【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
相关博客
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
近日,RMT的作者放出的评测报告中声称其可以将Transformer能够处理的最大长度放宽到超过100万个tokens。让我们来看看RMT的原理及其实验细节。
一、RMT
论文地址:https://arxiv.org/pdf/2207.06881.pdf
1. 背景
自注意力机制为Transformer的核心组件之一,赋予模型针对单个token聚合上下文tokens的能力。因此,每个token在编码结束后,都能够获得丰富的上下文表示。但是,这种方式会造成全局信息和局部信息都被存储在单个表示中。全局特征被分别存储在所有的token表示上,导致全局特征“模糊”且难以访问。此外,自注意力机制的计算复杂度是输入长度的平方,这也造成模型难以应用在长文本输入上。
RMT(Recurrent Memory Transformer)是一种片段级、记忆增强的Transformer,用于解决Transformer在长文本上的问题。RMT使用一种附加在输入序列上的特定记忆token
来实现记忆机制。这些"记忆token"为模型提供了额外的存储容量,便于模型处理那些没有直接表达至任何token的信息。
2. 方法
2.1 Transformer-XL
Transformer-XL基于片段级循环和相对位置编码,实现了一种state重用的缓存机制。对于每个transformer层 n n n,前一个片段 M n M^n Mn计算出的hidden state会被缓存。第 n n n层的输入的组成:(1) 前 m m m个缓存的内容;(2) 前一个Transformer层针对当前片段 τ \tau τ的输出;即
H ~ τ n − 1 = [ S G ( M − m : n − 1 ) ∘ H τ n − 1 ] \tilde{H}_{\tau}^{n-1}=[SG(M_{-m:}^{n-1})\circ H_{\tau}^{n-1}] \\ H~τn−1=[SG(M−m:n−1)∘Hτn−1]
这里, M − m : n − 1 M_{-m:}^{n-1} M−m:n−1是第 n − 1 n-1 n−1层的前 m m m个缓存内容, S G SG SG表示不需要梯度, ∘ \circ ∘表示拼接, H τ n − 1 H_{\tau}^{n-1} Hτn−1表示模型第 n − 1 n-1 n−1层的输出。
H ~ τ n − 1 \tilde{H}_{\tau}^{n-1} H~τn−1是片段 τ \tau τ针对模型第 n n n层(TL)的输入,产生输出的过程为
Q τ n = W q n H τ n − 1 K τ n = W k n H ~ τ n − 1 V τ n = W v n H ~ τ n − 1 H τ n = T L ( Q τ n , K τ n , V τ n ) \begin{align} Q_\tau^n&=W_q^n H_{\tau}^{n-1} \\ K_\tau^n&=W_k^n \tilde{H}_{\tau}^{n-1} \\ V_\tau^n&=W_v^n\tilde{H}_{\tau}^{n-1} \\ H_\tau^n&=TL(Q_\tau^n,K_\tau^n,V_\tau^n) \end{align} \\ QτnKτnVτnHτn=WqnHτn−1=WknH~τn−1=WvnH~τn−1=TL(Qτn,Kτn,Vτn)
其中, W q n , W k n , W v n W_q^n,W_k^n,W_v^n Wqn,Wkn,Wvn是注意力的投影矩阵。注意, K τ n K_{\tau}^n Kτn和 V τ n V_{\tau}^n Vτn在计算时使用的是包含了缓存内容的 H ~ τ n − 1 \tilde{H}_{\tau}^{n-1} H~τn−1,而 Q τ n Q_\tau^n Qτn则使用了 H τ n − 1 H_\tau^{n-1} Hτn−1。在Transformer-XL的自注意力层中使用了相似位置编码。
2.2 RMT
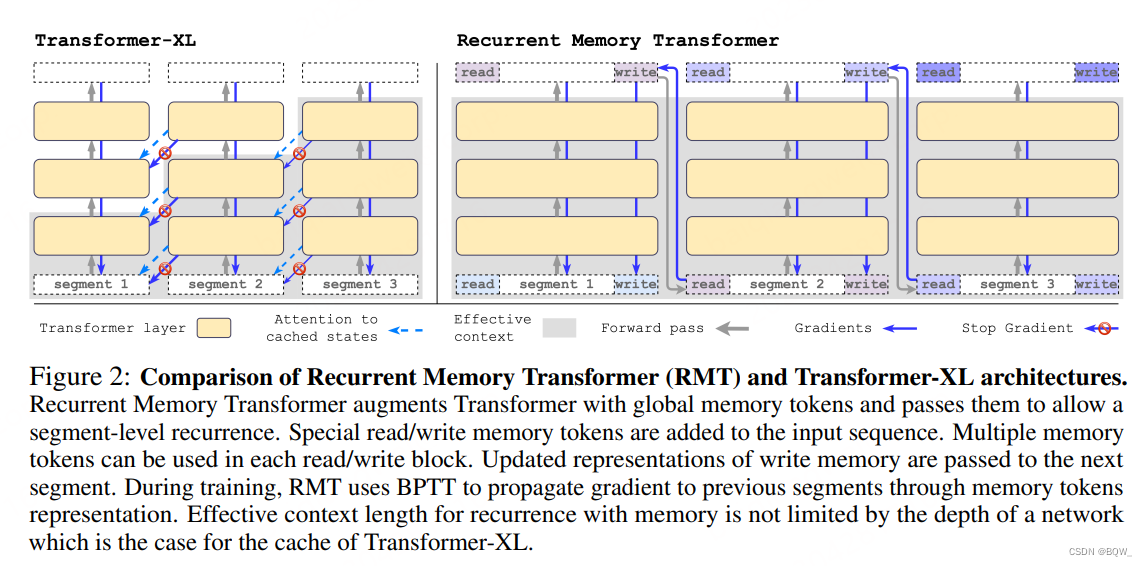
像GMAT、ETC、Memory Transformer等记忆增强的Transformer模型,通常会使用特殊的全局tokens来存储表示。通常,"记忆token"s会被添加至输入序列的开头位置。然而,decoder-only架构的causal attention mask使得在序列开始处的"记忆token"s无法收集到后续tokens的信息。若把"记忆token"放置在序列的末尾,前面的token就无法访问这些表示。为了解决这个问题,在序列样本处理时添加了一个循环。"记忆token"的表示放置在当前片段的末尾,然后作为下一个片段开始和末尾的记忆表示初始化。
RMT的输入是在标准方式基础上,添加了特殊tokens [ mem ] [\text{mem}] [mem]。每个"记忆token"都是一个实值向量。 m m m个"记忆token"分别被拼接至当前片段表示 H r 0 \text{H}_r^0 Hr0的开始和末尾:
H ~ τ 0 = [ H τ m e m ∘ H τ 0 ∘ H τ m e m ] H ˉ τ N = Transformer ( H ~ τ 0 ) [ H τ r e a d ∘ H τ N ∘ H τ w r i t e ] : = H ˉ τ N \begin{align} &\tilde{H}_{\tau}^0=[H_{\tau}^{mem}\circ H_{\tau}^0\circ H_{\tau}^{mem}] \\ &\bar{H}_\tau^N=\text{Transformer}(\tilde{H}_{\tau}^0) \\ &[H_\tau^{read}\circ H_\tau^{N}\circ H_{\tau}^{write}]:=\bar{H}_\tau^N \end{align} \\ H~τ0=[Hτmem∘Hτ0∘Hτmem]HˉτN=Transformer(H~τ0)[Hτread∘HτN∘Hτwrite]:=HˉτN
其中, N N N的模型的层数。总的来说,就是前一片段的"记忆token"拼接当前片段,然后进行前向传播。传播的结果中包含了当前层的表现以及"记忆token"的表示。
序列开始处的一组"记忆token"被称为"读记忆",其允许后续的tokens能够读取前一个片段的信息。末尾处的一组"记忆token"则称为"写记忆",其能够更新“记忆”的表示。因此, H τ w r i t e H_{\tau}^{write} Hτwrite包含了片段 τ \tau τ的更新后"记忆token"s。
输入序列中的片段会被顺序处理。为了使片段间能够循环链接,将当前片段输出的"记忆token"传递给下一个片段的输入:
H τ + 1 m e m : = H τ w r i t e H ~ τ + 1 0 = [ H τ + 1 m e m ∘ H τ + 1 0 ∘ H τ + 1 m e m ] \begin{align} & H_{\tau+1}^{mem}:= H_{\tau}^{write} \\ & \tilde{H}_{\tau+1}^0 = [H_{\tau+1}^{mem}\circ H_{\tau+1}^0\circ H_{\tau+1}^{mem}] \end{align} \\ Hτ+1mem:=HτwriteH~τ+10=[Hτ+1mem∘Hτ+10∘Hτ+1mem]
RMT是基于全局"记忆token"实现的,其能够保证骨干Transformer不变的情况下,增强任意Transformer类模型的能力。“记忆token”仅在模型的输入和输出上进行操作。
2.3 两者的区别
(1) RMT为每个片段存储 m m m个记忆向量,而Transformer-XL则为每个片段存储 m × N m\times N m×N向量。
(2) RMT会将前一个片段的记忆表示与当前片段的tokens一起送入Transformer层进行处理。
(3) "读/写记忆"块能够访问当前块的所有tokens,causal attention mask仅应用在输入序列上。
(4) 不同于Transformer-XL,RMT反向传播时不会去掉"记忆"部分的梯度。(本文实验的片段间梯度传播范围从0到4)
3. 原论文实验
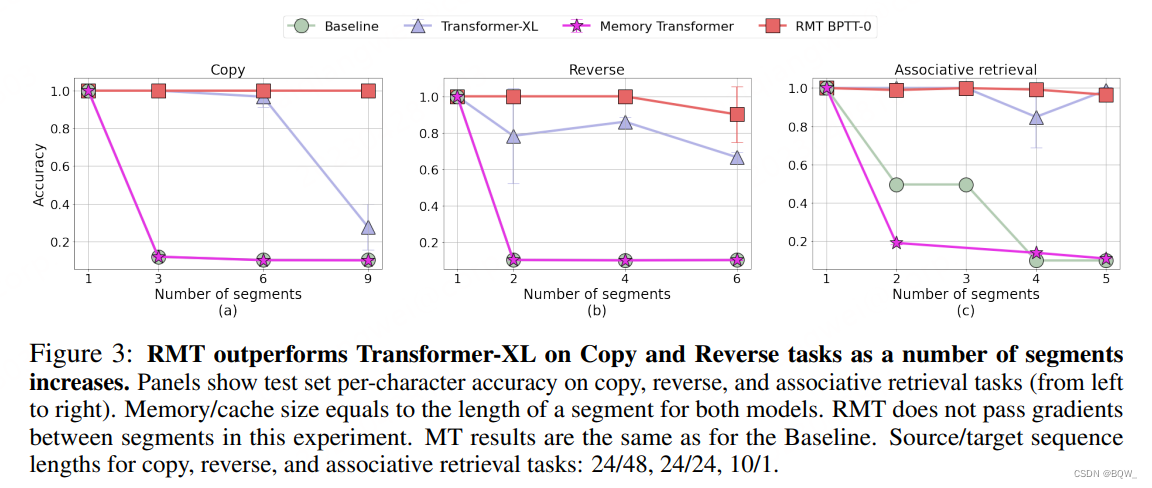
上图是RMT在三个需要长文本处理能力的任务Copy、Reverse和Associative retrieval上的实验结果。图的横坐标是切分的片段数,纵坐标是准确率。可以看到,RMT的效果都更好。
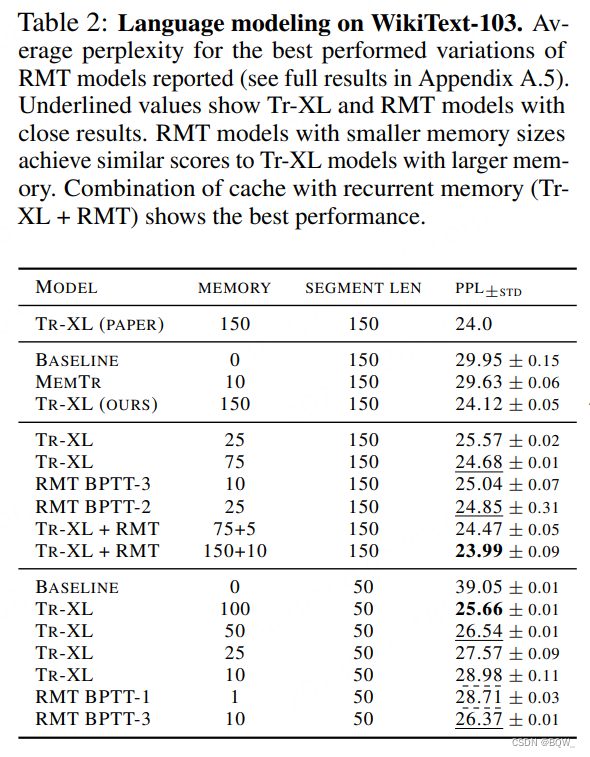
上表是语言建模任务的困惑度指标。显然,Transformer-XL和RMT的效果要好于baseline模型和Memory Transformer。
二、扩展至100万tokens
论文地址:https://arxiv.org/pdf/2304.11062.pdf
1. RMT Encoder版
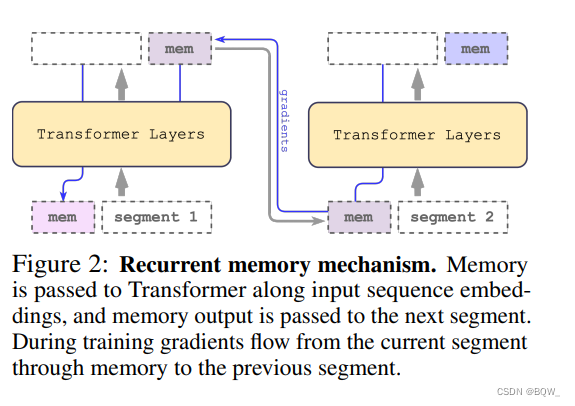
输入样本被分割为 m m m个片段,"记忆token"被添加到片段的开始,并与片段的其余tokens一起处理。对于BERT这样的encoder-only结构,"记忆token"仅被添加到片段的开始,而不像decoder-only那样分别添加read和write。对于时间步 τ \tau τ和片段 H τ 0 H_{\tau}^0 Hτ0,执行步骤为:
H ~ τ 0 = [ H τ m e m ∘ H τ 0 ] H ˉ τ N = Transformer ( H ~ τ 0 ) [ H ˉ τ m e m ∘ H τ N ] : = H ˉ τ N \begin{align} &\tilde{H}_{\tau}^0=[H_{\tau}^{mem}\circ H_{\tau}^0] \\ &\bar{H}_{\tau}^N=\text{Transformer}(\tilde{H}_{\tau}^0) \\ &[\bar{H}_{\tau}^{mem}\circ H_{\tau}^N]:=\bar{H}_{\tau}^N \end{align} H~τ0=[Hτmem∘Hτ0]HˉτN=Transformer(H~τ0)[Hˉτmem∘HτN]:=HˉτN
其中, N N N是Transformer的层数。
在前向传播后, H ˉ τ m e m \bar{H}_{\tau}^{mem} Hˉτmem片段 τ \tau τ的记忆token。输入序列的片段会按顺序逐个被处理。为了确保能够实现递归的连接,将当前片段的"记忆token"传递为下一个片段的输入:
H τ + 1 m e m : = H ˉ τ m e m H ~ τ + 1 0 = [ H τ + 1 m e m ∘ H τ + 1 0 ] \begin{align} & H_{\tau+1}^{mem}:=\bar{H}_{\tau}^{mem} \\ & \tilde{H}_{\tau+1}^0=[H_{\tau+1}^{mem}\circ H_{\tau+1}^0] \end{align} \\ Hτ+1mem:=HˉτmemH~τ+10=[Hτ+1mem∘Hτ+10]
2. 记忆任务
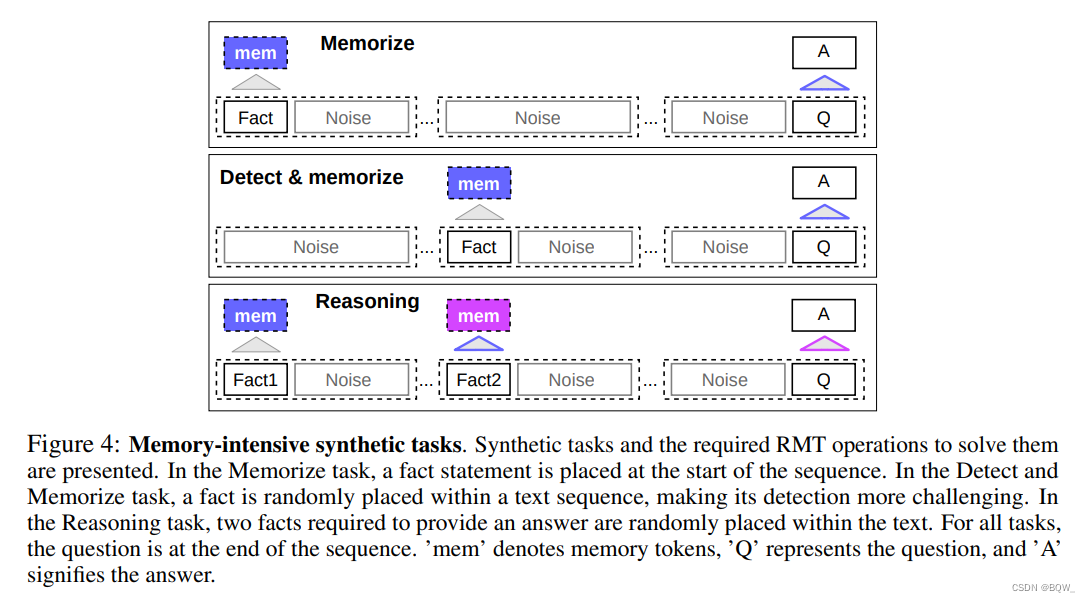
为了测试记忆能力,构建了需要记忆简单事实和基本推理的合成数据集。任务的输入是若干个事实和一个需要通过这些事实才能回答的问题。任务的形式为6分类,每个类别表示一个独立的答案选项。
-
事实记忆
该任务是测试RMT长时间存储信息的能力。在最简单的例子中,事实总是位于输入的开始,而问题在输入的末尾。问题和答案之间插入不相关的文本,完整的输入无法放入单个模型中。
-
事实检测和记忆
该任务增加了难度,将事实移动到随机的位置。需要模型从不相关文本中区分出事实,写入到记忆中,随后用来回答问题。
-
用记忆的事实进行推理
两个事实被添加至输入的随机位置上,问题放置在输入的末尾,该问题需要所有的事实才能回答。
3. 实验
实验使用bert-base-cased作为backbone。所有模型都是用尺寸为10的memory来增强,并使用AdamW优化器进行优化。
3.1 课程学习
使用训练schedule能够极大的改善准确率和稳定性。初始,RMT在较短的任务上进行训练,在训练收敛之后,再继续增加长度。
3.2 外推能力
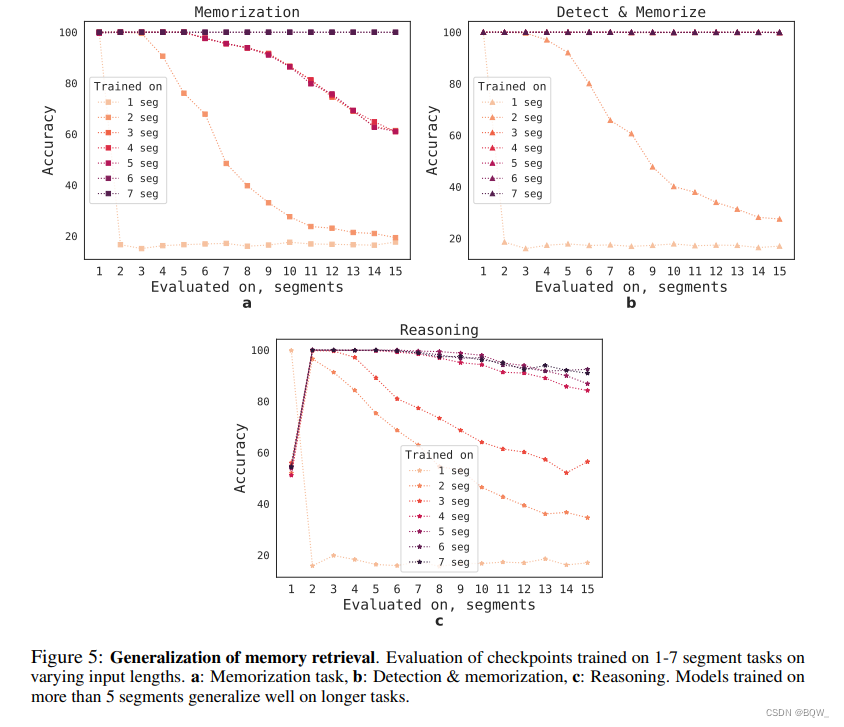
为了评估RMT泛化到不同序列长度的能力,评估了在不同长度上训练的模型,结果如上图。模型在较短的任务上效果更好。唯一的例外是单片段推理任务,模型一旦在更长序列上训练,那么效果就会变差。
随着训练片段数量的增加,RMT也能够泛化到更长的序列上。在5个或者更长的片段上进行训练后,RMT几乎可以完美的泛化到两倍的长度。

为了能够测试泛化的极限,将验证任务的尺寸从4096增加至2043904,RMT在如此长的序列上也能够有很好的效果。
三、总结
- 总的来说,RMT的思路简单。相比Transformer-XL来说,片段间传递的参数会少很多。
- RMT采用递归的方式传递信息,那么训练时梯度也需要回传,这导致训练时不太能并行。
- 原始论文中采用decoder-only架构,但是在扩展至百万tokens的实验中采用了encoder-only架构,是decoder-only的效果不够好吗?
- 评测的任务总体比较简单,迁移至当前的LLM上效果怎么样还比较难以确定。
相关文章:
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
相关博客 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer 【自然语言处理】【大模型】MPT模型结构源码解析(单机版) 【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版) 【自然语言处理】【大模型】BLOOM模型结构源码解析(…...
交叉编译工具链(以STM32MP1为例)
1.什么是交叉编译工具链? 在一个系统上进行编译,在另一个系统上进行执行 2.STM32MP1交叉编译工具链 3.交叉编译器内容 4.两种工具链模式 5.两种链接模式 6.工具使用 注意:OpenSTLinux已经提供了编译框架,不需要命令行手工编译 …...
使用 Pyro 和 PyTorch 的贝叶斯神经网络
一、说明 构建图像分类器已成为新的“hello world”。还记得当你第一次接触 Python 时,你的打印“hello world”感觉很神奇吗?几个月前,当我按照PyTorch 官方教程并为自己构建了一个运行良好的简单分类器时,我也有同样的感觉。 我…...

How to install the console system of i-search rpa on Centos 7
How to install the console system of i-search rpa on Centos 7 1、 准备1.1 、查看磁盘分区状态1.2、上传文件1.2.1、添加上传目录1.2.2、上传安装包1.2.3、解压安装包1.2.4、查看安装包结构 1.3、安装依赖包1.3.1、基础依赖包1.3.2 相关依赖 1.4、关闭防火墙1.5、解除SeLin…...
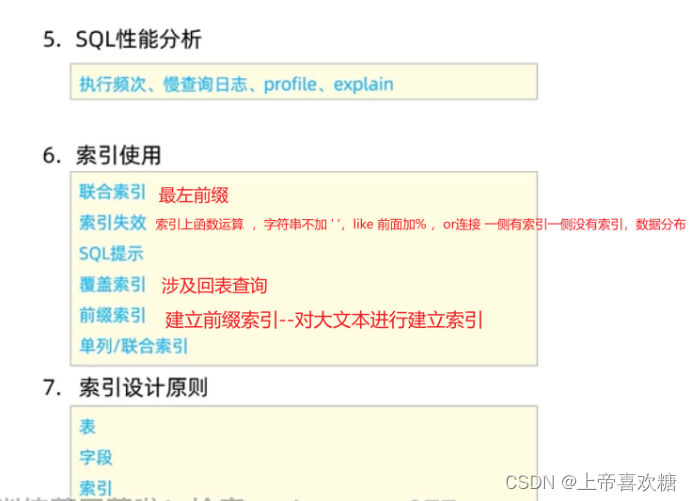
sql--索引使用 ---覆盖索引
覆盖索引 Select 后接 * 走id索引才是最优,使用二级索引则需要回表(性能稍差) 前缀索引 Create index 索引名 on 表名( 字段名( n ) ) n数字 n代表提取这个字符串的n个构建索引 ??那么 n 为几性能是最好的呢&…...

系统平台同一网络下不同设备及进程的话题通讯--DDS数据分发服务中间件
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言(1)中间件的介绍(2)DDS介绍(3)发布者(4)订阅者(5)idl文件(定义msg结构体)(6)QoS(Quality of Service)策略(7)DDS测试工具介绍(…...

轻量级 IDE 文本编辑器 Geany 发布 2.0
Geany 是功能强大、稳定、轻量的开发者专用文本编辑器,支持 Linux、Windows 和 macOS,内置支持 50 多种编程语言。 2005 年Geany 发布首个版本 0.1。上周四刚好是 Geany 诞生 18 周年纪念日,官方发布了 2.0 正式版以表庆祝。 下载地址&#…...

好用工具分享 | tmux 终端会话分离工具
目录 1 tmux的安装 2 tmux的基本操作 2.1 启动与退出 2.2 分离会话 2.3 查看会话 2.4 重接会话 2.5 杀死会话 2.6 切换会话 tmux是一个 terminal multiplexer(终端复用器),它可以启动一系列终端会话。 我们使用命令行时,…...

计算机网络重点概念整理-第三章 数据链路层【期末复习|考研复习】
计算机网络复习系列文章传送门: 第一章 计算机网络概述 第二章 物理层 第三章 数据链路层 第四章 网络层 第五章 传输层 第六章 应用层 第七章 网络安全 计算机网络整理-简称&缩写 文章目录 前言三、数据链路层3.1 数据链路层的基础概念3.2 帧3.2.1 帧的概念3.2…...

迅速的更改conda 环境的名称!
快速的做法是,复制之前创建的环境 重新命名 然后再删除旧的环境即可!!! 因为之前已经装过环境了,只是名字不叫A而是B,所以现在把B(old_name)改成A(new_name)。 具体方法如下: 1. 复制出来一份…...

基本微信小程序的外卖点餐订餐平台
项目介绍 餐饮行业是一个传统的行业。根据当前发展现状,网络信息时代的全面普及,餐饮行业也在发生着变化,单就点餐这一方面,利用手机点单正在逐步进入人们的生活。传统的点餐方式,不仅会耗费大量的人力、时间…...
十大排序算法(C语言)
参考文献 https://zhuanlan.zhihu.com/p/449501682 https://blog.csdn.net/mwj327720862/article/details/80498455?ops_request_misc%257B%2522request%255Fid%2522%253A%2522169837129516800222848165%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&…...

iTransformer: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
#论文题目:ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING #论文地址:https://arxiv.org/abs/2310.06625 #论文源码开源地址:https://github.com/thuml/Time-Series-Library #论文所属会议:Mach…...

QT C++ AES字符串加密实现
使用方法:在.h中引入类库。然后在cpp中直接引入使用即可 类库的下载地址https://download.csdn.net/download/u012372365/88478671 具体代码: #include <QCoreApplication> #include <QTest> #ifdef __cplusplus #include "unit_tes…...

关于mysql json字段创建索引
前言: 创建索引的方式分为两种,CREATE index 和 ALTER TABLE; 被创建索引的关键字类型又分两种,数字(UNSIGNED)和字符串(char(128)) 一、给json对象属性param_value(假…...

“探索Linux世界:从CentOS安装到常见命令使用“
目录 引言一、安装CentOS二、Linux的常见命令文件夹和目录操作命令文件编辑命令vi或vim编辑器命令模式编辑模式末行模式 总结 引言 在计算机领域,Linux作为一种强大而灵活的操作系统,在服务器、嵌入式设备和个人电脑等领域广泛应用。本文将引导您了解并…...
SVN出现Cleanup failed to process the following paths...
SVN报错,需要执行SVN的清理命令clean up,但clean up时出现错误Cleanup failed to process the following paths... 解决办法: 1、clean up的窗口,勾选Break locks和Fix time stamps(简单方便);…...
gitee上传项目
目录 首先在gitee新建一个仓库 接下来创建好项目,先找到生成公钥SSH的目录 接下来是生成公钥SSH 仓库创建好后,接着开始链接项目 首先在gitee新建一个仓库 接下来创建好项目,先找到生成公钥SSH的目录 接下来是找目录:C盘&a…...

实现文件上传和下载
文件上传的前端页面: multiple表示支持一次上传多个文件 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>上传文件</title> </head> <body> <form action"/ge…...
大数据-Storm流式框架(七)---Storm事务
storm 事务 需求 storm 对于保证消息处理,提供了最少一次的处理保证。最常见的问题是如果元组可以被 重发,可以用于计数吗?不会重复计数吗? strom0.7.0 引入了事务性拓扑的概念,可以保证消息仅被严格的处理一次。因此可…...
)
ROS路径规划实战:用move_base让机器狗在Gazebo中自主导航(避坑指南)
ROS路径规划实战:用move_base让机器狗在Gazebo中自主导航(避坑指南) 当机器狗在仿真环境中流畅地绕过障碍物走向目标点时,那种成就感就像看着自家宠物第一次成功接住飞盘。作为ROS开发者,掌握move_base实现自主导航的能…...

foobox-cn:foobar2000现代化DUI皮肤配置的终极音乐管理方案
foobox-cn:foobar2000现代化DUI皮肤配置的终极音乐管理方案 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn foobox-cn是为foobar2000播放器设计的现代化默认用户界面(DUI&…...

Meta2d.js终极指南:从零构建专业级Web SCADA与数字孪生应用
Meta2d.js终极指南:从零构建专业级Web SCADA与数字孪生应用 【免费下载链接】meta2d.js The meta2d.js is real-time data exchange and interactive web 2D engine. Developers are able to build Web SCADA, IoT, Digital twins and so on. Meta2d.js是一个实时数…...

暗黑破坏神2终极单机优化:PlugY生存工具包完整指南
暗黑破坏神2终极单机优化:PlugY生存工具包完整指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 厌倦了暗黑破坏神2单机模式的储物空间限制?…...

APK Studio安全最佳实践:合规使用逆向工程工具
APK Studio安全最佳实践:合规使用逆向工程工具 【免费下载链接】apkstudio Open-source, cross platform Qt based IDE for reverse-engineering Android application packages. 项目地址: https://gitcode.com/gh_mirrors/ap/apkstudio 在移动应用开发与安全…...
在静电模拟中的应用)
GAMES201实战:5分钟搞懂快速多极展开(FMM)在静电模拟中的应用
GAMES201实战:5分钟搞懂快速多极展开(FMM)在静电模拟中的应用 当你在游戏引擎中设计一个带电粒子系统时,是否遇到过这样的困境:随着粒子数量增加,计算速度呈指数级下降?传统N体问题计算需要处理每个粒子间的相互作用&a…...

LeRobot SO100主从臂配置全流程:从硬件组装到模型训练
LeRobot SO100主从臂实战指南:从零搭建到智能控制 1. 项目概述与硬件准备 LeRobot SO100作为HuggingFace开源社区推出的机器人学习平台,为开发者提供了从硬件组装到AI模型训练的全套解决方案。这套主从臂系统最吸引人的特点在于其模块化设计——六自由度…...

CDAN不只是论文里的公式:深入浅出图解‘条件对抗’如何让领域自适应更精准
CDAN不只是论文里的公式:深入浅出图解‘条件对抗’如何让领域自适应更精准 想象你是一位冰淇淋品鉴师,需要将一家老牌店铺(源域)的配方迁移到新店铺(目标域)。传统方法粗暴混合所有原料,导致巧…...
)
别光看公式了!用Multisim 14.0手把手仿真这8个经典运放电路(附工程文件)
别光看公式了!用Multisim 14.0手把手仿真这8个经典运放电路(附工程文件) 在电子工程的学习过程中,运算放大器(Op-Amp)无疑是一个让人又爱又恨的存在。爱的是它强大的功能和广泛的应用,恨的是那些…...

如何通过BaiduNetdiskPlugin实现下载性能提升:面向macOS用户的实用指南
如何通过BaiduNetdiskPlugin实现下载性能提升:面向macOS用户的实用指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 百度网盘作为常用的…...