Python爬虫-经典案例详解
爬虫一般指从网络资源的抓取,通过Python语言的脚本特性,配置字符的处理非常灵活,Python有丰富的网络抓取模块,因而两者经常联系在一起Python就被叫作爬虫。爬虫可以抓取某个网站或者某个应用的内容提取有用的价值信息。有时还可以模拟用户在浏
览器或app应用上的操作行为,从而实现程序自动化。
1、爬虫架构
爬虫架构通常由5个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序。
- 调度器:相当电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL。实现URL管理器通常有三种方式,通过内存、数据库、缓存方式实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)。
- 网页解析器:用于某个网页字符串进行解析,可以按照我们的要求来提取出有用的信息,也可以根据DOM树的解析方式来解析。常用的解析器有html.parser(python自带的)、beautifulsoup(也可以使用python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(可以解析 xml 和 HTML),通过html.parser 和 beautifulsoup 以及 lxml 都是以DOM 树的方式进行解析。
- 应用程序:用于从网页中提取的有用数据组成的一个应用。
2、爬虫实现
2.1、Url管理器(基于内存)
class UrlManager():"""url 管理器,用来装载网址所有地址"""def __init__(self):# 新url 集合self.new_urls = set()# 旧url 集合self.old_urls = set()def add_new_url(self, url):"""添加新的url到集合:param url: url:return:"""if url is None or len(url) == 0:returnif url in self.new_urls or url in self.old_urls:returnself.new_urls.add(url)def add_new_urls(self, urls):"""批量添加urls:param urls: url:return:"""if urls is None or len(urls) == 0:returnfor url in urls:self.add_new_url(url)def get_url(self):"""获取url: 从new_urls集合获取url,放入到old_urls:return:"""if self.has_new_url():url = self.new_urls.pop()self.old_urls.add(url)return urlelse:return Nonedef has_new_url(self):"""判断是否有新的url:return:"""return len(self.new_urls) > 0if __name__ == '__main__':url_manager = UrlManager()url_manager.add_new_url('url1')url_manager.add_new_urls(['url1','url2'])print(url_manager.new_urls, url_manager.old_urls)print("#" * 30)new_url = url_manager.get_url()print(url_manager.new_urls, url_manager.old_urls)print("#" * 30)new_url = url_manager.get_url()print(url_manager.new_urls, url_manager.old_urls)print("#" * 30)print(url_manager.has_new_url())
2.2 网页解析
import re
from utils import url_manager
import requests
from bs4 import BeautifulSoupdef download_all_urls(root_url):"""爬取根网址所有页面的url:param root_url: 根网址地址:return:"""urls = url_manager.UrlManager()urls.add_new_url(root_url)fout = open("craw_all_pages.txt", "w", encoding="utf-8")while urls.has_new_url():curr_url = urls.get_url()r = requests.get(curr_url, timeout=5)r.encoding = "utf-8"if r.status_code != 200:print("error, return status_code is not 200", curr_url)continuesoup = BeautifulSoup(r.text, "html.parser", from_encoding="utf-8")title = soup.title.stringfout.write("%s\t%s\n" % (curr_url, title))fout.flush()print("success: %s, %s, %d" % (curr_url, title, len(urls.old_urls)))links = soup.find_all("a")for link in links:href = link.get("href")if href is None:continue#模式匹配pattern = r'^https://www.runoob.com/python/\s+.html$'if re.match(pattern, href):urls.add_new_url(href)fout.close()if __name__ == '__main__':#定义根网址urlroot_url = "https://www.runoob.com/python/python-tutorial.html"download_all_urls(root_url)3、经典案例
例如:读取某网站Top250电影。
import pprint
import json
import requests
from bs4 import BeautifulSoup
import pandas as pd"""
# requests 请求网站地址
# beautifulsoup4 解析网址的elements(div,class,<a>,<img> id)等
# pandas 将数据写入到excel
# 其他额外安装包openpyxl
"""# 构造分页数字列表(步长/pageSize/step=25)
page_indexs = range(0, 250, 25)
list(page_indexs)def download_all_htmls(root_url, headers):"""下载所有页面的html内容,用于后续分析:return:"""htmls = []for idx in page_indexs:url = "%s?start=%d&filter=" % (root_url, idx)# url = f"https://movie.douban.com/top250?start={idx}&filter="print("craw html:", url)r = requests.get(url, timeout=5, headers=headers)if r.status_code != 200:raise Exception("error")htmls.append(r.text)return htmlsdef parse_single_html(html_doc):soup = BeautifulSoup(html_doc, "html.parser")article_items = (soup.find("div", class_="article").find("ol", class_="grid_view").find_all("div", class_="item"))datas = []for item in article_items:rank = item.find("div", class_="pic").find("em").get_text()info = item.find("div", class_="info")title = info.find("div", class_="hd").find("span", class_="title").get_text()stars = (info.find("div", class_="bd").find("div", class_="star").find_all("span"))rating_star = stars[0]["class"][0]rating_num = stars[1].get_text()comments = stars[3].get_text()datas.append({"rank": rank,"title": title,"rating_star": rating_star.replace("rating", "").replace("-t", ""),"rating_num": rating_num,"comments": comments.replace("人评价", "")})return datasdef save_to_excel(all_datas):"""保存解析后数据到excel:param all_datas: 传人数据:return:"""# print tabledf = pd.DataFrame(all_datas)print(df)df.to_excel("豆瓣电影TOP250.xlsx")if __name__ == '__main__':# 模拟用户行为headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}# 定义根网址urlroot_url = "https://movie.douban.com/top250"htmls = download_all_htmls(root_url, headers)# beatiful print textpprint.pprint(parse_single_html(htmls[0]))# extend迭代添加到list,保存到excelall_datas = []for html in htmls:all_datas.extend(parse_single_html(html))print(len(all_datas))save_to_excel(all_datas)
相关文章:

Python爬虫-经典案例详解
爬虫一般指从网络资源的抓取,通过Python语言的脚本特性,配置字符的处理非常灵活,Python有丰富的网络抓取模块,因而两者经常联系在一起Python就被叫作爬虫。爬虫可以抓取某个网站或者某个应用的内容提取有用的价值信息。有时还可以…...

【信创】银河麒麟V10 安装postgis
安装postGis步骤 1、安装 proj4 #tar -zxvf proj-4.8.0.tar.gz #cd proj-4.8.0 #mkdir -p /opt/proj-4.8.0 #./configure --prefix=/opt/proj-4.8.0 #make && make install #vi /etc/ld.so.conf.d/proj-4.8.0.conf #ldconfig 2、安装 geos #tar -xjf geos-3.6.1.tar.b…...

OpenCV常用功能——灰度处理和图像二值化处理
文章目录 一、灰度处理1.1 cvtColor函数 二、图像二值化处理2.1 全局阈值2.2 自适应阈值 一、灰度处理 1.1 cvtColor函数 函数原型: cv2.cvtColor(src, code[, dst[, dstCn]]) -> dst功能:转换图像颜色空间。 参数: src: 输入图像。co…...
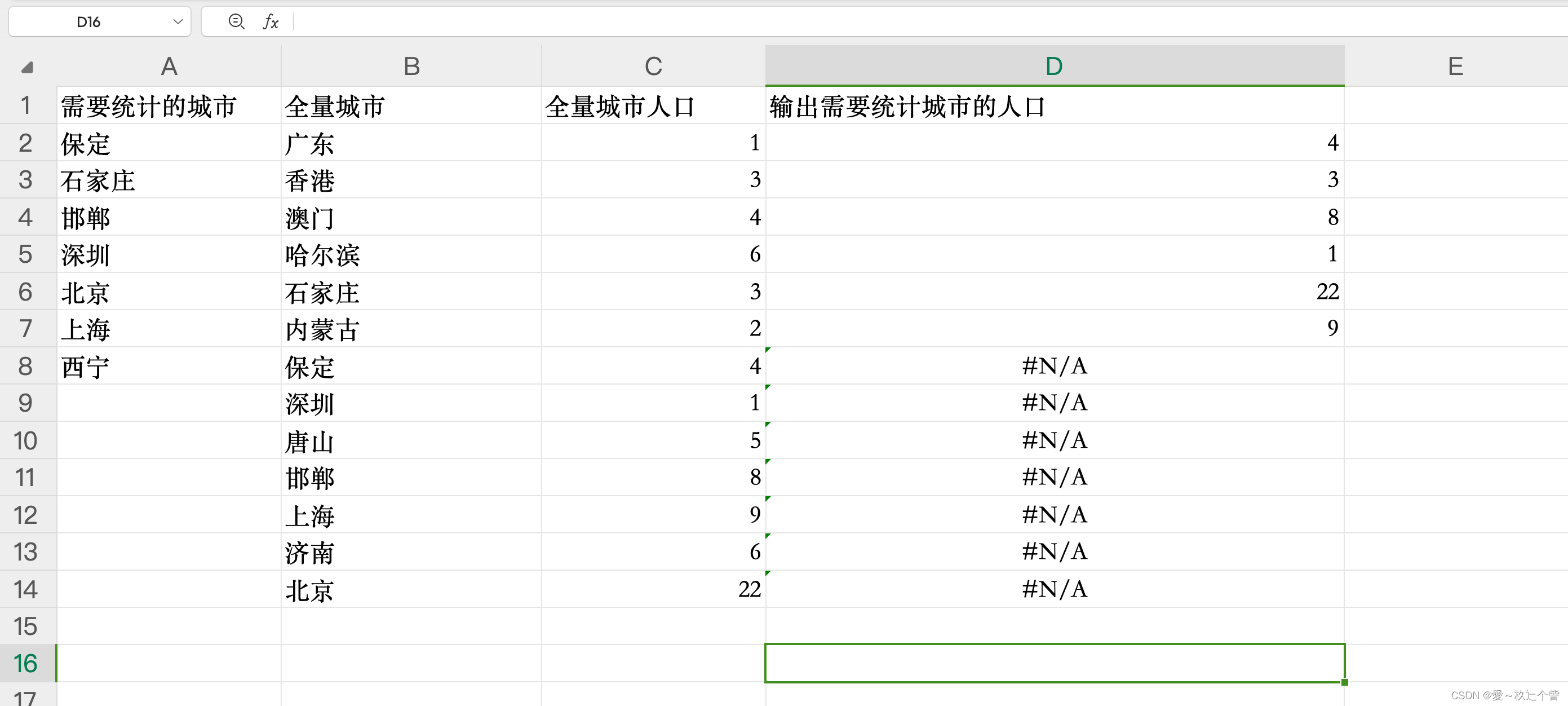
excel巧用拼接函数CONCAT输出JSON、SQL字符串
一、前言 工作中有时候需要用Excel对数据进行组装,需要输出JSON或者SQL语句,然后通过脚本或Java程序完成一些特定功能,总结了一下用到的函数,方便以后使用。这里使用的是WPS软件。 二、输出JSON 例如:需要将几列数据…...
Redis桌面管理工具:Redis Desktop Manager for Mac
Redis Desktop Manager是一款非常实用的Redis管理工具,它不仅提供了方便易用的图形用户界面,还支持多种Redis数据结构,可以帮助用户轻松地完成Redis数据库的管理工作。 以下是一些推荐Redis Desktop Manager的理由: 多平台支持&a…...

基于SSM的汽车维修管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SSM的汽车维修管理系统,java项目。 …...

volatile 系列之如何解决可见性问题
下面我们来看一下volatile是如何解决可见性问题的呢?如果我们针对stop字段增加volatile关键字: public static volatile boolean stopfalse; 然后,使用hsdis工具获取IT编译器生成的汇编指令来查看volatile写操作带来的影响和变化。 接着,设置J…...

网络安全(黑客技术)—小白自学
目录 一、自学网络安全学习的误区和陷阱 二、学习网络安全的一些前期准备 三、网络安全学习路线 四、学习资料的推荐 想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客! 网络安全可以基于攻击和防御视角来分类&am…...

MTK AEE_EXP调试方法及user版本打开方案
一、AEE介绍 AEE (Android Exception Engine)是安卓的一个异常捕获和调试信息生成机制。 手机发生错误(异常重启/卡死)时生成db文件(一种被加密过的二进制文件)用来保存和记录异常发生时候的全部内存信息,经过调试和仿真这些信息,能够追踪到异常的缘由。 二、调试方法…...
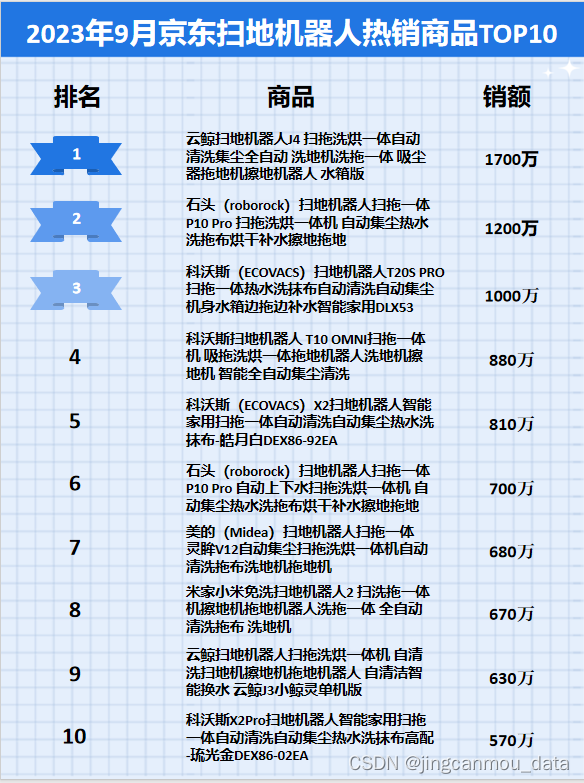
京东平台数据分析:2023年9月京东扫地机器人行业品牌销售排行榜
鲸参谋监测的京东平台9月份扫地机器人市场销售数据已出炉! 根据鲸参谋平台的数据显示,9月份,京东平台扫地机器人的销量近14万,环比增长约2%,同比降低约4%;销售额为2.9亿,环比降低约4%࿰…...

pytorch 笔记:index_select
1 基本使用方法 index_select 是 PyTorch 中的一个非常有用的函数,允许从给定的维度中选择指定索引的张量值 torch.index_select(input, dim, index, outNone) -> Tensorinput从中选择数据的源张量dim从中选择数据的维度index 一个 1D 张量,包含你想…...
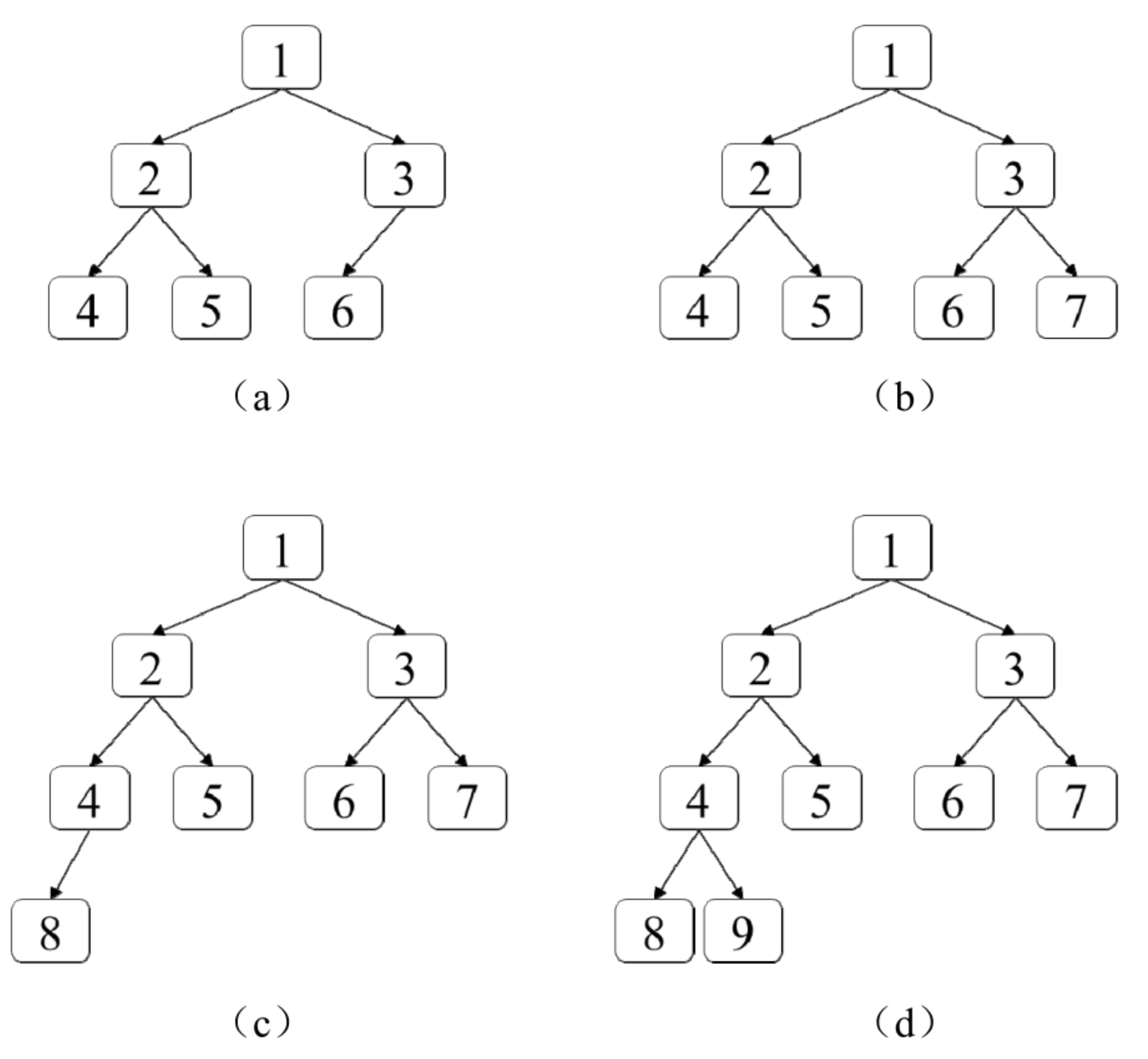
面试算法43:在完全二叉树中添加节点
题目 在完全二叉树中,除最后一层之外其他层的节点都是满的(第n层有2n-1个节点)。最后一层的节点可能不满,该层所有的节点尽可能向左边靠拢。例如,图7.3中的4棵二叉树均为完全二叉树。实现数据结构CBTInserter有如下3种…...

Python算法例3 检测2的幂次
1. 问题描述 检测一个整数n是否为2的幂次。 2. 问题示例 n8,返回True;n6,返回False。 3.代码实现 # 采用UTF-8编码格式 # 参数n是一个整数 # 返回True或者False class Solution:def checkPowerOf2(self,n):ans 1for i in range(31):if …...
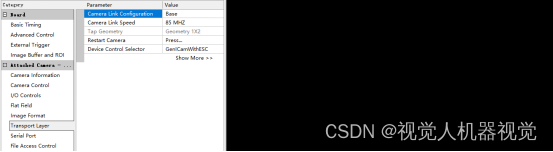
线扫相机DALSA--采集卡Base模式设置
采集卡默认加载“1 X Full Camera Link”固件,Base模式首先要将固件更新为“2 X Base Camera Link”。 右键SCI图标,选择“打开文件所在的位置”,找到并打开SciDalsaConfig的Demo,如上图所示: 左键单击“获取相机”&a…...
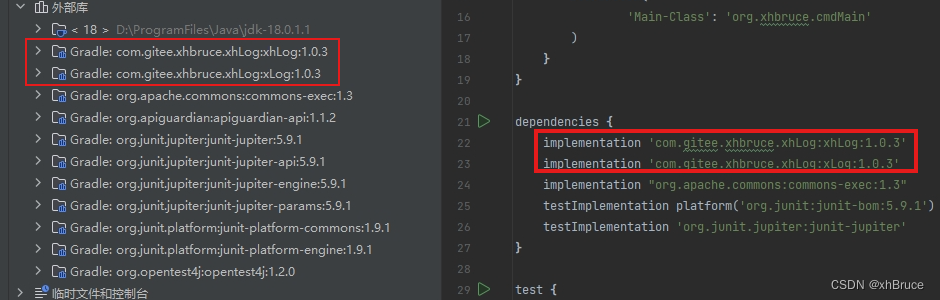
Gitee 发行版
Gitee 发行版 1、Gitee 发行版管理2、项目仓库中创建发行版本3、项目中导入3.1 gradle配置3.2 dependencies执行正常,包没有下载 1、Gitee 发行版管理 Gitee 发行版(Release)管理 2、项目仓库中创建发行版本 按照Gitee官网操作就行 3、项目…...

python面向对象
用animal举例代码如下: class Animal:name age 0def call(self):print(I am %s, and I\m %d years old. % (self.name, self.age))def isMe(self, name) -> bool:return self.name nameanimal Animal() animal.name coco animal.age 10 animal.call()prin…...
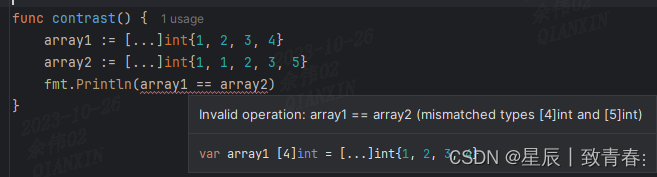
Go基础——数组、切片、集合
目录 1、数组2、切片3、集合4、范围(range) 1、数组 数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。 Go 语言数组声明需要指定元素类型及元素个数,与…...
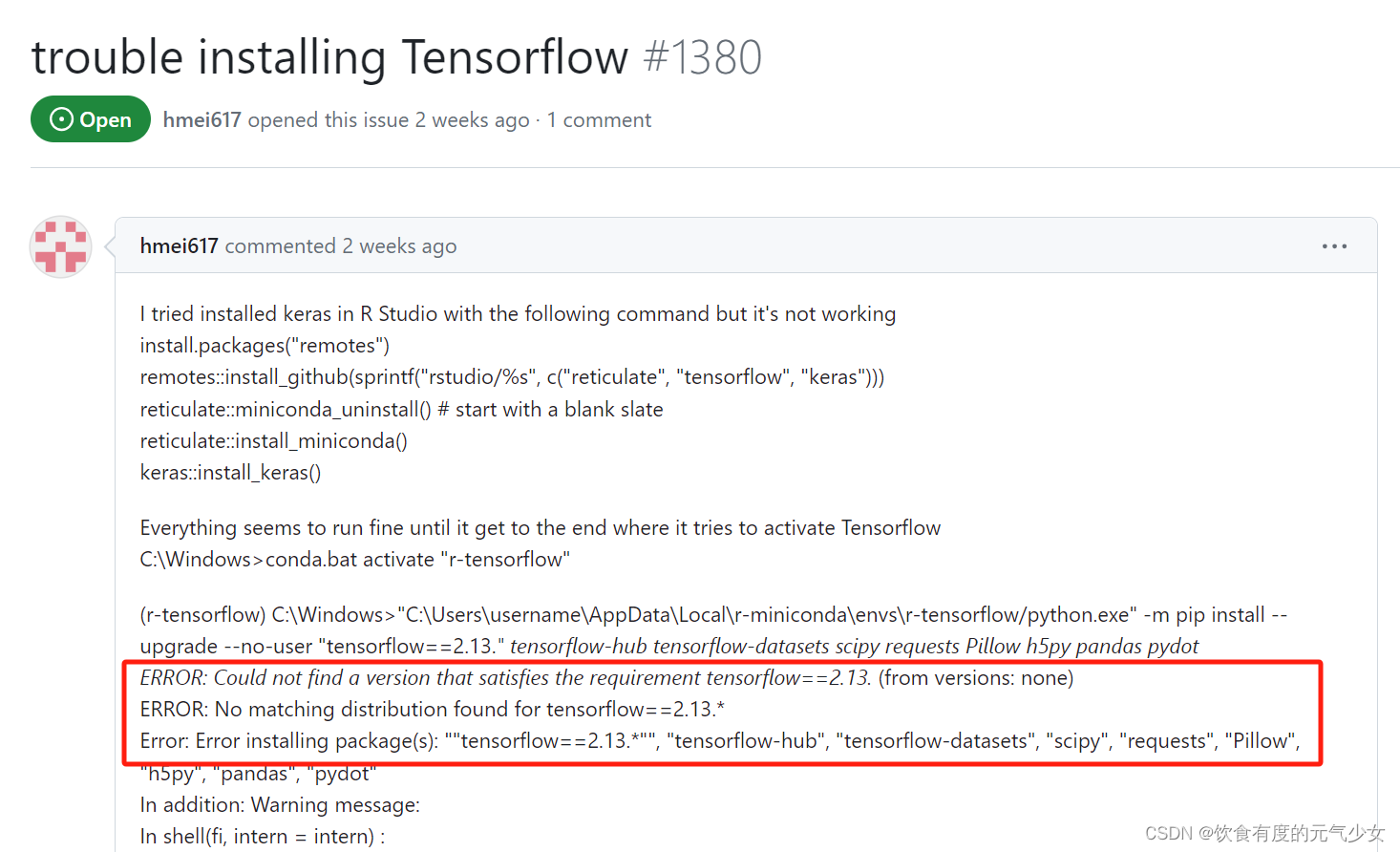
Error: no matching distribution found for tensorflow-cpu==2.6.*
目录 install_tensorflow()安装过程中遇到的问题 查找解决方案过程中: 解决办法: install_tensorflow()安装过程中遇到的问题 在服务器上安装tensorflow时,遇到了一个报错信息: 在网上找到一个类似的错误(TensorFlow…...
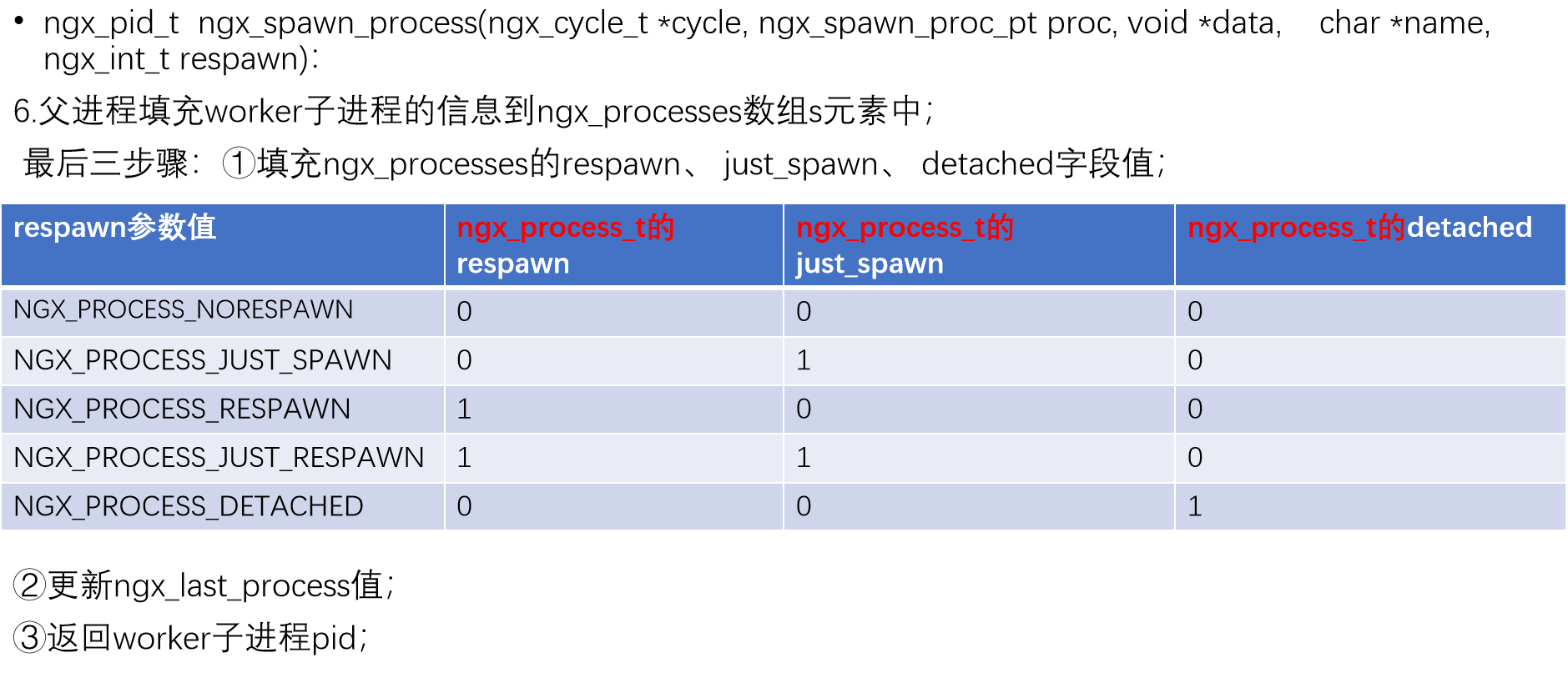
nginx 进程模型
文章目录 nginx运行模式与进程模式进程模式流程图默认初始化运行模式与进程模式(宏展开)cpu_affinity多CPU绑定合理性判定Nginx的daemon创建(os/unix/ngx_daemon.c)运行模式、进程模式启动 多进程模式下master处理流程设置进程信号、初始化信号掩码、屏蔽…...

TypeScript - 枚举类型 -字符型枚举
什么是枚举 枚举就是有固定的元素的一个对象。 对象的元素可以直接列举出来。 什么是字符型枚举 字符型枚举,就是元素的值是字符串。 就这么简单。 定义一个我看看 来,让我们实际看一下字符型的枚举。 // 定义字符型枚举 enum COLOR2{RED red,BLUE blu…...

长期项目使用Taotoken聚合API的稳定性与容灾感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken聚合API的稳定性与容灾感受 1. 项目背景与接入初衷 我们团队负责一个面向内部用户的中型知识问答系统&#…...
一键脚本 + 完整配置)
OpenClaw 3 机集群(Windows + Linux 混合)一键脚本 + 完整配置
集群架构规划(1 主 2 从)统一安装脚本(Windows PowerShell / Linux bash)主节点配置(gateway 调度)从节点配置(worker 注册到主)集群通信、端口、令牌、存储一键启停、扩容、状态检…...

抖音批量下载终极指南:免费高效获取无水印视频与音乐
抖音批量下载终极指南:免费高效获取无水印视频与音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

如何快速掌握ComfyUI_InstantID:从零到一的AI人脸编辑完整实战指南
如何快速掌握ComfyUI_InstantID:从零到一的AI人脸编辑完整实战指南 【免费下载链接】ComfyUI_InstantID 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_InstantID 在AI图像生成领域,保持特定人物身份的同时实现风格转换一直是个技术挑战…...

告别混淆!一文讲透 Flink State Backend 与 Checkpoint Storage
一、引言在 Flink 1.13 版本之前,StateBackend 接口是一个“大杂烩”,它同时负责两件事:状态的本地访问与存储(Task 运行时状态存在哪?内存还是 RocksDB?)Checkpoint 数据的持久化(做…...

别再只把 AI 当聊天框了!探索 Google DeepMind 的 `agy` 命令行工具与人机协同新姿势
别再只把 AI 当聊天框了!探索 Google DeepMind 的 agy 命令行工具与人机协同新姿势 在 AI 辅助编程(AI Coding)卷到飞起的今天,大部分开发者最习惯的可能还是在 IDE 侧边栏里装个插件,或者在网页端和 AI 缝缝补补地复制…...

LLaMA论文里没细说的三个‘炼丹’细节:RMSNorm、SwiGLU和RoPE到底怎么用?
LLaMA论文里没细说的三个‘炼丹’细节:RMSNorm、SwiGLU和RoPE到底怎么用? 在构建现代大型语言模型时,论文往往聚焦于宏观架构和性能对比,而将关键实现细节留给读者自行揣摩。LLaMA论文中提到的RMSNorm、SwiGLU和RoPE三项改进&…...
)
告别低速串口:用STM32的FSMC总线驱动FPGA,实现高速数据交换的完整流程(基于STM32F407)
STM32与FPGA的高速数据通道:基于FSMC总线的实战设计指南 在嵌入式系统开发中,数据吞吐量常常成为制约系统性能的关键瓶颈。当STM32微控制器需要与FPGA进行大数据量交互时——无论是实时图像处理、高速数据采集还是复杂算法加速——传统的串行通信接口如…...

Word怎么转图片?免费在线转换工具对比|2026实用方案
Word文档转换为图片是职场和学习中常见的需求。无论是为了方便分享、制作演示素材,还是保护文档隐私,掌握多种转换方法都能大幅提升工作效率。本文将为你盘点2026年最实用的Word转图片在线工具,以及电脑和手机端的完整解决方案。为什么要把Wo…...

Clutch故障排查手册:常见问题及解决方案汇总
Clutch故障排查手册:常见问题及解决方案汇总 【免费下载链接】clutch Extensible platform for infrastructure management 项目地址: https://gitcode.com/gh_mirrors/clu/clutch Clutch是一个可扩展的基础设施管理平台,旨在简化运维操作并提升开…...