如何使用goquery进行HTML解析以及它的源码分析和实现原理
目录
goquery 是什么
goquery 能用来干什么
goquery quick start
玩转goquery.Find()
查找多个标签
Id 选择器
Class 选择器
属性选择器
子节点选择器
内容过滤器
goquery 源码分析
图解源码
总结
goquery 简介
goquery是一款基于Go语言的HTML解析库,它使用了类似于jQuery的语法,使得在Go语言中进行HTML解析变得更加方便。使用goquery,开发者可以在HTML文档中轻松地查询、遍历和操作文档中的各种元素和属性。
具体而言,goquery可以用来实现如下功能:
- 在HTML文档中查找、筛选和遍历元素
- 获取元素的属性、文本内容、HTML内容等信息
- 对元素进行添加、修改、删除等操作
- 在HTML文档中执行CSS选择器操作
- 支持链式调用,可以方便地进行多个操作组合
总的来说,goquery是一款非常实用的HTML解析工具,它可以大大简化开发者在Go语言中进行HTML解析的工作。
goquery quick start
Document 是 goquery 包的核心类之一,创建一个 Document 是使用 goquery 的第一步:
type Document struct {*SelectionUrl *url.URLrootNode *html.Node
}func NewDocumentFromNode(root *html.Node) *Document
func NewDocument(url string) (*Document, error)
func NewDocumentFromReader(r io.Reader) (*Document, error)
func NewDocumentFromResponse(res *http.Response) (*Document, error)通过源码可以知道 Document 继承了 Selection(先不管 Selection 是什么),除此之外最重要的是rootNode,它是 HTML 的根节点,Url这个字段作用不大,在使用NewDocument和NewDocumentFromResponse时会对该字段赋值。
拥有Document类后,我们就可以利用从Selection类继承的Find函数来获得自己想要的数据,比如我们想拿到
func TestFind(t *testing.T) {html := `<body><div>DIV1</div><div>DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("div").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind
DIV1
DIV2玩转goquery.Find()
goquery 提供了大量的函数,个人认为最重要的是Find函数,把它用好了才能快速从大量文本中筛选出我们想要的数据,下面这一章主要展示使用Find函数的各种姿势:
查找多个标签
使用,逗号找出多个标签:
func TestMultiFind(t *testing.T) {html := `<body><div>DIV1</div><div>DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("div,span").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestMultiFind
DIV1
DIV2
SPANId 选择器
使用#代表 Id 选择器。
func TestFind_IdSelector(t *testing.T) {html := `<body><div id="div1">DIV1</div><div>DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("#div1").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_IdSelector
DIV1Class 选择器
使用.代表 Class 选择器。
func TestFind_ClassSelector(t *testing.T) {html := `<body><div>DIV1</div><div class="name">DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find(".name").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_ClassSelector
DIV2属性选择器
使用[]代表属性选择器。
func TestFind_AttributeSelector(t *testing.T) {html := `<body><div>DIV1</div><div lang="zh">DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("div[lang]").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_AttributeSelector
DIV2属性选择器也支持表达式过滤,比如:
func TestFind_AttributeSelector_2(t *testing.T) {html := `<body><div>DIV1</div><div lang="zh">DIV2</div><div lang="en">DIV3</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("div[lang=zh]").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_AttributeSelector_2
DIV2| 选择器 | 说明 |
|---|---|
| Find(“div[lang]”) | 筛选含有lang属性的div元素 |
| Find(“div[lang=zh]”) | 筛选lang属性为zh的div元素 |
| Find(“div[lang!=zh]”) | 筛选lang属性不等于zh的div元素 |
| Find(“div[lang¦=zh]”) | 筛选lang属性为zh或者zh-开头的div元素 |
| Find(“div[lang*=zh]”) | 筛选lang属性包含zh这个字符串的div元素 |
| Find(“div[lang~=zh]”) | 筛选lang属性包含zh这个单词的div元素,单词以空格分开的 |
| Find(“div[lang$=zh]”) | 筛选lang属性以zh结尾的div元素,区分大小写 |
| Find(“div[lang^=zh]”) | 筛选lang属性以zh开头的div元素,区分大小写 |
当然也可以将多个属性筛选器组合,比如:Find("div[id][lang=zh]")
子节点选择器
使用>代表子节点选择器。
func TestFind_ChildrenSelector(t *testing.T) {html := `<body><div>DIV1</div><div>DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("body>span").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_ChildrenSelector
SPAN此外+表示相邻,~表示共有(父节点相同即为true)
内容过滤器
过滤文本
使用:contains($text)来过滤字符串。
func TestFind_ContentFilter_Contains(t *testing.T) {html := `<body><div>DIV1</div><div>DIV2</div><span>SPAN</span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("div:contains(V2)").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_ContentFilter_Contains
DIV2过滤节点
func TestFind_ContentFilter_Has(t *testing.T) {html := `<body><span>SPAN1</span><span>SPAN2<div>DIV</div></span></body>`dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))if err != nil {log.Fatalln(err)}dom.Find("span:has(div)").Each(func(i int, selection *goquery.Selection) {fmt.Println(selection.Text())})
}
------------运行结果--------------
=== RUN TestFind_ContentFilter_Has
SPAN2
DIV此外,还有:first-child、:first-of-type过滤器分别可以筛选出第一个子节点、第一个同类型的子节点。
相应的:last-child、:last-of-type、:nth-child(n)、:nth-of-type(n)用法类似,不做过多解释。
goquery 源码分析
Find函数 是 goquery 最核心的函数:
func (s *Selection) Find(selector string) *Selection {return pushStack(s, findWithMatcher(s.Nodes, compileMatcher(selector)))
}Find函数 的功能由pushStack函数实现:
func pushStack(fromSel *Selection, nodes []*html.Node) *Selection {result := &Selection{nodes, fromSel.document, fromSel}return result
}该函数就是拿着nodes参数去创建一个新的 Selection 类,构建一个 Selection 链表。
无论是函数命名pushStack,还是 Selection 类的字段都可以证实上面的判断:
type Selection struct {Nodes []*html.Nodedocument *DocumentprevSel *Selection // 上一个节点的地址
}现在焦点来到了pushStack函数的nodes参数,nodes参数是什么直接决定了我们构建了一个怎样的链表、决定了Find函数的最终返回值,这就需要我们研究下findWithMatcher函数的实现:
func findWithMatcher(nodes []*html.Node, m Matcher) []*html.Node {return mapNodes(nodes, func(i int, n *html.Node) (result []*html.Node) {for c := n.FirstChild; c != nil; c = c.NextSibling {if c.Type == html.ElementNode {result = append(result, m.MatchAll(c)...)}}return})
}findWithMatcher函数 的功能由mapNodes函数实现:
func mapNodes(nodes []*html.Node, f func(int, *html.Node) []*html.Node) (result []*html.Node) {set := make(map[*html.Node]bool)for i, n := range nodes {if vals := f(i, n); len(vals) > 0 {result = appendWithoutDuplicates(result, vals, set)}}return result
}mapNodes函数把参数f的返回值[]*html.Node做去重处理,所以重点在于这个参数f func(int, *html.Node) []*html.Node的实现:
func(i int, n *html.Node) (result []*html.Node) {for c := n.FirstChild; c != nil; c = c.NextSibling {if c.Type == html.ElementNode {result = append(result, m.MatchAll(c)...)}}return
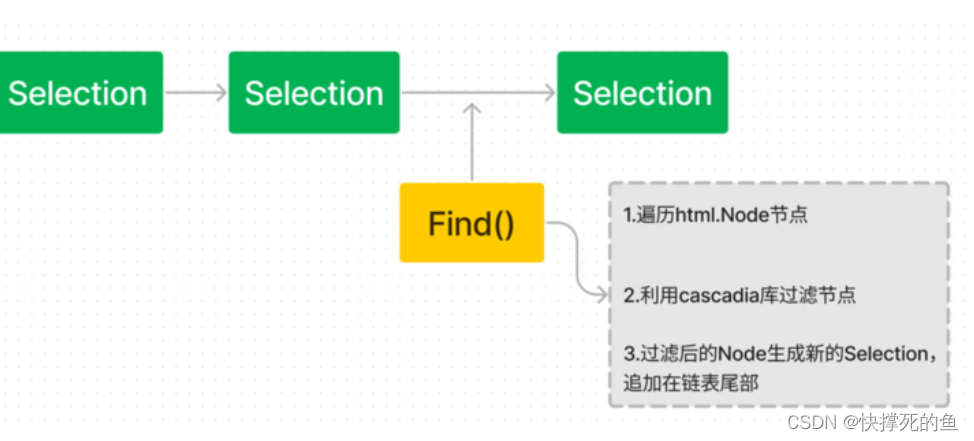
}函数遍历html.Node节点,并利用MatchAll函数筛选出想要的数据
type Matcher interface {Match(*html.Node) boolMatchAll(*html.Node) []*html.NodeFilter([]*html.Node) []*html.Node
}func compileMatcher(s string) Matcher {cs, err := cascadia.Compile(s)if err != nil {return invalidMatcher{}}return cs
}MatchAll函数由Matcher接口定义,而compileMatcher(s string)恰好通过利用cascadia库返回一个Matcher实现类,其参数s就是我们上文提到的匹配规则,比如dom.Find("div")
图解源码
使用Find函数时,goquery 做了什么:
总结
本文主要介绍了 goquery 最核心的Find函数的用法及其源码实现,其实除了Find函数,goquery 还提供了大量的函数帮助我们过滤数据,因为函数众多且没那么重要,本人就没有继续研究,以后有机会再深入研究下。
相关文章:
如何使用goquery进行HTML解析以及它的源码分析和实现原理
目录 goquery 是什么 goquery 能用来干什么 goquery quick start 玩转goquery.Find() 查找多个标签 Id 选择器 Class 选择器 属性选择器 子节点选择器 内容过滤器 goquery 源码分析 图解源码 总结 goquery 简介 goquery是一款基于Go语言的HTML解析库,…...

【Java 数组和集合 区别及使用案例】
Java中数组和集合都是用来存储一组数据的容器,但是在实际使用中,它们有一些区别和不同的使用场景。 数组 vs 集合:存储方式 数组是一个固定长度的容器,它的长度一旦被初始化之后,就无法再改变了。而集合是一个动态长…...
使用pynimate制作动态排序图
大家好,数据可视化动画使用Python包就可以完成,效果如下:想要使用Pynimate,直接import一下就行:import pynimate as nim输入数据后,Pynimate将使用函数Barplot()来创建条形数据动画。…...
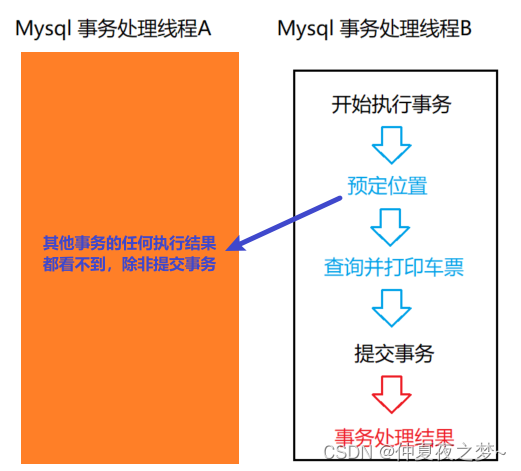
Mysql 事务的隔离性(隔离级别)
Mysql 中的事务分为手动提交和自动提交,默认是自动提交,所以我们在Mysql每输入一条语句,其实就会被封装成一个事务提交给Mysql服务端。 手动提交需要先输入begin,表示要开始处理事务,然后就是常见的sql语句操作了&…...

2023年网络安全竞赛——Python渗透测试PortScan.py
端口扫描Python渗透测试:需求环境可私信博主获取 任务环境说明: 服务器场景:PYsystem0041服务器场景操作系统:未知服务器场景FTP用户名:anonymous 密码:空1. 从靶机服务器的FTP上下载PortScan.py,编辑Python程序PortScan.py,实现...

【数据结构】栈的接口实现(附图解和源码)
栈的接口实现(附图解和源码) 文章目录栈的接口实现(附图解和源码)前言一、定义结构体二、接口实现(附图解源码)1.初始化栈2.销毁栈3.入栈4.判断栈是否为空5.出栈6.获取栈顶元素7.获取栈中元素个数三、源代码…...
)
LC-1255. 得分最高的单词集合(回溯)
1255. 得分最高的单词集合 难度困难60 你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。 请你帮忙计算玩家在单词拼写游戏中所能获得的「最高得分」:能够由…...

从中国文化看面试挑人标准
文章目录标准一、面相1. 1 四白眼1.2 浓眉二、讲话2.1 言多与气虚总结本文结合中国面相,是个概率性问题,对于个体无效。 标准 正直,三观正,沟通好,技术。从概率上讲: 正直且三观正的人----有恒心&#x…...

谦卑对象设计模式
谦卑设计模式介绍 “谦卑”在这里是拟人化的,指难以测试的对象清晰地认识到自己的局限性,只发挥自己的桥梁和通信作用,并不从中干预信息的传输。 谦卑对象模式‘最初的设计目的是帮助单元测试的编写者区分容易测试的行为与难以测试的行为,并将它们隔离。其设计思路…...

QML Animation动画详解
1.Animation简介 Animation类型提供了四个属性: alwaysRunToEnd:该属性接收布尔类型的参数。该属性保存动画是否运行到完成才停止。当loops属性被设置时,这个属性是最有用的,因为动画将正常播放结束,但不会重新启动。…...

C#开发的OpenRA的加载界面边框的细节
C#开发的OpenRA的加载界面边框的细节 在前面已经看到加载整个界面, 如果仔细地看,会发现加载界面的边框有一个红色的框。 这个红色的边框到底是怎么样来的呢? 其实它不是实时画上去的,而从纹理贴图里贴上去的。 也许有一些人会问,纹理贴图里的图片这么小,怎么样会有这么大…...

计算机网络笔记、面试八股(四)—— TCP连接
本章目录4. TCP连接4.1 TCP报文段的首部格式4.2 TCP连接如何保证可靠4.3 ARQ协议4.3.1 停止等待ARQ协议4.3.1.1 无差错情况4.3.1.2 出现差错情况4.3.1.3 确认丢失和确认迟到4.3.2 连续ARQ协议4.3.2.1 流水线传输4.3.2.2 累积确认4.3.2.3 滑动窗口协议4.3.3 停止等待ARQ和连续AR…...
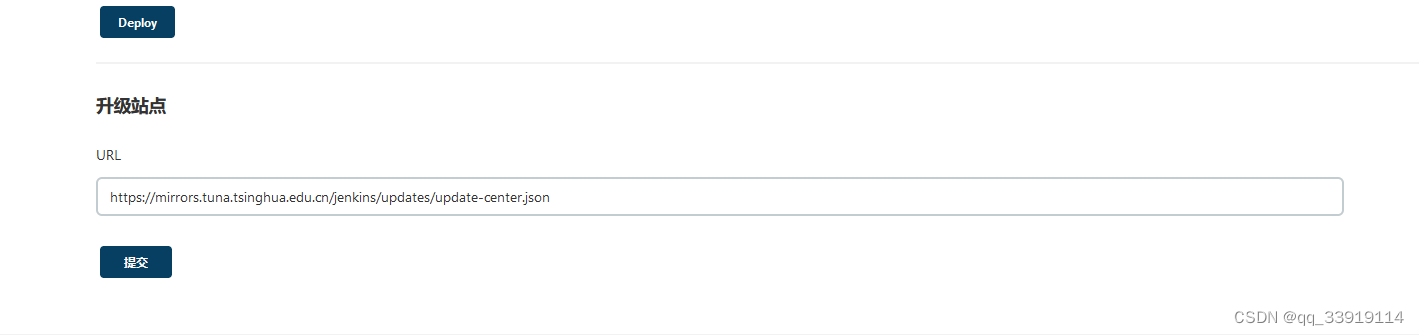
Centos7 安装jenkins java1.8版本
1. 首先安装好jdk1.8 2. 安装jenkins 命令:(可以在根目录,创建文件夹 mkdir home 然后在此文件夹下操作 cd /home) a 清华源,获取jenkins安装包 wget https://mirrors.tuna.tsinghua.edu.cn/jenkins/redhat/jenkins-2.346-1.1.noarch.rp…...
【每日阅读】JS知识(三)
var声明提升 js是一个解释性语言类型,预解析就是在执行代码之前对代码进行通读 var关键字是,在内存中声明一个变量名 js在代码执行之前 会经历两个环节 解释代码 和执行代码 声明式函数 内存中 先声明一个变量名是函数 这个名代表的是函数 乘法表 // for…...
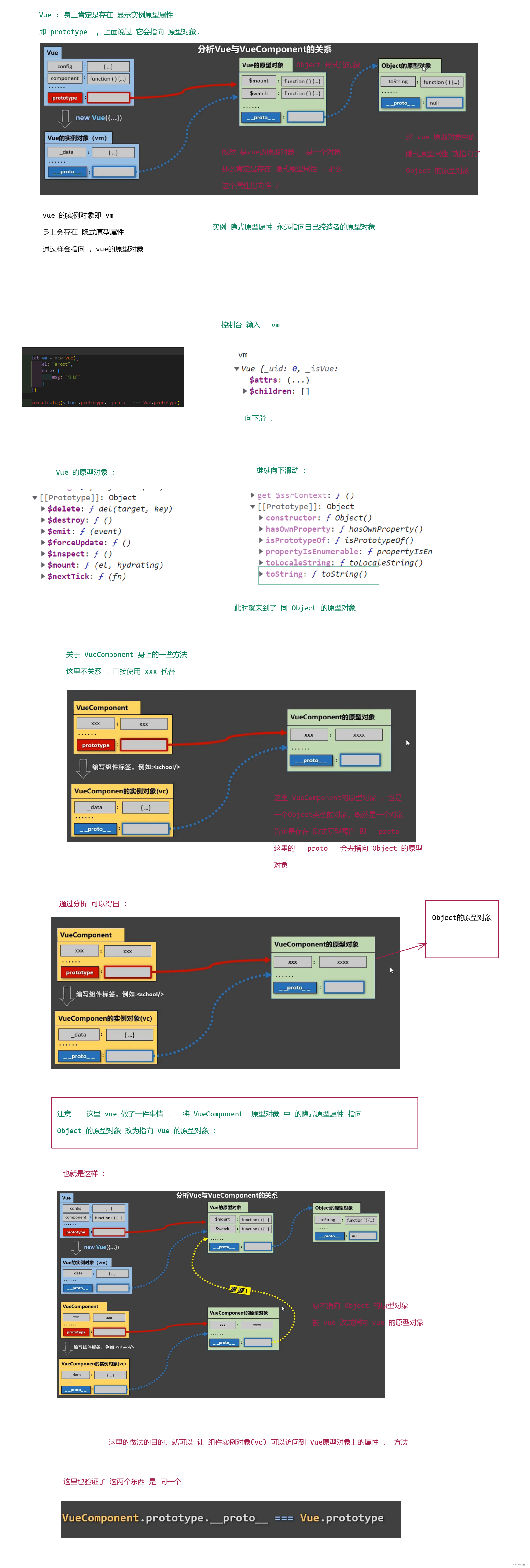
Vue(6)
文章目录1. 自定义指令1.1 函数式1.2 对象式1.3 自定义指令常见坑1.4 创建全局指令2. 生命周期2.1 引出生命周期2.2 分析生命周期2.3 总结3. 组件3.1 认识组件3.2 使用组件 (非单文件组件)3.3 全局组件3.4 组件的几个注意点3.5 组件的嵌套3.6 VueComponent 构造函数3.7 一个重要…...
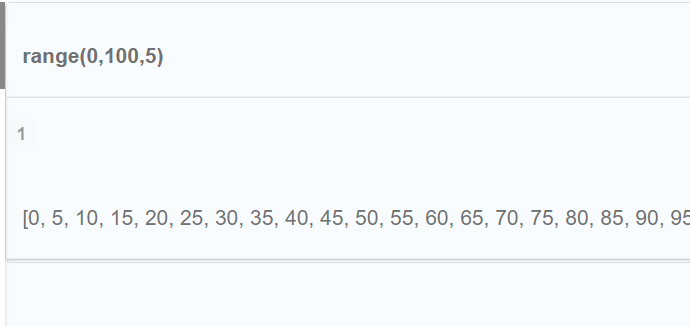
Neo4j列表函数
使用列表 标量列表函数 size() 函数返回列表中的元素的数量 MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WITH p, collect (m.title) AS MovieTitles WITH p, MovieTitles, size(MovieTitles) AS NumMovies WHERE NumMovies > 20 RETURN p.name AS Actor, NumMovies, Movie…...

55. 跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标。示例 1:输入:nums [2,3,1,1,4]输出:true解释:可以先跳 1 步&#…...

typedef在c语言中的作用
在 C 语言中,typedef 是一个非常有用的关键字,用于给数据类型定义一个新的名字。typedef 的作用有以下几个方面: 定义新类型名:typedef 可以定义一个新的数据类型名称,使得该类型名称可以在程序中使用。这样可以提高代…...
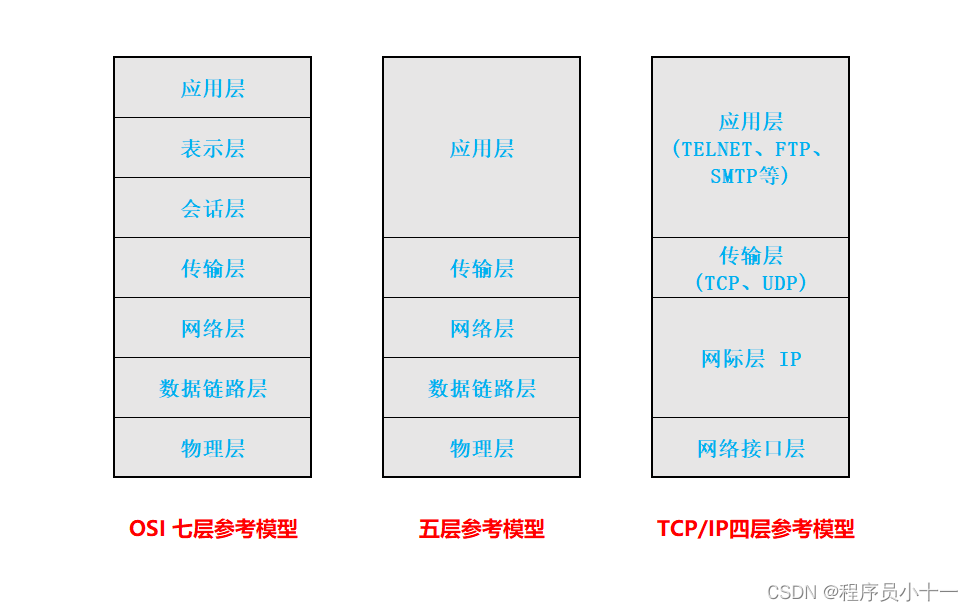
计算机网络体系结构及分层参考模型
文章目录一、分层设计思想的提出二、网络分层的必要性三、什么是计算机网络体系结构四、计算机网络参考模型OSI参考模型/五层参考模型/TCP/IP参考模型一、分层设计思想的提出 最早提出分层思想的是 ARPANET网。1969年11月,美国国防部开始建立一个命名为ARPANET的网络…...
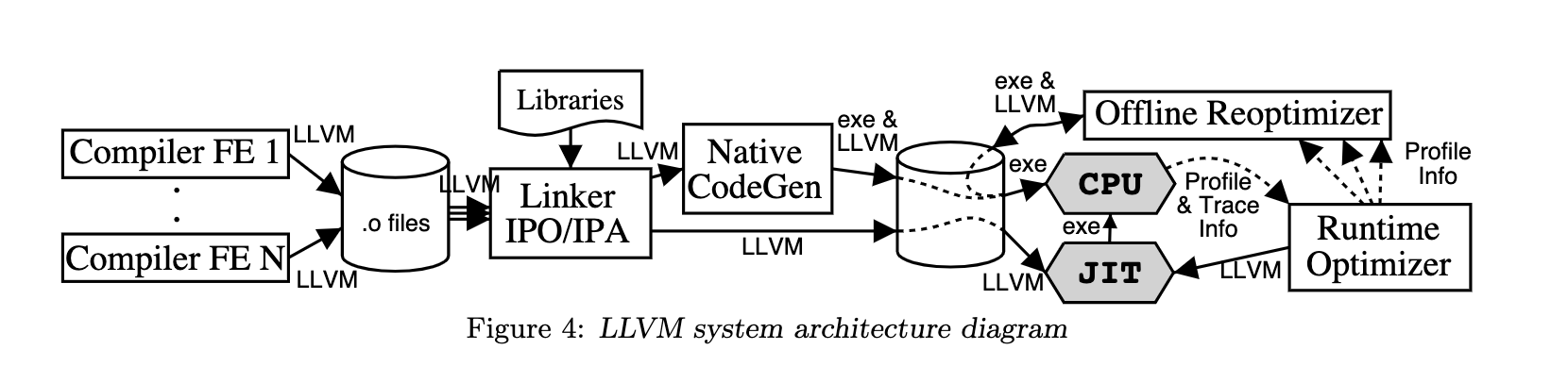
LLVM程序分析与编译转换框架论文分享
LLVM 2004年论文原文 概述 本文描述了 LLVM(低级虚拟机),一种编译器框架,旨在通过在编译时、链接时、运行时,以及运行之间的空闲时间。 LLVM 以静态单一赋值 (SSA) 形式定义了一种通用的低级代码表示,具有…...
)
别再只会点灯了!用51单片机和继电器模块,做个智能插座控制台灯(附完整代码)
从点灯到智能家居:51单片机与继电器模块的实战进阶指南 当你已经能够熟练地用51单片机点亮LED灯时,是否想过将这些基础技能转化为实际生活中的实用工具?本文将带你跨越实验板与真实世界的鸿沟,用最常见的51单片机和继电器模块&…...
FSMC配置避坑指南:从硬件连接到时序计算)
STM32F1/F4外部SRAM(IS62WV51216)FSMC配置避坑指南:从硬件连接到时序计算
STM32F1/F4外部SRAM(IS62WV51216)FSMC配置避坑指南:从硬件连接到时序计算 在嵌入式系统开发中,当STM32的内部SRAM容量不足以满足需求时,扩展外部SRAM成为提升系统性能的有效方案。IS62WV51216作为一款常见的16位宽512K…...

模拟真人手写软件,支持随机调节
软件介绍 前阵子公司要求我们签一份保密承诺书,还特别强调必须手写。这下可把不少同事难住了,平时都用电脑打字,手写都快生疏了。于是有同事让我帮忙找找能把手写字做出来的软件。我一开始找了几款手写字体,但写出来的效果太规整…...

开发预告:关于改造Hermes-agent这件事,我想说的比上一篇多得多
先声明一点:这不是什么技术布道,更不是产品软文。这篇文章里写的东西,要么是我花了真金白银和睡眠时间换来的,要么是我接下来要去踩的坑。你要觉得哪里不对,直接怼。你要觉得哪里说到你心坎里了,欢迎一起搞…...
)
手把手教你用MOS管搭建防反接电路:从原理图到PCB布局的避坑指南(以立创EDA为例)
从零构建MOS管防反接电路:立创EDA实战全流程解析 电源反接是电子设计中最常见的"低级错误"之一,却可能造成毁灭性后果。想象一下:你花费数周完成的智能家居控制器,因为电池装反而瞬间烧毁主控芯片——这种场景在创客社区…...

工业DC-DC电源模块性能选型解析|钡特电源 VB15-48S24MD 与 URB4824YMD-15WR3 封装互通
在工业控制、通信设备、仪器仪表等领域,工业 DC-DC 模块电源作为核心供电单元,其稳定性、兼容性与性价比直接影响系统整体可靠性。随着国产化进程加速,国产工业电源模块在技术、品质上已达到国际先进水平,成为硬件工程师选型的重要…...

一次搞清楚:Agent、Skill、Prompt、MCP
文章深入探讨了AI Agent在落地过程中面临的三大核心痛点:Prompt的临时性与不可复用性、Agent专业能力的难以沉淀与迁移、以及AI能力无法融入现有工程化流程。文章提出Agent Skills作为AI Agent的专业能力说明书,通过标准化能力描述与执行框架,…...

如何在Blender中实现工程级精确建模:CAD_Sketcher完全指南 [特殊字符]
如何在Blender中实现工程级精确建模:CAD_Sketcher完全指南 🚀 【免费下载链接】CAD_Sketcher Constraint-based geometry sketcher for blender 项目地址: https://gitcode.com/gh_mirrors/ca/CAD_Sketcher 你是否曾经在Blender中尝试创建精确的机…...

从灾难电影到现实防疫:技术视角下的系统脆弱性与韧性构建
1. 从科幻到现实:流行病史与灾难电影的预言性对话作为一名长期关注科技与社会交叉领域的写作者,我发现自己近年来越发沉迷于一种特殊的电影类型——灾难片,尤其是那些以病毒大流行为主题的影片。这并非单纯的娱乐消遣,而更像是一种…...

科技成果转化平台建设成本高如何解决?
观点作者:科易网-国家科技成果转化(厦门)示范基地现状概述(成效与短板) 近年来,我国科技成果转化平台建设取得显著进展,各地政府部门、高校、科研院所积极探索,累计建成各类技术转移…...