基于windows10的pytorch环境部署及yolov8的安装及测试
第一章 pytorch环境部署留念
第一步:下载安装anaconda 官网地址
(也可以到清华大学开源软件镜像站下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)
我安装的是下面这个,一通下一步就完事儿。
第二步:下载显卡驱动程序(大家一般都不需要,可以直接跳过)(cmd–nvidia-smi)
第三步:通过anaconda来安装pytorch
在这个base环境中先不要着急安装各种各样的python包,因为默认情况下在anaconda中创建的新的环境都是以base环境为模板的,也就是意味着新创建的环境会包含与base环境相同的Python版本和已安装的软件包列表,所以为了不必要的麻烦,我们新创建一个环境,创建环境的命令如下
conda create -n name python=3.8
-n是名字的意思,name自己取名,后面那个3.8是版本号。
在base环境中运行此命令可以进入我们创建的环境
第四步:激活环境
conda activate name (注:name是你自己创建的环境的名字)
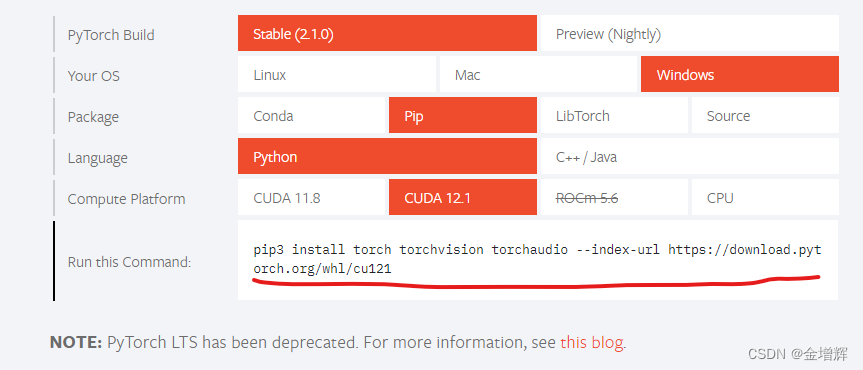
第五步:在激活环境中下载安装pytorch
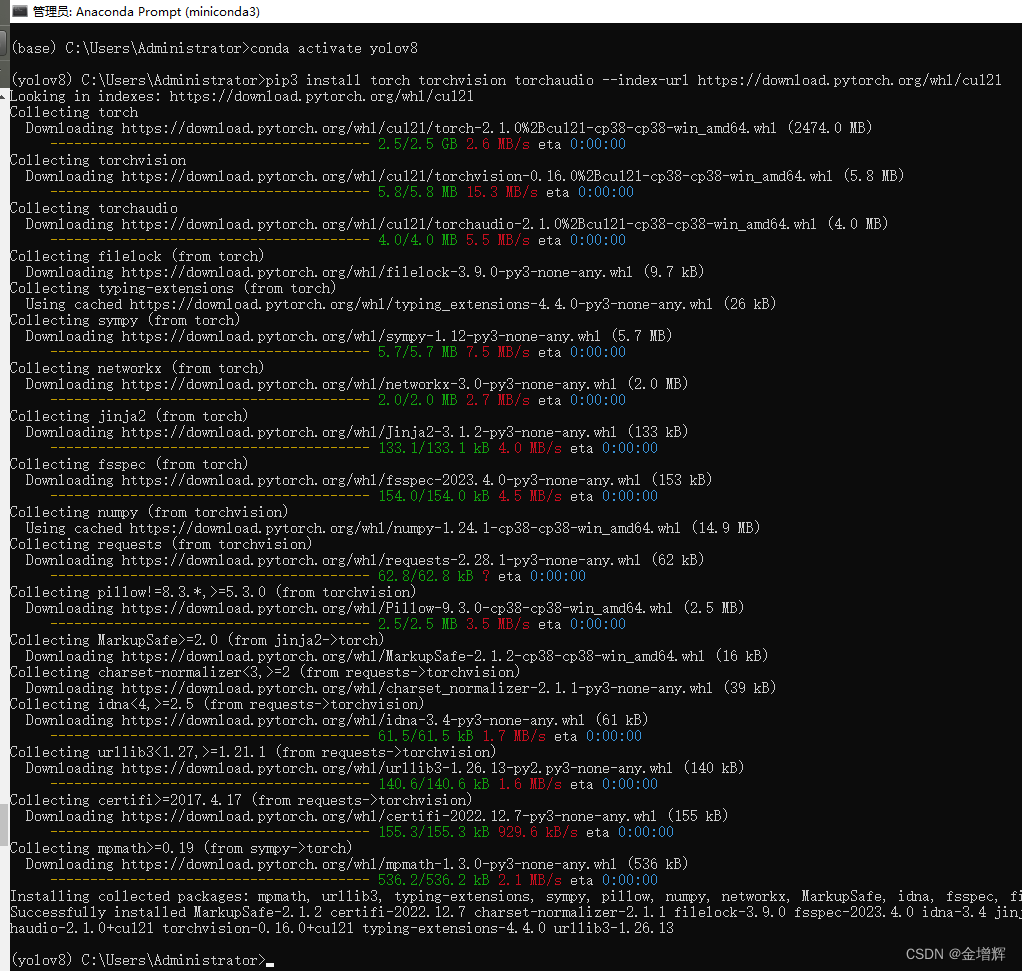
到官网去获取指令,官网链接:https://pytorch.org/,成功后的样子如图所示。
第六步:配置刚下载的环境作为pycharm中我们的python解释器
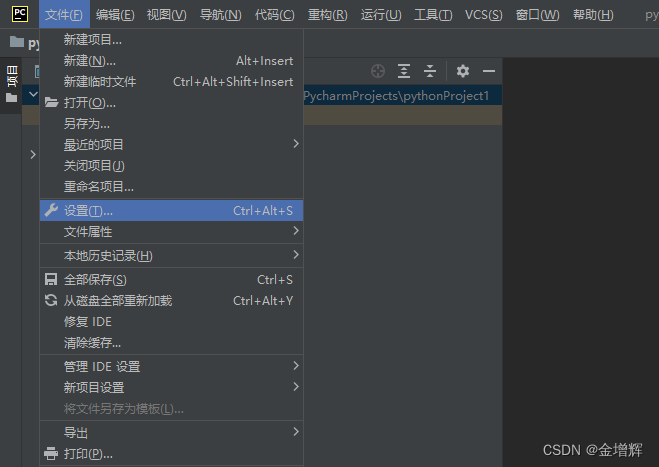
1.打开pycharm选择“文件”——设置
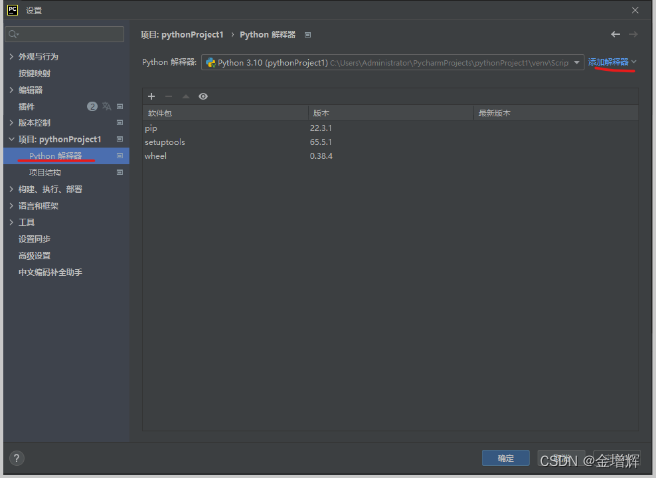
2.选择编辑器、添加解释器
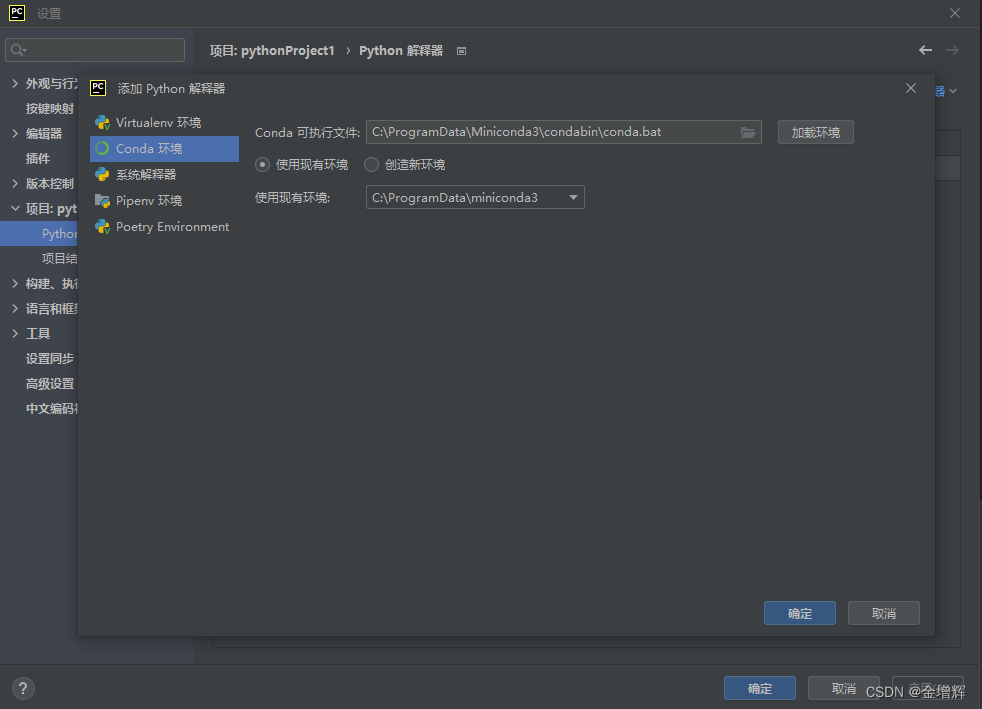
3.选择conda环境,单击确定。
到这里就完事了。
第二章 YOLOV8的安装及测试
1.下载代码,到官网去找,或者其他人上传的都可以,主要下载两个内容:
第一个如下图的代码
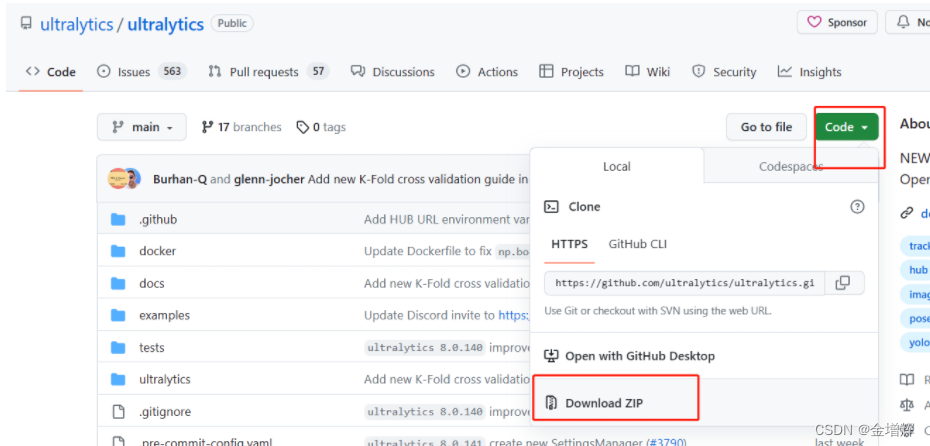
第二个如下图的模型,上面的那个把网页下拉就看到了
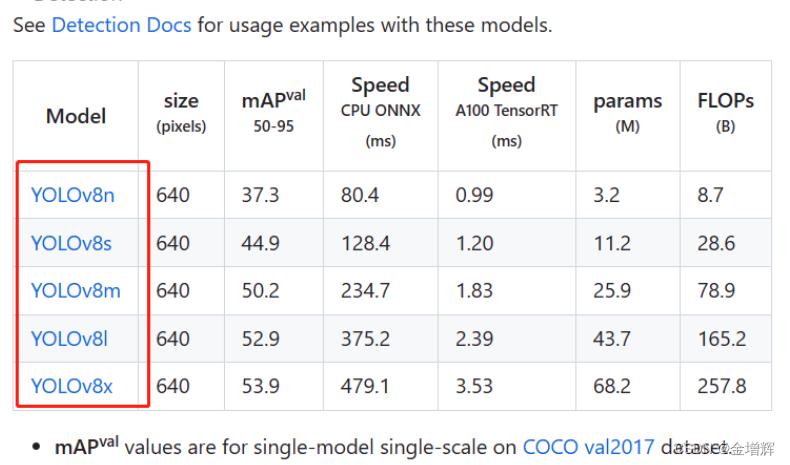
2.将下载完的代码解压拷贝到D盘的文件夹中,如下图所示
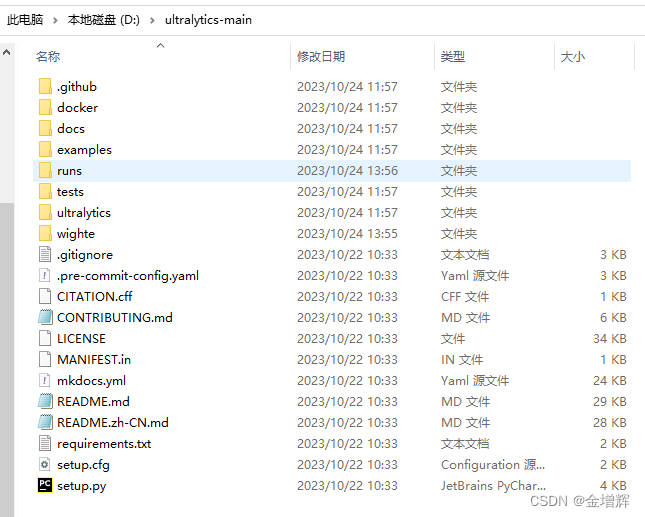
3.将下载完的模型解压拷贝到如下图所示文件夹中
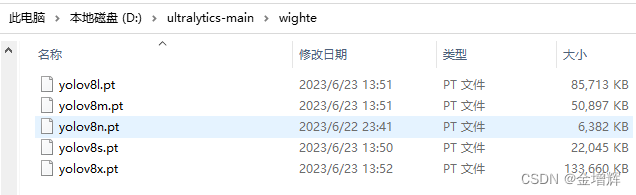
4.在Anaconda中执行下面的指令
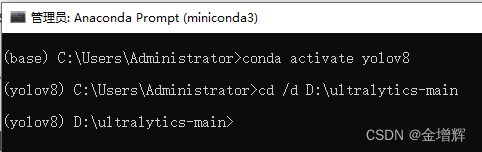
5.安装依赖包
使用指令 pip install -r requirements.txt 安装的时候各种报错,更换源就好了。 更换源的方法就是在pip install的后面增加 -i +源名+安装包的形式,采用下面的指令进行安装即可
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
6.安装YOLO
出现下图表示成功,警告不用管。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ultralytics

7.测试
用yolov8s.pt来测试 :
yolo task=segment mode=predict model=wighte/yolov8s.pt source=ultralytics/assets/bus.jpg save=true
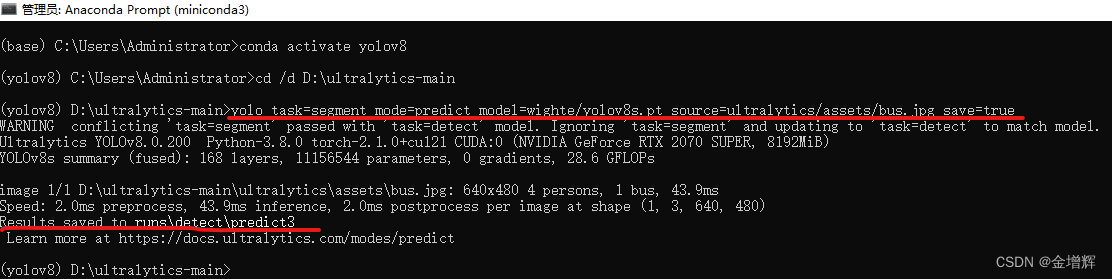
在程序文件夹中可以找到结果
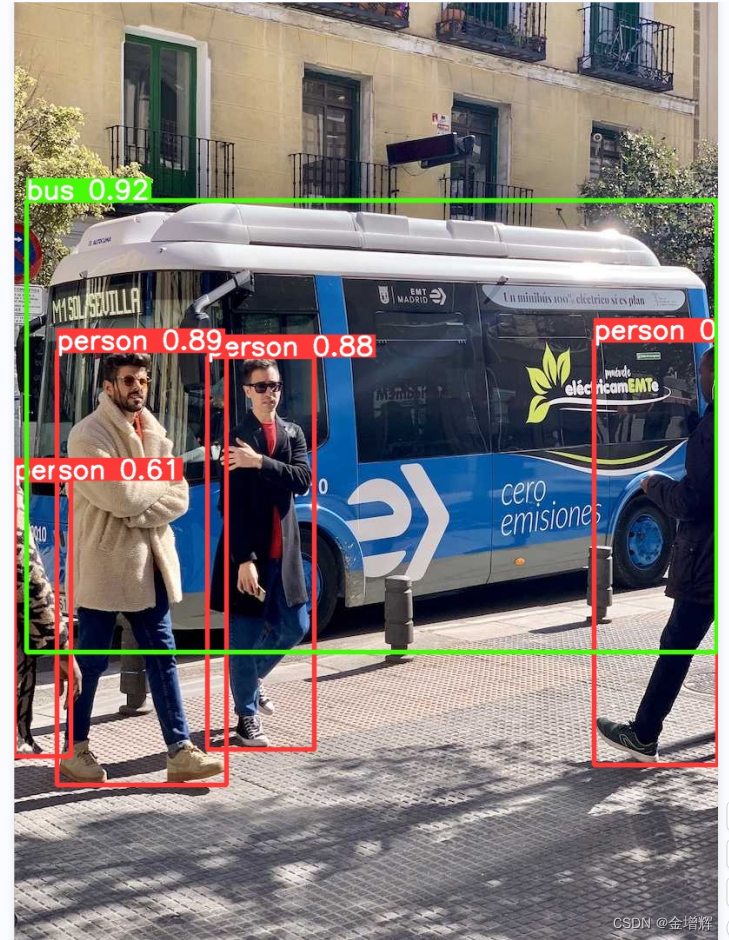
结果如下图所示:
测试视频/摄像头/文件夹:(source=自己的绝对路径就行,照片也可以用绝对路径,刚才用的是相对路径),素材可以上网去找别人下载好的直接用就行,文件夹没有测试不知道是啥,前三个测试了效果挺好,尤其是摄像头,直接计算机上插一个摄像头就行。
conda activate yolov8
cd /d D:\ultralytics-main
#测试图片
yolo task=segment mode=predict model=wighte/yolov8s.pt source=ultralytics/assets/bus.jpg save=true#测试视频
yolo task=segment mode=predict model=wighte/yolov8s.pt source=D:\car.mp4 show=true#测试摄像头
yolo task=segment mode=predict model=wighte/yolov8s.pt source=0#测试文件夹
yolo task=segment mode=predict model=wighte/yolov8s.pt source=D:\myimgs
第三章 制作自己的数据集
1.安装labelme,这里注意更换源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme
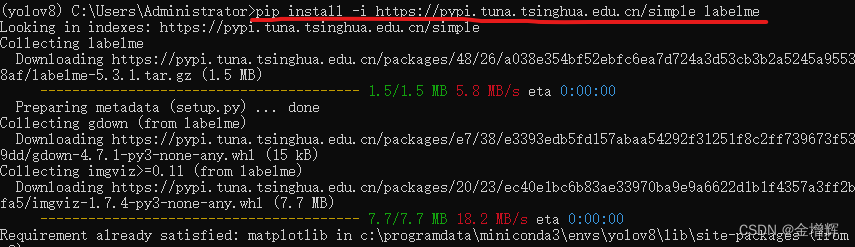
出现下图表示安装成功
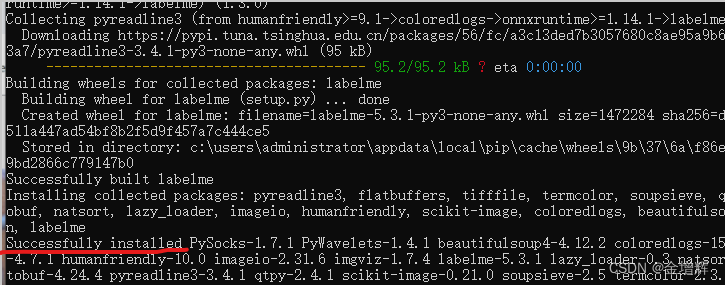
2.输入下图指令,打开labelme,结果如图所示
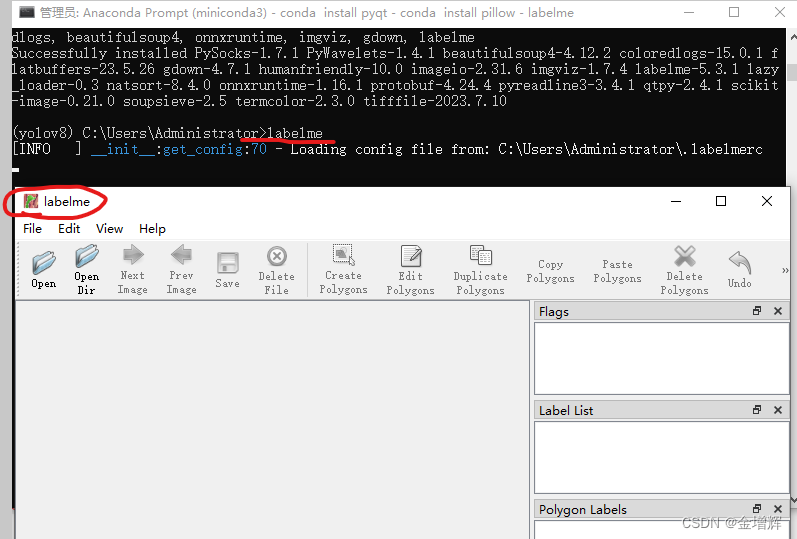
3.打开一张图片,进行标注。如果是目标检测就选择Create Rectangle框选图形即可,如果是图像分割就选择Create Plogons绘制边框,然后定义分类后保存成.json格式。
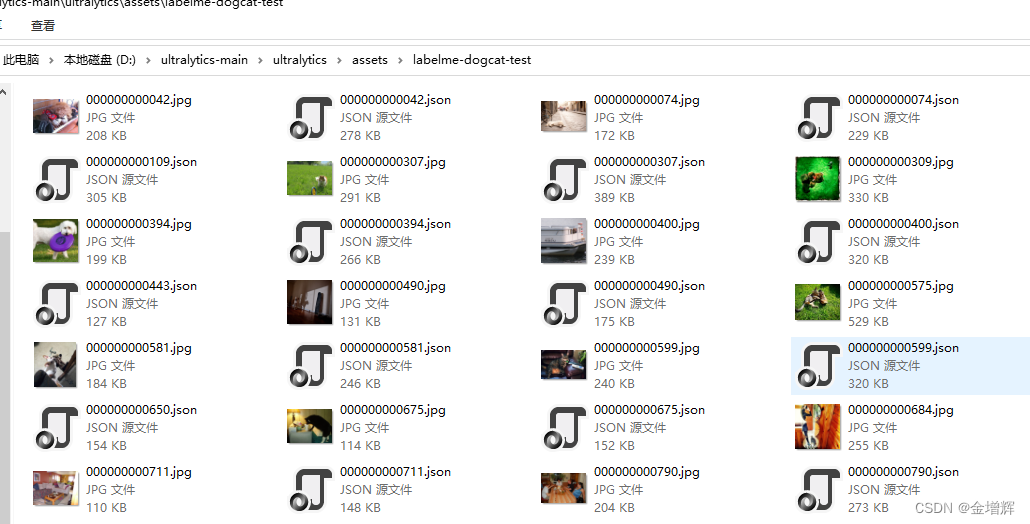
3.在网上找到的别人下载的标注好的图片库labelme-dogcat-test文件夹,里面是一些猫和狗的图片及标注文件,把他们拷贝到了D:\ultralytics-main\ultralytics\assets这个文件夹,如下图所示,在它的上一级目录中新建一个文件夹命名为yoloForm,用于存储转换后的文件。
4.把labelme格式转化成yolov8支持的数据集格式,需要下面的脚本,只需要改最后一行,就是数据源地址和目标地址( cm.start(r’源文件路径’, r’保存新位置路径’)),将其存储为JsonToYolo.py格式,执行即可,执行时,如果缺少东西就安装对应的库即可。
import base64
import random
import shutil
from tqdm import tqdm
import math
import json
import os
import numpy as np
import PIL.Image
import PIL.ImageDraw
import cv2class ConvertManager(object):def __init__(self):passdef base64_to_numpy(self, img_bs64):img_bs64 = base64.b64decode(img_bs64)img_array = np.frombuffer(img_bs64, np.uint8)cv2_img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)return cv2_img@classmethoddef load_labels(cls, name_file):'''load names from file.one name one line:param name_file::return:'''with open(name_file, 'r') as f:lines = f.read().rstrip('\n').split('\n')return linesdef get_class_names_from_all_json(self, json_dir):classnames = []for file in os.listdir(json_dir):if not file.endswith('.json'):continuewith open(os.path.join(json_dir, file), 'r', encoding='utf-8') as f:data_dict = json.load(f)for shape in data_dict['shapes']:if not shape['label'] in classnames:classnames.append(shape['label'])return classnamesdef create_save_dir(self, save_dir):images_dir = os.path.join(save_dir, 'images')labels_dir = os.path.join(save_dir, 'labels')if not os.path.exists(save_dir):os.makedirs(save_dir)os.mkdir(images_dir)os.mkdir(labels_dir)else:if not os.path.exists(images_dir):os.mkdir(images_dir)if not os.path.exists(labels_dir):os.mkdir(labels_dir)return images_dir + os.sep, labels_dir + os.sepdef save_list(self, data_list, save_file):with open(save_file, 'w') as f:f.write('\n'.join(data_list))def __rectangle_points_to_polygon(self, points):xmin = 0ymin = 0xmax = 0ymax = 0if points[0][0] > points[1][0]:xmax = points[0][0]ymax = points[0][1]xmin = points[1][0]ymin = points[1][1]else:xmax = points[1][0]ymax = points[1][1]xmin = points[0][0]ymin = points[0][1]return [[xmin, ymin], [xmax, ymin], [xmax, ymax], [xmin, ymax]]def convert_dataset(self, json_dir, json_list, images_dir, labels_dir, names, save_mode='train'):images_dir = os.path.join(images_dir, save_mode) + os.seplabels_dir = os.path.join(labels_dir, save_mode) + os.sepif not os.path.exists(images_dir):os.mkdir(images_dir)if not os.path.exists(labels_dir):os.mkdir(labels_dir)for file in tqdm(json_list):with open(os.path.join(json_dir, file), 'r', encoding='utf-8') as f:data_dict = json.load(f)image_file = os.path.join(json_dir, os.path.basename(data_dict['imagePath']))if os.path.exists(image_file):shutil.copyfile(image_file, images_dir + os.path.basename(image_file))else:imageData = data_dict.get('imageData')if not imageData:imageData = base64.b64encode(imageData).decode('utf-8')img = self.img_b64_to_arr(imageData)PIL.Image.fromarray(img).save(images_dir + file[:-4] + 'png')# convert to txtwidth = data_dict['imageWidth']height = data_dict['imageHeight']line_list = []for shape in data_dict['shapes']:data_list = []data_list.append(str(names.index(shape['label'])))if shape['shape_type'] == 'rectangle':points = self.__rectangle_points_to_polygon(shape['points'])for point in points:data_list.append(str(point[0] / width))data_list.append(str(point[1] / height))elif shape['shape_type'] == 'polygon':points = shape['points']for point in points:data_list.append(str(point[0] / width))data_list.append(str(point[1] / height))line_list.append(' '.join(data_list))self.save_list(line_list, labels_dir + file[:-4] + "txt")def split_train_val_test_dataset(self, file_list, train_ratio=0.9, trainval_ratio=0.9, need_test_dataset=False,shuffle_list=True):if shuffle_list:random.shuffle(file_list)total_file_count = len(file_list)train_list = []val_list = []test_list = []if need_test_dataset:trainval_count = int(total_file_count * trainval_ratio)trainval_list = file_list[:trainval_count]test_list = file_list[trainval_count:]train_count = int(train_ratio * len(trainval_list))train_list = trainval_list[:train_count]val_list = trainval_list[train_count:]else:train_count = int(train_ratio * total_file_count)train_list = file_list[:train_count]val_list = file_list[train_count:]return train_list, val_list, test_listdef start(self, json_dir, save_dir, names=None, train_ratio=0.9):images_dir, labels_dir = self.create_save_dir(save_dir)if names is None or len(names) == 0:print('class names will load from all json file')names = self.get_class_names_from_all_json(json_dir)print('find {} class names :'.format(len(names)), names)if len(names) == 0:returnself.save_list(names, os.path.join(save_dir, 'labels.txt'))print('start convert')all_json_list = []for file in os.listdir(json_dir):if not file.endswith('.json'):continueall_json_list.append(file)train_list, val_list, test_list = self.split_train_val_test_dataset(all_json_list, train_ratio)self.convert_dataset(json_dir, train_list, images_dir, labels_dir, names, 'train')self.convert_dataset(json_dir, val_list, images_dir, labels_dir, names, 'val')if __name__ == '__main__':cm = ConvertManager()cm.start(r'D:\ultralytics-main\ultralytics\assets\labelme-dogcat-test', r'D:\ultralytics-main\ultralytics\assets\yoloForm')
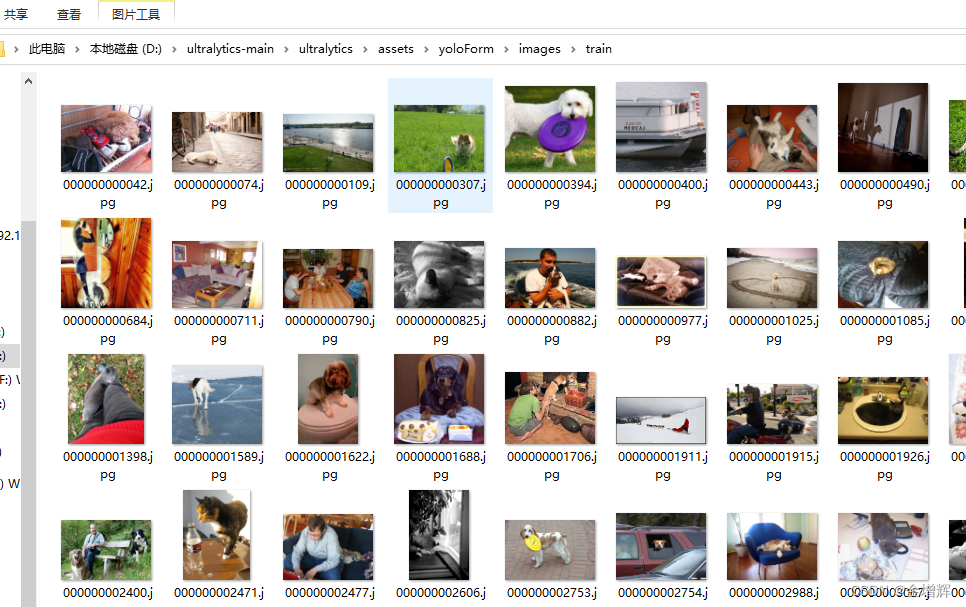
5.在Pycharm中执行上面的脚本,执行完成后,刚刚新建的文件夹就会有转换后的数据了,如下图所示。
相关文章:
基于windows10的pytorch环境部署及yolov8的安装及测试
第一章 pytorch环境部署留念 第一步:下载安装anaconda 官网地址 (也可以到清华大学开源软件镜像站下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/) 我安装的是下面这个,一通下一步就完事儿。 第二步…...
面试算法40:矩阵中的最大矩形
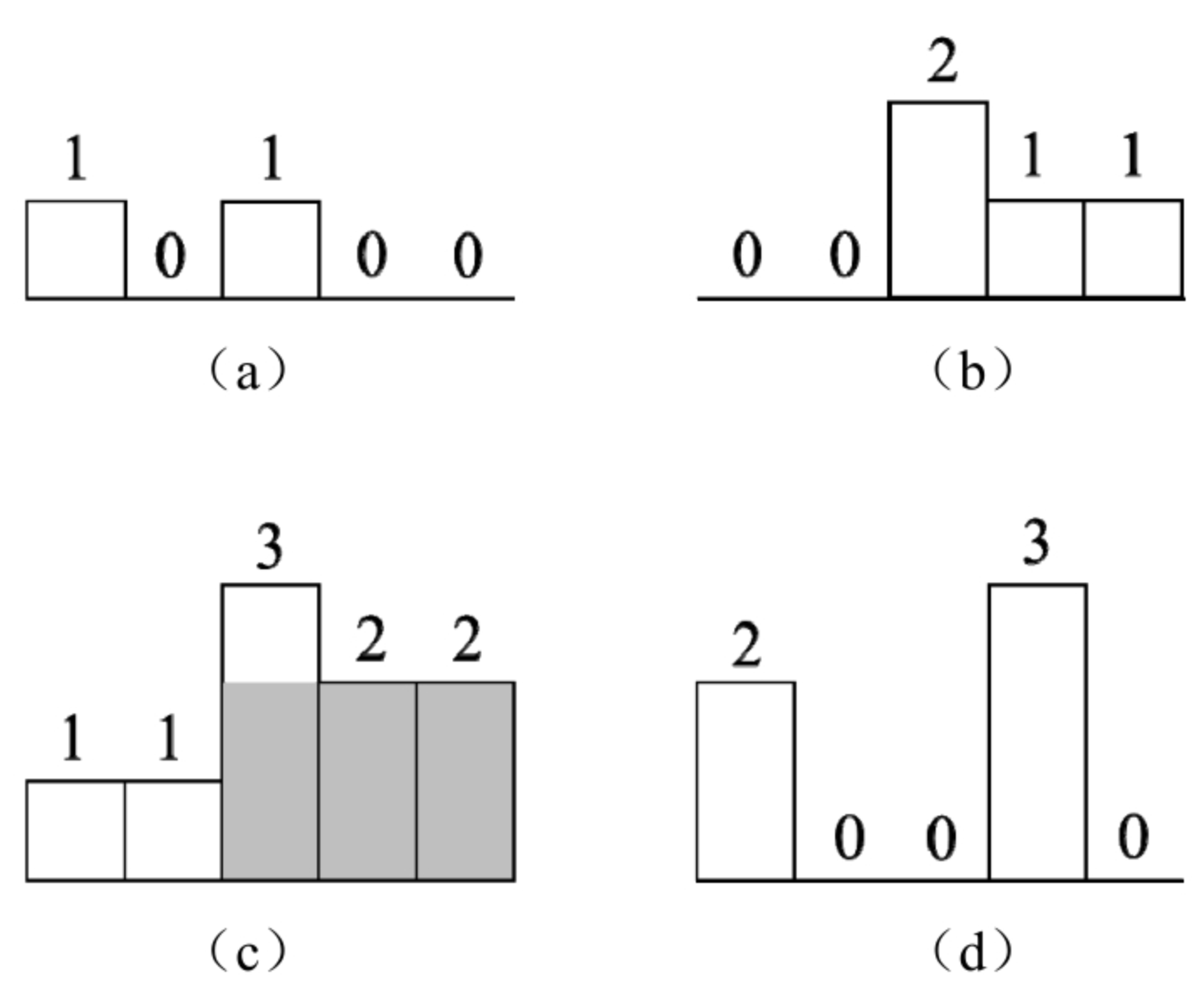
题目 请在一个由0、1组成的矩阵中找出最大的只包含1的矩形并输出它的面积。例如,在图6.6的矩阵中,最大的只包含1的矩阵如阴影部分所示,它的面积是6。 分析 直方图是由排列在同一基线上的相邻柱子组成的图形。由于题目要求矩形中只包含数字…...

was下log4j设置日志不输出问题
was下log4j设置日志不输出问题 WAS 也是用的 commons-logging 日志框架 commons-logging 确定 LogFactory 实现的顺序是 从应用的 META-INF/services/org.apache.commons.logging.LogFactory 中获得 LogFactory 实现从系统环境中获得 org.apache.commons.logging.LogFactory…...
小米14系列, OPPO Find N3安装谷歌服务框架,安装Play商店,Google
10月26号小米发布了新款手机小米14,那么很多大家需求问是否支持谷歌服务框架,是否支持Google Play商店gms。因为毕竟小米公司现在安装的系统是HyperOS澎湃OS。但是我拿到手机之后会发现还是开机初始界面会显示power by android,证明这一点他还是支持安装谷歌,包括最近一段时间发…...

Servlet 与Spring对比!
前言: Spring相关的框架知识,算是目前公司在用的前沿知识了,很重要!! 那么以Spring为基础的框架有几个? 以Spring为基础的框架包括若干模块,其中主要的有Spring Framework、Spring Boot、Spring…...
粤嵌实训医疗项目--day03(Vue + SpringBoot)
往期回顾 粤嵌实训医疗项目day02(Vue SpringBoot)-CSDN博客 粤嵌实训医疗项目--day01(VueSpringBoot)-CSDN博客 目录 一、SpringBoot AOP的使用 二、用户模块-注册功能(文件上传) 三、用户模块-注册实现…...

spark3.3.x处理excel数据
环境: spark3.3.x scala2.12.x 引用: spark-shell --jars spark-excel_2.12-3.3.1_0.18.5.jar 或项目里配置pom.xml <!-- https://mvnrepository.com/artifact/com.crealytics/spark-excel --> <dependency><groupId>com.crealytics</groupId><art…...

哪一个更好?Spring boot还是Node.js
前言 本篇文章有些与众不同,由于我自己手头有些关于这个主题的个人经验,受其启发写出此文。虽然SpringBoot和Node.js服务于很不一样的场景,但是这两个框架共性惊人。其实每种语言都有不计其数的框架,但仅仅一部分是真正卓越的。如…...

AD7321代码SPI接口模数转换连接DAC0832输出verilog
名称:AD7321代码12位ADC,SPI接口模数转换连接DAC0832输出 软件:QuartusII 语言:VHDL 代码功能: 使用VHDL语言编写代码,实现AD7321的控制,将模拟信号转换为数字信号,再经过处理后…...
JavaScript_Pig Game切换当前玩家
const current0El document.getElementById(current--0); const current1El document.getElementById(current--1); if (dice ! 1) {currentScore dice;current0El.textContent currentScore;} else {} });这是我们上个文章写的代码,这个代码明显是有问题的&…...
EtherNet Ip工业RFID读写器与欧姆龙PLC 配置示例说明
一、准备阶段 POE交换机欧姆龙PLC 支持EtherNet Ip协议CX-Programmer 9.5配置软件 二、配置读卡器 1、打开软件 2、选择网卡,如果多网卡的电脑请注意对应所接的网卡,网卡名一般为“Network adapter Realtek PCIe GBE Family” 3、点击“选择网卡”&…...

UE5简化打包大小
UE5.3默认空项目带初学者包的打包后1G多 简化思路: 1.不打包初学者包(或者创建时不包括初学者包,跳过第一条) 导航:ProjectSettings->Project->Packaging->Packaging->Advanced->List of maps to incl…...
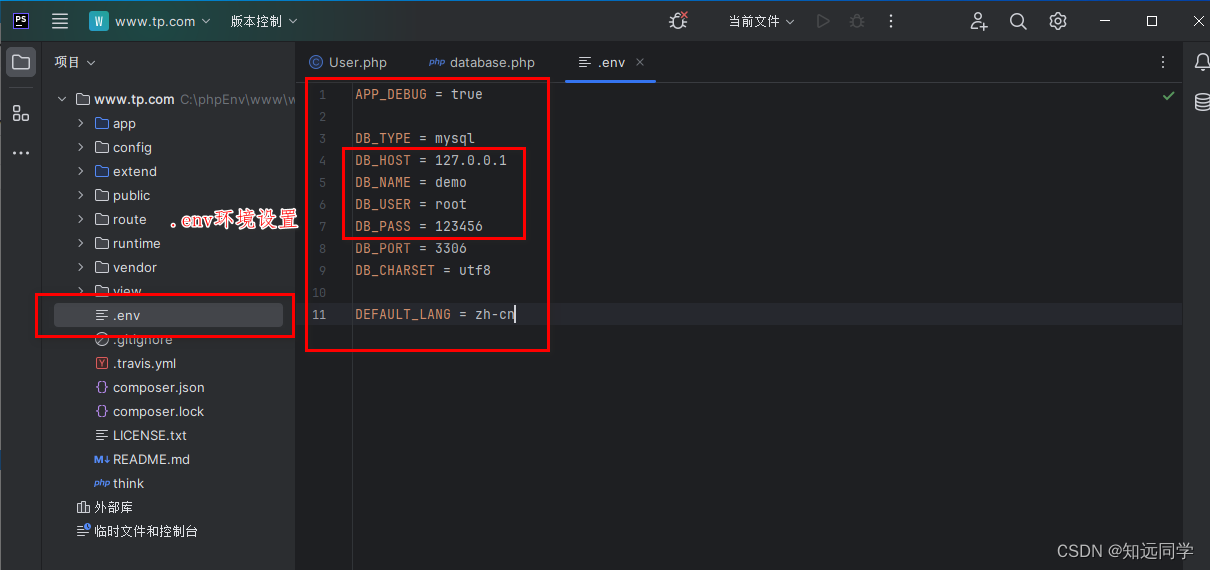
ThinkPHP8学习笔记
ThinkPHP8官方文档地址:ThinkPHP官方手册 一、composer换源 1、查看 composer 配置的命令composer config -g -l 2、禁用默认源镜像命令composer config -g secure-http false 3、修改为阿里云镜像源composer config -g repo.packagist composer https://mirror…...
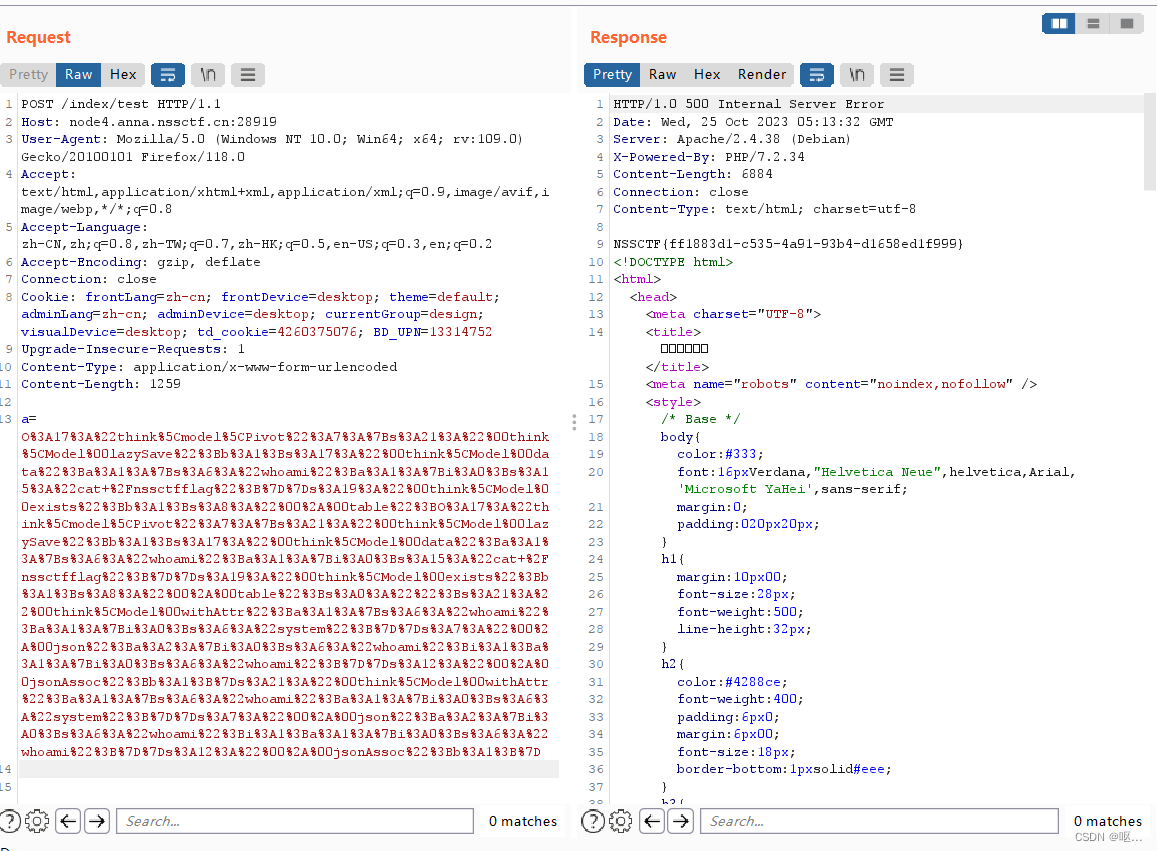
NSSCTF做题第9页(2)
[SWPUCTF 2022 新生赛]ez_1zpop <?php error_reporting(0); class dxg { function fmm() { return "nonono"; } } class lt { public $impohi; public $md51weclome; public $md52to NSS; function __construct() { $this-&…...

Rust笔记【1】
元组和解构语法 let tup : (i32, f64, u8) (666, 2.0, 1);let tup (666, 2.0, 1); let (x, y, z) tup;let x tup.0; let y tup.1; let z tup.2;数组类型 数组定义是方括号:[ ] 元组定义是小圆括号:( ) 结构体定义是大括号:{ }…...

代码随想录训练营day3:链表part1
理论 链表的增删操作时间复杂度O(1),查询时间复杂度O(n),因为要从头结点开始。使用场景和数据完全相反 链表的储存地址是不连续的。也和数组不同。 移除链表元素 利用虚拟头结点可以同意操作。不然删除头结点需要额外写。 记得返回的是虚拟头结点的next而不是虚拟头结点retu…...

Bootstrap的咖啡网站实例代码阅读笔记
目录 01-index.html的完整代码02-图片可以通过类 rounded-circle 设置为圆形显示03-<li class"nav-item mt-1 a">中,类mt-1是什么意思?类a又是什么意思?04-href"javascript:void(0);"是什么意思?05-类f…...

2021年06月 Python(二级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 执行下列代码后,运行结果是? seq[hello,good,morning] s*.join(seq) print(s)A: hello*good*m…...
FileWriter文件字符输出流
一.概念 以内存为基准,把内存中的数据以字符形式写出到文件中 二.构造器 public FileWriter(Filefile) 创建字节输出流管道与源文件对象接通 public FileWriter(String filepath) 创建字节输出流管道与源文件路径接通 public Filewriter(File file,boolean append) …...

Vue的八个基础命令及作用
1.v-text 作用:获取data数据, 设置标签的内容,以纯文本进行显示v-text 会覆盖 标签中的内容,如果想要拼接数据,可以直接在v-text中拼接如果拼接的是数字:直接使用 “”如果拼接的是字符串,需要使用与外部不同的引号进…...

jvm垃圾回收器 - G1详解
G1垃圾收集器发展史与工作原理 G1(Garbage First,垃圾优先)收集器是JVM垃圾收集技术发展史上的里程碑之作,它开创了面向局部收集的设计思路和基于Region的内存布局形式,定位为CMS收集器的替代者和继承人。一、发展史 1…...

实战揭秘:3步解锁你的微信聊天记忆宝库
实战揭秘:3步解锁你的微信聊天记忆宝库 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾因为手机丢失或更换设备,眼睁睁看着珍贵的微信聊天记录消失无踪?那些承…...

量子机器学习可解释性:从经典XAI到XQML的挑战与创新方法
1. 项目概述:当量子机器学习遇上“黑盒”挑战作为一名长期关注前沿技术交叉领域的从业者,我最近花了大量时间研究一个既烧脑又极具潜力的方向:如何让量子机器学习(QML)模型变得“透明”。我们都知道,经典深…...

Win10下ENSP USG6000镜像加载卡在###?别慌,VirtualBox网卡桥接这个设置是关键
Win10下ENSP USG6000镜像加载卡在###的终极解决方案 当你满怀期待地在Windows 10上启动ENSP模拟器,拖入USG6000防火墙设备,却只看到一串无情的 ### 符号时,那种挫败感我深有体会。作为一名曾经被这个问题折磨数小时的网络工程师,…...

3步突破微信限制:wechat-need-web插件终极使用手册
3步突破微信限制:wechat-need-web插件终极使用手册 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否经常遇到微信网页版无法正常使用…...

SELA框架:融合MCTS与LLM的智能AutoML新范式
1. SELA框架:当MCTS的“棋手”思维遇上LLM的“专家”直觉在数据科学项目里,最耗时的往往不是敲代码,而是做决策。面对一个新的表格数据集,从数据清洗、特征工程到模型选型、调参,每一步都像站在一个岔路口,…...

内存访问向量技术如何提升CPU性能模拟精度
1. 从20%误差到98%精准:内存访问向量如何革新CPU性能模拟 在处理器设计领域,性能模拟的准确性直接关系到数亿美元研发投入的成败。传统SimPoint采样方法虽然大幅降低了仿真时间,但当遇到523.xalancbmk_r这类具有复杂间接内存访问模式的基准测…...

用while循环语句求和
在“用for循环语句求和”中,学习了for循环语句,这篇博文继续学习另一种形式的循环程序结构while循环语句。while循环语句一般用于事先不能确定循环次数的情况,格式为while 表达式循环体end如果表达式为真,就执行循环体的内容&…...

非交换多项式优化:利用稀疏性破解大规模矩阵优化难题
1. 非交换多项式优化:从理论到计算的深度解析在优化理论的世界里,我们习惯了处理那些“听话”的变量——实数、向量,它们满足交换律,x*y总是等于y*x。然而,当我们踏入量子力学、鲁棒控制或高级矩阵分析等领域时&#x…...

从矩阵分解到聚类:构建可评估电影推荐系统的实战指南
1. 项目概述:从零构建一个可评估的推荐引擎 做推荐系统这些年,我最大的感受是:理论模型千千万,但真正决定项目成败的,往往不是选择了最前沿的算法,而是对基础模型深刻的理解、扎实的工程实现,以…...