Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别
背景
本文基于Spark 3.1.1
目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的,
那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大小的参考呢
结论
先说结论 dataSzie指标是 是存在内存中的UnsafeRow 的大小的总和,AQE阶段(规则OptimizeSkewedJoin/CoalesceShufflePartitions)用到判断分区是否倾斜或者合并分区的依据是来自于这个值,
而shuffle bytes written指的是写入文件的字节数,会区分压缩和非压缩,如果在开启了压缩(也就是spark.shuffle.compress true)和未开启压缩的情况下,该值的大小是不一样的。
开启压缩如下:

未开启压缩如下:

先说杂谈
这两个指标的值都在 ShuffleExchangeExec中:
case class ShuffleExchangeExec(override val outputPartitioning: Partitioning,child: SparkPlan,shuffleOrigin: ShuffleOrigin = ENSURE_REQUIREMENTS)extends ShuffleExchangeLike {private lazy val writeMetrics =SQLShuffleWriteMetricsReporter.createShuffleWriteMetrics(sparkContext)private[sql] lazy val readMetrics =SQLShuffleReadMetricsReporter.createShuffleReadMetrics(sparkContext)override lazy val metrics = Map("dataSize" -> SQLMetrics.createSizeMetric(sparkContext, "data size")) ++ readMetrics ++ writeMetrics
dataSize指标来自于哪里
涉及到datasize的数据流是怎么样的如下,一切还是得从ShuffleMapTask这个shuffle的起始操作讲起:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
insertRecordIntoSorter||\/
UnsafeRowSerializerInstance.writeValue||\/
dataSize.add(row.getSizeInBytes)这里的 row 是UnsafeRow的实例,这样就获取到了实际内存中的每个分区的大小,
而ShuffleMapTask runTask 方法最终返回的是MapStatus,而该MapStatus最终是在UnsafeShuffleWriter的closeAndWriteOutput方法中被赋值的:
void closeAndWriteOutput() throws IOException {assert(sorter != null);updatePeakMemoryUsed();serBuffer = null;serOutputStream = null;final SpillInfo[] spills = sorter.closeAndGetSpills();sorter = null;final long[] partitionLengths;try {partitionLengths = mergeSpills(spills);} finally {for (SpillInfo spill : spills) {if (spill.file.exists() && !spill.file.delete()) {logger.error("Error while deleting spill file {}", spill.file.getPath());}}}mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths, mapId);}
shuffle bytes written指标来自哪里
基本流程和dataSize 一样,还是来自于ShuffleMapTask:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
closeAndWriteOutput||\/
sorter.closeAndGetSpills() -> writeSortedFile -> writer.commitAndGet -> writeMetrics.incBytesWritten(committedPosition - reportedPosition) -> serializerManager.wrapStream(blockId, mcs) // 这里进行了压缩||\/
mergeSpills||\/
mergeSpillsUsingStandardWriter||\/
mergeSpillsWithFileStream -> writeMetrics.incBytesWritten(numBytesWritten)||\/
writeMetrics.decBytesWritten(spills[spills.length - 1].file.length())相关文章:
Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别
背景 本文基于Spark 3.1.1 目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的, 那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大…...

Java——Map.getOrDefault方法详解
Java——Map.getOrDefault方法详解 Map.getOrDefault(Object key, V defaultValue)是Java中Map接口的一个方法,用于获取指定键对应的值,如果键不存在,则返回一个默认值。 该方法的签名如下: V getOrDefault(Object key, V defau…...

银河集团香港优才计划95分获批案例展示!看看是如何申请的?
银河集团香港优才计划95分获批案例展示!看看是如何申请的? 今天来分享一则银河集团香港优才计划获批案例!客户本科学历非名校、从事业务支援及人力资源行业,优才打分95分,这个条件可能在很多人的印象里,会觉…...

Python class中以`_`开头的类特殊方法
在学基础的时候没学到过(可能见过但是又忘了),在学习深度学习项目的时候遇见了很多; 以论文Multi-label learning from single positive label为例; 这些方法都是程序自行调用的,不需要(也不可以…...

2023云栖大会开幕:全球数万开发者参会,展现AI时代的云计算创新
10月31日,2023云栖大会在杭州开幕,大会吸引全球数万开发者参会。阿里巴巴集团董事会主席蔡崇信在致辞中表示,今年云栖大会主题回归“计算,为了无法计算的价值”,这也是2015年云栖大会的主题,当时云计算支撑…...

[量化投资-学习笔记004]Python+TDengine从零开始搭建量化分析平台-EMA均线
在之前的文章中用 Python 直接计算的 MA 均线,但面对 EMA 我认怂了。 PythonTDengine从零开始搭建量化分析平台-MA均线的多种实现方式 高数是我们在大学唯一挂过的科。这次直接使用 Pandas 库的 DataFrame.ewm 函数,便捷又省事。 并且用 Pandas 直接对之…...

KaiwuDB 获山东省工信厅“信息化应用创新优秀解决方案”奖
10月23日,山东省工信厅正式公示《2023年山东省信息化应用创新典型应用案例及优秀解决方案名单》,面向全省、全国重点推荐山东省技术水平先进、应用示范效果突出、产业带动性强的信息化解决方案及应用实践,对于进一步激发山东省信息技术产业创…...

Python-常用的量化交易代码片段
算法交易正在彻底改变金融世界。通过基于预定义标准的自动化交易,交易者可以以闪电般的速度和比以往更精确的方式执行订单。如果您热衷于深入了解算法交易的世界,本指南提供了帮助您入门的基本代码片段。从获取股票数据到回溯测试策略,我们都能满足您的需求! 1. 使用 YFina…...

Netty优化-rpc
Netty优化-rpc 1.3 RPC 框架1)准备工作 1.3 RPC 框架 1)准备工作 这些代码可以认为是现成的,无需从头编写练习 为了简化起见,在原来聊天项目的基础上新增 Rpc 请求和响应消息 Data public abstract class Message implements …...
:概念、作用、术语)
【Docker 内核详解】cgroups 资源限制(一):概念、作用、术语
cgroups 资源限制(一):概念、作用、术语 1.cgroups 是什么2.cgroups 的作用3.cgroups 术语表 当谈论 Docker 时,常常会聊到 Docker 的实现方式。很多开发者都知道,Docker 容器本质上是宿主机上的进程(容器所…...
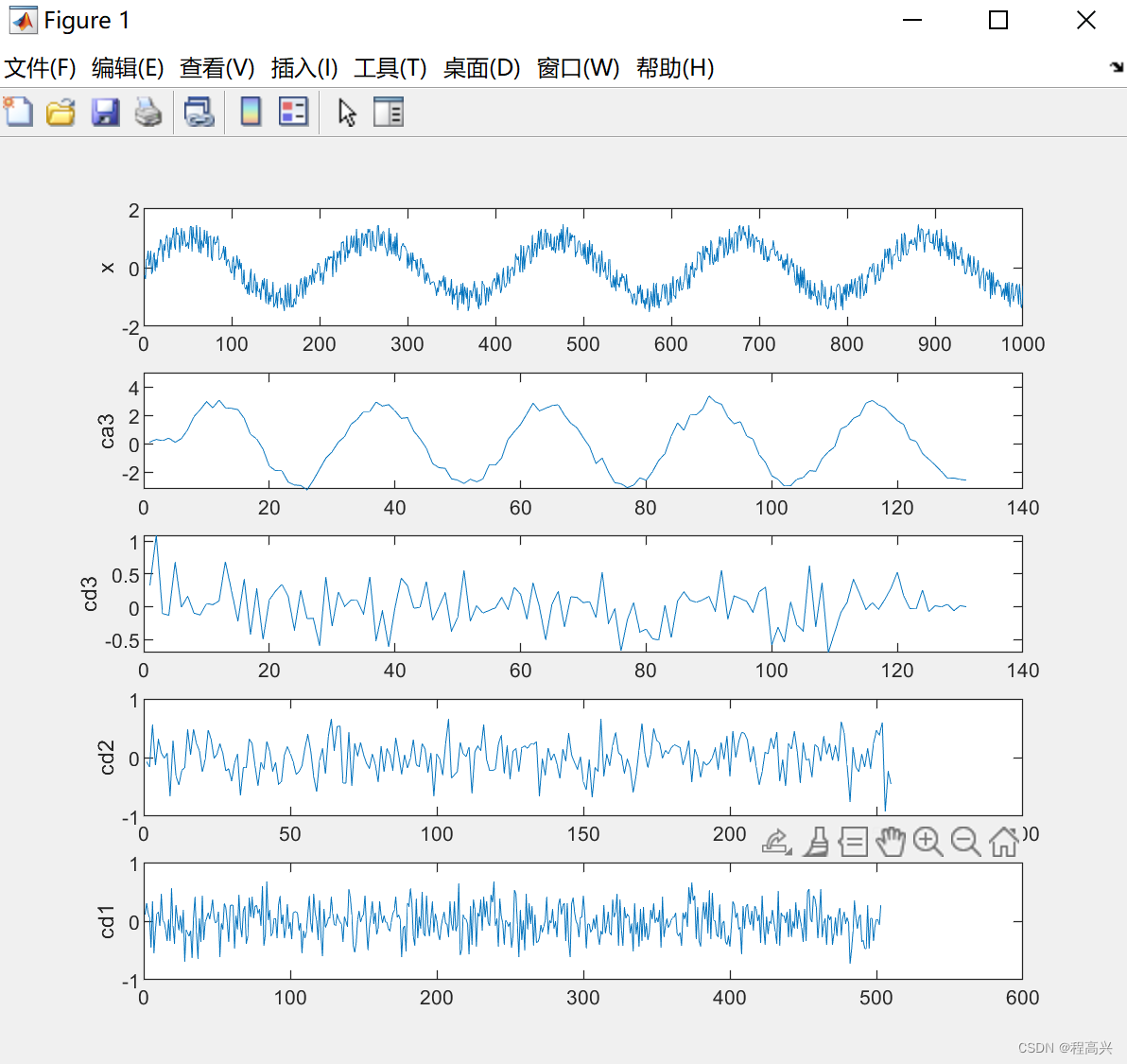
MATLAB——一维小波的多层分解
%% 学习目标:一维小波的多层分解 clear all; close all; load noissin.mat; xnoissin; [C,L]wavedec(x,3,db4); % 3层分解,使用db4小波 [cd1,cd2,cd3]detcoef(C,L,[1,2,3]); % 使用detcoef函数获取细节系数 ca3appcoef(C,L,db4,3); …...
C++的拷贝构造函数
目录 拷贝构造函数一、为什么用拷贝构造二、拷贝构造函数1、概念2、特征1. 拷贝构造函数是构造函数的一个重载形式。2. 拷贝构造函数的参数3. 若未显式定义,编译器会生成默认的拷贝构造函数。4. 拷贝构造函数典型调用场景 拷贝构造函数 一、为什么用拷贝构造 日期…...
【手机端远程连接服务器】安装和配置cpolar+JuiceSSH:实现手机端远程连接服务器
文章目录 1. Linux安装cpolar2. 创建公网SSH连接地址3. JuiceSSH公网远程连接4. 固定连接SSH公网地址5. SSH固定地址连接测试 处于内网的虚拟机如何被外网访问呢?如何手机就能访问虚拟机呢? cpolarJuiceSSH 实现手机端远程连接Linux虚拟机(内网穿透,手机端连接Linux虚拟机) …...

Jupyter Notebook的使用
文章目录 Jupyter Notebook一、Jupyter Notebook是什么?二、使用步骤1.安装Miniconda2.安装启动**Jupyter Notebook**3.一些问题 三、Jupyter Notebook的操作1.更换解释器2.在指定的文件夹中打开3 运行的快捷键 四.报错解决1.画图的时候出现报错2.画图的时候空白3.p…...

vue 使用vue-office预览word、excel,pdf同理
在此,我只使用了docx和excel, pdf我直接使用的iframe进行的展示就不作赘述了 //docx文档预览组件 npm install vue-office/docx//excel文档预览组件 npm install vue-office/excel//pdf文档预览组件 npm install vue-office/pdf如果是vue2.6版本或以下还…...
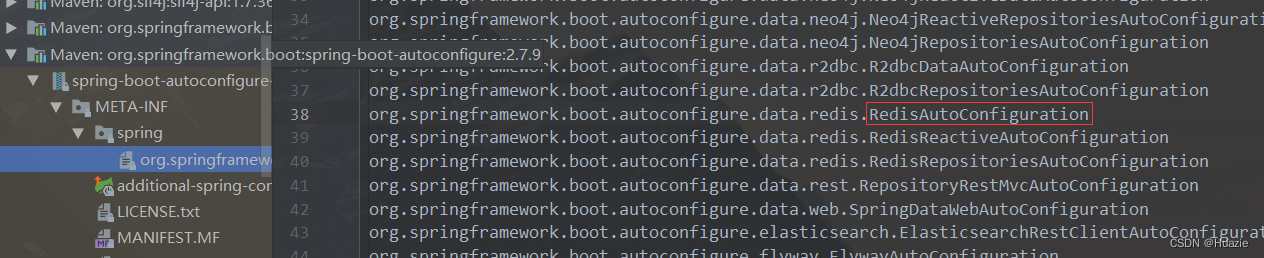
【Spring Boot 源码学习】RedisAutoConfiguration 详解
Spring Boot 源码学习系列 RedisAutoConfiguration 详解 引言往期内容主要内容1. Spring Data Redis2. RedisAutoConfiguration2.1 加载自动配置组件2.2 过滤自动配置组件2.2.1 涉及注解2.2.2 redisTemplate 方法2.2.3 stringRedisTemplate 方法 总结 引言 上篇博文࿰…...

Linux中如何进行粘贴复制
因为CTRLC在Linux中具有特定的含义:终止当前操作 xshell提供了CTRLinsert(复制)/shiftinsert(粘贴) 上述快捷键在Windows中依旧支持,...
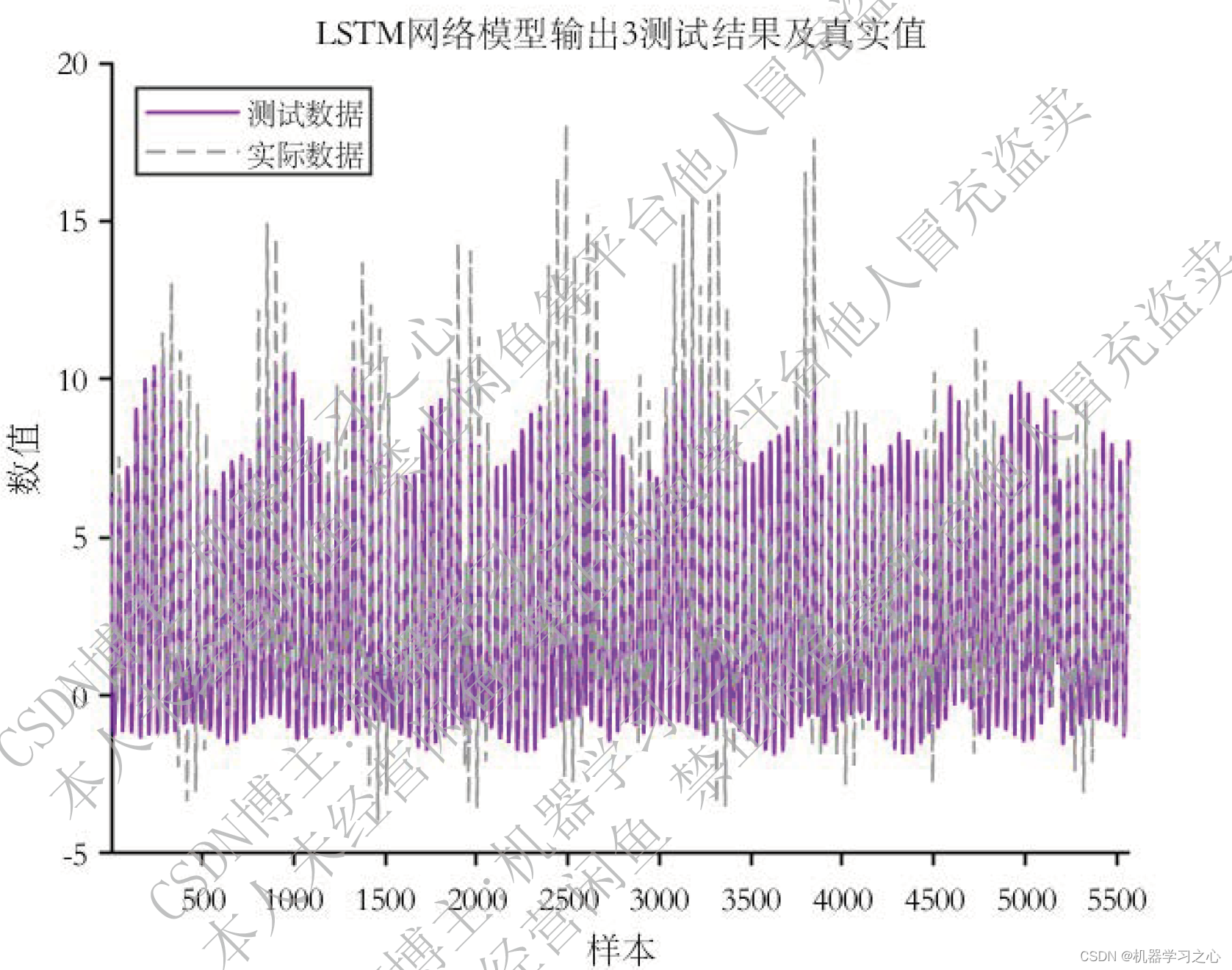
多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测
多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测 目录 多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测预测效果基本描述程序设计参…...
学习笔记3——JVM基础知识
学习笔记系列开头惯例发布一些寻亲消息 链接:https://baobeihuijia.com/bbhj/contents/3/196593.html JVM(Write Once,Run Anywhere) 以下是一些学习时有用到的资料,只学习了JVM的基础知识,对JVM整体进…...

图像处理:图片二值化学习,以及代码中如何实现
目录 1、了解下图片二值化的含义 2、进行图像二值化处理的方法 3、如何选择合适的阈值进行二值化 4、实现图片二值化(代码) (1)是使用C和OpenCV库实现: (2)纯C代码实现,不要借…...

别再傻傻用FFT了!用MATLAB的czt函数5分钟搞定频谱细化,精准定位98Hz和99Hz信号
别再被FFT分辨率坑了!MATLAB工程师的频谱细化实战指南 当你在分析一段包含98Hz和99Hz混合信号的频谱时,是否遇到过这样的尴尬:明明知道有两个频率成分存在,但FFT给出的结果却像被打了马赛克,两个峰值糊成一团…...

5.3、从双亲表示法看树的存储设计哲学
1. 双亲表示法的本质:用数组重构树形关系 第一次接触双亲表示法时,我被它的简洁性惊艳到了——仅用数组就能完整描述整棵树的拓扑结构。这种存储方式的核心在于:每个节点只需要记住自己的父亲是谁。就像现实中的家族族谱,我们通过…...

别再一段段拼了!用UE4蓝图+Spline Component一键生成连续管道/道路模型
UE4蓝图Spline Component自动化生成复杂路径模型实战指南 在游戏开发中,创建蜿蜒的管道、复杂的赛道或是连绵的城墙往往需要耗费大量时间。传统的手动拼接SplineMesh组件的方式不仅效率低下,而且难以保证模型的连续性和一致性。本文将深入探讨如何利用UE…...

保姆级避坑指南:从模之屋PMX到Unity,搞定Blender导出FBX的纹理丢失问题
保姆级避坑指南:从模之屋PMX到Unity,搞定Blender导出FBX的纹理丢失问题 如果你是一位二次元风格游戏开发者或MMD模型爱好者,那么从模之屋下载PMX模型后,在Blender中处理并导出为FBX格式,最后导入Unity的过程中…...

告别触摸漂移!手把手教你为ESP32和XPT2046电阻屏制作LVGL校准工具
ESP32电阻屏精准触控实战:从硬件校准到LVGL交互优化 电阻式触摸屏在嵌入式设备中广泛应用,但精度问题一直困扰着开发者。当你在ESP32上连接XPT2046触摸控制器时,是否遇到过点击位置漂移、响应不准确的烦恼?本文将带你深入解决这一…...

从外卖配送范围到跨国航线规划:Geopy距离计算的3个实战场景与避坑经验
从外卖配送范围到跨国航线规划:Geopy距离计算的3个实战场景与避坑经验 在数字化浪潮席卷各行各业的今天,地理距离计算已成为许多商业应用的核心技术组件。无论是外卖小哥的手机App上闪烁的配送范围提示,还是国际物流系统中精确到米的航线规划…...

AI Coding 言出法随,未来什么还会值钱?
本文整理自播客《AI炼金术》任鑫(云九资本)与徐文浩的深度对话,探讨 AI Coding 如何重塑个人开发方式、组织形态,以及在生产力极大释放的时代,究竟什么能力还会持续增值。—本文资料通过Ai好记智能解析获取。一、AI Co…...

NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案 NotebookLM 作为 Google 推出的 AI 增强型笔记工具,其“共享链接即协作”的默认机制在提升效率的同…...

别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道
别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道 交叉验证是机器学习模型评估的黄金标准,而K折交叉验证(KFold)作为其中最常用的方法,看似简单却暗藏玄机。许多数据科学家在Kaggle竞…...

别再手动改参数了!用Fluent 2023R1的Parametric模块,5分钟搞定N个工况的批量仿真
Fluent 2023R1参数化模块实战:从单点仿真到智能设计空间探索 在计算流体动力学(CFD)领域,工程师们常常需要面对一个现实困境:如何高效完成数十种工况的参数扫描?传统手动修改边界条件的方式不仅耗时费力&am…...