Spark_SQL函数定义(定义UDF函数、使用窗口函数)
一、UDF函数定义
(1)函数定义
(2)Spark支持定义函数
(3)定义UDF函数
(4)定义返回Array类型的UDF
(5)定义返回字典类型的UDF
二、窗口函数
(1)开窗函数简述
(2)窗口函数的语法
一、UDF函数定义
(1)函数定义
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
Hive中自定义函数有三种类型:
第一种:UDF(User-Defined_-function)函数
· 一对一的关系,输入一个值经过函数以后输出一个值;
· 在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function)聚合函数
· 多对一的关系,输入多个值输出一个值,通常于groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions)函数
· 一对多的关系,输入一个值输出多个值(一行变多为行);
· 用户自定义生成函数,有点像flatMap;
(2)Spark支持定义函数
目前来说Spark框架各个版本及各种语言对自定义函数的支持:在SparkSQL中,目前仅仅支持UDF函数和UDAF函数,目前Python仅支持UDF。
| Apache Spark Version | Spark SQL UDF(Python,Java,Scala) | Spark SQL UDAF(Java,Scala) | Spark SQL UDF(R) | Hive UDF,UDAF,UDTF |
| 1.1-1.4 | √ | √ | ||
| 1.5 | √ | experimental | √ | |
| 1.6 | √ | √ | √ | |
| 2.0 | √ | √ | √ | √ |
(3)定义UDF函数
①sparksession.udf.register()
注册的UDF可以用于DSL和SQL,返回值用于DSL风格,传参内给的名字用于SQL风格。

②pyspark.sql.functions.udf
仅能用于DSL风格。

其中F是:from pyspark.sql import functions as F。其中,被注册为UDF的方法名是指具体的计算方法,如:def add(x, y): x + y 。 add就是将要被注册成UDF的方法名
# cording:utf8
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType
if __name__ == '__main__':spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()sc = spark.sparkContext# 构建一个RDDrdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x:[x])df = rdd.toDF(['num'])# TODO 1:方式1 sparksession.udf.register(),DSL和SQL风格均可使用# UDF的处理函数def num_ride_10(num):return num * 10# 参数1:注册的UDF的名称,这个UDF名称,仅可以用于SQL风格# 参数2:UDF的处理逻辑,是一个单独定义的方法# 参数3:声明UDF的返回值类型,注意:UDF注册时候,必要声明返回值类型,并且UDF的真实返回值一定要和声明的返回值一致# 当前这种方式定义的UDF,可以通过参数1的名称用于SQL风格,通过返回值对象用户的DSL风格udf2 = spark.udf.register('udf1', num_ride_10, IntegerType())# SQL风格中使用# selectExpr 以SELECT的表达式执行,表达式SQL风格的表达式(字符串)# select方法,接受普通的字符串字段名,或者返回值时Column对象的计算df.selectExpr('udf1(num)').show()# DSL 风格使用# 返回值UDF对象,如果作为方法使用,传入的参数一定是Column对象df.select(udf2(df['num'])).show()# TODO 2:方式2注册,仅能用于DSL风格udf3 = F.udf(num_ride_10, IntegerType())df.select(udf3(df['num'])).show()方式1结果:
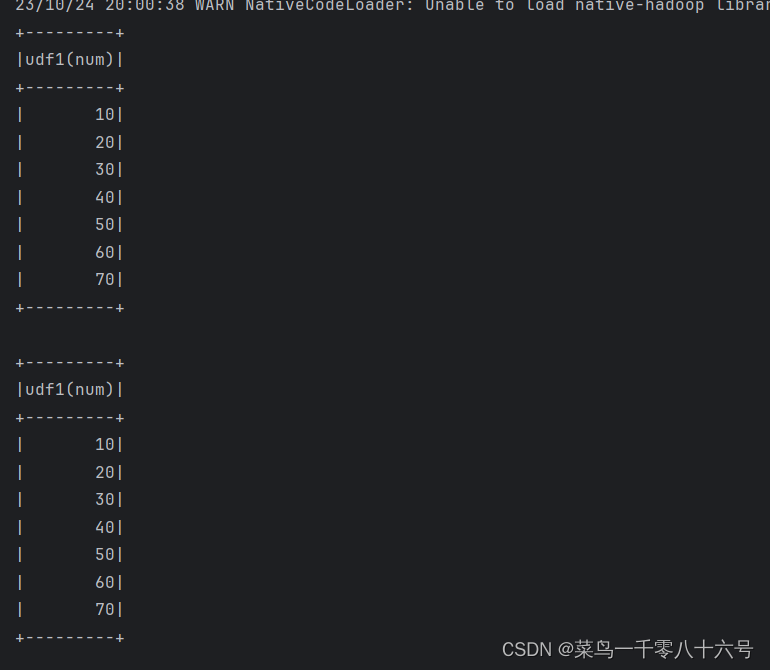
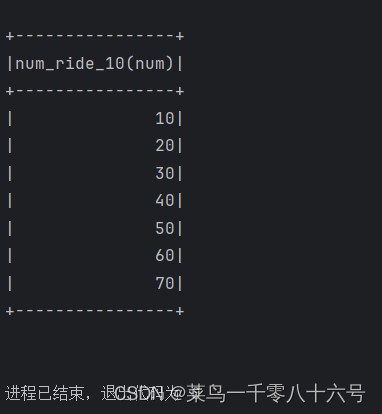
方式2结果:
(4)定义返回Array类型的UDF
注意:数组或者list类型,可以使用spark的ArrayType来描述即可。
注意:声明ArrayType要类似这样::ArrayType(StringType()),在ArrayType中传入数组内的数据类型。
# cording:utf8
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()sc = spark.sparkContext# 构建一个RDDrdd = sc.parallelize([['hadoop spark flink'], ['hadoop flink java']])df = rdd.toDF(['line'])# 注册UDF,UDF的执行函数定义def split_line(data):return data.split(' ')# TODO 1:方式1 后见UDFudf2 = spark.udf.register('udf1', split_line, ArrayType(StringType()))# DLS 风格df.select(udf2(df['line'])).show()# SQL风格df.createTempView('lines')spark.sql('SELECT udf1(line) FROM lines').show(truncate=False)# TODO 2:方式的形式构建UDFudf3 = F.udf(split_line, ArrayType(StringType()))df.select(udf3(df['line'])).show(truncate=False)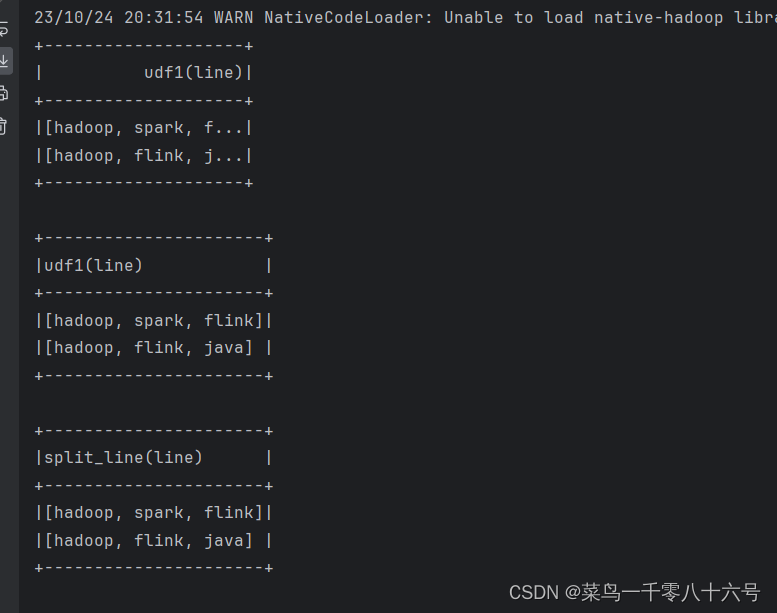
(5)定义返回字典类型的UDF
注意:字典类型返回值,可以用StructType来进行描述,StructType是—个普通的Spark支持的结构化类型.
只是可以用在:
· DF中用于描述Schema
· UDF中用于描述返回值是字典的数据
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()sc = spark.sparkContext# 假设 有三个数字: 1 2 3 在传入数字,返回数字所在序号对应的 字母 然后和数字结合组成dict返回# 例:传入1 返回{'num':1, 'letters': 'a'}rdd = sc.parallelize([[1], [2], [3]])df = rdd.toDF(['num'])# 注册UDFdef process(data):return {'num': data, 'letters': string.ascii_letters[data]}'''UDF返回值是字典的话,需要用StructType来接收'''udf1 = spark.udf.register('udf1', process, StructType().add('num', IntegerType(), nullable=True).\add('letters', StringType(), nullable=True))# SQL风格df.selectExpr('udf1(num)').show(truncate=False)# DSL风格df.select(udf1(df['num'])).show(truncate=False)
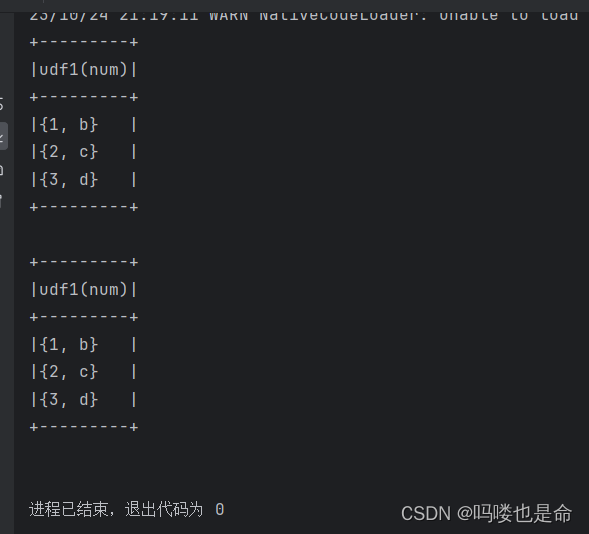
(6)通过RDD构建UDAF函数
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()sc = spark.sparkContextrdd = sc.parallelize([1, 2, 3, 4, 5], 3)df = rdd.map(lambda x: [x]).toDF(['num'])# 方法:使用RDD的mapPartitions 算子来完成聚合操作# 如果用mapPartitions API 完成UDAF聚合,一定要单分区single_partition_rdd = df.rdd.repartition(1)def process(iter):sum = 0for row in iter:sum += row['num']return [sum] # 一定要嵌套list,因为mapPartitions方法要求返回值是list对象print(single_partition_rdd.mapPartitions(process).collect())
二、窗口函数
(1)开窗函数简述
●介绍
开窗函数的引入是为了既显示聚集前的数据又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。 开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
●聚合函数和开窗函数
聚合函数是将多行变成一行,count,avg...
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中,开窗函数可以不使用group by,直接将所有信息显示出来。
●开窗函数分类
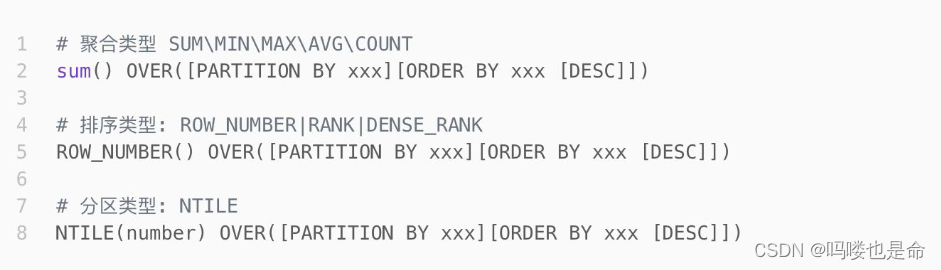
1.聚合开窗函数 聚合函数(列)OVER(选项),这里的选项可以是PARTITION BY子句,但不可以是ORDER BY子句。
2.排序开窗函数 排序函数(列)OVER(选项),这里的选项可以是ORDER BY子句,也可以是OVER(PARTITION BY子句ORDER BY子句),但不可以是PARTITION BY子句。
3.分区类型NTILE的窗口函数
(2)窗口函数的语法
窗口函数的语法:
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
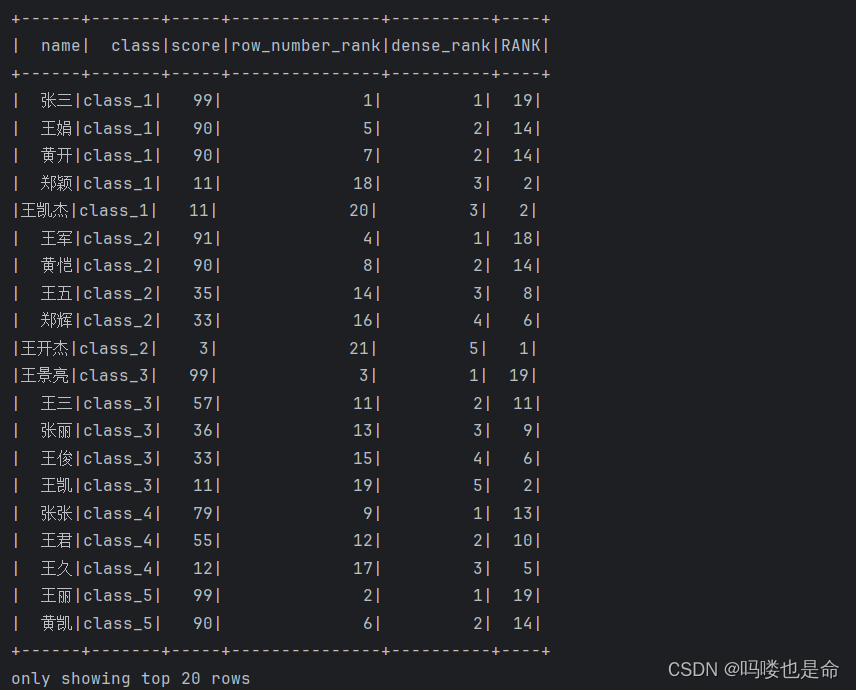
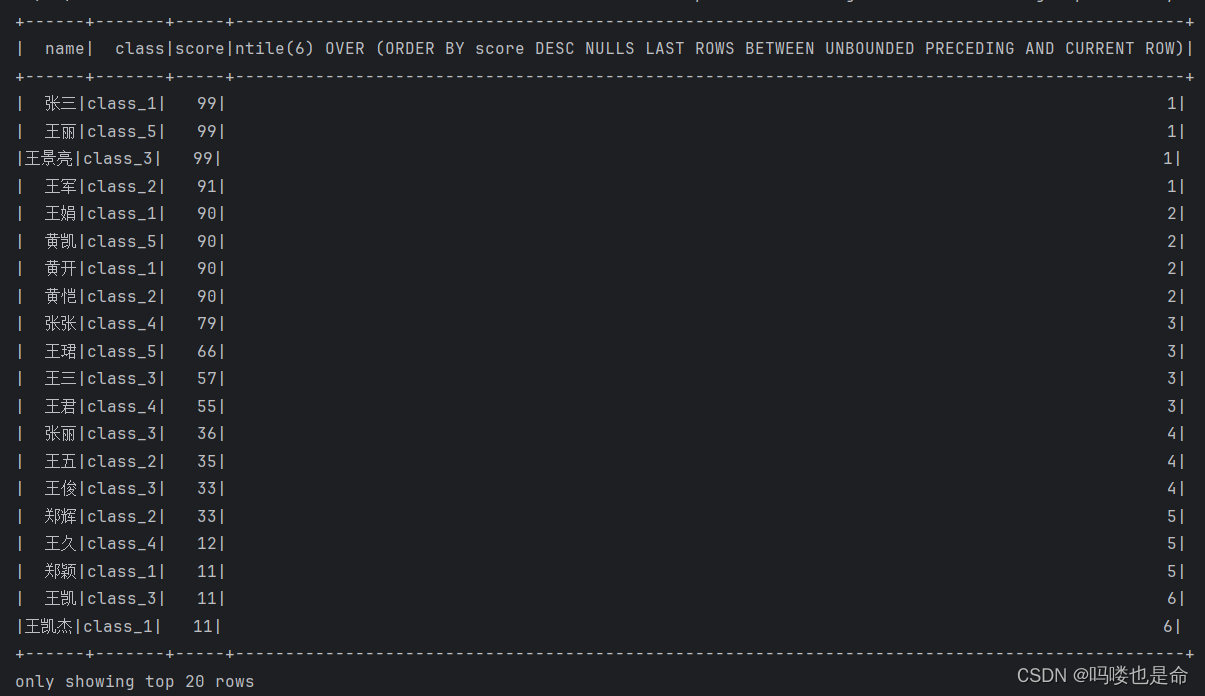
if __name__ == '__main__':spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()sc = spark.sparkContextrdd = sc.parallelize([('张三', 'class_1', 99),('王五', 'class_2', 35),('王三', 'class_3', 57),('王久', 'class_4', 12),('王丽', 'class_5', 99),('王娟', 'class_1', 90),('王军', 'class_2', 91),('王俊', 'class_3', 33),('王君', 'class_4', 55),('王珺', 'class_5', 66),('郑颖', 'class_1', 11),('郑辉', 'class_2', 33),('张丽', 'class_3', 36),('张张', 'class_4', 79),('黄凯', 'class_5', 90),('黄开', 'class_1', 90),('黄恺', 'class_2', 90),('王凯', 'class_3', 11),('王凯杰', 'class_1', 11),('王开杰', 'class_2', 3),('王景亮', 'class_3', 99)])schema = StructType().add('name', StringType()).\add('class', StringType()).\add('score', IntegerType())df = rdd.toDF(schema)# 创建表df.createTempView('stu')# TODO 1:聚合窗口函数的演示spark.sql('''SELECT *, AVG(score) over() AS avg_socre FROM stu''').show()# TODO 2: 排序相关的窗口函数计算# RANK over, DENSE_RANK over, ROW_NUMBER overspark.sql('''SELECT *, ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,RANK() OVER(ORDER BY score) AS RANKFROM stu''').show()# TODO NTILEspark.sql('''SELECT *, NTILE(6) OVER(ORDER BY score DESC) FROM stu''').show()
TODO1结果:

TODO2结果展示:
TODO3结果展示:
相关文章:
Spark_SQL函数定义(定义UDF函数、使用窗口函数)
一、UDF函数定义 (1)函数定义 (2)Spark支持定义函数 (3)定义UDF函数 (4)定义返回Array类型的UDF (5)定义返回字典类型的UDF 二、窗口函数 (1&…...

【Leetcode】【每日一题】【中等】274. H 指数
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/h-index/description/?envTyped…...

MySQL读写分离技术及实现方案
MySQL读写分离技术及实现方案 本文主要介绍了MySQL读写分离技术的原理、实现方案以及示例。通过使用读写分离技术,可以提高数据库的性能,降低服务器的压力。 一、MySQL读写分离技术简介 读写分离是指将数据库的读操作和写操作分别分配到不同的服务器上…...
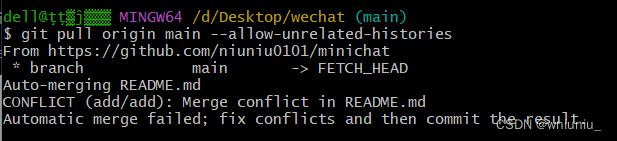
git 推送到github远程仓库细节处理(全网最良心)
我查看了很多网上的教程都不是很好 我们先在github创建一个仓库,且初始化 readme 我们到本地文件初始化仓库 添加远程仓库 这时候我们就 git add . , git commit ,再准备git push 的时候 显示没有指定远程的分支 我们按照提示操作 提示我们要先git pull 提示我…...

算法训练|数据流中的中位数
LCR 160. 数据流中的中位数 - 力扣(LeetCode) 总结:这题自己最开始的想法是直接使用vector容器,每次取中位数的时候就进行一次排序,超时。题解很巧妙的利用大根堆和小根堆来解决问题,大根堆和小根堆各存一…...

LeetCode 2558. 从数量最多的堆取走礼物【模拟,堆或原地堆化】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
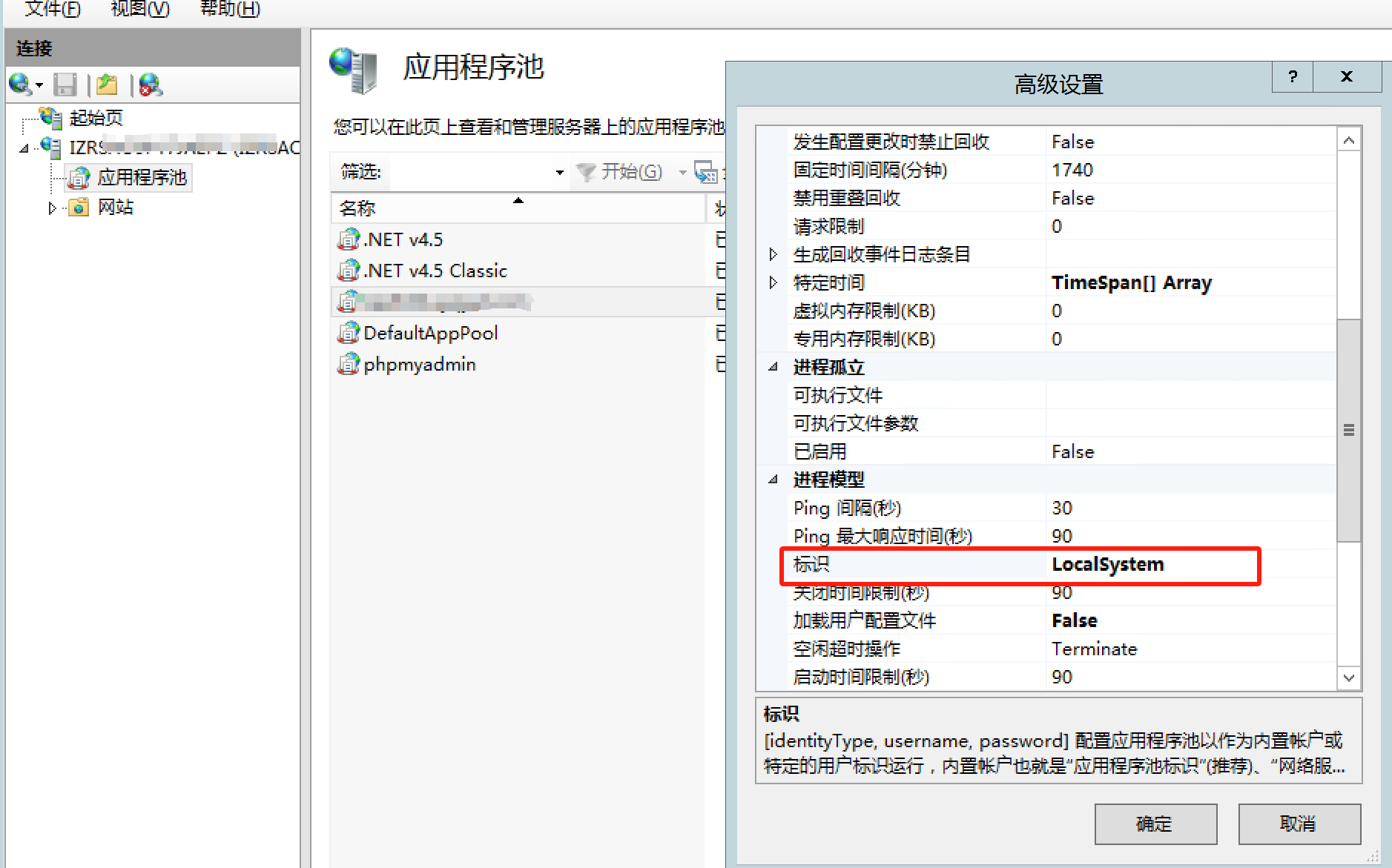
windows服务器环境下使用php调用com组件
Office设置 安装 office2013 且通过正版激活码激活 在组件服务 计算机 我的电脑 DOM 中找到 Microsoft Word 97 - 2003 文档 服务,右键属性 身份验证调整为 无 在 标识中 调整为 交互式用户 php环境设置 开启com组件扩展 在php.ini中设置 extensionphp_com_dotn…...

3DCAT+东风日产:共建线上个性化订车实时云渲染方案
近年来,随着5G网络和云计算技术的不断发展,交互式3D实时云看车正在成为一种新的看车方式。 与传统的到4S店实地考察不同,消费者可以足不出户,通过网络与终端设备即可实现全方位展示、自选汽车配色、模拟效果、快捷选车并进行个性…...

【VR开发】【Unity】【VRTK】1-无代码VRVR开发介绍
本篇开始精简讲解VRTK相关的知识。 VRTK是基于Unity的一套提供无代码VR开发的插件,这套插件开源,可商用,集合了目前可能的VR体验组件,可以让不会C#编程但想要开发VR体验的人在不写一行代码的前提下开发出心仪的VR作品。 这套组件问世后也很受欢迎,目前已经进化到了第四代…...
)
全国地级市最新城投债数据(2006-2023.2)
地级市-城投债数据是关于各地级市发行的城市投资建设项目资金债券的统计数据。这些数据对于研究者来说有着一定的参考价值。首先,地级市-城投债数据能够提供全国各地级市城投债发行的数量和规模情况,帮助研究者了解城市基础设施建设和经济发展的情况。其…...
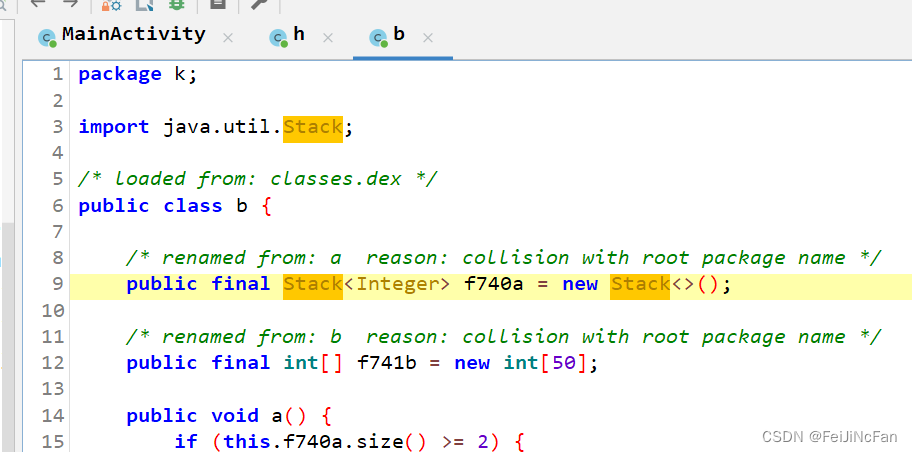
vm_flutter
附件地址 https://buuoj.cn/match/matches/195/challenges#vm_flutter 可以在buu下载到。 flutter我也不会,只是这个题目加密算法全部在java层,其实就是一个异或和相加。 反编译 package k;import java.util.Stack;/* loaded from: classes.dex */ pu…...
MySQL数据库#6
Python操作mysql 在使用Python连接mysql之前我们需要先下载一个第三方的模块 pymysql的模块,导入后再进行操作。 操作步骤:1. 先连接mysql host,port,charset,username password 库,等等。 import pymysql…...

YOLO v1(2016.5)
文章目录 AbstractIntroduction过去方法存在的问题我们提出的方法解决了... Unified DetectionNetwork DesignTrainingInference Comparison to Other Detection SystemsDeformable parts modelsR-CNNOther Fast DetectorsDeep MultiBoxOverFeatMultiGrasp ExperimentsConclusi…...

SQL比较两次的字段集合,找出并返回差异,主要用于更新记录事件
Create PROCEDURE [dbo].[SysGetTableFieldsCompare] -- Description: <比较两次的字段集合,找出并返回差异,主要用于更新记录事件> -- Return 0- 成功, -1- 没有这个表 -- Rev: 1.00 -- FieldsSource Nvarchar(max) , FieldsTarg…...

muduo源码剖析之Acceptor监听类
简介 Acceptor类用于创建套接字,设置套接字选项,调用socket()->bind()->listen()->accept()函数,接受连接,然后调用TcpServer设置的connect事件的回调。 listen()//在TcpServer::start中调用 封装了一个listen fd相关…...
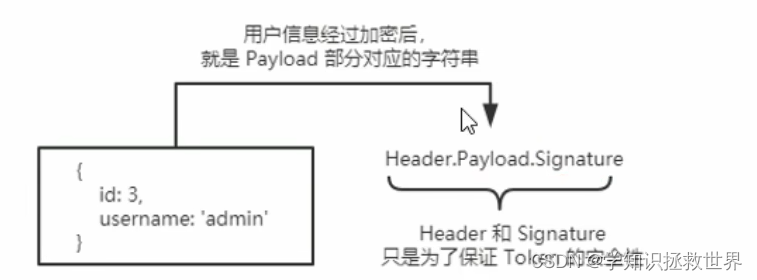
express session JWT JSON Web Token
了解 Session 认证的局限性 Session 认证机制需要配合 cookie 才能实现。由于 Cookie 默认不支持跨域访问,所以,当涉及到前端跨域请求后端接口的时候,需要做很多额外的配置,才能实现跨域 Session 认证。 注意: 当前端…...

负载均衡策略 LVS
一、集群功能分类 1、LB (1) 概念: LB:负载均衡 (Load Balancing) 是一种分发网络流量的技术,LB 负载均衡的基本原理是将传入的网络流量分发到多个后端服务器,以确保这些服务器都承担相似的工作负载,从而避免某一台…...
驱动开发6 IO多路复用——epoll
核心操作:一棵树、一张表、三个接口 相关案例 #include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <stdlib.h> #include <string.h> #include <sys…...

【python学习笔记——列表】
1、列表定义 列表是写在方括号 [] 之间、用逗号分隔开的元素列表。 空列表 list[]非空列表 列表定义时例如list[‘csdn’, ‘is’ ,‘good’ ,2023],直接给列表内赋值 2、列表索引规则 列表名[start:stop:step],前闭后开,即取索引为start…...

TensorRT量化实战课YOLOv7量化:YOLOv7-PTQ量化(一)
目录 前言1. YOLOv7-PTQ量化流程2. 准备工作3. 插入QDQ节点3.1 自动插入QDQ节点3.2 手动插入QDQ节点 前言 手写 AI 推出的全新 TensorRT 模型量化实战课程,链接。记录下个人学习笔记,仅供自己参考。 该实战课程主要基于手写 AI 的 Latte 老师所出的 Tens…...

2026年想做美缝施工?专业靠谱的美缝施工究竟哪家好?
在装修领域,美缝施工虽看似是小工程,却对家居整体美观度和实用性影响重大。然而,美缝行业乱象丛生,让众多业主在选择美缝施工团队时犯了难。2026年若想做美缝施工,怎样才能选到专业靠谱的团队呢?下面为大家…...

2026年企业AI落地新趋势!RAG知识库实战指南:环境搭建到生产部署全解析
本文介绍了RAG(检索增强生成)技术在企业知识库中的应用,通过从环境搭建到生产部署的完整实战指南,阐述如何利用RAG提升大语言模型回答的准确性、可追溯性和时效性。文章涵盖了基础环境配置、技术选型、数据准备、知识库构建、RAG系…...
)
Vue3项目里SignalR怎么用?一个聊天室Demo带你从配置到上线(.NET 6 + Vue 3)
Vue3与SignalR实战:构建高互动聊天室的全栈指南 引言 在当今追求实时交互体验的Web应用中,传统的HTTP请求-响应模式已无法满足即时通讯、实时通知等场景需求。SignalR作为ASP.NET Core生态中的实时通信库,通过自动选择最佳传输协议࿰…...

image.nvim高级功能:虚拟填充、窗口重叠处理完全解析
image.nvim高级功能:虚拟填充、窗口重叠处理完全解析 【免费下载链接】image.nvim 🖼️ Bringing images to Neovim. 项目地址: https://gitcode.com/gh_mirrors/im/image.nvim image.nvim是一款专为Neovim打造的图片显示插件,它突破了…...

yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化
yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化 【免费下载链接】yt-fts YouTube Full Text Search - Search all of YouTube from the command line 项目地址: https://gitcode.com/gh_mirrors/yt/yt-fts yt-fts是一款强大的YouTube全文搜索工具&…...

链游3.0时代:GameFi+NFT+SocialFi如何引爆万亿级“数字乌托邦“?
——区块链游戏开发的全栈解密与商业落地指南引言:当游戏世界开始"造富" 当Axie Infinity的玩家在菲律宾靠打怪月入过万,当Decentraland的虚拟土地拍出243万美元天价,当StepN的运动鞋NFT创造45天回本神话——链游已不再是加密圈的小…...

【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架》. Lea…...
:Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.24):Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

分布式团队的代码协作规范:从分支策略到提交信息格式
在分布式团队模式下,代码协作的地域分散、时区差异和沟通成本,给版本控制和质量保障带来了严峻挑战。作为软件测试从业者,我们不仅是代码质量的“守门员”,更需要深入理解并推动执行规范的代码协作流程,从分支管理到提…...

2021年5月AI工程化三大关键突破:Deformable DETR、REALM与WB Model Registry
1. 项目概述:这不是一份榜单,而是一份2021年5月AI领域真实水位的切片报告“The AI Monthly Top 3 — May 2021”这个标题乍看像一份轻量级资讯简报,但在我连续追踪AI领域动态超过十年、亲手部署过从BERT-base到GPT-3早期API调用、从YOLOv3训练…...