3台Centos7快速部署Kafka集群
首先,我要说,Kafka 是强依赖于 ZooKeeper 的,所以在设置 Kafka 集群之前,我们首先需要设置一个 ZooKeeper 集群。
部署ZooKeeper需要安装jdk
yum install java-1.8.0-openjdk
安装完以后
下面是详细的步骤:
1. 安装和配置 ZooKeeper 集群
1.1 下载 ZooKeeper:
cd /data1
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.3/apache-zookeeper-3.8.3-bin.tar.gz
1.2 解压缩:
tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz
cd /data1/
mkdir kafka
mv apache-zookeeper-3.8.3-bin /data1/kafka/zookeeper
1.3 在每台机器上创建 myid 文件,并存放在一个特定的目录,例如 /data1/zookeeper_data。文件中的内容是每台机器的唯一ID,从 1 开始增加。
mkdir /data1/zookeeper_data
echo "1" > /data1/zookeeper_data/myid # 对于第二台机器为2,第三台为3
1.4 编辑 ZooKeeper 的配置文件:
cd /data1/kafka/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
编辑 zoo.cfg:
vi zoo.cfg
添加/修改以下内容:
dataDir=/data1/zookeeper_data
clientPort=2181
initLimit=10
syncLimit=5
tickTime=2000
server.1=192.142.25.119:2888:3888
server.2=192.142.25.120:2888:3888
server.3=192.142.25.121:2888:3888
2. 安装和配置 Kafka 集群
2.1 下载 Kafka:
cd /data1
wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
2.2 解压缩:
tar -zxvf kafka_2.13-3.6.0.tgz
mv kafka_2.13-3.6.0 /data1/kafka/kafka
2.3 编辑 Kafka 的配置文件:
cd /data1/kafka/kafka/config
vi server.properties
添加/修改以下内容:
broker.id=1 # 对于第二台机器为2,第三台为3
zookeeper.connect=192.142.25.119:2181,192.142.25.120:2181,192.142.25.121:2181
log.dirs=/data1/kafka/kafka-logs
2.4 设置 Kafka 的堆内存:
export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"
3. 启动 ZooKeeper 和 Kafka 集群
在每台机器上:
# 启动 ZooKeeper(先把3台的zookeeper都启动,再分别启动kafka)
/data1/kafka/zookeeper/bin/zkServer.sh start# 启动 Kafka
/data1/kafka/kafka/bin/kafka-server-start.sh /data1/kafka/kafka/config/server.properties &
4. Spring Boot 连接到 Kafka 集群
添加 Maven 依赖:
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>your_version</version>
</dependency>
配置 application.yml 或 application.properties:
spring:kafka:bootstrap-servers: 192.142.25.119:9092,192.142.25.120:9092,192.142.25.121:9092
之后,你可以使用 @KafkaListener 和 KafkaTemplate 来进行消息的消费和生产。
注意:以上步骤提供了基本的集群设置,可能需要根据实际环境进行适当调整。尤其在生产环境中,需要考虑安全性、高可用性和性能优化等问题。
为 Kafka 设置身份验证通常涉及使用 SASL。在这里,我将向您展示如何使用 SASL/PLAIN 为 Kafka 设置简单的用户名和密码,并为 Spring Boot 提供相应的连接方式。
1. Kafka 设置使用 SASL/PLAIN:
1.1. 编辑 Kafka 的 server.properties:
cd /data1/kafka/kafka/config
vi server.properties
在文件中添加以下内容:
listeners=SASL_PLAINTEXT://:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
1.2. 在 Kafka 配置目录下创建一个 JAAS 配置文件,例如 kafka_server_jaas.conf:
vi /data1/kafka/kafka/config/kafka_server_jaas.conf
添加以下内容:
KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret"user_admin="admin-secret"user_otheruser="otherpassword";
};
在这里,我们创建了两个用户:admin 和 otheruser。
1.3. 在启动 Kafka 之前,设置以下环境变量:
export KAFKA_OPTS="-Djava.security.auth.login.config=/data1/kafka/kafka/config/kafka_server_jaas.conf"
确实,当您直接在终端中执行export命令设置环境变量时,这些设置只对当前的shell会话有效。当会话结束或您关闭终端时,这些设置会丢失。为了让这些设置在每次用户登录或开启新的shell会话时都生效,您需要将这些export命令添加到某些特定的shell初始化文件中。
以下是几种常见的shell以及相关的初始化文件:
-
bash:
/etc/profile: 所有用户都会执行此文件。~/.bashrc或~/.bash_profile: 只对特定用户生效。
-
zsh:
/etc/zsh/zshenv: 所有用户都会执行此文件。~/.zshrc: 只对特定用户生效。
根据您的需要和所用的shell,您可以选择将以下内容添加到相应的文件中:
export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"
export KAFKA_OPTS="-Djava.security.auth.login.config=/data1/kafka/kafka/config/kafka_server_jaas.conf"
例如,如果您使用的是bash并希望这些设置对所有用户都生效,可以执行以下命令:
echo 'export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"' | sudo tee -a /etc/profile
echo 'export KAFKA_OPTS="-Djava.security.auth.login.config=/data1/kafka/kafka/config/kafka_server_jaas.conf"' | sudo tee -a /etc/profile
或者,如果您只希望这些设置对当前用户生效,您可以将上述export命令添加到您的~/.bashrc或~/.bash_profile中。
完成上述步骤后,您可以通过执行source命令来重新加载配置文件,使设置立即生效,例如:
source /etc/profile
或者
source ~/.bashrc
这样,每次您登录或开启新的shell会话时,这些环境变量设置都会自动应用。
1.4. 重启 Kafka 服务器以应用更改。
2. Spring Boot 连接到受密码保护的 Kafka:
2.1. 在您的 pom.xml 或 build.gradle 文件中确保已添加了以下依赖:
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>your_version</version>
</dependency>
2.2. 在 application.yml 或 application.properties 文件中添加以下内容:
spring:kafka:bootstrap-servers: 192.142.25.119:9092,192.142.25.120:9092,192.142.25.121:9092consumer:group-id: your-group-idkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerproperties:security.protocol: SASL_PLAINTEXTsasl.mechanism: PLAINsasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-secret";
这里我们使用了 admin 用户和对应的密码来连接到 Kafka。根据您的需求调整用户名和密码。
现在,您应该能够使用 Spring Boot 连接到受密码保护的 Kafka 集群并进行消息生产和消费。
注意:SASL/PLAIN 文本身份验证不提供传输安全性。在生产环境中,您应该考虑使用 SSL/TLS 与 SASL/PLAIN 结合来确保数据的机密性和完整性。
相关文章:

3台Centos7快速部署Kafka集群
首先,我要说,Kafka 是强依赖于 ZooKeeper 的,所以在设置 Kafka 集群之前,我们首先需要设置一个 ZooKeeper 集群。 部署ZooKeeper需要安装jdk yum install java-1.8.0-openjdk 安装完以后 下面是详细的步骤: 1. 安装和…...
)
最小栈(C++解法)
题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。i…...

Python 算法高级篇:堆排序的优化与应用
Python 算法高级篇:堆排序的优化与应用 引言 1. 什么是堆?2. 堆的性质3. 堆排序的基本原理4. 堆排序的 Python 实现5. 堆排序的性能和优化6. 堆排序的实际应用7. 总结 引言 堆排序是一种高效的排序算法,它基于数据结构中的堆这一概念。堆排序…...
视频下载软件 Downie4 mac中文介绍
Downie mac是一款Mac平台上非常实用的视频下载工具。它支持下载各种视频网站上的视频,并且具有快速、稳定、易于使用的特点。 Downie支持下载各种视频网站上的视频,包括YouTube、Vimeo、Netflix、Hulu、Amazon等等。它具有快速、稳定的下载速度ÿ…...

计算机操作系统重点概念整理-第一章 计算机系统概述【期末复习|考研复习】
第一章 计算机系统概述 【期末复习|考研复习】 计算机操作系统系列文章传送门: 第一章 计算机系统概述 第二章 进程管理 第三章 进程同步 第四章 内存管理 第五章 文件管理 第六章 输出输出I/O管理 文章目录 第一章 计算机系统概述 【期末复习|考研复习】前言一、计…...
树莓派基金会近日发布了新版基于 Debian 的树莓派操作系统
树莓派基金会(Raspberry Pi Foundation)近日发布了新版基于 Debian 的树莓派操作系统(Raspberry Pi OS),为树莓派单板电脑带来了新的书虫基础和一些重大变化。 新版 Raspberry Pi OS 的最大变化是它现在基于最新的 Deb…...
Web项目如何做单元测试
你可能会用单元测试框架,python的unittest、pytest,Java的Junit、testNG等。 那么你会做单元测试么!当然了,这有什么难的? test_demo.py def inc(x):return x 1def test_answer():assert inc(3) 4 inc() 是定义的…...

MySQL主从复制(基于GTID--事务ID方式)
目录 一、GTID相关概念1.GTID 是什么?2.GTID主从复制方式概念3.GTID的优缺点 二、GTID工作原理三、部署主从复制四、测试同步1.主库上新建数据库2.从库上查看是否同步成功 五、重设从库六、常见故障七、故障切换八、GTID的一些疑问1.为什么基于GTID的同步也要打开bi…...
3.72 Command Buffer及URP概述
一、Command Buffer 1.概念 CommandBuffer携带一系列的渲染命令,依赖相机,用来拓展渲染管线的渲染效果。而且可以指定在相机渲染的某个点执行本身的拓展渲染。Command buffers也可以结合屏幕后期效果使用。 简单来说就是可以在渲染流程中插入一些自定…...
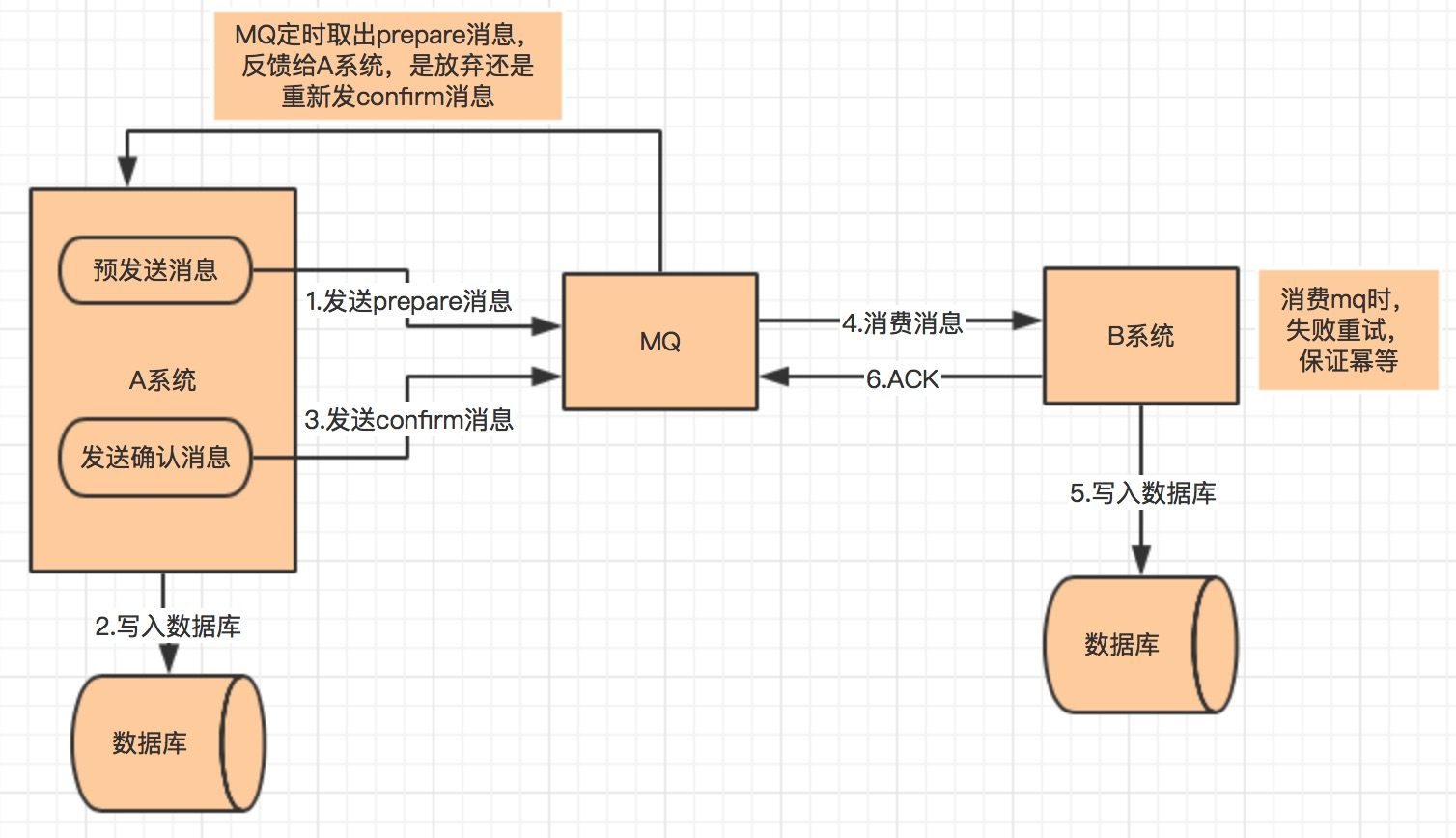
分布式理论和分布式锁知识点总结
文章目录 (一) 分布式理论算法和协议1)CAP理论总结 2)BASE理论BASE 理论的核心思想基本可用软状态最终一致性 3)Paxos算法Basic Paxos 算法4) Raft算法1 拜占庭将军 5)Gossip协议 (二) 分布式锁分布式锁应该具备哪些条…...

IOC课程整理-17 Spring事件
1. Java 事件/监听器编程模型 2. 面向接口的事件/监听器设计模式 3. 面向注解的事件/监听器设计模式 4. Spring 标准事件-ApplicationEvent 5. 基于接口的 Spring 事件监听器 6. 基于注解的 Spring 事件监听器 7. 注册 Spring ApplicationListener 8. Spring 事件发布器 9. Spr…...

大数据Flink(一百零五):SQL性能调优
文章目录 SQL性能调优 一、 MiniBatch 聚合...
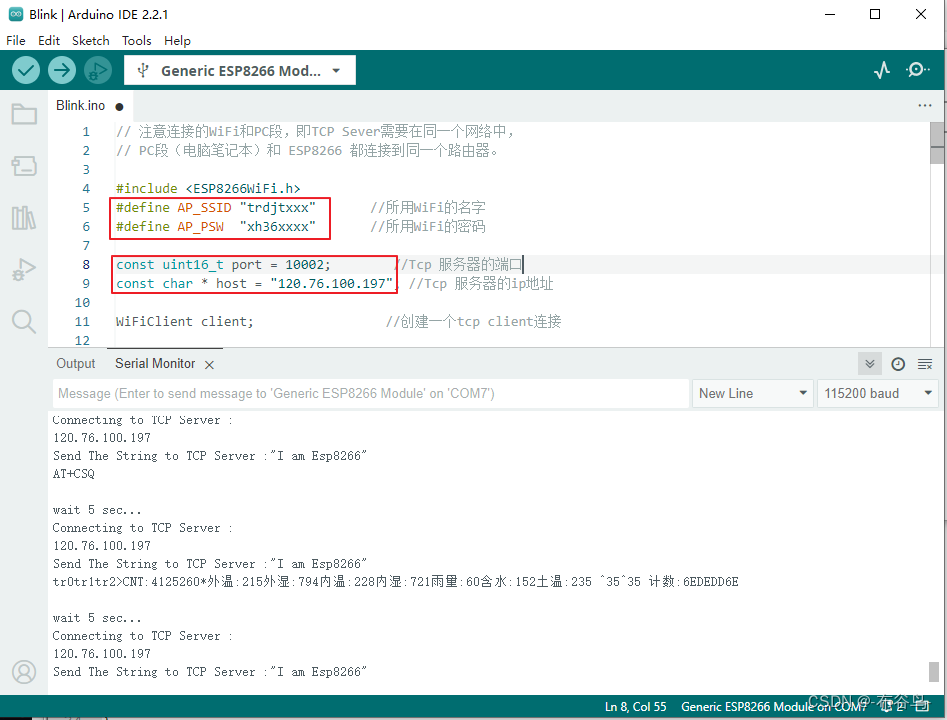
ESP8266,手机与电脑之间的TCP通讯
电脑端运行通讯猫调试助手,作为服务端: 电脑端 电脑的IP地址是: 192.168.2.232 手机与电脑之间的TCP通讯 手机端运行网络调试精灵,作为客户端: 手机端 如果从手机端点击"发送"按钮,则也会将"ghhh东方红广场"几个字发送到电脑上(服务端). ESP8266作为客户…...

vue的数据监听是如何实现的?
Vue的数据监听是通过数据劫持和发布订阅模式来实现的。 数据劫持:Vue通过使用Object.defineProperty()方法来劫持数据对象的属性,并使用getter和setter来监听属性的变化。当属性被修改时,setter方法会被调用,从而触发相应的监听函…...

埋点日志解决方案——Golang+Gin+Sarama VS Java+SpringCloudGateway+ReactorKafka
埋点日志解决方案——GolangGinSarama VS JavaSpringCloudGatewayReactorKafka 之前我就写过几篇OpenRestylua-kafka-client将埋点数据写入Kafka的文章,如下: Lua将Nginx请求数据写入Kafka——埋点日志解决方案 python定时任务执行shell脚本切割Nginx…...

LeetCode 541 反转字符串 II 简单
题目 - 点击直达 1. 541 反转字符串 II 简单1. 题目详情1. 原题链接2. 题目要求3. 基础框架 2. 解题思路1. 思路分析2. 时间复杂度3. 代码实现 1. 541 反转字符串 II 简单 1. 题目详情 给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个…...

从入门到精通:深入了解CSS中的Grid网格布局技巧和应用!
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一…...

Android Studio Giraffe 添加 maven { url “https://jitpack.io“ }报错
Android Studio Giraffe 添加 maven { url “https://jitpack.io” }报错 settings.gradle.kts:13:21: Unexpected tokens (use ; to separate expressions on the same line)解决方法 新版maven写法发生了改变: maven { url uri("https://jitpack.io"…...

Linux C/C++ 实现网络流量分析(性能工具)
网络流量分析的原理基于对数据包的捕获、解析和统计分析,通过对网络流量的细致观察和分析,帮助管理员了解和优化网络的性能、提高网络安全性,并快速排查和解决网络故障和问题。 Linux中的网络流量常见类型 在Linux中,网络流量可以…...

python门牌制作,统计某个数字出现的次数
题目: 小蓝要为一条街的住户制作门牌号。 这条街一共有 2022位住户,门牌号从 1 到 2022 编号。 小蓝制作门牌的方法是先制作 0 到 9 这几个数字字符,最后根据需要将字符粘贴到门牌上,例如门牌 1017 需要依次粘贴字符 1、0、1、…...

Chrome-Charset:三步解决浏览器网页乱码问题的终极指南
Chrome-Charset:三步解决浏览器网页乱码问题的终极指南 【免费下载链接】Chrome-Charset An extension used to modify the page default encoding for Chromium 55 based browsers. 项目地址: https://gitcode.com/gh_mirrors/ch/Chrome-Charset 你是否曾经…...

企业级AI Agent安全治理:从“能用“到“敢用“的五维框
一、为什么企业需要Agent治理框架我们公司最近在帮一家制造业客户做AI Agent数字员工的落地项目。客户之前已经自己部署了一批Agent,分别处理品质查询、物料追踪、报表生成等业务。运行三个月后,IT部门发现了三个让人头疼的问题:有个Agent累计…...

在Taotoken平台观测大模型API用量与成本的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken平台观测大模型API用量与成本的实际体验 对于需要持续调用多个大模型API的开发者或团队而言,成本控制与预算…...

如何快速上手Hertz.dev:5分钟完成首个全双工音频对话
如何快速上手Hertz.dev:5分钟完成首个全双工音频对话 【免费下载链接】hertz-dev first base model for full-duplex conversational audio 项目地址: https://gitcode.com/gh_mirrors/he/hertz-dev 想要体验革命性的全双工音频对话技术吗?Hertz.…...

告别手动翻日志!用Log Parser 2.2 + Login工具,5分钟自动化分析Windows安全事件
从日志泥潭到智能洞察:Log Parser与Login工具的高效协同实战 Windows安全事件日志就像一座未经开采的金矿,每天产生海量的4624、4625等登录事件记录。传统的手动翻查不仅效率低下,还容易遗漏关键安全线索。本文将带你突破手工操作的瓶颈&…...

终极指南:3步在电脑上免费畅玩PS4游戏的神器——shadPS4模拟器
终极指南:3步在电脑上免费畅玩PS4游戏的神器——shadPS4模拟器 【免费下载链接】shadPS4 PS4 emulator for Windows,Linux,MacOS 项目地址: https://gitcode.com/gh_mirrors/shad/shadPS4 还在为无法在电脑上体验PS4独占游戏而烦恼吗?shadPS4模拟…...

VSCodium终极指南:零监控的VS Code开源替代方案
VSCodium终极指南:零监控的VS Code开源替代方案 【免费下载链接】vscodium binary releases of VS Code without MS branding/telemetry/licensing 项目地址: https://gitcode.com/gh_mirrors/vs/vscodium VSCodium是一款基于Visual Studio Code源代码构建的…...

CTF 实战必备 Hashcat 密码破解工具 零基础全套教程
HashCat密码破解工具介绍 hashcat号称世界上最快的密码破解,世界上第一个和唯一的基于GPU的规则引擎,免费多GPU(高达128个GPU),多哈希,多操作系统(Linux和Windows本地二进制文件)&a…...

深入解析Godot PCK解包技术:从二进制黑盒到可编辑资源的完整指南
深入解析Godot PCK解包技术:从二进制黑盒到可编辑资源的完整指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 还在为Godot引擎生成的PCK文件无法访问而烦恼吗?想要深入分析…...

告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍
告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍 作为一名长期在Windows和Mac双平台切换的开发者,最令人抓狂的莫过于快捷键的差异。每次从Mac切换到Windows,肌肉记忆总会在关键时刻背叛你——当你…...