chatgpt生成文本的底层工作原理是什么?
文章目录
- 🌟 ChatGPT生成文本的底层工作原理
- 🍊 一、数据预处理
- 🍊 二、模型结构
- 🍊 三、模型训练
- 🍊 四、文本生成
- 🍊 总结
📕我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO专家博主、阿里云专家博主、清华大学出版社签约作者、产品软文创造者、技术文章评审老师、问卷调查设计师、个人社区创始人、开源项目贡献者。🌎跑过十五公里、徒步爬过衡山、🔥有过三个月减肥20斤的经历、是个喜欢躺平的狠人。
📘拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、SpringBoot、Spring MVC、SpringCould、Mybatis、Dubbo、Zookeeper),消息中间件底层架构原理(RabbitMQ、RockerMQ、Kafka)、Redis缓存、MySQL关系型数据库、 ElasticSearch全文搜索、MongoDB非关系型数据库、Apache ShardingSphere分库分表读写分离、设计模式、领域驱动DDD、Kubernetes容器编排等。🎥有从0到1的高并发项目经验,利用弹性伸缩、负载均衡、报警任务、自启动脚本,最高压测过200台机器,有着丰富的项目调优经验。
📙经过多年在CSDN创作上千篇文章的经验积累,我已经拥有了不错的写作技巧。同时,我还与清华大学出版社签下了四本书籍的合约,并将陆续在明年出版。这些书籍包括了基础篇、进阶篇、架构篇的📌《Java项目实战—深入理解大型互联网企业通用技术》📌,以及📚《解密程序员的思维密码–沟通、演讲、思考的实践》📚。具体出版计划会根据实际情况进行调整,希望各位读者朋友能够多多支持!

希望各位读者大大多多支持用心写文章的博主,现在时代变了,信息爆炸,酒香也怕巷子深,博主真的需要大家的帮助才能在这片海洋中继续发光发热,所以,赶紧动动你的小手,点波关注❤️,点波赞👍,点波收藏⭐,甚至点波评论✍️,都是对博主最好的支持和鼓励!
- 💂 博客主页: 我是廖志伟
- 👉开源项目:java_wxid
- 🌥 哔哩哔哩:我是廖志伟
- 🎏个人社区:幕后大佬
- 🔖个人微信号:
SeniorRD
💡在这个美好的时刻,本人不再啰嗦废话,现在毫不拖延地进入文章所要讨论的主题。接下来,我将为大家呈现正文内容。

🌟 ChatGPT生成文本的底层工作原理
ChatGPT是一种基于人工智能的文本生成技术,采用了深度学习的方法来实现。它的核心是一个预训练的神经网络模型,这个模型可以在大量的语料库数据上进行训练,从而学习到人类语言的规律和模式,进而实现对文本的自动生成。
在ChatGPT中,文本的生成过程可以看作是一种序列生成问题。具体而言,它的任务就是在给定前面的文本序列的情况下,生成一段新的文本序列,使得生成的文本序列与真实语言的文本序列越接近越好。
下面,我们具体介绍ChatGPT生成文本的底层工作原理。
🍊 一、数据预处理
在ChatGPT中,首先要做的就是对训练数据进行预处理。预处理的目的是将原始的文本数据转换成可以输入到模型中的数值型数据。具体而言,这个过程包括以下几个步骤。
- 分词
在自然语言处理中,分词是一个非常重要的步骤。分词的目的是将文本按照词的单位进行划分,方便模型进行进一步的处理。在ChatGPT中,通常采用的是基于BPE(Byte Pair Encoding)的分词方法。这种方法可以根据训练数据中的频次信息自适应地将单词划分成子词,从而避免了许多词汇的歧义问题。
- 编码
分词之后,需要将每个词汇映射成一个唯一的数值ID。这个过程称为编码。在ChatGPT中,通常采用的是基于字典的编码方法。具体而言,就是将每个词汇映射成一个唯一的ID,然后使用这个ID来表示这个词汇。
- 构建样本
在将文本数据转换成数值型数据之后,还需要将这些数据组织成样本,方便模型进行学习。在ChatGPT中,通常采用的是滑动窗口的方法构建样本。具体而言,就是将文本分成若干个固定长度的序列,然后将这些序列作为样本输入到模型中进行训练。
🍊 二、模型结构
ChatGPT的核心是一个基于Transformer的神经网络模型。与传统的循环神经网络相比,Transformer具有更好的并行化能力和更短的训练时间。同时,它还可以有效地处理长序列数据,能够更好地满足ChatGPT中对长文本生成的需求。
具体而言,ChatGPT增加了一些待生成文本长度的控制机制和文本内容约束机制。这些机制可以控制生成的文本长度和内容,从而使得ChatGPT在生成文本时更加可控和灵活。
🍊 三、模型训练
模型训练是ChatGPT生成文本的关键。在模型训练过程中,需要使用大量的语料库数据对模型进行预训练,从而使得模型能够具备理解人类语言的能力,并能够自动地生成文本。
具体而言,ChatGPT采用的是无监督预训练的方式。在预训练过程中,模型会根据输入的文本序列,试图预测下一个单词。这个过程与语言模型的训练非常相似。通过这种方式,模型可以在大量的语料库数据上进行训练,从而学习到人类语言的规律和模式,进而实现对文本的自动生成。
🍊 四、文本生成
在训练完模型之后,就可以使用ChatGPT来生成新的文本序列了。具体而言,文本生成的过程可以分为两个步骤。
- 前向传播
文本生成的第一步是前向传播。在前向传播过程中,需要将给定的前面的文本序列输入到模型中,然后让模型自动地生成下一个单词。这个过程可以重复进行,直到生成一段满足要求的文本序列为止。
- 采样策略
在前向传播的过程中,还需要指定采样策略。采样策略是指生成文本时选择下一个单词的方式。目前,ChatGPT中通常采用的是基于温度的采样策略。这种策略可以控制生成文本的多样性和准确性,从而使得生成的文本更加符合要求。
🍊 总结
综上所述,ChatGPT生成文本的底层工作原理是基于预训练的神经网络模型。在模型训练过程中,需要使用大量的语料库数据对模型进行无监督预训练。在文本生成的过程中,需要将给定的前面的文本序列输入到模型中,然后通过采样策略自动地生成下一个单词。通过这种方式,ChatGPT可以自动地生成符合要求的文本序列,具有广泛的应用前景。
🔔如果您需要转载或者搬运这篇文章的话,非常欢迎您私信我哦~
希望各位读者大大多多支持用心写文章的博主,现在时代变了,信息爆炸,酒香也怕巷子深,博主真的需要大家的帮助才能在这片海洋中继续发光发热,所以,赶紧动动你的小手,点波关注❤️,点波赞👍,点波收藏⭐,甚至点波评论✍️,都是对博主最好的支持和鼓励!
- 💂 博客主页: 我是廖志伟
- 👉开源项目:java_wxid
- 🌥 哔哩哔哩:我是廖志伟
- 🎏个人社区:幕后大佬
- 🔖个人微信号:
SeniorRD
📥博主的人生感悟和目标

- 🍋程序开发这条路不能停,停下来容易被淘汰掉,吃不了自律的苦,就要受平庸的罪,持续的能力才能带来持续的自信。我本身是一个很普通程序员,放在人堆里,除了与生俱来的盛世美颜,就剩180的大高个了,就是我这样的一个人,默默写博文也有好多年了。
- 📺有句老话说的好,牛逼之前都是傻逼式的坚持,希望自己可以通过大量的作品、时间的积累、个人魅力、运气、时机,可以打造属于自己的技术影响力。
- 💥内心起伏不定,我时而激动,时而沉思。我希望自己能成为一个综合性人才,具备技术、业务和管理方面的精湛技能。我想成为产品架构路线的总设计师,团队的指挥者,技术团队的中流砥柱,企业战略和资本规划的实战专家。
- 🎉这个目标的实现需要不懈的努力和持续的成长,但我必须努力追求。因为我知道,只有成为这样的人才,我才能在职业生涯中不断前进并为企业的发展带来真正的价值。在这个不断变化的时代,我必须随时准备好迎接挑战,不断学习和探索新的领域,才能不断地向前推进。我坚信,只要我不断努力,我一定会达到自己的目标。
有需要对自己进行综合性评估,进行职业方向规划,让专门的技术大牛模拟面试、针对性的指导、传授面试技巧、简历优化、进行技术问题答疑等服务。
可访问:https://java_wxid.gitee.io/tojson/

相关文章:
chatgpt生成文本的底层工作原理是什么?
文章目录 🌟 ChatGPT生成文本的底层工作原理🍊 一、数据预处理🍊 二、模型结构🍊 三、模型训练🍊 四、文本生成🍊 总结 📕我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN…...

javaEE -11(10000字HTML入门级教程)
一: HTML HTML 代码是由 “标签” 构成的. 例如: <body>hello</body>标签名 (body) 放到 < > 中大部分标签成对出现. 为开始标签, 为结束标签.少数标签只有开始标签, 称为 “单标签”.开始标签和结束标签之间, 写的是标签的内容. (h…...

LeetCode75——Day21
文章目录 一、题目二、题解 一、题目 1207. Unique Number of Occurrences Given an array of integers arr, return true if the number of occurrences of each value in the array is unique or false otherwise. Example 1: Input: arr [1,2,2,1,1,3] Output: true Ex…...

学习笔记---更进一步的双向链表专题~~
目录 1. 双向链表的结构🦊 2. 实现双向链表🐝 2.1 要实现的目标🎯 2.2 创建初始化🦋 2.2.1 List.h 2.2.2 List.c 2.2.3 test.c 2.2.4 代码测试运行 2.3 尾插打印头插🪼 思路分析 2.3.1 List.h 2.3.2 List.…...

vscode格式化代码, 谷歌风格, 允许短if同行短块同行, tab = 4舒适风格
ctrl ,输入format, 点开C风格设置 在这块内容输入{ BasedOnStyle: Chromium, IndentWidth: 4, ColumnLimit: 200, AllowShortIfStatementsOnASingleLine: true, AllowShortLoopsOnASingleLine: true} C_Cpp: Clang_format_fallback Style 用作回退的预定义样式的名称&#x…...
百度富文本上传图片后样式崩塌
🔥博客主页: 破浪前进 🔖系列专栏: Vue、React、PHP ❤️感谢大家点赞👍收藏⭐评论✍️ 问题描述:上传图片后,图片会变得很大,当点击的时候更是会顶开整个的容器的高跟宽 原因&#…...

autoware.ai中检测模块lidar_detector caffe
lidar_apollo_cnn_seg_detect模块:该模块主要是调用百度apollo的目标分割。 1.需要安装caffe进行实现: caffe安装步骤: git clone https://github.com/BVLC/caffecd caffe && mdkir build && cd buildcmake ..出现报错: CM…...

CentOS安装Ruby环境
安装依赖项 sudo yum install -y perl zlib-devel openssl-devel安装git sudo yum install -y git git config --global http.sslVerify falsecurl取消ssl认证 echo "insecure" >> ~/.curlrc安装rbenv https://github.com/rbenv/rbenv git clone https://…...
 c++)
力扣第509题 斐波那契数 新手动态规划(推荐参考) c++
题目 509. 斐波那契数 简单 相关标签 递归 记忆化搜索 数学 动态规划 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0&a…...

canvas绘制签名并保存
实现签名的三个关键方法: 1.mousedown:当鼠标按下时开始绘制签名。 2.mousemove:鼠标移动时持续绘制。 3.mouseup:鼠标抬起时结束绘制。 html: <div class"setSign"><canvasref"canvas&q…...
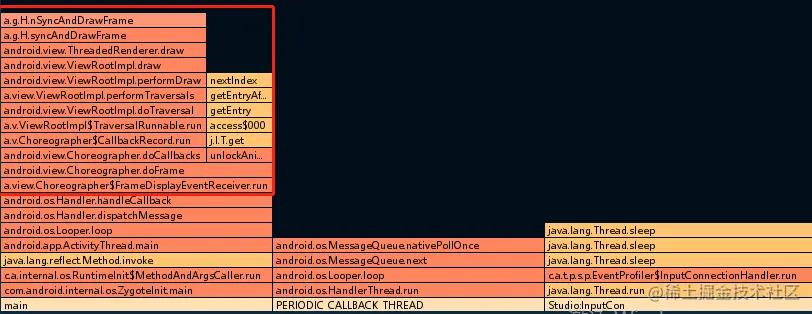
Android渲染流程
目录 缓冲区的不同生命周期代表当前缓冲区的状态: 多个源 ViewRootImpl: Android4.0: Android5.0: Android应用程序调用SurfaceFliger将测量,布局,绘制好的Surface借助GPU渲染显示到屏幕上。 一个Acti…...

牛客-【237题】算法基础精选题单-第二章 递归、分治
第二章 递归、分治 递归NC15173 The Biggest Water ProblemNC22164 更相减损术 递归 NC15173 The Biggest Water Problem 简单递归,直接暴力 #include <math.h> #include <stdio.h> #include <algorithm> #include <cstring> #include &…...

leetcode-字符串
1.反转字符串LeetCode344. 20230911 难度为0,此处就不放代码了 注意reverse和swap等一系列字符串函数什么时候该用,记一记库函数 swap可以有两种实现,涨知识了,除了temp存值还可以通过位运算:s[i] ^ s[j]; s[j] ^ s[i…...

多线程---synchronized特性+原理
文章目录 synchronized特性synchronized原理锁升级/锁膨胀锁消除锁粗化 synchronized特性 互斥 当某个线程执行到某个对象的synchronized中时,其他线程如果也执行到同一个对象的synchronized就会阻塞等待。 进入synchronized修饰的代码块相当于加锁 退出synchronize…...
Qt实现卡牌对对碰游戏
效果 闲来无事,实现一个对对碰游戏,卡牌样式是火影动漫。 先上效果: 卡牌对对碰_火影主题 玩法 启动游戏,进入第一关卡,所有卡牌都为未翻开状态,即背面朝上;点击卡牌,则将卡牌翻开…...

【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割7(数据预处理)
在上一节:【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割6(数据预处理) 中,我们已经得到了与mhd图像同seriesUID名称的mask nrrd数据文件了,可以说是一一对应了。 并且,mask的文件,还根据结…...

极米科技H6 Pro 4K、H6 4K高亮定焦版——开启家用投影4K普及时代
智能投影产业经过几年发展,市场规模正在快速扩大。洛图数据显示,预计今年中国投影出货量有望超700万台,2027年达950万台,可见智能投影产业规模将逐渐壮大,未来可期。2023年,投影行业呈现出全新面貌…...
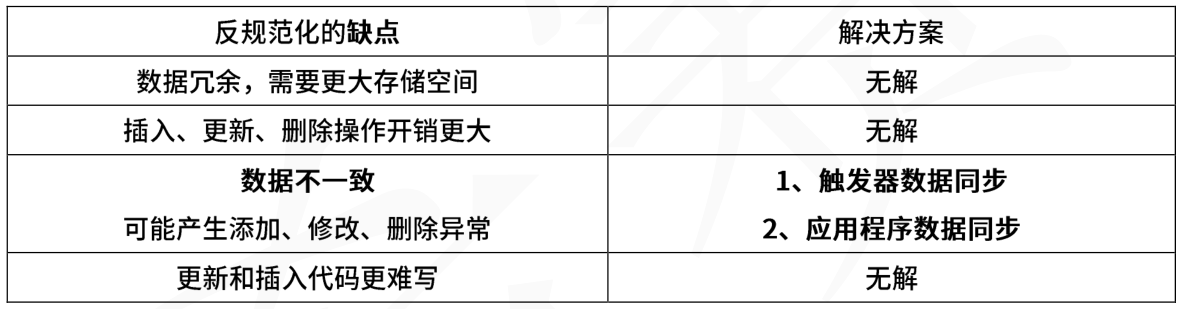
软考系统架构师知识点集锦九:数据库系统
一、考情分析 二、考点精讲 2.1数据库概述 2.1.1数据库模式 (1)三级模式:外模式对应视图,模式(也称为概念模式)对应数据库表,内模式对应物理文件。(2)两层映像:外模式-模式映像,模式-内模式映像;两层映像可以保证数据库中的数据具有较高的…...

IOC课程整理-6 Spring IoC 依赖注入
1 依赖注入的模式和类型 模式 类型 2 自动绑定(Autowiring) 官方定义 “自动装配是Spring框架中一种机制,用于自动解析和满足bean之间的依赖关系。通过自动装配,Spring容器可以根据类型、名称或其他属性来自动连接协作的bean&…...
FANUC机器人PRIO-621和PRIO-622设备和控制器没有运行故障处理
FANUC机器人PRIO-621和PRIO-622设备和控制器没有运行故障处理 如下图所示,新的机器人开机后提示报警: PRIO-621 设备没有运行 PRIO-622 控制器没有运行 我们首先查看下手册上的报警代码说明,如下图所示, 如下图所示,…...

SMBus协议深度解析:从基础时序到高级应用
1. SMBus协议基础:从I2C到系统管理总线 第一次接触SMBus时,我误以为它只是I2C的"马甲"。实际调试智能电池项目后才发现,这个1996年由Intel提出的二线制串行总线,在系统管理领域有着独特的价值。简单来说,SMB…...

【SITS2026权威前瞻】:AI研发自动化测试的5大范式跃迁与2024落地避坑指南
更多请点击: https://intelliparadigm.com 第一章:AI研发自动化测试:SITS2026专题 随着大模型驱动的研发范式演进,AI系统本身的可测试性面临全新挑战——模型行为非确定、输入空间高维、验证标准模糊。SITS2026(Softw…...

GPU并行计算:SIMT架构与性能优化实践
1. SIMT架构的本质与硬件挑战 在GPU计算领域,单指令多线程(SIMT)执行模型是实现大规模并行的核心机制。与传统的SIMD(单指令多数据)不同,SIMT允许同一warp(通常包含32个线程)中的每个…...

联想拯救者15ISK加装NVMe SSD实战:从硬件兼容到系统部署的避坑指南
1. 联想拯救者15ISK加装NVMe SSD前的准备工作 我手上这台联想拯救者15ISK已经陪伴我征战了五年多,最近明显感觉到系统响应变慢,游戏加载时间变长。经过一番排查,发现瓶颈主要出在机械硬盘上。于是决定给它加装一块NVMe SSD,让老战…...

别再傻傻分不清!从Arduino到树莓派,一文搞懂舵机、步进、直流无刷和永磁同步电机的选型与控制
从Arduino到树莓派:四大电机选型实战指南 刚接触机器人制作时,面对琳琅满目的电机型号和参数,我曾在机械臂项目里错误选用了普通舵机导致精度不足,也因步进电机驱动配置不当烧毁过三个驱动器。这些教训让我意识到——电机选型不是…...

通过审计日志追溯团队内每个API Key的详细使用记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过审计日志追溯团队内每个API Key的详细使用记录 在团队协作使用大模型API时,一个常见的管理难题是:如何…...

如何快速掌握FunClip:阿里开源AI视频剪辑的完整指南
如何快速掌握FunClip:阿里开源AI视频剪辑的完整指南 【免费下载链接】FunClip Open-source, accurate and easy-to-use video speech recognition & clipping tool, LLM based AI clipping intergrated. 项目地址: https://gitcode.com/GitHub_Trending/fu/Fu…...

Arclight故障排除与性能调优:解决常见问题的终极方案
Arclight故障排除与性能调优:解决常见问题的终极方案 【免费下载链接】Arclight A Bukkit(1.20/1.21) server implementation in modding environment using Mixin. ⚡ 项目地址: https://gitcode.com/gh_mirrors/ar/Arclight Arclight作为基于Mixin技术的Bu…...
)
告别虚拟机:用RK3399开发板搭建你的移动机器人SLAM实验平台(ROS Kinetic + OpenCV 3.4.0)
基于RK3399的移动机器人SLAM实验平台全栈搭建指南 在机器人技术快速发展的今天,同时定位与地图构建(SLAM)已成为自主移动系统的核心技术之一。然而,高性能计算设备的高昂成本往往成为学习者和开发者面临的首要障碍。Rockchip RK3399开发板以其出色的性价…...

如何快速部署Windows系统:MediaCreationTool.bat终极实战指南
如何快速部署Windows系统:MediaCreationTool.bat终极实战指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...