GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-ChatGLM2模型的微调训练参数解读
目录
- GPT实战系列-ChatGLM2模型的微调训练参数解读
- ChatGLM2模型
- 1、P-Tuning模型微调
- 2、微调训练配置参数
- train.sh中配置参数
- 训练配置信息
- 模型配置信息
- 附录:训练正常运行打印信息
ChatGLM2模型
ChatGLM-6B是开源的文本生成式对话模型,基于General Language Model(GLM)框架,具有62亿参数,FP16 半精度下,ChatGLM-6B 需要 13GB 左右的显存进行推理。
ChatGLM-6B另一个突出优点是 可以部署在消费级显卡上,结合模型蒸馏技术和模型量化技术,可以进一步降低到 10GB(INT8) 和 6GB(INT4)。实测在2080ti显卡预测上(INT4)显存占用6G左右。
1、P-Tuning模型微调
P-Tuning的全称是Prefix-tuning,意为“前缀调优”。它通过在模型输入前添加小段Discrete prompt(类似填空句),并只优化这个prompt来实现模型微调。P-tuning-v2是基于Prompt-tuning方法的NLP模型微调技术。总体来说,P-tuning-v2是Prompt tuning技术的升级版本,使得Prompt的表示能力更强,应用也更灵活广泛。它被认为是Prompt tuning类方法中效果最优且易用性最好的版本。
代码实现对于 ChatGLM2-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量,减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,预测最低只需要 7GB 显存即可运行。
将训练和测试数据解压后的 AdvertiseGen 目录放到ptuning目录下。
ChatGLM2的训练源代码:https://github.com/THUDM/ChatGLM2-6B
文件目录结构:
├── FAQ.md
├── MODEL_LICENSE
├── README.md 说明文档
├── README_EN.md
├── api.py
├── cli_demo.py
├── evaluation
│ ├── README.md
│ └── evaluate_ceval.py
├── openai_api.py
├── ptuning
│ ├── README.md 说明文档
│ ├── arguments.py
│ ├── deepspeed.json
│ ├── ds_train_finetune.sh
│ ├── evaluate.sh
│ ├── evaluate_finetune.sh
│ ├── main.py
│ ├── train.sh 训练脚本
│ ├── train_chat.sh
│ ├── trainer.py
│ ├── trainer_seq2seq.py
│ ├── web_demo.py
│ └── web_demo.sh 测试脚本
├── requirements.txt 环境依赖文件
├── resources
│ ├── WECHAT.md
│ ├── cli-demo.png
│ ├── knowledge.png
│ ├── long-context.png
│ ├── math.png
│ ├── web-demo.gif
│ ├── web-demo2.gif
│ └── wechat.jpg
├── utils.py
├── web_demo.py
└── web_demo2.py
2、微调训练配置参数
训练之前,需要根据自己的训练需求,训练数据和机器配置情况修改配置参数。
train.sh中配置参数
PRE_SEQ_LEN=128 # soft prompt 长度
LR=2e-2 # 训练学习率
NUM_GPUS=2 # GPU卡的数量torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \--do_train \ # 执行训练功能,还可以执行评估功能--train_file AdvertiseGen/train.json \ # 训练文件目录--validation_file AdvertiseGen/fval.json \ # 验证文件目录--prompt_column content \ # 训练集中prompt提示名称,对应训练文件,测试文件的"content"--response_column summary \ # 训练集中答案名称,对应训练文件,测试文件的"summary"--overwrite_cache \ # 缓存,重复训练一次的时候可删除--model_name_or_path THUDM/chatglm-6b \ # 加载模型文件目录,也可修改为本地模型的路径--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ # 保存训练模型文件目录--overwrite_output_dir \ # 覆盖训练文件目录--max_source_length 64 \ # 最大输入文本的长度--max_target_length 128 \--per_device_train_batch_size 1 \ # batch_size 训练批次根据显存调节--per_device_eval_batch_size 1 \ # 验证批次--gradient_accumulation_steps 16 \ # 梯度累加的步数--predict_with_generate \--max_steps 3000 \ # 最大训练模型的步数--logging_steps 10 \ # 多少步打印日志一次--save_steps 1000 \ # 多少步保存模型一次--learning_rate $LR \ # 学习率--pre_seq_len $PRE_SEQ_LEN \--quantization_bit 4 # 量化,也可修改为int8
训练配置参数具体解释
# 长度和 学习率
–PRE_SEQ_LEN 是 soft prompt 长度,可以进行调节以取得最佳的效果。
–LR 是训练的学习率
# 本地数据,训练集和测试集的路径
–train_file AdvertiseGen/train.json
–validation_file AdvertiseGen/dev.json \
# 模型目录。
如果你想要从本地加载模型,可以将THUDM/chatglm2-6b 改为你本地的模型路径。
–model_name_or_path THUDM/chatglm-6b
# 最大训练步数
–max_steps 3000
# 模型量化,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。在默认配置 quantization_bit=4
–quantization_bit 4 # 量化,也可修改为int8
# 批次,迭代参数,在默认配置 per_device_train_batch_size=1、gradient_accumulation_steps=16 下,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
–per_device_train_batch_size 1 \ # batch_size 训练批次根据显存调节
–per_device_eval_batch_size 1 \ # 验证批次
–gradient_accumulation_steps 16 \ # 梯度累加的步数
训练配置信息
执行训练脚本后,训练过程中屏幕打印信息如下:
***** Running training *****
Num examples = 114,599Num Epochs = 100 Instantaneous batch size per device = 4Total train batch size (w. parallel, distributed & accumulation) = 16Gradient Accumulation steps = 4Total optimization steps = 3,000Number of trainable parameters = 1,949,696
这些参数是深度学习模型训练过程中的一些关键设置。
Num examples = 114,599: 表示在训练集中有114,599个样本,即114,599个独立的训练数据用于训练。
Num Epochs = 100: 一个epoch指的是模型在训练过程中遍历整个训练集一次。因此,Num Epochs = 100意味着模型会遍历整个训练集100次。
Instantaneous batch size per device = 4: 在深度学习中,通常不会同时处理所有的训练样本,而是将它们分成“批次”进行处理。每个批次的大小就是每次模型训练的样本数量。在这个例子中,每个设备上的即时批量大小为4,意味着每个设备一次处理4个样本。
Total train batch size (w. parallel, distributed & accumulation) = 16: 表示在并行、分布式和积累情况下,总的训练批次大小为16。这可能意味着在多个设备上同时进行训练,每个设备处理一部分批次,然后把这些批次加起来,总和为16。
Gradient Accumulation steps = 4: 梯度累积是一种在内存不足的情况下训练大模型的技巧。它的工作原理是:在进行反向传播并更新模型权重之前,先计算并累积一定步数的梯度。在该例中,每4个批次后进行一次权重更新。
Total optimization steps = 3,000: 优化步数是模型训练过程中权重更新的总次数。在这个例子中,模型权重将被更新3000次。
Number of trainable parameters = 1,949,696: 这是模型中可以通过训练改变的参数的数量。深度学习模型的性能通常与其可训练参数的数量有关。但是,更多的参数并不总是意味着更好的性能,因为过多的参数可能导致过拟合,即模型过于复杂,不能很好地泛化到训练集之外的新数据。
模型配置信息
"add_bias_linear": false,"add_qkv_bias": true,"apply_query_key_layer_scaling": true,"apply_residual_connection_post_layernorm": false,"architectures": ["ChatGLMModel"],"attention_dropout": 0.0,"attention_softmax_in_fp32": true,"auto_map": {"AutoConfig": "configuration_chatglm.ChatGLMConfig","AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"},"bias_dropout_fusion": true,"eos_token_id": 2,"ffn_hidden_size": 13696,"fp32_residual_connection": false,"hidden_dropout": 0.0,"hidden_size": 4096,"kv_channels": 128,"layernorm_epsilon": 1e-05,"model_type": "chatglm","multi_query_attention": true,"multi_query_group_num": 2,"num_attention_heads": 32,"num_layers": 28,"original_rope": true,"pad_token_id": 2,"padded_vocab_size": 65024,"post_layer_norm": true,"quantization_bit": 0,"rmsnorm": true,"seq_length": 32768,"tie_word_embeddings": false,"torch_dtype": "float16","transformers_version": "4.30.2","use_cache": true
这些参数是深度学习模型配置的详细设置,特别是对于ChatGLM的模型。以下是每个参数的含义:
“add_bias_linear”: false: 表示是否在线性层中添加偏置项。
“add_qkv_bias”: true: 表示是否在注意力机制的查询(Q)、键(K)和值(V)计算中添加偏置项。
“apply_query_key_layer_scaling”: true: 表示是否对注意力机制中的查询和键进行缩放处理。
“apply_residual_connection_post_layernorm”: false: 表示是否在层归一化后应用残差连接。
“architectures”: [“ChatGLMModel”]: 表示该配置用于的模型架构。
“attention_dropout”: 0.0: 表示在注意力计算中应用的dropout的比率。Dropout是一种防止模型过拟合的技术。
“attention_softmax_in_fp32”: true: 表示是否在单精度浮点格式(FP32)中执行注意力机制的Softmax计算。
“auto_map”: 这部分将自动配置,模型映射到ChatGLM的配置和模型。
“bias_dropout_fusion”: true: 表示是否融合偏置和dropout。这通常用于优化和提高训练速度。
“eos_token_id”: 2: 定义结束符(End of Sentence)的标识符。
“ffn_hidden_size”: 13696: 表示前馈神经网络(Feedforward Neural Network,FFN)的隐藏层的大小。
“fp32_residual_connection”: false: 表示是否在单精度浮点格式(FP32)中应用残差连接。
“hidden_dropout”: 0.0: 隐藏层的dropout率。
“hidden_size”: 4096: 隐藏层的大小。
“kv_channels”: 128: 键值(Key-Value)的通道数。
“layernorm_epsilon”: 1e-05: 层归一化的epsilon值,为了防止除数为零。
“model_type”: “chatglm”: 模型类型。
“multi_query_attention”: true: 表示是否使用多查询注意力。
“multi_query_group_num”: 2: 在多查询注意力中的查询组数。
“num_attention_heads”: 32: 注意力机制的头数。
“num_layers”: 28: 模型的层数。
“original_rope”: true: 是否使用原始的ROPE模式。
“pad_token_id”: 2: 定义填充符的标识符。
“padded_vocab_size”: 65024: 表示经过填充后的词汇表大小。
“post_layer_norm”: true: 是否在层后应用层归一化。
“quantization_bit”: 0: 表示量化的位数。
“rmsnorm”: true: 表示是否使用RMS归一化。
“seq_length”: 32768: 序列长度。
“tie_word_embeddings”: false: 是否绑定输入和输出的词嵌入。
“torch_dtype”: “float16”: 使用的数据类型,这里是半精度浮点数。
“transformers_version”: “4.30.2”: 使用的Transformers库版本。
“use_cache”: true: 是否使用缓存以加快计算速度。
请注意,上述是训练开始前打印信息的解释,针对ChatGLM模型配置的解释。
附录:训练正常运行打印信息
执行以下指令进行训练:
./train.sh
当出现以下信息后,模型训练迭代开始后屏幕输出如下:
{'loss': 3.0614, 'learning_rate': 0.018000000000000002, 'epoch': 4.21}
{'loss': 2.2158, 'learning_rate': 0.016, 'epoch': 8.42}
训练完成后,屏幕将打印信息:
***** train metrics *****epoch = xxtrain_loss = xxtrain_runtime = xxtrain_samples = xxtrain_samples_per_second = xxtrain_steps_per_second = xx
End
相关文章:
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
相关文章:

GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-ChatGLM2模型的微调训练参数解读 目录 GPT实战系列-ChatGLM2模型的微调训练参数解读ChatGLM2模型1、P-Tuning模型微调2、微调训练配置参数train.sh中配置参数训练配置信息模型配置信息附录:训练正常运行打印信息 ChatGLM2模型 ChatGLM-6B是开源的文本生…...
RabbitMQ入门到实战教程,消息队列实战,改造配置MQ
RabbitMQ入门到实战教程,MQ消息中间件,消息队列实战-CSDN博客 3.7.Topic交换机 3.7.1.说明 Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。 只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候…...
phar反序列化学习
PHP反序列化常见的是使用unserilize()进行反序列化,除此之外还有其它的反序列化方法,不需要用到unserilize()。就是用到phar反序列化。 Phar phar文件 Phar是将php文件打包而成的一种压缩文档,类似于Java中的jar包。它有一个特性就是phar文…...
十年回望 -- JAVA
十年 十年时间,弹指一挥,好像一直都是在为工作奔波,匆匆忙忙的十年。 一、个人介绍 本人毕业于一所很普通的公办专科院校(全日制统招大专),专业是软件技术,当初能进入计算机这一行业࿰…...

Linux 环境下 安装 Elasticsearch 7.13.2
Linux 环境下 安装 Elasticsearch 7.13.2 前言镜像下载(国内镜像地址)解压安装包修改配置文件用 Es 自带Jdk 运行配置 Es 可被远程访问然后启动接着启动本地测试一下能不能连 Es 前言 借公司的 centos 7 服务器,搭建一个 Es,正好熟…...
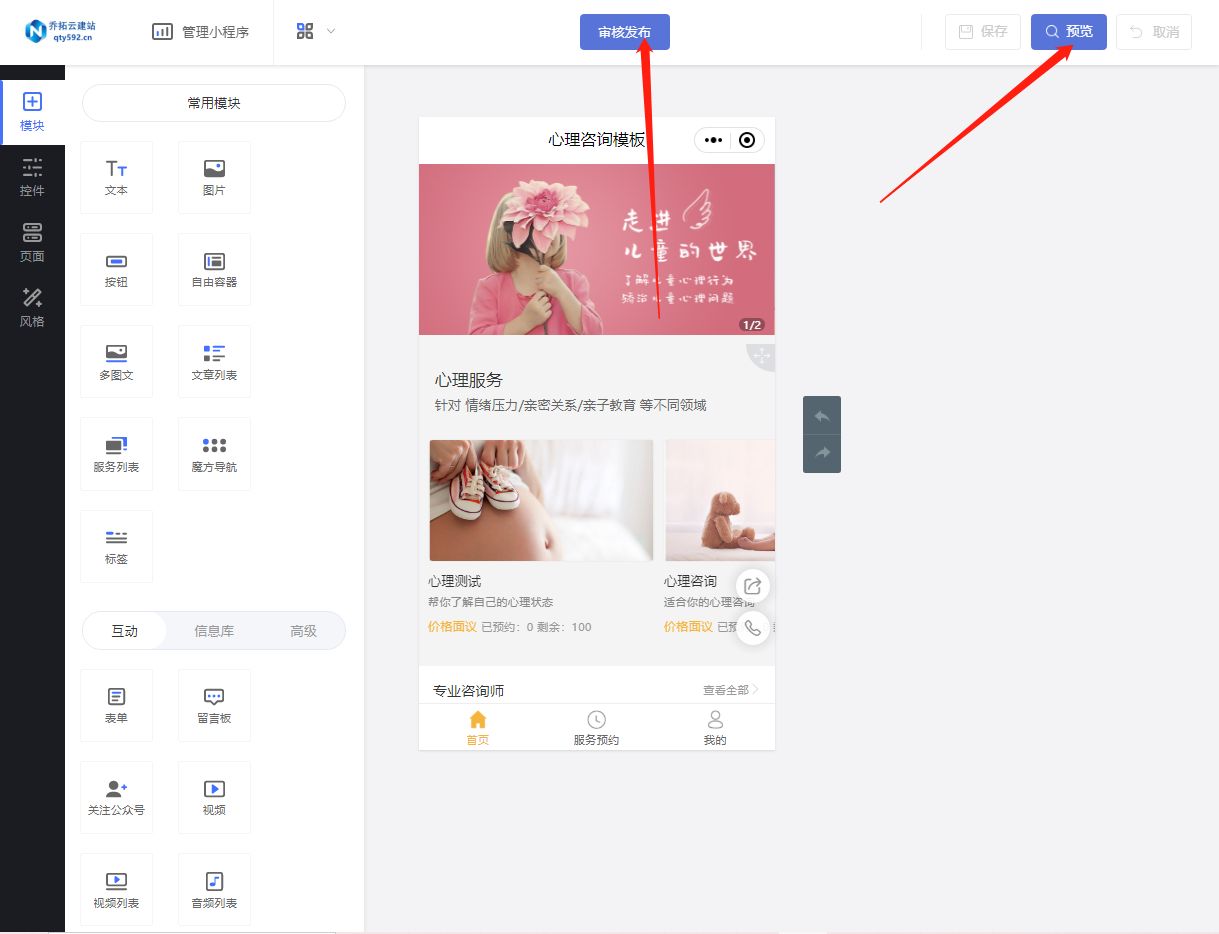
心理咨询预约小程序
随着微信小程序的日益普及,越来越多的人开始关注如何利用小程序来提供便捷的服务。对于心理咨询行业来说,搭建一个心理咨询预约小程序可以大大提高服务的效率和用户体验。本文以乔拓云平台为例,详细介绍如何轻松搭建一个心理咨询预约小程序。…...

常用排序算法的理解
1.插入排序 插入排序的思想是将一个记录插入到已经排好序的有序表中,从而形成一个新的、记录数加1的有序表。在其实现过程使用双层循环,外层循环是进行插入的次数(也可以理解为比较的轮数),内层循环是当前记录查找插入…...

Python小程序 - 文件解析
1. 目录下文件解析:特定文件、文件列表、文件数 Windows文件目录分格使用“ / ” 或 “ \\ ”文件目录路径包含空格的,绝对路径使用“双引号”,保证文件路径的可识别性保存和读取结果时,使用 encodingUTF-8可以添加对文件目录的过…...

.mxdown-V-XXXXXXXX勒索病毒的最新威胁:如何恢复您的数据?
导言: 在数字时代,网络安全威胁层出不穷,其中.mxdown-V-XXXXXXXX、.vollhavhelp-V-XXXXXXXX、.arricklu-V-XXXXXXXX勒索病毒已成为备受关注的问题。这种病毒以其高级加密技术和威胁勒索金的方式,严重危害用户和企业的数据安全。本…...

audio 标签动态src 且src是http无法播放问题
<audioref"audio" :src"src"alt"加载失败"controls/>src是动态传参的 无法播放因为动态src需要在赋值后对audio进行重载 this.$refs.audio.load()注意如果,src跟本项目地址IP端口协议不同,会出现跨域问题。audio标…...

Leetcode—485.最大连续1的个数【中等】明天修改
2023每日刷题(十五) Leetcode—2.两数相加 迭代法实现代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* addTwoNumbers(struct ListNode* l1, struct ListNode* l…...
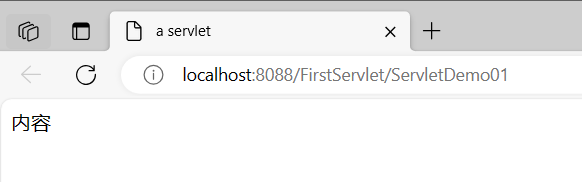
JavaWeb 怎么在servlet向页面输出Html元素?
service()方法里面的方法体: resp.setContentType("text/html;charsetutf-8");//获得输出流PrintWriter对象PrintWriter outresp.getWriter();out.println("<html>");out.println("<head><title>a servlet</title>…...
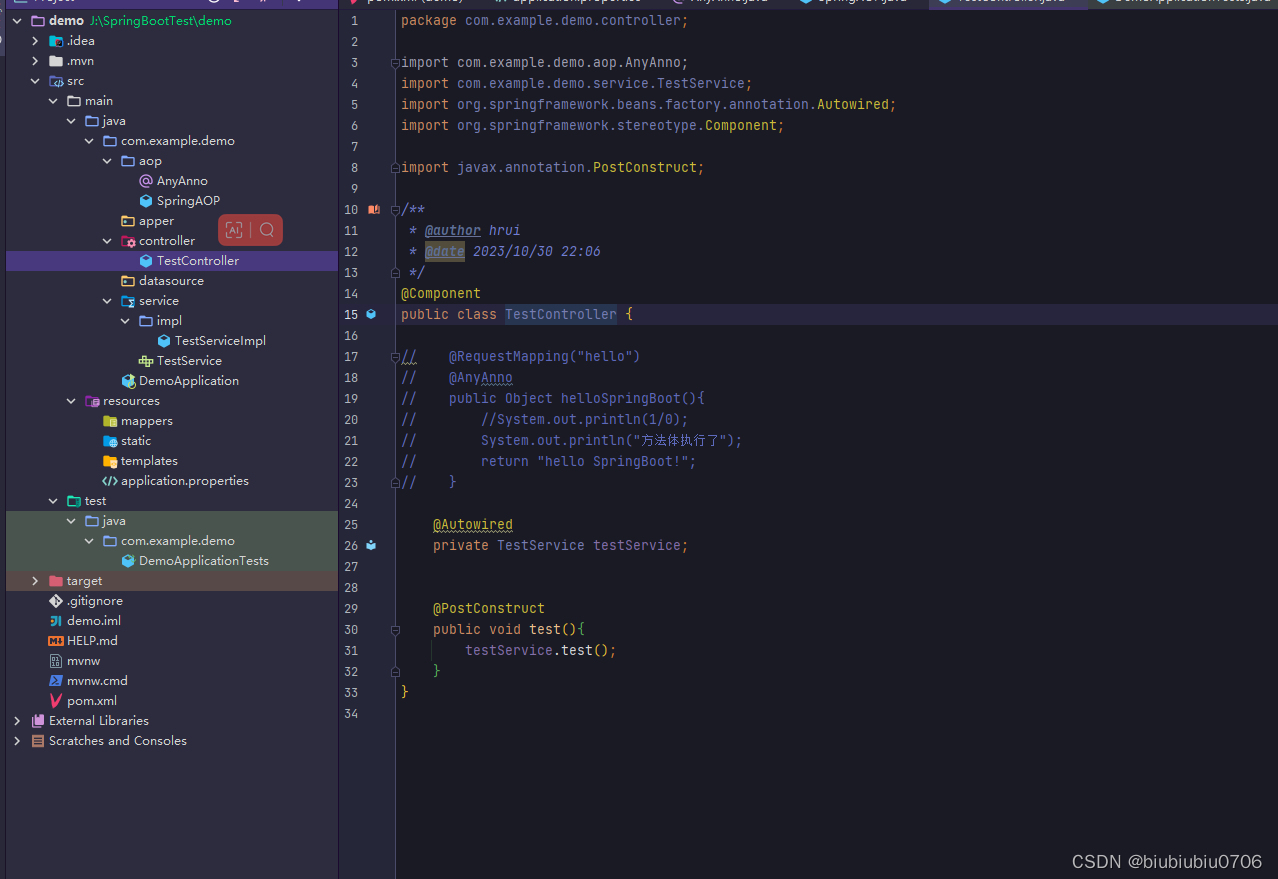
Spring及SpringBoot中AOP的使用
Spring中AOP示例 <dependencies><!--Spring核心包--><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>5.3.6</version></dependency><!--引入SpringBean--&…...
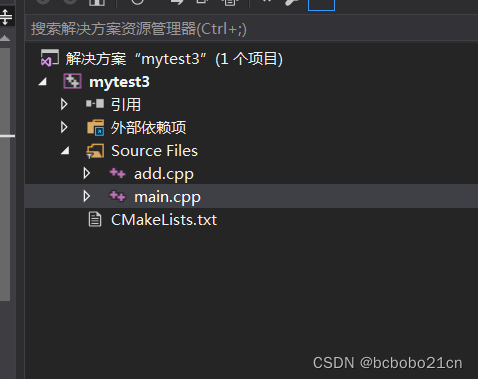
cmake多目录构建初步成功
目录和代码和 首次cmake 多目录构建失败 此文一样; 只有一个CMakeLists.txt; cmake_minimum_required(VERSION 3.10) project(mytest3 VERSION 1.0) include_directories("${PROJECT_SOURCE_DIR}/include") add_executable(mytest3 src/main…...
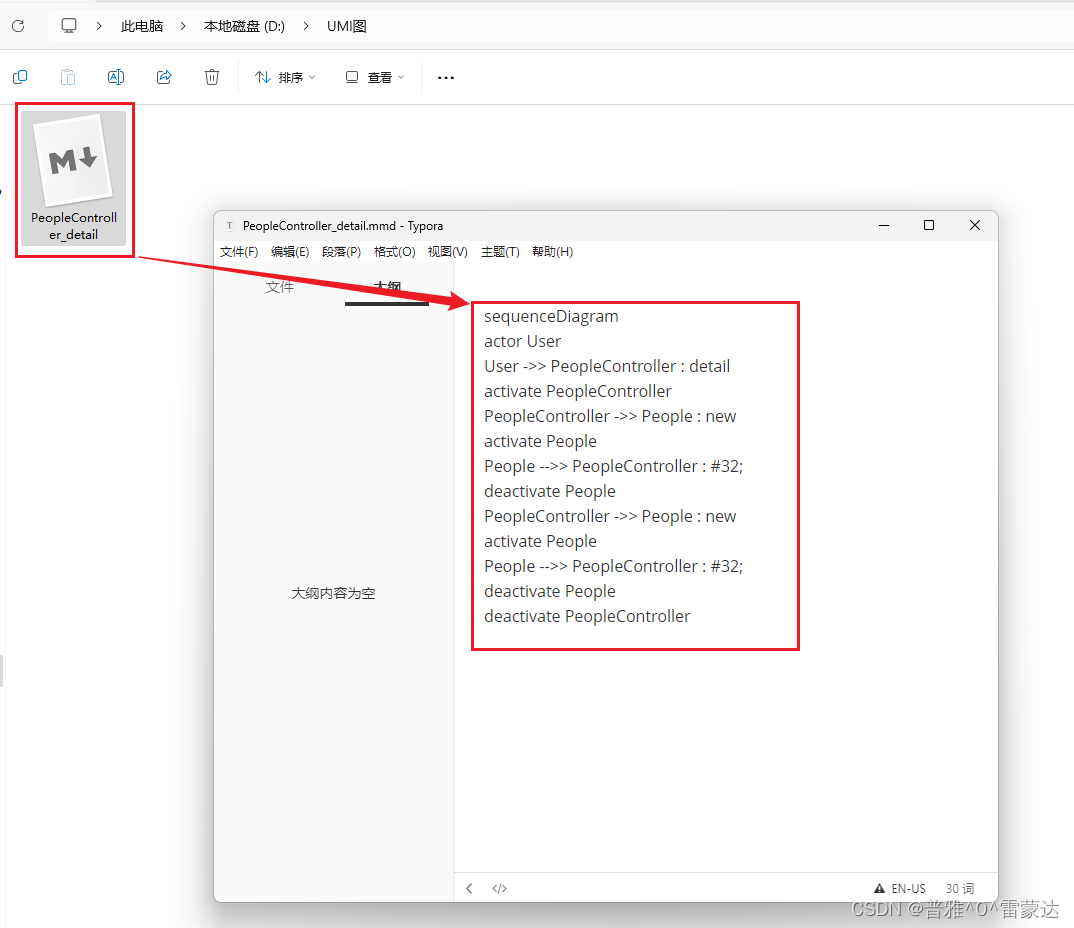
idea插件(一)-- SequenceDiagram(UML自动生成工具)
目录 1. 安装 2. 默认快捷键 3. 操作说明 4. 导出为图片与UML类图 4.1 导出为图片: 4.2 导出 UML 类图 SequenceDiagram是从java、kotlin、scala(Beta)和groovy(limited)代码生成简单序列图(UML&…...

STM32 APP跳转到Bootloader
stm32 app跳转到bootloade 【STM32】串口IAP功能的实现,BootLoader与App相互跳转 STM32 从APP跳入BootLoader问题...

[RISC-V]verilog
小明教IC-1天学会verilog(7)_哔哩哔哩_bilibili task不可综合,function可以综合...
Log4j-tag丢失
一、引言 最近有个线上日志丢失tag的问题,是组内封装了后置请求的拦截器把请求的响应结果存到ClickHouse里面去,但是日志总有一些tag丢失。 作者提出父级线程的threadlocal被清空,同事认为可能是threadlocal的弱引用在gc的时候被回收。两种想…...

代码随想录算法训练营第五十六天|1143.最长公共子序列 ● 1035.不相交的线 ● 53. 最大子序和 动态规划
1143. 最长公共子序列 int longestCommonSubsequence(char * text1, char * text2){int len1 strlen(text1);int len2 strlen(text2);int dp[len11][len21];for (int i 0; i < len1; i){for (int j 0; j < len2; j){dp[i][j] 0;}}for (int i 1; i < len1; i){f…...
虚拟机和Windows的文件传输
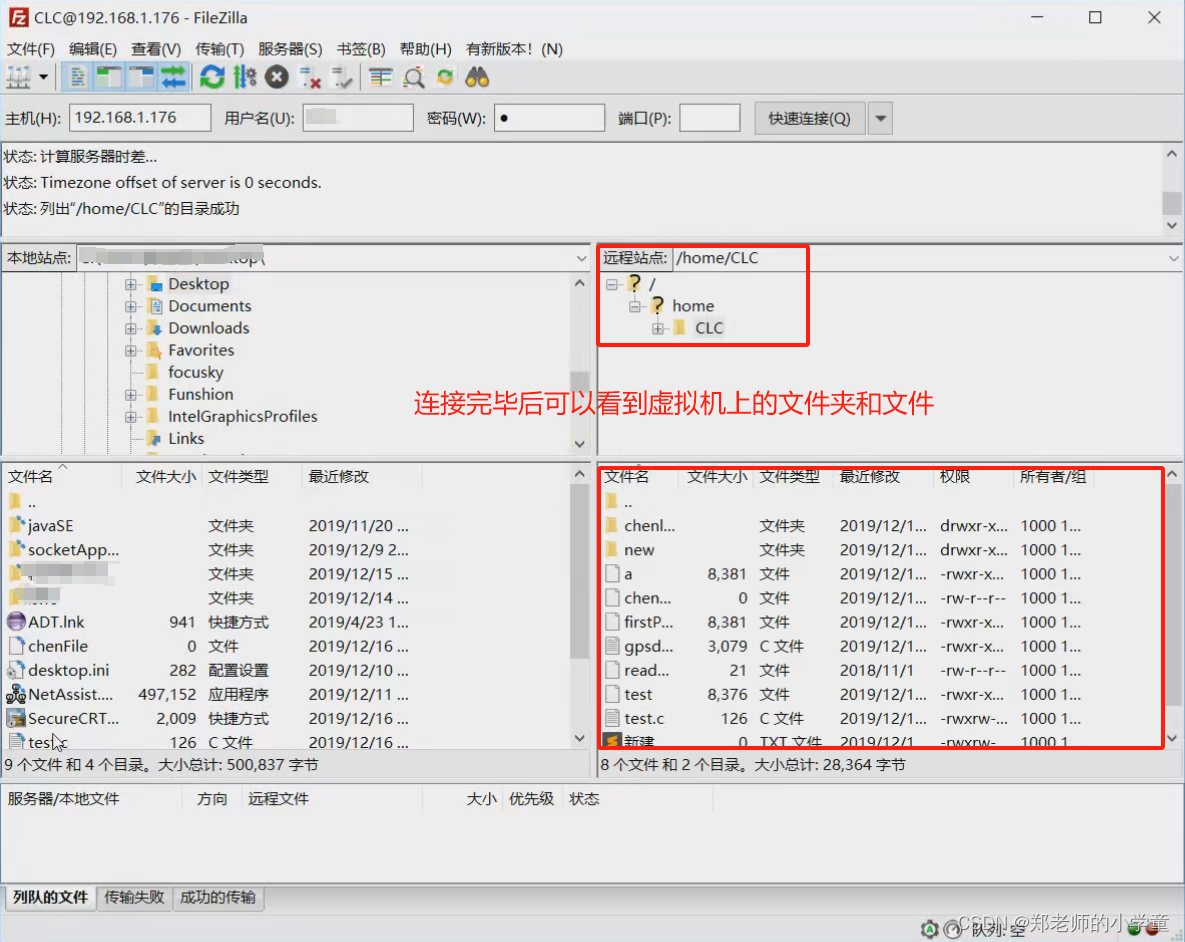
拖拽/复制粘贴 直接将虚拟机linux系统的文件拖曳到windows桌面,或者直接将windows的文件拖曳到虚拟机linux系统当中,可以实现文件传输。当然复制粘贴方式也可以,但是前提是需要下载安装好VMware tools。 共享文件夹 概念:在Win…...

开源智能激活方案:KMS_VL_ALL_AIO如何彻底解决Windows和Office激活难题
开源智能激活方案:KMS_VL_ALL_AIO如何彻底解决Windows和Office激活难题 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统或Office办公软件未激活而烦恼…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

SFT别急着接RL!你的多模态大模型可能一直在“带伤训练”
PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式&…...

终极指南:5步掌握番茄小说下载器的完整使用方案
终极指南:5步掌握番茄小说下载器的完整使用方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,我们常常面临一个共同的问题࿱…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...