Python 算法高级篇:堆排序的优化与应用
Python 算法高级篇:堆排序的优化与应用
- 引言
- 1. 什么是堆?
- 2. 堆的性质
- 3. 堆排序的基本原理
- 4. 堆排序的 Python 实现
- 5. 堆排序的性能和优化
- 6. 堆排序的实际应用
- 7. 总结
引言
堆排序是一种高效的排序算法,它基于数据结构中的堆这一概念。堆排序的时间复杂度为 O ( n log n ),这使得它在处理大规模数据时非常有用。本文将深入讨论堆排序的原理、堆的概念、堆排序的 Python 实现,以及一些堆排序的优化和实际应用。
😃😄 ❤️ ❤️ ❤️
1. 什么是堆?
在计算机科学中,堆是一种特殊的树形数据结构,它满足以下两个性质:
- 堆的每个节点都有一个值。
- 堆中每个节点的值都必须大于等于或小于等于其子节点的值,具体取决于堆是大顶堆还是小顶堆。
大顶堆的根节点的值最大,小顶堆的根节点的值最小。
堆通常用数组来实现,其中根节点存储在索引 0 处。对于大顶堆,父节点的值大于或等于其子节点的值,对于小顶堆,父节点的值小于或等于其子节点的值。
2. 堆的性质
堆有两个主要性质:
- 堆是一棵完全二叉树,这意味着堆中的节点从左到右填充,没有“空洞”。
- 堆中每个节点的值都满足堆性质,即大顶堆或小顶堆性质。
这些性质使得堆非常适合实现堆排序算法。
3. 堆排序的基本原理
堆排序是一种基于比较的排序算法,其基本原理可以概括为以下几个步骤:
-
1 . 构建一个初始堆:将待排序的数据构建成一个堆结构。这一步通常涉及将数组转换为一个堆,需要从最后一个非叶子节点开始,从右到左,逐个将它们“下沉”到合适的位置,以满足堆的性质。
-
2 . 堆排序:从堆中不断移除根节点,并将其放置在已排序的部分。重复此过程,直到堆为空。
-
3 . 结果:排序完成后,数组中的数据已按升序或降序排列,具体取决于堆是大顶堆还是小顶堆。
4. 堆排序的 Python 实现
下面是堆排序的 Python 实现:
def heapify(arr, n, i):largest = i # 将根节点看作最大的节点left = 2 * i + 1right = 2 * i + 2# 如果左子节点存在且大于根节点if left < n and arr[left] > arr[largest]:largest = left# 如果右子节点存在且大于根节点if right < n and arr[right] > arr[largest]:largest = right# 如果最大节点不是根节点if largest != i:arr[i], arr[largest] = arr[largest], arr[i] # 交换heapify(arr, n, largest)def heap_sort(arr):n = len(arr)# 构建最大堆for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)# 一个一个取出元素for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i] # 交换heapify(arr, i, 0)# 测试堆排序
arr = [12, 11, 13, 5, 6, 7]
heap_sort(arr)
print("堆排序结果:", arr)
在这个实现中, heapify 函数用于维护堆的性质, heap_sort 函数用于进行堆排序。首先,我们构建一个最大堆,然后一个一个地取出堆的根节点并放在已排序的部分,最终得到排序后的数组。
5. 堆排序的性能和优化
堆排序的时间复杂度是 O ( n log n ),这使得它在大规模数据的排序中表现出色。然而,堆排序不稳定,因为它可能改变相等元素的相对顺序。
堆排序的一个重要优化是使用堆的数据结构来实时处理数据流。在这种情况下,新数据可以不断添加到堆中,并且可以立即获得最大或最小的元素,而不必等待整个数据流结束。
6. 堆排序的实际应用
堆排序的实际应用非常广泛,特别是在需要实时获取最大或最小元素的情况下。以下是一些堆排序的应用场景:
-
操作系统调度:操作系统可以使用堆排序来确定下一个要执行的进程,根据其优先级来选择。
-
优先级队列:堆排序可以用于实现优先级队列,其中具有较高优先级的元素首先被处理。
-
最小(大)的 k 个元素:在一组元素中查找最小或最大的 k 个元素时,堆排序非常有用。
-
堆排序还用于一些图算法,如最短路径算法和最小生成树算法。
7. 总结
堆排序是一种高效的排序算法,基于堆这一数据结构。它的时间复杂度为 O ( n log n ),使得它在大规模数据的排序中表现出色。堆排序的实现相对简单,但需要理解堆的概念和性质。
在实际应用中,堆排序用于处理需要实时获取最大或最小元素的情况,例如操作系统调度、优先级队列、查找最小(大)的 k 个元素等。此外,堆排序还在图算法中发挥重要作用。
希望通过本文,你对堆排序的原理、实现和应用有更深入的了解。
[ 专栏推荐 ]
😃 《Python 算法初阶:入门篇》😄
❤️【简介】:本课程是针对 Python 初学者设计的算法基础入门课程,涵盖算法概念、时间复杂度、空间复杂度等基础知识。通过实例演示线性搜索、二分搜索等算法,并介绍哈希表、深度优先搜索、广度优先搜索等搜索算法。此课程将为学员提供扎实的 Python 编程基础与算法入门,为解决实际问题打下坚实基础。

相关文章:
Python 算法高级篇:堆排序的优化与应用
Python 算法高级篇:堆排序的优化与应用 引言 1. 什么是堆?2. 堆的性质3. 堆排序的基本原理4. 堆排序的 Python 实现5. 堆排序的性能和优化6. 堆排序的实际应用7. 总结 引言 堆排序是一种高效的排序算法,它基于数据结构中的堆这一概念。堆排序…...
视频下载软件 Downie4 mac中文介绍
Downie mac是一款Mac平台上非常实用的视频下载工具。它支持下载各种视频网站上的视频,并且具有快速、稳定、易于使用的特点。 Downie支持下载各种视频网站上的视频,包括YouTube、Vimeo、Netflix、Hulu、Amazon等等。它具有快速、稳定的下载速度ÿ…...

计算机操作系统重点概念整理-第一章 计算机系统概述【期末复习|考研复习】
第一章 计算机系统概述 【期末复习|考研复习】 计算机操作系统系列文章传送门: 第一章 计算机系统概述 第二章 进程管理 第三章 进程同步 第四章 内存管理 第五章 文件管理 第六章 输出输出I/O管理 文章目录 第一章 计算机系统概述 【期末复习|考研复习】前言一、计…...
树莓派基金会近日发布了新版基于 Debian 的树莓派操作系统
树莓派基金会(Raspberry Pi Foundation)近日发布了新版基于 Debian 的树莓派操作系统(Raspberry Pi OS),为树莓派单板电脑带来了新的书虫基础和一些重大变化。 新版 Raspberry Pi OS 的最大变化是它现在基于最新的 Deb…...
Web项目如何做单元测试
你可能会用单元测试框架,python的unittest、pytest,Java的Junit、testNG等。 那么你会做单元测试么!当然了,这有什么难的? test_demo.py def inc(x):return x 1def test_answer():assert inc(3) 4 inc() 是定义的…...

MySQL主从复制(基于GTID--事务ID方式)
目录 一、GTID相关概念1.GTID 是什么?2.GTID主从复制方式概念3.GTID的优缺点 二、GTID工作原理三、部署主从复制四、测试同步1.主库上新建数据库2.从库上查看是否同步成功 五、重设从库六、常见故障七、故障切换八、GTID的一些疑问1.为什么基于GTID的同步也要打开bi…...
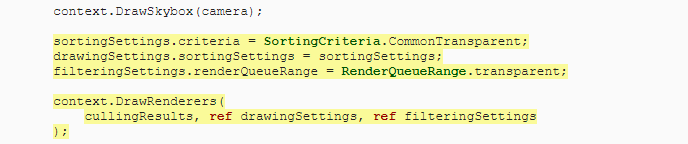
3.72 Command Buffer及URP概述
一、Command Buffer 1.概念 CommandBuffer携带一系列的渲染命令,依赖相机,用来拓展渲染管线的渲染效果。而且可以指定在相机渲染的某个点执行本身的拓展渲染。Command buffers也可以结合屏幕后期效果使用。 简单来说就是可以在渲染流程中插入一些自定…...
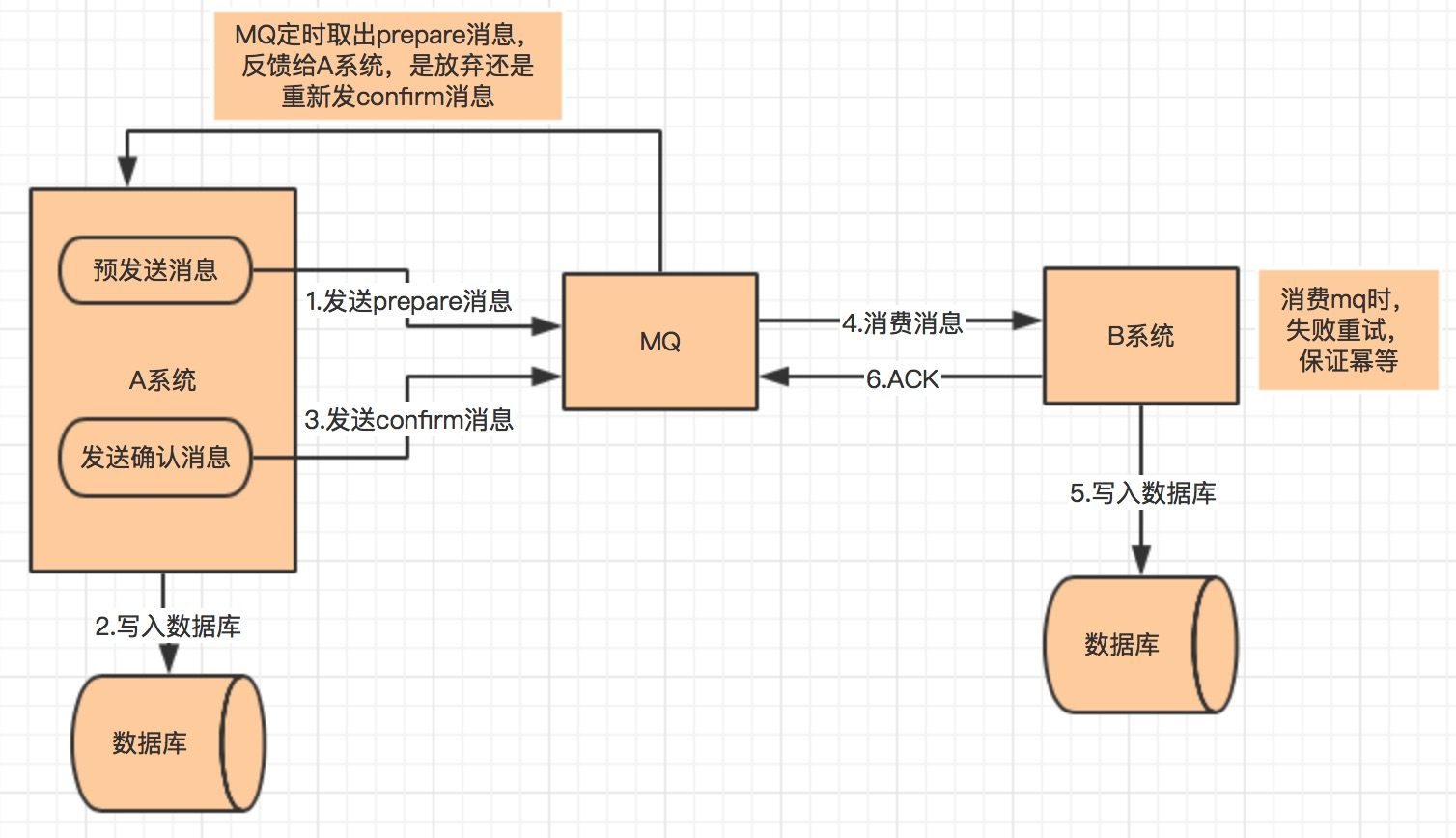
分布式理论和分布式锁知识点总结
文章目录 (一) 分布式理论算法和协议1)CAP理论总结 2)BASE理论BASE 理论的核心思想基本可用软状态最终一致性 3)Paxos算法Basic Paxos 算法4) Raft算法1 拜占庭将军 5)Gossip协议 (二) 分布式锁分布式锁应该具备哪些条…...

IOC课程整理-17 Spring事件
1. Java 事件/监听器编程模型 2. 面向接口的事件/监听器设计模式 3. 面向注解的事件/监听器设计模式 4. Spring 标准事件-ApplicationEvent 5. 基于接口的 Spring 事件监听器 6. 基于注解的 Spring 事件监听器 7. 注册 Spring ApplicationListener 8. Spring 事件发布器 9. Spr…...

大数据Flink(一百零五):SQL性能调优
文章目录 SQL性能调优 一、 MiniBatch 聚合...
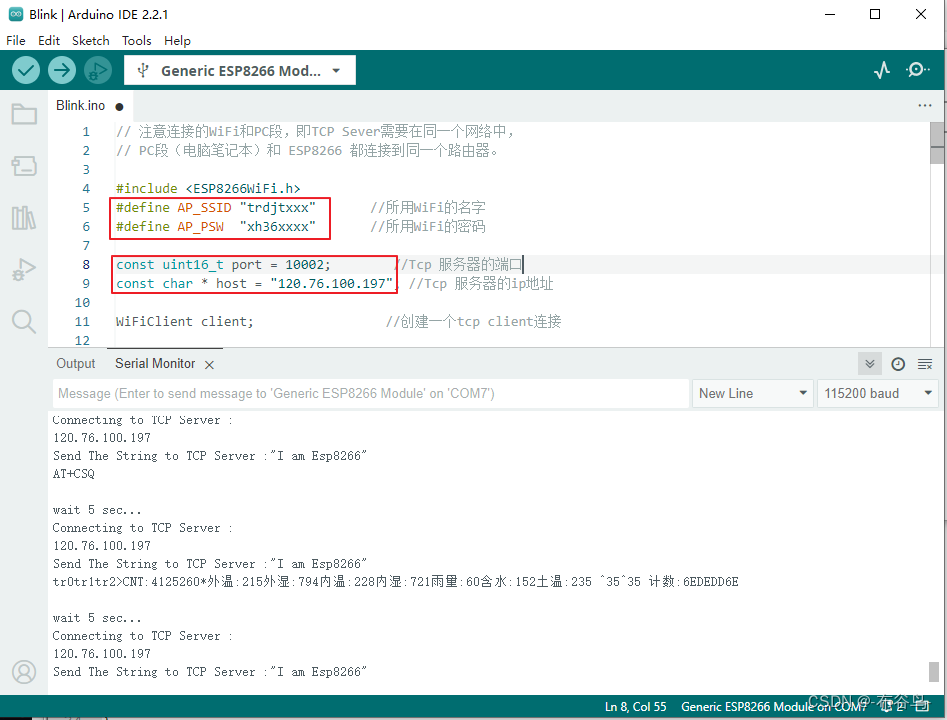
ESP8266,手机与电脑之间的TCP通讯
电脑端运行通讯猫调试助手,作为服务端: 电脑端 电脑的IP地址是: 192.168.2.232 手机与电脑之间的TCP通讯 手机端运行网络调试精灵,作为客户端: 手机端 如果从手机端点击"发送"按钮,则也会将"ghhh东方红广场"几个字发送到电脑上(服务端). ESP8266作为客户…...

vue的数据监听是如何实现的?
Vue的数据监听是通过数据劫持和发布订阅模式来实现的。 数据劫持:Vue通过使用Object.defineProperty()方法来劫持数据对象的属性,并使用getter和setter来监听属性的变化。当属性被修改时,setter方法会被调用,从而触发相应的监听函…...

埋点日志解决方案——Golang+Gin+Sarama VS Java+SpringCloudGateway+ReactorKafka
埋点日志解决方案——GolangGinSarama VS JavaSpringCloudGatewayReactorKafka 之前我就写过几篇OpenRestylua-kafka-client将埋点数据写入Kafka的文章,如下: Lua将Nginx请求数据写入Kafka——埋点日志解决方案 python定时任务执行shell脚本切割Nginx…...

LeetCode 541 反转字符串 II 简单
题目 - 点击直达 1. 541 反转字符串 II 简单1. 题目详情1. 原题链接2. 题目要求3. 基础框架 2. 解题思路1. 思路分析2. 时间复杂度3. 代码实现 1. 541 反转字符串 II 简单 1. 题目详情 给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个…...

从入门到精通:深入了解CSS中的Grid网格布局技巧和应用!
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一…...

Android Studio Giraffe 添加 maven { url “https://jitpack.io“ }报错
Android Studio Giraffe 添加 maven { url “https://jitpack.io” }报错 settings.gradle.kts:13:21: Unexpected tokens (use ; to separate expressions on the same line)解决方法 新版maven写法发生了改变: maven { url uri("https://jitpack.io"…...

Linux C/C++ 实现网络流量分析(性能工具)
网络流量分析的原理基于对数据包的捕获、解析和统计分析,通过对网络流量的细致观察和分析,帮助管理员了解和优化网络的性能、提高网络安全性,并快速排查和解决网络故障和问题。 Linux中的网络流量常见类型 在Linux中,网络流量可以…...

python门牌制作,统计某个数字出现的次数
题目: 小蓝要为一条街的住户制作门牌号。 这条街一共有 2022位住户,门牌号从 1 到 2022 编号。 小蓝制作门牌的方法是先制作 0 到 9 这几个数字字符,最后根据需要将字符粘贴到门牌上,例如门牌 1017 需要依次粘贴字符 1、0、1、…...

轻量封装WebGPU渲染系统示例<7>-材质多pass(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/version-1.01/src/voxgpu/sample/MultiMaterialPass.ts 此示例渲染系统实现的特性: 1. 用户态与系统态隔离。 2. 高频调用与低频调用隔离。 3. 面向用户的易用性封装。 4. 渲染数据和渲染机制分离。 …...
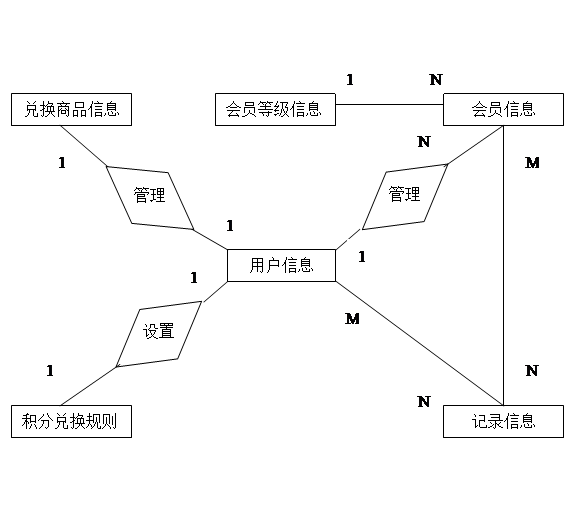
0030Java程序设计-积分管理系统论文
文章目录 摘 要**目 录**系统实现系统功能需求3.2.1 管理员功能3.2.2 柜员功能 开发环境 摘 要 随着计算机和网络的不断革新,世界已经进入了前所未有的电子时代。作为实用性强、应用范围广泛的会员管理系统也正在被越来越多的各类企业用于消费管理领域。然…...

Windows 11系统优化终极指南:用Win11Debloat一键清理系统垃圾,提升电脑性能
Windows 11系统优化终极指南:用Win11Debloat一键清理系统垃圾,提升电脑性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various ot…...

跨平台AI应用开发终极指南:ChatGPT Web Midjourney Proxy移动端适配全解析
跨平台AI应用开发终极指南:ChatGPT Web Midjourney Proxy移动端适配全解析 ChatGPT Web Midjourney Proxy是一款集成ChatGPT、Midjourney和GPTs功能的一站式AI应用,本文将详细解析其移动端适配方案,帮助开发者快速掌握跨平台AI应用的开发技巧…...

Kernel-Bridge API完全参考手册:从CPU操作到内存管理
Kernel-Bridge API完全参考手册:从CPU操作到内存管理 【免费下载链接】Kernel-Bridge Windows kernel hacking framework, driver template, hypervisor and API written on C 项目地址: https://gitcode.com/gh_mirrors/ke/Kernel-Bridge Kernel-Bridge是一…...

百度网盘直链解析工具:三步实现全速下载的终极方案
百度网盘直链解析工具:三步实现全速下载的终极方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘作为国内主流云存储平台,其下载限速问题一直…...
)
别急着换件!汇川伺服报Er.136/Er.740编码器故障,先按这3步自查(附线缆选购建议)
汇川伺服编码器故障排查指南:从干扰溯源到线缆优化 工业现场最让人头疼的莫过于设备间歇性抽风——明明昨天还运行良好,今天却频繁报Er.136或Er.740编码器故障。作为经历过数十次类似案例的技术老兵,我必须强调:80%的编码器问题根…...

PG数据库空间查询添加空间索引后提速10倍
以下语句直接在Navicat软件中链接PG数据库后实现 添加空间索引之前查询第一次要10几秒,添加空间索引之后不到1秒 -- 创建支持 UTM 32650 投影查询的空间索引 CREATE INDEX idx_fjdmdz_geom_32650 ON tablename USING GIST (ST_Transform(geom, 32650));SELECT * FROM tabl…...

即时通讯IM:从聊天工具到企业数字底座
即时通讯IM在2026年已不再只是员工桌面上用来收发消息的软件。它正经历一场深刻的角色蜕变——从“聊天工具”升级为支撑企业核心业务运转的“数字底座”。即时通讯系统已成为支撑企业核心运营的关键基础设施,IM正在被赋予连接一切、打通信息流的关键角色。 这种进化…...

杰理微蓝牙芯片AC696系列入门
1.文章背景 此篇文章以ac696n_soundbox_sdk_v1.7.0版本进行入门讲解: 写这篇文章的目的是因为自己在尝试入门杰理微的时候遇到了好多的问题点,想尝试用买到的开发板来驱动一颗LED闪烁却一直没有按自己想象的逻辑成功跑出效果,在网上到处翻找手…...

Android 开发问题:It‘s possible to extract method returning XXX from a long surrounding...
在 Android 开发中,Android Studio 出现如下提示信息 Its possible to extract method returning TakeCardRecordListDTO from a long surrounding method# 解读可以从长方法中提取返回“TakeCardRecordListDTO”的方法问题原因这段提示是提取方法重构策略ÿ…...

2026年5月19日:谷歌云误停账户致Railway全平台服务中断8小时
事件报告:2026年5月19日 - GCP账户暂停Chandrika Khanduri 与 Cody De Arkland于2026年5月20日发布此报告。据悉,本报告反映了发布时所掌握的信息,可能会根据谷歌云(Google Cloud)的内部审查结果进行更新。影响2026年5…...