SpringBoot集成与应用Neo4j
文章目录
- 前言
- 集成
- 使用
- 定义实体
- 配置
- 定义Repository
- 查询方法
- 方式一:@Query
- 方式二:Cypher语法构建器
- 方式三:Example条件构建器
- 方式四:DSL语法
- 自定义方法
- 自定义接口
- 继承自定义接口
- 实现自定义接口
- neo4jTemplate
- Neo4jClient
- 自定义抽象类(执行与结果转换)
前言
本篇主要是对neo4j的集成应用,会给出普遍的用法,但不是很详细,如果需要详细的话,每种方式都可以单独一篇说明,但应用都是举一反三,并没有必要都进行详解,而且,一些特殊的用法也举例了,也给出了一个自定义方式的查询和结果转换,虽然算不上完美,但也是很简单的,也希望大家有所收获。
集成
使用高版本的Spring data,我boot版本2.7,下面两个依赖,随便引入一个就行,我试过都是可以地
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-neo4j</artifactId></dependency>
<!--两者任选其一,--><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-neo4j</artifactId><version>3.3.11</version></dependency>
使用
定义实体
我们先定义三个实体
- job:作业实体
- table:表实体
- JobRelationship:关系实体
@Data
@Node("Job")
public class Job {@Id@GeneratedValueprivate Long id;private String name;@Propertyprivate String type;@Relationship("dep")private List<TableRelationship> tables;@Relationship("dep")private List<JobRelationship> jobs;
}@Data
@Node
public class Table {@Id@GeneratedValueprivate Long id;private String name;private String type;@Relationship("dep")private List<Job> jobs;
}@Data
@RelationshipProperties
public class JobRelationship {@Id@GeneratedValueprivate Long id;@TargetNodeprivate Job job;
}@Data
@RelationshipProperties
public class TableRelationship {@Id@GeneratedValueprivate Long id;@TargetNodeprivate Table table;
}上面三个实体的写法都一些不同,这里需要注意下:
@Node:标注的实体为数据库对象实体,表示一个节点,其value值就是标签,如果不设置就是类名;@Id:标注的属性是主键字段;@GeneratedValue:主键字段,必须设置它的一个生成方式,如果是自己设置可以忽略;@Property标注的属性为数据库属性字段,可以不写这个注解,@Node标注的实体中的属性默认为数据库属性字段,同样,其value值也是数据库属性字段,也可以不写,类似做了映射;@Relationship:标注的属性为关系属性,值为关系的标签值,另一个值为关系的指向,默认从当前节点向外指向,类似关系型数据库的关系;@RelationshipProperties:标注的类为关系实体,是对@Relationship类型的描述;@TargetNode:标注的属性是关系中的目标节点;
更加详细说明在:spring Data Neo4j
配置
application.yml
spring:neo4j:uri: bolt://192.168.0.103:7687authentication:username: neo4jpassword: password
定义Repository
这里使用的是spring jpa的开发方式,它提供了增删改查的基础功能,定义如下:
@Repository
public interface TableRepository extends Neo4jRepository<Table, Long> {
}
@Repository
public interface JobRepository extends Neo4jRepository<Job, Long> {/*** 根据名称查找*/Job findByName(String name);/*** 节点name是否包含指定的值*/boolean existsByNameContaining(String name);/*** 强制删除节点*/Long deleteByName(String name);
}那这个JPA的方式的话可以通过关键字和属性名定义查询方法,如上面的的findByName就可以实现通过名称查询,不需要写实现,这里只说这么多,详细的可以看:Spring Data JPA - Reference Documentation
查询方法
spring data提供的基础增删改查其实在在业务中是不够用的,但是,它额外的提供了一些条件构建器,使得我们可以借助一些快捷的API进行查询条件构造,以适应这些复杂查询,也就是动态语法。
方式一:@Query
说起JPA,自定义查询好像大多是用@Query注解进行标注的,比如:
@Query("match(a:Job{name:$name}) return a")Job findByName2(@Param("name") String name);@Query("match(a:Job{name: $0) return a")List<Job> findByName3(@Param("name") String name);
这样的方式很简单是不是,但是存在的问题是,语句中的Job,name都是对应数据库里的标签和字段,所以这就和mybatis xml里的方式一样,如果数据库字段变更或标签变更需要全局替换。
方式二:Cypher语法构建器
Spring data提供了针对Cypher语法的构建器,可以让我们对复杂cypher的语法构建;
示例一:
match(a:Job) where a.name=‘liry’ return a order by a.id limit 1
// match(a:Job) where a.name='liry' return a order by a.id limit 1// 创建节点对象:标签为 Job,别名 a -> (a:Job)
Node temp = Cypher.node("Job").named("a");
// 构建查询声明对象
// 创建match查询:-> match(a:Job)
ResultStatement statement = Cypher.match(temp)// 添加条件:-> a.name=$name.where(temp.property("name").isEqualTo(Cypher.anonParameter(job.getName())))// 返回对象:return 别名 -> return a.returning(temp.getRequiredSymbolicName())// 排序:以属性id正序.orderBy(temp.property("id"))// 限制数量:1.limit(1)// 构建为语法对象.build();
示例二:
// merge(a:Job{name:$name}) set a.type=$type return a// 构建参数
Map<String, Object> pro = new HashMap<>();
pro.put("name", job.getName());
// 创建节点对象:标签Job,别名a,并且设置参数 -> (a:Job{name:$name})
Node temp = Cypher.node("Job").named("a").withProperties(pro);
// 创建merge查询: -> merge(a:Job{name:$name})
ResultStatement statement = Cypher.merge(temp)// 设置值:-> a.type=$type.set(temp.property("type"),Cypher.anonParameter(job.getType()))// 返回对象:return别名 -> return a.returning(temp.getRequiredSymbolicName())// 构建声明对象.build();
示例三:
// MATCH (a:`Job` {name: $pcdsl01})-[r*..2]-(b:`Job`) RETURN a,b,r// 创建两个节点给,都死标签Job,别名分别是a,b,a节点关联属性name
Node node = Cypher.node("Job").named("a").withProperties("name", Cypher.anonParameter(name));
Node node2 = Cypher.node("Job").named("b");// 创建a-r-b的关系
Relationship r = node.relationshipBetween(node2).named("r").max(length);
// a-r->b
// Relationship r = node.relationshipTo(node2).named("r").max(length);
// a<-r-b
// Relationship r = node.relationshipFrom(node2).named("r").max(length);
// 创建match查询
ResultStatement statement = Cypher.match(r)// 返回对象.returning("a","b","r")// 构建声明对象.build();
这里的withProperties,我又用了另一种方式.withProperties("name", Cypher.anonParameter(name));,上面我传的是一个map,它这里其实很巧妙的做了一个适配,只要你以key value,那么便是偶数个参数,他会自动帮你绑定,或者传map也行。
方式三:Example条件构建器
Spring Data默认的Neo4jRepository是继承 了QueryByExampleExecutor,如下:
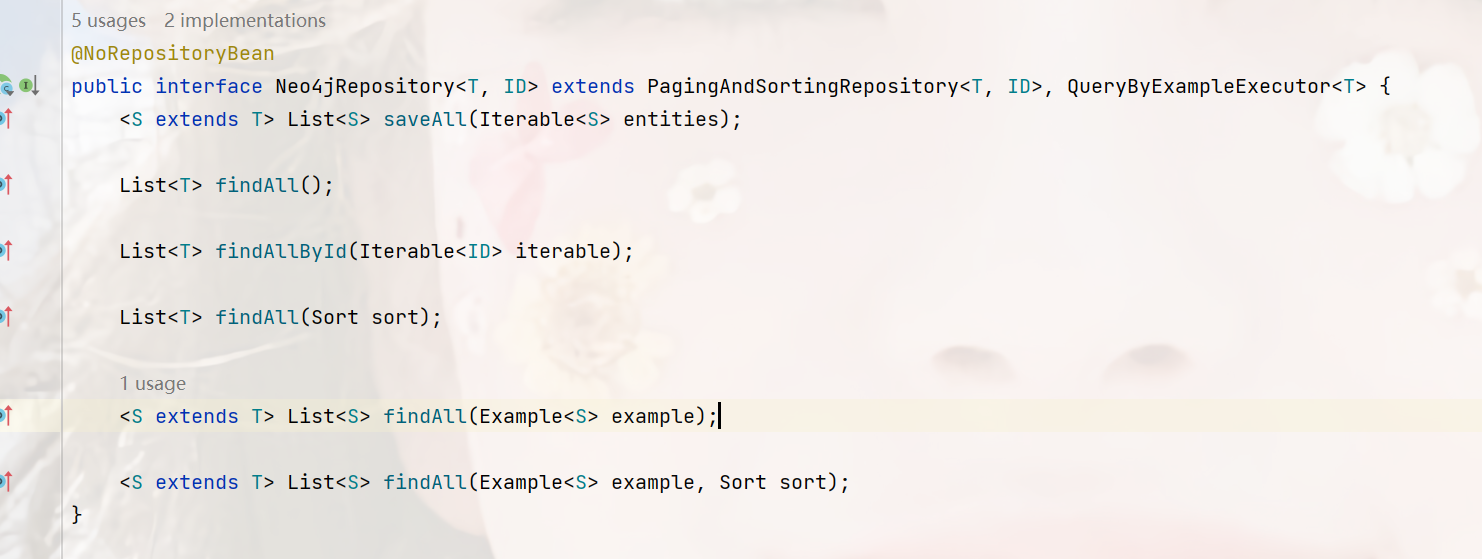
那么它所能使用的方法是这些:

其应用示例一:
// Neo4jRepository默认继承了example功能Job job = new Job();job.setName("liry");ExampleMatcher exampleMatcher = ExampleMatcher.matching().withMatcher("na", ExampleMatcher.GenericPropertyMatchers.endsWith());// 根据示例匹配器规则进行条件重组 查询List<Job> all1 = jobRepository.findAll(Example.of(job, exampleMatcher));// 精确查询List<Job> all2 = jobRepository.findAll(Example.of(job));List<Job> all3 = jobRepository.findAll(Example.of(job), Sort.by(Sort.Order.desc("id")));Page<Job> all4 = jobRepository.findAll(Example.of(job), PageRequest.of(1, 10));
示例二:
流处理查询
Job job = new Job();job.setJobName(name);// 查询一个一个值Job one = jobRepository.findBy(Example.of(job), query -> query.oneValue());// lambda简化
// Job one = jobRepository.findBy(Example.of(job), FluentQuery.FetchableFluentQuery::oneValue);// 查询countLong count = jobRepository.findBy(Example.of(job), query -> query.count());// lambda简化
// Long count = jobRepository.findBy(Example.of(job), FluentQuery.FetchableFluentQuery::count);// 是否存在Boolean exist = jobRepository.findBy(Example.of(job), query -> query.exists());// lambda简化
// Boolean exist = jobRepository.findBy(Example.of(job), FluentQuery.FetchableFluentQuery::exists);// 查询全部List<Job> list = jobRepository.findBy(Example.of(job), query -> query.all());// lambda简化
// List<Job> list = jobRepository.findBy(Example.of(job), FluentQuery.FetchableFluentQuery::all);// 查询2个List<Job> list2 = jobRepository.findBy(Example.of(job),query -> query.stream().limit(2).collect(Collectors.toList()));// 查询并进行处理List<Object> list3 = jobRepository.findBy(Example.of(job),query -> query.stream().peek(d -> d.setName(d.getName() + "1")).collect(Collectors.toList()));// 查询并排序List<Job> list4 = jobRepository.findBy(Example.of(job),query -> query.sortBy(Sort.by(Sort.Order.asc("id")))).all();
上面这个流处理查询都可以用lambda表达式来处理。
注意:使用example查询时,不要有关联关系,不然他会报错,即不要有@Relationship这个注解
方式四:DSL语法
这个是借助DSL框架实现的语法构建,添加DSL依赖
<dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId></dependency><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-apt</artifactId></dependency>
添加插件
<plugin><groupId>com.mysema.maven</groupId><artifactId>apt-maven-plugin</artifactId><version>1.1.3</version><executions><execution><goals><goal>process</goal></goals><configuration><outputDirectory>target/generated-sources/java</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor></configuration></execution></executions>
</plugin>
- 实体类上需要加上
@Entity
但是只引入neo4j的依赖,是不行的,还需要jpa的依赖,因为JPA依赖数据库,所以可以先引入,生成之后,再删除掉。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version>
</dependency>
然后maven compile编译,一下,会在target/generated-sources/java目录下找到生成的Q类,把它复制到我们实体目录下
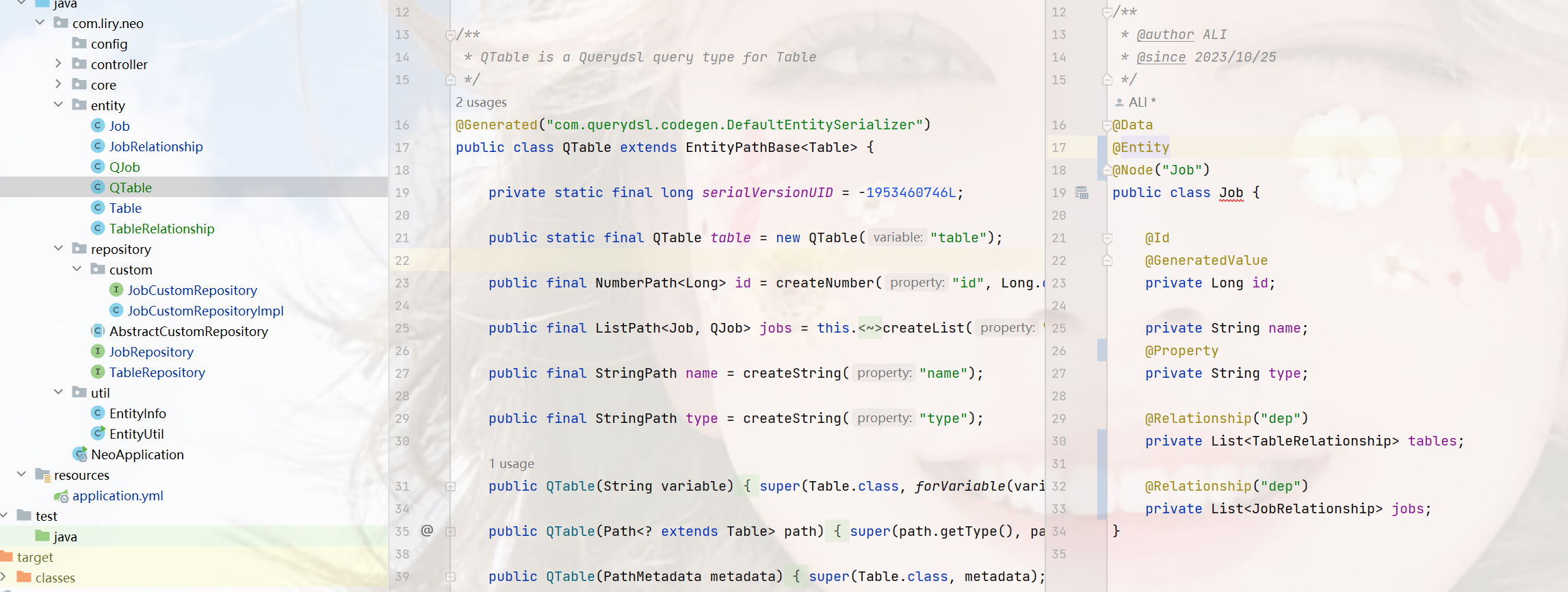
-
继承接口
QuerydslPredicateExecutor它的使用方式和Example一样。
@Repository public interface JobRepository extends Neo4jRepository<Job, Long> , QuerydslPredicateExecutor<Job>{ }这个接口下的功能都可以使用

示例一:
QJob job = QJob.job;
// name=$nameIterable<Job> all = jobRepository.findAll(job.name.eq(name));// name like $name and type = $typeBooleanExpression exp = job.name.like(name).and(job.type.eq("test"));boolean exists = jobRepository.exists(exp);Iterable<Job> all1 = jobRepository.findAll(exp);
// 排序Iterable<Job> id = jobRepository.findAll(exp, Sort.by(Sort.Order.desc("id")));
// 分月Page<Job> all2 = jobRepository.findAll(exp, PageRequest.of(1, 10));// in查询 exp = job.name.in("liryc", "xx");jobRepository.findAll(exp);
示例二:
// 查询一个一个值Job one = jobRepository.findBy(exp, query -> query.oneValue());// lambda简化// Job one = jobRepository.findBy(exp, FluentQuery.FetchableFluentQuery::oneValue);// 查询countLong count = jobRepository.findBy(exp, query -> query.count());// lambda简化// Long count = jobRepository.findBy(exp, FluentQuery.FetchableFluentQuery::count);// 是否存在Boolean exist = jobRepository.findBy(exp, query -> query.exists());// lambda简化// Boolean exist = jobRepository.findBy(exp, FluentQuery.FetchableFluentQuery::exists);// 查询全部List<Job> list = jobRepository.findBy(exp, query -> query.all());// lambda简化// List<Job> list = jobRepository.findBy(exp, FluentQuery.FetchableFluentQuery::all);// 查询2个List<Job> list2 = jobRepository.findBy(exp,query -> query.stream().limit(2).collect(Collectors.toList()));// 查询并进行处理List<Object> list3 = jobRepository.findBy(exp,query -> query.stream().peek(d -> d.setName(d.getName() + "1")).collect(Collectors.toList()));// 查询并排序List<Job> list4 = jobRepository.findBy(exp,query -> query.sortBy(Sort.by(Sort.Order.asc("id")))).all();
自定义方法
上面都是spring data自带的方法,已经可以实现大部分的复杂查询了,当时在业务层的时候我们一般不会把这些数据访问放在业务层中,这些都应该是置于底层作为最基本的数据能力,不该带入业务,并且也不该把数据访问的逻辑赤裸的放到业务层中,那么我们就会需要子党员方法。
自定义接口
public interface JobCustomRepository {/*** 查询所有*/Object selectAll();/*** 保持节点信息,会先判断是否存在*/Job saveCondition(Job job);/*** 创建或合并节点*/Job saveMerge(Job job);
}
继承自定义接口
@Repository
public interface JobRepository extends Neo4jRepository<Job, Long> , JobCustomRepository {}
实现自定义接口
@Component("jobCustomRepository")
public class JobCustomRepositoryImpl implements JobCustomRepository {
}
如此我们就可以在业务层中这样:
// 这里引入的接口,就具备了原本spring的能力,和你自定义的能力
@Autowiredprivate JobRepository jobRepository;neo4jTemplate
在自定义中可以引入这个作为执行类,这个类实现Neo4jOperations,template它是支持直接写cypher语句的,比如下面这个


如果需要参数分离的话,参数占位用$,那么cypher语句应该是这样:
match(a) where a.name=$name return a
示例:
// 方式一:template执行cql字符串String cql = String.format("merge(a:Job{name:'%s'}) set a.time=2 return a", job.getName());List<Job> all = neo4jTemplate.findAll(cql, Job.class);// 方式二:cypher语句cql = String.format("merge(a:Job{name:'%s'}) set a.time=$time return a", job.getName());Map<String, Object> param = new HashMap<>();param.put("time", 1);all = neo4jTemplate.findAll(cql, param, Job.class);// 方式三:Cypher构建声明对象Map<String, Object> pro = new HashMap<>();pro.put("name", job.getName());Node temp = Cypher.node("Job").named("a").withProperties(pro);ResultStatement statement = Cypher.merge(temp).set(temp.property("type"), Cypher.anonParameter(job.getType())).returning(temp.getRequiredSymbolicName()).build();List<Job> all1 = neo4jTemplate.findAll(statement, statement.getParameters(), Job.class);
Neo4jClient
除了neo4jTemplate还可以用neo4jClient
示例
String cpl = "match(a) where a.name contains 'liry' return a limit 1";// 执行cypherResult run = client.getQueryRunner().run(cpl);// 结果获取的方式// **** 注意,下面的几种方式中,只能选用一种,在结果读取后,就不能在读取了 ****// 方式一:迭代器while (run.hasNext()) {Record d = run.next();// 这几个的结构差不多List<Pair<String, Value>> fields = d.fields();List<Value> values = d.values();Map<String, Object> stringObjectMap = d.asMap();System.out.println(d);}// 方式二:lambda// 或者直接获取列表List<Record> list = run.list();List<Record> dd = list.stream().map(d -> {List<Pair<String, Value>> fields = d.fields();List<Value> values = d.values();Map<String, Object> stringObjectMap = d.asMap();return d;}).collect(Collectors.toList());// 方式三:函数式接口List<Object> result = run.list(map -> {return map;});
这里有需要注意的地方,就是在run执行后,只能获取一次结果,如上代码所示,不论用那种方式进行结果的获取,都只能获取一次;
自定义抽象类(执行与结果转换)
但是很多人就会觉得这个方式需要自己处理结果集,确实,它的这个结果集不是很友好,所以我这里也提供一个结果处理案例;
我这里就直接贴已经完成的代码了,可以直接复制使用,同时这个类也提供了执行cypher语句的方法,和JPA一样。
package com.liry.neo.repository;import com.liry.neo.entity.RelationshipInfo;
import java.util.Map;
import java.util.function.BiFunction;
import java.util.function.Supplier;
import org.neo4j.driver.internal.types.InternalTypeSystem;
import org.neo4j.driver.internal.value.NodeValue;
import org.neo4j.driver.types.MapAccessor;
import org.neo4j.driver.types.Relationship;
import org.neo4j.driver.types.TypeSystem;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.data.neo4j.core.Neo4jOperations;
import org.springframework.data.neo4j.core.Neo4jTemplate;
import org.springframework.data.neo4j.core.PreparedQuery;
import org.springframework.data.neo4j.core.mapping.EntityInstanceWithSource;
import org.springframework.data.neo4j.core.mapping.Neo4jMappingContext;
import org.springframework.lang.Nullable;
import org.springframework.util.Assert;/*** @author ALI* @since 2023/10/25*/
public abstract class AbstractCustomRepository implements ApplicationContextAware {protected ApplicationContext applicationContext;private Neo4jMappingContext neo4jMappingContext;private Neo4jTemplate neo4jTemplate;private static <T> Supplier<BiFunction<TypeSystem, MapAccessor, ?>> getAndDecorateMappingFunction(Neo4jMappingContext mappingContext, Class<T> domainType, @Nullable Class<?> resultType) {Assert.notNull(mappingContext.getPersistentEntity(domainType), "Cannot get or create persistent entity.");return () -> {BiFunction<TypeSystem, MapAccessor, ?> mappingFunction = mappingContext.getRequiredMappingFunctionFor(domainType);if (resultType != null && domainType != resultType && !resultType.isInterface()) {mappingFunction = EntityInstanceWithSource.decorateMappingFunction(mappingFunction);}return mappingFunction;};}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;}private Neo4jMappingContext getNeo4jMappingContext() {if (neo4jMappingContext == null) {neo4jMappingContext = applicationContext.getBean(Neo4jMappingContext.class);}return neo4jMappingContext;}private Neo4jTemplate getNeo4jTemplate() {if (neo4jTemplate == null) {neo4jTemplate = applicationContext.getBean(Neo4jTemplate.class);}return neo4jTemplate;}/*** 执行cypher查询** @param domainType 实体类型* @param cypherStatement cypher语句* @param parameters 参数*/protected <T> Neo4jOperations.ExecutableQuery<T> createExecutableQuery(Class<T> domainType, String cypherStatement,Map<String, Object> parameters) {return createExecutableQuery(domainType, domainType, cypherStatement, parameters);}/*** 执行cypher查询** @param domainType 实体类型* @param resultType 返回的结果类型* @param cypherStatement cypher语句* @param parameters 参数*/protected <T> Neo4jOperations.ExecutableQuery<T> createExecutableQuery(Class<?> domainType, Class<T> resultType, String cypherStatement,Map<String, Object> parameters) {PreparedQuery.OptionalBuildSteps<T> step = PreparedQuery.queryFor(resultType).withCypherQuery(cypherStatement).withParameters(parameters);// 基本类型转换if (!Number.class.isAssignableFrom(resultType) && !Boolean.class.isAssignableFrom(resultType) && !String.class.isAssignableFrom(resultType)) {Supplier<BiFunction<TypeSystem, MapAccessor, ?>> mappingFunction = getAndDecorateMappingFunction(getNeo4jMappingContext(),domainType,resultType);step.usingMappingFunction(mappingFunction);}return getNeo4jTemplate().toExecutableQuery(step.build());}protected <T> T mapping(Class<T> domainType, NodeValue node) {Object apply = getMappingFunction(domainType).get().apply(InternalTypeSystem.TYPE_SYSTEM, node);return (T) ((EntityInstanceWithSource) apply).getEntityInstance();}protected RelationshipInfo mapping(Relationship node) {RelationshipInfo result = new RelationshipInfo();result.setStart(node.startNodeId());result.setEnd(node.endNodeId());result.setType(node.type());result.setId(node.id());return result;}/*** 结果映射** @param domainType 实体类型,也是结果类型* @return 映射方法*/protected <T> Supplier<BiFunction<TypeSystem, MapAccessor, ?>> getMappingFunction(Class<T> domainType) {return () -> {BiFunction<TypeSystem, MapAccessor, T> mappingFunction = getNeo4jMappingContext().getRequiredMappingFunctionFor(domainType);return EntityInstanceWithSource.decorateMappingFunction(mappingFunction);};}
}之后我们自定义的Repository就要继承这个抽象类,以达到可以直接使用的功能,如下:
@Component("jobCustomRepository")
public class JobCustomRepositoryImpl extends AbstractCustomRepository implements JobCustomRepository {@Autowiredprivate Neo4jTemplate neo4jTemplate;
}
再定义一个关系实体:
@Data
public class RelationshipDto {private Long id;private Long start;private Long end;private String type;
}然后我们查询并转换如下:
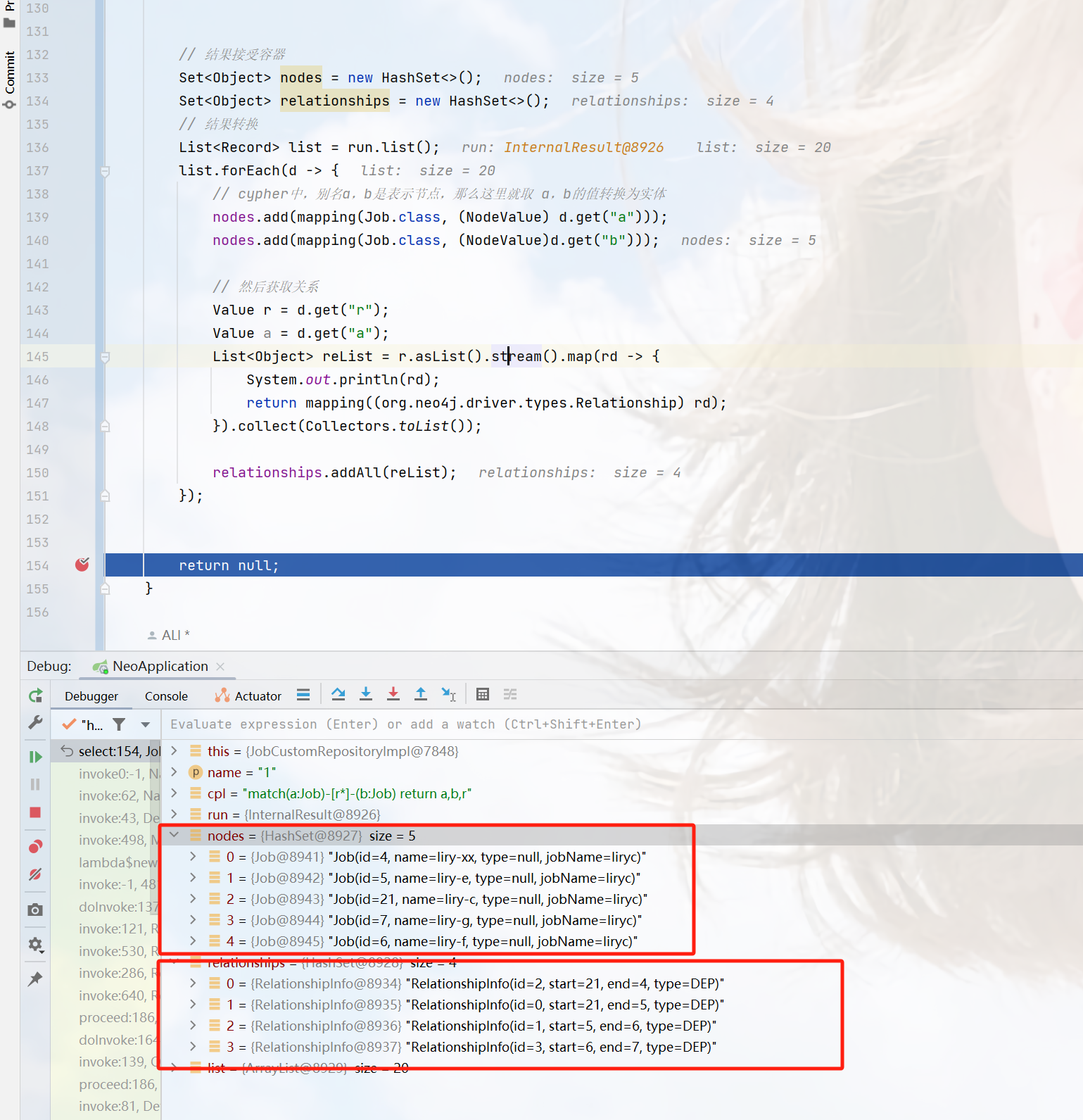
String cpl = "match(a:Job)-[r*]-(b:Job) return a,b,r";// 执行cypher
Result run = client.getQueryRunner().run(cpl);// 结果接受容器
Set<Object> nodes = new HashSet<>();
Set<Object> relationships = new HashSet<>();
// 结果转换
List<Record> list = run.list();
list.forEach(d -> {// cypher中,别名a,b是表示节点,那么这里就取 a,b的值转换为实体nodes.add(mapping(Job.class, (NodeValue) d.get("a")));nodes.add(mapping(Job.class, (NodeValue)d.get("b")));// 然后获取关系Value r = d.get("r");Value a = d.get("a");List<Object> reList = r.asList().stream().map(rd -> {System.out.println(rd);return mapping((org.neo4j.driver.types.Relationship) rd);}).collect(Collectors.toList());relationships.addAll(reList);
});
相关文章:
SpringBoot集成与应用Neo4j
文章目录 前言集成使用定义实体配置定义Repository查询方法方式一:Query方式二:Cypher语法构建器方式三:Example条件构建器方式四:DSL语法 自定义方法自定义接口继承自定义接口实现自定义接口neo4jTemplateNeo4jClient 自定义抽象…...

做人,不一定要风风光光,但一定要堂堂正正。处事,不一定要尽善尽美,但一定要问心无愧。
做人,不一定要风风光光,但一定要堂堂正正。处事,不一定要尽善尽美,但一定要问心无愧。以真诚的心,对待身边的每一个人。以感恩的心,感谢拥有的一切。 未来,不是穷人的天下,也不是富人…...
51单片机实验:数码管动态显示00-99
1、实验要求 利用STC89C52RC单片机开发板实现:使用2位数码管循环显示00-99,每次间隔1s,并且当计数到20时,则蜂鸣器鸣响1次。 2、实验分析 程序实现分析: 1、定义数码管位选引脚(P2.4、P2.5、P2.6、…...

【教3妹学编程-java实战5】结构体字段赋值的几种方式
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 2哥 :3妹,考考你,你知道java结…...

阿里蚂蚁淘宝等多次一面面试面经
一面采用电话面试笔试链接做算法题(可能开视频)的形式 蚂蚁第一次: 自我介绍 技术一般使用开源技术还是自己研发 开源spring cloud等 流水线用来做什么 用户是什么人 应用场景 是toB的对吧 学到的最前沿的技术有哪些 gateway全局权限…...
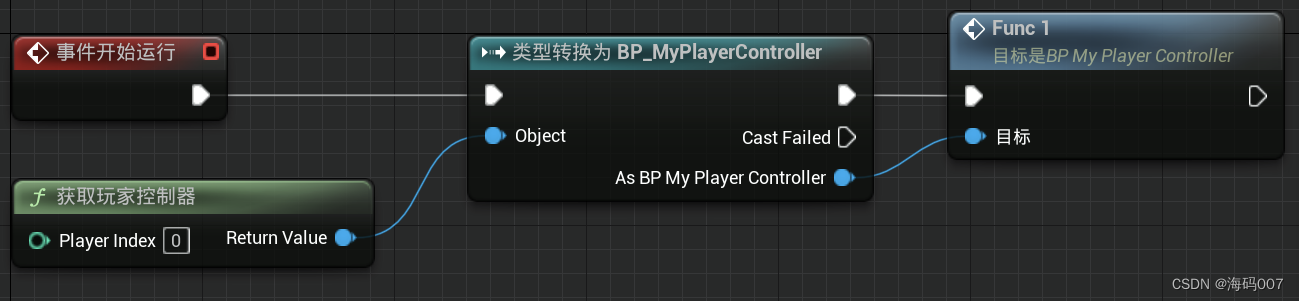
UE4 中可全局获取的变量(例如游戏实例、玩家控制器等) 详解
目录 0 引言1 全局对象(全局变量)1.1 游戏实例 GameInstance1.1.1 介绍1.1.2 使用 GameInstance 1.2 玩家控制器 PlayerController1.3 游戏世界类 UWorld 🙋♂️ 作者:海码007📜 专栏:UE虚幻引擎专栏&…...
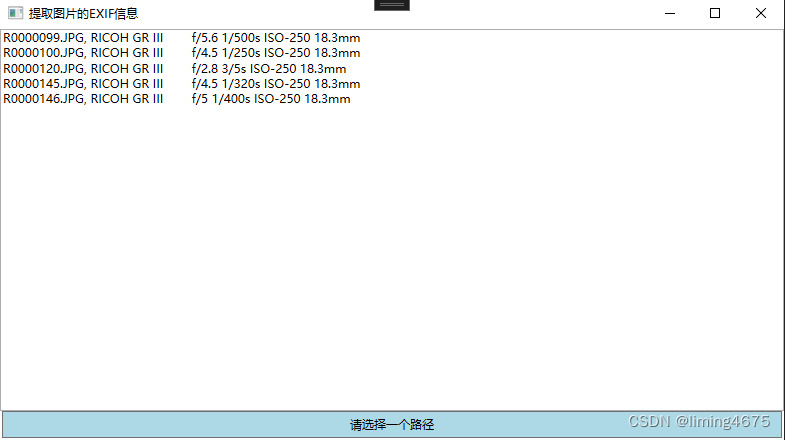
c#使用ExifLib库提取图像的相机型号、光圈、快门、iso、曝光时间、焦距信息等EXIF信息
近期公司组织了书画摄影比赛,本人作为摄影爱好者,平时也会拍些照片,这次比赛当然不能错过。为了提高获奖概率,选了19张图像作为参赛作品。但是,摄影作品要提交图像的光圈、曝光时间等参数。一两张还可以通过电脑自带软…...
C++入门05—指针
1. 指针的基本概念 指针的作用: 可以通过指针间接访问内存 内存编号是从0开始记录的,一般用十六进制数字表示 可以利用指针变量保存地址 2. 指针变量的定义和使用 指针变量定义语法: 数据类型 * 变量名; 示例: …...

Go学习第十六章——Gin文件上传与下载
Go web框架——Gin文件上传与下载 1. 文件上传1.1 入门案例(单文件)1.2 服务端保存文件的几种方式SaveUploadedFileCreateCopy 1.3 读取上传的文件1.4 多文件上传 2. 文件下载2.1 快速入门2.2 前后端模式下的文件下载2.3 中文乱码问题 1. 文件上传 1.1 …...

2.MySQL的调控按钮——启动选项和系统变量
2.MySQL的调控按钮——启动选项和系统变量 1.启动选项和配置文件1.1 在命令行上使用选项1.2 配置文件中使用选项1.2.1 配置文件路径1.2.2 配置文件的内容1.2.3 特定 MySQL 版本的专用选项组1.2.4 配置文件的优先级1.2.5 同一个配置文件中多个组的优先级1.2.6 defaults-file 的使…...
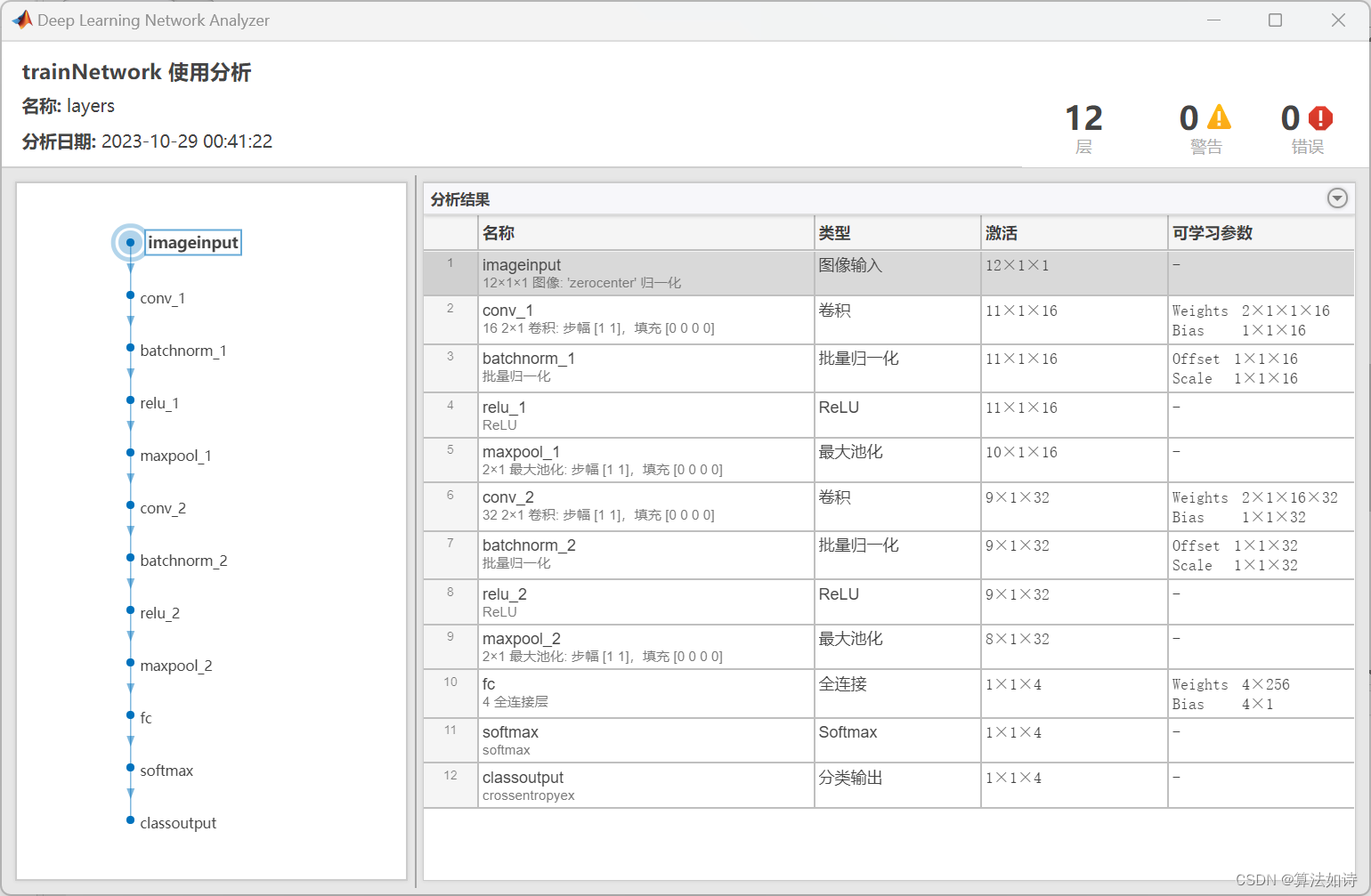
故障诊断模型 | Maltab实现CNN卷积神经网络故障诊断
文章目录 效果一览文章概述模型描述源码设计参考资料效果一览 文章概述 故障诊断模型 | Maltab实现CNN卷积神经网络故障诊断 模型描述 卷积神经网络(convolutional neural network)是具有局部连接、权重共享等特性的深层前馈神经网络,最早主要是用来处理图像信息。 相比于全…...

qt高精度定时器的使用停止线程应用
##线程停止 //线程停止应用 public: explicit WorkerThread(QObject *parent 0) :QThread(parent), m_bStopped(false){qDebug() << "Worker Thread : " << QThread::currentThreadId();}~WorkerThread(){stop();quit();wait();}void stop() {qDebug()…...

Spring Boot Actuator 介绍
Spring Boot Actuator是什么 Spring Boot Actuator 模块提供了生产级别的功能,比如健康检查,审计,指标收集,HTTP 跟踪等,帮助我们监控和管理Spring Boot 应用。 这个模块是一个采集应用内部信息暴露给外部的模块&…...
【MATLAB】安装Psychtoolbox
目录 一、下载Psychtoolbox工具包 1. 一个是这个ZTP文件 2. 分别下载 Subversion 1.7.x command-line client 和 gstreamer.freedesktop.org 二、解压工具包,保存至同一文件 三、安装到matlab 1. 安装psychtoolbox 2. 检查是否安装成功 一、下载Psychtoolbox…...

【Python机器学习】零基础掌握GradientBoostingClassifier集成学习
什么能有效地解决分类问题,特别是在数据复杂、特征多样的情况下? 面对这个问题,许多人可能会想到复杂的神经网络或深度学习方法。然而,有一种称为“梯度提升分类器”(Gradient Boosting Classifier)的算法,以其高准确度、灵活性和易用性赢得了大量用户的青睐。 假设在…...

RFNet模型数据集采集处理流程
文章目录 cityscapes数据集内容如何标注数据得到标签图片 cityscapes数据集内容 训练模型的时候下载了cityscapes里的disparity、gtFine和leftImg8bit。 共5000张图片。2975张训练,500张验证,1525test。每个目录下都有train、test和val的子目录,这些子…...
sql-50练习题6-10
sql练习题6-10题 前言数据库表结构介绍学生表课程表成绩表教师表 0-6 查询"李"姓老师的数量0-7 查询学过"李四"老师授课的同学的信息0-8 查询没学过"李四"老师授课的同学的信息0-9 查询学过编号为"01"并且也学过编号为"02"的…...

【刷题宝典NO.1】
Nim游戏 https://leetcode.cn/problems/nim-game/description/ 你和你的朋友,两个人一起玩 Nim 游戏: 桌子上有一堆石头。 你们轮流进行自己的回合, 你作为先手 。 每一回合,轮到的人拿掉 1 - 3 块石头。 拿掉最后一块石头的人…...

如何在深度学习领域取得个人的成功
要在深度学习领域取得个人的成功,可以考虑以下建议: 学习深度学习的基础知识:首先,建立坚实的深度学习基础知识是非常重要的。你可以学习深度学习的基本概念、神经网络的原理、常用的深度学习框架(如TensorFlow、PyTor…...

数据结构【DS】B树
m阶B树的核心特性: Q:根节点的子树数范围是多少?关键字数的范围是多少? A:根节点的子树数∈[2, m],关键字数∈[1, m-1]。 Q:其他结点的子树数范围是多少?关键字数范围是多少? Q:对任…...
XUnity Auto Translator:打破语言壁垒的Unity游戏翻译解决方案
XUnity Auto Translator:打破语言壁垒的Unity游戏翻译解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过精彩的Unity游戏?面对日文、韩文或其他…...

Pills CSS Grid高级技巧:嵌套布局、偏移量与自定义宽度全解析
Pills CSS Grid高级技巧:嵌套布局、偏移量与自定义宽度全解析 【免费下载链接】pills A simple responsive CSS Grid for humans. View Demo - 项目地址: https://gitcode.com/gh_mirrors/pi/pills Pills CSS Grid是一个简单、响应式、轻量级的CSS网格系统&…...

ElevenLabs广西话输出突然失真?一文定位3类隐藏错误:声母浊化丢失、入声韵尾截断、连读变调失效
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广西话语音输出失真现象概览 ElevenLabs 作为当前主流的AI语音合成平台,其多语言支持能力广受开发者青睐。然而,在针对广西话(粤语勾漏片与邕浔片混合变体…...

opencode使用安装
确保已经安装好node npm安装opencode C:\WINDOWS\system32>npm install -g opencode-aiadded 3 packages in 2mC:\WINDOWS\system32>npm安装mcp-chrome C:\WINDOWS\system32>npm...

Agentic o3调度器与Gemma/Nemotron-H推理范式演进
1. 项目概述:一场悄然发生的模型推理范式迁移最近在几个核心AI工程团队的内部技术简报里,反复看到一个代号“TAI#149”的专项分析报告被高频引用——它不是某家公司的新品发布会通稿,而是一份由一线模型部署工程师自发整理、持续迭代的实战观…...

量子加速,多模态跃迁:国产大模型的下一站机遇
量子加速,多模态跃迁:国产大模型的下一站机遇 引言 当国产多模态大模型在理解图文、生成内容上不断突破时,一个更具颠覆性的技术变量正在悄然融入——量子计算。这不仅是实验室里的前沿概念,更是百度、华为、阿里等科技巨头竞相布…...

【MySQL 三大日志深度解析】:redo log、undo log、binlog 作用与两阶段提交原理
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 前言…...

深入解析SAR ADC:从二分搜索原理到高精度数据采集实战
1. 项目概述:从“猜数字”游戏理解SAR ADC在模拟信号处理的世界里,我们常常需要将现实世界中连续变化的物理量(比如温度、声音、压力)转换成计算机能够理解和处理的数字信号。这个关键的桥梁,就是模数转换器。而在众多…...

一文看懂 Hermes Agent 的 Prompt Builder:系统提示词到底拼进了什么?
一、先说结论:Prompt Builder 是 Hermes 的“提示词总装车间”普通 Chatbot 的系统提示词往往是一段固定文字,告诉模型“你是谁、怎么回答”。Hermes Agent 的 Prompt Builder 更像一条总装线:它会把身份、记忆、用户画像、项目规则、技能目录…...

还在熬夜起草各类通知?2026便捷AI办公好物,轻松写完正式公文
作为一名在行政岗摸爬滚打五年的职场人,我每天的工作不是泡在各类会议里,就是埋头起草通知、整理纪要。相信不少行政、文秘岗位的朋友都和我有一样的困扰:公司部门多、会议密,每周光是例会、项目协调会、临时部署会就要开三四场&a…...