智能问答技术在百度搜索中的应用

作者 | Xiaodong
导读
本文主要介绍了智能问答技术在百度搜索中的应用。包括机器问答的发展历程、生成式问答、百度搜索智能问答应用。欢迎大家加入百度搜索团队,共同探索智能问答技术的发展方向,文末有简历投递方式。
全文6474字,预计阅读时间17分钟。
01 什么是机器问答
机器问答,就是让计算机软件系统自动回答人类提出的描述性问题。例如问:“王小丫的主持的节目叫什么”,我们可以在百度搜索框里输入任意用自然语言描述的问题,并在搜索的首位结果中可以直接得相关答案,如下图所示:
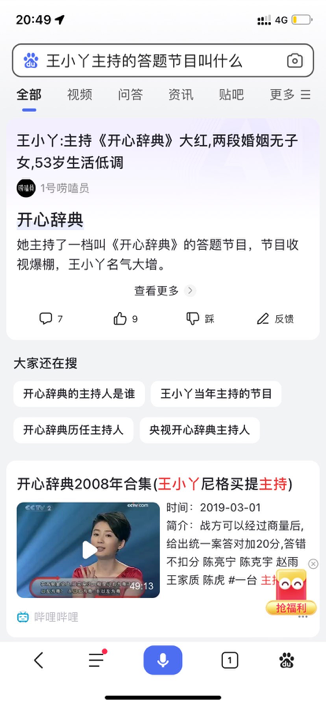
区别于传统搜索引擎根据多个关键词反馈检索的网页链接,机器问答根据自然语言描述的问题直接获取答案,可以极大地提高大家获取信息的效率。机器问答在生活中无处不在,经统计,有约40%的搜索需求、约30%的对话需求都跟机器问答相关。
那么,百度搜索的机器问答应用现状如何?目前首条结果可以直接满足大部分的问答需求,并且,在百度搜索中,不限定用户问题领域,是一个开放式的问答系统,可以询问任何信息。
1.1 机器问答的发展历程
机器问答的发展历程如下,与机器学习发展相吻合。
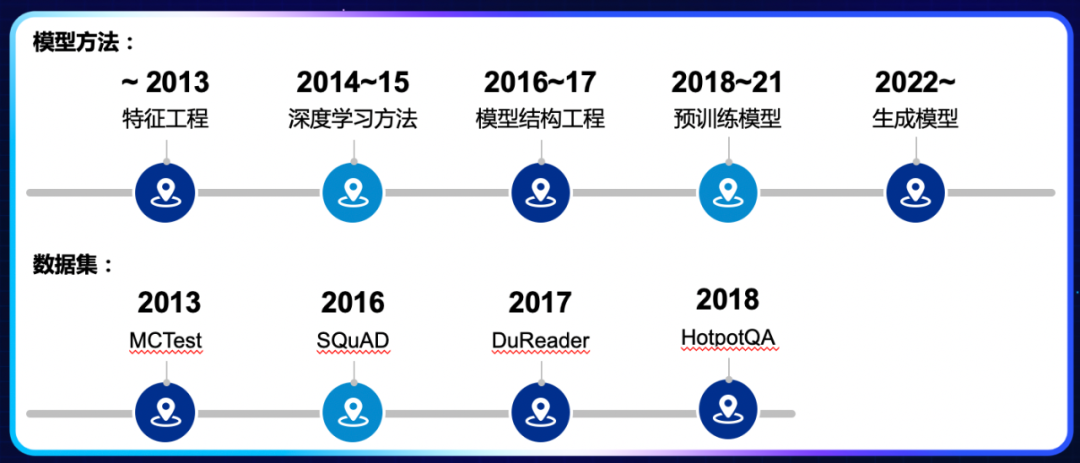
从模型方法的发展上看:
2013年以前,大家主要做一些特征工程相关工作,即给定一个问题和一些候选答案,设计多种字面匹配特征,并计算问题与答案之间词的匹配度,例如BM25等算法。
2014~2015年,随着深度学习的发展,大家会使用神经网络来计算问题和答案间表示的语义距离,例如CNN、RNN等。
2016~2017年,大家会使用Attention网络结构设计各类模型结构,进一步刻画问题和答案间的深层语义匹配关系。
2018~2021年,研究主要集中在训练模型上,会使用一些更大、效果更好的预训练模型来完成复杂的问答匹配任务。
自2022年开始,大家更多关注生成模型的应用。
从数据集的发展上看:
2013年,MCTest出现,以选择题和完形填空形式为主。
2016年,SQuAD诞生,这是第一个大型阅读理解数据信息,会根据用户问题从提供的一篇文章中进行答案抽取。
2017年,百度发布了DuReader数据集,这是首个中文的阅读理解的数据集。
2018年,HotputQA等发布,更加深入研究了多跳推理、常识推理等复杂的问答场景。
1.2 机器问答建模
目前的主流范式:Retriever + Reader
Retriever = 基于query查询候选。即给定一个query,获得该query的相关候选,可能是网页、视频、表格、知识图谱等。
Reader = 从给定候选中获取答案信息。即在给定候选的基础上,结合query进一步进行答案抽取。
百度搜索就是一个非常强的一个Retriever ,它可以提供相关候选查询,所以我们的研究工作更多集中在Reader上,即基于搜索结果如何更好地完成答案抽取。
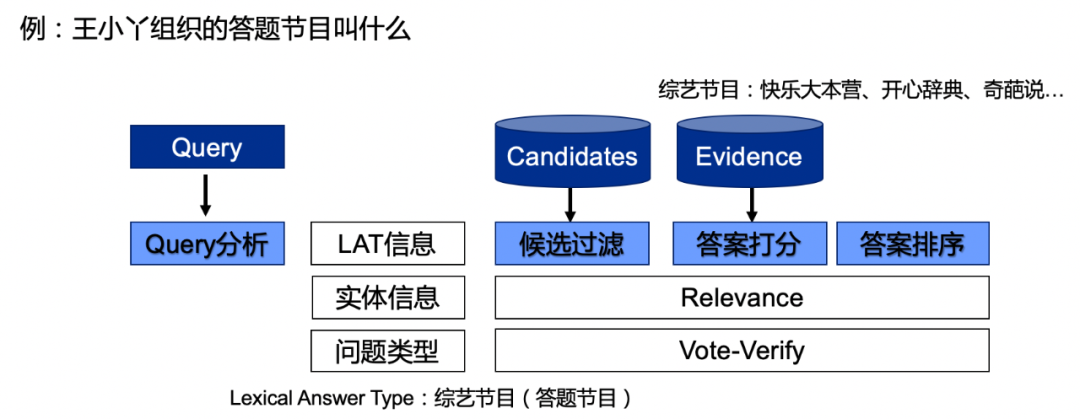
早期的Reader,主要基于传统的特征工程方法,是一个很复杂的系统化pipeline流程:先分析query获得期望的答案类型、实体信息、问题类型等,并根据这些信息从候选库里检索若干候选,并设计复杂的匹配特征来计算query和候选的相关性打分,并设计排序函数进行排序,得到排序最高的答案,过程如下图。
这个流程是管道串联的,每一步都存在误差的积累,整个训练流程也不可整体迭代,维护成本较高。后来,大家希望找到一种更加端到端的方法来解决以上问题,机器阅读理解(Machine Reading Comprehension,MRC)被提出出来。
MRC的任务的定义是:输入Question+Document,直接用一个模型替代复杂流程,输出Answer。早期的MRC工作会设计一些比较复杂的网络结构,来对问题和答案之间的关系进行建模。一个比较经典的方法是BiDAF,它的输入层是对整个 document 和 query 分别映射到 enbedding 表示上,各自通过 LSTM 等网络来学习问题和文档上下文的表示,之后通过 Attention 交互层,采用双向注意力对 query 和 document的关系进行建模,在此基础上再通过 LSTM 网络获取更丰富的上下文表示,最终输出层预测每个位置作为答案开始和终止的概率,概率最高的片段被抽取作为答案。
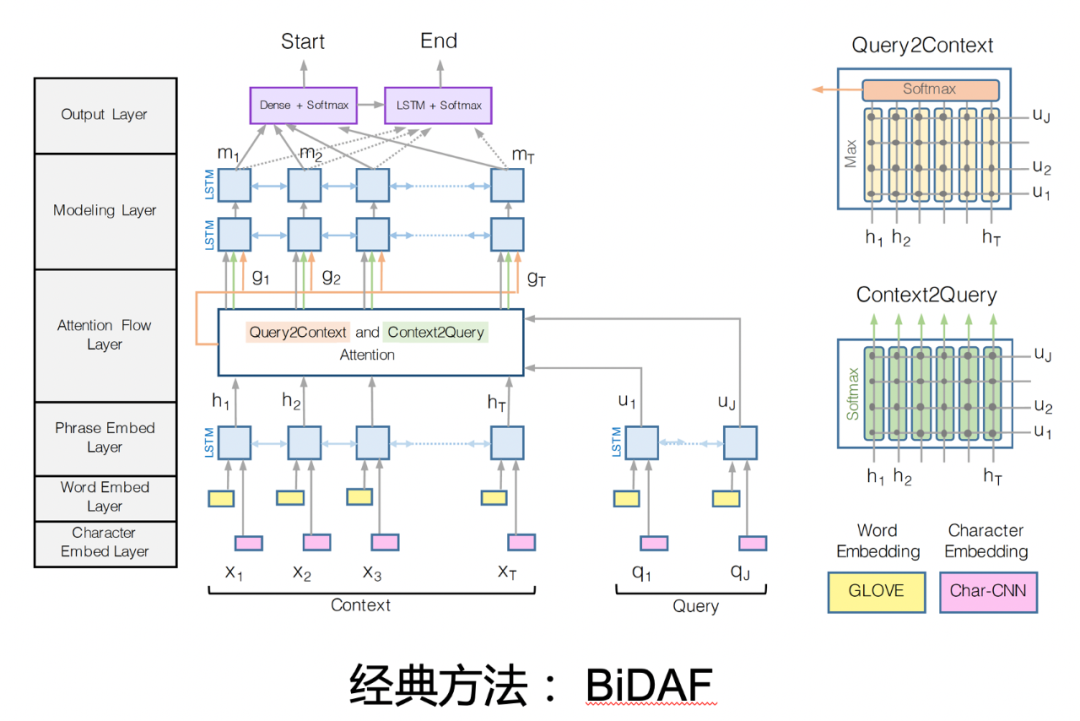
早期的模型结构设计呈现百花齐放的状态,以期更好解决问题和答案的建模。
后来,预训练模型逐渐发展起来,大家意识到,复杂的模型结构设计并不太必要,transformer就是目前为止最好的模型结构,这样可以释放更多研究精力到预训练工作中,更多关注预训练的任务设计、 loss函数、预训练的数据等。
在这种情况下,产生了多种预训练模型,比如说最早的BERT和百度的ERNIE等,这些预训练模型会使MRC更加简单,大家会把query和document整体作为一个序列进行输入,query和document之间可以用一些特殊符号进行分割。经过预训练模型的语义表示建模,最后依旧预测答案开始和结束的位置并进行抽取。
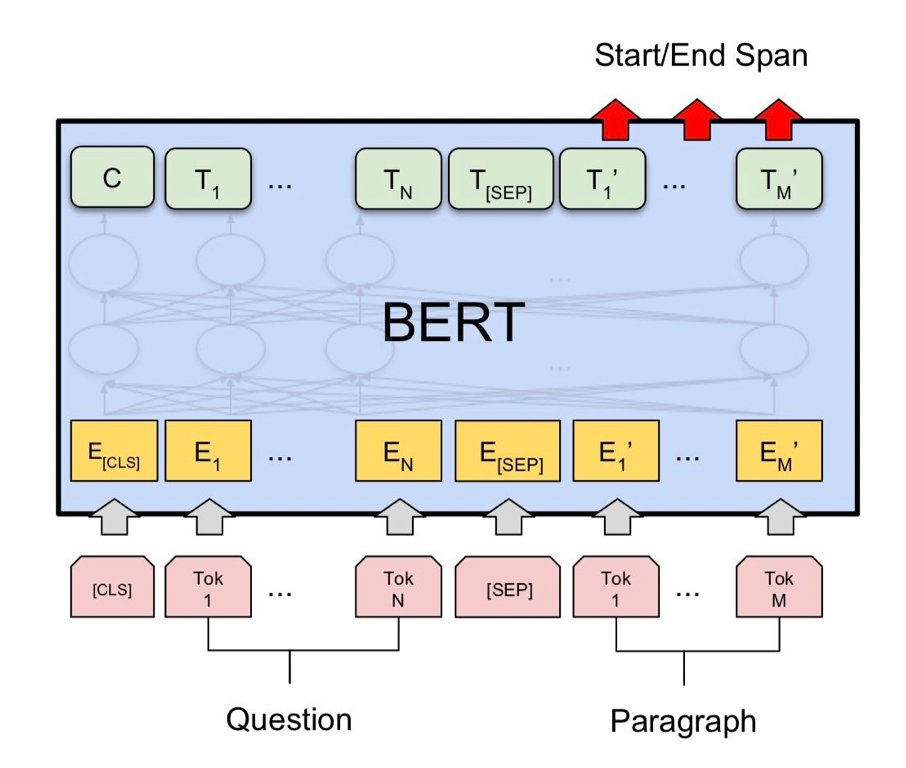
02 生成式问答
近期生成式技术的发展非常火热,也有非常多的工作发表。
早期一个比较有代表性的生成式Reader,是2017年的S-NET,它是针对MS-MARCO数据集专门设计的,该数据集的特点是答案来自多篇文章并且与原文中词汇不一定相同。
针对这样的任务,很自然的想法是用生成的方式来解决这个问题。它设计了一套两阶段的流程,第一阶段是答案抽取模型,跟我们上面介绍的模型非常一致,并额外引入了passage排序任务对候选文章进行相关性排序。第二阶段是生成模型,输入得到抽取结果,生成答案的总结,如下图所示。
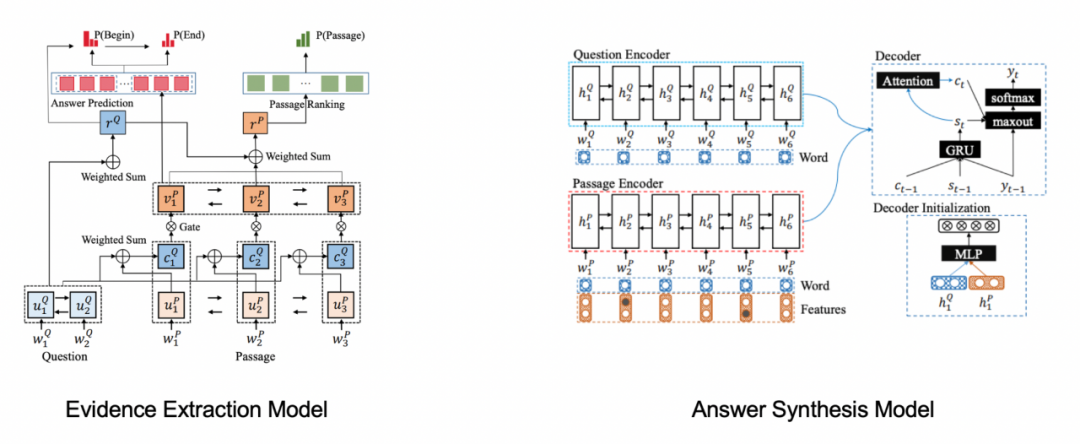
可以看出,早期的这些工作跟我们现在所使用的生成式问答流程非常相似,我们还会加一个检索模块,就是我们刚才最早提到的Retriever,然后就是候选抽取、排序、生成。但是,这个工作还是依赖于额外信息来做参考总结。大家会想,是不是可以有一个生成模型,直接生成答案,而不依赖于我们输入额外的信息知识?
2019年的T5模型首先解决了这个问题,当时它是采用了一种“预训练+迁移学习”的思路,将不同NLP任务统一到生成范式下,来统一完成问答、机器翻译、情感分析、对话等一系列任务,且通过百亿参数量的大模型(在当时算是比较大的规模)中存储的知识直接回答问题。它也验证了不同生成模型的结构,包括Encoder-Decoder方式的、Decoder-only的和混合式的。
但是,T5这类模型虽然可以完成一些简单问答,但还不足以达到可直接使用的商用状态,它的参数量及训练方式还存在改进空间,对于一些通用问题也不能直接取得非常好的效果。直到ChatGPT的出现,它会采用更大的参数规模(千亿级),并有更强的人类回复对齐能力,去理解用户指令,从而完成更加复杂的问答。可以说,ChatGPT是已达商用级别的对话和问答产品。
03 百度搜索的智能问答应用
百度搜索的问答场景是丰富多样的。答案抽取方式也有多种,比如说我们可以从百科或者网页通过信息抽取的方式得到一些知识图谱,在知识图谱上来进行答案提取;更通用的方式是从网页文本中,通过阅读理解直接抽取答案;还可以通过对一些半结构化的数据,比如表格,来进一步的提取信息,并组织成更结构化的方式展现。不止是文本,也包括对视频内容的理解和抽取。

面临着这样一个丰富多样的问答场景,我们会有哪些挑战呢?
挑战1:机器问答面临复杂语义理解、推理、上下文建模难点?
挑战2:面对搜索的高流量和机器问答对复杂模型的需求,如何实现快速响应?
挑战3:开放领域的搜索场景下网页数据非常复杂,答案质量参差不齐(错误、片面),如何提供正确且高质量的答案?
、
3.1 解决复杂语义理解、推理、上下文建模难点
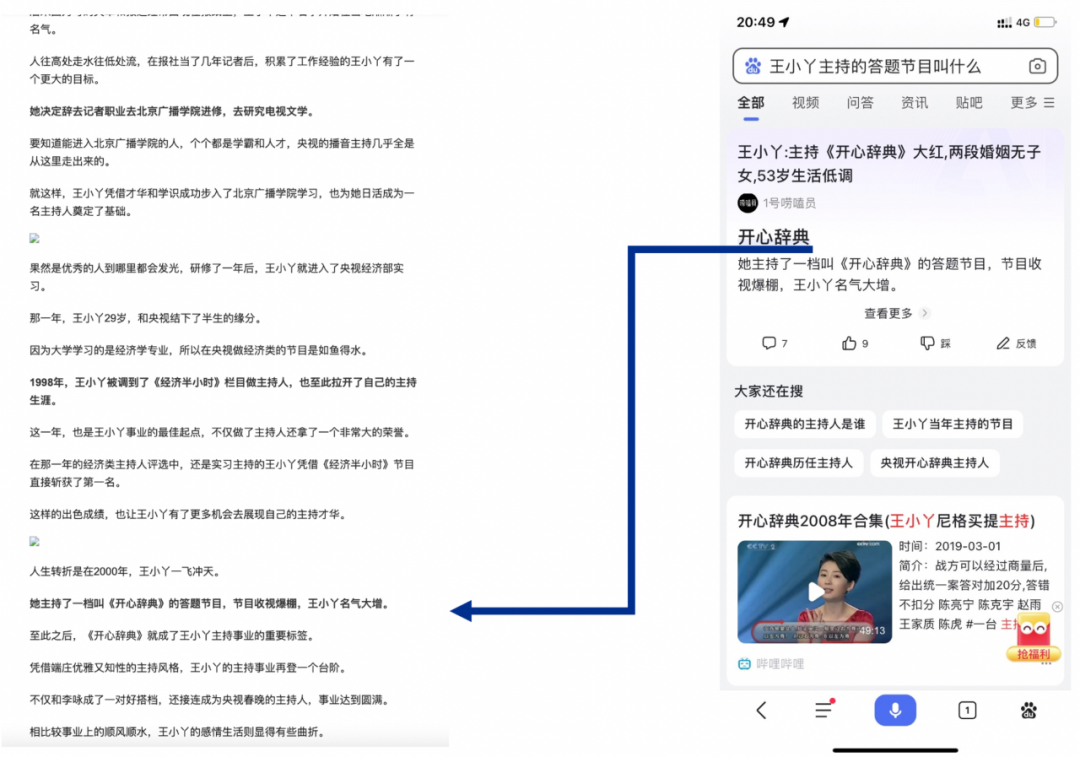
比如最开始的这个例子,如下图所示,答案中提到一个“她”,就需要做指代消解、对上下文的理解,并且上下文篇幅可能很长,通过深层次的理解才能知道所需的是一个答题节目,而不是其他节目。这个问题的解决依赖一些很复杂的模型。

我们采用的解决方案是“大模型+预训练”。
在预训练中,我们会使用非常丰富的数据,包括几个阶段:
-
首先,用T级别通用文本进行Pretrain学习基础语言模型;
-
并且,使用百G级业务日志进行Post-pretrain实现领域和目标迁移;
-
此外,进行细致的数据挖掘,通过G级人工标注数据进行Finetune拟合业务效果;
-
最后,通过远程监督数据增强、标注数据质量识别、薄弱数据自动挖掘和定向标注、用户行为指引,实现数据和模型的闭环反馈。
而在大模型方面:
-
使用百亿级参数量模型,提升知识记忆和语言理解能力
-
通过长序列建模,充分理解上下文
例如,我们正在使用的一个模型,我们称之为 DocMRC 模型,它模拟人做阅读理解答题,阅读整个文章,逻辑如下图所示。

输入层支持长序列建模,将整个doc segment sents进行切分;特别的是,我们在每句话前插入token表示,CLS用来汇聚每个句子的表示,整体输入浅层词级模型结构来学习局部表示;基于这个表示经过层次化结构学习深层上下文关系;最后输出CLS特殊token表示标注,输出答案。
输出层会有两种输出:一种是针对问题输出偏摘要等多句话答案介绍,会使用句子层的输出,然后做序列标注的输出;另一种是强调答案中的关键内容,可能是几个实体,会将token表示做序列标注预测。
3.2 提升整体模型的速度,实现快速响应
搜索每天的用户流量非常大,前面也提到,我们需要用到较大或较复杂模型,整个模型的耗时以及资源消耗也是非常大的。那么,有没有其他方式来提升整体模型的速度,实现快速响应及资源平衡?
刚才介绍的层次化的建模,对模型结构的优化,是一种解决方案。
另外有一种通用的方式:知识蒸馏,知识蒸馏是将大模型的知识提炼给单个小模型,在效果接近的情况下提升推理速度。这里我们采用了一种“多teacher多阶段蒸馏”模式。
针对问答的业务场景,我们会训练多个不同的teacher,通过不同 teacher 的集成来提升学习目标的上限。然后对于多个teacher蒸馏,一种基线方案是将每个teacher的打分或loss加权直接做平均,让student拟合,但是我们认为这种方式可能并不能确保达到非常极致的效果。我们期望根据不同样本动态做出选择(因为不同teacher的侧重有差异),设计了一种多阶段蒸馏的模式,并在其中根据数据动态选择teacher,如下图所示。
第一阶段,Teacher模型训练,训练多teacher提升学习上限;
第二阶段,无监督蒸馏,无标数据很难判断teacher的好坏,所以采用 teacher 间投票的方式,依据梯度方向动态选择teacher,剔除可能的噪声teacher;
第三阶段,有监督蒸馏,依据标注样本对teacher动态赋权。
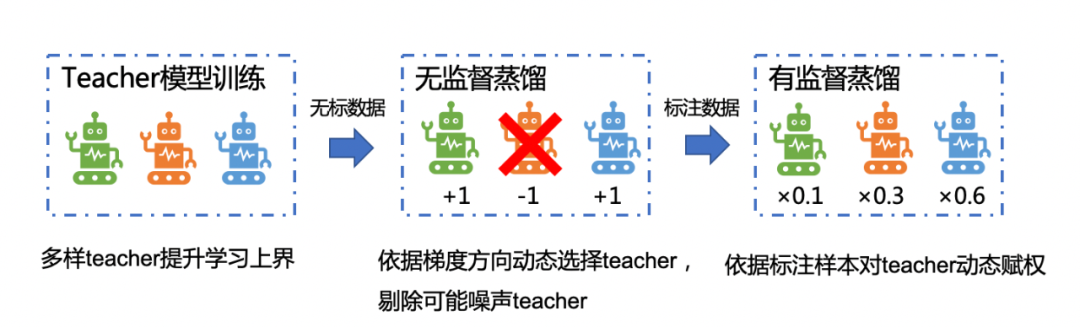
通过这样一种多阶段多teacher蒸馏的方式,我们最终得到一个效果非常好的student模型,甚至超过单个大模型效果。
3.3 如何提供正确且高质量的答案
搜索场景的问答数据非常复杂,答案质量也参差不齐,很多网页中可能存在一些错误信息或片面介绍,如何提供正确且高质量的答案是我们面临的第三个挑战。
如下图所示,是搜索中场景的复杂答案的例子。左侧是冗长答案,用户无法快速抓住重点,这种情况下需要一种方式进行总结,用户才能快速理解的答案关键信息,提升满足效率。抽取式答案提取方式已经无法满足,我们需要用生成技术对答案进行深层次压缩总结。

另外,对于单篇文章中提取的答案可能不够全面,我们需要从多篇网页中做答案总结,也需要生成模型,如下图所示。我们从多篇文章中总结答案,并在答案中标注来源,用户可以清晰看到答案出处。

综上,如果要生成全面、高效、正确的答案,就需要有一个更好的生成模型。目前的大语言模型非常多,但怎样的大语言模型才能完成搜索场景的问答任务呢?
04 检索增强生成
目前大语言模型直接做问答还有几个问题:
第一,大预言模型难以记住所有知识,对于一些偏长尾知识可能有错误或者不知道的情况;
第二,大语言模型的知识容易过时、更新困难,对于新知识无法及时感知;
第三,大语言模型的输出难以验证,目前用户的信赖感较差,我们无法完全信赖生成模型直接生成的答案。
所以在这种情况下,大家希望能有一些方式来进行一些辅助的答案验证。
4.1 检索增强生成流程
针对搜索问答场景,我们设计了检索增强生成方案,已在百度搜索落地。检索增强生成是基于搜索引擎补充相关信息,可有效缓解大模型幻觉,来提升答案的正确性、时效性以及可信度。整体流程分为几个阶段:
1、文档检索阶段,会检索得到多种参考来源;
2、答案抽取阶段,会把文章抽取关键信息,减轻生成模型负担;
3、prompt组成阶段,会根据获取的参考来源来回答问题,并提供具体要求,比如说在答案内容中序号标注来源;
4、答案生成阶段,将prompt输入生成大模型中,最终得到搜索结果。

如上图所示,可以看到右侧答案是总结了多篇文章的一个结果,并且也会在其中标注上参考来源,这就是我们期望给用户提供的答案。
4.2 生成大模型训练流程
我们生成大模型的训练流程分为四个阶段,如下图所示,前两个阶段跟目前主流的生成大模型训练比较接近,后两个阶段我们做了检索增强生成问答场景下的特殊适配。

第一阶段,通用预训练,我们会有一些通用的网页语料以及垂类语料,比如书籍、表格、对话等,来获得通用的预训练基础模型;
第二阶段,进行指令微调,我会提供一些通用的指令,使得模型拥有理解指令的能力;
第三阶段,标注业务指令,并用其做具体的微调,使其能理解搜索场景下的多结果组织的问答场景;
第四阶段,基于用户行为反馈做细致微调,以及通过强化学习等方式,提高生成答案的质量。
4.3 通过指令拆解,学习复杂指令
搜索的业务场景指令非常复杂,我们会提出非常具体的要求,并提供参考来源。那么如何让生成模型来理解这种复杂的指令?一种解决方案是标注很多这类复杂指令,并输入到生成模型中,但这种方式并不一定是最佳的。如果模型学习这类指令偏多了,反而无法达到更好泛化效果,造成模型效果下降。有没有其他的方式?
这里,我们借鉴推理链(CoT)的思想,提出通过指令拆解的方式,学习检索生成场景下复杂指令。
上述复杂指令通常可以通过三步简单步骤完成:
第一步,选择能用来回答问题的搜索结果;
第二步,根据选择的搜索结果进行答案的组织和生成;
第三步,用编号的形式,加上参考来源。
可以看出,对于很复杂的指令,我们可以通过多步拆解变成多个简单指令,我们会让模型先去学习并理解简单指令,之后可能不用太多复杂指令的数据,就能使模型在复杂指令上的表现达到一个非常好的水平。
4.4 推理加速及降低资源消耗
对于一些判别式模型,可以用蒸馏或一些其他的技术来做。但对于生成模型来说,模型尺寸小了对效果的影响较大,蒸馏并不特别适用,需要有一些其他的加速手段。近期业内有很多相关的工作研究,例如Inference with Reference,就是针对检索增强生成的业务场景,通过检测固定prefix,从参考中复制固定长度文本作为候选序列,验证如与模型输出一致则实现并行解码多步,如下图所示。

另外也有一些更加通用的生成加速的手段,例如可以用小模型快速生成多步,把小模型的预测结果直接输入大模型,大模型验证是否解码一致,类似前一个工作也可以实现加速,但要求是尽量使我们的小模型和大模型效果接近,预测准确的概率会更大,加速比就会更大。
最后我给大家留一个问题,大家可以想一想: “下一代的搜索引擎会是什么样子?” 很期待你的回答,也欢迎与我们一起探讨。
交流&简历投递邮箱:sti01@baidu.com
——END——
推荐阅读
通过Python脚本支持OC代码重构实践(一):模块调用关系分析
CVPR2023优秀论文 | AIGC伪造图像鉴别算法泛化性缺失问题分析
一文搞定专属码的设计与开发
AI原生应用速通指南
代码理解技术应用实践介绍
相关文章:
智能问答技术在百度搜索中的应用
作者 | Xiaodong 导读 本文主要介绍了智能问答技术在百度搜索中的应用。包括机器问答的发展历程、生成式问答、百度搜索智能问答应用。欢迎大家加入百度搜索团队,共同探索智能问答技术的发展方向,文末有简历投递方式。 全文6474字,预计阅读时…...

STM32F4X SDIO(一) SD卡介绍
STM32F4X SDIO(一) SD卡介绍 SD卡分类外观分类容量分类传输速度分类 在之前的章节中,讲过有关嵌入式的存储设备,有用I2C驱动的EEPROM、SPI驱动的FLASH和MCU内部的FLASH,这类存储设备的优点是操作简单,但是缺…...
10分钟了解JWT令牌 (JSON Web)
10分钟了解JSON Web令牌(JWT) JSON Web Token(JWT)是目前最流行的跨域身份验证解决方案。今天给大家介绍JWT的原理和用法。 1.跨域身份验证 Internet服务无法与用户身份验证分开。一般过程如下。 1.用户向服务器发送用户名和密码。…...

【经验总结】ECU系统休眠后通过诊断报文唤醒ECU且唤醒网络后快发NM报文
目录 前言 正文 1.CanNM状体机分析 2.ComM状态机分析 3.解决方案 4.总结 前言...

基于Android 10系统的ROC-RK3399-PC Pro源码编译
基于Android 10系统的ROC-RK3399-PC Pro源码编译 一、开发环境搭建二、下载Android 10 SDK三、编译Android 10 SDK ROC-RK3399-PC Pro资料下载处:https://www.t-firefly.com/doc/download/145.html一、开发环境搭建 Android 10 SDK的编译对PC机的要求不低ÿ…...

网络滤波器/网络滤波器/脉冲变压器要怎样进行测试,一般要测试哪些参数?
Hqst华强盛导读:网络滤波器/网络滤波器/脉冲变压器要怎样进行测试,一般要测试哪些参数?测试网络滤波器的测试方法和步骤如何,需用到哪些测试工具和仪器设备呢? 一,网络流量的监控和过滤能力测试&am…...
基于vue天气数据可视化平台
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

Go 语言常见的 ORM 框架
ORM(Object-Relational Mapping)是一种编程技术,用于将面向对象编程语言中的对象模型和关系数据库中的数据模型相互映射。ORM框架可以把数据操作从 SQL 语句中抽离出来,将关系型数据库中的表映射成对象,通过面向对象的…...

【错误解决方案】ModuleNotFoundError: No module named ‘cPickle‘
1. 错误提示 在python程序中试图导入一个名为cPickle的模块,但Python提示找不到这个模块。 错误提示:ModuleNotFoundError: No module named cPickle 2. 解决方案 实际上,cPickle是Python的pickle模块的一个C语言实现,通常用于…...

NodeJS14.18.0 安装,以及安装相应版本node-sass
安装了NVM, NodeJS 14.18.0 安装nvm 到c:\nvm目录 务必!!!!!!!! nvm文档手册 - nvm是一个nodejs版本管理工具 - nvm中文网 编辑c:\nvm\settings.txt添加 node_mirror: CNPM Binar…...
cosover是什么?crossover23又是什么软件
cosover是篮球里的过人技巧。 1.crossover在篮球中的本意是交叉步和急速交叉步。crossover 是篮球术语,有胯下运球、双手交替运球,交叉步过人、急速大幅度变向等之意。 2.在NBA里是指包括胯下运球、变向、插花在内的过人的技巧。 NBA有很多著名的Cross…...

AR眼镜安卓主板,智能眼镜光机方案定制
AR智能眼镜是一项涉及广泛技术的创新产品,它需要考虑到光学、显示、功耗、散热、延迟、重量以及佩戴人体工学等多个方面的因素,每一个项目都是技术进步所需攻克的难题。 在本文中,我们将重点讨论AR眼镜的主板和光学方案。 首先是AR智能眼镜的…...
Qt中实现页面切换的两种方式
文章目录 方式一 :使用QStackedWidget讲解代码结构main.cpp完整代码运行结果: 方式二 :代码结构完整代码mainwindow.hnewmainwindow.hmain.cppmainwindow.cppnewmainwindow.cppmainwindow.uinewmainwindow.ui 效果 方式一 :使用QS…...
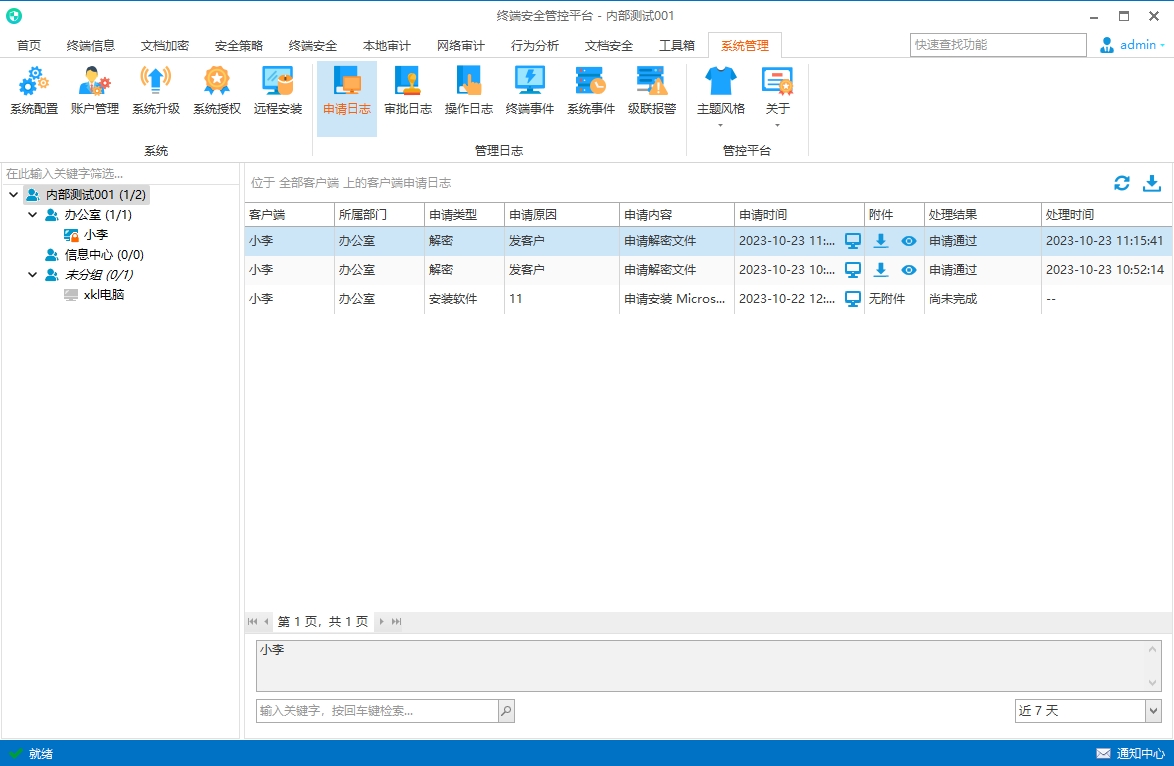
公司电脑如何限制安装软件
公司电脑如何限制安装软件 安企神终端管理系统下载使用 在企业环境中,电脑已经成为企业中必不可少的办公工具,确保员工的生产力和公司的信息安全是至关重要的。为了实现这一目标,公司可能会限制员工在某些情况下安装软件或者由管理员来为终…...
【C++】STL容器——list类的使用指南(含代码演示)(13)
前言 大家好吖,欢迎来到 YY 滴C系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! 目录 一、list 类——基本介绍二、list 类——…...
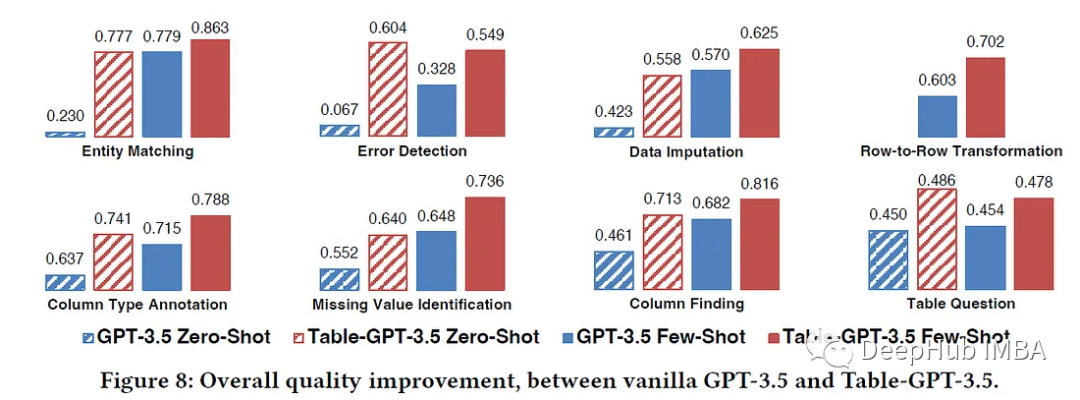
Table-GPT:让大语言模型理解表格数据
llm对文本指令非常有用,但是如果我们尝试向模型提供某种文本格式的表格数据和该表格上的问题,LLM更有可能产生不准确的响应。 在这篇文章中,我们将介绍微软发表的一篇研究论文,“Table-GPT: Table- tuning GPT for Diverse Table…...

基于单片机的温湿度和二氧化碳检测系统设计
目录 摘 要... 2 第一章 绪论... 5 1.1 研究课题背景... 5 1.2 国内外发展概况... 7 1.3 课题研究的目的... 8 1.4 课题的研究内容及章节安排... 9 第二章 二氧化碳和温湿度检测系统控制系统的设计方案... 11 2.1 设计任务及要求... 11 2.2 二氧化碳和…...

leetcode做题笔记204. 计数质数
给定整数 n ,返回 所有小于非负整数 n 的质数的数量 。 示例 1: 输入:n 10 输出:4 解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。示例 2: 输入:n 0 输出:0示例 3&#…...

MySQL Server 5.5 软件和安装配置教程
MySQL 5.5.58(32/64位)下载链接: 百度网盘:百度网盘 请输入提取码 提取密码:7act 软件简介: MySQL 是由瑞典MySQL AB 公司开发一个关系型数据库管理系统,目前属于 Oracle 旗下产品。MySQL 是最…...
【23种设计模式】依赖倒置原则
个人主页:金鳞踏雨 个人简介:大家好,我是金鳞,一个初出茅庐的Java小白 目前状况:22届普通本科毕业生,几经波折了,现在任职于一家国内大型知名日化公司,从事Java开发工作 我的博客&am…...

从加密狗激活到平台注册:dSPACE MicroAutoBOX II 与 MATLAB 2016b 联调实战记录
从加密狗激活到平台注册:dSPACE MicroAutoBOX II 与 MATLAB 2016b 联调实战记录 在汽车电子控制单元(ECU)开发领域,dSPACE MicroAutoBOX II 作为一款实时硬件在环(HIL)测试平台,与 MATLAB/Simul…...
)
餐饮门店AI Agent上线倒计时:错过Q3政策补贴窗口期,将多付47%算力成本(附工信部认证服务商名录)
更多请点击: https://kaifayun.com 第一章:餐饮门店AI Agent的核心价值与政策窗口期紧迫性 在人力成本持续攀升、消费者预期快速迭代的双重压力下,餐饮门店正面临从“经验驱动”向“智能协同”跃迁的关键拐点。AI Agent 不再是实验室概念&am…...

3分钟快速指南:如何使用Forza Painter将任何图片变成《极限竞速》专业涂装
3分钟快速指南:如何使用Forza Painter将任何图片变成《极限竞速》专业涂装 【免费下载链接】forza-painter Import images into Forza 项目地址: https://gitcode.com/gh_mirrors/fo/forza-painter 还在为《极限竞速:地平线》系列游戏中复杂的车辆…...

免费AI搜索工具怎么选?2026年实测TOP8工具性能、响应速度与隐私合规性深度评测
更多请点击: https://codechina.net 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及以及WebAssembly在浏览器端的成熟…...

C51编译器内存空间警告解析与指针操作实践
1. 理解C51编译器中的内存空间警告 在Keil C51开发环境中,我们经常会遇到各种内存空间相关的警告和错误。其中"WARNING 259: POINTER: DIFFERENT MSPACE"是一个典型的指针操作问题,它揭示了8051架构下内存管理的特殊性。作为一名长期使用C51的…...
)
告别低效手动:用Amass的intel命令挖掘目标企业所有关联域名(实战演示)
企业级攻击面测绘:Amass intel模块的深度情报挖掘实战 在渗透测试或红队行动中,传统子域名枚举往往只触及企业数字资产的表层。真正的高手会从组织架构、商业关系和技术基础设施三个维度构建立体化的攻击面图谱。Amass的intel模块正是这样一把瑞士军刀—…...

初次使用taotoken模型广场进行模型选型与对比试用的直观体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken模型广场进行模型选型与对比试用的直观体验 对于需要接入大模型能力的开发者或团队而言,面对市场上众…...

LivePortrait技术突破:企业级肖像动画生成与部署实战指南
LivePortrait技术突破:企业级肖像动画生成与部署实战指南 【免费下载链接】LivePortrait Bring portraits to life! 项目地址: https://gitcode.com/GitHub_Trending/li/LivePortrait 从静态到动态:如何用AI技术让肖像"活"起来 在数字…...

ABAP中OAuth 2.0最小权限落地:从Authorization Code到AUTHORITY-CHECK
1. 这不是“配个Token就完事”的集成——为什么ABAP系统里OAuth 2.0落地总卡在“权限收不紧、业务接不住”上你有没有遇到过这样的场景:前端调用SAP Fiori应用时,后端ABAP系统明明配置了OAuth 2.0授权服务器,但一到实际业务环节就出问题——用…...

终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求
终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求 【免费下载链接】uncle-novel 📖 Uncle小说,PC版,一个全网小说下载器及阅读器,目录解析与书源结合,支持有声小说与文本小说,可下载mob…...