图神经网络论文笔记(一)——北邮:基于学习解纠缠因果子结构的图神经网络去偏


作者 :范少华
研究方向 :图神经网络
论文标题 :基于学习解纠缠因果子结构的图神经网络去偏
论文链接 :https://arxiv.org/pdf/2209.14107.pdf
https://doi.org/10.48550/arXiv.2209.14107
大多数图神经网络(GNNs)通过学习输入图和标签之间的相关性来预测不可见图的标签。然而,通过对具有严重偏差的训练图进行图分类调查,我们惊奇地发现,即使因果关系始终存在,GNNs也总是倾向于探索虚假相关来进行决策。这意味着现有的基于这些有偏差数据集训练的GNNs泛化能力较差。从因果关系的角度分析这个问题,我们发现从有偏图中分解和解相关因果变量和偏差潜变量都是消除偏差的关键。
在此启发下,我们提出了一个通用的解纠缠GNN框架来分别学习因果子结构和偏差子结构。特别地,我们设计了一个参数化的边缘掩码生成器来显式地将输入图分割成因果和偏差子图。然后训练两个由因果/偏差感知丢失函数监督的GNN模块,将因果子图和偏差子图编码成相应的表示。利用解纠缠表征,我们合成反事实的无偏训练样本,进一步解关联因果变量和偏倚变量。
此外,为了更好地对严重偏差问题进行基准测试,我们构造了3个新的图数据集,它们的偏差程度可控,易于可视化和解释。实验结果表明,该方法具有较好的泛化性能。此外,由于学习边缘掩码的存在,所提出的模型具有良好的可解释性和可移植性


一、引言
图神经网络(GNNs)在各种应用中显示了对图数据的强大性能。一个主要的应用类别是图分类任务,如分子图属性预测、超像素图分类和社会网络分类。众所周知,图的分类通常是由一个相关的子结构决定的,而不是由整个图结构决定的。例如,对于MNIST超像素图分类任务,数字子图对于标签来说是因果的(即,确定性的)。分子图的致突变特性取决于官能团(即,二氧化氮(NO2)),而不是不相关的模式(即碳环)。因此,识别因果子结构,从而做出正确的预测,是GNNs的基本要求。
理想情况下,当图是无偏的,即只有因果子结构与图标签相关时,GNNs能够利用这些子结构来预测标签。然而,由于数据采集过程的不可控,图形不可避免地会有偏倚,即存在无意义的子结构与标签虚假关联。以3.1节中的有色MNIST超像素图数据集为例(如图1(a)所示),每一类数字子图主要对应一种颜色背景子图,如数字 0 子图与红色背景子图相关。因此,颜色背景子图将被视为偏差信息,在训练集中与标签高度相关但不确定标签。在这种情况下,GNNs还会稳定地利用因果子结构进行决策吗?
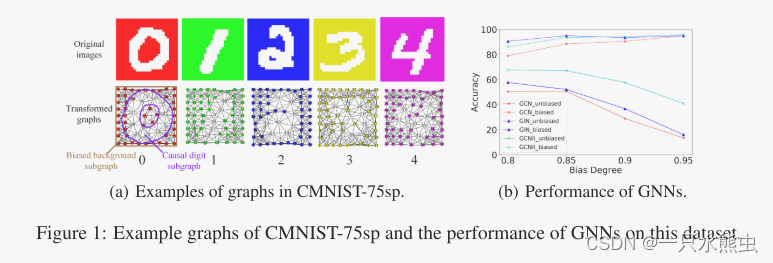
图1:CMNIST-75sp的示例图以及该数据集上GNN的性能。
为了研究偏差对GNNs的影响,我们进行了一项实验研究,以证明偏差(特别是在严重偏差情景下)对GNNs的泛化能力的影响(第3.1节)。我们发现GNNs实际上利用了偏差和因果子结构来进行预测。然而,由于偏倚相关性较强,即使是偏倚子结构也不能像因果子结构那样准确地确定标签,因此GNNs主要利用偏倚子结构作为捷径进行预测,导致泛化性能大幅度下降。为什么会这样?我们使用因果图分析图分类背后的数据生成过程和模型预测机制(第3.2节)。偶然图表明观测图是由因果潜变量和偏差潜变量生成的,现有的GNNs无法区分因果子结构和纠缠图。如何从观测图中分离出因果和偏差子结构,使GNNs只能在出现严重偏差时利用因果子结构进行稳定的预测?要解决这个问题,我们需要面对两个挑战。1)、如何识别严重偏倚图中的因果子结构和偏倚子结构?在严重偏置的情况下,偏置子结构更容易学习,最终主导预测结果。使用正常的交叉熵损失,如DIR,不能完全捕获这种侵略性的偏置特性。2)、如何从一个纠缠图中提取因果子结构?统计因果子结构通常是由整个图总体的全局性质决定的,而不是由单个图决定的。从图中提取因果子结构时,需要建立所有图之间的关系。
在本文中,我们提出了一种新的GNNs通过学习解纠缠因果子结构的去偏框架,称为DisC。给定一个输入偏置图,我们提出通过参数化边缘掩码生成器显式地将边缘过滤成因果和偏置子图,其参数在整个图种群中共享。因此,边缘掩盖器自然能够指定每个边缘的重要性,并从整个观察的全局视图中提取因果和偏差子图。然后,分别利用“偶然”感知(加权交叉熵)损失和“偏差”感知(广义交叉熵)损失来监督两个功能GNN模块。在此监督的基础上,边缘掩码发生器生成相应的子图,GNNs将相应的子图编码为解纠缠嵌入。在解纠缠嵌入中,我们将从不同图中提取的潜在向量随机置换,在嵌入空间中生成更多的无偏反事实样本。新生成的样本仍然包含因果信息和偏倚信息,而它们的相关性已不相关。此时,只有因果变量与标签之间存在相关性,这样模型就可以专注于因果子图与标签之间的真正相关性。我们的主要贡献如下:
• 据我们所知,我们首先研究的是gnn的泛化问题,它是在一个更具挑战性但更实用的场景下,即图具有严重的偏差。我们从实验研究和因果分析两方面系统地分析了偏差对gnn的影响。我们发现偏置子结构比因果子结构更容易支配gnn的训练。
• 为了消除GNN的偏差,我们开发了一种新的GNN框架来分解因果子结构,该框架可以灵活地构建在各种GNN的基础上,以提高泛化能力,同时具有固有的可解释性、鲁棒性和可移植性。
• 我们构建了三个新的数据集,这些数据集具有不同的性质和可控的偏差程度,可以更好地对新问题进行基准测试。我们的模型比相应的基本模型有很大的优势(从4.47%到169.17%的平均改进)。各种调查研究表明,我们的模型可以发现和利用因果子结构进行预测。
二、相关工作
野外环境下gnn的泛化
现有的大多数GNN方法都是在IID假设下提出的,即训练集和测试集都是从同一分布中独立抽取的。然而,在现实中,理想假设很难得到满足。近年来,人们提出了多种方法来提高gnn在野生环境下的泛化能力。一些文献研究了节点分类的OOD问题。对于OOD图分类任务,StableGNN提出学习图中的稳定因果关系。OOD-GNN提出将学习嵌入的各个维度独立约束。DIR发现了广义gnn的不变原理。它们虽然具有较好的OOD性能,但并不是针对偏差较大的数据集设计的,这对于保证gnn的泛化能力具有更大的挑战性。
解纠缠图神经网络
目前,研究解纠缠GNN的方法有很多。DisenGCN利用邻居路由机制将节点的邻居划分为几个互斥的部分。IPGDN通过独立约束嵌入特性的不同部分来提升DisenGCN。DisenGCN和IPGDN是节点级解纠缠,因此FactorGCN考虑了整个图信息,并将目标图解纠缠为几个分解后的图。尽管前人的研究成果,他们并没有考虑对图的因果信息和偏倚信息进行梳理。
一般的去偏方法
最近,去偏问题引起了机器学习界的广泛关注。其中一种方法是明确地预先定义某种偏差类型来减轻。例如,Wang et al.和Bahng et al.设计了一个纹理和颜色引导的模型来对抗有偏差的神经网络训练去偏差的神经网络。最近的研究方法没有定义特定类型的偏差,而是依赖于一个简单的假设,即模型容易利用偏差作为捷径来做出预测。与最近的研究一致,我们的研究属于第二类。然而,现有的方法大多是针对图像数据集设计的,不能有效地从图数据中提取因果子结构。值得注意的是,我们首先研究了图数据的严重偏倚问题,该方法可以有效地从图数据中提取因果子结构。
三、初步研究与分析
在本节中,我们首先说明现有的GNNs倾向于利用偏差子结构作为通过一个激励实验进行预测的捷径。然后从因果关系的角度分析了GNNs的预测过程。基于这种因果关系的观点,它促使我们采取解决方案来减轻偏见的影响。
激励范例
为了度量受偏差影响的gnn的泛化能力,我们构造了一个偏差程度可控的图分类数据集CMNIST-75sp。我们首先构建一个像[1]这样的有偏MNIST图像数据集,其中每个类别的数字与背景中的预定义颜色高度相关。例如,在训练集中,90%的0位数背景为红色(即有偏样本),剩余10%的图像背景为随机颜色(即无偏样本),此时的偏度为0.9。我们考虑四个偏差度{0.8,0.85,0.9,0.95}。
对于测试集,我们构造有偏测试集和无偏测试集。偏置测试集与训练集具有相同的偏置程度,目的是衡量模型依赖偏置的程度。无偏测试集,其中数字标签与背景颜色不相关,旨在测试模型是否可以利用固有的数字信号进行预测。注意,训练集和测试集具有相同的预定义颜色集。然后,利用将有偏置的MNIST图像转换为每个图节点数不超过75的超像素图,其中,基于超像素二维坐标,采用KNN方法构造边缘,节点特征为超像素坐标和平均颜色的拼接。每个图都用它的数字类标记,因此它的数字子图对于标签是确定的,而背景子图与标签是假相关的,但不是确定的。图1(a)举例说明了图的示例。
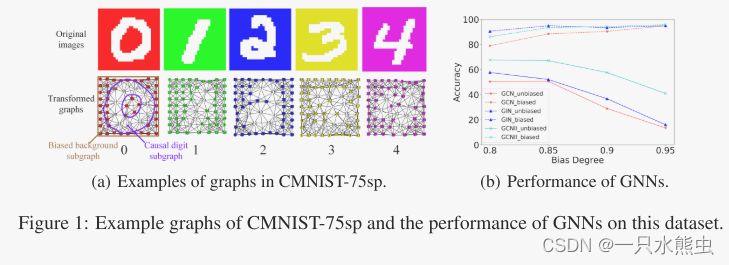
图1:CMNIST-75sp的示例图以及该数据集上GNN的性能。
我们在CMNIST-75sp上执行了三种常用的GNN方法:GCN、GIN和GCNII,结果如图1(b)所示。虚线和实线的相同颜色分别表示相应方法在有偏测试集和无偏测试集上的结果。总的来说,GNNs在有偏测试集中比在无偏测试集中获得了更好的性能。这一现象表明,虽然GNNs仍然可以学习一些因果信号进行预测,但意外偏差信息也被用于预测。具体来说,随着偏置程度的增大,GNNs在偏置测试集上的性能有所提高,精度值与偏置程度基本一致,而在无偏测试集上的性能急剧下降。因此,虽然因果子结构可以很好地确定标签,但在严重的偏倚情况下,GNNs倾向于利用更容易学习的偏倚信息而不是固有的因果信号进行预测,最终偏倚子结构将主导预测。
问题分析
去偏GNN进行无偏预测需要理解图分类任务的自然机制。我们提出了任务背后数据生成过程和模型预测过程结合的因果观点。在这里,我们通过检查5个变量之间的因果关系,将因果观形成化为结构因果模型(SCM)或因果图,这5个变量分别是:未观察到的因果变量C、未观察到的偏差变量B、观察到的图G、嵌入图E和基本事实标签/预测Y(我们将变量Y用于基本事实标签和预测,因为它们被优化为相同的)。图2(a)显示了结构因果模型,其中每个链接表示一个因果关系。
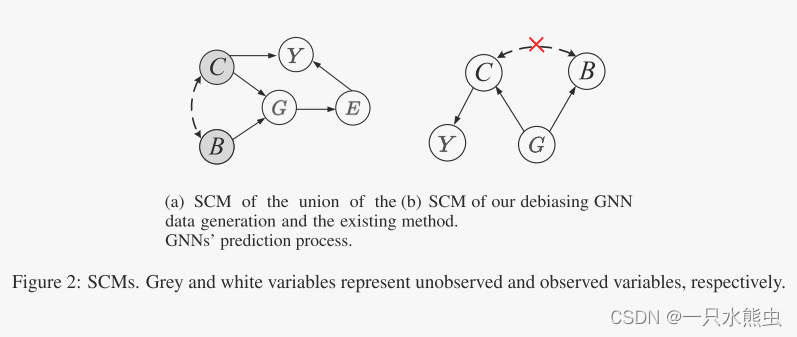
图2:结构因果模型,灰色和白色变量分别表示未观测变量和观测变量。
• C → G ← B 观测图数据由两个未观测到的潜在变量生成:因果变量C和偏倚变量B,如CMNIST-75sp数据集中的数字子图和背景子图。所有下列关系都由CMNIST-75sp说明。
•C → Y 这一联系意味着因果变量C是决定基本事实(ground-truth)标签Y的生成的唯一内生父变量。例如,C是oracle数字子图,这正好解释了为什么标签被标记为Y。
• C⇠⇢ B 这个链接表明了C和B之间的虚假关联。这种概率依赖通常是由直接原因或未观察到的混杂物引起的。这里我们不区分这些场景,只观察B和C之间的伪相关,例如颜色背景子图和数字子图之间的伪相关。
• G → E → Y 现有的GNN通常是根据观察图G学习嵌入E的图,然后根据学习到的嵌入E进行预测Y。
根据结构因果模型,GNNs将利用这两种信息进行预测。由于偏置子结构(如背景子图)通常比有意义的因果子结构(如数字子图)具有更简单的结构,如果GNN利用这种简单的子结构,可以很快实现低损耗。因此,当大多数图都有偏倚时,GNN更倾向于利用偏倚信息。根据图2(a)中的结构因果模型,根据d-connection 理论(参见App. a):两个变量是相互依赖的,如果它们之间至少有一条畅通的路径相连,那么我们可以找到两条路径,这两条路径会导致偏差变量B和标签Y之间产生假相关:(1) B → G → E → Y和(2) B ↔ → Y要使预测Y与偏置B不相关,需要截取两条畅通的路径。为此,我们建议从因果关系的角度对GNN进行去偏 ,如图2(b)所示。
• C ← G → B 和 C → Y 要截取路径(1),我们需要从观察图G中分离出潜在变量C和B,仅基于因果变量C进行预测。
 要截取路径(2),由于我们无法改变C和Y之间的链接,一种可能的解决方案是使C和B不相关。
要截取路径(2),由于我们无法改变C和Y之间的链接,一种可能的解决方案是使C和B不相关。
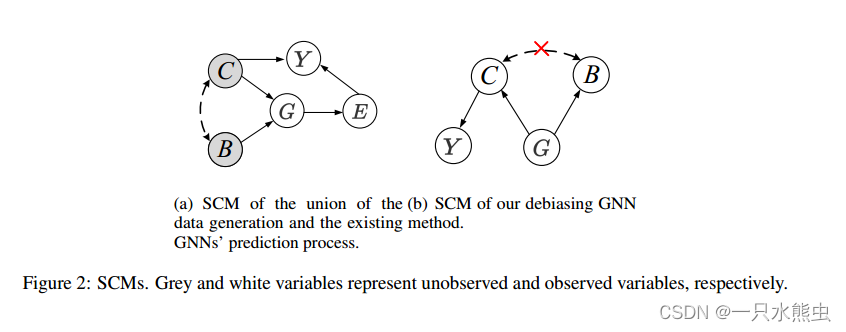
(a)结构因果模型的数据生成与现有GNNs的预测过程的结合。(b)我们的去偏GNN方法的结构因果模型。
图2:结构因果模型,灰色和白色变量分别表示未观测变量和观测变量。

四、方法
基于上述原因分析,在本节中,我们提出了我们提出的去偏GNN框架DisC,以去除伪相关。总体框架如图3所示。首先,学习边缘掩码发生器将原始输入图的边缘掩码成因果子图和偏置子图;其次,训练两个独立的GNN模块及其对应的掩码子图,分别将对应的因果子结构和偏置子结构编码为解纠缠表示;最后,在解纠缠表征经过良好训练后,对训练图中的偏差表征进行置换,生成反事实的无偏样本,从而消除了因果表征与偏差表征之间的相关性。
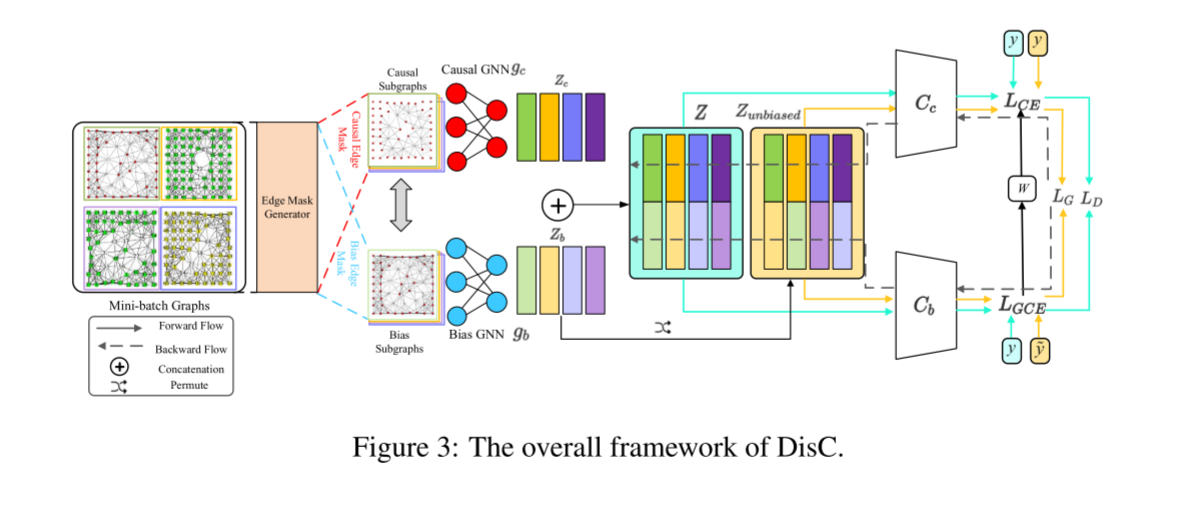
4.1 因果和偏置子结构发生器
给定一个小批量有偏图 G = {G1,⋯,Gn},我们的思想是:取一组图实例并设计一个生成概率模型来学习将边缘掩码成因果子图或有偏子图。特别地,给定一个图 G = { A , X },其中A为邻接矩阵, X 为节点特征矩阵,我们利用多层感知器(MLP)对节点 i 的节点特征 Xi 和节点 j 的节点特征 Xj 进行拼接,来度量因果子图的边 (i, j) 的重要性:
αij = MLP([xi, xj]) (1)
然后利用sigmoid函数 σ ( ⋅ ) 将 αij 投影到(0,1)范围内,表示边(i, j)边为因果子图中边的概率为:
cij = σ(αij) (2)
自然地,我们可以通过:bij = 1− cij 得到边 (i, j) 是偏置子图中的边的概率。现在我们可以构造因果边缘掩码 Mc = [cij] 和偏置边缘掩码 Mb = [bij] 。最后,将原始图G分解为因果子图 Gc = { Mc ⊙ A, X } 和偏置子图 Gb = { Mb ⊙A, X } 。边缘掩码可以直观地显示原始图的结构信息的不同部分,从而在不同子图上构建的GNNs可以对图信息的不同部分进行编码。
此外,掩模发生器还有两个优点:
(1) 全局视图(Global view):在单个图层,掩码生成器 ( mask generator ) (例如:MLP ) 的参数由图中的所有边共享,对图中的所有边采取全局视图,使我们能够识别图中的社区。众所周知,边的作用是不能独立判断的,因为边之间通常会相互协作,形成一个社区来进行预测。因此,从全球的角度来评估一个优势是至关重要的。在整个图种群级别,掩码生成器对训练集中的所有图采取全局视图,这使我们能够识别因果/偏倚子图。特别是,由于因果/偏倚是总体水平上的统计信息,因此需要查看所有的图表来确定因果/偏倚的子结构。同时考虑了这种联合效应和种群水平的统计信息,该生成器能够更准确地度量边缘的重要性。
(2) 概化 :掩码生成器可以将掩码生成机制概化到新的图上,而不需要再进行训练,因此能够有效地裁剪不可见的图。
4.2 学习解纠缠图表示
给定Gc和Gb,如何确保它们分别是因果子图和偏倚子图? 受[23]的启发,我们的方法用线性分类器(Cb, Cc)同时训练一对GNNs (gb, gc),如下所示:(1) 由于在3.1节中观察到偏置子结构更容易学习,我们利用偏置感知损失来训练偏置GNN gb和偏置分类器Cb;(2) 相比之下,我们在偏置GNN难以学习的训练图上训练因果GNN gc和因果分类器Cc。接下来,我们将详细介绍每个组件。
如图3所示,GNN gc和gb将对应的子图嵌入因果嵌入zc = gc(gc;γc)和偏置嵌入zb = gb(gb;γb),其中γ为gnn的参数。随后,串联向量z = [zc;为了训练gb和Cb作为偏置提取器,我们利用广义交叉熵(GCE)[51]损失来放大偏置GNN和分类器的偏置:
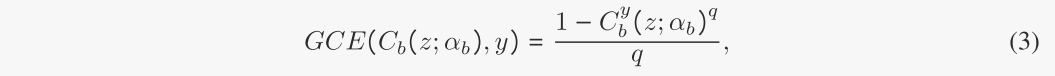
式中Cb(z;αb)和C y b (z;为偏置分类器的softmax输出,其概率分别属于目标类别y,为分类器的参数。这里q∈(0,1)是控制放大偏置程度的超参数。假设θb = [γb, αb], GCE损失的梯度增加了样品的标准交叉熵(CE)损失的梯度,具有预测正确目标类别的高可信度C y b,如下所示:
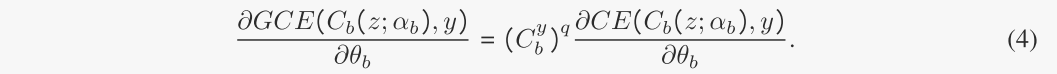
因此,与CE损失相比,GCE损失将通过置信度(C y b)q放大θb对样品的梯度。根据我们的观察,偏置信息通常更容易被学习,所以偏置图比无偏置图有更高的(cy b)q。因此,通过GCE损耗训练的模型gb和Cb将聚焦于偏置信息,最终得到偏置子图。注意,为了确保Cb主要基于该zb预测目标标签,Cb的损失不会反向传播到gc,即只更新式(4)中的θb,反之亦然。
同时,我们还利用加权CE损耗同时训练一个因果GNN。与低CE损耗的样品相比,高CE损耗的样品可视为无偏样品。因此,我们可以得到每个图的无偏分为
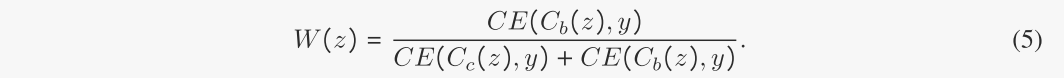
W的值越大,说明图是一个无偏样本,因此我们可以使用这些权值来重新加权这些图的损失,以训练gc和Cc,强制它们学习无偏信息。因此,学习解纠缠表示的目标函数为:
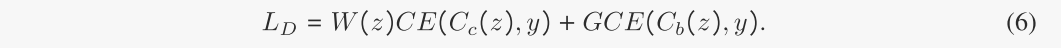
4.3 反事实无偏样本生成
到目前为止,我们已经实现了第3.2节中分析的第一个目标,即解开因果和偏见的子结构。接下来,我们将展示如何实现第二个目标,使因果变量zc和偏倚变量zb不相关。虽然我们已经解开了因果和偏差信息,但它们是从有偏差的观察图中解开的。因此,因果变量和偏倚变量之间将存在从有偏倚观察图继承来的统计相关性。为了进一步去关联zc和zb,根据数据生成过程的因果关系:C→G←B,我们提出通过交换zb在嵌入空间中生成反事实无偏样本。更具体地说,我们对每个小批量的偏差向量随机置换,得到zunbiased = [zc;ˆzb],其中ˆzb表示zb随机排列的偏差向量。由于zunbiased中的zc和ˆzb是由不同的图随机组合而成的,它们的相关性比z = [zc;Zb]这两个都来自同一个图。为了使gb和Cb仍然关注偏差信息,我们还将标签y交换为ˆy和ˆzb,这样ˆzb和ˆy之间的伪相关仍然存在。利用生成的无偏样本,我们利用以下loss函数来训练两个GNN模块:
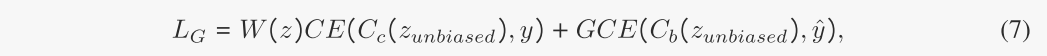
结合解缠损耗,总损耗函数定义为:
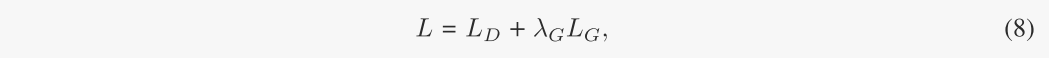
其中λG是表示生成分量重要性的超参数。此外,使用更多样化的样本进行训练还可以在不可见的测试场景中获得更好的泛化。我们的方法在App. b中进行了总结。注意,由于我们需要很好的解纠缠表征来生成高质量的无偏样本,所以在训练的早期阶段,我们只使用LD来训练模型。经过一定的时间后,我们使用L来训练模型。

五、实验
数据集
我们构建了三个具有不同属性和偏差比率的数据集来对这个新问题进行基准测试,这些数据集有清晰的因果子图,使得结果可以解释。在3.1节中引入CMNIST-75sp之后,我们使用类似的方法基于Fashion-MNIST[44]和Kuzushiji-MNIST[4]数据集构建CFashion-75sp和CKuzushiji-75sp数据集。由于这两个数据集的因果子图更复杂(时尚产品和平假名字符),它们更具有挑战性。由于页面的限制,这里我们设置偏移度为{0.8,0.9,0.95}。我们报告无偏测试集上的主要结果。详情见章末C.1部分。
基线和实验设置
由于DisC是一个通用的框架,可以建立在各种基础GNN模型上,因此我们选择了三个常用的GNN: GCN[19]、GIN[45]和GCNII[3]。相应的模型分别称为DisCGCN、DisCGIN和DisCGCNII。因此,基本模型是最直接的基线。另一种基线是基于因果关系的GNN方法DIR[43]和StableGNN[7]。我们还用gnn替代了一般的去偏方法LDD[23],并与之进行了比较。并对图池法DiffPool[48]和图解纠缠法FactorGCN[46]进行了比较。为了保持公平的比较,我们的模型与相应的基模型使用相同的GNN架构和超参数。所有的实验用不同的随机种子进行了4次,我们报告了准确度和标准误差。更多细节见章末C.2部分。
5.1 定量评估
主要结果
总体结果见表1,我们有以下观察:
(1) DisC具有比基模型更好的泛化能力。
DisC表现优于相应的基本模型,并有较大的差额。由于偏差较大,我们的模型比基本模型有更大的改进。其中,CMNIST-75sp、CFashion-75sp和CKuzushiji-75sp偏差度较小(0.8)时,我们的模型比相应的基模型平均分别提高了40.02%、4.47%和29.82%。令人惊讶的是,在更严重的偏差(0.9和0.95)下,DisC在三个数据集上分别比基本模型实现了169.17%、14.67%和49.35%的平均改进。结果表明,本文提出的方法是一个通用的框架,可以帮助现有的导航网络克服偏差的负面影响。
(2) DisC显著优于现有的去偏方法。
我们注意到DIR不能取得令人满意的结果。原因是DIR利用CE损耗来提取偏置信息,在严重偏置情况下不能完全捕捉到偏置的性质。而DIR对分割子图设置一个固定的阈值,这是次优的。StableGNN优于其基础模型DiffPool,并取得了具有竞争力的结果,表明其提出的因果变量区分正则化的有效性。然而,该框架基于原始数据集调整数据分布,当无偏样本稀缺时,难以生成无偏分布。基于解纠缠表示,DisC可以产生更多的无偏样本。此外,LDD是一种通用的去偏方法,它不是为图数据设计的。DisC的平均性能优于相应LDD变体的23.15%,表明全局种群感知边缘掩码与去偏解杂框架的无缝连接是非常有效的。
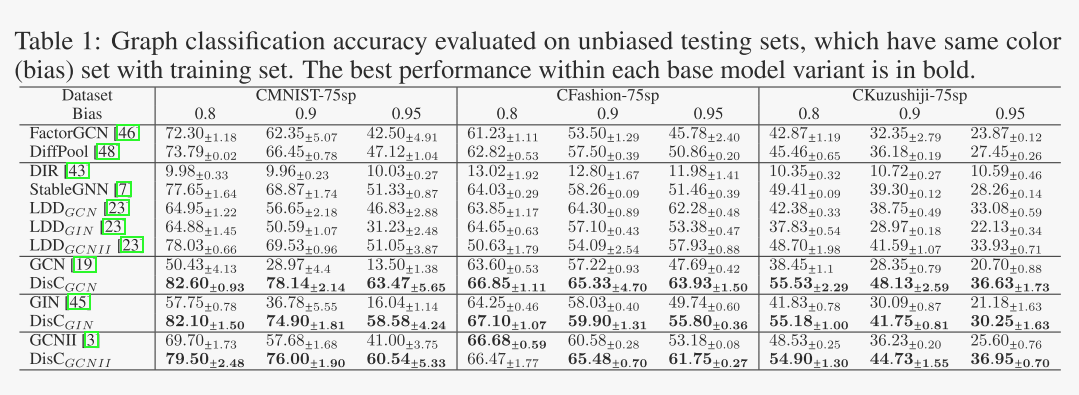
表1:在无偏测试集上评估的图分类精度,无偏测试集与训练集具有相同的颜色(偏置)集。每个基础模型变体的最佳性能以粗体显示。
消融研究
为了验证我们方法中每个模块的重要性,在图4中,我们对我们的变量(w.o. G的平均值没有样本生成模块)和LDD的相关变量进行消融研究。DisC/w.o之间的主要区别。G, LDD /w.o。G为边缘掩码。在大多数情况下,DisC/w.o。G显著优于LDD /w.o。G,表示学习图数据边缘掩码的必要性。而具有反事实样本生成模块的DisC可以进一步提高基于解纠缠嵌入的DisC/w.o的性能。然而,LDD很少优于LDD /w.o。G甚至达到更差的性能。也就是说,生成高质量的反事实样本需要很好地解开因果和偏见嵌入。如果嵌入没有很好地解纠缠,反事实样本可能会成为噪声样本,从而阻碍模型的进一步改进。边缘掩码可以帮助模型生成良好的解纠缠嵌入,这对整体性能至关重要。
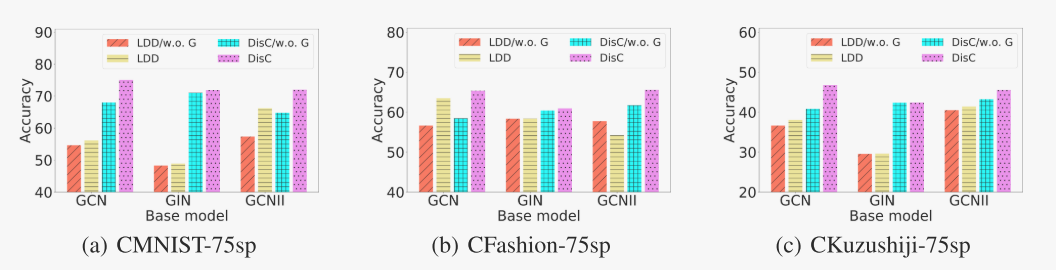
图4:在每个数据集的三个偏置度上,DisC相对于LDD的消融研究。
对不可见偏差的鲁棒性
表2报告了在具有不可见偏差的测试集上,DisC与其相应的基模型的比较结果,即训练集和测试集的预定义颜色(偏差)集是不相交的。与表1中偏倚情景下的结果相比,基本模型的性能进一步下降。然而,我们的模型仍然取得了非常稳定的性能,充分展示了我们的模型在不可知论偏见情景下的泛化能力。
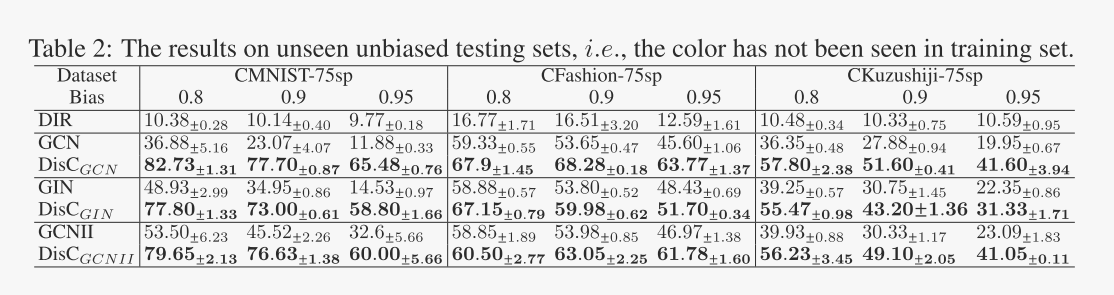
表2:在未见过的无偏测试集上的结果,即在训练集上未见过颜色。
超参数实验
图5为GCE损耗中放大偏置程度q和产生分量λG重要性的超参数实验。对于q,我们确定λG = 10, q在{0.1,0.3,0.5,0.7,0.9}范围内变化。对于λG,我们定q = 0.7,使λG从{1,5,10,15}变化。从结果可以看出,我们的模型在不同的q值和λG值下都取得了稳定的性能。当q = 0.1时,表示GCE损耗几乎降低到正常的CE损耗。我们可以看到,DisCGCN的性能比其他场景要差,证明了利用GCE损耗的有效性。
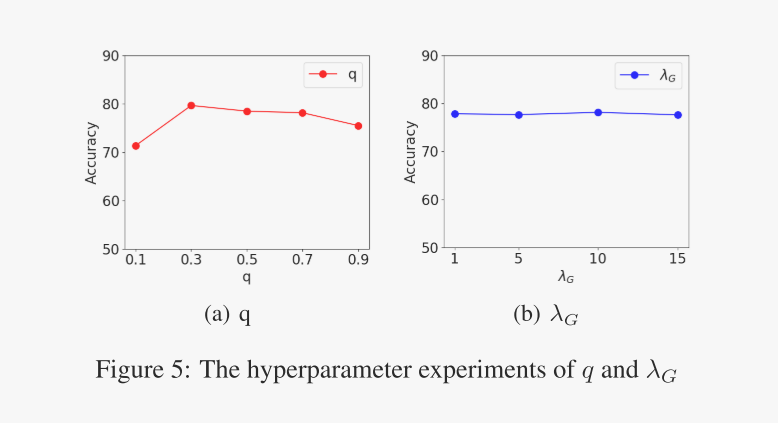
图5:q和λG超参数实验
5.2 定性评价
边缘掩码的可视化。为了更好地说明DisCGCN提取的显著的因果和偏倚子图,我们将原始图像、原始图以及CMNIST-75sp相应的因果子图和偏倚子图以0.9偏倚程度进行可视化,如图6所示,其中边的宽度表示学习权重cij或bij的值。图6(a)显示了在训练集中看到的带有偏置(颜色)的测试图的可视化结果。正如我们所看到的,我们的模型可以发现因果子图中最显著的边在数字子图中。由于这些因果子图突出了数字结构信息,因此gnn可以更容易地提取出这些因果信息。图6(b)为不可见偏差测试图的可视化结果。根据可视化,我们的模型仍然可以发现因果子图的大纲,表明我们的模型可以识别因果子图,无论偏差是可见的还是不可见的。CFashion-75sp和CKuzushiji-75sp的可视化结果显示在App. D中。
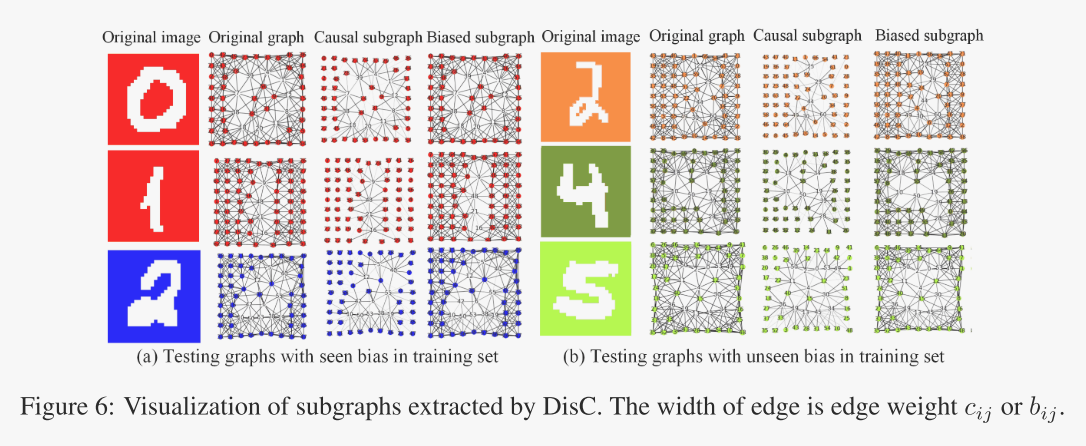
图6:DisC提取的子图的可视化。边的宽度是边权值cij或bij。
解纠缠表示的投影。从DisCGCN的因果GNN gc和偏置GNN gb中分别提取潜在向量zc和zb,使用t-SNE[21]在CMNIST-75sp上进行投影,结果如图7所示。图7 (a-b)为目标标签(数字)和偏置标签所标记的zc的投影(颜色)。图7 (c-d)为目标标签和偏置标签所标记的zb的投影,分别我们观察到zc是根据目标标签聚类的,而zb是聚类的带有偏置标签。zc与偏置标签混合,zb与目标标签混合。结果表明,DisC成功地学习了解开的因果和偏倚表征。
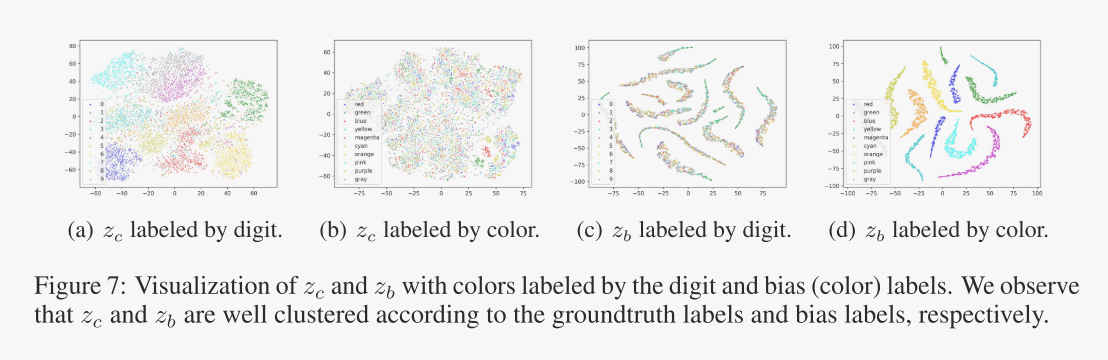
图7:zc和zb的可视化,颜色由数字和偏置(颜色)标签标记。我们观察到zc和zb分别根据groundtruth标签和bias标签很好地聚类。
学习面具的可转移性。由于我们的模型可以提取与gnn无关的子图,因此可以使用学习的边权值来净化原始的有偏图。这些稀疏子图代表了重要的语义信息,可以普遍地转移到任何gnn上。为了验证这一点,我们通过DisCGCN学习了边缘掩码,并删除了{0%、20%、40%、60%}权重最少的边缘,同时保留了其余的边缘权重。然后在这些加权剪枝数据集上训练香草杜松子酒和GCNII。图8为结果比较,虚线表示基模型在原始有偏图上的结果,实线表示gnn在加权修剪数据集上的性能。结果表明,在经过修剪的数据集上训练的gnn具有较好的性能,说明我们学习的边缘掩码具有相当大的可移植性。
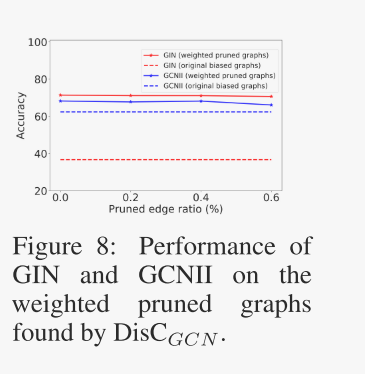
图8:在DisCGCN找到的加权剪枝图上,GIN和GCNII的性能。

六、总结
本文首先研究了gnn在严重偏差数据集上的泛化问题,这对于研究gnn的透明知识学习机制至关重要。我们从因果的角度分析了这个问题,即纠缠表示以及因果变量和偏差变量之间的相关性会阻碍gnn的泛化。为了消除这两个方面的影响,我们提出了一个通用的分离框架——DisC,它分别用两种不同的功能gnn来提取因果子结构和偏置子结构。在表示被很好地解纠缠后,我们通过随机交换解纠缠向量来扩充反事实无偏样本。通过新构造的基准,我们清楚地验证了我们方法的有效性、健壮性、可解释性和可移植性。
A、因果推理的必备知识
A.1 结构因果模型
为了严格形式化数据集背后的因果假设,我们采用结构因果模型(SCM)。 SCM 是一种描述特定问题的相关特征(变量)以及它们如何相互作用的方法。特别是,SCM 描述了系统如何为感兴趣的变量分配值。
形式上,SCM 由一组外生变量 U 和一组内生变量 V 以及一组函数 f 组成,该函数 f 根据模型中的其他变量确定 V 中变量的值。随意地,如果 X 存在于确定 Y 值的函数中,则变量 X 是变量 Y 的直接原因。如果 X 是 Y 的直接原因或 Y 的任何原因的直接原因,则 X 是 Y 的原因。 外生变量U 粗略地表示它们是模型外部的,因此,在大多数情况下,我们选择不解释它们是如何引起的。每个内生变量都是至少一个外生变量的后代。外生变量只能是根变量。如果我们知道每个外生变量的值,利用 f 中的函数,我们可以完美地确定每个内生变量的值。在许多情况下,我们通常假设所有外生变量都是不可观察的变量,例如噪声,并且独立分布,期望值为零,因此我们只关心与内生变量的相互作用。每个 SCM 都与一个图形因果模型相关联,或者简称为“因果图”。因果图由代表 U 和 V 中变量的节点以及代表 f 中函数的节点之间的直接边组成。请注意,在第 3.2 节的 SCM 中,我们仅显示我们感兴趣的内生变量。
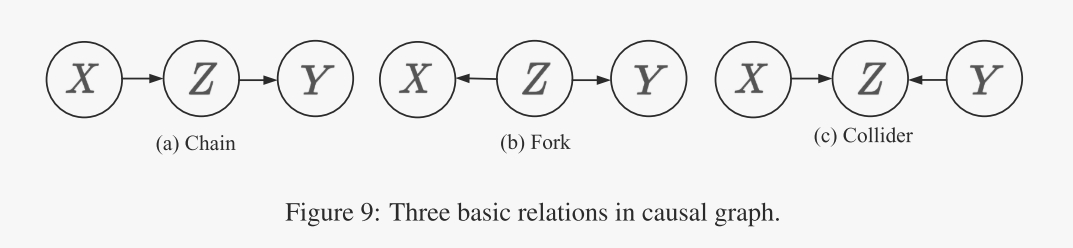
A.2 d-separation/connection
给定 SCM,我们对嵌入模型中的(条件)依赖信息特别感兴趣。 SCM 中存在三种基本的变量关系,即链、叉子和碰撞器,如图 9 所示。对于链和叉子,如果 Z 不在条件集中(即路径),则 X 和 Y 是相关的已畅通无阻,反之亦然。对于碰撞器,如果 Z 不在条件集中,即路径被阻塞,则 X 和 Y 将是独立的。基于这些规则,d-分离是一个可以应用于任何复杂程度的因果图中的标准,以便预测由图生成的所有数据集共享的依赖关系[13]。如果两个节点 X 和 Y 之间的每条路径都被阻塞,则它们是 d 分离的。即使 X 和 Y 之间的一条路径畅通,X 和 Y 也是 d 连接的。形式上,我们对 d-分离有以下定义:

根据这个原理,我们可以发现3.2节中的路径(1)B→G→E→Y和(2)B↔C→Y是畅通的路径,这会导致偏差变量B和预测Y之间出现意想不到的相关性。
B、算法

C、实验细节
C.1 数据集详细信息

我们在表3中总结了本文构建的数据集的统计数据。请注意,验证集的偏差度为0.5,我们用它来调整训练过程中的学习率。不失一般性,这里我们将原始 60K 训练样本二次采样为 10K 训练样本,以使训练过程更加高效。人们可以使用我们的方法轻松构建完整的数据集。 CFashion-75sp 的每张图都标有其所属的时尚产品类别,CKuzushiji-75sp 的每张图均标有 10 个平假名字符之一。此外,我们希望在表 4 中列出所有数据集的标签和预定义相关颜色之间的映射。源图像数据集的链接如下:
- MNIST: http://yann.lecun.com/exdb/mnist/.
- Fashion-MNIST: https://github.com/zalandoresearch/fashion-mnist. MIT License.
- Kuzushiji-MNIST: https://github.com/rois-codh/kmnist. CC BY-SA 4.0 License.
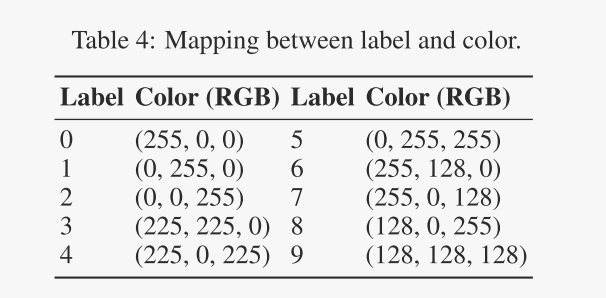
表 4:标签和颜色之间的映射。
对于表 2 中使用的具有不可见偏差的无偏差测试数据集,预定义颜色集的 RGB 值为 {(199, 21, 133), (255, 140, 105), (255, 127, 36), (139, 71, 38), (107, 142, 35), (173, 255, 47), (60, 179, 113), (0, 255, 255), (64, 224, 208), (0, 191, 255) }。
C.2 实验装置
对于GCN和GIN,我们使用与[15]6相同的模型架构,有4层,GCN有146个隐藏维度,GIN有110个隐藏维度。 GIN 使用其 GIN0 变体。对于GCNII,它有4层和146个隐藏维度。 DIR7 使用原始论文中 MNIST-75sp 数据集的默认参数。对于我们模型中的因果 GNN 或偏差 GNN,它与基础模型具有相同的架构。我们使用 Adam [18] 优化器和 0.01 的学习率来优化所有实验的所有模型。所有方法的批量大小均为 256。我们用 200 个 epoch 训练所有模型,并将方法 tgen 的生成迭代设置为 100。对于我们的模型,我们将所有实验的 GCE 损失 q 设置为 0.7,将 λG 设置为 10 。我们的子结构生成器是一个两层 MLP,其激活函数是 sigmoid 函数。对于 StableGNN,我们使用他们的 GraphSAGE 变体。对于其他基线,我们使用它们的默认超参数。 LDD8 与我们的模型具有相同的超参数。为了更好地反映无偏样本生成的性能,我们将最后一步的性能作为最终结果。所有实验均在单个 NVIDIA V100 GPU 上进行。
D、CFashion-75sp 和 CKzushiji-75sp 的可视化
图10和图11是CFashion-75sp和CKuzushiji-75sp数据集的可视化结果。正如我们所看到的,我们的模型还可以为这些具有挑战性的数据集发现合理的因果子图。
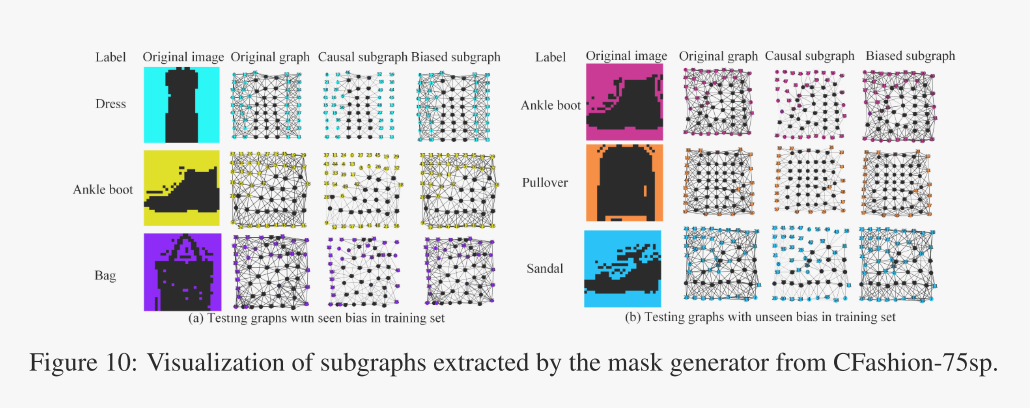
图 10:掩模生成器从 CFashion-75sp 中提取的子图的可视化。

图 11:掩模生成器从 CKuzushiji-75sp 中提取的子图的可视化。
6 https://github.com/graphdeeplearning/benchmarking-gnns
7 https://github.com/Wuyxin/DIR-GNN
8 https://github.com/kakaoenterprise/Learning-Debiased-Disentangled
相关文章:
图神经网络论文笔记(一)——北邮:基于学习解纠缠因果子结构的图神经网络去偏
作者 :范少华 研究方向 :图神经网络 论文标题 :基于学习解纠缠因果子结构的图神经网络去偏 论文链接 :https://arxiv.org/pdf/2209.14107.pdf https://doi.org/10.48550/arXiv.2209.14107 大多数图神经网络(GNNs)通…...

java初始化list的几种方式
在Java中初始化List有以下几种常见的方式: 使用Arrays.asList()静态方法: List<Integer> list1 Arrays.asList(1, 2, 3);使用List接口的实现类ArrayList的构造函数: List<String> list2 new ArrayList<>();使用Collections.singletonList() String obj…...
Linux:文件操作
目录 一、关于文件 1、文件类的系统接口 2、文件的含义 二、文件操作 1、C语言文件相关接口 2、系统接口 open close write read 三、文件描述符 关于fd fd的分配规则 输出重定向示例 输入重定向示例 追加重定向示例 dup2函数 缓冲区 stdout与stderr perror…...
vue源码笔记之——运行时runtime
源码中的位运算 按位于 运算 if (shapeFlag & ShapeFlags.TELEPORT) {解释:如果shapFlag本身值为8,type为1的话,那么转换为二进制(js都是32位)那就是 shapFlag:00000000 00000000 00000000 00001000 …...
)
MySQL数据库干货_09—— MySQL中的外键约束(Foreign Key)
外键约束(Foreign Key) 添加外键约束 使用DDL语句添加外键约束 ALTER TABLE 表名 ADD CONSTRAINT 约束名 FOREIGN KEY( 列 名 ) REFERENCES 参照的表名(参照的列名);示例一: 创建 departments 表包含 department_id 、department_name ,location_id。…...
springboot配置https
SSL : secure socket layer 是一种加密协议,SSL主要用于保护数据在 客户端和服务器之间的传输,,防止未经授权的访问和窃取敏感信息 在腾讯云申请ssl证书 申请了之后在我的域名中,,解析 解析了之后&…...
java - IDEA IDE - 设置字符串断点
文章目录 java - IDEA IDE - 设置字符串断点概述笔记END java - IDEA IDE - 设置字符串断点 概述 IDE环境为IDEA2022.3 在看一段序列化的代码, 想找出报错抛异常那个点, 理解一下代码实现. 因为序列化代码实现在第三方jar包中, 改不了(只读的). 根本数不清第几次才会开始报…...
【图像分类】基于计算机视觉的坑洼道路检测和识别(ResNet网络,附代码和数据集)
写在前面: 首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。(专栏订阅用户订阅专栏后免费提供数据集和源码一份,超级VIP用户不在服务范围之内,不想订阅专栏的兄弟们可以私信…...

关于readline方法使用的一个中文乱码引发的思考
故事起源于这段代码,我想给一个本地地址然后去读取文件内容,然后使用了reader.readLine();方法,但是本地没有任何报错,但是线上中文乱码导致直接报错了。 BufferedReader reader;try {reader new BufferedReader(new FileReader(…...

BUUCTF 神秘龙卷风 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 神秘龙卷风转转转,科学家用四位数字为它命名,但是发现解密后居然是一串外星人代码!!好可怕! 密文: 下载附件,解压得到一个.rar压缩…...
【JavaEE初阶】 认识文件与Java中操作文件
文章目录 🌴认识文件🚩树型结构组织和目录🚩文件路径(Path)🚩知识扩展 🎍Java 中操作文件🚩File 概述📌属性📌构造方法📌方法 🚩File使…...

数据结构───链表
花费一个周时间学完了链表(的一部分),简单总结一下。 链表的学习离不开画图,将其抽象成一种逻辑模型,可以减少思考时间,方便理解。 链表大致分为8种结构,自己学习并实现了两种结构,也…...

SQLAlchemy删除所有重复的用户|Counter类运用
Python标准库中的collections模块中的Counter类。Counter类用于计算可迭代对象中元素的出现次数,并以字典的形式返回结果,其中键是元素,值是该元素的出现次数。 for name, count in Counter(names).items() 是一个循环语句,它用于…...
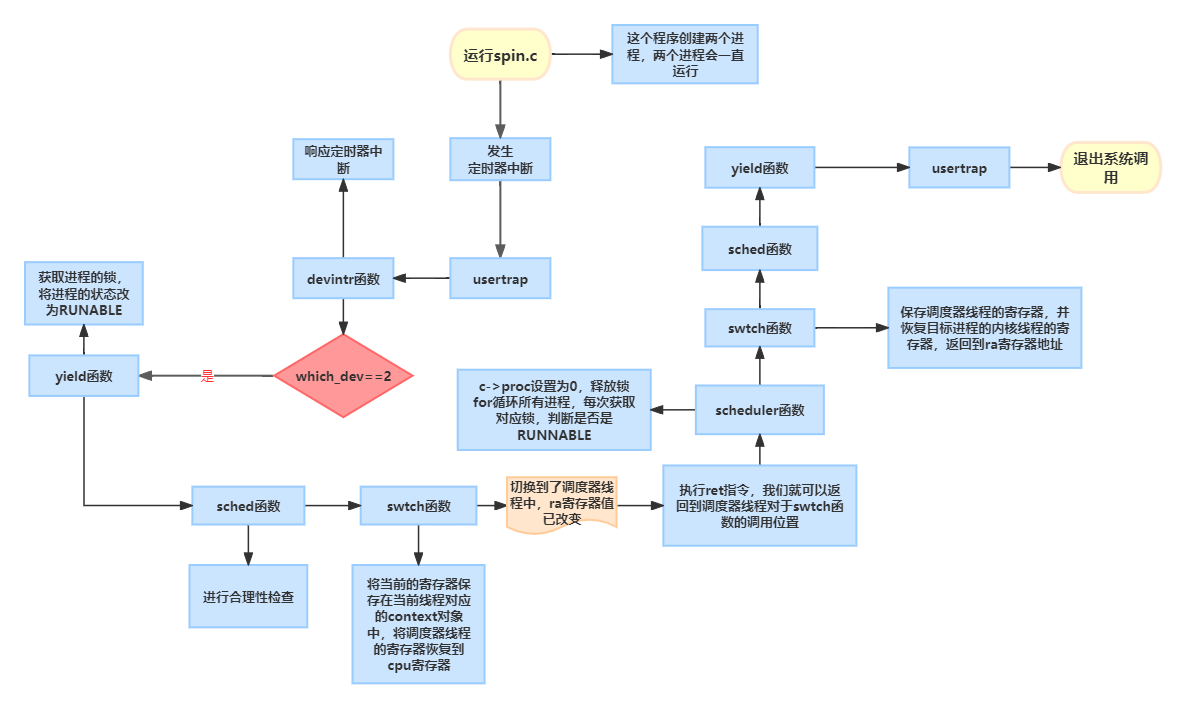
Lec11 Thread switching (Robert)
线程的概念 线程就是单个串行执行代码的单元,它只占用一个CPU并且以普通的方式一个接一个的执行指令。 线程还具有状态,我们可以随时保存线程的状态并暂停线程的运行,并在之后通过恢复状态来恢复线程的运行。 程序计数器(Progr…...
前端的简单介绍
前端核心的分析 CSS语法不够强大,比如无法嵌套书写,倒是模块化开发中需要书写很多重复的选择器 没有变量和合理的样式复用机制,使逻辑上相关的属性值必须字面量的心事重复的输出,导致难以维护 CSS预处理器,减少代码的笨重&#…...
云服务器 centos 部署 code-server 并配置 c/c++ 环境
将你的云服务器改为 centos 8 为什么要将云服务器的操作系统改成 centos 8 呢?原因就是 centos 7 里面的配置满足不了 code-server 的需求。如果你使用的是 centos 7 那么就需要你升级一些东西,这个过程比较麻烦。我在 centos 7 上面运行 code-server 的…...

Ubuntu 22.04 安装 Terraform
Ubuntu 22.04 安装 Terraform 安装 Terraform 安装 Terraform sudo apt updatesudo apt install software-properties-common gnupg2 curlcurl https://apt.releases.hashicorp.com/gpg | gpg --dearmor > hashicorp.gpgsudo install -o root -g root -m 644 hashicorp.gpg…...
MLF - 麻辣粉
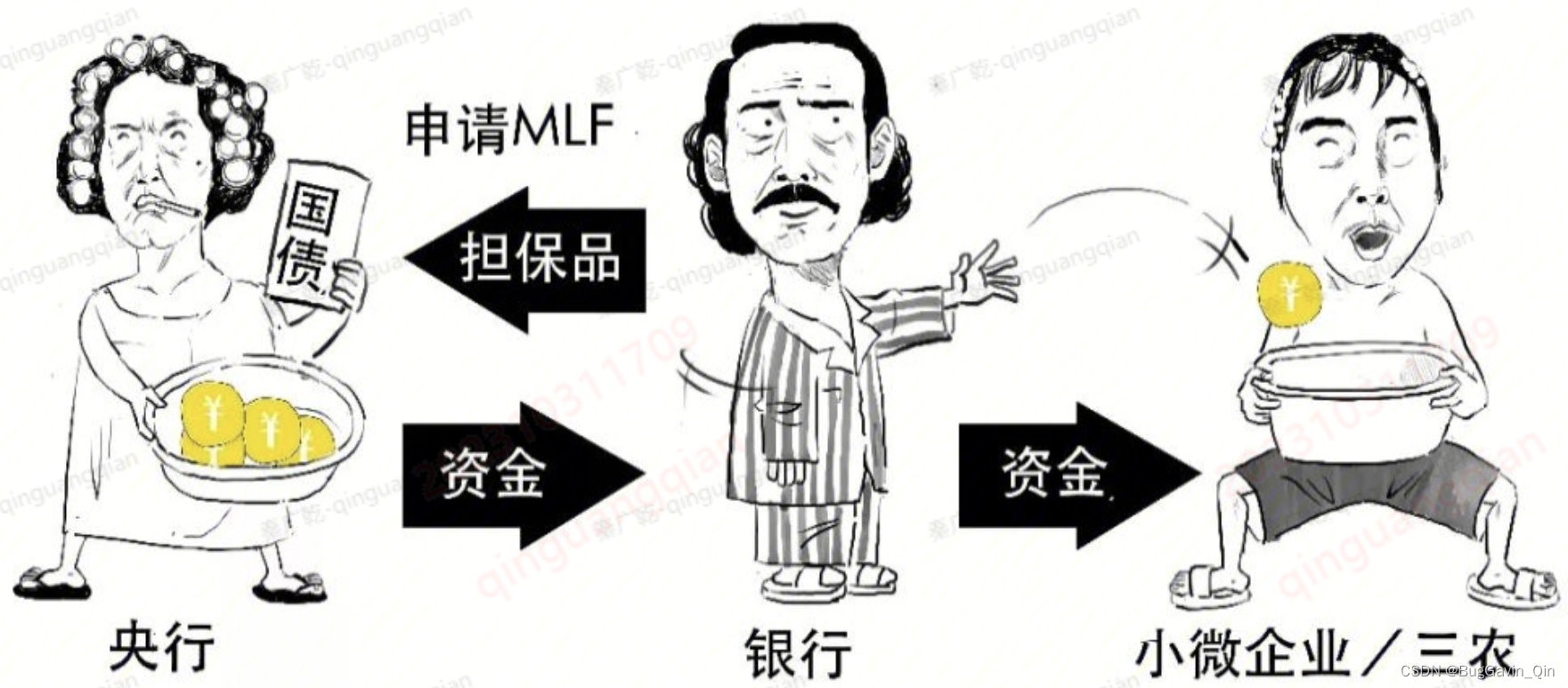
MLF全称中期借贷便利(Medium-term lending Facility),理解为央行向商业银行、政策银行发放的贷款,但需要符合一定要求才可向央行申请。银行通过MLF向央行借款的时候,需要提供担保品。一般为国债、央行票据、政策性金融债、地方债、…...
Flutter三棵树的创建流程
一、Flutter常见的家族成员 Widget常见的家族成员 Element常见的家族成员 Render常见的家族成员 二、示例代码对应的Flutter Inspector树 示例代码:MyApp->MyHomePage->ErrorWidget,包含了StatelessWidget、StatefulWidget、LeafRenderObjectWid…...

思维训练第二课 独立主格
系列文章目录 文章目录 系列文章目录前言一、独立主格特点 二、独立主格的构成1.名词/人称代词主格现在分词2. 名词/人称代词主格过去分词3. 名词/人称代词主格形容词/副词4. 名词/人称代词主格不定式5. 名词/人称代词主格介词短语6.介词复合宾语 三、独立主格结构的句法功能1、…...

长期使用 Taotoken 过程中对其服务稳定性的主观感受记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken 过程中对其服务稳定性的主观感受记录 1. 背景与使用模式 过去的一个季度,我负责的一个中型项目进入…...

为什么越来越多人放弃了传统日记本?因为他们发现了雷小兔写期刊
在这个信息爆炸的时代,我们每个人的心中都装满了故事、想法和情感。但往往,这些珍贵的内容在日常的忙碌中逐渐褪色,最终消散在时间的长河里。你是否也曾有过这样的遗憾——明明想记录下某个瞬间,却苦于没有合适的方式去表达&#…...

AI 视频创作系统:新媒体高效增收工具,AI 自动成片,持续输出优质内容
一、新媒体行业增收难,传统创作模式遇瓶颈如今做新媒体账号想要稳定盈利,离不开高频优质内容输出。但多数从业者普遍面临诸多难题:人工写脚本耗时费力,实拍剪辑流程繁琐,长期聘请专职人员开支巨大;内容产出…...

COLMAP实战:跳过特征提取,直接用已知位姿完成三角测量与稠密重建
COLMAP高效重建实战:基于已知位姿的三角测量与稠密重建加速方案 三维重建技术正在机器人导航、AR/VR内容生成等领域快速普及,但传统流程中特征提取与匹配环节往往消耗超过70%的计算时间。当相机位姿已通过SLAM或其他传感器获取时,如何跳过这些…...

ComfyUI-VideoHelperSuite:AI视频工作流的专业解决方案
ComfyUI-VideoHelperSuite:AI视频工作流的专业解决方案 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 你是否在ComfyUI中处理视频时感到困扰…...

3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备!
3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备! 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你知道吗?现在无需安装…...

英特尔马来西亚六厂布局:先进封装如何重塑半导体制造与供应链
1. 项目概述:从一则新闻到半导体制造的全球拼图前几天,行业里不少朋友都在转一条消息,说英特尔在马来西亚的封装产能布局又有新动作,计划要搞到六座工厂的规模。乍一看,这好像就是个普通的海外建厂新闻,但如…...

挑战 100ms 延迟极限:深度拆解 dograh,构建企业级开源 WebRTC 实时语音智能体平台
发布日期: 2026-05-18标签: #VoiceAgent #WebRTC #语音智能体 #dograh #大模型 #实时音视频一、 引言在 2026 年,随着大模型多模态能力的爆发,传统的“打字输入、文字输出”交互模式正迅速向“纯语音实时对讲”演进。然而…...

全栈AI应用开发框架Flappy:从智能体到生产级Web应用的快速构建指南
1. 项目概述:从“Flappy”到“Pleisto”的AI应用构建新范式最近在AI应用开发圈子里,一个名为“pleisto/flappy”的项目开始引起不少人的注意。乍一看这个名字,你可能会联想到那个经典的像素小鸟游戏,但此“Flappy”非彼“Flappy”…...

RV1126 NPU部署ResNet50全流程:从PyTorch训练到嵌入式板端推理
1. 项目概述:从零到一,在RV1126上跑通ResNet50最近在折腾一块EASY-EAI-Nano开发板,核心是瑞芯微的RV1126芯片,这玩意儿带了个NPU,不拿来跑跑AI模型实在说不过去。手头正好有个车辆分类的需求,就想试试经典的…...