【MySQL索引与优化篇】索引优化与查询优化
索引优化与查询优化
文章目录
- 索引优化与查询优化
- 1. 概述
- 2. 索引失效案例
- 3. 关联查询优化
- 3.1 Join语句原理
- 3.2 Simple Nested-Loop Join(简单嵌套循环连接)
- 3.3 Index Nested-Loop Join(索引嵌套循环连接)
- 3.4 Block Nested-Loop Join(块嵌套循环连接)
- 3.5 Hash Join
- 3.6 小结
- 4. 子查询优化
- 5. 排序优化
- 6. GROUP BY 优化
- 7. 分页查询优化
- 8. 字符串的前缀索引
- 9. 索引下推
- 10. 普通索引和唯一索引
- 10.1 更新过程
- 10.2 使用场景
- 11. 其它查询优化策略
- 11.1 EXISTS 和 IN 的区分
- 11.2 count(具体字段)的使用
- 11.3 关于select *
- 11.4 多使用commit
- 12. 推荐的主键策略
1. 概述
虽然 SQL 查询优化的技术有很多,但是大方向上完全可以分成 物理查询优化 和 逻辑查询优化 两大块
- 物理查询优化是通过
索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用 - 逻辑查询优化就是通过
SQL 等价变换提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高
2. 索引失效案例
MySQL 提升性能最有效的方式就是 设计合理的索引,但是否用索引都由优化器决定。
优化器是基于 开销(CostBaseOptimizer),它不是基于 规则(Rule-BasedOptimizer),也不是基于 语义。怎么开销小就怎么来。另外,SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。
索引失效情况:
- 最佳左前缀法则:对于MySQL多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
- 计算、函数、类型转换(自动或手动)都会导致索引失效
- 范围条件右边的列索引失效,多列索引中,过滤条件中索引左边有范围查询的话,则对应列右边的列索引将失效
- 应用开发中,金额和日期查询往往是范围查询,建立联合索引时务必把涉及范围查询的字段放在索引后面
- 不等于(!= 或者 <>)索引失效
- is null可以使用索引,is not null无法使用索引
- 最好在设计表的时候就将字段设置为not null约束,并给定默认值,int为0,字符串为’’
- like 以通配符 %开头将无法使用索引
- or 前后存在非索引的列,索引失效
- 数据库和表的字符集统一,不同字符集进行比较前需要进行
转换会造成索引失效
一般性建议:
- 对于单列索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好
- 在选择组合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面
3. 关联查询优化
3.1 Join语句原理
驱动表就是主表,被驱动表就是从表、非驱动表。Join连接时,无索引时,需遍历主表,逐个与被驱动表比对,嵌套循环遍历被驱动表。MySQL5.5后的版本引入了BNLJ算法来优化嵌套执行。MySQL8.0.18版本前,在被驱动表有索引的情况下运用了INLJ算法,无索引时采用BNLJ算法。从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join,默认都会使用hash join
3.2 Simple Nested-Loop Join(简单嵌套循环连接)
算法:从驱动表A中取出一条数据1,遍历被驱动表B,将匹配到的数据放入result…以此类推,驱动表A中的每一条记录与驱动表B的记录进行判断,算法复杂度为O(A * B),效率很低。MySQL当然不会这么粗暴的进行表的连接。
3.3 Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join优化的主要思路是 减少被驱动表数据的匹配次数,所以要求被驱动表上必须 有索引才行。通过驱动表匹配条件直接与被驱动表索引进行匹配,避免和被驱动表的每条记录比较,使得算法复杂度为O(A * LogB),其中因为索引的结构是B+树,LogB的大小一般不会超过4。如果在B上的索引不是主键,还需要进行回表操作,所以如果被驱动表的索引是主键索引的话效率会更高
3.4 Block Nested-Loop Join(块嵌套循环连接)
该算法不是按SNLJ算法一样逐条获取驱动表的数据,而是一块一块的获取,引入了 join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer缓冲区中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并为一次,降低了被驱动表的访问频率。
注意:这里缓存的不只是关联表的列,select 后面的列也会缓存起来。
在一个有N个join关联的sql中会分配N-1个join buffer,所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列

参数设置:
- block_nested_loop
- 通过
show variables like '%optimizer_switch%'查看block_nested_loop状态。默认是开启的
- 通过
- join_buffer_size:默认值:256k
3.5 Hash Join
- Nested Loop:对于被连接的数据子集较小的情况,嵌套循环还是个较好的选择
- Hash Join是做
大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立 散列表,然后扫描较大的表并探测散列表,找出与Hash表匹配的行,内存设置还是join_buffer_size- 这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和
- 在表很大的情况下并不能完全放入内存,这时优化器会将它分割成
若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高l/O 的性能 - 它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join只能应用于等值连接(如WHERE A.COL1= B.COL2),这是由Hash的特点决定的
3.6 小结
-
整体效率:INLJ > BNLJ > SNLJ
-
永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量) (小的度量单位指的是 表行数 * 每行大小,而不是单纯指行数)
-- STRAIGHT_JOIN就是在内连接中使用,而强制使用左表来当驱动表,所以这个特性可以用于一些调优,强制改变mysql的优化器选择的执行计划select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100; #推荐,t2取了所有字段,相对来说join buffer里能存的数据更多select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100; #不推荐 -
为被驱动表匹配的条件增加索引(减少被驱动表的循环匹配次数)
-
增大join_buffer_size的大小 (一次缓存的数据越多,那么被驱动表的扫表次数就越少)
-
减少驱动表不必要的字段查询 (字段越少,join buffer 所缓存的数据行数就越多)
4. 子查询优化
执行子查询时需要建立撤销临时表,且临时表还是磁盘都不会有索引,在MySQL中建议使用Join查询来替代子查询,尽量不用not in 或in 函数
select a.* from
(select a.* ,b.field from tabname as a left outer join tabname as b on a.field =b.field
) x where field is null
5. 排序优化
在MySQL 中,支持两种排序方式,分别是 FileSort 和 Index 排序。
- Index 排序中,索引可以保证数据的有序性,不需要再进行排序,
效率更高 - FileSort 排序则一般在
内存中进行排序,占用 CPU 较多。如果待排结果较大,会产生临时文件 /0 到磁盘进行排序的情况,效率较低
优化建议:
- FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率
- 尽量使用Index 完成ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引
- 如果靠过滤条件能过滤掉大部分数据,则使用 FileSort也能接受,order by 在数据过滤后剩余数据量还比较大的时候才会考虑使用索引,否则会优先使用成本低的FileSort
- 无法使用Index 时考虑对 FileSort 方式进行调优
filesort的两种排序方式:
- 双路排序:从磁盘取排序列,排序完再从磁盘取出对应数据输出
- 单路排序:从磁盘读取查询需要的所有列,排序后输出;需要更大内存空间,如果待排数据量很大,每次只能取sort_fuffer的容量,进行排序再合并,排完再取会导致大量的I/O操作,反而得不偿失
FileSort 优化策略
- 提高
sort_buffer_size,提升排序时可用的内存容量大小,innodb存储引擎默认值是1MB - 尝试提高
max_length_for_sort_data,如果需要返回的列的总长度大于max_length_for_sort_data,使用双路算法,否则使用单路算法,1024~8192字节之间调整。默认1024字节;即提高后会增加使用单路算法的阈值
注意:
order by 时 select * 是大忌,最好只取需要的字段,原因:
- 当查询的字段大小总和小于
max_length_for_sort_data时,而且排序字段不是TEXT|BLOB类型时,会用改进后的排序——单路排序,否则使用多路排序 - 两种算法的数据都有可能超过
sort_buffer_size的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size
6. GROUP BY 优化
- where效率高于having,能写在where限定的条件就不要写在having中
- 减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、 group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢
7. 分页查询优化
优化思路一:在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
SELECT * FROM student t,(SELECT id FRON student ORDER BY id LIMIT 2000000,10) aWHERE t.id = a.id;
优化思路二:该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询
SELECT * FROM student WHERE d > 2000000 LIMIT 10:
优化思路三:游标方式,适合单调递增的数据,每次查询时传入上次查询的末尾的值,需与前端一起配合,和方案二类似,但无法跳页查询
8. 字符串的前缀索引
如果不指定索引长度,则索引会包含整个字符串 index1,指定长度则为前缀索引 index2
mysql> alter table teacher add index index1(email);
#或
mysql> alter table teacher add index index2(email(6));
如果使用的是index1(即email整个字符串的索引结构),执行顺序是这样的:
- 从index1索引树找到满足索引值是’ zhangssxyz@xxx.com ’的这条记录,取得ID2的值;
- 到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
- 取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email=’ zhangssxyz@xxx.com ’的
条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如果使用的是index2(即email(6)索引结构),执行顺序是这样的:
- 从index2索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
- 到主键上查到主键值是ID1的行,判断出email的值不是’ zhangssxyz@xxx.com ’,这行记录丢弃;
- 取index2上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出ID2,再到ID索引上取整行然
后判断,这次值对了,将这行记录加入结果集; - 重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。前面已经讲过区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。
注意:使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是在选择是否使用前缀索引时需要考虑的一个因素
9. 索引下推
在二级索引或联合索引中,判断条件中如果还有对应索引中字段,则先判断再回表
select * from student where name > 'a' and sno like '%20'; -- index(name, sno)
上述查询会通过联合索引找到 name > 'a’的数据的同时判断 sno like ‘%20’,之后再进行回表;如无icp(索引下推),则找到 name > 'a’的数据就会回表,查出数据后再判断sno like ‘%20’
10. 普通索引和唯一索引
普通索引和唯一索引应该怎么选择?其实,这两类索引在查询能力上是没差别的,主要考虑的是对 更新性能 的影响。所以,建议 尽量选择普通索引,但要考虑业务正确性优先
10.1 更新过程
为了说明普通索引和唯一索引对更新语句性能的影响这个问题,介绍一下change buffer。
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下, InooDB会将这些更新操作缓存在change buffer中 ,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
将change buffer中的操作应用到原数据页,得到最新结果的过程称为 merge 。除了 访问这个数据页 会触发merge外,系统有 后台线程会定期 merge。在 数据库正常关闭(shutdown) 的过程中,也会执行merge操作。
如果能够将更新操作先记录在change buffer,减少读磁盘 ,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用 buffer pool 的,所以这种方式还能够 避免占用内存 ,提高内存利用率。唯一索引的更新就不能使用change buffer ,实际上也只有普通索引可以使用
10.2 使用场景
首先, 业务正确性优先 。我们的前提是“业务代码已经保证不会写入重复数据”的情况下,讨论性能问题。如果业务不能保证,或者业务就是要求数据库来做约束,那么没得选,必须创建唯一索引。
然后,在一些“ 归档库 ”的场景。比如,线上数据只需要保留半年,然后历史数据保存在归档库。这时候,归档数据已经是确保没有唯一键冲突了。要提高归档效率,可以考虑把表里面的唯一索引改成普通索引
innodb_change_buffer_max_size:Change Buffer的最大大小,默认为25%的缓冲池大小;innodb_change_buffering:Change Buffer的开启状态,默认为all,表示所有插入、更新和删除操作都会使用Change Buffer;
11. 其它查询优化策略
11.1 EXISTS 和 IN 的区分
遵守小表驱动大表
select * from a where cc in (select cc from b) -- a表比b表大select * from a where exist(select cc from b where b.cc = a.cc) -- a表比b表小
11.2 count(具体字段)的使用
使用innodb存储引擎的情况下,如果使用count(具体字段)要尽量选择二级索引,因为主键是聚簇索引,需要把所有数据加载到内存中。
11.3 关于select *
- MySQL在解析的过程中,会通过
查询数据字典将*按序转换为列名 - 无法使用
覆盖索引
11.4 多使用commit
commit所释放的资源:
- 回滚段上用于恢复数据的信息
- 被程序语句获得的锁
- redo / undo log buffer 中的空间
- 管理上述3种资源中的内部花费
12. 推荐的主键策略
非核心业务:对应表的主键自增ID,如警告、日志、监控等信息
核心业务:主键设计至少应该是全局唯一且是单调递增的
最简单的主键设计:有序的UUID,将UUID时间高位与低位交换,且去除无意义的“-”字符串
UUID = 时间 + UUID版本(16字节) - 时钟序列(4字节) - MAC地址(12字节)
MySQL8.0提供的uuid_to_bin函数实现上述功能
select uuid_to_bin(uuid(), true);
在当今的互联网环境中,非常不推荐自增ID作为主键的数据库设计。更推荐类似有序UUID的全局唯一的实现。
另外在真实的业务系统中,主键还可以加入业务和系统属性,如用户的尾号,机房的信息等。这样的主键设计就更为考验架构师的水平了。
相关文章:
【MySQL索引与优化篇】索引优化与查询优化
索引优化与查询优化 文章目录 索引优化与查询优化1. 概述2. 索引失效案例3. 关联查询优化3.1 Join语句原理3.2 Simple Nested-Loop Join(简单嵌套循环连接)3.3 Index Nested-Loop Join(索引嵌套循环连接)3.4 Block Nested-Loop Jo…...

DevChat:VSCode中基于大模型的AI智能编程助手
#AI编程助手哪家好?DevChat“真”好用# 文章目录 1. 前言2. 安装2.1 注册新用户2.2 在VSCode中安装DevChat插件2.3 设置Access Key 3. 实战使用4. 总结 1. 前言 DevChat是由Merico公司精心打造的AI智能编程助手。它利用了最先进的大语言模型技术,像人类…...

Scrum master的职责
首先,Scrum master负责建立Scrum团队。同时Scrum master要帮助团队(甚至大到公司)中的每个成员理解Scrum理论和实践。 Scrum master还需要有很强的软技能,用于指导Scrum团队。Scrum master要对Scrum团队的成功负责任,…...

数据结构:算法(特性,时间复杂度,空间复杂度)
目录 1.算法的概念2.算法的特性1.有穷性2.确定性3.可行性4.输入5.输出 3.好算法的特质1.正确性2.可读性3.健壮性4.高效率与低存储需求 4.算法的时间复杂度1.事后统计的问题2.复杂度表示的计算1.加法规则2.乘法规则3.常见函数数量级比较 5.算法的空间复杂度1.程序的内存需求2.例…...

SaaS 出海,如何搭建国际化服务体系?(一)
防噎指南:这可能是你看到的干货含量最高的 SaaS 出海经验分享,请准备好水杯,放肆食用(XD。 当越来越多中国 SaaS 企业选择开启「国际化」副本,出海便俨然成为国内 SaaS 的新角斗场。 LigaAI 观察到,出海浪…...

数据结构与算法-(7)---栈的应用拓展-前缀表达式转换+求值
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

泛型的使用
泛型是一种Java编程语法,它允许我们编写支持多种数据类型的通用类、方法和接口。使用泛型可以使代码更通用、更灵活、更健壮,并提高代码的重用性。 在Java中,泛型的语法使用尖括号<>和类型参数来定义。例如,我们可以定义一…...

docker导致远程主机无法访问,docker网段冲突导致主机网络异常无法访问
背景: 公司分配的虚拟机是172网段的,在上面部署了docker、docker-compose、mysql、redis,程序用docker-compose管理,也平稳运行了一个多周,某天用FinalShell连主机重启docker容器,忽然断开连接,然后虚拟机就…...
Selenium的显性、隐形等待)
Python的web自动化学习(三)Selenium的显性、隐形等待
引言: WebDriver的显性等待和隐形等待是用于在测试过程中等待元素加载或操作完成的两种等待方式。了解此两种方式是为后面自动化找到适合的方法去运用 显性等待(Explicit Wait) 显性等待是通过使用WebDriverWait类和ExpectedConditions类来…...

Linux--文件操作
1.什么是文件 对于文件来说,文件文件内容文件属性;对于文件来说,只有两种操作,对内容的修改和对文件属性的修改,这就是文件的范畴。 对于存放在磁盘上的文件,我们需要通过进程来进行访问,访问文…...
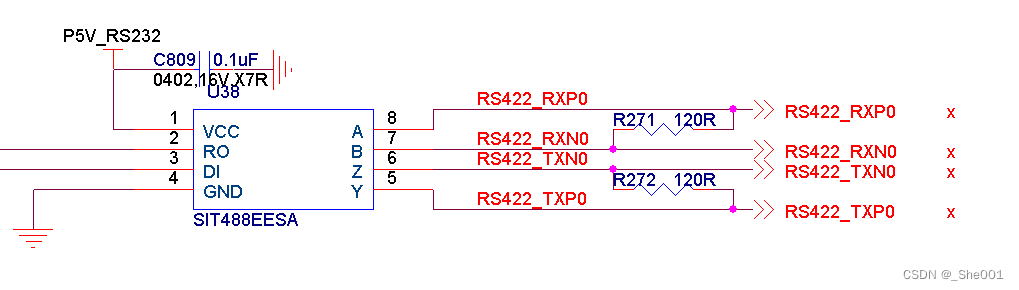
硬件知识积累 RS422接口
1. RS422 基本介绍 EIA-422(过去称为RS-422)是一系列的规定采用4线,全双工,差分传输,多点通信的数据传输协议。它采用平衡传输采用单向/非可逆,有使能端或没有使能端的传输线。和RS-485不同的是EIA-422不允…...
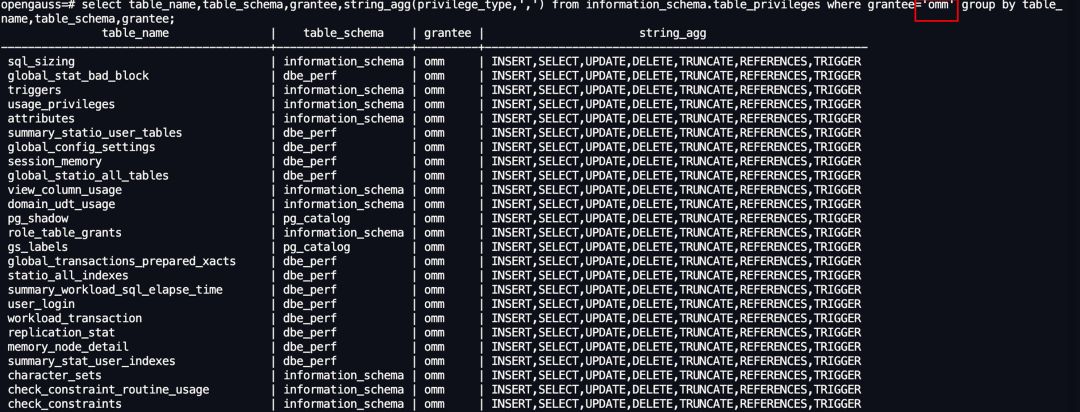
项目经验分享|openGauss 陈贤文:受益于开源,回馈于开源
开源之夏 项目经验分享 2023 #08 # 关于 openGauss 社区 openGauss是一款开源关系型数据库管理系统,采用木兰宽松许可证v2发行。openGauss内核深度融合华为在数据库领域多年的经验,结合企业级场景需求,持续构建竞争力特性。同时openGauss也是…...

实时检测并识别视频中的汽车车牌
对于基于摄像头监控的安全系统来说,识别汽车牌照是一项非常重要的任务。我们可以使用一些计算机视觉技术从图像中提取车牌,然后我们可以使用光学字符识别来识别车牌号码。在这里,我将引导您完成此任务的整个过程。 要求: import cv2import numpy as npfrom skimage impor…...

使用 pyspark 进行 Clustering 的简单例子 -- KMeans
K-means算法适合于简单的聚类问题,但可能不适用于复杂的聚类问题。此外,在使用K-means算法之前,需要对数据进行预处理和缩放,以避免偏差。 K-means是一种聚类算法,它将数据点分为不同的簇或组。Pyspark实现的K-means算法基本遵循以下步骤: 随机选择K个点作为初始质心。根…...

LeetCode75——Day22
文章目录 一、题目二、题解 一、题目 1657. Determine if Two Strings Are Close Two strings are considered close if you can attain one from the other using the following operations: Operation 1: Swap any two existing characters. For example, abcde -> aec…...
【SOC基础】单片机学习案例汇总 Part1:电机驱动、点亮LED
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...

【HTML】HTML基础知识扫盲
1、什么是HTML? HTML是超文本标记语言(Hyper Text Markup Language)是用来描述网页的一种语言 注意: HTML不是编程语言,而是标记语言 HTML文件也可以直接称为网页,浏览器的作用就是读取HTML文件ÿ…...
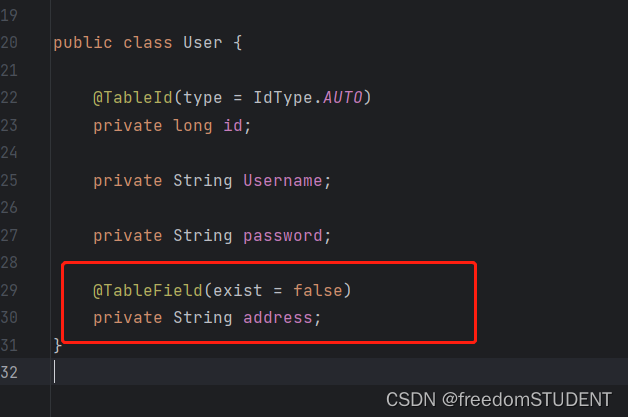
【Mybatis-Plus】常见的@table类注解
目录 引入Mybatis-Plus依赖 TableName 当实体类的类名在转成小写后和数据库表名相同时 当实体类的类名在转成小写后和数据库表名不相同时 Tableld TableField 当数据库字段名与实体类成员不一致 成员变量名以is开头,且是布尔值 编辑 成员变量名与数据库关…...
)
Android WMS——操作View(七)
上一篇文章我们将 view 传递给 ViewRootImpl 进行操作,这里我们主要分析 ViewRootImpl 对 View 进行操作。在正式分析之前我们先来介绍以下 View。 一、View介绍 最开始学习 View 的时候最先分析的是它的布局(LinearLayout、FrameLayout、TableLayout、RelativeLayout、Abso…...

算法__数组排序_冒泡排序直接选择排序快速排序
文章目录 冒泡排序算法说明代码实现 直接选择排序算法说明代码实现 快速排序算法说明代码实现 本篇主要讲解数组排序相关的三种算法,冒泡排序,直接排序和快速排序。 冒泡排序 算法说明 在数组中依次比较相邻的两个元素,当满足左侧大于右侧时…...

5秒无损转换B站缓存视频:m4s-converter完整使用指南
5秒无损转换B站缓存视频:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的学习…...

Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案
Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mountin…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...
基于Circuit Playground Express与NeoPixel的四季交互灯光装置设计与实现
1. 项目概述与核心思路几年前,我在一个艺术展上看到一组悬挂在枯树枝上的玻璃瓶,里面装着会呼吸般变幻光线的LED灯,那种静谧又灵动的美感让我念念不忘。作为一个喜欢把代码和电路“藏”进生活场景里的硬件爱好者,我一直在琢磨如何…...

基于CircuitPython与加速度计的魔法9号球:嵌入式交互项目实践
1. 项目概述:当硬件遇上玄学,用代码打造你的专属“决策神器”在嵌入式开发的世界里,我们常常与传感器、显示屏和逻辑代码打交道,构建着一个个解决实际问题的智能设备。但谁说硬件项目就一定要严肃刻板?今天,…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...
)
ElevenLabs克隆成功率从31%飙升至96.7%:基于LPC共振峰校准+Prosody Transfer双引擎微调法(实测数据包已脱敏上传)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆方法概览 ElevenLabs 提供了高保真、低延迟的语音克隆能力,其核心依赖于少量高质量语音样本(通常 1–3 分钟)与上下文感知的零样本/少样本微调技术…...

PAC技术演进与核心趋势:从多域控制到边缘智能的工业自动化平台
1. 项目概述:为什么今天还要聊PAC?如果你在工业自动化、楼宇控制或者任何涉及逻辑控制的领域工作,那么“PAC”这个词对你来说应该不陌生。但很多时候,它就像一个熟悉的陌生人——大家好像都知道它,但真要细说它现在发展…...

Noto Emoji字体架构深度解析:现代表情符号渲染的技术实现与性能优化
Noto Emoji字体架构深度解析:现代表情符号渲染的技术实现与性能优化 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji Noto Emoji作为Google开源的表情符号字体库,提供了跨平台的Unicode表…...