 Redis 缓存集群实例,数万多个 Redis 数据节点,其中内存规格超过 1T 的大容量集群多个。 自建 Redis 系统采…...
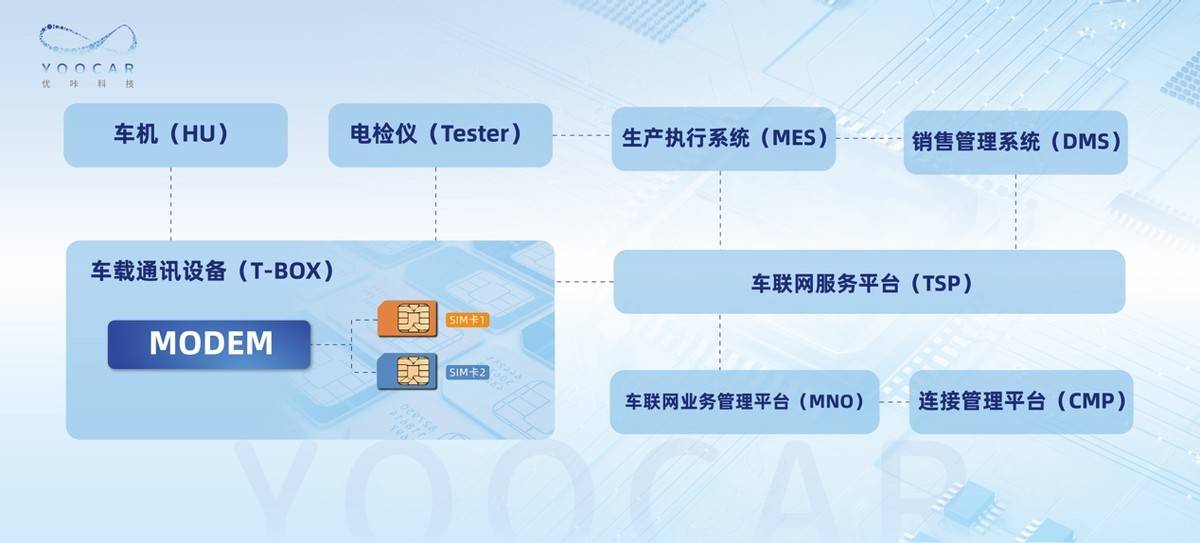
优咔科技创新连接方案助力高质量5G车联服务
上海优咔网络科技有限公司 CEO 闫楠 【摘要】本文就智能网联汽车对高质量5G车联服务的需求背景和行业趋势进行了分析,主要介绍采用5G双SIM卡的创新连接方案,重点讲述双SIM卡联网的端到端体系架构和技术方案,并就优咔科技全方位支撑行业领先车…...

(a /b)*c的值
系列文章目录 进阶的卡莎C++_睡觉觉觉得的博客-CSDN博客数1的个数_睡觉觉觉得的博客-CSDN博客双精度浮点数的输入输出_睡觉觉觉得的博客-CSDN博客足球联赛积分_睡觉觉觉得的博客-CSDN博客大减价(一级)_睡觉觉觉得的博客-CSDN博客小写字母的判断_睡觉觉觉得的博客-CSDN博客纸币(…...

Hive 常用DML操作
本专栏案例数据集链接: https://download.csdn.net/download/shangjg03/88478038 1.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE</...

三分钟掌握roop-unleashed:零门槛AI换脸终极指南
三分钟掌握roop-unleashed:零门槛AI换脸终极指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 你是否想过将视频中的人物面孔轻松替换&#x…...

Flut Renamer:免费跨平台批量文件重命名工具的完整使用指南
Flut Renamer:免费跨平台批量文件重命名工具的完整使用指南 【免费下载链接】renamer Flut Renamer - A bulk file renamer written in flutter (dart). Available on Linux, Windows, Android, iOS and macOS. 项目地址: https://gitcode.com/gh_mirrors/ren/ren…...

Appium 2.10.1环境搭建实战:JDK21+Android SDK34全链路排障指南
1. 这不是“装个软件”——Appium最新版环境搭建的真实水深 很多人点开“Appium环境搭建”教程,以为就是下载几个安装包、点几下下一步,顶多配个PATH变量就完事了。我去年带三个新人做自动化测试时,也这么想。结果光是让一台干净的Windows 1…...

Windows和Office激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程
Windows和Office激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗烦恼吗?Office突然变成只读模式影响…...

Struts2 S2-061漏洞深度解析:OGNL沙箱绕过与零代码应急加固
1. 这个漏洞不是“又一个Struts2漏洞”,而是权限失控的临界点S2-061(CVE-2020-17530)在2020年12月被Apache官方披露,但直到2022年中后期,我在三家不同行业的客户现场做渗透复测时,仍发现超过40%的存量Strut…...

3分钟快速解密Navicat密码:开源工具终极指南
3分钟快速解密Navicat密码:开源工具终极指南 【免费下载链接】navicat_password_decrypt 忘记navicat密码时,此工具可以帮您查看密码 项目地址: https://gitcode.com/gh_mirrors/na/navicat_password_decrypt 当您忘记Navicat中保存的数据库连接密码时&#…...

Applite:3步告别命令行,让Mac应用管理变得如此简单
Applite:3步告别命令行,让Mac应用管理变得如此简单 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 你是否曾因安装一个应用而被迫打开终端,…...

开发多语言翻译服务时借助Taotoken调用专用模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发多语言翻译服务时借助Taotoken调用专用模型 设想这样一个场景:你的团队正在开发一个内容平台或国际化应用…...

K210开发板固件烧录终极指南:kflash_gui完全使用手册
K210开发板固件烧录终极指南:kflash_gui完全使用手册 【免费下载链接】kflash_gui Cross platform GUI wrapper for kflash.py (download(/burn) tool for k210) 项目地址: https://gitcode.com/gh_mirrors/kf/kflash_gui 你是否正在为K210开发板固件烧录而烦…...

机器学习赋能心电图分析:探索神经认知障碍的早期筛查新路径
1. 项目概述:当心电图遇见机器学习,为大脑健康“把脉”作为一名长期关注医疗AI交叉应用的从业者,我常常思考一个问题:我们能否从那些看似常规、无处不在的临床检查中,挖掘出超越其传统用途的深层价值?心电图…...