(二开)Flink 修改源码拓展 SQL 语法
1、Flink 扩展 calcite 中的语法解析
1)定义需要的 SqlNode 节点类-以 SqlShowCatalogs 为例
a)类位置
flink/flink-table/flink-sql-parser/src/main/java/org/apache/flink/sql/parser/dql/SqlShowCatalogs.java
核心方法:
@Override
public void unparse(SqlWriter writer, int leftPrec, int rightPrec) {writer.keyword("SHOW CATALOGS");}
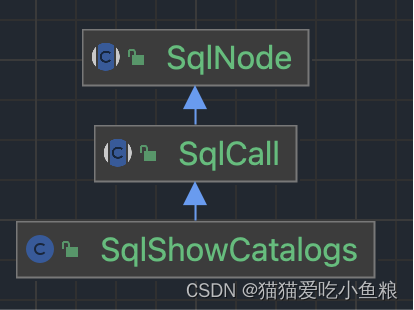
b)类血缘
2)修改 includes 目录下的 .ftl 文件,在 parserImpls.ftl 文件中添加语法逻辑
a)文件位置
b)语法示例
/**
* Parse a "Show Catalogs" metadata query command.
*/
SqlShowCatalogs SqlShowCatalogs() :
{
}
{<SHOW> <CATALOGS>{return new SqlShowCatalogs(getPos());}
}
3)将 Calcite 源码中的 config.fmpp 文件复制到项目的 src/main/codegen 目录下,修改内容,来声明扩展的部分
a)文件位置
b)config.fmpp 内容
data: {# 解析器文件路径parser: tdd(../data/Parser.tdd)
}# 扩展文件的目录
freemarkerLinks: {includes: includes/
}
c)Parser.tdd 部分内容
# 生成的解析器包路径
package: "org.apache.flink.sql.parser.impl",
# 解析器名称
class: "FlinkSqlParserImpl",
# 引入的依赖类
"org.apache.flink.sql.parser.dql.SqlShowCatalogs"
# 新的关键字
keywords: ["CATALOGS"]
# 新增的语法解析方法
statementParserMethods: ["SqlShowCatalogs()"]
# 包含的扩展语法文件
implementationFiles: ["parserImpls.ftl"]
4)编译模板文件和语法文件
5)配置扩展的解析器类
withParserFactory(FlinkSqlParserImpl.FACTORY)
2、自定义扩展 Flink 的 Parser 语法
1)定义 SqlNode 类
package org.apache.flink.sql.parser.dql;import org.apache.calcite.sql.SqlCall;
import org.apache.calcite.sql.SqlKind;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.SqlOperator;
import org.apache.calcite.sql.SqlSpecialOperator;
import org.apache.calcite.sql.SqlWriter;
import org.apache.calcite.sql.parser.SqlParserPos;import java.util.Collections;
import java.util.List;/** XSHOW CATALOGS sql call. */
public class SqlXShowCatalogs extends SqlCall {public static final SqlSpecialOperator OPERATOR =new SqlSpecialOperator("XSHOW CATALOGS", SqlKind.OTHER);public SqlXShowCatalogs(SqlParserPos pos) {super(pos);}@Overridepublic SqlOperator getOperator() {return OPERATOR;}@Overridepublic List<SqlNode> getOperandList() {return Collections.emptyList();}@Overridepublic void unparse(SqlWriter writer, int leftPrec, int rightPrec) {writer.keyword("XSHOW CATALOGS");}
}2)修改 includes 目录下的 parserImpls.ftl 文件
/**
* Parse a "XShow Catalogs" metadata query command.
*/
SqlXShowCatalogs SqlXShowCatalogs() :
{
}
{<XSHOW> <CATALOGS>{return new SqlXShowCatalogs(getPos());}
}
3)修改 Parser.tdd 文件,新增-声明拓展的部分
imports:"org.apache.flink.sql.parser.dql.SqlXShowCatalogs"keywords:"XSHOW"statementParserMethods:"SqlXShowCatalogs()"
4)重新编译
mvn generate-resources
5)执行测试用例
可以看到,自定义 SQL 的报错,由解析失败,变为了校验失败。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;public class CustomFlinkSql {public static void main(String[] args) throws Exception {TableEnvironment tEnv = TableEnvironment.create(EnvironmentSettings.newInstance().useBlinkPlanner().build());// 拓展自定义语法 xshow catalogs 前// SQL parse failed. Non-query expression encountered in illegal contexttEnv.executeSql("xshow catalogs").print();// 拓展自定义语法 xshow catalogs 后// SQL validation failed. org.apache.flink.sql.parser.dql.SqlXShowCatalogs cannot be cast to org.apache.calcite.sql.SqlBasicCall}
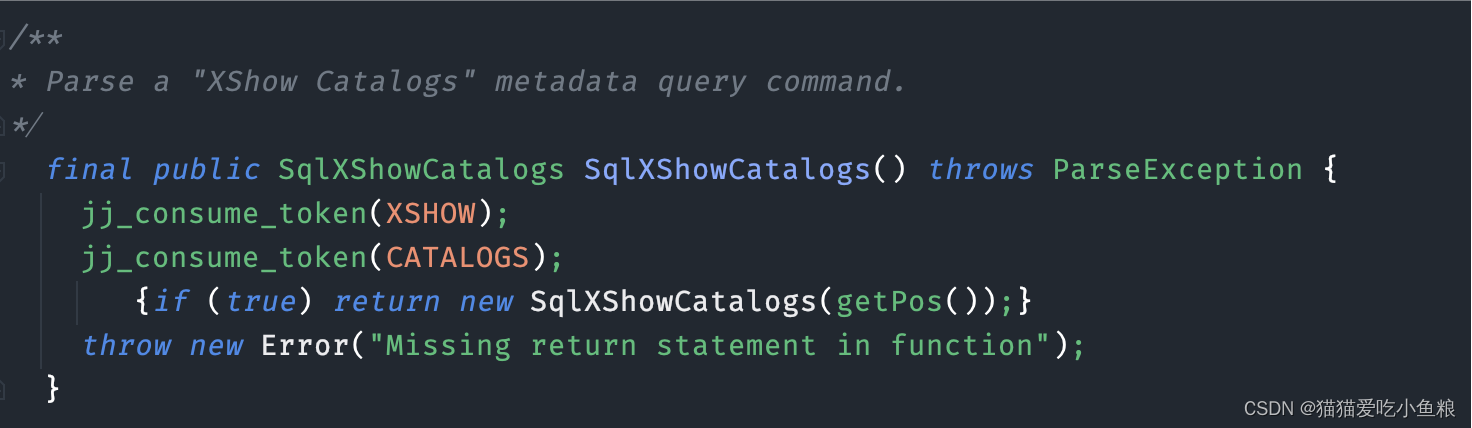
}6)查看生成的扩展解析器类
可以看到,在 FlinkSqlParserImpl 中,自定义的解析语法已经生成了。
3、validate 概述
在向 Flink 中添加完自定义的解析规则后,报错信息如下:
SQL validation failed. org.apache.flink.sql.parser.dql.SqlXShowCatalogs cannot be cast to org.apache.calcite.sql.SqlBasicCall
修改 validate 部分的代码
1)FlinkPlannerImpl#validate
作用:校验 SqlNode ,如果是 show catalogs 语法时直接返回。
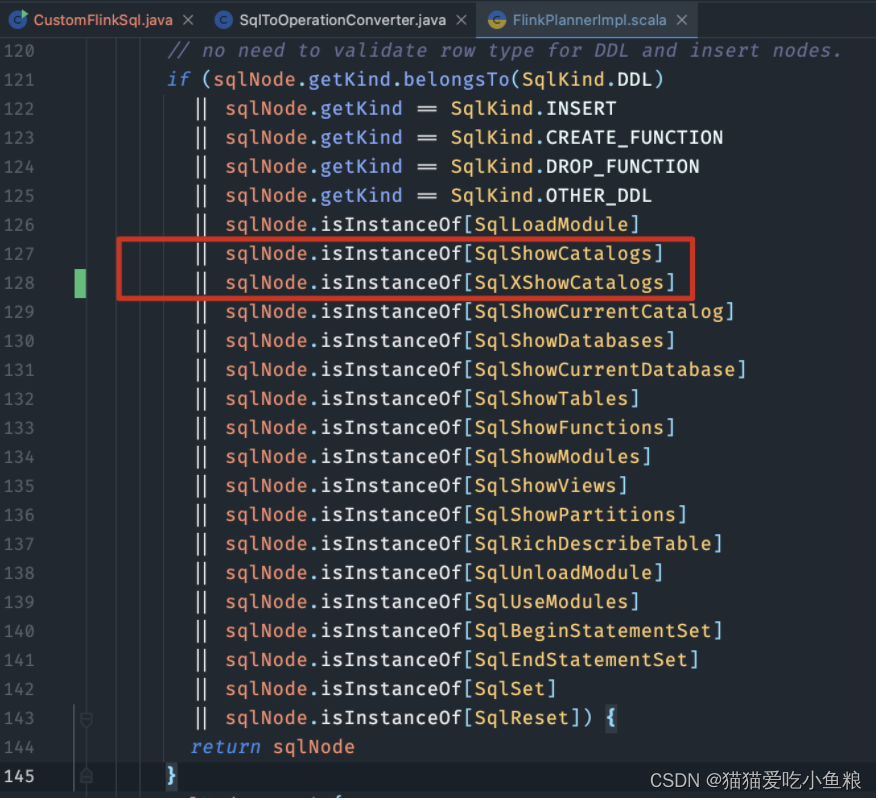
sqlNode.isInstanceOf[SqlXShowCatalogs]
2)SqlToOperationConverter#convert
作用:将校验过的 SqlNode 转换为 Operator。
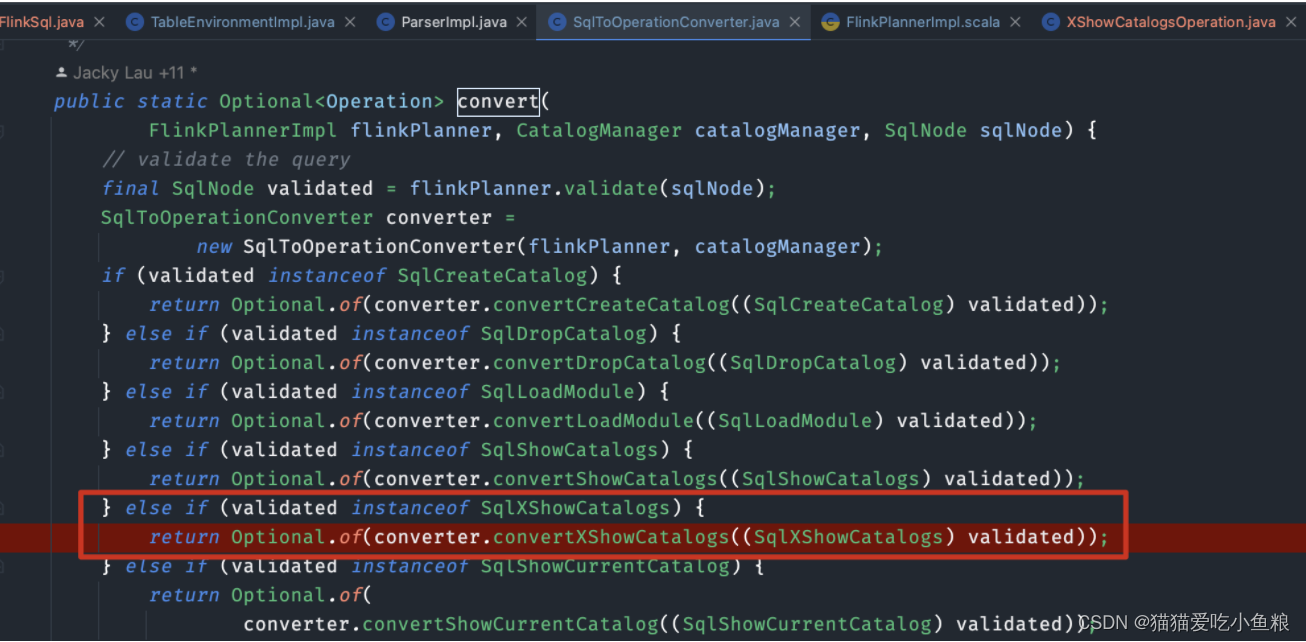
else if (validated instanceof SqlXShowCatalogs) {return Optional.of(converter.convertXShowCatalogs((SqlXShowCatalogs) validated));
}
3)SqlToOperationConverter#convertXShowCatalogs
/** Convert SHOW CATALOGS statement. */
private Operation convertXShowCatalogs(SqlXShowCatalogs sqlXShowCatalogs) {return new XShowCatalogsOperation();
}
4)XShowCatalogsOperation
package org.apache.flink.table.operations;public class XShowCatalogsOperation implements ShowOperation {@Overridepublic String asSummaryString() {return "SHOW CATALOGS";}
}
4、执行测试用例
package org.apache.flink.table.examples.java.custom;import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;public class CustomFlinkSql {public static void main(String[] args) throws Exception {TableEnvironment tEnv = TableEnvironment.create(EnvironmentSettings.newInstance().useBlinkPlanner().build());// FlinkSQL原本支持的语法tEnv.executeSql("show catalogs").print();// 自定义语法tEnv.executeSql("xshow catalogs").print();}
}
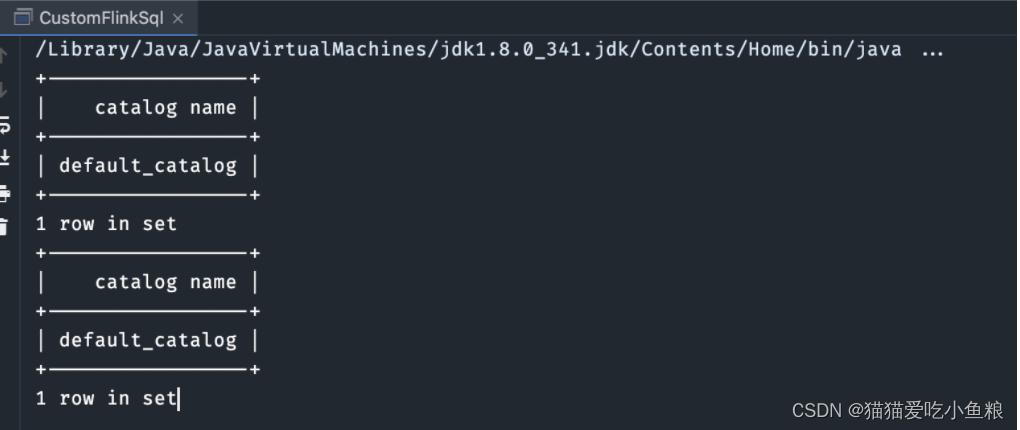
5、总结-FlinkSQL 的执行流程
1、对 SQL 进行校验final SqlNode validated = flinkPlanner.validate(sqlNode);2、预校验重写 Insert 语句3、调用 SqlNode.validate() 进行校验1)如果是:ExtendedSqlNode【SqlCreateHiveTable、SqlCreateTable、SqlTableLike】2)如果是:SqlKind.DDL、SqlKind.INSERT 等,无需校验,直接返回 SqlNode3)如果是:SqlRichExplain4)其它:validator.validate(sqlNode)1.校验作用域和表达式:validateScopedExpression(topNode, scope)a)将 SqlNode 进行规范化重写b)如果SQL是【TOP_LEVEL = concat(QUERY, DML, DDL)】,则在父作用域中注册查询c)校验 validateQuery i)validateFeatureii)validateNamespaceiii)validateModalityiv)validateAccessv)validateSnapshotd)如果SQL不是【TOP_LEVEL = concat(QUERY, DML, DDL)】进行类型推导2.获取校验之后的节点类型2、将 SQLNode 转换为 Operationconverter.convertSqlQuery(validated)1)生成逻辑执行计划 RelNodeRelRoot relational = planner.rel(validated);1.对查询进行转换sqlToRelConverter.convertQuery(validatedSqlNode)2)创建 PlannerQueryOperationnew PlannerQueryOperation(relational.project());3、将 Operation 转换为 List<Transformation<?>>
List<Transformation<?>> transformations = planner.translate(Collections.singletonList(modifyOperation));1)对 RelNode 逻辑执行计划进行优化,获取 optimizedRelNodesval optimizedRelNodes = optimize(relNodes)2)将 optimizedRelNodes 转换为 execGraphval execGraph = translateToExecNodeGraph(optimizedRelNodes)3)将 execGraph 转换为 transformations1.使用代码生成技术生成Function,后续可以反射调用val convertFunc = CodeGenUtils.genToInternalConverter(ctx, inputType)
相关文章:
(二开)Flink 修改源码拓展 SQL 语法
1、Flink 扩展 calcite 中的语法解析 1)定义需要的 SqlNode 节点类-以 SqlShowCatalogs 为例 a)类位置 flink/flink-table/flink-sql-parser/src/main/java/org/apache/flink/sql/parser/dql/SqlShowCatalogs.java 核心方法: Override pu…...

java中spi与api的区别
近期看了很多开源组件的源码,发现很多地方地方用到了 spi 的功能,开始思考 spi 与 api 的区别 发现 spi 侧重于抽象层次的概念,目前接触到的就是 java 里大量用到了这个,通过定义的接口来抽象通用的功能,然而 api 是不…...
)
【Android知识笔记】插件化专题(二)
在上一篇专题【Android知识笔记】插件化专题(一) 中详细介绍了Android三种插件化方案的实现以及它们的优缺点对比总结等。这一篇中主要来看一下一些插件化开源框架的实现原理,当然市场上的插件化框架有很多,层出不穷,如 DiDi VirtualApk、360 Replugin 等。本人在过去的工…...

赶紧收藏!史上最全IDEA快捷键大全
参考 IntelliJ IDEA 的官网,列举出了IntelliJ IDEA(Windows 版)的所有快捷键。 建议收藏,有需要的时候根据关键字来查找! idea专业版获取 kdocs.cn/l/ctYoaM6evJkl 该快捷键共分 16 类,可以方便的按各类…...
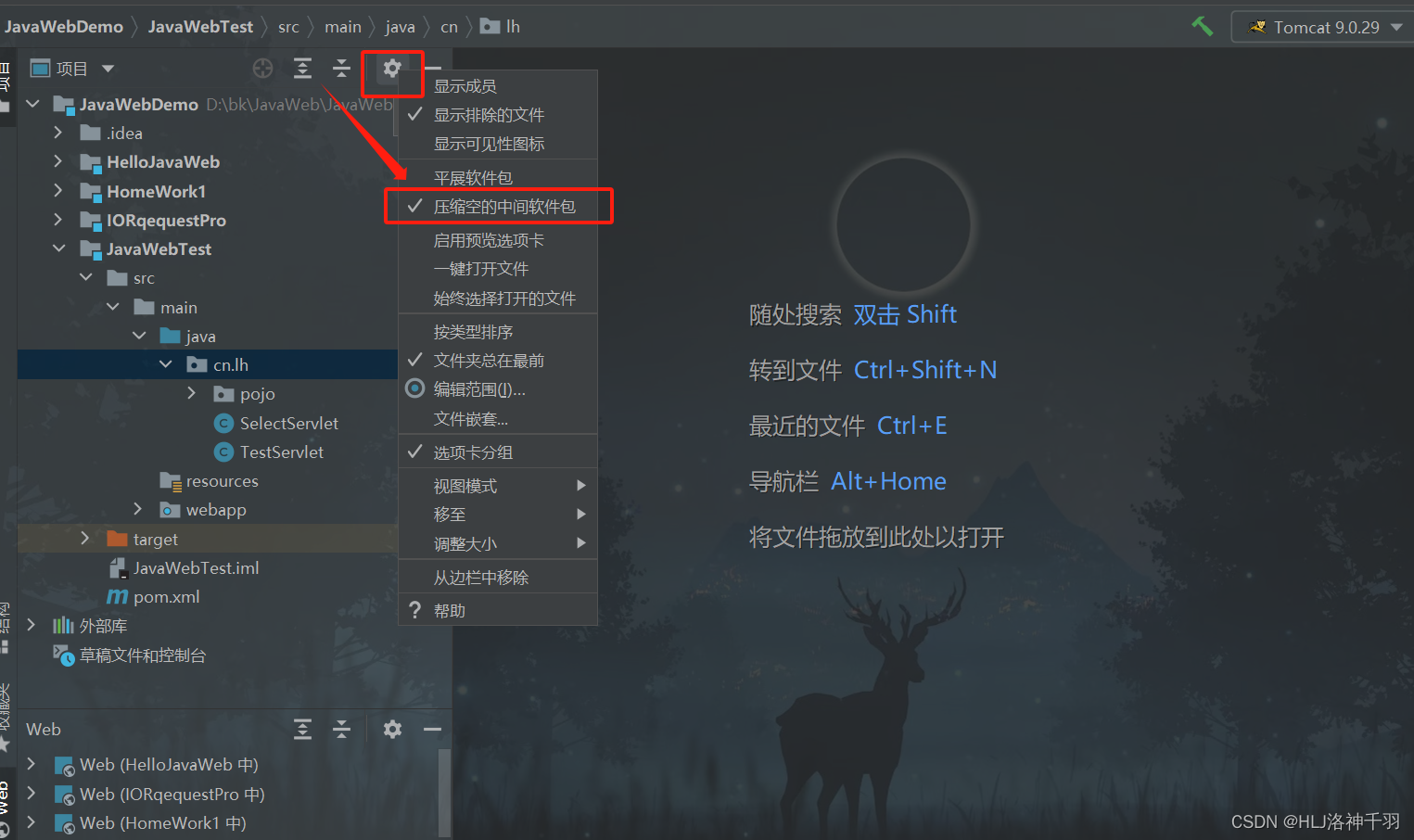
IntelliJ IDEA 把package包展开和压缩
想要展开就把对勾取消,想要压缩就勾上...

Python——自动创建文件夹
文章目录 前言一、判断文件夹或者文件是否存在二、创建一级文件夹三、创建多级文件夹四、代码封装前言 利用 Python编程语言实现自动创建文件夹,程序以函数形式封装,直接按要求传参即可调用。 在python中没有直接针对文件夹的操作方法,可以借助模块os,os.path和shutil来操作…...
Leetcode—21.合并两个有序链表【简单】
2023每日刷题(十三) Leetcode—21.合并两个有序链表 直接法实现代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* mergeTwoLists(struct ListNode* list1, struct…...
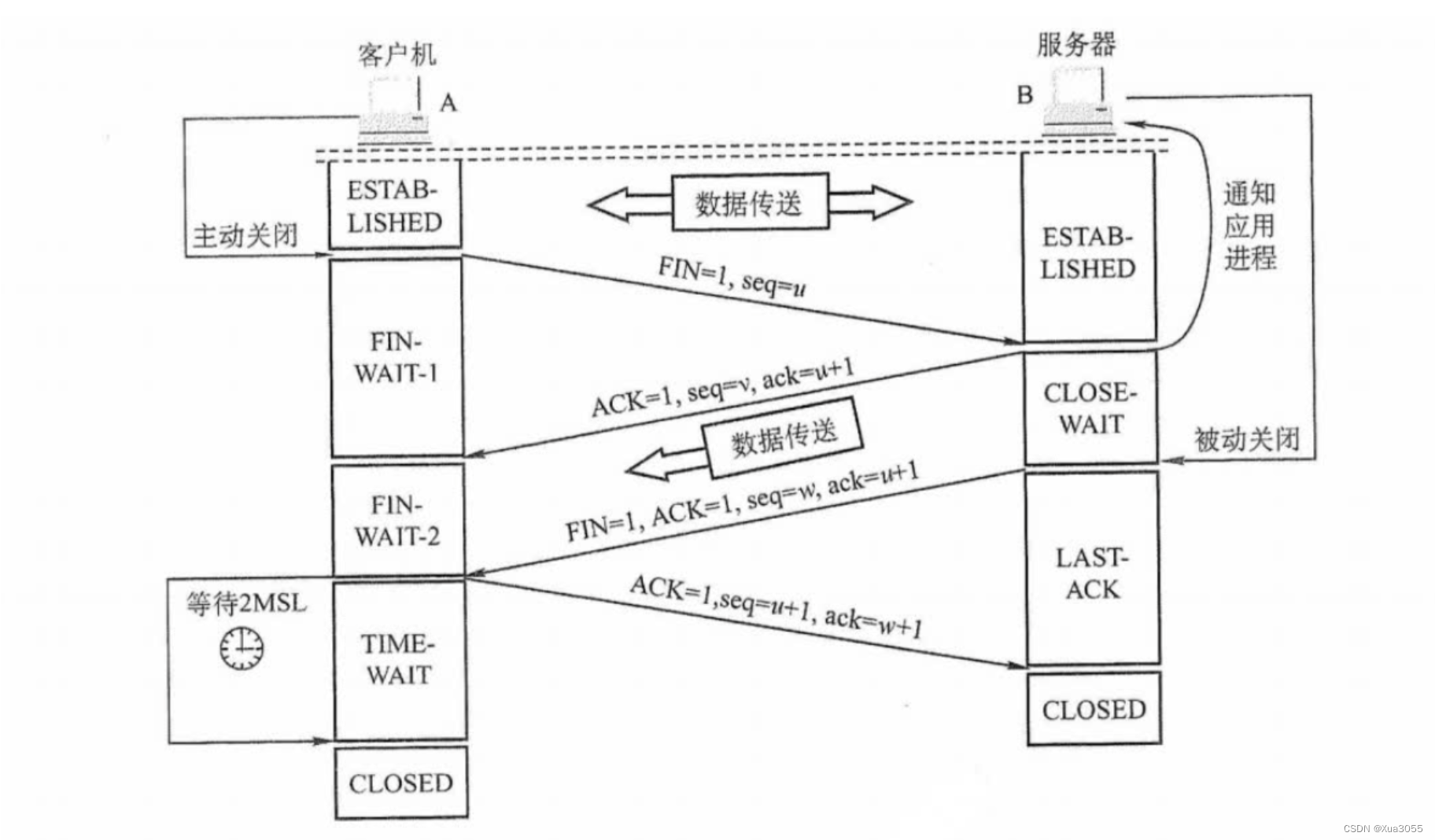
数据链路层和DNS之间的那些事~
数据链路层,考虑的是两个节点之间的传输。这里面的典型协议也很多,最知名的就是“以太网”。我们本篇主要介绍的就是以太网协议。这个协议规定了数据链路层,也规定了物理层的内容。 目录 以太网帧格式 帧头 载荷 帧尾 DNS 从输入URL到…...
Spring-声明式事务
声明式事务 一、简介1、准备工作2、测试 二、声明式事务概念1、编程式事务2、声明式事务3、基于注解的声明式事务1.测试无事务情况2.加入事务①Transactional注解标识的位置②事务属性:只读③事务属性:超时④事务属性:回滚策略⑤事务属性&…...

腾讯云轻量服务器地域选择教程,一篇文章就够了
腾讯云轻量应用服务器地域是指轻量服务器数据中心所在的地理位置,如上海、广州和北京等地域,如何选择地域?腾讯云百科txybk.com建议地域选择遵循就近原则,用户距离轻量服务器地域越近,网络延迟越低,速度就越…...

【斗罗二】王东升级三环,戴华斌挑衅,雨浩单手接鼎订下赌约
【侵权联系删除】【文/郑尔巴金】 深度爆料,《绝世唐门》第20集,一场瞩目的战斗即将爆发。王冬,这位一年级的强攻系班长,将与戴华斌进行一场激烈的较量。王冬拥有三大武魂,其中最为人们所熟知的是那光明女神蝶&#x…...

洛谷 B2135:单词替换
【题目来源】https://www.luogu.com.cn/problem/B2135【题目描述】 输入一个字符串,以回车结束(字符串长度 ≤200)。该字符串由若干个单词组成,单词之间用一个空格隔开,所有单词区分大小写。现需要将其中的某个单词替换…...
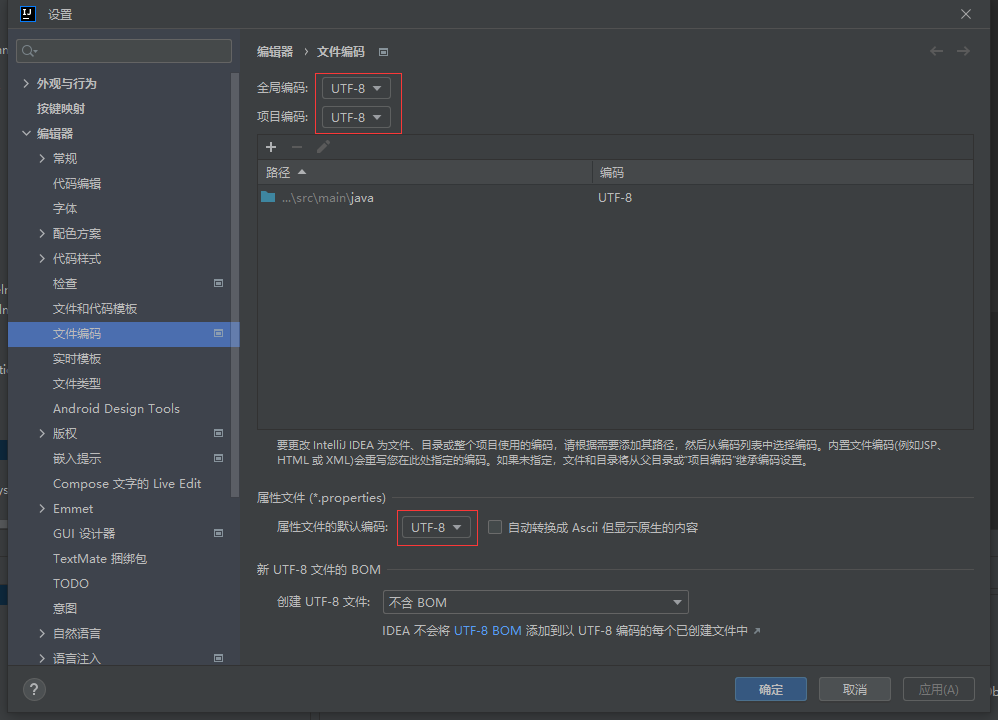
IDEA中application.properties文件中文乱码
现象: 原因: 项目编码格式与IDEA编码格式不一致导致的 解决办法: 在File->Settings->Editor->File Encodings选项中,将Global Encoding,Project Encoding,Default encoding for properties files这三个选项置为一致&a…...

Rust 模块系统
文章目录 模块系统crate包cargo 创建库库的使用 模块系统 Rust的{模块系统|the module system},包括: * 包(Packages): Cargo 的一个功能,它允许你构建、测试和分享 crate。 * Crates :一个模…...
)
面向服务架构-架构师(六十四)
SOA概述和发展、参考架构、协议和规范、标准和原则、设计模式、构件和实施。 SOA概述和发展 服务指系统对外提供的功能,SOA是一种应用框架。 微服务去掉了ESB企业服务总线,SOA集中式,SOA和微服务的区别: 微服务更加精细。服务…...

Linux之系统编程
1.yum 1.yum list可以出现所有可下载的程序 辅助grep进行查找 2.yum install可以下载并安装 3.yum remove可以卸载程序 不同的商业操作系统内核都是一样的,主要是配套社区不一样。 开源组织,各大公司,既得利益者。 同上 基础软件源可以保证…...

信道数据传输速率、信号传播速度——参考《天勤计算机网络》
一、缘起题目 二、解析 三、总结 信道数据传输速率和信号传播速度是两个不同的概念。 3.1 信道数据传输速率(Channel Data Transfer Rate) 指的是在通信系统中,通过信道传输的数据量,通常以 比特率(bits per second…...
微信小程序vue+uniapp旅游景点门票预订系统 名胜风景推荐系统
与此同时越来越多的旅游公司建立了自己的基于微信小程序的名胜风景推荐平台,管理员通过网站可以添加用户、景点分类、景点信息、在线预订、最新推荐,用户可以对景点信息进行在线预订,以及开展电子商务等。互联网的世界里蕴藏无限生机…...
)
每日一题之二分查找(一)
每日一题之二分查找(一) 1.题目(搜索插入位置) 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间…...

Redisson的看门狗策略——保障Redis数据安全与稳定的机制
前言 自定义redis分布式锁无法自动续期,比如,一个锁设置了1分钟超时释放,如果拿到这个锁的线程在一分钟内没有执行完毕,那么这个锁就会被其他线程拿到,可能会导致严重的线上问题,在秒杀场景下,…...

硬件工程选型解析:钡特电源VB60-24S12LD与金升阳URB2412LD-60WR3同属工业高可靠
在工业硬件研发、设备调试与批量量产工作中,大功率工业DC-DC模块的工况适配性、结构规范性与运行稳定性,是硬件研发工程师重点核查的核心指标,直接决定工控设备、电力终端、智能装备的长期运行可靠性。在60W级国产直流电源模块品类中…...

Promptfoo的搭建与测试,2026-0521成功版很简单
可能写的有点粗糙,但是我搞通了,有不懂的可以问我,懒得再更新了 其实我也是520当天搭建好的,现在的教程也不多,我就搜了搜,没什么具体的步骤,我想用windows感觉更方便一点但是一直不行各种版本…...

Godot开发RTS游戏的实战优化指南
1. 为什么说“用Godot做RTS”不是噱头,而是被低估的务实选择很多人第一次听说“用Godot开发即时战略游戏”,第一反应是皱眉——毕竟Unity和Unreal在大型3D项目上的生态优势太显眼,而传统RTS又以单位数量多、逻辑密集、网络同步严苛著称。我20…...

Open MCT性能压测实战:JMeter定制化四阶测试方法论
1. 为什么Open MCT的性能不能只靠“感觉”来判断?Open MCT——NASA开源的航天器监控与控制平台,这几年在工业SCADA、能源调度、实验室数据可视化等场景里越来越常见。但凡用过它的团队,几乎都经历过这样一个阶段:开发阶段一切丝滑…...

TV Bro:终极智能电视浏览器解决方案 - 让大屏上网变得简单快速
TV Bro:终极智能电视浏览器解决方案 - 让大屏上网变得简单快速 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾经对着智能电视的浏览器感到沮丧&…...

EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案
EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,您的电脑硬件信息正在被悄无声息地追踪。无论是…...

终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量
终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量 【免费下载链接】deepeval The LLM Evaluation Framework 项目地址: https://gitcode.com/GitHub_Trending/de/deepeval 你是否曾担心AI助手给出错误的医疗建议?是否焦虑金融AI客服…...

告别手动下载:用CNKI-download轻松实现知网文献批量获取
告别手动下载:用CNKI-download轻松实现知网文献批量获取 【免费下载链接】CNKI-download :frog: 知网(CNKI)文献下载及文献速览爬虫 (Web Scraper for Extracting Data) 项目地址: https://gitcode.com/gh_mirrors/cn/CNKI-download 还在为毕业论文的文献收…...

告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单
告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 还在为PPT演示超时而烦恼吗?每次演讲都像和时间赛跑,担心讲得太快或太…...

第十章:什么是Agentic AI?——让AI从“回答问题“到“替你办事“
难度级别:★★★★☆ | 预计阅读时间:15分钟 你将学到:Agentic AI的核心能力、技术架构、主流框架对比、PM选型决策框架、以及如何设计一个AI Agent系统 引言:从"工具"到"代理"的跨越 一个真实的痛点 某科技公司的研究员小王,每天需要花3小时完成以…...